
Abstract
Industrial defect detection is a hot topic in the field of computer vision. It is a challenging task due to complex features and many categories of industrial defects. In this paper, a deep learning model based on the multiscale feature extraction module is introduced for steel surface defect detection. The main focus on the feature extraction capability of the model and feature fusion capability to improve the accuracy of the model for steel surface defect detection. First, to improve the feature extraction ability of the model, a multiscale feature extraction (MSFE) module is introduced. The MSFE module can effectively extract multiscale features through three branches that have different convolution kernel sizes. Second, an efficient feature fusion (EFF) module is proposed to optimize feature fusion by adding features from the backbone network to the neck network. Third, this paper puts forward a new Bottleneck module by reducing the normalization layer and activation function in the original Bottleneck module. Finally, the backbone network is deepened to further enhance the feature extraction ability of the model. Extensive experiments are conducted on the public NEU-DET dataset. The experimental results validate the effectiveness of the designed modules and the proposed model. Compared with other state-of-the-art methods, the proposed model achieves optimal accuracy(73.08% mAP@0.5) while maintaining a small number of parameters.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction

Examples of steel surface defects. a inclusion. b scratches. c crazing. d patches. e pitted_surface. f rolled-in_scale
Steel is widely used in industrial manufacturing, so the detection of steel surface defect is crucial [1]. Steel has a wide variety of surface defects, such as “inclusion”, “scratches”, “crazing”, “patches”, “pitted_surface” and “rolled-in_scale”. These defects have complex features as shown in Fig. 1. Using manual inspection of steel surface defects, it is difficult to distinguish the type of defect and accurately detect the location of the defect [2]. The task of defect detection consists of identifying defect categories and locating defect locations, which is a very challenging task. With the emergence and development of machine learning, industrial defect detection methods based on machine learning have become useful tools [3]. In this regard, Krummenacher et al. [4] designed a novel wavelet features for time series data and they learned a classifier using a support vector machine to detect wheel defect. Chan and Pang [5] used a simulated fabric model to understand the relationship between the fabric structure in the image space and in the frequency space. In [6], a method based on acoustic emission was proposed to detect defect in carbon steel welded joints. However, the above traditional machine learning-based defect detection methods have low detection accuracy and cannot meet the needs of industry.
With the development of deep learning technology, deep learning-based object detection methods have been rapidly improved and advanced [7, 8]. The object detection models based on deep learning are mainly divided into two types: two-stage models and one-stage models. The SOTA two-stage object detection models include R-CNN [9], Fast R-CNN [10], and Faster R-CNN [11]. The well-known one-stage object detection models include SSD [12], YOLO series [13,14,15,16], and RetinaNet [17]. These methods are widely used in industrial defect detection. Lin et al. [18] achieved the application of convolutional neural network (CNN) for LED chip defect inspection. Wei et al. [19] used the Faster R-CNN to detect fastener defect. In [20], a novel defect detection network (DefectNet) is proposed to solve the problem of defect detection. However, the above deep learning-based industrial defect detection methods do not specifically optimize the model’s ability to extract and fuse features, which is crucial for defect detection. Studying how to improve the feature extraction ability and feature fusion capability of the model is this paper needs to solve.

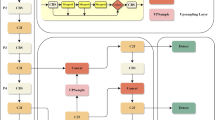
The structure diagram of the YOLOv5s model. The conv2d module represents a two-dimensional convolutional layer

