
Abstract
The aftermath of a natural disaster leaves victims trapped in rubble which is challenging to detect by smart drones due to the victims in low visibility under the adverse disaster environments and victims in various sizes. To overcome the above challenges, a transformer fusion-based scale-aware attention network (TFSANet) is proposed to overcome adverse environmental impacts in disaster areas by robustly integrating the latent interactions between RGB and thermal images and to address the problem of various-sized victim detection. Firstly, a transformer fusion model is developed to incorporate a two-stream backbone network to effectively fuse the complementary characteristics between RGB and thermal images. This aims to solve the problem that the victims cannot be seen clearly due to the adverse disaster area, such as smog and heavy rain. In addition, a scale-aware attention mechanism is designed to be embedded into the head network to adaptively adjust the size of receptive fields aiming to capture victims with different scales. Extensive experiments on two challenging datasets indicate that our TFSANet achieves superior results. The proposed method achieves 86.56% average precision (AP) on the National Institute of Informatics—Chiba University (NII-CU) multispectral aerial person detection dataset, outperforming the state-of-the-art approach by 4.38%. On the drone-captured RGBT person detection (RGBTDronePerson) dataset, the proposed method significantly improves the AP of the state-of-the-art approach by 4.33%.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Post-disaster conditions caused by natural disasters usually result in large numbers of victims trapped in the wilderness or ruins [1]. Search and rescue (SAR) drones are to assist emergency teams by telematics via images or sound to determine the presence of victims in high-risk or hard-to-access areas in the early stages of their activation. This work focuses on improving the detection accuracy of victims based on SAR drone-captured multispectral images for disaster relief. As displayed in Fig. 1a, the harsh post-disaster environment usually with smog and bad weather, will make it difficult for the victims to be captured by only the RGB camera. The fusion of multispectral data (RGB and thermal data) has been demonstrated effective in enabling robust pedestrian detection for advanced driving assistance system (ADAS) applications [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]. In addition, victims seen from SAR drone views have various scales, and most are too small to be captured, as shown in Fig. 1b. With the rapid development of deep learning, deep neural networks are used in various fields to solve classification and prediction problems [17,18,19,20,21,22], especially in object detection. Recent works have demonstrated that deep neural networks work well on object detection based on multispectral images. However, most existing multispectral data are captured by car-mounted multispectral sensors, mainly aimed at detecting larger objects in a single horizontal perspective. There is a research gap in multispectral small object detection under the changing unmanned aerial vehicle (UAV) perspective. Especially for victim detection from a drone perspective, few studies have been proposed to solve the challenging problem of detecting multispectral victims with low visibility and various sizes.

Examples to illustrate the challenging cases for multispectral victim detection. The top are RGB images and the bottom are thermal images
Therefore, a transformer fusion-based scale-aware attention network is developed to effectively combine the multispectral images captured by drones. This network aims to solve the problems of victim detection with different sizes and under low illumination conditions. Specifically, a transformer fusion model is inserted into a two-stream feature extraction backbone to fuse complementary information from multispectral data. In addition, considering victims vary in size from the view of the SAR drone, it will increase the difficulty for SAR drones to detect victims. A new scale-aware attention mechanism in the head network is presented to adaptively adjust the size of the receptive field of the network based on the scale of multiple inputs. It enables the network to capture victims with different scales. The main contributions of this work are summarized as follows.
-
A novel TFSANet is developed to effectively integrate the RGB and thermal images captured by SAR drones for victim detection, which can accurately detect victims in adverse disaster environments and on various scales.
-
In our TFSANet, a transformer fusion model is proposed to integrate the input RGB and thermal information in the two-stream backbone to extract multispectral features. It aims to deeply extract long-range multispectral features by effectively integrating high-level semantic and low-level detailed information.
-
A scale-aware attention mechanism in the head network is developed, which is a dynamic selective mechanism, that makes each neuron in the head network adaptively adjust its receptive field size according to the input scale information.
-
Experimental results show the proposed TFSANet obtains the best performance with an AP of 86.56%, which exceeds the state-of-the-art ensemble YOLOv5 [23] method by 4.38% in AP, on the NII-CU multispectral aerial person detection dataset [23]. On the challenging RGBTDronePerson dataset, the proposed method achieves an AP of 51.05% which outperforms the state-of-the-art quality-aware RGBT fusion detector (QFDet) [24] method by 4.33%.
The rest of this article is structured as follows. In Sect. “Related works”, the research on multispectral object detection is summarized. In Sect. “Proposed methods”, our proposed approach is described in detail. Sect. “Results and discussions” is devoted to the results and subsequent discussion. Finally, Sect. “Conclusions” summarizes our work.
