
Abstract
This paper introduces a flexible discrete transmuted record type discrete Burr–Hatke (TRT-DBH) model that seems suitable for handling over-dispersion and equi-dispersion in count data analysis. Further to the elegant properties of the TRT-DBH, we propose, in the time series context, a first-order integer-valued autoregressive process with TRT-DBH distributed innovations [TRBH-INAR(1)]. The moment properties and inferential procedures of this new INAR(1) process are studied. Some Monte Carlo simulation experiments are executed to assess the consistency of the parameters of the TRBH-INAR(1) model. To further motivate its purpose, the TRBH-INAR(1) is applied to analyze the series of the COVID-19 deaths in Netherlands and the series of infected cases due to the Tularaemia disease in Bavaria. The proposed TRBH-INAR(1) model yields superior fitting criteria than other established competitive INAR(1) models in the literature. Further diagnostics related to the residual analysis and forecasting based on the TRBH-INAR(1) model are also discussed. Based on modified Sieve bootstrap predictors, we provide integer forecasts of future death of COVID-19 and infected of Tularemia.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Count data are commonly encountered in everyday life phenomena, including insurance, economics, social sciences, medicines, transport and among an unlimited number of areas. In these applications, the count observations are normally expressed as positive integers that are collected on a daily, weekly, or monthly sequential basis. Hence, such repeated observations are more likely serially correlated. On the other side, these series of counts are commonly over-dispersed due to some outliers or presence of physical or latent effects and, in some cases, can be equi-dispersed or under-dispersed as well. Thus, there is an important need to appropriately model the series of counts via the suitable distribution that can accommodate as fully as possible different statistical features.
The prevalent probability models in the literature include the geometric, Poisson, Poisson mixtures (Karlis and Xekalaki 2005), Conway–Maxwell Poisson (Shmueli et al. 2005; Sellers and Shmueli 2010; Sellers et al. 2012) distributions. However, owing to the complex nature and some unique properties of the natural phenomena, such as skewness, dispersion, monotone or unimodal failure rate, inflation or deflation, these conventional density functions may not be fully relevant, as similarly argued in El-Morshedy et al. (2020), Eliwa and El-Morshedy (2021) and the references therein. This leads to introducing some other more flexible distributions for positive counts that emerge from discretizing some continuous functions. Examples of such distributions have been comprehensively studied by Gómez-Déniz and Calderín-Ojeda (2011), Chakraborty and Chakravarty (2012), Nekoukhou et al. (2013), Bakouch et al. (2014), Hussain et al. (2016), Bahti and Bakouch (2019), Altun (2020) and references therein.
In this same sense, this paper introduces a modified discrete Burr–Hatke (BH) model, based on the transmuted record type (TRT) constructor introduced by Shakil and Ahsanullah (2011). The discrete version of BH model has been recently proposed by El-Morshedy et al. (2020) to model count events exhibiting huge over-dispersion with various skewness features. The discrete version of BH stands out as a main competitor to the traditional count models as it yields far more superior fitting criteria. This paper focuses on the TRT construction strategy because it leads to skewed distributions and is compatible with one side long-tailed data. The transmuted distributions are special cases of extremal distributions (Kozubowski and Podgórski 2016).
Further to the choice of the probability model, there is a need to investigate the relevant time series structures related to the counts of correlated nature. For repeated count observations, McKenzie (1986), McKenzie (1988) and Al-Osh and Alzaid (1987) introduced the thinning-based INAR(1) processes. The classical INAR(1) model consists of two important components: a survival part that relates the current observation with its previous lagged via the thinning, in particular, the binomial thinning operation (Steutel and van Harn 1979) and a random innovation or error component. In the original INAR(1) model, the innovation was allowed to follow the benchmark Poisson, while the binomial thinning was defined with the fixed or random coefficient.
Over the years, in view of obtaining better fitting criteria or information criteria in severely over-dispersed or zero inflated data series, several authors have proposed a vast number of alterations to either the innovation terms. The INAR(1) model based on the geometric innovations was introduced by Jazi et al. (2012), which can handle the over-dispersed count data sets. The INAR(1) model with the binomial thinning operator and Poisson–Lindley innovation was established by Lívio et al. (2018), and several estimation methods, including the conditional least squares, Yule–Walker and conditional maximum likelihood, were used for estimating the parameters.
Recently, to cover some unique properties of real data sets, other distributions were designated for innovation of the IANR(1) models, such as power series (Bourguignon and Vasconcellos 2015), Poisson-transmuted exponential (Altun and Mamode Khan 2021) and Bell (Huang and Zhu 2021).
Borges et al. (2017) introduced a new operator called \(\rho\)-negative binomial thinning operator and provided a new INAR(1) process with geometric marginals that can be applied for phenomena with excess zeros. Liu and Zhu (2021) introduced a new flexible thinning operator named extended binomial that has two parameters. Considering the extended binomial operator, they defined a new INAR(1) model and estimated the unknown parameters through the two-step conditional least squares and conditional maximum likelihood methods.
Ristić et al. (2013) were the first to propose the INAR(1) process having a dependent count series. Shirozhan et al. (2019) combined the Pegram operator with the dependent thinning operator. A new dependent negative binomial thinning operator based on the inflated geometric counting series is introduced by Shamma et al. (2020).
In classical models, the counting series are expected to be independent, which is not often the case in real-world situations like contagious diseases. Also, the binomial thinning operator is not suitable for zero inflated demands. After an outbreak has gone, we occasionally come across data sets with too many zeros. As a result, we need a count model that can deal with zero inflation. All earlier drawbacks stimulate us to introduce a new INAR(1) model based on the generalized negative binomial (GNB) thinning operator with flexible discrete innovations. The most notable feature of the utilized thinning operator is that it may be used for data sets with additional observations. The principal aim of this paper is devoted to introducing an INAR(1) model with dependent counting series with flexible innovations, where the dependency of the count series makes the thinning operator more suitable for modeling practical count data sets. Some clinical data sets demonstrate the applicability of the suggested model.
