
Abstract
Federated learning has gained significant attention due to its groundbreaking ability to enable distributed learning while maintaining privacy constraints. However, as a consequence of data heterogeneity among decentralized devices, it inherently experiences significant learning degradation and slow convergence speed. Therefore, it is natural to employ the concept of clustering homogeneous clients into the same group, allowing only the model weights within each group to be aggregated. While most existing clustered federated learning methods employ either model gradients or inference outputs as metrics for client partitioning to group similar devices together, heterogeneity may still exist within each cluster. Moreover, there is a scarcity of research exploring the underlying reasons for determining the appropriate timing for clustering, resulting in the common practice of assigning each client to its own individual cluster, particularly in the context of highly non-independent and identically distributed (Non-IID) data. In this paper, we introduce a two-stage decoupling federated learning algorithm with adaptive personalization layers named FedTSDP, where client clustering is performed twice according to inference outputs and model weights, respectively. Hopkins amended sampling is adopted to determine the appropriate timing for clustering and the sampling weight of public unlabeled data. In addition, a simple yet effective approach is developed to adaptively adjust the personalization layers based on varying degrees of data skew. Experimental results show that our proposed method has reliable performance on both IID and non-IID scenarios.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Federated learning (FL) [28] is an emerging privacy-preserving machine learning scheme. It allows multiple participants to collaboratively learn a shared global model without sharing private local data, thus effectively alleviating the barrier of data silos. And distributed devices with high privacy concerns can benefit from this learning process. Nowadays, FL has already been widely adopted in many real-world scenarios, such as disease diagnosis [33], edge computing [24], autopilot [20], and so on. While, vanilla FL approaches are not robust to non-independent and identically distributed (non-IID) data, and enormous research works [44, 47] have indicated that performance deterioration of a single global model in FL is almost inevitable on non-IID or heterogeneous data. Although local models are often initialized with the same global model at each communication round, they would converge to different directions due to data heterogeneity. Consequently, the divergence between the global model (averaged by local models) and the ideal model accumulates over the training period, significantly slowing down the convergence speed and worsening the learning performance.
To address the divergence issue mentioned above, a plethora of methodologies have been proposed in the literature [18, 36, 40]. Data sharing [38, 39, 44] represents a straightforward yet efficacious approach aimed at alleviating the adverse impact of non-IID data. The fundamental concept entails priming the global model by incorporating a fraction of the shared dataset on each client, thereby mitigating the aforementioned side effects. However, it is important to note that this approach may introduce additional local data leakage, potentially compromising the privacy requirements of federated learning to some degree. Regular optimization [19, 27] serves as another prevalent approach for addressing non-IID challenges by incorporating an auxiliary regularization term into the local loss function. For instance, the FedProx algorithm [17] employs the \(l_2\) norm of the distance between the global and local models as the regularization term. By optimizing the local loss function with this regularization term, the local updates are guided to be more aligned with the global model, thereby mitigating model divergence arising from data heterogeneity. Similar principles are also employed in Ditto [16], wherein the regularization term is selectively introduced after a predetermined number of FL rounds. One shortcoming of regular optimization approaches is that they always consume more computational resources than the conventional FedAvg [28]. Meanwhile, certain literature [15] indicates that the regularization term might not provide benefits in the presence of data heterogeneity, particularly in highly non-IID scenarios.
Inspired by the principles of multi-task [37] and transfer learning [41], the inclusion of personalization layers in FL has been proposed as a means to solve highly non-IID problems. Arivazhagan et al. introduced FedPer [2], which employs shallow base layers for high-level representation extraction and deep personalization layers for classification. As the personalization layers in FedPer are not shared or aggregated on the server, the local model’s statistical characteristics are retained. And FedRep [6], an extension of FedPer, focuses on extracting representations specifically from personalized layers. By contrast, LG-FedAvg [21] incorporates shallow layers as personalization layers and deep layers as base layers. FedAlt [32] conducted a comprehensive investigation, including convergence analysis, to explore the influence and architectural considerations related to personalized layers. And it is found that the last few personalization layers have a direct impact on learning bias and serve as a key contributing factor to model divergence [26]. In a more recent development, Tashakori et al. proposed the SemiPFL framework [45] as a novel approach to amalgamate personalized federated learning and semi-supervised learning, with the objective of enhancing multi-sensory classifications.
The aforementioned approaches, by default, employ the aggregation of all uploaded model parameters from connected clients. However, this aggregation method is less advantageous for non-IID data scenarios due to the inherent limitations of a single global model in effectively accommodating all local learning tasks. Therefore, clustered FL presents itself as a promising solution in such contexts, where clients exhibiting similarity in their models are assigned to the same cluster group, and only models within the same cluster are aggregated. CFL [35], regarded as the pioneering clustered FL algorithm, employs gradient information to recursively bi-partition clients, effectively mitigating gradient conflicts. Nevertheless, in high-dimensional spaces, gradient information can often be ambiguous, leading to potential variations in convergence even among clients with the same bias. IFCA [11] represents another noteworthy approach in the realm of clustered FL. And it leverages loss information to estimate cluster identities, effectively grouping together well-trained clients within the same cluster. Over the past three years, an increasing number of clustered FL methods have emerged. These methods leverage various criteria, including gradient information [4, 8, 10, 43], model weights [22, 23, 34], and auxiliary models [5, 30], to identify clusters under different constraints, such as economic considerations, efficiency requirements, and low latency constraints [1, 14, 25, 42, 46]. Yet, all the clients can be easily allocated to distinct clusters for highly heterogeneous local data, where each cluster comprises a single client, rendering collaborative training no longer meaningful. Hence, the integration of cluster FL and personalized FL becomes imperative in order to mitigate this issue. And to the best of our knowledge, there exists limited research pertaining to this particular aspect.
Therefore, in this work, we propose a novel two-stage decoupling personalized FL algorithm called FedTSDP, where client models with dynamic personalization layers are clustered twice based on model inference and weights, respectively. The main contributions of this paper are listed as follows:
-
1.
This is the first work that extends the conventional single-stage clustered FL to a more sophisticated two-stage scheme. The first stage leverages the outcomes of model inference to gauge the preference of different clients, while the second stage utilizes model weights to assess their respective local learning directions, thus, exhibiting faster convergence speed compared to the single-stage clustering method.
-
2.
For the first stage of clustering, the Jensen–Shannon (JS) divergence [31] is employed as a similarity metric to quantify the divergence among participating clients. Furthermore, a Hopkins [3] amended sampling method is introduced to simultaneously determine the appropriate timing for clustering and ascertain the sampling weight of public unlabeled data on the server.
