
Abstract
In the context of the increasingly competitive post-epidemic social marketing era, the sustainable development of supply chain finance is also facing the impact of more complex risk factors. However, the issue concerning how to scientifically and reasonably select the appropriate applicant company for financing cooperation on the basis of risk evaluation remains unresolved. For the smooth operation of banks’ sustainable supply chain finance (SSCF) business, this paper aims to develop a novel multi-attribute group decision-making (MAGDM) method considering the robustness and comprehensiveness among risk attributes and decision-makers (DMs). First, based on the idea that quantitative assessment values and qualitative linguistic sets can more accurately express uncertain risk information and importance degree of indicators, a novel concept is proposed that combines the probabilistic linguistic term set (PLTS) with the plithogenic set to evaluate the risk attributes of each alternative. Additionally, risk decision matrices evaluated by DMs are integrated and transformed through the operation of PLTS scoring function aggregation operators and the plithogenic contradiction degree. For deriving the integrated weight information of attributes, the objective attribute weights are determined on the basis of the subjective weights by adjusting coefficients. Then, the ranking order of alternatives is generated by applying the VIKOR method and constructing a MAGDM model with plithogenic PLTSs. Finally, the solving of a practical example concerning the selection of financing objects for SSCF oriented by risk evaluation verifies the effectiveness of the proposed model, where five risk indicators are developed, and the superiority of our studies is demonstrated by comparing with the existing TOPSIS and ELECTRE methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since the outbreak of COVID-19 in 2020, the development of supply chain finance (SCF) business of commercial banks has been subjected to multiple tests by internal and external risk factors such as increased regulatory requirements, declining financial asset quality, and complex and severe operating environment [1, 2]. To cope with increasingly fierce competition and mitigate the pandemic’s adverse effects on the inherent profit model, it is necessary for banks to actively cooperate with financing companies to accelerate the adaptation to the new SCF development model with the goal of sustainability. On the one hand, SSCF can assist banks in developing effective capital flows throughout the supply chain, improve the performance of suppliers or retailers, and establish a stable business development framework based on the triple bottom line (TBL) (economic, social and environmental) [3]. On the other hand, the evaluation of the risk that can represent the uncertainty of possible losses due to the difference between the actuality and the expectation is also essential to promoting the smooth operation of SSCF business [4, 5]. How to opt for the most appropriate company for financing cooperation from a series of alternatives and risk attributes under the premise of minimum risk is a key aspect for banks to develop SSCF services, where such a problem can also be regarded as a multi-attribute decision-making (MADM) problem. MADM attempts to use reasonable mathematical logic methods to analyze and process various linguistic information collected through the assessment of DMs [6]. However, the diversity of risk evaluation problems and the complexity of the linguistic environment analyzed make a single DM inadequate to deal with the challenges in all situations. For that reason, many decision-making processes are taken place in the form of multiple-attribute group decision-making (MAGDM), which is a mainstream research direction and has aroused the interest of many scholars [7, 8].
With the continuous development of objective things, the vagueness and uncertainty of decision information in external environment are increasing. It is difficult to fully and truly express the DMs’ cognition preference of objective things with precise numbers only. Consequently, a series of powerful mathematical tools are continuing to spring up to facilitate solving such problems. After Zadeh [9] innovatively proposed the fuzzy set (FS) theory, some extended methods such as interval-valued fuzzy set (IVFS) [10], intuitionistic fuzzy set (IFS) [11] have been thoroughly explored and successfully applied to MAGDM problems. However, those tools, which incorporate membership degree, non-membership, or a combination of both, are unable to deal with indeterminate information in specific practical situation. To deal with this problem, the concept of the neutrosophic set (NS) was introduced by Smarandache [12], which studies the origin and the nature of entities, as well as their interaction with different intellectual visions, extending the above sets from a philosophical point of view. Later on, plithogenic set is developed on the basis of neutrosophic set with a high level of uncertainty and vagueness, which is of great significance for improving the evaluation accuracy of the DMs’ subjective judgments and has been comprehensively applied in numerous domains [13,14,15,16]. Although these membership-based theories can express uncertain information in detail, they can only be applied to express the quantitative information about evaluating objects, and lack qualitative considerations for the parts that are difficult to be quantified in practical decision-making problems. In this case, DMs may prefer to use qualitative language terms (LT) such as “good, medium, bad” that are more common in daily life rather than quantitative values to express their preference for evaluation information [17, 18]. Therefore, on the basis of the fuzzy linguistic variables (LVs) proposed by Zadeh [19], a large number of linguistic evaluation models are continuously emerging in the decision-making field [20,21,22].
However, due to the complexity of the decision-making environment and the inherent hesitation characteristics of DMs, scholars have gradually realized that it is difficult to express the DMs’ overall cognitive preference towards attributes by using a single linguistic term. To tackle this problem, Rodriguez et al. [23] proposed the concept of hesitant fuzzy linguistic term set (HFLTS) on the basis of hesitant fuzzy set (HFS) [24] to help DMs express preference information of multiple linguistic terms with the same importance degree. Although with good ability to express DMs’ hesitation, HFLTS ignores the importance weights of different linguistic terms that often exist in actual situations, that is, the probability distribution cannot be considered, which may lead to information confusion and loss. In order to accurately describe this kind of complicated linguistic information relationship, Pang et al. [25] extended the HFLTS to a more general concept, named probabilistic linguistic term set (PLTS). PLTS can not only enable DMs to express their complex preference information for decision objects as a collection of the importance degree of several possible linguistic terms combined with corresponding probabilistic information, but also reduce the loss of original information caused by the application of single linguistic terms in traditional HFLTS evaluation. The accuracy of decision-making has also been greatly improved. Many achievements have been made in PLTS research from different perspectives, such as the operation laws for PLTSs [26, 27], the application of combining with the MAGDM method [28], the improvement of PLTS [29], etc. Wu et al. [30] and Wei et al. [31] have also studied the distance measures and similarity characteristics of PLTS. Considering the respective advantages of plithogenic set and PLTS in processing quantitative and qualitative linguistic assessment information, it is necessary to combine them to investigate the risk evaluation problem of SSCF, which is just the research motivation of this paper.
Plithogenic PLTSs have the flexibility and richness in expressing complex, fuzzy and uncertain decision information. Especially, it is inevitable to bear more responsibilities and face great complexity when coming up with decisions in the presence of uncertain weight information. Hence, the determination of attribute weights also plays a vital role in the process of MAGDM, which has been extensively studied under different circumstances. From an objective point of view, Zhang et al. [32] established two optimization models to derive the weights of attributes with partially known or completely unknown PLTS information. Lu et al. [33] expanded the range of applications of the traditional entropy-weighted method to determine the weight by defining the probability linguistic score function. In addition, subjective, objective weight decision methods and their integration have also been applied to the expression of uncertain weight information in various complex environments, so as to make the decision results more accurate and convincing [34,35,36,37,38].