The following is the outline of the paper. Section 2 introduces a distribution using the TRT approach and the discrete BH baseline distribution. Also, the survival, hazard rate, probability generating functions and non-central moments of the proposed distribution are provided. The GNB thinning operator is reviewed in Sect. 3. With the proposed discrete innovations, the INAR(1) process is developed, which is based on the GNB thinning operator, and some properties of the process are investigated, including the conditional mean and variance. Several parametric and nonparametric estimation methods for the proposed INAR(1) process are reported in Sect. 4. Finally, in Sect. 5, two real-life count data are utilized to analyze the application of the introduced INAR(1) model, demonstrating our model’s suitability in contrast to several relevant INAR(1) models.
2 A Modified Version of Discrete Burr–Hatke Distribution
In this section, we provide a modified discrete distribution based on transmuted record type method and discrete Burr–Hatke baseline distribution. The survival and hazard rate function, along with some statistical properties of the distribution, are also given.
First, we consider the DBH distribution, which is introduced by El-Morshedy et al. (2020). The cumulative distribution function (CDF) and probability mass function (PMF) of DBH distribution are represented, respectively, as
Now, we review the TRT method, which is defined as
where \(Y_{U_{(1)}}\) and \(Y_{U_{(2)}}\) are, respectively, the first and second upper records [for more details, see Shakil and Ahsanullah (2011)].
Hence, the CDF of TRT distribution is shown as
where \(H_{_Y}(z)\) is an arbitrary CDF baseline distribution. Consider the DBH baseline distribution, the CDF of the proposed distribution is represented as
and the PMF is
We call this distribution as the transmuted record type-discrete Burr–Hatke.
The survival and hazard rate functions (HRF) of the TRT-DBH are demonstrated as below
The PMF and HRF plots of TRT-DBH distribution are depicted in Figs. 1 and 2, for different combinations of the parameters.

The PMF plots for TRT-DBH distribution with different combinations of parameters \((\lambda ,\gamma )\)

The HRF plots for TRT-DBH distribution with different combinations of parameters \((\lambda ,\gamma )\)
It is clear that the HRF of TRT-DBH distribution has different shapes, including decreasing and unimodal, which dedicate the capability of TRT-DBH distribution to model different types of data sets.
2.1 Some Statistical Properties of TRT-DBH Distribution
Now, some properties of the TRT-DBH distribution are investigated, such as the probability generating function, r-th non-central moments, and so on.
Let Z follow the TRT-DBH distribution with the parameters \((\lambda ,\gamma )\), then its probability generating function is obtained as follows
where \(\Phi (a,b,c)=\sum _{n=0}^{\infty }\dfrac{a^n}{(n+c)^b}, \;\vert a \vert <1\) is the LerchPhi function and we denote its derivative as
Noted that both \(\lambda\) and s are restricted \((0<\lambda<1,\vert s\vert <1)\); hence, the condition of the LerchPhi function is satisfied.
The r-th non-central moments of TRT-DBH distribution are represented as
It is concluded that the first and second moments of the TRT-DBH distribution are as follows
Accordingly, based on the first and second moments, the variance of TRT-DBH distribution can be obtained in closed form. The Fisher dispersion index (FDI) is defined as the variance to mean ratio, which indicates whether a certain distribution is suitable for under or over-dispersed data sets. If FDI \(<(>)1\), the distribution is under-dispersed (over-dispersed).
The numerical mean, variance, skewness, kurtosis and FDI of TRT-DBH distribution are provided in Table 1, for different combinations of the parameters. Based on Table 1, the mean and variance of TRT-DBH are increased by increasing values of parameters \(\lambda\) and \(\gamma\). Also, for small values of \(\lambda\) and large values of \(\gamma\), the FDI measure is near to one, which indicates the equi-dispersion of TRT-DBH distribution. For other combinations of \((\lambda ,\gamma )\), the FDI measure is more than one, so the TRT-DBH distribution is over-dispersion. The TRT-DBH distribution is severely skewed to right and leptokurtic. So, TRT-DBH distribution also has a perfect fit for right long-tailed data.
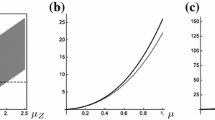
Based on Fig. 3, the values of \(Var(Z)-E(Z)\) are always positive, which confirms the results of Table 1 and the over-dispersion nature of the TRT-DBH model.

The \(Var(Z)-E(Z)\) plots for TRT-DBH distribution with different combinations of parameters \((\lambda ,\gamma )\)
3 Formulation of the INAR(1) Model with TRT-DBH Innovation
The purpose of this section is to introduce an INAR(1) time series model based on the TRT-DBH distribution. First, we review the definition of the GNB thinning operator defined by Shamma et al. (2020), and then, an INAR(1) model with TRT-DBH innovation is constructed.
Definition 1
(Shamma et al. 2020) Consider a sequence of independent identically distributed (iid) geometric random variables \(\{V_i\}_{i\in {\mathbb {N}}}\) with parameter \(\frac{\theta }{1+\theta }\) and Bernoulli random variable W with parameter \(\frac{\alpha }{\theta }\), \(0\le \alpha \le \theta \le 1\), where \(V_i\) and W are independent for all \(i\in {\mathbb {N}}\). Define a sequence of dependent random variables \(\{U_i\}_{i\in {\mathbb {N}}}\) as \(U_i=V_iW ,\; i\in {\mathbb {N}}\). It can be verified \(U_i\) has a mixture distribution as follows
denoted as zero inflated geometric distribution \(\big (ZIG(1-\frac{\alpha }{\theta },\frac{\theta }{1+\theta })\big )\).
