
Abstract
With the rapid growth of big data, extracting meaningful knowledge from data is crucial for machine learning. The existing Swarm Learning data collaboration models face challenges such as data security, model security, high communication overhead, and model performance optimization. To address this, we propose the Swarm Mutual Learning (SML). Firstly, we introduce an Adaptive Mutual Distillation Algorithm that dynamically controls the learning intensity based on distillation weights and strength, enhancing the efficiency of knowledge extraction and transfer during mutual distillation. Secondly, we design a Global Parameter Aggregation Algorithm based on homomorphic encryption, coupled with a Dynamic Gradient Decomposition Algorithm using singular value decomposition. This allows the model to aggregate parameters in ciphertext, significantly reducing communication overhead during uploads and downloads. Finally, we validate the proposed methods on real datasets, demonstrating their effectiveness and efficiency in model updates. On the MNIST dataset and CIFAR-10 dataset, the local model accuracies reached 95.02% and 55.26%, respectively, surpassing those of the comparative models. Furthermore, while ensuring the security of the aggregation process, we significantly reduced the communication overhead for uploading and downloading.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In the field of data sharing, traditional centralized model training methods pose security risks [1]. Since training data may contain sensitive information, leakage of such information could lead to severe consequences, even violating privacy regulations. Distributed machine learning frameworks, such as Swarm Learning (SL) [2], offer a solution to this problem. SL enables model training on dispersed data sources, extracting knowledge from devices across locations, and then aggregating it by transmitting model updates to further converge into a global model. As data used for research are no longer stored centrally, this enhances the capability of data privacy protection [3].
However, distributed machine learning frameworks also face the risk of privacy breaches [4]. To enhance the security of distributed machine learning frameworks, some researchers have introduced privacy-preserving methods [5]. To bolster model privacy, some propose utilizing large-scale unlabeled public datasets for knowledge transfer [6, 7]. In these methods, each client conducts model training and prediction on dispersed data, then uploads local training to the server for global model iteration updates. There are also studies that can effectively perform global optimization and parameter tuning without directly accessing the data [8, 9], thereby improving the overall performance and efficiency of machine learning systems.While these methods enhance privacy protection compared to traditional SL [10], local model predictions may still contain sensitive individual data, thus not fully ensuring user privacy.
Communication efficiency of distributed machine learning frameworks is also a significant concern. In recent years, researchers have invested considerable effort to improve communication efficiency. One approach is to implement compact yet precise models, including streamlined architecture designs, model compression [11], and pruning [12], directly reducing the size of model updates. However, these methods may lead to significant performance losses in some cases and could potentially diminish the capability to handle dispersed data. Another efficient communication approach is collaborative distillation [13], where models are not transmitted for updating [14], instead, local model updates occur across different clients through sharing a common dataset.
These methods face challenges in various real-life scenarios. For instance, in applications where data is highly privacy-sensitive, such as personalized health recommendations [15] and electronic medical records [16], data cannot be directly shared or exchanged [17]. Even with anonymization [15], achieving secure, efficient, and effective distributed machine learning remains a crucial and yet unresolved challenge [18].
Addressing the aforementioned limitations and challenges, this paper conducts an in-depth investigation, presenting the following key contributions:
-
1.
Swarm Mutual Learning (SML) Framework: Proposes the Swarm Mutual Learning (SML) framework, where local models and proxy models mutually distill knowledge and learn from each other, effectively reducing communication costs. Utilizes sensitive client models as local models and a public model aggregated by a swarm network as the proxy model, achieving knowledge transfer and model updates through mutual distillation learning.
-
2.
Ensures that local data and models stay within their respective locations, significantly lowering the risk of local data leakage.
-
2.
Adaptive Mutual Distillation Algorithm (AMD): Introduces the Adaptive Mutual Distillation Algorithm (AMD), enabling local models and proxy models to learn from the knowledge extracted from their predicted soft labels and intermediate results. Adapts the distillation intensity based on the adaptive correctness of their predictions, leading to a spiral improvement in the performance of both models.
-
3.
Global Parameter Aggregation Algorithm Based on Homomorphic Encryption (GPA-HE): Designs a Global Parameter Aggregation Algorithm Based on Homomorphic Encryption (GPA-HE), ensuring the security of model parameters when aggregating model parameters from various client models in the swarm network. Protects the confidentiality of model parameters during the aggregation process, mitigating the risk of privacy leakage.
-
4.
Dynamic Gradient Decomposition Algorithm (DGD): Introduces the Dynamic Gradient Decomposition Algorithm (DGD), utilizing singular value decomposition to dynamically decompose gradients. Enables encrypted parameter aggregation in the model while significantly reducing communication overhead for uploads and downloads. In conclusion, experiments conducted on real datasets validate the effectiveness of the proposed methods.
Related work
Research and applications of swarm learning
Swarm Learning (SL) is a decentralized machine learning framework, an enhanced version of decentralized federated learning, incorporating edge computing and peer-to-peer networking technologies. In SL, private data is stored locally, and participants do not need to share raw data. Data and parameters are computed at the edge for processing and analysis under data desensitization. Members can securely, transparently, and fairly join the network, with dynamic leader elections within the group for model parameter merging. Unlike traditional federated learning, Swarm Learning operates without a fixed central server, providing a higher level of assurance for data security and machine learning model defense.
