
Abstract
This paper studies the synchronization and control of chaotic systems while proposing a novel chaotic-based path-tracking application for mobile robots (MRs) to ensure their safety and security. In security-based applications that use MRs, such as patrol MRs, the path of the MRs must be complex enough to prevent easy prediction. Multiple chaotic systems with a chaotic switching mechanism are introduced for secure path planning. The main challenges are that the dynamics of MRs are entirely unknown. The modeled dynamics of the MRs are unreliable in practice due to a broad range of uncertainties related to the parameters, operating conditions, environmental impacts, time delays, unmodeled frictions, noisy sensors, and faulty actuators. Also, the chaotic switching of reference signals between chaotic signals imposes a high dynamic perturbation. The main novelties are as follows: (1) a strong secure path is introduced for MRs. (2) A powerful fractional-order predictive controller using type-3 (T3) fuzzy-logic systems (FLSs) is developed. (3) The estimation and prediction errors of T3-FLSs are compensated by a designed parallel compensator. (4) T3-FLSs are tuned online, such that stability is ensured, and prediction accuracy is guaranteed. (5) The suggested scheme is implemented on a real-world MR, and the results demonstrate the feasibility and accuracy of the proposed method. Also, in several simulations, the efficacy of the introduced controller is examined.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Mobile robots are increasingly being utilized in various engineering systems across a wide range of fields. These include industries, such as agriculture, forestry, mining, and healthcare, as well as applications in search and rescue, rehabilitation, and even entertainment. They are particularly useful in dangerous and remote locations where human intervention may be difficult or impossible. Therefore, the modeling and controlling of these MRs have been the focus of many researchers, in the past few decades. Wheeled mobile robots (MRs) are an example of systems that are subject to nonholonomic constraints due to the contact of their wheels with the ground. These constraints arise from the fact that the wheels can only move forward or backward without slipping in the direction of motion, limiting the robot’s ability to change direction or position in a smooth and unconstrained way. Numerous control concerns have been taken into consideration in the realm of motion control of these systems for the automated operation of wheeled robots. These problems include time-varying path following, stability around desirable scenarios, and path following [1,2,3].
In the last few decades, extensive research has been conducted in the field of mobile robot control and many studies have been reported in this regard. It can be said that a major part of this research has focused on the problem of tracking the path by the robot in the presence of uncertainties. There are many problems in implementing model-based controllers on real systems such as robots. One of the most important reasons is the inability to accurately model real systems. Furthermore, even in a few case studies, if this capability exists, the resulting model is so complex that makes controller design difficult. Inaccuracy in modeling is caused by two primary sources: 1—uncertainty in model parameters and 2—unmodeled dynamics. A considerable number of standard control methods to deal with these uncertainties are seen in the literature [4]. Many of the methods that were originally proposed for the control of the MRs, without considering the dynamics of the robot, were designed for the tracking control problem using only the kinematic mode of the robot [5]. Backstepping is one of the most commonly employed stabilizing control methods for kinematic control [6]. The sliding-mode controller (SMC) is another method that is widely employed for the control of MRs [7, 8]. Designing this controller is simple and it results in a relatively good response, but this controller has some problems such as control input chattering. The chattering issue of SMC is investigated in [9], and a self-organizing approach is suggested. By experimental studies on a robot, it is shown that the suggested controller is applicable, and the chattering is decreased. In [10], an adaptive controller is suggested, and an event-triggered scheme is developed for patrolling MRs. In [11], the slip effects are taken into account, and a mathematical model is developed for MRs in the presence of the slip effect. The stability of MR in the designed path is investigated using the Lyapunov approach. In [12], the aperiodic sampling is studied, and a cooperative controller is designed. A simple observer is also designed to estimate the disturbances.
Adaptive control and robust control are two important and complementary methods that have been proposed to overcome uncertainties and perturbations [13]. Adaptive control can adequately address this issue by adapting to the changing dynamics and canceling the effect from uncertainties and disturbances in a systematic manner, as suggested in [14, 15]. One of the simplest approaches in robust controller design is SMC. The high frequency of the control signal causes activation of unmodeled dynamics of MR. In addition to the difficulty of implementation, vibration caused by control signal fluctuations causes damage to mechanical parts. To solve the issues of traditional controllers, some intelligent neuro-fuzzy controllers have been studied. For instance, in [16], an FLS-based controller is developed, and it is tested on a surgery robot. Similarly, an SMC is developed in [17] using FLSs, and a Kalman filter is suggested for learning FLS. Finally, the effectiveness of the developed FLSs is evaluated by applying them to a 6-DOF robot. In [18], a fractional controller is suggested for MRs, and FLS is employed to handle the effect of disturbances. In [19], the terminal SMC is studied for MRs, and FLS is utilized for the estimation of uncertainties in MR dynamics. In some simulations, the validity of the controller is examined. The chattering problem of SMC is studied in [20] using FLSs, and by implementing it on a robot, the better accuracy of FLS-based SMC is demonstrated. In [21], mooring is developed, and FLS are used to dampen the undesired forces. In various sea conditions, the designed controller is examined, and the effectiveness of FLSs is shown. The effect of the overturning angle is studied in [22], and the feasibility of the controller is demonstrated using an eight-wheeled prototype. Also, it is verified that FLSs are effective in accuracy improvement. In [23], an FLS-based controller is suggested for navigation of MRs, and by Kinect sensors, the effectiveness is examined on an experimental setup.