Related works
Multispectral image-related studies have experienced a boom in the past few years, especially for pedestrian detection in ADAS applications by integrating the captured RGB and thermal bands. However, multispectral images have the least application in victim detection, which involves the study of new indicators that improve feature extraction by combining different bands. This section analyzes previous research in the field of multispectral pedestrian detection and victim detection.
Pedestrian detection using multispectral images
Multispectral pedestrian detection is designed to boost the performance of pedestrian detection by utilizing complementary characteristics from multispectral data (RGB and thermal) that are robust to changes in lighting and occlusion. In [2], a multispectral pedestrian detection dataset is established, and an improved aggregated channel feature (ACF) is introduced for multispectral pedestrian detection. In recent years, deep convolutional neural networks (CNNs) have developed rapidly in the field of computer vision, and some CNN-based multispectral pedestrian detection methods have been presented [3,4,5,6,7,8,9,10,11,12,13,14,15,16]. In [3], a two-stream CNN is first introduced to fuse multispectral information for pedestrian detection, in which a fusion strategy is conducted in the late layers of CNN. In [4], the authors try to fuse the multispectral information in the different layers of the Faster R-CNN [25], early layer, halfway layer, and late layer. Their experiments indicate that fusion in the halfway layer performs better. Chen et al. [5] designed a multiple layer fusion strategy that shows better performance than halfway layer fusion. Li et al. [6] found that the confidence score of the detected pedestrians is influenced by the illumination variance. Therefore, they designed a network to measure the illuminance value of the input images, which is used for guiding the fusion of the multispectral information. Zhou et al. [7] developed a differential weighting scheme to fuse the multispectral information along CNN channels. Chen et al. [8] introduced a deconvolutional single-shot CNN to detect multispectral pedestrians in which the multispectral features are integrated into multiple layers of the CNN. In [9], an attention mechanism is introduced into a CNN architecture to guide multispectral feature fusion.
Over and above the multispectral feature fusion, some approaches adopt additional tasks to assist in the detection of the multispectral pedestrian. In [10], a CNN network is proposed to jointly detect and segment pedestrians, which contains two subnetworks, one aims to generate candidate pedestrian proposals while the other refines the generated proposals to produce the final predicted pedestrians. In [11], a box-level segmentation task is introduced to help supervise multispectral pedestrian detection. Specifically, they proposed a box-level network to generate segmented masks that provide information to distinguish pedestrians and backgrounds and design a hierarchical fusion strategy to fuse multispectral feature maps. Zhang et al. [12] developed teacher and student networks to perform knowledge distillation which can improve the detection performance of multispectral pedestrian detection by fusing high-resolution features as well as low-resolution features. In [13], attention mechanisms were conducted locally and globally of a lightweight anchor-free network to help the task of multispectral pedestrian detection. In [14,15,16], resolving the misalignment issues was proven to help improve the performance of the multispectral information fusion. In [14], an aligned region module is presented to automatically align the multispectral images. In [15], modal-wise regression and multimodal intersection over union (IoU) is proposed to deal with the misaligned multimodal data. Hu et al. [16] focus on integrating the intra-modal and inter-modal features of multispectral information which is insensitive to non-strictly aligned multimodal data.
Victim detection from drone view using multispectral images
In [26], a pedestrian detection system based on drone vision is proposed. The authors adopted three different methods, Haar cascade, and support vector machines (SVM) and AlexNet for pedestrian classification on RGB images. The thermal images were only adopted to produce region of interest (ROI) proposals fed to CNN. In [27], a drone vision-based victim detection method was proposed. They fused RGB and thermal images with a simple linear formula with a manually selected parameter. For victim detection, they introduced a handcrafted template algorithm of human shape, which cannot detect victims in different scales and postures. In [28], a detection method for people in occlusion from a drone view was developed. This method detected occluded people by using several thermal images located at different positions and viewing angles of the drone. The visible images were only used to estimate the position of image pairs of RGB and thermal images in relation to other image pairs. After the occlusion was removed, the YOLOv3 [29] was employed to detect the people using thermal images. However, this method has a limited application scenery since it can only detect people lying on the ground, not people standing. Speth et al. [23] introduced a monitor and patrol AI drone system, which can be applied to human rescue missions in post-disaster scenarios. They proposed an ensemble method and a 4-channel method based on YOLOv3 [29], respectively, to combine RGB and thermal information. Ulloa et al. [30] developed an autonomous victim detection method that aims to be applied to SAR robots. They adopted YOLOv5 [31] for the automatic detection of victims in their proposed multispectral image dataset. In [24], two new datasets are proposed for multispectral person detection from a drone view. The authors first designed a quality-aware learning strategy to supervise tiny objects by focusing on high-quality samples. Then, they proposed a quality-aware cross-modality enhancement module to predict a quality-aware map for multispectral data.
