
Abstract
This study proposes an innovative deep learning algorithm for pose estimation based on point clouds, aimed at addressing the challenges of pose estimation for objects affected by the environment. Previous research on using deep learning for pose estimation has primarily been conducted using RGB-D data. This paper introduces an algorithm that utilizes point cloud data for deep learning-based pose computation. The algorithm builds upon previous work by integrating PointNet + + technology and the classical Point Pair Features algorithm, achieving accurate pose estimation for objects across different scene scales. Additionally, an adaptive parameter-density clustering method suitable for point clouds is introduced, effectively segmenting clusters in varying point cloud density environments. This resolves the complex issue of parameter determination for density clustering in different point cloud environments and enhances the robustness of clustering. Furthermore, the LineMod dataset is transformed into a point cloud dataset, and experiments are conducted on the transformed dataset to achieve promising results with our algorithm. Finally, experiments under both strong and weak lighting conditions demonstrate the algorithm's robustness.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
With the increasing demand for automation and intelligent production in industrial processes, machine vision plays a pivotal role in achieving this goal. Machine vision serves as the bridge for robots to perceive their environment. Different sensors provide various forms of data, such as monocular cameras capturing two-dimensional images of objects or 3D cameras capturing RGB-D images or point cloud data. These data store specific information about the objects, which is referred to as features. To enable environmental perception by robots, it is necessary to extract these features and subsequently determine the poses of the objects.
In the task of pose estimation using two-dimensional images as input data, mainstream approaches aim to find mappings from two-dimensional space to three-dimensional space to determine the pose information of objects. However, these methods tend to perform well only in relatively simple background conditions. Furthermore, researchers [1,2,3,4,5] have attempted to perform pose estimation tasks using deep learning. Yet, the lack of depth information in two-dimensional image data has resulted in significant errors, making it challenging to apply these methods in industrial production. Zakharov et al. [6] employ convolutional neural networks to detect objects in two-dimensional images, separate the objects, and then estimate their poses based on the correspondence between the objects and 3D models. Mainstream deep learning algorithms for object detection primarily fall into two categories: one-stage algorithms, with YOLO [7] as a representative example, and two-stage algorithms, with CNN [8, 9] as representative.
Three-dimensional data typically refer to RGB-D images and 3D point cloud data, which include depth information. Pose estimation algorithms using three-dimensional data as input can be classified into four categories: feature correspondence-based [10,11,12,13,14], template matching-based [15, 16], voting-based [17,18,19], and deep learning-based [1,2,3,4,5]. The first three approaches tend to have long runtime and less-than-ideal performance when handling large-scale data due to their characteristics. Deep learning-based methods are more efficient when dealing with large-scale data, but they require substantial amounts of well-annotated data for pre-training, making the preparation phase the lengthiest among all methods. Labeling point cloud data is more complex compared to two-dimensional images, but point cloud data, compared to 2D image information, can better represent the scene, providing more details for pose estimation. However, the development of deep learning specifically for point cloud data is less rapid than that for RGB-D data, primarily because point cloud data lacks publicly available datasets for pose estimation, and creating these datasets is a labor-intensive process [20, 21].
Due to the traditional algorithm employed in this paper, errors in pose estimation tend to occur when the point cloud of the target is chaotic, leading to a significant reduction in the accuracy of pose estimation. Therefore, in the initial stages of pose estimation in this paper, target detection and extraction of the scene point cloud were conducted to address this issue, thereby substantially improving the accuracy of the final pose estimation. PointNet + + stands as a milestone in deep learning methods for processing point clouds. PointNet + + [22] initiated point cloud object detection. Building upon PointNet's solution to the problem of point cloud disorder [23], Qi and his colleagues considered local features of point clouds for feature extraction, achieving excellent results in classification, semantic segmentation, and part segmentation. Inspired by PointNet + + , this paper employs a feature extraction framework based on PointNet + + for object detection. Subsequently, the algorithm employs an adaptive parameter-density clustering method for semantic segmentation and enhances the Point Pair Features (PPF) algorithm for pose estimation. Furthermore, the algorithm in this paper is designed to address scenarios involving non-occluded objects, such as tasks related to unordered grasping. In summary, our work contributes as follows:
-
An algorithm suitable for the pose estimation of objects in various scenes is proposed. Deep learning is utilized for object detection, and small scenes suitable for the classic PPF algorithm are extracted from larger scenes. After clustering segmentation, pose estimation is performed using PPF.
-
An adaptive parameter-density clustering method tailored for point clouds is introduced. By considering the object size and overall point cloud density in the scene, appropriate density clustering parameters are calculated, enabling clustering segmentation in various point cloud densities and resolving the issue of parameter determination for density clustering in different point cloud environments.
-
An integrated point cloud object detection algorithm is presented. The improved PPF algorithm is combined with a transfer learning algorithm based on PointNet + + . The advantages of PPF and PointNet + + are utilized to create a deep learning-based pose estimation algorithm that operates effectively in large scenes with limited samples.
The remaining sections of this paper are organized as follows. Section “Related Work” reviews the development of pose estimation algorithms. Section “Method” describes our proposed method. The experimental aspects of the algorithm will be presented in Section “Experiments” while Section “Conclusion” provides a summary of the paper and outlines future work.
