
Abstract
Aiming at the problem of poor autonomous adaptability of mobile robots to dynamic environments, this paper propose a YOLACT++ based semantic visual SLAM for autonomous adaptation to dynamic environments of mobile robots. First, a light-weight YOLACT++ is utilized to detect and segment potential dynamic objects, and Mahalanobis distance is combined to remove feature points on active dynamic objects, also, epipolar constraint and clustering are employed to eliminate feature points on passive dynamic objects. Then, in terms of the semantic labels of dynamic and static components, the global semantic map is divided into three parts for construction. The semantic overlap and uniform motion model are chose to track moving objects and the dynamic components are added to the background map. Finally, a 3D semantic octree map is constructed that is consistent with the real environment and updated in real time. A series of simulations and experiments demonstrated the feasibility and effectiveness of the proposed approach.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Simultaneous localization and mapping (SLAM), as a key supporting technology for autonomous environmental adaptation and navigation of mobile robots, enables robots to utilize their own sensors to perceive environmental information for localization in real time and gradually building a map. Currently, most visual SLAM (vSLAM) algorithms treat the surrounding environment as static, such as KinectFusion [1], Large-Scale Direct Monocular SLAM [2], Oriented FAST and Rotated BRIEF (ORB)-SLAM2 [3], Direct Sparse Odometry (DSO) [4], etc. But in practical application scenarios, there are many different types of moving objects, e.g. pedestrians, vehicles, etc. If the dynamic feature points are directly used for robots pose estimation, it will cause a large amount of error accumulation in the localization process, and the final map is inconsistent with the actual environment. Therefore, vSLAM that can autonomous adapt to complex dynamic environments has become a frontier research hotspot in the field of intelligent robots.
In recent years, various vSLAM solutions for dynamic environments have emerged one after another [5,6,7], and how to effectively distinguish between dynamic and static features is the key to improving the performance of these algorithms. Generally, research on vSLAM in dynamic environments can be divided into two categories, i.e. conventional methods and deep learning-based methods. Conventional methods are usually characterized by good real-time performance and low resource consumption, such as utilizing epipolar geometry constraints for dynamic consistency detection and employing Bayesian networks for probabilistic update detection of prior objects. Although these conventional methods are able to eliminate dynamic feature points to some extent, the pose estimation in high dynamic scenes may experience drift, and it is difficult to construct a 3D map that can accomplish navigation or other advanced applications. To overcome these shortcomings, many researchers have introduced deep learning-based semantic segmentation methods into vSLAM architectures. Although deep learning network models can achieve high recognition rates and accurately separate potential dynamic objects through iterative training, it also sacrifices the real-time performance of the algorithm. Considering the complexity of the network model, some other researchers adopt more light-weight networks to ensure the processing speed of the algorithm, but meanwhile the accuracy of segmentation is also reduced.
Overall, although the semantic networks are used to assist in removing dynamic feature points can improve the localization accuracy of vSLAM in dynamic environments, the operation of network models requires a large amount of computing resources, and it is difficult to meet real-time requirements even with the help of GPU to accelerate. In order to ensure the real-time performance of the algorithm, we introduce the light-weight YOLACT++ [8] in the front-end, and combine with the Mahalanobis distance to compensate for the insufficient accuracy of semantic network for active dynamic object segmentation. Then, we further combine with the epipolar constraint and clustering method, feature points on passive dynamic objects that are far from the active dynamic object or beyond the boundary of the target annotation box in YOLACT++ are eliminated. Considering that the common method of keyframe selection is difficult to adapt to the uncertainty of dynamic scenes, a high-quality keyframe selection strategy is constructed by combining the motions of potentially dynamic objects and the robot. In order to enhance the autonomous adaptability of mobile robots to dynamic environments, we track and reconstruct the potentially dynamic objects in the scene and add them to the background map to build a 3D semantic octree map that can be updated in real time.
The main contributions of this paper are as follows:
-
1.
On the basis of the semantic mask given by YOLACT++, Mahalanobis distance, epipolar constraint and clustering are introduced to eliminate the dynamic feature points on potential moving objects, thus obtaining the static feature point set with high confidence, which improves the localization accuracy while ensuring the real-time performance of the algorithm.
-
2.
A divisional map building method for the dynamic maintenance of semantic map is proposed, in which the semantic overlap and the uniform motion model are utilized to track the moving objects, and added them to the background map to achieve the tracking and reconstruction of dynamic objects.
The rest of the paper is organized as follows. Related work is outlined in “Related work”. The system framework, improvement strategies and implementation process of our algorithm are presented in “Framework and methods”. “Simulations and experiments” provides the simulation studies and experimental results, while “Conclusion and future work” summarizes the work and proposes the future research directions.
Related work
Conventional methods

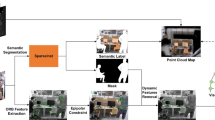
Scheme of the YOLACT++ based semantic visual SLAM for autonomous adaptation to dynamic environments of mobile robots
The commonly used conventional methods for distinguishing dynamic features include Bayesian network models, and static weights, geometric constraints, etc. Li et al. [9] proposed an RGB-D SLAM system based on real-time depth edges, which adopted static weighting for edge points in the keyframe and added this static weight into the Intensity Assisted Iterative Closest Point (IAICP) to perform registration, significantly reducing the tracking errors. Cheng et al. [10] employed a sparse motion removal model in terms of the similarity between adjacent frames and the difference between the current frame and the reference frame to detect and remove dynamic regions, and inputted the similarity and difference into a Bayesian framework, improving the accuracy and stability of the algorithm. Cheng et al. [11] used dynamic weights to select dynamic regions by setting the dynamic prior information of the object, and then chose Bayesian model updating to obtain dynamic regions with high confidence. Liu et al. [12] effectively improved the accuracy of pose estimation in dynamic scenes by assigning static weights to the feature points and combining double k-mean clustering and improved Random Sample Consistency (RANSAC) [13] algorithm to distinguish dynamic feature points. Liu et al. [14] introduced an unsupervised learning segmentation method to obtain semantic labels and fused the multi-view geometry and human detection capability, enabling the algorithm to perform robust tracking in indoor dynamic environments. Dai et al. [15] drew on the correlation between map points to effectively separate dynamic and static points in the scene. Due to the absence of a network model, the algorithm has excellent real-time performance.
Conventional methods have the characteristics of low consumption and good real-time performance, but it is difficult to realize some advanced applications in dynamic environments, e.g. obstacle avoidance, path planning, and target tracking, etc. With the development of deep learning, some researchers seek to introduce semantic networks into vSLAM algorithms.
Deep learning-based methods
Zhao et al. [16], Xie et al. [17], Yuan and Chen [18], Li et al. [19], Wen et al. [20] tend to use Mask-RCNN [21] for preliminary detection of dynamic objects, and then combine it with traditional methods to better separate potential dynamic feature points and improve the positioning accuracy of the algorithm. Moreover, Cheng et al. [22] combined semantic features and geometric constraints to remove dynamic feature points, and recorded the movement trajectory of dynamic objects during the tracking process, expanding the application field of the algorithm. Bescos et al. [23] applied an end-to-end deep learning framework to eliminate interference from dynamic objects and achieve dynamic object detection and static background reconstruction. Although the application of network models can enhance the recognition accuracy of dynamic objects, it sacrifices real-time performance and consumes a large amount of computing resources. Thus, some researchers try to improve the real-time performance of the algorithm in the case of adopting network models.
Yu et al. [24] utilized SegNet to implement caffe-based pixel level semantic segmentation and combined it with a geometric constraint approach to effectively reduce the impact of dynamic features while ensuring real-time performance. Vincent et al. [25] further capitalized on Kalman filtering (KF) to improve the performance of pose estimation and map construction in dynamic environments, based on the use of light-weight Detectron2 for instance segmentation. RDMO-SLAM [26] leveraged a semantic segmentation method that only segments keyframes, and combined it with optical flow prediction to improve the real-time performance of the algorithm. PLD-SLAM [27] introduced light-weight MobileNet and point-line features in the front-end, and made use of K-means algorithm, re-projection error, and depth value to distinguish dynamic features, significantly improving the accuracy of pose estimation. Chang et al. [28] utilized the real-time instance segmentation network YOLACT [29], combined with geometric constraints and dense optical flow methods to detect dynamic targets and reconstruct background map, effectively improving the performance of the algorithm in dynamic environments. Additionally, studies [30,31,32,33] further integrated a dynamic detection tracking module based on a light-weight semantic segmentation network to improve the localization accuracy and robustness of the algorithm.
In order to effectively improve the comprehensive performance of SLAM algorithm in dynamic environments, Song et al. [34] performed data association on semantic information acquired by dynamic environments, and then detected dynamic objects and judged loop closure through table retrieval. DGS-SLAM [35] adopted a semantic segmentation method for dynamic objects based on polynomial residual model, which uses semantic frames instead of keyframes to extract potential dynamic objects, ensuring the real-time performance of the algorithm and improving its accuracy. Chen et al. [36] used a multi-level knowledge distillation method to obtain a light-weight segmentation model that is more suitable for continuous frames, and combined the segmentation results with data matching method to achieve dynamic probability updating and propagation, reducing the impact of dynamic points on the pose optimization process. Several other studies [37, 38] have similarly introduced light-weight semantic networks, effectively rejected dynamic features, and added semantic labels to the mapping module to obtain a consistent 3D semantic map.
Framework and methods
The overall framework of our scheme is shown in Fig. 1. The RGB image and the depth image acquired by a depth camera are used as the input of the system, in which the RGB image sequences are detected and segmented by YOLACT++ network for active dynamic objects to get the corresponding semantic masks. For the moving objects in the scene, the dynamic feature points on the active dynamic objects are recognized by introducing the determination based on the Mahalanobis distance, and the feature points on the passive dynamic objects that are too far away from the active dynamic objects or beyond the boundary of the target bounding box are further eliminated by combining the epipolar constraint and clustering, and the obtained static feature points with high confidence are used for the estimation of the robot’s pose. When performing robot pose estimation, the uniform motion model is used to estimate the pose of the current frame, and then the following re-projection matching is utilized to obtain the static feature points that match the previous frame, i.e.
After this, two adjacent frames are added to the bundle adjustment (BA) [39] optimization along with the successfully matched static feature points for robot pose optimization, i.e.
where \(\left[ u\ v\right] ^\mathrm{{T}}\) and \(\left[ X\ Y\ Z\right] ^\mathrm{{T}}\) donote the coordinates of the pixel point and the spatial point, respectively; d denotes the depth value of the spatial point; K denotes the camera internal parameter; \(exp(\xi ^{\hat{\ }})\) denotes the Lie algebraic corresponding to the camera’s pose; \(p_i\) and \(P_i\) denote the \(i^{th}\) pixel point and spatial point, respectively.

