
Abstract
In the wave of research on autonomous driving, 3D object detection from the Bird’s Eye View (BEV) perspective has emerged as a pivotal area of focus. The essence of this challenge is the effective fusion of camera and LiDAR data into the BEV. Current approaches predominantly train and predict within the front view and Cartesian coordinate system, often overlooking the inherent structural and operational differences between cameras and LiDAR sensors. This paper introduces CL-FusionBEV, an innovative 3D object detection methodology tailored for sensor data fusion in the BEV perspective. Our approach initiates with a view transformation, facilitated by an implicit learning module that transitions the camera’s perspective to the BEV space, thereby aligning the prediction module. Subsequently, to achieve modal fusion within the BEV framework, we employ voxelization to convert the LiDAR point cloud into BEV space, thereby generating LiDAR BEV spatial features. Moreover, to integrate the BEV spatial features from both camera and LiDAR, we have developed a multi-modal cross-attention mechanism and an implicit multi-modal fusion network, designed to enhance the synergy and application of dual-modal data. To counteract potential deficiencies in global reasoning and feature interaction arising from multi-modal cross-attention, we propose a BEV self-attention mechanism that facilitates comprehensive global feature operations. Our methodology has undergone rigorous evaluation on a substantial dataset within the autonomous driving domain, the nuScenes dataset. The outcomes demonstrate that our method achieves a mean Average Precision (mAP) of 73.3% and a nuScenes Detection Score (NDS) of 75.5%, particularly excelling in the detection of cars and pedestrians with high accuracies of 89% and 90.7%, respectively. Additionally, CL-FusionBEV exhibits superior performance in identifying occluded and distant objects, surpassing existing comparative methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The task of environmental perception for autonomous driving vehicles involves converting sensor data into semantic information, which includes the identification, localization, and tracking of road agents such as motor vehicles, non-motorized vehicles, and pedestrians. In this context, 3D object detection is pivotal and forms the cornerstone of 3D scene perception and understanding. Accurate acquisition of distance and size information for road agents is crucial for preventing traffic accidents and enhancing active safety measures effectively. Over recent years, with the ongoing advancements in sensor technology, 3D object detection methods have diversified based on sensor types. This diversity encompasses camera-based methods that utilize image data for object detection, LiDAR-based methods that derive precise object positions through point cloud data processing, multimodal fusion methods that integrate information from multiple sensors to improve detection accuracy, and Bird’s Eye View (BEV) perspective-based multimodal fusion methods. The latter approach projects information onto the BEV perspective for processing, aiming to enhance the accuracy and efficiency of object detection. These varied strategies offer a range of effective solutions to the challenges inherent in 3D object detection.
Monocular vision-based methods enhance pixel intensity to provide rich visual information, capturing object shapes and texture attributes on a large scale. These details are instrumental for 3D object detection, where detectors convert image plane information into a three-dimensional coordinate system. Mono3D [1] initiates the process using a two-dimensional detector to identify candidate regions, which are then refined by integrating manually designed shape features, location priors, image context, and semantic cues to ascertain object positions. 3DOP [2] reformulates the 3D object detection challenge as an energy function minimization problem, encoding object dimensions and predicting ground plane depth. This approach is complemented by a convolutional neural network that outputs confidence scores for object categories. To boost performance, a subsequent work [3] expands 3DOP's capabilities to generate 2D candidate regions and orders them using depth maps and monocular images. Another approach [4] tackles the inaccuracy of three-dimensional bounding boxes due to erroneous pixel depth by training a standard 2D detector for depth estimation. Building on this, a subsequent study [5] translates the depth prediction into pseudo-LiDAR points, which are then fed into a LiDAR-based 3D detector for final detection. The essence of this method is the transformation of depth maps into pseudo-LiDAR points, allowing depth information to be processed by the 3D detector as if it were LiDAR data. This integration enhances the accuracy and comprehensiveness of object detection by leveraging LiDAR-like data.
LiDAR point cloud-based methods for 3D object detection are categorized into three primary approaches: voxel-based, point-based, and multi-view fusion methods. Voxel-based methods convert sparse point clouds into a denser voxel representation, which provides more detailed features than the original point cloud. VoxelNet [6] was a pioneering work in end-to-end 3D object detection, segmenting irregular point clouds into voxels to predict 3D bounding boxes. However, VoxelNet encountered challenges in real-time applications due to its computational intensity. To address this, SECOND [7] introduced 3D sparse convolution, enhancing performance and reducing computation time. SECOND leveraged a backbone network of 3D sparse convolutions to extract features from voxels. These features were concatenated along the height dimension, resulting in dense Bird’s Eye View (BEV) features through subsequent 2D convolution operations. Point-based methods, such as CenterPoint [8], assign a center point to each object, facilitating detection without relying on fixed-size anchor boxes. For more precise tuning of detection box dimensions, Part A2 [9] employed a two-stage framework to encode and decode non-empty voxels. Multi-view fusion methods, exemplified by PointPillars [10], offer an innovative pillar-based approach. PointPillars transforms point features into pseudo-images in bird's-eye-view space through pooling operations, enabling end-to-end learning with only 2D convolutional layers. This approach is well-suited for efficient deployment on embedded systems, meeting the criteria for low latency and minimal computational demands.
Point-based methods excel at learning local geometric features and the interactions among points within a point cloud. PointNet [11], a seminal approach, employs a shared Multi-Layer Perceptron (MLP) [12] to learn individual point features and extracts global features through pooling operations. PointNet ++ [13] builds upon PointNet by introducing a network architecture tailored for capturing local geometric features. It aggregates information from locally adjacent points to learn the characteristics of each point. Additionally, PointNet ++ utilizes Farthest Point Sampling (FPS) to perform point sampling, which aims to maximize the preservation of point cloud features. However, FPS incurs significant computational costs and can be slow for large-scale point clouds, potentially hindering its use in efficient semantic segmentation tasks. To mitigate this, a subsequent work [14] adopts Random Point Sampling (RPS) to reduce the complexity of point sampling. It is important to note that the performance of this network relies on color information from the point cloud rather than the original spatial information. In the context of autonomous driving, datasets such as SemanticKITTI [15] necessitate the fusion of point clouds with images to enrich the features of the point cloud. This fusion process enhances the detection performance and overall effectiveness of the network.
