
Abstract
In this work, we have used a fuzzy counter-propagation network (FCPN) model to control different discrete-time, uncertain nonlinear dynamic systems with unknown disturbances. Fuzzy competitive learning (FCL) is used to process the weight connection and make adjustments between the instar and the outstar of the network. FCL paradigm adopts the principle of learning, used for calculation of the Best Matched Node (BMN) in the instar–outstar network. FCL provides a control of discrete-time uncertain nonlinear dynamic systems having dead zone and backlash. The errors like mean absolute error (MAE), mean square error (MSE), and best fit rate, etc. of FCPN are compared with networks like dynamic network (DN) and back propagation network (BPN). The FCL foretells that the proposed FCPN method gives better results than DN and BPN. The success and enactments of the proposed FCPN are validated through simulations on different discrete-time uncertain nonlinear dynamic systems and Mackey–Glass univariate time series data with unknown disturbances over BPN and DN.








Similar content being viewed by others

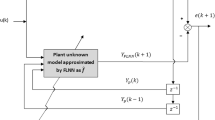
References
Soderstrom, T., Stoica, P.: System Identification. Prentice Hall, New York (1989)
Billings, S.A.: Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Saptio-Temporal Domains. Wiley, Chichester (2013)
Liu, M.: Decentralized control of robot manipulators: nonlinear and adaptive approaches. IEEE Trans. Autom. Control 44, 357–366 (1999)
Lin, C.M., Ting, A.B., Li, M.C.: Neural network based robust adaptive control for a class of nonlinear systems. Neural Comput. Appl. 20, 557–563 (2011)
Rivals, I., Personnaz, L.: Nonlinear internal model control using neural networks application to processes with delay and design issues. IEEE Trans. Neural Netw. 11, 80–90 (2000)
KenallaKopulas, I., Kokotovic, P.V., Morse, A.S.: Systematic design of adaptive controller for feedback linearizable system. IEEE Trans. Autom. Control 36, 1241–1253 (1991)
Kokotovic, P.V.: The joy feedback: nonlinear and adaptive. IEEE Control Syst. Mag. 12, 7–17 (1992)
Elmali, H., Olgac, N.: Robust output tracking control of nonlinear MIMO system via sliding mode technique. Automatica 28, 145–151 (1992)
Sadati, N., Ghadami, R.: Adaptive multi-model sliding mode control of robotic manipulators using soft computing. Neurocomputing 17, 2702–2710 (2008)
Kroll, A., Schulte, H.: Benchmark problems for nonlinear system identification and control using Soft Computing methods: need and overview. Appl. Soft Comput. 25, 496–513 (2014)
Hornik, K., Stinchcombe, M., White, H.: Multiforward feed forwards networks are universal approximators. Neural Netw. 2, 359–366 (1989)
Bortoletti, A., Di Flore, C., Fanelli, S., Zellini, P.: A new class of Quasi-Newtonian methods for optimal learning in MLP-networks. IEEE Trans. Neural Netw. 14, 263–273 (2003)
Lera, G., Pinzolas, M.: Neighborhood based Levenberg-Marquardt algorithm for neural network training. IEEE Trans. Neural Netw. 13, 1200–1203 (2002)
Alfaro-Ponce, M., Arguelles, A., Chairez, I.: Continuous neural identifier for certain nonlinear systems with time in the input signal. Neural Netw. 60, 53–66 (2014)
Wei, Q., Liu, D.: Neural-network based adaptive optimal tracking control scheme for discrete-time nonlinear system with approximation errors. Neurocomputing 149, 106–115 (2015)
Gao, S., Dong, H., Ning, B., Chen, L.: Neural adaptive control for uncertain nonlinear system with input: State transformation based output feedback. Neurocomputing 159, 117–125 (2015)
Peng, Z., Wang, D., Zhang, H., Lin, Y.: Coopeative output feedback adaptive control of uncertain nonlinear multi-agent systems with a dynamic leader. Neurocomputing 149, 132–141 (2015)
Zhang, T., Xia, X.: Decentralized adaptive fuzzy output feedback control of stochastic nonlinear large scale systems with dynamic un certainties. Inf. Sci. 315, 17–18 (2015)
Song, J., He, S.: Finite time robust passive control for a class of uncertain Lipschitz nonlinear systems with time delays. Neurocomputing 159, 275–281 (2015)