In all the studies devoted to rational MAGDM in recent years, the selection of the classical ranking approach as well as the analysis of the corresponding process is incontrovertibly one of the most attractive core research points and a lot of achievements have been made, including TOPSIS [39], VIKOR [40, 41], MABAC [42], etc. Among them, VIKOR method, based on the concept of aggregating function representing ‘‘closeness to the ideal” [43], is of great benefit to the analysis, comparing and rankings of the alternatives that applied in kinds of MAGDM problems [44,45,46]. This method can not only effectively consider the subjective preferences of DMs, but also determine the compromise solution of problems with conflicting attributes, which is an effective supplement to the decision-making strategy under uncertainty. Although many scholars have extended the VIKOR method based on the idea of uncertainty, few of which take plithogenic PLTS into consideration that characterized by indeterminacy or probabilistic information. On the basis of defining a new score function that considers the degree of concentration, Lin et al. [47] introduced the VIKOR method combined with ScoreC-PLTS to solve the problem of traditional model that only considers limited expectation value. Li et al. [48] developed an integrated VIKOR-QUALIFLEX method to measure the concordance index of each ranking combination, where the subjective and objective weights of attributes are both concerned based on the trapezoid fuzzy two-dimensional linguistic variable information. There are also some scholars that apply VIKOR to express plithogenic [14, 49] or probabilistic double hierarchy linguistic term set (PDHLTS) [50] decision information.
1.1 Motivation
In summary, although PLTSs and plithogenic sets have unique superiority in the expression of uncertain information, they still suffer from some limitations, which can be generalized from the following aspects: (1) Studies [32, 51] merely rely on plithogenic numerical or probabilistic linguistic information as an information aggregation tool for expressing DMs’ uncertain evaluation opinions, whereas there has not been any research on combining these two kinds of evaluation terms to solve MADM or MAGDM problems; (2) Little research focuses on the weighting for attributes based on a combination of subjective and objective weights with plithogenic linguistic and PLTSs, that is considering objective evaluation information about decision opinions as well as the subjective preferences of DMs; (3) The choice of an accurate solution [52] or a compromise solution [53] affects the complexity and applicability of the decision-making model. Hence, how to develop an effective optimal solution determination method is crucial for dealing with MAGDM problems; (4) The validity of PLTS or plithogenic linguistic information has been verified in many practical problems [6, 54], but its research and application in SSCF risk evaluation has not attracted enough attention from experts and scholars, who lacks a comprehensive and systematic analysis of research model.
1.2 Objective
To fill the research gap and overcome the above-stated limitations, in this paper, we propose a model to solve SSCF risk evaluation problem in the new environment of plithogenic PLTSs. First, on the basis of the defined PLTS score function and plithogenic related calculations, a de-neutrosophic process is carried out to integrate a comprehensive matrix of plithogenic probability linguistic information that gathers DMs’ evaluation opinions on each risk attribute. In addition, attributes’ weights are determined by the consistent degree and adjustment coefficient of integrating subjective weights with objective elements. Based on the comprehensive plithogenic PLTS evaluation matrix, VIKOR method, is proposed to process SSCF risk problem with plithogenic probabilistic linguistic information. To the best of our knowledge, this is the first work that proposes the VIKOR with the plithogenic PLTS.
1.3 Novelty
The contribution and innovation of this paper mainly lie in the expansion of the depth of understanding in the field of SSCF risk research under uncertain environment and can be summarized as follows:
-
(1)
By integrating the PLTSs score function and related operations of the plithohenic environment to the MAGDM problem, the accuracy of the DMs’ evaluation when faced with uncertain information is improved, and unnecessary information loss is avoided;
-
(2)
For deriving the integrated weights information of risk attributes under plithogenic PLTS, the idea of adjusted coefficients is applied on the basis of subjective weights of attributes to determine the objective attribute weights;
-
(3)
The probabilistic linguistic VIKOR method is proposed to solve the probabilistic linguistic MAGDM problems with incomplete weight information, in which the compromise solutions are sorted according to the approaching degree of group utility and individual regret to the ideal solutions;
-
(4)
The case study solves the problem for banks of how to select financing partners with sustainability orientation and risk minimization as the goal in the SCF business;
-
(5)
Based on the plithogenic environment and weight-determining method with PLTS information, two representative MAGDM methods, TOPSIS and ELECTRE, are applied for comparative analysis with VIKOR to verify the effectiveness of the proposed model.
The remainder of this paper is introduced as follows. Basic definitions and knowledge about the PLTSs, plithogenic set and related operations are briefly reviewed in Sect. 2. In Sect. 3, a risk evaluation model is constructed in detail under plithogenic PLTS with incomplete weight information where the adjusted coefficient is defined to derive attributes’ weights and the VIKOR method is introduced for MAGDM problems to determine the ranking orders of alternatives. Section 4 shows the superiority and feasibility of the proposed model by given a practical case study on pharmaceutical industry risk evaluation, and then a comparative analysis is conducted between the proposed model with the existing TOPSIS and ELECTRE methods in the form of plithogenic PLTSs. Finally, some valuable conclusions, limitations of the paper as well as the direction of future studies are given in Sect. 5.
2 Preliminaries
In this section, we will explore a series of concepts and operations related to LTSs, PLTSs and Plithogenic set.
2.1 Linguistic Term Set (LTS)
Definition 1
[55] Let \(S = \{ S_{\alpha } |\alpha = - \tau , \ldots , - 1,0,1, \ldots \tau \}\) be a finite and totally ordered discrete linguistic term set, where \(S_{\alpha }\) represents a possible value for a linguistic variable and the value of \({\uptau }\) is positive integer. The lower limit and upper limit of the term set \(S\) are represented by \(S_{{ - {\uptau }}}\) and \(S_{{\uptau }}\) respectively, \(S_{0}\) expresses an evaluation of “indifference,” and the rest of which are placed symmetrically around it. For any linguistic term \(S_{\alpha }\), \(S_{\beta } \in S\), the set order is \(S_{\alpha } > S_{\beta }\) if and only if \(\alpha > \beta\).
Definition 2
[35] Through the transformation functions \(g\) and \(g^{ - 1}\), the equivalent information relationship between the language term \(S_{\alpha }\) and the membership degree \(\gamma\) is expressed by:
where \(\gamma \in [0,1]\), \(g:\left[ { - \tau ,\tau } \right] \to \left[ {0,1} \right]\) and \(g^{ - 1} :\left[ {0,1} \right] \to \left[ { - \tau ,\tau } \right]\).