In the domain of object detection, multi-view fusion has garnered considerable research attention. Commonly, LiDAR point clouds are projected onto camera images, and the resulting RGB-D data is processed using 2D convolutional neural networks (CNNs). For instance, MV3D [17] projects LiDAR point clouds onto the RGB channels of both bird's-eye and frontal views derived from the front camera. It utilizes pooling layers to extract features for each view and subsequently generates the final 3D regions of interest. Building upon MV3D, a subsequent work [18] refines the representation by selectively sampling only the highest-scoring proposed regions and projecting them into the feature maps of the respective views. However, similar to MV3D, there is a potential for AVOD to lose feature details during the convolutional stage, which could affect the accurate detection of small objects.
BEVFusion [16] represents the latest research milestone, delivering state-of-the-art performance among current multi-modal fusion methods. It achieves an average detection accuracy of 71.7% by concatenatively fusing Bird’s Eye View (BEV) features from the surround-view cameras with LiDAR point cloud data. However, BEVFusion's approach to acquiring image BEV features operates independently, which does not fully leverage the information available from the LiDAR point cloud. Furthermore, its fusion strategy, which relies on simple element-wise concatenation, does not account for the interaction between features, leading to suboptimal information integration and potentially affecting detection accuracy. Figure 1 presents a qualitative comparison between our proposed method, CL-FusionBEV, and BEVFusion [16]. It is evident that BEVFusion occasionally misses detections of distant and occluded objects. In contrast, CL-FusionBEV demonstrates superior robustness in detection accuracy, successfully identifying objects that BEVFusion's method overlooked, as indicated by the red circles in Fig. 1.

A qualitative comparison is presented between our approach, CL-FusionBEV, and BEVFusion [16]. Our method showcases effective detection of previously missed objects, as highlighted by the red circles in the image
In this paper, we present CL-FusionBEV, a novel 3D object detection method that integrates camera and LiDAR data within the Bird’s Eye View (BEV) space. This approach is designed to enhance the precision of 3D object detection for autonomous vehicles, particularly in complex traffic scenarios. The key contributions of this research are as follows:
-
(1)
Built a feature alignment prediction module. We created an implicit learning module for aligning camera view features to BEV space features and transformed the LiDAR point cloud into LiDAR BEV space features. This transformation process is designed to align camera view features with LiDAR BEV space features, enabling improved fusion of multimodal information.
-
(2)
Designed a self-attention mechanism module. To address the shortcomings of the multimodal cross-attention module, including the lack of global reasoning in the generated BEV features’ context and insufficient interaction between features distributed at different positions, a self-attention mechanism module was designed for comprehensive feature operations. This module prevents issues of insufficient local reasoning and incomplete interaction of feature distributions.
-
(3)
Superior detection accuracy compared to the latest publicly available results. Through extensive experiments on the challenging nuScenes [19] dataset for large-scale autonomous driving, our method exhibits exceptional performance in 3D object detection tasks, achieving an impressive 73.3% mAP and 75.5% NDS. Notably, the detection accuracy for car and pedestrian categories reached 89% and 90.7%, respectively, surpassing the current state-of-the-art research results.
To comprehensively discuss our proposed CL-FusionBEV: 3D Object Detection Method with Camera-LiDAR Fusion in Bird’s-Eye View. This paper will be divided into the following parts. First, the related work of 3D object detection is introduced. Then, the framework of CL-FusionBEV is elaborated in detail. Next, the effectiveness of the method is verified through ablation experiments and comparative experiments. Finally, the research results are summarized.
Related works
Camera-only methods
In recent years, the field of autonomous vehicle perception has witnessed a significant upsurge in interest for 3D object detection using camera-based systems. Initially, these methods leveraged the outcomes of 2D object detection and incorporated depth prediction to achieve 3D detection capabilities [20, 21]. More recently, Bird’s Eye View (BEV)-based 3D detection methods have risen to prominence [22]. Unlike traditional methods, BEV-based approaches provide direct 3D object detection from multi-view camera images, sidestepping the need for post-processing, particularly in scenarios with overlapping object detections. The LSS [23] introduced an end-to-end architecture capable of extracting a BEV representation from an arbitrary number of camera images. This is accomplished by "lifting" each image into individual feature pyramids, which are then "projected" onto a rasterized BEV grid to construct a comprehensive representation. Building upon the foundation laid by LSS [23], subsequent studies [24, 25] have utilized depth prediction techniques to translate multi-view camera features into the BEV space. The PETR method [26] represents a notable advancement, employing Transformers and positional encoding to facilitate BEV detection from camera data. Additionally, other research [27, 28] has explored the use of deformable attention mechanisms to selectively query relevant local features within the BEV space, ensuring an efficient and accurate transformation from camera to BEV space. Collectively, these innovative approaches offer more direct and precise methods for enhancing the perceptual capabilities of autonomous vehicles through 3D object detection.
LiDAR-only methods
LiDAR-based 3D object detection techniques can be categorized into three main approaches: point-based, voxel-based, and Bird’s Eye View (BEV)-based methods. Point-based methods [29,30,31], such as PIXOR [29], project sparse LiDAR points onto a 2D grid to create a 2D BEV representation by extracting features. PointRCNN [30] and STD [31] leverage PointNet [11] and PointNet ++ [13] directly on raw point clouds to generate global features that encapsulate the entire geometric structure. Voxel-based methods [7, 32] preprocess raw point clouds into a compact voxel format, employing convolutional neural networks (CNNs) to extract features from voxels, which are then utilized for 3D object detection. BEV-based methods [6, 8, 10] voxelize the original point cloud and apply sparse 3D convolution to derive voxel features. For instance, VoxelNet [6] compresses these features along the Z-axis to obtain BEV space features. Other methods, like [8], construct intermediate features that are subsequently transformed into the BEV space. PointPillars [10], on the other hand, projects the point cloud onto multiple pillars, aggregating data within each pillar to extract BEV-based detection features. These diverse strategies for processing LiDAR data offer a range of solutions for 3D object detection, from direct point cloud analysis to voxelization and BEV representations.