Also,
The random variable \(\sum \nolimits _{i=1}^{n}U_{i}\) is a mixture of zero and negative binomial \((n,\frac{\theta }{1+\theta })\) distributed random variables with proportions \(1-\frac{\alpha }{\theta }\) and \(\frac{\alpha }{\theta }\), respectively, and the zero inflated negative binomial distribution is the name given to it.
Definition 2
(GNB thinning operator) Let X be a non-negative integer valued random variable and \(\left\{ {U_{i},\;i\in {\mathbb {N}}}\right\}\) as noted above by (2). The operator “\(\alpha *_{\theta }\)”\(,\;0\le \alpha \le \theta \le 1\), defined as \(\alpha *_{\theta }X_{t-1}= \sum _{i=1}^{X_{t-1}} U_{i,t}\) is called the GNB thinning operator.
Shamma et al. (2020) outlined the properties of the GNB thinning operator
3.1 The Proposed INAR(1) Model
The following recursive equation introduces the proposed stationary INAR(1) process \(\{X_{t}\}\) as
where “\(*_{\theta }\)” is the GNB thinning operator, \(\{Z _{t}\}\) be a sequence of TRT-DBH random variables with parameters \((\lambda ,\gamma )\) and given \(X_{t-1}\), the random variables \(\alpha *_{\theta }X_{t-1}\) and \(Z_{t}\) are independent of each other. We shall refer to this model as TRBH-INAR(1).
The one-step transition probabilities are
and for \(i\ge 1\), we get
where
This model may be fitted to infectious illness data and can be used to describe the disease’s transmission as follows: In the case of the INAR(1) model, if \(X_{t-1}\) represents the number of new patients throughout the time span \((t-2, t-1]\), \(\alpha *_\theta X_{t-1}\) will be the number of surviving patients from the previous month, which may stimulate new patients or likely cure, and \(\{Z_t\}\) will be the number of new patients infected in the current period.
Remark 1
Shamma et al. (2020) provided several properties of the GNB thinning operator as follows
-
(i)
\(E\left( \alpha *_{\theta }X\mid X \right) =\alpha X\),
-
(ii)
\(Var\left( \alpha *_{\theta }X\mid X \right) =\alpha (\theta -\alpha ) X +\alpha (\theta +1)X\),
-
(iii)
\(E\left( \alpha *_{\theta }X\right) =\alpha E(X)\),
-
(iv)
\(E\left( \alpha *_{\theta }X \right) =\alpha (\theta -\alpha ) E^2(X) +\alpha (\theta +1)E(X)+\alpha \theta \, Var(X)\).
The expectation and variance of the process \(\{X_t\}\) is obtained as
where \(\mu _{_Z}\) and \(\sigma ^2_{Z}\) are the mean and variance of TRT-DBH distribution, respectively.
Proposition 1
The Fisher dispersion index of \(\{X_t\}\) is obtained as
This readily demonstrates that \(I_X\) is more than one and obviously is over-dispersed.
Proof
In order to confirm \(I_ZX\ge 1\), it is required to show \(Var(X)- E(X)\ge 0\). Hence, we show the following inequality always holds
which can be rewritten as
Since the TRT-DBH model is over-dispersed or equi-dispersed, so \(I_Z>1\) (i.e., \(\sigma ^2_{_Z}-\mu _{_Z}\ge 0\)), and the proof is concluded. \(\square\)
Proposition 2
Suppose \(\{X_{t}\}\) is a stationary process defined by (3), then for \(\alpha<\theta <1\) and \(t\ge 1\),
-
(i)
The conditional expectation is
$$\begin{aligned} E\left( X_{t}\mid X_{t-k}\right) =\alpha ^{k}X_{t-k}+\dfrac{1-\alpha ^{k}}{1-\alpha }\mu _{_Z} . \end{aligned}$$(5)When \(k\rightarrow \infty\), then \(\lim _{k\rightarrow \infty }E\left( X_{t}\mid X_{t-k}\right) =\dfrac{\mu _{_Z}}{1-\alpha }\), which is the process’s unconditional expectation.
-
(ii)
The conditional variance is
$$\begin{aligned} Var(X_{t}\mid X_{t-1})=\alpha (\theta -\alpha )X_{t-1}^{2}+\alpha (\theta +1)X_{t-1}+\sigma ^2_{Z}, \end{aligned}$$(6)and
$$\begin{aligned} Var\left( X_{t}\mid X_{t-k}\right)&= \alpha ^k\left( \theta ^k-\alpha ^k\right) X_{t-k}^{2}+\alpha ^{k}\frac{(1+\theta )(1-\theta ^k)}{1-\theta } X_{t-k}\\ &\quad +\,2\mu _{_Z} \alpha ^k\Big (\dfrac{1-\theta ^k}{1-\theta } -\dfrac{1-\alpha ^k}{1-\alpha }\Big ) X_{t-k}\\ &\quad +\,\dfrac{\alpha \mu _{_Z}(1+\theta )}{1-\theta } \Big (\dfrac{1-\alpha ^{k-1}}{1-\alpha }-\dfrac{\theta (1-(\alpha \theta )^{k-1})}{1-\alpha \theta }\Big )\\ &\quad +\,\mu ^2_{_Z}\Big ( \dfrac{1-(\alpha \theta )^{k-1}}{1-\alpha \theta } -\dfrac{1-\alpha ^{2k-2}}{1-\alpha ^2} \Big ) \\ &\quad +\, 2\alpha \mu ^2_{_Z}\bigg [\frac{\theta }{1-\theta }\Big (\dfrac{\alpha (1-\alpha ^{k-1})}{1-\alpha }-\dfrac{\alpha \theta (1-(\alpha \theta )^{k-1})}{1-\alpha \theta }\Big ) \\ &\quad -\,\dfrac{\alpha }{1-\alpha }\Big (\dfrac{\alpha (1-\alpha ^{k-1})}{1-\alpha }-\dfrac{\alpha \theta (1-\alpha ^{2k-2})}{1-\alpha ^2}\Big )\bigg ]\\ &\quad +\,\sigma ^2_{Z}\dfrac{1-(\alpha \theta )^k}{1-\alpha \theta }. \end{aligned}$$hence,
$$\begin{aligned} \lim _{k\rightarrow \infty }Var\left( X_{t}\mid X_{t-k}\right)&= \dfrac{\alpha \mu _{_Z} (1+\theta )}{(1-\alpha )(1-\alpha \theta )}\\ &\quad +\,\dfrac{\alpha (\theta -\alpha )\mu ^2_{_Z}}{(1-\alpha )^2 (1-\alpha \theta )}+\dfrac{\sigma ^2_{Z}}{1-\alpha \theta }, \end{aligned}$$which is the process’s unconditional variance.