The process of obtaining a semantic mask after segmenting the input RGB image using the YOLACT++. First, the RGB image of size 640\(\times \)480 is input into Feature Backbone for deformable convolution and the processed image is further passed into Feature Pyramid for convolution and down-sampling. Then, the image processed by Feature Pyramid is sent to the Prediction Head and Protocol, respectively. In this way, three outputs of Class, Box and Mask are obtained after processing by the Prediction Head, and then the optimal ROI (region of interest) of each target is selected by NMS; while the mask of each class can be obtained by Protonet convolution. Finally, the images obtained from NMS and Protonet are processed through Assembly, followed by Crop cropping and Threshold filtering to obtain the final Semantic Mask
After completing the robot pose estimation, a series of keyframes are selected based on the degree of change in dynamic feature points and the motion amplitude of the robot. When the robot experiences extreme movements, it might cause significant changes in the pose between adjacent frames, which may result in the visual odometer generating deviations during tracking and localization, and even directly lead to tracking failures. Thus, if the motion amplitude \(D_t\) of the robot at time t, i.e. the translation and rotation, satisfies the following conditions, the robot’s motion amplitude is considered large:
where \(D_{t-1}\), \(D_{t-2}\) and \(D_{t-3}\) denote the movement amplitude of the robot in the previous three time intervals, respectively. Once Eq. (3) is satisfied, keyframes should be inserted in time, which can improve the stability of the algorithm and the accuracy of robot pose estimation.
Subsequently, the covisibility graph is used to associate the newly added keyframes with the previous keyframe sequence, and then the closely related keyframes and the covisibility points in the keyframes are constructed into a graph for local BA optimization to obtain more accurate pose estimation. Further, the optimized keyframe sequence is added to the loop closure detection module, which detects the similarity of each keyframe by the bag-of-words (BOW) model [40] and decides whether the global BA optimization should be performed to correct the closed loop based on the deviation of the pose. Finally, the newly added keyframes, along with their corresponding semantic masks and depth images, are incorporated into the mapping module to build a 3D semantic octree map. For the semantic labels of dynamic and static components, the global semantic map building is divided into three parts through the divisional mapping method, and the tracking and reconstruction of dynamic objects are realized by using the semantic overlap degree of dynamic objects and the uniform motion model, that is, tracking the moving objects and adding the dynamic components to the background map in time, so as to construct a 3D semantic octree map that enables mobile robots autonomous environment adaptation and navigation in dynamic environments.
Potential moving objects detection and rejection
Detection and segmentation with YOLACT++
In our work, to ensure the SLAM system to accurately detect and segment moving objects with good real-time performance, a lightweight YOLACT++ is introduced in the front-end. Compared to the Mask-RCNN with higher segmentation accuracy, YOLACT++ possesses better real-time performance, with a segmentation speed of 33.5 FPS on real-time instance segmentation models, and only slightly lower segmentation accuracy than Mask-RCNN. Figure 2 illustrates the process of obtaining a semantic mask after segmenting the input RGB image using the YOLACT++.
In dynamic environments, the state of moving objects has great uncertainty, and the introduction of a large number of dynamic feature points brings about a sharp decrease in the accuracy and stability of SLAM systems. Hence, utilizing the semantic information provided by YOLACT++ after detection and segmentation can contribute to the algorithm to effectively detect and reject dynamic feature points in the visual odometry, thereby improving the localization accuracy of the algorithm. Moreover, to further improve the real-time performance, we set the semantic segmentation thread, tracking thread, mapping thread and loop closure detection thread to execute synchronously during the algorithm implementation. After obtaining the semantic information, the semantic segmentation thread will generate the corresponding semantic mask. Herein, the semantic information \(S_Y\) is denoted as the following 6-tuple:
where \(O_y\) and \(C_y\) represent the recognized object and the corresponding color, respectively; \(\left( w_1,h_1\right) \) and \(\left( w_2,h_2\right) \) represent the coordinates of the top left corner and bottom right corner of the bounding box. The semantic information is further incorporated into the mapping thread to form the final semantic octree map.
It should be noted that, although the YOLACT++ ensures the real-time performance of the algorithm, the lack of segmentation accuracy will affect the rejection accuracy of dynamic feature points. Thus, in order to achieve higher localization accuracy, it is necessary to perform further judgment for dynamic features.
Rejection of potential dynamic features
Typically, there are some unknown dynamic objects in dynamic scenes, so the two pivotal notions involved in this work are active dynamic objects and passive dynamic objects. The former indicates objects that are capable of autonomous and independent movement, such as pedestrians; the latter refers to objects that move under the drive of active dynamic objects, such as different objects moved by humans in a scene. For the uncertainty of the motion direction and velocity of active dynamic objects, we exploit the semantic mask obtained by the YOLACT++ to process the feature points on them and obtain a preliminary set of dynamic feature points. Due to the insufficiency of YOLACT++ in terms of segmentation accuracy, there may also be some errors in the generated semantic masks. To further obtain dynamic feature points with higher confidence, we introduce the Mahalanobis distance to filter the static feature points around active dynamic objects. As compared to the Euclidean distance, the Mahalanobis distance corrects the problem of inconsistent and correlated dimensional scales in the Euclidean distance.
To determine whether a feature point is on a dynamic object or not, it is necessary to comprehensively consider the distance and depth difference between these feature points. By means of the Mahalanobis distance judgment, it is possible to eliminate the influence of dimensions and better separate dynamic and static feature points. The selection of feature points to be judged is determined by the target bounding box generated by YOLACT++, which is used to frame selection dynamic objects. Considering that the target bounding box may have inaccurate selections, in this case, the noise is highly likely to affect the integrity and accuracy of the semantic mask. In order to ensure the accuracy of the bounding box, the method in this paper extends the boundary of the box by adding \(\sigma \) pixels during the judgment process. The main purpose is to make further judgments on the suspicious point set \({P}_{dou}=\left\{ {b}_{1},{b}_{2}, \ldots ,{b}_{N}\right\} \) which refers to those points that are not enclosed by the bounding box on the dynamic objects or located on the edges of dynamic objects. Herein, the minimum distance between the suspicious point \(b_i\) and the dynamic object A within the bounding box satisfies the following constraints:
where N is the total number of suspicious points, \(\sigma \) is the threshold value of the pixel distance, and \(\sigma =\) 15 in this paper.
For a general case, a set of determined dynamic feature points \(P_{ini}=\left\{ p_1,p_2, \ldots ,p_M\right\} \) can be preliminarily obtained within the same box, where M is the total number of points in the bounding box that can be directly identified as dynamic feature points. Then, the two feature points \(p_{max}\) and \(p_{min}\) with the furthest and closest Mahalanobis distances from the suspect point \(b_i\) are filtered based on \(P_{ini}\), and the furthest and closest distances are respectively denoted as \(\delta _{max}\) and \(\delta _{min}\), as shown in Fig. 3. The Mahalanobis distance between points \(x_i\) and \(x_j\) is expressed as follows:
where \({D}_{Ma}\left( \cdot ,\cdot \right) \) denotes the Mahalanobis distance, \(d_i\) denotes the depth of the \(i^{th}\) pixel point, and \({\Sigma }^{-1}\) denotes the inverse matrix of the 2-dimensional covariance matrix.