The main components of the YOLOv5s model
In this paper, a steel surface defect detection model is introduced to solve the problems existing in the above methods. The YOLOv5s [21] is selected as the baseline model because of its small number of parameters and high inference speed. The features of steel surface defects are complex and it is difficult for the model to extract features. In order to improve the ability of the model to extract features, this paper introduces a module to extract multi-scale features called the Multiscale Feature Extraction (MSFE) module. The MSFE module extracts multi-scale features through three different branches having convolutional kernels of different sizes and fuses them. At the position behind the model, the features extracted from the shallow network of the model tend to disappear. To solve this problem, the features generated in the backbone network are fed into the neck network for feature fusion. This design is called the Efficient Feature Fusion (EFF) Module. The EFF Module can make the features generated in the backbone network and the features generated in the neck network fuse more efficiently. Further, some of the normalization layers and activation functions in the bottleneck module are removed to reduce the negative impact of having too many normalization layers and activation functions in the model. Also, the depth of the backbone network is deepened to further improve the ability of the model to extract features.
The main contributions of this paper are as follows.
-
(1)
A deep learning model for steel surface defect detection is proposed. The effectiveness of the proposed modules and model is validated by extensive ablation studies and contrast experiments on a challenging steel surface defect detection dataset (NEU-DET).
-
(2)
An efficient feature extraction module (MSFE) is introduced to improve the ability of the model to extract features effectively. The designed MSFE module uses three branches with convolutional kernels of different sizes for multiscale feature extraction.
-
(3)
An effective feature fusion scheme called EFF is introduced which efficiently fuses the generated features in the backbone network with the features in the neck network.
-
(4)
A new Bottleneck module is designed, which has fewer normalization layers and activation functions. Besides, the backbone network of the model is deepened for further enhancement of the model’s ability to extract features.
The rest of this paper is organized as follows. “Related works” section discusses related works on the YOLOv5s model and industrial defect detection methods. The proposed method and modules are presented in “The proposed method” section. Datasets used in the experiments, performance evaluation metrics, and extensive experimental results are provided in “Experiments and analyses” section. Finally, “Conclusion” section concludes the paper.
Related works
YOLOv5s
YOLOv5 [21] has five model structures of different sizes, namely YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. YOLOv5s maintains a relatively lightweight model size while having great detection accuracy. Therefore, YOLOv5s is chosen as the baseline model in this paper. The structure of YOLOv5s is shown in Fig. 2. The most basic module in YOLOv5s is called Conv as shown in Fig. 3a, which is composed of a convolution layer, normalization layer, and SiLU activation function. Figure 3b depicts the bottleneck module, which is made up of a \(1\times 1\) Conv and a \(3\times 3\) Conv connected in series.
In this context, it should be noted that the bottleneck module in the backbone network has residual structure to connect the input information and the output information, but has no residual structure in the neck network. The C3 module is shown in Fig. 3c. It has two branches. The first branch is composed of a \(1\times 1\) Conv module and X bottleneck modules. And the second branch only has a \(1\times 1\) Conv module. Following the two branches is a concat module, which splices the outputs of the two branches in channel dimension. At the end of the C3 module is a \(1\times 1\) Conv module, which is used to control the number of output channels. The final SPPF module of the backbone network is used for multi-scale feature fusion, whose structure diagram is shown in Fig. 3d. The YOLOv5s backbone network consists of Conv modules, C3 modules, and a SPPF. The neck network is the PANet [22] structure, and the head network is the YOLO head [15]. The backbone network of the YOLOv5s is responsible for feature extraction. It can get three feature maps, which have different sizes and channels. And the neck network is responsible for fusing the feature information. The head network outputs the prediction results.
Deep learning in industrial defect detection
With the rapid development of deep learning, more and more deep learning methods are being used to detect industrial defect [23]. Yu et al. [24] proposed a lightweight and efficient defect detection network (LEDD-Net) for PCB defect detection. They designed a novel backbone network and a neck work, which can effectively fuse the multiscale features. An adaptive localization loss function was designed to compute the localization loss. Cheng and Yu [25] used the optimized RetinaNet to detect steel surface defect. First, they proposed the differential evolution search algorithm to optimize anchor configuration. Then, a novel channel attention module is proposed to make the model learn more important channel information. They integrated the adaptively spatial feature fusion (ASFF) [26] module into the model to make full use of shallow and deep feature information. Su et al. [27] proposed a CNN-Based detector for photovoltaic cell defect detection. They designed a multihead cosine nonlocal attention module to make the model surpass the unfavorable features and learn the useful information. A BAFPN was proposed to enhance the feature fusion ability of the model.
Ying et al. [28] modified the YOLOv5s model to detect the wire braided hose defects. The K-means++ clustering algorithm was adopted to obtain more suitable anchor boxes, and the Focal loss function was adopted to balance between negative and positive samples. They used the efficient channel attention (ECA) mechanism to improve the detection performance. Chen et al. [29] proposed a method based on the deep convolutional neural networks to detect the defect of the fasteners. Zeng et al. [30] proposed a novel feature fusion method namely the ABFPN, which is for small object detection. And they came up with an IPDD framework where the developed ABFPN is embedded as the feature fusion method, which is used to detect PCB surface defect. In Li et al. [31] presented a tunnel surface image preprocessing approach. And they proposed a multi-layer feature fusion network based on Faster RCNN to detect the tunnel surface defect. Cui et al. [32] put forward a fast network for surface defect detection, called SDDNet. They introduced feature retaining block (FRB) and skip densely connected module (SDCM) to overcome issues of large texture variation and small size of defects. Chen et al. [33] designed a visual defect detection method based on multi-spectral deep convolutional neural network (CNN) to detect solar cell surface defect.

