
Abstract
Conformer-based models have proven highly effective in Audio-visual Speech Recognition, integrating auditory and visual inputs to significantly enhance speech recognition accuracy. However, the widely utilized softmax attention mechanism within conformer models encounters scalability issues, with its spatial and temporal complexity escalating quadratically with sequence length. To address these challenges, this paper introduces the Shifted Linear Attention Conformer, an evolved iteration of the conformer architecture. Shifted Linear Attention Conformer adopts shifted linear attention as a scalable alternative to softmax attention. We conducted a thorough analysis of the factors constraining the efficiency of linear attention. To mitigate these issues, we propose the utilization of a straightforward yet potent mapping function and an efficient rank restoration module, enhancing the effectiveness of self-attention while maintaining low computational complexity. Furthermore, we integrate an advanced attention-shifting technique facilitating token manipulation within attentional mechanisms, thereby enhancing information flow across various groups. This three-part approach enhances cognitive computations, particularly beneficial for processing longer sequences. Our model achieves exceptional Word Error Rates of 1.9% and 1.5% on the Lip Reading Sentences 2 and Lip Reading Sentences 3 datasets, respectively, showcasing its state-of-the-art performance in audio-visual speech recognition tasks.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In the digital age, the proliferation of smart devices and the ubiquity of multimedia content have emphasized the critical importance of robust audio-visual speech recognition (AVSR) systems. AVSR, which integrates audio signals with visual cues from lip movements, has emerged as a pivotal technology with diverse applications, ranging from improving communication in noisy environments to enabling speech recognition for the hearing impaired and facilitating more natural human-computer interactions. The convergence of auditory and visual information not only enhances the accuracy of speech recognition systems in acoustically challenging settings but also creates new opportunities for multi-modal human–machine interfaces. Deep neural networks [1] serve as the cornerstone of modern AVSR technologies.
Convolutional neural networks (CNNs) [2] have made significant advancements in various computer vision tasks [3], including image classification and speech recognition. Building upon the success of deep learning techniques in computer vision, several studies have started using deep CNNs for AVSR. Such as long short-term memory (LSTM) [4, 5], bidirectional long short-term memory (BLSTM) [6] and bidirectional gated recurrent units (BiGRU) [7]. Noda et al. [8] were the first to apply CNNs for feature extraction in visual speech recognition systems. [9,10,11,12] use either fully connected or convolution layers to extract features from the mouth region, and then feed them into a recurrent neural network to attention architecture. Later, equipped with residual connections, ResNet-based system [13] and its variations [14,15,16] become capable of training deeper networks and have shown an outstanding result. Recently, based on blocks of TCN [17] and squeeze and excitation [18] layers, the DC-TCN [19] and its variant PD-TCN [19] achieve a significant breakthrough in lip reading.
Despite their success, CNNs face certain limitations, primarily focusing on local spatial modeling and struggling with long-range dependencies. To address these challenges, the Transformer [20] and its variations [21, 22] have become prevalent architectures for many sequence processing tasks. Transformers excel at modeling long-range global contexts and enable efficient parallel training. However, existing studies [23, 24] suggest that Transformers may not achieve adequate performance in AVSR without intricate pre-training procedures and extensive parameters. The conformer [25] has emerged as a promising contender for enhancing speech processing performance. Combining CNNs and Transformers, the conformer includes convolution modules to better model local information. Initially yielding exceptional outcomes in end-to-end speech recognition [26], the conformer has been widely adopted in speech enhancement and speech separation [27, 28], producing remarkable results. In AVSR, conformer models leverage both auditory and visual inputs, adopting a dual-modality approach, which significantly enhances transcription precision, especially in challenging environments such as loud surroundings or situations where audio alone proves inadequate.
The integration of conformer-based models into AVSR systems introduces a critical challenge, primarily due to their struggle with managing lengthy sequences. This issue stems from the quadratic time and space complexities inherent in the self-attention mechanisms of Transformer-based models, including conformers. Such complexities, particularly accentuated by Multi-head Self-Attention (MHSA), lead to significant computational demands, highlighting a crucial research gap in creating efficient AVSR systems that maintain high performance without succumbing to these computational burdens.
To address the inherent limitations of existing attention mechanisms within AVSR systems, researchers have primarily explored two approaches: sparsification and linearization. Sparsification techniques, such as those utilized by the KS-Transformer [24], introduce inductive biases to reduce a majority of attention weights, theoretically reducing computational demands. This method identifies crucial tokens within the input data by aggregating their attention weights, thus selecting a subset of tokens with maximal relevance. Despite its potential to streamline computations, sparsification often requires tailored programming optimizations or poses challenges when applied in decoders due to its reliance on specific inductive biases that may not universally apply. Conversely, linearization methods, exemplified by Performer [29], cosFormer [30], and FlowFormer [31], aim to achieve computational efficiency by reconfiguring the traditional attention mechanism to operate with linear complexity. This is generally accomplished via techniques such as low-dimensional projection and selective row operations, aiming to convert the quadratic computational burden into a more manageable linear format [32, 33]. While this approach is commendable for its straightforward implementation, it is not without drawbacks. An important concern is the degradation of model performance attributed to the reduced rank of the attention matrix, compromising the ability of the model to capture complex dependencies within the data.
Despite significant advancements in AVSR technology, the widespread adoption faces hurdles primarily due to the computational inefficiencies of models like conformers. These models, while adept at unraveling complex dependencies across modalities, are hampered by the computational heft of softmax attention mechanisms, which scales quadratically with sequence length. This scalability issue poses a formidable barrier to processing extended audio-visual sequences crucial for real-time applications. Efforts to linearize the attention mechanism, aimed at reducing this computational load, often compromise model performance by simplifying attention to a lower rank. This dilemma highlights an urgent research gap: the need for an AVSR model that marries computational efficiency with the high performance necessary to handle long sequences without losing the capacity to discern intricate dependencies.
To bridge this gap, this paper introduces the Shifted Linear Attention Conformer (SLA-Former), an enhanced iteration of the conformer architecture. SLA-Former uses SLA as a scalable alternative to softmax attention. We conducted a comprehensive analysis of the factors limiting the efficiency of linear attention. To overcome these limitations, we proposed the utilization of a simple yet powerful mapping function and an efficient rank restoration module, enhancing the effectiveness of self-attention while maintaining a low degree of computational complexity. Additionally, we incorporated an advanced attention-shifting technique allowing for the manipulation of tokens inside attentional mechanisms, thereby improving the flow of information among different groups. This three-part approach enhances cognitive computations, particularly advantageous when processing longer sequences. Our model achieved exceptional Word Error Rates (WERs) of 1.9% and 1.5% on the Lip Reading Sentences 2 and Lip Reading Sentences 3 datasets, respectively, demonstrating cutting-edge performance in AVSR tasks.
The work presented in this paper encompasses includes four main primary contributions:
-
Analysis of limitations and introduction of SLA: we comprehensively examined linear attention limitations, laying the groundwork for our innovative approach. The introduction of the SLA mechanism represents a significant advancement, balancing computational efficiency with the integration of global context critical for AVSR.
-
Addressing low-rank challenge with Conv1d integration: we mitigated the low-rank challenge inherent in traditional attention mechanisms by integrating a Conv1d layer, thereby improving our model’s performance and robustness.
-
Efficient processing of long sequences: our model significantly reduces computational complexity associated with processing long sequences by adopting SLA, enabling real-time AVSR applications without compromising accuracy.
-
Superior performance and practical applicability: empirical evaluations on benchmark datasets such as LRS2 and LRS3 reveal the superiority of our SLA-Former over existing methods, highlighting its practical applicability in real-world scenarios and setting new standards for AVSR systems.
