
Abstract
Nowadays, Artificial Intelligence Generated Content (AIGC) has shown promising prospects in both computer vision and natural language processing communities. Meanwhile, as an essential aspect of AIGC, image to captions has received much more attention. Recent vision-language research is developing from the bulky region visual representations based on object detectors toward more convenient and flexible grid ones. However, this kind of research typically concentrates on image understanding tasks like image classification, with less attention paid to content generation tasks. In this paper, we explore how to capitalize on the expressive features embedded in the grid visual representations for better image captioning. To this end, we present a Transformer-based image captioning model, dubbed FeiM, with two straightforward yet effective designs. We first design the feature queries that consist of a limited set of learnable vectors, which act as the local signals to capture specific visual information from global grid features. Then, taking augmented global grid features and the local feature queries as inputs, we develop a feature interaction module to query relevant visual concepts from grid features, and to enable interaction between the local signal and overall context. Finally, the refined grid visual representations and the linguistic features pass through a Transformer architecture for multi-modal fusion. With the two novel and simple designs, FeiM can fully leverage meaningful visual knowledge to improve image captioning performance. Extensive experiments are performed on the competitive MSCOCO benchmark to confirm the effectiveness of the proposed approach, and the results show that FeiM yields more eminent results than existing advanced captioning models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Given an image, humans can immediately comprehend the visual content and describe the image with natural language, while it is quite challenging for computers to do the same. Image captioning [1] aims to equip the machine with the ability to provide sensible sentence descriptions for the input image automatically. Normally, generating acceptable captions relies largely on the semantic understanding of the image, which poses challenges to computer vision and natural language processing. Enlightened by neural machine translation [5], the encoder–decoder frameworks have been commonly employed to deal with the task over the last few years [6,7,8,9]. Typically, CNN is employed as the encoder to encode the image as fixed-length visual features. RNN is utilized as the decoder to produce valid and descriptive captions by decoding visual features. To achieve a more fine-grained understanding of the image, the attention mechanism [7, 10, 11] is used to focus on more relevant image regions when predicting words. The performance of image captioning has been greatly boosted by introducing the attention mechanism into the encoder–decoder architecture. Recently, Transformer [28] has set off a revolution in the artificial intelligence domain, and since then, image captioning models based on Transformer have been leading the advanced performance.
Generally, visual features play a crucial part in the semantic understanding of the image, and great efforts have been made to learn effective visual representations [2, 4]. For example, the local region-based and global grid-based convolutional features are broadly used in the existing image captioning models. Specifically, the region-based visual feature is usually extracted with a pre-trained object detector, such as Faster RCNN [12], which captures rich information about objects and other important image regions. However, the object detector is so bulky that it takes much time to extract image features; therefore, the cached region-based visual representations are more popular in current image captioning models. In terms of the global grid-based visual feature, it treats all elements of an image equally by directly dividing the image into uniform grids, which makes it hard for the decoder to generate high-quality textual sentences. However, a series of works [13, 14, 61] have shown that the grid-based visual features can also perform well on VQA, when they are obtained from the same layer of the region-based object detector. To improve the image captioning performance based on flattened grid visual representations, RSTNet [14] absorbed spatial information into the grid-based feature by introducing a grid-augmented module. RSTNet is sensitive to the geometry relationships between grid positions, but the augmented grid features ignore the information on the channel dimension, hence, limiting the model’s ability to fully understand visual content. Additionally, the offline grid-based visual features are usually not aligned with the linguistic features, making it difficult to directly learn the interaction between them.
In this paper, to handle the aforementioned issues, the learnable feature queries and the feature interaction module are designed to capture expressive information from the grid-based visual representation and improve the performance of the Transformer-based image captioning model. Feature queries are a group of learnable tokens, and they are exploited to query useful visual clues from the global grid representations. The feature queries serve as the local signals that interact with the overall image context to obtain the discriminative visual features, thus facilitating the alignment of visual features with textual features during decoding to enhance the quality of the generated descriptions. Then, a feature interaction module is introduced to enable interaction between the feature queries and the grid features to output refined visual representations. The feature interaction module is implemented by the cross-attention mechanism and linear mapping networks. Finally, adaptive attention is leveraged to investigate how visual and linguistic signals influence the generation of accurate descriptions. With our proposed feature queries and feature interaction module, more expressive and relevant visual information can be mined to generate high-quality captions for the given image. To evaluate the effectiveness of the proposed approach FeiM for image captioning, we carry out extensive experiments on the MSCOCO benchmark, where FeiM achieves superior performance.
Overall, the main contributions of the paper are threefold:
-
We design feature queries, which work as the local signals to query powerful visual details from the context of grid representations, by introducing a small amount of learnable continuous vectors. Benefiting from these flexible tokens, discriminative global visual information can be easily aggregated for better image captioning.
-
We design feature queries, which work as the local signals to query powerful visual details from the context of grid representations, by introducing a small amount of learnable continuous vectors. Benefiting from these flexible tokens, discriminative global visual information can be easily aggregated for better image captioning.
-
We propose a feature interaction module to capture the interdependencies on the spatial and the channel dimensions, respectively, by cross-attending the feature queries and the augmented grid visual features. It can provide refined and expressive visual features for the subsequent Transformer-based multi-modal fusion module to produce multi-modal signals.
-
We build a complete image captioning framework, namely FeiM (which is short for feature queries and feature interaction module), by applying the two designs in a Transformer-based captioning architecture. Extensive experiments on the MSCOCO benchmark demonstrate that FeiM enables remarkable image captioning capability with grid visual representations.