In recent years, Swarm Learning has garnered attention from numerous researchers. Saldanha et al. [19] adopted Swarm Learning to overcome challenges associated with large-scale datasets required for training robust artificial intelligence systems, along with practical, ethical, and legal obstacles related to data collection. By employing Swarm Learning on a billion-pixel pathology image dataset from over 5000 patients, they obtained a distributed artificial intelligence model. Results indicated that this training approach outperformed most locally trained models in terms of performance. Liu et al. [20] proposed the Direction Decision as a Service (DDaaS) scheme based on Swarm Learning to address vehicle path planning and resource allocation issues in urban traffic. They introduced improved models and aggregation methods to accurately predict traffic conditions, allowing dynamic traffic control algorithms to quickly adapt to changes. Through urban road simulations, they demonstrated that the proposed scheme effectively reduced traffic congestion. Sun et al. [21] presented a Swarm Learning framework combining adversarial domain networks and convolutional neural networks. Each factory was treated as an edge computing node, solving issues related to insufficient labeled data and privacy protection through the fusion of network parameters. Dynamic leader selection for model parameter merging occurred during training, and the SL algorithm selected a virtual central node, determining the process of exchanging model parameters between different nodes. Simulation experiments validated the reliability of this approach.
Although the mentioned studies have validated and applied Swarm Learning, there has been relatively little innovation in the Swarm Learning methods themselves within existing research. Therefore, this paper innovates Swarm Learning methods by introducing knowledge distillation and proposing Swarm Mutual Learning. This aims to enhance model training efficiency while ensuring the security of both data and models.
Research advances in knowledge distillation
Knowledge Distillation (KD) is an emerging model compression and transfer learning method first proposed in 2015, and it has garnered considerable attention from researchers in recent years, yielding notable achievements [22].
This paper specifically focuses on the research area of Mutual Knowledge Distillation. Knowledge distillation involves extracting knowledge from a large model and transferring it to a smaller model, achieving model compression and transfer learning. Mutual Knowledge Distillation further extends this concept by not only transferring knowledge from a large model to a small model but also allowing the small model to provide feedback to the large model, creating a mutually reinforcing learning process. This bidirectional knowledge transfer enhances the model’s performance and generalization capabilities, making it excel across various tasks and domains. For instance, Wu et al. [13] proposed FedKD, a federated learning method based on knowledge distillation and gradient compression techniques, significantly reducing communication cost overhead and providing a reliable solution for deployment in many intelligent system scenarios. Kong et al. [23] introduced a new mutual distillation framework, employing a confidence selection mechanism to extract superior labels. This framework adds different data augmentations, enabling reliable knowledge exchange between teacher and student models for alternating model improvements. Kalra et al. [24] presented ProxyFL, an efficient communication scheme for decentralized federated learning. ProxyFL involves two models, a private model and a public model, allowing participants to exchange information without the need for a centralized server. Differential privacy is incorporated to provide stronger privacy guarantees. Qi et al. [25] proposed PrivateKT, a knowledge transfer method based on federated learning. This method transfers high-quality knowledge in federated learning using actively selected small public datasets while ensuring privacy. Li et al. [26] addressed challenges in large model size, high computational costs, and impracticality for real-world applications in automatic speech recognition models. They proposed a mutual learning sequence-level knowledge distillation framework where each student has the opportunity to learn from pre-trained teachers and different peers. This approach helps overcome individual shortcomings and narrow the gap between students and teachers, enhancing the overall network's generalization capabilities. Mutual Knowledge Distillation, as an important branch of knowledge distillation, has become a research hotspot in the field of model compression and transfer learning. Wang et al. [27] summarized that introducing knowledge distillation in deep learning primarily aims at model compression, cross-domain, cross-modal learning, and privacy protection.
The aforementioned studies showcase innovations and applications in the field of knowledge distillation. In this paper, the use of knowledge distillation aims to achieve secure access to data by isolating datasets. Local models learn from local private data, and through mutual distillation learning, knowledge is transferred to external models via a proxy model, ultimately enhancing model performance.
Applications of homomorphic encryption in machine learning
Homomorphic Encryption (HE) holds significant potential and promising applications in distributed machine learning frameworks such as Federated Learning (FL) and Swarm Learning (SL). These frameworks involve multiple participants collaboratively training a global model without sharing raw data. While these frameworks contribute to maintaining data privacy, they still encounter privacy and security challenges. Homomorphic Encryption can address these challenges by enabling computations on encrypted data.
In FL and SL, parties can utilize Homomorphic Encryption to protect their local data while still being able to perform model parameter updates and gradient computations. This approach allows data to remain encrypted, enhancing privacy by avoiding exposure to other participants. Zhang et al. [28] proposed a system solution for cross-silo FL named BatchCrypt, which significantly reduces encryption and communication overhead caused by HE. The solution encodes batched gradients into a single integer and encrypts them in one go. They also developed new quantization and encoding schemes along with a novel gradient clipping technique. BatchCrypt was implemented as a plugin module in FATE, demonstrating accelerated training and reduced communication overhead.Chen et al. [29] introduced a privacy-preserving Swarm Learning solution based on Homomorphic Encryption. Without compromising model accuracy, they employed a threshold Paillier cryptosystem to encrypt shared local model information. Additionally, they designed a partial decryption algorithm to prevent privacy leaks resulting from aggregated model information. Experimental results verified the robust privacy protection of the proposed solution with minimal impact on the final model's accuracy. Madni et al. [30] addressed data privacy leaks in SL, especially in the presence of malicious participants, by proposing a Swarm Learning Fully Homomorphic Encryption method (Swarm-FHE). This method encrypts model parameters before sharing with participants registered and authenticated using blockchain technology.
Homomorphic Encryption also aids in addressing the model merging challenge in FL and SL. In these frameworks, parties need to merge their local model parameters into a global model, and Homomorphic Encryption ensures the completion of this process without revealing individual participants' model information. Park et al. [31] presented a Homomorphic Encryption-based federated learning scheme that allows arithmetic operations on ciphertexts without decryption, safeguarding the privacy of model parameters. Using Homomorphic Encryption, the Privacy-Preserving Federated Learning (PPFL) algorithm enables the central server to aggregate encrypted local model parameters without decryption.
In conclusion, Homomorphic Encryption provides a robust privacy protection and security enhancement solution for FL and SL. It enables multiple parties to collaboratively train a global model while protecting data privacy, reducing the risks of data leakage and security threats, and holds the potential to drive widespread applications of FL and SL in various fields. Despite facing challenges such as performance and complexity, this paper addresses the issue by introducing dynamic gradient decomposition for parameters.
