
Abstract
Purpose of Review
Climate change and associated ecological impacts have challenged many conventional, observation-based approaches for predicting ecosystem and landscape responses to natural resource management. Complex spatial ecological models provide powerful, flexible tools which managers and others can use to make inferences about management impacts on future, no-analog landscape conditions. However, land managers who wish to use ecosystem and landscape models for natural resource applications are faced with the difficult task of deciding among many models that differ in important ways. Here, we summarize a process to aid managers in the selection of an appropriate model for natural resource management.
Recent Findings
To guide management planning, scientifically credible information on how landscapes will respond to management actions under changing climate is required. Landscape models are increasingly used in a management context to evaluate of impacts of changing climate and interacting stressors on ecosystems and to test effects of alternative management options on desired conditions. However, the wide range of available models makes selection of appropriate and viable models a complex process.
Summary
We present a series of preliminary steps to define critical scales of time, space, and ecological organization to guide an experimental design for a modeling project and then list a set of criteria for selecting a landscape or ecological model. Material presented includes the preliminary steps (crafting modeling objective, designing modeling project), organizational concerns (resources available, expertise on hand, timelines), and modeling details (complexity, design, documentation) of model selection.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Natural resource management depends on scientifically credible projections of future conditions under both passive and active managements to plan and implement desired actions [1,2,3]. Historically, land management professionals used results from empirical studies, coupled with their own expertise and wisdom, to plan and evaluate management activities. However, changes in the Earth’s climate systems due to greenhouse warming may create new climate futures that have few analogs in the past [4, 5]. As a result, past empirical studies and the accrued wisdom of the last 100 years may not be entirely appropriate for the management of tomorrow’s landscapes [6, 7]. Adding to the problem are the invasion of exotics, a legacy of past management actions, and the expansion of the human footprint across landscapes, all of which contribute to increasingly novel environments and different management challenges [8,9,10]. Landscape models are increasingly used to integrate relevant historical information with well-studied physical, chemical, and biological relationships to project the consequences of alternative land management actions across space into our new future [11, 12].
Landscape simulation models are important tools for land management because they provide a means to synthesize state-of-the-art knowledge, current research findings, and general information to understand ecosystems and landscape dynamics [13]. Myriad interacting and highly dynamic ecological processes result in diverse and potentially unexpected biotic and abiotic responses [14,15,16], making it nearly impossible for one person to understand the effects of all possible interactions across relevant spatial and temporal scales and somewhat impractical to collect enough data on these interactions to completely understand their consequences for land management [6, 7, 17]. Landscape models can be used to extrapolate spotty empirical data over larger areas and longer time spans to provide greater spatiotemporal scope for management decisions [18]. Moreover, these models identify those ecological processes that are poorly understood and need for further research [19, 20].
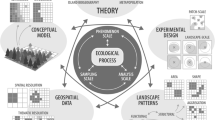
Perhaps the greatest strength of ecological modeling in land management is its ability to compare effects of alternative actions on management targets or desired goals [21,22,23]; the impacts of varying levels of fire suppression are, for example, on subsequent fire activity [24], vegetation, and stream thermal regimes [25]. However, deciding which management actions and disturbance agents to include in a model is one of the most demanding tasks of a modeler [26, 27]. Landscape models can also be used for many other types of management applications, from planning to real-time decision making [28], and they can be used across the many organizational levels of management, especially when climate and disturbance regimes are expected to change over time [29, 30] (Fig. 1).

Land managers who want to use landscape models are often faced with the difficult task of deciding which model to use. There are numerous research and management-oriented models that were developed by different modelers for different purposes and for different ecosystems [32,33,34,35]. Keane et al. [33], for example, evaluated 44 landscape models that simulate vegetation and fire dynamics. It would be difficult for any manager to devote enough time to develop a deep knowledge of all available modeling systems—it is just too complicated, especially as climate change becomes increasingly important [36]. In this paper, we summarize a process to aid managers in the selection of an appropriate model for natural resource management applications, including preliminary steps that frame the selection process and then a set of criteria for selecting a specific landscape model. This process will clearly identify the most appropriate landscape model that provides much-needed, scientifically credible information on how landscapes will respond to changes in climate, disturbance, and human activity [37, 38].
Modeling Primer
Landscape and ecosystem models range in complexity from simple conceptual models such as state-and-transition models that simulate vegetation dynamics using discrete successional pathways [39,40,41,42,43] to complex biogeochemical models that explain vegetation processes and related energy and matter exchanges between vegetation, soil, and the atmosphere [44,45,46]. Other models of intermediate complexity include cohort models that simulate vegetation abundance by diameter or cover classes [35] and spatial gap models that mechanistically simulate growth, mortality, and regeneration of individual plants [23]. We feel that there are no “bad” models as most were successful for their designed purpose, but the usefulness of any model depends on its appropriate application for a given objective. Landscape models have been described according to their levels of complexity, design, spatial dynamics, and scales [33, 47, 48].