Related works
Image captioning
There have been two main phases in the development of image captioning [2,3,4]. To begin with, traditional captioning models [15,16,17,18,19,20] are based on retrieval and template, attempting to automatically generate simple descriptions of certain scenes for the image. In particular, the retrieval-based methods [15,16,17] generate descriptions by retrieving the most relevant sentences to the image from the predefined image-caption pool. The models [18,19,20] based on the template fill the detected words from the visual concepts into slots of the predesigned template. Although these traditional methods enable simple caption generation, they rely on hand-crafted visual features, resulting in the poor linguistic, syntactical, and semantic performance of the generated sentences.
Recent years have witnessed the overwhelming evolution of the deep neural network, and the methods [3, 4, 6,7,8,9] based on deep learning have been universally employed for image captioning. Currently, many image captioning methods adopt the encoder–decoder structure, where CNN is for feature extraction and RNN is for caption generation. For example, Neural Image Captioning (NIC) [4] treated the image captioning task as a translation problem from vision to text, and it was the first image captioning model that exploited the encoder-decoder paradigm. After that, the attention mechanisms [7, 21, 22], the training strategy with reinforcement learning [23,24,25], and the large-scale pre-trained vision-language models [26, 27] enrich the captioning methods based on deep learning.
Nowadays, illuminated by the successful application of self-attention in natural language processing, Transformer [28] has made great breakthroughs in the field of computer vision. Therefore, the CNN–RNN architecture is gradually replaced by the Transformer-based captioning models [14, 29,30,31,32, 55]. Transformer is also an encoder–decoder framework and its encoder has the same structure as its decoder, including residual connection, self-attention layer, layernorm, and feed-forward network. Compared with previous CNN-RNN-based methods, the self-attention mechanism enables Transformer-based models to model long-range dependencies of the sequence and ensure effective contextual information interaction. For example, Cornia et al. [30] introduced the Meshed-Memory Transformer (\(M^2\) Transformer) for better image captioning with a fully attentive network. Li et al. [29] extended the attention mechanism that connected the encoder and decoder of the Transformer to maximize the use of visual and semantic information. And Zhang et al. [14] utilized the grid-augmented visual features to incorporate more spatial information via a relationship-sensitive Transformer-based (RSTNet) image captioning model.
Convolutional representation learning
The convolutional visual features currently used in the image captioning model generally fall into two groups. One is the local region feature, and the other is the global grid feature, as shown in Fig. 1. For example, Karpathy et al. [2] observed that the descriptions for the image usually contained rich objects and attributes; thus, they generated captions with information from image regions. Anderson et al. [33] obtained a set of salient region features via Faster RCNN. Furthermore, Datta et al. [34] used the Faster RCNN pre-trained on VisualGenome to extract Regions-of-Interest (RoIs) for the image. The most significant advantage of region features is that they contain fine-grained information from the objects and are beneficial for the comprehensive understanding of image content. However, the region feature is typically captured through the pre-trained object detector. The detection process is time-consuming and the detector cannot be trained end-to-end in the captioning model.

The region-based features (left) and grid-based features (right)
The global grid features divide the entire content of an image in a uniform fashion. In the NIC [4], GoogleNet [35] was employed to extract visual representations with fixed length. Instead of using the image feature output from the last fully connected layer, Xu et al. [7] focused on the output from a lower convolutional layer. To generate more reliable language descriptions, Wu et al. [36] not only captured the global grid representation with pre-trained CNN but also learned explicit high-level concepts from the image. In contrast to the region feature, the grid feature is easier to obtain, but it ignores the distinctive information that is important for image semantic understanding and text description generation. Recently, several works [13, 14, 61] have revealed that grid visual features obtained from the same layer of the pre-trained object detector were as competitive as region features. RSTNet [14] studied the augmented grid features by introducing spatial information. However, RSTNet fails to capture meaningful visual content from both spatial and channel dimensions and restricts the performance improvement of the captioning model. In this paper, based on the Transformer architecture, we introduce the feature queries and the feature interaction module to take advantage of the expressive features embedded in the grid-based visual representations for better image captioning.
Methods
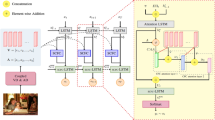
We aim to automatically generate textual descriptions for the given image with a Transformer-based architecture. Previous Transformer-based image captioning models [14, 29,30,31,32] attach more importance to boosting the performance from the perspective of the encoder, decoder, or attention mechanism. Instead, we concentrate on building a Transformer-based captioning model by maximizing the use of the grid visual information. Figure 2 depicts the overall framework of our image captioning model FeiM, and it can be divided into the semantic understanding and description generation parts conceptually. For semantic understanding, FeiM begins by extracting the grid-based image features and text features; similar to RSTNet [14], the image features are then augmented with spatial information in FeiM. We introduce a small amount of learnable continuous tokens as feature queries to capture expressive visual details from the augmented overall grid visual features. Then, we take the input of both feature queries and spatial-augmented grid features for feature interaction. Next, the features of the word sequence and the output of the feature interaction module go through the Transformer-based multi-modal fusion module, where the \(M^2\) Transformer [30] is exploited. The Transformer encoder is in charge of the multi-level relationships encoding of the feature interaction module output, while the decoder cross-attends the word sequence features and the latent representation of all Transformer encoder layers. For description generation, adaptive attention [14, 37] is used to generate words conditioned on vision, language, and vision-language signals.
Essentially, FeiM is a Transformer-based captioning framework to generate descriptive sentences for given images. In this section, we first formulate the image captioning task and introduce how visual and textual features are obtained. Then, we give the details of the designed feature queries and feature interaction module, respectively. Finally, we briefly introduce the Transformer-based multi-modal fusion and captioning module.