-
3.
For the second stage, model weights are utilized as metrics to conduct clustering within each group formed during the first stage. In addition, a simple yet effective paradigm is developed to dynamically adjust the number of personalization layers according to varying degrees of data skew in FL.
-
4.
Empirical experiments are conducted to showcase the promising performance achieved by the proposed FedTSDP algorithm on both heterogeneous and homogeneous client data.
Background and motivation
In this section, a concise overview of federated learning with personalization layers is given at first, followed by an introduction to clustered federated learning. Lastly, the motivation of the present work is reiterated.
Federated learning with personalization layers
The original FL algorithm, known as FedAvg [28], aims to find the optimal global server model w capable of minimize total K aggregated local loss \(F_{i}(w_{i})\) of each client i as shown in Eq. (1):
where \(\mathcal {D}_{i}\) is the local training data, \(w_{i}\) is the model weights or parameters. And \(n_{i}=\left| \mathcal {D}_{i} \right| \) is the local data size, \(n=\sum _{i=1}^{K}n_{i}\) is the total data size, respectively. In FedAvg, a uniform weight initialization is applied to all local models sharing the same architecture at each communication round. Subsequently, each client returns its entire model weights to the server for federated aggregation (right panel of Eq. (1)) after local training.
However, as a result of data heterogeneity, direct federated aggregation upon the entire client models may lead to model divergence. [44]. Hence, it is imperative to introduce the concept of FL with personalization layers [2] as a remedy for the aforementioned issue. As depicted in Fig. 1, where the shallow layers of the neural network model are base layers uploaded to the server for aggregation, while deep layers are personalization layers stored locally on each user. During each communication round of the training period, every client receives identical base layers from the server and incorporates them with their respective personalization layers. The resulting integrated local model, which comprises both the base and personalization layers, is then updated through training on local data. After that, only the updated base layers are returned back to the server for subsequent model aggregation. This process not only facilitates collaborative learning but also preserves the personalized features of each user’s model.

A simple example of FL with personalization layers. The filled blocks of each user are shallow layers, while the dashed blocks are personalization layers
And several work [6, 21] have been proposed to enhance above mentioned personalized FL scheme by identifying the optimal placement of personalized layers. This is motivated by the inherent capability of personalization layers to encapsulate significant pattern signals, which aids in the identification of participants’ bias. As a result, determining the appropriate number of personalization layers becomes a critical factor for the successful implementation of personalized FL.
Clustered federated learning
Another effective approach addressing data heterogeneity issue is to partition the connected clients into several groups or clusters, which particularly relevant in scenarios where distinct user groups possess respective learning objectives. Yet through the aggregation of their local models with others in the same cluster sharing similar tasks, they can harness the power of collective intelligence to achieve more efficient FL.
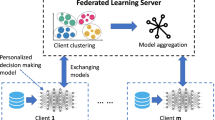
This is the reason why clustered FL has emerged as a promising solution to Non-IID data. As shown in Fig. 2, each client initiates local training and subsequently uploads the trained local model to the server. The server proceeds to perform client clustering based on metrics, typically computed on each client using Eq. (2):

An illustrative example of clustered FL (boxes with the same color represent a cluster). \(\textcircled {1}\) Perform local training on connected clients. \(\textcircled {2}\) Perform clustering to partition clients into different groups. \(\textcircled {3}\) Perform multi-center aggregation on the server. \(\textcircled {4}\) Clients receive the model of the corresponding cluster from the server
where j is the cluster index, and \(\hat{j}\) denotes the cluster index for client i with the lowest local empirical loss \(F_{i}(w_{j})\). This is actually the core concept introduced in IFCA algorithm [11], wherein J global models are simultaneously downloaded to connected clients, and each client is assigned to the group corresponding to the lowest \(F_{i}(w_{j})\) value. Other methodologies like CFL [35] utilize the distance of gradient information as a metric to reduce both communication costs and local computational costs.
After client clustering, the server conducts multi-center aggregation within each group and subsequently distributes the aggregated global models to the respective clients belonging to the corresponding cluster. Note that, in most clustered FL algorithms, the number of clusters, denoted as k, is predetermined and remains constant throughout the training process.
However, it is likely that each client is assigned to its own individual cluster, resulting in one client per cluster, renders the clustering process meaningless, particularly in highly Non-IID data scenarios. Consequently, the integration of clustered FL and personalized FL becomes imperative to address this issue and limited research has been conducted in this specific area to date.
Proposed algorithm
In this section, the proposed FedTSDP algorithm would be discussed in detail. At first, We would like to introduce the methodology of the first stage decoupling including the calculation of similarity metrics based on Jensen–Shannon (JS) divergence and Hopkins amended sampling. Subsequently, weight constraint-based clustering together with adaptive personalization layer adjustment for the second stage is presented, aiming to further reduce the client model divergence. And the overall framework of FedTSDP is illustrated at the last.
Problem description
In this work, we consider a setting of clustered FL with personalization layers where each user works as a client and the server possesses an unlabeled dataset. Let \(\mathcal {C}_{j}^{l}, j=1,\ldots , J, l = 1, 2\) denotes the j-th group of the l-th stage clustering, \(\mathcal {D}_{i}\) and \(\mathcal {D}_{u}\) are the training data of client i and public unlabeled data on the server, respectively, \(\left[ \mathcal {L}^{s};\mathcal {L}^{\textrm{per}} \right] \) represents all layers of the learning model where \(\mathcal {L}^{s}\) is the number of shared (base) layers and \(\mathcal {L}^{\textrm{per}}\) is the number of personalization layers. It aims to simultaneously find a group of optimal model weights \(\left\{ w_{1}^{*},w_{2}^{*}, \ldots , w_{J}^{*}\right\} \) for all clusters and their (appropriate) number of personalized layers \(\mathcal {L}^{\textrm{per}}\). And all the other notations used in this section are listed in Table 1.
The first stage of decoupling
Unlike CFL [35] adopting the distance of model gradients to recursively bi-partition clients, the first stage of our proposed method employs the inference outputs of the learning model from each connected client for clustering. The underlying reason is that the inference output inherently encapsulates the characteristics of data information and possesses better ability to reflect the local data distribution compared to model gradients.
