
Abstract
A comprehensive understanding of the multifaceted ramifications of the coronavirus disease 2019 (COVID-19) on transit ridership is imperative for the optimization of judicious traffic management policies. The intricate influences of this pandemic exhibit a high degree of complexity, dynamically evolving across spatial and temporal dimensions. At present, a nuanced understanding remains elusive regarding whether disparate influencing factors govern inbound and outbound passenger flows. This study propels the discourse forward by introducing a methodological synthesis that integrates time series anomaly detection, impact inference, and spatiotemporal analysis. This amalgamation establishes an analytical framework instrumental in elucidating the spatiotemporal heterogeneity intrinsic to individual impact events, grounded in extensive time series data. The resulting framework facilitates a nuanced delineation, affording a more precise extraction of the COVID-19 impact on subway ridership. Empirical findings derived from the daily trip data of the Beijing subway in 2020 substantiate the existence of conspicuous spatiotemporal variability in the determinants influencing relative shifts in inbound and outbound ridership. Notably, stations situated in high-risk areas manifest a conspicuous absence of correlation with outbound trips, exhibiting a discernibly negative impact solely on inbound trips. Conversely, stations servicing residential and enterprise locales demonstrate resilience, evincing an absence of significant perturbation induced by the outbreak.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Coronavirus disease 2019 (COVID-19) has spread widely since January 2020 [1], bringing great challenges to people's lives. The pandemic had a considerable effect on transportation [2]. Since the transmission and impact of the virus were unknown at the beginning of the epidemic, many studies have examined how travel behaviours changed during the lockdown phase and reopening phase [3,4,5]. It is necessary to understand the spatial and temporal differences in the impact of the epidemic on ridership when formulating management policies and adjusting transport capacity during the epidemic [6].
Most research analyzing travel behaviour typically assumes globally stationary regression coefficients for independent variables, commonly employed in methods such as ordinary least squares (OLS) or structural equation modelling (SEM) [7, 8]. Although the local regression model has advantages in solving the spatial autocorrelation and stationarity of passenger data, it is rarely used in practical applications and verifications [9]. To the best of our knowledge, there is still a gap in the research on accounting for both temporal nonstationarity and spatial characteristics during the epidemic period. In addition, research during the epidemic period focused on comparing the characteristics of passenger volume during weekdays and weekends, peak periods and off-peak periods [3, 6, 10], and only a few studies have explored both inbound and outbound situations.
Beijing, as the capital city of China, stands as one of the world's most populous urban centres, boasting a population exceeding 21 million individuals in 2020. The Beijing Subway, a critical component of the city's transportation infrastructure, plays an indispensable role in facilitating travel for residents, commuters, tourists, and various other demographics. With its extensive network comprising multiple lines and stations, the Beijing Subway serves as a lifeline for daily commuting and addresses the diverse travel needs of the populace. However, the enclosed nature of subway carriages, stations, and underground platforms, combined with high passenger volumes, presents a risk of clustered virus outbreaks [11]. Against the backdrop of the COVID-19 pandemic, understanding its implications on subway passenger flow in Beijing is of utmost importance. Based on data from the Beijing Subway, this study investigated whether there were any temporal and spatial heterogeneities in subway passenger flow during the epidemic period. This study enriches the current understanding of the response to subway ridership during the epidemic period. Specifically:
-
1.
This study delves into the association between the oscillation in Beijing subway ridership and the COVID-19 epidemic in 2020, discerning pivotal moments conducive to a detailed analysis of the epidemic's influence from the time series data.
-
2.
Employing a Bayesian structural time series (BSTS) model for each station, the analysis involves the computation of counterfactual passenger numbers, facilitating a rigorous quantification of the epidemic's impact on passenger flow dynamics.
-
3.
A comprehensive examination of influencing factors, encompassing land use characteristics, epidemic attributes, and weather conditions, is undertaken to gain a nuanced understanding of the determinants affecting ridership. The identification of key contributing variables influencing inbound and outbound flows during the epidemic period is achieved through a stepwise regression model.
-
4.
The investigation into the spatiotemporal heterogeneity of the impact on inbound and outbound passenger flows during the epidemic period is conducted using a geographically and temporally weighted regression (GTWR) model.
The ensuing sections of this manuscript are structured as follows. Section 2 furnishes a comprehensive survey of the existing literature pertaining to the repercussions of COVID-19 on transportation systems. Section 3 delineates the dataset employed in this investigation. Section 4 expounds upon the methodologies applied in this study. The primary findings are elucidated in Sect. 5, succeeded by the discourse and conclusions expounded upon in Sect. 6.
2 Literature Review
Over the past few years, the pervasive global dissemination of COVID-19 has led to a marked reduction in the utilization of public transportation [12]. There has been a concerted effort to quantify the repercussions of COVID-19 on public transport ridership. Notably, Liu and Stern [4] affirmed the substantial impact of the COVID-19 pandemic and the "stay at home" directives on traffic volume. Specifically, in urban areas of Minnesota, traffic was 50% lower than historical baseline traffic at the start of stay-at-home orders. Hu and Chen [13] identified a pronounced impact of the COVID-19 epidemic on transfer stations, with bus passenger volume experiencing an average decline of 72.4%. Fang et al. [14] conducted a comprehensive analysis, employing the difference-in-differences (DID) model to quantify the causal impact of the closure of Wuhan city on January 23, 2020, considering panic, virus, and Spring Festival effects on the flow of people. Interestingly, previous studies have investigated the influence of a range of other factors on travel behaviour. Wang et al. [15] employed a linear mixed model to investigate the impact of COVID-19 on travel to eight types of destinations. Brough et al. [16] identified significant associations between transit ridership during the pandemic and sociodemographic characteristics, education level, and household income. Utilizing a partial least squares (PLS) regression model, Hu and Chen [13] assess sociodemographic factors and land use characteristics that might explain this decline. Liu et al. [3] employed a stepwise multiple regression method to quantify the impact of various factors, such as population migration index, population migration rate, socioeconomic indicators, and epidemic statistic indicators, on vehicle traffic after reopening.
The investigation of factors influencing passenger flow in urban rail transit has been a recurring theme in scholarly inquiries. Multiple studies have substantiated the notable impact of building environment factors on passenger flow [17,18,19,20,21]. These variables have further revealed associations with individuals' travel behaviour, particularly during the COVID-19 pandemic [22,23,24]. Additionally, inquiries have delved into the intricate relationship between weather conditions and passenger flow [25]. Singhal et al. [26] found that precipitation is positively correlated with subway passenger flow. Li et al. [27] found that the impact of climate on bus passenger flow varies with time, and confirmed that meteorological variables can affect the fluctuation of daily subway ridership. Weather variables, encompassing precipitation, temperature, and wind speed, have undergone extensive consideration [28]. Lin et al. [29] conducted a comprehensive analysis, considering the interplay between weather conditions and the built environment's impact on public transport ridership. Moreover, some scholars have investigated the influence of weather variables on transport movements during the COVID-19 epidemic. In efforts to analyse the impact of the COVID-19 outbreak on travel, specific researchers have endeavoured to control for weather variables [30, 31]. When investigating factors influencing urban rail transit passenger flow, the fare system may affect passenger patterns by influencing both the economic burden on passengers and the accessibility of public transportation, with existing research highlighting the importance of fare policies in meeting supply and demand [32,33,34]. During the COVID-19 pandemic, three Chinese cities, Hangzhou, Ningbo, and Xiamen, implemented fare-free policies to attract passengers back to public transport. Dai et al. [35] utilized the synthetic control method (SCM) to assess the impact of post-COVID-19 era fare-free policies on subway passenger volume. The adjustment of fare policies had varying effects on passenger travel behaviour across different cities. However, since Beijing did not implement any fare adjustment policies during the pandemic, this study does not consider the impact of fare policies.