2.2 Probabilistic Linguistic Term Set (PLTS)
Definition 3
[56] Let \(S = \{ S_{ - \tau } , \ldots ,S_{0} ,S_{1} , \ldots ,S_{\tau } \}\) be a linguistic term set, then probabilistic linguistic term set (PLTS) can be defined as:
where \(L^{\left( k \right)} (p^{\left( k \right)}\)) represents the linguistic term \(L^{\left( k \right)}\) associated with the probability \(p^{\left( k \right)} ,\) \(\# L\left( p \right)\) denotes the number of different linguistic terms contained in \(L\left( p \right)\). If \(0 < \mathop \sum \limits_{k = 1}^{\# L\left( p \right)} p^{\left( k \right)} \le 1\), then we have complete information or partial unknown evaluation information of the probabilistic distribution of all possible linguistic terms.
Definition 4
[56] For a given a probabilistic linguistic term set \(L\left( p \right)\) when \(\mathop \sum \limits_{k = 1}^{\# L\left( p \right)} p^{\left( k \right)} < 1\), normalize it so that the sum of probability is 1, and we can obtain the normalized PLTS \(\dot{L}\left( p \right)\):
where \(\dot{p}^{\left( k \right)} = p^{\left( k \right)} /\mathop \sum \limits_{k = 1}^{\# L\left( p \right)} p^{\left( k \right)}\); \(\mathop \sum \limits_{k = 1}^{\# L\left( p \right)} \dot{p}^{\left( k \right)} = 1\) \(\left( {k = 1,2, \ldots ,\# L\left( p \right)} \right)\).
Definition 5
[56] Let \(L_{1} \left( p \right) = \{ L_{1}^{{(k_{1} )}} (p_{1}^{{(k_{1} )}} )| k = 1,2, \ldots ,\# L_{1} \left( p \right)\}\) and \(L_{2} \left( p \right) = \{ L_{2}^{{(k_{2} )}} (p_{2}^{{(k_{2} )}} )|k = 1,2, \ldots ,\# L_{2} \left( p \right)\}\) be two PLTSs, the numbers of linguistic terms contained in \(L_{1} \left( p \right)\) and \(L_{2} \left( p \right)\) are represented by \(\# L_{1} \left( p \right)\) and \(\# L_{2} \left( p \right)\) respectively, and their values are not the same. If \(\# L_{1} \left( p \right)\) > \(\# L_{2} \left( p \right)\), then we will add \(\# L_{1} \left( p \right) - \# L_{2} \left( p \right)\) linguistic terms to \(L_{2} \left( p \right)\), so that the two PLTSs contain the same number of linguistic terms. The added linguistic terms \(\# L_{1} \left( p \right) - \# L_{2} \left( p \right)\) are the smallest ones in \(L_{2} \left( p \right)\) and the probabilities are zero for all linguistic terms. At this time, the probabilistic language term set \(L\left( p \right)\) is transformed into a normalized PLTS:\(\tilde{L}\left( p \right) = \{ \tilde{L} ^{\left( k \right)} (\tilde{p}^{\left( k \right)} )|k = 1,2 \ldots ,\# \tilde{L}\left( p \right)\}\), and the resultant matrix is called the normalized probabilistic linguistic decision matrix \(\tilde{U}\).
Definition 6
[57] Let \(\tilde{L}_{1} \left( p \right) = \left\{ {\tilde{L}_{1}^{{(k_{1} )}} \left( {\tilde{p}_{1}^{{(k_{1} )}} } \right)|k = 1,2, \ldots ,\# \tilde{L}_{1} \left( p \right)} \right\}\) and \(\tilde{L}_{2} \left( p \right) = \left\{ {\tilde{L}_{2}^{{\left( {k2} \right)}} \left( {\tilde{p}_{2}^{{\left( {k2} \right)}} } \right)|k = 1,2, \ldots ,\# \tilde{L}_{2} \left( p \right)} \right\}\) be two normalized PLTSs. Then, the general formula for measuring the distance between them can be expressed as:
Among them, when β = 1, the Hamming distance can be obtained, and when β = 2, it is converted into the Euclidean distance measure.
From this, the Hamming distance between the normalized probabilistic linguistic decision matrix \(\tilde{U}_{1} = \left( {\tilde{L}_{ij}^{1} \left( p \right)} \right)_{m \times n}\) and \(\tilde{U}_{2} = \left( {\tilde{L}_{ij}^{2} \left( p \right)} \right)_{m \times n}\) can be represented as follows:
Definition 7
[25] Let \(L\left( P \right)\) be the PLTS on \(S,\)\(r^{\left( k \right)}\) be the subscript of linguistic term \(L^{\left( k \right)} .\) Then, the mean and variance of \(L\left( P \right)\) are \(S_{\alpha }\) and \(\delta \left( {L\left( P \right)} \right)\) respectively, shown as:
Definition 8
[58] Let \(L\left( P \right)\) be the PLTS on \(S,\) \(r^{\left( k \right)}\) be the subscript of linguistic term \(L^{\left( k \right)} .\) Then, the score function \(SF\left( {L\left( P \right)} \right)\) of \(L\left( P \right)\) can be defined as follows:
2.3 Plithogenic Set and Plithogenic PLTS
Definition 9
[13, 59] Plithogenic set \((p,a,V,d,c),\) as an extension of crisp set, fuzzy set, intuitionistic fuzzy set, and neutrosophic set, is a set characterized by one or more attributes \(A = \{ \alpha 1,\alpha 2,...,\alpha m\} .\) Each attribute in \(A\) may have multiple values \(V = \{ v1,v2,...,vn\}\)(membership, non-membership and indeterminacy), among which contradiction degree and the appurtenance degree are two of the unique features, denoted by \(c(v,D)\) and \(d(x,v)\), respectively. Let \(\tilde{a} = (a1,a2,a3)\) and \(\tilde{b} = (b1,b2,b3)\) be two plithogenic sets. The intersection operation of plithogenic is:
The union operation of plithogenic is:
where
Definition 10
Let \(L = \left\{ {\left( {a,b,c} \right),S_{\alpha } \left( {p^{1} } \right),S_{\beta } \left( {p^{2} } \right),S_{\gamma } \left( {p^{3} } \right)} \right\}\) be a plithogenic probabilistic linguistic term set, where \(a,b,c,p \in \left[ {0,1} \right],\) \(\alpha ,\beta ,\gamma \in \left[ { - \tau ,\tau } \right]\) and \(\tau \in R.\) Compared with neutrosophic linguistic term, it increases the consideration of probability information when expressing decision-making evaluation, which is more in line with the fuzzy and uncertain decision-making environment.
