
Abstract
User–item interactions on e-commerce platforms involve various intents, such as browsing and purchasing, which require fine-grained intent recognition. Existing recommendation methods incorporate latent intent into user–item interactions; however, they overlook important considerations. First, they fail to integrate intents with semantic information in knowledge graphs, neglecting intent interpretability. Second, they do not exploit the structural information from multiple views of latent intents in user–item interactions. This study established the intent with knowledge-aware multiview contrastive learning (IKMCL) model for explanation in recommendation systems. The proposed IKMCL model converts latent intent into fine-grained intent, calculates intent weights, mines latent semantic information, and learns the representation of user–item interactions through multiview intent contrastive learning. In particular, we combined fine-grained intents with a knowledge graph to calculate intent weights and capture intent semantics. The IKMCL model performs multiview intent contrastive learning at both coarse-grained and fine-grained levels to extract semantic relationships in user–item interactions and provide intent recommendations in structural and semantic views. In addition, an intent-relational path was designed based on multiview contrastive learning, enabling the capture of semantic information from latent intents and personalized item recommendations with interpretability. Experimental results using large benchmark datasets indicated that the proposed model outperformed other advanced methods, significantly improving recommendation performance.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
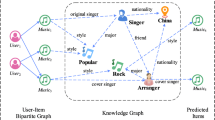
Recommendation systems employ user–item interaction metrics to suggest desirable items from a large product inventory. Numerous studies have proposed recommendation methods that capture users’ item preferences. On e-commerce platforms, the intents of different users are determined by their preferences for specific items. Users on these platforms review item specifications and feedback, add items to their shopping carts, and ultimately make purchase decisions based on their preferences. For example, as depicted in Fig. 1, User 1 browsed three types of lipsticks: Lancome, Dior, and Givenchy. They specifically favored the brand effect of Givenchy and made a purchase accordingly. User 2 explored Givenchy, Lancome, and Chanel. She intended to purchase an "Internet red lipstick" and added the Chanel lipstick to her shopping cart. Hence, a recommendation system should consider users’ purchase history, items in their shopping carts, and common attributes shared among the items. This information reflects a user’s interest in item acquisition and contributes to enhancing recommendation performance. Previous studies have demonstrated that different intents can result in varying interactions with items

A toy example of user intent.
[1, 2, 4, 5]. For example, utilizing a temporal convolutional network, the ASLI model infers intent from user actions and identifies item similarities by capturing historical user–item interactions [1]. The ICL model employs contrastive learning to derive user action sequences and intents, thereby enhancing recommendations based on the obtained optimized sequence view and corresponding intents [2]. Despite their effective improvement of recommendation performance, these models fail to consider the semantic information embedded within user intent nor can they establish connections between item information and contextual factors.
-
Existing methods neglect the semantic relationship between intent and the knowledge graph [1, 2, 5, 13], and the intent-relational path that cannot be interpreted using said methods. As demonstrated in Fig. 1, when User 1 explored the three lipstick brands Lancome, Givenchy, and Dior, the model could have recommended a more diverse range of items to the user by leveraging knowledge graph information. The knowledge graph connects heterogeneous information within the network and recommends items to User 2 based on their actions; it could potentially suggest different makeup products to User 2. Consequently, integrating intent and semantic information within a knowledge graph can enhance the diversity of item recommendations. A knowledge graph relational path such as \(\{User1\rightarrow Lancome{\mathop {\longrightarrow }\limits ^{function}}Givenchy {\mathop {\longrightarrow }\limits ^{brand}}Bracelet\}\), can depict the process of intent recommendation based on User 1’s actions. Hence, the semantic relationship within a knowledge graph can serve as a foundation for an interpretable reasoning path regarding user intent of users. Therefore, the semantic relationship in a knowledge graph can serve as a basis for an interpretable reasoning path for the user intent.
-
Existing methods neglect the weight of fine-grained user intent and fail to integrate intent with item preferences. Fine-grained user intent reflects user preferences and is manifested through actions such as browsing, clicking, and adding items to the shopping cart. For instance, as depicted in Fig. 1, User 1 explored different items, and the weightage of the intent to make a purchase was higher compared with the intent to browse or add items to the shopping cart. If User 2 recommended Chanel to other users while browsing products, the intent of the recommendation would outweigh the user’s preference for the items, even if they intended to make a purchase. Therefore, assigning different weights to fine-grained intents and user preferences for different items is necessary to enhance recommendation performance.
-
Existing intent contrastive learning models do not utilize multiview contrastive learning methods for intents. Furthermore, only user–item intent contrastive learning is insufficient [1, 2, 4]. Knowledge graphs should be combined with user–item interaction graphs under latent intents. Additionally, the entire structure of intent contrastive learning at the coarse-grained layer should be considered to leverage collaborative and semantic information. A multiview contrastive learning model should be capable of processing encoding information from multiple types of user, item, and entity nodes. Although existing methods can represent the semantic view, they do not account for user–item interaction in multiview intent contrastive learning.