Multi-modal fusion methods
In recent years, the domain of 3D object detection has witnessed significant progress, driven by innovations in multimodal fusion techniques. Notable methods such as F-PointNet [33], RoarNet [34], F-ConvNet [35], and PointFusion [36] have emerged. F-PointNet [33] enhances region proposal accuracy by fusing image and point cloud data. RoarNet [34] introduces RoI-aware features with rotational invariance, enhancing detection stability. F-ConvNet [35] employs 3D convolution to better integrate multimodal data, thereby improving detection performance. PointFusion [36] achieves more effective multimodal fusion through advanced point cloud projection techniques. Despite these advancements, challenges remain, particularly in complex scenes with object occlusions that can affect detection accuracy. Consequently, recent research has focused on BEV-based 3D object detection methods [16, 37, 38]. These methods transform image data into BEV features and concatenate them with LiDAR BEV features to form a comprehensive multi-modal feature representation. However, they may not fully exploit the interaction among multi-modal features. Another category of methods, such as BEVFusion [39,40,41], utilizes Transformer-based mechanisms to integrate complementary information from camera and LiDAR data. Yet, these methods can be highly dependent on the synergy between modalities, which may impact robustness when camera or LiDAR data is absent. Divergent from the aforementioned approaches, our proposed CL-FusionBEV method employs a voxelization strategy. It converts LiDAR data into a unified grid representation and processes it through 3D sparse convolution to generate LiDAR BEV space features. Concurrently, it propagates multi-view camera features into the 3D voxel space, compressing along the Z-axis to produce camera BEV space features. Furthermore, we introduce cross-attention mechanisms for BEV feature fusion and BEV self-attention mechanisms to bolster feature interaction across scales. These innovations render the CL-FusionBEV method presented in this paper more robust and accurate in tackling the intricacies of multimodal fusion.
The proposed method
In this section, we present a detailed exposition of our 3D object detection methodology, CL-FusionBEV, which harmonizes camera and LiDAR data within the Bird’s Eye View (BEV) framework. The schematic of CL-FusionBEV's architecture is illustrated in Fig. 2. Our approach commences with the extraction of preliminary shallow features from both point clouds and images, utilizing the established VoxelNet [6] and ResNet101 [42] as foundational backbones. We then proceed with a voxelization technique to standardize LiDAR features into a grid representation, followed by the application of 3D sparse convolution, yielding LiDAR BEV spatial features. Subsequently, we integrate dispersed dense multi-view image features into the 3D voxel space, effecting compression along the Z-axis to generate camera BEV features. To enhance the amalgamation of LiDAR and camera BEV features, we devise a cross-attention mechanism. This mechanism calculates the correlation between camera and LiDAR features, effectively linking object depth with feature representation, thus enhancing the integration of multi-modal BEV spatial features. To delve into complex deep-level fusion, we introduce a BEV self-attention mechanism. This innovation facilitates more robust feature interaction across various scales, bolstering the network's capability to process multi-scale information adeptly.

The comprehensive framework of CL-FusionBEV. Our method is primarily segmented into five components: 1 Initial feature extraction from LiDAR and the creation of Bird’s Eye View (BEV) features; 2 Initial feature extraction from the camera and the establishment of BEV features; 3 Construction of a multimodal cross-attention mechanism for LiDAR-Camera BEV feature fusion (MCM); 4 BEV Self-Attention Mechanism (BSM); 5 Formulation of prediction header and loss functions
Initial feature extraction from LiDAR and the creation of Bird’s Eye View (BEV) features
A single frame of raw LiDAR point cloud data typically contains tens of thousands of three-dimensional points. Using this data directly as input for fusion or network processing places a significant burden on computational resources, and not every point contains essential semantic information. Therefore, it is crucial to compress the quantity of the point cloud and transform it into a multi-channel feature set. We have employed a voxelization method, widely recognized in the literature [6], to extract deep-level features from the point cloud, as shown in Fig. 3. Specifically, we initially input the point cloud data (with dimensions n × 4, where n is the number of points and 4 represents the x, y, z coordinates, and the reflectance intensity) into a Multi-Layer Perceptron (MLP), which elevates the original points to 512 dimensions. Ultimately, we apply a max-pooling layer to reduce the number of points, resulting in a condensed 1 × 512 feature vector \({q}_{i}\) for each point. The processed point cloud feature vectors collectively form the input Query for the Bird’s Eye View (BEV), where “Query” represents the set \({q}_{1},{q}_{2},{q}_{2},\dots {q}_{i}\) of feature vectors prepared for further analysis or multi-modal fusion.

LiDAR initial feature extraction
Initial feature extraction from the camera and the establishment of BEV features
For three-channel camera images with a resolution of (1600, 640) pixels, we have chosen ResNet101 [42] as our 2D feature extractor to capture more nuanced semantic features. The backbone structure of ResNet101 includes convolutional blocks (Conv Blocks) and identity residual blocks (Identity Blocks), as shown in Fig. 4. We begin by employing 2D convolution to transform the image dimensions to (800, 320, 64); after this, we apply batch normalization (BatchNorm) and a ReLU activation function. Subsequently, we reduce the image size using a max-pooling layer (MaxPool). Eventually, after passing through two sets of consecutive convolutional and identity residual blocks, we derive a feature map with dimensions of (200, 80, 512).

Preliminary extraction of image features
Camera to BEV View Transformation (BEV-CV): currently, there are two primary methods for generating Bird’s Eye View (BEV) space features from camera data. Lift: (1) Splat, Shoot (LSS) [23]: this approach uses a neural network to predict depth distribution, creating an intermediate BEV representation by estimating the depth of image features. (2) BEVFormer [28]: this method employs a spatiotemporal transformer to learn a unified BEV representation, capturing spatial and temporal information through predefined grid-like BEV queries. Both methods learn the transformation from the camera view to BEV space through implicit supervision. Our CL-FusionBEV fusion method also constructs camera BEV space features using implicit supervision, building on the state-of-the-art perception method BEVFusion [16]. This method takes multi-view images as input and converts camera features into the BEV space with depth prediction and geometric projection. The process is as follows: (1) Feature Generation: Multi-view image features are initially extracted using a camera feature extraction network [42]. (2) Space Discretization: The dense multi-view image features are then scattered into a discrete 3D space using the LSS method [23]. (3) Feature Compression: The generated 3D voxel features are compressed along the Z-axis within the three-dimensional space, following the BEVFusion method [16], to produce the camera BEV space feature representation, completing the construction of image BEV space features.