In terms of research methodologies, regression models stand out as the predominant analytical tools, classified into two primary categories: global regression and local regression. The ubiquity of global regression models, exemplified by ordinary least squares (OLS), stems from their recognized flexibility, simplicity, and broad applicability [36, 37]. Fotheringham et al. [38] proposed the geographically weighted regression (GWR) model as an alternative, acknowledging the limitations of global regression models when grappling with spatial data. Recently, the existence of spatial heterogeneity in ridership has been widely recognized [39], leading to an escalating trend in the utilization of GWR models [40]. Local regression methods, rooted in geographic location, have demonstrated superior fitting results compared to structural equation modelling (SEM), spatial lag models (SLM), and OLS models [39]. Li et al. [41] utilized points of interest (POIs) to identify fine-scale land use types and, employing the GWR model, explored the spatial variation in built environment impacts on rail transit passenger traffic. Moreover, temporal nonstationarity may be present in station-level ridership, given its time sensitivity and historical influence. The GWR model, while effective in capturing spatial effects, often requires data summarization or averaging over specific periods and may not address temporal nonstationarity simultaneously. Addressing this gap, Huang et al. [42] introduced the geographically and temporally weighted regression (GTWR) model as an extension of the GWR model, proficient in accommodating both spatial and temporal local effects. Ma et al. [43] pioneered its application to analyse the spatiotemporal relationship between bus stop-level ridership and the built environment. Although Li et al. [44] explored the accessibility of subway stations and its impact on spatiotemporal variation in outbound ridership, the comprehensive application and validation of the GTWR model in the study of subway station-level ridership and its influencing factors remain incomplete.
Not only have the methods improved, but there has also been a significant shift in the data sources utilized in urban transportation research. Traditionally, researchers have heavily relied on survey data to understand travel behaviour [45]. However, with advancements in technology, particularly the widespread adoption of smart card systems in public transportation, there has been a transition towards utilizing smart card data for more accurate and comprehensive analyses. Smart card data offer several advantages over traditional surveys, including higher granularity, real-time tracking, and reduced respondent burden. By capturing actual travel patterns and behaviours within the transit system, smart card data provide researchers with a more detailed understanding of passenger movements and preferences [46, 47]. This transition has facilitated more precise and scientific analyses of factors influencing passenger flow.
Based on the aforementioned studies, it is evident that investigating travel behaviour during the epidemic period holds significant importance, highlighting the spatiotemporal heterogeneity inherent in travel behaviour. However, preceding investigations predominantly operated under the assumption that alterations in passenger flow over time and space were static, neglecting the consideration of spatiotemporal nonstationarity.
This paper endeavours to identify representative cases during COVID-19 outbreaks, quantify the epidemic's impact on various stations, and introduce geographic and time-weighted regression models. The objective is to meticulously probe into the heterogeneity characterizing the epidemic's influence on passenger flow at distinct stations, thereby enriching our understanding of the intricate effects.
3 Data and Data Preprocessing
3.1 Study Area
The Beijing Urban Rail Transit, widely known as the Beijing Subway, serves as an efficient mass transit system catering to the exigencies of a resident population exceeding 20 million. It stands as one of the most extensive and bustling urban rail networks on a global scale, boasting a comprehensive expanse that exceeded 630 km, featuring a constellation of 20 lines, as of the end of 2019.
3.2 Data
3.2.1 Beijing Subway Smart Card Data
The ridership statistics dataset consists of the hourly inbound and outbound ridership data for 338 subway stations, obtained directly from the Beijing Subway Operation Co., Ltd. We gathered data on the number, latitude and longitude, and hourly inbound and outbound passenger flow for these stations from 1 January 2019 to 31 December 2020. It is important to note that this dataset does not contain any personal information.
3.2.2 COVID-19
Information on COVID-19, including the number of new confirmed cases, new deaths, and the locations of risk areas (areas where confirmed cases were located), was collected from the official websites of the Beijing Health Commission and the Beijing Center for Disease Control and Prevention. Information on policy interventions was gathered from the official website of the Beijing Municipal People's Government (http://www.beijing.gov.cn). For instance, in response to the development of COVID-19, Beijing took actions including emergency responses and gradual return to work in response to COVID-19 developments.
Based on the location of the confirmed cases and the degree of transmission risk, the districts, communities, and streets (townships) to which they were near were divided into high-risk areas and medium-risk areas when there was a local epidemic in Beijing. It is noteworthy that in our study, we categorize both high-risk areas and medium-risk areas as "risk areas." This decision arose from our preliminary exploratory analysis, which revealed a strong correlation between medium-risk and high-risk areas, despite our efforts to standardize or normalize preprocessing techniques. This correlation may be attributed to their shared geographical characteristics and the implementation of similar preventive measures against infectious outbreaks. By consolidating them under a single designation, our aim was to streamline analysis, prevent the exclusion of any variable, and ensure a comprehensive representation of risk levels. This approach enhances the interpretability and applicability of our model. The shortest distance between the Beijing subway station and the COVID-19 risk area was calculated using a geographic information system platform (ESRI ArcGIS Desktop suite), as shown in Fig. 1. In our study, distance calculation is approached in two scenarios: when a subway station is located within a risk area, the distance is set to 0; when the station is outside the risk area, the distance is computed as the straight-line distance from the station to the boundary of the risk area. This methodology allows for an assessment of proximity to risk areas, considering both direct spatial relationships and the influence of risk zones on subway ridership patterns.

Location of COVID-19 risk areas and Beijing subway stations
3.2.3 The Built Environment
The built environment around subway stations has generally been described by the number of POIs within walking distance (500 m) of the station in many previous studies [48, 49]. POI data, which include information such as name, address, latitude, and longitude, were collected from AMAP API (https://lbs.amap.com/api/webservice/guide/api/search), one of the most popular location service providers in China. A total of 1,340,500 POI data points were obtained. Specifically, some POI categories had to be removed or reclassified. For example, information on place names refers to commonplace names (province, city, district names), natural place names (mountains, rivers, or lakes), and events (festivals, natural disasters) that are not built environments.
Therefore, to standardize the size of the data and to avoid duplication, as many large facilities as possible were selected, including factories, industrial parks, shopping centres, universities, general hospitals, and gymnasiums, which were finally divided into 14 categories, as shown in Table 1.
