
Abstract
Feature selection plays a crucial role in machine learning, as it eliminates data noise and redundancy, thereby significantly reducing computational complexity and enhancing the overall performance of the model. The challenges of feature selection for hybrid information systems stem from the difficulty in quantifying the disparities among nominal attribute values. Furthermore, a significant majority of the current methodologies exhibit sensitivity to noise. This paper introduces techniques that address the aforementioned issues from the perspective of fuzzy evidence theory. First of all, a new distance incorporating decision attributes is defined, and then a relation between fuzzy evidence theory and fuzzy \(\beta \) covering with an anti-noise mechanism is established. In this framework, two robust feature selection algorithms for hybrid data are proposed based on fuzzy belief and fuzzy plausibility. Experiments on 10 data sets of various types show that compared with the other 6 state-of-the-art algorithms, the proposed algorithms improve the anti-noise ability by at least 6% with higher average classification accuracy. Therefore, it can be concluded that the proposed algorithms have excellent anti-noise ability while maintaining good feature selection ability.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Research background and related works
A crucial application of rough set theory lies in the realm of data feature selection. Given the presence of numerous redundant features and noises in various datasets, feature selection becomes a prerequisite before data mining. Feature selection is an indispensable "data preprocessing" step. It serves not only to reduce the size of the dataset but also to enhance the accuracy of knowledge mining. Currently, a significant focus of feature selection research revolves around devising improved heuristic functions that effectively assess the importance of features within a dataset [1].
Rough set theory finds extensive applications in handling imprecise, inconsistent, and incomplete information, demonstrating its prowess in managing data with varying degrees of uncertainty [2]. Its extensive application in feature selection stems from its independence from prerequisite information, making it a highly versatile tool [3]. Due to its stringent equivalence requirements, traditional rough set theory is confined to discrete data. However, the vast majority of real-world data, including gene data and sensor data, are continuous. Discretizing such data inevitably leads to a certain level of information loss.
To tackle the aforementioned challenges, two distinct approaches have emerged: neighborhood theory and fuzzy theory.
By identifying other objects adjacent to a given object, neighborhood theory analyzes the relationships and characteristics between objects, thus recognizing patterns and regularities among them, playing a significant role in the field of artificial intelligence. Researchers have integrated neighborhood theory with rough set theory to devise a neighborhood-based rough set model, subsequently proposing diverse feature selection algorithms grounded in this innovative framework. Hu et al. [4] formulated a neighborhood rough set model for feature selection in heterogeneous data through the employment of a heuristic function known as feature dependency. Wang et al. [5] used the local conditional information entropy for feature selection based on the neighborhood rough set model. Zhang et al. [6] put forward an attribute reduction algorithm using the evidence theory and the neighborhood rough set model. Wang et al. [7] introduced the concept of decision self-information based on the neighborhood rough set model and employed it for effective feature selection.
Fuzzy set theory quantifies uncertainty through fuzzy membership degrees, enabling it to effectively handle fuzzy and uncertain information. People have combined fuzzy set theory with various theories, such as neural network theory [8,9,10,11], rough set theory [12,13,14,15,16,17], and covering theory [18,19,20,21,22], among others. Li et al. [11] constructed a neural network and utilized its weight connections for feature selection. Wang et al. [12] proposed an advanced feature selection algorithm that utilizes distance metrics grounded in fuzzy rough set theory. Hu et al. [13] introduced a multi-kernel fuzzy rough set model and successfully applied it to the task of feature selection. Wang et al. [14] formulated a rough set model with adjustable parameters to modulate the similarity between samples, thereby enhancing the accuracy of feature selection. Zeng et al. [15] introduced a fuzzy rough set model, leveraging the Gaussian kernel, to achieve incremental feature selection. Zhang et al. [16] employed a fuzzy rough information structure to facilitate the selection of features from categorical data. Sun et al. [17] presented a feature selection algorithm for heterogeneous data, leveraging a fuzzy neighborhood rough set model. Huang et al. [20, 21] introduced a robust rough set model, along with a noise-tolerant discrimination index, which relies on the fuzzy \(\beta \)-covering approach for feature selection. Huang et al. [22] introduced a meticulous fitting model rooted in fuzzy \(\beta \)-covering for the purpose of feature selection.
The evidence theory describes the uncertainty of evidence using the uncertain interval composed of a belief function and a plausibility function [23]. The belief and the plausibility of a set are the quantitative descriptions of the uncertainty. The upper and lower approximations of a set are qualitative descriptions of the information. Therefore, there is a close relation between the evidence theory and rough set theory [24]. Some scholars applied the evidence theory to feature selection by combining it and rough set theory. Chen et al. [25] established a bridge between the fuzzy covering and evidence theory, and then reduced the attributes of the decision information system based on the evidence theory. Peng et al. [26] studied feature selection in an interval-valued information system based on the Dempster-Shafer evidence theory.
Evidence theory based on the crisp sets is difficult to deal with the fuzzy phenomenon. Fuzzy set theory is good at dealing with this kind of phenomenon and enjoys widespread application in various fields, including control systems, artificial intelligence, and decision analysis [27]. For instance, in automotive autonomous driving systems, fuzzy sets effectively capture the intricate relationship between a vehicle’s speed and its distance from obstacles, significantly enhancing the precision of vehicle movement control. Similarly, in intelligent robots, fuzzy sets accurately represent the robot’s perception and comprehension of its surroundings, enabling it to execute tasks with greater efficiency. Furthermore, in the realm of investment decision-making, fuzzy sets aptly characterize the risks and potential returns of diverse investment options, ultimately facilitating a more informed and comprehensive analysis of decision alternatives. Therefore, the fuzzy evidence theory is proposed to deal with fuzzy information. Wu et al. [28] extended the evidence theory to the fuzzy evidence theory and defined a pair of fuzzy belief and plausibility functions. Yao et al. [29] proposed two reduction methods based on the fuzzy belief and fuzzy plausibility in fuzzy decision systems. Tao et al. [30] studied the relative reduction of a fuzzy covering system using fuzzy evidence theory.
The feature selection algorithms based on evolutionary computation methods are also an important research direction in the field of artificial intelligence. In recent years, scholars have proposed many feature selection algorithms based on swarm intelligence and evolutionary computation, which have solved the NP-hard problem of feature selection to a certain extent. Xue et al. [31] transformed the feature selection problem of datasets with missing data into a three-objective optimization problem using the NSGA-III algorithm. Xue et al. [32] crafted a new self-adaptive PSO algorithm with multiple CSGSs and implemented it to address intricate large-scale feature selection challenges. Song et al. [33] delved into a variable-sized cooperative coevolutionary particle swarm optimization algorithm, leveraging the “divide and conquer" approach, for the purpose of optimizing feature selection in high-dimensional data. Hu et al. [34] introduced a fuzzy multi-objective feature selection approach that incorporates Fuzzy Cost and is grounded in particle swarm optimization techniques.
Motivation and inspiration
The actual data in real life are obtained through measurement, so missing values and noise are inevitable. Feature selection algorithms based on rough set and fuzzy rough set are sensitive to noise.
The findings about feature selection based on the fuzzy evidence theory are very few, and no findings in this field have been found in recent years. Yao et al. [29] and Feng et al. [30] established a theory of feature selection based on fuzzy evidence theory but did not give the corresponding algorithms. Yao et al. [29] only did experiments on an artificial data set containing nine samples. Feng et al. [30] only did experiments about coverings reduction in an artificial fuzzy coverings system containing three samples. Their feature selection methods based on fuzzy evidence theory are not noise-resistant. The reflective fuzzy \(\beta \) covering has a good anti-noise ability [20, 21]. In addition, Euclidean distance is difficult to accurately measure the difference between nominal attribute values.
Given the above problems, this paper proposes two robust feature selection algorithms by combining fuzzy evidence theory with reflective fuzzy \(\beta \) covering based on the newly defined distance. The contributions of this paper are as follows:
-
A new distance for replacing Euclidean distance is defined to solve the problem that it is difficult to measure the similarity between nominal attribute values accurately for more accurate feature selection.
-
The corresponding relationship between fuzzy \(\beta \) covering with an anti-noise mechanism and fuzzy evidence theory is established. Fuzzy belief and plausibility can be calculated by fuzzy \(\beta \) covering.
-
Two robust feature selection algorithms for hybrid data are proposed based on fuzzy belief and plausibility with a good ability to resist noise.
Organization
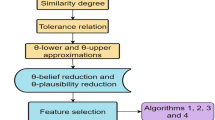
The rest of the paper is organized as follows. Section “Preliminaries” reviews the relevant concepts and theories of fuzzy relation, fuzzy rough set and fuzzy evidence theory. Section “Fuzzy  covering decision information systems” defines the fuzzy \(\beta \) covering decision information system and gives some properties. Section “Hybrid information system” defines a new distance function for hybrid information systems. Section “Feature selection for hybrid data based on fuzzy \(\beta \) covering and fuzzy evidence theory” establishes a connection between fuzzy evidence theory and fuzzy \(\beta \) covering and designs two feature selection algorithms using fuzzy belief and plausibility. Section “Experimental analysis and results” conducts some experiments to verify the performances of our algorithms. Section “Conclusion” sums up the paper.
covering decision information systems” defines the fuzzy \(\beta \) covering decision information system and gives some properties. Section “Hybrid information system” defines a new distance function for hybrid information systems. Section “Feature selection for hybrid data based on fuzzy \(\beta \) covering and fuzzy evidence theory” establishes a connection between fuzzy evidence theory and fuzzy \(\beta \) covering and designs two feature selection algorithms using fuzzy belief and plausibility. Section “Experimental analysis and results” conducts some experiments to verify the performances of our algorithms. Section “Conclusion” sums up the paper.
