
Abstract
Multi-scale representation provides an effective answer to the scale variation of objects and entities in semantic segmentation. The ability to capture long-range pixel dependency facilitates semantic segmentation. In addition, semantic segmentation necessitates the effective use of pixel-to-pixel similarity in the channel direction to enhance pixel areas. By reviewing the characteristics of earlier successful segmentation models, we discover a number of crucial elements that enhance segmentation model performance, including a robust encoder structure, multi-scale interactions, attention mechanisms, and a robust decoder structure. The attention mechanism of the asymmetric non-local neural network (ANNet) is merged with multi-scale pyramidal modules to accelerate model segmentation while maintaining high accuracy. However, ANNet does not account for the similarity between pixels in the feature map channel direction, making the segmentation accuracy unsatisfactory. As a result, we propose EMSNet, a straightforward convolutional network architecture for semantic segmentation that consists of Integration of enhanced regional module (IERM) and Multi-scale convolution module (MSCM). The IERM module generates weights using four or five-stage feature maps, then fuses the input features with the weights and uses more computation. The similarity of the channel direction feature graphs is also calculated using ANNet’s auxiliary loss function. The MSCM module can more accurately describe the interactions between various channels, capture the interdependencies between feature pixels, and capture the multi-scale context. Experiments prove that we perform well in tests using the benchmark dataset. On Cityscapes test data, we get 82.2% segmentation accuracy. The mIoU in the ADE20k and Pascal VOC datasets are, respectively, 45.58% and 85.46%.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
One of the most important research areas in computer vision, semantic segmentation, has received a lot of attention in the past 10 years. Its goal is to label each pixel in an image by giving it a semantic class [1,2,3], which is a fundamental direction for computer vision tasks. Semantic segmentation is frequently used in autonomous driving [4, 5], human–computer interaction [6], augmented reality [7], and medical imaging [8]. Given that it is a labor-intensive segmentation process, more model parameters must be included. Early deep convolutional neural networks, like MNIST [9], were the primary method for character recognition. Convolution-based neural networks [10], such as image classification networks [11, 12] and deep detection networks [13, 14], became the norm in computer vision in the preceding years. Convolutional neural networks are better at extracting features than conventional machine learning techniques. Fully convolutional networks (FCN), as Long et al. [15] suggested, substitute fully connected layers with convolutional layers to support inputs of any size. This allowed FCNs to be trained end-to-end and increased the effectiveness of semantic segmentation. Since then, developments motivated by FCNs and neural networks [12, 16] have aided in the development of a number of networks [17, 18], the core of which is the FCN. Their encoder multiplies the feature channels and shrinks the spatial dimension to extract features, while their decoder employs upsampling to restore the size of the feature map. Building on this strategy, numerous scholars later concentrated their efforts on these two issues in order to enhance the effectiveness of semantic segmentation. The coding structure needs to be improved in order for the encoder to extract more full feature information, which is the first issue. In particular, Chen et al. upgraded the ASPP module in the encoder [19] in DeeplabV2 [20] and attempted to serialize or parallelize the modules, which are made up of heterogeneous convolutional and BN layers with various sampling rates. The second difficulty is to better represent each pixel by modeling the multi-scale background and encoding the background data into the original feature map data. For instance, OCRNet [17], SegNet [21], and Deeplabv3 + [18]. As part of its multi-scale context modeling, Deeplab V2 introduces spatial pyramid pooling (ASPP), allowing it to capture multi-scale context data using a variety of extended convolutions. The “PSPNet” approach was proposed by Zhao et al. [22] and aggregates multi-scale contextual data using a spatial pyramid pool. Wang et al. [23] created a non-local block to weight aggregate contextual information in the entire image. Using this method, it is possible to collect long-range interdependencies between pixels by merely forming a self-attention. Zhu et al. [24] created ANNet based on the asymmetric pyramidal non-local block to reduce the computation and GPU memory consumption of typical non-local modules since matrix multiplication of non-local blocks is computationally demanding and adds an additional memory burden. Small things, including traffic lights, fences, etc., are frequently predicted inaccurately because there is a lack of global contextual semantic information [25].
In addition, just as important as pixel information in the channel direction is pixel information in the feature space direction. The weighted sum of all channel mappings is utilized to update each channel mapping, and the channel attention module of DANet [26] determines the channel dependencies between any two-channel mappings. The segmentation of small target objects and edge objects suffers nonetheless when there are too many channels because some feature maps may have less contextual information than others. Another significant but difficult issue in semantic segmentation is the prediction of semantic boundaries [27].
