
Abstract
As a carrier of multi-industrial technology integration and the key to industrial competition, the intelligent connected vehicle (ICV) has been taken seriously around the world. However, as a fast-growing emerging industry, its development process varies greatly from place to place. Hence, the merits and demerits are analyzed for the development of the ICV industry in different cities scientifically and to clarify the development of different links in each city, this paper suggests an extensive assessment framework integrating rough set theory and projection pursuit-based computation to systematically assess and thoroughly evaluate the level of competitiveness of the ICV industry. First, through big data text analysis technology, we constructed a "5 + 24" two-tier evaluation index system composed of 24 level-II evaluation indexes as well as five level-I evaluation indexes and selected 19 typical cities as input data for the comprehensive evaluation system. Further, the Adaptive Random Forest based Crossover Tactical Unit (ARF-CTU) algorithm is proposed for evaluating the performance of the industrial vehicle industry. However, the ARF algorithm is employed to estimate the lowering of overfitting issues and handling of high dimensional data. Moreover, the continuously varying conditions are analyzed by CTU. Then, we constructed a comprehensive evaluation system in the rough set theory and projection pursuit: (I) Quoting the rough set non-decision-making algorithm for attribute reduction, that is, under the premise of unchanged classification ability, derive a new evaluation system, and calculate the index weight and score based on the new system. (II) Based on the projection pursuit technology, the index score is mapped by a genetic algorithm to a linear structure, and a one-dimensional projection vector is an output.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The ICV industry has become a vital strategic process that upgrades and alters the global automobile industry nowadays. The worldwide locations accelerated their respective strategic deployments to promote the development of the industry by releasing policies, formulating top-level plans, establishing and revising relevant regulations, encouraging technological research and development, and supporting road tests and project operations [1]. For instance, the U.S. government has been improving the environment for innovative development and guiding and promoting the development of the ICV industry by continuously strengthening strategic planning and accelerating testing and application. The EU has been promoting the EU-level consensus and cross-industrial collaborations, continuously strengthening the research on digital infrastructure and speeding up the development of connected auto-driving vehicles through strategic planning, setting up a technology roadmap, and supporting innovative research projects [2]. Japan has masterminded a large number of top-level design plans to develop auto-driving through the deep integration of automobiles with intelligent transportation systems and smart cities. China has incorporated the ICV industry into the national top-level planning to seize the high ground of ICV development by formulating and revising regulations and standards, exploring the Chinese technology roadmap, accelerating cross-industrial collaboration, and promoting testing and demonstration. Slime Mould Algorithm (SMA) within the context of the Evaluation of Urban Intelligent Connected Vehicle (ICV) Industry based on Rough Set Theory aims to utilize the principles of bio-inspired computation to simulate and analyze intricate urban mobility patterns. The utilization of SMA within the framework of Rough Set Theory enables researchers to handle complex, uncertain, and imprecise data [3]. The neural adaptive decentralized finite-time prescribed performance (FTPP) control investigates a different aspect of control theory, focusing on interconnected nonlinear time-delay systems and this operates within the domain of advanced computational methodologies offering complementary insights into distinct areas of research and application within the broader field of engineering and technology [45]. The study on hybrid-driven fuzzy filtering addresses the challenge of dealing with cyber attacks in systems governed by complex equations. To tackle this, the research first used a fuzzy model to simplify the systems. Then, they developed a hybrid-driven filter to manage system performance and network resources when facing cyber attacks involving deception and denial of service. By applying mathematical techniques, they ensured the stability of the system and derived the parameters for the filter. Through simulations and comparisons, they showed how their approach effectively handles cyber attacks. This contributes to improving the security and reliability of systems facing such threats [48].
Emerging trends in ICV industry evaluation
So far, China's ICV industry has achieved remarkable results, and in the academic field, scholars have carried out a lot of research on ICV. For example, the test and evaluation methods of the technical index of ICV have certain guiding significance to the test and evaluation of ICV; the ICV modeling and the benefit evaluation model of mixed traffic flow, and according to the evaluation results, it was found that ICV had a positive impact on mixed traffic flow in peak periods, and the benefit was higher than that in flat peak periods, and proposed the energy saving and emission reduction evaluation in the life cycle of ICVs [4]. Although the evaluation method has been successfully applied in many fields of ICV, there is little literature on the evaluation and research of such an industry from the lens of development of urban. Therefore, this paper evaluates the ICV industry from the perspective of urban development to scientifically evaluate the strengths and weaknesses of the ICV industry, sort out and summarize the advanced experience of industrial development in advantageous cities, and then provide experience for industrial development in later-emerging regions. The implementation of the Runge Kutta method (RUN) in the context of emerging trends in ICV industry evaluation focuses on leveraging advanced numerical techniques to model and predict the dynamic behaviors and performance metrics within the ICV industry [5]. The other approach named the optimal iterative learning control method helps improve how automated vehicles function. It deals with challenges in controlling multiple aspects of the vehicle at once, especially when there are limits on what the vehicle can do. The method introduces a special way of handling these limits and makes sure that the vehicle works smoothly within them. This helps to make automated vehicles more efficient and perform better overall, which is important for the industry [46]. The study on fixed-time prescribed performance trajectory tracking control for unmanned surface vehicles contributes to the broader field of autonomous vehicle technology by addressing the challenge of controlling vehicles with unknown dynamics and disturbances. It introduces an improved method for controlling the trajectory of these vehicles by incorporating a prescribed performance function that allows users to define desired performance characteristics. By combining fixed-time stability and event-triggered control mechanisms, the study develops an adaptive controller that ensures stable and accurate trajectory tracking within a specified time frame. This controller also minimizes communication costs by proposing efficient signal encoding and decoding mechanisms. Ultimately, through simulation tests, the study demonstrates the effectiveness of the developed control approach. In comparison to the strategic analysis of the intelligent connected vehicle industry competitiveness, this study offers a practical solution for enhancing the control and performance of autonomous vehicles, complementing the broader efforts to advance the technology and competitiveness of the intelligent transportation sector [47].
Enhancing evaluation index weighting methods for complex influencing factors in the intelligent connected industry
The intricate and varied factors that shape the intelligent-connected industry underscore the importance of assessing their respective significance. Hence, it's essential to initially find out both the primary influencing factors and their relative weightings to conduct a thorough evaluation of the industry's environment [6]. In the academic field, there are a variety of index weighting methods, such as subjective weighting methods, like the principal component analysis, objective weighting methods, like the entropy evaluation, and combined weighting methods jointly constructed by them. The principal component analysis is combining the original data with a new dataset. The independent dataset is used to remove the original indexes from a new dataset. The replacement process will cause the information reflected by some indexes to be lost, and it is impossible to achieve a comprehensive evaluation of the original problem [7]. To prevent information loss, the entropy evaluation is introduced to compute the weight of each index, but the method can only be used on the premise that there is no correlation between the indexes. It can thus be seen that the existing weighting methods either ignore the integrity of the evaluation or have the problem of repeated evaluation. Therefore, it is essential to analyze the problem accurately based on the premise of ensuring that the classification of the index knowledge remains unchanged, and improves the rational and scientific level of the evaluation index weighting [8].
Advancing evaluation accuracy through integrated rough set theory and projection pursuit method in the analysis
The rough set theory for weight computation has been applied to many fields. For example, the characteristics of the Rough set theory in the determination of the weight of intelligence analysis indexes. Such a method does not require any prior information to complete the computation of the index weight, which makes the index weight result more objective and effective than other methods [9]. A weight determination method based on rough sets proved that the proposed method can solve the problems of subjective arbitrariness and feature redundancy in weight determination to further improve the applicability of the weight determination method. It has defined the comprehensive soil fertility evaluation results by using AHP and rough set theory respectively. The result showed that, when related to the AHP model, the weight coefficient of every index determined by the attribute reduction method based on rough sets was more accurate with the weighting results being more reasonable. To sum up, the rough set theory has strong advantages in the field of index weighting. Additionally, the data of the intelligent connected industry is characterized by high dimensionality, non-normality, and nonlinearity. The projection pursuit is just a method to solve the above problems [10].
Novelty
The novel functions of the article are discussed in the below sections.
Analysis of Intelligent Connected Vehicle Industry: It analyzed the landscape of the industrial vehicle functionalities by validating with different strategies namely competitive positioning of industries, market trends, technological advancements as well as environmental conditions regulations.
Performance evaluation approach: The article determines the evaluation system from multiple criteria that assess the industrial applications by solving the queries raised by customers, innovation capability, financial performance as well as product quality.
Integration of Roughset Theory and Projection Pursuit: These are the two significant approaches that are utilized to analyze the data arranged in the pattern recognition model. The ambiguity of the data is identified and analyzed in the functioning of high-dimensional data features. Also, it diminished the validation of complex datasets.
Adaptive Random Forest-based Crossover Tactical Unit Algorithm: This algorithm is implemented by obtaining a specific algorithm in which the ARF is a machine learning approach that diminishes the overfitting issues and monitors the high dimensionality of the data for minimizing the complexity burden. In data varying conditions the stable result is provided by crossover tactical unit.
Contributions
The major contributions of the paper are.
-
This paper proposes a comprehensive evaluation method based on the Rough Set theory and projection pursuit for the evaluation of the ICV industry in cities and further derives the evolution status of the industry of ICV in each city.
-
To construct a comprehensive evaluation system that calculates the dependence, index weight, and score of the reduction index through the theory of the rough set.
-
Based on the projection pursuit model, the high-dimensionality data is subjected to the genetic algorithm for projection down-dimensioning, and the optimal linear projection vector is obtained.
The study makes significant theoretical contributions by employing a comprehensive evaluation framework utilizing rough set theory and projection pursuit method to assess the competitiveness of cities in the intelligent-connected vehicle (ICV) industry. It offers a structured approach for evaluating multiple dimensions such as urban policy, industrial chain, infrastructure, application data, and urban influence, providing valuable insights for policymakers and industry stakeholders. Furthermore, the study's practical contributions lie in its ability to offer actionable insights for urban planners, policymakers, and industry leaders to strategically enhance the competitiveness of their respective cities in the rapidly evolving ICV industry.