Preliminaries
The section is a review of fuzzy relations and fuzzy evidence theory.
The meanings of some symbols used in this article are as follows.
\(\Omega \): a finite set of objects.
I: [0, 1].
\(2^\Omega \): all subsets of \(\Omega \).
\(I^\Omega \): all fuzzy sets of \(\Omega \).
Let
and
where \(|\Psi |~(\Psi \subseteq \Omega )\) denotes the cardinality of \(\Psi \).
Fuzzy relations and fuzzy rough sets
A fuzzy set F on \(\Omega \) is a map \(F:\Omega \rightarrow I\), where \(F(\omega )~(\omega \in \Omega )\) is called the membership degree of \(\omega \) to F.
\(\forall a\in I\), \({\bar{a}}\) is a constant fuzzy set on \(\Omega \), i.e., \(\forall ~\omega \in \Omega \), \({\bar{a}}(\omega )=a\).
\(\forall F\in I^\Omega \), then F is expressed as
and
denotes the cardinality of F. Put
R is called a fuzzy relation on \(\Omega \) when R is a fuzzy set on \(\Omega \times \Omega \). R can be expressed as \(M(R)=(R(\omega _i,\omega _j))_{nn}\), where \(R(\omega _i,\omega _j)\in I\) is the similarity between \(\omega _i\) and \(\omega _j\).
\(I^{\Omega \times \Omega }\) denotes the set of all fuzzy relations on \(\Omega \).
\(\forall ~\omega ,~ \omega '\in \Omega \), define
Obviously, \(S_R(\omega )\) can be regarded as a fuzzy set and the fuzzy information granule of \(\omega \).
Let \((\Omega ,R)~(R\in I^{\Omega \times \Omega })\) denote a fuzzy approximation space.
\(\forall \Upsilon \in I^\Omega \), define
where \({\underline{R}}(\Upsilon )\) is called the lower fuzzy approximation to \(\Upsilon \) and \({\overline{R}}(\Upsilon )\) is called the upper fuzzy approximation to \(\Upsilon \).
The above fuzzy rough set model can be counted as the extension of the classical rough set model.
Fuzzy evidence theory
Fuzzy evidence theory is capable of handling fuzzy phenomena, whereas traditional evidence theory lacks this ability. Fuzzy evidence theory uses the membership function to construct the fuzzy belief and plausibility functions.
Definition 1
([28]) A function \(m: I^\Omega \rightarrow I\) is called a fuzzy basic probability assignment (FBPA) on \(\Omega \), if it meets the following conditions:
Definition 2
([28]) \(Bel:I^\Omega \rightarrow I\) is called a fuzzy belief function, if
Definition 3
([28]) \(Pl:I^\Omega \rightarrow I\) is called a fuzzy plausibility function, if
Fuzzy \(\beta \) covering decision information systems
\(\forall ~{\mathcal {C}}=\left\{ C_1,C_2,\ldots ,C_s\right\} \in \left[ I^\Omega \right] ^{<\epsilon },\) denote
Definition 4
[18] \({\mathcal {C}}~({\mathcal {C}}\in [I^\Omega ]^{<\epsilon })\) is called a fuzzy covering for \(\Omega \), if \(\cup {\mathcal {C}}={\overline{1}}\).
Definition 5
[18] \({\mathcal {C}}~({\mathcal {C}}\in [I^\Omega ]^{<\epsilon })\) is called a fuzzy \(\beta ~(\beta \in (0, 1])\) covering for \(\Omega \), if \(\cup {\mathcal {C}}\supseteq {\overline{\beta }}\).
Let \({\mathcal {C}}\) be a fuzzy \(\beta \) covering for \(\Omega \). \(\forall \omega \in \Omega \), denote \({\mathcal {C}}_\omega ^\beta =\{C\in {\mathcal {C}}: C(\omega )\ge \beta \}\) and \([\omega ]_{\mathcal {C}}^\beta =\cap {\mathcal {C}}_\omega ^\beta .\) Then \([\omega ]_{\mathcal {C}}^\beta \) is called the fuzzy \(\beta \) neighborhood of \(\omega \).
Obviously, \([\omega ]_{\mathcal {C}}^\beta (\omega )\ge \beta .\) Denote \(\Omega /{\mathcal {C}}=\{[\omega ]_{\mathcal {C}}^\beta :\omega \in \Omega \}.\)
Proposition 1
The following properties hold.
-
(1)
If \(\cup {\mathcal {C}}\supseteq \overline{\beta _1}\), and \(\beta _1\ge \beta _2\), then \([\omega ]_{\mathcal {C}}^{\beta _1}\supseteq [\omega ]_{\mathcal {C}}^{\beta _2};\)
-
(2)
If \(\cup {\mathcal {C}}_1\supseteq {{\overline{\beta }}}\), and \({\mathcal {C}}_1\subseteq {\mathcal {C}}_2\), then \([\omega ]_{{\mathcal {C}}_1}^\beta \supseteq [\omega ]_{{\mathcal {C}}_2}^\beta .\)
Proof
It is obviously true. \(\square \)
Definition 6
[18] Let \({\mathcal {C}}\) be a fuzzy \(\beta \) covering for \(\Omega \). \(\forall ~ \Upsilon \in I^\Omega \), define
Then \(\underline{{\mathcal {C}}}^\beta (\Upsilon )\) is called the lower approximation to \(\Upsilon \) and \(\overline{{\mathcal {C}}}^\beta (\Upsilon )\) is called the upper approximation to \(\Upsilon \).
Definition 7
Let \(\Delta =\{{\mathcal {C}}_1,{\mathcal {C}}_2,\ldots ,{\mathcal {C}}_m\}\) and \(\beta \in (0, 1]\). Then \((\Omega ,\Delta )\) is called a fuzzy \(\beta \) covering information system (fuzzy \(\beta \) CIS), if \(\forall ~i\), \({\mathcal {C}}_i\) is a fuzzy \(\beta \) covering for \(\Omega \).
If \({\mathcal {P}}\subseteq \Delta \), then \((\Omega ,{\mathcal {P}})\) is a fuzzy \(\beta \) covering information subsystem of \((\Omega ,\Delta )\); if \(\Delta =\{{\mathcal {C}}\}\), then \((\Omega ,\Delta )\) is a fuzzy \(\beta \) covering approximation space.
Let \((\Omega ,\Delta )\) be a fuzzy \(\beta \) CIS with \(\Delta =\{{\mathcal {C}}_1,{\mathcal {C}}_2,\ldots ,{\mathcal {C}}_m\}\). \(\forall {\mathcal {P}}\subseteq \Delta \) and \(\omega \in \Omega \), denote \([\omega ]_{\mathcal {P}}^\beta =\bigcap \nolimits _{{\mathcal {C}}_i \in {\mathcal {P}}}[\omega ]_{{\mathcal {C}}_i}^\beta .\) Then \([\omega ]_{{\mathcal {P}}}^\beta \) is called the fuzzy \(\beta \) neighborhood of \(\omega \) in \((\Omega ,{\mathcal {P}})\).
Obviously, \([\omega ]_{{\mathcal {P}}}^\beta (\omega )\ge \beta .\)
The parameterized fuzzy \(\beta \) neighborhood is designed as follows:
where \(\lambda \in [0,1]\) is called the neighborhood radius.
This design makes the fuzzy \(\beta \) covering noise-resistant because too small value is likely to be noise.
Clearly, \([\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }\left( \omega '\right) \le [\omega ]_{\mathcal {P}}^\beta \left( \omega '\right) ~\left( \forall \omega ,\omega ' \in \Omega \right) .\)
Denote \((\Omega /{{\mathcal {P}}})^\beta _\lambda =\left\{ [\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }:\omega \in \Omega \right\} .\)
Proposition 2
[27] \(\forall \omega \in \Omega \), the following properties hold:
- (1):
-
If \(\beta _1\le \beta _2\), then \([\omega ]_{{\mathcal {P}}}^{\beta _1,\lambda }\subseteq [\omega ]_{{\mathcal {P}}}^{\beta _2,\lambda };\)
- (2):
-
If \({\mathcal {P}}\subseteq {\mathcal {Q}}\), then \([\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }\supseteq [\omega ]_{{\mathcal {Q}}}^{\beta ,\lambda };\)
- (3):
-
If \(\lambda _1\le \lambda _2\), then \([\omega ]_{{\mathcal {P}}}^{\beta ,\lambda _1}\supseteq [\omega ]_{{\mathcal {P}}}^{\beta ,\lambda _2}.\)
Huang et al. [22] pointed out that Definition 6 has a shortcoming, i.e., \(\underline{{\mathcal {C}}}^\beta (\Upsilon )\not \subseteq \overline{{\mathcal {C}}}^\beta (\Upsilon )\). Thus, they gave the following definition to overcome the shortcoming.