In this study, we propose the incorporation of fine-grained intent with a knowledge graph to explore latent intent recommendations based on user–item interactions. We introduce an intent with knowledge-aware multiview contrastive learning (IKMCL) model to integrate explanations into recommendation systems. The IKMCL model integrates the fine-grained intents of users into recommendation systems through multiview contrastive learning, thereby enhancing both the performance and explainability of recommendations. User–item interactions for specific action types involve latent intent. Although the corresponding items may share common features, intent cannot be related to items without semantic information. Therefore, additional information (such as brand or function) in a knowledge graph can be used to establish correlations between intents, preventing the isolation of item interaction nodes. To differentiate between different interpretations of user intents, we assigned varying weights to the intents, enabling the model to capture the weights of different intents and user preferences for items. We designed a multiview contrastive learning model with user–item intent graphs and knowledge graphs as coarse-grained structural representations and representations of users, items, and entities as fine-grained semantic representations. Additionally, we designed an intent-relational path to aggregate intent information. Intent-relational paths facilitate the identification of fine-grained intents and the encoding of intents as representations. Thus, the intent-relational paths of different users may have distinct interpretations, enabling the reasonable interpretation of user intent recommendations.
The contributions of this study can be summarized as follows:
-
An IKMCL framework was developed for explanations in recommendation systems.
-
The proposed model combines intent weight with the entities in a knowledge graph to comprehensively understand user preferences.
-
Users, entities, and items were represented through intent multiview contrastive learning, enabling different multilevel structural views and their integration into fine-grained semantic representations.
-
An intent-relational path that enhances user interpretability and facilitates fine-grained intent recommendations was designed.
-
Extensive experiments were conducted on three real-world datasets to validate the effectiveness of IKMCL. The results showed improvements over the baselines of NDCG@10 by 6.86%, 15.01%, and 3.6%; of HR@10 by 19.47%, 13.35%, and 11.79%; of Prec@10 by 13.52%, 13.91%, 4.09%; of Recall@10 by 4.11%, 8.68%, and 9.70%.
Problem formulation
This study focused on structured data comprising a user–item intent graph and a knowledge graph and formulated recommendation tasks based on this data.
User–intent graph.The designed user–item intent graph emphasizes the fine-grained intent actions of users, for example, browsing, clicking, and purchasing, which reflect users’ preferences for items. In this study, we developed a recommendation system that leverages fine-grained user intents. We considered a set of users U, a set of intents I, and a set of items V. Then \(IG=\{(u,i,v)\mid u\in U, i\in I, v\in V\}\) represented a user–item intent graph, where each triplet (u, i, v) indicates a user–item interaction under intent i.
Knowledge graph. A knowledge graph represents structured information about entities and their relationships in the real world. The entities and the edges in a knowledge graph correspond to nodes and edges in a graph structure. The knowledge graph \(G=\{(h,r,t)\mid h,t\in E, r\in R\}\) represents a set of triplets, where E denotes entities, R denotes relations, h denotes the head entity, and t denotes the tail entity, h and t are linked by r.
Task description. For user u, using the user–item intent interaction graph IG and the knowledge graph G is used to predict the likelihood of the user purchasing an item \(v_{t+1}\), the agent in reinforce learning generates a probability distribution \(\hat{y}_{v}=\{\hat{y}_{1}^{v}, \hat{y}_{2}^{v},..., \hat{y}_{N}^{v}\} \) for all candidate items. The top-K items with the highest probabilities are included in the recommendation list. The auxiliary task has intent-relational path generations, and the top-K items form a reasoning path.
Methodology
Model overview
We developed an IKMCL interpretable recommendation framework using the IKMCL model, which seamlessly integrates user intent and a knowledge graph to enhance the learning of user–item representations, as depicted in Fig. 2. We introduced the IKMCL pipeline, which describes the sequential steps from left to right, to provide a more detailed explanation of the operational mechanism of the proposed IKMCL model. The pipeline selects a user and employs an attention mechanism to calculate the weightage of fine-grained intent at randomly selected initial states \(s_{0}\). The item embedding and entity embedding of each user are learned through multiview contrastive learning. The resulting low-dimensional vectors are concatenated and fed into a deep reinforcement learning network. After interacting with two ReLU layers and one TanH layer, the agent performs action according to the transition probability and interacts with the external environment. After the interaction, a feedback reward signal is generated. The agent then selects the next state as the current state (recommended item) and proceeds with the subsequent action. Through several iterations, the agent can effectively infer the intent path and provide item recommendations to the user. User–item interactions are embedded under the specific intent of each user through multiview contrastive learning, resulting in small distances between recommended items for each user. Conversely, the distance between the recommended items of different users is large. Each user’s intent-relational path possesses its own interpretability and unique characteristics.

Illustration of the IKMCL framework
Table 1 displays the notations and descriptions used in this paper
User–intent graph encoder
A user’s intent reflects the internal motivation of the user in selecting an item. Items interacted with by users with different intents may exhibit common properties, suggesting that users with similar intents share similar preferences for those items. To delve further into the contrastive learning and encoding of the same item in two distinct views for supervised learning, we partitioned IG into two views: the user–item view and the item–item view.
Intent encoder
While we can intuitively express these intents, explicitly identifying the semantic information associated with intents poses a challenge. However, the intents involved in item interactions tend to possess shared features. Thus, intent can be linked with the relationships within a knowledge graph, and intent encoding can be realized through the attention mechanism:
where \(e_{r}\) denotes the ID embedding of the relation r, and the attention mechanism \(\gamma (r,i)\) is used to quantify its importance:
where \(\omega _{ri}\) denotes a trainable weight of relation r and intent i.