One of the important applications of MR is to follow a path, in a secure scheme. Many approaches have been suggested for secure path planning. One of the fundamental approaches is chaotic systems. The main foundation of chaos theory is the idea that order and chaos are not always opposites. The fusion of order and chaos in chaotic systems is remarkable. Although these systems appear chaotic and operate in an unpredictable manner when viewed from the outside, they really include a set of deterministic equations that function with the order. Chaos is a name that is often applied to a non-linear dynamic. This expression is used to explain the complex behavior of the so-called simple, linear, and well-behaved systems. Chaotic behavior appears irregular and often random, similar to the behavior of a system strongly affected by random external noise. Chaos is described mathematically as the long-term, unexpected behavior of a deterministic dynamical system that is sensitive to the beginning circumstances [24]. Chaos theory is the in-depth analysis of unstable periodic behavior in deterministic non-linear dynamical systems. The origins of chaos theory go back to Henry Poincaré, who tried to solve an unsolved problem of Newtonian Laplacian celestial mechanics (the three-body problem). Poincaré realized that it is possible for there to be orbits that are acyclic and are not constantly increasing or converging to a fixed point. During this research, Poincaré realized that in non-linear systems, there may be infinitely complex behavior. Chaos theory has fascinated scientists and engineers for two reasons: (1) Chaos theory provides theoretical and empirical tools to categorize and understand complex behavior in which other theories fail. (2) Chaos is universal; that is, it is used in mechanical oscillators, electrical circuits, chemical reactions, optical systems, nerve cells, lasers, etc. Universality means that what we learn from studying the chaotic behavior of a mechanical oscillator, we can quickly apply it to understand the chaotic behavior of other systems. The chaos theory in MR has been studied in a few papers. For example, in [25], Hénon chaotic map is used for generating paths for MRs, and it is evaluated using multi-robots. In [26], the chaos theory is combined with the ant colony algorithm to design a path for MRs. The control of MR in a chaotic path is studied in [27]. In [28], a chaotic map is designed for vacuum cleaning MRs, and it is shown that by the chaotic path, the number of collisions and motion commands is decreased while covering the working space more effectively. In [29], the robot’s chaotic beginning state parameters and initial coordinates are used to generate the moving route points. The mobile space of the robot meshes, and the dynamic mesh activity value is computed in accordance with the excitation, taking into account the local optimum path planning solution. The mobile route planning is divided using the mesh activity, and the local path and angular displacement changes are then determined. To correct the planning outcomes, the relevant index assessment is also created for local path planning. The secure communication system for MR is studied in [30]. The transmission of images between MRs is encrypted by chaotic systems. In [31], a random bit generator is initially created using the dynamic equations of two straightforward chaotic systems. Autonomous robots use this as a source to develop a set of navigational instructions that it uses to explore space while maintaining unexpected and random mobility. This navigational method covers a large region, but it also results in many trips back to earlier cells. In this paper, a memory approach is used to restrict the robot’s chaotic navigation that has received the fewest visits, improving performance all around. In [32], a coupled-oscillator particle model is examined with an emphasis on the special scenario of agents forming symmetric clusters while traveling in a circular motion. The findings in this paper show that some areas of the parameter are conducive to the emergence of these clusters. In [33], the real output trajectory-tracking performance of an MR is improved using an intelligent controller and offline and online tuning back-propagation methods. The objectives of this approach are to construct a trajectory-tracking controller and identify the best path to direct the movement of the non-linear kinematics MR system. Since the route should prevent colliding with barriers and must have the shortest possible length, a chaotic-based swarm optimization technique is employed to solve these two challenges of path design.
More recently, type-3 FLSs have been introduced in a wide range of practical problems, such as forecasting [34], industrial controllers [35], chaotic financial system [36], robotic applications [27], optimization [37], among many others. However, the stable fractional-order T3-FLS-based controllers with stable learning schemes have not been studied. Regarding the literature review, the research gap is summarized as:
-
In most studies, the suggested approach can be applied just to a specific robot task.
-
The complicated path for secure applications has been quite rarely studied. In most studies, the simple path is considered for tracking.
-
The robot dynamics are derived with simplifications on nonholonomic constraints and lack of kinetodynamics considerations of the robot.
-
There is little known about the type-3 FLS-based controllers for MRs that can potentially yield better performance.
-
The stability under complicated references and perturbations is neglected in most of the above-investigated studies.
-
A few of the studies in the literature have incorporated the experimental tests of the proposed control scheme.
Regarding the above discussion, the main motivation is to design a new predictive control scheme using T3-FLSs and fractional-order calculus with a stable learning scheme, such that the controller to be applicable in real-world environments. The main contributions are as follows:
-
A new fractional-order fuzzy predictive controller with an online stable learning scheme is introduced.
-
Type-3 FLSs are used for online estimation and prediction.
-
A new strong secure path planning scheme is introduced for MRs.
-
The feasibility of the suggested controller is examined by a real-world setup.
-
The robustness is analyzed under unknown dynamics of MR, chaotic reference, and sudden changes of path based on a chaotic scheme.
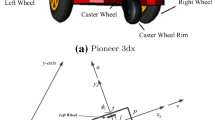
System description
Kinematic model
The linear and angular velocities are given as
where r/l denotes the radius/distance of wheels. Then, it can be written
In (X,Y) coordination, it can be written
Dynamic model
The general dynamics of MRs are written as
where \(\Psi \) and V are inertia and Coriolis matrices. G denotes the gravitational effects. \(\tau _d\) is disturbance. B is a constant matrix. \(\tau \) and \(\varsigma \) are kinematic terms and Lagrange vector. \(\xi \), \({{\dot{\xi }}}\), and \(\ddot{\xi }\) are position, velocity, and acceleration. From \(G=0\), we write
Considering a transformation Z, such that \({{\dot{\xi }}} = Z\left( \xi \right) \eta \), \(\eta = {\left[ {\begin{array}{ll} {{{\dot{\theta }}_r}}&{{{{{\dot{\theta }}} }_l}} \end{array}} \right] ^T}\), \(\ddot{\xi }= \dot{Z}\left( \xi \right) \eta + Z\left( \xi \right) {{\dot{\eta }}} \), and \({Z^T}{A^T} = 0\), we obtain
From (9), we have
where
The linear/angular velocities from (4) and (10) are written as
Multi-switching path
The path of MR is planned by the M chaotic systems
The controller u should be designed, such that the error (17) is approached zero
where \(\xi \) denotes robot x-axis position. The switching scheme is given in Fig. 1. The key idea is that the switching is also managed by a chaotic system.

Switching modes
It should be noted that the reference path is generated using some chaotic signals. In other words, the reference path is switched between some chaotic signals. To enhance the security of the path, the switching mechanism is also controlled by a chaotic signal. The idea is that the time switching is constant, but the target of switching is determined by a chaotic signal. For example, suppose that we have five chaotic signals. The first signal is used for the switching mechanism, and four others are used for path generation. The switching period is constant, and suppose it is 5 s. Therefore, after every 5 s, the value of the first signal determines which of the four chaotic signals should be used to generate the path. For example, if the value of the first signal is between a and b, the reference is switched to signal 3; if it is between b and c, the reference is switched to signal 2, and so on.
General view
A general view of the schemed controller is depicted in Fig. 2.

Control scheme
For the described MR, a T3-FLS-based model estimator is suggested
where \({{{\hat{\xi }}}}\) is the estimation of \({ \xi }\), \(f\left[ {X_f(t),\vartheta _f (t)} \right] \) represents a T3-FLS, \({{\vartheta _f}}\) denotes a vector that includes the parameters of f, U is the upper bound of u, and \(X_f\) includes the inputs of f. Therefore, \(X_f\) is defined as
where \(\tau \) is specified delay, and \(D_t^q{{\hat{\xi }}}(t)\) denotes the Caputo fractional derivative. \(D_t^q{{\hat{\xi }}}(t)\) is written as
where \(0< q < 1\), and \(\Gamma ( \cdot )\) is Gamma function. T3-FLSs are learned by the tuning laws, extracted from a fractional-order stability analysis. From (18), the estimation error (\({{\hat{e}}} = \xi -{{\hat{\xi }}}\)) dynamics are written as
where \(f\left[ {X_f(t),{\vartheta _f ^*}(t)} \right] \) is a T3-FLS with optimal \(\vartheta _f ^*\), and \({\delta }\) denotes the approximation error. The suggested controller is generally written as
where \({u_{c}}(t)\) and \({u_p}(t)\) are predictive controller and compensator. The predictive controller is a T3-FLS and is denoted as \(g\left[ {{X_g}(t),{\vartheta _g}(t)} \right] \). \({X_g}\) and \({{\vartheta _g}}\) are the input and rule vectors of \(g\left[ {{X_g}(t),{\vartheta _g}(t)} \right] \). The predictive controller is tuned in the direction of minimizing of (23)
where \(\pi \) denotes a prediction horizon, and \({\xi }_d\) is the reference signal.