Our work not only addresses the crucial need for robust AVSR systems but also bridges the existing gap with a scalable solution that efficiently integrates and processes long sequences of audio-visual data. Beyond merely enhancing speech recognition accuracy, our contributions have significant practical implications, especially in noisy environments and for aiding individuals with hearing impairments [51,52,53]. By tackling computational challenges and showcasing the SLA-Former’s practical applicability, our research sets a solid foundation for the wider adoption of AVSR technologies. The SLA-Former’s efficiency and effectiveness are instrumental in improving telecommunications, bolstering assistive technologies, and fostering more interactive human-computer interfaces, thereby ensuring the overall robustness and reliability of AVSR systems.
The remainder of this paper is structured as follows: “Related work” is a review of recent advancements in AVSR, conformer models, and linear attention mechanisms, discussing key techniques and approaches in these fields. “Methodology” introduces related conformer-based models, system architecture, the schematic pipeline workflow, and the proposed hybrid model for AVSR. “Experiments” outlines experimental results and discussions on real datasets. Lastly, “Conclusions” concludes this paper with some future research directions.

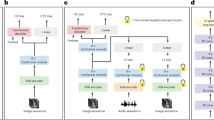
a The overall architecture of our AVSR model. The model comprises modality SLA-Former encoders, a fusion layer, a visual-audio SLA-Former, and a CTC block. The encoders procure videos and audio as inputs and extract their features for speech recognition. Encoded features from both modalities are concatenated by the fusion layer and subsequently embedded using a visual-audio SLA-Former. The model is ultimately trained end-to-end with the CTC loss function. b Illustration of SLA conformer (SLA-Former): The MHSA is replaced by the SLA in the vanilla conformer. c SLA module. Sim () denotes the similarity function, whereas Shift denotes the attention shift mechanism. In the following text, we have provided a detailed description of each component
Related work
Audio-visual speech recognition
Research in AVSR has been ongoing for nearly two decades, starting with the work of Dupont and Luettin [34]. They revealed that manually designed visual characteristics could improve Automatic Speech Recognition (ASR) systems based on Hidden Markov Models [35]. However, currently, the advent of AVSR can be attributed to the contributions of Afouras et al. [11], who introduced deep neural networks. Since then, the field has rapidly evolved, with researchers emphasizing the improvement of architectural features and the use of various learning methods. The primary focus of most AVSR research is the development of innovative architectures and supervised learning techniques capable of accurately representing and combining audio-visual modalities. For instance, TM-seq2seq [11] introduced a Transformer-based AVSR system employing a sequence-to-sequence loss, whereas HybRNN [36] proposed an RNN-based AVSR system combining a seq2seq and Connectionist Temporal Classification (CTC) loss [37]. RNN-T [38] utilized an RNN transducer [39] for AVSR tasks, and EG-seq2seq [40] constructed a combined system for audio enhancement and multimodal speech recognition using RNN as its foundation. Concurrently, research efforts have been directed toward various learning strategies. Li et al. [41] presented a cross-modal student-teacher training scheme, while Paraskevopoulos et al. [42] suggested a multi-task learning strategy predicting at both character and sub-word levels. Shukla et al. [43] investigated self-supervised learning by predicting video frames from audio inputs in cross-modality contexts. Tao and Busso [44] were the first to introduce end-to-end learning in AVSR systems. More recently, Ma et al. [45] reported remarkable advancements in end-to-end learning on the LRS2 dataset using a conformer acoustic model and a hybrid CTC/attention decoder [37].
Conformer
Recent research has explored substantial improvements in neural network topologies, including RNNs [46], CNNs, and Transformer networks utilizing self-attention mechanisms [20], for sequence modeling purposes. These architectures exhibit unique abilities, with newer studies focusing on combining different networks to enhance overall performance. The conformer, a widely adopted architecture, integrates convolutional augmentation into Transformer encoders and has gained recognition for its exceptional performance in various voice-processing tasks [25, 47, 48]. The conformer effectively captures both broad and specific contexts within feature sequences by integrating cascaded self-attention and convolution modules. This approach addresses the challenges posed by long- and short-term dependencies observed in other designs such as RNNs and CNNs. Deng et al. [49] enhanced conformer-based ASR systems by including Learning Hidden Unit Contributions (LHUC), confidence score-based speaker adaptability, and Bayesian estimation techniques to minimize word mistake rates on evaluation sets. Burchi et al. [50] developed an auditory-visual efficient conformer model utilizing both auditory and visual modalities to greatly enhance noise-robust [51,52,53] speech recognition. Zhang et al. [54] introduced the Multi-scale Feature Aggregation (MFA) Conformer, which combines the Convolution-augmented Transformer (Conformer) with convolution subsampling and multi-scale feature aggregation. Andrusenko et al. [55] introduced Uconv-conformer, a modified conformer architecture incorporating upsampling blocks to significantly decrease the length of the input sequence, resulting in accelerated training, higher inference speed, and improved WER compared to the baseline conformer model. Hernandez et al. [56] proposed a technique to decrease the number of parameters in conformer-based voice recognition models from over 100 million to 5 million, enabling efficient always-on ambient speech recognition on low-memory edge devices. The reduction is achieved by implementing weight-sharing algorithms while maintaining the model’s quality. Chang et al. [57] presented a study demonstrating enhanced visual speech recognition by employing a simpler linear front-end in combination with a larger conformer encoder, resulting in reduced latency and improved WER performance.
Linear attention
Linear attention, a computational method employed in neural networks, particularly in sequence-to-sequence models like Transformers, serves to calculate attention weights. This process involves applying the softmax function to a set of scores, often termed attention scores or energies, computed between a query and a set of key-value pairs. These scores indicate the significance or relevance of each element in the input sequence (values) with respect to the query. The softmax function standardizes these scores across the entire sequence, generating attention weights that determine the contribution of each element to the final attended output. This method enables the model to selectively focus on specific segments of the input sequence while generating its output. The challenge with softmax attention lies in its exponential increase in computational complexity as sequence length grows. To address this limitation, linear attention is introduced, offering improved scalability and computational efficiency compared to softmax attention. Linear attention is a modification of self-attention wherein the softmax function is replaced with distinct kernel functions. It eliminates the need for initially computing the pairwise similarity \(QK^{{\textrm{T}}}\), using the associative property of matrix multiplication by first calculating \(K^{{\textrm{T}}}V\), thereby altering the calculation order. Consequently, computational complexity decreases from \({\mathcal {O}}(N^2d)\) to \({\mathcal {O}}(Nd^2)\). Developing a linear attention module that matches the effectiveness of softmax attention proves challenging despite its efficiency. The Performer [29] utilizes orthogonal random features to approximate softmax attention, yet it is constrained by potential significant errors stemming from its positive-definite kernel approximation, restricting its applicability across tasks. The cosformer [30] replaces the nonlinear cosine-based re-weighting process, yet its cosine weighting method serves as a heuristic, limiting its ability to approximate attention to specific patterns. The reformer [22] enhances efficiency by replacing dot-product attention with locality-sensitive hashing. Efficient attention applies the Softmax function individually to Q and K [58], ensuring that the sum of each row in the \(QK^{{\textrm{T}}}\) matrix equals one. The Hydra Attention [59] optimizes Vision Transformers by utilizing an equal number of attention heads as features, resulting in a linear computational complexity for both tokens and features without hidden constants. This approach significantly accelerates self-attention in high-resolution images while maintaining or even improving accuracy.
Methodology
Conformer and softmax attention
Speaker representations require both local features (e.g., pitch, intonation, pronunciation) and global context modeling. While CNNs excel at capturing local features, they often struggle with capturing global context. On the other hand, Transformers’ self-attention mechanism can capture extensive context but may lack local details. To enhance the representation of both general and specialized characteristics, we employ the conformer block to improve the detection of speaker attributes with greater effectiveness and efficiency. The conformer introduces a sophisticated architectural concept that integrates CNNs and Transformers for ASR coding. By incorporating a convolutional layer into a transformer block, the conformer enhances the capacity of the basic transformer model to model local information. Crucial components of a conformer block include the MHSA and Convolution modules. The MHSA in the conformer model utilizes the relative position-coding methodology, initially proposed in Transformer-XL [60]. Inputs are encoded using relative positional deviation, considering both the overall content offset and position offset. The conformer block and the Transformer block possess unique architectures. The structure comprises two Feed Forward Network (FFN) modules, resembling macarons, interconnected by half-residual connections. These modules are placed intermediate between the MHSA and convolution (Conv) modules. Let’s denote the input to the i-th block as \(z_i\). The computation of the output for the i-th block is as follows:
FFN: feed forward network; MHSA: multi-head self-attention module; Conv: convolution module; LayerNorm: layer normalization.