Related work
Pose estimation is a critical problem in the field of computer vision and finds broad applications in various domains, including robot navigation, autonomous driving, virtual reality, and more. Over the past few decades, researchers have been actively seeking effective methods to accurately estimate the poses of objects. There are four main types of pose estimation algorithms, including methods based on correspondence relationships, template-based methods, and voting-based methods, which fall under the category of traditional methods. Traditional methods typically rely on feature extraction and matching techniques, and while they perform well in certain scenarios, they may have limitations in complex environments and lighting conditions. Furthermore, traditional methods often require manual feature design, making them less adaptable to object variations and deformations. The following sections will introduce the developments in both traditional and learning-based algorithms.
Traditional algorithms
Methods based on correspondence relationships can be categorized into two types: those using image data and those using 3D point cloud data. In the early research on feature correspondence, image-based methods involved rendering multiple images by projecting the 3D model from different angles onto images. They established 2D-3D correspondences by matching 2D feature points, relying on 2D descriptors like SIFT, SURF, and ORB [10,11,12]. Additionally, Pham et al. [24] introduced Local Cross-Domain (LCD) descriptors for matching 2D images and 3D point clouds. Object poses are usually calculated using the Perspective-n-Point (PnP) algorithm. Chen et al. [25] proposed Epro-PnP, a PnP algorithm based on the CDPN network, which enables end-to-end function learning for estimating 6D poses. The second type of correspondence-based methods uses 3D point cloud data. These methods involve establishing correspondences between partial point clouds from a single viewpoint and complete point clouds of a model, facilitating the calculation of 6D poses based on 3D-3D correspondences. However, these methods require the target object to have rich geometric features. Common 3D local shape descriptors include Spin Image [13], FPFH [26], and SHOT [14].
Template-based 6D pose estimation involves finding the most similar template in the region of interest. In the 2D scenario, templates can be 2D images projected from known 3D models, where the templates contain corresponding 6D pose information in camera coordinates. This transforms the 6D pose estimation problem into an image retrieval problem. Template matching methods search for the most similar template image and, if discriminative feature points are available, they can be used for 2D correspondences. Therefore, template-based methods are primarily designed for handling textureless or non-textured objects. In the 3D scenario, templates can be the complete point clouds of the target objects. Aligning partial point clouds with the complete template point cloud will yield the best 6D pose information. Estimating 6D poses in this case a coarse registration problem. Hodan et al. [16] proposed a method for the detection and accurate 3D pose estimation of multiple textureless and rigid objects described in RGB-D images. They verify candidate object instances by matching feature points from different modalities and further optimize the approximate object poses associated with each detected template.
Voting-based methods involve using voting for 6D pose estimation, where each pixel or point cloud point contributes to the vote. This method can be seen as an extension of template-based methods by voting. In the 2D scenario, this method is primarily used for estimating the poses of occluded objects. Every visible part in the image contributes to voting for the 6D pose. Tejani et al. [27] conducted 6D pose estimation from RGB-D images using trained Hough Forest algorithms. In the 3D scenario, Drost et al. [28] introduced Point Pair Features (PPF) to recover the 6D poses of objects from depth images. PPF encodes information about distance and normals between two arbitrary 3D points, providing an asymmetric description of the relative pose between the two points. PPF is one of the most successful 6D pose estimation methods, serving as an efficient and integrated alternative to traditional local and global pipelines.
PPF is constructed based on two points with directional information (i.e., both points have normals). The PPF algorithm selects any two points on the object model's surface to construct a four-dimensional feature, modeling the surface information of the entire model, referred to as global information. In contrast, point pair features in the scene reflect information about the object's partial surface, known as local information. Local information can be paired with global information. PPF defines an asymmetric description of the relative pose between two points by encoding the relative distance and normal information between the two points. Following the introduction of PPF, subsequent researchers proposed improvements based on PPF. Drost and Ilic [18] extended the PPF method using multimodal information, such as edge information extracted from RGB images. Their method also includes steps for posture selection after clustering and posture refinement based on ICP. Subsequently, many researchers analyzed some shortcomings of the PPF method and made improvements [29, 30].
Learning-based methods
Learning-based methods can mainly be divided into two categories: direct learning and indirect learning. The first category, direct learning, involves learning object poses [3, 4, 31], where pose information can be directly mapped after inputting an image. Such methods often use the CNN framework in conjunction with object detection and segmentation techniques, allowing 6D object poses to be estimated alongside object detection. The second category, indirect learning, refers to learning the target location, and 6D pose estimation is performed after target detection by other algorithms. Depending on the data modality, there are two subtypes: the first subtype is image-based, primarily learning the positions of key points that provide 2D and 3D correspondences [1, 32]. Unlike the previous methods, these deep learning methods learn the intermediate mapping from input images to pose parameterization representations and pose estimation is often performed after the network has completed object detection. It can be thought of as implicitly finding the most similar image from pre-trained and labeled images. The second subtype is point cloud-based, which has gained wider attention from researchers since the emergence of the PointNet algorithm. Unlike methods that estimate object poses from image data using a multi-stage strategy, these methods directly extract position features between points, enabling object detection within point clouds. Subsequently, other algorithms are used to estimate the object's pose.