3 VIKOR Method for Plithogenic PLTS MAGDM with Incomplete Weight Information
In this section, aiming at solving the decision-making problem of sustainable supply chain financial risk evaluation with unknown attribute weights under the plithogenic PLTS environment, we first outline the applied decision-making methods, and then put forward the principles and steps of a decision-making model to better understand and solve MAGDM problems.
3.1 Methods Description
To solve the SSCF risk evaluation problem in which the evaluation values are expressed in plithogenic PLTSs, we next develop a plithogenic probabilistic linguistic VIKOR multi-attribute analysis approach with unknown weight information. The proposed model utilizes the following methods: method of adjusting the consistency coefficient [60] is employed to determine the weights of attributes from a subjective and objective perspective, based on which, the decision matrix aggregated by the plithogenic PLTS is weighted, VIKOR method [53] is introduced from the point of maximum group benefit and minimum individual regret to derive the compromise solution and properly rank the alternatives. A brief description of the model building process is provided below.
3.2 The Proposed Model
The advantage and importance of this research lies not only in highly considering the uncertainty in the evaluation process, but also in the comprehensive analysis of the weight characteristics of the various attributes and alternatives in the MAGDM problem.
Plithogenic PLTSs can simultaneously reflect the evaluation information and probability information of the research object, providing us with additional possibilities to better express the uncertain and inaccurate information exist in various types of research problems. This model integrates the advantages of PLTS, consistency adjustment coefficient and VIKOR method in a plithogenic environment. The conceptual framework of the proposed model can be illustrated by Fig. 1 and the detailed steps are as follows:

The conceptual framework of the proposed model with plithogenic PLTS
Step 1 Problem description and determine the aggregated decision matrix.
For plithogenic probabilistic linguistic MAGDM problem. Suppose \(A = (A_{1}\),\({ }A_{2}\),…,\({ }A_{m} )\) (\(m \ge 1\)) be a set of m alternatives, \(C = \left\{ {c_{1} ,c_{2} , \ldots c_{n} } \right\}\) (\(n \ge 1\)) be a set of \({\text{n}}\) attributes. The initial subjective weight vector corresponding to the attribute is set as \(w^{\prime} = (w^{\prime}1,w^{\prime}2, \ldots ,w^{\prime}n)\), where \(0 \le wj \le 1,\,\sum\nolimits_{j = 1}^{n} {wj} = 1\), and the final weight vector of the attribute obtained by the adjustment coefficient is \(w = \left( {w_{1} , w_{2} , \ldots , w_{n} } \right)\). A group of DMs are indicated by \(D = \left\{ {d_{1} ,d_{2} , \cdot \cdot \cdot d_{k} } \right\}\)(\(k \ge 1\)). The evaluation on alternative \({\text{x}}_{j}\) under attribute \(a_{j}\) provided by DM \(d_{k}\) is in form of plithogenic PLTS \(L\), \(L = \left\{ {\left( {a,b,c} \right),S_{\alpha } \left( {p^{1} } \right),S_{\beta } \left( {p^{2} } \right),S_{\gamma } \left( {p^{3} } \right)} \right\}\). Next, we can obtain the original evaluation matrix according to the triangular neutrosophic probabilistic linguistic scale, as shown in Table 1.
Adopt Eqs. (6)–(8) to integrate the individual evaluation of each DM and further establish a comprehensive evaluation matrix based on the initial plithogenic probability evaluation matrix. Then the contradiction degree \(c\) \(\left( {c = \frac{n - 1}{n}} \right)\) of each attribute with respect to the dominant is defined to aggregate the neutrosophic evaluation opinions of each DM towards attributes by means of Eqs. (9)–(10). The aggregated neutrosophic number decision matrix is transformed into crisp number to facilitate further calculations, as shown in Eq. (11).
Step 2 Determine the comprehensive weights of attributes.
On the basis of the integrated plithogenic probabilistic linguistic term evaluation matrix, by combining the given initial subjective weights, the adjusted coefficient is applied to adjust the objective weights of attributes, so as to obtain the comprehensive weights considering both subjective and objective factors. The adjustment coefficient of weight is calculated according to the degree of consistency of the attribute related to other attribute evaluation information. The calculation steps are as follows:
Based on the normalized PLTS decision matrices \(\tilde{U}_{q} = \left( {\tilde{L}_{ij}^{q} \left( p \right)} \right)_{m \times n} \left( {q = 1,2, \ldots ,n} \right)\), a consistent degree \(\rho_{qr}\) between \(c_{q}\) and \(c_{r}\) is defined as:
where \(d\left( {\tilde{U}_{q} ,\,\tilde{U}_{r} } \right)\) can be obtained by Eq. (5), and the larger the value of consistent degree \(_{qr}\), the higher the consistent degree of evaluation information between \(c_{q}\) and \(c_{r}\). Next, the adjustment coefficient \(_{q}\) between attributes is defined as:
Obviously, the adjustment coefficient \(\rho_{q}\) represents the overall degree of consistency of attribute \(c_{q}\) with other attributes, that is, the degree to which \(c_{q}\) is favored by DMs, reflecting its relative importance. On the other hand, the larger the value of \(\rho_{q}\), the more important the attribute \(c_{q}\). Therefore, the comprehensive weights \(w_{k}\) of attributes can be determined according to the given initial subjective weight \(w^{\prime}q\) and the adjusted coefficient \(_{q}\):
Step 3: Determine the order of alternatives based on VIKOR
As an effective MAGDM technique, VIKOR method (the Serbian name: VIseKriterijumska Optimizacija I Kom-promisno Resenje, multi-criteria optimization and compromise solution) was developed by Opricovic for multi-attribute optimization of complex system, and obtaining the final compromise solution from a set of alternatives in the presence of conflicting attributes by means of maximizing group utility and minimizing individual regret [54]. In this stage, VIKOR is applied to rank the alternatives and select the optimal one [28].
Based on the comprehensive plithogenic probabilistic linguistic evaluation matrix, the positive ideal solution (PIS) and negative ideal solution (NIS) for each attribute can be obtained as following equations:
Next, calculating the plithogenic PLTS group benefit value \(Si\) and individual regret value \(Ri\) of each evaluation alternative expressed by the following relations:
where \(Si\) and \(Ri\) represent the group utility measure and individual regret measure for each alternative \(i,\) respectively, among which, the smaller the value \(Si,\) the greater the group utility of the alternative. And on the contrary, the smaller the value \(Ri,\) the lower the individual regret. The value of \(wj\) expresses the weight of the jth attribute.