As a fundamental part of contemporary deep learning, global relevance discovery depends on attention mechanisms, particularly self-attention. Transformer-based methods [28] have recently dominated the field of semantic segmentation due to the effectiveness of self-attention in encoding spatial information. Self-attentive mechanisms have recently dominated several computer vision disciplines, despite being initially developed for natural language processing applications. The quadratic complexity is too difficult for high-resolution images, and self-attention in computer vision considers images as one-dimensional sequences, neglecting their two-dimensional structure. As a result, we use a convolution-based network structure in this paper.
We discovered that successful semantic segmentation requires (1) multi-scale interactions because, unlike image classification tasks, which primarily recognize individual images, semantic segmentation is a demanding prediction task that necessitates the processing of objects of various sizes within a single image. (2) spatial attention, which enables segmentation by determining the relative importance of the semantic region’s various regions. Low computational complexity is crucial when working with cityscapes and high-resolution photos from remote sensing.
In this paper, we propose enhanced multi-scale networks for semantic segmentation, which include two novel structures named the Integration of Enhanced Regional Modules (IERM) and the Multi-Scale Convolution Module (MSCM). These networks take into account the analyses shown above. The improved area Module We use a number of asymmetric convolutions and deformable multi-scale convolutions, etc., for the MSCM. We specifically alter the layout of conventional convolutional blocks and employ multi-scale convolutional features to arouse spatial attention through the straightforward multiplication of elements. We discover that this straightforward technique for establishing spatial attention is superior to conventional convolution in encoding spatial information. Finally, by combining the data from each stage, global contextual features are further retrieved, and in this environment, multi-scale contexts from local to global and averaging information from low to high levels can be obtained.
In summary, the contributions of this paper can be summarized as follows:
-
1.
For semantic segmentation, we suggest a quick and efficient phase-enhanced multi-scale network (EMSNet).
-
2.
We created the IERM with inspiration from DANet and DMNet. For better segmentation accuracy, IERM can record spatial and channel information between feature maps.
-
3.
To increase the segmentation accuracy even more, we created the MSCM. To update each channel mapping with a weighted sum of all channel mappings, the MSCM detects channel interdependence between any two-channel mappings. In addition to creating long-range dependencies between pixels, the MSCM also creates a spatial attention matrix to enhance dependencies between spatial features. MSCM significantly enhances the efficiency of semantic segmentation by building rich contextual dependencies for pixels in the spatial direction of the feature maps.
Related work
In this part, we provide a brief overview of the history of semantic segmentation and associated research. Due to its outstanding performance in semantic segmentation tasks [29, 30], FCN has supported the development of a number of additional works, including SegNet, UNet [31], Deeplabv3 + , and DeconvNet [32].
Semantic segmentation
After large-scale datasets and computer resources were made available, convolutional neural networks were adopted as the standard for visual recognition. Numerous deep and efficient neural network architectures, including VGG [33], ResNet [16], ResNeXt [34], etc., have been presented. Semantic segmentation is a classification task performed at the pixel level, whereas FCNs first apply whole convolutional networks to the entire image. At the pixel level, there are two kinds of semantic prediction tasks. Designing a new backbone network [35,36,37,38] is the initial step to obtaining a more reliable feature map for pixels. Zhang et al. [39] applied channel attention to distinct branches of the network to leverage their methods for capturing cross-feature interactions and learning different representations since it is essential to maintain the backbone network’s high resolution to extract spatial position information. Another challenge is to create several decoders that typically cooperate with the encoder to produce the best results. There are various kinds of decoders for various jobs. For instance, to acquire various perceptual fields [18, 19, 21], to improve edge features [40,41,42], and to acquire comprehensive environmental knowledge [31, 43], In recent years, a number of transformer-based topologies have also been developed. Due to its global perceptual fields and dynamic spatial aggregation, ViT has proven to be the most accurate model and has performed exceptionally well in vision tests. Global attention in ViT, especially for large feature maps, suffers from excessive computational or memory complexity, which restricts its application in subsequent tasks.
Encoder–decoder structure
To increase the perceptual field, the encoder often shrinks the feature map’s spatial size. The decoder then receives the encoded feature map and determines the size of the expected map. The decoding channel is carried out by a deconvolution technique described by Long et al. [32] and Noh et al. [15]. Jump connections are introduced by Ronneberger et al. [44] to link encoded features with their corresponding decoded features, which can enrich the segmentation output. To predict the weight to be given to categories and to selectively strengthen or weaken the feature maps of particular categories, Zhang et al. [45] proposed a contextual encoding block.
Multi-scale networks
A common area of research in computer vision is designing multi-scale networks [46, 47], which are essential for tasks that resemble segmentation. The segmentation model’s encoder and decoder typically contain multiscale blocks. To accomplish multi-scale feature extraction, Google Net [11] employs a multi-branch architecture. For multi-scale feature extraction, HRNet [48] also keeps high-resolution features that have been combined with low-resolution features at a later stage. In addition to being able to capture multi-scale characteristics, we differ from prior methods by introducing an effective multi-scale architecture with fewer and larger kernel convolutions with fewer parameters.