Although the above approaches have contributed greatly to the advancement of multispectral object detection, multispectral victim detection from drone view still faces some unresolved limitations such as poor performance in victim detection in low visibility and of various sizes. Therefore, this paper aims to develop a multispectral victim detection method with high accuracy, and strong generalization, and provide a new idea for the further development of multispectral victim detection in the future.
Proposed methods
Overview
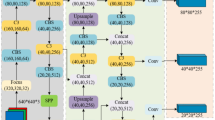
Figure 2 displays the framework of TFSANet. A transformer fusion model and a scale-aware attention mechanism are proposed to enable multispectral victim detection and are incorporated with the redesigned YOLOv5 [31]. Specifically, the original one-stream YOLOv5 is adapted into a two-stream YOLOv5 in which transformer fusion models and scale-aware attention mechanisms are added. The backbone of TFSANet contains a two-stream network in which transformer fusion models have been inserted to extract fused multispectral features. The head of TFSANet consists of three outputs Y1, Y2, and Y3, each being strengthened by scale-aware attention. The input RGB and thermal images are first processed by the two-stream backbone to extract multispectral features. In the two-stream backbone, the Focus module performs a slicing operation on the input image to make the number of channels of the input image from the original three RGB channels to twelve channels. The cross stage partial (CSP) Network splits the feature map into two parts, the first part performs the convolution operation, and the second part is concated with the result of the convolution operation of the first part. Then, the introduced transformer fusion models integrate the extracted multispectral features at different positions of the backbone. Finally, the scale-aware attention mechanisms are embedded in the head network to strengthen the detection of various-sized victims.

Framework of the proposed TFSANet. The TFSANet contains a two-stream backbone with three transformer fusion models and a head network with outputs Y1, Y2, and Y3, each being strengthened by scale-aware attention
Transformer fusion
The harsh environment of the disaster area is usually accompanied by smoke, dust, bad weather, etc., which is easy to make the victims of poor visibility. The use of multispectral data (RGB and thermal images) with supplementary information can improve victim detection performance in these environments. The existing methods for RGB and thermal information fusion mainly contain summation fusion, cascade fusion, and illumination-aware fusion. These fusion methods mainly focus on integrating local features without making full use of long-range context information in intra-modality and cross-modality and are not robust to the complexity and variability of the disaster area environment. Recently, transformers [32, 33] have been widely used in CNN for feature extraction and have been demonstrated to be effective in modeling long-range dependencies. Inspired by the advantages of the transformer, a transformer fusion model is proposed to effectively fuse RGB and thermal features.
The architecture of the proposed transformer fusion model is displayed in Fig. 3. The inputs of the proposed transformer fusion model are the feature maps \({F}_{R}\) and \({F}_{T}\) of RGB and thermal information respectively. The output of the proposed transformer fusion model is a fused multispectral feature map \({F}_{M}\). 3-D attention weights are firstly performed on the inputs \({F}_{R}\) and \({F}_{T}\) to enhance the ability of feature representation. Specifically, the input \({F}_{R}\) and \({F}_{T}\) respectively go through 3-D weights and are combined with itself by a dot product. Then, the flattened features \({F}_{R}{\prime}\) and \({F}_{T}{\prime}\) are concatenated along the channel dimension to generate the feature vector \({F}_{C}{\prime}\). Then, the \({F}_{C}{\prime}\) is summed with a learnable positional embedding to generate the feature map \(I\) which will be an input of the transformer block. The utilization of positional embedding is to distinguish spatial information between different symbols during training by encoding the position information into \({F}_{C}{\prime}\). Eight transformer blocks form a transformer module, where each block has two normalization layers, a multi-head attention mechanism, and a multi-layer perceptron (MLP). The MLP includes a two-layer fully connected feedforward network with a gaussian error linear unit (GELU) [34] activation.
where h is the number of heads and \({\upomega }^{\text{O}}\) represents the projection matrix of Concat(\({\text{T}}_{1},...,{\text{T}}_{\text{h}}\)). \(\text{Q},\text{K},\text{V}\) are three weight projection matrices from \(I\) and are inputs of \(MultiHead\). \({\upomega }^{\text{Q}}\), \({\upomega }^{\text{K}}\), and \({\upomega }^{\text{V}}\) are weight matrices. The \(Q{\omega }_{i}^{Q},K{\omega }_{i}^{K},V{\omega }_{i}^{V}\) are used to compute the weights of attention and to produce the refined output \({\text{T}}_{i}\).