Subsequently, we analyzed the attention mechanism in a fundamental conformer model. Softmax attention is a technique utilized to model and examine distant relationships in a conformer. The softmax attention mechanism conducts pairwise comparisons between all items in the input sequence and adjusts the corresponding positions in the output sequence. The softmax attention layer performs key-value searches on each input in the input sequence and incorporates the results into the output sequence.
Given an input sequence \(X=[x_1,\dots ,x_N]^{{\textrm{T}}}\in {\mathbb {R}} ^{N\times d}\) of N feature vectors, we initially converted X into the query matrix Q, the key matrix K, and the value matrix V using linear transformations:
The weight matrices \(W_Q\) and \(W_K\) were both of size \(D\times d\), whereas the weight matrix \(W_V\) was of size \(D_v\times d\), where D, d, and \(D_v\) were real numbers. Q was the transpose of the vector \([q_1,\dots ,q_N]\), K was the transpose of the vector \([k_1,\dots ,k_N]\), and V denoted the transpose of the vector \([v_1,\dots ,v_N]\). The vectors \(q_i\), \(k_i\), and \(v_i\) for \(i=1,\dots ,N\) represented the query, key, and value vectors, respectively. Next, we calculated the output by taking a weighted average. The resulting sequence \(H=[h_1,\dots ,h_N]^{{\textrm{T}}}\) was determined as follows:
The softmax function was applied to every row of the matrix \(QK^{{\textrm{T}}}/\sqrt{d_k}\). To calculate the output vector \(h_i\) for each query vector \(q_i, i=1,\dots ,N\), \(a_{i,j}\) represented the attention weight between the i-th query vector \(q_i\) and the j-th key vector \(k_j\). Equation (6) can be expressed in vector form as:
The attention function was concurrently calculated on a collection of queries, consolidated into a matrix Q. The keys and values were consolidated into matrices K and V. The matrix \(QK^{{\textrm{T}}}\) was typically scaled by dividing it by the square root of \(d_k\). In this scenario, the attention map was derived by calculating the similarity between all pairs of query and key, resulting in a computational complexity of \({\mathcal {O}}(N^2d)\). Consequently, the overall space and time complexity for calculating \({\mathcal {O}}\) increased quadratically as the length of the input grew.
Linear attention

Illustrations of softmax and linear attention computations. The length of the input is denoted as N, whereas the dimension of the features is represented by d
Based on the critical drawback of softmax attention, linear attention was considered a viable option that reduces the computational complexity from \({\mathcal {O}}(N^2d)\) to \({\mathcal {O}}(Nd^2)\), making it more efficient.
We first altered the definition of softmax attention as follows:
Thus softmax attention is the weighted average of \(v_j\) with \(e^{q^{{\textrm{T}}}_ik_j}\) as the weight, and we have accordingly proposed a general definition of attention:
where sim(., .) denotes the similarity function.
Based on Eq. (9), we had the flexibility to choose any similarity functions for calculating the attention matrix. To ensure efficient computation, one approach was to utilize a decomposable similarity function that satisfies the following criteria:
Here, \(\phi (.)\) represents a kernel function that transforms the queries and keys into their respective hidden representations. Equation (9) can be reformulated using kernel functions as follows:
In this formulation, rather than directly computing the attention matrix \(A=QK^{{\textrm{T}}}\in {\mathbb {R}}^{N\times d}\), we first calculated \(\phi (K)^{{\textrm{T}}}V \in {\mathbb {R}} ^{d\times d}\) and subsequently multiplied it by \(\phi (Q)\in {\mathbb {R}} ^{N\times d}\). Using this technique, we encountered a computational complexity of \({\mathcal {O}}(Nd^2)\).
As previously indicated, the criticalities of linear attention lie in identifying a decomposable similarity function sim(., .) that exhibits strong generalization across many tasks. However, current linear attention approaches exhibit the challenge of finding a balance between model complexity and effectiveness. Using basic approximations, including the use of the Rectified Linear Unit (ReLU) activation function, could lead to a significant decline in performance. Nevertheless, the use of carefully designed kernel functions or matrix decomposition processes can lead to a higher computing workload. In general, differences continue to exist in the concrete effectiveness between linear attention and softmax attention.
SLA
Attention linearization
While linear attention offers the advantage of scaling computing costs linearly, previous research [29, 30] has indicated that substituting softmax attention with linear attention often results in a significant decline in performance.
The fundamental characteristics of the softmax attention mechanism have been validated in previous studies [30]. Attention matrices are always non-negative, ensuring that attention weights for items remain positive. The non-linearity of the system allows for nonlinear modifications of weights, enhancing the emphasis on key aspects while reducing the impact of irrelevant elements. This promotes a more efficient and contextually aware distribution of attention.
However, we acknowledge the benefits of softmax attention regarding its sparse nature. As an attention mechanism, softmax is specifically designed to direct and intensify focus. If the distribution becomes overly dispersed, it may resemble average pooling. Conversely, concentration implies that each token should have significant relationships with only a limited number of tokens. Mathematically, this indicates that the attention matrix has a low density of non-zero elements or has the potential for a low density of non-zero elements.
For standard attention, normalization is achieved by softmax:
where \(a_{i,j}\) represents the attention weight between the i-th query vector \(q_i\) and the j-th key vector \(k_j\). The vectors \(q_i\), \(k_j\) for \(i,j=1,\dots ,N\) represent the query and key, respectively. The exponential function \({e^{q_i\cdot k_j}}\) functions as a multiplier. If each product of \(q_i\) and \(k_j\) can widen a certain gap, then the exponential function \({e^{q_i\cdot k_j}}\) will further amplify the magnitude of this gap. Following normalization, all probabilities, with the exception of the highest value, remain unaltered. All of them exhibit values close to zero, suggesting that standard attention possesses the capacity to concentrate. Linear attention is the result of a straightforward inner product calculation without any extra amplification, leading to a rather dense attention. Long sequences sometimes exhibit a high degree of resemblance to average pooling.
Based on the abovementioned observations, our proposed linear model eliminates softmax normalization while retaining non-negativity and re-weighting mechanisms. This results in the sum of each attention matrix row being one due to softmax operation. In this paradigm, \(\sum _{j}^{n} e^{b_{i,j}}\) denotes the L1 paradigm for vector \(e^{b_{i,:}}\), wherein softmax acts as L1 normalization for vector \(e^{b_{i,:}}\). To avoid re-normalization of \(\sum _{j}^{n} a_{i,j}=1\), we can employ \({\textrm{L}}2\) normalization.
In our linear attention modules, we used the \(\textrm{ReLU}\) function to ensure that the input remains non-negative. The attention density decreases when the activation function is substituted with \(\mathrm {ReLU^2}\). The reason for this is that the \(\textrm{ReLU}\) operation exhibits the specific consequence of setting values to zero, unlike the exponential function, which is always positive. Thus, we possess:
For enhanced comprehension, we have provided an illustrative scenario to demonstrate the impact of Equation (15) (3). It is evident that the function effectively pushes each vector toward its closest axis. Accordingly, it aids in categorizing the features into distinct groups based on their closest axis, improving the similarity within each group while diminishing the similarity across groups.