As a simple FL example shown in Fig. 3, wherein three different clients possesses training data with label classes \(\left[ 1,2,3 \right] \), \(\left[ 1,2,3 \right] \), and \(\left[ 8,9,0 \right] \), respectively. The learning model is trained using FedAvg until convergence, after which two types of distances between clients are evaluated based on the model gradients and inference outputs in pairwise comparisons. It is evident that the client belonging to the label class \(\left[ 8, 9, 0\right] \) exhibits a notable difference in gradient distance to the other two clients belonging to \(\left[ 1, 2, 3\right] \) (one is 29694 and the other is 29566), whereas the inference distance demonstrates a robust relationship with the underlying data distribution. This empirical evidence suggests that inference outputs have a stronger capability to represent the local data distribution compared to gradient information, thus, is proper to be the clustering metrics. And in the subsequent section, we will introduce the methodology for calculating the distance based on the inference outputs.

A simple FL example to demonstrate inadequacy of using model gradients as a clustering metric, where clients with same color indicate that they possess training data with the same label classes
Jensen–Shannon divergence
Aforementioned inference distance can also be interpreted as a similarity measure when considering pairwise comparisons between clients. And Kullback–Leibler (KL) divergence [7] is widely used as a technique to quantify the dissimilarity between two probability distributions.
Given two probability distributions P and Q, the KL divergence \(D_{\text {KL}}(P||Q)\) from P to Q is defined in the following Eq. (3):
where \(\mathcal {X}\) is the set of all possible outcomes, P(x) is the probability of the outcome x according to distribution P, and Q(x) is the probability of the outcome x based on distribution Q. For a typical classification problem in machine learning, the model inference is often represented as logits which can be interpreted as a discrete probability distribution. And during the training process of FL, once the server receives model weights \(w_{i}\), \(w_{i^{'}}\) from two distinct clients, their corresponding inferences can be computed as \(p_{i}=F_{i}(w_{i};\mathcal {D}_{\textrm{pub}})\) and \(p_{i^{'}}=F_{i^{'}}(w_{i^{'}};\mathcal {D}_{\textrm{pub}})\), respectively, using public unlabeled dataset \(\mathcal {D}_{\textrm{pub}}\). Then, the similarity from client i to client \(i^{'}\) can be computed using the KL divergence as shown in Eq. (4):
where c is the class index of the model inference, and \(p_{i}\) satisfies \(\sum _{c}p_{i,c}=1\). However, it is important to note that KL divergence is not symmetric and does not measure the physical distance in Hilbert space, which means \(D_{\text {KL}}(p_{i}||p_{i^{'}}) \ne D_{\text {KL}}(p_{i^{'}}||p_{i})\). This property is not suitable for client clustering, as it implies that the pairwise distances between the same two clients may not be equal. Consequently, Jensen–Shannon (JS) Divergence [29] is instead applied here in Eq. (5):
where \(\hat{p}_{i,i^{'}}=\frac{1}{2}(p_{i}+p_{i^{'}})\) is the average distribution of \(p_{i}\) and \(p_{i^{'}}\), and it has been theoretically proved that \(D_{\text {JS}}(p_{i}||p_{i^{'}})=D_{\text {JS}}(p_{i^{'}}||p_{i})\).
Assuming there are a total of m connected clients in FL system, the server can construct an \(m \times m\) similarity matrix, where each element \(\text {elem}_{i,i^{'}}\) represents the computed result of JS divergence \(D_{\text {JS}}(p_{i}||p_{i^{'}})\) between the inference outputs of two client models \(w_{i}\) and \(w_{i^{'}}\). An illustrative example of \(10 \times 10\) similarity matrix is depicted in Fig. 4, where both horizontal and vertical axes represent client indices. The values within each square of the matrix, calculated using JS divergence, indicate the similarity between two clients corresponding to the respective client indices. It is evident that the smaller the value, the greater the similarity between two clients. And this similarity matrix serves as the metric for the subsequent clustering algorithm. In our proposed scheme, we select density-based spatial clustering of applications with noise (DBSCAN) [9] as the clustering algorithm due to its ability to determine the number of clusters without prior specification.

An example of the similarity matrix computed among 10 clients, where the value of each element is calculated by Eq. (5). The smaller the value, the more similar two clients will be
Hopkins amended sampling
As discussed previously, the timing of clustering plays a crucial role in clustered FL algorithms. For those scenarios of high non-IID data, it is likely that each client is assigned to its own cluster. And this actually is equivalent to single client training, rendering collaborative learning meaningless.
To address the above-mentioned issue, Hopkins statistic is adopted to automatically specify the timing of clustering. The Hopkins statistic, originally a quantitative measure used to assess the clustering tendency of a dataset, is adapted in our FL scenarios to evaluate the clustering tendency based on inference outputs of client models. Let \(I = \{p_{i} \in \mathbb {R}^{d} | i=1\ldots m \}\) denote a set of m flattened inferences where the vector dimension \(d=B \times C\). B is the batch size of the public data, and C is the total number of classification outputs. Note that, the reason for adopting only batch data instead of the entire public dataset for inference computation is to reduce the computational overhead. And also given \(\widetilde{I}\) be a set of \(\widetilde{m} \ll m\) elements randomly sampled without replacement from I, \(\widehat{I}\) be a set of \(\widetilde{m}\) elements uniformly randomly sampled from the sampling space of I. Then, the Hopkins statistic can be defined as Eq. (6):
where \(z_{i} \in \mathbb {R}\) is the minimum distance of \(\widehat{p}_{i} \in \widehat{I}\) to its nearest neighbor in I, and \(v_{i} \in \mathbb {R}\) is the minimum distance of \(\widetilde{p}_{i} \in \widetilde{I} \subseteq I\) to its nearest neighbor \(p_{i^{'}} \in I\), where \(\widetilde{p}_{i} \ne p_{i^{'}}\). The L2-norm is selected as the metric for computing the pairwise distances.
The resulting Hopkins statistic H is compared with a predefined threshold \(h_\text {th}\) afterward. If H is greater than \(h_\text {th}\), client clustering is performed using DBSCAN algorithm, and vice versa. Furthermore, the sampling weights of the aforementioned batch data would be updated to facilitate successful clustering operations as shown in Eq. (7):
where \(W_{k}^{r-1}\) is the sampling weight or ratio of data k at communication round \(r-1\), \(|\mathcal {D}_{\textrm{pub}}|\) indicates the total size of the public unlabeled dataset, \(|\mathcal {D}_B|\) represents the batch size, and \(\mathcal {D}_B \subseteq \mathcal {D}_{\textrm{pub}}, |\mathcal {D}_B| \ll |\mathcal {D}_{\textrm{pub}}|\). It is important to note that only the sampling weights of data within the corresponding batch data \(\mathcal {D}_B\) are allowed to be updated. Afterward, the new sampling weights \(W_{k}^{r}\) for the next communication round are obtained by normalizing the updated weights \( W_{k}^{r-1}\), as shown in Eq. (8):
The objective of updating the sampling weights is to increase the likelihood of sampling public data with inference outputs that satisfy the Hopkins statistic. In other words, the sampling process prioritizes data samples that exhibit substantial discrepancies among different client models, thereby significantly enhancing the clustering tendency in the first stage.