Transformer fusion model
Scale-aware attention mechanism
Victims from the perspective of SAR drones show large differences in size, especially when the target of victims is small, it is difficult to be captured by SAR drones. The receptive field size of each layer of neurons in existing CNN-based object detectors is usually designed to be the same size. The neuroscience community recognizes that the receptive field size of visual cortex neurons can be modulated by stimulation, but this is rarely considered when building CNNs. Li et al. [35] propose a dynamic selection mechanism so that each neuron in CNN can adaptively adjust its receptive field size according to the scale of multiple input information. Inspired by [35], a scale-aware attention mechanism is designed based on selective kernel convolution which is embedded in the detection head to solve the issue of detection of various-sized victims. Figure 4 shows the scale-aware attention mechanism. First, three branches of the selective kernel rather than two are adopted, since more kernel sizes can bring more receptive field information. Using branch information of different kernel sizes, softmax attention is used for fusion. Different attention to these branches results in different sizes of the effective receptive fields of the fusion layer neurons. In addition, an extra skip connection is added aiming at simplifying the training process. As shown in Fig. 4, given a feature map \(\text{X }\in {\text{R}}^{\text{C}\times \text{H}\times \text{W}}\), three convolutional layers with different kernel sizes (3 \(\times \) 3, 5 \(\times \) 5, and 7 \(\times \) 7) conduct transformations to get U1, U2, and U3, respectively. Then, U1, U2, and U3 are integrated through element-wise summation operation to get the fused multi-scale features U:

Scale-aware attention mechanism
Then, a global average pooling (GAP) is used to encode the global information to produce initial channel-wise weights \(\text{W}\) ∈ RC×1×1. The \(\text{c}\)th element of \(\text{W}\) can be expressed as:
where \(\text{GAP}(\cdot )\) indicates the GAP operation and \({\text{U}}_{\text{c}}(\text{i},\text{j})\) denotes the value at coordinate position \((\text{i},\text{j})\) of \(\text{U}\).
The selection weights \({\text{W}}_{\text{s}}\) is computed by
where \(\text{max}(0,\text{ x})\) indicates the rectified linear unit (ReLU) activation. The \(\text{FC}\) layers are implemented by \(1\times 1\) convolutional layers.
After that, the selection weights of each channel is normalized by the softmax operation, and the normalized weights are divided into three vectors: \({\text{Z}}_{1}\), \({\text{Z}}_{2}\), and \({\text{Z}}_{3}\). Thus, the fused features A are obtained as
Finally, the output \(\text{Y}\) is obtained as
Training
Loss function
The final loss is computed by summation of the regression loss (\({\text{L}}_{\text{bbox}}\)) of the bounding box, the classification loss(\({\text{L}}_{\text{cls}}\)), and the confidence loss (\({\text{L}}_{\text{conf}}\)),
The \({\text{L}}_{\text{bbox}}\), \({\text{L}}_{\text{cls}}\), and \({\text{L}}_{\text{conf}}\) are computed by the functions (9-11), where a generalized intersection over union (GIoU) loss[36] is applied to compute the \({\text{L}}_{\text{bbox}}\).
where \({\text{S}}^{2}\) and N denote the number of image grids in the prediction process and the number of prediction boxes in each grid. \({\text{B}}^{\text{g}}, {\text{B}}^{\text{p}},\text{ and }{\text{B}}^{\text{c}}\) are the ground truth, the prediction box, and the smallest closed box surrounding \({\text{B}}^{\text{g}}\) and \({\text{B}}^{\text{p}}\), respectively. The coefficient \({\text{C}}_{\text{i},\text{j}}^{\text{obj}}\) represents whether the \(\text{jth}\) prediction box of the \(i\text{th}\) grid is a positive sample. The classification loss \({\text{L}}_{\text{cls}}\) adopts cross-entropy, \({\text{p}}_{\text{i}}(\text{c})\) represents the probability that the real sample belongs to class c, and \(p_{i}^{ \wedge } \left( c \right)\) represents the probability that the predicted sample belongs to class c. The final confidence loss consists of two squared error losses. The definition of the parameter \({\text{C}}_{\text{i},\text{j}}^{\text{noobj}}\) is defined in contrast to the coefficient \({C}_{i,j}^{obj}\). Finally, c and \({\text{c}}^{ \wedge }\) denote the true confidence value and the prediction confidence value of the network.
Training details
During training, the network was optimized using stochastic gradient Descent (SGD), where the initial learning rate, momentum, and weight decay were set to 0.01, 0.9, and 0.0005, respectively. The experiments were conducted on a computer equipped with an Intel Xeon W-2223 3.6 GHz central processing unit (CPU), 64 GB random access memory, and an NVIDIA GeForce RTX 3090 GPU. Inspired by Mosaic’s method [37], our model is initially weighted with a YOLOV5 model pre-trained on the COCO dataset [38] with a batch size of 4 and trained with 100 epochs. Figure 5 shows the evaluation results during the training.

