
Abstract
Forecasting the dam displacement is an important problem in dam monitoring. By using multi-temporal monitoring data to make predictions and forecast dam structure health, it is possible to detect abnormalities over time of the dam so that remedial measures can be taken promptly to minimize risks. The paper proposes a method of applying the interval type-2 fuzzy logic system (IT2FLS) and ant colony optimization (ACO) technique to forecast hydroelectric dams’ displacement. The method consists of two stages: The first is to design an IT2FLS according to the input and output data with base rules and newly constructed membership functions. The second is to find the optimal parameters for an interval type-2 fuzzy logic system based on the ACO technique and give the final fuzzy forecasting system. Experimental data are measured from hydroelectricity monitoring data of Ialy, Gia Lai Province, Vietnam, in the period from 2004 to 2016. The proposed method is compared with some other methods to compare prediction efficiency and accuracy. The experimental results show that the proposed model has the best performance compared to other standard methods in both accuracy and stability of prediction. This shows that a predictive model based on the IT2FLS is a promising method and can be used for forecasting time-series data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Hydroelectricity plays an important role for people. Besides other energy sources, hydroelectricity provides a significant amount for human activities and production. With economic efficiency and operational efficiency, hydropower also plays an essential role in water treatment and is considered as one of the most effective solutions for water treatment [1]. For hydroelectric projects already in operation, the assessment of the safety of the works and issues related to the residential community is a challenging but very important issue [2].
However, due to the movement of the earth and the soil characteristics of the hydropower construction area, over time, the hydroelectric dams often change. Therefore, the study of predicting the displacement of hydroelectric dam works is extremely important to help evaluate the safety and life of the project [3]. The factors affecting the displacement on the surface of a hydroelectric dam can be observed based on geodetic techniques at different intervals. The change in observed value in the following cycles is compared with the first period.
Studies have shown that, besides the factors caused by natural disasters, the temperature, water level, and age of a hydroelectric dam have a great influence on the lateral displacement of the dam, and affect the safety of the dam over time [4, 5]. Therefore, the use of observed data on temperature, water level, and age is necessary in the problems of predicting the horizontal displacement of hydroelectric dams [6].
Many studies to provide predictive solutions have been carried out based on multi-time monitoring data. However, studies around the world have shown that dam displacement is a typical non-linear process, so it is difficult to predict with high accuracy [7]. Accordingly, the types of research models can be classified into three main groups: the group of deterministic models, statistical models, and artificial intelligence models. The deterministic models are often used in the design and early stages of operation when there are not much monitoring data, so the forecasting results are quite limited [8].
Although the type-1 fuzzy logic system has been widely used in many analytical and forecasting problems [9, 10]. However, because the type-1 fuzzy membership functions have a crisp value, they have difficulty dealing with data with high uncertainty [11]. Therefore, for problems requiring high accuracy, people often use the interval type-2 fuzzy logic system, IT2FLS [12,13,14,15]. IT2FLS is extended from the type-1 fuzzy logic system, which has been successfully studied and applied in many forecasting problems [16]. In this study, we propose a method to predict the displacement of the hydroelectric dam using an IT2FLS with optimized parameters based on the swarm optimization technique.
In studies of hydroelectric dam displacement prediction, studies based on intelligent computational models have many advantages and often bring higher accuracy than traditional methods. Li et al. propose a novel combined model for predicting the dam displacement time series by using an improved stacked LSTM neural network model to predict the dam displacement [1]. Furthermore, most data have errors during acquisition and processing, leading to uncertainty in the information derived from the data. Usually, deep learning-based algorithms often require large enough label data for training. However, labeling data are not always available. Moreover, different hydroelectric dams have different topographic, geological, and structural features [7]. As a result, it is not easy to use the data of one hydroelectric dam for other dams. Besides developed predictive models, recently, some hybrid models between methods have also been studied by many people. Development of hybrid models based on back-propagation neural networks applying dam displacement prediction optimizes the neural fuzzy inference model using particle swarm optimization [8], so on.
Fuzzy logic-based forecasting techniques have the advantage of working well on data where uncertainty exists and can give predictive results with high accuracy [14]. Therefore, many recent studies use fuzzy logic systems to solve forecasting problems. In the paper [17], a hybrid genetic algorithm-adaptive network-based FIS (GA-ANFIS) model has been developed in which both clustering and rule base parameters are simultaneously optimized using GAs and artificial neural nets (ANNs). This model was applied to predict wave parameters, i.e., significant wave height and peak spectral period, under a time-limited condition in Lake Michigan. The method using GA-ANFIS gives higher accuracy than other methods.
Research to predict investment environment based on an improved fuzzy rule system using evidence reasoning and subtractive clustering [10]. A whale optimization algorithm and a least-squares estimator develop multi-objective prediction using an aim-object-based asymmetric neuro-fuzzy system. This method has the advantage of multi-objective prediction but reduces the number of parameters [18]. Rathnayake et al. have improved the ANFIS model by using optimization techniques to determine the parameters for the ANFIS model [19]. Recently, research-based techniques of using artificial intelligence in forecasting problems have attracted much attention from scientists.
Studies based on the type-1 fuzzy sets are like the type-1 fuzzy logic systems despite having many advantages in modeling real data [20]. In fact, the accuracy is often lower than that of fuzzy logic systems based on type-2 fuzzy sets and interval type-2 fuzzy sets [21]. This is because the type-2 fuzzy set can better model the uncertain observed data than the type-1 fuzzy set. Unfortunately, however, the computational complexity on the type-2 fuzzy set is much higher than on the type-1 fuzzy set [22]. In the study [23], Siminski presents an interval type-2 neuro-fuzzy system with interval type-2 fuzzy sets both in premises (Gaussian interval type-2 fuzzy sets with uncertain fuzziness) and consequences (trapezoid interval type-2 fuzzy set). In another study, the hybridization of type-2 fuzzy logic systems (type-2 FLS) and sensitivity-based linear learning method is proposed in [24] for permeability prediction of carbonate reservoir. Application in predicting the spread of the COVID-19 pandemic using a type-2 fuzzy inference system is to combine the responses of individual artificial neural networks [25].