The map function applies a transformation that moves each vector toward the nearest axis, hence assisting linear attention in focusing on relevant features
Relative position encoding
The conformer model requires positional encoding, unlike RNNs or CNNs, to provide sequence order information. This aspect is crucial since an attention-based module alone cannot adequately discern sequence order. To address this, two primary strategies are commonly employed: Absolute Positional Encoding (APE) [20] assigns distinct encoding vectors to each token, specifying their exact positions within the sequence. This aids in positional understanding and is commonly used in many transformer-based models. Relative Positional Encoding (RPE) [61,62,63] captures relative distances between input elements, establishing pairwise relationships among symbols. RPE computes interactions between query tables with learnable parameters [64] and queries/keys within the self- attention module, effectively handling long dependencies among tokens. While APE utilizes trainable parameters for position vectors and updates them during training, it is limited by the input length N. In contrast, RPE focuses on relative distances between current and attended positions during attention computation [65], without detailing every input. In tasks such as lip-reading, where relying on relative positions often demonstrates superior performance [73], RPE is preferred due to its ability to handle long dependencies effectively.
RPE, seemingly inspired by APE, augments general attention mechanisms by integrating positional information, as follows:
where \(x_i\) represents the original feature vector at the ith position in the input sequence, and \(p_i\) indicates the positional coding vector at that position. The vectors \(q_i\), \(k_i\), and \(v_i\) for \(i=1,\dots ,N\) denote the query, key, and value vectors, respectively.
We initially unfolded \(q_ik^{\textrm{T}} _j\):
To introduce relative position information, we removed the first term position and changed the second term \(W_{K}^{\textrm{T}} p_{j}^{\textrm{T}}\) to a binary position vector \(R_{i, j}^{K}\), which becomes:
And \(p_{j} W_{V} \) in \(O_{i}=\sum _{j} a_{i, j} v_{j}=\sum _{j} a_{i, j}\left( x_{j} W_{V}+p_{j} W_{V}\right) \)for \(R_{i, j}^{V}\):
In this way, pairwise positional relationships can be learned during training. Considering the abovementioned abandonment of the softmax operation in linear attention, the approach for RPE also required revision:
Hence, we have:
Attention shifted

Illustration of the attention shifted mechanism
Conformers excel at performing global self-attention computations, enabling robust modeling of long-distance relationships. However, in speech-related tasks, feature sequences are typically much longer compared to written text sentences. Consequently, conformers entail significant computational and memory expenses in speech-related applications. Drawing inspiration from the effectiveness of grouped convolutions in efficient CNNs, a method of segmenting the initial attention matrix into subgroups along specified dimensions has proven to be an efficient approach for computing attention. This strategy, similar to the approach used in effective CNNs, divides the attention matrix into smaller parts, facilitating more concentrated and efficient attention calculations within specific subgroups. Utilizing a grouped attention technique can efficiently decrease computing complexity by dividing it into several parallelizable subtasks. This grouping maximizes memory utilization, particularly beneficial for longer sequences. However, a significant drawback is that the attention of each group is restricted to its assigned subsequence, potentially limiting the model’s ability to capture extensive long-range connections or correlations among distant segments of the sequence. To facilitate communication across different groups, we implement a shift mechanism, as illustrated in Fig. 4. It consists of three key steps. Initially, it involves splitting features along the head dimension into three distinct chunks. Within the initial stage of attention heads, a token shift occurs by one-third of the group size. The tokens remain unchanged in the subsequent step, and in the latter part of attention heads, there is another token shift occurring backward by one-third of the group size. Tokens are segmented into groups in the final step and reshaped within the batch dimensions. Attention computation is limited within each group, whereas self-attention spans across all tokens. The critical information exchange between different groups is facilitated through the shifting mechanism. This three-step process enables a clear depiction of the Attention Shift technique, allowing token manipulation within attention heads and establishing information flow among distinct groups. This strategy systematically repositions tokens within attention heads by dividing the temporal length into many groups and performing attention within each group individually. Specifically, in the beginning section of attention heads, tokens are moved forward by one-third of the group size. This is followed by consistent token alignment in the next section. Lastly, there is a backward movement by one-third of the group size in the latter section of attention heads.
Given \(X \in {\mathbb {R}}^{n \times d}\), if we shift X by L locations on the d axis, then we have:
Here, Eq. (23) represents the operation of shifting left and right by L places on the d axis, respectively. After the shift, the resulting tensor is denoted as \(X_{merged}\) and is obtained by concatenating the tensors \(X_{left}\), \(X_{original}\), and \(X_{right}\). The shifting approach allows information transmission among adjacent groups while preserving the token positions in the core region. This technique enables improved information interchange among diverse organizations without incurring any further computational costs.
SLA refinement
Research by Bhojanapalli et al. [66]. emphasizes the significance of low rank as a constraining element. The softmax attention matrix typically has higher ranks in terms of information preservation, indicating its proximity to invertible matrices and its greater ability to store relevant information. However, the primary function of softmax involves the exponential of the dot product between the matrices Q and the transpose of K. This exponential nature of each element within the matrix has the potential to elevate the rank of the new matrix, thereby enhancing the efficacy of softmax attention in processing information. Conversely, the attention matrix rank in linear attention is limited by the number of tokens N and the channel dimension d for each head.
In this formulation, d is generally smaller than N. The maximum rank of the attention matrix is restricted to a lower proportion. Consequently, many rows in the attention map become overly uniform. The process of homogenizing attention weights results in the creation of similarities among the combined characteristics, as the output of self-attention is a weighted sum of the identical set of features V. To depict this phenomenon, we substituted the original softmax attention in conformer models with linear attention and evaluated the ranking of the attention map depicted in Fig. 5. Evidently, the rank demonstrated a large fall, leading to several rows becoming similar inside the attention matrix. To address the limitation of linear attention, we propose a straightforward yet powerful solution: incorporating a Conv1d module into the attention matrix. This enhancement facilitates the output expression in the following manner:
The Conv1d module has a similar effect on attention, with each query considering only neighboring features in space rather than the complete set of features V. By adopting this method, we effectively raise the maximum limit of the rank of the comparable attention matrix. This leads to minimal additional computational burden while significantly enhancing the linear attention performance. Furthermore, we made comparable alterations to the conformer model. The use of the Conv1d module reinstated the rank of the attention map in linear attention to its maximum capability (Fig. 5). This ensured that the feature variety remained comparable to the initial softmax attention.

Analysis of attention maps with and without the Conv1d module
Model overall architecture
Visual Front-End The Visual Front-End of our architecture is meticulously designed to capture both spatial and temporal dynamics from video frames, which are critical for comprehending the nuanced visual cues in speech. The first component comprises a 3D convolutional kernel with dimensions \((5\times 7\times 7)\), particularly selected for its ability to efficiently process spatiotemporal information. This kernel size strikes an optimal balance between capturing fine-grained details and maintaining computational efficiency. Following this, we used the ResNet-18 architecture for frame-by-frame feature extraction because of its proven effectiveness in various computer vision tasks. ResNet-18 offers a good compromise between depth and complexity, ensuring robust feature extraction without excessively burdening computational resources. Subsequent spatial averaging was employed to eliminate dimensionality while preserving critical features, facilitating focused analysis by the backend network. This step ensures that essential information is not lost during dimensionality reduction. The transition of features to the backend network is managed through a linear layer, projecting the temporally aggregated information into a suitable form for further processing. The configuration explicitly aligns with the dimensions of a ResNet-18 model complemented by a \((5 \times 7 \times 7)\) 3D convolutional layer, optimized for the input tensor represented as \(B \times T \times H \times W\) (where B is the batch size, T the number of frames, and H and W the height and width respectively). This design ensures comprehensive feature extraction across both spatial and temporal dimensions. Global average pooling was applied at the culmination of the residual blocks to achieve effective spatial aggregation, leading to a feature tensor of dimensions \(B \times C \times T\). The use of Swish activation across all layers enhances non-linear feature transformation without introducing excessive complexity. Further details on the Visual Front-End architecture are provided in Table 2, which outlines the detailed configuration. This structured approach in our Visual Front-End ensures an effective balance between capturing essential visual cues for speech recognition and maintaining computational efficiency, laying a solid foundation for the subsequent stages of our model.