We utilized the weight of fine-grained intent to gage the user’s potential preference for items. By combining the attention mechanism of knowledge graph entities with relations, we obtained the weight of intents \(\psi \):
where \(\odot \) denotes the element-wise product, and \(\alpha (u,i)\) denotes the weight of user’s preference for entities.
User–item encoder
In the IG model, users with similar intents prefer similar items. Therefore, the historical interaction data of users reflects user characteristics. A user u in IG is aware of its nearest neighbors, and the item v interacting with the intent is aware of its neighboring nodes. The aggregation of users and items is expressed as follows:
where \(e_u^{k} \in {R^d}\) represents the embedding of the user. The neighbor feature is used to update the next hidden layer, called aggregate. In this case (5), aggregate is the embedded vector of user node information and also represents the information of its surrounding nodes. Its surrounding nodes are the upper layer user and items, and user’s intent vectors. \(f_{IG_{u}}(.)\) denotes the aggregation function.
where \(N_{u}\) denotes the neighbors of the user u.
Item–item encoder
When considering item-item aggregation, we previously overlooked the semantic information of the item in relation to the user’s intent behavior. As a result, an aggregation mechanism should be employed to preserve information regarding the item along with its neighboring entities and relationships. Similar to the aggregation of users and items, this can be expressed as follows:
where \(f_{IG_{v}}(.)\) denote aggregation function. In this case (7), aggregate is the embedded vector of item node information and also represents the information of its surrounding nodes. Its surrounding nodes are the upper layer users and item, and user’s intent vectors.
\(N_{v}\) denotes the neighbors of the user u and item v, and \(e_v^{k} \in {R^d}\) represents the embedding of the item v.
KG encoder
User–entity encoder
Within a knowledge graph, we can distinguish between two subviews: the user–entity view and the entity–entity view. In the user–entity view, a user in the knowledge graph is aware of the entities that interact with users as neighboring entities. The model aggregates these interacting entities to generate a user embedding, which can be expressed as follows:
where \(e_h^{(i)}\) denotes the ID representation of the entity h, \(N_{e}\) denotes the entity that interacts with the user u and \(f_{G_{u}}(.)\) is the aggregation function, which aggregates connection information of \(N_{e}\). In this case (9), aggregate is the embedded vector of user node information and also represents the information of its neighbor nodes. Its neighbor nodes are the upper layer user, head entities h and the relations r.
Entity–entity encoder
Within a knowledge graph, the triplets contain valuable connection information between different entities, which often exhibit similarities. The relationships represented in a triplet (h, r, t) can have various interpretations, and related triplets can provide insights into the same entity. Therefore, the aggregation of entity and relation information within the knowledge graph can be expressed as follows:
where \(f_{G_{e}}\) denotes the aggregation function, which aggregates connection information of (h, r, t).
where \(e_t^{(k)}\) denotes the embedding of tail entity t and \(N_{h}\) denotes the neighbors of the entity h. In this case (11), aggregate is the embedded vector of head node information and also represents the information of its neighbor nodes. Its neighbor nodes are the upper layer head entity h, the relations r and the upper layer title entities t .
Multiview contrastive learning
Structural view contrastive learning
Within IG and G, we obtained user representations that exhibited a semantic gap between different views. To address this semantic gap and enhance alignment, we employed a coarse-grained contrastive learning method to merge and align the contextual data of users from the two views. For the sake of simplicity, we refer to the user representations in IG and G as \(e_{IG}\) and \(e_{G}\), respectively, and the user preferences captured from these two views are semantically similar. Considering the different views of the same user as positive examples and other users as negative examples, the contrastive learning losses can be expressed as follows:
where u and \(u+\) denote two types of representations in two different views, and \({u^{-}}\) denotes the negative example set of other users.
Semantic view contrastive learning
The structural view within IG and G facilitates the integration of the semantic space of user–item interactions at a coarse-grained level in contrastive learning. We captured the fine-grained semantic representations of the same items in both IG and G. Consequently, we implemented fine-grained semantic contrastive learning to effectively merge the semantic space of items. This involved capturing intent representations, item representations in IG, and item representations in G. As a result, we constructed semantically consistent intent–item–entity representations as triplets \((e_{i}, e_{h}, e_{v})\) to depict user preferences for items within intent interactions. These triplets consist of \((e_{i}, e_{h})\), \((e_{h}, e_{v})\), \((e_{i}, e_{v})\), which interact with the same intent and constitute a positive example. On the other hand, items interacting with different intents form a set of negative examples. Hence, the fine-grained contrastive learning loss function can be formulated as follows:
where \(L_{CL}\) defined as Eq. 5. The optimization of contrastive learning enables alignment of the semantic space of the same item in different views. The final objective loss function can be expressed as follows:
where \(\lambda \) denotes the objective optimization weight. We designed a semantic fusion space from coarse to fine in two different views, IG and G, which gradually decreased the distance between the items of the same user’s in the semantic space.