Complexity
The simple-to-complex gradient (Fig. 2) provides a straightforward way to evaluate ecosystem and landscape models [48]. Simple models are easier to learn, use, and interpret but have a limited set of output variables that are often highly dependent on input parameters [47]. Complex models require abundant training, greater computing resources, longer simulation times, and more data to implement [49] but provide greater exploratory power and an extensive array of output variables. Complex models also provide the ability to explicitly simulate emergent and dynamic processes such as climate change impacts or disturbance interactions [50]. There are always tradeoffs between model complexity and practical utility for any particular problem, and a model’s structure should be consistent with both the question(s) asked and the assessments being made by the manager [51].

The tradeoffs between simple and complex models and the relative magnitude of several characteristics for simple to complex models for a number of tasks. The width of the triangle represents the magnitude of that characteristic. Increasing effort triangles are in black, and decreasing efforts are in blue
Design
The inherent design and structure of the model is also important to model selection, but describing the design of a model is a complex and demanding task. For simplicity, we use pairs of contrasting terms to describe the general design and application of the models, but commonly, most models are created using a mixture of the following design elements.
Stochastic vs. Deterministic Models
Stochastic models use probability functions to represent highly dimensional ecological processes with complicated behavior over an extensive range of spatial and temporal scales of variability [52]; ignition locations of wildland fires, for example, are often represented by a probabilistic model based on fuel, weather, and topography variables because the process of ignition is highly uncertain and complex [53]. Stochastic models produce realistic variability in the trajectories of their state variables through time, whereas deterministic models describe the relationships between model variables using mathematical equations or rules. Deterministic models have no random components and therefore always give the same results thereby lowering simulation times and simplifying analyses. These models assume that the future responses of a system are completely determined by present-state, measured inputs [27, 51, 54].
Empirical vs. Mechanistic Models
Empirical models represent relationships determined strictly by data, such as growth and yield models [55], and are most useful when used within the bounds of the data with which they are developed [51]. An example might be a regression equation relating annual net primary production to annual precipitation and temperature [56]. When used within the range of precipitation and temperature included in the formulation of the regression equation, the model can produce realistic predictions, but the model may fail when applied to conditions outside the range of the input data, such as new climates or to a different ecosystem [57]. Mechanistic, or process-based, models use ecophysiological and physical equations and algorithms to simulate specific ecological processes such as seed dispersal or wildfire spread and describe cause and effect relationships (e.g., how abiotic environmental factors, disturbances and management activities interact to affect tree species and age composition and their spatial patterns, and other ecosystem attributes) [7, 58]. Because these models are not constrained by parameter estimations reflecting past conditions, they provide a useful framework for exploring diverse ecosystem responses to altered environmental conditions. As a result, these models can offer significant advantages in predicting the effects of global change as compared to purely empirical models [11].
Spatial Dynamics
Spatially explicit models consider both ecological relationships (e.g., species and their habitats) and the arrangement of landscape features (e.g., habitat characteristics) in space and time [12, 59, 60]. These models can address questions of fragmentation, patch size, and landscape heterogeneity and incorporate important spatial processes, such as seed or animal dispersal, wildfire spread, and interactions of species or communities across environmental gradients [61, 62]. Spatially explicit models may be required if the project objectives are focused on a question such as whether changes in fire frequency or area burned may affect the spatial distribution of a tree species [51]. Non-spatial models, such as the VDDT state-and-transition model [63], ignore spatial relationships for simplicity in design. A stand-level model where input and output apply to a specific pixel or polygon, for example, may simplify ecological processes to reflect only stand-level processes such as tree growth and competition, without incorporating the interactions from neighboring stands or the effects of broad scale ecological processes such as disturbance.
Scale
Spatiotemporal scale in a modeling context refers to both the resolution (spatial grain size, or time step) and extent (time span, space domain, and number of components modeled) of the simulation [64]. Recent technological advances in remote sensing, GIS, and computational power have enabled models to be built at increasingly finer resolutions over increasingly larger spatial scales and longer time periods [65] (Fig. 1). Often, the integration of environmental information across various ecological scales—such as combining coarse-scale climate drivers with finer-scale land cover information—can improve understanding of fundamental ecological processes and enable improved model predictions of landscape patterns under changing environmental conditions [66]. If a model’s native pixel size is large (e.g., > 100 m) or if modeled entities are broad (e.g., cover types), then the model might have limited application to detailed investigations of individual-species responses to processes operating at scales finer than the model’s designed spatial (e.g., pixel size), temporal (e.g., time step), and organizational (e.g., variables) resolution [67].