3.2.4 Weather Conditions
Undoubtedly, weather conditions are inherently intertwined with the propensity for travel. Positioned in the northeastern corner of the North China Plain, Beijing boasts a continental climate marked by hot, humid summers and cold, dry winters. Notably, the city is susceptible to robust winds, particularly during sandstorms originating from the Gobi Desert that can sweep through the urban landscape. Our weather data were obtained from the National Meteorological Information Center based on ground observation stations. The meteorological data of each subway station are based on the data of the weather station with the shortest straight-line distance from it. This dataset encompasses four key meteorological parameters, namely temperature (°C), visibility (m), wind speed (m/s), and accumulated precipitation (mm).
3.2.5 Calendar Events
Holiday events were taken into consideration, acknowledging the distinct nature of travel during these special periods. The holidays encompassed both traditional holidays (including the Spring Festival, Tomb-Sweeping Day, Dragon Boat Festival, and Mid-Autumn Festival) and nontraditional holidays (such as New Year’s Day, May Day, and National Day). Figure 2 shows the distribution of all holidays in 2020.

Holiday distribution in 2020
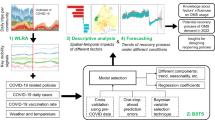
4 Methodology
The framework of this study is shown in Fig. 3. Studying subway ridership during the pandemic and exploring the underlying causes of spatiotemporal heterogeneity includes the following main components:
-
1.
The time series anomaly detection model identifies key moments where passenger flow changed dramatically. Our dataset covers a long time series. Anomaly detection of the time series allows the selection of typical events that are most sensitive to ridership fluctuations during the COVID-19 period, providing the basis for more detailed analysis.
-
2.
The BSTS model is utilized to estimate subway ridership in the absence of pandemic occurrences, and these estimations are compared with historical baseline data to assess the impact of the pandemic on passenger dynamics.
-
3.
In the stepwise regression model, with the relative impact of inbound and outbound passenger traffic as the dependent variable, from a group of variables that have a potential impact on subway passenger flow, the most significant contributing factors are selected through significance testing and multicollinearity analysis factors.
-
4.
The GTWR model analyses the spatial and temporal heterogeneity of contributing factors in the change in passenger flow at subway stations. The GTWR model was used to measure the spatiotemporal heterogeneity of each major contributing factor with subway ridership in response to the pandemic.

Research methodology framework
4.1 Anomaly Detection
In datasets covering a long period, holidays are inevitable disruptions. This study aimed to identify the typical events that were most sensitive to fluctuations in ridership during the COVID-19 epidemic.
In this study, we employ a probabilistic Bayesian offline change point detection model for anomaly detection. This model has been selected for several compelling reasons:
Firstly, the Bayesian solution provides the posterior distributions of model parameters, elucidating the likelihood that the detected transition is indeed a ‘real’ change point [50]. The probabilistic nature of the model facilitates the interpretation of results, providing insights into the underlying processes driving observed changes in the data. Secondly, Erdman and Emerson [51] proposed an innovative model incorporating a Markov chain Monte Carlo (MCMC) approximation, mitigating the computational load associated with change point detection, especially for long data series with many change points [52]. Grounded in a Bayesian framework and utilizing MCMC methods, the model offers robust inference capabilities, capable of accommodating diverse data structures and levels of uncertainty. Finally, the model's robust performance in detecting change points in time series data has been extensively validated and applied across various domains, establishing its effectiveness. The ‘bcp’ R package, developed based on this model, is utilized in this study [53].
In the context of Bayesian change point detection models, the observed data \(X\) refers to the time series dataset under investigation. Specifically, \(X\) is a vector containing \(n\) observations, denoted as \(X = \{ x_{1} ,x_{2} , \ldots ,x_{n} \}\) . Each \(x_{i}\) represents an individual observation in the time series, and they are typically arranged in chronological order. A set of indicator variables \(U = (U_{1} ,U_{2} , \ldots ,U_{n} )\) is introduced to signify the presence of change points at each location \(i + 1\) in the time series, where \(U_{i}\) takes the value of 1 if a change point is present and 0 otherwise. It is assumed that the data within different segments are independently and identically distributed, with stable statistical properties within each segment but potentially varying properties across segments.
The objective is to infer the latent variables \(U\), representing change point locations, from the observed data \(X\). Establishing the relationship between the observed data and the latent variables is crucial, thus introducing the concept of joint probability distribution, expressed as
Here, the conditional probability \(p(X|U)\) expresses the probability of observing the data given the change point locations, also known as the likelihood function. The likelihood function encapsulates the probability of observing the data under a specific set of change point locations. The prior distribution \(p(U)\) represents assumptions about the presence of change points before observing the data. Bayesian inference aims to derive the posterior distribution of the latent variables \(U\) given the observed data \(X\), denoted as \(p(U|X)\). This posterior distribution captures the probability distribution of change point locations after incorporating the observed data.
However, directly calculating the posterior distribution is often computationally infeasible due to model complexity. Hence, Markov chain Monte Carlo (MCMC) methods are employed for approximating the posterior distribution. A value of \(U_{i}\) is taken at each stage of the Markov chain from the current partition for each location \(i\) and the conditioned distribution \(U_{i}\) of the provided data. Using the simplified ratio presented in [53], one may compute the transition probability, \(p\), which is the conditional likelihood of a shift at location \(i + 1\).
where b represents the number of blocks acquired for \(i \ne j\) when \(U_{i} = 0\) is conditional on \(U_{j}\). The data are denoted by \(X\), the similarity definitions \(W_{1}\) and \(B_{1}\) are the similarity definitions when \(U_{i} = 1\), and \(w_{0}\) is the intrablock sum of squares. \(B_{0}\) represents the between-block sum of squares obtained when \(U_{i} = 0\). The parameters \(p_{0}\) and \(w_{0}\) are prespecified numbers in \([0,1]\) that give a constraint on the ranges of p and w. When there are little changes (when \(p\) is small) and minor changes in magnitude (when \(w\) is small), the model performs best. As conditioned means for the present partition, its posterior means are revised following each MCMC iteration.
4.2 Bayesian Structural Time Series Model for Intervention Analysis
The BSTS model offers a robust solution for estimating the impact of the COVID-19 pandemic amidst challenges posed by various influencing variables such as weather, holidays, and seasonality. Its flexible model structure accommodates multiple time-sensitive covariates, including seasonality and holidays, enabling simulation of counterfactual scenarios to infer the pandemic's impact [5, 54]. We believe that the flexibility of the BSTS model enables it to capture other influencing factors in passenger flow dynamics, such as seasonal variations, weather, and holidays, thereby aiding in isolating the impact of the pandemic. Additionally, previous studies have also emphasized the reliability of Bayesian structural time series analysis in quantifying changes in transportation activities following the outbreak of COVID-19 [5, 13, 54,55,56].