Intent-relational path
After modeling users and items in the structural and semantic views, we incorporated the embeddings of user, intent, and item input vectors into a deep reinforcement learning model [6, 7] to establish a comprehensible knowledge graph. User–intent modeling involves learning the representations of users and items using graph neural networks (GNNs) that can aggregate multihop neighbors into the representations. However, existing aggregation methods overlook the multiview contrastive learning representations under different user and node views and cannot be used to capture semantic fusion at both the structural and semantic levels. First, we address the structural level by realizing different user embeddings under IG and G through the contrastive learning method. The representations of the same user under different views are aggregated to align the semantic space of user–item interaction. This approach enables capturing users’ preferences for items from multiple complementary views. Second, we focused on the semantic level by obtaining fine-grained representations of intent, item, and entity. The contrastive learning method represents the same item in different views, integrating the contextual semantic spaces of these three data types. The representations of users and items obtained through contrastive learning lead to considerable similarities among items on the intent-relational recommendation path. Each user possesses unique characteristics that distinguish them from other users. In the intent-relational modeling approach, these representations encapsulate the contextual semantics of multihop paths at both the structural and semantic levels, showcasing dependencies between intent-relational paths. Intent weights are applied to differentiate the strengths of intents on each path to ensure the interpretability of an intent-relational path. Reinforcement learning networks guide the selection of the next hop. Thus, the inference path of explainable intents from the starting state \(s_{0}\) to the target state \(s_{P}\) can be represented as follows: \( (s_{0}{\mathop {\longrightarrow }\limits ^{\alpha }}i_{1}{\mathop {\longrightarrow }\limits ^{\alpha }}i_{2}{\mathop {\longrightarrow }\limits ^{\alpha }}...{\mathop {\longrightarrow }\limits ^{\alpha }}i_{t}{\mathop {\longrightarrow }\limits ^{\alpha }}s_{P}).\) The intent-relational path represents user–item interactions under the user intents and accounts for the user’s preference for an item. However, existing intent methods based on contrastive learning neglect the semantic relationships between the entities in G and do not capture relation path [1, 2].
Experiments
This section outlines the experimental setup, describes the dataset used, reports the results, and provides a detailed analysis of the experimental outcomes.
Experimental settings
Data set description
The evaluation of all compared models is conducted using the following three real datasets:
KKBOXFootnote 1: This music dataset consists of 2200 users and 36,575 music tracks. The data was obtained from the renowned music service KKBOX, which records the historical data of numerous music listeners. The intent behind music selection is reflected in activities such as accessing the library, listening, discovering, and playing the radio. The attributes of the music used in our experiments include genre, artist, language, and composer.
MovieFootnote 2:The movie dataset comprises 1800 users and 66,830 movies. The intent behind movie selection is reflected in activities, such as browsing, accessing the library, watching, and clicking. The attributes of movies include rating, actors, director, and genre.
BookFootnote 3:The book dataset consists of 2000 users and 52,107 books. The intent behind book selection is reflected in activities, such as browsing, accessing the library, reading, and clicking. The attributes of books used in our experiments include title, author, publication, and publisher.
For each of the three datasets, we mapped them to CN-DBpedia to construct the corresponding sub-knowledge graphs [8]. CN-DBpedia can be accessed through the API of the Knowledge Works website, similar to DBpedia. The details of the three data sets are shown in Table 2.
Evaluation metrics
We used four popular metrics evaluation measures to evaluate the recommendation performance of the tested model:
-
Normalized discounted Cumulative Gain (NDCG): The most frequently used list evaluation measure that takes into account the position of correctly recommended items. NDCG is averaged across all the testing users.
-
Hit Radio (HR): HR, which is the percentage of users that have at least one correctly recommended item in the list.
-
Precision: Percentage of correctly recommended items in a user’s recommendation list, averaged across all testing users.
-
Recall: Percentage of purchased items that are really recommended in the list. Recall is averaged across all the testing users.
We provide top-N recommendation list for each user in the testing set, where N = 10 is token to report the numbers and compare different algorithms.
Compared models
To emphasize our model’s superior performance, we compared it with the following state-of-the-art models.
-
Bayesian personalized ranking (BPR) [9]: This method enhances the matrix factorisation paradigm by combining user and item bias with corresponding implicit feedback.
-
Deep Q-learning network (DQN) [10]: A DQN model represents complex dynamic user–item interactions and user preferences. The DQN method accounts for current and future rewards to realize better recommendations.
-
Collaborative knowledge-based Embedding (CKE) [11]. In CKE model, three components are designed to extract semantic representation of items from structural content, text content, and visual content, respectively. The heterogeneity of nodes and relationships is used to extract the structural representation.
-
Knowledge graph attention Network (KGAT) [12]: This model represents high-order end-to-end connectivity in the KG. This method recursively propagates embeddings from a node’s neighbors to refine the node’s embedding and employs an attention mechanism to discriminate the importance of the neighbors using the GAT framework.
-
Knowledge graph-based intent Network (KGIN) [13]: Path-based deep network (PDN) incorporate both personalization and diversity to enhance matching performance. This KGIN aggregates the relevance weights of the related two-hop paths.