Direct learning of object poses was one of the earliest methods introduced. Yu et al. [3] proposed PoseCNN for direct 6D object pose estimation. Do et al. [4] introduced an end-to-end deep learning framework called Deep-6DPose, which jointly detects, segments, and recovers the 6D poses of object instances from a single RGB image. He et al. [9] extended the instance segmentation network Mask R-CNN with a pose estimation branch to directly learn 6D object poses without any post-processing. Liu et al. [33] introduced a two-stage CNN architecture that directly outputs 6D poses without the need for multi-stage or additional post-processing, effectively transforming the pose estimation problem into classification and regression tasks. Lin et al. [34] introduced SAR-Net, which explores the shape alignment of each object class concerning the category-level template shape and computes the symmetric correspondences for each object class. It reconstructs a coarse object point cloud from the observed point cloud and the symmetric point cloud, enabling object pose estimation. When learning with 3D features, there are different approaches to confirm the 3D features. 3DMatch [35] was introduced, using a voxel-based deep learning network to match 3D feature points, replacing 3D feature points with voxels. 3DFeat-Net [36] proposed a weakly supervised network that learns 3D feature detectors and descriptors from 3D point clouds labeled only with GPS/INS data. This method is based on distinctive 3D points, offering more details than 3DMatch's alternative 3D points but with a slower processing speed. However, all these methods require substantial datasets for pre-training the models. To alleviate the dataset issue, Yuan et al. [37] introduced a self-supervised learning method for point cloud descriptors, which does not require manual labeling of datasets and significantly reduces the difficulty of dataset creation, achieving competitive performance.
The second category of methods indirectly learns pose estimation based on image data. Typically, these methods first compute 2D-3D correspondences and then solve the Perspective-n-Point (PnP) problem to obtain the final pose values. Rad and Lepetit [1] obtained 2D-3D correspondences by predicting the 2D projections of 3D object bounding box vertices. Kehl et al. [2] proposed an approach similar to the SSD network [38]. Tekin et al. [32], in contrast, introduced a CNN framework to directly detect the 2D projection of 3D bounding boxes without requiring any subsequent refinement. Crivellaro et al. [39] used convolutional neural networks to predict the 2D projections of several control points, which were used to predict the pose of each part of the object. Hu et al. [40] presented a segmentation-driven pose estimation framework in which each visible part of the object was involved in local pose prediction in the form of 2D keypoint positions. These candidate poses were combined to establish a robust set of 3D-2D correspondences, resulting in reliable pose estimation.
Apart from image-based indirect learning, point cloud-based indirect learning methods combine feature extraction with deep learning networks and point cloud registration from traditional algorithms. Approaches based on RGB-D data can effectively utilize 3D geometric information in depth images, particularly when manual feature crafting is required. The PointNet and PointNet + + algorithms, which excel in point feature extraction, are highly suitable for object detection and semantic segmentation but cannot be directly applied to pose estimation. PointNetGPD [41] is a neural network model for analyzing sparse point cloud geometry, combining PointNet and the Grasping Point Detection (GPD) algorithm to achieve excellent results, making it suitable for robot grasping tasks. PointNetLK [42] combines PointNet with the Lucas-Kanade (LK) optical flow algorithm. It first maps point cloud data to a high-dimensional space using PointNet and then performs point cloud registration using the LK optical flow algorithm. A similar algorithm is PCRNet [43], which has fast computation speed but compromises accuracy. PCRNet needs to learn the entire registration task, limiting its performance. In contrast, PointNetLK only needs to learn point cloud feature representation, making it more generalizable, though it lacks robustness against noise. Other algorithms targeting real-world scenarios, such as AlignNet-3D [44], are also similar in approach.
However, pose estimation has broad applications, and the mentioned methods excel in large-scale environments. The term "large-scale environments" typically refers to scenes containing a variety of cluttered objects, such as warehouses or outdoor storage yards. However, such spatially extensive settings, with their abundance of miscellaneous items, can introduce interference when attempting to recognize the target. Additionally, these methods may encounter challenges in large environments due to the sheer volume of data, whether in RGB-D or point cloud format. This research aims to address pose estimation tasks in both large and small environment settings. In smaller scenes, where only the target for pose estimation and its immediate surroundings are present, subsequent computational demands are significantly reduced, leading to an enhancement in pose estimation accuracy. Therefore, this study combines the PointNet + + framework with adaptive density clustering for object semantic segmentation and subsequently employs an improved PPF algorithm for pose estimation.
Method
Overview
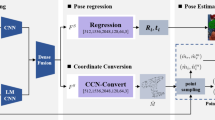
The proposed object pose estimation algorithm in this paper is designed to work in both large and small environment settings, making scene discrimination a crucial step in the object localization phase. In large environment settings, such as warehouses and storage yards, the variety and clutter of objects can pose a significant challenge. Traditional algorithms often struggle to provide accurate pose estimation in such cluttered environments due to their inherent limitations. Deep learning methods, on the other hand, exhibit significant advantages in such scenarios. The algorithm presented in this paper draws inspiration from PointNet + + [22] and is primarily composed of two stages. The first stage is object localization, which utilizes the PointNet + + framework to extract global and local features of the target point cloud. PointNet + + is illustrated in Fig. 1. Semantic segmentation is employed to identify the specific parts of the point cloud that represent the object of interest. The semantic segmentation part of this algorithm employs a multi-level structure, gradually establishing global and local feature representations of the point cloud through point cloud subsampling, feature aggregation, and multi-scale feature extraction. These features are fused to enable the network to better understand the semantic information within the point cloud. The point classification head assigns semantic labels to each point, achieving precise segmentation of different semantic parts within the point cloud.