The structure diagram of the proposed MSFE module
The proposed method
Multiscale feature extraction module
There are many categories of steel surface defects and the size of each defect category varies widely. The average size of each category in the NEU-DET [34] dataset is shown in Table 1. To enhance the feature extraction ability of the model, this work designs a Multiscale Feature Extraction (MSFE) module as shown in Fig. 4. The MSFE module has three branches. The first branch is composed of a \(1\times 1\) Conv module and X bottleneck modules. And the second Conv of the bottlenecks is a \(3\times 3\) Conv module. The second branch includes a \(1\times 1\) Conv module and X bottleneck modules. The second Conv of the bottlenecks is a \(5\times 5\) Conv module. The third branch only has a \(1\times 1\) Conv module. There is a Concat module after the three branches, which can splice the outputs of the three branches in the channel dimension. The final module of the MSFE module is a \(1\times 1\) Conv module, which is used to fuse the outputs of the three branches. Finally, the convolutional layer of the second Conv module in the bottleneck module is substituted by the depthwise convolutional [35] layer to save parameters, as shown in Fig. 4b. The proposed MSFE module extracts multiscale features through three branches, which have different convolutional kernel sizes. It then fuses the obtained multiscale features by a Concat module and a \(1\times 1\) Conv module. Compared with the C3 module of the baseline model, the proposed MSFE module can extract features more effectively. This work uses the designed MSFE module to replace the C3 module of the baseline model.
Efficient feature fusion module
Feature fusion is a key research area in the field of object detection. The front feature map generated by the backbone network of the model has stronger location information, while the back feature map has stronger semantic information. Strong location information facilitates the prediction of the location of defects, while powerful semantic information facilitates the prediction of the category of defects. Effective fusion of strong location information with powerful semantic information can improve the detection performance of the model. The FPN (Feature Pyramid Network) [36] is a well-known feature fusion method. It has a top-to-bottom process that can pass strong semantic information from top to bottom. And it effectively fuses the strong semantic information with the powerful location information through a lateral connection. Compared with the FPN, the PANet [22] has an additional bottom-to-top process that can pass strong location information from bottom to top. And it effectively fuses the strong location information with the powerful semantic information through a lateral connection. Therefore, PANet has a better fusion effect than FPN. However, as the model deepens, the features extracted by the backbone network become blurred in the bottom-to-top process of PANet. To solve this problem, the features generated in the backbone network are fed into the bottom-to-top process of PANet for feature fusion. And the operation is called the EFF (Efficient Feature Fusion) module. The EFF module is illustrated in Fig. 5 and is computed as:
where \(F_{1}\) is the feature from the front layer of the EFF module, \(F_{2}\) is the feature from the top-to-bottom process of PANet, and \(F_{3}\) is the feature from the backbone network. The Conv1 includes a \(1\times 1\) convolutional layer, a normalization layer, and a SiLU activation function. And the Conv2 includes a \(3\times 3\) convolutional layer, a normalization layer, and a SiLU activation function.

The structure diagram of the EFF module, where Conv module includes a convolutional layer, a normalization layer, and a SiLU activation function
New bottleneck
ConvNeXt [37] reduces the normalization layer and activation function of its blocks. This change brings improvement for ConvNeXt. We think that too many activation functions and normalization layers will make the model overfit the data, which will adversely affect the training and prediction of the model. Thus, this paper designs a new bottleneck module with fewer normalization layers and activation functions to solve the problem. As shown in Fig. 6a, the original bottleneck module of the MSFE module has two normalization layers and two activation functions. And the new bottleneck proposed in this work is shown in Fig. 6b. It has a single normalization layer and a single activation function. And the designed new Bottleneck is integrated into the MSFE module.