Judgment of suspicious feature points on active dynamic objects
Further, two sets \({X}=\left\{ p_{max},p_{min}\right\} \) and \({Y}\!=\!\{p_{max},p_{min},b_i\}\) are formed by using feature points \(p_{max}\), \(p_{min}\) and \(b_i\), and then the variance of depth is calculated for each feature point in the set. The variance could be expressed as follows:
where \({s}^{2}\) denotes the variance, \({d}_{i}\) and \(\mu \) denote the depth of the i th feature point in the set and their mean, respectively, and n denotes the total number of feature points in the set.
According to Eq. (7), one can obtain the depth variances \(S_X^2\) and \(S_Y^2\) of sets X and Y, respectively. Finally, the suspicious feature points are determined based on the following constraints:
where \(P_S\) denotes the static feature point set, \(\varepsilon \) denotes the threshold value of the variance difference, and \(\varepsilon =\) 0.1 in this paper. In Eq. (8), if \(\mid S_X^2-S_Y^2\mid \le {\varepsilon }\) is satisfied, the suspicious point \(b_i\) is judged as a dynamic feature point, and all the suspicious points that are judged to be dynamic feature points are further formed into a set \({P}_{cer}\); otherwise, the suspicious point \(b_i\) is added to the static feature point set \({P}_{S}\).
In terms of the Mahalanobis distance, the dynamic feature points can be effectively separated from the static feature points around the dynamic objects. However, in addition to the existence of active dynamic objects in dynamic scene, there may also be passive dynamic objects that can be driven by active dynamic objects, and such objects also have some potential dynamic feature points on them. Due to the fact that passive dynamic objects themselves do not have the ability to move, they are mostly stationary and only move when driven by active dynamic objects. When the passive dynamic object is within the target bounding box of YOLACT++ and is close to the active dynamic object, it is possible to distinguish potential dynamic feature points on the passive dynamic object by relying on the determination of the Mahalanobis distance. Nevertheless, for the case where the feature points on the passive dynamic object are too far away from the active dynamic object or even beyond the boundary of the YOLACT++ target bounding box, it is difficult to recognize the potential dynamic features on the passive dynamic object by relying only on the Mahalanobis distance. Therefore, we further introduce the method of epipolar constraint and combine it with semantic masks to reject potential dynamic feature points on passive dynamic objects.

Judgement of the candidate dynamic feature points on passive dynamic objects
Through polar search, it is possible to find the pixel point \(p_2=\left[ u_2,v_2,1\right] ^\mathrm{{T}}\) of the current frame that satisfies the epipolar constraint with the pixel point \(p_1=\left[ u_1,v_1,1\right] ^\mathrm{{T}}\) of the previous frame, which is expressed as follows:
where \(l_1\) and \(l_2\) denote the polar line of the previous frame and current frame, respectively, and F denotes the fundamental matrix.
However, if \(p_2\) is a dynamic feature point, it does not satisfy the epipolar constraint and appears around the polar line \(l_2\). In order to further determine whether the point is a dynamic feature point, the distance \(D_{Ep}\) from the point \(p_2\) to the polar line needs to be calculated and the distance needs to satisfy the following constraints:
where \(A_2\) and \(B_2\) are the two parameters of polar line \(l_2\), respectively; and \(\theta \) is the distance threshold. If the calculated distance is greater than \(\theta \), \(\theta =5\) in this paper, the point is determined to be a dynamic feature point; otherwise, it is considered as a static feature point, as illustrated by Fig. 4.
After the determination of the epipolar constraint, the dynamic feature points on the current frame can be obtained and these points are used as the candidate dynamic feature point set \(P_{cand}=\left\{ p_1,p_2, \ldots ,p_{N_c}\right\} \), where \(N_c\) is the total number of candidate dynamic feature points. But there may be following two cases:
-
1.
There may exist a few static feature points in \(P_{cand}\) that are misclassified as dynamic feature points, i.e., false dynamic points, denoted as the set \(P_{err}=\Big \{p_1^{\prime },p_2^{\prime },...,p_{N_e}^{\prime }\Big \}\), \(P_{err}\subset P_{cand}\), \(N_c\gg N_e\);
-
2.
Not all feature points on passive dynamic objects are determined as dynamic feature points after being constrained by epipolar constraint, and there may be \(N_m\) few feature points that are incorrectly judged as static feature points, i.e. false static points, denoted as the set \(P_{mis}=\left\{ a_1,a_2,...,a_{N_m}\right\} \).
Since \(P_{err}\) is sparsely distributed within \(P_{cand}\), the clustering method can be utilized to cluster \(P_{cand}\). In this way, the feature points in \(P_{err}\) are re-judged as static feature points, and the feature points in \(P_{mis}\) that satisfy the following conditions are re-judged as dynamic feature points, i.e.
where \(D_{Eu}\left( \cdot ,\cdot \right) \) denotes the Euclidean distance; \(dif\left( \cdot ,\cdot \right) \) denotes the depth difference between two feature points; \(p_l\) and \(p_k\) denote two different points in \(P_{cand}\), while \(d_l\) and \(d_k\) denote the corresponding depth values; \(\alpha \) and \(\beta \) denote the threshold value of the Euclidean distance and the depth difference, respectively, and \(\alpha =\) 20, \(\beta =\) 0.2 in this paper.