The paper's structure is as follows: the introduction of past literature works is presented in Sect. "Literature review", Sect. "Theoretical framework" introduces the theoretical framework of this paper, The conceptual framework of the research is proposed in the 4th section, and thereafter the research hypothesis is proposed. The methods employed in this study are presented in the 5th section. The study is discussed in the 6th section, followed by theoretical and practical implications. Finally, the paper concludes in the 7th section, followed by limitations and future directions including the determination of a hierarchical evaluation index, the construction of a comprehensive evaluation system (the rough set for the reduction attribute, the calculation of the weight of the reduction attribute, and the approach of projection pursuit), and the evaluation of the score of the ICV industry.
Research motivation
The ICV is a significant process and fastly emerging industrial technology around the world. In recent days it emerged in different places that determine the significant use of ICV in different cities. However to reduce complexity issues various approaches namely LFT-LMI, LFT-LMI, AHCF, On-Board Road Friction Estimation Technique, FS-MS, GA-ACO, and L-MADRL are developed to validate the controllers, characteristics, and structure of ICV. Further, the working of vehicle features and selection of optimal path but the effectiveness is diminished due to some issues. In the routing transmission process, the vehicle features maximized the complexity burden and increased delay due to limited resources. The power utilization has also increased and to overcome these issues the ARF-CTU method is proposed that validates the efficiency of the vehicle industry and lowers the overfitting issues with efficient handling of high dimensional data. Also, it frequently validated the present condition of the vehicle effectively minimizing the complexity formation and enhancing the computing results.
Research objectives
RO1: To assess the significance of the emergence of trends in ICV Industry Evaluation.
RO1: To evaluate the enhancing index weighting methods for complex influencing factors in the intelligent connected industry.
RO1: To determine the evaluation accuracy through integrated rough set theory and projection pursuit method in the analysis of high dimensional data for intelligent connected industries.
Literature review
The literature review examines the Evaluating Intelligent Connected Vehicles in Urban Transport Systems. It explores various aspects of the Influence of Technological Innovations in Intelligent Connected Vehicles on Transportation Systems and Integration of Projection Pursuit and High-Dimensional Data Processing for Comprehensive Evaluation in Urban Development. This review also identifies research gaps that need to be addressed in future research.
The enhancement of industrial vehicles with the presence of advanced features improved their development and it reaches all over the world. The speed, time, power, and complexity process of each vehicle features are significant to analyze and this is done by developing various approaches namely FS-MS, GA-ACO, LFT-LMI, LFT-LMI, AHCF, On-Board Road Friction Estimation Technique and L-MADRL. These methods validated each tier feature of the vehicles individually which is very effective in identifying the complexity. But in the process of optimal path selection, the complexity burden is increased and also it failed to travel long distances with limited time, These limitations are solved by the proposed ARF-CTU algorithm that validated the index weight based on two-tier level and diminished the overfitting issues by managing long dimensional data. Also, the utilization of time and power is lowered for ICV based on technological development that determines effective accuracy.
Evaluating intelligent connected vehicles in urban transport systems
It has established a valuation on the urban transport system of Intelligent connected vehicles (ICV) based on the Lyapunov function theory and linear matrix inequality (LFT-LMI) approach. Time to get the information changed from one vehicle to another as there are manual and automated vehicles on the road. LFT-LMI was developed in this paper to make a closed-loop system asymptotic under a varied congestion flow environment [11]. As a result, these developed approaches were attained to minimize fuel loss. On the other hand, time consumption is higher. It has illustrated an urban intersection of intelligent connected vehicles (ICV) by using the distributed model predictive control (DMPC) method. One of the main challenging tasks of this paper is to address the management of ICVs in multi-intersection and unsignaled roads. The DMPC method was used to optimize energy conservation. The performance of the DMPC method was validated using the MATLAB platform [12]. Thus, the introduced approach effectively saves energy and reduces congestion. Meanwhile, the low accuracy rate was the disadvantage of this method. An evaluation of Intelligent connected vehicles by an Adaptive hierarchical control framework (AHCF). One of the main purposes of this paper is to provide optimal speed for every vehicle with complex congestion rules. Several existing methods have been utilized for providing speed plan resolution, but they were time-consuming. To overcome this issue AHCF was introduced in this paper. Hence, the AHCF approach achieved better performance in saving 22.0% of energy. However, the consolidation of power was high [13].
Exploring the influence of technological innovations in intelligent connected vehicles on transportation systems
It discussed a cost verification of upgrading the transport system of intelligent connected vehicles (ICV) based on a transportation framework. The introduced framework was utilized to find the best path for vehicles and improve communication between the vehicles [14]. As a result, these frameworks were enhancing the performance to minimize the consumption of energy and accelerate the protection of the environment. Meanwhile, these frameworks were not suitable for long distances. It has illustrated the On-Board Road Friction Estimation Technique for the estimation of a vehicle ‘s road friction [15]. However, the complexity burden was maximized. This technique was performed by drawing upon the bicycle model to assess the condition of vehicles and the Magic Formula Model based on the slip-slope approach for the evaluation of latent friction [16]. However, the power utilization was high due to limited sources. Here, the vehicle condition and successful grip value in the autonomous driving vehicle were reached. In any environment, the development of a control system was capable of rejecting collisions. It has elaborated on an eco-driving controller with the combination of technology of wireless communication and vehicular dynamics for sustainable transportation. The eco-driving controller was verified via PreScan and ROS software. This controller decreased the intake of fuel and emission of carbon dioxide. However, the control of eco-driving was affected due to the availability of conventional vehicles in ICVs [17].
The prediction of lane vectors from the extracted features to assist the vehicle industry using Flight Straight of Moth Search (FS-MS) is explained in [49]. In the convolutional layer, the weight function in lane detection was optimized in a two-tier process. As a result, the time utilization in the detection process was diminished by 31.2%. However, not provide optimized vector features due to the presence of a lack of data. The estimation of real-time functioning processes in intelligent vehicles for choosing optimal paths is illustrated in [50] by the Genetic Algorithm Ant Colony Optimization (GA-ACO). The routing process in artificial intelligence is determined and the vehicle analysis is performed in a real-time application process. The results revealed that the vehicle routing transmission process is maximized with lowered delay. On the other hand, it maximized the complexity burden and required more time to transmit the data regarding vehicle features.
Integration of projection pursuit and high-dimensional data processing for comprehensive evaluation in urban development
It minimized the high-dimensional data loss based on retaining the structure and characteristics of the data, which reflect the inherent laws of data, and solved the problem that the inherent laws and characteristics of traditional high-dimensional non-normal data cannot be found, making the high-dimensional and nonlinear data researchable and analyzable accurately and reliably [18]. Meanwhile, the speed of the vehicle was minimized due to limited sources. It can be seen that the projection pursuit method is used to process the high-dimensional data perfectly. It can be found that a single evaluation method cannot meet the evaluation requirements of high dimensionality, and nonlinearity data [19]. Therefore, the integrated evaluation method is constructed by combining both methods to guarantee the evaluation's scientific rigor. But the complexity is maximized. In this paper, Finally, data from 19 cities are used as system inputs for integrated evaluations. The results show that the scores of 19 cities can be divided into three echelons according to their rankings [20]. On the other hand, limited data were obtained.
The updating of robust models in intelligent vehicle systems based on machine learning updates was explained by TinyMLOps [51]. The utilized factors were employed with numerous controllers that transmit the data in the communication protocol. As a result, the established method maximized the robustness but maximized delay due to overloading of data. To perform the intelligent vehicle forecasting process in offloading features using Long Short Term Memory with Multi-Agent Deep Reinforcement Learning (L-MADRL) [52]. The developed model was obtained by associating deep learning as well as deep reinforcement learning approaches that demanded the extracted edge servers. In the automatic functionality, the energy consumption was diminished for the developed model by 5 to 20%. However limited resources were utilized while integrating the approaches.
Deep learning and GNN in ITS
In Intelligent Transportation System (ITS) the enhancement of traffic congestion is determined due to environmental pollution is discussed in [53]. Mostly in ITS the deep learning algorithm is developed to validate traffic behavior and analyze the speed of the vehicle. The policy gradient model was established that identified the vehicle misused in network topology. As a result, the ITS enhanced the prediction accuracy and diminished delay but the time required to control congestion is high with increased complexity.
Graph Neural Networks (GNN) are highly utilized in the ITS process that determines the structure of the vehicle as illustrated in [54]. In traffic forecasting issues technological development was significant that enhanced transportation safety. The results determined that the GNN model enhanced the performance in the efficient vehicle industry. However, it maximized the complexity burden.
The determination of Graph Convolutional Network (GCN) in the ITS system to predict the features of vehicle congestion is reviewed in [55]. The developed model validated the parameters of varied configurations and predicted the errors employed in congestion. As a result, the established method lowered the error rate of RMSE to 8.3 which extracted the variations of each data feature independently. Meanwhile, it failed to solve complex dynamic congestion issues.
Research gap
The results are more in line with the facts with certain reference values available for urban industrial development. Thereby, relevant government departments can analyze the overall gap between their cities and the target city and the gap between each index based on the scores of different indexes, and draw up plans according to the scores in regional industrial planning to improve the accuracy of planning schemes, stimulate the urban economic vitality and enhance the competitiveness of the city in the field of ICV. Some of the gaps are explained below.
Maximization of power utilization and delay: The speed of the vehicle is maximized in a congestion process that consumes time. But to enhance speed the power requirement is more and in such cases, the transmission of power is delayed. The proposed method addresses this gap by presenting a crossover tactical strategy that validates the big data with limited time and energy.
Time consumption: In connected vehicles the transportation process to identify the optimal path is significant and in long distances, it is not suitable to process with limited time. The proposed method addresses this gap by developing a tier evaluation index that evaluates the input data in various cities with minimum time consumption.
Optimized feature vehicle vectors: The weight index of each vehicle is evaluated based on the tier process and the optimal path for the vehicle is not estimated. The proposed method addresses this gap by introducing an ARF-CTU algorithm that effectively handles the high dimensional data in the optimal path election process.