-
Attentive sequential latent Intent (ASLI) [1]: The ASLI model users a temporal convolutional network to learn intent from user actions and identify item similarities by capturing user–item historical interactions. The model uses self-attention for latent intent representation to predict the next item.
-
Intent contrastive learning Recommendation (ICLRec) [2]:The ICLRec method integrates the unlabeled user latent intent into a sequential recommendation (SR) model. Then, the SR model is optimized through self-supervised contrastive learning, and the representation of user intents is learned through clustering to improve the robustness of recommendation performance.
Parameters settings
We implemented IKMCL and all baseline methods in TensorFlow and carefully tuned key parameters, All experiments were performed using a single GPU. We updated the model parameters with Adam [14] and a the batch size of 1024. The optimal setting was determined through grid search, and the learning rate was adjusted to \(\{1\times 10^{-6}, 1\times 10^{-5}, 1\times 10^{-4}, 1\times 10^{-3}, 1\times 10^{-2}\}\). KGIN model was used to fix the number of user intents to 4, and the relationship between the path aggregation layer was fixed to 3. According to the original text, the depth of KGAT aggregation was set to 4. In the ICLRec model, the hyper-parameters were set according to the parameters specified in the original paper.
Overall performance
We compared the performance of the proposed IKMCL model with that of baseline models. Table 3 displays the results obtained using two data sets. According to the results, we obtained the following inferences:
-
IKMCL model achieved the best performance with all data sets compared with other existing methods. Because the data of books and music are sparse, the performance of book and music recommendation in NDCG, HR, and Prec and Recall were lower than that of movie recommendations. Compared with the optimal baseline, NDCG, HR, and Prec and Recall improved by 3.60%–19.47%; thus, fine-grained intents and knowledge graphs are crucial to the IKMCL model, and the relationships between user intents and the knowledge graph help improve recommendation performance. By exploring fine-grained user intents, the IKMCL model can effectively reveal user–item interactions. The weights of different fine-grained intents represent the user preference for items. The proposed model uses the multiview intent contrastive learning method to learned the representations of users, items and entities at the structural and semantic levels. It decreases the distance between the same user and the same node and increases the distance from other users. Therefore, the model has improved recommendation performance. Compared with ASLI, ICLRec, and KGAT, the proposed model IKMCL combines fine-grained intent and item information and preserves the historical semantics information of the relational path. The model learns the sequential fine-grained intents of different users through contrastive learning and compares the intents of the same user and different users.
-
BPR has the least desirable recommendation performance; this indicates the importance of mining intention and knowledge under user action.
-
CKE incorporates knowledge graphs as auxiliary information into the recommendation system, and the performance of CKE is better than that of DQN and BPR, indicating the importance of auxiliary information.
-
KGAT is a GNN-based method with better performance than CKE because KGAT has multihop connectivity paths; this indicates that multihop neighbors can improve entity learning.
-
ASLI and CLRec are recommended methods for sequential intents. ASLI only considers the sequential intents of users and does not involve the contrastive learning of the intents of different users. CLRec optimizes the SR model through self-supervised contrastive learning, with better performance than ASLI.
Ablation study
Ablation study of variants
We considered different variants of the IKMCL model from four perspectives and analyzed their effects. The results are presented in Table 4.
-
RL model. We evaluated the performance of a reinforcement learning policy network referred to as RL.
-
IG+RL model. We combined intent with the RL model and evaluated the performance of intent action.
-
KG+RL model. We integrated knowledge graph information with the RL model and evaluated its performance.
-
IKMCL model. We inputted intent combines with a knowledge graph into the RL model and compared the model’s performance with those of RL, IG+RL and KG+RL.
The contrastive learning method is applied to user intent to achieve the best recommendation performance. The following three conclusions were drawn: (1) Considering the user–item interaction mode of fine-grained patterns, user intents inputted the RL model’s performance is better than that of the RL model. (2) Knowledge graphs can represent additional information on items and should thus be used knowledge graph in recommendation systems. (3) The combination of user intent and items help encode the multidimensional preferences of users.
The influence of intent multiview contrastive learning
Multiview contrastive learning notably influences on user intent embedding and entity embedding. The IKMCL model compares the intents, items and entities of the same user as positive examples and the intents, items and entities of different users as negative examples. The model randomly samples the same number of negative examples and positive examples from negative examples of different users, and visualizes the embedding of movie and book data sets, as illustrated in Fig. 3.
-
The blue circle represents positive examples from the same user, and the dark green square represents negative examples from different users. The positive examples for the same user are clustered together, and the negative cases of different users are clustered together.
-
The items are related by different attributes, the user–item interaction data of the same user are similar, and the items recommended through the intent-relational path are close in terms of semantic distance. By contrast, the negative example value is small, indicating that the semantic distance between different items that different users interact with is small.
-
Comparing the IKMCL model and its variants revealed that through the multiview contrastive learning method, the intent-relational path of the same user had characteristics different from those of other users.