Model Application
Most modeling projects are accomplished in six major phases spanning development of model inputs to analysis and interpretation of outputs (Fig. 3): initialization, parameterization, calibration, validation, execution, and analysis [13, 26, 27, 47, 49, 68, 69]. Knowledge of these phases will influence model selection because complex models often need more time for some of these phases. Initialization (the process of quantifying initial conditions that form the starting place for model simulation) and parameterization (the quantification of parameters needed by model algorithms to simulate ecological processes) are required before a model can be run. The calibration phase, in which model parameters are adjusted to better reflect the ecological patterns and processes expected for a landscape, occurs after a series of test simulations that verify the model is working with initial conditions and parameters. Once the model is calibrated, the validation phase estimates the accuracy and precision of model results as compared with available empirical data, historical records, or expert evaluation. Calibration and validation provide several important aspects: [1] a notion of the uncertainty and accuracy of model results, [2] confidence in using the model, and [3] experience and knowledge of model behavior important in the interpretation of model results. Execution is the process of actually running the model to complete the project experimental design under the simulation specifics, and analysis is the process of synthesizing and summarizing model results, typically using statistical and spatial (e.g., GIS) analytical platforms.

The six critical phases of a modeling project. Initialization (light green) and parameterization (orange) need to be complete before validation and calibration. Once the model is calibrated, the model can be validated and the simulation experiment can be executed. Results of the model are then analyzed, and summaries are integrated into various reports and publications. Arrows run in two directions to denote that initialization and parameterization are constantly being redone based on results of the calibration process
Preliminary Steps Before Model Selection
There are important preliminary steps that managers should complete before evaluation to ensure that the best model is selected for their application. In this paper, we assume that the user wishes to use a spatially explicit landscape model for their project, but we also recognize these steps can be used for any spatial or non-spatial ecological model.
Craft a Succinct Modeling Objective
The most important phase in any modeling project is the design of concrete modeling objectives [13]. The modeling objective sets the context for the entire modeling project and forms the sideboards of all future decision-making [70, 71]; decisions made during a modeling project, such as which parameters to use, how long to simulate, and how to summarize the results, can only be done by referencing the objective. For example, a modeling objective for evaluating changes in wildlife habitat in response to timber management can be identified as “identify short-term (< 5 years) and long-term (~ 80 years) impacts (positive or negative) of a range of harvest treatments on wildlife species habitat in the Bitterroot drainage of western Montana, and produce results that can be used to guide design of future forest treatments to enhance habitat” [72].
Design Structure of Anticipated Results
Designing the tables and figures for portraying the anticipated modeling results, even before a specific landscape model has been selected, will help evaluate potential landscape models, determine experimental design criteria (e.g., number of model replications necessary to achieve sufficient statistical power), and will save time and resources by eliminating unnecessary exploration of modeling results in subsequent analysis. Using the example in step 1, a table that has management alternatives as columns, time spans (long vs short term) as rows, and acres of wildlife habitat in each cell may help frame an evaluation of models. There is nothing more frustrating than completing months of simulations, only to find that the most appropriate variables were never available from the selected model or were not output in the desired format. Conversely, copious output for numerous variables that then go unused in final reporting can substantially increase simulation times and file sizes and add unnecessary complexity to modeling projects.
Delineate the Simulation Landscape
It is important that a simulation area encompass a sufficient amount of land to meet management objectives, while still conforming to commonly used land management spatial domains. For example, if hydrologic boundaries are used to define management zones, then a watershed may be the most appropriate boundary to define the modeling extent. If the modeling objective is focused on evaluating impacts of forest treatments, the simulation area could be the proposed treatment area and perhaps the surrounding area. A simulation landscape must be large enough to encompass the spatial footprint of native ecological processes, while also matching management objectives. One general rule of thumb is that the simulation landscape should be at least five times the expected area of the largest important disturbance event. For example, if large wildfires in the project area mentioned in the step 1 example are typically around 50,000 ha, the simulation landscape should be at least 250,000 ha and it should be centered on the harvest areas. This may be difficult to accomplish given the large size of many disturbances, and often, the available data, computing resources, and project timeline will influence decisions about the size of the simulation landscape. The risk in using a small area, however, is the failure to fully capture those landscape-level processes that are highly influential in dictating ecological patterns. This may result in greater uncertainty in simulating spatial patterns and can bias subsequent model interpretation [67].
The shape of a simulation landscape is also an important consideration. Any landscape should be delineated in a manner that minimizes edge effects, which we define in the context of ecological modeling as potential changes in ecological patterns or processes that occur near the edges of the finite simulation space [73]. Simulation landscapes that are long and thin have a high perimeter to area ratio and therefore will be subject to extensive edge effects if the selected model explicitly simulates spatial processes [74]. This occurs because landscape edges influence the spread of disturbance or vegetation processes that occur outside of the landscape into the landscape or the spread from inside the landscape to outside the landscape (e.g., seed dispersal, spread of fires) [75, 76]. The most realistic method for minimizing edge effects is by creating a buffer around the target or context landscape [40, 73]. However, buffering can substantially increase the simulation area, resulting in long simulation times and high memory requirements; as a result, the buffer size is often adjusted to fit a realistic project timeline or computational constraints.