Research questions
RQ1: What are the Emerging trends in ICV industry evaluation?
RQ2: What are the factors influencing the evaluation enhancement of index weighting methods in the intelligent connected industry?
RQ3: How can it be analyzed for advancing evaluation accuracy through integrated Rough Set Theory and projection pursuit method?
Theoretical framework
The theoretical framework discusses ICV industry dynamics through rough set theory, the ICV industry evaluation, technological innovation, and urban transport system, policy dynamics and governance in sustainable transportation, and Integrating Rough Set Theory and projection pursuit-based computation.
Analyzing ICV industry dynamics through rough set theory.
China is widely acknowledged as the world's foremost automotive hub, boasting a substantial population of vehicles which leads to many challenges in transportation management and sectors. The Government of China formulated policies and enlarged the investments to promote the evolution and execution of ICV [21]. The ICV industry gets technological advantages and other domestic manufacturers that lack the industry attention and ICT technology provide incremental parts and complete solutions for ICVs [22]. Complex structures describe the formal mechanism, law, and culture that conspire to this industry dynamic technique which takes place through rough set theory. Primary agents modify the environmental interactions, generate resource consumption, and manage unnecessary ICV industry products; this mechanism focuses on the needed outputs to guide the primary supportive environment where agent interactions take the expected result [23].
The ICV industry evaluation using rough set theory.
The emergence of the ICV sector follows the profound merging of self-propelled technologies with cutting-edge advancements in information technology which can coordinate and combine technologies from many fields such as automobiles, transportation, communication, and the internet. Industrial chain formation merges multiple industries to broaden the scope of research concepts within ICV industries and enhance the depth of research theories [24]. ICV technology is one of the important styling vehicle technologies based on the evaluation study among other technologies. ICV is a water-intensive vehicle among the alternatives and should be noted for the water consumption which impacts the ICV scenario than all other alternatives. Other fuel consumption is also possible like solar power and so on, and water remains the best approach for ICVs [25].
Technological innovation and urban transport system
Urban air mobility was introduced by Airbus (2018) for the integration of a third dimension to urban transport networks which consists of on-demand sharing mobility which operates vertical take-off and landing aircraft for intra-city passenger trips. Airbus assures to provide safer and trustworthy and other environmental choices that reduce congestion on the transport network [26]. Many different kinds of urban planners introduce policies related to maximum speed, mandatory use of bicycle infrastructure, and other dedicated parking which limit the number of licensed operators. Volitional control, technological innovation, and attributes of the technology prevail in the consumption ethos and practice in transportation like shared mobility and environmental sustainability [27]. Addressing the complexities of urban transportation, particularly in regions experiencing burgeoning population growth, poses significant challenges for both rural and urban traffic management, notably in developing nations. The integration of AI technologies across various transportation domains offers diverse solutions. From corporate decision-making to strategic planning and resource management, AI presents opportunities to alleviate the strain of ever-growing demands on finite road infrastructure [28].
Policy dynamics and governance in sustainable transportation.
Legitimate policies for the system of transportation are a bit challenging and complex because of the presence of conflicting interests of multiple stakeholders, and socio-economic environmental factors that could change the behavior over some time. A high number of transportation cause scarcity of fossil fuel active and dynamic element policies need to be redesigned with system changes [29]. Different urban transportation policies aid in the design and implementation of different transport policies for similar cities, especially highly populated and rapidly developing cities. Policy dynamics plays an important part in the governance of sustainable transportation which evaluates the effect of transportation policies on mobility patterns [30]. The transport sector has a high environmental, social, and economic impact on human society. Apart from that, the transport sector has contributed 27.6% of natural energy consumption in 2018. Sustainable development should be embraced by the concept of the transport sector [31].
Integrating rough set theory and projection pursuit-based computation
Projection pursuit is based on the computational method which overcomes the defect of dimensionality in the reduction which automatically finds reconceptualizing the inherent principles governing data to effectively represent the nonlinear aspects of complex, high-dimensional issues. Projection pursuit computational methods generally project high-dimensional data condensed into one-dimensional space using a projection index function, thereby forming features [32]. Rough Set Theory (RST) introduces various mathematical techniques for managing uncertainty, which are pivotal in identifying valuable characteristics that streamline information processing and facilitate the comprehension of imprecise and uncertain data. From data analysis perception RST can summarize prior knowledge of data, an inherent capability to efficiently seek out the most concise data set, conduct a thorough analysis of both qualitative and quantitative data, and establish decision-making protocols based on the data present [33].
Conceptual framework
The Conceptual framework of this investigation visualizes the significant variables discussed in the research and its contribution to evaluating the ICV industry based on rough set theory and projection pursuit-based computation. The paper mainly formulated five hypotheses that illustrate the evaluation of the urban ICV industry.
In Fig. 1, the conceptual framework of this paper is illustrated. It highlights the integration of Rough Set Theory and projection pursuit-based computation for comprehensive analysis of urban ICV industry dynamics and the impact of Rough Set Theory and projection pursuit-based computation on the innovation of technology. The focus of the paper illustrates urban transport systems influenced by the Rough Set Theory and projection pursuit-based computation Resulting in the examination of the urban sector of ICV with the involvement of technological innovation, urban ICV industry dynamics, and urban transport systems which all points to the evaluation of ICV industry.

Conceptual framework based on the evaluation of the ICV industry
Comprehensive analysis of urban ICV industry dynamics
The convergence of intelligent connected vehicles with telematics and smart vehicles has been recognized as a key component of the national strategy outlined in the Made in China project, aiming to tackle new developmental opportunities effectively. Scientific and technological innovation is bound by the principle of driving forces for transport power construction [34]. ICV sectors choose one among two technological paths: Single vehicle Intelligence (SVI) and Vehicle-infrastructure collaboration (VIC) popular research done by Google initiates autonomous driving development. The rise of autonomous vehicles and the expansion of the automotive market were moved by the drawbacks associated with costly pricing and limited safety features of traditional SVI. Against this backdrop, the VIC system emerged as an innovative advancement from SVI [35]. The automotive sector and its products are undergoing significant transformation due to innovations like ICV. With ICV sales constituting half of all car sales, similar to the transition from conventional mobile phones to smartphones, ICVs offer immense convenience and, crucially, help reduce traffic accidents that come from erratic driving behaviors [36].
H1:
Integrating Rough Set Theory and Projection Pursuit-based Computation for Comprehensive Analysis of Urban ICV Industry Dynamics
The repercussions of innovation technology
The International repercussions of a country are barely divided into macro and micro levels. The macro level consists of scientific, technological, political, economic, military, and cultural influences. The micro level encompasses factors such as corporate technology research and development, managerial proficiency, financial reserves, and funding capacities within a company's sphere of influence [37]. The inception of innovation technology originated predominantly from the domains of humanities and social sciences, diverging from the focus on innovation found in literature and economic discourse, not all innovations agree with the conceptual aspect. Technology innovation assists the understanding of education, when considering innovation technology within the ICV industry, the emphasis on enhancing efficiency and effectiveness in education through technical advancements may not be as prioritized [38].
H2:
The impact of Rough Set Theory and projection pursuit-based computation for the innovation of technology.
Dynamic effects of the urban ICV Industry
There are different kinds of system dynamic (SD) models, and the exploration of dynamic relationships among government, manufacturers, and consumers is a focal point in understanding industrial dynamics. Through an industrial case study, the impacts of different subsidy initiatives on the advancement of the urban ICV industry are examined. The results help to enhance the holistic understanding of the ICV industry system which encourages the urban ICV industry. By examining shifts in decision-making patterns among consumers and manufacturers throughout various stages of the ICV industry, a foundation for analysis can be established. Static and dynamic subsidies are more effective for ICV industry acquisition [39]. System Dynamic model to successfully explain the evolution, adoption, and enhancement of the ICV industry. The System Dynamic model allows the study of the dynamic process of investigating problems. An integrated and comprehensive framework makes it possible to account for all three dimensions of sustainability.
H3:
Effect of Rough Set Technology and Projection Pursuit-based Computation for the Dynamic Changes in the Urban ICV Industry.
Effect of urban transport system
The intersection of the natural environment and urban development poses a significant challenge for projection pursuit-based computation. Aligning with the resilience goal offers a more suitable trajectory for accommodating the potential shifts in urban development. Focus on rough set theory and projection pursuit-based computation is related to public management, regional coordination, operational efficiency, and urban planning benefits for the urban transport system [40]. Rough set theory misses the data complementation method which mainly focuses on utilizing the ROUSTDIA algorithm derived from rough set theory for data completion, with numerous researchers contributing enhancements to refine the accuracy of rough set methods. A rough set only uses a mined data set given information and it stands independently devoid of reliance on any other models or presupposed parameters. The rough set method is unable to recover a substantial amount of absent data [41].
H4:
Urban transport system influenced by the Rough Set Theory and Projection Pursuit-based computation.
Evaluation of the urban ICV industry
The ICV industry has experienced significant growth and transportation due to technological innovations and the evolving dynamics of urban transport systems. This industry has been shaped by various factors, including advancements in connectivity, autonomous driving technologies, electric propulsion, and the integration of smart infrastructure [42]. Urban ICV industry evaluation consists of technological innovation which includes the integration of sensors, cameras, and radar to enhance safety and efficiency. Urban ICV industry dynamics also assist in the evaluation of the urban ICV industry; companies are increasingly focusing on the development of electrical and hybrid ICVs [43]. Urban transport system integration helps the deployment of smart traffic management systems, infrastructure-to-vehicle communication technologies, and the development of shared mobility platforms. Urban planners develop innovative solutions that address the complexities of urban mobility and establish the groundwork for a transportation system that operates with greater efficiency and sustainability [44].
H5:
Resulting in the evaluation of the urban ICV industry with the involvement of technological innovation, urban ICV industry dynamics, and urban transport system.