PointNet + + framework
However, in small environment settings, such as in scenarios like material handling with containers, the point cloud is confined to the area within the container. In such cases, deep learning methods may not offer a significant advantage over traditional algorithms. Experimental results have shown that density-based clustering segmentation is sufficient to accomplish pose estimation tasks in small scene environments. When considering the point cloud capture characteristics, it becomes evident that the point clouds in areas where objects come into contact with each other are sparser compared to the point clouds in the central region of the objects. Moreover, in small scene environments, the objects being identified are often of the same type. Therefore, the algorithm presented in this paper directly employs density clustering for object localization in small-scene environments. After completing the object localization in the first stage, the second stage processes only the point cloud of the object. This point cloud is used for feature extraction, and a voting scheme similar to that proposed by Drost et al. [28] is applied to obtain multiple coarse pose hypotheses. After obtaining these hypotheses, they are verified and refined. The false-positive pose hypotheses are filtered out, and the remaining valid pose hypotheses are voxelized to calculate corresponding scores. The pose hypothesis with the highest score is further refined through ICP (Iterative Closest Point) registration [45] to obtain the final pose. The specific framework is illustrated in Fig. 2.

Overview of the algorithm in this article
Improvement
Adaptive density clustering
The density clustering method proposed in this paper is inspired by the DBSCAN [46] clustering method and has been improved upon. The operation of the DBSCAN algorithm requires the setting of two parameters, namely \(eps\) and \(\text{MinPts}\). Here, \(eps\) is the distance metric used to locate points within the neighborhood of any point, while \(\text{MinPts}\) refers to the minimum number of points clustered together, beyond which they are considered a cluster. The algorithm traverses each point in the point cloud and if there are more than \(\text{MinPts}\) points within the \(eps\) range of that central point, it is considered to belong to the current cluster. Setting parameters for the DBSCAN clustering requires a rich amount of experience. Therefore, this algorithm incorporates the scene point cloud density \(\text{R}(p)\) and the cluster target size \(\text{D}(p)\) for adaptive calculation. The point cloud density \(\text{R}(p)\) usually refers to the number of data points within a certain region. The parameter \(\text{MinPts}\) defines the minimum number of data points required within the neighborhood of a specific data point. A larger one restricts the minimum density required to divide data points into a cluster for denser point clouds, while a smaller one may be suitable for sparser point clouds. The point cloud diameter \(d\) typically refers to the distance between the two farthest points in a particular point cloud. The parameter \(eps\) defines the distance threshold used in the DBSCAN algorithm to determine if two points are within each other's neighborhoods. A smaller one will only partition nearby data points into the same cluster, thereby limiting the point cloud diameter, while a larger \(eps\) allows distant points to be grouped into the same cluster, thereby increasing the point cloud diameter. The specific formulas are as follows:
Among them, \(\text{Data}\) represents the data point set, \(d(P,Q)\) is the distance between point \(P\) and point \(Q\), and \(e\) is the unit distance.
Hypothesis verification
To address the issue of false-positive poses commonly found in clustered pose recommendations, this paper proposes a more effective voxel-based pose verification method. Before verifying candidate poses, the scene point cloud is voxelized, with the voxel size set to \({\text{L}}_{voxel}\). To accelerate the verification process while ensuring accuracy, \({\text{L}}_{voxel}\) is set to one-twentieth of the model's diameter. The position of each voxel, \(\text{Voxel}({s}_{i})\), is calculated using Eq. (5), Finally, as illustrated in Eq. (6), the computed voxel coordinates are assigned to the current calculated point:
where \({\text{L}}_{voxel}\) represents the voxel size, INT function denotes the floor function, and \({x}_{si}\), \({y}_{si}\), \({z}_{si}\) are the coordinates of the current calculated point. (\({x}_{i}\), \({y}_{i}\), \({z}_{i}\)) represents the three-dimensional coordinates of the scene space, and (\({x}_{min}\), \({y}_{min}\), \({z}_{min}\)) are the components of the origin coordinates of the scene point cloud. The candidate pose model \(\text{Voxel}({m}_{i})\) is computed in a similar way to the scene, with the parameters (\({x}_{min}\), \({y}_{min}\), \({z}_{min}\)) representing the origin coordinates of the scene point cloud. The scene point cloud is voxelized, as shown in Fig. 3.

Voxelization of scene point cloud
The process of verifying candidate poses is as follows, as shown in Fig. 4: first, based on the recommended pose \({P}_{i}\), the model is transformed to place it within the scene space. This transformation is done using Eq. (6). Then, \(\text{Voxel}({m}_{i})\) is searched for using the transformed model, and the recommended pose's score \({S}_{pi}\) is initialized to zero. The 3D coordinates of each voxel in the recommended model are recorded as \(\text{Voxel}\left[{x}_{i}\right]\left[{y}_{i}\right]\left[{z}_{i}\right]\), which serves as an index in the scene point cloud. The algorithm goes through these 3D coordinates and checks if \(\text{Voxel}({m}_{i})\) contains any scene point \({S}_{i}\). If a scene point is found within the voxel, the recommended pose's score \({S}_{pi}\) is incremented by one. Each recommended model contains \(k\) voxels, so the maximum score is \(k\). After hypothesis verification, ICP (Iterative Closest Point) refinement is performed to obtain the final estimated pose.