It can be seen that the fuzzy logic system is widely and successfully applied in many different fields, including forecasting problems [26,27,28]. However, the difficulty when working with the IT2FLSs is the high computational complexity and difficulty in choosing the optimal parameters [29]. There are many different optimization techniques, each with specific advantages and disadvantages. In particular, the technique based on swarm intelligence has many advantages due to the flexibility of the algorithm and is widely used in optimization problems [30]. Therefore, the paper proposes to apply the IT2FLS for dam displacement prediction problems with parameters optimized by the ant colony optimization (ACO) algorithm. This method both takes advantage of the type-2 fuzzy sets in handling uncertain data and can select the optimal parameters of the system. This helps the interval type-2 fuzzy logic system to reduce the computational complexity and increase the accuracy of the prediction system.
The type-2 and interval type-2 fuzzy sets have many advantages over the type-1 fuzzy set because of its ability to represent and work on noisy and uncertain datasets [31]. However, the application of fuzzy systems, especially IT2FLSs for dam displacement prediction problems, is still very limited because they have difficulty in choosing the optimal parameters for the system. ACO is an algorithm for finding optimal solutions based on the behavior of individual ants [32]. This is an algorithm with the advantage of swarm intelligence that can help find optimal parameters for fuzzy systems. Therefore, the combination of IT2FLS and ACO is a good idea, which can help improve the accuracy of hydroelectric dam displacement prediction results.
The main contribution of the paper is to propose a combined model of IT2FLS and ACO for the problem of predicting the horizontal displacement of hydroelectric dams. Firstly, the formula for calculating the Gaussian function parameters for IT2FLS was proposed according to the Formula 16 and 17 including the centroid, the upper and lower standard uncertainty deviation of the Gaussian function. Second, we have built a set of rules for IT2FLS with parameters optimized by the ACO algorithm suitable for the problem of predicting the displacement of the dam.
The paper is organized as follows: Section 1 is a general introduction and related works; Sect. 2 is the background knowledge; Sect. 3 is the proposed method; Sect. 4 is experimental, and Sect. 5 is the conclusion and future development direction.
2 Background
2.1 Interval Type-2 Fuzzy Set
A type-2 fuzzy set in X is denoted \({\tilde{A}}\), and its membership grade of \(x \in X\) is \({\mu _{\tilde{A}}}(x,u),u \in {J_{x}} \subseteq [0,1]\), which is a type-1 fuzzy set in [0, 1]. The elements of the domain of \({\mu _{\tilde{A}}}(x,u)\) are called primary memberships of x in \({\tilde{A}}\) and memberships of primary memberships in \({\mu _{\tilde{A}}}(x,u)\) are called secondary memberships of x in \({\tilde{A}}\).
A type-2 fuzzy set [?], denoted \({\tilde{A}}\), is characterized by a type-2 membership function \({\mu _{\tilde{A}}}(x,u)\) where \(x \in X\) and \(u \in {J_{x}} \subseteq [0,1]\), i.e.,
or
in which \(0 \le {\mu _{\tilde{A}}}(x,u) \le 1\).
At each value of x, say \(x = x'\), the 2D plane whose axes are u and \({\mu _{\tilde{A}}}(x',u)\) is called a vertical slide of \({\mu _{\tilde{A}}}(x,u)\). A secondary membership function is a vertical slice of \({\mu _{\tilde{A}}}(x,u)\). It is \({\mu _{\tilde{A}}}(x = x',u)\) for \(x \in X\) and \(\forall u \in {J_{x'}} \subseteq [0,1]\):
in which \(0 \le {f_{x'}}(u) \le 1\).
Type-2 fuzzy sets are called an interval type-2 fuzzy sets if the secondary membership function \({f_{x'}}(u) = 1\;\forall u \in {J_{x}}\) i.e., A type-2 fuzzy set is defined as follows: An interval type-2 fuzzy set \({\tilde{A}}\) [19] is characterized by an interval type-2 membership function \({\mu _{\tilde{A}}}(x,u) = 1\) where \(x \in X\) and \(u \in {J_{x}} \subseteq [0,1]\), i.e.,
Uncertainty of \({\tilde{A}}\), denoted FOU, is union of primary functions, i.e., \({\text {FOU}}({\tilde{A}}) = \bigcup \nolimits _{x \in X} {J_{x}}\). Upper/lower bounds of membership function (UMF/LMF), denoted \({{\overline{\mu }} _{\tilde{A}}}(x)\) and \({{\underline{\mu }} _{\tilde{A}}}(x)\), of \({\tilde{A}}\) are two type-1 membership function and bounds of FOU (see Fig. 1).
2.2 Interval Type-2 Fuzzy Logic System
The IT2FLS is described as Fig. 2, consisting of five main parts fuzzifier, inference, rule base, type reducer, and defuzzifier [11].

IT2 fuzzy logic system with: a type-reduction + defuzzification and b direct defuzzification [11]
IT2FLS works as follows: the crisp inputs are the attributes of the initial data, which fuzzify into the input IT2FSs and then activate the inference engine and rule base to maps input IT2FSs into output IT2FSs. These output IT2FSs are then processed by the type reducer to obtain T1FSs (type reducers). The defuzzifier then defuzzifies output T1FSs to create the crisp output.
2.2.1 Fuzzifier
With T1FSs, two types of fuzzifiers are used as singleton and non-singleton, meanwhile with IT2FSs, there are three types of fuzzifiers used including singleton, type-1 non-singleton, and IT2 non-singleton. The fuzzifier maps a crisp input will depend on the choice of the type of fuzzifier. Assuming there are n inputs \(X = ({x_{1}},{x_{2}},\ldots ,{x_{n}}) \in {X_{1}}\cdot {X_{2}}\cdots {X_{n}}\), \({{\tilde{A}}_{x}}\) is a set of type-2 fuzzy inputs. For example, if \({{\tilde{A}}_{x}}\) is a type-2 fuzzy singleton fuzzifier, then \({\mu _{{\tilde{A}}({x_{i}})}} = 1/1\) when \({x_{i}} = x_{i}^{\prime }\) and \({\mu _{{\tilde{A}}({x_{i}})}} = 1/0\) when \({x_{i}} \ne x_{i}^{\prime }\) and \({x_{i}} \in {X_{i}}\).