The parameters of the BSTS model are deduced from observed data under previous specifications [22, 57]. Three parts make up the BSTS model: Kalman filtering to evaluate the trend and seasonality of the time series, Bayesian averaging of the best-performing models to provide final predictions, and spike and slab regression for variable selection [58]. The following illustrates the model's fundamental structure:
Equation (2) represents the observation equation in which yt is the observed daily ridership on day \(t\); \(\alpha_{t}\) presents the latent variable's state vector; \(Z_{t}\) represents the link vector connecting observable and latent variables; and \(\varepsilon_{t}\) stands for the Gaussian-distributed system errors and independent observation errors with noise variances \(\sigma_{t}\). The state equation is expressed in Eq. (3), where \(T_{t}\) represents the transition matrix defining the development of the state vector \(\alpha_{t}\), and \(\eta_{t}\) is the system errors of the independent observations and the system errors according to Gaussian distributions with associated noise variances.
With the use of Kalman filters, the time series may be divided into four parts: the level, the local tendency, seasonal influences, and error terms. Here is how the fundamental structural time series model is defined. For more detailed information, refer to Scott and Varian [59].
Based on Bayesian inference, we estimate that the relative impact of COVID-19 on station passenger flow can be regarded as the rate of change between actual passenger flow and counterfactual passenger flow (BSTS model results). The BSTS model function utilized in this study is implemented using the ‘bsts’ R package [59], a statistical tool specifically designed for Bayesian structural time series modelling. The relative impact (RI) can be formulated as follows:
where \(RI\) is the relative impact, \(y_{t}\) is the real ridership, and \(\hat{y}_{t}\) is the predicted ridership. The reliability of the results is evaluated using two key indicators, the mean absolute percentage error (MAPE) and the root mean square error (RMSE), to gauge the effectiveness of the model.
4.3 Geographically and Temporally Weighted Regression
Regression models on a global scale, exemplified by OLS models, maintain constant relationships between dependent variables and independent variables. However, GWR models allow these relationships to vary spatially to reflect the non-smoothness of parameters in spatial settings. The following is a description of a GWR model's fundamental expression:
where \(k\) is the total number of parameters that need to be estimated, and \(n\) is the number of samples that need to be observed. For each observation \(i\), \(X_{ik}\) stands for the \(kth\) explanatory variable, and \(Y_{i}\) for the response variable. The coordinates of point i in space are shown by \((u_{i} ,v_{i} )\). The regression coefficient,\(\beta_{0} (u_{i} ,v_{i} )\) is the value of the intercept, and \(\beta_{k} (u_{i} ,v_{i} )\) indicates how much the explanatory variable \(X_{ik}\) influences the dependent variable \(Y_{i}\). The error term for location \(i\) is \(\varepsilon_{i}\).
The GTWR model, which integrates both spatial and temporal details into a weighted matrix, is an extended version of the GWR model that takes into account both spatial and temporal heterogeneity in the actual data [60]. In this way, the model of the GTWR may be represented in the following way:
The space-time coordinates of observation \(i\) are represented by the expression \((u_{i} ,v_{i} ,t_{i} )\), where \(t_{i}\) is the projected temporal coordinate, and \(u_{i}\) and \(v_{i}\) are the projected spatial coordinates; The \(\beta_{k} (u_{i} ,v_{i} ,t_{i} )\) and \(\beta_{0} (u_{i} ,v_{i} ,t_{i} )\) are similar to the parameters in the GWR model. Based on local weighted least squares, the estimated coefficient \(\beta_{0} (u_{i} ,v_{i} ,t_{i} )\) at each space-time observation \(i\) is represented as follows:
The space-time weight matrix is represented by \(W(u_{i} ,v_{i} ,t_{i} ) = diag(w_{i1} ,w_{i2} , \cdots ,w_{in} )\) , and its diagonal elements \(w_{ij} (1 \le j \le n)\) are the weights given to the observation point \(j\) adjacent to the observation point \(i\). In the GTWR model, \(w_{ij}\) is a space-time distance decay function. Functions based on Gaussian distance decay are one of the typical functions of spatial autocorrelation; Consequently, the Gaussian kernel function is the weighting function that is most frequently utilized [61].
where \(h\) is the bandwidth parameter estimation that controls the radial influence's range. To choose the ideal bandwidth in practice, a goodness-of-fit criterion like cross-validation or the Akaike information criterion (AIC) is typically employed. \(d_{ij}^{ST}\) is the space-time distance, measuring the proximity of observations \(i\) and \(j\). It is defined as a linear combination of the temporal distance \(d_{ij}^{T}\) and the spatial distance \(d_{ij}^{S}\)[42] and can be depicted as follows:
where the scale parameters \(\lambda\) and \(\mu\), respectively, are used to balance the spatial and temporal impacts. In practice, cross-validation is another method for obtaining the optimal scale parameters.
The GTWR model is used in this study to investigate the spatiotemporal relationship between the spread of COVID-19 and changes in Beijing Subway ridership. The GTWR model was implemented using GTWR-Addins [42], a software package that can be installed and run on ArcGIS. This procedure can automatically complete the selection of optimal parameters through cross-validation. The dependent variable \(Y_{i}\) represents the change in ridership affected by COVID-19, which is the relative impact mentioned in Sect. 4.2. For independent variables, a stepwise regression model is used to select significant variables from all possible latent variables [10]. In order to identify possible high correlations between independent variables , a multicollinearity test is also carried out using the variance inflation factor (VIF) value. Variables with VIFs above 10 were removed from the sample; Moran's I was used to quantify spatial correlation.
5 Results
5.1 Key Moments Identified
The inbound and outbound passenger volumes of each station of the Beijing Subway in 2020 were analysed, and the results were roughly similar, as shown in Fig. 4. The advantages of the Bayesian change point detection model are evident, as we can visually observe the probability of each point being a change point on the graph, enabling a more scientific and convenient selection of typical cases. The passenger flow changed significantly three times in 2020: on January 22, June 12, and October 8. Changes were also noticeable on May 5 and October 1.

Results of anomaly detection
When contrasting with holidays, it became apparent that other fluctuations were influenced by holiday effects. Consequently, June 12 stood out as the most likely candidate for significant key case. Subsequently, we corroborated this observation by cross-referencing it with the epidemiological data we had collected previously. The drastic change in ridership we observe on June 12, 2020, was not due to a holiday or bad weather but rather to the impact of the epidemic, as shown in Fig. 5. One new confirmed case was reported in Beijing on June 11, breaking the 56-day streak without new confirmed cases. Considering that June 25 was the Dragon Boat Festival, it is difficult to distinguish between the holiday and the impact of the epidemic. Therefore, a more detailed analysis of the selected period around June 12, 2020, will be conducted (2020-6-11 to 2020-6-24).

Daily ridership before and after 2020-6-12
It is worth noting that in June 2020, Beijing experienced a COVID-19 epidemic related to the Xinfa market. This event garnered significant attention from local authorities and received widespread coverage both domestically and internationally. The COVID-19 impact discussed in this work specifically refers to the outbreak at the Xinfa market.
5.2 Inferring the Impact of COVID-19
The analysis in the preceding section leads to the conclusion that the research timeframe is crucial for determining the actual value of the epidemic’s impact. Hence, we further investigated the key moments discovered utilizing anomaly detection to better estimate the impact of the pandemic.