Develop an Appropriate Experimental Design
After the objectives are defined, analysis and figures structures created, and the landscape delineated, a simulation “experiment” must be designed to answer the specifications of the objective. One approach to simulation design is to model a set of alternatives that encompass the range of potential ecological responses from management actions. By varying particular model inputs (e.g., future climates, grazing regimes, or potential for interacting stressors such as insect and disease outbreaks) [16], modelers can explore the range of possible landscape-level ecological impacts. This approach can be described as conducting experiments in the “model” world to obtain insights for resource management and evaluation [77]. Using the example in step 1, four timber harvest scenarios might be evaluated (none, clear-cut, partial cuts, and fuel treatments). Usually, a statistical fully factorial approach is used where various levels of climate, management, and other factors of interest are implemented in combinations of factor-levels often called “scenarios.” After all factors and levels are designed, experimental specifications must be defined including the number of replicates, the length of simulation time, and the types of output and their reporting interval—all of which influence model selection [13]. In our example, a simulation time of 250 years with the wildlife habitat area response variable reported at 50 and 250 years using 10 replicates may be appropriate. Details of the experimental design can be refined once a landscape model is selected for a project.
Create a List of Potential Models
We recommend that a comprehensive list of all potential models be developed through a literature review or consultation with local modeling experts and other managers. This list does not need to be exhaustive but should contain those models that the users feel are most important for accomplishing the objectives. In addition, the preliminary modeling steps outlined above should be summarized and documented to guide model selection via our seven model selection criteria.
Landscape Model Selection Criteria
Although models have been acknowledged as important tools for land management decision-making and planning [27, 51], criteria for model selection for management applications are rarely available in the literature. In general, model selection will mostly depend on the objective, available resources, and local ecological conditions, which makes developing project-specific model selection criteria quite difficult. Instead, we developed a set of seven questions that can be generalized across management objectives to aid in selection of an appropriate landscape model.
Which Model Can Answer the Modeling Objective?
Well-defined modeling objectives identify those response variables that are necessary for subsequent analysis; therefore, a suitable model will be one that includes these variables as outputs. A candidate model should also simulate those ecological processes that are important to the project objectives in the form of modules or algorithms that fully represent the spirit and vision of the modeling objective. For example, using the example in step 1 of the previous section, the candidate model(s) should include explicit simulations of wildlife dynamics and timber harvest actions at relevant scales, along with climate, wildland fire, and wildfire suppression management.
Identifying a list of key ecological processes to match objectives is a fundamental step in evaluating the suitability of candidate models. Models that do not simulate key disturbances (e.g., wildfires, insect outbreaks, plant invasions) that influence real-world processes of interest may limit project inferences. Models must also be capable of representing the influences of topography, vegetation dynamics, and other key environmental aspects on the ecological processes in the delineated simulation area. Often, a model developed for one particular landscape is highly constrained to reflect only the important ecological processes influencing that landscape and it is inflexible in its application to a new landscape (e.g., a model developed for tropical forests may not be useable for a boreal landscape).
Which Model Is Most Appropriate for Project Timelines?
Project timelines, rather than ecological complexity, may dictate model selection. Projects that need to be done quickly will demand simple models that are relatively easy to execute, analyze, and understand (Fig. 2). Longer projects may make use of more complex models that allow for a wider scope of evaluation. Users must remember that the execution of the model is not the only task in a modeling project—initialization, parameterization, and calibration phases may require more time than the actual simulations (see earlier sections). Unfortunately, it is difficult to estimate development and execution times for models that are unfamiliar to the user. The only way to obtain this information is from the literature or in consultation with the model developer or past users of the model.
Which Model Best Fits with Existing Computing Resources?
It is crucial that the hardware and software requirements of the landscape models match the available computer resources. A complex model may require abundant computing resources for normal simulations, which may be impossible when only one computer with a single processor is available. All possible computers available to the modeling project should be inventoried, and their software and hardware specifics should be noted as information for evaluation criteria. One of the most important computing resources is the amount of memory available for the model. Most models keep simulated variable values in memory to reduce execution times, and when memory becomes full, the program slows to a crawl. Users should assess the memory requirements of the available models and the memory resources of the available computers. Sometimes, memory can be upgraded and that cost should be also included as evaluation criterion.
Is There Modeling Expertise Available to Run Each Model?
It is important to identify those people that have the time, knowledge, and experience in modeling to help in your project. It may be more beneficial to use a modeling system in which someone has expertise than to use an unknown model that better meets the project objectives. It is also critical that someone have the expertise to analyze model output for management plans. This criteria can be met by one person or by a team of people; a team is always more effective because team members can be used in other phases of the project including evaluation of parameterization and calibration, creation of analysis plans, and review of model results. It is also critically important that the team has a broad ecological knowledge of the ecosystem(s) being modeled to evaluate the degree of realism in model results.
Are There Enough Data to Prepare Each Model?