2.2.2 Rule Base
Consider the input \({x_{1}} \in {X_{1}},{x_{2}} \in {X_{2}},\ldots ,{x_{n}} \in {X_{n}}\) and c output \({y_{1}} \in {Y_{1}},{y_{2}} \in {Y_{2}},\ldots ,{y_{c}} \in {Y_{c}}\). The rules of IT2FSs are similar to those of T1FSs, and only different antecedents and consequents instead of T1FSs will be replaced by IT2FSs:
\({R^{i}}\): IF \({x_{1}}\) is \({\tilde{F}}_{1}^{i}\) and \(\ldots\) and \({x_{n}}\) is \({\tilde{F}}_{n}^{i}\) THEN \({y_{1}}\) is \({\tilde{G}}_{1}^{i},\ldots , {y_{c}}\) is \({\tilde{G}}_{c}^{i}\). with M is the number of rules in the rule base, \(i = 1,\ldots ,M\).
2.2.3 Fuzzy Inference Engine
The inference engine and the rules that allow the mapping from input IT2FSs to the output IT2FSs. Each rule in a fuzzy rule base with M rules having n inputs \({x_{1}} \in {X_{1}},{x_{2}} \in {X_{2}},\ldots ,{x_{n}} \in {X_{n}}\) and output \({y_{k}} \in {Y_{k}}\), they can be written as follows:
\(R_{k}^{i}\): \({\tilde{F}}_{1}^{i}\cdot {\tilde{F}}_{2}^{i}\cdots {\tilde{F}}_{n}^{i} \rightarrow {\tilde{G}}_{k}^{i} = {{\tilde{A}}^{i}} \rightarrow {\tilde{G}}_{k}^{i}\), where \({\tilde{F}}_{j}^{i}\) is the jth IT2FS, \(j = 1,\ldots ,n\), which is defined by a lower and upper bound membership function \({\mu _{{\tilde{F}}_{j}^{i}}}({x_{j}}) = {{[}}{{\underline{\mu }}_{{\tilde{F}}_{j}^{i}}}({x_{j}}),{{\overline{\mu }} _{{\tilde{F}}_{j}^{i}}}({x_{j}}){{]}}\), \(i = 1,\ldots ,M;k = 1,\ldots ,c\).
2.2.4 Type Reduction
There are several algorithms used in type reduction [11], such as Karnik–Mendel algorithm (KM), Enhanced Karnik–Mendel algorithm (EKM), iterative algorithm and stopping condition (IASC), and enhanced IASC algorithm (EIASC).
2.2.5 Defuzzification
The final crisp value of output of the IT2FLS model is calculated by combining the corresponding outputs of M rules. For defuzzification solution, we calculate the average left most point and right most point; therefore, the crisp output for each output is calculated as follows:
2.3 Ant Colony Optimization
ACO algorithm is a well-known bio-inspired technique for solving combinatorial optimization problems and inspired by the foraging behavior of natural ants, where a colony of ants seeks the shortest path between the food source and their nest [32]. Each ant starts its journey from the nest searching for food sources and comes back to the nest, completing an iteration. During the journey, each ant lays a substance known as pheromone on their journey. The pheromone concentration on each path depends on the distance and the quality of the food source available. Each ant probabilistically selects a path that depends on the pheromone concentration and some heuristic value, such as the objective function value.

Algorithm 1 describes a state that mimics a colony of ants when foraging for food. ACO can be easily combined with other methods; it successfully solves complex optimization problems. ACO optimizes the problem by updating the pheromone traces and moving these ants around the search space according to simple mathematical formulas based on transition probabilities and total pheromones in the area.
In the beginning, the location of the ant colony is randomly initialized at different nodes. Ants will only visit each node once. Each ant will carry a certain amount of pheromone. In the process of visiting the next node, the ant will release pheromone on the way between visited nodes. Pheromones will evaporate over time, so shorter paths will have more pheromones and more pheromones and will attract more ants to the selection in the next iteration. The probability that the ant chooses the next node to be visited is
Here, \(p_{{{ij}}}^{k}(t)\) is the probability of choosing the next node of ant k at node i at time t, \({\tau _{{{ij}}}(t)}\) is the amount of pheromone deposited for transition from state i to j, \({\eta _{{{ij}}}(t)}\) is the desirability of state transition \({ij}\) (a priori knowledge, typically \({1/d_{ij}}\), where \({d}\) is the distance). \(0 \le {\alpha }\) is a parameter to control the influence of \({\tau _{ij}}\), and \({\beta } \ge 1\) is a parameter to control the influence of \({\eta _{ij}}\). \({\tau _{il}}\) and \({\eta _{il}}\) represent the trail level and attractiveness for the other possible state transitions. \({N_{i}^{k}}\) is the set of possibilities that ant k can go from i.
Once the ants have found their way, the pheromone will be updated by decreasing the amount of the pheromone over time (evaporation):
where \(\rho\) is the pheromone evaporation rate, m is the number of ants at each iteration and \({\displaystyle \Delta \tau _{ij}^{k}}\) is the amount of pheromone deposited by kth ant.
in which, q is the total number of pheromone taken by ant, \(c^{k}\) denotes the total length of the paths gone through by ant k in this iteration.
3 Materials and Methods
3.1 Materials
The Ialy Hydropower Plant is the third-largest hydroelectric project in Vietnam after Son La and Hoa Binh (Fig. 2). It is the third project of the cascade hydropower system on the Se San River—a large tributary of the Mekong River, comprising Dakbla and Krong Poko Tributary. The Ialy Hydropower Station is the biggest of six plants on the Se San River within Vietnam. Three other hydroelectric plants are located in Cambodia. The Ialy Hydroelectric Project was started on November 4, 1993, and completed on April 27, 2003. The Ialy Dam is an earth-rockfill dam connecting with a concrete spillway across the stream with a total of 1142 m in length, 71 m of height, and the dam crest is 522 m height above the mean sea level. Some detailed information about the Ialy Hydroelectric Dam can be found in Table 1.

Ialy Hydroelectric Dam, Vietnam. Source from the Internet
The selection of input features is based on factors that affect the operation of the hydroelectric dam. Many studies have shown that factors such as water level, ambient temperature, and age of the dam are closely related to the horizontal displacement of hydroelectric dams [4,5,6]. Input data are the time-series data observed and measured at the Ialy hydroelectricity during the period from 2004 to 2016 (see Fig. 2).
The horizontal expansion depends on the change of the temperature difference and the change/fluctuation of the reservoir water level. Therefore, the use of these fuzzy inputs can effectively explain and predict the behavior of the dam. The crisp input data are fuzzifier (fuzzy input features) before using in IT2FLS. In this paper, we choose the Gaussian membership function because the continuity and periodicity of the Gaussian function are suitable for the data characteristics (for example, temperature and water level are related to the seasons of the year).