Audio Front-End The Audio Front-End of our model is intricately designed to accurately capture the auditory features crucial for speech recognition. This process commences with the application of the Short-Time Fourier Transform, a pivotal step in converting raw audio waveforms into Mel spectrograms, a more analyzable format. The choice of a 20-millisecond window duration and a 10-millisecond hop duration is grounded in the typical temporal dynamics of speech, ensuring detailed capture without temporal blurring. The Mel spectrograms then undergo processing through an 80-dimensional Mel-scale logarithmic filter bank. This transformation is indispensable for emulating the human ear’s frequency response, thus directing our model’s focus toward the most informative segments of the audio spectrum for speech recognition. The selection of 80 dimensions strikes a balance between capturing a wide spectrum of frequencies while maintaining computational efficiency. To further refine the frequency characteristics and extract local temporal-frequency features, we employ 2D convolutional kernels on the Mel spectrograms. This crucial step aids in identifying patterns within the frequency domain that signify specific phonetic features. The meticulous configuration of the 2D convolution stem is geared towards optimizing the extraction of these local features, fostering a comprehensive understanding of the auditory input. This carefully structured approach ensures the efficient transformation of raw audio waveforms into a format rich in speech-relevant information. Subsequent processing stages are designed to extract and refine these features, preparing them for effective integration with visual cues in the later stages of our model. For a detailed breakdown of the architecture components and their specifications, please consult Table 3. This table provides a step-by-step outline of the process and the specific configurations utilized in our Audio Front-End, offering clarity on the transformation and preparation of audio data for further analysis within our AVSR system.
Back-End networks The back-end networks adopt the SLA-Former architecture. To enhance efficiency and reduce computational demands, the temporal sequence undergoes systematic scaling down using strided convolutions and is then expanded to higher feature dimensions. In the audio back-end network, a three-stage technique is employed to decrease the audio signal’s sampling rate to an 80-millisecond frame rate. Conversely, reducing the visual signal’s resolution to match the frame rate requires only two steps.
Audio-visual fusion module This section integrates features from both auditory and visual modalities. The features are combined using a linear layer with an output size of \(d_{ff} = 4 \times d_{model}\), initially expanding them. The merged features have a size of \(2 \times d\) model. A non-linear transformation is applied using the Swish activation function, followed by projecting the features back to the original model dimension \(d_{model}\).
Audio-visual encoder The audio-visual encoder comprises a single-stage back-end network consisting of five SLA-Former blocks, with no downsampling.
Loss function The training methodology in this study employed the CTC attention loss. The input frame sequence at the inception of the fusion module’s conformer encoder is denoted as \(x = [x_1,\dots , x_T]\), whereas the targets are represented as \(y = [y_1,\dots , y_L]\). Here, T denotes the length of the input sequence, and L represents the length of the target sequence. The CTC loss assumes that each output prediction is conditionally independent and is expressed as follows:
Experiments
Datasets
The study utilized publicly available English AVSR datasets, namely Lip Reading in the Wild (LRW) [67], Lip Reading Sentences 2 (LRS2) [11], and Lip Reading Sentences 3 (LRS3) [68]. These datasets were chosen for their widespread availability and standardization. Initially, the LRW dataset was used for visual pre-training, followed by training and evaluation stages using the LRS2 and LRS3 datasets. This selection ensured the inclusion of diverse and extensive audio-visual speech data for developing and evaluating the proposed models. Each dataset is divided into three sections: Pre-train, Train-val, and Test. The composition of utterances, words, and vocabulary for each split in both datasets is presented in Table 4.
LRW The LRW dataset comprises a lexicon of 500 unique lexical units, each pronounced by multiple speakers. It consists of 488,766 precisely annotated video segments, offering a comprehensive representation of the subtle nuances of lip movement during speech production. The dataset is partitioned into distinct training, validation, and test sets, crucial for the development and meticulous evaluation of lip-reading algorithms.
LRS2 &LRS3 The LRS2 dataset consists of 144,482 video clips sourced from BBC television, with a combined duration of 224.1 h. These videos are meticulously annotated with caption text and word-level alignments, making them valuable resources for training and evaluating voice recognition, lip-reading, and cross-modal learning tasks.
The LRS3 dataset comprises 151,819 video clips obtained from TED and TEDx lectures, with a total duration of 438.9 h, exceeding that of the LRS2 dataset. Like LRS2, LRS3 provides caption text and word-level alignments. However, LRS3 offers a broader range of speech themes and features a diverse group of speakers, making it advantageous for comprehensive investigations into speech recognition and lip-reading topics. Both datasets include pre-training splits, train-validation divisions, and test splits, facilitating extensive academic study with remarkable flexibility and comprehensive coverage.
Implementation details
Data pre-processing Preprocessing of data is crucial to guarantee precision and uniformity in lip-reading activities. This section presents a concise overview of the data pretreatment workflow. To account for rotation and scaling differences, we employ a cropping technique that isolates the specific area of the lips in each video frame. Additionally, we establish a standard size for the lip region using a bounding box of dimensions \(96\times 96\) pixels. Standardizing the lip area facilitates easier analysis and ensures consistency across all frames. Subsequently, the RetinaFace model [69] is employed to detect faces, while the Facial Alignment Network (FAN) [70] is utilized for precise facial alignment, pinpointing 68 facial landmarks. This meticulous procedure ensures the exact identification of the lip area, enabling precise feature extraction. Following this, photos undergo cropping, grayscale conversion, and normalization to ensure consistency and reduce the impact of intensity fluctuations on visual characteristics. Furthermore, text undergoes preprocessing alongside picture processing. The Sentence Piece tool, as described in [71], is employed to create a byte pair encoding tokenizer, constructed using textual data from the LRS2 and LRS3 datasets. With a vocabulary size of 256, including the CTC blank token, this encoding technique transforms textual data into organized sequences for training lip reading models. Comprehensive preprocessing procedures ensure consistent and efficient processing of lip-reading data, establishing a dependable basis for subsequent model training and evaluation.
Data augmentation Data augmentation is a crucial preprocessing approach that enhances model robustness and performance. Various methods are carefully implemented to increase dataset diversity and improve the model’s prediction performance without overfitting training data. For audio data, the Spec-Augment technique [72] is judiciously employed during the training phase, particularly with Mel spectrograms. This involves combining two frequency masks, each with a size parameter of \(F=27\), and subsequently applying five-time masks with a variable size parameter of \(p_s=0.05\). Masks are deliberately applied to specific regions in the frequency and time domains, introducing variation within the dataset. For video data, temporal masking [73] is utilized, inserting a mask every second lasting no more than 0.4 s. Moreover, random cropping and resizing are applied to each video, resulting in a size of \(88\times 88\) pixels. Horizontal flipping is also used to increase the diversity of video data by altering viewpoints and positions. Furthermore, during trials relying solely on visual data, methods suggested by Prajwal et al. [74] are implemented, including center cropping and horizontal flipping during testing. Dropout is employed to mitigate overfitting, particularly with limited training datasets, preventing the repeated extraction of identical features [75]. The extensive application of these augmentation methods enhances model resilience and generalization, enabling reliable performance across diverse environmental settings.
Experiment setup We strictly followed the technique outlined in [50]. Initially, we trained the visual encoder for 30 epochs using the LRW dataset. Subsequently, we retained only the frontend weights from the pre-training to initialize the frontend for future training stages. The audio and visual encoders were extensively trained using the LRS2 &3 dataset, employing Noam scheduling [20]. This scheduling method involved 10,000 preliminary steps and achieved a peak learning rate of 0.001. To enhance model performance, we employed the Adam optimizer [76] with \(\beta _1\) and \(\beta _2\) values set to 0.9 and 0.98, respectively. Moreover, L2 regularization was implemented on all trainable weights, with a regularization weight of 0.000001 to control model complexity. Throughout the training process, a constant batch size of 128 was maintained. However, the number of epochs varied among different models. Nvidia RTX 4090 24GB GPUs were used for visual-only (VO) and audio-visual (AV) experiments, whereas Nvidia RTX 3090 24GB GPUs were used for audio-only (AO) experiments. The Python version was 3.8, Pytorch version 1.8, torchvision version 1.8, and CUDA toolkit version 10.2. The audio model underwent 200 epochs of training, the visual model was trained for 100 epochs, and the audio-visual model underwent 70 epochs. To handle the training data, video filtering was employed to select videos with a maximum duration of 500 frames (comparable to 20 s). This curation technique was crucial for ensuring consistency and efficiency of the training dataset.