The second stage of decoupling
The second stage of decoupling builds upon the results obtained from the first stage, further refining the clustering process. And its initial purpose is to further minimize the distance of model weights between clients in pairwise comparisons. Except that, personalization layers are introduced as an additional component, which not only provides novel assistance to the clustering process but also aims to preserve the statistical characteristics of local models, particularly in the context of non-IID data.
Weight constraint-based clustering
In this stage, the model weights of each client are used as the clustering metric instead, since they directly represent the properties of the models, unlike gradients or other auxiliary information. And the pairwise distance between any two clients are calculated by Eq. (9):
where \(w_{i}\) and \(w_{i^{'}}\) are model weights of client i and client \(i^{'}\), respectively, \(\Upsilon \) is a small constant added to avoid division by zero, e represents the vector of ones. \(\left\| *\right\| _{2}\) is the L2-norm given by Eq. (10):
As mentioned earlier, this step continues to perform clustering within each group that was formed in the previous stage. The reason for this operation is that the convergence direction of the models may differ, even for data with a homogeneous distribution (shown in Fig. 3). These two stages are combined to form a directed hierarchical decoupling flow, as depicted in Fig. 5, where 5 client models at the first stage are partitioned into two different groups. And weight constraint based clustering is performed afterward with each clustered group and continues to partition, for instance, 3 models located at the left panel into two distinct clusters.

An example of two-stage decoupling process, where 5 client models are divided into two groups by the first stage of clustering. And the second stage is performed within each clustered group and continues to, for example, partition 3 client models located at the left panel into two distinct clusters
Adaptive personalization layer adjustment
Despite the ability of our proposed hierarchical decoupling method to partially reduce model divergence resulting from distinct local data distributions, model heterogeneity still persists even after the two-stage decoupling process. Consequently, the integration of personalization layers is introduced as an effective measure to adequately address this concern.
Nevertheless, determining the optimal number of personalization layers necessary to handle varying levels of data skew, as well as their integration with our proposed decoupling scheme, remains uncertain. Furthermore, it is worth noting that many prior research efforts overlook the fact that personalization layers do not always contribute positively to the learning performance of federated learning, especially in scenarios where data follows IID distribution. As illustrated in Fig. 6, to achieve a relatively similar global model performance, the number of personalization layers exhibits an increasing trend as the client data distribution transitions from IID to non-IID, which means for more non-IID data, each client is expected to reserve more personalization layers without being shared to the server to preserve more local data attributes, and vice versa.
This observation is reasonable, as aggregating models with all layers trained on significantly different datasets would be harmful and result in significant performance degradation. Conversely, aggregating models with only a few layers trained on similar datasets would lead to a reduced learning capacity, as they would capture less diverse information. Hence, it would be beneficial to dynamically adjust the number of personalization (shared) layers, allowing the learning model to automatically adapt to varying degrees of data skew. However, due to the strict prohibition on accessing local training data in FL, conducting the aforementioned layer adjustment becomes challenging.

An example indicates the relationship between data skew and the number of personalization layers. For more non-IID data, the number of shared layers should decrease to alleviate the impact of performance degradation, and vice versa. As a result, each local model is able to reserve more individual local attributes, avoiding possible side effect from federated model aggregation caused by non-IID data
Naturally, a connection can be established between data skew and the application of Hopkins statistic theory in the first stage of decoupling. The degrees of data heterogeneity can be quantitatively assessed through clustering tendency analysis. Specifically, a higher clustering tendency indicates greater data divergence, while a lower clustering tendency suggests lower data divergence. And our proposed layer adjustment scheme is performed by decaying the number of shared layers \(\mathcal {L}^{s}\) (equivalent to increasing the number of personalization layers \(\mathcal {L}^{\textrm{per}}\)) as long as Hopkins statistic criterion H is satisfied. As shown in Eq. (11):
where \(\psi ^{r}\) is the dampening ratio at the communication round r.
Overall framework
Both clustering and personalization layers are integrated to form a federated two-stage decoupling with adaptive personalization layers approach named FedTSDP. The complete pseudo code illustrating the overall procedure is presented in Algorithm.1.

Federated Two-Stage Decoupling With Adaptive Personalization Layers (FedTSDP)
At the beginning of the training procedure, the server initializes the global model parameters w and defines the number of shared or personalized layers \(\left[ \mathcal {L}_{s};\mathcal {L}_{\textrm{per}} \right] \). Meanwhile, all the clients are allocated to the same cluster j. And for each communication round r, we assume only \(m=\text {max}\left( \delta \cdot K, 1 \right) \) clients are connected to the server, where \(\delta \) is the connection ratio and K is the total number of clients.
Then, the server sends clustered (shared) global model \(w_{\mathcal {L}_{j}^{s}}^{r}\) (\(w_{\mathcal {L}^{s}}\) for the first communication round) to all the clients \(i \in [m]\) belonging to their respective cluster j. After that, each client i upgrades the local shared model parameters \(w_{i}^{s}\) using the received global model \(w_{\mathcal {L}_{j}^{s}}^{r}\) and integrates it with the local personalization layer \(w_{i}^{\textrm{per}}\) to form the local model \(w_{i}\). Subsequently, E epochs of training loops are performed on local batch data \(\mathcal {D}_{B} \in \mathcal {D}_{i}\) and the updated model parameters \(w_{i}\) will be returned back to the server (from line 36 to line 39 of Algorithm.1).
Upon receiving \(w_{i}\) from any connected client i, the server proceeds to sample \(\mathcal {D}^{B}_{\textrm{pub}}\) from the public unlabeled dataset \(\mathcal {D}_{\textrm{pub}}\). These sampled data are then utilized to compute the inference output \(p_{i}\), as indicated in line 14 of Algorithm.1. The resulting set of m inference outputs, denoted as I, is subsequently employed to calculate the Hopkins statistic H. Once the Hopkins statistic H exceeds the threshold \(h_{\text {th}}\), the DBSCAN algorithm is executed using the similarity matrix \(\text {Sim}\), which is calculated based on JS divergence, as the clustering criterion The result of this clustering process is denoted as \(\mathcal {C}^{1}\) and represents the first stage decoupling outcome.