Details of input data features information are described below:
+ Reservoir water level (H): Lake level (upstream water level). Water levels of Ialy Reservoir (in m) are normally observed once a day and manually recorded.
+ Temperature (T): Air temperature (in degree Celsius or \(^{\circ }\)C) is the daily temperature average value that is recorded at Ialy Hydro-meteorological Station (\(14^{\circ }\, 12^{\prime }\,{\text {N}}\), \(107^{\circ }\, 45^{\prime }\,{\text {E}}\)).
+ Aging (month): Age of the dam (Ag), calculated from the time when the reservoir starts to store water and the hydroelectricity starts operating. Dam age is calculated from the Ialy Hydropower Station’s construction phase, and the operation phase starts.
+ Horizontal displacement (HD): The total displacement of the monitoring point from the vertical and horizontal component displacement (in cm). Horizontal displacement and settlement of the Ialy Dam are monthly measured using high-accuracy total station and leveling in monitoring networks.

Measured data at Ialy Hydroelectric Dam from year 2004 to year 2016
Figure 3 shows the observed data at the Ialy Hydroelectric Dam, including upstream water level, temperature, aging, and horizontal displacement. It is possible that in Fig. 3, the measured temperature and water level data are cyclical because they are seasonally repetitive. In winter, the temperature is usually lower than in summer. Collected data during the observation period were 339 samples from January 2004 to December 2016.
3.2 Proposal Method
Evaluating the safety of hydroelectric dams is one of the important tasks that greatly affects social life. The objective of the study is to provide a method (model) to assess the safety of a hydroelectric dam (in terms of horizontal displacement) based on monitoring data including water level, ambient temperature, and age of the hydroelectric dam (factors that affect the quality of hydroelectric dams).
The measurement and interpretation of dam strain data are an important part of dam safety assessment. Therefore, the objective of this study is to provide a method to predict the horizontal displacement of a hydroelectric dam. From there, there is a basis for assessing the health and safety of the dam. The proposed method in the paper is to use IT2FLS in combination with the ACO algorithm, in which ACO helps optimize the parameters of IT2FLS. In which, the main contribution is to propose the method of calculating the center of centroids, the upper and lower standard uncertainty deviation of the Gaussian function according to Formulas 16 and 17, and optimize the parameters of fuzzy rules for IT2FLS fuzzy system by ACO algorithm.
Because there are only three features used for input data and to increase the diversity of data, the water level data are divided into four different attributes including H1, H2, H3, and H4. This does not affect other features but can increase the diversity of the input data, which can help improve the accuracy of the model. Likewise, for temperature data, we use information about the temperature at the time of observation and the previous temperature in the period before 0, 7, 14, 28, 42, 56, 70, 84, and 98 days from the time of observation.
The value of water level elevation (H) can give four new attributes (H1, H2, H3, H4) by exponential, H1 = \(H^{1}\), H2 = \(H^{2}\), H3 = \(H^{3}\), and H4 = \(H^{4}\); The dam age innnformation can introduce two new attributes [Ag and ln(Ag)]. Average air temperature during the day T0, T7, T14, T28, T42, T56, T70, T84, T98 (before 0, 7, 14, 28, 42, 56, 70, 84, 98 days from the time of observation). Thus, the input data for the forecasting problem will include attributes H1, H2, H3, H4, T, T7, T14, T28, T42, T56, T70, T84, T98, Ag, and ln(Ag). Output data are HD attribute. Due to the equality between the attributes and the convenience of calculations, before entering the predictive model, the attributes are normalized in the interval [0, 1].
3.2.1 Fuzzifier
There are many types of fuzzy membership functions such as Gaussian, triangular, trapezoidal, etc., due to the continuity of the research data. In this paper, we choose a Gaussian function to convert crisp data into fuzzy data. The Gaussian membership function was chosen because it is a continuous function and has few parameters to determine their shape (namely, there are three parameters for each Gaussian function including the center of centroids, the upper and lower standard uncertainty deviation).
The crisp input data need to be fuzzifier by fuzzy membership functions to apply a fuzzy system. Instead of randomly initializing the fuzzy membership functions, we choose the parameters for the fuzzy membership function using the cluster information from the original dataset. The fuzzy c-means clustering algorithm [33] is selected to cluster on the initial dataset into c clusters (corresponding to the number of fuzzy membership functions). Dam displacement is a continuous process, so in this paper, the Gaussian membership function is chosen to fuzzifier the input data. A popular IT2 fuzzy MF is the Gaussian primary MF with uncertain standard deviation:
With \(x_{i}\) as input, whose mean is located at \(m_{j}^{i}\), the center of the Gaussian MF. The UMF and the LMF; they can be expressed as follows:
Note that both the upper and lower MFs do not change formulas over \(x \in X\), and they are differentiable over \(x \in X\). The latter is important when an optimization algorithm is used to optimize MF parameters while designing an IT2FLS.
3.2.2 Rule Base
Just as the rules of a type-1 fuzzy logic system can have two different canonical structures, Zadeh and TSK, rules of an IT2 fuzzy logic system can also have these two different structures. When an IT2 fuzzy logic system uses TSK rules, it will be referred to as an IT2 TSK fuzzy logic system. The structure of the ith generic IT2 Takagi, Sugeno, and Kang (TSK) rule for an IT2 fuzzy logic system is
\({R^{l}_{\text {TSK}}}\): IF \({x_{1}}\) is \({\tilde{F}}_{1}^{l}\) and \(\ldots\) and \({x_{p}}\) is \({\tilde{F}}_{p}^{l}\) THEN \({y^{l}} = C_{0}^{l} + C_{1}^{l}{x_{1}} + C_{2}^{l}{x_{2}} +\cdots + C_{p}^{l}{x_{p}}\), with M is the number of rules in the rule base, \(l = 1,\ldots ,M\). The function \(y^{l}\) has a linear dependency upon \(x_{1}\); \(x_{2};\ldots ;\) and \(x_{p}\).