Comparison of dynamic feature point elimination effects for different algorithms. In this scene, a person is moving a book in their hand and turns around to flip through it. The green feature points are static feature points, while the blue feature points are potential dynamic feature points detected by epipolar constraint

Scenarios for the semantic map tracking and reconstruction in dynamic environment at time t
By performing clustering, the set \(G=\left\{ g_1,g_2,\ldots ,g_L\right\} \) can be obtained, where L is the total number of categories after clustering, and \(g_i\) is a set of feature points, \(i\in L\). According to the ratio of the number of feature points in \(g_i\) to the total number of feature points on the passive dynamic object on which it is located, it is possible to determine whether the feature points in \(P_{err}\) are true static feature points, and whether the feature points in \(P_{mis}\) are true dynamic feature points. The judgment conditions are as follows:
where \(P_{cand}^*\) denotes the new set obtained by removing \(P_{err}\) from \(P_{cand}\) and adding the feature points identified as dynamic feature points in \(P_{mis}\) to \(P_{cand}\); \(n_i\) denotes the total number of feature points in \(g_i\); and n is the total number of feature points on the semantic object where \(g_i\) is located. If \(n_i\ge n/3\) is satisfied, the feature points in \(P_{mis}\) and \(P_{cand}\) are identified as dynamic feature points, otherwise, they are considered as static feature points.
With the above steps, we can obtain the following dynamic feature points \(P_D\) with high confidence on potential dynamic objects, i.e.
According to the semantic mask, further introducing the epipolar constraint and clustering method, it is possible to exclude feature points on passive dynamic objects that are too far away from the active dynamic object or beyond the boundary of the target bounding box. Indeed, the combination of epipolar constraint and semantic masks compensates for the shortcomings of the Mahalanobis distance, which in turn improves the localization accuracy of the algorithm.
As can be seen in Fig. 5, the original version of YOLACT++ relies solely on semantic masks, which not merely fails to completely exclude key points on active moving objects (i.e., edge points of the human), but also unable to detect potential dynamic feature points on passive moving objects (i.e., treating extracted feature points from books as static feature points). Instead, the proposed method has the capability to accurate detect potential dynamic feature points on both active and passive dynamic objects, and eliminate them completely. This is because the main advantage of our approach lies in it combines Mahalanobis distance, epipolar constraint and clustering on the basis of semantic mask to accurately judge dynamic feature points.
Dynamic maintenance of semantic map
Regarding the map building in dynamic environment, most existing SLAM algorithms only remove the dynamic objects in the scene and construct a map of the static background. However, these types of maps cannot effectively meet the robot’s needs for performing advanced tasks such as path planning and obstacle avoidance in a dynamic environment, and the robot’s adaptability to its surroundings is unsatisfactory. Additionally, since dynamic objects appear to obscure static objects as they move, this reduces the semantic integrity to some extent. In order to enhance the consistency and functionality of the constructed map, enabling the robot to adapt and navigate in the environment autonomously, we propose a divisional mapping method for dynamic maintenance of map, which tracks and reconstructs dynamic objects and utilizes semantic information to generate a real-time updated 3D semantic octree map.
Tracking
Since YOLACT++ is only capable of detecting objects in the scene but not tracking moving objects. In order to track dynamic objects using the generated semantic masks, we first perform affine transformation on the semantic mask to make the image after affine transformation more fitted to the next frame, thereby reducing the impact of the robot’s own motion on the similarity of image frames. Notably, the algorithm capitalizes on epipolar constraint for feature point detection at the front-end can obtain the feature points corresponding to the two adjacent frames, and by matching the extracted feature points, the transformation matrix H between the two adjacent frames can be obtained as follows:
where \(A_{2\times 2}\) and \(B_{2\times 1}\) denote the rotation matrix and translation matrix of the image, respectively. Assuming that the semantic mask at time \(t-1\) is \(M_{t-1}\), and the new semantic mask after the affine transformation is \(M_{t-1}^{\prime }\), then the transformation rule is written as:
where \(\left[ \begin{matrix}u^\prime &{}v^\prime \\ \end{matrix}\right] ^\mathrm{{T}}\) and \(\left[ \begin{matrix}u&{}v\\ \end{matrix}\right] ^\mathrm{{T}}\) denote a pixel in \(M_{t-1}^\prime \) and \(M_{t-1}\), respectively. Then, the transformed \(M_{t-1}^\prime \) is compared with the semantic mask \(M_t\) at time t to further determine whether the moving object detected at time \(t-1\) is the same object as the moving object detected at time t. Since the objects in the two adjacent frames are closer together, the overlap of their corresponding semantic masks is also higher. Hence, more accurate tracking is achieved by comparing the overlap degree \(S_c\) of the semantic mask. The degree of overlap \(S_c\) is calculated as follows:
where \(\varphi _{t-1}^{(i)}\) and \({\ \varphi }_t^{(j)}\) denote the semantic masks of a moving object in \(M_{t-1}^\prime \) and \(M_t\), respectively. When there is more than one dynamic object in the scene, a higher \(S_c\) indicates a higher probability that the two moving objects are the same object. But when any two dynamic objects are too close to each other, it will make the \(S_c\) of these two dynamic objects very similar. If we only rely on the value of \(S_c\) for comparison, it is easy to be affected by the error.
Considering that the changes in the motion of the moving objects to be tracked in the adjacent two frames are relatively small, it can be approximated that the moving objects are in a uniform motion at this moment. Thus, the uniform motion model is introduced to estimate the pose of the moving object and back-projected it to the pixel coordinates for matching, which compensates for the shortcomings of \(S_c\) and improves the accuracy of tracking.
Specifically, the camera motion model \(T_{cl}\) acquired by the front-end is utilized to convert the world coordinates \(T_{wl}^{t-1}\) of the camera at time \(t-1\) to the coordinates \(T_{wc}^t\) at time t, i.e.
where \(T_{cl}\) denotes the motion model of the camera from time \(t-2\) to \(t-1\). Then, the motion model \(T_{pl}\) of the moving object is used to estimate the coordinates \(Q_{t\vert t-1}\) of the moving object at time t, i.e.
where \(Q_{t-1}\) denotes the coordinates of the moving object at time \(t-1\). After obtaining \(Q_{t\vert t-1}\), the estimated dynamic object is then projected under the pixel coordinates at time t by inverse projection to obtain the predicted pixel coordinates \(p_t^{(i)}\) of the ith moving object, i.e.
where \(d_t\) is the depth value corresponding to \(Q_{t\vert t-1}\). Finally, the predicted \(p_t\) is combined with the calculated \(S_c\) to determine whether the two dynamic objects are the same dynamic object, i.e.
where \(p_d\) is the pixel coordinate representation of the dynamic object detected at time t, and \(\delta \) is the set overlap threshold. If \(p_t\) is closest to the pixel coordinates of the dynamic object detected at time t and \(S_c\) is greater than the set threshold, the two dynamic objects are determined to be the same object. Considering the effects of the robot’s own motion and the motion of the moving object, \(\delta =\) 0.65 in this paper.
After confirming that it is the same object, the semantic mask of the moving object in \(M_t\) can be separately extracted to form a dynamic mask \(DM_t\), and then add it to the point cloud of the dynamic objects. By incorporating these successfully tracked dynamic objects into the construction of the background map, a real-time updated 3D semantic octree map can be obtained.
Reconstruction
To improve the consistency of the 3D semantic octree map, the global semantic map is divided into three parts for construction, i.e. the point cloud \(P_{ds}\) with semantic labels in dynamic objects, the point cloud \(P_{ss}\) with semantic labels in static objects, and the point cloud \(P_{ns}\) without semantic labels. First, the pixel points with semantics are projected through inverse depth to obtain a 3D point cloud \(P_c=\left\{ P_{dy},P_{ss},P_{ns}\right\} \), where the 3D point cloud \(P_c\) can be represented by inverse depth projection as follows:
where \(p_{ij}\) and \(d_{ij}\) denote a pixel in the image and its corresponding depth value, respectively; \(K^{-1}\) denotes the inverse matrix of camera internal parameters; R and t denote the rotation matrix and the translation vector, respectively, and \(T_m\) denotes the transformation matrix, whose function is to transform the point cloud \(P_c\) to the same coordinate system, facilitating subsequent point cloud fusion. Then, \(P_c\) is classified into the corresponding three types of point clouds according to the regions where the pixel points are located.
In our method, the dynamic object point cloud at time t is reconstructed from the dynamic mask \(DM_t\) obtained the tracking stage. Inasmuch as the uncertainty of the motion of dynamic objects, if the dynamic point cloud is updated for each frame, it will waste a lot of computational resources and reduce the real-time performance of the algorithm. Along these lines, the newly generated dynamic point cloud needs to be judged in the following two aspects, i.e.
-
1.
Whether the point cloud at time t is the point cloud of the same object as the point cloud at time \(t-1\);
-
2.
If it belongs to a point cloud of the same object, whether the object has moved.
Therefore, the conditions for determining whether two different sets of point clouds are point clouds of the same object are as follows:
where \(D_{pc}\) is the Euclidean distance between the two sets of point clouds, \(P_{dy}^t\) is the point cloud generated at time t, and \(D_c\left( i\right) \) is the maximum point distance represented by the Euclidean distance of the two 3D points furthest apart in \(P_{dy}^{t-1}\). In Eq. (22), if \(D_{pc}>D_c\left( i\right) /2\), it is determined that these two point clouds are not the point clouds of the same object, and the newly added point clouds are added to \(P_{dy}^{t-1}\); if \(D_{pc}<D_c\left( i\right) /2\), it is indicated that these two point clouds are the point clouds of the same object, and then the distance is shortened to \(D_c\left( i\right) /4\) to assess whether the point cloud of the same object needs to be updated; if \(D_{pc}\ge D_c\left( i\right) /4\), it is judged that the object has moved and needs to be updated with a new point cloud \(P_{dy}^t\), otherwise the point cloud \(P_{dy}^{t-1}\) is left unchanged.