We recommend an initial, thorough inventory of available data to quantify initial conditions and parameters of a model and to provide calibration metrics for evaluation of model results. If the necessary data are unavailable, field campaigns can be developed to provide data, or existing data from outside sources might be identified. If data required for a particular model are scarce, perhaps an alternative model should be considered, as high uncertainty in data inputs often results in greater uncertainty in outputs. Data can come from many sources, but often, model inputs can be “modeled” themselves; remotely sensed data, for example, can be used to derive a classified map of vegetation types [31], or tree inventories can be expanded for use across large land areas [78, 79]. Parameter values can also be derived from published literature, with careful consideration as they may or may not be applicable to the specific context of a modeling project.
Which Model Best Matches the Resolution of the Objective?
Some modeling objectives can be successfully completed with broad general estimates, such as “yes” or “no” answers, and this means that the resolutions of the output variables can be coarse and the model results can be summarized to broad ranges or thresholds. For other objectives, more specific information, such as plant density, biomass, and productivity estimates summarized by vegetation type and management zones, may be required. If a project demands highly specific types of detailed reports, then complex models are often the only alternative. It is important that the design of the landscape simulation model match the precision of the project objectives.
Which Model Is Documented and Published?
Users can look to the publication record of a model in the literature to demonstrate its acceptance within the science and management communities. Important items to assess include [1] has the model been successfully implemented and reported on by others, [2] are model results published in high impact journals, and [3] is the application of the model consistent with the current modeling project?
From a user’s perspective, it is important that the model is well-documented, including ample information on using the model and available example input files to demonstrate model setup. A user’s manual is priceless for novice users. From an advanced user’s perspective, it is important that the source code of the model is accessible, well-documented, portable (can be installed on a variety of operating systems), and stand-alone (does not require commercial software to run). Open science principles are changing how models are developed and shared, such as Github for the LANDIS model [80] and Frames for wildland fire models (https://www.frames.gov/models). Batch-processing scripts to execute multiple runs of a model are useful for stochastic models that must be run multiple times for a given scenario, and models with input and output structures that are easy to understand facilitate ready parameterization, calibration, and implementation.
Model Assessment and Selection
Now it is time to start evaluating potential models. Model users can step through each criterion and rank candidate models against the model selection criteria using a well-documented rating system. The ranking process could be recorded in a spreadsheet in which candidate models are listed as rows, criteria as columns, and each model is rated via a numbering system that evaluates its appropriateness along a scale. To account for varying importance among criteria, a weighting system can be developed; for example, a user may place a higher weight on criteria that must be met for the project to succeed, such as available expertise or computing resources. Rankings multiplied by the weights summarized across all the model selection criteria will often identify one or two models that stand out as best fits for the project. This process will also identify areas of possible compromise in project objectives; if the objective is impossible to meet with the identified slate of models, then it can be revised to reflect the attributes of candidate models.
Conclusion
George Box, in a 1979 paper, wrote “…it would be very remarkable if any system existing in the real world could be exactly represented by any simple model. However, cunningly chosen parsimonious models often do provide remarkably useful approximations…For such a model there is no need to ask the question “Is the model true?” If “truth” is to be the “whole truth” the answer must be “No.” The only question of interest is “Is the model illuminating and useful?”” [81]. We feel that the most important thing to know when selecting a model is that there is no perfect model for any modeling project. Even models that are built specifically for the modeling project have limitations, and in modeling, compromises are invariably made to accommodate timelines, computing resources, and data constraints over model complexity. However, a concrete plan describing modeling objectives and project details and comparison of available models with well-written criteria will simplify the process of model selection.
References
Herrick J, Bestelmeyer B, Archer S, Tugel A, Brown J. An integrated framework for science-based arid land management. J Arid Environ. 2006;65(2):319–35.
Brussard PF, Reed JM, Tracy CR. Ecosystem management: what is it really? Landsc Urban Plan. 1998;40:9–20.
Slocombe DS. Implementing ecosystem-based management. BioScience. 1993;43(9):612–22.
Whitlock C, Shafer SL, Marlon J. The role of climate and vegetation change in shaping past and future fire regimes in the northwestern US and the implications for ecosystem management. For Ecol Manag. 2003;178(1–2):5–21.
Marlon JR, Bartlein PJ, Walsh MK, Harrison SP, Brown KJ, Edwards ME, et al. Wildfire responses to abrupt climate change in North America. Proc Natl Acad Sci U S A. 2009;106(8):2519–24.
Keane RE, McKenzie D, Falk DA, Smithwick EAH, Miller C, Kellogg L-KB. Representing climate, disturbance, and vegetation interactions in landscape models. Ecol Model. 2015;309–310(0):33–47.
Gustafson E. When relationships estimated in the past cannot be used to predict the future: using mechanistic models to predict landscape ecological dynamics in a changing world. Landsc Ecol. 2013;28(8):1429–37.
