
Abstract
Probability hesitation fuzzy sets(PHFSs) have been paid increasing attention in the fuzzy domain nowadays, and correlation coefficient is becoming an important research content in fuzzy data analysis, many scholars have been conducted relevant researches on it. However, the existing correlation coefficients between PHFSs have some limitations, such as not considering the number of membership degrees and having counter-intuitive phenomenon to some extent. Therefore, we propose the mixed correlation coefficient between PHFSs. To begin with, we give the concepts of the average, variance, and length ratio of PHFE to illustrate the integrity, distribution, and length. Then, we define the average, variance, and length three correlation coefficients respectively on the above basic concepts. Furthermore, we construct the mixed correlation coefficient through combining these basic correlation coefficients, and extend to weighted form in addition, which addresses the issues of the available correlation coefficients. Finally, we utilize proposed correlation coefficient to analysis problems of data association and decision making. The effectiveness and rationality of the proposed method is illustrated at length.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In 1965, Zadeh [1] put forward the concept of fuzzy sets, to represent uncertain information through membership and non-membership. After that, Torra [2] proposed the hesitant fuzzy sets (HFSs), which further enriched the theory and application of fuzzy sets. Besides, many scholars have made research on HFSs, which have been extended into hesitant fuzzy linguistic term sets [3], interval value-hesitant fuzzy sets [4], dual-hesitant fuzzy sets [5], generalized hesitant fuzzy sets [6], and hesitant triangular fuzzy sets [7] and so on in recent years.
However, HFSs assume that the probability of each element is equal, so it cannot express the preference of experts; in order to improve this problem, Zhu [8] applied probability information into HFS, firstly proposed the probability hesitant fuzzy sets(PHFSs); and due to the full use of probability information, the PHFS can not only describe decision makers’ cognition of uncertainty, but also illustrate the difference of the importance of all evaluations. Because of the perfect mathematical form, the PHFS has received wide attention of scholars, a series of achievements have been made in integration operators [9,10,11,12], preference relation theory [13, 14], and decision-making method [15,16,17]; among them, the preference relation has great application prospects because it conforms to the process of group decision making. In addition, scholars have also extended the PHFS to interval value probability hesitant fuzzy sets [18], dual probability hesitant fuzzy sets [19], and so on, which provided a great supplement to PHFS theory.
In the researches mentioned above, correlation coefficient measure is an important field to be further studied. Correlation coefficient, as a common mathematical method in data analysis, is widely used in multi-attribute decision making. Different from the distance measure [20], similarity [21], and entropy measure [22], the correlation coefficient studies the degree of linear correlation between two variables, which has the necessity and uniqueness of analysis. In this paper, we devote ourselves to the correlation coefficient of PHFS. Some scholars have studied the correlation coefficient of HFSs and obtained some remarkable achievements.
Xu [23] first defined five correlation coefficients of HFEs and applied them to medical diagnosis. On this basis, Chen [24] given some correlation coefficients of HFSs to solve the clustering problem. Guan [25] analyzed the limitations of the available correlation coefficients of HFSs and proposed a new correlation coefficient that not only satisfies statistical intuition, but does not require the same quantity of membership degrees in HFE. In addition, the team also proposed a comprehensive correlation coefficient [26] by defining the characteristics of several types of HFSs, which solved the anti-intuition phenomenon in the existing correlation coefficients. Regarding the current concerns that the existing correlation coefficients of HFS violate the statistical intuition and stochastic process, Xu [27, 28] proposed a novel correlation coefficient of HFS based on a more rigorous mathematical definition and utilized it to solve multi-sensor decision-making problems. Furthermore, Reference [29,30,31,32] also extended the correlation coefficients to dual-hesitant fuzzy set, interval value-hesitant fuzzy set, interval value dual-hesitant fuzzy set, and hesitant fuzzy linguistic term set, which were applied in fields of cluster analysis, water quality assessment, medical diagnosis, and so on. Nevertheless, compared with the HFS, the measurement theory of PHFS is much more complex [33], so there are still few researches on the correlation coefficients of PHFS at present. Farhadinia [34] proposed five correlation coefficients of PHFSs and employed them to medical diagnosis. By defining mean and variance of PHFE, Wang [35] studied the correlation coefficient of PHFEs and expanded it into weighted form. Zhu [36] defined the correlation coefficients of discrete and continuous PHFSs, and proposed a multi-attribute decision model based on them. Song [37] proposed an improved correlation coefficient of PHFS and applied it to cluster analysis.
Although the above correlation coefficients have been put to use in many fields, they all have corresponding shortcomings. The value of correlation coefficient should be positive and negative. However, the value range of correlation coefficient proposed by Farhadinia [34] is lie in [0, 1], which only reflects the positive correlation and ignores the negative correlation, which does not conform to the strict mathematical definition of correlation coefficient condition, and it is necessary to meet the condition of equal number of elements through element continuation; some correlation coefficients consider the case of negative correlation, such as reference [35, 37], but they are essentially a kind of mean correlation coefficient, that is, no matter how the membership degree in PHFE is distributed; as long as its mean value is equal, the calculation results are equal. It ignores the specific distribution and quantity of membership degree and other factors, so it may lead to counter-intuitive phenomenon and has certain limitations.
Although some literature considers the case of negative correlation, such as references [35, 37], it is essentially an average correlation coefficient,
The primary motivations and contributions of this paper are summarized as follows.