Definition 8
[22] Let \((\Omega ,\Delta )\) be a fuzzy \(\beta \) CIS with \({\mathcal {P}}\subseteq \Delta \) and \(\beta \in (0,1]\). \(\forall ~ \Upsilon \in I^\Omega \), define
Then \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\) is called the lower approximation to \(\Upsilon \) and \({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\) is called the upper approximation to \(\Upsilon \).
Theorem 3
\(\forall \Upsilon , \Xi \in I^\Omega \), then the following properties hold:
- (1):
-
\({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{0}})={\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{0}})={\bar{0}}\), \(\ {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}})={\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}})={\bar{1}}\).
- (2):
-
\( {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\). Moreover, if \(\lambda \le \beta \), then \( {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq \Upsilon \subseteq {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\).
- (3):
-
\(\Upsilon \subseteq \Xi \Rightarrow \ {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq \ {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi ),~{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq \ {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi )\).
- (4):
-
If \(\beta _1\le \beta _2\), then \({\underline{apr}}_{{\mathcal {P}}}^{\beta _2,\lambda }(\Upsilon )\subseteq \ {\underline{apr}}_{{\mathcal {P}}}^{\beta _1,\lambda }(\Upsilon ), ~{\overline{apr}}_{{\mathcal {P}}}^{\beta _1,\lambda }(\Upsilon )\subseteq {\overline{apr}}_{{\mathcal {P}}}^{\beta _2,\lambda }(\Upsilon ).\)
- (5):
-
If \({\mathcal {P}}\subseteq {\mathcal {Q}}\), then \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq \ {\underline{apr}}_{{\mathcal {Q}}}^{\beta ,\lambda }(\Upsilon ), ~{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon ) \supseteq {\overline{apr}}_{{\mathcal {Q}}}^{\beta ,\lambda }(\Upsilon ).\)
- (6):
-
If \(\lambda _1\le \lambda _2\), then \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda _1}(\Upsilon )\subseteq \ {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda _2}(\Upsilon ), ~{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda _1}(\Upsilon )\supseteq {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda _2}(\Upsilon ).\)
- (7):
-
\( {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon \cap \Xi )= {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\cap {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi )\); \( {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon \cup \Xi )= {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\cup {\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi )\). (8) \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}}-\Upsilon )= {\bar{1}}-{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\); \({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}}-\Upsilon )= {\bar{1}}-{\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\).
Proof
(1) It is obvious.
(2) (1)“\({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq ~{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\)" is proved in Theorem 3.1 of [22].
(2) In order to prove that “\(\lambda \le \beta ~\Rightarrow ~{\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq ~ \Upsilon \)", it is sufficient to show that
Let \(\lambda \le \beta ,~\Upsilon (\omega )\ge 1-\beta .\) Put \(A(\omega )=\{\omega '\in \Omega :[\omega ]^\beta _{{\mathcal {P}}}(\omega ')\ge \lambda \},~B(\omega )=\Omega -A(\omega ).\)
Since \(\lambda \le \beta \), we have \([\omega ]^\beta _{{\mathcal {P}}}(\omega )\ge \beta \ge \lambda \). So \(\omega \in A(\omega )\).
Note that \(\Upsilon (\omega )\ge 1-\beta \). Then
(3) In order to prove that “\(\beta \ge \lambda ~\Rightarrow ~ \Upsilon ~\subseteq ~{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\), it is sufficient to show that
Note that \(\Upsilon (\omega )\le \beta \). Then
(3) Let \(\Upsilon \subseteq \Xi \). Then \(\forall ~\omega \in \Omega \), \(\Upsilon (\omega )\le \Xi (\omega )\).
In order to prove that \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq \ {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi )\) and \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\subseteq \ {\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi )\), it is sufficient to show that
Suppose \(\Upsilon (\omega )\ge 1-\beta \). Then
Suppose \(\Xi (\omega )\le \beta \). Then
(4) It follows from Proposition 2(1).
(5) It can be proved by Proposition 2(2).
(6) It can be proved by Proposition 2(2).
(7) It is sufficient to show that
Suppose \((\Upsilon \cap \Xi )(\omega )\ge 1-\beta \). Then \(\Upsilon (\omega ),\Xi (\omega )\ge 1-\beta \). Thus
Hence
Suppose \(\Upsilon (\omega ),\Xi (\omega )\le \beta \). Then \((\Upsilon \cup \Xi )(\omega )\le \beta \). Thus
Thus \({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )(\omega )=\bigvee \nolimits _{\omega '\in \Omega }\{[\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }(\omega ')\wedge \Upsilon (\omega ')\}\),
\({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Xi )(\omega )=\bigvee \nolimits _{\omega '\in \Omega }\{[\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }(\omega ')\wedge \Xi (\omega ')\}\),
\({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon \cup \Xi )(\omega )=\bigvee \nolimits _{\omega '\in \Omega }\{[\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }(\omega ')\wedge (\Upsilon \cup \Xi )(\omega ')\}\).
Hence
(8) Obviously,
Suppose \(({\bar{1}}-\Upsilon )(\omega )< 1-\beta \). Then \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}}-\Upsilon )(\omega )=0\), \({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )(\omega )=1\). Thus
Suppose \(({\bar{1}}-\Upsilon )(\omega )\ge 1-\beta \). Then
Thus \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}}-\Upsilon ) ={\bar{1}}-{\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\).
Similarly, it can be proved that \({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }({\bar{1}}-\Upsilon ) ={\bar{1}}-{\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(\Upsilon )\). \(\square \)
Definition 9
Let d denote the decision attribute and \(\Delta =\{{\mathcal {C}}_1,{\mathcal {C}}_2,\ldots ,{\mathcal {C}}_m\}\). Then \((\Omega ,\Delta , d)\) is called a fuzzy \(\beta ~ (\beta \in (0, 1])\) covering decision information system (fuzzy \(\beta \) CDIS), if \(\forall ~i\), \({\mathcal {C}}_i\) is a fuzzy \(\beta \) covering of \(\Omega \).
Definition 10
Let \((\Omega ,\Delta , d)\) be a fuzzy \(\beta \) CDIS with \(U/d = \{D_1, D_2, \ldots , D_r \}\), \(\beta ,\lambda \in [0, 1]\). Define
where \(([\omega ]_\Delta ^{\beta ,\lambda }\cap D_i)(\omega ')= {\left\{ \begin{array}{ll} [\omega ]_\Delta ^{\beta ,\lambda }(\omega '),&{}\omega '\in D_i\\ 0,&{} \omega '\not \in D_i. \end{array}\right. }\)
Then \(\{D_1^\lambda ,D_2^\lambda ,\ldots ,D_r^\lambda \}\) is called the fuzzy decision of objects concerning d.
Definition 11
Let \((\Omega ,\Delta ,d)\) be a fuzzy \(\beta \) CDIS with \({\mathcal {P}}\subseteq \Delta \). Define \({\underline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(D_i^\lambda )(\omega )\)
\(={\left\{ \begin{array}{ll} \bigwedge \limits _{\omega '\in \Omega }\{(1-[\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }(\omega '))\vee D_i^\lambda (\omega ')\},&{}D_i^\lambda (\omega )\ge 1-\beta \\ 0,&{}D_i^\lambda (\omega )< 1-\beta \end{array}\right. }\)
and
\({\overline{apr}}_{{\mathcal {P}}}^{\beta ,\lambda }(D_i^\lambda )(\omega )\)
\(={\left\{ \begin{array}{ll} \bigvee \limits _{\omega '\in \Omega }\{[\omega ]_{{\mathcal {P}}}^{\beta ,\lambda }(\omega ')\wedge D_i^\lambda (\omega ')\},&{}D_i^\lambda (\omega )\le \beta \\ 1,&{}D_i^\lambda (\omega )>\beta . \end{array}\right. }\)
Hybrid information system
Definition 12
Let \(\Theta \) denote a finite set of conditional attributes. Then \((\Omega ,\Theta ,d)\) is called a decision information system (DIS), if \(\forall \theta \in \Theta \) decides a function \(\theta :\Omega \rightarrow V_\theta \), where \(V_\theta =\{\theta (\omega ): \omega \in \Omega \}\). If \(\Phi \subseteq \Theta \), then \((\Omega ,\Phi ,d)\) is referred to as a subsystem of \((\Omega ,\Theta ,d)\).
Let \(V_d=\{d(\omega ):\omega \in \Omega \}=\{d_1,d_2,\ldots ,d_r\},\) where \(d_i~(i=1,2,\ldots ,r)\) is the decision attribute value.
Definition 13
Let \((\Omega ,\Theta ,d)\) be a DIS. Then \((\Omega ,\Theta ,d)\) is called an incomplete decision information system (IDIS), if \(\exists *\in V_\theta \) (“\(*\)” denotes an unknown value).
Let \(V_\theta ^*=V_\theta -\{\theta (\omega ):\theta (\omega )=*\}~(\theta \in \Theta )\) denote all known information values of \(\theta \).