Swarm mutual learning model design
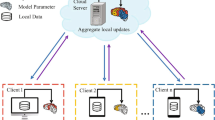
To achieve the secure and efficient utilization of local data without leaving the domain, we propose the Swarm Mutual Learning (SML) model. The SML framework, illustrated in Fig. 1, comprises a Swarm Learning network and multiple clients, each represented by a different color. The objective of the model is to collaboratively train a global proxy model (a globally shared public model) across multiple clients through local training and mutual distillation, iterating to produce local models for each client (locally unique private models). Data privacy is ensured through the use of homomorphic encryption, and communication efficiency is enhanced through dynamic gradient decomposition. The model encompasses three key algorithms: Adaptive Mutual Distillation Algorithm, Global Parameter Aggregation Algorithm Based on Homomorphic Encryption, and Dynamic Gradient Decomposition Algorithm.

Swarm mutual learning model
In each training iteration of the Swarm Mutual Learning model, clients undergo the following steps:
-
1.
First, each client receives and decrypts the proxy parameters of the global model from the previous round. These parameters are sent to the client after aggregation by the swarm network.
-
2.
Subsequently, the client locally updates the proxy model parameters based on the decrypted proxy parameters. It then utilizes local data for model training, updating the local model parameters. During this process, the client adjusts the distillation weight balance parameters and calculates the distillation strength using the Adaptive Mutual Distillation Algorithm. This ensures effective knowledge transfer and distillation.
-
3.
Next, the client engages in mutual distillation between the local model and the proxy model, facilitating the extraction and exchange of knowledge. This step contributes to improving the model's performance and generalization capabilities.
-
4.
Finally, the client uploads the updated local model parameters and proxy model parameters to the swarm network. Before uploading, the Dynamic Gradient Decomposition Algorithm is applied to decompose the gradients and encrypt them to safeguard data privacy.
On the swarm network side, the framework executes the following operations:
-
1.
The swarm network receives the proxy model parameters from each client.
-
2.
Subsequently, it decrypts and reconstructs these proxy model parameters.
-
3.
Using the Global Parameter Aggregation Algorithm based on homomorphic encryption, the swarm network aggregates these proxy model parameters to obtain the latest version of the global model.
-
4.
Finally, the global model parameters are distributed to each client. The clients decrypt and update the proxy model for the next round of training.
The entire Swarm Mutual Learning framework iterates continuously until meeting the stopping conditions or reaching the maximum iteration count. This framework allows multiple clients to collaboratively train a global model while safeguarding data privacy. The combination of knowledge distillation, parameter aggregation, and privacy-preserving techniques enhances the model's performance. The algorithmic description of the Swarm Mutual Learning algorithm is detailed in Algorithm 1.

Swarm Mutual Learning
Adaptive mutual distillation
On each client device in the swarm learning system, a local model (private) and a proxy model (public) are designed. The proxy model in the swarm learning network is aggregated. The proxy model iterates continuously in the network and engages in adaptive mutual distillation with the local model. The local model gains improved performance through distillation learning from the proxy model in each round, while the proxy model extracts useful knowledge from the mentor model during knowledge distillation. Ultimately, both models converge to a final model with enhanced performance. Adaptive mutual distillation is illustrated in Fig. 2.

Adaptive mutual distillation
We set up a group of clients K for Swarm Learning (SL), where each client has a local data distribution Dk, with ∀k ∈ K.. We establish a local model ML: x → y and a proxy model MP: x → y, where x represents the input sample, and y represents the predicted output. During model training, the local model incurs cross-entropy(CE) loss:
In the above equation, K is a random variable (x,y) representing the mathematical expectation of the distribution Dk, denotes the true label of the sample, and \(\forall k \in k\) represents the prediction result of the local model on a specific task. Similarly, the proxy model incurs cross-entropy loss during model training:
To achieve mutual distillation between models, similar to DML [32], we also introduce the KL divergence:
KL() represents the Kullback–Leibler divergence, used to measure the difference between two distributions. As shown in Fig. 2, if the predictions of the local model or proxy model are unreliable, meaning they have larger task losses, the distillation strength is weaker. If the local model or proxy model optimizes the task loss effectively, the distillation loss becomes dominant, potentially mitigating the risk of overfitting.
Therefore, the learning objective for the local model is as follows:
where 0 < α < 1 is used to balance the weights of two types of losses. Similarly, the proxy model can also draw insights from the local model. The learning objectives for the local model are as follows:
In the above equation,0 < β < 1 is used to balance the weights of the two losses. Following the aforementioned process, the local model and the proxy model can achieve mutual distillation.
To dynamically adjust the distillation strength between the proxy model and the local model based on sample predictions, we propose an adaptive distillation mechanism. We measure the uncertainty of each sample data in the local data distribution with respect to the global model based on information entropy. Higher distillation strength is assigned to sample data with higher uncertainty in the model. For the proxy model of the i-th client, the uncertainty of the model after aggregation for all Dk sample data is given by:
Here, \(p(x_{i} ,M_{P} )\) is the probability of the proxy model correctly predicting the label. Thus, the distillation strength from the i-th client's local model to the proxy model is as follows:
Similarly, the distillation strength from the i-th client's proxy model to the local model is given by:
Adaptive mutual knowledge distillation, through the design of adaptive distillation loss and adaptive hidden loss, achieves adaptive learning in swarm learning. In each iteration, the proxy model updates its parameters based on the weights of distillation loss and hidden loss. The weight of the distillation loss is dynamically adjusted based on the quality of the task loss, ensuring weaker distillation strength in unreliable predictions and making distillation loss dominant in reliable predictions. The adaptive mutual distillation algorithm is presented in Algorithm 2.