Deformable convolution
Deformable convolution is a type of spatial transformer network-based convolution operation that incorporates a deformable module in the convolution kernel to dynamically adapt to the position and shape of the target in the input feature map. By doing this, it can better accommodate the target’s deformation characteristics and increase the model’s robustness, allowing the convolution operation to more effectively capture the target’s information.
Methods
In this part, we will describe the overall design of our network. We chose the encoder–decoder architecture because it is straightforward, user-friendly, and generally follows earlier work [15, 32, 44, 45]. We will first outline the general structure of our network before describing how the IERM and MSCM modules affect the effectiveness of semantic segmentation.
Network architecture
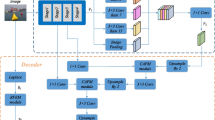
With the introduction of IERM and MSCM, as seen in Fig. 1, we suggest EMSNet. We decide to use ResNet101 as the network’s backbone. In the fourth and fifth stages, IERM is used to model rich contextual interactions on local features and capture long-range pixel associations in the feature map’s channel direction. The IERM module, which can consider both channel and spatial information, processes the characteristics in the fourth and fifth stages. In order to track and learn the category regions of the fourth stage’s output feature map, we add a cross-entropy loss function to the output of the stage. By carrying out such an activity, the fourth stage’s output feature map can be improved to contain more contextual data. The output of the MSCM module is combined with the features from the fifth stage, which are better able to model the interactions between various channels, capture long-distance interdependencies between pixels in the spatial direction of the feature map, and capture the context of several scales. The final prediction results will then be derived by upsampling and adding separately the feature maps from the second stage, the feature maps from the IERM output, and the feature maps from the MSCM output.

Overview of the proposed EMSNet for semantic segmentation
Integration of enhanced regional modules
The convolutional kernel size has previously been increased to provide large perceptual fields. While ASPP [19] scales the kernel size sparingly, conception [11] scales it intensively. As a result, having several kernels with varied scaling rates might lead to the creation of multi-scale representations. The parameters of the prior receptive field, however, burst as the receptive field rises and suffers from overfitting and high computing costs. Sparse sampling techniques may lose fine-detail information and result in grid artifacts because the latter method has the ability to arbitrarily enlarge the receptive field.
Both ASPP and PPM [21] employ pooling processes with various grids and predefined hole convolutions with various growth rates. These two techniques are sensitive to the scale disparity between the images in the training and inference stages as well as the input image size. The internal scale fluctuation of the input images of various scales and sizes cannot be captured by the set weights, predetermined expansion rates, or pooling grids.
To further achieve high segmentation accuracy, multi-level features must be combined. In this study, we propose a integration of enhanced region module (IERM) that makes use of a DCS to enhance the fused feature representation. The specific procedure is given in the sections that follow. Figure 2 depicts the structure of the dynamic convolution module. The stage 4 feature map will be transformed to [b, c, k2] by global adaptive pooling, convolution, and reshape, while the stage 5 feature map will be modified to [b, k2, h × w] by convolution and reshape, before being altered back to the stage 4 feature map’s original [b, c, h, w] by matrix multiplication and reshape, where b represents the batch size, c represents the number of channels, k represents the k parameter set in the DCS module, and h and w represent the height and width of the picture respectively. IERM uses the dynamic convolution structure to generate the output F and the weight α and fuses the input features with α by Mul and Add operations. The above process can be written as Eq. (1):
where F represents the features after the dynamic convolution structure; F4 and F5 represents the features in the fourth and fifth stages of the backbone; α represents F the weight parameter generated after Sigmod; Fup represents the result after sampling on F4; and Fout denotes the upper half of the output of the integration of regional enhancement modules (IERM).

Flow chart of one of the stages of the dynamic convolutional structure (DCS)
Different dynamic convolution sections, which are more adaptable and flexible, can capture various scale feature representations, while each DCS can only record one scale feature representation related to the input image. We set up the two dynamic convolutions structure in parallel to preserve their capacity to consistently represent features at various scales. To create the final feature representation for each pixel, the output from each individual feature representation is combined with the initial information that the backbone extracted.