Visualization of contrastive learning on movie and book
Sensitivity analysis
The trade-off parameter \(\lambda \) controls the contrastive loss impact of the structural and semantic views. To analyze the impact of \(\lambda \) on the structural and semantic views, \(\lambda \) values range within \(\{0, 0.2, 0.4, 0.6, 0.8, 1.0\}\). As illustrated in Figs 4, 5, 6, (1) when \(\lambda =1\), the recommendation performance was the worst, indicating the importance of the structural view contrastive loss. (2) when \(\lambda =0\), the recommendation performance was slightly better than that when \(\lambda =1\), thereby validating structural and semantic contrastive loss. When \(\lambda =0.2\), the recommendation performance was optimal and structural and semantic contrastive losses were balance.

Impact of contrastive loss weight \(\gamma \) on movie

Impact of contrastive loss weight \(\gamma \) on book

Impact of contrastive loss weight \(\gamma \) on KKBOX
Impact of multiHop depth
By changing the length of the intent-relational path, the multihop path can integrate the aggregated information carried by long-distance connection into node representation. The length range of multihop path was set as \(\{1, 2, 3, 4, 5\}\) in Table 5, and the following observations were as follows:
-
The improvement of recommendation performance can be attributed to the following factors: (1) The fusion of intent and knowledge graph captured the complete semantic information of the knowledge graph, forming strong semantic connections. (2) Fine-grained intents can mine deeper user preferences, and multihop paths can link the information of items. (3) Through multiview contrastive learning, the intent-relational path represented each user’s unique interaction with items different from that of other users.
-
In the movie data set, NDCG and Prec on IKMCL-5 had better results than IKMCL-4. Thus, longer paths can derive more item information related to users intent to analyze users preferences for items more effectively.
-
According to the results of KKBOX and the book data in NDCG, the performance of IKMCL-5 and IKMCL-4 was worse than those of IKMCL-1, IKMCL-2, and IKMCL-3. Thus, KKBOX and book data are sparse, and the low-order connectivity of the knowledge graph is desirable.
The analysis of weight of intent
Figure 7 displays the user–item interaction graph and the corresponding knowledge graph. We analyzed the multiview contrastive learning intent-relational path and the weight of intent. The green square represents the type of intent, the small orange square represents the item, and the numbers between item–item pairs indicate the weight of user attention. Figure 7 illustrates the historical interaction data of user u and the movie To live. The user had three intents: collect, watch, and browse. In G, the three triplets were \(<To live, actors, Leap>\), \(<To live, director, Cliff Walkers>\), and \(<To live, genre, Shoplifters>\). The intent to watch had the highest weightage of 0.3835; therefore, the next hop selected for the film was Cliff Walkers. The movie To live and Cliff Walkers had the same director as represented in the semantic relationship between the items. This indicated the importance of the relationship between intent and the knowledge graph, which contained semantic information of intent. Similar, from Cliff Walkers to the next hop, the movie Home Coming, which had the intent with the highest weight was still selected. The triplet relationship of the knowledge graph was \(<Cliff Walkers, actor, Home Coming>\). Thus, Cliff Walkers and Home Coming had the same actor, as represented in the knowledge graph relationship. The last hop was the movie Operation Red Sea related by genre in the knowledge graph.

The analysis of intent weight
Case studies of intent-relational path
For the intuitive understanding of user intent-based IG and G and generate user, item representations were generated in two views. An experimentally generated intent-relational path helped understand the IKMCL model. Figure 8 illustrates the interactions of the user \(u_{1}\), in IG, where users interacted with items under different intents, and the fine-grained intents of interaction includes collection, watching and browsing. According to the historical data of user–item interactions and user preferences, the movie To live was selected as the initial state. In IG and G, the representations of user \(u_{1}\) and the movie To live were represented through contrastive learning to reduce the semantic space in IG and G. According to the calculated intent weight and preference, we selected Click Walkers as the next state, whose representation was obtained through contrastive learning in IG and G. In IG, the items interacted with by different users with fine-grained intents had certain similarities. The similarities between the items were used to correlate different users, and user \(u_{3}\) was selected. In the next hop, the movies included Home Coming, Sniper and Sheep Without a Shepherd. In G, Cliff Walkers was related to Home Coming, Sniper and Sheep Without a Shepherd in terms of the movie attributes director and actor. Similarly, based on the calculated intent weight and the representations obtained through multiview contrastive learning, Home Coming was selected as the state of the next hop. Therefore, the relational path under intent interaction was as follows: \((u_{1}\rightarrow item\rightarrow user\rightarrow item\rightarrow user\rightarrow item)\). In addition, the relational path formed using the knowledge graph was as follows: \((u_{1}\rightarrow item\rightarrow item\rightarrow item)\). Thus, the proposed IKMCL model well explains the item recommendations achieved through multiview contrastive learning interaction. Each user has characteristics different from those of other users, enabling accurate recommendations.