Construction of a multi-modal cross-attention mechanism for LiDAR-Camera BEV feature fusion (MCM)
The overall architecture of the multi-modal cross-attention mechanism we have constructed is illustrated in Fig. 5. Given the input BEV LiDAR features \({A}_{i}\) and camera BEV feature \({g}_{j}\), we first employ a set of learnable weights \({w}_{1}\) and \({w}_{2}\) to linearly transform the input feature matrices. Subsequently, we apply position encoding to the BEV LIDAR features \(\left( {\rho_{i}^{P} ,\emptyset_{j}^{P} } \right)\), designating the encoded features as \({q}^{1}\). Similarly, the linearly transformed camera features \({g}_{j}\) are designated as \({k}^{1}\) and \({v}^{1}\), respectively. Following this, we use \({q}^{i}\) to query the correlation of each image feature sequence \({k}^{j}\), establishing a correlation matrix \(a_{i}\):
where the normalization factor \(\sqrt{D}\) is employed to confine the numerical range. The correspondence between LIDAR features and image features can be ascertained by the position of the maximum correlation matrix \(a_{i}\). Following this, the paper utilizes the SoftMax operation for normalization and differentiation:

The overall architecture of multi-modal cross-attention mechanism
Moreover, the final attention feature is obtained by computing a weighted sum of the normalized weights \(m_{i}\) and the original linear transformation \(v_{i}\) of camera features \(g_{j}\). This computation yields the final attention feature \(b_{i}\), concluding the query update process for the BEV features. During this integration, modal information from both LiDAR and camera is harmoniously combined.
Our proposed modality-agnostic feature fusion method is versatile and suitable for any combination of sensors. It allows for flexible adjustment of the number of cross-attention mechanism queries and the dimensions of the output features, tailored to the image feature size and the specific requirements of the task at hand.
BEV self-attention mechanism (BSM)
Because the context \({b}_{i}\) generated by the multimodal cross-attention mechanism lacks global reasoning, features with different spatial distributions cannot interact adequately. At this stage, the features are more inclined to express local information and fail to provide holistic global reasoning. To address this challenge, we introduced a Bird’s Eye View (BEV) self-attention mechanism for comprehensive global feature operations. This mechanism helps infer the contextual positions of the fused features across the entire BEV layout, enabling the generation of aggregated information about the shapes of relevant objects.
We have chosen a soft attention-based self-attention mechanism as the tool for global feature interaction. The flowchart of the BEV self-attention mechanism is shown in Fig. 6. Initially, for the original BEV features, three linear transformations are applied to yield query, key, and value feature sequences. Subsequently, the transposed key is used to calculate the similarity with the query to derive weights. Then, the SoftMax operation is employed to normalize these weights. Finally, the normalized weights are combined with the corresponding values through a weighted summation, resulting in the final self-attention feature map. The mathematical formulation for the self-attention mechanism is as follows:
where \(q\) represents the query of the point cloud elements and positions that are currently being processed. \(k\) represents the key matrix of all camera BEV feature elements in the sequence, and \(v\) represents the value of all elements in the sequence. \(d\) represents the dimension of the key, which is used to scale the dot product when calculating the attention score to prevent the gradient from disappearing or exploding. Furthermore \(k^{T}\) represents the transpose of the key so that \(q\) and \(k\) can perform the dot product operation.

BEV self-attention mechanism flow chart
Prediction header
We have chosen the object detection head from PointPillars [10] to serve as our prediction module, which inputs the fused Bird’s Eye View (BEV) features into a Single Shot Multi Box Detector (SSD) [43] for 3D object detection. The SSD object detection head is a single-stage method that operates on convolutional neural networks. It conducts object classification and regression concurrently, directly within the network architecture, thereby enhancing the real-time performance of object detection. The SSD framework employs multiple loss functions to refine the prediction of object positions and classifications, effectively propelling the network's training process. This approach allows for a more efficient and accurate optimization, making it well-suited for the demands of real-time 3D object detection tasks.
Loss functions
The CL-FusionBEV fusion method presented in this paper incorporates three distinct loss functions for evaluation: object classification loss, 3D bounding box regression loss, and 3D object box azimuth classification loss. The composite loss of the network is the aggregate sum of these individual loss components. For the object classification loss, which is designed to balance the positive and negative sample distribution and to address challenging samples, we have elected to employ the Focal Loss function [44]. The Focal Loss is particularly effective in mitigating the issue of class imbalance and focusing on hard-to-classify examples, thereby improving the network’s ability to learn from a diverse range of samples.
where \(L_{cls}\) represents the classification loss, \(\alpha_{a}\) is the weight of prediction box \(a\), which balances the importance of different prediction boxes. \(p^{a}\) represents the probability of the prediction box \(a\). \({\upgamma }\) is a hyperparameter used to adjust the shape of the loss function. \({\upalpha }\) is 0.25 and \({\upgamma }\) is 2.0.
Furthermore, for the 3D bounding box regression loss, we define the regression residuals between the actual and predicted boxes as follows:
where \(\left( {x,y,z} \right)\) represents the position of the center point of the 3D bounding box, \(\left( {l,w,h} \right)\) represents the dimensions of the 3D bounding box, and \(\theta\) represents the rotation angle. \(*^{gt}\) denotes the ground truth values of the 3D bounding box, while \(*^{a}\) denotes the predicted values. The term \(d^{a} = \sqrt {\left( {w^{a} } \right)^{2} + \left( {l^{a} } \right)^{2} }\) is used to calculate the regression residuals. To prevent excessive loss when errors are large, this paper employs the Smooth L1 loss function to compute the geometric loss, which results in the 3D bounding box regression loss \(L_{reg}\):
where \(\Delta b\) represents the difference between the ground truth and the predicted values of the 3D bounding box, with \(\Delta b\) being a vector in the form \(\left( {\Delta x,\Delta y,\Delta z,\Delta l,\Delta w,\Delta h,\Delta \theta } \right)\).
As the orientation regression loss can significantly affect the precision of model training, this paper employs a 3D bounding box orientation regression loss function, denoted as \(L_{reg\_\theta }\), which is defined as follows:
where \(\theta^{a}\) represents the predicted orientation, while \(\theta^{gt}\) is the actual orientation of the object. When \(\theta^{a} = \theta^{gt} \pm \pi\), the orientation regression loss approaches 0, mitigating the effects of opposite object orientations and enhancing the effectiveness of model training.