Adaptive Mutual Distillation Algorithm
Global parameter aggregation based on homomorphic encryption
In the context of Swarm Mutual Learning, the transmission of proxy model parameters among various clients and the swarm network poses a potential risk of attacks or unauthorized access if these parameters are propagated without protection. Homomorphic encryption provides an effective means to encrypt parameters, ensuring the security of model parameters and allowing only authorized users to access decrypted model parameters. In the process of global model aggregation, homomorphic encryption enables the swarm network to aggregate model parameters from various clients while preserving the security of these parameters, ensuring the privacy of model aggregation. Therefore, this paper proposes a global parameter aggregation algorithm based on homomorphic encryption. The steps for global parameter aggregation based on homomorphic encryption are as follows, outlined in Algorithm 3.
-
1.
Client k generates a key pair and encrypts the proxy model parameters for the current iteration using the public key. The encrypted ciphertext CT is then sent to the swarm network.
-
2.
The swarm network aggregator A processes the ciphertext using a pre-defined function.
-
3.
The swarm network aggregator A aggregates these parameters and sends the aggregated result back to client k.
-
4.
Client k, upon receiving the ciphertext, decrypts it using the private key, obtaining the aggregated parameters for the current iteration of training.
-
5.
Client k, based on the obtained aggregated proxy model parameters, performs mutual distillation between the proxy model and the local model, continuing with model training.
-
6.
Repeat the process from (1) to (5) until the model reaches the desired state or reaches the maximum iteration count.
For the i-th client in the t-th round of Swarm Learning proxy model aggregation, the proxy model parameters \(\theta_{{P_{i} }}^{(t)}\) are encrypted using the encryption function E, resulting in the ciphertext CTi, as represented below:
In the above context, where n = pq and pq are two distinct prime numbers, and pq satisfies qcd() as shown in formula (11), where qcd() is a function to find the greatest common divisor, g is a randomly chosen integer satisfying \(g \in Z_{{n^{2} }}^{*}\), and r is a randomly selected number during the encryption process, meeting the condition in \(r \in Z_{{n^{2} }}^{*}\).
The aggregator A in the swarm network receives the encrypted proxy model parameters from all clients. The ciphertext \(E\left( {\sum\nolimits_{i = 1}^{n} {\theta_{{P_{i} }}^{(t)} } } \right)\) is processed (as explained in the model analysis section) to obtain result \(\sum\nolimits_{i = 1}^{n} {\theta_{{P_{i} }}^{(t)} }\), utilizing a parameter processing function f. This yields the aggregated proxy model for the current round of swarm learning and the global parameters \(\frac{1}{\eta }\sum\nolimits_{i = 1}^{n} {\theta_{{P_{i} }}^{(t)} }\) for the proxy model in this round of swarm learning.Subsequently, the global parameters are distributed for the next aggregation round.

Global Parameter Aggregation Algorithm Based on Homomorphic Encryption
Dynamic Gradient Decomposition
In the framework of swarm mutual learning, a challenge arises: the update magnitude of the proxy model may not necessarily be smaller than that of the local model. In cases where the proxy model is also large, communication costs might remain relatively high. To overcome this challenge, we attempt to further compress the gradient information transmitted between the server and clients to reduce communication costs. Given that model parameters exhibit low-rank characteristics, we propose the Dynamic Gradient Decomposition Algorithm (DGD). This algorithm employs Singular Value Decomposition (SVD) to decompose parameter gradients into smaller matrices, which are then uploaded. Before aggregation, the server multiplies these decomposed matrices to reconstruct the parameter gradients. The aggregated global gradient is further decomposed and distributed to clients for the reconstruction and updating of the model.
During the aggregation process of the Swarm Learning proxy model in the t-th round at the i-th client, we represent the gradient of the client's proxy model, denoted as gi as a matrix with P rows and Q columns (assuming P ≥ Q). Utilizing singular value decomposition, we can approximate it as the product of three matrices:
where Ui is a matrix in \(Ui \in {\mathbf{R}}^{P \times K}\), ∑i is a matrix in \(\Sigma i \in {\mathbf{R}}^{K \times K}\), Vi is a matrix in \(Vi \in {\mathbf{R}}^{K \times Q}\), and K is the number of retained singular values. If the chosen value of K satisfies the following condition:
So, the size of the gradients uploaded and downloaded can be reduced, thereby minimizing communication costs. For ease of understanding, we denote gi as a single matrix, but in swarm learning, different parameter matrices in the model are independently decomposed, and the global gradient on the server is also decomposed in the same manner. We use \({[}\sigma_{{1}} {, }\sigma_{{2}} {, }...{ ,}\sigma_{{\text{Q}}} {]}\) to represent the singular values of gi, sorted by their absolute values.
To control the approximation error, we use a threshold α to determine how many singular values to retain. The specific formula is as follows:
Generally, a larger α value retains more singular values, providing higher accuracy but consuming more storage space and computational resources. A smaller α value retains fewer singular values, reducing accuracy but decreasing storage and computation costs. Therefore, choosing an appropriate α value involves balancing storage, computation, and model performance.To dynamically adjust the threshold, we use linear interpolation for dynamic threshold adjustment. The formula is as follows:
where t ∈ (0,1), α(t) is a linear function of t, and the value linearly changes between as and ae. The values of as and ae are parameters controlling the start and end values of t, which can be tuned based on model performance. Dynamic adjustment allows the proxy model to start learning on approximately approximated gradients and gradually shift to more accurate approximations as the model converges, enabling the training of a more accurate proxy model.
SML model analysis
(1) Performance and security analysis
① Performance analysis
In terms of model efficiency: Firstly, the model leverages distributed computing and parallelism, allowing multiple clients to simultaneously train local models, thereby enhancing training efficiency. Since each client can locally compute gradients and update model parameters, it maximizes the utilization of distributed computing resources. Secondly, the model facilitates knowledge exchange through dynamic distillation. Using the adaptive mutual distillation learning algorithm, it allows the dynamic adjustment of distillation weights and distillation strength balancing parameters. This contributes to ensuring effective and efficient knowledge transfer, ultimately improving the model's generalization ability and enhancing performance during the training process.