Methodology
The block diagram of this paper is shown in Fig. 2, which is mainly determined by three parts: determination of hierarchical indexes, construction of a comprehensive evaluation system, and evaluation of the score of urban intelligent connected industry. Among which, the hierarchical indexes mainly determine the level-I and level-II indexes of the index system; the construction of a comprehensive evaluation system is divided into two steps: Firstly, by adopting the algorithm of rough set non-decision-making theory, the weight of every index can be further generated by constructing knowledge systems among the index systems and computing the dependence of the index and by reducing the attributes of the knowledge system, so that the underlying index can be computed; then, the scores of five level-I indexes are normalized by using the projection pursuit method, mainly using a genetic algorithm to map multiple indexes to the linear structure through spatial stereo projection technology; the scores of intelligent connected industries in cities are evaluated, that is, the data of 19 cities are selected as the cases to evaluate the scores of intelligent connected industries. Each section will be described separately below.

Overall workflow of the proposed method
Determination of hierarchical evaluation indexes
This paper considers strengthening the groundwork for industrial progress during the index selection procedure. At the same time, combined with big data text technology, it uses text analysis technology (theme analysis technology, content analysis technology) to analyze relevant technical indexes in relevant intelligent connected industry reports. According to the reference rate of the index, the indexes are sorted, and the top indexes are selected taking the Policy initiatives addressing urban development, infrastructure enhancement, and industrial supply chains as the basic element indicators for the development of the urban ICV industry. However, it incorporates and evaluates the influential aspects of industrial progress, contrasting perspectives, considering factors like the degree of integration of the ICV industry and intelligent transportation systems and smart cities (application data), the catalyst behind regional scientific and technological advancement, alongside pioneering the development of novel business frameworks (city influence) as potential value indexes for the development of urban ICV industry. To sum up, five elements of urban policy, infrastructure, industrial chain, application data, and urban influence are selected in this paper as the level-I evaluation indexes. To score the development status of the city's ICV industry objectively and scientifically, 24 level-II indexes are further selected through big data text analysis technology to facilitate the scientific and effective evaluation of the score of the development of the city's ICV industry. The system-selected index method is shown in Fig. 3 below.

Index System Selected model
As shown in Fig. 3, the basis of the five-in-one integrated evaluation index system adopted in this paper, four level-II indexes are selected, namely, the top-level planning, standard formulation, testing and demonstration application management, and special supporting policy based on the level-I index of urban policy; three level-II indexes of the number of intersections in the test area, mileage of test road sections and number of test scenarios, are selected based on the level-I index of infrastructure; seven level-II indexes are selected, including the automobile company, auto parts company, perceptual recognition company, company that planning along with making decisions, control and execution company, IOV system company, and cloud computing company based on the level-I index of industrial chain; two level-II evaluation indexes, namely, the selection encompasses the open test road and open test mileage based on the level-I index of application data; eight level-II evaluation indexes are selected, including the entrepreneurial impact, workforce size, media coverage, public perception, regulatory approvals, professional credentials, patent status, software copyrights, and investment activities, based on the level-I index of urban influence.
Comprehensive evaluation system
This section mainly covers two aspects. First, a rough set of the non-decision-making theoretical method is generated which constructs the reduction attributes, computational weights, and level-I index score, and second, a genetic algorithm is adopted for the projection dimensional treatment of the five level-I index scores based on the projection pursuit model, the five-dimensional non-linear data is mapped to a one-dimensional linear structure to the output data. The data flow of the comprehensive evaluation system is given in Fig. 4 below.

Data Flow Graph of the Integrated Evaluation System
Rough set theory
This section mainly includes two aspects. First, it introduces the advantages of this theoretical method compared with other methods. Second, it introduces the method of building simple attributes of the covenant, calculating index weight and index score according to the Rough set theory.
The Rough set theory can ensure that on the premise of fixed classification of uncertain knowledge, redundant knowledge, and information can be removed utilizing knowledge reduction (removing some evaluation indexes), and the speed and accuracy of data analysis can be improved. The advantages of rough set theory are as follows:
Objective weighting: When employing rough set theory to address uncertain information, no prior knowledge is needed, and weights can be computed only by objective data. For example, when computing the importance of attributes in the evaluation system, the general processing method is to have the weights given by experts, which feature greater subjectivity and human factors. However, in rough set theory, the weights can be computed only with objective index data. It can mine data and compute the relationship between various indexes from the original data, for example, the weights of indexes are computed indirectly by attribute membership. Unlike traditional methods such as fuzzy sets and probability statistics, which need to provide additional information or prior knowledge, the results of rough set computations are more objective.
Simplify the process (simplify the original data analysis process through attribute reduction): The rough set theory can mine the data using the relationship between data indexes on the premise of retaining key information for obtaining the minimal representation of the knowledge system (i.e., so-called attribute reduction).
Compatibility: The rough set theory can be combined with other theories and methods to complete the analysis and study of problems.
Rough set theory method
The different steps of the rough set model are shown in Fig. 5, which contains five parts in general: data standardization, sample data discretization, attribute reduction, weight determination, and index computation. The purpose of data standardization is to remove the interference of dimensions to get more accurate results; since rough set theory can only be used to deal with discrete data. The attribute reduction is the most essential step in rough sets, regarding as the basis of forming a new index system. When the number of samples is small, manual methods can be used; while the number of samples is large, an identifiable matrix and logical operation can be used. For the weight computation, the importance of the index shall be computed first before normalizing the index and evaluating the index weight; finally, the score of the index according to the size of the weight can be computed. The steps are analyzed one by one as below.

Steps of Evaluation Model Based on Rough Sets
Assuming the evaluation object (or the universe of discourse, the number of sample data) is \(U = \{ u_{1} ,u_{2} ,...,u_{n} \}\), the evaluation index (conditional attribute) is \(C = \{ c_{1} ,c_{2} ,...,c_{m} \}\), and the evaluation data of the evaluation object \(u_{i}\) under the index \(c_{j}\) is \(x_{i,j}\), so the evaluation matrix of the evaluation object \(U\) under the evaluation index \(C\), as illustrated by the subsequent formula (1).
Standardization of sample data:
The evaluation index data involves the existence of different dimensions. The original data is not directly discretized to ensure the evaluation accuracy, but it is standardized with the standardization method first and the standardization methods of indexes with different meanings are also different, as follows:
(a) For the benefit-type index features (with larger and better characteristic values), the standardization is performed with formula (2) to eliminate the interference of the dimension [18]:
(2) For the cost-based index features (with smaller and better characteristic values), the standardization is performed with formula (3) to eliminate the interference of the dimension [24]:
Therefore, the standard evaluation matrix R can be obtained as follows:
Discretization of sample data
The discretization of sample data classifies the range of value from the continuous attributes into several discrete intervals and finally represents the attribute values that fall in each sub-interval with different symbols or integer values.
The data structure is simplified in the discretization method and it can be used to reduce the given attribute values. Also, the discretization of sample data reduces the reliance on distributional assumptions, so discrete data is more effective sometimes.
The sample data contain various category information which can be divided into supervised and unsupervised methods. With the supervised discretization method, the category information (such as city code and gender) needs to be taken into account, while it is not required for the unsupervised discretization method.
-
(a)
Unsupervised discretization
With the unsupervised discretization method, the category attribute is not considered, and its input data set only contains the value of the attribute to be discretized. Equal frequency, equal depth, K-means, and equal width are all unsupervised discretization methods, and from this, the equal frequency, K-means, and equal depth are more scientific.
-
(b)
Supervised discretization
Discretizing sample data containing category information (class tag) with an entropy-based method will lead to better evaluation results.
In this paper, different methods will be selected according to the specific meaning of the evaluation indexes.
Reduction of the attributes of the index system
Assuming \(C\) is an attribute set, with the attribute of \(a \in C\), if \(ind(c) - ind(C - \{ a\} )\), the attribute \(a\) can be omitted in the set \(C\); else it cannot be omitted in \(C\) [25].
If any attribute \(a \in C\) cannot be omitted \(C\), the attribute set \(C\) is said to be independent; otherwise, \(C\) is dependent. If the attribute set \(C\) is independent, all the attributes \(C\) cannot be omitted, and are indispensable, which can independently determine the information system; if the attribute set \(C\) is dependent, the redundant attributes \(a\) can be removed, forming a reduced attribute set \(C\).
Attribute set reduction steps: The assumptive data table of the non-decision-making system is shown in Table 1 below.
In the table, \(U\) is the universe of discourse, \(C\) is a conditional attribute, \(C = \{ a,b,c\}\), and \({\raise0.7ex\hbox{$U$} \!\mathord{\left/ {\vphantom {U {c_{i} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${c_{i} }$}}\) represents sub-categories \(U\) based on the valueof the \(c_{i}\) attribute.
The following can be drawn from Table 1:
Meanwhile:
Therefore, it can be seen from the results that \(a\) are indispensable in the attribute set \(C\), and \(b\) or \(c\) can be omitted in the attribute set, and because \(U/ind\{ a,b\} \ne ind\{ a\}\), and \(U/ind\{ a,b\} \ne ind\{ b\}\), so \(\{ a,b\}\) is a reduction of the attribute set \(C\). Similarly, \(\{ a,c\}\) is a reduction of the attribute set \(C\), that is, the attribute set \(A\) has two reductions: the \(\{ a,b\}\) and the \(\{ a,b\}\).
Weight computation
Assuming there is a table of decisions \(S = (U,C \cup D,V,f)\), \(U\) stands for the universe of discourse, \(C\) and \(D\) is the conditional and decisions attribute set respectively. If there is \(C_{1} \subseteq C\), then \(\sigma_{CD} (C_{1} ) = r_{C} (D) - r_{{C - C_{1} }} (D)\) is called the importance of the \(C_{1}\) to the \(D\). In particular, the importance of the attribute \(a \in C_{1}\) to the \(D\) is the \(\sigma_{CD} (C_{1} ) = r_{C} (D) - r_{{C - \{ a\} }} (D)\).
For the degree of influence on the decision attribute \(D\) after a certain attribute, the subset \(C^{\prime}\) is removed from the conditional attribute \(C\), namely, the \(\sigma_{CD} (C^{\prime}) = r_{C} (D) - r_{C - C^{\prime}} (D)\). In terms of computation of urban intelligent connected industry, the computing results are not known in advance, which means that the system is a non-decision-making system; thus, the following formula can be used to express the importance of the attribute \(C^{\prime}\), as shown in the formula (4).