Results during training
Results and discussions
Datasets
The NII-CU multispectral aerial person detection dataset [23] includes 5880 pairs of aligned RGB and thermal images that are captured by a drone. All images are captured by a drone camera tilted at a 45-degree angle at an altitude of 20–50 m. The sensor for capturing RGB images is a Zenmuse X3 (3840 × 2160) while the sensor for capturing thermal images is a FLIR Vue Pro 640 in White Hot palette (640 × 512 before alignment). The thermal images and the RGB images are aligned by applying lens distortion correction and homography warping. The NII-CU dataset was captured under various lighting conditions and contains persons of various sizes and a variety of postures, the shooting scenes are mainly in natural rural areas, suitable for disaster rescue scenes.
The drone-captured RGBT person detection dataset (RGBTDronePerson) [24] contains 6125 pairs of RGB and thermal images. The dataset has been split into 4900 pairs of training images and 1225 airs of testing images. Among all images, 70,880 instances have been annotated. The resolutions of RGB images and thermal images are resized to 640 × 512. The images were captured from winter to summer during both day and night time, which contains environments with different temperatures and different illuminations. In addition, all images were captured at a height of 50–80 m, which contains absolute person sizes less than 32. This kind of tiny person size makes the detection task more challenging and more consistent with actual victim detection scenarios.
Evaluation metrics
The precision-recall curve is a commonly used evaluation metric for object detection methods. It measures the overlap between predicted bounding boxes and ground truth boxes, classifying detection results into three classes: true positive (TP), false positive (FP), and false negative (FN). TP represents correctly predicted victims. Typically, if the overlap ratio between the predicted bounding box and the ground truth exceeds 0.5, it is considered a TP. FN counts the number of missed victims, while FP accounts for non-victim areas incorrectly identified as victims. Precision is defined as TP/(TP + FP), and recall is defined as TP/(TP + FN). The AP is calculated by averaging accuracy values at evenly spaced recall levels, achieved by adjusting the confidence score threshold. The AP value is set to 100 and evenly distribute the recall levels between 0 and 1 to calculate AP.
Detection evaluation on the NII-CU multispectral aerial person detection dataset
In this section, our TFSANet is verified and compared with other approaches, including RGB YOLOv5, thermal YOLOv5, and ensemble YOLOv5 [23], on the NII-CU dataset. Figures 6 present the precision-recall curves. It is clear that the AP of our method is significantly better than all other methods, achieving an AP of 86.56%, which is evidently higher than the state-of-the-art baseline results, ensemble YOLOv5 [23] by 4.38%. Moreover, the performance gap is quite large when compared with RGB YOLOv5 and thermal YOLOv5, 86.56% AP of ours versus 72.18% AP of the RGB YOLOv5 and 63.94% AP of the thermal YOLOv5, respectively. Our method evidently outperforms RGB YOLOv5 and thermal YOLOv5, which proves that the developed transformer fusion model is useful for overcoming the influence of low illuminations on victim detection. It makes sense that the proposed approach outperforms other techniques since the NII-CU dataset is taken from a drone view, the majority of the persons are far-scale instances, and the proposed scale-aware attention mechanism can dramatically improve the detection accuracy of small instances.

Comparison of precision-recall curves on the NII-CU dataset
Figure 7 shows a visual comparison of the detection results of our method with those of other methods in several challenging scenarios, including low illumination, people of different proportions, and dense occlusion. It can be clearly observed that the proposed approach is superior to the state-of-the-art ensemble YOLOv5 method. The ensemble YOLOv5 methods missed many persons and mistakenly detected backgrounds as persons while the proposed approach correctly detects objects at different scales. In Fig. 7, the false negative and false positive detection of ensemble YOLOv5 are zoomed in. One can see in Fig. 7a, c, d, that the ensemble YOLOv5 falsely detected persons. In Fig. 7b, ensemble YOLOv5 missed 1 person. It can be concluded that the proposed method is effective in victim detection from drone view. This result is meaningful because the NII-CU dataset involves the presence of many small persons and low resolution, which demonstrates that our transformer fusion model and scale-aware mechanism can not only robustly fuse multispectral data, but also cover pedestrians of various scales.

Visual comparison of our detection results in the NII-CU dataset with the Ensemble YOLOv5 method
Figure 8 shows the detection results of our method for various challenging detection situations. The occluded persons, persons at different scales, and persons with low visibility can all be correctly detected by the proposed method.

Visualization of detection results of the proposed method on challenging cases of the NII-CU dataset
Detection evaluation on the RGBTDronePerson dataset
Our proposed TFSANet is further evaluated on the RGBTDronePerson dataset. The RGBTDronePerson dataset was taken at altitudes ranging from 50 to 80 m and contains persons of different scales, with a maximum person size of 32. Moreover, the RGBTDronePerson dataset contains images with different temperatures and illumination conditions. Therefore, this dataset is more challenging and is suitable for evaluating the performance of our model on small-scale victim detection under various illumination environments.