Evaluation metric We employed the WER to measure the precision of predicted voice recognition text compared to the actual transcript. WER is a widely used metric measuring the closeness between the anticipated and target sequences of words. We denoted S as the number of substitutions, D as the number of deletions, I as the number of insertions required to achieve the target sequence, and N as the total number of words in the target sequence. With these assumptions, the metric may be defined as:
Results
Comparison with the state-of-the-art
Table 5 presents a comparison of the performance of our proposed SLA-Former with existing approaches on the LRS2/3 test. Our proposed SLA-Former model demonstrates superior performance on the LRS2 and LRS3 test sets, largely attributed to the innovative use of the SLA mechanism. This attention model remarkably enhances the capability of the model to process and integrate information across both audio and visual modalities, contributing to the observed state-of-the-art results. For the audio-only (AO) modality, the SLA-Former exhibits exceptional performance, with WERs of 2.1% and 1.8% on LRS2 and LRS3 respectively. This highlights the effectiveness of the SLA in handling long-range temporal dependencies inherent in audio data, allowing the model to focus on salient auditory features crucial for speech recognition, even in challenging acoustic environments. In the VO modality, where traditional lip-reading models might struggle due to the subtlety of visual cues, the SLA-Former achieves WERs of 29.2% and 37.3% on LRS2 and LRS3, respectively. This improvement highlights the role of SLA in enhancing the ability of the model to discern and prioritize relevant visual information, such as lip movements and facial expressions, essential for accurate lip-reading. In the AV modality, the SLA-Former achieves WERs of 1.9% and 1.5% on LRS2 and LRS3, respectively, showcasing its capability to effectively fuse and leverage complementary information from both audio and visual streams. The SLA mechanism facilitates this multimodal integration by dynamically adjusting the focus between auditory and visual cues, ensuring the model capitalizes on the most informative features from each modality. This fusion is particularly beneficial in scenarios where one modality may be compromised, such as in noisy environments or when the face of the speaker is partially occluded. Furthermore, comparison with state-of-the-art methods reveals the advantages of the SLA-Former model in effectively using attention mechanisms to enhance AVSR performance. Conventional models often depend on softmax attention or other less efficient attention mechanisms. In contrast, our model’s utilization of SLA offers a more scalable and computationally efficient approach without compromising accuracy. This advancement is important for deploying AVSR systems in real-world applications where computational resources and response times are crucial.
Utterance duration impact analysis
In video processing and live online meetings, the variability in utterance lengths is significant, ranging from brief snippets lasting less than three seconds to prolonged speech segments exceeding 20 s. For an AVSR system to function optimally, it must adeptly handle this variability by extracting meaningful global features from utterances of any length. The attention mechanism, a hallmark of transformer and conformer architectures, is distinctly advantageous over traditional CNN-based models with its capability to capture and process global interactions within speech data. This section aims to highlight how attention mechanisms influence the performance of the model across utterances of varying lengths. To investigate this, we conducted experiments evaluating the performance of the model across different lengths of utterances within the LRS2/LRS3 datasets. We organized the test utterances into predefined time ranges, creating a new trial series. The resultant WERs are shown in Fig. 6. The emerging pattern from our findings reveals that as the length of the utterances increases, a corresponding enhancement is noted in the performance of the SLA-Former. This improvement demonstrates the pivotal role of the attention mechanism in the model’s ability to efficiently aggregate and process extensive contextual information from longer speech segments. This observation supports the notion that the SLA-Former, equipped with its sophisticated attention mechanisms, excels in determining the underlying speech structure and context, regardless of the utterance length. The proficiency of the model in handling longer utterances is noteworthy, indicating its capability to maintain a comprehensive understanding of the broader context, which is indispensable for accurately recognizing speech in diverse and dynamic real-world scenarios. This enhanced understanding and the resultant performance gains validate the critical role of attention mechanisms in advancing AVSR system capabilities, particularly in their application to environments characterized by wide variations in speech patterns.

Performance of shifted linear attention, softmax attention and linear attention with different utterance durations

WER comparison of different attention mechanisms on audio-only

An illustration of the progression of attention patterns across different layers and heads of the network, denoted as Lx-Hy, where ‘L’ stands for ‘Layer’ and ‘H’ stands for ‘Head’
Visualization of attention map
At the model’s outset, the attention mechanism is predominantly characterized by self-attention, wherein individual tokens primarily focus on themselves. This initial stage is visually represented in the attention maps of the first layer, which demonstrate distinct diagonal patterns, highlighting the engagement of each token with its own representation. As the model advances through successive layers, it begins expanding its focus, incorporating information from adjacent tokens. This perspective broadening is evident in the attention maps as they begin to show various diagonal patterns, highlighting the information integration from neighboring tokens and a wider field of information assimilation. The visualizations clearly illustrate the progression of attention maps across the network layers. The maps are initially marked by pronounced diagonal patterns that signify the self-attention phase of the model. As the model navigates through the layers, these maps evolve to reveal multiple diagonal patterns, reflecting the increasing capability of the model to integrate a broader array of information. This progression underscores the ability of the model to extend its receptive field, thereby enhancing its comprehension of the connections and interdependencies among tokens within a larger context.
However, as the model delves into deeper layers, a notable shift in the attention mechanism occurs. The focus moves away from broad and query-based attention to a more concentrated form, with essential information clustering around specific tokens. This shift is visually represented in the attention maps by clear vertical lines, indicating attention patterns that are independent of the initial query. Such patterns indicate a significant simplification in information processing, where certain tokens become pivotal in gathering crucial details. The model consequently demonstrates a reduced reliance on the original question to comprehend the context, indicating a sophisticated level of information processing and abstraction. This evolution in the attention mechanism, from self-focused to an integrated and then simplified approach, demonstrates the increasing efficiency of the model in distilling and focusing on relevant information as it progresses through its layers.
Ablation study
This section entails a thorough ablation research on the fundamental elements of our SLA paradigm. We aimed to evaluate the efficiency of the architectural improvements. We analyzed the influence of each alteration on the improvement of the achieved WER. In all ablation studies, we conduct training for 200 epochs for audio-only models and for 50 epochs for VO/AV models.
Attention shift and 1D convolution Initially, we assessed the efficacy of our suggested attention shifting mechanism and Conv1d convolution. As indicated in Table 6, before using Conv1d, the WER of linear attention demonstrated poorer performance in comparison to softmax attention. Applying Conv1d to reduce the WER of linear attention, and then integrating attention shifting to further decrease the WER, the results demonstrated that our Conv1d and attention shifting techniques significantly enhanced the expressive capacity of linear attention. Consequently, our SLA module outperformed softmax attention in terms of performance. The results indicated that the proposed Conv1d and attention shifting strategies greatly improved the ability of linear attention to represent information, resulting in the SLA module surpassing softmax attention.
Shifted linear attention at different stages We replaced the softmax attention mechanism in the conformer model with our module at different stages. As depicted in Table 7, it is evident that substituting the initial stage results in improved performance, while substituting the subsequent stages only slightly diminished the overall accuracy. We attribute this result to the longer input sequence length and better compatibility of the early phase of the conformer with our module, which has a broad receptive field.
Attention group size To evaluate the influence of attention group size, we performed studies wherein we systematically and gradually enlarged the size of the attention group. Table 8 reveals that choosing a group size of three resulted in the lowest WER when compared to group sizes of two, four, and five. When the group size was two, the analysis may be overly constrained to only studying the connection between nearby elements. However, when the group size exceeds four, it may fail to consider certain subtle details. Choosing a group size of three can help mitigate the trade-off between capturing medium-dimensional data and considering both local details and a wider range of information, consequently enhancing the performance of the model.