Comparison of the feature point extraction effects among different algorithms under TUM and Bonn datasets. The red box marks dynamic object, the green point represents static feature point that has been successfully matched, and the blue point represents dynamic feature point selected by epipolar constraint and semantic masks. The left two images are \(fr3\_walking\_xyz\) dataset, the middle two images are synchronous2 dataset, and the right two images are crowd dataset
Then, to ensure the semantic integrity of the static objects, the update of their point clouds requires the fusion of the local semantic object point cloud \(P_{ss}^t\) at time t with the global semantic object point cloud \(P_{ss}^{1:t-1}\) at time \(t-1\) to form the global semantic object point cloud \(P_{ss}^{1:t}\) at the time t. As a note, the semantic network may misclassify non-semantic objects as semantic objects when recognizing objects, resulting in less consistent maps. Therefore, it is necessary to perform denoising on \(P_{ss}^t\), namely, for the case of semantic object misclassification, the difference between the static semantic point cloud \(P_{ss}^t\) at time t and the static semantic point cloud \(P_{ss}^{t-1}\) at time \(t-1\) is compared to determine whether to integrate with the global static semantic point cloud, i.e.
where \(P_{con}^t\) is the overlap between \(P_{ss}^{t-1}\) and \(P_{ss}^t\).
Moreover, whether the point clouds overlap or not is determined by the size of the 3D points \(s_p\), and the overlapping point clouds need to satisfy the following conditions:
where \(p_i\) and \(p_j\) denote an arbitrary spatial points in \(P_{ss}^t\) and \(P_{ss}^{1:t-1}\), respectively.
Extracting \(P_{con}^t\) can remove the noise and misclassified point clouds, and then add it to the global static semantic point cloud fusion. For the newly added semantic object, they are removed as noise at the current moment. If they still present at the next time, they will satisfy the above constraints, also adding them to the global static semantic point cloud fusion. In this way, the denoised \(P_{ss}^t\) and \(P_{ss}^{1:t-1}\) are together added to the process of point cloud fusion. The point cloud fusion is performed in two parts, i.e. the overlapping part adopts the iterative nearest point (ICP) [41] method, while the non-overlapping part exploits voxel filtering [42] to remove outliers. In the process of point cloud fusion, it is necessary to divide \(P_{ss}^t\) and \(P_{ss}^{1:t-1}\) into two parts using the condition of Eq. (26) to determine the overlapping points, i.e.
where \(P_{ss}^t\left( x_1\right) \) and \(P_{ss}^t\left( x_2\right) \) denote the overlapping and non-overlapping point clouds with\(P_{ss}^{1:t-1}\) in \(P_{ss}^t\), and \(P_{ss}^{1:t-1}\left( x_1\right) \) and \(P_{ss}^{1:t-1}\left( x_2\right) \) denote the overlapping and non-overlapping point clouds with \(P_{ss}^t\) in \(P_{ss}^{1:t-1}\), respectively. Then, \(P_{ss}^t\left( x_1\right) \) and \(P_{ss}^{1:t-1}\left( x_1\right) \) are fused using ICP to obtain the point cloud \(P_{ss}^{1:t}\left( x_1\right) \). The fusion is performed as follows:
where \(p_i^t\) and \(p_i^{1:t-1}\) denote the points that are successfully matched by the next point iteration, and \(P_{ss}^t\left( e_1\right) \) and \(P_{ss}^{1:t-1}\left( e_1\right) \) denote the points that are not matched but satisfy Eq. (26) in \(P_{ss}^t\left( x_1\right) \) and \(P_{ss}^{1:t-1}\left( x_1\right) \), respectively.
It is noticed that, since the number of 3D points in the two overlapping point clouds is not necessarily equal, there may be additional spatial point matching failures and nothing is done for such points. For the successfully matched points, a weighted average method is used for fusion, and finally all the points in Eq. (28) are spliced into \(P_{ss}^{1:t}\left( x_1\right) \). The remaining \(P_{ss}^t\left( x_2\right) \) is filtered by voxel filtering to remove outliers, and then fused with \(P_{ss}^{1:t-1}\left( x_2\right) \) to obtain the point cloud \(P_{ss}^{1:t}\left( x_2\right) \). The fusion is performed as follows:
where n and m are the number of spatial points in the voxel lattice and the number of voxel grid, respectively, and \(p_{ij}^t\) is the j th spatial point in the i th voxel. The point cloud is first divided into n voxel grids, each containing m spatial points, and then the centroid of these m spatial points is used to replace these m spatial points. The advantage of voxel filtering is that it dilutes the point cloud by down-sampling the point cloud without destroying the geometric structure of the point cloud itself, which can improve operational efficiency and preserve the geometric structure of the point cloud during frequent point cloud fusion.
The global static semantic point cloud \(P_{ss}^{1:t}\) at time t is obtained by fusion of the overlapping and non-overlapping point clouds, i.e.
The fusion of global static and non-semantic point clouds \(P_{ns}^{1:t}\) at time t only needs to superimpose the point clouds, i.e.
where \(P_{ns}^{1:t-1}\) and \(P_{ns}^t\) denote the global static non-semantic point cloud at time \(t-1\) and the local static non-semantic point cloud at time t, respectively.
Finally, the three parts of the global point cloud are merged to obtain the global semantic map \(P_{glo}^t\) at time t. The fusion is performed as follows:
The full scheme of the semantic map tracking and reconstruction in dynamic environment at time t is given in Fig. 6. In our scheme, the divisional mapping method is adopted to separate semantic and non-semantic objects can ensure that an accurate static object background is constructed. In response to the uncertainty of dynamic scenes, we perform tracking and reconstruction on dynamic objects, improving the environmental adaptability of the algorithm and the consistency of 3D map.
Simulations and experiments
To validate the performance of the proposed approach, a series of simulations and experiments were conducted in this section. The simulation studies were respectively performed under the TUM (Technical University of Munich) [43] and Bonn [44] datasets, where the TUM dataset was characterized by the presence of dynamic objects and different camera transformations, while the Bonn public dataset had dynamic objects in multiple states of motion, and both datasets owned texture-rich offices as backgrounds. The experiment was carried out in a laboratory using a wheeled mobile robot equipped with a depth camera. All of the experiment studies were performed on a mobile computer with an Intel i7-11700H CPU with 16 GB of DDR4 RAM, and NVIDIA GTX3060 GPU, running under Ubuntu 18.04 operating system.
Simulation studies under dataset
In this study, a comparative analysis of the proposed method and several state-of-the-art dynamic SLAM approaches was conducted using the five series datasets of TUM, which belong to high dynamic scenes and have different camera transformations. To further assess the error performance of the algorithm, we also selected nine series datasets from the Bonn, which contain four scenes with different motion states. In the simulation, we adopted absolute trajectory error (ATE) as indicator, and chose root mean square error (RMSE) to evaluate these errors. Table 1 lists the main experimental parameters including the proposed method and the baseline method, ORB-SLAM2.