-
(1)
We analyzed the shortcomings of existing PHFS correlation coefficients. For example, the range of some correlation coefficients is unreasonable, that is, negative correlation cannot be characterized, in addition, some correlation coefficients are essentially a kind of mean correlation coefficient, which only measures the aggregation of PHFE, so there is one-sidedness and counter-intuitive phenomena when expressing the correlation between data;
-
(2)
We defined mean, variance, and length ratio three characteristics of PHFE through strict mathematical derivation, which characterized the integrity, distribution, and number of elements in PHFE, respectively. On this basis, we defined mean, variance, and length three basic correlation coefficients; then we obtained the mixed correlation coefficient by combining the three, and proved that it meets the conditions of correlation coefficient, and finally extend it to PHFS.
-
(3)
Based on the research emphasis of this paper, a multi-attribute decision-making model based on correlation coefficient is constructed, and the advantages of improved correlation coefficient are verified through two simulations of data association and multi-attribute decision making.
Since the main task of this paper is correlation coefficient, it is necessary to provide a clear explanation of the advantages of improving correlation coefficients as follows:
-
(1)
Avoid counter-intuitive phenomena and make the results more reasonable;
-
(2)
The mixed correlation coefficient has greater flexibility and can achieve results that better align with decision makers’ intentions by adjusting parameters;
-
(3)
The results of the mixed correlation coefficient are more comprehensive, and its decision making is more convincing compared to a single feature.
The chapters of this paper are arranged as follows:
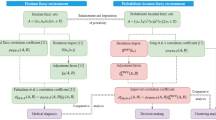
First, we summarized the current research status and achievements of PHFS in Sect. 1, and some basic concepts of PHFS are introduced in Sect. 2. In Sect. 3, we analyze the existing correlation coefficient and its deficiencies; In Sect. 4, we give the three basic concepts of mean, variance, and length ratio of PHFE, and define the corresponding three basic correlation coefficients, and then integrate the three correlation coefficients to obtain the mixed form, which is expanded to the weighted form. In Sect. 5, the validity and superiority of the proposed correlation coefficient are verified through two examples of data association analysis and multi-attribute decision making. Finally, we summarize the work done in this paper and make prospects for future research directions in Sect. 6.
2 Preliminary
The basic concept and operation rules of PHFS are briefly introduced in this section.
Definition 1
The reference domain is any nonempty set X, and the PHFS H is expressed as a probability distribution function mapping from X to the interval [0,1], which is defined as follows:
where h(x) represents the membership degree of X belonging to a certain set, the value is the subset on the interval [0,1]. \({p_x}\) is the corresponding probability of a membership degree in h(x), which is also a subset of [0,1]. Besides,\({h_x}({p_x})\) is known as probability hesitant fuzzy element(PHFE), which is abbreviated as h(p) and can be expressed as follows:
in which \(\left| {h(p)} \right|\) represents the quantity of membership degree, \({\gamma ^\lambda }\) depicts the possibility that x belongs to H, and \({p ^\lambda }\) is the corresponding occurrence probability of \({\gamma ^\lambda }\), which satisfies \(\sum \nolimits _{\lambda = 1}^{\left| {h(p)} \right| } {{p^\lambda } \le 1}\).
3 PHFS Correlation Coefficient Analysis
In this section, we summarize the existing probability hesitation fuzzy correlation coefficient, and analyze its shortcomings emphatically; then we mainly makes comparison in the subsequent simulation analysis with the correlation coefficient defined in reference [37].
3.1 Existing PHFS Correlation Coefficient
The PHFS correlation coefficient in reference [37] is described as follows.
Definition 2
Assume the reference domain \(X = \{ {x_1},{x_2}, \cdots ,{x_n}\}\),and two random PHFSs \(A = \{ \langle x,{h_{Ai}}({p_x})\rangle \vert {x_i} \in X\}\) and \(B = \{ \langle x,{h_{Bi}}({p_x})\rangle \vert {x_i} \in X\}\), where the PHFE of A is \({h_{Ai}}({p_x}) = \{ \gamma _{Ai}^\lambda \vert p_{Ai}^\lambda ,\lambda = 1,2, \cdots ,{l_{Ai}}\}\), then the average and variance of A, the covariance and correlation coefficient between A and B are respectively expressed as follows:
The average of PHFS A is defined as follows:
where \({{\bar{h}}_{Ai}}({p_x})\) represents the average of PHFE \({h_{Ai}}({p_x})\):
The variance of PHFS A based on the average \({\bar{A}}\) is defined as follows:
The covariance between PHFSs A and B is expressed as follows:
Based on the covariance C(A, B), the correlation coefficient between PHFSs A and B is expressed as follows:
Definition 3
If the weights of elements on X are taken into account, assuming that the weight vector on X is \({\omega _i} \in [0,1],i = 1,2, \cdots ,n\), which satisfies \(\sum \nolimits _{i = 1}^n {{\omega _i}} = 1\), then the weighted average, variance of PHFS A, as well as the weighted covariance and correlation coefficient between A and B are expressed as follows respectively.
The weighted average of PHFS A is
The weighted variance of PHFS A is
The weighted covariance between PHFSs A and B is expressed as follows:
Based on covariance \({C_\omega }(A,B)\), the weighted correlation coefficient between PHFSs A and B is expressed as follows:
3.2 Existing Correlation Coefficient Limitation Analysis
Example 1
Given a PHFE \(h(p) = \{ 0.8\vert 0.7,0.2\vert 0.3\}\), which means the membership degree of x belonging to H is 0.8 or 0.2, and the probability being 0.8 is 0.7, the probability being 0.2 is 0.3. When all the probability of membership degree is \(1/\left| {h(p)} \right|\), h(p) turns to \(\{ 0.8\vert 0.\mathrm{{5}},0.2\vert 0.\mathrm{{5}}\}\). At this time, it can be obtained that all membership degrees have the same probability through the probability information, in other words, decision makers do not prefer any membership degree.