Schematic diagram of pose verification
Experiments
In this section, the proposed algorithm is evaluated and compared with open-source methods, DenseFusion and PVN3D, on the LineMod dataset and Test dataset. The average point distance (ADD) is used as the pose error metric to determine the success of the registration, and the recognition rate is computed. These algorithms were implemented in Python on an Ubuntu 18.04 system and executed on an Intel Core i5-8500 CPU, two NVIDIA 1080ti GPUs, and 32 GB of RAM.
Dataset
To validate the performance of the proposed algorithm, experiments were conducted on the Linemod dataset and the Test dataset established in the laboratory environment. The Test dataset includes various non-occluded objects. While Linemod is a widely used dataset, it is important to emphasize that our experiments primarily focus on non-occluded scenes, and therefore, no testing has been performed on the Occ-LineMOD dataset. Due to this experimental scope, the performance of our algorithm in scenes with occluded objects may not have been fully validated.
LineMod dataset
The LineMod dataset [47] is a widely used dataset for object recognition research in the fields of robotics and computer vision. This dataset consists of 13 objects, including bottles, cups, TVs, keyboards, and more, each with multiple RGB-D images and 3D models from different viewpoints. Each object in the dataset has unique colors and textures, making them easily distinguishable in images. Additionally, the dataset provides ground-truth object poses, indicating the real positions and orientations of the objects in 3D space. This feature makes the dataset valuable for research in object pose estimation. Our algorithm relies on point cloud input for pose estimation, while the compared algorithms use RGB-D image data. The capability to determine if the input data is a point cloud exists, and if it is an RGB-D image, it is converted into point cloud data for computation. Therefore, to eliminate the impact of conversion time, the algorithm's runtime excludes the time for data conversion. Below (Fig. 5) are images of a scene from the dataset, including RGB images, depth maps, and a point cloud generated from RGB-D images.

Point cloud image generated from RGB-D image
Test dataset
To validate the recognition performance in a real-world environment, this paper conducted a comparison between the proposed algorithm, DenseFusion, and PVN3D in an actual laboratory setting. The scene environment was captured using Microsoft's Kinect V2, providing RGB images, depth images, and point cloud (PCD) files. The experiments were conducted in various lighting conditions, including normal lighting, high-intensity lighting, and low-light conditions for comparison. Figure 6 displays the data captured in a specific scene. The dataset comprises a total of 450 scenes categorized into three lighting environments: normal lighting corresponds to the normal exposure category, representing indoor environments with regular illumination; high-intensity lighting corresponds to the overexposure category, denoting scenarios with direct sunlight; low-light conditions correspond to the underexposure category, signifying situations with dim lighting due to shading from external sources. Each lighting category includes 150 different scenes, with 120 scenes allocated for training and 30 scenes for testing in each category.

Data collection in a laboratory environment under three lighting environments
Evaluation metrics
To assess the accuracy of the estimated poses, the average distance metric (ADM) is commonly used as the evaluation metric. ADM measures the distance between corresponding points on the model transformed by the estimated pose and the model transformed by the ground-truth pose. ADM can be further divided into ADD (Average Distance in 3D) and ADI (Average Distance in Image). The calculations are as follows in Eq. (7):
where \(x\) represents a model point, \(M\) is the set of 3D model points, \(\overline{{T }_{x}}\) is the ground-truth pose, and \(\widehat{{T}_{x}}\) is the estimated pose. \({e}_{ADD}\) represents the average error between the estimated and ground-truth poses, while \({e}_{ADI}\) represents the average error in which each point of the estimated pose has the minimum error compared to the ground-truth points. Typically, \({e}_{ADI}\) is smaller than \({e}_{ADD}\) [48]. This paper uses the Average Point Distance (ADD) as the pose error metric. The pose is considered correct if the error is smaller than one-tenth of the model's size or if the angular deviation is less than 10 degrees. Subsequently, the Recognition Rate (RR) quantifies the performance of detecting each object, which is the ratio of correctly recognized poses to all retrieved poses. In this paper, the Mean Recall (MR) is employed to assess overall performance in the dataset, as shown in Eq. (8):
Among them, \(M\) and \(S\) are collections of templates and scenarios \(\left|P(m,s)\right|\) is the number of correct postures determined, \(\left|G(m,s)\right|\) is the number of true postures of object \(m\) in scene \(s\).