Calculating the value of compromise sort index \(Qi\) using the relation as follows:
where \(S^{ + } = \mathop {\min }\limits_{i} Si,\) \(S^{ - } = \mathop {\max }\limits_{i} Si,\) \(R^{ + } = \mathop {\min }\limits_{i} Ri\) and \(R^{ - } = \mathop {\max }\limits_{i} Ri.\) \(\mu\) \((\mu \in [0,1])\) is the compromise sorting coefficient that denotes the weight of group utility, while \(1 - \mu\) is the weight of individual regret. If \(\mu > 0.5,\) then the proportion of the group benefit of the alternatives is greater than that of the individual regret and make decisions based on the objective of maximum group utility. However,\(\mu < 0.5\) indicates that the decision is based on a decision-making mechanism that minimizes individual regret. In this paper, the value of \(\mu\) is set to 0.5, which implies that the decision.
Finally, ranking the alternatives based on the obtained values of \(Si,\) \(Ri\) and \(Qi\) \((i = 1,2, \ldots ,m)\) in descending order, which means the greater the value of \(Qi\), the worse the alternative and vice versa. We can get a ranking table of all the alternatives with respect to the three index values of VIKOR.
4 Case Study
In this section, to illustrate the effectiveness and feasibility of the proposed methods, a practical numerical example concerned with the pharmaceutical industry in China evaluates the most substantial risk metrics for enhancing the risk management performance of SSCF. Meanwhile, a comparative analysis is also conducted to show the superiority of the proposed model.
4.1 Application to the Pharmaceutical Industry
Affected by the COVID-19 epidemic, the pharmaceutical industry in China has become one of the most promising and competitive industries in recent years. However, due to the rapid growth of orders, some small and medium-sized companies are gradually affected by the cash flow gaps, inherent uncertainty and other risk factors, which seriously affect the normal operation of supply chain production and operation activities. With the gradual rise of SCF business in the industry and the active promotion of sustainable development by relevant departments, a large state-owned bank decided to select the optimal alternative to implement corresponding financial services on the basis of assessing the SSCF risk level of relevant companies. For enterprises, whether seeking cooperation or choosing investment, the risk evaluation of SSCF is particularly important. It is also of great significance to make corresponding risk prevention and control measures on the premise of comparing these risk evaluation attributes and ranking them according to their importance degree. Therefore, it is necessary to consider the risk sources of SSCF from a multi-dimensional perspective. For the purposes of this case study, five representative risk attributes are chosen as the evaluation attributes set of plithogenic PLTS on the basis of TBL and its extensions [59] (All attributes are of the negative type): (1) \(C_{1} :\) Economic performance risk; (2) \(C_{2} :\) Social responsibility risk; (3) \(C_{3} :\) Environmental performance risk; (4) \(C_{4}\): Sustainable supply risk; (5) \(C_{5}\): Information and control capability risk. The weight vectors of these attributes are completely unknown. Suppose that there are four influential candidate companies (alternatives) to be evaluated, which are the Shanghai Pharma (\(a_{1} )\), the CSPC Pharma (\(a_{2} )\), Yunnan Baiyao (\(a_{3} )\), the Hengrui Medicine (\(a_{4} )\). We examined the actual situation of four companies whose data is assessed by four DMs \(d = \left\{ {d_{1} ,d_{2} ,d_{3} ,d_{4} } \right\}\) from the relevant department of the bank with significant insights and influence on the pharmaceutical industry. In the case of uncertainty, plithogenic probability linguistic evaluation scale \(L = \left\{ {\left( {a,b,c} \right),S_{\alpha } \left( {p^{1} } \right),S_{\beta } \left( {p^{2} } \right),S_{\gamma } \left( {p^{3} } \right)} \right\}\) (see the details in Table 1) is used by DMs to express their preferences for different risk attributes under different alternatives. The evaluation results of SSCF risk are integrated to form the plithogenic PLTS decision matrix \(U_{1}\),\({ }U_{2}\),\(U_{3} ,U_{4}\), as shown in Table 2.
Step 1: According to the aggregation operation of the PLTS score function of Eqs. (6)–(8) and the plithogenic aggregation operator of Eqs. (9)–(10), plithogenic aggregation operator is applied to combine all single assessments of each DM about the sub-criteria based on the equidistance contradiction degree (CD) of each criterion to the dominant. The aggregated evaluation matrix is shown in Table 3.
In order to simplify the calculation, a de-neutrosophic process is conducted to transform the aggregated neutrosophic number matrix into crisp number matrix according to Eq. (11), as shown in Table 4. The normalized evaluation matrix can be further obtained and the result is presented in Table 5.
Step 2: On the basis of the normalized de-neutrosophic PLTS evaluation matrix, assuming that the given initial subjective weights of attribute are \(w^{\prime}q\) = (0.1, 0.4, 0.3, 0.2, 0.1), the objective weights of attributes can be calculated by adjusted coefficient, shown in Eqs. (12)–(13). Therefore, the comprehensive weight vector of attributes is \(w_{k}\) = (0.0996\(,\) 0.3894\(,\) 0.2111\(,\) 0.1959\(,\) 0.1040) according to Eq. (14). That is to say, \(C_{2}\), \(C_{3}\) and \(C_{4}\) are the three most important risk attributes, occupying a larger proportion in the process of evaluation. After obtaining the comprehensive weight of each risk attribute, the result is brought into the normalized evaluation matrix, and the comprehensive normalized decision matrix of SSCF risk evaluation of each alternative can be obtained as shown in Table 6.
Step 3: In this step, the idea of VIKOR method is applied to evaluate the SSCF risk of each alternative, where \(\tilde{V}_{{}}^{ + }\) and \(\tilde{V}_{{}}^{ - }\) can be obtained on the basis of aggregated evaluation matrix shown in Table 6, and the specific calculation results, according to Eqs. (15)–(16), are positive ideal solution (PIS) \(V^{ + }\) = (0.0389,0.0692,0.0798,0.073,0.0586) and negative ideal solution (NIS)\(V^{ - }\) = (0.0526,0.1274,0.1031,0.0952,0.0681).
Now,\(Si\) and \(Ri\) is calculated based on the values of \(\tilde{V}^{ + } ,\) \(\tilde{V}_{{}}^{ - }\) and \(w_{k} { }\) using Eqs. (17)–(18). The calculation results of \(Si\) and \(Ri\) for four alternatives are listed in Table 7. Suppose \(\gamma\) = 0.5, and we can calculate the values of \(Qi\) by means of Eq. (19). From Table 7, it can be seen that \(S^{ + }\) = 0.1845, \(S^{ - }\) = 0.7112,\(R^{ + }\) = 0.0996,\(R^{ - }\) = 0.3894, hence the values of \(Qi\) can be obtained as well as the ranking table of the three parameters, as shown in the last line. The ranking order of the \(Si\),\(Ri\) and \(Qi\) are the same, that is \({ }a_{2} > a_{1}\) > \({ }a_{4} > a_{3}\).