Similarly, the hesitation fuzzy element (HFE) \(\{ 0.8,0.2\}\) cannot determine which membership degree decision makers prefer because it does not contain probability information. Therefore, when the probability of membership degree is equal, the information delivered by the PHFS is equivalent to that of hesitation fuzzy set(HFS), that is to say, the HFS can be understood as a special case of the PHFS. Therefore, we consider the following example.
Example 2
Considering the simplest case, given the reference domain \(X = \{ {x_1},{x_2},{x_3}\}\), three PHFSs A, B, and C are expressed as below, respectively:
The correlation coefficients between A, B, and C are calculated according to definition 2, and the specific process is as follows:
The average values of PHFE in A, B, and C are
The average values of PHFSs A, B, and C are
The variance of PHFSs A, B, and C is
The covariance between PHFSs A, B, and C is
Then the correlation coefficients between A, B, and C are
Obviously, the above conclusion is counter-intuitive, because PHFSs A, B, and C are completely distinct and there is no linearity between them, so the correlation coefficient between them should not be 1, indicating that the existing method fails in this example, the reasons can be summarized as follows:
(1) The existing correlation coefficient is essentially a kind of average correlation coefficient, namely it ignores the specific distribution characteristic of membership degrees of PHFE, only calculates the average of each PHFE to reconstruct a new HFE, so we can say that no matter how the membership degrees are distributed, as long as the corresponding PHFE average is equal, the calculation result is the same.
(2) The existing correlation coefficient does not take into account the influence of quantity of membership degrees. Although it is not mandatory to have equal quantity of membership degrees but also makes this factor not play an important part during the calculation, if the number of membership degrees is inconsistent, the corresponding correlation coefficients should not be equal; therefore, the membership number of PHFS shall be as an important feature in the definition of correlation coefficient.
4 PHFS Mixed Correlation Coefficient
Mathematically, the correlation coefficient is defined as ’random variable normalization covariance.’ Therefore, this section defines a mixed correlation coefficient from the viewpoint of statistics and stochastic process to make it more mathematical. First, the definitions of variance and covariance of PHFSs are given from the aspect of statistics. Then, according to the strict mathematical definition of covariance, the new correlation coefficient is defined according to the mathematical meaning of ’random variable normalization covariance.’
According to previous analysis, the new correlation coefficient should take the entirety, specific distribution, and number of membership degrees in PHFEs into account. Therefore, on the basis of reference [38], this section uses the average value to represent the entirety of PHFE, variance to indicate its specific distribution, length ratio to reflect the number of membership degrees, which are used to construct average, variance, and length three basic correlation coefficients, respectively; finally, they are integrated to obtain the mixed correlation coefficient, and the basic definition is described below.
4.1 Basic Definition of PHFE Characteristics
Definition 4
Given the reference domain set \(X = \{ {x_1},{x_2}, \cdots ,{x_n}\}\), a random PHFS \(A = \{ \langle x,{h_{Ai}}({p_x})\rangle \vert {x_i} \in X\}\), where the PHFE is \({h_{Ai}}({p_x}) = \{ \gamma _{Ai}^\lambda \vert p_{Ai}^\lambda ,\lambda = 1,2, \cdots ,{l_{Ai}}\}\), then the average, variance, and length ratio of \({h_{Ai}}({p_x})\) are respectively defined as follows.
The average of PHFE \({h_{Ai}}({p_x})\) is
The variance of PHFE \({h_{Ai}}({p_x})\) is
The length ratio of PHFE \({h_{Ai}}({p_x})\) is
where \(u\left( {{h_{Ai}}({p_x})} \right)\) satisfies \(0 \le u\left( {{h_{Ai}}({p_x})} \right) \le 1\), when the number of membership degrees is 1, \(u\left( {{h_{Ai}}({p_x})} \right) = 0\), which indicates that the PHFE has the minimum membership degrees, when the number of membership degrees approaches infinity, \(u\left( {{h_{Ai}}({p_x})} \right) = 1\), indicates that the PHFE has the maximum membership degrees. Besides, the length ratio of PHFS A is expressed as follows:
4.2 Three Basic PHFS Correlation Coefficients
According to the analysis in Sect. 4.1, the average, variance, and length three basic correlation coefficients are defined respectively as below.
Assume the reference domain \(X = \{ {x_1},{x_2}, \cdots ,{x_n}\}\), and two random PHFSs \(A = \{ \langle x,{h_{Ai}}({p_x})\rangle \vert {x_i} \in X\}\) and \(B = \{ \langle x,{h_{Bi}}({p_x})\rangle \vert {x_i} \in X\}\), where the PHFE of A and B are respectively \({h_{Ai}}({p_x}) = \{ \gamma _{Ai}^\lambda \vert p_{Ai}^\lambda ,\lambda = 1,2, \cdots ,{l_{Ai}}\}\) and \({h_{Bi}}({p_x}) = \{ \gamma _{Bi}^\lambda \vert p_{Bi}^\lambda ,\lambda = 1,2, \cdots ,{l_{Bi}}\},i = 1,2, \cdots ,n\).