Cui, G., Wang, Z., Zhuang, G., Chu, Y.: Adaptive Centralized NN control of large scale stochastic nonlinear time delay systems with unknown dead zone inputs. Neurocomputing 158, 194–203 (2015)
Zhou, J., Er, M.J., Veluvolu, K.C.: Adaptive output control of Nonlinear Time-Delayed systems with uncertain Dead-zone input, IEEE, 2006, pp. 5312–5317
Zhang, T.P., Ge, S.S.: Adaptive dynamic surface control of nonlinear systems with unknown dead zone in pure feedback form. Automatica 44, 1895–1903 (2008)
Liu, Y.-J., Zhou, N.: Observer-based adaptive fuzzy-neural control for a class of uncertain nonlinear systems with unknown dead zone input. ISA Trans. 49, 462–469 (2010)
Ibrir, S., Xie, W.F., Su, C.-Y.: Adaptive tracking of nonlinear systems with non-symmetric dead zone input. Automatica 43, 522–530 (2007)
Hu, Q., Ma, G., Xie, L.: Robust and adaptive variable structure output feedback control of uncertain systems with input nonlinearity. Automatica 44, 552–559 (2008)
Zhuo, J., Wen, C., Zang, Y.: Adaptive output control of Nonlinear systems with uncertain dead zone nonlinearity. Autom. Control 51, 504–511 (2006)
Zhang, X., Pariini, T.: Adaptive fault tolerant control of nonlinear uncertain systems: a information based diagnostic approach. Autom. Control 49, 1259–1274 (2004)
Zhuo, S., Feng, G., feng, C.-B.: Robust Control for a class of uncertain nonlinear systems adaptive fuzzy approach based on backstepping. Fuzzy Sets Syst. 151, 1–20 (2003)
Lewis, F.L., Campos, J., Selmic, R.: Neuro Fuzzy Control of Industrial Systems with Actuator Nonlinearities. Society for Industrial and Applied Mathematics, Philadelphia (2002)
Hecht-Nielsen, R.: Theory of the back propagation neural network. Neural Netw. 1, 593–605 (1989)
Hagan, M.T., Demuth, H.B., Beale, M.H.: Orlando De Jesus, Neural Network Design, 2nd Edition, Cengage Learning, 2014
Chang, F.J., Chen, Y.-C.: A counter propagation fuzzy neural network modeling approach to real time stream flow prediction. J. Hydrol. 245, 153–164 (2001)
Dwivedi, A., Bose, N.S.C., Kumar, A., Kandula, P., Mishra, D. and Kalra, P.K.: A novel hybrid image compression technique: wavelet-MFOCPN, in Proc. of 9th SID, 2006, pp. 492–495
Burges, C.J.C., Simard, P., Malvar, H.S.: Improving Wavelet Image Compression with Neural Networks. Microsoft Research, Redmond (2001)
Woods, D.: Back and counter propagation aberrations, IEEE International Conference on Neural Networks, 1988, pp. 473–479
Mishra, D., Chandra Bose, N., Tolambiya, A., Dwivedi, A., Kandula, P., Kumar A., and Kalra, P.K., Color image compression with modified forward-only counter propagation neural network improvement of the quality using different distance measures, ICIT’06. 9th International Conference on Information Technology, 2006, pp. 139–140
Sakhre, V., Jain, S., Sapkal, V.S., Agarwal, D.P.: Fuzzy Counter Propagation Neural Network for a class of nonlinear dynamical systems. Comput. Intell. Neurosci. 2015, 1–12 (2015)
Sarangapani, J.: Neural Network Control of Nonlinear Discrete Time Systems with Actuator Nonlinearties, p. 265. Taylor & Francis, London (2006)
Jagannathan, S., Lewis, F.L.: Discrete Time Neural net Controller for a class of nonlinear dynamical systems. IEEE Trans. Autom. Contr. 41, 1693–1699 (1996)
Jaddi, N.S., Abdullah, S., Hamdan, A.R.: Optimization of neural network model using modified bat-inspired algorithm. Appl. Soft Comput. 37, 71–86 (2015)
Acknowledgments
The author is gratefully acknowledged the financial assistance provided by the All India Council of Technical Education (AICTE) in the form of Research Promotion Scheme (RPS) project in 2012.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Dynamic Learning for CPN
Learning stability are fundamental issues for CPN, however there are few studies on the learning issue of FNN. BPN for learning is not always successful because of its sensitivity to learning parameters. Optimal learning rate always change during the training process. Dynamic learning of CPN is carried out using lemma 1, lemma 2 and lemma 3 [37, 38].