-
(iii)
The autocorrelation function of the process \(\left\{ X_{t}\right\}\) is represented as
$$\begin{aligned} \rho (k)=Corr(X_t,X_{t-k})=\alpha ^{k}. \end{aligned}$$
Proof
See Appendix A. \(\square\)
3.2 Different Estimation Method
The conditional maximum likelihood, modified conditional least square, modified maximum empirical likelihood, and Yule–Walker estimation procedures for the parameters of the TRBH-INAR(1) model are discussed in this section.
3.2.1 Conditional Maximum Likelihood Estimation
The log-likelihood function is maximized in terms of the model parameters \(\varvec{\delta }=\) \((\alpha ,\theta ,\lambda ,\gamma )\) in order to produce conditional maximum likelihood (CML) estimators. The log-likelihood function for sample observation \(X_{1},\ldots ,X_{n}\) from the TRBH-INAR(1) model can be written as
where \(P\left( X_{t}=j\mid X_{t-1}=i\right)\) is transition probability given by (4). The CML estimator of the unknown parameters are numerically obtained by maximizing the log-likelihood function with commands “nlm” or “optim” from statistical package “R”.
3.2.2 Modified Conditional Least Square Estimation
The modified conditional least squares (MCLS) estimators of the parameters \(\alpha ,\mu _{_Z}\) are found by minimizing the expression below
where \(\mu _{_Z}\) is a function of the parameters \((\lambda ,\gamma )\). The estimators are given by
and
It is worth mention that the MCLS estimation of parameters \((\lambda ,\gamma )\) is obtained by finding the root of the equation (1) equal to the estimation of the \({\hat{\mu }}_{_{Z, MCLS}}\).
The one-step conditional expectation of the process depends only on the parameters \(\alpha\) and \(\mu _{_Z}\) and is not possible to use it for the estimation of the parameter \(\theta\). Hence, the parameter \(\theta\) can be estimated under the modified method proposed by Karlsen and Tjøstheim (1988). The parameter \(\theta\) can be estimated by minimizing the following expression
where
and \(Var(X_{t}\vert X_{t-1})\) is defined in (6) with estimated values of the parameters \((\alpha ,\lambda ,\gamma )\) as below
where \(\sigma ^2_{Z}\) is a function of the parameters \((\lambda ,\gamma )\) and can be estimated easily by \(({\hat{\lambda }}_{_{MCLS}},{\hat{\gamma }}_{_{MCLS}})\).
3.2.3 Modified Maximum Empirical Likelihood Estimation
The nonparametric modified empirical likelihood (MEL) technique for the TRBH-INAR(1) model is discussed in this section, which comprises two phases. In the first step, we obtain the maximum MEL estimators for the parameters \(\alpha\) and \(\mu _{_Z}\) as follows. By taking the derivative of \(Q(\alpha ,\mu _{_Z})\) defined in (7) with respect to \(\varvec{\beta }=(\alpha ,\mu _{_Z})\), we have the estimating equation
where \(m_{t}(\varvec{\beta } )=(m_{1,t}(\varvec{\beta }),m_{2,t}(\varvec{\beta }))^{\prime }\) with \(m_{1,t}(\varvec{\beta } )=X_{t-1}(X_{t}-\alpha X_{t-1}-\mu _{_Z})\), \(m_{2,t}(\varvec{\beta })=X_{t}-\alpha X_{t-1}-\mu _{_Z}\). Following Qin and Lawless (1994), we can define the log MEL function as
where \(d(\varvec{\beta } )\) satisfies
The maximum MEL estimator (MMELE) for the parameter \(\varvec{\beta }\) is defined by minimizing the above equation, i.e.,
The MMEL estimation of the parameters \((\lambda ,\gamma )\) can be easily obtained based on the \({\hat{\mu }}_{_{Z ,mmel}}\) and finding the root of the Eq. (1).
The maximum MEL estimator for the parameter \(\theta\) is obtained in the second phase. By considering the function \(T(\theta )\) which is defined in (8), we have
where \(m_{t}(\theta )={\hat{\alpha }}_{_{mmel}}X_{t-1}(X_{t-1}+1)\Big [V_{t}-{\hat{\alpha }}_{_{mmel}}(\theta -{\hat{\alpha }}_{_{mmel}})X_{t-1}^{2} -{\hat{\alpha }}_{_{mmel}}(\theta +1)X_{t-1}-{\hat{\sigma }}^2_{_{Z,mmel}}\Big ],\) and \(V_{t}=\left( X_{t}-{\hat{\alpha }}_{_{mmel}}X_{t-1}-{\hat{\mu }}_{_{Z,mmel}}\right) ^{2}\). The MMELE for the parameter \(\theta\) will be obtained by minimizing log MEL function.