To address the issue of the orientation regression loss in 3D bounding boxes treating oppositely oriented predicted boxes as identical, we employ the cross-entropy loss function, denoted as \(L_{dir}\), to train the orientation categories derived from the 3D object prediction head. This approach aims to achieve more precise predictions of orientation categories.
where \(\theta_{dir}^{gt}\) represents the ground truth azimuth angle, and \(\theta_{dir}^{a}\) represents the predicted azimuth category. \(1_{b}\) is an indicator function that outputs 1 when the condition within the parentheses is true; otherwise, it outputs 0.
The final total loss function of the CL-FusionBEV method is formed by the weighted combination of the four aforementioned loss functions:
where \(\lambda_{cls}\), \(\lambda_{reg}\), and \(\lambda_{dir}\) represent fixed coefficients used for weighting the losses.
Experiments
In this section, we aim to validate the performance of our framework through rigorous testing experiments. Furthermore, we will conduct ablation studies to confirm the effectiveness, flexibility, and robustness of the model's components.
Dataset
For our experiments and evaluations, we have selected the nuScenes dataset [19], which is specifically designed for autonomous driving scene perception. This dataset captures intricate road environments in both Boston and Singapore. It comprises a total of 1000 scenes and over 400,000 frames of data. nuScenes utilizes six sensors to collect multimodal data, including 360-degree panoramic images, LiDAR point clouds, and radar data. The dataset provides detailed annotations for crucial elements such as vehicles, pedestrians, and traffic signs. Beyond offering comprehensive annotations, nuScenes presents a rich variety of scenarios and data for a range of environmental perception tasks, including 3D object detection, tracking, and high-definition (HD) map generation.
Evaluation metrics
To validate the effectiveness of our proposed method, we employ the evaluation metrics provided by the nuScenes dataset [19]: the nuScenes Detection Score (NDS) and the mean Average Precision (mAP). The mAP is calculated as the average precision across matching thresholds for bird's-eye-view center distances D=\(\left\{\text{0.5,1},\text{2,4}\right\}\) meters and the class set CC. NDS integrates mAP with other object attribute detection results, encompassing the Average Translation Error (ATE), Average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE), and Average Attribute Error (AAE). The calculation formula for NDS is as follows:
where mAP represents the mean Average Precision, \(AP_{c,d}\) stands for the Average Precision at a specific category c and difficulty level d, and \({TP}_{c}\) denotes the set of five average error metrics for category c. Consequently, NDS goes beyond assessing detection performance alone; it quantifies the quality of detection by considering factors such as bounding box position, size, orientation, attributes, and velocity. This comprehensive evaluation enables a thorough assessment of 3D object detection results. Furthermore, we offer detailed comparisons for the outcomes across 10 detection categories.
Implementation details
To assess our network, we utilize the open-source tool MMDetection3D [45], which is a 3D object detection toolbox built on the PyTorch [46] deep learning framework. It has been extensively tested and validated on various 3D object detection datasets, including Waymo [47], nuScenes [19], and KITTI [48]. The toolbox has demonstrated outstanding performance, making it a reliable choice for our evaluation.
In the image branch, we utilize the robust ResNet101 [42] as the backbone network. ResNet101 is a typical network for image classification that constructs a deep network structure by stacking multiple residual blocks, effectively extracting high-level semantic features from images. For the LiDAR branch, our choice for the backbone network for point cloud feature learning is VoxelNet [6]. VoxelNet partitions the point cloud into a voxel grid and then applies dense 3D convolution to extract spatial features. Unlike other point cloud processing networks, VoxelNet can handle raw point clouds directly, thus preventing information loss.
During the testing phase, we configure the image resolution to be 1600 × 640 pixels. For the LiDAR point cloud, we follow the voxel size settings from previous works [6, 10, 37, 39], setting it to (0.075 m, 0.075 m, 0.2 m). Our training and inference processes are conducted on an Ubuntu 18.04 server, equipped with an Intel Core i7-10,700 CPU and a GeForce RTX 3060 GPU. The experiments are implemented in Python 3.7, using the PyTorch deep learning framework for model development. We use the AdamW [49] optimizer, with a learning rate of 2e-4 and a weight decay of 1e-2, to optimize the network parameters.
Performance compared to previous methods
We conducted a comparative analysis of our proposed method against leading 3D object detection methods that utilize multimodal fusion, evaluating performance on both the nuScenes [19] validation and test sets. As detailed in Table 1, our method shows superior detection performance on the nuScenes validation set compared to state-of-the-art multimodal fusion methods, including FUTR3D [50], AutoAlignV2 [51], BEVFusion [16], BEVFusion [37], and DeepInteraction [41]. Notably, compared to the multimodal fusion method DeepInteraction [41], our method achieves a significant improvement of 2.4% in mAP and 1.8% in NDS detection accuracy. Additionally, our mAP and NDS detection scores exceed those of the state-of-the-art BEV fusion method BEVFusion4D [38], with respective improvements of 1.4% and 1.5%. When compared to the highly advanced BEV fusion method BEVFusion [37], our CL-FusionBEV method demonstrates even greater improvements of 2.7% in mAP and 2.3% in NDS, marking a significant advancement in multimodal BEV fusion-based 3D object detection.
Table 2 outlines the validation results on the test set, where we compare our method with previous approaches that are based solely on Bird's-Eye-View (BEV) cameras (e.g., M2BEV [22], BEVerse [52], BEVFormer [28], and BEVStereo [53]), those based solely on LiDAR (e.g., MEGVLL [54], CVCNet [55], HotSpotNet [56], and CenterPoint [8]), as well as multimodal fusion-based methods (including PointPainting [57], MVP [59], PointAugmenting [60], TransFusion [39], BEVFusion [16], DeepInteraction [41], BEVFusion [37], and BEVFusion4D [38], among others). Our method significantly outperforms these previous approaches, achieving detection scores of 73.3% in mAP and 75.5% in NDS on the test set. As shown in Table 2, our method surpasses previous state-of-the-art methods in most detection categories. This overall performance improvement can be attributed to our proposed multimodal cross-attention mechanism for LiDAR-camera BEV feature fusion and the BEV self-attention mechanism. Both modules emphasize the spatial priors of the fused features from the camera and LiDAR in the BEV space. Additionally, our method enhances the detection capabilities for objects such as cars, trucks, buses, bicycles, and pedestrians in common scenarios.