Type-3 FLSs
The MR dynamics are considered entirely unknown. The T3-FLS is used for online dynamic identifying and trajectory prediction. T3-FLSs have been successfully used for estimations and prediction applications. In this paper, new fractional-order learning laws are presented for T3-FLSs [38]. Also, a predictive controller is designed on the basis of the T3-FLS model of MR. In this section, the T3-FLS is illustrated.
-
(1)
The input variables for T3-FLS (\({{x _i}}, \,i=1,\ldots ,4\)) in modeling part are \( {{\hat{\xi }}} (t)\), \({{\hat{\xi }}} \left( {t - \tau } \right) \), \({{\hat{\xi }}} \left( {t - 2\tau } \right) \), and \({\hat{\xi }} \left( {t - 3\tau } \right) \). \(\tau \) denotes a delay. In the predictive control part, the input variables for T3-FLS are \(\xi \), e, \(D_t^qe\), and \(D_t^{ - q}e\).
-
(2)
Regarding the upper and lower bounds of input signals, just two membership functions are considered for input signals (\(\tilde{\Omega }_i^j\), \(i=1,..,4\), \(j=1,2\)). The memberships of \({\tilde{\Omega }_i^j}\) at horizontal slice levels \({ {{{{\underline{\alpha }}}}_i}}\) and \({ {{{{\bar{\alpha }}} }_i}}\) are given as [39] (see Fig. 3)
$$\begin{aligned}{} & {} {{{\bar{H}} }_{{{\tilde{\Omega }}}_{i\,\,| {{{{\bar{\alpha }}} }_i}}^j}} = \left\{ {\begin{array}{ll} {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{{\bar{\alpha }_i}}}\,if\,{C_{{{\tilde{\Omega }}}_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}< x_i \le {C_{{{\tilde{\Omega }}}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{{{{{\bar{\alpha }}} }_i}}}\,if\,{C_{{{\tilde{\Omega }}}_i^j}} < x_i \le {C_{\tilde{\Omega }_i^j}} + {{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,if\,x_i > {C_{{{\tilde{\Omega }}}_i^j}} + {{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}\,or\,x_i \le {C_{{{\tilde{\Omega }}}_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}} \end{array}} \right. \nonumber \\ \end{aligned}$$(24)$$\begin{aligned}{} & {} {{{\bar{H}} }_{{{\tilde{\Omega }}}_{i\,\,| {{{{\underline{\alpha }}} }_i}}^j}} = \left\{ {\begin{array}{ll} {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{{{{{\underline{\alpha }}} }_i}}}\,if\,{C_{{{\tilde{\Omega }}}_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}< x_i \le {C_{\tilde{\Omega }_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{{{\underline{\alpha }}_i}}}\,if\,{C_{{{\tilde{\Omega }}}_i^j}} < x_i \le {C_{\tilde{\Omega }_i^j}} + {{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,if\,x_i > {C_{{{\tilde{\Omega }}}_i^j}} + {{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}\,or\,x_i \le {C_{{{\tilde{\Omega }}}_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}} \end{array}} \right. \nonumber \\ \end{aligned}$$(25)$$\begin{aligned}{} & {} {{\underline{H}} _{{{\tilde{\Omega }}}_{i\,\,| {{{{\bar{\alpha }}} }_i}}^j}} = \left\{ {\begin{array}{ll} {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{\frac{1}{{{{{{\bar{\alpha }}} }_i}}}}}\,if\, {C_{\tilde{\Omega }_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}< x_i \le {C_{{{\tilde{\Omega }}}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{\frac{1}{{{{{{\bar{\alpha }}} }_i}}}}}\,if\, {C_{\tilde{\Omega }_i^j}} < x_i \le {C_{{{\tilde{\Omega }}}_i^j}} + {{{{\bar{s}}}}_{\tilde{\Omega }_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,if\,x_i > {C_{{{\tilde{\Omega }}}_i^j}} + {{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}\,or\,x_i \le {C_{{{\tilde{\Omega }}}_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}} \end{array}} \right. \nonumber \\ \end{aligned}$$(26)$$\begin{aligned}{} & {} {{\underline{H}} _{{{\tilde{\Omega }}}_{i\,\,| {{{{\underline{\alpha }}} }_i}}^j}} = \left\{ {\begin{array}{ll} {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{\frac{1}{{{{{{\underline{\alpha }}} }_i}}}}}\, if\,{C_{\tilde{\Omega }_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}< x_i \le {C_{{{\tilde{\Omega }}}_i^j}}}\\ {1 - {{\left( {\frac{{\left| {x_i - {C_{{{\tilde{\Omega }}}_i^j}}} \right| }}{{{{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}}} \right) }^{\frac{1}{{{{{{\underline{\alpha }}} }_i}}}}}\, if\,{C_{\tilde{\Omega }_i^j}} < x_i\le {C_{{{\tilde{\Omega }}}_i^j}} + {{{{\bar{s}}}}_{\tilde{\Omega }_i^j}}}\\ {0\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,if\,x_i > {C_{{{\tilde{\Omega }}}_i^j}} + {{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}\,\,or\,\,x_i \le {C_{\tilde{\Omega }_i^j}} - {{{\underline{s}} }_{{{\tilde{\Omega }}}_i^j}}}, \end{array}} \right. \nonumber \\ \end{aligned}$$(27)where \({{{\bar{H}} }_{{{\tilde{\Omega }}}_{i| {{{{\bar{\alpha }}} }_i}}^j}}\)/\({{{\bar{H}} }_{{{\tilde{\Omega }}}_{i| {{\underline{\alpha }}_i}}^j}}\) and \({{\underline{H}} _{{{\tilde{\Omega }}}_{i| {{{{\bar{\alpha }}} }_i}}^j}}\)/\({{\underline{H}} _{{{\tilde{\Omega }}}_{i | {{{{\underline{\alpha }}} }_i}}^j}}\) are the upper/lower memberships for \({{{\tilde{\Omega }}}_i^j}\) at \({ {{{{\underline{\alpha }}} }_i}}\) and \({ {{{{\bar{\alpha }}} }_i}}\). \({{C_{{{\tilde{\Omega }}}_i^j}}}\) are the center of \({{C_{{{\tilde{\Omega }}}_i^j}}}\) and \({{{{\underline{s}} }_{\tilde{\Omega }_i^j}}}\) and \({{{{{\bar{s}}}}_{{{\tilde{\Omega }}}_i^j}}}\) are the distances of \({{C_{{{\tilde{\Omega }}}_i^j}}}\) to the beginning/last points of \({{{\tilde{\Omega }}}_i^j}\) (see Fig. 3).