According to the calculation results, the SSCF business of \(a_{2}\) is most likely to suffer risks, hence banks should carefully consider cooperation with it, while the \(a_{3}\) pharmaceutical enterprise can be seen as the optimal solution with the best risk management level and can carry out corresponding financing business to achieve a win–win situation. In summary, the final decision for the least risky company result is: company \(a_{3}\) > company \(a_{4}\) > company \(a_{1}\) > company \(a_{2}\).
4.2 Comparative Analysis and Discussion
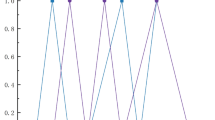
In the above-mentioned SSCF risk assessment process, the third pharmaceutical company was the least risky and the optimal alternative, followed by the fourth company, and the second company ranked last. To validate the superiority of the proposed model in evaluating the risk of SSCF, and to further analyze the differences in the scoring results of various companies, a brief comparative analysis is performed in this section under plithogenic PLTS environment with existing MAGDM techniques including TOPSIS method [54] and ELECTRE method [61]. Figure 2 summarizes the performance values of alternatives under different methods. For \(a_{3}\), the performance coefficient values determined by the three comparison methods are always bigger than other alternatives, which to some extent highlights the superiority of company \(a_{3}\) in risk evaluation and also accords with the results obtained in this paper, thus demonstrating the validity of the proposed approach. The specific comparative ranking results are shown in Table 8.

Comparison of alternative performance values
According to the ranking results of different methods in Table 8, it can be seen that the other two methods in the plithogenic PLTS environment are roughly the same as the VIKOR method applied in this paper, with only partial differences. The following analysis can account for this difference, first, it should be noticed that the TOPSIS method obtains performance values based on the Euclidean distance measure between each alternative and ideal solutions, while ignoring the possible interrelated characteristics among attributes. However, the proposed model in this paper can not only consider the interrelationship among more than two risk attributes, but also give the more reasonable decision result, which is more in line with the practical application of decision-making. On the other hand, there is no need for VIKOR to take whether optimal solution should be the closest from the PID and farthest from the NID into consideration. Second, the normalized value of matrix in the proposed method does not rely on the evaluation unit of an attribute function, while the value generated by vector normalization in the TOPSIS method may depend on it.
We can see from the ranking results that the ELECTRE method and the VIKOR-based method derive the same ranking of the alternatives, and get the same optimal alternative \(a_{3}\). Compared with the ELECTRE method, which weakens poor solutions to acquire the optimal solution, the VIKOR method emphasizes maximizing group utility and minimizing personal regret to obtain a compromise solution that satisfies the corresponding constraints and pays more attention to the opinions of group DMs. Moreover, the proposed approach places more emphasis on the characteristics of local individual attributes and alternatives, rather than taking the entire incomplete information as a whole.
Therefore, from the above analysis, it can be seen that the model proposed in this paper is more convincing in expressing decision results.
This paper has proposed the VIKOR to solve the SSCF risk evaluation problem and adopted the plithogenic PLTS to present theDMs’ preferences. On the basis of the results of the case study and the above comparative example, we can summarize the following advantages:
-
(1)
Compared with other fuzzy linguistic terms [22, 23], the plithogenic PLTSs can simultaneously describe two kinds of uncertain information, hesitation and probability, which can express the preferences of DMs more flexibly and accurately combining quantitative and qualitative evaluation information.
-
(2)
The combined consideration of the contradiction degree of plithogenic set and the scoring function of PLTS can simplify the computational complexity of MAGDM problem in the analysis process.
-
(3)
The consistency adjustment coefficients can comprehensively consider the subjective and objective weight of risk attributes and obtain the integrated weight in the case that the weight information is incomplete.
-
(4)
With the plithogenic PLTSs, the VIKOR method can maintain the integrity of the decision information and reflects the approximation degree of group utility and individual regret to the ideal solutions by means of integrated decision matrix, which results in much more reasonable decisions.
In general, the contribution of assessing the risks of SSCF financing alternatives with different decision-making methods is to allow DMs to think about the practical problem from dissimilar perspectives, which helps increase the flexibility of decision-making progress. However, under the evaluation of linguistic information that combines quantitative calculation and qualitative analysis, the differential characteristics of DMs will also have a considerable impact on the decision results. Therefore, we can further extend the proposed method by combining some emerging artificial intelligent techniques with multi-source plithogenic probabilistic information, making it feasible to express the preference characteristics of DMs and deal with various kinds of uncertainties.
5 Conclusion
It is unreasonable to ignore risk factors in the development of SSCF and not to consider the importance of probabilistic language terms in decision-making. Under the premise of considering risk factors, the financing company selection is a crucial strategy for banks who engage in SCF business with the goal of sustainability, which can be regarded as a MAGDM problem. A variety of expressions of fuzzy decision information have been proposed by scholars to intuitively describe cognitive preferences for such problems. However, the existing evaluation models also have limitations such as not fully considering the impact of inaccurate subjective and objective information of risk attributes weights on the decision-making results, while there is also little involvement in the prioritization of risk factors and solutions that affect sustainable supply chain financial business in an uncertain environment. To address these deficiencies and effectively prevent and control the risk indicators that have negative impacts on the SSCF business, this paper extends the VIKOR method to evaluate the selected five risk attributes with unknown weight information through the PLTS under plithogenic environment. In order to facilitate the application of PLTSs under plithogenic environment to evaluate SSCF risks, single evaluation decision matrices from DMs towards risks attributes are integrated and transformed into crisp numbers through the operation of plithogenic contradiction degree and the PLTS scoring function aggregation operators. Then, after deriving the integrated weights of risks based on the subjective and objective attribute weights from the thought of adjustment coefficients, the VIKOR method was developed to evaluate the risk level of all alternatives. The feasibility and rationality of the proposed technique are verified by a case study in the pharmaceutical industry and we obtain the optimal alternative is \(a_{3}\), which provides a new idea for the application of MAGDM theory and the risk evaluation of SSCF. In addition, the advantages of this paper include reducing the vagueness of expert judgments by evaluating in a plithogenic environment, adjusting the value of weight coefficient according to the risk attitude and actual preference of DMs with PLTSs, and highlighting the interpretability and superiority of the decision results by comparing with other representative decision-making methods.