4.2.1 Average Correlation Coefficient
The average correlation coefficient is actually the same as that mentioned in reference [37]. In order to unify the mathematical expression, it is briefly described as follows.
Definition 5
The average covariance between PHFSs A and B is
Based on \({C_M}(A,B)\), the average correlation coefficient between A and B is defined as follows:
4.2.2 Variance Correlation Coefficient
Definition 6
The average of the variance of PHFE \({h_{Ai}}({p_x})\) is defined as follows:
The variance of the variance of PHFE \({h_{Ai}}({p_x})\) is defined as follows:
On this basis, the covariance of the variance between PHFSs A and B is
Based on \({C_V}(A,B)\), the variance correlation coefficient between A and B is expressed as follows:
4.2.3 Length Correlation Coefficient
Definition 7
The average of the length ratio of PHFE \({h_{Ai}}({p_x})\) is defined as follows:
It can be found that the above formula is consistent with equation (15).
The variance of the length ratio of PHFE \({h_{Ai}}({p_x})\) is defined as follows:
On this basis, the covariance of length ratio between PHFSs A and B is expressed as follows:
Based on \({C_L}(A,B)\), the length correlation coefficient between A and B is expressed as follows:
Besides, the correlation coefficient should meet the following three axiom theorems:
-
(1)
\(\rho (A,B) = \rho (B,A)\),
-
(2)
if \(A = B\), then \(\rho (A,B) = 1\),
-
(3)
\(- 1 \le \rho (A,B) \le 1\).
Therefore, we need to prove that the three basic correlation coefficients meet the theorems. We only prove the variance correlation coefficient here because of the homologous definition process, the proof of other two correlation coefficients is similar.
Since theorems (1) and (2) are clearly true, we need only prove theorem (3).
Proof of Theorem(3)
Assuming \({\rho _i} = Var({h_{Ai}}({p_x})) - {{\bar{A}}_V}\),\({\theta _i} = Var({h_{Bi}}({p_x})) - {{\bar{B}}_V}\), according to the Cauchy-Schwarz inequality:
we can get
that is, \(\left| {{\rho _V}(A,B)} \right| = \frac{{\left| {{C_V}(A,B)} \right| }}{{{{\left[ {{C_V}(A,A){C_V}(B,B)} \right] }^{1/2}}}} \le 1\),
so we can get \(- 1 \le {\rho _V}(A,B) \le 1\). \(\square\)
4.3 Mixed Correlation Coefficient
Based on three basic correlation coefficients of PHFSs, the mixed correlation coefficient is defined as follows:
where \(\alpha , \beta\) and \(\gamma\) are the weights of average, variance, and length correlation coefficients, respectively, which satisfy \(\alpha + \beta + \gamma = 1\).
The following is to prove that the mixed correlation coefficient \({\rho _{MVL}}(A,B)\) meets the three theorems of correlation coefficient.
Proof
Theorem (1) clearly holds;
With regard to theorem (2), if \(A=B\), according to the conclusion in the previous section, there is \({\rho _M}(A,B) = {\rho _V}(A,B) = {\rho _L}(A,B) = 1\), then \({\rho _{MVL}}(A,B) = \alpha + \beta + \gamma = 1\).
With respect to theorem (3), by reason of
and \(\alpha \ge 0,\beta \ge 0,\gamma \ge 0\),
there are
so
therefore, \(- 1 \le {\rho _{MVL}}(A,B) \le 1\). \(\square\)
Example 3
The mixed correlation coefficient is applied to recalculate the correlation coefficient between PHFSs A, B, and C in example 2. Assuming that the weight of three basic correlation coefficients is 1/3 equally, the calculation process is as follows:
The variance and length ratio of each PHFE in A, B, and C is
Based on the variance and length ratio, the variance and length correlation coefficient between A, B, and C are respectively as follows:
Therefore, according to equation (26), the mixed correlation coefficient between A, B, and C can be obtained:
From above, it can be seen that the result of the mixed correlation coefficient is different from that in reference [37]. Although the average correlation coefficient is equal to 1, with the help of variance and length correlation coefficient, the mixed correlation coefficient can overcome the deficiency of reference [37], distinguish the data well, which makes the calculation result more convincing.
4.4 Weighted Mixed Correlation Coefficient
Actually, in practical problems, the weight of each element in the domain \(X = \{ {x_1},{x_2}, \cdots ,{x_n}\}\) is often different. Assuming that the weight vector of elements in X is \(\omega = {({\omega _1},{\omega _2}, \cdots ,{\omega _n})^\mathrm{{T}}}\), which satisfies \(\sum \nolimits _{i = 1}^n {{\omega _i}} = 1\), then the three weighted basic correlation coefficients are defined as follows.
Weighted average correlation coefficient:
Weighted variance correlation coefficient:
Weighted length correlation coefficient:
Then, the weighted mixed correlation coefficient is expressed as follows:
where \({\alpha _\omega }\),\({\beta _\omega },\) and \({\gamma _\omega }\) are the weights of weighted average, variance, and length correlation coefficients, respectively, which satisfy \({\alpha _\omega } + {\beta _\omega } + {\gamma _\omega } = 1\).
It should be noted that the weight \({\omega _i}\) in the above equations cannot be reduced like \(\frac{1}{n}\) in ordinary correlation coefficients of Sect. 4.2.
5 Simulation Applications
In this section, we apply the improved correlation coefficient to the analysis of two examples to verify its effectiveness.