Evaluation
In the training setup, the algorithms compared were configured with their respective optimal parameters. The parameter settings for this paper involve using the same input data size (1024 points) and features (coordinates only). A total of 200 training epochs were conducted with a learning rate set at 0.001 and a decay rate set at 0.0001. Additionally, a comparison was made with the approach using DBSCAN + PPF, where the two most critical parameters in DBSCAN are eps and the minimum number of points per cluster. In the Linemod dataset, the eps value for DBSCAN was set to 0.02, with a minimum of 10 points per cluster. For the Test Dataset in this paper, while keeping the minimum points per cluster unchanged, the eps value was set to 0.005. The rationale behind this adjustment lies in optimizing the clustering performance for the Test Dataset, which may have distinct characteristics compared to the Linemod dataset. While the minimum points per cluster remained unchanged to maintain consistency, a smaller eps was selected to accommodate potentially denser clusters or finer structures present in the Test Dataset, This choice was made to accommodate potentially denser clusters or finer structures present in the Test Dataset, with the aim of reducing errors caused by overlapping and occlusion.
LineMod dataset
In the LineMod dataset, a runtime comparison of various pose estimation algorithms was conducted, using DenseFusion, PVN3D, and DBSCAN + PPF as representatives. The runtime is measured from the time the model and point cloud are inputted until the final pose is obtained. The time values presented in Table 1 represent the average pose estimation time for the respective targets across all scenes. DenseFusion exhibited an absolute advantage in runtime, requiring only 0.05 s, which can achieve a processing speed of almost 20 frames per second, meeting the requirements for real-time pose estimation. PVN3D also had a relatively fast runtime of 0.19 s, while the proposed algorithm was slightly slower, with a runtime of 0.28 s. However, it can still achieve a processing speed of 3 frames per second, suitable for industrial production pacing. In summary, the runtime performance of different algorithms plays a crucial role in pose estimation, especially for applications requiring real-time performance.
Table 2 presents the evaluation results for 13 recognition objects in the LineMod dataset. The determination of recognition rates is based on a 10° or 0.1d criterion, where the rotational error angle between the estimated pose and the ground truth pose is less than 10°, and the translational error is less than 1/10 of the model's diameter. The results were compared with SSD-6D [2], PoseCNN [3], DenseFusion [19], PVN3D [5], DBSCAN + PPF, and RCVPose3D [49]. Firstly, it is evident that the RCVPose3D algorithm performed exceptionally well across all 13 objects, showcasing its robust performance. PVN3D and PoseCNN also demonstrated strong recognition capabilities, achieving accuracy rates of over 90% for most objects. DenseFusion performed well on some objects but exhibited shortcomings on others, resulting in an overall balanced performance. The SSD-6D algorithm showed relatively lower recognition rates on many objects, particularly performing poorly on "duck" and "hole p." objects. Secondly, the algorithm proposed in this paper achieved a fundamental estimation correctness rate of around 95% for each object. In Fig. 7, standard deviation is employed to illustrate the algorithm's robustness. Furthermore, this algorithm demonstrated high stability in processing point clouds, mitigating the impact of color on recognition results. Therefore, it could consistently achieve recognition rates across different objects. Overall, although the proposed algorithm may not have a runtime advantage, it exhibits high stability. Additionally, the proposed algorithm maintains relatively consistent recognition rates across various types of objects.

Recognition rate of each method in the scene point cloud
Figure 8 shows the visual results of DenseFusion, PVN3D, and the algorithm proposed in this paper, using the Driller model from the LineMod dataset as an example. The results are projected onto two-dimensional images. DenseFusion and PVN3D are RGB-D methods, while the algorithm in this paper is based on point clouds, so the results are presented on point clouds. In the figure, it can be observed that DenseFusion had significant errors in determining the orientation of the "driller." In contrast, the adaptive downsampling clustering algorithm proposed in this paper has a favorable impact on the final pose estimation accuracy compared to DBSCAN. It could locate the target's position reasonably well, but it struggled to accurately estimate the orientation. PVN3D exhibited some errors in orientation estimation. The algorithm proposed in this paper naturally excels in handling orientation issues because it is based on point cloud processing.

Visualization results of pose estimation on LineMod dataset
Test dataset
From the above comparison, it can be observed that the algorithm proposed in this paper has a significant advantage over DBSCAN + PPF. Therefore, DBSCAN + PPF is not included in the comparison on the Test dataset. As shown in Table 3 for the dataset created in this paper, lighting conditions did not have a significant impact on recognition times. Since the shooting angle is from a top-down perspective, the background environment is a single plane, which speeds up the runtime of pose estimation using RGB-D data. PVN3D achieved a processing speed of 8 frames per second, while the algorithm proposed in this paper exhibited similar speeds, achieving 5 frames per second on this dataset.
In the pose estimation experiments under different lighting conditions for six target objects, the performance of DenseFusion, PVN3D, and the algorithm proposed in this paper was compared. The results are presented in Table 4. The algorithm proposed in this paper showed a high degree of stability and accuracy in normal and high lighting conditions, achieving average recognition rates of 96.23 and 96.19%, respectively. It also maintained a 95.75% average recognition rate in low-light conditions. Compared to DenseFusion and PVN3D algorithms, the algorithm proposed in this paper demonstrated superior stability in various lighting conditions, highlighting its excellent robustness and high accuracy in multi-object pose estimation. It is suitable for practical application scenarios in different environments.
Recognition results are shown in Fig. 9. Pallet and box have larger volumes relative to the number of points in the scene, making it easier to achieve better results. Additionally, there is no occlusion between the objects in this dataset, which contributes to improved accuracy in object recognition with the algorithm proposed in this paper.