Definition 14
Let \((\Omega ,\Theta ,d)\) be an IDIS. Then \((\Omega ,\Theta ,d)\) is called a hybrid information system (HIS), if \(\Theta =\Theta ^{c}\cup \Theta ^{r}\), where \(\Theta ^{c}\) is the category attribute set and \(\Theta ^{r}\) is the numerical attribute set.
Example 1
Table 1 shows an HIS, where \(\Omega =\{\omega _1,\omega _2,\ldots ,\omega _8\}\), \(\Theta =\{\theta _1,\theta _2,\theta _3\}\), \(\Theta ^{c}=\{\theta _1,\theta _2\}\) and \(\Theta ^{r}=\{\theta _3\}\).
Example 2
(Continue with Examples 1) \(V_{\theta _1}^*=\)\(\{No, Middle,Sick \}\), \(V_{\theta _2}^*=\{No,Yes\}\), \(V_{\theta _3}^*=\{36,37,39,39.5,40,37.5\}\), \(V_{d}^*=V_{d}=\{Health, Flu, Reinitis\}\).
The difference between objects is comprehensively reflected by the distance between the information values under attributes. An HIS has different types of conditional attributes. To measure the difference between two objects more accurately, a distance function is proposed as follows.
Definition 15
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\forall \theta \in \Theta ^c\) and \(\theta (\omega )\ne *~(\forall \omega \in \Omega )\). Define \(N(\theta ,\omega )=|\{\omega '\in \Omega :\theta (\omega )=\theta (\omega ')\}|,\) \(N_i(\theta ,\omega )=|\{\omega '\in \Omega :\theta (\omega )=\theta (\omega '),~d(\omega ')=d_i\}|.\)
Obviously,
Definition 16
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\theta \in \Theta ^c \), \(\omega ~and~\omega '\in \Omega \) with \(\theta (\omega )\ne *\) and \(\theta (\omega ')\ne *\). Then the distance between \(\theta (\omega )\) and \(\theta (\omega ')\) is defined as
Proposition 4
Let \((\Omega ,\Theta ,d)\) be an HIS. Then the following conclusions hold:
- (1):
-
\(\rho _c (\theta (\omega ),\theta (\omega ))=0;\)
- (2):
-
\(0\le \rho _c (\theta (\omega ),\theta (\omega '))\le 1.\)
Definition 17
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\theta \in \Theta ^r \), \(\omega ~and~\omega '\in \Omega \) with \(\theta (\omega )\ne *\) and \(\theta (\omega ')\ne *\). Then the distance between \(\theta (\omega )\) and \(\theta (\omega ') \) is defined as follows:
where \(M=max\{\theta (\omega ):\omega \in \Omega \}-min\{\theta (\omega ):\omega \in \Omega \}\).
If \(M=0\), let \(\rho _r(\theta (\omega ),\theta (\omega '))=0\).
Obviously, we have \(\rho _r(\theta (\omega ),\theta (\omega ))=0~~ and ~~0\le \rho _r(\theta (\omega ),\theta (\omega '))\le 1.\)
According to the above analysis, we define a new distance function between information values of HIS.
Definition 18
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\theta \in \Theta \), \(\omega _1\in \Omega \), and \(\omega _2 \in \Omega \). Then the distance between \(\theta (\omega _1)\) and \(\theta (\omega _2)\) is defined as follows:
The difference between nominal attribute values is measured by a probability distribution, which is more consistent with reality. Definition 18 can effectively handle incomplete hybrid information systems.
Example 3
(Continue with Examples 1)
According to Definitions 16, 17 and 18, we have
- (1):
-
\(\rho (\theta _1(\omega _1),\theta _1(\omega _3))=0,\)
- (2):
-
\(\rho (\theta _1(\omega _1),\theta _1(\omega _4))=(|\frac{2}{2}-\frac{0}{3}|+|\frac{0}{2}-\frac{1}{3}|+|\frac{0}{2}-\frac{2}{3}|)/2=1,\)
- (3):
-
\(\rho (\theta _2(\omega _1),\theta _2(\omega _4))=1-\frac{1}{2}=\frac{1}{2}=0.500,\)
- (4):
-
\(\rho (\theta _2(\omega _1),\theta _2(\omega _5))=(|\frac{2}{3}-\frac{0}{1}|+|\frac{1}{3}-\frac{1}{1}|+|\frac{0}{3}-\frac{0}{1}|)/2=\frac{2}{3}\approx 0.667,\)
- (5):
-
\(\rho (\theta _3(\omega _2),\theta _3(\omega _8))=1-\frac{1}{6^2}=\frac{35}{36}\approx 0.970,\)
- (6):
-
\(\rho (\theta _3(\omega _4),\theta _3(\omega _6))=\frac{|39-40|}{40-36}=\frac{1}{4}=0.250.\)
Definition 19
Let \((\Omega , \Theta ,d)\) be an HIS with \(\Psi \subseteq \Theta \), \(\Omega =\{\omega _1,\omega _2,\ldots ,\omega _n\},\) \(\Psi =\{\theta _{k_1},\theta _{k_2},\ldots ,\theta _{k_s}\}.\) Define \(R_{k_i}(\omega _u,\omega _v)=1-\rho (\theta _{k_i}(\omega _u),\theta _{k_i}(\omega _v))~(i=1,\ldots ,s;\omega _u,~\omega _v\in \Omega ).\) Denote \(K_{ij}=S_{R_{k_i}}(\omega _j)~(j=1,\ldots ,n), ~{\mathcal {C}}_i=\{K_{ij}\}_{j=1}^n,\) \(\triangle _\Psi =\{{\mathcal {C}}_1,{\mathcal {C}}_2,\ldots ,{\mathcal {C}}_s\}.\) Then \(\triangle _\Psi \) is a fuzzy \(\beta \) covering derived from \(\Psi \) and \((\Omega ,\triangle _\Psi ,d)\) is a fuzzy \(\beta \) CDIS derived from the subsystem \((\Omega ,\Psi ,d)\).
For simplicity, let’s assume \(\triangle _\theta =\triangle _{\{\theta \}}~(\theta \in \Theta ).\)
Feature selection for hybrid data based on fuzzy  covering and fuzzy evidence theory
covering and fuzzy evidence theory
 covering and fuzzy evidence theory
covering and fuzzy evidence theoryFuzzy belief function and fuzzy plausibility function
Theorem 5
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\in (0,1]\) and \(B\subseteq \Theta \). Define \(Bel^{\beta ,\lambda }_B(\Upsilon )=p^f({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(\Upsilon )),~Pl^{\beta ,\lambda }_B(\Upsilon )=p^f({\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(\Upsilon ))~(\forall ~\Upsilon \in I^\Omega ).\) Then \(Bel^{\beta ,\lambda }_B\) is fuzzy \(\lambda \)-belief function, \(Pl^{\beta ,\lambda }_B\) is fuzzy \(\lambda \)-plausibility function, and \(m^{\beta ,\lambda }_B(F)=p(j^{\beta ,\lambda }_B(F))~(\forall ~F\in I^\Omega ),\) where \(j^{\beta ,\lambda }_B(F) = \{\omega \in \Omega :[\omega ]_{\triangle _B}^{\beta ,\lambda }= F\}\).
Proof
(1) Since \(j^{\beta ,\lambda }_B({\bar{0}})=\emptyset ,\) we have \(m^{\beta ,\lambda }_B({\bar{0}})=\frac{|\emptyset |}{n}=0.\)
\(\forall ~\omega \in \Omega ,\) pick \(F^*=G_B^{\lambda }(\omega ),\) we have \(\omega \in j^{\beta ,\lambda }_B(F^*)\) and \(F^*\in I^\Omega \). Then \(\omega \in \bigcup \nolimits _{F\in I^\Omega }j^{\beta ,\lambda }_B(F)\). This implies that \(\Omega \subseteq \bigcup \nolimits _{F\in I^\Omega }j^{\beta ,\lambda }_B(F).\)
Thus \(\bigcup \nolimits _{F\in I^\Omega }j^{\beta ,\lambda }_B(F)= \Omega .\)
Note that \(F_1\ne F_2\), \(j^{\beta ,\lambda }_B(F_1)\cap j^{\beta ,\lambda }_B(F_2)=\emptyset \). Then \(\sum \nolimits _{F\in I^\Omega }|j^{\beta ,\lambda }_B(F)|= n.\)
This follows that \(\sum \nolimits _{F\in I^\Omega }m^{\beta ,\lambda }_B(F)=\sum \nolimits _{F\in I^\Omega }\frac{|j^{\beta ,\lambda }_B(F)|}{n}=1.\)
By Definition 1, \(m^{\beta ,\lambda }_B\) is a FBPA on \(\Omega \).
(2) Let \(\Upsilon \in I^\Omega \). Then \(x,y\in j^{\beta ,\lambda }_B(F)\),
Thus, \(\sum \nolimits _{\omega \in j^{\beta ,\lambda }_B(F)}\bigwedge \nolimits _{\omega '\in \Omega }[(1-[\omega ]_{\triangle _B}^{\beta ,\lambda }(\omega '))\vee \Upsilon (\omega ')] =|j^{\beta ,\lambda }_B(F)|\bigwedge \nolimits _{\omega '\in \Omega }[(1-F(\omega '))\vee \Upsilon (\omega ')].\)
Note that \(\bigcup \nolimits _{F\in I^\Omega }j^{\beta ,\lambda }_B(F)= \Omega .\) Then
Thus, \(Bel^{\beta ,\lambda }_B\) is a belief function on \(\Omega \) according to Definition 2.