5.1 Data Association Application
5.1.1 Simulation Analysis
Assuming that the reconnaissance agency detects two groups of data and reports the data to the fusion center in the form of PHFS after the primary decision. These data are shown in Table 1.
The decision-making department needs to determine whether the two sets of data belong to the same observation object. We will utilize the proposed correlation coefficient for association analysis to solve this problem.
According to the equations in Sect. 4.2, the basic average, variance, and length correlation coefficients of two groups of data are 0.9042, \(-\)0.784, and \(-\)0.5, then the mixed correlation coefficient can be represented by \(0.9042\alpha -0.784\beta -0.5\gamma\), with the restrictions of \(\alpha +\beta +\gamma =1\) and \(0 \le \alpha ,\beta ,\gamma \le 1\); as the weights vary, the calculation result of the mixed correlation coefficient is shown as figure 1.

Four-dimensional diagram of mixed correlation coefficient
According to figure 1, when the weight value is (1,0,0), the maximum correlation coefficient is 0.9042, and when the weight value is (0,1,0), the minimum value is \(-\)0.784. When the weights are all equal to 1/3, the calculation result is \(-\)0.1266.
The above analysis shows that when only one characteristic is considered, the conclusion is strong correlation or negative correlation, which is one sided actually. Only when all three characteristics are fully considered, we conclude that there is no correlation exists, which is more practical.
5.1.2 Comparison Analysis
In order to illustrate the advantages of the mixed correlation coefficient, the correlation coefficients in reference [34, 37] are used to solve the above data association problem, and compared with the proposed correlation coefficient. We selected \(\rho _{WHFS1}\) among multiple correlation coefficients in reference [34], the calculation results are shown in Table 2.
According to Table 2, because the negative correlation cannot be calculated in reference [34], the conclusion is 0.3188; that is, it is difficult to judge whether there is an association between the two targets; the method in reference [37] is essentially the same as basic mean correlation coefficient of this paper, so the conclusion of “strong association” is obtained, because it neglects the scatter and length of the two groups of data, while the mixed correlation coefficient takes all above factors into account, and the result is \(-\)0.1266, indicating that there is no association between the two groups of data, which is more practical. However, when the weight setting is unreasonable, the wrong conclusion will also be obtained.
Therefore, it can be concluded that the mixed correlation coefficient can obtain more reasonable and comprehensive decision results by evaluating the different characteristics of the data overall, but how to select reasonable weight parameters is significant and still worth further research.
5.2 Multi-attribute Decision Making in PHFSs
This paper focuses on the study of the new correlation coefficient, instead of the innovation of multi-attribute decision-making method, so only on the basis of existing theory, we provide a simple ideal scheme proximity-ranking method for decision making, the multi-attribute decision-making problem is described as follows.
5.2.1 Decision-Making Method
Assuming that in the multi-attribute decision-making problem, there are n alternative schemes \(A = \{ {A_1},{A_2}, \cdots ,{A_n}\}\) and m attributes \(G = \{ {G_1},{G_2}, \cdots ,{G_m}\}\), the attribute weights are unknown and independent of each other, there are t decision-making experts \(D = \{ {D_1},{D_2}, \cdots ,{D_t}\}\) in total. Assuming that the weight of each expert is equal, then the evaluation information of scheme \(A_i\) under attribute \(G_j\) by expert k is expressed as follows:
According to the information integration method in reference [22], the evaluation information of all experts on scheme \(A_i\) under attribute \(G_j\) is expressed as follows:
Then the evaluation information of all experts about alternative scheme \(A_i\) is obtained as follows:
Finally, the decision matrix D is expressed as follows:
Through the above description, the problem model is established. The following mainly introduces the steps of multi-attribute decision-making method.
Firstly, assume that all attributes are benefit attributes, the optimal ideal scheme is obtained as follows:
Calculate the correlation coefficients \(\rho ({A_i},{A^*})\) between each scheme and \({A^*},\) respectively.
The higher the correlation coefficient is, the higher the similarity between the corresponding scheme and \({A^*}\) is, and the better the scheme is. On this basis, the correlation coefficient is taken as the decision-making index to determine the decision scheme with the largest correlation coefficient and output the corresponding scheme label:
The specific steps of decision-making method based on mixed correlation coefficient are described as follows:
Step 1. Obtain the evaluation information of each expert \(D_i\) presented in the form of PHFS.
Step 2. Integrate all expert evaluation information to obtain comprehensive evaluation information D;
Step 3. Calculate the optimal ideal scheme \({A^*}\);
Step 4. According to equation (26), calculate the mixed correlation coefficients \({\rho _{MVL}}({A_i},{A^*})\) of each alternative scheme with \({A^*},\) respectively, and rank the decision schemes according to the correlation coefficient. The scheme with the largest value is determined as the final decision result.
5.2.2 Simulation Analysis
In order to facilitate comparison, an example in reference [36] is used to verify the proposed method.
Four candidates apply for one doctoral supervisor for the only doctoral enrollment. In order to select the best student fairly, PHFSs are introduced. The candidates were asked to be interviewed by 4 experts, each with equal weight, the interview process was assessed on 3 attributes: computing ability \(A_1\), academic level \(A_2,\) and English ability \(A_3\).
In order to facilitate comparison and keep consistent with reference [36], attribute weight vector is set as (0.39,0.26,0.35), and all three attributes are benefit type. Assume that the weights of average, variance, and length correlation coefficients are (0.5,0.25,0.25), respectively. The specific steps of multi-attribute decision making are described as follows.