3.2.4 Yule–Walker Estimation
The Yule–Walker (YW) estimators of the unknown vector \(\varvec{\delta }\) are obtained as follows. Using the fact that \(E(X_{t})=\dfrac{\mu _{_Z}}{1-\alpha }\) and \(Corr(X_{t},X_{t-1})= \alpha\), the YW estimations of the parameters \((\alpha ,\mu _{_Z})\) are generated using the sample mean and sample autocorrelation function as follows:
Similarly, the YW estimation of the parameters \((\lambda ,\gamma )\) is performed using the \({\hat{\mu }}_{_{Z ,mmel}}\), and finding the equation’s root (1).
We utilize the second moment of the procedure to estimate the parameter \(\theta\) as follows:
which is obtained based on Remark 1. Let \(\overline{X^2}=\frac{1}{n}\sum _{t=1}^n X_t^2\), then
as a result, estimate of the parameter \(\theta\) is determined by computing the root of the Eq. (9) numerically.
4 Simulation Approach
We examine the efficiency of the parameter estimate approaches for the TRBH-INAR(1) model using Monte Carlo simulation, under different sample sizes \(\varvec{n}=(100,200,500, 1000)\) over \(h=1000\) iterations. Two distinct parameter combinations are evaluated as \(\left( \alpha ,\theta ,\lambda \right) =\left( 0.4,0.8,0.7,0.3\right)\) and \(\left( 0.2,0.4,0.9,0.6 \right)\). We use the mean squared error (MSE) metric to assess the estimators’ performance. The results are summarized in Tables 2 and 3, where represent that all estimates of the parameters are convergent to their actual values. Furthermore, when the sample size grows larger, the MSE decreases. Among different kinds of estimation methods, the CML and MMEL provide better performance than MCLs and YW estimations, since they have small MSE for all parameters. In comparison among the CML and MMEL methods, we provide the computer running time (R.time), which indicates that the MMEL method is faster than CML and as well as CML in MSE measure. As a result, the nonparametric MMEL technique outperforms other methods of estimation.
5 Application of Real-World Data
In this section, we investigate the application of the TRBH-INAR(1) process by using two types of clinical count data.
The first data set is devoted to daily counts of death from the COVID-19 disease, reported from Netherland and consists of 46 observations, from second July until 16-th August at 2021, by the World Health Organization (https://covid19.who.int).
The second data set represents the weekly counts of Tularemia disease, reported from Bavaria, and it consists of 48 observations, from first week until 48-th week on 2020, from the Robert Koch Institute: SurvStat@RKI 2.0 (https://survstat.rki.de) site.

The sample path, ACF and PACF of both data sets
Figure 4 depicts the sample path, autocorrelation function (ACF), and partial autocorrelation function (PACF) of the two data series, indicating that the data sets should be modeled using a first-order autoregressive model. Furthermore, the augmented Dickey–Fuller test is used to justify stationarity of the two clinical data sets, where the p-value of augmented Dickey–Fuller test for COVID-19 data is less than 0.01 and for Tularemia data is equal 0.022, which confirm the stationarity of both data sets.
The mean, variance and autocorrelation of the two data sets are (3.565, 7.717, 0.557) and (2.125, 5.047, 0.310), respectively. Both data series are empirically over-dispersed with dispersion indices \(\hat{\mathrm{I}}_{X}=(2.164,2.375) \), respectively.
We compare the TRBH-INAR(1) model to some competitive INAR(1) models as:
PINAR(1) (Al-Osh and Alzaid 1987), GINAR(1) (Alzaid and Al-Osh 1988), NBIINAR(1) (Al-Osh and Aly 1992), GPQINAR(1) (Alzaid and Al-Osh 1993), NBRCINAR(1) (Weiß 2008), NGINAR(1) (Ristić et al. 2009), DCGINAR(1) (Ristić et al. 2013), NDCINAR(1) (Miletić Ilić 2016), \(\rho\)-NGINAR(1) (Borges et al. 2017), GADCINAR(1) (Nastić et al. 2017) and GNBINAR(1) (Shamma et al. 2020).
We reported the CML estimates, the information criterion (IC) statistics as AIC, BIC, HQIC and CAIC, and the root mean squares of differences of observations and predicted values (RMS) for each INAR model. Tables 4 and 5 show the results for two different data series. Regarding Tables 4 and 5, the values of the IC and RMS are the smallest for the TRBH-INAR(1) model. Therefore, we can conclude that the TRBH-INAR(1) model provides the best loss information among other competitive INAR(1) models.
5.1 The Clinical Data Sets’ Residual Analysis
We provide the results of a residual analysis of clinical data sets, which confirmed the suitability of the proposed model. The Pearson residuals are defined as
where \(E(X_t\mid X_{t-1})\) and \(Var(X_t\mid X_{t-1})\) are defined in (5) and (6), respectively. Note that, estimation of the parameters of the TRBH-INAR(1) model are substituted in each \(E(X_t\mid X_{t-1})\) and \(Var(X_t\mid X_{t-1})\) to compute the Pearson residuals.
The Pearson residuals ACF of both data sets is shown in Fig. 5. The residuals are non-correlated, as shown in Fig. 5, and the results are supported by the Ljung-Box test p-values (0.679, 0.935). Figure 6 shows the Pearson residuals cumulative periodogram, which shows how residuals are distributed randomly and without trend.