Regarding model overhead:The model reduces the size of uploaded and downloaded gradients through dynamic gradient decomposition, thereby diminishing computational and communication overhead. As the framework utilizes distributed computing, computational overhead can be distributed among multiple clients, expediting the training process. Although the introduction of homomorphic encryption may introduce some computational overhead, these costs are manageable, and appropriate parameter choices can optimize computational efficiency.
② System Security Analysis.
In terms of the security of local data and local models:
-
Local Training: Clients utilize their local data for training models locally. Since local data stays within its domain, data privacy is protected as this data is not transmitted to other clients or the swarm network, ensuring the confidentiality of the data.
-
Knowledge Exchange: Knowledge exchange between local models and the proxy model ensures that the updates to the local model occur only locally on the client-side and are not transmitted elsewhere. This helps prevent the leakage of model updates.
Regarding client identity authentication:
-
Client Authentication Mechanism: To ensure system security, a client identity authentication mechanism is employed. Only authorized clients are allowed to participate in training and parameter aggregation. Digital certificates and token verification are used to validate the identity of each client, preventing malicious participants from entering the system. Only authenticated clients can participate, thus preventing dishonest participants from attacking or abusing the system.
Regarding homomorphic encryption parameter aggregation:
-
Homomorphic Encryption: The model adopts a globally parameter aggregation algorithm based on homomorphic encryption for secure transmission of proxy model parameters between clients and the swarm network. This algorithm securely aggregates the proxy model parameters from various clients into a global model, distributing it afterward. By encrypting the parameters during transmission, direct exposure of parameters is avoided, effectively preventing third-party inference and data analysis through parameter deduction.
(2)Validity analysis
Proof of Homomorphic Encryption Algorithm Ciphertext.
Proof The global ciphertext based on homomorphic encryption is denoted as \(E\left( {\sum\nolimits_{i = 1}^{n} {\theta_{{P_{i} }}^{(t)} } } \right)\).
Proof In swarm learning, let the parameter processing function f be the summation and averaging of parameters. According to Eq. (10), the processing result of ciphertext satisfies the additive homomorphic property. Assuming the parameter ciphertexts of two clients, i and j, are independently encrypted, it can be expressed by the following formula:
Substituting into Eq. (10), we obtain:
Simplifying the above expression, we get:
Therefore, the following equation holds:
Similarly, when the swarm network receives the encrypted parameters C from all clients, the global ciphertext based on homomorphic encryption is given by:
Proof completed.\( \hfill \square \)
(3) Complexity analysis
Before delving into the complexity analysis, let's set some parameters for Swarm Mutual Learning (SML): total iteration rounds T, number of clients K, average dataset size D, proxy model parameter set θP, local model parameter set θL, model compression ratio R(R < 1), and the order of magnitude of the prime number required for homomorphic encryption p.
The computational costs in Swarm Mutual Learning mainly include proxy model learning, local model learning, parameter decomposition/reconstruction, homomorphic encryption, and communication costs (assuming communication costs are proportional to the model size). These are represented as O(KTD|θP|),O(KTD|θL|),O(2KTP2Q2), O(log2(p)),O(KTR|θP|) respectively. Therefore, the total cost of Swarm Mutual Learning is O(KTD|θP|+ KTD|θL|+ 2KTP2Q2 + log2(p) + KTR|θP|). In practical training, Swarm Mutual Learning exhibits higher communication efficiency and stronger data and model security compared to conventional Swarm Learning, without introducing excessive computational costs.
Experiments and analysis
Experimental environment and data
Experimental Environment: In this section, we evaluate the effectiveness of the proposed model. For the experiments, the host operating system is Windows 10, with an AMD Ryzen 7 4800H processor with Radeon Graphics (2.90 GHz), 24 GB RAM, and Python version 3.6.8. The virtual machine, running on VMware Workstation Pro 16, uses Ubuntu 20.04 with Python version 3.6.8. The experiments are conducted using Keras version 2.10.0 and TensorFlow-GPU version 2.11.0 for training the models. A Convolutional Neural Network (CNN) is employed to test the training performance, with ReLU activation functions.
Experimental Datasets: The experiments are conducted on real datasets, utilizing two datasets: the MNIST handwritten character dataset and the CIFAR-10 small image classification dataset. The MNIST dataset consists of grayscale images representing handwritten digits (10 classes of numeric labels). The training set includes 60,000 28 × 28 pixel grayscale images, and the test set comprises 10,000 28 × 28 pixel grayscale images. The CIFAR-10 dataset includes colored images from 10 different classes, providing a more challenging task than MNIST. The training set consists of 50,000 32 × 32 color images, and the test set comprises 10,000 32 × 32 color images.
Experimental Setup: For the experiments, a local centralized machine learning setup is constructed using the complete MNIST handwritten character dataset and the CIFAR-10 small image classification dataset. In the Swarm Mutual Learning (SML) approach, the client datasets are partitioned Randomly from the MNIST and CIFAR-10 datasets, with each client having an equal share of both datasets.
During training, a Convolutional Neural Network (CNN) is employed locally to test the training performance. The local model is trained with a learning rate of 0.01, utilizing the ReLU activation function. The model architecture consists of two convolutional layers with 16 and 32 features, respectively. A 5 × 5 convolutional kernel with a stride of 1 is used, along with a fully connected layer with an input tensor of size 7 × 7 × 32 and an output tensor of size 10. The training is performed using the gradient descent algorithm with a batch size of 64.In each iteration round, each client's local model is trained 10 times on their local data.