Ablation studies
To assess the effectiveness of our proposed CL-FusionBEV method, we conducted ablation studies on the nuScenes [19] dataset, focusing on the performance of different network modules. To enhance the efficiency of the 3D object detection process, we trained and tested the entire ablation study using a quarter of the training data from the nuScenes dataset. Specifically, we compared the detection accuracy of the baseline detection network and analyzed the performance changes following the incorporation of BEV-CV, MCM, and BSM components. The results of these experiments are presented in Table 3, where the baseline refers to a voxel-based detection framework that solely relies on LiDAR data, without the fusion of point clouds and images.
Quantitative analysis
Analyzing Table 3 reveals that incorporating the BEV-CV module enhances both mAP and NDS values across all categories, highlighting the effectiveness of our proposed BEV-CV fusion approach. Notably, there is a significant improvement in the precision of 3D object detection, particularly for cars, pedestrians, and bicycles, with gains of 1.0%, 1.8%, and 0.3%, respectively. Compared to the baseline, our method shows a 1.1% increase in mAP and a 0.7% increase in NDS detection scores. The likely explanation for these improvements is the sparsity of point clouds, which limits the effective information for distant objects and leads to suboptimal performance of the baseline network in 3D object detection. These distant objects require additional semantic information from images.
The introduction of the MCM module allows the network to generate BEV fusion features that better align with real-world distributions, further enhancing our method's detection accuracy. Specifically, detection accuracy for cars, pedestrians, and bicycles improved by 1.1%, 0.2%, and 0.9%, respectively. However, for small objects like pedestrians and bicycles, the increase in detection accuracy is marginal. This could be due to the BEV fusion features generated by the MCM lacking global context reasoning, which limits the interaction among features from different spatial distributions. As a result, BEV fusion features provide only localized information, failing to offer comprehensive global reasoning and leading to a less noticeable improvement in the accuracy of small objects.
The addition of the BSM module, which applies a global operation on BEV fusion features, enables these features to infer their contextual positions throughout the entire BEV layout. This facilitates the generation of aggregated information related to the shapes of relevant objects, contributing to further advancement in the detection performance of our method. Improvements for cars, pedestrians, and bicycles were 0.6%, 0.4%, and 2.4%, respectively. In comparison to the baseline, our approach achieved a 1.1% increase in mAP and a 1.2% increase in NDS detection scores. This series of ablation studies provides compelling evidence of the effectiveness of each module in our network architecture.
Qualitative analysis
-
(1)
Validation of the efficacy of multimodal cross-attention mechanism and bev self-attention mechanism
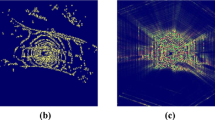
Figure 7 offers an in-depth illustration of the effectiveness of the multimodal cross-attention and BEV self-attention mechanisms through visual results. Figure 7a shows the attention feature map generated by the multimodal cross-attention, which lacks clarity, suggesting that the integration of camera and LiDAR BEV features may not be optimal. In contrast, Fig. 7b presents a more discerning attention map produced by the BEV self-attention mechanism. This mechanism promotes effective interaction between the fused BEV features, enabling more robust feature correlations.

Comparison of attention feature maps. To improve visualization, we selected predictions with high confidence scores and generated corresponding attention feature maps, as shown in Fig. 7. The attention maps indicate the strength of relevance, with higher values signifying greater importance. a presents the attention feature map produced by the multimodal cross-attention mechanism, whereas b displays the map generated by the BEV self-attention mechanism. Notably, the map in b shows more distinct discriminative features, suggesting superior capability in distinguishing relevant areas. In comparison, the attention map from the multimodal cross-attention in a appears less distinct, whereas the BEV self-attention mechanism in b more effectively highlights key features, thus preserving and enhancing relevance. This comparison underscores the significant advantage of our method in feature attention and extraction, which is crucial for precise 3D object detection
The enhanced clarity and discriminative power in Fig. 7b demonstrate the BEV self-attention mechanism’s ability to refine feature attention, thereby improving the overall performance of feature interaction. This comparison validates the rationale behind the proposed mechanisms, highlighting their excellence in enhancing feature interaction performance.
-
(2)
Comparison of 3D object detection results from the BEV perspective
To further validate the effectiveness of our proposed CL-FusionBEV method, we conducted comparative experiments with other state-of-the-art solutions, carefully selecting a representative 3D object detection method: BEVFusion [37]. Figure 8 presents a qualitative comparison between our CL-FusionBEV and BEVFusion. It is evident that BEVFusion has certain limitations in detecting distant and occluded objects, likely due to its deficiencies in feature fusion and context understanding. In contrast, our CL-FusionBEV method demonstrates significant advantages in these challenging scenarios by effectively enhancing feature expressiveness and the model's global reasoning ability through the introduction of a multi-modal cross-attention mechanism and a BEV self-attention mechanism.

Comparative experimental detection results in the nuScenes test set
In Fig. 8, we highlight several typical missed objects with red circles. These objects, which were not accurately identified in BEVFusion's detection results, are clearly marked in CL-FusionBEV's results. This illustrates that CL-FusionBEV possesses higher robustness when handling occlusion and long-distance objects, offering more reliable detection outcomes. Through these comparative experiments with state-of-the-art solutions, we not only confirm the effectiveness of the CL-FusionBEV method but also showcase its potential and advantages for practical applications.
-
(3)
Visualization of 3D object detection results from BEV perspective
To further validate the efficacy of the proposed network in this paper, we present visualizations of the 3D detection results from CL-FusionBEV in various scenarios, as depicted in Fig. 9. These scenarios include complex roads, urban streets, and intersections, demonstrating the excellence of our approach. Figure 9a, b, and e showcase CL-FusionBEV's outstanding performance in diverse situations, such as complex roads, intersections, and conditions involving distant and occluded objects. This highlights our method's remarkable ability to tackle challenges in 3D object detection within complex environments.

Qualitative detection results in the nuScenes test set. The six images depicted in the figure are taken from distinct viewpoints of six cameras within the nuScenes dataset: front-left, front-center, front-right, rear-left, rear-center, and rear-right. The image on the far right showcases the detection outcomes of objects in the BEV perspective derived from the LiDAR point cloud. Various colored bounding boxes denote different types of objects, including cars (filled circle), pedestrians (filled circle), buses (filled circle), trucks (filled circle), cyclists (filled circle), and motorcycles (filled circle)
The seamless integration of the multimodal cross-attention mechanism and BEV self-attention mechanism in CL-FusionBEV enables effective utilization of depth-interacted BEV fusion features, enhancing the detection of occluded objects. Even in scenarios with partial or complete occlusion, our method maintains admirable performance, confirming its resilience and effectiveness in complex settings.