Figure 7 shows the result of the parametric re-sampling method. First, 5000 data sets with bootstrap sample size \(\varvec{n}=(46,48)\) are obtained using the fitted TRBH-INAR(1) model (with CML estimates of the parameters of each data set). Second, using the bootstrap samples, the ACF of each specific lag is calculated. The acceptance bounds \(100(0.975)\%\) and \(100(0.025)\%\) quantiles are shown as “\(+\)”, and the samples ACF are presented by “\(\bullet\)” symbols, in Fig. 7. According to Fig. 7, all of the sample autocorrelations were assigned between the acceptance boundaries, indicating that the model was adequate.

The Pearson residuals ACF for the two data sets

The Pearson residuals cumulative periodogram for the two data sets

The acceptance areas and the bootstrap ACF
5.2 Methods of Forecasting
To test the TRBH-INAR(1) model’s appropriateness and predictability, we present forecasts of the specified data sets using both the traditional and modified Sieve bootstrap approaches.
The k-step ahead classical predictor of the TRBH-INAR(1) model is represented as
where unknown parameters \(\alpha\) and \(\mu _{_Z}\) are substituted by the related CML estimates.
5.2.1 Modified Sieve Bootstrap Approach
The integer nature of the count data is not preserved by the classical predictor, despite the fact that the count time series is an integer. The Sieve bootstrap technique is a distribution-free predictor that preserves the integer nature of the count data. Hence, we modified the bootstrap approach proposed by Pascual et al. (2004) to apply for the TRBH-INAR(1) model via the following steps. Since \(\alpha *_{\theta }\left( \alpha *_{\theta }X\right) \overset{d}{\ne }\alpha ^{2}*_{\theta }X\), we can only provide the one-step modified Sieve bootstrap prediction.
-
1.
The thinning parameters \((\alpha ,\theta )\) are estimated based on the YW estimation approach.
-
2.
Compute residuals \({\hat{Z}}_{t}=X_{t}-{\hat{\alpha }}X_{t-1},\) for \(t=2,...,n\).
-
3.
The empirical distribution of the modified residuals \({\tilde{Z}}_{t}\) is provided, where \({\tilde{Z}}_{t}=\left[ {\hat{Z}}_t\right]\), and \([\cdot ]\) shows the nearest integer value.
-
4.
The bootstrap series \(X_{t}^{b}\) is given by
$$\begin{aligned} X_{t}^{b}={\hat{\alpha }}*_{{\hat{\theta }}} X_{t-1}^{b}+Z_{t}^{b}, \qquad b=1,\ldots ,B, \end{aligned}$$where B is the bootstrap sample size that was chosen to be \(B=500\), and \(Z_{t}^{b}\) is generated from the empirical distribution in step 3, for \(t=1,2,...,n\).
-
5.
The YW estimation of the parameters \(({\hat{\alpha }}_{{YW}},{\hat{\theta }}_{{YW}})\) is obtained by inserting the sample mean, variance, and solving the following equations
$$\begin{aligned} E\left( X_{t}\right) (1-\alpha )&= E\left( Z_{t}\right) \\ Var(X_{t})&= \dfrac{\alpha (\theta -\alpha )\mu ^2_{_Z}}{(1-\alpha )^2(1-\alpha \theta )}\\ &\quad +\,\dfrac{\alpha (\theta +1)\mu _{_Z}}{(1-\alpha )(1-\alpha \theta )} +\dfrac{\sigma ^2_{Z}}{1-\alpha \theta }. \end{aligned}$$ -
6.
Based on the sample means \({\hat{\alpha }}=\frac{1}{B}\sum _{i=1}^{B}{\hat{\alpha }}_{_{i,YW}}\) and \({\hat{\theta }}= \frac{1}{B}\sum _{i=1}^{B} {\hat{\theta }}_{_{i,YW}}\), the parameters \(\left( \alpha ,\theta \right)\) are estimated.
-
7.
The recursion method is used to acquire future bootstrap observations by the expression
$$\begin{aligned} {\hat{X}}_{t+1}^{b}={\hat{\alpha }}*_{{\hat{\theta }}}X_{t}^{b}+Z_{t+1}^{b}. \end{aligned}$$
The traditional and modified Sieve bootstrap predictions of the relevant data series, for which we know the observed values, are provided in Table 6 as a result of evaluating two prediction approaches. When there are zero or near-zero data demands, the symmetric mean absolute percent error (SMAPE) is applied to compare the forecast systems. The less SMAPE value leads to a better forecasting scheme. According to Table 6, the modified Sieve bootstrap predictors’ SMAPE values are lower than classical, and the modified Sieve bootstrap predictors are integers, which are consistent with the nature of actual data.
6 Conclusions
We provide a first-order integer-valued autoregressive [INAR(1)] time series model based on the transmuted record type-discrete Burr–Hatke (TRT-DBH) distribution, which is a more flexible version of the discrete Burr–Hatke distribution. The TRT-DBH distribution is proved to over-dispersed, asymmetric and leptokurtic. The hazard rate function of the proposed distribution has different shapes as monotone and unimodal. The applicability of the TRT-DBH distribution is demonstrated in time series modeling based on an INAR(1) model with TRT-DBH distributed innovations. Properties of the model are studied as well as different estimation approaches for the model parameters. The assessment of the properties and estimation approaches is conducted via some simulation studies. The adequacy of fit of the proposed INAR(1) model is checked via two clinical data sets, including the Covid-19 series and is compared with other competitive models. For both clinical data sets, we perform the residual analysis (Pearson residuals), as well as traditional and modified Sieve bootstrap forecasting methods.