Although this paper has enriched the theoretical system on risk evaluation of SSCF, there are also some limitations that are worthy of future research. Since the constructed risk attribute set only covers risk attributes from five dimensions, it may not fully reflect all aspects of the interaction between risk and sustainability, which may lead to deviation between theoretical results and practical application to some extent. In addition, the combination of the MAGDM techniques with plithogenic PLTSs could also be employed to solve other practical uncertain decision-making problems, such as predictive policy evaluation, blockchain risk assessment, city happiness index rankings, etc. In the future, we will also set out to expand the breadth of the plithogenic PLTSs with more comprehensive risk indicator evaluation and more complex problem structures.
References
Moretto, A., Caniato, F.: Can Supply Chain Finance help mitigate the financial disruption brought by Covid-19. J. Purch. Supply Manag. 27, 100713 (2021)
Gupta, N., Soni, G.: A decision-making framework for sustainable supply chain finance in post-COVID era. Int. J. Glob. Bus. Compet. (2021). https://doi.org/10.1007/s42943-021-00028-6
Tseng, M.L., Lim, M.K., Wu, K.J.: Improving the benefits and costs on sustainable supply chain finance under uncertainty. Int. J. Prod. Econ. 218, 308–321 (2019)
Haimes, Y.Y.: On the complex definition of risk: a systems-based approach. Risk. Anal. 29, 1647–1654 (2019)
Tseng, M.L., Bui, T.D., Lim, M.K., Tsai, F.M., Tan, R.R.: Comparing world regional sustainable supply chain finance using big data analytics: a bibliometric analysis. Ind. Manag. Data. Syst. 121, 657–770 (2021)
Su, Y., Zhao, M., Wei, C., Chen, X.: PT-TODIM method for probabilistic linguistic MAGDM and application to industrial control system security supplier selection. Int. J. Fuzzy Syst. (2021). https://doi.org/10.1007/s40815-021-01125-7
Yue, Z.: A method for group decision-making based on determining weights of decision makers using TOPSIS. Appl. Math. Model. 35, 1926–1936 (2011)
Wan, S.P., Jin, Z., Dong, J.Y.: Pythagorean fuzzy mathematical programming method for multi-attribute group decision making with Pythagorean fuzzy truth degrees. Knowl. Inf. Syst. 55, 437–466 (2018)
Zadeh, L.A.: A fuzzy-set-theoretic interpretation of linguistic hedges. J. Cybern. 2, 4–34 (1972)
Turksen, I.B.: Interval valued fuzzy sets based on normal forms. Fuzzy. Set. Syst. 20, 191–210 (1986)
Takeuti, G., Titani, S.: Intuitionistic fuzzy logic and intuitionistic fuzzy set theory. J. Symb. Log. 49, 851–866 (1984)
Smarandache, F.: A unifying field in logics: neutrosophic logic. In: Philosophy, pp. 1–141. American Research Press (1999)
Smarandache, F.: Plithogenic set, an extension of crisp, fuzzy, intuitionistic fuzzy, and neutrosophic sets-revisited. Infinite Study 21, 153–166 (2018)
Abdel-Basset, M., El-Hoseny, M., Gamal, A., Smarandache, F.: A novel model for evaluation Hospital medical care systems based on plithogenic sets. Artif. Intell. Med. 100, 1–8 (2019)
Sankari, H., Abobala, M.: n-Refined neutrosophic modules. Infinite Study 36, 1–11 (2020)
Abdel-Basset, M., Mohamed, R., Smarandache, F., Elhoseny, M.: A new decision-making model based on plithogenic set for supplier selection. Cmc-Comput. Mater. Continua 66, 2751–2769 (2021)
Wu, Z., Xu, J.: Possibility distribution-based approach for MAGDM with hesitant fuzzy linguistic information. IEEE. T. Cybern. 46, 694–705 (2015)
Xu, Z., Wang, H.: On the syntax and semantics of virtual linguistic terms for information fusion in decision making. Inform. Fusion. 34, 43–48 (2017)
Zadeh, L.A.: The concept of a linguistic variable and its application to approximate reasoning—I. Inform. Sci. 8, 199–249 (1975)
Herrera, F., Martínez, L.: A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy. Syst. 8, 746–752 (2000)
Ye, J.M., Xu, Z., Gou, X.J.: Virtual linguistic trust degree-based evidential reasoning approach and its application to emergency response assessment of railway station. Inform. Sci. 513, 341–359 (2020)
Wei, G., Lu, M., Alsaadi, F.E., Hayat, T., Alsaedi, A.: Pythagorean 2-tuple linguistic aggregation operators in multiple attribute decision making. Int. J. Fuzzy Syst. 33, 1129–1142 (2017)
Rodriguez, R.M., Martinez, L., Herrera, F.: Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy. Syst. 20, 109–119 (2011)
Torra, V.: Hesitant fuzzy sets. Int. J. Intell. Syst. 25, 529–539 (2010)
Pang, Q., Wang, H., Xu, Z.: Probabilistic linguistic term sets in multi-attribute group decision making. Inform. Sci. 369, 128–143 (2016)
Zhang, Y., Xu, Z., Wang, H., Liao, H.: Consistency-based risk assessment with probabilistic linguistic preference relation. Appl. Soft. Comput. 49, 817–833 (2016)
Gou, X., Xu, Z.: Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inform. Sci. 372, 407–427 (2016)
Zhang, X.L., Xing, X.M.: Probabilistic linguistic VIKOR method to evaluate green supply chain initiatives. Sustainability Basel 9, 1231 (2017)
Zhai, Y., Xu, Z., Liao, H.: Probabilistic linguistic vector-term set and its application in group decision making with multi-granular linguistic information. Appl. Soft. Comput. 49, 801–816 (2016)
Wu, X., Liao, H., Xu, Z., Hafezalkotob, A., Herrera, F.: Probabilistic linguistic MULTIMOORA: a multicriteria decision making method based on the probabilistic linguistic expectation function and the improved Borda rule. IEEE Trans. Fuzzy Syst. 26, 3688–3702 (2018)
Wei, G., Wei, C., Wu, J., Guo, Y.: Probabilistic linguistic multiple attribute group decision making for location planning of electric vehicle charging stations based on the generalized Dice similarity measures. Artif. Intell. Rev. 54, 4137–4167 (2021)
Zhang, X., Gou, X., Xu, Z., Liao, H.: A projection method for multiple attribute group decision making with probabilistic linguistic term sets. Int. J. Mach. Learn. Cyb. 10, 2515–2528 (2019)