Figure 9 displays the average-precision curves of the proposed TFSANet which achieves an AP of 51.05%. The performance comparison of the proposed TFSANet with state-of-the-art QFDet and cross-modality fusion transformer (CFT) methods is shown in Table 1. It is obvious that the proposed method dramatically outperforms all other methods. Compared with the best method QFDet, our method is 4.33% higher in AP. Our method significantly outperforms the CFT method, achieving 22.36% higher AP.

Precision-recall curve of the proposed TFSANet on the RGBDronePerson dataset
Figure 10 shows a visualization of the detection results of our method on the RGBDronePerson dataset. Challenging samples taken in day and night scenes are selected. The first column shows the visible images in which the red rectangles mark the ground truth, and the second column displays the detection results of the proposed approach marked by the blue bounding boxes. The person sizes are marked in height pixels. The person’s height ranges from 10 to 18 pixels, which is very small. Our method successfully detects all persons. This result shows that our method can detect tiny persons in different illumination environments.

Visualization of detection results of the proposed method on challenging cases of the RGBTDronePerson dataset. The red bounding boxes denote the ground truth, and the blue bounding boxes show the detection results
Ablation studies
In this section, an ablation study is conducted using the NII-CU multispectral aerial person detection dataset to evaluate the effectiveness of our TFSANet. In the first simulation, the transformer fusion model and scale-aware mechanism are removed, and only retained the two-stream YOLOv5 for experiments to check performance. Then, the transformer fusion-based module is added to make an improved version. This simulation is to evaluate how the transformer fusion-based module contributes to detection performance. Finally, the scale-aware mechanism is added to the detection head to evaluate the effect of the scale-aware mechanism. Table 1 shows the AP for each simulation.
Evaluation of the transformer fusion-based model
As shown in Table 2, the AP is improved by 2.77% by adding the transformer fusion model to two-stream YOLOv5. It can be concluded that the introduced transformer fusion model can effectively combine the RGB and thermal streams to boost detection performance. Existing multispectral object detectors widely employ summation or concatenation operations to integrate RGB and thermal information. However, the summation or concatenations make the RGB and thermal feature contributions equal, ignoring the different effects of RGB and thermal images on object detection. The proposed transformer fusion model is able to automatically learn weights and effectively fuse RGB and thermal features. Specifically, the proposed transformer fusion model utilizes a self-attention mechanism to learn the binary relationship between RGB and thermal images, using a correlation matrix to weight each position of the input feature maps. In addition, the transformer is effective in modeling long-range dependencies, which is helpful in exploiting long-range contextual dependencies of different input elements.
Evaluation of the scale-aware mechanism
Table 2 compares the performance of the use of scale-aware mechanisms. One can observe that the AP is further improved by 3.66% on the NII-CU dataset after adding the scale-aware mechanisms. This result demonstrates that the proposed scale-aware mechanism employed in the detection head significantly improves detection performance. It is hard for the original detection head of YOLOv5 to classify small-sized as well as large-sized victims since its receptive field is consistent. To resolve this problem, the scale-aware mechanism is developed which is based on the selective kernel convolution that can adaptively adjust the receptive fields based on the scale of multiple input information. This is helpful to boost the victim detection rate by covering various-sized victims.
Discussion
The objective of this work is to accurately detect victims based on SAR drones. There are two shortcomings in the existing works: the detection accuracy is greatly reduced in adverse illumination environments and when the victims are in small sizes. To solve the issue of victim detection in adverse illumination environments, a transformer fusion model is proposed to effectively fuse RGB and thermal information. To solve the issue of detecting small-sized victims, a scale-aware attention mechanism is proposed to enable the network to detect victims of different sizes. The results of the ablation experiment are described in detail in Sect. "Ablation studies", the effectiveness of the developed transformer fusion model and scale-aware attention mechanism are verified on the NII-CU dataset respectively. The proposed transformer fusion model and scale-aware attention mechanism improve the AP by 2.77% and by 3.66% respectively.
In addition, the performance of our approach is verified and compared qualitatively and quantitatively with the state-of-the-art methods on two well-known datasets. Through the detailed experiments in Sects. “Detection evaluation on the NII-CU multispectral aerial person detection dataset” and “Detection evaluation on the RGBTDronePerson dataset”, it can be concluded that our method shows the best results on both datasets. On the NII-CU dataset, our method exceeds the state-of-the-art ensemble YOLOv5 method by 4.38% in AP. On the RGBTDronePerson dataset, our method exceeds the state-of-the-art QFDet method by 4.33% in AP. This result is reasonable since these two datasets are captured by drones, of which the flying angles and the flight heights keep changing, making victims of different sizes and shapes. In addition, the datasets contain a large amount of images taken at night. The performance of our method outperforms other methods indicate the proposed method is good at handling the detection of small-sized victims under adverse illumination conditions. We believe that our work can be applied to SAR drones or other intelligent detection equipment, and can facilitate future research on multispectral victim detection and other object detection tasks.