In the second half of the IERM, Similar pixel points should still maintain their close link since features at any position on the feature map have all other positions connected with them, i.e., the relationship between the two points is assessed globally. Therefore, we do the following operation on the feature map: The input feature map has the following shape: c × h × w. First, we obtain two feature maps using two convolution layers, respectively. Next, we reshape them as c × n, where n = h × w. Finally, we perform a transpose operation on one of them to obtain n × c. Matrix multiplication can be used in this manner to produce the n × n feature maps. At this point, we have a feature map that just takes the h and w into account and ignores the channels. The output F is then reshaped using the IERM’s upper portion, and matrix multiplication is then used to create a feature map with the shape c × n. Then, we reshape it to take on the form c × h × w. This is done by restoring the original input feature map shape so that it can be summed with the input feature map to obtain the output. The above process can be expressed in Eq. (2):
where F1 and F2 represent the features of the fifth stage after reshaping and transposing respectively, representing matrix multiplication, F represents Fout in Eq. (1), and Foutput represents the output of the second half of the region enhancement module.
Figure 3 depicts the whole flow, with Fup representing the output of stage 5 and Flow representing the corresponding output of stage 4. The dynamic convolution structure then receives the inputs Fup and Flow and outputs F along with the weights α. After that, we use the multiplication operation in Flow to acquire the attention-weighted characteristics. Last but not least, the top half of IERM sums the weighted features element by element, combines them with the bottom half of IERM, and outputs the fused features.

Detailed architecture of the Integration of regional enhancement modules (IERM), where ⊕ represents element-by-element addition and ⊗ represents matrix multiplication
Multi-scale convolution modules
We applied a brand-new MSCM (multi-scale convolution) module. The regular convolution was replaced with an asymmetric one under the influence of Inception, which speeds up computation and permits the network depth to grow even further, hence enhancing the network’s nonlinearity. By adding a deformable module, deformable convolution can also be utilized to increase the model’s accuracy and robustness to transformations including target deformation, rotation, and translation. As shown in Fig. 4, this module contains three parts: a deformable depth convolution for aggregating local information, a multi-branch depth asymmetric convolution for collecting multi-scale context, and a 1 × 1 convolution for modeling the interaction between various channels are the three components of this module, as shown in Fig. 4. The output of this module is reweighted using attention weights that are directly derived from the output of the 1 × 1 convolution. The MSCM can be expressed in Eq. (3):
where input stands for input features. Out and output, which stand for element-by-element matrix multiplication, are the attention mapping and output fusion enhancing region modules, respectively. D-DWConv stands for the deformable depth convolution, and the ith branch is represented by 0, 1, 2, and 3. The jump connection is Scale0. We approximate a deformable depth convolution with a big kernel in each branch using two deformed depth bar convolutions.

The details of the multi-scale convolution modules
A novel deep convolutional neural network layer called Deformable Depthwise Convolution (D-DWConv) enhances the model’s perceptual field and accuracy by adapting to irregularly shaped picture features. Traditional deep convolutional neural networks extract features using preset convolutional kernels, but this approach is unable to accommodate a wide range of visual shapes, leading to information overlap. By using deformable convolutional kernels and the concept of depth-separable convolution to dynamically modify the shape and position of convolutional kernels during convolution, D-DWConv may better capture essential details in images. In addition to being able to adjust to unusual image forms, D-DWConv may also reduce the number of parameters to quicken training and inference. D-DWConv can adapt to a variety of image forms, decrease the number of parameters, and speed up the model’s training and inference processes.
Each branch’s kernel size is set to 3, 7, and 11 in this case. Strip convolution is our choice for two reasons: Strip convolution is lightweight, on the one hand. We simply require a pair of 7 × 1 and 1 × 7 convolutions to approximate a typical 2D convolution with a kernel size of 7 × 7. On the other hand, the striped convolution can effectively segment out several striped items in the segmentation scene, including individuals and poles. Strip convolution can therefore be a supplement to grid convolution and aid in the extraction of strip characteristics.
Before the MSCM, a feed-forward network is added. It can be applied to the feature mapping as a reduction and reconstruction. The CNN decoder’s job is to convert the network’s image feature mapping back to the original image. The final few levels of the feed-forward network are now utilized to remap the encoded features back to the original image. The feed-forward neural network participates in the decoder in the image segmentation task to restore the resolution based on the compressed features and convert the features to pixel-level output after the network has finished feature extraction and compression from the convolutional layer to the encoder. Due to the use of feed-forward neural networks in the decoder, the network can rebuild the image utilizing the matching features offered by all encoders through global sensing. Second, feed-forward neural networks are able to retrieve the image’s overall features, producing more accurate results for image reconstruction. In the decoding stage, the feed-forward neural network can also ensure model generalization capabilities, i.e., the network can reconstruct any input image by feeding the learned features backward without retraining the entire model. The feed-forward layer processes it to create the probability distribution of the desired sequence. By doing this, the decoder can more effectively model nonlinear systems, and its nonlinear modeling capability will be enhanced. Thus, the efficiency and precision of picture synthesis and segmentation tasks can be enhanced by the use of feed-forward neural networks in decoders.