According to Hu and Chen [13], employing ridership data from 2019 directly as a baseline may lack robustness due to the unsmooth, incomplete, and noisy nature of the time series in that year. By using the ridership predictions from the BSTS model for 2020, the gaps are filled, and noisy fluctuations are removed.
Considering that Beijing resumed business and work on 10 February 2020, lifting strict measures, the epidemic gradually stabilized, and residents' daily travel gradually returned to normal, which represented a new beginning [62]. Therefore, for the inbound and outbound volume of each station of the Beijing Subway, we use the time series before the second outbreak of COVID-19 (2020-2-10 to 2020-6-10) as training data to fit the BSTS model. The fitting results are ideal, and the average RMSE and MAPE values of all station inbound volumes are 826.448 and 12.843, respectively, which are considered acceptable.
Figure 6 shows the COVID-19 impact calculation for a station. The actual daily passenger flow is shown by the solid line in Fig. 6a, while the expected daily volume of passengers is represented by the dotted line. Figure 6b shows the difference between the point-wise true ridership and the forecasted result. Based on Eq. (5), Fig. 6c illustrates the relative effect, which is the point-wise difference divided by the predicted ridership.

Calculation process of the impact of COVID-19
A negative impact of COVID-19 on ridership (RI < 0) was observed for all subway stations during the study period. In the previous sections, the epidemic's effects were examined from a time perspective. As shown in Fig. 7, we separated the relative effect into quartiles to depict the geographical distribution of the impact on stations to investigate the spatial impact of the epidemic. Figure 7a shows that the stations at the end of the line were initially affected by the pressure effect; then, over time, the stations in the central area were more strongly affected (Fig. 7b). Before government measures were implemented (2020-6-16) (Fig. 7c), the stations most affected by ridership were concentrated near the outbreak. As shown in Fig. 7d, the fluctuations in passenger flow did not change significantly in space and could be considered to have entered a relatively stable state, with a time lag in the lifting of the policy.

Spatial distribution of daily ridership changes after 2020-6-12
5.3 Identified Contributors to the Relative Impact of COVID-19
Based on previous studies and available data, potential independent variables were identified for the subsequent regression models. Table 2 summarizes the potential independent variables for station-level ridership.
We noticed that there are infinite values in the distances in Table 2. When applying regression models, handling infinite values prevents them from adversely affecting model performance. A common approach is to replace them with a large finite value or exclude them from the model. Here, we apply an exponential decay transformation function, which allows the distances to better fit the actual distribution of data features, thereby enhancing the model's ability to model distance features.
New confirmed cases and weather variables are temporal variables, and there is no need to take their spatial autocorrelation into account [63]. The VIF value, P value, and Moran’s index were used to assess the stepwise regression model's output, and variables with VIF values larger than 5 and P values greater than 0.05 were eliminated. Table 3 shows the selected variables and their related parameters.
According to the factors in the global regression results, there are notable variations in the building environment that impacted the flow of subway entry and exit. From the regression coefficient, it can be speculated that stations with more residential and entertainment POIs in the service area had a relatively small influence, while stations with more accommodation and tourism POIs in the service area had a relatively larger impact. The outbound passenger flow of stations in the service area that had more enterprise, residential, accommodation, and catering POIs had a relatively small impact compared to the outbound passenger flow of stations in the service area that had more education, service, government, and bus stop POIs. Moreover, we discovered that the number of cumulative confirmed cases had a considerable influence on both inbound and outbound passenger flows following the outbreak, with weather and epidemic factors seemingly having the same effects.
5.4 GTWR Model Results and Comparison
Using the same dataset, the local modelling approaches GWR and TWR were also evaluated for comparison. The AIC was used to evaluate the model's fit and complexity. To evaluate the extent to which the independent factors account for the dependent variable, the adjusted \(R^{2}\) was chosen. The model fit performs better when the residual sum of squares (RSS) value is smaller. Table 4 displays the model evaluation results. With respect to highest \(R^{2}\), lowest RSS, and lowest AIC, the GTWR model performed the best. Furthermore, both the GWR and TWR models performed well, with the TWR model outperforming the GWR model, suggesting that non-smoothness was more prominent on the temporal scale than on the spatial scale. In other words, temporal nonstationarity is more significant to the relative impact of the epidemic, and the time factor dominates the spatiotemporal evolution of the relative impact of the epidemic.
The GTWR model 's results are presented in Table 5. The distribution of the estimated coefficients was summarized using seven statistics: the mean, the minimum (min.), the maximum (max.), the lower quartile (LQ), the median, the upper quartile (UQ), and the standard deviation (std. dev.).
An LQ > 0 means that although there is a negative correlation between several spatial units or time scales, the positive correlation is dominant. Taking the inbound passenger flow as an example, the coefficient of scenic spots shows that passengers entering a station with more scenic spots in the service area were more affected by the epidemic. In contrast, subway stations with more residential areas and entertainment facilities in the service area tended to attract more passengers, which is consistent with previous studies [64]. There is a significant difference in the correlation between the number of entertainment POIs around the station and the inbound ridership for the entertainment variable. The coefficients for the entertainment variable are −8.613 and 16.270, respectively, suggesting that the number of entertainment POIs near the station significantly affected the inbound passenger flow.
The distribution of regression coefficients can be understood using descriptive statistics, while the visualization of each station provides insight into the spatial and temporal heterogeneity of the built environment as well as the impact of COVID-19 on subway ridership. Figures 8 and 9 show the relative contributions of COVID-19 factors to inbound and outbound passenger flows over time and space, respectively. Figure 8 shows a calendar heatmap representing each day during the study period and a vertical axis showing the change in ridership at each subway station during the study period. Additionally, the colours and shades of colour show the relative contributions of factors to the impact of ridership at each station. Red indicates that changing the explanatory variable has a positive impact on subway travel (less passenger loss due to the epidemic), and blue represents the opposite.


Relative impact of variables on inbound ridership
Figure 8a–c shows the epidemic variable. Cumulative newly confirmed cases had a greater impact on the inbound passenger flow than newly confirmed cases. The distance from risk areas positively affected ridership; the longer the distance from the risk area was, the smaller the relative impact of the epidemic, but not all stations showed this.
The built environment variables are shown in Fig. 8d–g. The relative influence represented by this category shows a clear heterogeneity in space and that the degree of impact changes over time. Stations with more surrounding POIs in the hotel and entertainment categories were less likely to be affected by the epidemic. The passengers may not have been permanent residents of Beijing and may have been in the city for business or leisure. There is a greater need for travel among these people, as they are more mobile. Due to stricter control measures for residential and tourist locations, nearby stations with more residential and tourist locations were more likely to be affected by the epidemic. Figure 8h–j shows weather variables, which are mainly used as control variables here. This category has obvious spatiotemporal heterogeneity.