Assumption
Let us assume ϕ(x) is a sigmoidal function, if it is a bounded, continuous, and increasing function. Since input to the neural network in this model is bounded, we consider the lemma 1, and lemma 2 as given below:
Lemma 1
Let ϕ(x) be a sigmoid function and Ω be a compact set in \({\mathbb{R}}^{n} , \,{\text{and}} \quad f:{\mathbb{R}}^{n} \to {\mathbb{R}}\) on Ω is a continuous function and for arbitrary ∈ > 0, ∃ a integer N and real constants c i , θ i , w ij , i = 1, 2,…, N, j = 1, 2,…, n. Such that
Satisfies
Using lemma 1, dynamic learning for a three-layered CPN can be formulated where the hidden-layer transfer functions are ϕ(x) and the transfer function at the output layer is linear.
Let all the vectors be column vectors, and superscript \(d_{p}^{k}\) refer to specific output vectors component.
Let \(X = \left[ {x_{1} , x_{2} , \ldots , x_{p} } \right] \in {\mathbb{R}}^{L \times P}\), and \(Y = \left[ {y_{1} , y_{2} , \ldots , y_{p} } \right] \in {\mathbb{R}}^{H \times P} O = \left[ {o_{1} , o_{2} , \ldots , o_{p} } \right] \in {\mathbb{R}}^{K \times P}\) be the input-hidden, the output vectors, and \(D = \left[ {d_{1} , d_{2} , \ldots , d_{p} } \right] \in {\mathbb{R}}^{K \times P}\) be the desired vector, respectively, where L, H, and K denote the numbers of input, hidden, and output layer neurons. Let V and W represent the input-hidden and hidden-output layer weight matrices, respectively. The objectives of the network training to minimize an error function J where J is given by
Appendix B: Optimal Learning of Dynamic System
While considering a three-layered CPN, the network error matrix is defined as the error between the differences of the desired and the FCPN outputs at any iteration, and is given as [37, 38]
The objective of the network to realize the minimization of error given in Eq. (31) is defined as follows:
where \(T_{r}\) represents the trace of matrix. Using gradient-descent method, the updated weight is given by
or
To obtain the minimum error for multilayer network, by simplification of above equation, we have
Using Eq. (31), we have
Solving for the above term, we get
For simplification, omit subscript t; then, we have, i.e.,
where
where
Equation (35) is a polynomial of degree 4, and to obtain optimum value of \(\beta ,\) we have to solve
where \(a = \frac{3B}{4A} , b = \frac{2C}{4A} , c = \frac{M}{4A}\)
Lemma 2
For solution of general real cubic equation, we use the following Lemma:
where D is the discriminant of f(x).
Then
-
1.
If D < 0, f(x) has one real root.
-
2.
If D ≥ 0, f(x) has three real roots.
-
(a)
D > 0, f(x) has three different real roots.
-
(b)
D = 0, 6b – 2a 2 # 0, f(x) has one single root and one multiple root.
-
(c)
D = 0, 6b – 2a 2 = 0, f(x) has one root of three multiplicity.
-
(a)
Lemma 3
For a given polynomial g(β) given Eq. (40) if optimum \(\beta = \left\{ {\beta_{i} |g\left( {\beta_{i} } \right) = \hbox{min} \left( {g\left( {\beta_{1} } \right), g\left( {\beta_{2} } \right), g\left( {\beta_{3} } \right)} \right), i \in \left\{ {1, 2, 3} \right\}} \right\}\), where β i is the real root of \(\frac{\partial g}{\partial \beta },\) then the optimum (β) is the optimal learning rate, and this learning process is stable.
Proof
To find stable learning range of β, consider Lyapunov function
and the dynamic system is guaranteed to be stable if \(\Delta V_{t} < 0 \;{\text{i}} . {\text{e}} .\,\;J_{t + 1} - J_{t} < 0\).
Since in the training process, input matrices remain the same during the whole training process, we have to find the range of β which satisfies \(\left( {A\beta^{4} + B\beta^{3} + C\beta^{2} + M\beta } \right) < 0\). Since \(\frac{\partial g}{\partial \beta }\) has at least one real root, one of these roots gives optimum β. Obviously, minimum value of g(β) gives the largest reduction in J t at each step of learning process. Equation (39) shows that g(β) has two or four real roots, one including β = 0. Thus, the minimum value of β shows largest reduction in error at two successive times, minimum value is obtained by differentiating Eq. (30) w.r.t. β, we have from theorem (1).
where \(a = \frac{3B}{4A} , \,b = \frac{2C}{4A} , \,c = \frac{M}{4A}\)
Solving \(\frac{\partial g}{\partial \beta } = 0\), we obtain optimum β, which gives minimum error.
Rights and permissions
About this article

Cite this article
Sakhre, V., Singh, U.P. & Jain, S. FCPN Approach for Uncertain Nonlinear Dynamical System with Unknown Disturbance. Int. J. Fuzzy Syst. 19, 452–469 (2017). https://doi.org/10.1007/s40815-016-0145-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-016-0145-5