3.2.3 Fuzzy Inference Engine
\({\tilde{F}}_{i}^{l}\) is the IT2 fuzzy set composed of a lower and upper bound MF (\(i = 1,\ldots ,p\)), \(\mu _{{\tilde{F}}_{1}^{i}}=[{\underline{\mu }} _{{\tilde{F}}_{1}^{i}}, {\overline{\mu }} _{{\tilde{F}}_{1}^{i}}]\). \(C_{i}^{l}\) is also an interval set and the consequent parameters of the IT2 TSK FLS model, where its center and spread are \(c_{i}^{l}\) and \(s_{i}^{l}\), respectively, \(C_{i}^{l}=[c_{i}^{l}-s_{i}^{l}, c_{i}^{l}+s_{i}^{l}]\).
Figure 4 shows an example of input, antecedent operations, and firing interval operations for an IT2 TSK fuzzy logic system.

An example of input, antecedent operations, and firing interval operations for an IT2 TSK fuzzy logic system [?]
Given an input \(x=(x_{1}, x_{2}. x_3,\ldots , x_{p})\), the result of the input and antecedent operations (firing strength) is an interval type-2 fuzzy set, \(F^{l}(x)=[\underline{f^{i}}(x), \overline{f^{i}}(x)]\). Compute the firing interval of the ith rule, where \(*\) denotes the product operation.
where \(*\) represents a t-norm, it assumes the singleton fuzzifier. \(y^{l}\) is the output from the lth IF–THEN rule, which is a T1FSs, \(y^{l}=[y_{\text {l}}^{l}, y_{\text {r}}^{l}]\). The final output of the IT2 TSK FLS model is obtained through combining the outcomes of M rules.
3.2.4 Type Reduction
The interval type-2 fuzzy output is processed by the type-reduction operation, combining the output sets and performing the centroid calculation resulting in a type-1 fuzzy set. In this study, the EIASC algorithm is used because they are easy to set up, and the computational complexity is smaller than the remaining algorithms. Compute the output interval of the kth fuzzy rule for the output, which is an interval T1FS \(y_{k}^{} = {{[}}y_{kl}^{},y_{kl}^{}{{]}}\), the steps for calculating left most output \(y_{kl}^{}\) and right most output \(y_{kr}^{}\) using the EIASC algorithm are detailed in Algorithm 2, 3, where L and R are switch points computed by the EIASC algorithm.


3.2.5 Defuzzification
Finally, the defuzzified crisp output from the IT2 TSK FLS is the mean of \(y_{\text {l}}\) and \(y_{\text {r}}\),
3.2.6 Optimization of IT2 TSK FLS Using ACO
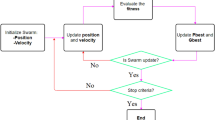
In this section, the paper will present parameters optimization solution for IT2FLS using the ACO algorithm. The number of employed ants or the onlooker ants is equal to the number of solutions in the swarm. Let \(X = \{{x_{1}},{x_{2}},\ldots ,{x_{n}}\}\) is the input dataset, in which \({\displaystyle x_{i}=(x_{i,1},x_{i,2},\ldots ,x_{i,n})}\) represent the ith solution in the swarm, where \({\displaystyle n}\) is the population size.

General IT2 TSK FLS–ACO model of the proposed method
It can be seen that the design of an IT2 TSK FLS model consists of the selection of MFs for inputs and the determination of the parameters of premise (MF parameters) and consequent (linear coefficients) parameters. The design of an IT2 TSK FLS model consists of selecting MFs for inputs and determining the parameters of premise (MF parameters) and consequent (linear coefficients) parameters.
Figure 5 is the general model of the proposed method. In which the input data are fuzzified into the interval type-2 fuzzy sets using the interval type-2 fuzzy membership functions. The ACO algorithm is used to optimize the input data path through the fuzzy rules \(R^{1}, R^{2}, \ldots , R_{M}\) for the best output. Starting from the nest, the ants will move through the fuzzy rules \(R^{1}, R^{2}, R^{3},\ldots\) and stop at \(R_{M}\). For each fuzzy rule, the nodes that the ant’s visit will be chosen as the consequential values of the fuzzy rule. The selection of the ant’s path from one fuzzy rule to another is based on the pheromone density between the fuzzy rules on the path. The pheromone value matrix was constructed during ant migration as shown in Table 2. The number of pheromones increases if the number of ants passes through many times and if few ants pass, the number of pheromones will decrease over time.
Initially, the pheromone \(\tau _{il}\) (\(i=1,\ldots , N; l=1,\ldots , M\)) values need to be initialized to a small and equal value (since it is not known where there will be more food) in order to choose the consequential action of the first fuzzy rule. Then the pheromone values will be updated according to Formula 7. The probability that the ant chooses the next node is calculated by Formula 6. The process is repeated until the optimal path is found through the fuzzy rules, with M being the number of ants. Do interval type-2 fuzzy data normalization and then defuzzify to get crisp output. The calculated output is compared with the actual output to evaluate the accuracy of the forecast results.
The proposed method for hydropower dam displacement forecasting using IT2 TSK FLS–ACO is as follows: The input sample data are divided by 70% for training and 30% for testing. Initialize the parameters for the ACO algorithm and the IT2 TSK FLS model. In each loop, the antecedent and consequence parameters of the IT2 TSK FLS model are adjusted by minimizing the MSE objective function (the Eq. 19). This process is performed until no significant improvement, or the maximum number of iterations is reached. Finally, the accuracy of the proposed model is evaluated.
a. Antecedent

Gaussian membership function with uncertainty standard deviation [11]
Figure 6 shows a Gaussian membership function with uncertainty standard deviation \(\sigma _{1}, \sigma _{2}\) that takes on values in [\(\sigma _{j,2}^{i}, \sigma _{j,1}^{i}\)]. The fuzzy c-means clustering algorithm initially calculates the parameters of the antecedent for the Gaussian fuzzy membership function (FCM) [33]. The number of clusters for the FCM algorithm is the number of Gaussian membership functions used in the proposed model. The parameter \(m_{j}^{i}\) is the value of the cluster centroids obtained from the clustering results by the FCM algorithm (m is a fuzzy parameter, usually set to 2).
The parameters \(\sigma _{j,2}^{i}\) and \(\sigma _{j,1}^{i}\) are the values of the upper and lower uncertainty standard deviation (\(\sigma _{j,2}^{i} \ge \sigma _{j,1}^{i}\)).