Experiments
In this section, we first present the data set and implementation details. Then, we compare the experimental results with other state-of-the-art methods in terms of accuracy. Finally, we demonstrate the effectiveness of the proposed module through an ablation study.
Datasets
Three key datasets, PASCALVOC2012 [49], Cityscapes [50], and ADE20k [51] were used to evaluate our method. The full scene dataset for PASCALVOC 2012 consists of 2913 photos and 20 categories. The 2913 photos were divided into 1464 training images, 1449 validation images, and 1456 testing images. The 5000 high-quality, pixel-level annotated photos of urban driving situations that make up the Cityscapes dataset are divided into 30 categories. 2975 of the 5000 total photos were used for training, 500 for assessment, and 1525 for testing. These images were captured across 50 different cities. The collection also includes 19,998 images with coarse annotations; however, we only finely annotate the images from the 19 categories in this study. Over 25,000 photos (20k-train, 2k-val, and 3k-test) from ADE20k have a rich amount of vocabulary tags annotating them.
Implementation details
Our optimizer uses stochastic gradient descent (SGD) [52] with a multiple learning rate decay method, where the initial learning rate is multiplied by \({\left(1-\frac{\text{ iter }}{ \, \text{max\_iter} \, }\right)}^{\text{power}}\), to train the model on these three datasets. In addition, employ the warm-up approach with 3500 warm-up iterations. We employ a learning rate of 0.002, a weight decay of 0.9, momentum of 0.0005, and a weight decay of 0.9 for the training and validation of the Cityscape dataset. We divided the original photos into three sizes for the training and validation phases: 1024 × 512 (cityscape), 512 × 512 (PASCAL VOC 2012), and 520 × 520 (ADE20k). The input images used to assess the CNN model during training were arbitrarily scaled from 0.5 to 2. The test images were also rotated and scaled to different levels, and bilinear interpolation was used to predict the semantic label of each pixel to determine the target size. ResNet101, which has already been trained on the ImageNet dataset [53], served as our backbone network. The batch size and training duration for the Cityscape dataset is 4 and 160,000 iterations, respectively. The batch size and training duration for the PASCALVOC2012 dataset is 8 and 100,000 iterations, respectively. The batch size and training time for ADE20k is 8 and 200K iterations, respectively. Each experiment made use of a 1 × V100 GPU. Two cross-entropy losses are used in the optimization of our model. The fourth stage of ResNet101’s output is subjected to the first loss function, and the model’s output is subjected to the second loss function. The total loss function is as follows:
where \({l}_{{\mathrm{backbone}}_{\mathrm{stage}4}}\) denotes the loss function at the output of the backbone \({\mathrm{Stage}}_{4}\), \({l}_{\mathrm{model}}\) denotes the loss function at the output of the model, and \(\lambda \) is set to 0.4.
Evaluation metrics: In this paper, we use pixel accuracy (PA), intersection/merge (IoU), and the average value of IoU (mIoU) as evaluation metrics. The results are calculated as follows:
where n represents the number of categories of semantic segmentation. PA: PA represents the proportion of correctly detected pixels to all pixels. IoU: The intersection of the true and forecasted values is used to determine the IoU for each category. MIoU: To determine this measure, the IoU is first calculated for each category, and then the average of these ratios is derived.
Ablation study
In order to test our methodology, we performed ablation experiments in this section. We chose different IERM and MSCM elements and showed how they affected the model. We used ResNet101 as the foundation network in all subsequent studies and ran 160,000 iterations on the Cityscapes dataset. In addition, we ran 120,000 and 200,000 iterations on the PASCAL VOC 2012 dataset and the ADE20K dataset, respectively. The ultimate mIoU value was affected by each component, as we found out through experimentation.