Experimental results and analysis
Model performance experiments
Machine learning model accuracy and training loss are crucial metrics for assessing the performance of machine learning algorithms and models. To explore the performance of the Swarm Mutual Learning (SML) model, experiments are conducted comparing the SML method proposed in this study with existing methods, namely SL [2] and FML [25], in terms of model accuracy. The SML model includes both a proxy model (SML-Proxy) and a local model (SML-Local). The impact of mutual distillation on the model can be observed by comparing these two models. Similarly, FML consists of a global model (FML-Proxy) and private models (FML-Local). Each method is configured with four clients.
The experimental results are presented in Fig. 3, where the x-axis represents accuracy (ACC), and the y-axis represents training epochs. The left plot of Fig. 3 displays the results for the MNIST dataset, while the right plot shows the results for the CIFAR-10 dataset (Table 1).

Performance comparison experimental chart
Experimental results and analysis:
-
1.
SML-Local Outperforms: The local model of SML (SML-Local) demonstrates superior performance on both the MNIST and CIFAR-10 datasets, achieving approximately 1% higher accuracy compared to the centralized FML model. SML consistently outperforms other methods on these datasets, showcasing the superior performance of the SML model.
-
2.
Stability and Convergence: SML exhibits stability and convergence after approximately 40 iterations on both the MNIST and CIFAR-10 datasets. This indicates the strong usability of the model. Given that CIFAR-10 is a more complex dataset than MNIST, the performance of all methods is generally better on MNIST.
-
3.
SML vs. SL: SML shows slightly better performance compared to the SL method on both datasets. The accuracy of the local model in SML is around 0.5% higher than that of the SL method. This suggests that mutual distillation in SML contributes to improved model accuracy. Furthermore, the adoption of the global parameter aggregation based on homomorphic encryption and dynamic gradient decomposition in SML does not compromise model accuracy, confirming the effectiveness of these techniques.
4.2.2 Effectiveness experiment of adaptive mutual distillation algorithm
To investigate the effectiveness of the adaptive mutual distillation algorithm, this section employs a controlled variable method. A comparison is conducted on the MNIST and CIFAR-10 datasets among SML, SML with removed adaptive strength (SML-S), and SML with removed adaptive weighting (SML-W). The global accuracy (ACC) of the models is compared. SML-S represents the model without the adaptive distillation strength function during knowledge extraction, while SML-W represents the model without the adaptive weighting function used to balance the distillation losses between the two models. The experimental groups are as follows: (1) Conducting SML, SML-S, and SML-W experiments on the local model on the MNIST dataset. (2) Conducting SML, SML-S, and SML-W experiments on the proxy model on the MNIST dataset. (3) Conducting SML, SML-S, and SML-W experiments on the local model on the CIFAR-10 dataset. (4) Conducting SML, SML-S, and SML-W experiments on the proxy model on the CIFAR-10 dataset. The experiment involves four clients, and the performance of the local model is averaged. The total number of training rounds is set to 100. The experimental results are presented in Fig. 4, with the left graph displaying results for the MNIST dataset and the right graph for the CIFAR-10 dataset.

Effectiveness experiment of adaptive mutual distillation
Experimental results and analysis:
-
1.
When comparing the performance of the local and proxy models on both datasets, it is evident that removing any of the adaptive distillation functions results in a decrease in model performance. This reduction is particularly pronounced when SML-W is removed, with local model accuracies dropping by 1.50 percentage points and 2.65 percentage points, respectively. In terms of proxy model performance, SML significantly outperforms the cases where both adaptive methods are removed. This highlights the effectiveness of the adaptive mutual distillation algorithm in SML.
-
2.
The experimental results from Figs. 4 and 5 reveal that SML achieves slightly better final accuracy compared to SL on both datasets, with local model accuracies reaching 95.02% and 55.26%, respectively. This indicates that the mutual distillation between local and proxy models in SML improves model accuracy, underscoring the effectiveness of the adaptive mutual distillation algorithm.
-
3.
Figure 4 illustrates that the overall performance of the experimental methods is better on the MNIST dataset than on the CIFAR-10 dataset. The complexity of image data in CIFAR-10 leads to superior model performance for all four scenarios on the CIFAR-10 dataset compared to the MNIST dataset.

Diagram of required communication time for client addition
Experiment on the relationship between the number of clients and communication time
To investigate the relationship between the number of clients and communication time, experiments were conducted comparing the proposed SML method (without adopting homomorphic encryption) with existing methods FedAvg [13], FML, and SL. The experiments were carried out on both the MNIST and CIFAR-10 datasets to observe the changes in model communication time with an increase in the number of clients. The results are presented in Fig. 5, with the left graph displaying the outcomes for the MNIST dataset and the right graph for the CIFAR-10 dataset.
Experimental results and analysis:
-
1.
Comparing the experimental results on both datasets, both SML and FML employ mutual distillation techniques. However, SML exhibits a constant time complexity with an increase in the number of clients, indicating its stronger scalability.
-
2.
Similar to SL, SML maintains a nearly constant time complexity as the number of clients increases. Across both datasets, for each additional client, the average increase in communication time per iteration is approximately 1.02S and 1.55S. With an equivalent increase in clients, SML, being a decentralized solution, incurs fewer communication costs compared to the centralized FML. This suggests that SML has enhanced usability.
-
3.
Comparing the required communication time with an increase in the number of clients for various methods, the overall performance of the mentioned approaches is better on the MNIST dataset than on the CIFAR-10 dataset. This discrepancy is attributed to the CIFAR-10 dataset's higher complexity, causing these methods to experience longer communication times as the number of clients increases, compared to the MNIST dataset.
Communication overhead comparative experiment
To validate the impact of Homomorphic Encryption (HE) and Dynamic Gradient Decomposition (DGD) algorithms on the model's runtime, a comparative experiment on communication overhead is set up to contrast the algorithm runtime. Employing the controlled variable method, the runtime impact of the algorithms on the SML model is compared using CNN on different MNIST and CIFAR-10 datasets. The experiment involves 4 clients with a total of 100 iterations, The threshold α for DGD is set to 0.85 and 0.90 respectively. The runtime is compared for the following four scenarios on both the MNIST and CIFAR-10 datasets: (1) HE + DGD, (2) HE + non-DGD, (3) non-HE + DGD, and (4) non-HE + non-DGD. The experimental results are shown in Fig. 6.