References
Al-Osh MA, Aly EEAA (1992) First order autoregressive time series with negative binomial and geometric marginals. Commun Stat-Theory Methods 21:2483–2492
Al-Osh MA, Alzaid AA (1987) First-order integer-valued autoregressive (INAR(1)) process. J Time Ser Anal 8:261–275
Altun E (2020) A new generalization of geometric distribution with properties and applications. Commun Stat-Simul Comput 49(3):793–807
Altun E, Mamode Khan N (2021) Modelling with the Novel INAR(1)-PTE Process. Methodol Comput Appl Probab. https://doi.org/10.1007/s11009-021-09878-2
Alzaid AA, Al-Osh MA (1988) First-order integer-valued autoregressive (INAR(1)) process: distributional and regression properties. Stat Neerl 42:53–61
Alzaid AA, Al-Osh MA (1993) Some autoregressive moving average processes with generalized Poisson marginal distributions. Ann Inst Stat Math 45:223–232
Bahti D, Bakouch HS (2019) A new infinitely divisible discrete distribution with applications to count data modeling. Commun Stat-Theory Methods 48:1401–1416
Bakouch HS, Jazi AM, Nadarajah S (2014) A new discrete distribution. Statistics 48:200–240
Borges P, Bourguignon M, Molinares FF (2017) A generalized NGINAR(1) process with inflated parameter geometric counting series. Aust N Z J Stat 59:137–150
Bourguignon M, Vasconcellos KLP (2015) First order non-negative integer valued autoregressive processes with power series innovations. Braz J Probab Stat 29(1):71–93
Chakraborty S, Chakravarty D (2012) Discrete gamma distribution: properties and parameter estimation. Commun Stat-Theory Methods 41:3301–3324
Eliwa MS, El-Morshedy M (2021) A one-parameter discrete distribution for over-dispersed data: statistical and reliability properties with applications. J Appl Stat. https://doi.org/10.1080/02664763.2021.1905787
El-Morshedy M, Eliwa MS, Altun E (2020) Discrete Burr–Hatke distribution with properties, estimation methods and regression model. IEEE Access 8:74359–74370
Gómez-Déniz E, Calderín-Ojeda E (2011) The discrete Lindley distribution: properties and applications. J Stat Comput Simul 81(11):1405–1416
Huang J, Zhu F (2021) A new first-order integer-valued autoregressive model with Bell innovations. Entropy 323:713
Hussain T, Aslam M, Ahmad M (2016) A two parameter discrete Lindley distribution. Rev Colomb Estadíst 39(1):45–61
Jazi MA, Jones G, Lai CD (2012) Integer valued AR(1) with geometric innovations. J Iran Stat Soc 11:173–190
Karlis D, Xekalaki E (2005) Mixed Poisson distributions. Int Stat Rev 73(1):35–58
Karlsen H, Tjøstheim D (1988) Consistent estimates for the NEAR(2) and NLAR(2) time series models. J R Stat Soc. Ser B (Methodol), 50(2), 313–320
Kozubowski TJ, Podgórski K (2016) Transmuted distributions and random extrema. Stat Probab Lett 116:6–8
Liu Z, Zhu F (2021) A new extension of thinning-based integer-valued autoregressive models for count data. Entropy 23(1):62
Lívio T, Mamode Khan N, Bourguignon M, Bakouch SH (2018) An INAR(1) model with Poisson–Lindley innovations. Econ Bull 38(3):1505–1513
McKenzie E (1986) Autoregressive moving-average processes with negative binomial and geometric distributions. Adv Appl Probab 18:679–705
McKenzie E (1988) Some ARMA models for dependent sequences of Poisson counts. Adv Appl Probab 20:822–835
Miletić Ilić AV (2016) A geometric time series model with a new dependent Bernoulli counting series. Commun Stat-Theory Methods 45:6400–6415
Nastić AS, Ristić MM, Miletić Ilić AV (2017) A geometric time series model with an alternative dependent Bernoulli counting series. Commun Stat-Theory Methods 46(2):770–785
Nekoukhou V, Alamatsaz MH, Bidram H (2013) Discrete generalized exponential distribution of a second type. Statistics 47(4):876–887
Pascual L, Romo J, Ruiz E (2004) Bootstrap predictive inference for ARIMA processes. J Time Ser Anal 25(4):449–65
Qin J, Lawless J (1994) Empirical likelihood and general estimating equations. Ann Stat 22(1):300–325
Ristić MM, Bakouch HS, Nastić AS (2009) A new geometric first-order integer-valued autoregressive (NGINAR(1)) process. J Stat Plan Inference 139:2218–2226
Ristić MM, Nastić SA, Miletić Ilić VA (2013) A geometric time series model with dependent Bernoulli counting series. J Time Ser Anal 34(4):423–516
Sellers KF, Shmueli G (2010) A flexible regression model for count data. Ann Appl Stat 4(2):943–961
Sellers KF, Borle S, Shmueli G (2012) The COM-Poisson model for count data: a survey of methods and applications. Stat Qual, Ind Technol 28(2):104–116
Shakil M, Ahsanullah M (2011) Record values of the ratio of Rayleigh random variables. Pak J Stat 27:307–325
Shamma N, Mohammadpour M, Shirozhan M (2020) A time series model based on dependent zero inflated counting series. Comput Stat 35:1737–1757
Shirozhan M, Mohammadpour M, Bakouch HS (2019) A new geometric INAR(1) model with mixing Pegram and generalized binomial thinning operators. Iran J Sci Technol, Trans A: Sci 43:1011–1020
Shmueli G, Minka TP, Kadane JB, Borle S, Boatwright P (2005) A useful distribution for fitting discrete data: revival of the Conway–Maxwell–Poisson distribution. J Appl Stat 54:127–142
Steutel FW, van Harn K (1979) Discrete analogues of self-decomposability and stability. Ann Probab 7:893–899
Weiß CH (2008) Thinning operations for modeling time series of count—a survey. AStA Adv Stat Anal 92:319–341
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no relevant financial or non-financial interests to disclose.