Comparison of trajectories for different algorithm under TUM series dataset
To evaluate the individual contributions of each components involved in our algorithm, Table 2 shows the RMSE comparison of absolute trajectory errors (ATE/m) using different methods under highly dynamic scene datasets from TUM and Bonn sequences, where Y denotes using only YOLACT++ segmentation, Y+M denotes adopting Mahalanobis distance compensation for YOLACT++ segmentation, Y+E+C denotes utilizing YOLACT++ segmentation, epipolar constraints, and clustering, and Y+M+E+C denotes combining all of the above methods. It can be seen that using only YOLACT++ segmentation has lower accuracy in dynamic scenes, this is because the performance of the algorithm decreases when YOLACT++ segmentation results are inaccurate. On this basis, by introducing a combination of Mahalanobis distance or epipolar constraints & clustering methods, the accuracy of the algorithm can be significantly improved. The main difference is that the introduction of Mahalanobis distance can achieve better results in most dynamic scenes, while polar constraints and clustering have more advantages when the camera is in translational motion or remains stationary. In contrast, the method of applying the compensated judgement of Mahalanobis distance to reject potential dynamic feature points on active dynamic objects and combining the polar constraints & clustering to reject potential dynamic feature points on passive dynamic objects results in better accuracy and robustness of the overall algorithm.
Figure 7 illustrates the feature point extraction effects of our algorithm and ORB-SLAM2 under different series datasets. Since the removal of dynamic feature points on active dynamic objects in the front-end of our algorithm, the quality and quantity of successfully matched static feature points were better than ORB-SLAM2. In addition, combining epipolar constraint and semantic masks can effectively eliminate potential dynamic feature points in the environment, thereby obtaining a set of static feature points with high confidence.
The RMSE of ATE for different algorithms under TUM dataset is reported in Table 3. We concluded that, the proposed algorithm was generally superior to several other tested algorithms. The main reason is that our method not merely employed the determination of the Mahalanobis distance to obtain the true dynamic feature points, but also introduced a pair of epipolar constraint to eliminate the feature points on the passive dynamic objects. Additionally, it is worth noting that the high-quality keyframes selected also improved the localization accuracy of the algorithm. As compared to DS-SLAM, the proposed algorithm relies on epipolar constraint assisted semantic mask to remove dynamic feature points in the front-end, thereby reducing the impact of dynamic objects. However, the improvement on \(fr3\_walking\_rpy\) was lower than that on other high-dynamic datasets. This is because frequent rotation of the camera made it difficult to search for polar lines, resulting in insufficient removal of dynamic feature points. Although SLAM [38] and SG-SLAM also drew on epipolar constraint to assist in removing dynamic features, the difference is that the SLAM [38] improved the extraction quality of dynamic feature points by adding K-means clustering, while the SG-SLAM compensated for the drawback of epipolar constraint by introducing dynamic weights. Instead, the YOLO-SLAM [30] employed the deep RANSAC to remove dynamic feature points, but it is easy to misjudge static feature points with the same depth as dynamic objects as dynamic feature points, thereby limiting the potential for improving accuracy. SLAM [34] provided a solution for data association and loop closure detection using table retrieval, which can effectively strengthen the association between objects in the scene and thus discriminate dynamic features more accurately. It should be emphasized that, the method was based on object-level dynamic judgment, it is more accurate than the method based on semantic categories in this paper. Also, the table retrieval was used to improve the graph optimization module, resulting in better results on the dataset. Unfortunately, the method did not fully take into account the case when the object detection results were inaccurate, and the frequent rotation of the camera makes the target detection network worse, resulting in poorer performance of the algorithm on the \(fr3\_walking\_rpy\) dataset. Moreover, recording the position and related information of multiple objects also consumed more time and storage space. SLAM [36] discriminated dynamic feature points by combining semantic segmentation and dynamic probabilistic propagation, but since dynamic probabilistic propagation requires a priori values, the accuracy decreased in more complex and highly dynamic scenes. In contrast, the proposed algorithm was more adaptable to changes in dynamic environments and can achieve better results in dynamic environments.

A series of frames on the \(fr3\_walking\_xyz\) dataset and the corresponding semantic octree map. In Fig. 9a, the first row is the instance segmentation result obtained by YOLACT++, the second row is the corresponding semantic mask, the third row is the tracking mask of the dynamic object, and the fourth row is the semantic octree map at the corresponding moment
Furthermore, compared to ORB-SLAM2, the ATE of the proposed algorithm on the TUM dataset was improved, particularly in four high dynamic scenes. Herein, the improvements are calculated as follows:
where \(\eta \) denotes the value of the RMSE improvement, \(\gamma \) and \(\phi \) denote the RMSE of ORB-SLAM2 and the proposed algorithm, respectively. If the more the value of \(\phi \) is smaller than \(\gamma \), the larger the calculated value of \(\eta \) is indicating that the accuracy of the proposed algorithm is better than ORB-SLAM2. From Table 3, it can be found that, for the four series datasets with high dynamic scenes, the enhancement of our algorithm was more than 96%, but it was not obvious in slightly dynamic scenes, which is due to the fact that there were too few dynamic features in slightly dynamic sequences, and a small number of dynamic feature points were treated as noise by the ORB-SLAM2, allowing the algorithm to localize without large bias.
Table 4 further reports the RMSE of the ATE for different algorithms under the Bonn series dataset. As the Bonn dataset does not involve camera variations, there was no significant difference in the results of various tested SLAM algorithms, but the proposed algorithm performed better overall. It is worth mentioning that the passive dynamic objects often appeared in the Bonn dataset, and our algorithm included the processing of passive dynamic objects, so it can achieve better results. However, the feature point rejection of passive dynamic objects relies on the accuracy of the semantic mask. When active dynamic objects obscured passive dynamic objects, the semantic network was unable to obtain the corresponding mask, resulting in a decrease in the quality of dynamic feature points, as can be seen from \(moving\_no\_box\) dataset.
Figure 8 compares the trajectories of ORB-SLAM2 and our algorithm in four high dynamic scenes of the TUM series dataset. Clearly, the estimated trajectory of our algorithm exhibited a better fit and less error with the real trajectory. As compared to ORB-SLAM2, our algorithm effectively eliminated dynamic feature points in the front-end and developed a high-quality keyframe selection strategy, which effectively improved the localization accuracy and stability of the algorithm in dynamic sequences.
To evaluate the computational costs of different SLAM algorithms, Table 5 shows the running time of different algorithms under the \(fr3\_walking\_xyz\) dataset. In the simulations, the running time of the algorithm is affected by the hardware configuration of computer in addition to the complexity of the algorithm itself. Although both the proposed algorithm and DS-SLAM have selected a lightweight network and used multi-threaded to improve the real-time performance of the algorithm, there are also some differences in the running time of the system due to differences in algorithm details and hardware. YOLO-SLAM also used a target detection algorithm, its real-time performance was poor due to hardware platform limitations, whereas the SG-SLAM not merely utilized multi-threading and target detection algorithms, but also employed Single Shot MultiBox Detector (SSD) to improve the efficiency of target detection algorithms and has good hardware support, so it possessed excellent real-time performance. Similarly, although SLAM [36] did not involve lightweight network, it improved the real-time performance of the algorithm by using higher performance hardware configurations. In spite of a lightweight YOLACT++ and multi-threaded operations were adopted to improve the real-time performance of our method, there were still some gaps compared to other algorithms that do not involve semantic networks or only use target detection technique. Nevertheless, the main advantage of semantic networks lies in its ability to provide more accurate and consistent semantic maps. Thus, the experimental results show that, in addition to excellent performance in localization accuracy, the algorithm in this paper also exhibited good real-time performance.