Creutzburg MK, Halofsky JE, Halofsky JS, Christopher TA. Climate change and land management in the rangelands of Central Oregon. Environ Manag. 2015;55(1):43–55.
Heller NE, Zavaleta ES. Biodiversity management in the face of climate change: a review of 22 years of recommendations. Biol Conserv. 2009;142(1):14–32.
Millar CI, Stephenson NL, Stephens SL. Climate change and forests of the future: managing in the face of uncertainty. Ecol Appl. 2007;17(8):2145–51.
Cuddington K, Fortin M-J, Gerber L, Hastings A, Liebhold A, O’connor M, et al. Process-based models are required to manage ecological systems in a changing world. Ecosphere. 2013;4(2):1–12.
Mladenoff DJ, Baker WL. Spatial modeling of forest landscape change. Cambridge: Cambridge University Press; 1999. 350 p.
Keane RE. Using ecosystem and landscape models in natural resource management applications. Hoboken: Wiley; 2019. [in prep]
Allen CD. Interactions across spatial scales among Forest dieback, fire, and erosion in northern New Mexico landscapes. Ecosystems. 2007;10(5):797–808.
Green DG, Sadedin S. Interactions matter—complexity in landscapes and ecosystems. Ecol Complex. 2005;2(2):117–30.
Loehman RA, Keane RE, Holsinger LM, Wu Z. Interactions of landscape disturbances and climate change dictate ecological pattern and process: spatial modeling of wildfire, insect, and disease dynamics under future climates. Landsc Ecol. 2017;32(7):1447–59.
Keane RE, Loehman RA, Holsinger LM, Falk DA, Higuera P, Hood SM, et al. Use of landscape simulation modeling to quantify resilience for ecological applications. Ecosphere. 2018;9(9):e02414.
Keane RE. Creating historical range of variation (HRV) time series using landscape modeling: overview and issues. In: Wiens JA, Hayward GD, Stafford HS, Giffen C, editors. Historical environmental variation in conservation and natural resource management. Hoboken: John Wiley and Sons; 2012. p. 113–28.
Botkin DB. Forest dynamics: an ecological model. New York: Oxford University Press; 1993. 309 p.
Bugmann H, Cramer W. Improving the behavior of forest gap models along drought gradients. For Ecol Manag. 1998;103(2/3):247–63.
Hansen AJ, Garman SL, Weigand JF, Urban DL, McComb WC, Raphael MG. Alternative silvicultural regimes in the Pacific Northwest: simulations of ecological and economic effects. Ecol Appl. 1995;5(3):535–54.
Heppell SS, Walters JR, Crowder LB. Evaluating management alternatives for red-cockaded woodpeckers: a modeling approach. J Wildl Manag. 1994;58(3):479–87.
Miller CU, Dean L. Modeling the effects of fire management alternatives on Sierra Nevada mixed-conifer forests. Ecol Appl. 2000;10(1):85–94.
Loehman R, Flatley W, Holsinger L, Thode A. Can land management buffer impacts of climate changes and altered fire regimes on ecosystems of the southwestern United States? Forests. 2018;9(4):192.
Holsinger L, Keane RE, Isaak DJ, Eby L, Young MK. Relative effects of climate change and wildfires on stream temperatures: a simulation modeling approach in a Rocky Mountain watershed. Clim Chang. 2014;124(1–2):191–206.
Jorgensen SE. Principles of ecological modeling. In: Mitsch WJ, Jorgensen SE, editors. Ecological engineering: an introduction to ecotechnology. New York: John Wiley & Sons; 1989. p. 39–5.
Jorgensen SE. Handbook of environmental and ecological modeling. Boca Raton: CRC Press; 2017.
Keane RE, Karau EC. Evaluating the ecological benefits of wildfire by integrating fire and ecosystem models. Ecol Model. 2010;221:1162–72.
Loehle C. Forest responses to climate change. J For. 1996;72:13–5.
Bachelet D, Neilson RP, Hickler T, Drapek RJ, Lenihan JM, Sykes MT, et al. Simulating past and future dynamics of natural ecosystems in the United States. Glob Biogeochem Cycles. 2003;17(2):1045.
Zhu Z. Forest density mapping in the lower 48 states: a regression procedure. USDA Forest Service; 1994. Report No.: Research Paper SO-280.
He HS. Forest landscape models, definition, characterization, and classification. For Ecol Manag. 2008;254:484–98.
Keane RE, Cary G, Davies ID, Flannigan MD, Gardner RH, Lavorel S, et al. A classification of landscape fire succession models: spatially explicit models of fire and vegetation dynamic. Ecol Model. 2004;256(1):3–27.
Baker WL. A review of models of landscape change. Landsc Ecol. 1989;2(2):111–33.
Mladenoff DJ. LANDIS and forest landscape models. Ecol Model. 2004;180:7–19.
Scheller RM. The challenges of forest modeling given climate change. Landsc Ecol. 2018;33(9):1481–8.