-
(3)
The upper rule firings \({{\bar{\mu }}} _{{{{{\bar{\alpha }}} }_i}}^l\), \(\bar{\mu }_{{{{{\underline{\alpha }}} }_i}}^l\), and lower firings \(\underline{\mu }_{{{{{\bar{\alpha }}} }_i}}^l\) and \({{\underline{\mu }}} _{{{\underline{\alpha }}_i}}^l\) are written as
$$\begin{aligned}{} & {} {{\bar{\mu }}} _{{{{{\bar{\alpha }}} }_i}}^l = {{{\bar{H}} }_{\tilde{\Omega }_{1\,\,\,\,|\, {{{{\bar{\alpha }}} }_i}}^{{p_1}}}} \cdot {{{\bar{H}} }_{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{{{\bar{\alpha }}} }_i}}^{{p_2}}}} \cdots {{{\bar{H}} }_{{{\tilde{\Omega }}}_{1\, \, \,\,|\, {{{{\bar{\alpha }}} }_i}}^{{p_n}}}} \end{aligned}$$(28)$$\begin{aligned}{} & {} {{\bar{\mu }}} _{{{{{\underline{\alpha }}} }_i}}^l = {{{\bar{H}} }_{\tilde{\Omega }_{1\,\,\,\,|\, {{{{\underline{\alpha }}} }_i}}^{{p_1}}}} \cdot {{{\bar{H}} }_{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{{{\underline{\alpha }}} }_i}}^{{p_2}}}} \cdots {{{\bar{H}} }_{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{{{\underline{\alpha }}} }_i}}^{{p_n}}}} \end{aligned}$$(29)$$\begin{aligned}{} & {} {{\underline{\mu }}} _{{{{{\bar{\alpha }}} }_i}}^l = {{\underline{H}} _{\tilde{\Omega }_{1\,\,\,\,|\, {{{{\bar{\alpha }}} }_i}}^{{p_1}}}} \cdot {\underline{H} _{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{{{\bar{\alpha }}} }_i}}^{{p_2}}}} \cdots {{\underline{H}} _{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{{{\bar{\alpha }}} }_i}}^{{p_n}}}} \end{aligned}$$(30)$$\begin{aligned}{} & {} {{\underline{\mu }}} _{{{{{\underline{\alpha }}} }_i}}^l = {{\underline{H}} _{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{{{\underline{\alpha }}} }_i}}^{{p_1}}}} \cdot {{\underline{H}} _{{{\tilde{\Omega }}}_{1\,\,\,\,|\, {{\underline{\alpha }}_i}}^{{p_2}}}} \cdots {{\underline{H}} _{\tilde{\Omega }_{1\,\,\,\, |\, {{{{\underline{\alpha }}} }_i}}^{{p_n}}}}, \end{aligned}$$(31)where form of \(l-th\) rule is given as
$$\begin{aligned}{} & {} {l - th\,Rule:}\nonumber \\{} & {} if\,{{\hat{\xi }}} \,is\,\,{{\tilde{\Omega }}} _{1\,\,\,\,}^{{p_1}}\,and\,\xi \left( {t - \tau } \right) \,is\,\,{{\tilde{\Omega }}} _2^{{p_2}}\,and\, \nonumber \\{} & {} \quad \cdots \,\,\xi \left( {t - 3\tau }\right) \,\,is\,\,{{\tilde{\Omega }}} _n^{{p_n}}\nonumber \\{} & {} Then\,f \in \left[ {{{{{\underline{\vartheta }}} }_l},{{\bar{\vartheta }}_l}} \right] ,l = 1,\ldots ,M, \end{aligned}$$(32)where \({{{\underline{\vartheta }}} _l} \in \left[ {{{{{\underline{\vartheta }}} }_{l,{{\underline{\alpha }}} }},{{{{\underline{\vartheta }}} }_{l,{{\bar{\alpha }}} }}} \right] \), \({{{{\bar{\vartheta }}} }_l} \in \left[ {{{{{\bar{\vartheta }}} }_{l,{{\underline{\alpha }}} }},{{{{\bar{\vartheta }}} }_{l,{{\bar{\alpha }}} }}} \right] \), \({{\tilde{\Omega }}}_i^{{p_j}}\) denotes the MF for input \(x_i\), and \({{{{\underline{\vartheta }}} }_l}\) and \({{{\bar{\vartheta }}} }_l\) denote the rule parameters.
-
(4)
The output signal f is
$$\begin{aligned} f = \frac{{\sum \nolimits _{i = 1}^{{n_\alpha }} {\left( {{{\underline{\alpha }}_i}{{{{\underline{\ell }}} }_i} + {{{{\bar{\alpha }}} }_i}{{{{\bar{\ell }}} }_i}} \right) } }}{{\sum \nolimits _{i = 1}^{{n_\alpha }} {\left( {{{{{\underline{\alpha }}} }_i} + {{{{\bar{\alpha }}} }_i}} \right) } }}{\mathrm{}}, \end{aligned}$$(33)where
$$\begin{aligned}{} & {} {{{{\bar{\ell }}} }_i} = \frac{{\sum \nolimits _{l = 1}^{{n_r}} {\left( {\bar{\mu }_{{{{{\bar{\alpha }}} }_i}}^l{{{{\bar{\vartheta }}} }_{l,{{{{\bar{\alpha }}} }_i}}} + {{\underline{\mu }}} _{{{{{\bar{\alpha }}} }_i}}^l{{\underline{\vartheta }}_{l,{{{{\bar{\alpha }}} }_i}}}} \right) } }}{{\sum \nolimits _{l = 1}^{{n_r}} {\left( {{{\bar{\mu }}} _{{{{{\bar{\alpha }}} }_i}}^l + \underline{\mu }_{{{{{\bar{\alpha }}} }_i}}^l} \right) } }} \end{aligned}$$(34)$$\begin{aligned}{} & {} {{{\underline{\ell }}} _i} = \frac{{\sum \nolimits _{l = 1}^{{n_r}} {\left( {{{\bar{\mu }}} _{{{{{\underline{\alpha }}} }_i}}^l{{{{\bar{\vartheta }}} }_{l,{{{{\underline{\alpha }}} }_i}}} + {{\underline{\mu }}} _{{{\underline{\alpha }}_i}}^l{{{{\underline{\vartheta }}} }_{l,{{{{\underline{\alpha }}} }_i}}}} \right) } }}{{\sum \nolimits _{l = 1}^{{n_r}} {\left( {{{\bar{\mu }}} _{{{{{\underline{\alpha }}} }_i}}^l + {{\underline{\mu }}} _{{{\underline{\alpha }}_i}}^l} \right) } }}. \end{aligned}$$(35)

Type-3 MF
The output is rewritten as
where
Predictive T3-FLS leaning
The BBO algorithm is formulated to optimize the predictive controller \(g\left[ {{X_g}(t),{\vartheta _g}(t)} \right] \). The parameter vector \({\vartheta _g}(t) \) is adjusted, such that (43) is minimized
where \({{\hat{\xi }}}(t)\) is the estimated position of MR, \(\pi \) denotes the prediction horizon, and \(\xi _d(t)\) is the expected path of MR. The cost function J is defined as
The optimization procedure is described as
-
(1)
Consider a set of possible vectors \({{\vartheta _g}}\) as an initial population \(P_{N \times \left( {\kappa + 4K} \right) }\). \(\kappa \) is the rule numbers, N denotes the number \({{\vartheta _g}}\) in P, and K represents the \(\alpha \)-cut numbers.