(3) Let \(\Upsilon \in I^\Omega \). Then \(x,y\in j^{\beta ,\lambda }_B(F)\),
Thus, \(\sum \nolimits _{\omega \in j^{\beta ,\lambda }_B(F)}\bigvee \nolimits _{\omega '\in \Omega }\) \( \{[\omega ]_{\triangle _B}^{\beta ,\lambda }(\omega ')\wedge \Upsilon (\omega ')\}=|j^{\beta ,\lambda }_B(F)|\bigvee \nolimits _{\omega '\in \Omega }\{F(\omega )\wedge \Upsilon (\omega ')\}.\)
Note that \(\bigcup \nolimits _{F\in I^\Omega }j^{\beta ,\lambda }_B(F)= \Omega .\) Then,
Thus, \(Pl^{\beta ,\lambda }_B\) is a plausibility function on \(\Omega \) according to Definition 3. \(\square \)
Proposition 6
Suppose that \((\Omega ,\Theta ,d)\) is an HIS.
- (1):
-
If \(B_1\subset B_2\subseteq \Theta \), then \(\forall ~\Upsilon \in I^\Omega \), \(\forall ~\in (0,1],\)
$$\begin{aligned} Bel^{\beta ,\lambda }_{B_1}(\Upsilon )\le Bel^{\beta ,\lambda }_{B_2}(\Upsilon ) \le p(\Upsilon )\le Pl^{\beta ,\lambda }_{B_2}(\Upsilon )\le Pl^{\beta ,\lambda }_{B_1}(\Upsilon ). \end{aligned}$$ - (2):
-
If \(\Upsilon _1\subseteq \Upsilon _2\) \(\Upsilon _1,\Upsilon _2\in I^\Omega \), then \(\forall ~B\subseteq \Theta \), \(\forall ~\in (0,1],\)
$$\begin{aligned} Bel^{\beta ,\lambda }_B(\Upsilon _1)\le Bel^{\beta ,\lambda }_B(\Upsilon _2)~and~Pl^{\beta ,\lambda }_B(\Upsilon _1)\le Pl^{\beta ,\lambda }_B(\Upsilon _2). \end{aligned}$$ - (3):
-
If \(0\le \lambda _1< \lambda _2\le 1\), then \(\forall ~B\subseteq \Theta \), \(\forall ~\Upsilon \in I^\Omega ,\)
$$\begin{aligned} Bel^{\beta ,\lambda _2}_B(\Upsilon )\le Bel^{\beta ,\lambda _1}_B(\Upsilon )~and~Pl^{\beta ,\lambda _1}_B(\Upsilon )\le Pl^{\beta ,\lambda _2}_B(\Upsilon ). \end{aligned}$$
Proof
(1) Let \(\Upsilon \in I^\Omega \) and \(\in (0,1]\).
By Theorem 3(2), we have \({\underline{apr}}_{\triangle _{B_2}}^{\beta ,\lambda }(\Upsilon )\subseteq \Upsilon {\subseteq } {\overline{apr}}_{\triangle _{B_2}}^{\beta ,\lambda }(\Upsilon )\).
Then \(|{\underline{apr}}_{\triangle _{B_2}}^{\beta ,\lambda }(\Upsilon )|\le |\Upsilon |\le |{\overline{apr}}_{\triangle _{B_2}}^{\beta ,\lambda }(\Upsilon )|\).
Hence, \(Bel^{\beta ,\lambda }_{B_2}(\Upsilon ) \le p(\Upsilon )\le Pl^{\beta ,\lambda }_{B_2}(\Upsilon ).\)
Since \(B_1\subset B_2\subseteq \Theta \), by Theorem 3(4), we have
Then \(|{\underline{apr}}_{\triangle _{B_1}}^{\beta ,\lambda }(\Upsilon )|\le ~|{\underline{apr}}_{\triangle _{B_2}}^{\beta ,\lambda }(\Upsilon )|, ~|{\overline{apr}}_{\triangle _{B_2}}^{\beta ,\lambda }(\Upsilon )| \le ~|{\overline{apr}}_{\triangle _{B_1}}^{\beta ,\lambda }(\Upsilon )|.\)
Hence, \(Bel^{\beta ,\lambda }_{B_1}(\Upsilon )\le Bel^{\beta ,\lambda }_{B_2}(\Upsilon ),~~Pl^{\beta ,\lambda }_{B_2}(\Upsilon )\le Pl^{\beta ,\lambda }_{B_1}(\Upsilon ).\)
Thus, \(Bel^{\beta ,\lambda }_{B_1}(\Upsilon )\le Bel^{\beta ,\lambda }_{B_2}(\Upsilon ) \le p(\Upsilon )\le Pl^{\beta ,\lambda }_{B_2}(\Upsilon )\le Pl^{\beta ,\lambda }_{B_1}(\Upsilon ).\)
(2) Let \(B\subseteq \Theta \) and \(\in (0,1]\).
Since \(\Upsilon _1\subseteq \Upsilon _2\), by Theorem 3(3), we have
Then, \(|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(\Upsilon _1)|\le |{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(\Upsilon _2)|,~~ |{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(\Upsilon _1)|\le |{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(\Upsilon _2)|.\)
Hence, \(Bel^{\beta ,\lambda }_B(\Upsilon _1)\le Bel^{\beta ,\lambda }_B(\Upsilon _2),~~Pl^{\beta ,\lambda }_B(\Upsilon _1)\le Pl^{\beta ,\lambda }_B(\Upsilon _2).\)
(3) Let \(B\subseteq \Theta \) and \(\Upsilon \in I^\Omega \).
Since \(0\le \lambda _1< \lambda _2\le 1\), by Theorem 3(5), we have
Then \(|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda _2}(\Upsilon )|\le |{\underline{apr}}_{\triangle _B}^{\beta ,\lambda _1}(\Upsilon )|\), \(|\overline{G_B^{\lambda _1}}(\Upsilon )|\)\(\le |\overline{G_B^{\lambda _2}}(\Upsilon )|\).
Thus, \(Bel^{\beta ,\lambda _2}_B(\Upsilon )\le Bel^{\beta ,\lambda _1}_B(\Upsilon ),~~Pl^{\beta ,\lambda _1}_B(\Upsilon )\)\(\le Pl^{\beta ,\lambda _2}_B(\Upsilon ).\) \(\square \)
Definition 20
Define the belief and plausibility of the decision attribute d in relation to the conditional attribute \(\forall ~B\subseteq \Theta \) as follows:
Proposition 7
Suppose that \((\Omega ,\Theta ,d)\) is an HIS.
-
(1)
If \(B_1\subset B_2\subseteq \Theta \), then \(\forall ~\beta ,\lambda \in [0,1]\),
$$\begin{aligned} Bel^{\beta ,\lambda }_{B_2}(d)\le Bel^{\beta ,\lambda }_{B_1}(d) \le 1\le Pl^{\beta ,\lambda }_{B_1}(d)\le Pl^{\beta ,\lambda }_{B_2}(d). \end{aligned}$$ -
(2)
If \(0\le \lambda _1< \lambda _2\le 1\), then \(\forall ~B\subseteq \Theta \),
$$\begin{aligned} Bel^{\beta ,\lambda _1}_B(d)\le Bel^{\beta ,\lambda _2}_B(d)~and~Pl^{\beta ,\lambda _2}_B(d)\le Pl^{\beta ,\lambda _1}_B(d). \end{aligned}$$
Proof
(1) By Proposition 6(1), we have
Then
Thus, \(Bel^{\beta ,\lambda }_{B_2}(d)\le Bel^{\beta ,\lambda }_{B_1}(d) \le 1\le Pl^{\beta ,\lambda }_{B_1}(d)\le Pl^{\beta ,\lambda }_{B_2}(d).\)
(2) These two inequalities can be easily proved by Proposition 6(3). \(\square \)
\(\lambda \)-belief reduction and \(\lambda \)-plausibility reduction in an HIS
Definition 21
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \).
- (1):
-
B is called a fuzzy \(\lambda \)-belief coordinated subset of \(\Theta \) concerning d, if
$$\begin{aligned} Bel^{\beta ,\lambda }_B\left( D_i^\lambda \right) =Bel^{\beta ,\lambda }_\Theta \left( D_i^\lambda \right) . \end{aligned}$$(22) - (2):
-
B is called a fuzzy \(\lambda \)-plausibility coordinated subset of \(\Theta \) concerning d, if
$$\begin{aligned} Pl^{\beta ,\lambda }_B\left( D_i^\lambda \right) =Pl^{\beta ,\lambda }_\Theta \left( D_i^\lambda \right) . \end{aligned}$$(23)
Let \(co^{\beta ,\lambda }_b(\Theta )\) denote all fuzzy \(\lambda \)-belief coordinated subsets of \( \Theta \) concerning d and \(co^{\beta ,\lambda }_p(\Theta )\) denote all fuzzy \(\lambda \)-plausibility coordinated subsets of \( \Theta \) concerning d.