Efficacy of the IERM and MSCM
IERM and MSCM make up the two key parts of our concept. We’ll now assess how well each module performs. In the fourth stage of ResNet101, we add the cross-entropy loss function following the 1 × 1 conv, as seen in Table 1. mIoU’s performance improved from 81.8% to 82.2% when compared to a cross-entropy loss of zero. This experiment demonstrates that semantic segmentation performance can be enhanced by maximizing the use of characteristics obtained by the loss function. In comparison to not merging, Table 1 demonstrates that performance improved by 0.26% when the feature maps produced by MSCM and the feature maps of ResNet101’s fifth stage were combined. This will enhance the model’s capacity for generalization and enable it to adjust to changes in the data more effectively, enhancing the model’s performance. Experiments show that adding residual structure can make full use of the depth of the network, and the network can learn more complex and deep feature representation. This can improve the expression ability of the network, and then improve the performance of the network. As shown in Table 1, In order to study the impact of IERM on EMSNet, we set mid channels to 256 when k is 4 or 512 otherwise to explore the effect of IERM on EMSNet. According to the previous research work [24, 54], and to reduce the training time and consider the number of channels, we set the size of k in DCS at IERM to (1,5), (3,5), and (1,3,5,7). The experiment revealed that there was no significant difference between the mIoU values when k was set to (3,5) and (1,3,5,7); however, when k was (1,3,5,7), there were more parameters and a longer training time needed; therefore, we decided to set k to (3,5). The experiment demonstrates that the right k value can account for both training speed and accuracy in capturing a certain proportional representation associated with the input image. As shown in Table 1, we set the inputs of the dynamic convolution structure in IERM to be entirely composed of the output of stage 4, to test the mIoU value of the network when different stage inputs are set. Experiments show that the performance of semantic segmentation can be improved by combining the feature maps of each stage. Figure 5 shows the inference time of our model compared to ANNet. Experiments show that the inference time of our model is less than that of ANNet, and the segmentation precision is also higher, so our model has more advantages than ANNet (Tables 2, 3, 4, 5).

Visual comparison on PASCAL VOC 2012 Dataset. a Image, b Ground Truth, c ANNet, d Ours
Comparisons with other methods on PASCAL VOC 2012
The dataset PASCAL VOC 2012 includes 2913 images across 20 categories. The 2913 photos were divided into 1464 training, 1449 validation, and 1456 testing images. Figure 5 displays the results of the segmentation. Our approach, which obtained 85.46% of mIoU, is superior to the one described previously, as demonstrated in Table 6. The segmentation results are shown in Fig. 5. Our model can perform good segmentation for the human hand and wine bottle in the first row, the fence in the second row, the bicycle tire in the third row, and the human hand in the fourth row.
Comparisons with other methods on cityscapes and ADE20K datasets
Cityscapes. We used a test dataset to contrast our methodology with other methods in order to demonstrate its effectiveness. Significantly, we did not use the validation set when training the model; instead, we ran 160K iterations directly on the improved photos. As illustrated in Table 7, our method outperforms the previously mentioned technique by achieving a mIoU of 82.2%.
Furthermore, we conducted a qualitative comparison with other methods on the urban landscape dataset, as showcased in Fig. 6. Our IERM approach yields rich information about class areas and consistent partitioning results within classes. Specifically, IERM assigns identical labels to classes belonging to the same category. For instance, in Fig. 6, when compared to other methods, our approach accurately segments streetlight and motorcycles in the first row of images, assigning them to the same class. In addition, our model outperforms other methods by effectively segmenting the tail of the truck and the front of the car in the fourth row. Our model also excels in segmenting long objects, such as the sidewalks in the second and third rows, which other models fail to do. Experiments show that our model has good results in segmentation accuracy, small object segmentation, and boundary segmentation.

Visual comparison on the Cityscapes Dataset: a image, b ground truth, c ANNet, d DANet, e ours
Table 8 presents our model’s segmentation performance on the ADE20K dataset, which contains images of varied sizes and several semantic category gaps in the training and validation sets. PSPNet used the deepest backbone network, and our model achieved a remarkable segmentation performance of 45.58%, outperforming all other methods in the comparison. As shown in Table 9, the segmentation indicator of our model still produces a satisfactory result, even when we employ a different backbone, demonstrating the benefits of our suggested model. Although our network has achieved better results, it still needs to be improved in terms of speed, and there are still some problems in the segmentation of small objects.
Conclusion
In this paper, we suggest an improved multi-scale semantic segmentation network. The suggested IERM and MSCM is the primary contribution of the enhanced multi-scale network. To provide rich contextual links on local features, the IERM module may record long-range pixel dependencies in the feature map channel direction. The MSCM module, however, is capable of modeling the relationships between various channels and efficiently capturing multi-scale contextual data as well as long-range dependencies between pixels in the feature map’s spatial direction. Our model can efficiently capture long-distance interdependencies between pixels by merging the features of the IERM and MSCM modules, increasing the regional representation of categories, and obtaining more precise segmentation. Extensive experimentation was used to assess the effectiveness of our model on three scene segmentation datasets: Cityscapes, Pascal VOC 2012, and ADE20k. The outcomes demonstrate considerable performance gains, proving the viability of our suggested strategy. For cityscapes, our miou was 82.2%. Future applications of EMSNet may include semi-supervised semantic segmentation, segmentation of medical images, semantic segmentation of three-dimensional space, and other areas as technology advances.
Data availability
Data related to the current study are available from the corresponding author on reasonable request.