-
(2)
For each row of P, as \(P_j,\,j=1,\ldots ,N\), the immigration/emigration rates \({\lambda _j}\)/\(\gamma _j\) are defined as
$$\begin{aligned}{} & {} {\lambda _j} = \frac{1}{N}\left( {j - 1} \right) \end{aligned}$$(45)$$\begin{aligned}{} & {} {\gamma _j} = - \frac{1}{N}\left( {j - 1} \right) + 1. \end{aligned}$$(46) -
(3)
For each row of P, do:
-
(3.a)
Obtain the output of T3-FLS as
$$\begin{aligned} {u_{{p_j}}}(t) =g\left( {{X_g}|{P_j}} \right) , \end{aligned}$$(47)where \({u_{{p_j}}}(t)\) represents the jth predictive control signal based on the jth row of P.
-
(3.b)
Construct \({X_f}\) as \({X_f} = \big [{{\hat{\xi }}} (t),{{\hat{\xi }}} \left( {t - \tau } \right) , {{\hat{\xi }}} \left( {t - 2\tau } \right) ,{{\hat{\xi }}} \left( {t - 3\tau } \right) \big ]^T\), the control signal becomes \({u_j}(t) = {u_{{p_j}}}(t) + {u_c}(t)\).
-
(3.c)
For \({u_j}(t)\) that was obtained in the previous step, calculate \({{\hat{\xi }}} \left( {t + x} \right) \) for \(x = 1,\ldots ,\rho \) as follows: Using the Adams–Bashforth approach, we have
$$\begin{aligned}{} & {} {{\hat{\xi }}} \left( {t + x} \right) = {{\hat{\xi }}} (t) + \frac{{{j^q}}}{{\Gamma \left( {q + 2} \right) }}\left[ {f\left[ {{X_f}(t),{\vartheta _f}(t)} \right] } \right. \nonumber \\{} & {} \quad + \frac{{{u_j}(t)}}{U}\left( {{{\left( {x - 1} \right) }^{q + 1}} - \left( {x - 1 - q} \right) {x^q}} \right) \nonumber \\{} & {} \quad \left( {f\left[ {{X_f}(t),{\vartheta _f}(t)} \right] + \frac{{{u_j}(t)}}{U}} \right) + \mathop {\sum }\limits _{i = 0}^{x - 1}\nonumber \\{} & {} \quad \left. \times { {\left( {f\left[ {{X_f}\left( {t + i} \right) ,{\vartheta _f}(t)} \right] + \frac{{{u_j}(t)}}{U}} \right) a\left( {x,i} \right) } } \right] , \nonumber \\ \end{aligned}$$(48)where \({X_f}\left( {t + x} \right) \), \({X_f}\left( {t + i } \right) \) and \({{{{{\hat{\xi }}}}_p}\left( {t + x } \right) }\), are
$$\begin{aligned}{} & {} {X_f}\left( {t + x} \right) = \,\,\left[ {{{{{\hat{\xi }}} }_p}\left( {t + x} \right) ,{{{{\hat{\xi }}} }_p}\left( {t + x - \tau } \right) } \right. ,\nonumber \\{} & {} \left. {{{{{\hat{\xi }}} }_p}\left( {t + x - 2\tau } \right) ,{{{{\hat{\xi }}} }_p}\left( {t + x - 3\tau } \right) } \right] \end{aligned}$$(49)$$\begin{aligned}{} & {} {X_f}\left( {t + i} \right) = \,\,\,\,\left[ {{{\hat{\xi }}} \left( {t + i} \right) ,{{\hat{\xi }}} \left( {t + i - \tau } \right) } \right. ,\nonumber \\{} & {} {{\hat{\xi }}} \left. {\left( {t + i - 2\tau } \right) ,{{\hat{\xi }}} \left( {t + i - 3\tau } \right) } \right] \end{aligned}$$(50)$$\begin{aligned}{} & {} {{{{\hat{\xi }}} }_p}\left( {t + x} \right) = {{\hat{\xi }}} (t) \nonumber \\{} & {} \quad + \frac{{{j^q}}}{{\Gamma \left( {q + 1} \right) }}\mathop {\sum }\limits _{i = 0}^{x - 1} \nonumber \\{} & {} \quad {\left[ {f\left[ {{X_f}\left( {t + i} \right) ,{\vartheta _f}(t)} \right] + \frac{{{u_j}(t)}}{U}} \right] b\left( {x,i} \right) }, \end{aligned}$$(51)where
$$\begin{aligned} b\left( {x,i} \right)= & {} {\left( {x - i} \right) ^q} - {\left( {x - i - 1} \right) ^q} \end{aligned}$$(52)$$\begin{aligned} a\left( {x,i} \right)= & {} {\left( {x - i + 1} \right) ^{q + 1}} - 2{\left( {x - i} \right) ^{q + 1}} \nonumber \\{} & {} + {\left( {x - i - 1} \right) ^{q + 1}}. \end{aligned}$$(53) -
(3.d)
Examine (44) and calculate the value of cost function.
-
(3.a)
-
(4)
Sort the rows of P from the best to worst fitness.
-
(5)
For each row of \(P_j,\,h=1,\ldots ,N\), the mutation is applied as follows. If the randomly produced number is less than \({\lambda _h}\), then the jth row participates in a mutation operation. To apply mutation, another \({P_{j'}}\) is randomly selected, and \(P_j\) is updated as
$$\begin{aligned} {{P'}_j} = {P_j} + \eta \left( {{P_{j'}} - {P_j}} \right) , \end{aligned}$$(54)where \(0<\eta \le 1\).