The experimental platform of the mobile robot and the reference trajectory

The tracking and reconstruction effects of real scene containing different active dynamic objects. The first row is the feature point extraction results of different grayscale image frames in the scene, while the second and third rows are the corresponding dynamic semantic masks and 3D semantic octree maps, respectively
To validate the mapping performance of our algorithm in dynamic environments, we randomly selected four different image frames on the \(fr3\_walking\_xyz\) dataset and given their corresponding map building effects. As can be found from Fig. 9, the proposed algorithm used YOLACT++ to be able to perform accurate instance segmentation and obtained complete semantic and dynamic masks. As a result, the constructed 3D semantic octree maps had good consistency and were also capable of tracking and reconstructing dynamic objects with strong environment adaptation.
Experiments with a mobile robot
In the experiment, our approach was implemented and tested employing a wheeled mobile robot equipped with an ASUS Xtion depth camera. The experimental scene was a laboratory with an area of 8.4 m\(\times \)6.4 m, as described in Fig. 10. During the experiment, two pedestrians with a speed of 0.5 ms walked back and forth within the robot’s field-of-view to simulate a dynamic scene.

The tracking and reconstruction effects of real scene containing both active and passive dynamic objects. The first row is the feature point extraction results of different grayscale image frames in the scene, while the second and third rows are the corresponding dynamic semantic masks and 3D semantic octree maps, respectively
Figure 11 describes the tracking and reconstruction results of different active dynamic objects in a real scene. It is obvious that the dynamic objects selected by the red box, the dynamic feature points in the box were successfully eliminated. In addition, the blue feature points are dynamic feature points selected using the epipolar constraint and semantic mask, which can assist the algorithm to recognize the dynamic feature points efficiently and thus improve the accuracy of the algorithm. This indicated that, the method in this paper has good consistency in the static background map constructed by effectively eliminating dynamic feature points. Also, by tracking and reconstructing the dynamic objects, the moving objects were successfully added to the static background and can be updated in real time.
Figure 12 further demonstrates the tracking and reconstruction effects of both active and passive dynamic objects in real scene. We find that, an active dynamic object (person) moved a passive dynamic object (package) without ghosting in the constructed map. This is because the proposed algorithm also dynamically maintained the passive dynamic object during the mapping process, improving the consistency of the map. Since the passive dynamic objects were generally stationary, they only move when driven by active dynamic objects. As a note, all static semantic components were constructed in the same part during the mapping, while in the process of map dynamic maintenance, dynamic objects inevitably affected the construction of other static semantic objects. Hence, the maintenance of passive dynamic objects can easily affect the construction of other static semantic objects at the same time.

Estimated trajectory for different algorithms in real dynamic scene
To further validate the global localization accuracy of the algorithm, comparison experiments were conducted between our algorithm and ORB-SLAM2 in real dynamic environment. Figure 13 compares the trajectories estimated by our algorithm and ORB-SLAM2 in a real dynamic scene. We observed that the trajectory provided by our algorithm fitted better to the reference trajectory, while the trajectory estimated by ORB-SLAM2 produced a significant deviation. This is because the ORB-SLAM2 did not involve the identification of dynamic features, and when dynamic objects entered the robot’s field-of-view (i.e., points A and B), the dynamic feature points will cause the algorithm to produce many mismatches, which in turn introduced a large amount of error accumulation, causing the estimated trajectory to drift. In contrast, for the entire process, our algorithm can effectively distinguish and eliminate the dynamic feature points, so it can get the localization results with high accuracy.

Reconstructed 3D global semantic octree maps for different SLAM algorithms in real dynamic scene