Step 1. Obtain the PHFS evaluation information of four experts under the 3 attributes(the specific data refer to reference [36]).
Step 2. The PHFS evaluation information of all experts is integrated as Table 3.
Step 3. Calculate the optimal ideal scheme. According to equation (35), the optimal ideal scheme is shown in Table 4.
Step 4. Calculate the three basic correlation coefficients of each scheme with \(A^*\) respectively, as shown in Table 5.
Step 5. According to the calculation results of the mixed correlation coefficient, the ranking of all schemes is \({x_1}> {x_2}> {x_3} > {x_4}\).
Therefore, the candidate \({x_1}\) is determined to be the best choice for doctoral candidate through multi-attribute decision making. The results are consistent with those obtained by entropy measure in reference [22], which proves the effectiveness of our proposed algorithm.
In order to verify the effectiveness and comprehensiveness of the mixed correlation coefficient in this paper, only one basic correlation coefficient is adapted and the results were compared with those of the mixed correlation coefficient. The calculation results are shown in Table 5.
It can be seen that the ranking results of three basic correlation coefficients are not the same, especially the length correlation coefficient determines \(x_1\) and \(x_3\) as the best candidate, which has the biggest gap with the conclusion of the mixed correlation coefficient; the reason is that the length correlation coefficient only considered the factor of membership degree number, without considering the specific distribution of membership degrees. Therefore, it is one sided to use any basic correlation coefficient for evaluation. In practical application, three basic correlation coefficients must be considered comprehensively to obtain reasonable discriminant results.
5.2.3 Weight Sensitivity Analysis of Basic Correlation Coefficients
The influence is further analyzed brought by weight changes of different basic correlation coefficients. Assume that the weight of any basic correlation coefficient increases from 0.1 to 0.9 in step size of 0.2, the weights of others are equally divided. The calculation results are shown in figure 2.

Comparison result under different basic correlation coefficient weights
From figure 2, we can analyze that the result changes with the weight of the basic correlation coefficient, leading to the change of ranking order. Taking figure 2 as an example, with the increase of the weight of the average correlation coefficient, the correlation coefficient of \(x_1\) slowly increases, and the correlation coefficient of \(x_2\) and \(x_4\) gradually increases, and the correlation coefficient of \(x_3\) gradually decreases, and the sorting result gradually approximates that the result of only average correlation coefficient is used \({x_1}> {x_2}> {x_4} > {x_3}\), and when the weight is around 0.45 and 0.75, the sorting result changes correspondingly;; that is, the correlation coefficient of \(x_2\) exceeds \(x_3\), and the correlation coefficient of \(x_4\) exceeds \(x_3\). Similarly, with the change of the weight of the variance correlation coefficient, the sorting result also changes twice, while with the weight varying, the length correlation coefficient always keeps the sorting result of \({x_1}> {x_3}> {x_2} > {x_4}\).
Based on the above analysis, it is shown that the mixed correlation coefficient in this paper is sensitive to the weight parameters of the basic correlation coefficient. In application, the weight value needs to be set according to the specific situation. Since only the number of membership degree is involved in the calculation process of length correlation coefficient, the average correlation coefficient should be considered as the main decision basis in practical application, and the variance and length correlation coefficient should be considered as auxiliary decision.
5.2.4 Sensitivity Analysis of Attribute Weight
In the above discussion, the attribute weight is always set as (0.39,0.26,0.35). Nevertheless in the actual decision-making process, the role of attribute weight on decision making cannot be ignored. Therefore, it is necessary to study the sensitivity of weighted correlation coefficient to the change of attribute weight. Assuming that the weight of each attribute changes from 0.1 to 0.9 in step size of 0.2, and the weights of others are equally divided, the weight of the three basic correlation coefficients is set as (0.5,0.25,0.25), and then the calculated results are shown in figure 3.

Comparison result under different attribute weights
As can be seen from figure 3, with the change of attribute weight, the overall situation of ranking results does not change much,\(x_1\) is always the best candidate, \(x_4\) is always the worst choice, only the relative size of \(x_2\) and \(x_3\) fluctuates. With the increase of the weight of computing ability \(A_1\), the correlation coefficient of \(x_2\) increases gradually, while that of \(x_3\) decreases gradually. And the order of \(x_2\) and \(x_3\) is exchanged when it is near 0.3. With the increase of the weight of academic level \(A_2\), when the weight value is 0.5, the ordering of \(x_2\) and \(x_3\) is changed. With the increase of weight of English ability \(A_3\), the correlation coefficient difference between \(x_2\) and \(x_3\) shows a trend of decreasing.
The above analysis shows that the mixed correlation coefficient in this paper is less sensitive to attribute weight parameters, but the determination of attribute weight is always an important part of multi-attribute decision making, so scientific weight calculation method should be adopted to solve it in practical application.
5.2.5 Comparative Analysis
In this section, we conducted comparative simulations with several existing correlation coefficients with our decision algorithm and the improved TOPSIS method in reference [39], so as to confirm the universality and advantages of the mixed correlation coefficient under different methods.
First of all, in order to illustrate the advantages of the correlation coefficient proposed in this paper, strength analysis was made with the correlation coefficients in reference [34, 35] and [37]. We selected \(\rho _{WHFS1}\) among multiple correlation coefficients in reference [34], assume that the attribute weights of all methods are (0.39,0.26,0.35), and the weight of three basic correlation coefficients in this paper is (0.5,0.25,0.25). The calculation results are shown in Table 6.