The overall framework of the proposed FeiM. FeiM starts with extracting grid-based image features and text features, and the image features are augmented with spatial information. We design feature queries to capture useful knowledge from the augmented global grid visual representations. Then, both feature queries and spatial-augmented grid representations are fed into the feature interaction module, to refine expressive visual features from the interaction of spatial and channel dimensions. Next, the features of the word sequence and the output of the feature interaction module go through the Transformer-based multi-modal fusion module. Finally, adaptive attention is used to generate words conditioned on multi-modal, visual, and textual signals
Visual and textual features
The standard image captioning task can be stated as: Given a dataset D with image–text pairs \(\{I^i, y^i\}\) and a test image I, the goal is to generate a fluent and plausible description \(y = \{y_1^I,...,y_L^I\}\) corresponding to I, where \(y_i^I\) represents the \(i-\)th word in the caption sequence y generated for image I.
During training, the original grid features of images are obtained following the operation in [13]. Recent works usually flatten the grid features and then encode them directly with a Transformer encoder, which fails to capture the relationship between the image grids. Therefore, to take advantage of the more readily available grid features without losing position information, the augmented grid image feature [14] is exploited as the visual representation in our work.
Specifically, the image encoder outputs the original grid feature \(F_o\in {{\mathbb {R}}^{(h\times {w})\times {2048}}}\) with grid size \(h\times {w}\). To adapt the original gird feature to our method, \(F_o\) is projected to \(F_d\in {{\mathbb {R}}^{(h\times {w})\times {d}}}\) \((d = 512)\) via a linear network with a ReLU activation and dropout layer, which can be written as
where \(f_{d(i)}\in F_d\), \(f_{o(i)}\in F_o\) are the ith elements of \(F_d\) and \(F_o\), respectively. p is the dropout rate, and B(p) denotes a binomial probability distribution function with a probability of p. \(W_o\in {\mathbb {R}}^{2048\times d}\) is the weights matrix, and b is the bias term.
Following [14, 56], each grid can be specified with a triple \(\left( (x_i, y_i), w_i, h_i\right) \), where \((x_m, y_m)\) is the center coordinates of the grid m. Additionally, w and h denote the width and height of the grid m. And the relational vector \(R(m,n)\in {\mathbb {R}}^{(h\times w)\times (h\times w)\times 4}\) between grid m and n are determined with
Then, a 4-dimensional relational vector R(m, n) is casted to \(R_h(m,n)\in {\mathbb {R}}^{(h\times w)\times (h\times w)\times d_h}\) with a high dimension \(d_h\) through a linear projection layer with learnable matrix \(W_h^T\) and bias \(b_h\) as
and we compute the relational features \(R_f(m,n)\in {\mathbb {R}}^{(h\times w)\times (h\times w)}\) between grid m and n with the weights matrix \(W_g^T\) and the ReLU activation function by
To capture the message of the relative position between the grids, the relational features \(R_f\) are delivered to the attention mechanism as a bias term to figure out the relational attention weights \(A_R\), which can be defined as
where Q, K, and V are relational query, key, and value matrices obtained by projecting the processed grid feature \(F_d\). \(W_Q\), \(W_K\), and \(W_V\) are learnable weight parameters, while \(d_k\) is a scaling factor. Then, the relational attention weights \(A_R\) of the image grids are involved in \(F_d\) to obtain the augmented grid feature \(F_f\)
For the text, there are two ways to characterize the word sequence depending on the subsequent modules. In particular, as for the input of the Transformer-based multi-modal fusion module, a linear embedding layer combined with the positional embedding is utilized to turn the word sequence into a d-dimensional word embedding \(S_e\in {\mathbb {R}}^{L\times d}\). As for the input of the captioning module, we leverage the text encoder based on the BERT language model [26] for linguistic feature extraction. Figure 2 shows the structure of the text encoder in our captioning model, where the pre-trained BERT BERT(.) is employed to extract the textural features, and the masked multi-head attention MMHA(.) is for preventing the information leakage of subsequent words. To train the text encoder, an additional feed-forward network is added at the end of the masked multi-head attention module for sequence prediction.
During training, for a given word sequence \(S = (<bos>, s_1,s_2,...,s_L)\) of text T, the text encoder is fine-tuned with cross-entropy loss to predict the target sequence \(S^* = (s^*_1,s^*_2,...,s^*_L, <eos>)\). This operation can be expressed by
where \(L_f\) is the language feature output by the pre-trained BERT and \(P_s\) is the positional embedding of the word sequence S. \(W_{s1}\) and \(W_{s2}\) are learnable weights matrices, and \(b_{s1}\) and \(b_{s2}\) are bias terms. In this paper, the output \(T_f\) of the tuned text encoder is used as the linguistic feature to represent the text T.
Feature queries

The structure of the feature interaction module. We first align feature queries c and augmented grid features \(F_f\) through a linear layer. Then, to capture the interdependencies of the inputs, we cross-attend c and \(F_f\) in both the spatial and channel domains to obtain the position and scale factor for information interaction. Finally, feature queries c is projected into the parameter space to incorporate joint embedding \(A_{FeiM}\)
Although the augmented grid features enable global representations to carry spatial information, they lose most of the local details. In this paper, we investigate employing a small number of learnable vectors as feature queries, and it works as the local visual signals to compensate for the failure of augmented grid features in capturing relevant visual details from both spatial and channel domains.
Feature query is derived from the idea of the prompt that is used for inducing the pre-trained language models to produce the next word tokens [39]. Earlier works [40, 41] attempt to develop hand-crafted prompts, which is quite time-consuming and requires knowledge of specific fields. In comparison with the hand-crafted prompt, the automatic prompt is more flexible and efficient to the model. For example, Jiang et al. [41] employed the mining and paraphrasing-based method to generate high-quality and diverse candidate prompts, and the one with the highest accuracy on the training dataset was selected as the final prompt. Shin et al. [42] developed an automated prompt-generating method based on a gradient search, which was friendly to multi-tasks. Taking inspiration from CoOp [43], we resort to learnable tokens as feature queries to query visual clues that are beneficial to the task from global grid features, as expressed in Eq. (12)
where \(c_i\in {\mathbb {R}}^d\), and n is the number of tokens in the feature queries to be learned. Note that there are three groups of feature queries in FeiM that share the same parameters, as Fig. 3 shows. Two groups associated with augmented grid features pass through the feature interaction module to calculate the cross-attention maps. The other group is transformed to the parameter space via a linear function in the backend of the feature interaction module.
Feature interaction module
We introduce a feature interaction module to insert feature queries into the Transformer-based captioning architecture, which cross-attends the feature queries and the augmented grid visual features to learn the interconnections on the spatial and channel dimensions. Therefore, the refined visual features can be obtained for the subsequent Transformer-based multi-modal fusion module to output the multi-modal signals.
Inspired by [44], to achieve feature interaction between the feature queries and augmented grid visual representations, we present a feature interaction module consisting of the cross-attention mechanism and linear mapping networks, as Fig. 3 illustrates. In the feature interaction module, to enable the model to process feature queries with different semantic meanings, we align the feature queries c and augmented grid features \(F_f\) through a linear layer. Then, we cross-attend c and \(F_f\) in both the spatial and channel domains to obtain the position and scale factor for information interaction.
Recall that the self-attention and cross-attention mechanism in the Transformer block involve Q, K, and V embedding matrices. Q and K are employed to explore the interaction between tokens determining the probability distribution over V. According to the cosine similarity between queries and the keys, the weighted average of the value vectors is calculated with the attention mechanism.
In the spatial domain, the feature queries are regarded as the query \(Q_{sp}\in {\mathbb {R}}^{n\times d}\), while the key \(K\in {\mathbb {R}}^{(h\times w)\times d}\) and value \(V\in {\mathbb {R}}^{(h\times w)\times d}\) stem from augmented grid features \(F_f\)
And then, the cross-attention map \(Att_{sp}\in {\mathbb {R}}^{n\times (h\times w)}\) in the spatial domain is calculated with the softmax operation as
The scale vector \(S\in {\mathbb {R}}^{n\times 1}\) is obtained by a linear layer with the learnable weights \(W_{sp}\in {\mathbb {R}}^{(h\times w)\times 1}\)
where \(W_{sp}\in {\mathbb {R}}^{(h\times w)\times 1}\), \(W_{sq}\), \(W_{sk}\), and \(W_{sv}\in {\mathbb {R}}^{d\times d}\). Then, \(M_{FeiM}\) embedded with scale knowledge can be calculated via multiplication between the scale vector S and value V by
In the channel domain, a new query \(Q_{ch}\in {\mathbb {R}}^{(h\times w)\times d}\) corresponding to the feature queries is calculated using a linear function with parameter \(W_{cq}\), and we keep K and V the same as the ones in the spatial domain. Then, we cross-attend the feature queries c and augmented grid features \(F_f\) to calculate the channel-wise cross-attention map \(Att_{ch} \in {\mathbb {R}}^{d\times d}\)
The updated value \(V'\) is obtained by multiplying \(Att_{ch}\) and V
Then, an adaptive average pooling AP(.) is applied to transform \(V'\) into a position vector \(P_{FeiM}\in {\mathbb {R}}^{1\times d}\), which can be formulated as
The joint embedding \(A_{FeiM}\) incorporated with position and scale knowledge captured from the local query signals and augmented grid representations is obtained through the following calculation:
Then feature queries c are projected into the parameter space to incorporate with \(A_{FeiM}\) via learnable factors \(\alpha \in {\mathbb {R}}^{1\times d}\) and \(\beta \in {\mathbb {R}}^{1\times d}\) in the backend of the feature interaction module, with \( O_{FeiM}\) as the final output of the proposed feature interaction module. This process can be defined as
where \(LN(A_{FeiM})\) represents the layer normalization operation for \(A_{FeiM}\), and \(E[A_{FeiM}]\) and \(Var[A_{FeiM}]\) are the mean and standard deviation of \(A_{FeiM}\), respectively. \(\epsilon \) is a small constant, \(\gamma \) and \(\lambda \) are learnable affine transform parameters. And the incorporation parameters \(\alpha \) and \(\beta \) for feature queries can be learned with linear functions. \( O_{FeiM}\) is the output of the feature interaction module. In practice, we stack N feature interaction modules for FeiM, and the output of the last module is used to reduce the modality gap by propagating the refined and expressive features from the feature queries and augmented grid visual representation in the Transformer-based multi-modal fusion module.
This cross-attention-based feature interaction method models the interactions between augmented grid features (\(F_f\)) and feature queries (c) to obtain the refined and expressive visual representation (\(A_{FeiM}\)), which absorbs the information from both the global visual features and the feature queries with local properties, thus enabling the captioning model to generate accurate and high-quality captions. Moreover, the feature interaction module is plug-and-play and can be easily and flexibly used in other captioning models.
Transformer-based multi-modal fusion module
Transformer performs well in incorporating the knowledge from different modalities, because it can capture long-range dependencies in the data. Consequently, referring to \(M^2\) Transformer [30], we apply a Transformer-based module for multi-modal fusion. Typically, the module is an encoder–decoder framework with stacked encoder and decoder layers.
The encoder takes the output \(O_{FeiM}\) of the feature interaction module as its input to learn the high-level relationship between visual features via self-attention. The decoder integrates both the output of the last encoder layer and the text embedding with position encoding via cross-attention to fuse the information from visual and textual modality, and to improve the understanding of the vision and language. In our FeiM, we take the output \(M_f\) of the Transformer decoder \(TMFM_{dec}(.)\) in the multi-modal fusion module, and the output \(V_f\) of the last Transformer encoding layer \(TMFM_{enc}(.)\) in the multi-modal fusion module as the multi-modal and visual signals, respectively
Captioning module
Typically, the hidden state of the current word can be generated by incorporating visual information with the guidance of linguistic representations. However, the contribution of the vision and language signals to the currently generated token is confusing, leading to the inconsistency between the generated word and the signal that should be given more attention. Therefore, we apply adaptive attention to the captioning module to address the problem by simultaneously attending to the visual and linguistic signals. The captioning module is used to transform the visual \(V_f\), linguistic \(T_f\), and multi-modal \(M_f\) signals to adaptive attention score \(S_{aam}\) for word generation with the adaptive attention mechanism, which can be expressed by
The attention weights \(Aam^i\) of the word sequence for the ith head is written as
\(Aam^{(i,t)}\) is the attention weights of the tth time step for the ith attention head
where \(Q_{aam}^{(i, t)}\) is the query of the ith head in the multi-head attention for the tth time step, obtained from the multi-modal signal \(M_f\) with parameter \(W_{aq}^i\). \(K_{aam}^{(i, t)}\) and \(V_{aam}^{(i, t)}\) are the key and value of the ith head in the multi-head attention for the tth time step, respectively, both derived from the combination \(C_f\) of visual and linguistic representations. [; ] refers to the concatenation operation, and \(T_f^t\) is the linguistic representation in the tth time step.
Training and inference
We optimize the proposed captioning model FeiM following the standard practice. First, cross-entropy loss [45, 46] is employed to calculate the probability distribution difference between the target word sequences and the predicted ones. The calculation of the cross-entropy loss can be written as
where \(\theta \) is the parameters of FeiM, \(y^*= \{y^*_1,..., y^*_T\}\) is the ground-truth caption and the probability distribution P is obtained from the language model. In each time step of the training, although the cross-entropy loss maximizes the probability of each word in the target caption sequence at the word level, it ignores the long-range dependencies between the generated words.
The CIDEr metric [51] is commonly leveraged to evaluate the information and fluency of sentences; thus, it is taken as the reward and FeiM is further optimized with self-critical sequence training [23]. It is a sentence-level training strategy that aims to remedy the flaw of the word-level cross-entropy training loss. To update the loss gradient, following [30], we leverage the average of rewards instead of greedy decoding to determine the baseline of rewards. The calculation of the loss gradient is defined as follows:
where \(y^i\) is the ith sampled sentence, bs is the reward baseline of the sentence, and re(.) is the reward function depending on the CIDEr score.
Experiment
To validate the effectiveness of the proposed approach FeiM, we first evaluate it on the MSCOCO benchmark. Then, a series of ablation studies is performed to confirm the contribution of each designed part of FeiM.
Dataset
MSCOCO [47] is one of the most widely used large-scale datasets for image captioning. Typically, the dataset is made up of more than 120,000 images with about five different English annotations for each image, including 82,783 images for training, 40504 for validation, and 40,775 for testing. In practice, due to the non-public annotations of the testing images, the training and the validation images are usually re-divided according to the Karpathy split [2] setting. Correspondingly, 5000 images are leveraged for testing, 5000 for validation, and the others for training. In our experiments, we follow the Karpathy split for a fair comparison with the existing captioning approaches. Besides, the sentences in the annotated captions are converted to lowercase, all punctuation marks and words that appear less than five times are removed, and a vocabulary of 10,201 words is formed.
Evaluation metrics
We adhere to the standard evaluation protocol, where BLEU (B) [48], METEOR (M) [49], ROUGE (R) [50], CIDEr (C) [51], and SPICE (S) [64] metrics are adopted to measure the performance of image captioning task. Specifically, BLEU (including BLEU-1, BLEU-2, BLEU-3, and BLEU-4) enables quick and simple automatic evaluation for image captioning. METEOR deeply analyzes the word order and is more aligned with human judgments. ROUGE is extensively applied to examine the sufficiency and authenticity of the generated sentence. CIDEr is based on consensus and attaches more significance to descriptions with salient image content. SPICE analyzes the semantic content of the predicted captions to determine the generation quality. In general, the higher the four evaluation metrics, the better the generated language descriptions.
Experimental setup
We mainly follow the implementation of [13, 14] and [30]. The visual features with a grid size of \(7\times 7\) \((h=w=7)\) and a dimension of 2048 for the input images are first extracted, and then, according to [14], we obtain the 512-dimensional augmented grid representations. In our experiment, the number of learnable tokens in the feature queries is set as 1, and the number of feature interaction modules is 4. In addition, we stack 4 Transformer blocks in FeiM, and the dimensionality d of each Transformer layer is 512 with 8 attention heads. We employ the Adam [65] optimizer, the dropout with probability 0.1, the batch size of 50, and the beam size of 5 to train the captioning model FeiM. The evolutionary algorithms [66] also help us to determine some parameters.
In terms of the cross-entropy training, we apply the epoch decay schedule in [14], as defined in Eq. (34), to change the learning rate with the base learning rate \(lr_b = 1e-4\). During training, the learning rate lr changes based on the current training epoch number \(n_e\). For the self-critical sequence training based on reinforcement learning, we resort to the CIDEr score as the reward and use a fixed learning rate of \(5e-6\)
Normally, we start the optimization for FeiM with cross-entropy loss and then adopt the self-critical sequence training once the CIDEr metric declines for 5 continuous epochs. When the CIDEr metric falls continuously for 5 epochs during self-critical sequence training, the entire training process is finished.
Quantitative analysis
Comparisons with state-of-the-arts
The comparison methods include Up-Down [33], GCN-LSTM [52], SGAE [53], AoANet [54], Transformer [32], X-Transformer [31], and RSTNet [14]. For clarity, the Up-Down [33] approach utilized two LSTM layers combined with bottom–up and top–down attention mechanisms to boost the performance. In GCN-LSTM [52], the graph convolutional neural network was leveraged to obtain visual representations from the spatial and semantic relationships of the scene graphs, and in [53], a scene graph auto-encoder was used. In [54], the Attention on Attention (AoA) approach further analyzed the relevance between the queries and attention results by extending the traditional attention methods. In terms of the Transformer-based captioning model, Sharma et al. [32] demonstrated that the captioning model based on Transformer architecture for sequence modeling was able to achieve the best performance. Furthermore, in X-Transformer [31], a bilinear pooling was applied to a basic Transformer’s attention module. Zhang et al. [14] developed a relationship-sensitive Transformer-based image captioning model to fuse the spatial information of the visual representations.
The performance comparisons between FeiM and a series of powerful image captioning baselines on the MSCOCO Karpathy split under the cross-entropy training are reported in Table 1. Under the cross-entropy loss optimization setting, FeiM outperforms all the other approaches on all the metrics except METEOR. Then, we compare FeiM with more state-of-the-art models on the MSCOCO Karpathy test split under the self-critical sequence training, where expressive information embedded in grid representations is utilized with CIDEr score optimization, as Table 2 summarizes. We can observe that our approach excels all the other advanced approaches across all the evaluation metrics. It should be noted that FeiM achieves the CIDEr score of 135.2, surpassing the previous Transformer-based approaches that employ the cross-attention mechanism to boost the interaction between vision and language. Specifically, FeiM outperforms the \(M^2\) Transformer [30], X-Transformer [31], and RSTNet [14] by 4.0%, 2.4%, and 1.9% CIDEr score, respectively. The results demonstrate the positive meaning of incorporating the feature queries and feature interaction module into the Transformer-based captioning model. Besides, FeiM is superior to the RNN-based captioning models, such as the Up–Down [33] and GCN-LSTM [52] approach, with FeiM sharply improving the CIDEr metric by 15.1% and 7.6%, respectively.
Notably, FeiM not only comprehensively outperforms its corresponding counterparts RSTNet with the same grid features, but also outperforms \(M^2\) Transformer and X-Transformer with fine-grained region features by a decent margin across all metrics. The comparison results against the state-of-the-art approaches indicate the effectiveness of FeiM for caption generation. We explain the reasons why our grid-level Transformer-based model yields better performance than the region-level ones from the following aspects. On the one hand, the region-based visual features are usually extracted from the prominent parts of the image; thus, meaningful information of the overall context in the region features is missing, failing to capture robust global representations and accurate relationships between regions. On the other hand, even though global grid representations are employed in our proposed approach FeiM, we incorporate a small number of learnable feature queries and the feature interaction module to capture more expressive visual concepts.
Comparisons with state-of-the-arts on the same ResNet101 grid features
We compare FeiM against other state-of-the-art approaches on the same ResNet101 grid features to exclude the impact of various visual representations. As illustrated in Table 3, FeiM unsurprisingly still outperforms the state-of-the-art approaches with ResNet101 grid visual features in terms of most evaluation metrics, which shows the strong ability of FeiM to understand the image and generate high-quality descriptions.

Examples of image captioning results generated by the proposed FeiM and the corresponding ground-truth captions
Qualitative analysis
We give several examples of the original image, three human-annotated ground-truth captions (GT), and the captions produced with our proposed approach FeiM in Fig. 4. Intuitively, the description for the given image generated by FeiM are very close to the human-annotated captions, demonstrating the effectiveness and superiority of FeiM from a qualitative perspective.
Ablative analysis
To explore the impact of the feature queries, the feature interaction module, and the best parameters for FeiM, we perform a series of ablation studies to assess the performance of our approach on the MSCOCO Karpathy test split.

Ablation studies on the number of the attention heads
Effect of the feature queries and feature interaction module
We begin by varying the different components of our method FeiM to investigate the impact of the feature queries and feature interaction module. The captioning model with the same configuration but without the feature queries and feature interaction module is regarded as the baseline. As is shown in Table 4, for setting (a), we first insert the feature interaction module into the baseline captioning model. In comparison with the baseline, setting (a) showcases that the feature interaction module is beneficial to generate better descriptions. In setting (b), we remove the feature interaction module and add the feature queries into the baseline model. Compared with the results in setting (a), setting (b) demonstrates that the feature queries play a more powerful role in the Transformer-based captioning model than the feature interaction module. Setting (c) is our full model FeiM, which achieves significantly better performances than its variants, with performance gains of 2.3% and 9.6% on the BLEU-1 and CIDEr scores compared with the baseline. This indicates that our feature queries and feature interaction module enable better captioning performance by promoting each other.
In general, when adding different components, the proposed FeiM presents consistent improvements over the baseline, suggesting that both the feature queries and feature interaction module are effective for achieving superior captioning generation.
Effect of the number of the feature queries tokens
We then conduct experiments by varying the number of learnable tokens to explore the best length of the feature queries. Due to limitations in computing resources, we set the number of the feature query tokens to no more than the grid size \(7\times 7=49\), and the minimum number of the tokens is 1. As reported in Table 5, we could find that the captioning performance does not keep improving when we further increase the number of the feature queries tokens, which is also observed in [62] and [63]. Specifically, when the number of feature query tokens is 49, noisy information is more likely absorbed in the visual representations, resulting in the performance drop of the captioning model. Therefore, we set the number of the learnable tokens in the feature queries to 1 for our experiments.
Effect of the stacked number of the feature interaction module
The feature interaction module is stacked to propagate expressive messages from the local query signals and global augmented grid visual representation, by incorporating the feature queries into the aligned hidden space from the spatial and channel dimensions via learnable factors \(\alpha \) and \(\beta \). To study the influence of the feature interaction module, we change the stacked number N of the feature interaction module. Similarly, due to limitations in computing resources, we only perform six sets of experiments on the number of stacked feature interaction modules. From Table 6, we could observe that by increasing N from 1 to 4, all the evaluation metrics are gradually increasing, and then, a drop is observed when increasing N from 5 to 6. The main reason may lie in that appropriate feature interaction modules encourage the expression of the grid visual features, but too much of them can lead to the overfitting of the model, degrading the captioning performance. Therefore, we stack four feature interaction modules in FeiM to make the most of the grid features.