Real case of reasoning path
Related work
Knowledge-based recommendation
Recommendation methods that utilize knowledge graphs can be classified into several groups: (1) Embedding-based methods [11, 15,16,17,18]. Knowledge graph triplets are preprocessed through embedding-based methods [11, 15,16,17,18], wherein recommendation systems use the TransE [19] and TransH [20] methods to learn entity embedding and relation embedding. CKE combines TransE with the CF model to learn text, visualization, and knowledge embeddings on the knowledge graph [11]. KTUP leverages the TransH method to learn node embeddings associated with user–item interactions and KG, capturing user preferences in user–item interaction and knowledge graph [17]. While these methods enhance recommendation performance, they overlook higher-order connectivity and fail to capture the semantic relationships between distantly connected nodes, limiting their ability to reveal user–item relationships. (2) Path-based methods [21,22,23,24,25]. Path-based methods employ multihop paths to explore the connections between users and items and predict user preferences, thereby improving recommendation performance [21,22,23]. For example, KPRN utilizes RNNs to extract relationships and model paths based on these relationships [26]. However, the accuracy of path-based methods heavily relies on the quality of paths, and the lack of existing paths can significantly impact recommendation performance. (3) GNN-based methods [7, 26,27,28,29]. GNN-based approaches leverage the aggregation mechanism of GNNs to capture node features and graph structure by aggregating information from neighboring nodes. These methods enable updating single-hop nodes and establishing long-range connections through paths. KGAT integrates user–item interaction graphs and knowledge graphs into heterogeneous networks and employs GNNs to recursively aggregate node neighbor information [12]. However, this method solely focuses on the knowledge graph and does not consider user intention. On the other hand, KGIN incorporates user–item interactions and user intent, revealing user intention by combining user–item interaction graphs with knowledge graphs and performing aggregation [13]. Although this approach accounts for intent, it overlooks multilevel and contrastive learning of the knowledge graph. Moreover, these methods do not maintain path dependence through supervised learning during model training. In this study, we implemented user–item relationships by leveraging fine-grained intents and utilizing supervised signals from the data to enhance node representation learning.
Contrastive learning
In contrastive learning, a pair of positive and negative examples are used to learn representations by comparing them [30]. Typically, positive–negative example pairs consist of semantically related neighbors. By defining training objectives, related representations are grouped, reducing the distance between them, while the distance between unrelated representations increases. Contrastive learning leverages data augmentation to construct positive–negative pairs based on the original data and has been successfully applied in computer vision [31], natural language processing [32], and other fields. It has also been studied in graph theory [33, 34] and knowledge recommendation systems [29, 35]. DGI utilizes graph representation learning to compare local node representations with global graph node representations [36]. MVGRL contrasts node-level and graph-level node representations in structural graphs [28]. MCCLK constructs multilevel views at the knowledge graph level to learn node representations at multiple levels [29]. It considers the collaborative, semantic, and structural views, using contrastive learning to represent different nodes. However, MCCLK only considers the coarse-grained properties of the knowledge graph and overlooks the fine-grained properties. CRS constructs multigranularity semantic units using different data signals and aligns them through coarse-to-fine contrastive learning [35]. CRS applies contrastive learning to different data types, including coarse-grained and fine-grained data. However, it does not consider user intentions, which are crucial in recommendation systems. The consideration of user intentions is essential. Furthermore, contrastive learning enables the fusion of different data types, enhancing the representation of diverse data types, such as image–text fusion [31] and text–graph fusion [37]. However, limited research has focused on combining contrastive learning with intent-based user–item interactions and intent-based knowledge reasoning.
Conclusion
This study established a novel IKMCL model, which combines fine-grained intent with knowledge graphs and assigns weight to fine-grained intents to identify user preferences for items. In addition, the model incorporates multiview intent contrastive learning. Through multiview contrastive learning, users, items and entities can be represented in structural and semantic views. Furthermore, we analyzed the relational path and explainability of intent multiview contrastive learning. Finally, the effectiveness of the proposed model was verified using three real-world data sets.
References
Tanjim MM, Su EBC-Z, DH, et al (2020) Attentive sequential models of latent intent for next item recommendation. Proceedings of The Web Conference 2020:2528–2534
Chen Y-J, Liu JLZ-W, M J-L, et al (2022) Intent contrastive learning for sequential recommendation. Proceedings of The Web Conference 2022:2172–2182
Cai R-Q, Wu AS J-B, et al., CW (2021) Category-aware collaborative sequential recommendation. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 388–397
Ma J-X, Zhou H-XY C, et al., PC (2020) Disentangled self-supervision in sequential recommenders. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 483–491