As can be seen from the results in Table 6, the best candidate obtained by the mixed correlation coefficient is \(x_1\), the same as the methods in reference [34, 35, 37].
However, it can be analyzed that the methods in reference [34, 35, 37] have different defects: the correlation coefficient in reference [34] cannot reflect the true linear proximity between data because it cannot calculate negative correlation, which has certain limitations in expression. reference [35] uses the method of calculating the correlation coefficient of PHFE first, and then summing it, so it will be greater than 1, it is essentially a kind of mean correlation coefficient similar to reference [37], so the ranking results are all \({x_1}> {x_2}> {x_4} > {x_3}\). On the basis of mean correlation coefficient, this paper takes into account the overall distribution of the membership degree and the number of membership degrees in PHFSs, and determines that \(x_4\) is the worst candidate decision, which is consistent with the conclusion obtained by other measurement in reference [22], so the decision result is more comprehensive and reasonable.
Secondly, in order to verify the universality and advantages of the mixed correlation coefficient under different methods, the improved TOPSIS decision-making method in reference [39] was used for comparative simulation. Firstly, the positive and negative ideal solutions are determined as shown in Table 7, and the sorting results are shown in figure 4.

Sorting results under TOPSIS method
As can be seen from figure 4, the ranking results under different correlation coefficients are different. The ranking result is \({x_1}>{x_3}>{x_2}>{x_4}\) by referencer [34], while the results are all \({x_1}>{x_2}>{x_4}>{x_3}\) in references [35] and [37]. The ranking result through the proposed correlation coefficient is \({x_1}>{x_2}>{x_3}>{x_4}\), which is consistent with the situation obtained by the decision-making method in this paper, and verifies the universality of the method in this paper and the strong stability of proposed correlation coefficient.
Based on the above experimental analysis, the simulations in Sects. 5.2.3 and 5.2.4 show that the mixed correlation coefficient has greater flexibility and can obtain more subjective results by adjusting parameters according to the decision maker’s intention. The comparative simulation in Sect. 5.2.5 validates the universality of the proposed algorithm, and compared with existing correlation coefficients, due to the consideration of multiple features, more comprehensive decision results can be obtained.
6 Conclusion
We consider the integrity, scatter, and length of PHFEs comprehensively in this paper, then define average, variance, and length the three basic correlation coefficients, and propose a brand-new mixed correlation coefficient, and the corresponding weighted form is also extended. Then, we utilize the proposed correlation coefficient to some practical applications, such as correlation analysis and multi-attribute decision making. Compared with the existing correlation coefficients, the mixed correlation coefficient has several advantages: on the one hand, by taking into account the number and the specific distribution of membership degrees, the proposed correlation coefficient can avoid the occurrence of counter-intuitive phenomena and obtain more comprehensive results; on the other hand, the weight of attributes and basic correlation coefficients can be determined according to the needs of practical problems, which has better flexibility. The comparison results show that the proposed correlation coefficient is superior and effective.
Next, we will introduce the proposed correlation coefficient to the fields of machine learning and pattern recognition. In addition, we will pay close attention to how to improve the existing multi-attribute decision-making methods to improve the computational efficiency and accuracy.
Data Availability
The evaluation data used to support the findings of this study are included within the article.
References
Zadeh, L.A.: Fuzzy sets. Inf. Control 8(3), 338–356 (1965)
Torra, V.: Hesitant fuzzy sets. Int. J. Intell. Syst. 25(6), 529–539 (2010)
Lin, R., Zhao, X.F., Wei, G.W.: Models for selecting an ERP system with hesitant fuzzy linguistic information. J. Intell. Fuzzy Syst. 26(5), 2155–2165 (2014)
Chen, N., Xu, Z.S., Xia, M.M.: Interval-valued hesitant preference relations and their applications to group decision making. Knowl-Based Syst. 37(2), 528–540 (2013)
Zhu, B., Xu, Z.S., Xia, M.M.: Dual hesitant fuzzy sets. J. Appl. Math. 26(5), 410–425 (2012)
Qian, G., Wang, H., Feng, X.Q.: Generalized hesitant fuzzy sets and their application in decision support system. Knowl.-Based Syst. 37(4), 357–365 (2013)
Wei, G.W., Wang, H.J., Zhao, X.F., et al.: Hesitant triangular fuzzy information aggregation in multiple attribute decision making. J. Intell. Fuzzy Syst. 26(3), 1201–1209 (2014)
Zhu, B.: Decison Making Methods and Applications based on Preference Relations. Southeast University (2014)
Zhang, S., Xu, Z.S., He, Y.: Operations and integrations of probabilistic hesitant fuzzy information in decision making. Inf. Fusion 38, 1–11 (2017)
Park, J., Park, Y., Son, M.: Hesitant probabilistic fuzzy information aggregation using Einstein operations. Information 9(9), 226 (2018)