Folke C, Carpenter S, Walker B, Scheffer M, Elmqvist T, Gunderson L, et al. Regime shifts, resilience, and biodiversity in ecosystem management. Annu Rev Ecol Evol Syst. 2004;35:557–81.
Uusitalo L, Lehikoinen A, Helle I, Myrberg K. An overview of methods to evaluate uncertainty of deterministic models in decision support. Environ Model Softw. 2015;63:24–31.
Wimberly MC. Spatial simulation of historical landscape patterns in coastal forests of the Pacific Northwest. Can J For Res. 2002;32:1316–28.
Keane RE, Holsinger L, Pratt S. Simulating historical landscape dynamics using the landscape fire succession model LANDSUM version 4.0. Fort Collins, CO USA: USDA Forest Service Rocky Mountain Research Station; 2006. Report No.: General Technical Report RMRS-GTR-171CD.
Chew JD. Simulating vegetation patterns and processes at landscape scales. In: Integrating spatial information technologies for tomorrow : GIS ‘97 conference proceedings, Feb 17–20, 1997. Fort Collins Colo: GIS World 1997; 1997. p. 287–90.
Tipton C, Ocheltree T, Mueller K, Turk P, Fernández-Giménez M. Revision of a state-and-transition model to include descriptions of state functional attributes. Ecosphere. 2018;9(5):e02201.
Bestelmeyer BT, Ash A, Brown JR, Densambuu B, Fernández-Giménez M, Johanson J, et al. State and transition models: theory, applications, and challenges. In: Rangeland systems. Berlin: Springer; 2017. p. 303–45.
Keane RE, Loehman RA, Holsinger LM. The FireBGCv2 landscape fire and succession model: a research simulation platform for exploring fire and vegetation dynamics. Fort Collins, CO USA: U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station; 2011. Report No.: General Technical Report RMRS-GTR-255.
Dong Z, Driscoll CT, Johnson SL, Campbell JL, Pourmokhtarian A, Stoner AM, et al. Projections of water, carbon, and nitrogen dynamics under future climate change in an old-growth Douglas-fir forest in the western Cascade Range using a biogeochemical model. Sci Total Environ. 2018.
Li Y, Zhang T, Liu Q, Li Y. Temporal and spatial heterogeneity analysis of optimal value of sensitive parameters in ecological process model: the BIOME-BGC model as an example. J Appl Ecol. 2018;29(1):84–92.
Jørgensen SE, Bendoricchio G. Fundamentals of ecological modelling. Amsterdam: Elsevier; 2001.
Wainwright J, Mulligan M. Environmental modelling: finding simplicity in complexity. Hoboken: John Wiley & Sons; 2005.
Grant WE, Swannack TM. Ecological modeling: a common-sense approach to theory and practice. Hoboken: John Wiley & Sons; 2011.
Lucash MS, Scheller RM, Sturtevant BR, Gustafson EJ, Kretchun AM, Foster JR. More than the sum of its parts: how disturbance interactions shape forest dynamics under climate change. Ecosphere. 2018;9(6):e02293.
Jackson LJ, Trebitz AS, Cottingham KL. An introduction to the practice of ecological modeling. AIBS Bull. 2000;50(8):694–706.
Black AJ, McKane AJ. Stochastic formulation of ecological models and their applications. Trends Ecol Evol. 2012;27(6):337–45.
Fuquay DM, Robert G. Baughman, Latham DJ. A model for predicting lightning-fire ignition in wildland fuels. Research Paper. USDA Forest Service; 1979. Report No.: INT-217.
Jenkins MA, Hebertson E, Page W, Jorgensen CA. Bark beetles, fuels, fire and implications for forest management in the Intermountain West. For Ecol Manag. 2008;254:16–34.
Box GEP, Draper NR. Empirical model-building and response surfaces. New York: Wiley and Sons; 1987. 424 p.
Schimel DS, Participants VEMAP, Braswell BH. Continental scale variability in ecosystem processes: models, data, and the role of disturbance. Ecol Monogr. 1997;67(2):251–71.
Duarte CM, Amthor JS, DeAngelis DL, Joyce LA, Maranger RJ, Pace ML, et al. The limits to models in ecology. Models in Ecosystem Science. 2003;437–51.
Schoener TW. Mechanistic approaches to community ecology: a new reductionism. Am Zool. 1986;26(1):81–106.
Turner MG, Arthaud GJ, Engstrom RT, Hejl SJ, Liu J, Loeb S, et al. Usefulness of spatially explicit population models in land management. Ecol Appl. 1995;5(1):12–6.
He HS, Mladenoff DJ. Spatially explicit and stochastic simulation of forest‐landscape fire disturbance and succession. Ecology. 1999;80(1):81–99.
Dunning JB Jr, Stewart DJ, Danielson BJ, Noon BR, Root TL, Lamberson RH, et al. Spatially explicit population models: current forms and future uses. Ecol Appl. 1995;5(1):3–11.