Comparison of communication costs
Experimental results and analysis:
-
1.
Comparing the results of Experiment Groups 1 and 2, as well as Groups 3 and 4, it is evident that SML effectively reduces communication time with the introduction of Dynamic Gradient Decomposition (DGD), demonstrating the effectiveness of the DGD method. When the threshold α for dynamic gradient decomposition method is set to 0.85, it reduces communication time by approximately 10%. Setting the threshold α to 0.90 decreases communication time by around 7%. Since different singular value decomposition thresholds lead to varying degrees of gradient compression, the reduction in communication time also varies accordingly.
-
2.
Analyzing the results of Experiment Groups 1 and 3, as well as Groups 2 and 4, it is observed that the addition of homomorphic encryption increases the model's runtime. This increase is primarily attributed to the additional time consumed by encryption and decryption. The inclusion of homomorphic encryption in SML is essential for secure model aggregation.
-
3.
The overall performance on the MNIST dataset surpasses that on the CIFAR-10 dataset, as evident from the results of Experiment Groups 1 and 3, as well as Groups 2 and 4. This discrepancy is due to the more complex image data in the CIFAR-10 dataset compared to the MNIST dataset, resulting in longer runtimes for all four scenarios on the CIFAR-10 dataset.
Experimental validation of homomorphic encryption algorithms
To validate the effectiveness of homomorphic encryption algorithms, this paper conducted experimental comparisons of different homomorphic encryption methods: SML method, swarm-FHE method [30], DS2PM method [33], and PFMLP method [34]. Encryption and decryption times were compared among these methods. The SML method utilized the GPA-HE algorithm and employed the DGD algorithm with a threshold set to 0.85. The aforementioned methods were experimented with on both the MNIST and CIFAR-10 datasets. Experiments were conducted with 4 clients and 10 clients respectively for comparative analysis, where more clients imply a more complex model. The experimental results are depicted in Fig. 7.

Comparison of Encryption and Decryption Times for Different Methods
-
1.
Comparing several different homomorphic encryption schemes, the SML scheme proposed in this paper demonstrates outstanding performance in model encryption and decryption across different datasets, affirming the effectiveness of our approach.
-
2.
Comparing the performance of various homomorphic encryption schemes across 4 and 10 clients, it is observed that the SML scheme proposed in this paper exhibits only approximately 1.5% higher average encryption and decryption time on 10 clients compared to 4 clients. This makes it the most optimal among the tested schemes, thus further validating the effectiveness of our approach.
Conclusion
We proposed Swarm Mutual Learning (SML) based on the existing swarm learning, which employs a mutual distillation approach. By dynamically controlling the learning intensity through distillation weights and strength, the model efficiently extracts and transfers knowledge during the mutual distillation process. The use of a homomorphic encryption-based global parameter aggregation algorithm ensures the security of the model aggregation process, and dynamic gradient decomposition through singular value decomposition significantly reduces the communication overhead during parameter aggregation.Therefore, SML enables more secure and efficient data sharing.
Future research will further investigate model schemes to enhance efficiency, such as optimizing adaptive mutual distillation algorithms to accommodate different types of datasets (medical, vehicular IoT, financial, etc.), or introducing more effective parameter aggregation compression methods. Future research will also consider integrating privacy protection technologies to enhance data confidentiality, such as differential privacy schemes.
Data Availability
The data is available upon request. The datasets used in the experiments are all open-source. The download URL for the MNIST dataset is https://yann.lecun.com/exdb/mnist/, and the download URL for the CIFAR-10 dataset is https://www.cs.toronto.edu/~kriz/cifar.html.
References
Blanco-Justicia A, Domingo-Ferrer J, Martínez S et al (2021) Achieving security and privacy in federated learning systems: survey, research challenges and future directions. Eng Appl Artif Intell 106:104468. https://doi.org/10.1016/j.engappai.2021.104468
Warnat-Herresthal S, Schultze H, Shastry KL et al (2021) Swarm learning for decentralized and confidential clinical machine learning. Nature 594(7862):265–270. https://doi.org/10.1038/s41586-021-03583-3
Saldanha OL, Muti HS, Grabsch HI et al (2023) Direct prediction of genetic aberrations from pathology images in gastric cancer with swarm learning. Gastric Cancer 26(2):264–274. https://doi.org/10.1007/s10120-022-01347-0
Mothukuri V, Parizi RM, Pouriyeh S et al (2021) A survey on security and privacy of federated learning. Fut Gen Comput Syst 115:619–640. https://doi.org/10.1016/j.future.2020.10.007
Doan TVT, Messai ML, Gavin G et al (2023) A survey on implementations of homomorphic encryption schemes. J Supercomput 79(13):15098–15139. https://doi.org/10.1007/s11227-023-05233-z
Sui D, Chen Y, Zhao J, et al (2020) Feded: federated learning via ensemble distillation for medical relation extraction. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pp. 2118–2128. https://doi.org/10.18653/v1/2020.emnlp-main.165
Lin T, Kong L, Stich SU et al (2020) Ensemble distillation for robust model fusion in federated learning. Adv Neural Inf Process Syst 33:2351–2363
Nedic N, Prsic D, Dubonjic L et al (2014) Optimal cascade hydraulic control for a parallel robot platform by PSO. Int J Adv Manuf Technol 72:1085–1098. https://doi.org/10.1007/s00170-014-5735-5