Shao, S.T., Zhang, X.H., Zhao, Q.: Multi-attribute decision making based on probabilistic neutrosophic hesitant fuzzy Choquet aggregation operators. Symmetry 11(5), 623 (2019)
Li, J., Wang, Z.X.: Multi-attribute decision making based on prioritized operators under probabilistic hesitant fuzzy environments. Soft Comput. 23(11), 3853–3868 (2019)
Zhou, W., Xu, Z.S.: Group consistency and group decision making under uncertain probabilistic hesitant fuzzy preference environment. Inf. Sci. 414, 276–288 (2017)
Li, J., Wang, Z.X.: Consensus building for probabilistic hesitant fuzzy preference relations with expected additive consistency. Int. J. Fuzzy Syst. 20(5), 1495–1510 (2018)
He, Y., Xu, Z.S.: Multi-attribute decision making methods based on reference ideal theory with probabilistic hesitant information. Expert Syst. Appl. 118, 459–469 (2019)
Wu, J., Liu, X.D., Wang, Z.W., et al.: Dynamic emergency decision-making method with probabilistic hesitant fuzzy information based on GM(1,1) and TOPSIS. IEEE Access 7, 7054–7066 (2019)
Gao, J., Xu, Z.S., Liao, H.C.: A dynamic reference point method for emergency response under hesitant probabilistic fuzzy environment. Int. J. Fuzzy Syst. 19(5), 1261–1278 (2017)
Wu, W.Y., Li, Y., Ni, Z.W., et al.: Probabilistic interval-valued hesitant fuzzy information aggregation operators and their application to multi-attribute decision making. Algorithms 11, 0120 (2018)
Hao, Z.N., Xu, Z.S., Zhao, H., et al.: Probabilistic dual hesitant fuzzy set and its application in risk evaluation. Knowl.-Based Syst. 127, 16–28 (2017)
Fang, B., Han, B., Wen, C.H.: Probabilistic hesitant fuzzy group decision-making based on new distance measure. Control Decis. https://doi.org/10.13195/j.kzyjc.2020.1118
Farhadinia, B.: Utility of correlation measures for weighted hesitant fuzzy sets in medical diagnosis problems. Math. Model. Appl. 1(2), 36–45 (2016)
Liu, Y.M., Zhu, F., Jin, L.L.: Multi-attribute decision method based on probabilistic hesitant fuzzy entropy. Control Decis. 34(04), 861–870 (2019)
Xu, Z.S., Xia, M.: On distance and correlation measures of hesitant fuzzy information. Int. J. Intell. Syst. 26(5), 410–425 (2011)
Na, C., Z x, A., Mx, A.: Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis. Appl. Math. Model. 37(4), 2197–2211 (2013)
Guan, X., Sun, G.D., Yi, X., et al.: Multi-source heterogeneous data fusion recognition based on statistical correlation coefficients between hesitant fuzzy sets. Syst. Eng. Electron. 40(03), 509–517 (2018)
Guan, X., Sun, G.D., Yi, X., et al.: Synthetic correlation coefficient between hesitant fuzzy sets with applications. Int. J. Fuzzy Syst. 20, 1968–1985 (2018)
Xu, J.Y., Sun, G.D., Zhao, J.: Novel correlation coefficients between hesitant fuzzy sets and their applications in multi-attribute decision making. Acta Electron. Sin. 46(06), 1327–1335 (2018)
Song, C., Xu, Z.S.: Techniques of Decision Making, Uncertain Reasoning and Regression Analysis Under the Hesitant Fuzzy Environment and Their Applications. Springer, New York (2021)
Meng, F., Wang, C., Chen, X., et al.: Correlation coefficients of interval-valued hesitant fuzzy sets and their application based on the shapley function. Int. J. Intell. Syst. 31(1), 17–43 (2016)
Tyagi, S.K.: Correlation coefficient of dual hesitant fuzzy sets and its applications. Appl. Math. Model. 39(22), 7082–7092 (2015)
Farhadinia, B.: Correlation for dual hesitant fuzzy sets and dual interval-valued hesitant fuzzy sets. Int. J. Intell. Syst. 29(2), 184–205 (2014)
Liao, H., Xu, Z., Zeng, X.J., et al.: Qualitative decision making with correlation coefficients of hesitant fuzzy linguistic term sets. Knowl.-Based Syst. 76(mar.), 127–138 (2015)
Xu, Z.S., Zhang, S.: An overview of probabilistic hesitant fuzzy decision-making theory and methods. Control Decis. 36(1), 42–51 (2021)
Farhadinia, B.: Utility of correlation measures for weighted hesitant fuzzy sets in medical diagnosis problems. Math. Model. Appl. 1(2), 36–45 (2016)
Wang, Z.X., Jian, L.: Correlation coefficients of probabilistic hesitant fuzzy elements and their applications to evaluation of the alternatives. Symmetry 9(11), 259 (2018)
Zhu, F., Liu, Y.M., Jin, L.L.: Probabilistic hesitant fuzzy multi-attribute decision-making method based on correlation coefficient. Stat. Decis. 35(18), 41–45 (2019)
Song, C., Xu, Z., Zhao, H.: New Correlation Coefficients Between Probabilistic Hesitant Fuzzy Sets and Their Applications in Cluster Analysis[J]. International Journal of Fuzzy Systems (2018)
Xu, Z.S., Zhou, W.: Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment. Fuzzy Optim. Decis. Mak. 16(4), 481–503 (2017)
Sun, G., Guan, X., Yi, X., et al.: An innovative TOPSIS approach based on hesitant fuzzy correlation coefficient and its applications. Appl. Soft Comput. 68, 249–267 (2018)
Acknowledgements
This work is supported by the National Defense Science and Technology Excellence Young Talent Foundation (Grant no. 2017-JCJQ-ZQ-003).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflict of interest regarding the publication of this article.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ying, L., Xin, G. Mixed Correlation Coefficient Between Probability Hesitation Fuzzy Sets and Applications. Int. J. Fuzzy Syst. 26, 154–167 (2024). https://doi.org/10.1007/s40815-023-01581-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-023-01581-3