Relative impact of variables on outbound ridership
The difference between Figs. 8 and 9 is that the latter shows the coefficient of the outbound passenger flow, which is significantly different. In particular, the distance to risk areas shows that most stations had no significant effect, and some stations even had a significant negative effect. The outbound passenger flow can indicate the purpose of the passengers' trips [65]. It can be inferred that people travelling by subway during the epidemic period preferred to go to stations with more residential, accommodation, and business POIs in the service area. There were significant spatial differences among stations with government, education, and bus stop POIs, and the temporal difference was the degree of influence. Catering and services showed not only significant spatial heterogeneity but also significant temporal heterogeneity. The impact of weather variables on station passenger flow was the same as that on station inbound flow, and the difference was the level of the coefficient value.
6 Discussion and Conclusions
Based on multisource big data (Beijing subway smart card data, COVID-19 epidemic data, and POIs), this paper establishes a research framework to analyse the impact of COVID-19 on subway station passenger flow to analyse its influencing factors and spatial and temporal impact. The following are this study's primary contributions:
-
1.
This study provides a framework to identify a single epidemic impact event node based on a long time series by combining spatiotemporal investigation, affect inference, and time series anomaly detection. This allows for a more precise extraction of the effect of COVID-19 on subway ridership. This framework may be expanded to analyse the influence of other emergencies or catastrophes on residents' travel, such as heavy rainfall, since it can quantify the impact and incorporate additional potential impact factors.
-
2.
This study confirmed that the goodness of fit of the GTWR model was higher than that of the GWR, TWR, and OLS models, emphasizing its effectiveness in accounting for spatiotemporal nonstationarity. Based on the analysis, COVID-19 had a spatiotemporally heterogeneous impact on passenger flow in subway stations. Station inbound and outbound passenger flows were influenced by different factors.
-
3.
This analysis supports the finding that there was a substantial positive link between the drop in subway use and the number of COVID-19 cases that were identified [13]. We showed that stations in risk regions considerably impacted inbound passenger flow negatively but had no significant impact on outbound passenger flow. This is in line with Beijing's measures to strengthen source control. Residents in risk areas were restricted from travelling, but travelling to risk areas was not restricted, meaning that those living outside these areas were better protected when travelling normally.
-
4.
According to this study, stations with more residential POIs in their service area were more likely to face increased travel demand following an outbreak. As a result, inbound passenger flow was less impacted, while outbound passenger flow was more impacted. Going to work or home may be the primary reason for taking the train. It is highly advised that the operational unit adapts the services of various stations given the wide variations in passenger flow at the station level.
-
5.
Although not a direct cause-and-effect relationship, this apparent correlation trend is sufficient to encourage subway operators to offer personalized service depending on spatial needs. It is strongly advised that the operational unit adapts the services at various stations with flexibility since the ridership at the station level is quite variable.
Based on the analysis of this article, some conclusions of practical significance for subway station planning and operation can be preliminarily speculated. The following is a further discussion of these findings and relevant recommendations:
-
1.
Impact of epidemic variables on passenger flow: We found that the cumulative number of newly confirmed cases has a greater impact on inbound passenger flow than the daily count of newly confirmed cases. Additionally, the distance from risk areas positively influences passenger volume, with greater distances from risk areas resulting in a relatively smaller impact of the epidemic. However, not all stations exhibit this trend. Therefore, subway operators can formulate differentiated response strategies based on station location and proximity to risk areas. For stations heavily affected by the epidemic, enhancing cleaning and disinfection measures and strengthening crowd management may be warranted.
-
2.
Influence of built environment variables on passenger flow: We observed clear spatial heterogeneity in the impact of built environment variables, which also varies over time. Stations surrounded by more hotels and entertainment venues experience less impact from the epidemic, possibly due to these passengers being temporary residents travelling for business or leisure. Conversely, stations near residential areas and tourist attractions are more susceptible to epidemic effects. Hence, subway operators can adjust service strategies based on the characteristics of surrounding environments, such as increasing train frequencies to specific destinations.
-
3.
Effects of weather variables on passenger flow: We found significant spatial and temporal heterogeneity in the impact of weather variables, similar to patterns observed in inbound passenger flow. However, the magnitude of the impact varies. Subway operators can adjust service schedules in response to changing weather conditions, such as increasing train frequencies during adverse weather to meet passenger travel demands.
In summary, our study results provide valuable insights for subway station planning and operations. Subway operators can develop differentiated service strategies tailored to the characteristics of each station to address challenges posed by events such as epidemics, thereby enhancing operational efficiency and service levels of the subway system.
This study may be improved and enhanced much more by the following: First, the impact of the epidemic estimated in this study was still a mixed effect of virus panic effects and government intervention. The distinctions between the two might be made clearer in future research. Second, due to limited data, some factors that may have affected changes in subway ridership, such as economic development and population growth and air pollution levels, were not accounted for. The results of this study are region-specific because only one city was examined, and more validation is needed to determine if the results are generalizable. Additionally, in our study, we utilized the Euclidean distance metric to calculate the distance between Beijing subway stations and COVID-19 risk areas. The decision was based on several factors, including its simplicity, ease of interpretation, and relevance to spatial analysis tasks. However, we acknowledge that the use of Euclidean distance may have potential implications on the results, such as underestimating actual travel distance and sensitivity to the spatial distribution of risk areas. Therefore, we encourage future research to explore alternative distance metrics or spatial analysis techniques to further enhance the robustness of proximity assessments in similar studies. Lastly, future studies are needed on the long-term impacts of COVID-19 on passenger travel, and analysing the time evolution of the impacts on passenger travel can provide a more intuitive and scientific basis for similar occurrences in the future.