Stojanovic V, Nedic N (2016) A nature inspired parameter tuning approach to cascade control for hydraulically driven parallel robot platform. J Optim Theory Appl 168:332–347. https://doi.org/10.1007/s10957-015-0706-z
Yin X, Zhu Y, Hu J (2021) A comprehensive survey of privacy-preserving federated learning: a taxonomy, review, and future directions. ACM Comput Surv (CSUR) 54(6):1–36. https://doi.org/10.1145/3460427
Deng L, Li G, Han S et al (2020) Model compression and hardware acceleration for neural networks: a comprehensive survey. Proc IEEE 108(4):485–532. https://doi.org/10.1109/JPROC.2020.2976475
Wang Z, Liu X, Huang L et al (2022) Qsfm: model pruning based on quantified similarity between feature maps for ai on edge. IEEE Internet Things J 9(23):24506–24515. https://doi.org/10.1109/JIOT.2022.3190873
Wu C, Wu F, Lyu L et al (2022) Communication-efficient federated learning via knowledge distillation. Nat Commun 13(1):2032. https://doi.org/10.1038/s41467-022-29763-x
Han S, Park S, Wu F, et al (2022) Fedx: unsupervised federated learning with cross knowledge distillation. In: European Conference on Computer Vision (pp. 691–707). Springer Nature, Cham. https://doi.org/10.1007/978-3-031-20056-4_40
Acosta JN, Falcone GJ, Rajpurkar P et al (2022) Multimodal biomedical AI. Nat Med 28(9):1773–1784. https://doi.org/10.1038/s41591-022-01981-2
Nguyen DC, Pham QV, Pathirana PN et al (2022) Federated learning for smart healthcare: a survey. ACM Comput Surv (Csur) 55(3):1–37. https://doi.org/10.1145/3501296
Ali M, Naeem F, Tariq M et al (2022) Federated learning for privacy preservation in smart healthcare systems: a comprehensive survey. IEEE J Biomed Health Inform 27(2):778–789. https://doi.org/10.1109/JBHI.2022.3181823
Kang H, Ji Y, Zhang S (2022) Enhanced privacy preserving for social networks relational data based on personalized differential privacy. Chin J Electron 31(4):741–751. https://doi.org/10.1049/cje.2021.00.274
Saldanha OL, Quirke P, West NP et al (2022) Swarm learning for decentralized artificial intelligence in cancer histopathology. Nat Med 28(6):1232–1239. https://doi.org/10.1038/s41591-022-01768-5
Liu Y, Huo L, Wu J et al (2023) Swarm learning-based dynamic optimal management for traffic congestion in 6G-driven intelligent transportation system. IEEE Trans Intell Transp Syst. https://doi.org/10.1109/TITS.2023.3234444
Sun S, Huang H, Peng T et al (2023) A data privacy protection diagnosis framework for multiple machines vibration signals based on a swarm learning algorithm. IEEE Trans Instrum Measur 72:1–9. https://doi.org/10.1109/TIM.2023.3234035
Gou J, Yu B, Maybank SJ et al (2021) Knowledge distillation: a survey. Int J Comput Vis 129(6):1789–1819. https://doi.org/10.1007/s11263-021-01453-z
Kong L, Yang J (2022) MDFlow: unsupervised optical flow learning by reliable mutual knowledge distillation. IEEE Trans Circ Syst Video Technol 33(2):677–688. https://doi.org/10.1109/TCSVT.2022.3205375
Kalra S, Wen J, Cresswell JC et al (2023) Decentralized federated learning through proxy model sharing. Nat Commun 14(1):2899. https://doi.org/10.1038/s41467-023-38569-4
Qi T, Wu F, Wu C et al (2023) Differentially private knowledge transfer for federated learning. Nat Commun 14(1):3785. https://doi.org/10.1038/s41467-023-38794-x
Li Z, Ming Y, Yang L et al (2021) Mutual-learning sequence-level knowledge distillation for automatic speech recognition. Neurocomputing 428:259–267. https://doi.org/10.1016/j.neucom.2020.11.025
Wang L, Yoon KJ (2021) Knowledge distillation and student-teacher learning for visual intelligence: a review and new outlooks. IEEE Trans Pattern Anal Mach Intell 44(6):3048–3068. https://doi.org/10.1109/TPAMI.2021.3055564
Zhang C, Li S, Xia J, et al. (2020) {BatchCrypt}: efficient homomorphic encryption for {cross-silo} federated learning. In: 2020 USENIX annual technical conference (USENIX ATC 20), pp. 493–506
Chen L, Fu S, Lin L, et al. (2021). Privacy-preserving swarm learning based on homomorphic encryption. In: International Conference on Algorithms and Architectures for Parallel Processing (pp. 509–523). Springer International Publishing, Cham. https://doi.org/10.1007/978-3-030-95391-1_32
Madni HA, Umer RM, Foresti GL (2023) Swarm-fhe: fully homomorphic encryption-based swarm learning for malicious clients. Int J Neural Syst 33(08):2350033. https://doi.org/10.1142/S0129065723500338
Park J, Lim H (2022) Privacy-preserving federated learning using homomorphic encryption. Appl Sci 12(2):734. https://doi.org/10.3390/app12020734
Zhang Y, Xiang T, Hospedales T M, et al (2018) Deep mutual learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4320–4328
Chen Y, Li J, Wang F et al (2021) DS2PM: a data-sharing privacy protection model based on blockchain and federated learning. IEEE Internet Things J 10(14):12112–12125. https://doi.org/10.1109/JIOT.2021.3134755
Fang H, Qian Q (2021) Privacy preserving machine learning with homomorphic encryption and federated learning. Fut Internet 13(4):94. https://doi.org/10.3390/fi13040094
Acknowledgements
This research was supported by the National Social Science Foundation of China (No.21BTO079), Beijing Advanced Innovation Center for Future Blockchain and Privacy Computing project (No.GJJ-23).
Author information
Authors and Affiliations
Contributions
Wang Jiakang was responsible for data collection, manuscript writing and design, and conducted the experiments. Kang Haiyan guided and revised the paper. Su Jingru recommended this journal to Wang Jiakang and reviewed the draft. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Haiyan, K., Jiakang, W. Swarm mutual learning. Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01573-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01573-2