The second stage of decoupling is applied to the results of \(\mathcal {C}^{1}\) obtained in the previous stage. However, in contrast to the previous stage, the second stage employs model weight distance as the clustering metric (lines 23–24 in Algorithm.1). Consequently, each \(\mathcal {C}^{1}_{j}\) may be further partitioned into several sub clusters, denoted as \(\mathcal {C}^{2}_{j}\), which are then combined and flattened to form a newly generated cluster \(\mathcal {C}^{2}\). By the way, the sampling weight \(W^{r}_{k}\) of each public data point k is updated by Eq. (7) and Eq. (8).
Afterward, the server aggregates the client models within each cluster \(\mathcal {C}_{j^{'}}^{2}, j^{'} \in [ J^{'} ]\) in \(\mathcal {C}^{2}\), where the aggregation weights are determined by the ratio of the local data size \(n_{i}\) to total data size \(n_{j^{'}}\) of all the clients in \(\mathcal {C}_{j^{'}}^{2}\). It is worth noting that if the criterion of Hopkins statistic is not satisfied, then the model aggregation is performed based on the clustering outcome \(\mathcal {C}^{2}\) from the last communication round \(r-1\). Finally, the number of shared layers \(\mathcal {L}_{j^{'}}^{s}\) is reduced by a dampening factor \(\psi ^{r}\) if two stages of decoupling is conducted. The aforementioned processes are repeated for R communication rounds until convergence.
Experiments
To empirically verify the effectiveness and robustness of our proposed FedTSDP algorithm, extensive experimental studies are performed together with some state-of-the-art clustered FL methods on three image classification datasets. In this section, we first compare the learning performance of FedTSDP with other popular approaches on both IID and non-IID data, followed by the case study validating the effectiveness of Hopkins amended sampling strategy.
Experimental settings
Datasets
Three image classification datasets are adopted in our simulations, namely CIFAR10 [13], CIFAR100, and SVHN. As shown in Table 2, CIFAR10 contains 50,000 training and 10,000 testing \(32 \times 32 \times 3\) images with 10 different kinds of objects, CIFAR100 contains 50,000 training and 10,000 testing \(32 \times 32 \times 3\) images with 100 different types of objects, SVHN contains 73,257 \(32 \times 32 \times 3\) images with digits \(0 \sim 9\).
To simulate the data distribution in FedTSDP, the original testing images are regarded as the public data \(\mathcal {D}_{\textrm{pub}}\) on the server by removing their labels. And all training image data are evenly and randomly allocated to connected clients without overlap for IID experiments. While for non-IID scenarios, each client is allocated a proportion of training data of each label class based on Dirichlet distribution \(p_{c}\sim \text {Dir}_{k}\left( \beta \right) \), where \(\beta \) is the concentration parameter and is selected to be 0.2 and 0.5 in our simulations. A smaller \(\beta \) value would lead to a more unbalanced data partition. Except that, 20% of the allocated data on each client are used for testing and the rest are used for training in all experiments.
Models
Two types of neural network models are selected as the global model used in our proposed FedTSDP. One is a convolutional neural network (CNN) with two convolutional layers: one is a convolutional layer with a \(3 \times 3\) kernel and 32 output channels, followed by another convolutional layer with a \(3 \times 3\) kernel and 64 output channels. It further includes two fully connected layers, the first with 512 neurons and the second with 10 neurons. Additionally, two dropout layers are incorporated with dropout ratios of 0.25 and 0.5, respectively.
The other one is a more deeper ResNet18. It consists of one convolutional layer with a \(3 \times 3\) kernel and 64 output channels, followed by a batch normalization layer [12]. It is then followed by four BasicBlock structures, each of which comprises two groups of \(3 \times 3\) convolutional layers and two batch normalization layers. Finally, fully connected layers are appended after the last BasicBlock.
Algorithms under comparison
Our proposed FedTSDP is compared to the following popular personalized and clustered FL algorithms:
-
1.
FedAvg [28]: The earliest and most classical FL, which often serves as the baseline algorithm, adopts direct weighted averaging for model aggregation on the server.
-
2.
FedProx [17]: A influential modification of FedAvg, which incorporates local regularization terms to enhance convergence speed, is widely recognized as a baseline approach in personalized FL.
-
3.
Ditto [16]: A recent and highly regarded work in personalized FL. Different from traditional model aggregation approaches, it adopts a unique strategy by directly replacing the global model with the local optimal model.
-
4.
FedPer [2]: The pioneering work that introduces the concept of utilizing personalization layers to address data distribution heterogeneity in FL.
-
5.
CFL [35]: An exemplary study that proposes bi-partitioning clustering for conducting multi-center FL, leading to successful personalization, is regarded as a notable contribution in this field.
All hyperparameters settings for both our proposed FedTSDP and above five algorithms are kept consistent to ensure a fair comparison. Furthermore, it is crucial to acknowledge that our main objective is not to attain state-of-the-art performance but rather to obtain comparative outcomes. This consideration arises due to the sensitivity of FL to numerous hyperparameters that can significantly impact the results.
Other settings
All other experimental settings for FedTSDP are listed as follows:
-
Total number of clients K: 20
-
Connection ratio \(\delta \): 1.0
-
Total number of communication rounds R: 200
-
Number of local epochs: 2
-
Training batch size: 50
-
Local initial learning rate: 0.05
-
Local learning momentum: 0.5
-
Learning rate decay over each communication round: 0.95
-
Epsilon threshold \(\epsilon _{1}\), \(\epsilon _{2}\) for DBSCAN: 0.15, 3.5
-
Minimum points threshold for DBSCAN \(\text {min}_{\textrm{pts}}\): 2
-
Threshold of Hopkins statistic \(h_{\text {th}}\): 0.65
-
The dampening ratio of the shared layers \(\psi ^{r}\): 0.98
Performance on IID data
At first, the learning performance of FedTSDP on IID data are compared against five FL baseline algorithms. It is important to note that the learning performance is measured by the weighted average test accuracy of the global model (or within each cluster) on each local test set. In addition, for FL methods that incorporate personalization layers, it is sufficient to download and combine only the global shared layers with the local personalization layers for calculating the test accuracy.