The weight of the index is determined by the importance of the index, and the weight of the \(i\) index after the normalization process is shown in the formula (13).
Level-I index score by computation
The computation of the level-I index score of the \(i\) index is shown in formula (14).
Projection pursuit
This is a developing statistical method that is applied for processing and analyzing high-dimensional data observation, particularly the double data called non-normal and nonlinear. To solve the optimal projection value (i.e., the projected vector) of each dimension with the genetic approach based on the scores of the five level-I indexes (dimensions) and gain the optimal intelligent connected industry score for each city. The computing process by the projection pursuit approach is illustrated in Fig. 6.

Computing Process by Projection Pursuit Method
-
(1)
Data non-dimensionalization (data standardization)
This project is data standardization. Due to the different measurement dimensions and measuring methods for each index, the dimensions of each index are different and the data range varies significantly, which can be normalized according to formulas (2) and (3).
-
(2)
Constructing linear projection
Assuming \(\vec{a}\) is a vector of the m-dimensional unit, projection pursuit is to comprehensively project data \(\left\{ {x_{i,j} \left| {j = 1,..n} \right.} \right\}\) with n dimensions into a one-dimensional projection value with \(a = \{ a_{1} ,a_{2} ,..a_{n} \}\) as the projection direction, as shown in formula (15), the sum of the squares of the projection vectors of each dimension is 1, namely, \(a\) is the unit vector length, as shown in formula (16) [22]:
-
(3)
Constructing projection index
Assuming the projection eigenvalues set of the sample index is \(\Omega = \{ z_{1} ,z_{2} ,...,z_{n} \}\), denoted as \(s = \{ z_{i} ,z_{k} \}\), which is the absolute value distance between any two projection eigenvalues, and the absolute value distance is shown in the following formula (17) [32]:
-
(4)
Constructing an objective function
The objective function \(Q(a)\) is defined as the product of the between-class distance \(S(a)\) and the intraclass density \(D(a)\) [32], namely, the \(Q(a) = S(a) \times D(a)\).
Wherein, \(S(a)\) is shown in formula (10), \(D(a)\) is shown in formula (11), and the constraints are shown in formula (18):
\(R - \left| {z_{j} - z_{k} } \right|\) is a unit step function. When \(R > \left| {z_{j} - z_{k} } \right|\), \(f(R - \left| {z_{j} - z_{k} } \right|) = 1\); or it is 0; The density bandwidth parameter is denoted by R, and the intra-class density is represented by \(D(a)\) [23].
-
(5)
Determination of value R
Selecting the parameter value R is critical since different R values correspond to different optimal projection directions. Generally, it is believed that \(r_{\max } + \frac{n}{2} \le R \le 2n\) is a reasonable R-value [33]
-
(6)
Optimization of projection direction (projection vector)
It can be seen from the above analysis that when \(Q(a)\) the maximum value, the optimal projection value is computed. Thus, the maximum optimization value [33] is shown in the formula (13).
Adaptive random forest (ARF)
In the field of data stream categorization an advanced algorithm namely adaptive random forest (ARF) eliminates available hyperparameter tuning making it a stable off-the-shelf student for complex cycles. With the help of the based approach, Random Forest (RF) became renowned by using a machine learning approach. In this approach, every tree in this forest commits a unit vote in determining the class label for every entry. In this technique, this categorization approach includes some advantages including efficient identification of nonlinear patterns, speed, and robustness by handling both the numeric and categorical data. Moreover, using a feature selection method that includes gain ratio, correlation, and data gain in identifying optimal appearance. Utilizing the bootstrap algorithm helps in organizing imbalance issues and data training issues. Some of the benefits used in bootstrap resampling used for ROC algorithm performance especially while managing non-uniform information. Here, this dataset consisting of bootstrap modules is uniform. The generated bootstrap dataset is combined with the random forest strategy sensitivity, F metric, specificity, ROC, and classification accuracy. These are some of the performance metrics. The ARF approach can be parallelized by consuming the time of the ensemble classifiers, which is often based on the training and its base learners. Here, the base learners are responsible for another task, by keeping track of drift and updating individual data structures that represent their weights. Moreover, a parallel version of ARF present in the training tree is controlled using a standard serial application of random forest. Here, the parallel version shows improved performance than the sequential one with no compromise in precise execution and some activities that run continuously. Earlier, the detached attributes are to be pruned by employing the Hoeffding tree approach. Thus, the ARF operation involved by pruned by minimizing the variability of the Random Forest approach.
Crossover with tactical unit algorithm
The integration of tactical units with a crossover strategy is determined to diminish the overfitting issue while handling a large set of data. Also, it is used to analyze the complexity in frequently varying conditions of information. The high dimensional data are handled efficiently by ARF and the rough set theory is employed with pursuit projection that validates the inefficiency condition of the model. It is also utilized to analyze the complex data sets determined in vehicle industry applications.
Tactical unit algorithm
This algorithm is utilized to maintain the stable velocity in the initial search strategy function for attaining the target in a tactical unit. It is a metaheuristic algorithm that performs an effective search of the population. The mathematical validation of this unit is formulated as
The individual search agent in the tactical function is expressed as
where the optimized dimension of decision variables is denoted as \(f\) and population size is indicated as \(r\). The numerical validation of fitness to minimize complexity issues is expressed as
From the above equation, the fitness range is signified as \(h_{u}\).
Search phase: The initial search agents are generated to manage the target data to attain optimal search. The position of each search algorithm is formulated as
where maximum iteration is indicated as \(N_{\max p}\), the size of the matrix is represented as \(Rz\), the current iteration is denoted as \(m\), the new position is signified as \(U_{s,p}^{m + 1}\), and the formation of the random number is indicated as \(\mu\). Also, the target search range is indicated as \(T_{SC}\).
Execution phase: In each subset group, the secondary target function is employed for circulating the information and the updated locations are expressed as
where coefficient executions are indicated as \(vm\), the position of search space is signified as \(U_{s,p,k}^{m}\), and optimal position updation is represented as \(U_{m + 1}\).
Assessment phase: The information obtained by the search agents is gathered and the target ranges in both searchers and executors. The optimal solution in each weighted range is analyzed and updated information based on weighted parameters that are expressed as
where the best position of searchers, as well as executors, are indicated as \(U_{fT}^{m + 1}\) and \(U_{fD}\). The validation of the non-linear adaptive weight factor is mathematically expressed as
Crossover strategy
This is determined to estimate the population diversity in mutant chromosomes of crossover operation. The random numbers are formed optimally and the probability function is evaluated whether it is equal to or less than the crossover strategy. The mathematical expression is formulated as
From the above equation, cross chromosomes are indicated as \(m_{u}^{n}\) crossover gene mutation is signified \(v_{RAND} \in \left[ {1,2, \cdots ,K} \right]\) and crossover probability function is represented as \(c_{r}\). The original progeny are not identical and the information transmission is performed in large amounts that attained a global optimization by reducing the delay and dimensionality issues.
Figure 7 depicts the flowchart of the proposed approach for the ICV.

Flowchart of the proposed approach
Hyperparameter tuning
Hyperparameter tuning is employed to enhance the scalability of the proposed approach by evaluating the ICV industries in cities. For this purpose, the parameters are to be tuned by employing hyperparameter tuning to enhance the reliability of the ICVs. The proposed approach is integrated with the Adaptive Random Forest approach and the Crossover with the tactical unit algorithm. The parameters are to be initialized, and then the category of the approach is separated by employing the categorization process. After that resampling is done by employing the resampling method. However, the ARF approach can have overfitting issues. To enhance the overfitting fitting issues a crossover wth tactic unit algorithm is employed, here, the parameters are to be initialized. After that, the agents are to be extracted, and the size of the population is to be determined. The fitness values are validated and the crossover strategy is employed to enhance the overfitting issues. Finally, update the position of the individuals. If the condition is to be satisfied then the obtained output is obtained otherwise it leads to the optimization process, and so on.
According to the optimized projection vector \(a^{ * }\) and the score x of each index, the final comprehensive computing result \(z^{ * }\) can be obtained, and the \(z^{ * }\) formula (30) is shown below.
\(a^{ * }\) represents the optimal projection direction, and \(z^{ * }\) is the computing result of the projection value.
Computational complexity
The efficiency of the interconnecting vehicle industry is analyzed to estimate traffic control, energy consumption, and several environmental impacts. The complexity of the model is diminished by extracting the hidden patterns of the ICV industry. The complexity analysis is performed \(O\left( {u \times v} \right)\) in which the number of pixels is indicated \(u\). This is used to analyze the total complexities formed in the uncertainty condition.
Urban intelligent connected industry score computation
Since the level-I indexes selected in this paper are five-dimensional, and according to the constraints of the projection vector, the higher projection value is obtained for solving the nonlinear equations [26, 27], as shown in the following formula (31).
where in, st represents the satisfaction of conditions, \(a_{1}^{2} ,i = 1..,5\) represents the sum of squares of each projection vector, \(f_{\max } (z)\) represents the maximum value function, \(z_{i} ,i = 1..,5\) represents the projection value of each level-I index, and the value of \(f_{\max } (z)\) can be obtained with the aid of the Matlab software.
Assuming \(f_{\max } (z) = z_{\max } = 2.2361\), and mapping the projection value \(z^{ * }\) to the score between [0-m], the formula (32) is shown below:
where the score is the point gained for the intelligent connected industry of a city.
Limitations of methodology
The determination of hierarchical evaluation indexes heavily relies on big data text technology, specifically theme and content analysis. While these methods are valuable for extracting relevant technical indexes from intelligent connected industry reports, they are susceptible to the quality and comprehensiveness of the available textual data. Incomplete or biased information in the analyzed reports may lead to the exclusion of critical indexes or introduce potential subjectivity. The use of rough set theory, while advantageous in handling uncertain information and simplifying data analysis, has its limitations. The method's effectiveness depends on the appropriateness of attribute reduction, and the results may vary based on the chosen methods. Besides, the application of a genetic algorithm for projection pursuit introduces complexity, and the success of the approach relies on the proper tuning of parameters, such as the density bandwidth parameter (R). The sensitivity of the results to parameter selection may impact the robustness of the comprehensive evaluation system and the study's evaluation of intelligent connected industries is based on data from 19 cities, potentially limiting the generalizability of findings to a broader context.