References
Zhu N, Zhang DY, Wang WL et al (2020) A novel coronavirus from patients with pneumonia in China, 2019. N Engl J Med. https://doi.org/10.1056/NEJMoa2001017
Abdullah M, Ali N, Hussain SA et al (2021) Measuring changes in travel behavior pattern due to COVID-19 in a developing country: a case study of Pakistan. Transp Policy 108:21–33. https://doi.org/10.1016/j.tranpol.2021.04.023
Liu ZY, Wang XK, Dai JC et al (2022) Impacts of COVID-19 pandemic on travel behavior in large cities of China: investigation on the lockdown and reopening phases. J Transp Eng Part Syst 148:05021011. https://doi.org/10.1061/JTEPBS.0000630
Liu ZX, Stern R (2021) Quantifying the traffic impacts of the COVID-19 shutdown. J Transp Eng Part Syst 147:04021014. https://doi.org/10.1061/JTEPBS.0000527
Zhang YC, Fricker JD (2021) Quantifying the impact of COVID-19 on non-motorized transportation: a Bayesian structural time series model. Transp Policy 103:11–20. https://doi.org/10.1016/j.tranpol.2021.01.013
Jiang SX, Cai CH (2022) Unraveling the dynamic impacts of COVID-19 on metro ridership: an empirical analysis of Beijing and Shanghai, China. Transp Policy 127:158–170. https://doi.org/10.1016/j.tranpol.2022.09.002
Nasri A, Zhang L (2015) Assessing the impact of metropolitan-level, county-level, and local-level built environment on travel behavior: evidence from 19 U.S. urban areas. J Urban Plan Dev 141:04014031. https://doi.org/10.1061/(ASCE)UP.1943-5444.0000226
Sohn K, Shim H (2010) Factors generating boardings at Metro stations in the Seoul metropolitan area. Cities 27:358–368. https://doi.org/10.1016/j.cities.2010.05.001
Chen EH, Ye ZR, Wang C, Zhang WB (2019) Discovering the spatio-temporal impacts of built environment on metro ridership using smart card data. Cities 95:102359. https://doi.org/10.1016/j.cities.2019.05.028
Li SY, Lyu D, Liu XP et al (2020) The varying patterns of rail transit ridership and their relationships with fine-scale built environment factors: Big data analytics from Guangzhou. Cities 99:102580. https://doi.org/10.1016/j.cities.2019.102580
Yin YH, Li DW, Zhang SL, Wu LF (2021) How does railway respond to the spread of COVID-19? Countermeasure analysis and evaluation around the world. Urban Rail Transit 7:29–57. https://doi.org/10.1007/s40864-021-00140-z
Zhang JY, Zhang RS, Ding HX et al (2021) Effects of transport-related COVID-19 policy measures: a case study of six developed countries. Transp Policy 110:37–57. https://doi.org/10.1016/j.tranpol.2021.05.013
Hu SH, Chen P (2021) Who left riding transit? Examining socioeconomic disparities in the impact of COVID-19 on ridership. Transp Res Part Transp Environ 90:102654. https://doi.org/10.1016/j.trd.2020.102654
Fang HM, Wang L, Yang Y (2020) Human mobility restrictions and the spread of the novel coronavirus (2019-nCoV) in China. J Public Econ 191:104272. https://doi.org/10.1016/j.jpubeco.2020.104272
Wang JY, Kaza N, McDonald NC, Khanal K (2022) Socio-economic disparities in activity-travel behavior adaptation during the COVID-19 pandemic in North Carolina. Transp Policy 125:70–78. https://doi.org/10.1016/j.tranpol.2022.05.012
Brough R, Freedman M, Phillips DC (2021) Understanding socioeconomic disparities in travel behavior during the COVID-19 pandemic. J Reg Sci 61:753–774. https://doi.org/10.1111/jors.12527
Chakraborty A, Mishra S (2013) Land use and transit ridership connections: implications for state-level planning agencies. Land Use Policy 30:458–469. https://doi.org/10.1016/j.landusepol.2012.04.017
Chen C, Chen J, Barry J (2009) Diurnal pattern of transit ridership: a case study of the New York City subway system. J Transp Geogr 17:176–186. https://doi.org/10.1016/j.jtrangeo.2008.09.002
Jun MJ, Choi K, Jeong JE et al (2015) Land use characteristics of subway catchment areas and their influence on subway ridership in Seoul. J Transp Geogr 48:30–40. https://doi.org/10.1016/j.jtrangeo.2015.08.002
Zhu YD, Chen F, Wang ZJ, Deng J (2019) Spatio-temporal analysis of rail station ridership determinants in the built environment. Transportation 46:2269–2289. https://doi.org/10.1007/s11116-018-9928-x
Shen LF, Long Y, Tian L et al (2023) The impact of built environment on the commuting distance of middle/low-income tenant workers in mega cities based on nonlinear analysis in machine learning. Urban Rail Transit 9:294–309. https://doi.org/10.1007/s40864-023-00202-4
Xiao WY, Wei YD, Wu YY (2022) Neighborhood, built environment and resilience in transportation during the COVID-19 pandemic. Transp Res Part Transp Environ 110:103428. https://doi.org/10.1016/j.trd.2022.103428
Yang HT, Guo ZS, Zhai GC et al (2022) Exploring the spatially heterogeneous effects of the built environment on bike-sharing usage during the COVID-19 pandemic. J Adv Transp 2022:e7772401. https://doi.org/10.1155/2022/7772401
Zhou MZ, Ma HX, Wu JY, Zhou JP (2023) Metro travel and perceived COVID-19 infection risks: a case study of Hong Kong. Cities 137:104307. https://doi.org/10.1016/j.cities.2023.104307
Wu JW, Liao H (2020) Weather, travel mode choice, and impacts on subway ridership in Beijing. Transp Res Part Policy Pract 135:264–279. https://doi.org/10.1016/j.tra.2020.03.020
Singhal A, Kamga C, Yazici A (2014) Impact of weather on urban transit ridership. Transp Res Part Policy Pract 69:379–391. https://doi.org/10.1016/j.tra.2014.09.008
Li JL, Li XH, Chen DW, Godding L (2018) Assessment of metro ridership fluctuation caused by weather conditions in Asian context: using archived weather and ridership data in Nanjing. J Transp Geogr 66:356–368. https://doi.org/10.1016/j.jtrangeo.2017.10.023
Wu P, Xu LH, Zhong LS et al (2022) Revealing the determinants of the intermodal transfer ratio between metro and bus systems considering spatial variations. J Transp Geogr 104:103415. https://doi.org/10.1016/j.jtrangeo.2022.103415
Lin PF, Weng JC, Brands DK et al (2020) Analysing the relationship between weather, built environment, and public transport ridership. IET Intell Transp Syst 14:1946–1954. https://doi.org/10.1049/iet-its.2020.0469
Shi GF, Luo LM (2023) Prediction and impact analysis of passenger flow in urban rail transit in the postpandemic era. J Adv Transp 2023:e3448864. https://doi.org/10.1155/2023/3448864
Wang HY, Noland RB (2021) Bikeshare and subway ridership changes during the COVID-19 pandemic in New York City. Transp Policy 106:262–270. https://doi.org/10.1016/j.tranpol.2021.04.004
Weng JC, Tu Q, Yuan RL et al (2018) Modeling mode choice behaviors for public transport commuters in Beijing. J Urban Plan Dev 144:05018013. https://doi.org/10.1061/(ASCE)UP.1943-5444.0000459
Zhang Z, Fujii H, Managi S (2014) How does commuting behavior change due to incentives? An empirical study of the Beijing Subway System. Transp Res Part F Traffic Psychol Behav 24:17–26. https://doi.org/10.1016/j.trf.2014.02.009
Zhao PJ, Zhang YX (2019) The effects of metro fare increase on transport equity: new evidence from Beijing. Transp Policy 74:73–83. https://doi.org/10.1016/j.tranpol.2018.11.009
Dai JC, Liu ZY, Li RM (2021) Improving the subway attraction for the post-COVID-19 era: the role of fare-free public transport policy. Transp Policy 103:21–30. https://doi.org/10.1016/j.tranpol.2021.01.007