References
Zhou B, Zhao H, Puig X, et al (2017) Scene parsing through ADE20K dataset. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR). IEEE, Honolulu, HI, pp 5122–5130
Li Y, Guo Y, Kao Y, He R (2016) Image piece learning for weakly supervised semantic segmentation. IEEE Trans Syst Man Cybern Syst 47(4):648–659. https://doi.org/10.1109/TSMC.2016.2623683
Gao G, Xu G, Yu Y et al (2021) MSCFNet: a lightweight network with multi-scale context fusion for real-time semantic segmentation. IEEE Trans Intell Transport Syst 23(12):25489–25499. https://doi.org/10.1109/TITS.2021.3098355
Teichmann M, Weber M, Zollner M, et al (2018) MultiNet: real-time joint semantic reasoning for autonomous driving. In: 2018 IEEE intelligent vehicles symposium (IV). IEEE, Changshu, pp 1013–1020
Siam M, Elkerdawy S, Jagersand M, Yogamani S (2017) Deep semantic segmentation for automated driving: taxonomy, roadmap and challenges. In: 2017 IEEE 20th international conference on intelligent transportation systems (ITSC). IEEE, Yokohama, pp 1–8
Hardens M, Szekely G (2003) Enhancing human-computer interaction in medical segmentation. Proc IEEE 91:1430–1442. https://doi.org/10.1109/JPROC.2003.817125
Alhaija H A, Mustikovela S K, Mescheder L et al (2017) Augmented reality meets deep learning for car instance segmentation in urban scenes. In: British machine vision conference, vol 1, p 2
Zhou Z, Rahman Siddiquee MM, Tajbakhsh N, Liang J (2018) UNet++: a nested U-Net architecture for medical image segmentation. In: Stoyanov D, Taylor Z, Carneiro G et al (eds) Deep learning in medical image analysis and multimodal learning for clinical decision support. Springer International Publishing, Cham, pp 3–11
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86:2278–2324. https://doi.org/10.1109/5.726791
Li Z, Liu F, Yang W, Peng S, Zhou J (2021) A survey of convolutional neural networks: analysis, applications, and prospects. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2021.3084827
Szegedy C, Liu W, Jia Y et al (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 1–9
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/ARXIV.1409.1556
Li Y, Chen W, Zhang Y et al (2020) Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens Environ 250:112045. https://doi.org/10.1016/j.rse.2020.112045
Tao C, Qi J, Li Y et al (2019) Spatial information inference net: Road extraction using road-specific contextual information. ISPRS J Photogramm Remote Sens 158:155–166. https://doi.org/10.1016/j.isprsjprs.2019.10.001
Long J, Shelhamer E, Darrell T (2015) Fully Convolutional Networks for Semantic Segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3431–3440
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 770–778
Yuan Y, Chen X, Wang J (2020) Object-contextual representations for semantic segmentation. In: Vedaldi A, Bischof H, Brox T, Frahm J-M (eds) Computer vision—ECCV 2020. Springer International Publishing, Cham, pp 173–190
Chen L-C, Zhu Y, Papandreou G, et al (2018) Encoder-decoder with Atrous separable convolution for semantic image segmentation. In: Proceedings of the European conference on computer vision (ECCV), pp 801–818. https://doi.org/10.48550/ARXIV.1802.02611
Chen L-C, Papandreou G, Schroff F, Adam H (2017) Rethinking Atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587
Chen L-C, Papandreou G, Kokkinos I et al (2018) DeepLab: semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell 40:834–848. https://doi.org/10.1109/TPAMI.2017.2699184
Badrinarayanan V, Handa A, Cipolla R (2015) SegNet: a deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv preprint arXiv:1505.07293
Zhao H, Shi J, Qi X et al (2017) Pyramid scene parsing network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2881–2890
Wang X, Girshick R, Gupta A, He K (2018) Non-local neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 7794–7803
Zhu Z, Xu M, Bai S et al (2019) Asymmetric non-local neural networks for semantic segmentation. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 593–602
Li T, Wei Y, Cui Z et al (2023) Mutually reinforcing non-local neural networks for semantic segmentation. Complex Intell Syst. https://doi.org/10.1007/s40747-023-01056-w
Fu J, Liu J, Tian H, et al (2019) Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3146–3154
Dai F, Zhang S, Liu H, Ma Y, Zhao Q (2022) Global boundary refinement for semantic segmentation via optimal transport. In: Khanna S, Cao J, Bai Q, Xu G (eds) PRICAI 2022: trends in artificial intelligence. PRICAI 2022. Lecture notes in computer science, vol 13631. Springer, Cham
Dosovitskiy, A, Beyer, L, Kolesnikov, A et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Mottaghi R, Chen X, Liu X, et al (2014) The role of context for object detection and semantic segmentation in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 891–898
Zhao B, Zhang X, Li Z, Hu X (2019) A multi-scale strategy for deep semantic segmentation with convolutional neural networks. Neurocomputing 365:273–284. https://doi.org/10.1016/j.neucom.2019.07.078