Result
To explore the scope of the article, the investigation proposed research variables and hypotheses. To prove the proposed variables and hypothesized relationship, the examination conducted a case study, the number of each index, reduction of computation attribute and weight, computing results with projection pursuit, and score analysis of the ICV industry. All analysis results are as follows;
Parameter setting
In ICV industrial applications the parameters are tuned to optimize the weight functions for minimizing the dimensionality issues that are delineated in Table 2.
Evaluation measures
To validate the performance of the model different metrics are determined to extract the effectiveness by performing analysis with different methods and they are discussed below.
Accuracy
It is used to measure the standard range of the optimized weight ranges and provide the classified outcome based on the predicted range. It is mathematically formulated as
Precision
The ideal functionality of the actual and predicted ranges is estimated and the total information transmitted is estimated with the expression
Delay
It validates the time taken to transmit the data in evaluating the vehicle functionalities. It maximized the performance by categorizing the factors to diminish the lag of data.
Energy consumption
The total energy required to transmit the data is validated and the performance is calculated based on the industrial development applications for sustainable transportation.
Case study
The cities chosen for assessment are determined by their early advancements in the intelligent-connected industry, their established infrastructure within this sector, and the intelligent-connected industry with strong development momentum. Through preliminary screening of the cities located in the six economic regions namely North, South, Southwest, Northeast, East parts of China, Central China, and the six major industrial clusters namely Northeast Industrial Cluster, Central Industrial Cluster, Beijing-Tianjin-Hebei Industrial Cluster, Western Industrial Cluster, Pearl River Delta Industrial Cluster and Yangtze River Delta Industrial Cluster, and Western Industrial Cluster) across China and experts' recommendations, etc., \(U1_{i} = 1,2,.....,19\) Key cities are finally picked as the evaluation objects to analyze the competitiveness of the urban ICV industry.
Number of each index
For the convenience of reading and writing, the indexes at each level are numbered, as given in Table 3 below.
Reduction of computation attribute and weight
The reduction of attributes and the corresponding index weights are computed with the rough set theory above. As there are five index systems in this paper, the level-I indexes of urban policy are detailed here, and the other indexes are similar.
Data discretization
As defined herein, if the data of a level-II index is less than or equal to 19 and is an integer, such index data can be considered as discrete data; or it is considered as continuous data. Regarding the continuous data processing method: Firstly, standardize the data by combining formula (2) and formula (3) according to the meaning of the index; then, conduct discretization with the following formula (35).
The round represents the rounding function, \(r\) represents the data after standardization, \(r^{\prime}\) represents the data after discretization, and \(len(U)\) represents the number of cities selected.
Since the dimension range of the level-I index of urban policy data is \(0 \le n \le 8,n \le len(U),n \in N^{ * }\) (representing a positive integer between 0 and 8), the level-II index data of urban policy is discrete, and the discrete data values of urban policy are shown in Table 4 below.
Attribute reduction and weight
The following relationships can be obtained in terms of urban policy:
Therefore, after reduction with rough sets of the level-I index of urban policy, the level-II index of top-level planning can be deleted. The reduced dimensional data is shown in Table 5, and the weights of the reduced indexes computed according to formula (4) and formula (5) are given in Table 6.
Computation of index score
-
(1)
Computation of level-II index
The data obtained for the level-II index does not represent the score. The corresponding score shall be set according to the size of the data, assuming the minimum score is 60 points and the maximum score is 100 points. The mapping function is shown in Formula 41 below.
\(s\) stands for the set score, and \(x_{i,j}\) denotes discrete data of the level-II indexes of urban policy. The computed scores of each level-II index of urban policy are shown in Table 7.
-
(2)
Level-I index score
The scores of urban policy can be computed with formula (6). The scores of the urban policy of the 19 cities are shown in Table 8.
Computing results of other indexes
According to the aforementioned computing steps, the scores of the four level-I indexes of infrastructure, industrial chain, application data, and urban influence can be obtained.
The reduced attributes and attribute weights of the industrial chain after attribute reduction are as follows in Table 9 below, and the industrial chain scores of every city are presented in Table 10. As shown in Table 9, when the level-I index of the industrial chain has undergone a rough set reduction, two level-II indexes (auto parts companies and cloud computing companies) are obtained.
The reduced attributes and attribute weights of the infrastructure after attribute reduction are shown in Table 11 below, and the infrastructure scores are given in Table 12. From Table 11 the level-I index infrastructure has the same results before and after rough set reduction.
The reduced attributes and attribute weights of the application data after attribute reduction are shown in Table 13 below, and the application data scores of every city are provided in Table 14. Table 13 explains that the level-I index of application data has the same results before and after rough set reduction.
The reduced attributes and attribute weights of the urban influence after attribute reduction are shown in Table 15 below, and the urban influence scores are given in Table 16. In Table 15, it can be explained that the level-I index of application data through rough set reduction can keep three level-II indexes (entrepreneurial influence, news and public opinion, and patent information) retained.
Results after attribute reduction
This is performed on the level-II indexes of each level-I index, and the results after attribute reduction are shown in Table 17.
Computing results with projection pursuit
Through the computation above, the level-I index scores of each city are shown in Table 18. Based on the five level-I index scores of the 19 cities computed in Sect. "Technological innovation and urban transport system", the optimal projection vector of each level-I index is computed with the projection pursuit method. The optimal projection vector is shown in Table 19.
According to formula (16), the comprehensive score of the ICV industry in each city can be computed. Assuming that the projection value \(z^{ * }\) is mapped to the score between (60 and 100), the comprehensive score of the ICV industry in each city measured is show in Table 20.
Score analysis of the ICV industry
The competitiveness ranking results of the 19 major cities selected in this paper are obtained from various indexes; the results are divided into three echelons; \(80 < u_{3} ,u_{1} ,u_{4} ,u_{8} ,u_{5} ,u_{9} \le 100\) is the first echelon, \(70 < u_{6} ,u_{2} ,u_{11} ,u_{10} ,u_{17} \le 80\) the second echelon, and \(60 < u_{7} ,u_{19} ,u_{13} ,u_{14} ,u_{12} ,u_{18} ,u_{16} ,u_{15} \le 70\) the third echelon. By conducting thorough research, it becomes evident that the first echelon excels on a global scale across five key areas: industrial chain, urban policy, infrastructure, urban influence, and application data. Similarly, the second echelon demonstrates leadership in urban policy, industrial chain, research and development capabilities, and developmental potential, showing promising growth trajectories. Meanwhile, the third echelon has established a solid groundwork within the industrial chain but with a relatively lagging enterprise scale and R&D capability, being at a stage of development.
Result evaluation
This consists of the definition of evaluation rules and evaluation result computation. It is briefly described in the below sections.
Definition of evaluation rules
The evaluation adopts both subjective and objective methods, that is, experts make subjective judgments according to their experience based on the results in Sect. "Integrating rough set theory and projection pursuit-based computation".
The specific steps are as follows:
-
1.
First, relevant experts in the ICV field are invited to evaluate the grouping results of the above 19 cities. Each expert will score each city separately. If the expert thinks that a city is grouped correctly, then one point is given to this city. If the expert does not approve the grouping result, then 0 points are given. The scoring table is shown in Table 21 below (example).
Table 21 Scoring Table (example) -
2.
A total of 20 experts are invited to score the cities according to step (1).
-
3.
Calculate the total points of each city.
-
4.
If more than 80% of the experts agree with the grouping result of a city, the city is labeled positive; otherwise, negative.
When calculating the total points of each city, s is assumed to represent the sum. It can be seen from the above that if s satisfies the formula (42), it means that the grouping of the city is in a positive category; otherwise, it is in the negative category.
Evaluation results computation
According to the formula (19), the categories of cities are shown in Table 22 below.
The accuracy of the computation model is calculated according to the formula (43) below.
The above equation \(num\left( {Positive} \right)\) signifies the total number of cities in the positive category. The number of cities is denoted by \(num\left( u \right)\).
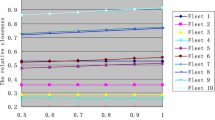
Figure 8 depicts the validation of accuracy for predicting the actual ranges in the vehicle industry for the proposed method. The closed ranges of the accepted values are determined and the similarity of each measure diminishes the complexity. The proposed method improved the analysis outcome by attaining 91% and they are compared with existing FS-MS, GA-ACO, AHCF as well as LFT-LMI that achieved 79%, 85%, 81%, and 87% respectively.

Accuracy validation for the proposed method
The precision evaluation for the proposed approach to estimate the efficiency of technological advancement is delineated in Fig. 9. The positive predicted ranges at each metric are validated by determining the proposed approach for evaluating the effectiveness of various approaches. The proposed method is obtained to diminish the overfitting issues and they are lowered by 89.9% than state-of-the-art methods.

Evaluation of precision to extract the effectiveness of the proposed approach
The delay validation in the data transmission process is depicted in Fig. 10. While transmitting the data regarding the ICV industry the hidden patterns are analyzed and this maximizes the transferring process. Also, there occurs a lag when multiple data are obtained in the determined features. The total delay developed in the model is validated by comparing the proposed and existing approaches in which the better reduction of delay is achieved by the ARF-CTU method as 78. The remaining approaches namely FS-MS, GA-ACO, AHCF as well as LFT-LMI maximized the delay rate as 87, 89, 85, and 81 respectively.

Measuring the total delay occurs in the techniques
Figure 11 depicts the amount of energy required in ICV to diminish the congestion process. The energy required to process the data is analyzed based on multifaced hidden pattern features. The comparison performed to extract the superiority of the model is undertaken with the proposed ARF-CTU and existing FS-MS, GA-ACO, AHCF as well as LFT-LMI, and from this, the energy requirement for the proposed method is low as 56 than existing techniques.