Furthermore, Fig. 9c, d, and f illustrate that our method maintains robust detection performance in high-traffic scenarios, including urban streets and intersections with dense vehicle traffic. It also demonstrates the capability to detect small objects like pedestrians and cyclists, emphasizing the applicability of our proposed method for 3D object detection in complex traffic scenes. These results not only highlight the significant improvements in detection performance achieved by our method but also attest to its convincing reliability when addressing challenges in complex scenes.
Conclusions
In this paper, we introduce an advanced 3D object detection method named CL-FusionBEV, designed to efficiently fuse camera and LiDAR data from a Bird’s Eye View (BEV) perspective. Our primary motivation is to bolster the precision and robustness of object detection for autonomous vehicles, particularly in dynamic traffic environments. We achieve this by enhancing the integration of information from disparate sensor modalities. Our approach begins with the construction of BEV spatial features. We ingeniously integrate rich multi-view image features into the 3D voxel feature space, compressing them along the Z-axis to generate camera-derived BEV spatial features. We then apply voxelization to the LiDAR-captured point cloud data, converting it into a consistent gridded format. This representation is subsequently enhanced through 3D sparse convolution techniques, yielding precise LiDAR BEV spatial features. At the crux of BEV feature fusion, we introduce an innovative cross-attention mechanism tailored for the amalgamation of LiDAR and camera BEV features. This mechanism is complemented by a BEV self-attention mechanism, which bolsters the interaction and integration of features across various scales. Through extensive experiments on the nuScenes dataset, we demonstrate that CL-FusionBEV excels across multiple evaluation metrics, substantiating the effectiveness of our method. While these results are promising, we acknowledge that for broader application, our model requires further optimization. This includes reducing computational demands and assessing its generalizability under a wider array of environmental conditions. We are committed to tackling these challenges in future research, with the goal of enhancing the performance and practicality of CL-FusionBEV.
Data availability
In our paper, we use nuScenes dataset, it is a public available dataset, and from the reference [19].
References
Yan C, Salman E (2017) Mono3D: open source cell library for monolithic 3-D integrated circuits. IEEE Trans Circuits Syst Video Technol 65(3):1075–1085
Chen X, Kundu K, Zhu Y et al (2017) 3d object proposals using stereo imagery for accurate object class detection. IEEE Trans Pattern Anal Mach Intell 40(5):1259–1272
Pham C, Jeon JW (2017) Robust object proposals re-ranking for object detection in autonomous driving using convolutional neural networks. Signal Process: Image Commun 53:110–122
Xu B, Chen Z (2018) Multi-level fusion based 3d object detection from monocular images. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2345–2353.
Dou H, Liu Y, Chen S, Bilal H et al (2023) A hybrid CEEMD-GMM scheme for enhancing the detection of traffic flow on highways. Soft Comput 27:16373–16388
Zhou Y, Tuzel O. Voxelnet (2018) End-to-end learning for point cloud based 3d object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 4490–4499.
Yan Y, Mao Y, Li B (2018) Second: sparsely embedded convolutional detection. Sensors 18(10):3337
Yin T, Zhou X, Krahenbuhl P (2021) Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 11784–11793.
Shi S, Wang Z, Shi J et al (2020) From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans Pattern Anal Mach Intell 43(8):2647–2664
Lang A H, Vora S, Caesar H, et al. (2019) Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 12697–12705.
Qi C R, Su H, Mo K, et al. (2017) Pointnet: deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 652–660.
Zhang C, Pan X, Li H et al (2018) A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J Photogramm Remote Sens 140:133–144
Qi C R, Yi L, Su H, et al. (2017) Pointnet++: deep hierarchical feature learning on point sets in a metric space. Adv Neural Inf Process Syst. p 30.
Bilal H, Yao W, Guo Y, Wu Y, Guo J (2017) “Experimental validation of fuzzy PID control of flexible joint system in presence of uncertainties” 2017 36th Chinese Control Conference (CCC), Dalian, China. pp. 4192-4197
Behley J, Garbade M, Milioto A, et al. (2019) Semantickitti: a dataset for semantic scene understanding of lidar sequences. In: Proceedings of the IEEE/CVF international conference on computer vision. pp 9297–9307.
Liu Z, Tang H, Amini A, et al. (2023) Bevfusion: multi-task multi-sensor fusion with unified bird’s-eye view representation. In: 2023 IEEE international conference on robotics and automation (ICRA). IEEE. pp 2774-2781
Chen X, Ma H, Wan J, et al. (2017) Multi-view 3d object detection network for autonomous driving. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. pp 1907–1915.
Wu Q, Li X, Wang K, Bilal H et al (2023) Regional feature fusion for on-road detection of objects using camera and 3D-LiDAR in high-speed autonomous vehicles. Soft Comput 27:18195–18213
Caesar H, Bankiti V, Lang A H, et al. (2020) nuscenes: a multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11621–11631.
Yan H, Yu X, Zhang Y, Zhang S, Zhao X, Zhang L (2017) Single image depth estimation with normal guided scale invariant deep convolutional fields. IEEE Trans Circuits Syst Video Technol 29(1):80–92
Bilal H, Yin B, Aslam MS et al (2023) A practical study of active disturbance rejection control for rotary flexible joint robot manipulator. Soft Comput 27:4987–5001
Xie E, Yu Z, Zhou D, et al. M $^ 2$ (2022) BEV: multi-camera joint 3D detection and segmentation with unified birds-eye view representation. arXiv preprint arXiv:2204.05088. Accessed 1 Dec 2023
Philion J, Fidler S (2020) Lift, splat, shoot: encoding images from arbitrary camera rigs by implicitly unprojecting to 3d, in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020. Proceedings, Part XIV 16. Springer International Publishing, New York. pp 194-210
Huang J, Huang G, Zhu Z, et al. (2021) Bevdet: high-performance multi-camera 3d object detection in bird-eye-view, arXiv preprint arXiv:2112.11790. Accessed 29 Nov 2023
Bilal H, Yin B, Kumar A et al (2023) Jerk-bounded trajectory planning for rotary flexible joint manipulator: an experimental approach. Soft Comput 27:4029–4039
Liu Y, Wang T, Zhang X, et al. (2022) Petr: position embedding transformation for multi-view 3d object detection. In: European Conference on Computer Vision. Springer Nature, Cham. pp 531–548.