Appendix A: The Proof of Proposition 2
Appendix A: The Proof of Proposition 2
-
(i)
The model’s conditional expectation is calculated as follows:
$$\begin{aligned} E(X_t\mid X_{t-1})&= \alpha X_{t-1}+\mu _{_Z}, \\ E(X_{t}\mid X_{t-2})&= E(E(X_{t}\mid X_{t-1})\mid X_{t-2})\\&= \alpha ^{2}X_{t-2}+(1+\alpha )\mu _{_Z}. \end{aligned}$$So, it is induced via the induction that
$$\begin{aligned} E(X_{t}\mid X_{t-k})=\alpha ^{k}X_{t-k}+\frac{(1-\alpha ^{k})\mu _{_Z}}{1-\alpha }, \end{aligned}$$which is a linear function of \(X_{t}\).
-
(ii)
Based on Remark 1, the conditional variance of the TRBH-INAR(1) process is computed as
$$\begin{aligned} Var\left( X_{t}\mid X_{t-1}\right)&= Var\left( \alpha *_{\theta }X_{t-1}\mid X_{t-1}\right) +Var(Z_t)\\&= \alpha (\theta -\alpha )X_{t-1}^{2}+\alpha (\theta +1)X_{t-1}+\sigma ^2_{Z}, \end{aligned}$$and
$$\begin{aligned} Var\left( X_{t}\mid X_{t-2}\right)&= E\left( Var\left( X_{t}\mid X_{t-1}\right) \mid X_{t-2}\right) \\ &\quad +\,Var\left( E\left( X_{t}\mid X_{t-1}\right) \mid X_{t-2}\right) \\&= \alpha (\theta -\alpha )E\big (X_{t-1}^{2}\mid X_{t-2}\big )+\alpha (\theta +1)E\big (X_{t-1}\mid X_{t-2}\big )\\ &\quad +\,\sigma ^2_{Z}+\alpha ^2 Var\left( X_{t-1}\mid X_{t-2}\right) \\&= \alpha \theta Var\left( X_{t-1}\mid X_{t-2}\right) +\alpha (\theta -\alpha )E^{2}\big (X_{t-1}\mid X_{t-2}\big )\\ &\quad +\,\alpha (\theta +1)E\big (X_{t-1}\mid X_{t-2}\big )+\sigma ^2_{Z} \\&= \alpha ^2 (\theta ^2 -\alpha ^2 )X_{t-2}^{2}+\alpha ^2 (\theta +1)^2 X_{t-2}\\ &\quad +\,2\alpha ^2(\theta -\alpha )\mu _{_Z} X_{t-2}\\ &\quad \,+\alpha (\theta +1)\mu _{_Z}+\alpha (\theta -\alpha )\mu ^2_{_Z}+(1+\alpha \theta )\sigma ^2_{Z}, \end{aligned}$$subsequently
$$\begin{aligned} Var\left( X_{t}\mid X_{t-3}\right)&= \alpha ^3 (\theta ^3-\alpha ^3 )X_{t-3}^{2}\\ &\quad +\,\alpha ^3 (\theta +1)(1+\theta +\theta ^2) X_{t-3}\\ &\quad +\,2\alpha ^3 \Big ((\theta -\alpha )+(\theta ^2-\alpha ^2)\Big )\mu _{_Z} X_{t-3}\\ &\quad +\,\alpha (\theta +1)\Big (1+\alpha (1+\theta )\Big )\mu _{_Z}\\ &\quad +\,\Big [\alpha (\theta -\alpha )+\alpha ^2(\theta ^2-\alpha ^2)\Big ]\mu ^2_{_Z}\\ &\quad +\,2\alpha ^2(\theta -\alpha )\mu ^2_{_Z}+(1+\alpha \theta +\alpha ^2\theta ^2)\sigma ^2_{Z} . \end{aligned}$$By induction, we can conclude that
$$\begin{aligned} Var(X_{t}\mid X_{t-k})&= \alpha ^k\left( \theta ^k-\alpha ^k\right) X_{t-k}^{2}+\alpha ^{k}(1+\theta ) \sum _{i=0}^{k-1}\theta ^i X_{t-k}\\ &\quad +\,2\mu _{_Z} \alpha ^k \sum _{i=0}^{k-1}\Big (\theta ^i-\alpha ^i\Big ) X_{t-k}\\ &\quad +\,\mu _{_Z}(1+\theta )\sum _{i=1}^{k-1}\alpha ^i\sum _{j=0}^{i-1}\theta ^j \\ &\quad +\,\mu ^2_{_Z}\sum _{i=0}^{k-1}\alpha ^i \Big (\theta ^i- \alpha ^i\Big )\\ &\quad +\,2\alpha \mu ^2_{Z}\sum _{i=1}^{k-1}\alpha ^i\sum _{j=1}^{i}\Big (\theta ^j-\alpha ^j\Big )\\ &\quad +\,\sigma ^2_{Z}\sum _{i=0}^{k-1} (\alpha \theta )^i. \end{aligned}$$After some elementary calculations, the proof is complete.
-
(iii)
The proof is unimportant and may be ignored.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shirozhan, M., Mamode Khan, N.A. & Bakouch, H.S. An INAR(1) Time Series Model via a Modified Discrete Burr–Hatke with Medical Applications. Iran J Sci 47, 121–136 (2023). https://doi.org/10.1007/s40995-022-01387-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40995-022-01387-2