Graphical analysis of energy consumption
Figure 12 delineates the effectiveness of the proposed model is validated. This is used to analyze the ability to process the data with the determined resources and the feasible conditions of data transmission are analyzed. This is validated by performing the comparison with the proposed ARF-CTU and existing FS-MS, GA-ACO, AHCF as well as LFT-LMI methods. In this validation compared to existing techniques, the proposed improved efficiency by 89.9%.

Validation of efficiency
Table 23 depicts the comparison of recent existing methods with the proposed ARF-CTU approach. The comparison result shows the performance validation of various methods to check the effectiveness and the proposed achieved a better result than other state-of-the-art techniques.
Discussion
In industrial technology, intelligent connected vehicles are significant in evaluating the complexity issues regarding input systems. The rough set theory and projection pursuit are integrated to clarify the information regarding computation. The theory's ability to deal with complex, non-linear data has allowed a more refined understanding of the interplay between various variables like traffic flow, energy consumption, and environmental impact. Integration of projection pursuit-based computation has increased the research’s capacity to expose hidden patterns and structures within the ICV industry data. Retaining the inherent characteristics of the data, this approach has provided a more accurate and dependable assessment of the industry’s performance offering a valuable tool for policymakers and industry stakeholders to make decisions. The gauging outcomes highlighted the importance of fostering sustainable transportation solutions that improve energy consumption and traffic management. In addition to that, it also contributes to reducing the overall environmental footprint of urban mobility. Also, the novel ARF-CTU algorithm is proposed that is widely applied to diminish the overfitting issues and the dimensionality problems. The enhancement of the proposed method is compared with various existing techniques such as FS-MS, GA-ACO, AHCF, LFT-LMI, and DMPC methods to analyze the transport system in high dimensional data processing. The technological innovations are evaluated based on the improvement of communication in industrial applications. But in transmission data, the complexity is maximized and a huge delay occurs due to overfitting issues. This is solved by the proposed ARF-CTU algorithm that improved the performance by diminishing the delay and overfitting issue by handling the high dimensional data efficiently. The performance of the proposed method is evaluated based on accuracy and precision that showed the effectiveness based on a comparison of existing approaches. Moreover, the discussion underscores the theoretical implications of the research, emphasizing the contribution of advanced computational methods to the border field of urban transportation and data analysis.
The experimental validations are undertaken to determine the score level of industrial applications in varied cities and analyze the attribute weights of the index. With different weight indices, the urban score is calculated based on public opinion. The score values of the ICV industry are estimated by level 1 and 2 indexes. Also, the evaluations undertaken by comparing different methods are used to show the better validation range of the vehicle and obtain enhanced efficiency results with diminished complexity. This outcome is finalized by performing comparison results with existing and proposed methods among various metrics. The parameters are set in the proposed ARF-CTU to diminish the complexity and adjust the ICV data collection process. The parameters will need to be tuned based on the complexity of the ICV problem and the available computational resources. Further, the optimal ranges are identified by tuning the parameters that improve the result by assessing the accuracy indexes.
Practical implications
The identification of key cities with competitive advantages in the ICV industry provides valuable insights for policymakers to adopt policies and regulations that encourage sustainable industry growth. Then, the study highlights the importance of industry development and innovation, suggesting directions for technological advancement, product development, and service enhancement to meet the evolving demands of ICV markets. Infrastructure planning and investments are crucial, emphasizing the need for the strategic development of intelligent traffic management systems, charging infrastructure for ICVs, and smart mobility solutions to enhance urban connectivity and support the growth of the ICV ecosystem. These implications emerge for policymakers, urban planners, and industry stakeholders.
Theoretical Implications
The study's utilization of high-dimensional and nonlinear data analysis methods offers insights into the effective management and interpretation of complex urban transportation datasets, contributing to advancements in urban transportation research. Then, the study underscores the relevance of system theory and urban dynamics, emphasizing the application of systems thinking to analyze the interdependencies between intelligent transportation networks, environmental sustainability, and urban development. The exploration of artificial intelligence, big data analytics, and communication technologies in shaping the future of ICVs and urban mobility encourages theoretical frameworks for leveraging technological advancements toward sustainable and efficient transportation solutions, enriching the discourse on urban mobility and transportation planning.
Conclusion
In this paper, the urban ICV industry score is comprehensively computed based on five aspects: the infrastructure, industrial chain, application data, urban policy, and urban influence, and the accuracy rate of the model is over 80%. Although the computing results of this method reflect the facts truthfully, there is still a leeway for optimization. In terms of index selection, for example, the index factor of the security coefficient of the urban industrial chain will also be considered in the future, as the city's fully independent industrial chain enjoys a higher security coefficient than the industrial chain of foreign investment and joint ventures; that is to say, the more independent industrial structures in a city's industrial chain have, the higher the city's resilience index will be, and the city will be less affected in the face of unfavorable factors such as foreign capital withdrawal. Such a method can not only be used for computing the city's ICV industry score but also for computing the industry score of real estate and other bulk consumer goods in the future, which can better guide future region-wide industrial planning. It can also attract foreign investment based on the scores of the level-II indexes to further stimulate economic growth, promote employment, and provide more jobs.
Limitations
The study’s sample size was relatively small, which may limit the generalizability of the findings to a broader population. The utilization of sophisticated methodologies such as rough set theory and projection pursuit may introduce complexities that limit the replicability of research findings. Subjective interpretations in the process of weighting influenced the final evaluation of the study. The dynamic nature of the ICV industry including technological advancements and market shifts could challenge the long-term relevance of the research it has limited in the study.
Future scope
The study is about the parameter that estimates for the comparison could shed the effectiveness of different policies, infrastructural developments, and technological interventions in promoting the growth of the ICV industry across diverse urban contexts. The future scope focuses on the assessment of policy interventions, regulatory frameworks, and incentives that can promote innovation, efficiency, and environmental sustainability within the ICV sector.
Availability of data and material
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Code availability
Not applicable.
References
Zhang H, Qi Y, Zhang G (2023) Comparative analysis of the intelligent connected vehicle industry in China, the United States, and the European Union from a technology lifecycle perspective. Kybernetes. https://doi.org/10.1108/K-05-2023-0928
Götz M (2021) Clusters, digital transformation, and regional development in Germany. Routledge. https://doi.org/10.4324/9781003005506
Qiu T, Chi J, Zhou X, Ning Z, Atiquzzaman M, Wu DO (2020) Edge computing in the industrial internet of things: architecture, advances and challenges. IEEE Commun Surv Tutorials 22(4):2462–2488. https://doi.org/10.1109/COMST.2020.3009103
Zhou F, Liu Y, Chen R (2021) Research on collaborative innovation of intelligent connected vehicles industry based on test field: embedded case study from the perspective of open innovation. Sustainability 13(11):5880. https://doi.org/10.3390/su13115880
Liu X, Guan Z (2020) A comparative study of industrial development policies for intelligent connected vehicle. In CICTP, pp. 3333–3345.
Mishra M, Nayak J, Naik B, Abraham A (2020) Deep learning in electrical utility industry: acomprehensive review of a decade of research. Eng Appl Artif Intell 96:104000. https://doi.org/10.1016/j.engappai.2020.104000
Tripathi M, Singal SK (2019) Use of principal component analysis for parameter selection for development of a novel water quality index: a case study of river Ganga India. Ecol Ind 96:430–436. https://doi.org/10.1016/j.ecolind.2018.09.025
Gourisetti SNG, Mylrea M, Patangia H (2019) Evaluation and demonstration of blockchain applicability framework. IEEE Trans Eng Manag 67(4):1142–1156. https://doi.org/10.1109/TEM.2019.2928280
Yu D, Xu Z, Pedrycz W (2020) Bibliometric analysis of rough sets research. Appl Soft Comput 94:106467. https://doi.org/10.1016/j.asoc.2020.106467
Hu X, Sun B, Chen X (2020) Double quantitative fuzzy rough set-based improved AHP method and application to supplier selection decision making. Int J Mach Learn Cybern 11(1):153–167. https://doi.org/10.1007/s13042-019-00964-z
Cao J, Lin L, Zhang J, Zhang L, Wang Y, Wang J (2021) The development and validation of the perceived safety of intelligent connected vehicles scale. Accid Anal Prev 154:106092. https://doi.org/10.1016/j.aap.2021.106092
Ge Q, Sartoretti G, Duan J, Li SE, Yin Y, Zheng S (2022). Distributed model predictive control of connected multi-vehicle systems at unsignalized intersections. In 2022 IEEE International Conference on Unmanned Systems (ICUS), pp. 1466–1472. IEEE. https://doi.org/10.1109/ICUS55513.2022.9986954