Our approach still has shortcomings. As shown in the two failure cases shown in Fig. 11, the yellow bounding boxes mark the missed detection. Our method is likely to be stuck while detecting dense persons. This issue will be further explored in future work by trying to strengthen the positions of useful information and soft non-maximum suppression (NMS) strategies. In addition, the current work has not yet considered the economics of the device in practical applications. How to make our method cost-effective will be investigated in the future, such as reducing running memory by optimizing network structure and size to memory equipment costs.

Failure cases of the proposed method. Yellow bounding boxes denote the false negatives and blue bounding boxes denote the detected persons by our method
Conclusions
In this work, a novel TFSANet is presented for accurate multispectral victim detection. Our TFSANet includes a transformer fusion-incorporated two-stream backbone network and a scale-aware attention mechanism-guided detection head network. The presented transformer fusion model enables the detector to overcome the interference of harsh disaster environments on victim detection performance by maximizing the complementary characteristics of RGB and thermal information. The proposed scale-aware attention mechanism effectively makes the detection head robust to a variety of victim sizes. Empirical experiments conducted on the NII-CU dataset and RGBTDronePerson dataset evaluate the effectiveness of our approach. Our TFSANet achieves state-of-the-art performance with an 86.56% AP on the NII-CU dataset and a 51.05% AP on the RGBTDronePerson dataset, respectively.
The proposed method supports victim detection in adverse weather and illumination environments by effectively fusing multispectral information. Furthermore, our method can detect victims of different sizes from the drone view. Compared with traditional object detection methods based on drone vision, our method is more suitable for practical application scenarios of SAR drones. It is expected that our work can facilitate future research on multispectral victim detection.
Data availability
The data of this paper are available from the corresponding author on reasonable request.
Abbreviations
- TFSANet:
-
Transformer fusion-based scale-aware attention network
- AP:
-
Average precision
- NII-CU:
-
National Institute of Informatics—Chiba University
- RGBTDronePerson:
-
Drone-captured RGBT person detection
- SAR:
-
Search and rescue
- ADAS:
-
Advanced driving assistance system
- UAV:
-
Unmanned aerial vehicle
- QFDet:
-
Quality-aware RGBT fusion detector
- ACF:
-
Aggregated channel features
- CNN:
-
Convolutional neural networks
- IoU:
-
Intersection over union
- SVM:
-
Support vector machines
- ROI:
-
Region of interest
- CSP:
-
Cross stage partial
- MLP:
-
Multi-layer perceptron
- GELU:
-
Gaussian error linear unit
- GAP:
-
Global average pooling
- ReLU:
-
Rectified linear unit
- FC:
-
Fully connected
- GIoU:
-
Generalized intersection over union
- SGD:
-
Stochastic gradient descent
- CPU:
-
Central processing unit
- TP:
-
True positive
- FP:
-
False positive
- FN:
-
False negative
- CFT:
-
Cross-modality fusion transformer
References
Arnold RD, Yamaguchi H, Tanaka T (2018) Search and rescue with autonomous flying robots through behavior-based cooperative intelligence. J Int Hum Act 3(1):1–18
Hwang S, Park J, Kim N, et al. (2015) Multispectral pedestrian detection: benchmark dataset and baseline. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1037–1045
Wagner J, Fischer V, Herman M et al (2016) Multispectral pedestrian detection using deep fusion convolutional neural networks. ESANN 587:509–514
Liu J, Zhang S, Wang S et al. (2016) Multispectral deep neural networks for pedestrian detection. arXiv preprint https://arXiv.org/1611.02644
Chen Y, Xie H, Shin H (2018) Multi-layer fusion techniques using a CNN for multispectral pedestrian detection. IET Comput Vision 12(8):1179–1187
Li C, Song D, Tong R et al (2019) Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recogn 85:161–171
Zhou K, Chen L, Cao X (2020) Improving multispectral pedestrian detection by addressing modality imbalance problems. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16. Springer International Publishing, pp 787–803
Chen Y, Shin H (2020) Multispectral image fusion based pedestrian detection using a multilayer fused deconvolutional single-shot detector. JOSA A 37(5):768–779
Zhang H, Fromont E, Lefèvre S et al. (2021) Guided attentive feature fusion for multispectral pedestrian detection. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 72–80
Li C, Song D, Tong R et al. (2018) Multispectral pedestrian detection via simultaneous detection and segmentation. arXiv preprint https://arXiv.org/1808.04818
Cao Y, Guan D, Wu Y et al (2019) Box-level segmentation supervised deep neural networks for accurate and real-time multispectral pedestrian detection. ISPRS J Photogramm Remote Sens 150:70–79