Opdam P, Foppen R, Vos C. Bridging the gap between ecology and spatial planning in landscape ecology. Landsc Ecol. 2001;16(8):767–79.
Kurz WA, Beukema SJ, Merzenich J, Arbaugh M, Schilling S, editors. Long-range modeling of stochastic disturbances and management treatments using VDDT and TELSA. Society of American Foresters 1999 National Convention; 1999; Portland: Society of American Foresters.
Costanza R, Wainger L, Folke C, Mäler K-G. Modeling complex ecological economic systems: toward an evolutionary, dynamic understanding of people and nature. In: Ecosystem management. Berlin: Springer; 1993. p. 148–63.
Renner IW, Warton DI. Equivalence of MAXENT and Poisson point process models for species distribution modeling in ecology. Biometrics. 2013;69(1):274–81.
Luoto M, Virkkala R, Heikkinen RK. The role of land cover in bioclimatic models depends on spatial resolution. Glob Ecol Biogeogr. 2007;16(1):34–42.
Karau EC, Keane RE. Determining landscape extent for succession and disturbance simulation modeling. Landsc Ecol. 2007;22:993–1006.
Janssen PHM, Heuberger PSC. Calibration of process-oriented models. Ecol Model. 1995;83(1):55–66.
Dale VH. Ecological modeling for resource management. Berlin: Springer Science & Business Media; 2003.
Alewell C, Manderscheid B. Use of objective criteria for the assessment of biogeochemical ecosystem models. Ecol Model. 1998;107:213–24.
Collie JS, Botsford LW, Hastings A, Kaplan IC, Largier JL, Livingston PA, et al. Ecosystem models for fisheries management: finding the sweet spot. Fish Fish. 2016;17(1):101–25.
Marzluff JM, Millspaugh JJ, Ceder KR, Oliver CD, Withey J, McCarter JB, et al. Modeling changes in wildlife habitat and timber revenues in response to forest management. For Sci. 2002;48(2):191–202.
Haefner JW, Poole GC, Dunn PV, Decker RT. Edge effects in computer models of spatial competition. Ecol Model. 1991;56:221–44.
Keane RE, Cary GJ, Parsons R. Using simulation to map fire regimes: an evaluation of approaches, strategies, and limitations. Int J Wildland Fire. 2003;12:309–22.
Keane RE, Finney MA. The simulation of landscape fire, climate, and ecosystem dynamics. In: Veblen TT, Baker WL, Montenegro G, Swetnam TW, editors. Fire and global change in temperate ecosystems of the Western Americas. Ecological Studies Vol. 160. New York, New York, USA: Springer-Verlag; 2003. p. 32–68.
Laurance WF, Yensen E. Predicting the impacts of edge effects in fragmented habitats. Biol Conserv. 1991;55:77–92.
Berger T. Agent-based spatial models applied to agriculture: a simulation tool for technology diffusion, resource use changes and policy analysis. Agric Econ. 2001;25(2–3):245–60.
Drury SA, Herynk JM. The national tree list layer. Ft Collins, CO USA: USDA Forest Service Rocky Mountain Research Station; 2011. Report No.: General Technical Report RMRS-GTR-254.
Riley KL, Grenfell IC, Finney MA, Wiener JM. In: U.S Department of Agriculture FS, editor. Fire lab tree list: a tree-level model of the western US circa 2009 v1. Fort Collins, CO USA: Research Data Archiv; 2018.
Tonini F, Jones C, Miranda BR, Cobb RC, Sturtevant BR, Meentemeyer RK. Modeling epidemiological disturbances in LANDIS-II. Ecography. 2018;41(12):2038–44.
Box GE. Robustness in the strategy of scientific model building. In: Robustness in statistics. Amsterdam: Elsevier; 1979. p. 201–36.
Acknowledgements
We would like to thank Chris Stalling, US Forest Service, for thoughtful comments on the draft manuscript.
Author information
Authors and Affiliations
Contributions
REK designed the paper and wrote 50% of the material; RAL wrote 40% of the paper; LMH wrote one section (10%) and provided review.
Corresponding author
Ethics declarations
Conflict of Interest
REK, RAL, and LHM declare no conflict of interest.
Human and Animal Rights and Informed Consent
This article does not contain any studies with human or animal subjects performed by any of the authors.
Disclaimer
Any use of trade, firm, or product names is for descriptive purposes only and does not imply endorsement by the U.S. Government. This paper was partly written and prepared by U.S. Government employees on official time and therefore is in the public domain and not subject to copyright.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Methodological Developments in Landscape Ecology and Related Fields
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Keane, R.E., Loehman, R.A. & Holsinger, L.M. Selecting a Landscape Model for Natural Resource Management Applications. Curr Landscape Ecol Rep 4, 31–40 (2019). https://doi.org/10.1007/s40823-019-00036-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40823-019-00036-6