Zadobrischi E, Cosovanu LM, Dimian M (2020) Traffic flow density model and dynamic traffic congestion model simulation based on practice case with vehicle network and system traffic intelligent communication. Symmetry 12(7):1172. https://doi.org/10.3390/sym12071172
Liu Z, Song H, Tan H, Hao H, Zhao F (2022) Evaluation of the cost of intelligent upgrades of transportation infrastructure for intelligent connected vehicles. J Adv Transp. https://doi.org/10.1155/2022/5841373
Santini S, Albarella N, Arricale VM, Brancati R, Sakhnevych A (2021) On-board road friction estimation technique for autonomous driving vehicle-following maneuvers. Appl Sci 11(5):2197. https://doi.org/10.3390/app11052197
Mastinu G, Gobbi M (2023) Force sensors for active safety, stability enhancement and lightweight construction of road vehicles. Veh Syst Dyn 61(9):2165–2233. https://doi.org/10.1080/00423114.2023.2240447
Lin Q, Li SE, Xu S, Du X, Yang D, Li K (2020) Eco-driving operation of connected vehicle with V2I communication among multiple signalized intersections. IEEE Intell Transp Syst Mag 13(1):107–119. https://doi.org/10.1109/MITS.2020.3014113
Ray P, Reddy SS, Banerjee T (2021) Various dimension reduction techniques for high dimensional data analysis: a review. Artif Intell Rev 54:3473–3515. https://doi.org/10.1007/s10462-020-09928-0
Malekloo A, Ozer E, AlHamaydeh M, Girolami M (2022) Machine learning and structural health monitoring overview with emerging technology and high-dimensional data source highlights. Struct Health Monit 21(4):1906–1955. https://doi.org/10.1177/14759217211036880
Gan L, Shi H, Hu Y, Lev B, Lan H (2020) Coupling coordination degree for urbanization city-industry integration level: Sichuan case. Sustain Cities Soc 58:102136. https://doi.org/10.1016/j.scs.2020.102136
Kuang X, Zhao F, Hao H, Liu Z (2019) Assessing the socioeconomic impacts of intelligent connected vehicles in China: a cost-benefit analysis. Sustainability 11(12):3273. https://doi.org/10.3390/su11123273
Hou L, Su J, Ye Y (2023) Exploring the influence of smart product service systems on enterprise competitive advantage from the perspective of value creation. Sustainability 15(18):13828. https://doi.org/10.3390/su151813828
Alogdianakis F, Dimitriou L (2023) Optimal mechanism design of public policies for promoting electromobility: a dynamic programming formulation. Transp Res Interdiscip Perspect 19:100807. https://doi.org/10.1016/j.trip.2023.100807
Che C, Geng X, Zheng H, Chen Y, Zhang X (2022) Optimization and benefit analysis of intelligent networked vehicle supply chain based on stackelberg algorithms. Sci Program. https://doi.org/10.1155/2022/3946744
Onat NC (2022) How to compare sustainability impacts of alternative fuel vehicles? Transp Res Part D: Transp Environ 102:103129. https://doi.org/10.1016/j.trd.2021.103129
Al Haddad C, Chaniotakis E, Straubinger A, Plötner K, Antoniou C (2020) Factors affecting the adoption and use of urban air mobility. Transp Res Part A: Policy Pract 132:696–712. https://doi.org/10.1016/j.tra.2019.12.020
Acheampong RA, Cugurullo F (2019) Capturing the behavioral determinants behind the adoption of autonomous vehicles: conceptual frameworks and measurement models to predict public transport, sharing and ownership trends of self-driving cars. Trans Res Part F: Traffic Psychol Behav 62:349–375. https://doi.org/10.1016/j.trf.2019.01.009
Abduljabbar R, Dia H, Liyanage S, Bagloee SA (2019) Applications of artificial intelligence in transport: an overview. Sustainability 11(1):189. https://doi.org/10.3390/su11010189
Nieuwenhuijsen MJ (2020) Urban and transport planning pathways to carbon neutral, liveable and healthy cities; a review of the current evidence. Environ Int 140:105661. https://doi.org/10.1016/j.envint.2020.105661
Diao M (2019) Towards sustainable urban transport in Singapore: policy instruments and mobility trends. Transp Policy 81:320–330. https://doi.org/10.1016/j.tranpol.2018.05.005
Zhao X, Ke Y, Zuo J, Xiong W, Wu P (2020) Evaluation of sustainable transport research in 2000–2019. J Clean Prod 256:120404. https://doi.org/10.1016/j.jclepro.2020.120404
Wang M, Wang Y, Shen F, Jin J (2021) A heuristic projection pursuit method based on a connection cloud model and set pair analysis for evaluation of slope stability. Symmetry 13(11):2016. https://doi.org/10.3390/sym13112016
Zhang P, Li T, Wang G, Luo C, Chen H, Zhang J, Yu Z (2021) Multi-source information fusion based on rough set theory: a review. Inf Fusion 68:85–117. https://doi.org/10.1016/j.inffus.2020.11.004
Zhang R, Zhong W, Wang N, Sheng R, Wang Y, Zhou Y (2022) The innovation effect of intelligent connected vehicle policies in China. IEEE Access 10:24738–24748. https://doi.org/10.1109/ACCESS.2022.3155167
Tang J, Wu W, Zhao D, Chen X (2023) Evolutionary game and simulation analysis of intelligent connected vehicle industry with cross-border collaborative innovation. IEEE Access 11:17721–17730. https://doi.org/10.1109/ACCESS.2023.3245078
Zhi P, Zhao R, Zhou H, Zhou Y, Ling N, Zhou Q (2021) Analysis on the development status of intelligent and connected vehicle test site. Intell Converged Netw 2(4):320–333. https://doi.org/10.23919/ICN.2021.0023
Shen Z, Siraj A, Jiang H, Zhu Y, Li J (2020) Chinese-style innovation and its international repercussions in the new economic times. Sustainability 12(5):1859. https://doi.org/10.3390/su12051859
Orón Semper JV, Akrivou K, Scalzo G (2019) Educational implications that arise from differing models of human development and their repercussions on social innovation. Front Educ 4:139. https://doi.org/10.3389/feduc.2019.00139
Li Y, Liang C, Ye F, Zhao X (2023) Designing government subsidy schemes to promote the electric vehicle industry: a system dynamics model perspective. Transp Res Part A: Policy Pract 167:103558. https://doi.org/10.1016/j.tra.2022.11.018
Ruan J, Chen Y, Yang Z (2021) Assessment of temporal and spatial progress of urban resilience in Guangzhou under rainstorm scenarios. Int J Disaster Risk Reduct 66:102578. https://doi.org/10.1016/j.ijdrr.2021.102578
Tang J, Zhang X, Yin W, Zou Y, Wang Y (2021) Missing data imputation for traffic flow based on combination of fuzzy neural network and rough set theory. J Intell Transp Syst 25(5):439–454. https://doi.org/10.1080/15472450.2020.1713772
Nanaki EA (2020) Electric vehicles for smart cities: trends, challenges, and opportunities.
Chen S, Hu J, Zhao L, Zhao R, Fang J, Shi Y, Xu H (2023) Cellular Vehicle-to-Everything (C-V2X). Springer Nature
Kakderi C, Oikonomaki E, Papadaki I (2021) Smart and resilient urban futures for sustainability in the post COVID-19 era: a review of policy responses on urban mobility. Sustainability 13(11):6486. https://doi.org/10.3390/su13116486
Song X, Sun P, Song S, Stojanovic V (2023) Quantized neural adaptive finite-time preassigned performance control for interconnected nonlinear systems. Neural Comput Appl 35:15429–15446. https://doi.org/10.1007/s00521-023-08361-y
Zhuang Z, Tao H, Chen Y, Stojanovic V, Paszke W (2022) An optimal iterative learning control approach for linear systems with nonuniform trial lengths under input constraints. IEEE Trans Syst Man Cybern: Syst 53(6):3461–3473. https://doi.org/10.1109/TSMC.2022.3225381
Song X, Wu C, Stojanovic V, Song S (2023) 1 bit encoding–decoding-based event-triggered fixed-time adaptive control for unmanned surface vehicle with guaranteed tracking performance. Control Eng Pract 135:105513. https://doi.org/10.1016/j.conengprac.2023.105513
Zhang Z, Song X, Sun X, Stojanovic V (2023) Hybrid-driven-based fuzzy secure filtering for nonlinear parabolic partial differential equation systems with cyber attacks. Int J Adapt Control Signal Process 37(2):380–398. https://doi.org/10.1002/acs.3529
Dewangan DK, Sahu SP (2023) Lane detection in intelligent vehicle system using optimal 2-tier deep convolutional neural network. Multimed Tools Appl 82(5):7293–7317. https://doi.org/10.1007/s11042-022-13425-7
Revanna JKC, Al-Nakash NYB (2024) Impact of ACO intelligent vehicle real-time software in finding shortest path. Softw Impacts 19:100625. https://doi.org/10.1016/j.simpa.2024.100625
Flores TK, Silva I, Azevedo MB, de Medeiros TDA, Medeiros MDA, Costa DG, Ferrari P, Sisinni E (2024) Advancing TinyMLOps: Robust Model Updates in the Internet of Intelligent Vehicles. IEEE Micro, pp. 1–12. https://doi.org/10.1109/MM.2024.3354323
Sun D, Chen Y, Li H (2024) Intelligent vehicle computation offloading in vehicular Ad Hoc networks: a multi-agent LSTM approach with deep reinforcement learning. Mathematics 12(3):424. https://doi.org/10.3390/math12030424
Ribeiro DA, Melgarejo DC, Saadi M, Rosa RL, Rodríguez DZ (2023) A novel deep deterministic policy gradient model applied to intelligent transportation system security problems in 5G and 6G network scenarios. Phys Commun 56:101938. https://doi.org/10.1016/j.phycom.2022.101938
Rahmani S, Baghbani A, Bouguila N, Patterson Z (2023) Graph neural networks for intelligent transportation systems: a survey. IEEE Trans Intell Transp Syst 24(8):8846–8885. https://doi.org/10.1109/TITS.2023.3257759
Khan RH, Miah J, Arafat SY, Syeed MM, Ca DM (2023) November. Improving Traffic Density Forecasting in Intelligent Transportation Systems Using Gated Graph Neural Networks. In 2023 15th International Conference on Innovations in Information Technology (IIT), IEEE, pp. 104–109. https://doi.org/10.1109/IIT59782.2023.10366426
Zhang X, Fang S, Shen Y, Yuan X, Lu Z (2023) Hierarchical velocity optimization for connected automated vehicles with cellular vehicle-to-everything communication at continuous signalized intersections. IEEE Trans Intell Transp Syst 25(3):2944–2955. https://doi.org/10.1109/TITS.2023.3274580
Nguyen TH, Jung JJ (2023) ACO-based traffic routing method with automated negotiation for connected vehicles. Complex Intell Syst 9(1):625–636. https://doi.org/10.1007/s40747-022-00833-3
Gokasar I, Pamucar D, Deveci M, Gupta BB, Martinez L, Castillo O (2023) Metaverse integration alternatives of connected autonomous vehicles with self-powered sensors using fuzzy decision making model. Inf Sci 642:119192. https://doi.org/10.1016/j.ins.2023.119192
Funding
Not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by any of the authors.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Y., Zhang, F., Feng, Q. et al. Strategic analysis of intelligent connected vehicle industry competitiveness: a comprehensive evaluation system integrating rough set theory and projection pursuit. Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01525-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01525-w