Visualization results of pose estimation in laboratory environment under different environments
Conclusion
In conclusion, this paper presents a 6D pose estimation algorithm that combines point cloud data with PointNet + + and the PPF algorithm. PointNet + + is used for feature extraction to obtain target point clouds, density clustering is employed for segmentation in multi-object scenarios, and the PPF algorithm is used for point cloud registration. The final pose estimation is achieved through ICP fine registration. Most existing algorithms perform pose estimation on RGB-D images, while this paper's algorithm processes point cloud data. Point cloud acquisition is less affected by environmental factors compared to RGB-D image acquisition, making it more suitable for industrial production scenarios. Furthermore, the proposed algorithm demonstrates improved recognition performance, particularly in addressing orientation issues, and it is based on point pair features, providing robustness. Overall, the algorithm proposed in this paper has achieved satisfactory results in tasks related to unordered grasping, particularly in scenarios involving non-occluded objects. However, it's important to note that the experiments in this paper are primarily based on datasets without occlusion, and the performance impact on scenes with occlusion has not been fully considered. To comprehensively assess the algorithm's robustness, future research could delve into the impact of early-stage target detection and segmentation on occlusion or abnormal noise scenarios. Furthermore, future work could explore the introduction of transfer learning to reduce the initial amount of required training data, facilitating quicker deployment in practical applications within production environments.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Rad M, Lepetit V. Bb8: a scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth. Proceedings of the IEEE international conference on computer vision. 3828–3836
Kehl W, Manhardt F, Tombari F et al. Ssd-6d: making rgb-based 3d detection and 6d pose estimation great again. Proceedings of the IEEE international conference on computer vision. 1521–1529
Xiang Y, Schmidt T, Narayanan V et al (2017) Posecnn: a convolutional neural network for 6d object pose estimation in cluttered scenes. arXiv preprint arXiv:171100199
Do T-T, Cai M, Pham T et al (2018) Deep-6dpose: recovering 6d object pose from a single rgb image. arXiv preprint arXiv:180210367
He Y, Sun W, Huang H et al. Pvn3d: a deep point-wise 3d keypoints voting network for 6dof pose estimation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11632–11641
Zakharov S, Shugurov I, Ilic S. Dpod: 6d pose object detector and refiner. Proceedings of the IEEE/CVF international conference on computer vision. 1941–1950
Jiang P, Ergu D, Liu F et al (2022) A review of Yolo algorithm developments. Procedia Comput Sci 199:1066–1073
Su H, Maji S, Kalogerakis E et al. Multi-view convolutional neural networks for 3d shape recognition. Proceedings of the IEEE international conference on computer vision. 945–953
He K, Gkioxari G, Dollár P et al. Mask r-cnn. Proceedings of the IEEE international conference on computer vision. 2961–2969
Lowe DG. Object recognition from local scale-invariant features. Proceedings of the seventh IEEE international conference on computer vision. IEEE, 2: 1150–1157
Bay H, Tuytelaars T, van Gool L (2006) Surf: speeded up robust features. Lect Notes Comput Sci 3951:404–417
Mur-Artal R, Montiel JMM, Tardos JD (2015) ORB-SLAM: a versatile and accurate monocular SLAM system. IEEE Trans Rob 31(5):1147–1163
Johnson AE (1997) Spin-images: a representation for 3-D surface matching. https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=4c09532c6ef9afd5f0dd1f3d2b0af313199a8520
Salti S, Tombari F, di Stefano L (2014) SHOT: unique signatures of histograms for surface and texture description. Comput Vis Image Underst 125:251–264
Vacchetti L, Lepetit V, Fua P (2004) Stable real-time 3d tracking using online and offline information. IEEE Trans Pattern Anal Mach Intell 26(10):1385–1391
Hodaň T, Zabulis X, Lourakis M et al (2015) Detection and fine 3D pose estimation of texture-less objects in RGB-D images. 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE: 4421–4428
Tong G, Liu R, Li H (2012) The monocular model-based 3D pose tracking. 2012 24th Chinese control and decision conference (CCDC). IEEE: 980–985
Drost B, Ilic S (2012) 3d object detection and localization using multimodal point pair features. 2012 Second international conference on 3D imaging, modeling, processing, visualization & transmission. IEEE: 9–16
Wang C, Xu D, Zhu Y et al. Densefusion: 6d object pose estimation by iterative dense fusion. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3343–3352
Wang Y, Wang C, Long P et al (2021) Recent advances in 3D object detection based on RGB-D: a survey. Displays 70:102077
Zhang Z, Dai Y, Sun J (2020) Deep learning based point cloud registration: an overview. Virtual Real Intell Hardw 2(3):222–246
Qi CR, Yi L, Su H, Guibas LJ (2017) Pointnet++: deep hierarchical feature learning on point sets in a metric space. In: Advances in neural information processing systems 30
Qi CR, Su H, Mo K et al. Pointnet: deep learning on point sets for 3d classification and segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition. 652–660