Wang Y, Guizilini V C, Zhang T, et al. (2022) Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In: Conference on Robot Learning. PMLR. 180–191.
Li Z, Wang W, Li H, et al. (2022) Bevformer: learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In: European conference on computer vision. Springer Nature, Cham. pp 1–18.
Yang B, Luo W, Urtasun R (2018) Pixor: real-time 3d object detection from point clouds. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. pp 7652–7660.
Shi S, Wang X, Li H (2019) Pointrcnn: 3d object proposal generation and detection from point cloud, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 70–779.
Yang Z, Sun Y, Liu S, et al. (2019) Std: Sparse-to-dense 3d object detector for point cloud. In: Proceedings of the IEEE/CVF international conference on computer vision. pp 1951–1960.
Fan B, Zhang K, Tian J (2024) HCPVF: hierarchical cascaded point-voxel fusion for 3D object detection. IEEE Trans Circuits Syst Video Technol. https://doi.org/10.1109/TCSVT.2023.3268849
Qi C R, Liu W, Wu C, et al. (2018) Frustum pointnets for 3d object detection from rgb-d data. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 918–927.
Shin K, Kwon YP, Tomizuka M. Roarnet (2019) A robust 3d object detection based on region approximation refinement. In: 2019 IEEE intelligent vehicles symposium (IV). IEEE. pp 2510-2515
Wang Z, Jia K (2019) Frustum convnet: sliding frustums to aggregate local point-wise features for amodal 3d object detection in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE. pp 1742–1749.
Xu D, Anguelov D, Jain A (2018) Pointfusion: deep sensor fusion for 3d bounding box estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 244–253.
Liang T, Xie H, Yu K et al (2022) Bevfusion: a simple and robust lidar-camera fusion framework. Adv Neural Inf Process Syst 35:10421–10434
Cai H, Zhang Z, Zhou Z, et al. (2023) BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird’s-Eye-View via Cross-Modality Guidance and Temporal Aggregation, arXiv preprint arXiv:2303.17099. Accessed 3 Dec 2023
Bai X, Hu Z, Zhu X, et al. (2022) Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 1090–1099.
Wang H, Tang H, Shi S, et al. (2023) UniTR: a unified and efficient multi-modal transformer for Bird’s-Eye-View Representation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp 6792–6802.
Yang Z, Chen J, Miao Z et al (2022) Deepinteraction: 3d object detection via modality interaction. Adv Neural Inf Process Syst 35:1992–2005
He K, Zhang X, Ren S, et al. (2016) Deep residual learning for image recognition, in Proceedings of the IEEE conference on computer vision and pattern recognition. pp 770–778.
Liu W, Anguelov D, Erhan D, et al. (2016) SSD: single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer International Publishing. pp 21–37
Lin T Y, Goyal P, Girshick R, et al. (2017) Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision. pp 2980–2988.
Contributors M (2020) MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.
Paszke A, Gross S, Massa F, et al. (2019) Pytorch: an imperative style, high-performance deep learning library. Adv Neural Inf Process Syst. p 32.
Sun P, Kretzschmar H, Dotiwalla X, et al. (2020) Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 2446–2454.
Geiger A, Lenz P, Urtasun R (2012) Are we ready for autonomous driving? The kitti vision benchmark suite. In 2012 IEEE conference on computer vision and pattern recognition. IEEE. pp 3354–3361
Loshchilov I, Hutter F (2017) Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101. Accessed 2 Jan 2024
Chen X, Zhang T, Wang Y, et al. (2023) Futr3d: a unified sensor fusion framework for 3d detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 172–181.
Chen Z, Li Z, Zhang S, et al. (2022) Autoalignv2: deformable feature aggregation for dynamic multi-modal 3d object detection. arXiv preprint arXiv:2207.10316. Accessed 5 Dec 2023
Zhang Y, Zhu Z, Zheng W, et al. (2022) Beverse: unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv preprint arXiv:2205.09743. Accessed 7 Dec 2023
Li Y, Bao H, Ge Z et al (2023) Bevstereo: enhancing depth estimation in multi-view 3d object detection with temporal stereo. Proc AAAI Conf Artif Intell 37(2):1486–1494
Zhu B, Jiang Z, Zhou X, et al. (2019) Class-balanced grouping and sampling for point cloud 3d object detection. arXiv preprint arXiv:1908.09492. Accessed 4 Dec 2023
Chen Q, Sun L, Cheung E et al (2020) Every view counts: cross-view consistency in 3d object detection with hybrid-cylindrical-spherical voxelization. Adv Neural Inf Process Syst 33:21224–21235
Chen Q, Sun L, Wang Z, et al. (2020) Object as hotspots: an anchor-free 3d object detection approach via firing of hotspots. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer International Publishing, Cham. pp 68–84
Vora S, Lang AH, Helou B, et al. (2020) Pointpainting: sequential fusion for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 4604–4612.
Yoo J H, Kim Y, Kim J, et al. (2020) 3d-cvf: generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In: Computer vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVII 16. Springer International Publishing, Cham. pp 720–736
Yin T, Zhou X, Krähenbühl P (2021) Multimodal virtual point 3d detection. Adv Neural Inf Process Syst 34:16494–16507
Wang C, Ma C, Zhu M, et al. (2021) PointAugmenting: cross-modal augmentation for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 11794–11803.
Xu S, Zhou D, Fang J, et al. (2021) Fusionpainting: Multimodal fusion with adaptive attention for 3d object detection. In: 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE. pp 3047–3054
Funding
This research was funded by the Yangtze River Delta Science and Technology Innovation Community Joint Research Project (2023CSJGG1600), the Natural Science Foundation of Anhui Province (2208085MF173) and Wuhu “ChiZhu Light” Major Science and Technology Project (2023ZD01,2023ZD03).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shi, P., Liu, Z., Dong, X. et al. CL-fusionBEV: 3D object detection method with camera-LiDAR fusion in Bird’s Eye View. Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01567-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01567-0