-
(6)
The new generated \({{P'}_j}\) is evaluated on the basis of fitness function.
-
(7)
The new population \(P_{new}\) is constructed by the use new generated solutions \({{P'}_j}\) and old matrix P. If new generated \({{P'}_j}\) is better than old, a row of matrix P is replaced with that row.
-
(8)
By the use od best of row of P, the predictive control signal \({u_p} = g\left( {{X_g}|{P_{best}}} \right) \) is generated.
Stability analysis
To analyze the stability, a Lyapunov function is considered, and tuning rules are extracted for \(f\left[ {{X_f}(t),{\vartheta _f}(t)} \right] \).
Theorem 1
The MR system is asymptotically stable by adaptation law (55) and compensator (56)
where \(0 < \mu \le 1\), \({{\hat{e}}} = \xi - {{\hat{\xi }}}\), \(\xi _f\) includes the rule parameters of \({f\left[ {{X_f}\left( {t } \right) ,{\vartheta _f}(t)} \right] }\), \(e = {\xi y_d} - {{\hat{\xi }}}\), \(\varepsilon \) is a small constant, and U, \({{{\bar{u}}_p}}\), \({{{{{\bar{f}}}}}}\), \({{\bar{\delta }}} \) and \({{{\bar{\xi }}} }\) denote upper bounds of u , \({{{ u}_p}}\) , \({f\left[ {{X_f}\left( {t } \right) ,{\vartheta _f}(t)} \right] }\), \(\delta (t)\), and \(D_t^q{\xi _d}(t)\), respectively.

Fabricated MR for the experimental tests of the proposed control scheme
Proof
The Lyapunov function is given as
where
where \({{\tilde{\vartheta }}} _f^{} = \vartheta _f^* - \vartheta _f^{}\). Considering the inequality \(D_t^q\left( {\frac{1}{2}{x^2}} \right) \le xD_t^qx\), from (57), we can write
The estimation error in (21) can be rewritten as
By substituting (60) into (59), we can obtain
From (61), we can write
Substituting the adaptation law (55) into (62) yields
From (18), (58), and (63), one has
where \(f\left[ {{X_f}(t),{\vartheta _f}(t)} \right] \) is a T3-FLS, and \(\delta (t)\) and U denote the estimation error and upper bound of u. From compensator (22), the inequality (64) becomes
From compensator (56), the inequality (65) becomes
Inequality (66) is rewritten as
Consider the inequalities
we can conclude that \(D_t^qV(t) \le 0\). Since \(\ddot{V}(t)\) is bounded, then considering Barbalat’s lemma, the proof is complete. For some related Lemmas, see [40]. \(\square \)

Implemented result: planned path 1
Simulations and experimental examination
Implementation
The robot is designed with Solid software. A series of parts of the robot were made using a 3D printer, which includes the base of the motors and four columns that were placed on the four sides of the robot to connect the Sharp sensors, so that the sensors could be placed at a suitable angle and height on the four sides of the robot. MR has two regular wheels, which are connected to two stepper motors with high precision, and two idler pins to maintain the balance of the robot. MR has eight Sharp sensors and one Angular acceleration sensor. The two-phase stepper motors have an accuracy of 1.8 degrees per step. Using four 7 cm spacers, the chassis surface is raised to place the PCB on it (see Fig. 4). The communication between the robot and the laptop is through the NRF24L01 radio transceiver module, the communication modulation of this module is GFSK and the communication frequency of this chip is 2.4 GHz, which is much easier to pass through the wall or other objects due to its high frequency. The maximum data rate of this chip is 2 MB per second, which can be used to transmit heavy data, such as audio or even video. The receiver that is connected to the laptop is connected to a microcontroller with the SPI protocol, and on the other hand, this microcontroller is connected to the laptop with a USB to serial converter, which is connected to the MATLAB software through a virtual serial port with 9600 baud rate. In the robot, this module is connected to one of the microcontrollers using the SPI protocol, the same microcontroller that controls the Sharp sensors, and this wireless module. This microcontroller is connected to the microcontroller that controls the motors using UART serial communication. The angular acceleration sensor is also connected to the microcontroller that controls the motors using the I2C protocol. The baud rate of these two microcontrollers on the board is considered to be 250,000. Motor drivers have three control pins, including the EN pin, which is the activator, the direction pin, and the pulse or step pin, which rotates the motor one step for each pulse received.
The results for experimental examination are given in Fig. 5. Two distinct chaotic systems are selected to generate the reference path. The aim is to assess the performance of a robot that is programmed to follow the generated chaotic path. Through conducting experiments, the results obtained demonstrate the practicality and effectiveness of the strategy that has been designed. Even in the face of having no prior knowledge about the dynamics of the MR, as well as various experimental limitations, it is observed that the MR successfully and accurately traces the intended chaotic path. This finding highlights the robustness and adaptability of the implemented approach, further emphasizing its potential for real-world applications.
Simulations
Example 1
The reference signal is generated using the states of (72). The first signal is used for switching control. After each 5s if \(\zeta _{11}>0\), the reference signal is switched (see Fig. 6). The MR should track the chaotic path under chaotic switching. The MR parameters are provided in Table 1. Output trajectory is given in Fig. 7. The output signal well tracks the chaotic path. The reference is changed four times between \(\zeta _{13}\) and \(\zeta _{14}\). The switching mechanism is controlled by the first date \(\zeta _{11}\). In spite of the hard path and unknown dynamics, MR well follows the designed route. The associated control signal is depicted in Fig. 8. The estimation accuracy is examined in Fig. 9. The good convergence in Fig. 9 demonstrates the good estimation ability of T3-FLSs with the suggested fractional-order learning technique

Example 1: switching modes

Example 1: output signal

Example 1: control signal

Example 1: estimation performance

Example 2: switching modes

Example 2: output signal

Example 2: control trajectory

Example 2: estimation performance
Example 2
In this example, two hyperchaotic systems are considered to produce the reference signal. The master systems are given in (73). Similar to the first example, the first signal is used for switching control. After each 5s, if \(\zeta _{11}>10\), then the reference signal is switched to \(\zeta _{21}\); if \(\zeta _{11}<10\) and \(\zeta _{11}>0\), the reference signal is switched to \(\zeta _{22}\); if \(\zeta _{11}<0\) and \(\zeta _{11}>-10\), the reference signal is switched to \(\zeta _{23}\); if \(\zeta _{11}<-10\), the reference signal is switched to \(\zeta _{14}\) (see Fig. 10). The output trajectory is shown in Fig. 11. The reference is changed four times between \(\zeta _{14}\), \(\zeta _{21}\), \(\zeta _{22}\), and \(\zeta _{23}\). The switching mechanism similar to the previous example is controlled by the first date \(\zeta _{11}\). It is evident that MR well follows the designed trajectory, under the difficult defined scenarios. The associated control signal is depicted in Fig. 8. The estimated signal is depicted in Fig. 9. The good accuracy in Fig. 9 demonstrates a good estimation scheme with a good fractional-order learning technique. It should be noted that the small difference in tracking accuracy of various modes is because of the big difference in the dynamics behavior of different chaotic systems in different modes
Example 3
In this example, the performance of the MR robot in accurately tracking the intended chaotic path is compared with other related controllers, namely, type-2 FLS-based controller (T2FPC) [41], and non-linear predictive controller (NPC) [42]. To assess the tracking accuracy, an additional perturbation in the form of Gaussian noise is introduced. The root-mean-square errors obtained from the experiments are presented in Table 2. The results indicate that the proposed predictive scheme exhibits better accuracy compared to the other controllers. Particularly, when subjected to higher noise conditions, the suggested type-3 FLS-based controller demonstrates superior resistance in accurately tracking the chaotic path. This further highlights the effectiveness and robustness of the implemented approach, making it highly suitable for real-world applications.