The learning performance over communication rounds on IID data
The final test results at the last communication round are presented in Table 3. And it can be observed that FedTSDP demonstrates superior performance compared to other baseline algorithms on all three datasets. However, the differences in performance are not statistically significant due to homogeneous data distribution which may result in grouping all clients into one cluster. In this scenarios, the clustered FL essentially reverts to general FL. To be more specifically for CNN model, FedTSDP achieves the highest test accuracy of 72.98%, 39.19% and 91.45% on CIFAR10, CIFAR100, and SVHN, respectively. These results are comparable to those obtained by FedAvg, FedProx, Ditto algorithms. Similar outcomes are observed as well, however, it is worth noting that FedProx achieves a test accuracy of 93.82% on the SVHN dataset, which is slightly higher by 0.10% compared to our proposed FedTSDP algorithm. It is surprising to see that the accuracy of FedPer is notably lower than that of all other algorithms. This discrepancy may be attributed to the fixed number of shared layers employed in FedPer, which restricts the ability of local personalization layers to learn information from other clients.
To take a closer look at the dynamic learning performance achieved by each algorithm, the convergence behavior across communication rounds are explored. As shown in Fig. 7, it is obvious that our proposed FedTSDP algorithm exhibits a slightly faster convergence speed compared to FedAvg, FedProx, and Ditto. While CFL and FedPer has a relatively much slower convergence speed, which can be attributed to the ’strong’ personalized operation that limits the assimilation of information from other participants. And in IID data scenarios, the incorporation of such information can enhance the learning process. Consequently, it can be concluded that clustering or personalization layers may not always be advantageous in the context of FL.
Performance on non-IID data
To further assess the applicability of FedTSDP in more complex heterogeneous scenarios, we conducted evaluations of all the algorithms under various non-IID settings. By varying the concentration parameter \(\beta \) of the Dirichlet distribution (\(\beta =0.2, 0.5\) in our experiments), it is possible to generate Non-IID data with varying degrees of data skew. Furthermore, the data partition method used in FedAvg is also utilized in our simulations, where each client owns data samples with a fixed number of two label classes. The client data generated using this method are often regarded as extreme non-IID data due to the significant variations in data distributions among the clients.
The results on both CNN and ResNet18 using Dirichlet partition method are shown in Table 4. It is evident that our proposed FedTSDP outperforms other baseline algorithms in scenarios involving non-IID data with varying degrees of data heterogeneity. In contrast to the results obtained on IID data, FedPer consistently achieves the second highest test accuracy, surpassing the FedAvg algorithm by approximately 9% on CNN model. This performance gap becomes more pronounced in non-IID scenarios, particularly with a concentration parameter of \(\beta =0.2\), where FedPer achieves a remarkable 15% higher test accuracy compared to other algorithms. In addition to FedPer, the CFL algorithm also demonstrates promising results in handling heterogeneous data distributions, particularly in scenarios with a concentration parameter of \(\beta =0.2\), In such cases, CFL achieves an approximately 5% higher test accuracy compared to non-clustered FL algorithms. These phenomena implicitly highlight the advantages of both clustering and incorporating personalization layers in non-IID scenarios, underscoring the importance of integrating these approaches together.

The learning performance over communication rounds on non-IID data partitioned follow Dirichlet distribution
Regarding the final results on CIFAR10 dataset (Table 5), where each client is assigned only two classes of objects, FedTSDP demonstrates superior learning performance. Specifically, it achieves a test accuracy of 90.49% on the CNN model and 90.20% on the ResNet18 model. These accuracies are 0.29% and 0.03% higher, respectively, compared to FedPer. FedAvg, FedProx, and Ditto share similar learning performance with a test accuracy of approximately 63%, which is about 27% lower than FedTSDP and FedPer. This empirically prove the effectiveness of personalization layers to deal with highly Non-IID data in FL.
Similarly, the real-time test performance over communication rounds are illustrated in Fig. 8, and the following three observations can be made. First, our proposed FedTSDP algorithm in general converges faster than other baseline algorithms. Second, there may be instances of sharp increases or decreases observed prior to the midpoint of the communication rounds, which is typically attributed to sudden clusters variations. It is important to note that FedTSDP does not perform clustering unless the Hopkins statistic criterion is satisfied. Thus, after an extended period of unchanged clustered training, aggregating re-clustered client models may cause a sudden performance drop. In addition, the sudden performance degradation also comes from adaptive layer adjustment. Decaying the number of shared layers directly changes the scale of local personalization layers which may bring in unexpected learning bias. And each modified personalization layers require several communication rounds of local training for recovery. Third, the performance gain on highly non-IID data mainly comes from personalization layers, as FedPer converges even faster than FedTSDP at the beginning of the training period.
What is worth mentioning is that well-organized groupings of clusters and appropriately shared layers are expected to accelerate the convergence speed of a FL system. This may lead to an improvement boost in model performance after a few rounds of training recovery, which further substantiates the effectiveness and significance of our proposed FedTSDP.
By the way, it is interesting to observe that the performance of our algorithm on SVHN dataset fluctuates, showing opposite behaviors on CNN and ResNet18. This is because SVHN dataset is comparatively much easier to be trained compared with other datasets. The learning model tends to converge during the early stages of the federated training period, after which it may begin to exhibit fluctuations. ResNet18, as a deeper and more complex architecture compared to a simple CNN, is more likely to achieve faster convergence. We also repeat the experiments several times, and the means and variances are reported in Table 6.
Ablation study on two-stage decoupling
To testify the validation of proposed two-stage decoupling scheme, we decompose FedTSDP and elaborate each stage one by one. For simplicity, this ablation study is conducted on CIFAR10 dataset with \(\beta =0.5\).

Ablation study on two-stage decoupling, where both single-stage and two-stage decoupling are included
The corresponding outcomes over communication rounds are shown in Fig. 9, where the learning curves of the first stage of decoupling, the second stage of decoupling and two-stage decoupling are included, respectively. Overall, it is apparent to see that two-stage decoupling scheme converges slightly slower than the first stage of decoupling at the early steps of the period, while it achieves the best learning performance after approximate 60 communication round. And the second stage of decoupling shows the worst convergence property among these three methods. This empirically illustrates the insufficiency of single-stage decoupling, and substantiates the effectiveness and significance of our proposed two-stage decoupling approach that can not only reflect the local data distribution, but also preserve the statistical characteristics of local models, especially for the context of Non-IID data.