Bottleneck modules. a The original bottleneck of the MSFE module. b The proposed bottleneck. conv2d is the convolutional layer, BatchNorm is the normalization layer, SiLU is the activation function, and dwconv2d is the depthwise convolutional layer

The structure diagram of the proposed method
Deepen the backbone network
The defects on the steel surface have complex textures, and their features are difficult to extract. To further enhance the feature extraction ability of the model, the backbone network of the model is deepened by changing the stage ratio. The original stage ratio of the backbone network is 1:2:3:1 as shown in Fig. 2, and the new stage ratio is 2:2:4:2 after deepening the backbone network as shown in Fig. 7.
Model structure
After the above four improvements, the steel surface defect detection model is obtained and shown in Fig. 7. The proposed model is composed of three components: the backbone network, the neck network, and the head network. The backbone network is responsible for extracting features; the neck network is used to fuse features; and the head network outputs the detection results.
Experiments and analyses
Dataset
In experiments, the public NEU-DET [34] dataset is used to verify the effectiveness and performance of the proposed method. The NEU-DET dataset shows the steel surface defect and it has 1800 images in total. The dataset has six categories of steel defect, namely “crazing”, “patches”, “inclusion”, “pitted_surface”, “rolled-in_scale” and “scratches”. Some samples of the dataset are shown in Fig. 8. This paper splits the dataset into a training dataset and a test dataset according to 8:2, and finally gets 1448 training images and 352 test images, respectively.

Samples of the NEU-DET dataset, where a–f represents crazing, patches, inclusion, pitted_surface, rolled-in_scale and scratches category of the steel surface defect, respectively
Implementation details
All experiments in this work are conducted on the RTX 3090 GPU with Python 3.8 version, PyTorch version 1.9.0, and CUDA version 11.1. The batch size is set to 16 to avoid memory overflow. The resolution of the input figures is set to \(640\times 640\). All models are trained for 300 epochs in total. The IoU threshold of the NMS operation is set to 0.6.
Evaluation metrics
TP represents true positive, which means the model detects true defects. FP represents false positive, which means the model obtains defects but the defects are false. FN stands for false negative, which refers to the missing detection defects. Precision measures how accurate a model is when it predicts a positive result, meaning the proportion of true positives divided by all positives. Recall, on the other hand, measures how well a model can identify all positive samples, meaning the proportion of true positives divided by all actual positives. A PR curve is a curve made with recall as the horizontal coordinate and precision as the vertical coordinate. AP is the area of the region enclosed by the PR curve of a defect category and the coordinate axis. In short, the precision, recall, AP, and mAP are computed as:
where P is precision, and R represents recall. The mAP is the average value of all APs. This paper chooses to use the mAP@0.5 and the mAP@0.5:0.95 as the evaluation metrics to verify the effectiveness of the proposed method.
In deep learning, FLOPs stands for “floating point operations” and is used to measure the computational complexity of a machine learning model. FLOPs is computed as:
where \(C_{\textrm{in}}\) represents the number of input channels, K is the kernel size. \(W_{\textrm{out}}\) and \(H_{\textrm{out}}\) denote the width and the height of the output feature map, respectively. \(C_{\textrm{out}}\) represents the number of output channels. This paper uses FLOPs as the evaluation metric to compare the computational complexity of the models.
Comparisons with other detection models
Several comparison experiments are conducted on the public NEU-DET dataset, and the results are reported in Table 2. The proposed method is compared with many state-of-the-art models, including YOLOv3, ScaledYOLOv4-csp [38], YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv7 [39]. It is clear that the proposed method achieves better performance at mAP@0.5 and mAP@0.5:0.95. From Table 2, the number of parameters in the proposed model is only 2.5 M larger than that of the smallest model. Also, the FLOPs of the proposed model is only a little larger than the smallest model. And the proposed model obtains the highest score, it achieves 73.08% and 37.57% in mAP@0.5 and mAP@0.5:0.95, respectively. Compared with the well-known YOLOv3 model, the proposed method is higher by 2.69% in mAP@0.5 and 1.56% in mAP@0.5:0.95. The number of parameters in our method is only 0.15 times the number of parameters in YOLOv3. