
Abstract
During the flyby mission of small celestial bodies in deep space, it is hard for spacecraft to take photos at proper positions only rely on ground-based scheduling, due to the long communication delay and environment uncertainties. Aimed at imaging properly, an autonomous imaging policy generated by the scheduling networks that based on deep reinforcement learning is proposed in this paper. A novel reward function with relative distance variation in consideration is designed to guide the scheduling networks to obtain higher reward. A new part is introduced to the reward function to improve the performance of the networks. The robustness and adaptability of the proposed networks are verified in simulation with different imaging missions. Compared with the results of genetic algorithm (GA), Deep Q-network (DQN) and proximal policy optimization (PPO), the reward obtained by the trained scheduling networks is higher than DQN and PPO in most imaging missions and is equivalent to that of GA but, the decision time of the proposed networks after training is about six orders of magnitude less than that of GA, with less than 1e−4 s. The simulation and analysis results indicate that the proposed scheduling networks have great potential in further onboard application.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Flyby is one of the most effective ways to explore celestial bodies in deep space. Employing different instruments and methods, valuable scientific data are obtained during the flyby operation of celestial bodies. In this way, missions like Galileo [1], Deep Space 1 [2] and Rosetta [3] have uncovered crucial information about the celestial bodies and made better known of our solar system.
The science acquisition phase generally refers to the period of several hours around the closest approach (CA) to small celestial body during the flyby operation [4]. Currently, optical imaging technique is one of the most useful methods to obtain scientific data of the celestial body in this phase, where the quality of photo is mainly affected by the resolution of camera, illumination condition and relative distance between the spacecraft and celestial body. In previous flyby missions, the imaging strategy is designed and modified by the support teams on ground according to the observation data on ground and onboard before the science acquisition phase [4, 5]. Then, instructions with time tag will be injected to the spacecraft and executed at the pre-defined time in science acquisition phase. This scheduling mode with man in-loop is suitable for flyby missions near Earth, as the communication delay is small and the accuracy of the flyby trajectory propagated by the guidance, navigation and control (GNC) system is enough.
However, there are several limitations of the traditional mode in the coming flyby scenarios of further small celestial bodies in deep space. On the one hand, large communication delays and low data transmission rate would greatly reduce the time for scheduling on ground, which puts a heavy burden on the measurement and control operators. On the other hand, the probability of data loss and the uncertainty of the environment are increased as the spacecraft flying away from Earth, which may lead to a bad performance of the strategy designed on ground. The above factors make it hard, even impossible for previous scheduling mode to implement in deep space flyby scenarios. Thus, autonomous imaging method is urgently needed for the requirements of future flyby missions in deep space, as it can timely generate the imaging strategy onboard according to the observation of instruments and provide a robust performance against the uncertain dynamics of environment.
The machine learning (ML) [6] technique has received widely attention in recent decades as a representative of artificial intelligence, and techniques based on different types of artificial neural networks have developed rapidly at the same time [7,8,9]. Among three main branches of the machine learning, reinforcement learning (RL) as well as the subsequently developed deep reinforcement learning (DRL) have natural advantages in decision-making scenarios, and they have been widely investigated in fields like robot path planning [10, 11], unmanned aerial vehicle planning and control [12,13,14], games [15,16,17] and mobile edge computing [18]. With well training, their excellent performance even surpasses the top human experts.
In the spacecraft domain, some scholars utilize the decision-making ability of RL and DRL technique in trajectory design and attitude control for surface landing on celestial bodies [19,20,21,22], while others apply it to satellite mission planning and scheduling. In the aspect of high-level mission planning for spacecraft, Harris et al. [23] designed an autonomous planner for mode execution sequence based on deep Q-network (DQN), where the operation of spacecraft was divided into a combination of several modes. The autonomous planner performed well in simulation scenarios of orbit insertion and science station keeping, respectively. Considering the security problem of stochastic policy adopted by agents in exploration, Harris et al. [24] proposed the correct-by-construction shield synthesis method to make the action chosen by agent away from the dangerous boundary. For the scheduling problem of AEOS, Wang et al. [25] proposed DRL-based scheduling networks for the mission arrangement of Earth observation satellites. Comparing with other heuristic algorithms like genetic algorithm (GA) and direct dynamic insert task heuristic (DITH), the proposed networks showed great performance with short response time in simulation. Focus on the single spacecraft, multiple ground stations AEOS scheduling problem, Herrmann et al. [26] formulated this problem in Markov decision process (MDP) and utilize neural networks regression of the state-action value generated by Monte Carlo tree search (MCTS). The trained neural networks demonstrated match or exceed performance of MCTS with six orders of magnitude less execution time. A further discussion about relationship between the performance and size of action space, and a new backup operator as well as wider search of hyperparameters in neural networks were investigated in [27, 28], respectively.
Focused on the scheduling problem of mapping celestial bodies, Chen et al. [29] relaxed several assumptions made by [30] and utilized the REINFORCE algorithm in autonomous imaging and mapping of small celestial bodies modeled under partially observable Markov decision process (POMDP) frame. The imaging and mapping policy trained with REINFORCE outperformed the random choose method and showed generalization ability in new scenarios with no additional training. Piccinin et al. [31, 32] developed a DRL-based decision-making policy for increasing the mapping efficiency and enhancing the shape model reconstruction of small celestial bodies. These literatures investigated the autonomous imaging strategy of small celestial bodies, but they mainly focus on the surrounding scenario rather than the flyby scenario. In these literatures, there are several imaging windows for the spacecraft to take photos and the relative distance between the spacecraft and the small celestial body is regarded as a constant. Different from the surrounding scenario, the imaging windows are much less and the relative distance is significantly changed in the science acquisition phase of flyby scenario. The relative distance variation leads to the change of imaging distance and may influence the quality of photos.
In this paper, autonomous scheduling networks based on Actor-Critic are proposed for the imaging scheduling problem in science acquisition phase of small celestial bodies flyby mission, where the objective of this networks is taking photos at proper positions to maximize the scientific reward. The main contribution of this paper is considering the influence of relative distance variation between the spacecraft and small celestial body to the quality of imaging photos in the science acquisition phase. More specifically, a novel reward function with the imaging distance, illumination condition and distribution of the sight of photos in consideration is designed. Two additional terms are also added in the reward function to encourage the scheduling networks to converge to a better imaging strategy. These two terms consider the phase angle of adjacent alternative points and the relationship of the obtained reward with respect to the average reward in current alternative point, respectively. After pre-training, the scheduling networks could utilize the observed data onboard as inputs and decide whether to take photo or not under current state within 1e−4 s, which is about six orders of magnitudes faster than the time cost of GA. Besides, the total scientific reward of imaging sequence obtained from the networks is comparable to the results globally optimized by GA.
This paper is organized as follows. In the next section, the imaging scheduling problem in scientific acquisition phase is described in the framework of Markov decision process. Then, the Actor-Critic based scheduling networks for determining imaging points are presented in the following section. The state and action space, reward function and structure of the networks are also given in this section. In the next section, the training process and simulation realization of the proposed networks are discussed. Following section deals with the validation of the capability of the scheduling networks. Simulation results in different imaging scenarios with several algorithms are compared, and the superiority of the proposed scheduling networks is validated. In the last section, the conclusion is drawn.
Problem description and mathematic statement
In this section, a brief introduction about the MDP is delivered and then the imaging scheduling problem in science acquisition phase is modeled under the MDP framework. Reinforcement learning and deep reinforcement learning are useful methods to cope with MDP through iteration. Thus, the basic thought and mathematic formulations of them are presented respectively.
Imaging scheduling problem modeled in the Markov decision process
The MDP is defined to make decisions sequentially for a stochastic process with the Markov property, which means that the next state \(s_{t + 1}\) is only decided on state \(s_{t}\) and action \(a_{t}\) in current time step. Generally, the MDP is formulated in a tuple with 5 elements: \(\left\langle {S, \, A, \, P, \, R, \, \gamma } \right\rangle\). Where \(S\) is the state space and \(A\) is the action space. \(P(s_{t + 1} |s_{t} , \, a_{t} )\) represents the transition probability to the new state \(s_{t + 1}\) based on current state \(s_{t}\) and action \(a_{t}\). \(R\) denotes the immediate reward obtained after doing action \(a_{t}\) at state \(s_{t}\). \(\gamma\) is the discount factor considering future reward and ranging in [0, 1]. The larger it is, the more long-term cumulative reward would be concerned.
To describe the scheduling problem under the MDP framework, some simplifications are adopted.
-
(1)
The flyby trajectory with error could be obtained by the GNC system before the science acquisition phase, thus we assume that the spacecraft knows its current time relative to the entire period in the science acquisition phase.
-
(2)
For the convenience of scheduling, we assume that alternative imaging points are discrete and evenly distributed in the propagated trajectory with a fixed time interval.
-
(3)
Considering that spacecraft attitude adjustments and long exposure time of instruments may be essential to take good photos in some conditions, we assume that at most one photo could be taken at each alternative point.
-
(4)
Taking into account the limited storage resource onboard, there is an upper bound to the number of imaged photos.
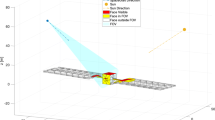
Based on former assumption, the target of imaging scheduling problem in science acquisition phase is to take photos at part of these points and maximize the cumulative scientific reward. The schematic diagram of scheduling problem in science acquisition phase is shown in Fig. 1.

The schematic diagram of scheduling problem in science acquisition phase. Where the black line is the flyby trajectory. The white points represent the alternative imaging points and locate on the flyby trajectory in an even distribution
Reinforcement learning and deep reinforcement learning
In reinforcement learning, the mapping relationship between state and action is established by the agent on account of interaction with the environment. At each time step \(t\), the agent receives a state \(s_{t}\) from the environment and chooses an action \(a_{t}\) according to a policy. Then, the environment generates a new state \(s_{t + 1}\) and an immediate reward \(r_{t + 1}\), which are used by the agent to decide the action in the next time step. Following this cycle, the policy is improved. Besides, a higher cumulative reward is obtained by the agent. The schematic diagram of reinforcement learning is shown in Fig. 2.

Schematic diagram of reinforcement learning
Q-value is defined to evaluate the quality of a certain action of the agent under a given state, and it is changed during the interaction between the agent and environment. Traditional RL algorithms mainly focus on problems with discrete state and action space, where the Q-value of state-action pairs are formulated in a Q-table in these cases. Considering that the scale of MDP in practical problems are generally large and low efficiency to solve directly, the Q-value of state-action pairs are generally solved by means of iteration, whose form is similar to Eq. (1). In Eq. (1), \(R(s_{t} , \, a_{t} )\) and \(Q(s_{t} , \, a_{t} )\) are the immediate reward of doing action \(a_{t}\) at state \(s_{t}\), and the Q-value of this state-action pair at time step \(t\), respectively. The meaning of other symbols is consistent with the former definition.
However, traditional RL algorithms perform bad in problem with high dimension of state or action space. It is difficult to converge as the size of Q-table becomes too large. The addition of deep neural networks (DNNs, artificial neural networks with multiple hidden layers) greatly enhances the nonlinear fitting ability of RL algorithms to calculate the Q-value, which enables these algorithms to deal with problems in continuous state and action space. The optimal policy \(\pi^{ * }\) is the policy with maximum Q-value, as shown in Eq. (2), where \({\varvec{\theta}}_{\pi }\) represents the hyperparameters of DNNs.
Actor-critic based autonomous imaging strategy
In this section, the imaging scheduling strategy is generated by the autonomous scheduling networks based on deep reinforcement learning. Actor-Critic is used here to deal with the continuous state space. The architecture of scheduling networks is introduced first, and then the state space, action space and reward function are presented successively. Finally, the structure as well as hyperparameters of neural networks used in Actor-Critic are given.
Architecture
The aim of the proposed autonomous scheduling networks is to decide the imaging points according to the observation data onboard. With limited computing resources available taking into account, it may be difficult to train the networks from scratch onboard. Thus, it is necessary to pre-train the scheduling networks on the ground under similar conditions. After well-training, hyperparameters inside the networks could be loaded or transmitted to the spacecraft before the science acquisition phase.
During the operation onboard, inputs of the scheduling networks come from the data measured by the GNC system and optical cameras. Before feeding into the networks, these data are pre-processed to only contain the most essential information like the relative distance and phase angle. Besides, the scientific reward of imaging at current alternative point is evaluated according to prior knowledge about the quality of photos with different illumination conditions, relative distance and some other factors. The model of prior knowledge is included in the reward of the scheduling networks and described in detail in "Reward function design of the scheduling networks". All of the pre-processed data and evaluated reward are formed into a vector of state and fed into the networks. Then, the scheduling networks decide whether to image at current alternative point or not according to the state. Two operation modes of the scheduling networks are considered in the architecture, the online mode and offline mode. In the online mode, hyperparameters inside the networks are updated with the iteration. While in the offline mode, hyperparameters inside the networks are fixed. The data flow of the scheduling networks operating onboard is shown in Fig. 3.

Data flow of the scheduling networks
State space and action space
To make the convergence of the scheduling networks easier, the state space is simplified to only contain the necessary information at each alternative imaging point, which consists of five parts: the distance state, angle state, reward state, storage state and time state. These states in the \(i{\text{th}}\) alternative point are defined as follows.
The distance state \(r(i)\) represents the relative distance between the spacecraft and small celestial body, as the angle state \([\alpha (i), \, \alpha_{{{\text{bin}}}} (i)]\) is a combination of phase angle and angle map. To quantify the influence of different illumination conditions, photos are divided into different bins according to their phase angle. Specific division criteria of phase angle are given in "Reward function design of the scheduling networks". The angle map \(\alpha_{{{\text{bin}}}} (i)\) records the coverage condition of each bin of phase angle. As former mentioned, the data of distance state and angle state come from onboard measurement. The reward state \({\text{Reward}}(i)\) and storage state \({\text{Stor}}(i)\) represent the immediate reward of imaging at the \(i{\text{th}}\) point and how much storage resource have been occupied before current point, respectively. The time state \({\text{time}}(i)\) is the moment of the \(i{\text{th}}\) point, which helps the scheduling networks better understand the process of the whole science acquisition phase. All of these states in state space are gathered into a 6 × 1 vector: \([r(i), \, \alpha (i), \, \alpha_{{{\text{bin}}}} (i),{\text{ Rewar}}d(i),{\text{ Stor}}(i),{\text{ time}}(i)]\), and sent to the scheduling networks as input. To facilitate the convergence of the networks, normalization of these states is implemented during the training and validating process in simulation.
The action space consists of actions that could be executed at current alternative point, which is also the set of potential output of the scheduling networks. According to the former description, high level command is considered as the output of the scheduling networks, which means specific imaging operations like spacecraft attitude adjustments are implemented by traditional methods in assumption. Thus, there are two alternative actions: imaging at the \(i{\text{th}}\) point (\(a(i) = 1\)) or not imaging at the point (\(a(i) = 0\)).
Reward function design of the scheduling networks
It is known that good photos benefit from proper illumination conditions, large phase angle variation and small relative distance. Inspired by [30], quality of the imaging photo is quantified in score in this section and some adjustments to the score model in [30] are implemented. Reference [30] focuses on the mapping problem in surrounding phase of small celestial body, where the effect of relative distance to the mapping score is not considered as the variation of relative distance is not significant in that phase. However, the relative distance changes rapidly during the science acquisition phase, influence of this factor to the imaging scheduling problem should be considered.
The reward obtained in the \(i{\text{th}}\) alternative point is formulated in Eq. (3). If the action at the point is imaging, a combination of original reward and additional reward is obtained. While the action at the point is not imaging, the reward is 0.
The original reward is designed to describe the target of imaging mission, which is a weighted sum of three terms and expressed in Eq. (4).
where \(q_{1} (i)\) represents the contribution of illumination condition and relative distance to the quality of imaging photo. A multiplication of these two factors is established in Eq. (5). Considering that the pixel resolution of optical camera is inversely proportional to the object distance, the former square bracket of the right-hand side in Eq. (5) denotes this characteristic and ranges in [0, 1], where \(r_{\min }\), \(r_{\max }\) are the minimum and maximum value of relative distance in the propagated trajectory, respectively. \(s_{\alpha } (i)\) is the phase angle score and is a simplification of the score model of photometric angles defined in [32]. Focusing on the shape reconstruction of the celestial body, a polyhedral shape model of the celestial body is investigated in [32]. The duration of scientific acquisition phase is much shorter compared with the surrounding phase, thus a point mass with no-rotating model of the celestial body is considered in this paper. At the same time, the incidence score and emission score are merged into the phase angle score.
To simplify the description of the sight variation, photos taken in science acquisition phase are divided into several bins according to a fixed gap \(A_{{{\text{gap}}}}\). The total number of these bins \(T_{b}\) can be calculated as Eq. (6), where \(\alpha_{\min }\), \(\alpha_{\max }\) are the minimum and maximum value of the phase angle in the propagated trajectory, respectively. Considering that the phase angle may change rapidly around the closest approach, the fixed gap \(A_{{{\text{gap}}}}\) is chosen as 20 in this paper based on [30].
As former mentioned, taking photos with different phase angles could provide different insights of the celestial body and is beneficial to the following scientific research on the ground. Meanwhile, limited storage resource onboard is another factor needs to be concerned. Thus, \(q_{2} (i)\) is designed to encourage the variation of photos with different phase angles and avoid taking too many photos in similar conditions as well. The expression of \(q_{2} (i)\) is shown in Eq. (7).
\(N_{p}\) is the upper bound of valuable photo taken at each bin of phase angle, where \(t_{b} (i)\) denotes the bin that the \(i{\text{th}}\) alternative imaging point corresponding to and is calculated in Eq. (8). In addition, \(n_{p} [t_{b} (i)]\) represents the number of photos has been taken in \(t_{b} (i)\) before the \(i{\text{th}}\) point.
\(p(i)\) represents the potential punishment for exceeding the upper bound of storage resource and is defined in Eq. (9). \(n_{s}\) is the number of photos that have been taken before the \(i{\text{th}}\) alternative imaging point, and \(T_{p}\) is the upper bound of photos admitted to be taken according to the storage resource onboard during the science acquisition phase. Whenever \(n_{s}\) reaches or exceeds \(T_{p}\), the punishment is executed as the scheduling networks choose to image at the \(i{\text{th}}\) point.
In ideal conditions, the scheduling networks could converge to the optimal strategy after enough interaction with the environment. However, due to insufficient exploration of state space and action space, the networks sometimes fail to converge to the optimal strategy. To solve this problem, an additional reward is adopted on the basis of original reward to guide the training of the networks. For encouraging the scheduling networks to image as close as possible in the bin of phase angle corresponding to current alternative point, the additional reward is designed in terms of Eq. (10) and contained of two parts.
The first part is a punishment for imaging at a further alternative point in the current bin of phase angle. Specifically, if the following two conditions are satisfied, imaging at the \(i{\text{th}}\) point is punished. These two conditions are:
-
1.
The \(i{\text{th}}\) point is in the same bin as the \((i + 1){\text{th}}\) point.
-
2.
The relative distance between spacecraft and small celestial body at the \(i{\text{th}}\) point is greater than that of the \((i + 1){\text{th}}\) point.
$$ r_{{{\text{ad1}}}} (i) = \left\{ \begin{gathered} - \min (w_{1} , \, w_{2} )/2,{\text{ if }}t_{b} (i) = t_{b} (i + 1){\text{ and }}r(i) > r(i + 1) \hfill \\ 0,{\text{ else}} \hfill \\ \end{gathered} \right. $$(11)
The second part is a punishment for imaging at the point that brings lower reward than \(r_{{{\text{ave}}}} [t_{b} (i)]\), which is the average reward obtained from imaging at points corresponding to \(t_{b} (i)\) in the last 100 times. \(r_{{{\text{ave}}}} [t_{b} (i)]\) is a global variable and updated whenever there is a photo taken at \(t_{b} (i)\) during the training process.
It is noted that although the reward function is new designed, it keeps as a scalar at every time step. Convergence of the scalar reward in the Actor-Critic algorithm has been proved in [33]. Once the structure and component of the networks changed, the optimality and convergency should be further analyzed and discussed as [18].
Structure of the scheduling networks
The proposed scheduling networks have a five-layer structure, as every adjacent two layers inside it are fully connected. Layer 1 is the input layer, with six units corresponding to six items of the state vector introduced in Sect. "State space and action space". Layer 2 to Layer 4 are the hidden layers. Two sets of neural networks with same scale are contained in the hidden layers belonging to the Actor networks and Critic networks, respectively. Each set of neural networks has 3 layers with 20 units in each layer. Layer 5 is the output layer consists of two parts: the output of Critic networks and the output of Actor networks. The output of Critic networks is the fitted Q-value guiding the Actor networks to choose action, while the output layer of Actor networks is the actual action selected by the scheduling networks. The activation function used in Layer 1 to Layer 4 is Relu, while the activation function for the output of Actor networks is Softmax. It is noted that there is no activation function for the output of Critic networks. The schematic structure of the scheduling networks is demonstrated in Fig. 4.

Structure of the scheduling networks
A-C policy training
In this section, the simulation environment and specific value of parameters utilized in the scheduling networks are given.
In simulation, the trajectory data in science acquisition phase is generated under the following manner. The absolute state (position and velocity) of the small celestial body and spacecraft are described in HCI frame. Firstly, the state of small celestial body at CA moment \([{\varvec{r}}_{c} (t_{CA} )^{{\text{T}}} , \, {\varvec{v}}_{c} (t_{CA} )^{{\text{T}}} ]^{{\text{T}}}\) and the amplitude of state deviation between the small celestial body and spacecraft at CA moment, i.e. \(\left| {\user2{\Delta r}(t_{CA} )} \right|\) and \(\left| {\user2{\Delta v}(t_{CA} )} \right|\), are randomly generated. Based on the geometrical relationship of two spatial lines, the state of spacecraft at CA moment \([{\varvec{r}}_{s} (t_{CA} )^{{\text{T}}} , \, {\varvec{v}}_{s} (t_{CA} )^{{\text{T}}} ]^{{\text{T}}}\) could be solved. Then, propagated a period of time forward from CA moment under two-body model, the states of small celestial body and spacecraft at the beginning of the science acquisition phase, i.e. \([{\varvec{r}}_{c} (t_{0} )^{{\text{T}}} , \, {\varvec{v}}_{c} (t_{0} )^{{\text{T}}} ]^{{\text{T}}}\) and \([{\varvec{r}}_{s} (t_{0} )^{{\text{T}}} , \, {\varvec{v}}_{s} (t_{0} )^{{\text{T}}} ]^{{\text{T}}}\), are obtained, respectively. Propagating backward from the beginning states in science acquisition phase, the absolute trajectories of small celestial body and spacecraft in the phase are generated. Finally, the relative trajectory used in the scheduling networks is resolved by subtraction of two absolute trajectories. The flow chart of flyby trajectory generation is shown in Fig. 5.

Generation of the simulated flyby trajectory in HCI frame
It is noted that different dynamics models are utilized in the backward propagation of different simulation scenarios. For the training process of the scheduling networks in "Training", a two-body model is used. The uncertain perturbation acceleration from environment and position noise produced by the optical instruments with limited amplitude are added to the two-body model in the validation process in "Generalization", as considering the real operation conditions onboard.
Following the steps introduced in Fig. 5, the simulated flyby trajectory with specific closest approach could be obtained. A flyby trajectory with closest approach of 1000 km is considered in this simulation, while the duration of science acquisition phase is set to 60 min. Besides, the velocity deviation at CA moment, which is \(\left| {\user2{\Delta v}(t_{CA} )} \right|\), ranges in [1, 3] km/s and is randomly generated. Meanwhile, the position and velocity of celestial body at CA moment are chosen to \([6{\text{AU}}, \, 0, \, 0]^{{\text{T}}}\), \([4, \, 10, \, 3]^{{\text{T}}}\) km/s, respectively. The astronomical unit (AU) is the average distance from the Earth to the Sun and approximately equal to 150 million kilometers. The value of these parameters is set according to the flyby missions have been performed as well as considering the safety of spacecraft in uncertain environment at the same time.
In parameter setting of the reward in the scheduling networks, the upper bound of valuable photo at each bin \(N_{p}\) is chosen as 2, where too many photos taken at similar phase angle may lead to onboard resource waste. Besides, the weights in Eq. (4), i.e. \(w_{1}\), \(w_{2}\) and \(w_{3}\), are set to 10, 7 and 2, respectively. Such values have been adjusted manually and keep a good balance of the potential reward and punishment received from imaging at the alternative point. In addition, according to the hyperparameters used in [25], hyperparameters inside the scheduling networks are chosen as Table 1 listed.
Implementation and result analysis
In this section, simulation results of the proposed scheduling networks in different scenarios are presented. Performance of the scheduling networks in both training and validation process are analyzed in "Performance analysis". To get an objective evaluation of the performance of the scheduling networks, strategies optimized by other algorithms are implemented in same imaging missions as the scheduling networks employed in "Performance analysis". The comparison results are concluded in "Comparison with other algorithms". All these simulations are encoded in PyCharm and run on a personal computer with Intel® Core™ i7-10700 CPU @ 2.90 GHz.
Performance analysis
Training
As former mentioned, the data generated under two-body propagation is used as inputs for the scheduling networks during the training process. To fully test the scheduling networks, they are trained in six different imaging missions. Considering the short period and limited imaging opportunities in science acquisition phase, the upper bound of imaging photos and alternative points in these missions are 3/7, 5/7, 3/13, 5/13, 7/13, 9/13, respectively. For all imaging missions, the scheduling networks are set to train 20,000 episodes. To encourage exploration, the upper bound of imaging photos could be exceeded in the first 15,000 episodes. While in the last 5000 episodes, the scheduling networks are set not image at the rest alternative points whenever the upper bound has been reached. Training results of scheduling networks with additional reward in imaging mission of 7/13 are shown in Fig. 6.

Training of the scheduling networks with additional reward in imaging mission of 7/13
The red line in Fig. 6a is the cumulative reward of the scheduling networks in the current episode, while the blue line represents its average value over the last 20 episodes. As shown in Fig. 6a, the average cumulative reward is converged, and the current cumulative reward tends to be stable with the increasement of training episodes. Similar results appear in the other 5 imaging missions. Figure 6b shows the variation of the number of photos that have been taken. The red line is the number of photos taken in the current episode, as the blue dot line is the upper bound of the number of imaged photos, which is 7 in this case. The scheduling networks gradually learn to decrease the number of photos to avoid punishment, and the number of photos is no more than the upper bound after 15,000 episodes as defined. Distribution of the imaging points in the last 1000 episodes is shown in Fig. 6c, where the black line is the flyby trajectory and the red stars represent the alternative imaging points. The green bars denote the imaging points, and their height represents the probability of imaging. The blue dot lines are the boundaries and divide these alternative imaging points into different bins of phase angle.
The imaging points selected by the scheduling networks without additional reward in the same conditions are shown in Fig. 7. Comparing the results of these two scheduling networks, it is found that the imaging sequence generated by the networks without additional reward covers only 6 bins of phase angle, where the results of the networks with additional reward covers all 7 bins.

Distribution of imaging points in the last 1000 episodes. This result is generated by the scheduling networks without additional reward in imaging mission of 7/13
To reduce the randomness of truncation, the average cumulative reward in the last 1000 episodes is adopted as the performance criteria of these scheduling networks. Comparison results of the scheduling networks with and without additional reward in six imaging missions are listed in Table 2. Apart from the imaging mission of 3/7, the scheduling networks with additional reward get higher cumulative reward in the other five imaging missions.
It should be noted that the additional reward is added on the reward function and may decrease the cumulative reward. For the convenience of comparison, all the results of scheduling networks with additional reward listed in Table 2 are recalculated according to their imaging points, thus the influence of additional reward is eliminated. The cumulative reward in the following part of this paper is processed in the same way.
Generalization
In the validation process, two operation modes of the scheduling networks are considered. The first offline mode is to test the networks without further training, while in the second online mode, the scheduling networks keep learning during the validation process. Differences of these two modes are whether the hyperparameters inside the scheduling networks update or not. To validate the generalization ability of the scheduling networks, two test cases are designed and their results are discussed.
Case 1: Verification without changing the imaging mission.
In this case, the trained scheduling networks with additional reward in "Training" are validated under the flyby trajectory considering the uncertain perturbation from environment and the position noise from measurement of optical instruments. This perturbed trajectory is generated under the manner introduced in Sect. 4. Here, the uncertain perturbation acceleration and position noise are subject to random distribution with amplitudes of 1e−4 km/s2 and 10 km, respectively.
The trained networks operated in both two modes are tested 5000 episodes under the perturbed flyby trajectory without changing the imaging mission. The average cumulative reward of the scheduling networks under these two modes is summarized in Table 3.
According to Table 3, it is found that the average cumulative reward of the scheduling networks under both two modes are similar. Compared with the results in Table 2, the scheduling networks get higher cumulative reward in the validation environment. This is because the distribution of the bin of phase angle changed due to the uncertain perturbation and position noise. This change is illustrated in the imaging mission of 5/7 in Fig. 8. Due to the reduction in the number of alternative points, at most 5 bins can be covered in imaging mission of 5/7. Besides, as a closer alternative imaging point is available in the same bin, the trained networks automatically adjust the imaging points and get higher cumulative reward. Similar change appears in the other imaging missions.

Distribution of the imaging points in imaging mission of 5/7 under two different environments. The bin of phase angle changed with the addition of uncertain perturbation and position noise
Case 2: Verification with changing the imaging mission.
Following the track started in Case 1, the scheduling networks with additional reward are tested under the same perturbed flyby trajectory. However, the imaging missions are changed during the validation process in this case. To validate the adaptability of the proposed scheduling networks, the networks are first training with 20,000 episodes in imaging mission of 5/7 as we have done in Sect. "Training". Then, the trained networks are further training with 20,000 episodes in five new imaging missions. These imaging missions are 3/7, 3/13, 5/13, 7/13 and 9/13, respectively. Performance of the further training networks are compared with the networks trained in the same imaging missions in "Training". The average cumulative reward of scheduling networks in these imaging missions in the last 1000 episodes are summarized in Table 4.
Compared with the networks trained in the same imaging mission, the further training networks have equivalent performance in imaging missions of 5/13 and 9/13 and have better performance in imaging missions of 3/7 and 3/13 according to Table 4. The simulation results of the networks in imaging mission of 3/13 are presented in Fig. 9. As the imaging mission changed, the further training networks gradually decrease the number of imaged photo and adjust the imaging points. A higher cumulative reward is obtained after about 1000 episodes of exploration in the new environment with the further training networks converge again. Similar results exist in simulation of the imaging missions of 3/7, 5/13 and 9/13, while in imaging mission of 7/13, the further training networks fall into a local optimal strategy and fail to cover all the bins of phase angle, as shown in Fig. 10. Although it is not optimal in some conditions, the proposed scheduling networks have proved to be adaptive to the change of imaging missions.

Further training results of the scheduling networks in imaging missions of 3/13

Further training results of the scheduling networks in imaging missions of 7/13
Comparison with other algorithms
To fully evaluate the performance of the proposed scheduling networks, GA, DQN and another DRL algorithm that widely used in several literatures [34, 35], i.e. Proximal Policy Optimization (PPO), are used to optimize the imaging sequence under same conditions in "Training". The parameters of them are stated in Table 5. Specifically, the parameters of DQN and PPO are chosen as same as possible of the proposed scheduling networks, for mitigating the effect of neural networks parameters. For example, there are 3 hidden layers with 20 units of each layer in the neural networks used in DQN and PPO, which is consistent with the proposed scheduling networks. In terms of GA, the population and generation of evolution are selected as 200 and 50, respectively for the sake of global optimization.
Average cumulative reward of the last 1000 episodes is used to compare the performance of these algorithms. DRL-based algorithms with and without additional reward are both considered in the comparison. Results of training and validation process in details are summarized in Table 6, and the performance of these algorithms in validation are drawn in Fig. 11.

Line chart of the performance of different algorithms in validation
In the training process, GA outperforms the other algorithms in imaging missions of 3/7 and 3/13 in the training process according to Table 6. While in the rest four imaging missions, the performance of scheduling networks with additional reward and GA are comparable and better than the other algorithms.
In the validation process, the scheduling networks with additional reward improve their performance due to the adaptability and have the best performance in four of the imaging missions. Compared to DQN and PPO, the Actor-Critic based scheduling networks perform more stable as the alternative imaging points increased.
As for the designed additional reward, it seems more effective for the policy-based DRL algorithms and improve the performance of the proposed scheduling networks and PPO in five of the six imaging scenarios in validation. While in the value-based algorithm, i.e., DQN, the additional reward not works so well. The performance of DQN with additional reward is improved in three imaging scenarios, but is deteriorated in the other imaging scenarios in validation.
The time cost of GA and three DRL-based algorithms with additional reward are calculated and shown in Fig. 12. Similar to other heuristic algorithms, GA operates in a batch-wise manner and could not obtain the imaging sequence until the whole optimization finished, which takes tens of seconds in these imaging missions. In contrast, the DRL-based method, i.e. scheduling networks, DQN and PPO, can determine whether to image or not at each alternative point. After training, the time cost of scheduling networks, DQN and PPO for each decision are both less than 1e−4 s, which is about six orders of magnitude smaller than that of GA.

Time cost of different algorithms among all imaging missions
Conclusion
Focusing on the imaging scheduling problem in science acquisition phase of the small celestial body flyby mission, the autonomous scheduling networks based on Actor-Critic are proposed in this paper, where a new reward function containing the variation of relative distance between spacecraft and small celestial body is established. Performance of the scheduling networks is tested in numerical simulation. After adding the designed additional reward, the scheduling networks improve their performance in five of the six imaging scenarios. In addition, robustness of the scheduling networks is proved for they keep good performance in imaging missions with the uncertain perturbation and position noise. Besides, the scheduling networks could converge again as the imaging mission changed after the training process, which reveals the adaptability of the scheduling networks. For fully evaluate the performance of the proposed scheduling networks, they are compared with DQN, PPO and GA. The trained scheduling networks have higher reward than DQN and PPO in most imaging missions and are comparable with GA, which has the ability of global optimization. Besides, the decision time of the scheduling networks after training is less than 1e−4 s, which is about six orders of magnitude less than that of GA and reveal their potential ability to schedule imaging position in real-time onboard. One limitation of the proposed method is that the alternative imaging points are distributed with equal time interval in assumption, while a non-equal time interval distribution may be more realistic and may lead to a better imaging result. In the following investigations, the time of imaging will be continuous distribution and regarded as an output which needs to be determined by the scheduling networks.
Data availability
The data that support the findings of this study are available.
References
Veverka J, Belton M, Klaasen K, Chapman C (1994) Galileo’s encounter with 951 Gaspra: overview. Icarus 107(1):2–17
Rayman MD, Varghese P, Lehman DH, Livesay LL (2000) Results from the Deep Space 1 technology validation mission. Acta Astronaut 47(2–9):475–487
Accomazzo A, Wirth KR, Lodiot S, Küppers M, Schwehm G (2010) The flyby of Rosetta at asteroid Šteins–mission and science operations. Planet Space Sci 58(9):1058–1065
Accomazzo A, Ferri P, Lodiot S, Hubault A, Porta R, Pellon-Bailon J-L (2010) The first Rosetta asteroid flyby. Acta Astronaut 66(3–4):382–390
Schulz R, Sierks H, Küppers M, Accomazzo A (2012) Rosetta fly-by at asteroid (21) Lutetia: an overview. Planet Space Sci 66(1):2–8
Jordan MI, Mitchell TM (2015) Machine learning: trends, perspectives, and prospects. Science 349(6245):255–260
Xing H, Xiao Z, Qu R et al (2022) An efficient federated distillation learning system for multitask time series classification. IEEE Trans Instrum Meas 71:1–12
Huang M, Xu Y, Qian L et al (2021) A bridge neural network-based optical-SAR image joint intelligent interpretation framework. Space Sci Technol. https://doi.org/10.34133/2021/9841456
Meng Q, Huang M, Xu Y et al (2021) Decentralized distributed deep learning with low-bandwidth consumption for smart constellations. Space Sci Technol. https://doi.org/10.34133/2021/9879246
Gu Y, Zhu Z, Lv J, Shi L, Hou Z, Xu S (2022) DM-DQN: dueling Munchausen deep Q network for robot path planning. Complex Intell Syst 9(4):4287–4300
Xie J, Shao Z, Li Y, Guan Y, Tan J (2019) Deep reinforcement learning with optimized reward functions for robotic trajectory planning. IEEE Access 7:105669–105679
Yan C, Xiang X, Wang C (2020) Towards real-time path planning through deep reinforcement learning for a UAV in dynamic environments. J Intell Robot Syst 98:297–309
Liu Q, Shi L, Sun L, Li J, Ding M, Shu F (2020) Path planning for UAV-mounted mobile edge computing with deep reinforcement learning. IEEE Trans Veh Technol 69(5):5723–5728
Song F, Xing H, Wang X et al (2022) Evolutionary multi-objective reinforcement learning based trajectory control and task offloading in UAV-assisted mobile edge computing. IEEE Trans Mob Comput. https://doi.org/10.1109/TMC.2022.3208457
Mnih V, Kavukcuoglu K, Silver D et al (2015) Human-level control through deep reinforcement learning. Nature 518(7540):529–533
Torrado RR, Bontrager P, Togelius J, Liu J, Perez-Liebana D (2018) Deep reinforcement learning for general video game ai. In: 2018 IEEE conference on computational intelligence and games (CIG), pp 1–8
Silver D, Hubert T, Schrittwieser J et al (2018) A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 362(6419):1140–1144
Chen J, Xing H, Xiao Z et al (2021) A DRL agent for jointly optimizing computation offloading and resource allocation in MEC. IEEE Internet Things J 8(24):17508–17524
Gaudet B, Furfaro R (2014) Adaptive pinpoint and fuel efficient mars landing using reinforcement learning. IEEE/CAA J Autom Sin 1(4):397–411
Gaudet B, Linares R, Furfaro R (2020) Deep reinforcement learning for six degree-of-freedom planetary landing. Adv Space Res 65(7):1723–1741
Furfaro R, Scorsoglio A, Linares R, Massari M (2020) Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach. Acta Astronaut 171:156–171
Gaudet B, Linares R, Furfaro R (2020) Terminal adaptive guidance via reinforcement meta-learning: applications to autonomous asteroid close-proximity operations. Acta Astronaut 171:1–13
Harris A, Teil T, Schaub H (2019) Spacecraft decision-making autonomy using deep reinforcement learning. In: 29th AAS/AIAA spaceflight mechanics meeting, AAS Paper 19–447
Harris A T, Schaub H (2020) Spacecraft command and control with safety guarantees using shielded deep reinforcement learning. In: AIAA SciTech, AIAA Paper 2020–0386
Wang H, Yang Z, Zhou W, Li D (2019) Online scheduling of image satellites based on neural networks and deep reinforcement learning. Chin J Aeronaut 32(4):1011–1019
Herrmann AP, Schaub H (2022) Monte Carlo tree search methods for the earth-observing satellite scheduling problem. J Aerospace Inf Syst 19(1):70–82
Herrmann A, Schaub H (2022) Autonomous on-board planning for earth-orbiting spacecraft. In: 2022 IEEE aerospace conference (AERO), pp 1–9
Herrmann A, Schaub H (2023) Reinforcement learning for the agile earth-observing satellite scheduling problem. IEEE Trans Aerosp Electron Syst
Chan DM, Agha-mohammadi A (2019) Autonomous imaging and mapping of small bodies using deep reinforcement learning. In: 2019 IEEE aerospace conference, pp 1–12
Pesce V, Agha-mohammadi A, Lavagna M (2018) Autonomous navigation & mapping of small bodies. In: 2018 IEEE aerospace conference, pp 1–10
Piccinin M, Lavagna MR (2020) Deep reinforcement learning approach for small bodies shape reconstruction enhancement. In: AIAA SciTech, AIAA Paper 2020–1909
Piccinin M, Lunghi P, Lavagna M (2022) Deep reinforcement learning-based policy for autonomous imaging planning of small celestial bodies mapping. Aerosp Sci Technol 120:107224
Konda V, Tsitsiklis J (1999) Actor-critic algorithms. Advances in neural information processing systems, p 12
Zavoli A, Federici L (2021) Reinforcement learning for robust trajectory design of interplanetary missions. J Guid Control Dyn 44(8):1440–1453
Brandonisio A, Capra L, Lavagna M (2023) Deep reinforcement learning spacecraft guidance with state uncertainty for autonomous shape reconstruction of uncooperative target. Advances in Space Research
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant No. 12150007) and the Basic Scientific Research Project (Grant No. JCKY2020903B002).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hu, H., Wu, W., Song, Y. et al. Autonomous imaging scheduling networks of small celestial bodies flyby based on deep reinforcement learning. Complex Intell. Syst. 10, 3181–3195 (2024). https://doi.org/10.1007/s40747-023-01312-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01312-z