Analysis on Hopkins amended sampling
To further validate the effectiveness of the proposed Hopkins amended sampling strategy, we conduct a dedicated experiment using both IID and non-IID data. For a brevity sake, this study is only performed on CNN model with SVHN dataset.

Hopkins statistic on IID data. The left axis represents the accuracy, while the right axis corresponds to the Hopkins statistic. It can be observed that in each round, none of the Hopkins statistics reach the threshold value

The Hopkins statistic on non-IID data. The two dashed vertical lines indicate the occurrence of layer shrinking
In the IID results illustrated in Fig. 10, the values on the left axis represent the test accuracy, while the values on the right axis represent Hopkins statistic. Furthermore, the dot points represent the calculated Hopkins statistic and the solid curve is test accuracy over communication rounds. It is evident that no clustering occurs as observed from the plot. As the training process progresses, the Hopkins statistic gradually increases, indicating a potential increase in model divergence. However, it does not exceed the Hopkins threshold (the dashed horizontal line), indicating that clustering does not occur under IID FL environment.
The non-IID situation is depicted in Fig. 11. As observed, the Hopkins statistic exhibits significant fluctuations, indicating a high degree of client bias. Additionally, the upward trend of the Hopkins statistic is attributed to the adopted sampling strategy. Except that, it is intriguing to observe a noticeable performance degradation occurring around the 50th communication round, coinciding with the reduction of shared layers from 4 to 3.5 and the simultaneous occurrence of clustering.
Conclusion
In this paper, we introduce FedTSDP, a two-stage decoupling mechanism that incorporates adaptive personalization layers to effectively handle heterogeneity issues arising from varying degrees of data skew. FedTSDP leverages unsupervised clustering using unlabeled data on the server, along with the Hopkins amended sampling technique to maintain active and valuable data information. Furthermore, it employs a dynamic adjustment strategy for the shared layers to automatically handle both IID and non-IID data.
Extensive experiments are performed to compare the proposed FedTSDP with five baseline FL algorithms. The results demonstrate that the solutions obtained by our method exhibit superior or comparable learning performance, and are well suited to varying levels of data heterogeneity. This advantage can be attributed to the Hopkins statistic, which selectively performs clustering only when there is a high clustering tendency present in the client data. In addition, it is intriguing to discover that personalization layers in FL may not always confer learning performance benefits, especially when dealing with homogeneous data. Overall, our proposed FedTSDP algorithm showcases promising performance on both heterogeneous and homogeneous data distributions.
The present work is an important initial step toward incorporating hierarchical clustering and personalization layers in FL. Despite the encouraging empirical results we have obtained, it is important to note that the classification performance of models over communication rounds may occur a sharp drop. Therefore, in the future, our focus will be on developing more robust FL algorithm to make the learning progress more stable.
References
Al-Abiad MS, Obeed M, Hossain MJ, Chaaban A (2023) Decentralized aggregation for energy-efficient federated learning via D2D communications. IEEE Trans Commun 71(6):3333–3351. https://doi.org/10.1109/TCOMM.2023.3253718
Arivazhagan MG, Aggarwal V, Singh AK, Choudhary S (2019) Federated learning with personalization layers. arXiv preprint arXiv:1912.00818
Banerjee A, Dave RN (2004) Validating clusters using the Hopkins statistic. In: 2004 IEEE international conference on fuzzy systems (IEEE Cat. No. 04CH37542), vol 1. IEEE, pp 149–153 (2004)
Briggs C, Fan Z, Andras P (2020) Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In: 2020 International joint conference on neural networks (IJCNN). IEEE, pp 1–9
Cho YJ, Wang J, Chirvolu T, Joshi G (2023) Communication-efficient and model-heterogeneous personalized federated learning via clustered knowledge transfer. IEEE J Sel Top Signal Process 17(1):234–247
Collins L, Hassani H, Mokhtari A, Shakkottai S (2021) Exploiting shared representations for personalized federated learning. In: International conference on machine learning. PMLR, pp 2089–2099
Csiszár I (1975) I-divergence geometry of probability distributions and minimization problems. Ann Probab 3:146–158
Duan M, Liu D, Ji X, Wu Y, Liang L, Chen X, Tan Y, Ren A (2021) Flexible clustered federated learning for client-level data distribution shift. IEEE Trans Parallel Distrib Syst 33(11):2661–2674
Ester M, Kriegel HP, Sander J, Xu X et al (1996) A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 96:226–231
Fu Y, Liu X, Tang S, Niu J, Huang Z (2021) CIC-FL: enabling class imbalance-aware clustered federated learning over shifted distributions. In: Database systems for advanced applications: 26th international conference, DASFAA 2021, Taipei, April 11–14, 2021, Proceedings, Part I 26. Springer, pp 37–52
Ghosh A, Chung J, Yin D, Ramchandran K (2020) An efficient framework for clustered federated learning. Adv Neural Inf Process Syst 33:19586–19597
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Bach F, Blei D (eds) Proceedings of the 32nd international conference on machine learning, proceedings of machine learning research, vol 37. PMLR, Lille, pp 448–456. https://proceedings.mlr.press/v37/ioffe15.html
Krizhevsky A, Hinton G (2009) Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto
Li K, Wang H, Zhang Q (2023) FEDTCR: communication-efficient federated learning via taming computing resources. Complex Intell Syst 9:5199–5219
Li Q, Diao Y, Chen Q, He B (2022) Federated learning on non-IID data silos: an experimental study. In: 2022 IEEE 38th international conference on data engineering (ICDE), pp 965–978. https://doi.org/10.1109/ICDE53745.2022.00077
Li T, Hu S, Beirami A, Smith V (2021) Ditto: fair and robust federated learning through personalization. In: International conference on machine learning. PMLR, pp 6357–6368
Li T, Sahu AK, Zaheer M, Sanjabi M, Talwalkar A, Smith V (2020) Federated optimization in heterogeneous networks. Proc Mach Learn Syst 2:429–450