Zhang X-K, Lin BXH-F, Li C-L, et al, (2022) Dynamic intent-aware iterative denoising network for session-based recommendation. Information Processing and Management 59:102936
Tao S-H, Qiu YPR-H, Ma H (2021) Multi-modal knowledge-aware reinforcement learning network for explainable recommendation. Knowled based Syst 227:107217
Tao S-H, Qiu BXR-H, Ping Y (2022) Multi-behaviour with reinforcement knowledge-aware reasoning for explainable recommendation. Knowledge based Syst 251:109300
Wang H-W, Zhang XX F-Z, Guo M-Y (2018) Cndbpedia: A never-ending chinese knowledge extraction system. In: Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, pp. 428–438
Rendle S, Freudenthaler ZG C, Thieme LS, et.al, (2012) Bpr: Bayesian personalized ranking from implicit feedback. In: Proceedings of the Twenty-fifth Conference on Uncertainty in Artificial Intelligence, pp. 452–461
Human-level control through deep reinforcement learning (2015) V. Mnih, D.S. K. Kavukcuoglu, A.- A. Rusu, e.a. Nature 518:529–533
Zhang F-Z, Yuan DL N-J, Xie X et.al, (2016) Collaborative knowledge base embedding for recommender systems. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 353–362
Wang X, He Y-XC X-N, Liu M, et.al (2019) Kgat knowledge graph attention network for recommendation. In: Proceedings of KDD’19, pp. 571–580
Wang X, Huang D-XW T-L, Liu Z-G (2021) Learning intents behind interactions with knowledge graph for recommendation. In: Proceedings of the International World Wide Web Conference Committee 2021, pp. 878–887
Kingma D-P, Ba J (2014) Adam: A method for stochastic optimization. In: Computer Sciences
Ai Q-Y, Azizi XCV, Zhang Y-F (2018) Learning heterogeneous knowledge base embeddings for explainable recommendation, algorithms. Algorithms 11:137–153
Huang J, Zhao H-JD W- X, Wen J-R, et.al, (2018) Improving sequential recommendation with knowledge-enhanced memory networks. In: Roceedings of the 41rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 505–514
Cao Y-X, Wang X-NH X, Hu Z-K (2019) Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In: Proceedings of The Web Conference 2019, pp. 151–161
Khan N, Ma AU Z-M, Polat K (2022) Similarity attributed knowledge graph embedding enhancement for item recommendation. Information Sciences 613, 69–95
Translating embeddings for modeling multi-relational data (2013) A. Bordes, A.G.-D. N. Usunier, J. Weston, e.a. Adv Neural Inf Process Syst 26:2787–2795
Wang Z-G, Li, J-Z (2016) Text-enhanced representation learning for knowledge graph. In: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, pp. 1293–1299
Wang P-F, Fan LX Y, Zhao W-X, et.al, (2020) Kerl: A knowledge-guided reinforcement learning model for sequential recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 209–218
Wang X, Xu X-NHY-K, Cao Y-X, et.al, (2020) Reinforced negative sampling over knowledge graph for recommendation. Proceedings of The Web Conference 2020:99–109
Zhao K-Z, Wang Y-RZ X-T, Zhao L, et.al, (2020) Leveraging demonstrations for reinforcement recommendation reasoning over knowledge graphs. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 239–248
Li H-Y, Chen C-LL Z-H, Xiao R, et.al, (2021) Path-based deep network for candidate item matching in recommenders. In: Proceedings of SIGIR2021, pp. 1493–1502
Chen J-Y, Yu W-JLJ, Y-RQ, et al (2021) Ir-rec: An interpretive rules-guidedrecommendation over knowledge graph. Information Sciences 563:326–341
Wang X, Wang C-RX D-X, He X-N (2019) Explainable reasoning over knowledge graphs for recommendation. In: AAAI, pp. 5329–5336
Xia L-H, Huang YX C, Dai P, et.al, (2020) Knowledge-enhanced hierarchical graph transformer network for multi-behavior recommendation. In: Proceedings of the 34th Association for the Advancement of Artificial Intelligence, pp. 4486–4493
Hu B-H, Shi W-XZ C, Yu P-S, et.al, (2020) Contrastive multi-view representation learning on graphs. In: Proceedings of ICML, pp. 4116–4126
Zhou D, We X-LM W, Yang Z-Y, e.a (2022) Multi-level cross-view contrastive learning for knowledge-aware recommender system. In: Proceedings of the 45nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1358–1368
Li S-K, Xie Y-CZR-B, Tang Z-W (2022) Self-supervised learning for conversational recommendation. Information Processing and Management 59:103067
Zhang H, Koh JB J-Y, Lee H, et.al, (2021) Cross-modal contrastive learning for text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 833–842
Cao T-Y, Y, X-C, Chen D-Q (2021) Simcse: Simple contrastive learning of sentence embeddings. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 6894–6910
You Y-N, Chen Y.-DS T-L, Chen T, et.al (2021) Graph contrastive learning with augmentations. In: Preceedings of the 34th Conference on Neural Information Processing Systems, pp. 157–166
Zhu Y-Q, Xu FYY-C, Liu Q, et.al, (2021) Graph contrastive learning with adaptive augmentations. Proceedings of International World Wide Web 2021:202–211
Zhou Y-H, Kun Zhou W.-XZ, Wang C, et.al, (2022) \(c^{2}\)-crs: Coarse-to-fine contrastive learning for conversational recommender system. Proceedings of WSDM 2022:1488–1496
Velickovic P, Fedus W-LH W, Bengio Y, et.al (2019) Deep graph informax. In: ICLR, pp. 259–270
Huang TY, Wang HSZ-C., YNg A (2021) Learning neighborhood representation from multi-modal multi-graph: Image, text, mobility graph and beyond. In: Proceedings of the CoRR2021, pp. 873–881
Acknowledgements
This work is supported by the Plan For Scientific Innovation Talent of He’nan Province under Grant 184100510012, Key Technologies R &D Program of He’nan Province under Grant 212102210084, and Innovation Scientists and Technicians Troop Construction Projects of He’nan Province Key Technologies R & D Program of He’nan Province under Grant NO.192102210295.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tao, S., Qiu, R., Cao, Y. et al. Intent with knowledge-aware multiview contrastive learning for recommendation. Complex Intell. Syst. 10, 1349–1363 (2024). https://doi.org/10.1007/s40747-023-01222-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01222-0