Cardozo OD, García-Palomares JC, Gutiérrez J (2012) Application of geographically weighted regression to the direct forecasting of transit ridership at station-level. Appl Geogr 34:548–558. https://doi.org/10.1016/j.apgeog.2012.01.005
Zhao JB, Deng W, Song Y, Zhu YR (2013) What influences Metro station ridership in China? Insights from Nanjing. Cities 35:114–124. https://doi.org/10.1016/j.cities.2013.07.002
Stewart Fotheringham A, Charlton M, Brunsdon C (1996) The geography of parameter space: an investigation of spatial non-stationarity. Int J Geogr Inf Syst 10:605–627. https://doi.org/10.1080/02693799608902100
Gan ZX, Feng T, Yang M et al (2019) Analysis of metro station ridership considering spatial heterogeneity. Chin Geogr Sci 29:1065–1077. https://doi.org/10.1007/s11769-019-1065-8
Tu W, Cao R, Yue Y et al (2018) Spatial variations in urban public ridership derived from GPS trajectories and smart card data. J Transp Geogr 69:45–57. https://doi.org/10.1016/j.jtrangeo.2018.04.013
Li SY, Lyu DJ, Huang GP et al (2020) Spatially varying impacts of built environment factors on rail transit ridership at station level: a case study in Guangzhou. China. J Transp Geogr 82:102631. https://doi.org/10.1016/j.jtrangeo.2019.102631
Huang B, Wu B, Barry M (2010) Geographically and temporally weighted regression for modeling spatio-temporal variation in house prices. Int J Geogr Inf Sci 24:383–401. https://doi.org/10.1080/13658810802672469
Ma XL, Zhang JY, Ding C, Wang YP (2018) A geographically and temporally weighted regression model to explore the spatiotemporal influence of built environment on transit ridership. Comput Environ Urban Syst 70:113–124. https://doi.org/10.1016/j.compenvurbsys.2018.03.001
Li XH, Xing GH, Qian XW et al (2022) Subway station accessibility and its impacts on the spatial and temporal variations of its outbound ridership. J Transp Eng Part Syst 148:04022106. https://doi.org/10.1061/JTEPBS.0000766
Fraszczyk A, Weerawat W, Kirawanich P (2019) Commuters’ willingness to shift to metro: a case study of Salaya, Thailand. Urban Rail Transit 5:240–253. https://doi.org/10.1007/s40864-019-00113-3
Kieu LM, Bhaskar A, Chung E (2015) Passenger segmentation using smart card data. IEEE Trans Intell Transp Syst 16:1537–1548. https://doi.org/10.1109/TITS.2014.2368998
Pelletier MP, Trépanier M, Morency C (2011) Smart card data use in public transit: a literature review. Transp Res Part C Emerg Technol 19:557–568. https://doi.org/10.1016/j.trc.2010.12.003
Sung H, Choi K, Lee S, Cheon S (2014) Exploring the impacts of land use by service coverage and station-level accessibility on rail transit ridership. J Transp Geogr 36:134–140. https://doi.org/10.1016/j.jtrangeo.2014.03.013
Li XH, Xiao QM, Zhu YD, Yang YT (2022) Influence of TOD modes on passenger travel behavior in urban rail transit systems. Urban Rail Transit 8:175–183. https://doi.org/10.1007/s40864-022-00179-6
Bian ZL, Zuo F, Gao JQ et al (2021) Time lag effects of COVID-19 policies on transportation systems: a comparative study of New York City and Seattle. Transp Res Part Policy Pract 145:269–283. https://doi.org/10.1016/j.tra.2021.01.019
Erdman C, Emerson JW (2008) A fast Bayesian change point analysis for the segmentation of microarray data. Bioinformatics 24:2143–2148. https://doi.org/10.1093/bioinformatics/btn404
Fearnhead P (2006) Exact and efficient Bayesian inference for multiple changepoint problems. Stat Comput 16:203–213. https://doi.org/10.1007/s11222-006-8450-8
Erdman C, Emerson JW (2008) bcp: an R package for performing a Bayesian analysis of change point problems. J Stat Softw 23:1–13. https://doi.org/10.18637/jss.v023.i03
Osorio J, Liu YN, Ouyang Y (2022) Executive orders or public fear: what caused transit ridership to drop in Chicago during COVID-19? Transp Res Part Transp Environ 105:103226. https://doi.org/10.1016/j.trd.2022.103226
Sung H (2023) Causal impacts of the COVID-19 pandemic on daily ridership of public bicycle sharing in Seoul. Sustain Cities Soc 89:104344. https://doi.org/10.1016/j.scs.2022.104344
Xi HN, Nelson JD, Hensher DA et al (2024) Evaluating travel behavior resilience across urban and rural areas during the COVID-19 pandemic: contributions of vaccination and epidemiological indicators. Transp Res Part Policy Pract 180:103980. https://doi.org/10.1016/j.tra.2024.103980
Yabe T, Zhang YC, Ukkusuri SV (2020) Quantifying the economic impact of disasters on businesses using human mobility data: a Bayesian causal inference approach. EPJ Data Sci 9:1–20. https://doi.org/10.1140/epjds/s13688-020-00255-6
Brodersen KH, Gallusser F, Koehler J et al (2015) Inferring causal impact using Bayesian structural time-series models. Ann Appl Stat 9:247–274. https://doi.org/10.1214/14-AOAS788
Scott SL, Varian HR (2014) Predicting the present with Bayesian structural time series. Int J Math Model Numer Optim 5:4–23. https://doi.org/10.1504/IJMMNO.2014.059942
Fotheringham AS, Crespo R, Yao J (2015) Geographical and temporal weighted regression (GTWR). Geogr Anal 47:431–452. https://doi.org/10.1111/gean.12071
Chu HJ, Kong SJ, Chang CH (2018) Spatio-temporal water quality mapping from satellite images using geographically and temporally weighted regression. Int J Appl Earth Obs Geoinf 65:1–11. https://doi.org/10.1016/j.jag.2017.10.001
Zhang WB, Ge Y, Liu MX et al (2021) Risk assessment of the step-by-step return-to-work policy in Beijing following the COVID-19 epidemic peak. Stoch Environ Res Risk Assess 35:481–498. https://doi.org/10.1007/s00477-020-01929-3
Zhou XZ, Ji YJ, Yuan YD et al (2022) Spatiotemporal characteristics analysis of commuting by shared electric bike: a case study of Ningbo. China. J Clean Prod 362:132337. https://doi.org/10.1016/j.jclepro.2022.132337
Wang C, Wang XJ, Pan RB, Yan YS (2022) Influence of built environment on subway trip origin and destination: insights based on mobile positioning data. Transp Res Rec J Transp Res Board 2676:693–710. https://doi.org/10.1177/03611981221088223
Wang YH, Correia GH de A, de Romph E, Timmermans HJP (2017) Using metro smart card data to model location choice of after-work activities: An application to Shanghai. J Transp Geogr 63:40–47. https://doi.org/10.1016/j.jtrangeo.2017.06.010
Acknowledgments
We are grateful to the anonymous reviewers for their helpful comments and recommendations. This work was supported by the Fundamental Research Funds for the Central Universities [No. 2022JBZY039], the National Natural Science Foundation of China [No. 52372299] and the Beijing Natural Science Foundation [No. L221019].
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
There is no conflict of interest declared by the authors.
Additional information
Communicated by Xuesong Zhou.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Z., Guo, R., Zou, L. et al. Impact Evaluation of COVID-19 on Transit Ridership: A Case Study of the Beijing Subway. Urban Rail Transit (2024). https://doi.org/10.1007/s40864-024-00224-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40864-024-00224-6