The antecedent parameters will be updated again in each iteration of the proposed algorithm.
b. Consequence
The choice of optimal fuzzy rules depends on the choice of pheromone values along the way. The parameters of the consequences are the pheromone value matrix. In each step of the algorithm, these parameters will be updated using the ACO optimization technique. Accordingly, the pheromone value at each time point will be updated according to Formulas 6, 7, and 8.
After each loop, the antecedent and consequence values are updated, and the IT2 TSK FLS has adjusted accordingly. From there, the output value will be calculated. Model training stops when the maximum number of iterations is reached or the value \({\text {MSE}} < \epsilon\) (\(\epsilon\) is a very small constant).
3.2.7 Evaluate Accuracy
To evaluate the proposed method’s effectiveness, we measure the difference between the actual output and the desired output on the datasets labeled by the following formulas:
+ MAE (mean absolute error) represents the difference between the original and predicted values extracted by averaging the absolute difference over the dataset.
+ MSE (mean-squared error) represents the difference between the original and predicted values extracted by squaring the average difference over the dataset.
+ RMSE (root-mean-squared error) is the error rate by the square root of MSE.
+ \(R^{2}\) (coefficient of determination) represents the coefficient of how well the values fit compared to the original values. The value from 0 to 1 is interpreted as percentages. The higher the value is, the better the model is.
where \({y_{i}}, {{{{\hat{y}}}_{i}}}\) are the desired output and the actual output of the fuzzy system and n is the number of data samples. \({\overline{y}_{i} }\) is the mean of the input data set.
4 Results and Discussion
4.1 Results
The authors have developed an application program based on the open-source IT2FLS library published at [34]. This work was funded by the Vietnam National Foundation for Science and Technology Development (NAFOSTED) for research and application at the Ialy Hydropower Plant, in Vietnam.
This paper performs the SVM, DT, RF, RNN, IT2FLS, and IT2FLS–ACO methods on the same dataset. The data are split into \(70\%\) for training and \(30\%\) for testing (with 271 samples for training and 68 samples for testing). Experimental data with 16 attributes from observed data, of which 15 attributes are input data, and 1 attribute is output data.
With the SVM model, we use both linear regression and non-linear regression; non-linear regression using kernel functions gives the best results. We also tested with a different number of trees for the DT and RF models and selected the best result among the tests. For the RNN model, the number of iterations is 1000, \({\text {batch-size}}=64\), 50 neurons in the first hidden layer, and 1 neurons in the output layer, using the MAE loss function and Adam version stochastic gradient descent with a sigmoid activation function.
It is difficult to know how many fuzzy rules are best for models IT2FLS and IT2FLS–ACO. A large number of fuzzy rules leads to sizeable computational complexity, and conversely, a small number of fuzzy rules may not be enough to give a good enough prediction result. The number of fuzzy rules used for the IT2FLS and IT2FLS–ACO models is \(M=8\). For the IT2FLS model, the parameters are selected based on experience and 10 times testing to choose the best value for the model. The maximum number of iterations used to train the IT2FLS–ACO model is 1000, \(\epsilon =10^{-6}\).
The number of Gaussian membership functions used to fuzzify the input data is 6. The FCM algorithm used to initialize the antecedent parameters is installed with 6 clusters corresponding to 6 Gaussian membership functions, the maximum number of iterations is 100, and the fuzzy parameter is set to 2 (\(m=2\)). For the ACO algorithm, ant population is initialized with 200 ants. The matrix of pheromone values is initialized to a very small value \({\tau _{{{ij}}}}(0) = {10^{ - 3}}\), \(\alpha = 0.2, \beta = 1.5\). After each loop, the amount of pheromone decreases (evaporates) by 10% (\(\rho = 0.9\)).
To evaluate the accuracy of the tested models, the paper uses the MAE, MSE, RMSE, and \(R^{2}\) Score indexes. Hydropower dams displacement forecasting results are shown in Figs. 7 and 8. The accuracy of the SVM, DT, RF, RNN, IT2FLS, and IT2FLS–ACO models is shown in Tables 3 and 4.

Accuracy assessment results on training data set

Accuracy assessment results on testing data set
4.2 Discussion
The forecast results show a difference between the actual data and the forecast data at different times in accordance with the cycle. This is because the hydrographic lake temperature and elevation data are seasonal in nature.
Figure 7 shows the relationship between the training data and the prediction results of the models, showing the prediction results of the proposed model IT2FLS–ACO on the training dataset with other forecasting models IT2FLS, RNN, DT, RF, and SVM, where the blue line is the training data and the red line is the forecast result. Looking at an overview on all six models, it can be seen that the forecast results are relatively accurate compared to the training dataset. However, when they are considered separately, there is a significant difference between the six methods. In which, it can be seen that the proposed method IT2FLS–ACO gives relatively close results to the training data.
Similarly, Fig. 8 is the result of the accuracy assessment on the testing dataset. The results in the figure also show that the IT2FLS–ACO model gives the closest predictive results to the testing data compared to the other five methods.
Tables 3 and 4 are the results of evaluating the accuracy of the predictive model on the training dataset and the testing dataset on the MAE, MSE, RMSE, and \(R^{2}\)-Score indexes. The results are averaged after 10 runs of the algorithms.
The MAE index measures the average of errors in a set of forecast results. It is the test sample average of the absolute difference between the predicted value and the actual observed value, where all differences are equally weighted. Test results on training and testing datasets, IT2FLS–ACO model gives the highest accuracy prediction results. While the SVM model gives the results with the lowest accuracy in the training dataset and the RF model gives the results with the lowest accuracy in the training dataset.
MSE and RMSE refer to the mean of the squared difference between predicted and observed results. The MSE is called the mean-square error value or the mean-square error. The RMSE value indicates the concentration of the predicted data around the observed data. The smaller the MSE and RMSE, the smaller the error, and the higher the reliability of the model. The values in Tables 3 and 4 show that the IT2FLS–ACO model gives the highest accuracy among the six tested models.
The \(R^{2}\)-Score index is a measure of the fit of the predictive model to the research data. The value of \(R^{2}\)-Score ranges from 0 to 1. The closer the \(R^{2}\)-Score value is to 1, the better the built model fits the test dataset. The closer \(R^{2}\)-Score is to 0, the less well the built model fits the test dataset. The results shown in Tables 3 and 4 show that the \(R^{2}\)-Score value for the proposed IT2FLS–ACO model is the highest with over 99% for training data and over 98% for testing data.