Conclusion
In this study, a new secure path planning and tracking scheme are developed for MRs with nonholonomic constraints and unknown dynamics. Multiple chaotic systems and a chaotic switching mechanism generate the reference trajectory. A strong controller is suggested that the robot well tracks the designed path, despite uncertain dynamics of MR, complicated chaotic reference path, and sudden changing of the reference. A new fuzzy controller based on fractional-order calculus is proposed. The suggested controller uses T3-FLSs to estimate the dynamics and predict the output. Also, an adaptive compensator is suggested to work in parallel with the main controller to guarantee stability.
The designed controller is experimentally applied on a real-world MR. The results confirm the feasibility of the suggested approach; it is shown that MR well follows the planned complicated path. Also, in two simulation examples, the controller’s accuracy is tested. In the first one, a hyperchaotic system with four states is considered the reference system. The first state is used for managing the switching mechanism, and the reference is chaotically switched between the other states. The simulation results demonstrate that the suggested controller results in the desired accuracy. In the second example, two hyperchaotic systems are considered, and the reference signal is switched between five signals, in a chaotic scheme. The MR well follows the designed path, and the results show good accuracy. Finally, a comparison with other related controllers is presented to show the superiority of the T3-FLS-based controller. It can be seen that under high-noisy conditions, the suggested technique has a much stable response.
The main limitation is that the controller does not support the resiliency of system against faults and cyber attacks. In future, the control of MR for resilience as well as fault tolerance will be studied. The concept of resilience along with its related concepts is referred to the literature [43, 44]. Also, the suggested controller can be improved by new prediction models [45], multi-agent task planning [46], and new optimization techniques [47]. Financial systems are another case of complicated systems that suggested method can be applied for. In our future studies, the suggested multi-switching chaotic systems and type-3 fuzzy control method are extended for modeling and analyzing of financial chaotic systems. We will use the suggested method for forecasting and controlling the chaotic behavior of financial problems.
Data availability
The manuscript has no associated data.
References
Lu C, Gao R, Yin L, Zhang B (2023) Human-robot collaborative scheduling in energy-efficient welding shop. IEEE Trans Indust Inform
Wang J, Liang F, Zhou H, Yang M, Wang Q (2022) Analysis of position, pose and force decoupling characteristics of a 4-ups/1-rps parallel grinding robot. Symmetry 14(4):825
Wang J, Tian J, Zhang X, Yang B, Liu S, Yin L, Zheng W (2022) Control of time delay force feedback teleoperation system with finite time convergence. Front Neurorobot 16:877069
Cheng L, Lin Y, Hou Z-G, Tan M, Huang J, Zhang W (2010) Adaptive tracking control of hybrid machines: a closed-chain five-bar mechanism case. IEEE/ASME Trans Mechatron 16(6):1155–1163
Liu M, Gu Q, Yang B, Yin Z, Liu S, Yin L, Zheng W (2023) Kinematics model optimization algorithm for six degrees of freedom parallel platform. Appl Sci 13(5):3082
Fierro R, Lewis FL (1997) Control of a nonholomic mobile robot: Backstepping kinematics into dynamics. J Robot Syst 14(3):149–163
Sun Q, Ren J, Zhao F (2022) Sliding mode control of discrete-time interval type-2 fuzzy markov jump systems with the preview target signal. Appl Math Comput 435:127479
Wang B, Shen Y, Li N, Zhang Y, Gao Z (2023) An adaptive sliding mode fault-tolerant control of a quadrotor unmanned aerial vehicle with actuator faults and model uncertainties. Int J Robust and Nonlinear Control. https://doi.org/10.1002/rnc.6631
Yu D, Chen CP, Xu H (2021) Fuzzy swarm control based on sliding-mode strategy with self-organized omnidirectional mobile robots system. IEEE Trans Syst Man Cybernet Syst 52(4):2262–2274
AlI ssa S, Kar I (2021) Design and implementation of event-triggered adaptive controller for commercial mobile robots subject to input delays and limited communications. Control Eng Pract 114:104865
Khalaji AK, Jalalnezhad M (2021) Robust forward\(\backslash \)backward control of wheeled mobile robots. ISA Trans 115:32–45
Shao X, Zhang J, Zhang W (2022) Distributed cooperative surrounding control for mobile robots with uncertainties and aperiodic sampling. IEEE Trans Intell Transp Syst 23(10):18951–18961
Li B, Tan Y, Wu A-G, Duan G-R (2021) A distributionally robust optimization based method for stochastic model predictive control. IEEE Trans Automat Control 67(11):5762–5776
Ouyang P, Zhang W, Gupta MM (2006) An adaptive switching learning control method for trajectory tracking of robot manipulators. Mechatronics 16(1):51–61
Cheng L, Lin Y, Hou Z-G, Tan M, Huang J, Zhang W (2012) Integrated design of machine body and control algorithm for improving the robustness of a closed-chain five-bar machine. IEEE/ASME Trans Mechatron 17(3):587–591
Su H, Qi W, Chen J, Zhang D (2022) Fuzzy approximation-based task-space control of robot manipulators with remote center of motion constraint. IEEE Trans Fuzzy Syst 30(6):1564–1573
Khanesar MA, Branson D (2022) Robust sliding mode fuzzy control of industrial robots using an extended kalman filter inverse kinematic solver. Energies 15(5):1876
Muñoz-Vázquez AJ, Treesatayapun C (2022) Model-free discrete-time fractional fuzzy control of robotic manipulators. J Frank Inst 359(2):952–966
Wu X, Huang Y (2022) Adaptive fractional-order non-singular terminal sliding mode control based on fuzzy wavelet neural networks for omnidirectional mobile robot manipulator. ISA Trans 121:258–267