The 3D local semantic octree map of real scene constructed by our method. Figure 15a shows from left to right: the instance segmentation result generated by YOLACT++, the semantic mask, the dynamic mask and the final constructed 3D semantic octree map, respectively
Figure 14 depicts the global semantic octree maps constructed by different algorithms in real dynamic scene. From Fig. 14a, we observed that, although ORB-SLAM2 had the capability to complete the map building, it contained clear deviations and a large amount of ghosting. It is clear from Fig. 14b that, the map generated by our method was consistent with the real environment, there was no distortion or overlap, and the semantic information of objects in the map was clearly visible. This is because a main advantage of our approach lies in its ability to effectively detect and remove dynamic feature points.
To clearly illustrate the details of the built semantic map, the 3D local semantic octree map was further constructed for the real scene. Different colors in the map indicate different semantic objects, and the objects that can be detected in the scene include a total of 8 semantic classes, as shown in Fig. 15b. We could reasonably to conclude from Fig. 15a that the objects in the scene were correctly identified and segmented for coloring, and the constructed map can clearly reflect the real environment, thereby demonstrating the feasibility and effectiveness of the proposed method.
As a note, the proposed method is effective in most cases for removing potential dynamic feature points on active dynamic objects. However, due to the use of Mahalanobis distance to compensate for the insufficient segmentation accuracy of YOLACT++, in certain cases, it is inevitable to misjudge a few static feature points closer to active dynamic objects as dynamic feature points. For passive dynamic objects, since the epipolar constraints is employed, significant errors are most probable to occur when the camera rotates frequently or too quickly, which in turn affects the judgement of dynamic feature points.
Furthermore, for some complex and/or high-dynamic scenes, there may be a shortage of matching static feature points. Although our algorithm has the capability to remove dynamic feature points, too few static feature points can also affect the localization accuracy of the algorithm. In the case of insufficient lighting and fewer feature textures, the quality of the feature points that can be obtained will also decrease, which also leads to a decrease in the positioning accuracy of the algorithm.
Conclusion and future work
This paper was concerned of semantic visual SLAM for autonomous environment adaptation of mobile robots in dynamic scenarios. A light-weight YOLACT++ semantic segmentation network was introduced to obtain precise semantic masks while ensuring the algorithm’s real-time performance. To compensate for the shortcomings of YOLACT++ in semantic segmentation accuracy, we further combined the Mahalanobis distance, epipolar constraint and clustering methods to effectively remove the feature points on the potentially dynamic objects in the scene, which improved the robustness and localization accuracy of the algorithm. Moreover, a divisional mapping method for dynamic maintenance of semantic maps was constructed, and dynamic objects were tracked and reconstructed to construct a 3D semantic octree map that was consistent with the environment and can be updated in real-time, providing assurance for mobile robot navigation and autonomous environment adaptation. A series of simulation studies and experimental results indicate that, the proposed algorithm exhibited good accuracy and robustness in dynamic environment, and the program ran smoothly with good real-time performance.
As part of future work, we plan to further improve the quality of feature point extraction on passive dynamic objects, thereby enhancing the effectiveness of tracking and reconstruction, and enabling the algorithm to adapt to more complex situations. Indeed, incorporating the motion of passive dynamic objects into the construction of maps is a challenging task. We also intend to fuse information from other sensors, such as lasers and inertial navigation, etc, with depth camera to compensate for the shortcomings of single camera sensors in scenes with insufficient lighting, strong light, or large light changes. In addition, the accuracy of feature processing in front-end can be improved by introducing deep learning networks, but it also consumes a large amount of computing resources. Hence, despite having good hardware as support, it is important to further optimize the network model and effectively combine it with the SLAM algorithm for next work. Another perspective of this research is to improve the performance of relocation and back-end optimization, or to ehance the efficiency of the work by using multi-robot collaboration instead of a single robot.
Data availability
The data cannot be made publicly available upon publication because they are owned by a third party and the terms of use prevent public distribution. The data that support the findings of this study are available upon reasonable request from the authors.
References
Newcombe RA, Izadi S, Hilliges O, et al (2011) Kinectfusion: real-time dense surface mapping and tracking. In: 2011 10th IEEE international symposium on mixed and augmented reality, pp 127–136. https://doi.org/10.1109/ISMAR.2011.6092378
Engel J, Schps T, Cremers D (2014) LSD-SLAM: large-scale direct monocular slam. In: European conference on computer vision. Springer, pp 834–849
Mur-Artal R, Tardós JD (2017) Orb-slam2: an open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans Robot 33(5):1255–1262. https://doi.org/10.1109/TRO.2017.2705103
Engel J, Koltun V, Cremers D (2018) Direct sparse odometry. IEEE Trans Pattern Anal Mach Intell 40(3):611–62. https://doi.org/10.1109/TPAMI.2017.2658577
Saputra MRU, Markham A, Trigoni N (2018) Visual slam and structure from motion in dynamic environments: a survey. ACM Comput Surv (CSUR) 51(2):1–36
Wang K, Ma S, Chen J et al (2020) Approaches, challenges, and applications for deep visual odometry: toward complicated and emerging areas. IEEE Trans Cogn Dev Syst 14(1):35–49
Wan Aasim WFA, Okasha M, Faris WF (2022) Real-time artificial intelligence based visual simultaneous localization and mapping in dynamic environments—a review. J Intell Robot Syst 105(1):15
Bolya D, Zhou C, Xiao F, Lee YJ (2022) YOLACT++ Better Real-Time Instance Segmentation. IEEE Trans Pattern Anal Mach Intell 44(2):1108–1121. https://doi.org/10.1109/TPAMI.2020.3014297
Li S, Lee D (2017) RGB-D slam in dynamic environments using static point weighting. IEEE Robot Autom Lett 2(4):2263–2270. https://doi.org/10.1109/LRA.2017.2724759
Cheng J, Wang C, Meng MQH (2020) Robust visual localization in dynamic environments based on sparse motion removal. IEEE Trans Autom Sci Eng 17(2):658–66. https://doi.org/10.1109/TASE.2019.2940543
Cheng J, Zhang H, Meng MQH (2020) Improving visual localization accuracy in dynamic environments based on dynamic region removal. IEEE Trans Autom Sci Eng 17(3):1585–1596. https://doi.org/10.1109/TASE.2020.2964938
Liu Y, Wu Y, Pan W (2021) Dynamic RGB-D SLAM based on static probability and observation number. IEEE Trans Instrum Meas 70:1–1. https://doi.org/10.1109/TIM.2021.3089228
Fischler MA, Bolles RC (1981) Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun ACM 24(6):381–395
Liu Y, Miura J (2021) KMOP-vSLAM: dynamic visual SLAM for RGB-D cameras using K-means and OpenPose. In: 2021 IEEE/SICE international symposium on system integration (SII), pp 415–420. https://doi.org/10.1109/IEEECONF49454.2021.9382724
Dai W, Zhang Y, Li P et al (2020) Rgb-d slam in dynamic environments using point correlations. IEEE Trans Pattern Anal Mach Intell 44(1):373–389
Zhao L, Liu Z, Chen J et al (2019) A compatible framework for RGB-D SLAM in dynamic scenes. IEEE Access 7:75604–7561. https://doi.org/10.1109/ACCESS.2019.2922733
Xie W, Liu PX, Zheng M (2021) Moving object segmentation and detection for robust RGBD-SLAM in dynamic environments. IEEE Trans Instrum Meas 70:1–8. https://doi.org/10.1109/TIM.2020.3026803
Yuan X, Chen S (2020) Sad-slam: a visual slam based on semantic and depth information. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 4930–4935
Li A, Wang J, Xu M et al (2021) DP-SLAM: a visual slam with moving probability towards dynamic environments. Inf Sci 556:128–142
Wen S, Li P, Zhao Y et al (2021) Semantic visual slam in dynamic environment. Auton Robots 45(4):493–504
He K, Gkioxari G, Dollár P et al (2017) Mask r-cnn. In: 2017 IEEE international conference on computer vision (ICCV), pp 2980–298. https://doi.org/10.1109/ICCV.2017.322
Cheng J, Wang C, Mai X et al (2021) Improving dense mapping for mobile robots in dynamic environments based on semantic information. IEEE Sens J 21(10):11740–1174. https://doi.org/10.1109/JSEN.2020.3023696
Bescos B, Cadena C, Neira J (2020) Empty cities: a dynamic-object-invariant space for visual slam. IEEE Trans Robot 37(2):433–451
Yu C, Liu Z, Liu XJ et al (2018) DS-SLAM: a semantic visual slam towards dynamic environments. In: 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 1168–117. https://doi.org/10.1109/IROS.2018.8593691
Vincent J, Labbé M, Lauzon JS, et al (2020) Dynamic object tracking and masking for visual slam. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 4974–497. https://doi.org/10.1109/IROS45743.2020.9340958
Liu Y, Miura J (2021) RDMO-SLAM: real-time visual slam for dynamic environments using semantic label prediction with optical flow. IEEE Access 9:106981–106997
Zhang C, Huang T, Zhang R et al (2021) PLD-SLAM: a new RGB-D SLAM method with point and line features for indoor dynamic scene. ISPRS Int J Geo-Inf 10(3):163
Chang J, Dong N, Li D (2021) A real-time dynamic object segmentation framework for slam system in dynamic scenes. IEEE Trans Instrum Meas 70:1–9
Bolya D, Zhou C, Xiao F, et al (2019) Yolact: real-time instance segmentation. In: 2019 IEEE/CVF international conference on computer vision (ICCV), pp 9156–916. https://doi.org/10.1109/ICCV.2019.00925
Wu W, Guo L, Gao H et al (2022) Yolo-slam: a semantic slam system towards dynamic environment with geometric constraint. Neural Comput Appl 34(8):6011–6026
Li GH, Chen SL (2022) Visual slam in dynamic scenes based on object tracking and static points detection. J Intell Robot Syst 104(2):33
Yb Ai, Rui T, Xq Yang et al (2021) Visual slam in dynamic environments based on object detection. Def Technol 17(5):1712–1721
Xing Z, Zhu X, Dong D (2022) DE-SLAM: SLAM for highly dynamic environment. J Field Robot 39(5):528–542
Song C, Zeng B, Su T et al (2022) Data association and loop closure in semantic dynamic slam using the table retrieval method. Appl Intell 52(10):11472–11488
Yan L, Hu X, Zhao L et al (2022) Dgs-slam: a fast and robust rgbd slam in dynamic environments combined by geometric and semantic information. Remote Sens 14(3):795
Chen L, Ling Z, Gao Y et al (2023) A real-time semantic visual SLAM for dynamic environment based on deep learning and dynamic probabilistic propagation. Complex Intell Syst 9(5):5653–5677
Cheng S, Sun C, Zhang S et al (2022) SG-SLAM: a real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information. IEEE Trans Instrum Meas 72:1–12
Jin J, Jiang X, Yu C et al (2023) Dynamic visual simultaneous localization and mapping based on semantic segmentation module. Appl Intell 53(16):19418–19432
Triggs B, McLauchlan PF, Hartley RI et al (1999) (2000) Bundle adjustment-a modern synthesis. In: Vision algorithms: theory and practice: international workshop on vision algorithms Corfu, Greece, September 21–22. Proceedings. Springer, pp 298–372
Gálvez-López D, Tardos JD (2012) Bags of binary words for fast place recognition in image sequences. IEEE Trans Robot 28(5):1188–1197
Besl PJ, Mckay ND (1992) A method for registration of 3-d shapes. Proc SPIE Int Soc Opt Eng 14(3):239–256
Jiang J, Wang J, Wang P et al (2019) POU-SLAM: scan-to-model matching based on 3d voxels. Appl Sci 9(19):4147
Sturm J, Engelhard N, Endres F et al (2012) A benchmark for the evaluation of rgb-d slam systems. In: Proc. of the international conference on intelligent robot systems (IROS)
Palazzolo E, Behley J, Lottes P, et al (2019) ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals. https://www.ipb.uni-bonn.de/pdfs/palazzolo2019iros.pdf
Funding
National Nature Science Foundation of China (Grant no. 62063036), ‘Xingdian Talent Support Program’Youth Talent Special Project of Yunnan Province (Grant no. 01000208019916008), Research Foundation for Doctor of Yunnan Normal University (Grant no. 01000205020503115).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No Conflict of interest exists in the submission of this manuscript.
Ethics approval
Not applicable (this article does not contain any studies with human participants or animals performed by any of the authors).
Consent to participate
All authors have participated in conception and design, or analysis and interpretation of the data; drafting the article or revising it critically for important intellectual content, and approval of the final version.
Consent for publication
The authors declare no interest conflict regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, J., Luo, J. YS-SLAM: YOLACT++ based semantic visual SLAM for autonomous adaptation to dynamic environments of mobile robots. Complex Intell. Syst. 10, 5771–5792 (2024). https://doi.org/10.1007/s40747-024-01443-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-024-01443-x