Table 3 is the result of evaluating the accuracy of dam displacement prediction on the training dataset. The results obtained on four indexes, MAE, MSE, RMSE, and \(R_{2}\)-Score, show the highest accuracy on the IT2FLS–ACO model and the smallest on the SVM algorithm. For the MAE index, the IT2FLS–ACO algorithm receives the smallest value with 0.022033, followed by the IT2FLS, RNN, DT, RF, and SVM algorithms with the value 0.025359, 0.032540, 0.037847, 0.039801, and 0.045392, respectively.
For the MSE and RMSE indexes, the IT2FLS–ACO algorithm also gave the best results among the six methods used. For the \(R^{2}\) Score index, the experimental algorithms give results with an accuracy of over \(96\%\). The highest accuracy is more than \(99\%\) for the IT2FLS–ACO model, followed by IT2FLS models and RNN algorithm with over \(98\%\), and RF, DT over \(97\%\).
Table 4 is the results of evaluating the accuracy of the proposed method IT2FLS–ACO and the methods IT2FLS, RNN, RF, DT, and SVM on the testing dataset. In general, it can be seen that the IT2FLS–ACO model also gives higher accuracy than the other methods. The MAE, MSE, and RMSE indexes all show that the IT2FLS–ACO model gives the best results, while on the testing dataset, the SVM algorithm gives the worst results compared to the remaining algorithms. The highest accuracy is more than \(98\%\) with the IT2FLS–ACO model, and the lowest is more than \(91\%\) for the SVM algorithm. The two methods, IT2FLS and RNN, both achieve an accuracy of over \(94\%\), while the remaining algorithms are below \(92.5\%\).
From the results in Tables 3 and 4, it can be seen that the accuracy on the training dataset is higher than on the testing dataset. The IT2FLS–ACO model gives results with superior accuracy than the other five methods. This result shows that using the ACO algorithm to find the optimal parameters for IT2FLS can significantly improve the accuracy of the forecast results.
Finally, it should be noted that this study only considers the horizontal displacement of the dam. To study vertical displacement, similar procedures can be followed. The research results in the paper and the above analysis show that the temperature, water level, and age of the dam have a relationship with and affect the displacement of the hydroelectric dam. Therefore, increased observation and monitoring of changes in the dam’s temperature and water level is needed to make even more accurate predictions of the dam’s horizontal displacement over time. This has important implications for assessing the safety of the dam.
5 Conclusion
The paper has proposed the hydroelectric dam displacement prediction solution using the IT2FLS and ACO. The main contribution of the paper is to propose formulas for calculating the center of centroids and standard deviation for Gaussian membership function, build a rule base set for IT2FLS fuzzy system, and optimize parameters of IT2FLS using the ACO algorithm. The experiment to predict the dam displacement from the measurement data set at Ialy Hydroelectric Dam, Vietnam, during the period from 2004 to 2016 shows that the proposed method gives the results with the highest accuracy among the experimental algorithms. The analysis of the results shows that the IT2FLS–ACO method can be used in the dam displacement prediction problem with an accuracy of over \(98\%\). This result confirms the correctness in approaching the research direction of applying fuzzy systems and optimization algorithms for prediction problems. Analysis of research results also shows that the proposed method in this paper has universal value in engineering and can be applied to other concrete dams.
In the future, further studies will focus on developing hybrid models between the IT2FLSs and other optimization techniques based on genetic algorithms, evolutionary computation, and deep learning. Moreover, parallel computational models are also one of the potential research directions in data processing when monitoring data is increasingly significant.
References
Li, Y., Bao, T., Gong, J., Shu, X., Zhang, K.: The prediction of dam displacement time series using STL, extra-trees, and stacked LSTM neural network. IEEE Access 8, 94440–94452 (2020). https://doi.org/10.1109/ACCESS.2020.2995592
Tabari, M.M.R., Sanayei, H.R.Z.: Prediction of the intermediate block displacement of the dam crest using artificial neural network and support vector the regression models. Soft Comput. 23, 9629–9645 (2019). https://doi.org/10.1007/s00500-018-3528-8
Shao, C., Gu, C., Yang, M., Xu, Y., Su, H.: A novel model of dam displacement based on panel data. Struct. Control Health Monit. 25(1), e2037 (2017). https://doi.org/10.1002/stc.2037
Wei, B., Chen, L., Li, H., Yuan, D., Wang, G.: Optimized prediction model for concrete dam displacement based on signal residual amendment. Appl. Math. Model. 78, 20–36 (2020). ISSN 0307-904X. https://doi.org/10.1016/j.apm.2019.09.046
Zhang, J.-H., Wang, J., Chai, L.-S.: Factors influencing hysteresis characteristics of concrete dam deformation. Water Sci. Eng. 10(2), 166–174 (2017). https://doi.org/10.1016/j.wse.2017.03.007
He, Q., Gu, C., Valente, S., et al.: Multi-arch dam safety evaluation based on statistical analysis and numerical simulation. Nat./Sci. Rep. 12, 8913 (2022). https://doi.org/10.1038/s41598-022-13073-9
Zou, J., Thi Bui, K.-T., Xiao, Y., Van Doan, C.: Dam deformation analysis based on BPNN merging models. Geospat. Inf. Sci. 21(2), 149–157 (2018). https://doi.org/10.1080/10095020.2017.1386848
Bui, K.-T.T., Tien Bui, D., Zou, J., Van Doan, C., Revhaug, I.: A novel hybrid artificial intelligent approach based on neural fuzzy inference model and particle swarm optimization for horizontal displacement modeling of hydropower dam. Neural Comput. Appl. 29(12), 1495–1506 (2018). https://doi.org/10.1007/s00521-016-2666-0