Conclusions
In this study, we introduced the SLA-Former, a cutting-edge AVSR approach that employs SLA as a scalable and efficient alternative to the conventional softmax attention mechanisms. By tackling the inherent limitations of linear attention, such as its computational complexity and low-rank matrix issues, the SLA-Former achieves remarkable performance improvements, evidenced by significant reductions in WERs on challenging AVSR datasets such as LRS2 and LRS3. We demonstrated the capability of the SLA-Former in effectively capturing and processing long-range temporal dependencies in AV data through detailed analysis and experimental validation. The adoption of an advanced attention shifting technique and the novel use of a Conv1d layer for rank restoration greatly improve the ability of the model to interpret complex speech patterns in environments characterized by noise and visual diversity.
However, the SLA-Former is not without its limitations. The incorporation of SLA and Conv1d layers introduces additional complexity, potentially impacting efficiency in environments with limited resources. Furthermore, the performance of the model may vary across languages and dialects, as it has been primarily optimized for English. Its dependency on the quality of AV data suggests that variations in lighting and background noise can significantly influence performance. It is essential to overcome these challenges to enhance robustness and widen global applicability.
The approach of SLA-Former to AVSR presents several promising directions for future research. Key areas include enhancing real-time processing capabilities to improve user experience in telecommunications, expanding the model to support multimodal learning for a more comprehensive understanding of environmental contexts, and bolstering robustness against various conditions such as background noise and visual obstructions. Further exploration of the adaptability of the model across different linguistic contexts could greatly expand its global usability. Optimizing and streamlining these aspects are vital toward making AVSR more efficient, versatile, and accessible for a broad range of applications.
Data Availability
The datasets generated during and analyzed during the current study are available from the corresponding author on reasonable request. BBC Lip Reading in the Wild Dataset LRW (https://www.robots.ox.ac.uk/vgg/data/lip_reading/lrw1.html). BBC Lip Reading Sentences 2 Dataset LRS2 (https://www.robots.ox.ac.uk/vgg/data/lip_reading/lrs2.html). BBC Lip Reading Sentences 3 Dataset LRS3 (https://www.robots.ox.ac.uk/vgg/data/lip_reading/lrs3.html).
References
Jain DK, Zhao X, González-Almagro G, Gan C, Kotecha K (2023) Multimodal pedestrian detection using metaheuristics with deep convolutional neural network in crowded scenes. Inform Fusion 95:401–414
Kurdi SZ, Ali MH, Jaber MM, Saba T, Rehman A, Damaševičius R (2023) Brain tumor classification using meta-heuristic optimized convolutional neural networks. J Personal Med 13(2):181
Zivkovic M, Bacanin N, Antonijevic M, Nikolic B, Kvascev G, Marjanovic M, Savanovic N (2022) Hybrid CNN and XGBoost model tuned by modified arithmetic optimization algorithm for COVID-19 early diagnostics from X-ray images. Electronics 11(22):3798
Jovanovic L, Jovanovic D, Bacanin N, Jovancai Stakic A, Antonijevic M, Magd H, Zivkovic M (2022) Multi-step crude oil price prediction based on lstm approach tuned by salp swarm algorithm with disputation operator. Sustainability 14(21):14616
Ng CSW, Ghahfarokhi AJ, Amar MN (2023) Production optimization under waterflooding with Long Short-Term Memory and metaheuristic algorithm. Petroleum 9(1):53–60
Zhou P, Shi W, Tian J, Qi Z, Li B, Hao H, Xu B (2016) Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2: Short papers) (pp. 207-212)
Zhao R, Wang D, Yan R, Mao K, Shen F, Wang J (2017) Machine health monitoring using local feature-based gated recurrent unit networks. IEEE Trans Indusl Electron 65(2):1539–1548
Noda K, Yamaguchi Y, Nakadai K, Okuno HG, Ogata T (2014, September). Lipreading using convolutional neural network. In Interspeech (Vol. 1, p. 3)
Stafylakis T, Tzimiropoulos G (2017) Combining residual networks with LSTMs for lipreading. arXiv preprint arXiv:1703.04105
Shillingford B, Assael Y, Hoffman MW, Paine T, Hughes C, Prabhu U, de Freitas N (2018) Large-scale visual speech recognition. arXiv preprint arXiv:1807.05162
Afouras T, Chung JS, Senior A, Vinyals O, Zisserman A (2018) Deep audio-visual speech recognition. IEEE Trans Pattern Anal Mach Intell 44(12):8717–8727
Son Chung J, Senior A, Vinyals O, Zisserman A (2017) Lip reading sentences in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6447-6456)
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778)
Koonce B, Koonce B (2021) ResNet 50. Convolutional neural networks with swift for tensorflow: image recognition and dataset categorization, 63-72
Hayou S, Clerico E, He B, Deligiannidis G, Doucet A, Rousseau J (2021, March) Stable resnet. In International Conference on Artificial Intelligence and Statistics (pp. 1324-1332). PMLR
Targ S, Almeida D, Lyman K (2016) Resnet in resnet: Generalizing residual architectures. arXiv preprint arXiv:1603.08029
Lea C, Flynn MD, Vidal R, Reiter A, Hager GD (2017) Temporal convolutional networks for action segmentation and detection. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 156-165)
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132-7141)
Ma P, Wang Y, Shen J, Petridis S, Pantic M (2021) Lip-reading with densely connected temporal convolutional networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 2857-2866)
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Polosukhin I (2017) Attention is all you need. Advances in neural information processing systems, 30
Beltagy I, Peters ME, Cohan A (2020) Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150
Kitaev N, Kaiser Ł, Levskaya A (2020) Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451
Wang C, Wu Y, Qian Y, Kumatani K, Liu S, Wei F, Huang X (2021, July) Unispeech: Unified speech representation learning with labeled and unlabeled data. In International Conference on Machine Learning (pp. 10937-10947). PMLR
Chen W, Xing X, Xu X, Yang J, Pang J (2022, May) Key-sparse transformer for multimodal speech emotion recognition. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6897-6901). IEEE
Gulati A, Qin J, Chiu CC, Parmar N, Zhang Y, Yu J, Pang R (2020) Conformer: Convolution-augmented transformer for speech recognition. arXiv preprint arXiv:2005.08100
Graves A, Jaitly N (2014, June) Towards end-to-end speech recognition with recurrent neural networks. In International conference on machine learning (pp. 1764-1772). PMLR
Pascual S, Bonafonte A, Serra J (2017) SEGAN: Speech enhancement generative adversarial network. arXiv preprint arXiv:1703.09452
Subakan C, Ravanelli M, Cornell S, Bronzi M, Zhong J (2021, June) Attention is all you need in speech separation. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 21-25). IEEE
Choromanski K, Likhosherstov V, Dohan D, Song X, Gane A, Sarlos T, Weller A (2020) Rethinking attention with performers. arXiv preprint arXiv:2009.14794
Qin Z, Sun W, Deng H, Li D, Wei Y, Lv B, Zhong Y (2022) cosformer: Rethinking softmax in attention. arXiv preprint arXiv:2202.08791
Huang Z, Shi X, Zhang C, Wang Q, Cheung KC, Qin H, Li H (2022, October) Flowformer: A transformer architecture for optical flow. In European conference on computer vision (pp. 668-685). Cham: Springer Nature Switzerland
Wang S, Li BZ, Khabsa M, Fang H, Ma H (2020) Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W (2021, May) Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence (Vol. 35, No. 12, pp. 11106-11115)
Dupont S, Luettin J (2000) Audio-visual speech modeling for continuous speech recognition. IEEE Trans Multimedia 2(3):141–151
Eddy SR (1996) Hidden markov models. Curr Opin Struct Biol 6(3):361–365
Petridis S, Stafylakis T, Ma P, Tzimiropoulos G, Pantic M (2018, December) Audio-visual speech recognition with a hybrid ctc/attention architecture. In 2018 IEEE Spoken Language Technology Workshop (SLT) (pp. 513-520). IEEE