Effect of the number of the attention heads and transformer blocks in our FeiM
We evaluate FeiM with different numbers of attention heads and Transformer blocks. We first fix the number of Transformer blocks to determine the best number of the attention heads. The results are shown in Fig. 5. As the number of attention heads increases from 4 to 12, the performance of FeiM improves and then decreases. Notably, FeiM obtains the best results on all metrics when the number of attention heads is set to 8. To choose the best number of Transformer blocks, we carry out a series of experiments by setting FeiM with different Transformer blocks ranging from 1 to 6, respectively. From Fig. 6, we can observe that the performance of image captioning gradually improves as the number of Transformer blocks increases from 1 to 4, but too many Transformer blocks will lead to performance degradation. Clearly, stacking 4 Transformer blocks shows superior performance on the CIDEr metric, thus, we stack 4 Transformer blocks for our FeiM if not specified.

Ablation studies on the transformer blocks
Conclusion
In this paper, we design feature queries and feature interaction modules for Transformer-based image captioning, which exploits feature interaction and fusion to improve the understanding of the image with grid features. Specifically, we introduce a small number of learnable tokens and design feature queries to leverage the expressive information embedded in the grid-based visual representations. The feature queries serve as the local signals to query relevant visual clues from global grid features and promote the interaction of different modalities. Additionally, we present the feature interaction module to interact with feature queries and augmented grid features on the spatial and channel dimensions. By incorporating the feature queries and feature interaction module into a Transformer-based captioning model, the experimental results on the MSCOCO dataset demonstrate the effectiveness and superiority of our FeiM over the current cutting-edge models. We also carry out extensive ablative experiments to further validate the impact of the two designed components, the number of the feature query tokens, the stacked number of the feature interaction modules on image captioning, etc. The novel and simple design of the feature queries and feature interaction module is plug-and-play and can be easily applied to other visual tasks as well.
Data availability
Data will be made available on request.
References
Fang H, Gupta S, Iandola F, Srivastava RK, Deng L, Dollar P, Gao J, He X, Mitchell M, Platt JC, Zitnick CL, Zweig G (2015) From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1473–1482
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3128–3137
Mao J, Xu W, Yang Y, Wang J, Huang Z, Yuille A (2015) Deep captioning with multimodal recurrent neural networks (m-rnn). In ICLR
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: a neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3156–3164
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems, pages 3104–3112
Vinyals O, Toshev A, Bengio S, Erhan D (2016) Show and tell: lessons learned from the 2015 MSCOCO image captioning challenge. IEEE Trans Pattern Anal Mach Intell 39(4):652–663
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning, pages 2048–2057
Cornia M, Baraldi L, Cucchiara R (2019) Show, control and tell: a framework for generating controllable and grounded captions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8307–8316
Mao J, Xu W, Yang Y, Wang J, Yuille AL (2014) Explain images with multimodal recurrent neural networks. arXiv preprint arXiv:1410.1090
Jiang W, Ma L, Jiang Y-G, Liu W, Zhang T (2018) Recurrent fusion network for image captioning. In Proceedings of the European Conference on Computer Vision, pages 499–515
You Q, Jin H, Wang Z, Fang C, Luo J (2016) Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4651–4659
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems, pages 91–99
Jiang H, Misra I, Rohrbach M, Learned ME, Chen X (2020) In defense of grid features for visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10267–10276
Zhang X, Sun X, Luo Y, Ji J, Zhou Y, Wu Y, Huang F, Ji R (2021) RSTNet: captioning with adaptive attention on visual and non-visual words. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 15465–15474
Farhadi A, Hejrati M, Sadeghi MA, Young P, Rashtchian C, Hockenmaier J, Forsyth D (2010) Every picture tells a story: generating sentences from images. In Proceedings of the European Conference on Computer Vision, pages 15–29
Gupta A, Verma Y, Jawahar CV (2012) Choosing linguistics over vision to describe images. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 606–612
Ordonez Vicente, Kulkarni Girish, Berg Tamara (2011) Im2text: describing images using 1 million captioned photographs. Adv Neural Inform Process Syst 24:1143–1151
Kulkarni G, Premraj V, Ordonez V, Dhar S, Li S, Choi Y, Berg AC, Berg TL (2013) Babytalk: understanding and generating simple image descriptions. IEEE Trans Pattern Anal Mach Intell 35(12):2891–2903
Mitchell M, Dodge J, Goyal A, Yamaguchi K, Stratos K, Han X, Mensch A, Berg A, Berg T, Daume H (2012) III. Midge: generating image descriptions from computer vision detections. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, pages 747–756
Ushiku Y, Yamaguchi M, Mukuta Y, Harada T (2015) Common subspace for model and similarity: Phrase learning for caption generation from images. In Proceedings of the IEEE International Conference on Computer Vision, pages 2668–2676
Li X, Liu Y, Wang K, Wang F-Y (2020) A recurrent attention and interaction model for pedestrian trajectory prediction. IEEE/CAA J Autom Sinica 7(5):1361–1370
Liu P, Zhou Y, Peng D, Dapeng W (2020) Global-attention-based neural networks for vision language intelligence. IEEE/CAA J Autom Sinica 8(7):1243–1252
Rennie SJ, Marcheret E, Mroueh Y, Ross J, Goel V (2017) Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7008–7024
Zhou T, Chen M, Zou J (2020) Reinforcement learning based data fusion method for multi-sensors. IEEE/CAA J Autom Sinica 7(6):1489–1497
Seo PH, Sharma P, Levinboim T, Han B, Soricut R (2020) Reinforcing an image caption generator using off-line human feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, 34(3): 2693–2700