Zanaganeh, M., Mousavi, S.J., Shahidi, A.F.E.: A hybrid genetic algorithm-adaptive network-based fuzzy inference system in prediction of wave parameters. Eng. Appl. Artif. Intell. 22, 1194–1202 (2009). https://doi.org/10.1016/j.engappai.2009.04.009
Yang, L.-H., Ye, F.-F., Liu, J., Wang, Y.-M., Haibo, H.: An improved fuzzy rule-based system using evidential reasoning and subtractive clustering for environmental investment prediction. Fuzzy Sets Syst. (2021). https://doi.org/10.1016/j.fss.2021.02.018
Mendel, J.: Uncertain Rule-Based Fuzzy Logic Systems: Introduction and New Directions, 2nd edn. Springer, Cham (2017)
Khosravi, A.: An interval type-2 fuzzy logic system-based method for prediction interval construction. Appl. Soft Comput. 24, 222–231 (2014). https://doi.org/10.1016/j.asoc.2014.06.039
Mendel, J.M., John, R.I., Liu, F.: Interval type-2 fuzzy logic systems made simple. IEEE Trans. Fuzzy Syst. 14(6), 808–821 (2006). https://doi.org/10.1109/TFUZZ.2006.879986
Mai, D.S., Dang, T.H., Ngo, L.T.: Optimization of interval type-2 fuzzy system using the PSO technique for predictive problems. J. Inf. Telecommun. 5(2), 197–213 (2021). https://doi.org/10.1080/24751839.2020.1833141
Mai, D.S., Ngo, L.T., Trinh, L.H., Hagras, H.: A hybrid interval type-2 semi-supervised possibilistic fuzzy c-means clustering and particle swarm optimization for satellite image analysis. Inf. Sci. 548, 398–422 (2021). https://doi.org/10.1016/j.ins.2020.10.003
Jiang, J.-A., Syue, C.-H., Wang, C.-H., Wang, J.-C., Shieh, J.-S.: An interval type-2 fuzzy logic system for stock index forecasting based on fuzzy time series and a fuzzy logical relationship map. IEEE Access (2018). https://doi.org/10.1109/ACCESS.2018.2879962
Jallal, M.A., González-Vidal, A., Skarmeta, A.F., Chabaa, S., Zeroual, A.: A hybrid neuro-fuzzy inference system-based algorithm for time series forecasting applied to energy consumption prediction. Appl. Energy 268, 114977 (2020). https://doi.org/10.1016/j.apenergy.2020.114977
Tu, C.-H., Li, C.: Multitarget prediction using an aim-object-based asymmetric neuro-fuzzy system: a novel approach. Neurocomputing 389, 155–169 (2020). https://doi.org/10.1016/j.neucom.2019.12.113
Rathnayake, N., Dang, T.L., Hoshino, Y.: A novel optimization algorithm: cascaded adaptive neuro-fuzzy inference system. Int. J. Fuzzy Syst. (2021). https://doi.org/10.1007/s40815-021-01076-z
Tsakiridis, N.L., Theocharis, J.B., Panagos, P., et al.: An evolutionary fuzzy rule-based system applied to the prediction of soil organic carbon from soil spectral libraries. Appl. Soft Comput. (2019). https://doi.org/10.1016/j.asoc.2019.105504
Karnik, N., Mendel, J., Liang, Q.: Type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 7(6), 643–658 (1999). https://doi.org/10.1109/91.811231
Liang, Q., Mendel, J.: Interval type-2 fuzzy logic systems: theory and design. IEEE Trans. Fuzzy Syst. 8(5), 535–550 (2000). https://doi.org/10.1109/91.873577
Siminski, K.: Interval type-2 neuro-fuzzy system with implication-based inference mechanism. Expert Syst. Appl. 79, 140–152 (2017). https://doi.org/10.1016/j.eswa.2017.02.046
Olatunji, S.O., Selamat, A., Abdul Raheem, A.A.: Improved sensitivity-based linear learning method for permeability prediction of carbonate reservoir using interval type-2 fuzzy logic system. Appl. Soft Comput. 14, 144–155 (2014). https://doi.org/10.1016/j.asoc.2013.02.018
Melin, P., Sánchez, D., Monica, J.C., Castillo, O.: Optimization using the firefly algorithm of ensemble neural networks with type-2 fuzzy integration for COVID-19 time series prediction. Soft Comput. (2021). https://doi.org/10.1007/s00500-020-05549-5
Batchuluun, G., Kim, J.H., Hong, H.G., Kang, J.K., Park, K.R.: Fuzzy system based human behavior recognition by combining behavior prediction and recognition. Expert Syst. Appl. (2017). https://doi.org/10.1016/j.eswa.2017.03.052
Jaafari, A., Zenner, E.K., Panahi, M., Shahabi, H.: Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 266–267, 198–207 (2019). https://doi.org/10.1016/j.agrformet.2018.12.015
Asklany, S.A., Elhelow, K., Youssef, I.K., Abd El-Wahab, M.: Rainfall events prediction using rule-based fuzzy inference system. Atmos. Res. 101, 228–236 (2011). https://doi.org/10.1016/j.atmosres.2011.02.015
Mendel, J., Liu, X.: Simplified interval type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 21(6), 1056–1069 (2013). https://doi.org/10.1109/TFUZZ.2013.2241771
Mai, D.S.: Interval type-2 fuzzy logic systems optimization with swarm algorithms for data classification. In: 13th International Conference on Knowledge and Systems Engineering (KSE), 2021, pp. 1–5 (2021). https://doi.org/10.1109/KSE53942.2021.9648598
Castillo, O., Melin, P., Alanis, A., et al.: Optimization of interval type-2 fuzzy logic controllers using evolutionary algorithms. Soft Comput. 15, 1145–1160 (2011). https://doi.org/10.1007/s00500-010-0588-9
Dorigo, M., Stützle, T.: Ant Colony Optimization. MIT Press, Cambridge (2004). ISBN 0-262-04219-3
Bezdek, J.C., Ehrlich, R., Full, W.: FCM: the fuzzy c-means clustering algorithm. Comput. Geosci. 10(2–3), 191–203 (1984). https://doi.org/10.1016/0098-3004(84)90020-7
Haghrah, A.A., Ghaemi, S.: PyIT2FLS: A New Python Toolkit for Interval Type 2 Fuzzy Logic Systems. arXiv (2019). https://doi.org/10.48550/arxiv.1909.10051
Acknowledgements
This research is funded by Vietnam National Foundation for Science and Technology Development (NAFOSTED) under Grant Number 105.08-2018.06. We also would like to thank Ialy Hydropower Company for providing the periodically monitoring data and supporting us in collecting anomaly observations.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mai, D.S., Bui, KT.T. & Van Doan, C. Application of Interval Type-2 Fuzzy Logic System and Ant Colony Optimization for Hydropower Dams Displacement Forecasting. Int. J. Fuzzy Syst. 25, 2052–2066 (2023). https://doi.org/10.1007/s40815-022-01452-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-022-01452-3