Zaare S, Soltanpour MR (2022) Adaptive fuzzy global coupled nonsingular fast terminal sliding mode control of n-rigid-link elastic-joint robot manipulators in presence of uncertainties. Mech Syst Signal Process 163:108165
Ding S, Zhao T, Gao F, Tang Z, Jin B (2022) Research on a motion-inhibition fuzzy control method for moored ship with multi-robot system. Ocean Eng 248:110795
Cao G, Zhao X, Ye C, Yu S, Li B, Jiang C (2022) Fuzzy adaptive pid control method for multi-mecanum-wheeled mobile robot. J Mech Sci Technol 36(4):2019–2029
Mishra DK, Thomas A, Kuruvilla J, Kalyanasundaram P, Prasad KR, Haldorai A (2022) Design of mobile robot navigation controller using neuro-fuzzy logic system. Comput Elect Eng 101:108044
Kuz’Menko A (2019) Synthesis of the sliding mode control law of synchronization of chaotic systems basing on sequential aggregate of invariant manifolds, In: III International Conference on Control in Technical Systems (CTS), IEEE, 2019, pp. 60–63
Cetina-Denis JJ, Lopéz-Gutiérrez RM, Cruz-Hernández C, Arellano-Delgado A (2022) Design of a chaotic trajectory generator algorithm for mobile robots. Appl Sci 12(5):2587
Li Y, Huang Y, Ge L, Li X (2022) Mobile robot path planning based on angle-guided ant colony algorithm. Int J Swarm Intell Res 13(1):1–19
Hua G, Wang F, Zhang J, Alattas KA, Mohammadzadeh A, The VuM (2022) A new type-3 fuzzy predictive approach for mobile robots. Mathematics 10(17):3186
Petavratzis E, Volos C, Ouannas A, Nistazakis H, Valavanis K, Stouboulos I (2021) A 2d discrete chaotic memristive map and its application in robot’s path planning, in: 2021 10th International Conference on Modern Circuits and Systems Technologies (MOCAST), IEEE, pp. 1–4
Walid M, Elnaggar MM, Sayed WS, Said LA, Radwan AG (2021) A comparative study of different chaotic systems in path planning for surveillance applications, In: 2021 International Conference on Microelectronics (ICM), IEEE, pp. 25–28
Zhang X, Yuan Z, Xu S, Lu Y, Zhu M (2021) Secure perception-driven control of mobile robots using chaotic encryption, in, American Control Conference (ACC). IEEE 2021:2575–2580
Petavratzis E, Moysis L, Volos C, Stouboulos I, Nistazakis H, Valavanis K (2021) A chaotic path planning generator enhanced by a memory technique. Robot Auton Syst 143:103826
Freitas VL, Yanchuk S, Zaks M, Macau EE (2021) Synchronization-based symmetric circular formations of mobile agents and the generation of chaotic trajectories. Commun Nonlinear Sci Numer Simul 94:105543
Wahhab O, Araji A (2021) Path planning and control strategy design for mobile robot based on hybrid swarm optimization algorithm. Int J Intell Eng Syst 14(3):565–579
Melin P, Sánchez D, Castro JR, Castillo O (2022) Design of type-3 fuzzy systems and ensemble neural networks for covid-19 time series prediction using a firefly algorithm. Axioms 11(8):410
Castillo O, Castro JR, Melin P (2022) Interval type-3 fuzzy fractal approach in sound speaker quality control evaluation. Eng Appl Artif Intell 116:105363
Tian M-W, Bouteraa Y, Alattas KA, Yan S-R, Alanazi AK, Mohammadzadeh A, Mobayen S (2022) A type-3 fuzzy approach for stabilization and synchronization of chaotic systems: Applicable for financial and physical chaotic systems. Complexity 2022
Amador-Angulo L, Castillo O, Melin P, Castro JR (2022) Interval type-3 fuzzy adaptation of the bee colony optimization algorithm for optimal fuzzy control of an autonomous mobile robot. Micromachines 13(9):1490
Taghieh A, Zhang C, Alattas KA, Bouteraa Y, Rathinasamy S, Mohammadzadeh A (2022) A predictive type-3 fuzzy control for underactuated surface vehicles. Ocean Eng 266:113014
Qasem SN, Ahmadian A, Mohammadzadeh A, Rathinasamy S, Pahlevanzadeh B (2021) A type-3 logic fuzzy system: Optimized by a correntropy based kalman filter with adaptive fuzzy kernel size. Inform Sci 572:424–443
Li D, Yu H, Tee KP, Wu Y, Ge SS, Lee TH (2021) On time-synchronized stability and control. IEEE Trans Syst Man Cybernet Syst 52(4):2450–2463
Mohammadzadeh A, Kumbasar T (2020) A new fractional-order general type-2 fuzzy predictive control system and its application for glucose level regulation. Appl Soft Comput 106241
Dao PN, Nguyen HQ, Nguyen TL, Mai XS (2021) Finite horizon robust nonlinear model predictive control for wheeled mobile robots. Math Prob Eng
Zhang T, Zhang W, Gupta MM (2017) Resilient robots: Concept, review, and future directions. Robotics 6(4):22
Wang F, Qian Z, Yan Z, Yuan C, Zhang W (2019) A novel resilient robot: Kinematic analysis and experimentation. IEEE Access 8:2885–2892
Xu Z, Lv Z, Li J, Sun H, Sheng Z (2022) A novel perspective on travel demand prediction considering natural environmental and socioeconomic factors. IEEE Intell Trans Syst Magazine 15(1):136–159
Chen M, Sharma A, Bhola J, Nguyen TV, Truong CV (2022) Multi-agent task planning and resource apportionment in a smart grid. Int J Syst Assurance Eng Manag 13:444–455. https://doi.org/10.1007/s13198-021-01467-3
Nguyen TV, Huynh N-T, Vu N-C, Kieu VN, Huang S-C (2021) Optimizing compliant gripper mechanism design by employing an effective bi-algorithm: Fuzzy logic and ANFIS. Microsyst Technol 27:3389–3412. https://doi.org/10.1007/s00542-020-05132-w
Funding
Ministry of Science and Technology of the People’s Republic of China (2019YFE0112400). Science and Technology Support Plan for Youth Innovation of Colleges and Universities of Shandong Province of China (2021CXGC011204).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tian, MW., Alattas, K.A., Guo, W. et al. A strong secure path planning/following system based on type-3 fuzzy control, multi-switching chaotic systems, and random switching topology. Complex Intell. Syst. 10, 1997–2012 (2024). https://doi.org/10.1007/s40747-023-01248-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01248-4