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. In: Navab N, Hornegger J, Wells WM, Frangi AF (eds) Medical image computing and computer-assisted intervention—MICCAI 2015. Springer International Publishing, Cham, pp 234–241
Noh H, Hong S, Han B (2015) Learning deconvolution network for semantic segmentation. In: Proceedings of the IEEE international conference on computer vision, pp 1520–1528
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: International conference on learning representations, pp 1–14
Xie S, Girshick R, Dollar P, Tu Z, He K (2017) Aggregated residual transformations for deep neural networks. In: IEEE conf. comput. vis. pattern recog., pp 1492–1500
Chen C-F(Richard), Fan Q, Panda R (2021) CrossViT: cross-attention multi-scale vision transformer for image classification. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 357–366
Liu Z, Lin Y, Cao Y et al (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 10012–10022
Guo M-H, Cai J-X, Liu Z-N et al (2021) PCT: point cloud transformer. Comp Vis Media 7:187–199. https://doi.org/10.1007/s41095-021-0229-5
Wang Q, Wu B, Zhu P et al (2020) Supplementary material for “ECA-Net: efficient channel attention for deep convolutional neural networks”. In: Proceedings of the 2020 IEEE/CVF conference on computer vision and pattern recognition. IEEE, Seattle, WA, USA, pp 13–19
Zhang H, Wu C, Zhang Z et al (2022) ResNeSt: split-attention networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2736–2746
Huang Z, Shi X, Zhang C et al (2022) FlowFormer: a transformer architecture for optical flow. arXiv preprint arXiv:2203.16194
Yuan Y, Huang L, Guo J et al (2018) OCNet: object context network for scene parsing. arXiv preprint arXiv:1809.00916
Zhang H, Goodfellow I, Metaxas D, Odena A (2019) Self-attention generative adversarial networks. In: International conference on machine learning. PMLR, pp 7354–7363
Guo M-H, Liu Z-N, Mu T-J, Hu S-M (2022) Beyond self-attention: external attention using two linear layers for visual tasks. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2022.3211006
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5–9, 2015, proceedings, part III 18. Springer International Publishing, pp 234–241
Zhang H, Dana K, Shi J, Zhang Z, Wang X, Tyagi A, Agrawal A (2018) Context encoding for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7151–7160
Gu J, Kwon H, Wang D, Ye W, Li M, Chen YH et al. (2022) Multi-scale high-resolution vision transformer for semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12094–12103
Tao A., Sapra K, Catanzaro B (2020) Hierarchical multi-scale attention for semantic segmentation. arXiv preprint arXiv:2005.10821. https://doi.org/10.48550/arXiv.2005.10821
Wang J, Sun K, Cheng T et al (2020) Deep high-resolution representation learning for visual recognition. IEEE Trans Pattern Anal Mach Intell 43(10):3349–3364
Everingham M, Winn J (2012) The PASCAL visual object classes challenge 2012 (VOC2012) development kit. In: Pattern Anal. Stat. Model. Comput. Learn., Tech. Rep 2007, pp 1–45
Cordts M, Omran M, Ramos S, et al (2016) The Cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3213–3223
Zhou B, Zhao H, Puig X et al (2019) Semantic understanding of scenes through the ADE20K dataset. Int J Comput Vis 127(3):302–321. https://doi.org/10.1007/s11263-018-1140-0
Krizhevsky A, Sutskever I, Hinton GE (2017) ImageNet classification with deep convolutional neural networks. Commun ACM 60(6):84–90. https://doi.org/10.1145/3065386
Deng J, Dong W, Socher R et al (2009) ImageNet: a large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, pp 248–255
He J, Deng Z, Qiao Y (2019) Dynamic multi-scale filters for semantic segmentation. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 3562–3572
Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y et al (2021) Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6881–6890
Li X, You A, Zhu Z, Zhao H, Yang M, Yang K et al (2020) Semantic flow for fast and accurate scene parsing. In: Computer vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, proceedings, part I 16, pp 775–793
Acknowledgements
The authors gratefully acknowledge the financial support from the National Natural Science Foundation of China (Grant No. 61472220, 61572286).
Funding
National Natural Science Foundation of China, Grant/Award Numbers: 61472220, 61572286.
Author information
Authors and Affiliations
Contributions
Formal analysis, ZC and TL; Methodology, ZC and TL; Supervision, DW; Writing original draft, TL.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest in the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, T., Cui, Z., Han, Y. et al. Enhanced multi-scale networks for semantic segmentation. Complex Intell. Syst. 10, 2557–2568 (2024). https://doi.org/10.1007/s40747-023-01279-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01279-x