Zhang H, Fromont E, Lefèvre S et al. (2022) Low-cost multispectral scene analysis with modality distillation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp 803–812
Zuo X, Wang Z, Liu Y et al (2023) LGADet: light-weight anchor-free multispectral pedestrian detection with mixed local and global attention. Neural Process Lett 55(3):2935–2952
Zhang L, Zhu X, Chen X et al. (2019) Weakly aligned cross-modal learning for multispectral pedestrian detection. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 5127–5137
Wanchaitanawong N, Tanaka M, Shibata T et al. (2021) Multi-modal pedestrian detection with large misalignment based on modal-wise regression and multi-modal IoU. In: 2021 17th International Conference on Machine Vision and Applications (MVA). IEEE, pp 1–6
Hu W, Fu C, Cao R et al (2023) Joint dual-stream interaction and multi-scale feature extraction network for multi-spectral pedestrian detection. Appl Soft Comput 147:110768
Dehghani M, Ghiasi M, Niknam T et al (2020) Blockchain-based securing of data exchange in a power transmission system considering congestion management and social welfare. Sustainability 13(1):90
Ghiasi M, Niknam T, Wang Z et al (2023) A comprehensive review of cyber-attacks and defense mechanisms for improving security in smart grid energy systems: past, present and future. Electr Power Syst Res 215:108975
Akbary P, Ghiasi M, Pourkheranjani MRR et al (2019) Extracting appropriate nodal marginal prices for all types of committed reserve. Comput Econ 53:1–26
Ghiasi M, Ghadimi N, Ahmadinia E (2019) An analytical methodology for reliability assessment and failure analysis in distributed power system. SN Appl Sci 1(1):44
Ghiasi M, Wang Z, Mehrandezh M et al (2023) Evolution of smart grids towards the Internet of energy: concept and essential components for deep decarbonisation. IET Smart Grid 6(1):86–102
Abdel-Basset M et al (2022) Responsible system based on artificial intelligence to reduce greenhouse gas emissions in 6G networks. DE202022105964, Applicant/Assignee: Zagazig University, Publication Number: 202022105964, Publication Date: 29.12.2022, WIPO, https://patentscope.wipo.int/search/en/detail.jsf?docId=DE383466530&_cid=P12-LPNEZV-30550-1 Accessed on 09 Mar 2023
Speth S, Goncalves A, Rigault B et al (2022) Deep learning with RGB and thermal images onboard a drone for monitoring operations. J Field Robot 39(6):840–868
Zhang Y, Xu C, Yang W et al (2023) Drone-based RGBT tiny person detection. ISPRS J Photogramm Remote Sens 204:61–76
Ren S, He K, Girshick R, et al. (2015) Faster R-CNN: towards real-time object detection with region proposal networks. Adv Neural Inform Process Syst 28
De Oliveira DC, Wehrmeister MA (2018) Using deep learning and low-cost RGB and thermal cameras to detect pedestrians in aerial images captured by multirotor UAV. Sensors 18(7):2244
Dawdi TM, Abdalla N, Elkalyoubi YM et al (2020) Locating victims in hot environments using combined thermal and optical imaging. Comput Electr Eng 85:106697
Schedl DC, Kurmi I, Bimber O (2020) Search and rescue with airborne optical sectioning. Nat Mach Intell 2(12):783–790
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement. arXiv preprint https://arXiv.org/1804.02767
Ulloa CC, Garrido L, Del Cerro J et al (2023) Autonomous victim detection system based on deep learning and multispectral imagery. Mach Learn: Sci Technol 4(1):015018
Zhang Y, Chen J, Huang D (2022) Cat-det: contrastively augmented transformer for multi-modal 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 908–917
Qingyun F, Dapeng H, Zhaokui W (2021) Cross-modality fusion transformer for multispectral object detection. arXiv preprint https://arXiv.org/2111.00273
Hendrycks D, Gimpel K (2016) Gaussian error linear units (gelus). arXiv preprint https://arXiv.org/1606.08415
Li X, Wang W, Hu X, et al. (2019) Selective kernel networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 510–519
Rezatofighi H, Tsoi N, Gwak J Y, et al. (2019) Generalized intersection over union: a metric and a loss for bounding box regression. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 658–666
Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: optimal speed and accuracy of object detection. arXiv preprint https://arXiv.org/2004.10934
Lin T Y, Maire M, Belongie S et al. (2014) Microsoft coco: common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13. Springer International Publishing, pp 740–755
Acknowledgements
This work was supported by the Natural Science Foundation of Hubei Province (2023AFB424) and the Wuhan Knowledge Innovation Project (No.2022020801010258).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, Y., Li, Y., Zheng, W. et al. Transformer fusion-based scale-aware attention network for multispectral victim detection. Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01515-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01515-y