Definition 22
([6]) Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \).
- (1):
-
B is called a fuzzy \(\lambda \)-belief reduction of \(\Theta \) concerning d, if \(B\in co_b^\lambda (\Theta )\) and \(\forall ~\theta \in B\), \(B-\{\theta \}\not \in co_b^\lambda (\Theta )\).
- (2):
-
B is called a fuzzy \(\lambda \)-plausibility reduction of \(\Theta \) concerning d, if \(B\in co_p^\lambda (\Theta )\) and \(\forall ~\theta \in B\), \(B-\{\theta \}\not \in co_p^\lambda (\Theta )\).
Lemma 8
Suppose \(U,V\in I^\Omega \). If \(U\subseteq V,\) \(|U|=|V|\), then \(U=V\).
Proof
Since \(|U|=|V|\), we have \(\sum \nolimits _{i=1}^n[V(\omega _i)-U(\omega _i)]=0~(\omega _i\in \Omega ).\)
\(U\subseteq V\) implies that \(\forall ~i,\) \(V(\omega _i)-U(\omega _i)\ge 0\).
Then \(\forall ~i,\) \(V(\omega _i)-U(\omega _i)=0\). Thus, \(U=V\). \(\square \)
Proposition 9
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then the following conclusions are equivalent to each other:
- (1):
-
\(B\in co^{\beta ,\lambda }_b(\Theta )\);
- (2):
-
\({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )~(i=1,2,\ldots ,r)\);
- (3):
-
\(Bel^{\beta ,\lambda }_B(d)=Bel^{\beta ,\lambda }_\Theta (d)\).
Proof
\((1)\Rightarrow (2)\). Let \(B\in co^{\beta ,\lambda }_b(\Theta )\). Then, \(~Bel^{\beta ,\lambda }_B(D_i^\lambda )=Bel^{\beta ,\lambda }_\Theta (D_i^\lambda ).\)
Hence, \(~|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|=|{\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|.\)
Since \(B\subseteq \Theta \), by Theorem 3(3), \(~{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )\subseteq {\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda ).\)
By Lemma 8, we have \({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda ).\)
\((2)\Rightarrow (3)\). Suppose \({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\). Then \(Bel^{\beta ,\lambda }_B(D_i^\lambda )=Bel^{\beta ,\lambda }_\Theta (D_i^\lambda ).\)
This implies that \(\sum \nolimits _{i=1}^rBel^{\beta ,\lambda }_B(D_i^\lambda )=\sum \nolimits _{i=1}^rBel^{\beta ,\lambda }_\Theta (D_i^\lambda ).\)
Thus, \(Bel^{\beta ,\lambda }_B(d)=Bel^{\beta ,\lambda }_\Theta (d).\)
\((3)\Rightarrow (1)\). Suppose \(Bel^{\beta ,\lambda }_B(d)=Bel^{\beta ,\lambda }_\Theta (d).\) Then \(\sum \nolimits _{i=1}^r\frac{|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|}{n}=\sum \nolimits _{i=1}^r\frac{|{\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|}{n}.\)
Thus, \(\sum \nolimits _{i=1}^r(|{\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|-|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|)=0.\)
Since \(B\subseteq \Theta \), by Theorem 3(3), we have \({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )\subseteq {\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\).
Then \(|{\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|-|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|\ge 0.\)
This implies that \(|{\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|=|{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|.\)
By Lemma 8, we have \({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )= {\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda ).\)
Hence, \(B\in co^{\beta ,\lambda }_b(\Theta )\). \(\square \)
Theorem 10
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then (1), (2) and (3) are equivalent to each other:
- (1):
-
\(B\in red^{\beta ,\lambda }_b(\Theta )\);
- (2):
-
\({\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )~(i=1,2,\ldots ,r)\) and \(\forall ~ a\in B\), \(\exists ~ i\in \{1,2,\ldots ,r\}\), \({\underline{apr}}_{\triangle _{B-\{a\}}}^{\beta ,\lambda }(D_i^\lambda )\ne {\underline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\);
- (3):
-
\(Bel^{\beta ,\lambda }_B(d)=Bel^{\beta ,\lambda }_\Theta (d)\) and \(\forall ~ a\in B\), \(Bel^{\beta ,\lambda }_{B-\{a\}}(d)\ne Bel^{\beta ,\lambda }_B(d).\)
Proof
The conclusions can be easily proved using Proposition 9. \(\square \)
Proposition 11
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then (1), (2) and (3) are equivalent to each other:
- (1):
-
\(B\in co^{\beta ,\lambda }_p(\Theta )\);
- (2):
-
\({\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )~(i=1,2,\ldots ,r)\);
- (3):
-
\(Pl^{\beta ,\lambda }_B(d)=Pl^{\beta ,\lambda }_\Theta (d)\).
Proof
\((1)\Rightarrow (2)\). Let \(B\in co^{\beta ,\lambda }_p(\Theta )\). Then \(Pl^{\beta ,\lambda }_B(D_i^\lambda )=Pl^{\beta ,\lambda }_\Theta (D_i^\lambda ).\)
Hence, \(|{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|=|{\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|.\)
Since \(B\subseteq \Theta \), by Theorem 3(3), \({\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\subseteq {\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda ).\)
By Lemma 8, we have \({\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda ).\)
\((2)\Rightarrow (3)\). Suppose \({\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\). Then \(Pl^{\beta ,\lambda }_B(D_i^\lambda )=Pl^{\beta ,\lambda }_\Theta (D_i^\lambda ).\)
This implies that \(\sum \nolimits _{i=1}^rPl^{\beta ,\lambda }_B(D_i^\lambda )=\sum \nolimits _{i=1}^rPl^{\beta ,\lambda }_\Theta (D_i^\lambda ).\)
Hence, \(Pl^{\beta ,\lambda }_B(d)=Pl^{\beta ,\lambda }_\Theta (d).\)
\((3)\Rightarrow (1)\). Suppose \(Pl^{\beta ,\lambda }_B(d)=Pl^{\beta ,\lambda }_\Theta (d).\) Then \(\sum \nolimits _{i=1}^r\frac{|{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|}{n}=\sum \nolimits _{i=1}^r\frac{|{\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|}{n}.\)
Thus, \(\sum \nolimits _{i=1}^r(|{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|-|{\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|)=0.\)
Since \(B\subseteq \Theta \), by Theorem 3(3), we have \({\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\subseteq {\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )\).
Then \(|{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|-|{\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|\ge 0.\)
This implies that \(|{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )|=|{\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )|.\)
By Lemma 8, we have \(\forall ~i,~{\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )= {\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda ).\)
Hence, \(B\in co^{\beta ,\lambda }_p(\Theta )\). \(\square \)
Theorem 12
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then (1), (2) and (3) are equivalent to each other:
- (1):
-
\(B\in red^{\beta ,\lambda }_p(\Theta )\);
- (2):
-
\({\overline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )={\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )~(i=1,2,\ldots ,r)\) and \(\forall ~ \theta \in B\), \(\exists ~ i\in \{1,2,\ldots ,r\}\), \({\overline{apr}}_{\triangle _{B-\{\theta \}}}^{\beta ,\lambda }(D_i^\lambda )\ne {\overline{apr}}_{\triangle _\Theta }^{\beta ,\lambda }(D_i^\lambda )\);
- (3):
-
\(Pl^{\beta ,\lambda }_B(d)=Pl^{\beta ,\lambda }_\Theta (d)\) and \(\forall ~ \theta \in B\), \(Pl^{\beta ,\lambda }_{B-\{\theta \}}(d)\ne Pl^{\beta ,\lambda }_\Theta (d).\)
Proof
The equivalence can be easily proved using Proposition 11. \(\square \)
Definition 23
([6]) Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) , \(B\subseteq \Theta \) and \(\theta \in B\).
(1) The significance of \(\theta \) based on fuzzy \(\lambda \)-belief is defined as follows:
(2) The significance of a based on fuzzy \(\lambda \)-plausibilty is defined as follows:
We specify \(sig^\lambda _b(\theta ,\emptyset ,d)=0~and~sig^\lambda _p(\theta ,\emptyset ,d)=0.\)
Theorem 13
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then
Proof
The conclusion can be proved easily according to Theorem 10. \(\square \)
Theorem 14
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then
Proof
The conclusion can be proved easily according to Theorem 12. \(\square \)
Definition 24
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Define \(POS^{\beta ,\lambda }_B(d)=\bigcup \nolimits _{i=1}^r{\underline{apr}}_{\triangle _B}^{\beta ,\lambda }(D_i^\lambda )\) and \(\Gamma ^{\beta ,\lambda }_B(d)=\frac{1}{n}|POS^{\beta ,\lambda }_B(d)|.\)
Definition 25
([6]) Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then B is called a \(\lambda \)-coordinated subset of \(\Theta \) concerning d, if \(POS^{\beta ,\lambda }_B(d)=POS^{\beta ,\lambda }_\Theta (d)\).
Let \(co^{\beta ,\lambda }(\Theta )\) denote all \(\lambda \)-coordinated subsets of \(\Theta \) concerning d.