Watanabe S, Hori T, Kim S, Hershey JR, Hayashi T (2017) Hybrid CTC/attention architecture for end-to-end speech recognition. IEEE J Sel Top Signal Process 11(8):1240–1253
Makino T, Liao H, Assael Y, Shillingford B, Garcia B, Braga O, Siohan O (2019, December) Recurrent neural network transducer for audio-visual speech recognition. In 2019 IEEE automatic speech recognition and understanding workshop (ASRU) (pp. 905-912). IEEE
Graves A (2012) Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711
Xu B, Lu C, Guo Y, Wang J (2020) Discriminative multi-modality speech recognition. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (pp. 14433-14442)
Li W, Wang S, Lei M, Siniscalchi SM, Lee CH (2019, May) Improving audio-visual speech recognition performance with cross-modal student-teacher training. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6560-6564). IEEE
Paraskevopoulos G, Parthasarathy S, Khare A, Sundaram S (2020) Multiresolution and multimodal speech recognition with transformers. arXiv preprint arXiv:2004.14840
Shukla A, Vougioukas K, Ma P, Petridis S, Pantic M (2020, May) Visually guided self supervised learning of speech representations. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6299-6303). IEEE
Tao F, Busso C (2020) End-to-end audiovisual speech recognition system with multitask learning. IEEE Trans Multimedia 23:1–11
Martinez B, Ma P, Petridis S, Pantic M (2020, May) Lipreading using temporal convolutional networks. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6319-6323). IEEE
Medsker LR, Jain L (2001) Recurrent neural networks. Design Appl 5(64–67):2
Burchi M, Vielzeuf V (2021, December) Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition. In 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 8-15). IEEE
Chen S, Wu Y, Chen Z, Wu J, Li J, Yoshioka T, Zhou M (2021, June) Continuous speech separation with conformer. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5749-5753). IEEE
Deng J, Xie X, Wang T, Cui M, Xue B, Jin Z, Meng H (2022) Confidence score based conformer speaker adaptation for speech recognition. arXiv preprint arXiv:2206.12045
Burchi M, Timofte R (2023) Audio-visual efficient conformer for robust speech recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 2258-2267)
Stojanovic V, Nedic N, Prsic D, Dubonjic L (2016) Optimal experiment design for identification of ARX models with constrained output in non-Gaussian noise. Appl Math Modell 40(13–14):6676–6689
Stojanovic V, Nedic N (2016) Robust Kalman filtering for nonlinear multivariable stochastic systems in the presence of non-Gaussian noise. Int J Robust Nonlinear Control 26(3):445–460
Stojanovic V, Nedic N (2016) Joint state and parameter robust estimation of stochastic nonlinear systems. Int J Robust Nonlinear Control 26(14):3058–3074
Zhang Y, Lv Z, Wu H, Zhang S, Hu P, Wu Z, Meng H (2022) Mfa-conformer: Multi-scale feature aggregation conformer for automatic speaker verification. arXiv preprint arXiv:2203.15249
Andrusenko A, Nasretdinov R, Romanenko A (2023, June) Uconv-conformer: High reduction of input sequence length for end-to-end speech recognition. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE
Hernandez SM, Zhao D, Ding S, Bruguier A, Prabhavalkar R, Sainath TN, McGraw I (2023, June) Sharing low rank conformer weights for tiny always-on ambient speech recognition models. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE
Chang O, Liao H, Serdyuk D, Shah A, Siohan O (2023) Conformers are All You Need for Visual Speech Recognition. arXiv preprint arXiv:2302.10915
Shen Z, Zhang M, Zhao H, Yi S, Li H (2021) Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF winter conference on applications of computer vision (pp. 3531-3539)
Bolya D, Fu CY, Dai X, Zhang P, Hoffman J (2022, October) Hydra attention: Efficient attention with many heads. In European Conference on Computer Vision (pp. 35-49). Cham: Springer Nature Switzerland
Dai Z, Yang Z, Yang Y, Carbonell J, Le QV, Salakhutdinov R (2019) Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860
Dai Z, Yang Z, Yang Y, Carbonell J, Le QV, Salakhutdinov R (2019) Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860
He P, Liu X, Gao J, Chen W (2020) Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654
Guo M, Ainslie J, Uthus D, Ontanon S, Ni J, Sung YH, Yang Y (2021) LongT5: Efficient text-to-text transformer for long sequences. arXiv preprint arXiv:2112.07916
Gehring J, Auli M, Grangier D, Yarats D, Dauphin YN (2017, July) Convolutional sequence to sequence learning. In International conference on machine learning (pp. 1243-1252). PMLR
Shaw P, Uszkoreit J, Vaswani A (2018) Self-attention with relative position representations. arXiv preprint arXiv:1803.02155
Bhojanapalli S, Yun C, Rawat AS, Reddi S, Kumar S (2020, November) Low-rank bottleneck in multi-head attention models. In International conference on machine learning (pp. 864-873). PMLR
Chung JS, Zisserman A (2017) Lip reading in the wild. In Computer Vision-ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, November 20-24, 2016, Revised Selected Papers, Part II 13 (pp. 87-103). Springer International Publishing
Afouras T, Chung JS, Zisserman A (2018) LRS3-TED: a large-scale dataset for visual speech recognition. arXiv preprint arXiv:1809.00496
Deng J, Guo J, Ververas E, Kotsia I, Zafeiriou S (2020) Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5203-5212)
Bulat A, Tzimiropoulos G (2017) How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE international conference on computer vision (pp. 1021-1030)
Kudo T, Richardson J (2018) Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv preprint arXiv:1808.06226
Park DS, Zhang Y, Chiu CC, Chen Y, Li B, Chan W, Wu Y (2020, May) Specaugment on large scale datasets. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6879-6883). IEEE
Ma P, Petridis S, Pantic M (2022) Visual speech recognition for multiple languages in the wild. Nat Mach Intell 4(11):930–939
Prajwal KR, Afouras T, Zisserman A (2022) Sub-word level lip reading with visual attention. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (pp. 5162-5172)
Bacanin N, Zivkovic M, Al-Turjman F, Venkatachalam K, Trojovský P, Strumberger I, Bezdan T (2022) Hybridized sine cosine algorithm with convolutional neural networks dropout regularization application. Sci Rep 12(1):6302
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
Zhang X, Cheng F, Wang S (2019) Spatio-temporal fusion based convolutional sequence learning for lip reading. In Proceedings of the IEEE/CVF International conference on Computer Vision (pp. 713-722)
Afouras T, Chung JS, Zisserman A (2020, May) Asr is all you need: Cross-modal distillation for lip reading. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2143-2147). IEEE
Yu J, Zhang SX, Wu J, Ghorbani S, Wu B, Kang S, Yu D (2020, May) Audio-visual recognition of overlapped speech for the lrs2 dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6984-6988). IEEE
Ma P, Petridis S, Pantic M (2021, June) End-to-end audio-visual speech recognition with conformers. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7613-7617). IEEE
Zhao Y, Xu R, Wang X, Hou P, Tang H, Song M (2020, April) Hearing lips: Improving lip reading by distilling speech recognizers. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 04, pp. 6917-6924)
Serdyuk D, Braga O, Siohan O (2021, December) Audio-visual speech recognition is worth \(32\times 32\times 8\) voxels. In 2021 IEEE automatic speech recognition and understanding workshop (ASRU) (pp. 796-802). IEEE
Shi B, Hsu WN, Mohamed A (2022) Robust self-supervised audio-visual speech recognition. arXiv preprint arXiv:2201.01763
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no potential Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiao, Y., Huang, J., Liu, X. et al. Sla-former: conformer using shifted linear attention for audio-visual speech recognition. Complex Intell. Syst. 10, 5721–5741 (2024). https://doi.org/10.1007/s40747-024-01451-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-024-01451-x