Lu, J., Wei, C., Wu, J., Wei, G.: TOPSIS method for probabilistic linguistic MAGDM with entropy weight and its application to supplier selection of new agricultural machinery products. Entropy-Switz. 21, 953 (2019)
Zhang, Z., Wu, C.: A novel method for single-valued neutrosophic multi-criteria decision making with incomplete weight information. Neutrosophic Sets Syst. 4, 35–49 (2014)
Gou, X., Xu, Z., Liao, H.: Multiple criteria decision making based on Bonferroni means with hesitant fuzzy linguistic information. Soft. Comput. 21, 6515–6529 (2017)
Chang, T.W., Lo, H.W., Chen, K.Y., Liou, J.J.: A novel FMEA model based on rough BWM and rough TOPSIS-AL for risk assessment. Mathematics Basel 7, 874–894 (2019)
Davoudabadi, R., Mousavi, S.M., Mohagheghi, V.: A new last aggregation method of multi-attributes group decision making based on concepts of TODIM, WASPAS and TOPSIS under interval-valued intuitionistic fuzzy uncertainty. Knowl. Inf. Syst. 62, 1371–1391 (2020)
Pang, J., Guan, X., Liang, J., Wang, B., Song, P.: Multi-attribute group decision-making method based on multi-granulation weights and three-way decisions. Int. J. Approx. Reason. 117, 122–147 (2020)
Shyur, H.-J.: COTS evaluation using modified TOPSIS and ANP. Appl. Math. Comput. 177, 251–259 (2005)
Qin, J.D., Liu, X.W., Pedrycz, W.: An extended VIKOR method based on prospect theory for multiple attribute decision making under interval type-2 fuzzy environment. Knowl.-Based. Syst. 86, 116–130 (2015)
Gul, M., Celik, E., Aydin, N., Gumus, A.T., Guneri, A.F.: A state of the art literature review of vikor and its fuzzy extensions on applications. Appl. Soft. Comput. 46, 60–89 (2016)
Peng, X.D., Dai, J.G.: Approaches to single-valued neutrosophic MADM based on MABAC, TOPSIS and new similarity measure with score function. Neural. Comput. Appl. 29, 939–954 (2018)
Opricovic, S., Tzeng, G.H.: Extended VIKOR method in comparison with outranking methods. Eur. J. Oper. Res. 178, 514–529 (2017)
Tavana, M., Di Caprio, D., Santos-Arteaga, F.J.: An extended stochastic VIKOR model with decision maker’s attitude towards risk. Inf. Sci. 432, 301–318 (2018)
Chatterjee, K., Samarjit, K.: Unified Granular-number-based AHP-VIKOR multi-criteria decision framework. Granul. Comput. 2, 199–221 (2017)
Zhou, W., Yin, W.Y., Peng, X.Q., Liu, F.M., Yang, F.: Comprehensive evaluation of land reclamation and utilisation schemes based on a modified VIKOR method for surface mines. Int. J. Min. Reclam. Environ. 32, 93–108 (2018)
Lin, M., Chen, Z., Xu, Z., Gou, X., Herrera, F.: Score function based on concentration degree for probabilistic linguistic term sets: an application to TOPSIS and VIKOR. Inform. Sci. 551, 270–290 (2021)
Li, Y., Liu, Y.S.: Extended VIKOR-QUALIFLEX method based on trapezoidal fuzzy two-dimensional linguistic information for multiple attribute decision-making with unknown attribute weight. Mathematics-Basel. 9, 37–63 (2020)
Abdel-Basset, M., Mohamed, R., Elhoseny, M., Chang, V.: Evaluation framework for smart disaster response systems in uncertainty environment. Mech. Syst. Signal. Pr. 145, 1–18 (2020)
Gou, X., Xu, Z., Liao, H., Herrera, F.: Probabilistic double hierarchy linguistic term set and its use in designing an improved VIKOR method: the application in smart healthcare. J. Oper. Res. Soc. 72, 2611–2630 (2021)
Liu, P., You, X.: Probabilistic linguistic TODIM approach for multiple attribute decision-making. Granul. Comput. 2, 333–342 (2017)
Wei, G., Wei, C., Wu, J., Wang, H.: Supplier selection of medical consumption products with a probabilistic linguistic MABAC method. Int. J. Env. Res. Pub. He. 16, 5082 (2019)
Opricovic, S., Tzeng, G.H.: Compromise solution by MCDM methods: a comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 156, 445–455 (2014)
Lei, F., Wei, G., Gao, H., Wu, J., Wei, C.: TOPSIS method for developing supplier selection with probabilistic linguistic information. Int. J. Fuzzy. Syst. 22, 749–759 (2020)
Xu, Z.: Deviation measures of linguistic preference relations in group decision making. Omega 33, 249–254 (2005)
Wang, Z.P., Peng, Z.W., Wang, H.C.: Research on probabilistic linguistic multi-attribute group decision making method based on improved possibility degree and distance measure. J. Math. Pract. Theory 11, 10–20 (2021)
Shen, L.L., Pang, X.D., Zhang, Q., Qian, G.: TODIM method based on probabilistic language term set and its application. J. Stat. Decis. 18, 80–83 (2019)
Chen, Z.S., Chin, K.S., Li, Y.L., Yang, Y.: Proportional hesitant fuzzy linguistic term set for multiple criteria group decision making. Inform. Sci. 357, 61–87 (2016)
Abdel-Basset, M., Mohamed, R.: A novel plithogenic TOPSIS- CRITIC model for sustainable supply chain risk management. J. Clean. Prod. 247, 119586 (2020)
Mao, X.B., Wu, M., Dong, J.Y., Wan, S.P., Jin, Z.: A new method for probabilistic linguistic multi-attribute group decision making: application to the selection of financial technologies. Appl. Soft. Comput. 77, 155–175 (2019)
Liao, H.C., Jiang, L.S., Lev, B., Fujita, H.: Novel operations of PLTSs based on the disparity degrees of linguistic terms and their use in designing the probabilistic linguistic ELECTRE III method. Appl. Soft. Comput. 80, 450–464 (2019)
Acknowledgements
This work was supported by the Fundamental Research Funds for the Central Universities under Grant No. 3132019353.
Author information
Authors and Affiliations
Contributions
YL was responsible for the analysis and preparation of the manuscript; ZW and MF contributed to the structure and main idea of the article, the revision of the full text; and PW performed the data processing and wrote the manuscript.
Corresponding author
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, P., Lin, Y., Fu, M. et al. VIKOR Method for Plithogenic Probabilistic Linguistic MAGDM and Application to Sustainable Supply Chain Financial Risk Evaluation. Int. J. Fuzzy Syst. 25, 780–793 (2023). https://doi.org/10.1007/s40815-022-01401-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-022-01401-0