Definition 26
([6]) Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then B is said to be a \(\lambda \)-reduction of \(\Theta \) concerning d, if \(B\in co^{\beta ,\lambda }(\Theta )\) and \(\forall ~\theta \in B\), \(B-\{\theta \}\not \in co^{\beta ,\lambda }(\Theta )\).
Let \(red^{\beta ,\lambda }(\Theta )\) denote all \(\lambda \)-reductions of \(\Theta \) concerning d.
Proposition 15
Let \((\Omega ,\Theta ,d)\) be an HIS, \(\beta \in (0,1]\), \(\lambda \in (0,1]\) and \(B\subseteq \Theta \). Then
Proof
Obviously. \(\square \)
Here are two feature selection algorithms, formulated based on fuzzy belief and fuzzy plausibility, which are outlined as follows:

Feature selection algorithm for HIS based on fuzzy belief (FSFB)

Feature selection algorithm for HIS based on fuzzy plausibility (FSFP)
Experimental analysis and results
In order to verify the performance of FSFB, it is compared with eight advanced feature selection algorithms in terms of classification performance and noise resistance on 10 datasets. These datasets are downloaded from UCI Machine Learning Repository,Footnote 1 KRBM Dataset Repository,Footnote 2 and ASU feature selection repository,Footnote 3 and their details are listed in Table 2.
Fuzzy belief and fuzzy plausibility
In this part, the anti-noise performance of fuzzy belief and fuzzy plausibility is verified.
The method of adding noise to data is as follows:
-
For real-valued attributes, first, transform the data to the interval [0,1], and then randomly select x% of the data to be randomly assigned a number between 0 and 1. x is taken as 0, 5, 10, 15, 20, and 25 respectively.
-
For categorical attributes, x% of randomly selected data are randomly assigned to the categorical attribute values. Similarly, x is taken as 0, 5, 10, 15, 20, and 25 respectively.
Parameters setting: \(\beta =0.8\), \(\lambda =0.2\).

Fuzzy belief of different noise levels with the increase of attributes

Fuzzy Plausibility of different noise levels with the increase of attributes

Mean and variance of fuzzy belief and fuzzy plausibility at different noise levels

Correlation between fuzzy belief and fuzzy plausibility at different noise levels
Figures 1 and 2 show fuzzy belief and fuzzy plausibility of each data set with the increase of attributes at different noise levels, respectively.
Figure 3 shows the mean and variance of fuzzy belief and fuzzy plausibility at different noise levels. When the noise level changes, the mean and variance of 9 data sets in 10 data sets almost remain unchanged, and those of Zoo have little change, as shown in Fig. 3. This indicates that noise has little effect on fuzzy belief and fuzzy plausibility.
Figure 4 shows that fuzzy belief and fuzzy plausibility are highly negatively correlated at various noise levels. Noise has little influence on the correlation between fuzzy belief and fuzzy plausibility. Therefore, only the performance of FSFB is shown below.
Parameters analysis
Parameter values affect feature selection results. Let \(\beta \) and \(\lambda \) take values of \(\{0.5,0.6,0.7,0.8,0.9\}\) and \(\{0.1,0.2, 0.3,0.4,0.5\}\), respectively. Thus, \(\beta \) and \(\lambda \) have a total of 25 combinations. Each combination may correspond to a feature selection result of FSFB. The classification accuracy of all feature selection results on ten datasets is shown in the Fig. 5 using CART classifier.

Classification accuracy of 10 datasets in the case of different parameter values by using CART classifier
Table 3 shows a pair of optimal parameter values for each dataset according to CART classifier.
The experimental results obtained by KNN are approximately consistent with CART.
Figure 5 shows that different values of parameters have a great impact on classification accuracy. Different values of parameter \(\beta \) mean different granularity. The larger the value of \(\beta \), the more accurate the granularity is. The value of \(\beta \) can also be regarded as the threshold of information fusion. The larger the threshold is, the more accurate the information involved in the fusion is. Different values of parameter \(\lambda \) mean different anti-noise capability. The larger the value of \(\lambda \) is, the stronger the anti-noise capability is, but it also means that the risk of filtering out useful information will increase.
The following conclusions can be summarized from Fig. 5 and Table 3.
-
Within the value range of the two parameters, FSFB has achieved relatively high classification accuracy on most datasets, which shows that it has good stability.
-
For those datasets with a small number of samples, the value of \(\lambda \) is small, which means that if it is too large, key information may be filtered out.
-
For those datasets with a small number of features, the value of \(\beta \) is small, which means that they have low threshold requirements for information fusion because of few features.
-
For three large gene datasets, the value of \(\beta \) is large, which means that they have high threshold requirements for information fusion because of a large number of features. The fusion information needs to have a high degree of membership and thus characterizes the knowledge more accurately.
Classification performance comparison
In this part, FSFB is compared with 6 state-of-the-art feature selection algorithms in classification performance and the size of selected feature subset on 10 datasets. They are FBC [22], FSI [36], MFBC [20], NDI [35], NSI [37], and VPDI [21], respectively.
FBC is based on the fuzzy \(\beta \)-covering, and its fuzzy relation does not meet the reflexivity. FSI is based on the fuzzy rough self-information, and its fuzzy relation meets the reflexivity. MFBC is based on the multi-granulation fuzzy rough sets, and its fuzzy relation does not meet the reflexivity. NDI is based on neighborhood discrimination index, and its neighborhood relation meets the reflexivity. NSI is based on neighborhood self-information, and its neighborhood relation meets the reflexivity. VPDI is based on the variable precision discrimination index, and its fuzzy relation meets the reflexivity. FSFB is based on the fuzzy evidence theory and fuzzy \(\beta \)-covering, and its fuzzy relation meets the reflexivity.
KNN (K-nearest neighbor, K=5) and CART (Classification And Regression Tree) are used to estimate the classification accuracy with the ten-fold cross-validation. All experimental results are the average of 100 repeated experiments. For those algorithms with parameters, their parameter values all take the optimal values. The final experimental data are shown in Tables 4, 5 and 6.
Table 4 indicates that all seven algorithms effectively reduce redundant features, especially for three large-scale gene datasets. The average size of the selected feature subsets is far smaller than that of the original datasets. FSFB achieved a dimension reduction of \(84.13\%\) for seven UCI datasets and \(99.90\%\) for three large-scale gene datasets. The average of features selected by FSFB is only slightly greater than NSI, but FSFB has the highest classification accuracy. Therefore, FSFB is not easy to overfit and underfit. The average of features selected by MFBC is the largest, but MFBC’s average classification accuracy is not high, which indicates that MFBC is overfitting.
Tables 5 and 6 show that FSFB is superior to the other six algorithms and the original datasets in terms of average classification accuracy. In a total of 20 experiments, FSFB achieved the highest classification accuracy 11 times and is far more than other algorithms. These results show that the proposed algorithm is effective. Table 7 shows the feature subsets obtained by FSFB. The bold data represent the maximum classification accuracy.
Each raw dataset is regarded as an algorithm and FSFB is regarded as the control algorithm. Friedman and Bonferroni–Dunn tests [38] are used for analyzing the statistical differences between the control algorithm and other comparison algorithms.
The Friedman test is defined as follows:
where
\(r_{k}\) is the average ranking of the k-th \((k=1,2,\ldots ,a)\) algorithm on all datasets and d represents the number of data sets..
\(F_{0.1}(7, 63)=1.8144\) according to F-distribution table when \(\alpha =0.1\), \(a=8\) and \(d=10\). According to Formula (19), Tables 8, and 9, the value of \(F_F\) is equal to 2.818 and 3.1524 respectively. Obviously, they are both greater than 1.8144. Therefore, the performance of 8 algorithms is statistically different for the two classifiers.
Next, the Bonferroni-Dunn test is used as a post hoc test to analyze the performance difference between the control algorithm and the comparison algorithms. Its critical value is defined as follows:
\(q_{0.1}=2.45\) when \(\alpha =0.1\) and \(a=8\). Therefore, \(CD_{0.1}=2.6838\) according to Formula (20) when \(\alpha =0.1\), \(a=8\) and \(d=10\). The CD diagrams of the KNN classifier and CART classifier are shown in Figs. 6 and 7, respectively. Figure 6 shows that FSFB is statistically superior to NSI, FSI, and the raw dataset at a confidence level of \(\alpha =\) 0.1. Figure 7 shows that FSFB is statistically superior to FBC, FSI, NDI, VPDI, and the raw dataset at a confidence level of \(\alpha = \) 0.1.

CD diagram of Bonferroni-Dunn test using KNN classifier

CD diagram of Bonferroni-Dunn test using CART classifier

Average similarity between feature subset obtained from original data and feature subsets obtained from noisy data
Robustness evaluation of seven feature selection algorithms
In this part, the anti-noise performance of seven feature selection algorithms is verified.
In many practical applications, the feature selection algorithm is required to be robust, that is, it can obtain a stable feature subset when encountering data noise. If the selected feature subset will change significantly when encountering data noise, this algorithm is said to be ill-conditioned.