Pham Q-H, Uy MA, Hua B-S et al. Lcd: learned cross-domain descriptors for 2d-3d matching. Proceedings of the AAAI conference on artificial intelligence. 34: 11856–11864
Chen H, Wang P, Wang F et al. Epro-pnp: generalized end-to-end probabilistic perspective-n-points for monocular object pose estimation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2781–2790
Rusu RB, Blodow N, Beetz M (2009) Fast point feature histograms (FPFH) for 3D registration. 2009 IEEE international conference on robotics and automation. IEEE: 3212–3217
Tejani A, Tang D, Kouskouridas R et al (2014) Latent-class hough forests for 3d object detection and pose estimation. Computer vision–ECCV 2014: 13th European conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part VI 13. Springer: 462–477
Drost B, Ulrich M, Navab N et al (2010) Model globally, match locally: efficient and robust 3D object recognition. 2010 IEEE computer society conference on computer vision and pattern recognition. IEEE: 998–1005
Birdal T, Ilic S (2015) Point pair features based object detection and pose estimation revisited. 2015 international conference on 3D vision. IEEE: 527–535
Hinterstoisser S, Lepetit V, Rajkumar N et al (2016) Going further with point pair features. Going further with point pair features. Computer vision–ECCV 2016: 14th European conference, Amsterdam, The Netherlands, October 11–14, 2016, PROCEEDINGS, Part III 14. Springer: 834–848
Karunakaran V (2021) Deep learning based object detection using mask RCNN. 2021 6th international conference on communication and electronics systems (ICCES). IEEE: 1684–1690
Tekin B, Sinha SN, Fua P. Real-time seamless single shot 6d object pose prediction. Proceedings of the IEEE conference on computer vision and pattern recognition. 292–301
Liu F, Fang P, Yao Z et al (2019) Recovering 6D object pose from RGB indoor image based on two-stage detection network with multi-task loss. Neurocomputing 337:15–23
Lin H, Liu Z, Cheang C et al. Sar-net: shape alignment and recovery network for category-level 6d object pose and size estimation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6707–6717
Zeng A, Song S, Nießner M et al. 3dmatch: learning local geometric descriptors from rgb-d reconstructions. Proceedings of the IEEE conference on computer vision and pattern recognition. 1802–1811
Yew Z J, Lee GH. 3dfeat-net: weakly supervised local 3d features for point cloud registration. Proceedings of the European conference on computer vision (ECCV). 607–623
Yuan Y, Borrmann D, Hou J et al (2021) Self-supervised point set local descriptors for point cloud registration. Sensors 21(2):486
Liu W, Anguelov D, Erhan D et al (2016) Ssd: single shot multibox detector. Computer vision–ECCV 2016: 14th European conference, Amsterdam, The Netherlands, October 11–14, 2016, proceedings, Part I 14. Springer: 21–37
Crivellaro A, Rad M, Verdie Y et al (2017) Robust 3D object tracking from monocular images using stable parts. IEEE Trans Pattern Anal Mach Intell 40(6):1465–1479
Hu Y, Hugonot J, Fua P et al. (2019) Segmentation-driven 6d object pose estimation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3385–3394
Liang H, Ma X, Li S, et al (2019) Pointnetgpd: detecting grasp configurations from point sets. 2019 international conference on robotics and automation (ICRA). IEEE: 3629–3635
Aoki Y, Goforth H, Srivatsan RA et al (2019) Pointnetlk: robust & efficient point cloud registration using pointnet. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7163–7172
Sarode V, Li X, Goforth H et al (2019) Pcrnet: point cloud registration network using pointnet encoding. arXiv preprint arXiv:190807906
GROß J, Ošep A, Leibe B. Alignnet-3d: fast point cloud registration of partially observed objects. 2019 international conference on 3d vision (3DV). IEEE: 623–632
Besl P J, Mckay ND (1992) Method for registration of 3-D shapes. Sensor fusion IV: control paradigms and data structures. Spie, 1611: 586–606
Hahsler M, Piekenbrock M, Doran D (2019) dbscan: fast density-based clustering with R. J Stat Softw 91:1–30
Hinterstoisser S, Lepetit V, Ilic S et al (2012) Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. Computer vision–ACCV 2012: 11th Asian conference on computer vision, Daejeon, Korea, November 5–9, 2012, revised selected papers, Part I 11. Springer: 548–562
Hodaň T, Matas J, Obdržálek Š (2016) On evaluation of 6D object pose estimation. Computer vision–ECCV 2016 workshops: Amsterdam, The Netherlands, October 8–10 and 15–16, 2016, Proceedings, Part III 14. Springer: 606–619
Wu Y, Javaheri A, Zand M et al (2022) Keypoint cascade voting for point cloud based 6DoF pose estimation. 2022 international conference on 3D vision (3DV). IEEE: 176–1786
Acknowledgements
Authors wish to thank the funding from Natural Science Foundation of Shandong Province (ZR2021QF031), the Tai Shan Scholar Foundation (tshw201502042), and China Postdoctoral Science Foundation (2023M743757).
Funding
This article is funded by Natural Science Foundation of Shandong Province, ZR2021QF031, Qingdang Li, Taishan Scholar Foundation of Shandong Province, tshw201502042, Qingdang Li, China Postdoctoral Science Foundation, 2023M743757, Mingyue Zhang.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, Y., Li, Z., Li, Q. et al. Pose estimation algorithm based on point pair features using PointNet + + . Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01508-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01508-x