Devlin J, Chang M.-W, Lee K, Toutanova K (2018) “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv: 1810.04805
Zhang P, Li X, Hu v, Yang J, Zhang L, Wang L, Choi Y, Gao J (2021) VINVL: revisiting visual representations in vision-language models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5579–5588
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008
Li G, Zhu L, Liu P, Yang Y (2019) Entangled transformer for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, pages 8928–8937
Cornia M, Stefanini M, Baraldi L, Cucchiara R (2020) Meshed-memory transformer for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10578–10587
Pan Y, Yao T, Li Y, Mei T (2020) X-linear attention networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10971–10980
Sharma P, Ding N, Goodman S, Soricut R (2018) Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pages 2556–2565
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6077–6086
Datta S, Sikka K, Roy A, Ahuja K, Parikh D, Divakaran A (2019) Align2Ground: weakly supervised phrase grounding guided by image-caption alignment. In Proceedings of the IEEE International Conference on Computer Vision, pages 2601–2610
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9
Wu Q, Shen C, Liu L, Dick A, Hengel A van den (2016) What value do explicit high level concepts have in vision to language problems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 203–212
Lu J, Xiong C, Parikh D, Socher R (2017) Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 375–383
Herdade S, Kappeler A, Boakye K, Soares J (2019) Image captioning: Transforming objects into words. In Advances in Neural Information Processing Systems, pages 11137–11147
Qiu L, Zhang R, Guo Z, Zeng Z, Li Y, Zhang G (2021) VT-CLIP: enhancing vision-language models with visual-guided texts. arXiv preprint arXiv: 2112.02399
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, Krueger G, Sutskever I (2021) Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Pages 8748–8763
Jiang Z, Xu FF, Araki J, Neubig G (2020) How can we know what language models know? Transactions of the Association for Computational Linguistics, pages 423–438
Shin T, Razeghi Y, Logan RL IV, Eric W, Sameer S (2020) Autoprompt: eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980
Zhou K, Yang J, Loy CC, Liu Z (2022) Learning to prompt for vision-language models. Int J Comput Vis 130(9):2337–2348
Zhu Y, Liu H, Song Y, Yuan Z, Han X, Yuan C, Chen Q, Wang J (2022) One model to edit them all: Free-form text-driven image manipulation with semantic modulations. In Advances in Neural Information Processing Systems, pages 25146–25159
Kim D-J, Choi J, Oh T-H, Kweon IS (2019) Dense relational captioning: Triple-stream networks for relationship-based captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6271–6280
Wang S, Lan L, Zhang X, Dong G, Luo Z (2020) Object-aware semantics of attention for image captioning. Multimed Tools Appl 79(3):2013–2030
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, pages 740–755
Papineni K, Roukos S, Ward T, Zhu W-J (2002) Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318
Banerjee S, Lavie A (2005) Meteor: an automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72
Lin C-Y (2004) Rouge: a package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81
Vedantam R, Zitnick CL, Parikh (2015) Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4566–4575
Yao T, Pan Y, Li Y, Mei T (2018) Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision, pages 684–699
Yang X, Tang K, Zhang H, Cai J (2019) Auto-encoding scene graphs for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10685–10694
Huang L, Wang W, Chen J, Wei X-Y (2019) Attention on attention for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, pages 4634–4643
Yang X, Gao C, Zhang H, Cai J (2021) Auto-parsing network for image captioning and visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, pages 2197–2207
Guo L, Liu J, Zhu X, Yao P, Lu S, Lu H (2020) Normalized and geometry-aware self-attention network for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10327–10336
Zha Z-J, Liu D, Zhang H, Zhang Y, Feng W (2019) Context-aware visual policy network for fine-grained image captioning. IEEE Trans Pattern Anal Mach Intell 44(2):710–722
Yang X, Zhang H, Qi G, Cai J (2021) Causal attention for vision-language tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9847–9857
Wang Y, Xu J, Sun Y (2022) A visual persistence model for image captioning. Neurocomputing. https://doi.org/10.1016/j.neucom.2021.10.014
Zhang Z, Qiang W, Wang Y (2021) and Fang Chen. Exploring pairwise relationships adaptively from linguistic context in image captioning, IEEE Transactions on Multimedia, pp 3101–3113
Ma Y, Ji J, Sun X, Zhou Y, Ji R (2023) Towards local visual modeling for image captioning. Pattern Recognit 138:109420
Li Xiang L, Liang P (2021) Prefix-tuning: optimizing continuous prompts for generation. In Proceedings of ACL
He J, Zhou C, Ma X, Berg-Kirkpatrick T, Neubig G (2022) Towards a unified view of parameter-efficient transfer learning. In ICLR
Anderson P, Fernando B, Johnson M, Gould S (2016) Spice: semantic propositional image caption evaluation. In Proceedings of the European Conference on Computer Vision, pages 382–398
Kingma DP, Ba J (2015) Adam: a method for stochastic optimization. In Proceedings of the International Conference for Learning Representations
Chauhan S, Singh M, Aggarwal AK (2021) Experimental Analysis of Effect of Tuning Parameters on The Performance of Diversity-Driven Multi-Parent Evolutionary Algorithm. 2021 IEEE 2nd International Conference On Electrical Power and Energy Systems (ICEPES), pages 1–6
Acknowledgements
The National Natural Science Foundation of China under Grant No. 61806218, the National Key Research and Development Program of China under Grant No. 2021YFB3100800, and the Ministry of Science and Technology of China under Grant No. 2020AAA0108800 which all provided financial support for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that we have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yan, J., Xie, Y., Guo, Y. et al. Exploring better image captioning with grid features. Complex Intell. Syst. 10, 3541–3556 (2024). https://doi.org/10.1007/s40747-023-01341-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01341-8