Li X, Jiang M, Zhang X, Kamp M, Dou Q (2021) FedBN: federated learning on non-IID features via local batch normalization. In: International conference on learning representations. https://openreview.net/forum?id=6YEQUn0QICG
Li X, Liu N, Chen C, Zheng Z, Li H, Yan Q (2020) Communication-efficient collaborative learning of geo-distributed jointcloud from heterogeneous datasets. In: 2020 IEEE international conference on joint cloud computing, pp 22–29. https://doi.org/10.1109/JCC49151.2020.00013
Li Y, Tao X, Zhang X, Liu J, Xu J (2022) Privacy-preserved federated learning for autonomous driving. IEEE Trans Intell Transp Syst 23(7):8423–8434. https://doi.org/10.1109/TITS.2021.3081560
Liang PP, Liu T, Ziyin L, Allen NB, Auerbach RP, Brent D, Salakhutdinov R, Morency LP (2020) Think locally, act globally: federated learning with local and global representations. arXiv preprint arXiv:2001.01523
Long G, Xie M, Shen T, Zhou T, Wang X, Jiang J (2023) Multi-center federated learning: clients clustering for better personalization. World Wide Web 26(1):481–500
Lu C, Ma W, Wang R, Deng S, Wu Y (2023) Federated learning based on stratified sampling and regularization. Complex Intell Syst 9(2):2081–2099
Lu R, Zhang W, Wang Y, Li Q, Zhong X, Yang H, Wang D (2023) Auction-based cluster federated learning in mobile edge computing systems. IEEE Trans Parallel Distrib Syst 34(4):1145–1158. https://doi.org/10.1109/TPDS.2023.3240767
Lu R, Zhang W, Wang Y, Li Q, Zhong X, Yang H, Wang D (2023) Auction-based cluster federated learning in mobile edge computing systems. IEEE Trans Parallel Distrib Syst 34(4):1145–1158
Luo M, Chen F, Hu D, Zhang Y, Liang J, Feng J (2021) No fear of heterogeneity: classifier calibration for federated learning with non-IID data. In: Ranzato M, Beygelzimer A, Dauphin Y, Liang P, Vaughan JW (eds) Advances in neural information processing systems, vol 34. Curran Associates, Inc., pp 5972–5984
Ma X, Zhu J, Lin Z, Chen S, Qin Y (2022) A state-of-the-art survey on solving non-IID data in federated learning. Future Gener Comput Syst 135:244–258
McMahan B, Moore E, Ramage D, Hampson S, Arcas BAY (2017) Communication-efficient learning of deep networks from decentralized data. In: Singh A, Zhu J (eds) Proceedings of the 20th international conference on artificial intelligence and statistics, proceedings of machine learning research, vol 54. PMLR, pp 1273–1282. https://proceedings.mlr.press/v54/mcmahan17a.html
Menéndez M, Pardo J, Pardo L, Pardo M (1997) The Jensen–Shannon divergence. J Franklin Inst 334(2):307–318
Morafah M, Vahidian S, Wang W, Lin B (2023) FLIS: clustered federated learning via inference similarity for non-IID data distribution. IEEE Open J Comput Soc 4:109–120
Nielsen F (2021) On a variational definition for the Jensen–Shannon symmetrization of distances based on the information radius. Entropy 23(4):464
Pillutla K, Malik K, Mohamed AR, Rabbat M, Sanjabi M, Xiao L (2022) Federated learning with partial model personalization. In: Chaudhuri K, Jegelka S, Song L, Szepesvari C, Niu G, Sabato S (eds) Proceedings of the 39th international conference on machine learning, proceedings of machine learning research, vol 162. PMLR, pp 17716–17758. https://proceedings.mlr.press/v162/pillutla22a.html
Priya KV, Peter JD (2022) A federated approach for detecting the chest diseases using densenet for multi-label classification. Complex Intell Syst 8(4):3121–3129. https://doi.org/10.1007/s40747-021-00474-y
Ruan Y, Joe-Wong C (2022) Fedsoft: soft clustered federated learning with proximal local updating. In: Proceedings of the AAAI conference on artificial intelligence, vol 36, pp 8124–8131
Sattler F, Müller KR, Samek W (2020) Clustered federated learning: model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans Neural Netw Learn Syst 32(8):3710–3722
Sattler F, Wiedemann S, Müller KR, Samek W (2020) Robust and communication-efficient federated learning from non-i.i.d. data. IEEE Trans Neural Netw Learn Syst 31(9):3400–3413. https://doi.org/10.1109/TNNLS.2019.2944481
Smith V, Chiang CK, Sanjabi M, Talwalkar AS (2017) Federated multi-task learning. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in neural information processing systems, vol 30. Curran Associates, Inc
Tian P, Chen Z, Yu W, Liao W (2021) Towards asynchronous federated learning based threat detection: a DC-ADAM approach. Comput Secur 108:102344
Tuor T, Wang S, Ko B, Liu C, Leung KK (2021) Overcoming noisy and irrelevant data in federated learning. In: 2020 25th International conference on pattern recognition (ICPR). IEEE Computer Society, Los Alamitos, pp 5020–5027. https://doi.org/10.1109/ICPR48806.2021.9412599
Wang H, Kaplan Z, Niu D, Li B (2020) Optimizing federated learning on non-IID data with reinforcement learning. In: IEEE INFOCOM 2020—IEEE conference on computer communications, pp 1698–1707. https://doi.org/10.1109/INFOCOM41043.2020.9155494
Weiss K, Khoshgoftaar TM, Wang D (2016) A survey of transfer learning. J Big Data 3(1):1–40
Yang Z, Liu Y, Zhang S, Zhou K (2023) Personalized federated learning with model interpolation among client clusters and its application in smart home. World Wide Web, pp 1–26
Ye T, Wei S, Cui J, Chen C, Fu Y, Gao M (2023) Robust clustered federated learning. In: International conference on database systems for advanced applications. Springer, New York, pp 677–692
Zhao Y, Li M, Lai L, Suda N, Civin D, Chandra V (2018) Federated learning with non-IID data. arXiv preprint arXiv:1806.00582
Zhong Z, Wang J, Bao W, Zhou J, Zhu X, Zhang X (2023) Semi-HFL: semi-supervised federated learning for heterogeneous devices. Complex Intell Syst 9(2):1995–2017
Zhou Y, Ye Q, Lv J (2022) Communication-efficient federated learning with compensated overlap-FEDAVG. IEEE Trans Parallel Distrib Syst 33(1):192–205. https://doi.org/10.1109/TPDS.2021.3090331
Zhu H, Xu J, Liu S, Jin Y (2021) Federated learning on non-IID data: a survey. Neurocomputing 465:371–390
Acknowledgements
This work was supported in part by the National Science Foundation of China (NSFC) under Grant 62272201, and in part by the Wuxi Science and Technology Development Fund Project under Grant K20231012.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, H., Fan, Y. & Xie, Z. Federated two-stage decoupling with adaptive personalization layers. Complex Intell. Syst. 10, 3657–3671 (2024). https://doi.org/10.1007/s40747-024-01342-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-024-01342-1