The robustness (stability) of the feature selection algorithm can be assessed according to its ability to select repeated features when different batches of data with the same distribution are given. As the true distribution of data is usually unknown, the data from different batches are generated by adding different levels of noise.
Let \(\Theta _j\) and \(\Theta _0\) denote the feature subsets selected by the jth batch of noisy data and the raw data, respectively. Then, the similarity between \(\Theta _j\) and \(\Theta _0\) can be defined by Jaccard Index [39] as follows:
\(T_j\) can provide a robust evaluation on the robustness and reflect the anti-noise ability of a feature selection algorithm. The greater the similarity, the stronger the anti-noise ability.
According to the method mentioned in 6.1, 5%, 10%, 15%, 20% and 25% noises are added to the original data respectively. The experimental result is the average value of 10 times of noise added randomly.
Figure 8 and Table 10 show the average similarity of different algorithms and data sets. Compared with the UCI datasets, the large-scale gene datasets are more affected by noise because of too few samples. FSFB achieves the maximum similarity on six data sets in ten data sets, far more than other algorithms. While the proportion of noise increases, both the distribution of data and the importance of features will change. This leads to obvious differences in the best feature subset selected by the algorithm. Even so, the average similarity of FSFB still reaches \(65\%\), at least \(6\%\) higher than other algorithms. Therefore, FSFB is more robust than the other six algorithms.
Conclusion
This paper defined a new distance guided by decision attribute. It is more accurate than Euclidean distance for measuring the difference between nominal feature values. The bridge connecting fuzzy evidence theory and fuzzy \(\beta \) covering with an anti-noise mechanism is built. Two feature selection algorithms are proposed based on the new distance, fuzzy \(\beta \) covering and fuzzy evidence theory. The experimental results show that the proposed algorithms surpass the other six state-of-the-art algorithms in terms of classification performance and noise resistance. Therefore, the proposed algorithms are robust and effective.
Data availability
The data that support the findings of this study are available at http://archive.ics.uci.edu/ml/index.php, http://leo.ugr.es/elvira/ and http://featureselection.asu.edu/datasets.php.
References
Zhou P, Li P, Zhao S, Wu X (2021) Feature interaction for streaming feature selection. IEEE Trans Neural Netw Learn Syst 32:4691–4702
Pawlak Z (1982) Rough sets. Int J Comput Inform Sci 11:341–356
Qian Y, Liang J, Pedrycz W, Dang C (2010) Positive approximation: an accelerator for attribute reduction in rough set theory. Artif Intell 174:597–618
Hu Q, Yu D, Liu J, Wu C (2008) Neighborhood rough set based heterogeneous feature subset selection. Inf Sci 178:3577–3594
Wang Y, Chen X, Dong K (2019) Attribute reduction via local conditional entropy. Int J Mach Learn Cybern 10(12):3619–3634
Zhang Q, Qu L, Li Z (2022) Attribute reduction based on D-S evidence theory in a hybrid information system. Int J Approx Reason 148:202–234
Wang C, Huang Y, Shao M, Chen D (2019) Uncertainty measures for general fuzzy relations. Fuzzy Sets Syst 360:82–96
Park S, Oh S, Kim E, Pedrycz W (2023) Rule-based fuzzy neural networks realized with the aid of linear function Prototype-driven fuzzy clustering and layer Reconstruction-based network design strategy. Expert Syst Appl 219:119655
Liang H, Yang C, Li Y, Sun B, Feng Z (2023) Nonlinear MPC based on elastic autoregressive fuzzy neural network with roasting process application. Expert Syst Appl 224:120012
Xu C, Liao M, Li P, Liu Z, Yuan S (2021) New results on pseudo almost periodic solutions of quaternion-valued fuzzy cellular neural networks with delays. Fuzzy Sets Syst 411:25–47
Li R, Mukaidono M, Turksen I (2002) A fuzzy neural network for pattern classification and feature selection. Fuzzy Sets Syst 130:101–108
Wang C, Huang Y, Shao M, Fan X (2019) Fuzzy rough set-based attribute reduction using distance measures. Knowl-Based Syst 164:205–212
Hu Q, Zhang L, Zhou Y, Pedrycz W (2018) Large-scale multimodality attribute reduction with multi-kernel fuzzy rough sets. IEEE Trans Fuzzy Syst 26:226–238
Wang C, Wang Y, Shao M, Qian Y, Chen D (2020) Fuzzy rough attribute reduction for categorical data. IEEE Trans Fuzzy Syst 28:818–830
Zeng A, Li T, Liu D, Zhang J, Chen H (2015) A fuzzy rough set approach for incremental feature selection on hybrid information systems. Fuzzy Sets Syst 258:39–60
Zhang Q, Chen Y, Zhang G, Li Z, Chen L, Wen C (2021) New uncertainty measurement for categorical data based on fuzzy information structures: an application in attribute reduction. Inf Sci 580:541–577
Sun L, Wang L, Ding W, Qian Y, Xu J (2021) Feature selection using fuzzy neighborhood entropy-based uncertainty measures for fuzzy neighborhood multigranulation rough sets. IEEE Trans Fuzzy Syst 29:19–33
Ma L (2020) Couple fuzzy covering rough set models and their generalizations to CCD lattices. Int J Approx Reason 126:48–69
Zhang K, Zhan J, Wu W, Alcantud J (2019) Fuzzy \(\beta \)-covering based (I, T)-fuzzy rough set models and applications to multi-attribute decision-making. Comput Ind Eng 128:605–621
Huang Z, Li J, Qian Y (2022) Noise-tolerant fuzzy-\(\beta \)-covering-based multigranulation rough sets and feature subset selection. IEEE Trans Fuzzy Syst 30:2721–2735
Huang Z, Li J (2024) Noise-tolerant discrimination indexes for fuzzy \(\gamma \) covering and feature subset selection. IEEE Trans Neural Netw Learn Syst 35:609–623
Huang Z, Li J (2021) A fitting model for attribute reduction with fuzzy \(\beta \)-covering. Fuzzy Sets Syst 413:114–137
Dempster A (1967) Upper and lower probabilities induced by a multivalued mapping. Ann Math Stat 38:325–339
Lin G, Liang J, Qian Y (2015) An information fusion approach by combining multigranulation rough sets and evidence theory. Inf Sci 314:184–199
Chen D, Li W, Zhang X, Kwong S (2014) Evidence theory based numerical algorithms of attribute reduction with neighborhood covering rough sets. Int J Approx Reason 55:908–923
Peng Y, Zhang Q (2021) Feature selection for interval-valued data based on D-S evidence theory. IEEE Access 9:122754–122765
Zhan J, Wang J, Ding W, Yao Y (2022) Three-way behavioral decision making with hesitant fuzzy information systems: survey and challenges. IEEE/CAA J Autom Sin 10:330–50
Wu W, Leung Y, Mi J (2009) On generalized fuzzy belief functions in infinite spaces. IEEE Trans Fuzzy Syst 17:385–397
Yao Y, Mi J, Li Z (2011) Attribute reduction based on generalized fuzzy evidence theory in fuzzy decision systems. Fuzzy Sets Syst 170:64–75
Tao F, Zhang S, Mi J (2012) The reduction and fusion of fuzzy covering systems based on the evidence theory. Int J Approx Reason 53:87–103
Xue Y, Tang Y, Xu X, Liang J, Neri F (2021) Multi-objective feature selection with missing data in classification. IEEE Trans Emerg Top Comput Intell 6:355–64
Xue Y, Xue B, Zhang M (2019) Self-adaptive particle swarm optimization for large-scale feature selection in classification. ACM Trans Knowl Discov Data 13:1–27
Song X, Zhang Y, Guo Y, Sun X, Wang Y (2020) Variable-size cooperative coevolutionary particle swarm optimization for feature selection on high-dimensional data. IEEE Trans Evol Comput 24:882–895
Hu Y, Zhang Y, Gong D (2020) Multiobjective particle swarm optimization for feature selection with fuzzy cost. IEEE Trans Cybern 51:874–888
Wang C, Hu Q, Wang X, Chen D, Qian Y, Dong Z (2018) Feature selection based on neighborhood discrimination index. IEEE Trans Neural Netw Learn Syst 29(7):2986–2999
Wang C, Huang Y, Ding W, Cao Z (2021) Attribute reduction with fuzzy rough self-information measures. Inf Sci 549:68–86
Wang C, Huang Y, Shao M, Hu Q, Chen D (2020) Feature selection based on neighborhood self-information. IEEE Trans Cybern 50:4031–4042
Demsar J (2006) Statistical comparison of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Kalousis A, Prados J, Hilario M (2007) Stability of feature selection algorithms: a study on high-dimensional spaces. Knowl Inf Syst 12:95–116
Acknowledgements
The authors extend their sincere gratitude to the editors and the anonymous reviewers for their insightful comments and invaluable suggestions. Their constructive feedback has significantly contributed to enhancing the overall quality of this paper.
Funding
This work was funded by University Natural Science Research Project of Anhui Province to Qinli Zhang with Grant number 2023AH040321.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
All authors declare that there is no Conflict of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, X., Hu, H., Zhang, Q. et al. Feature selection for hybrid information systems based on fuzzy \(\beta \) covering and fuzzy evidence theory. Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01560-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01560-7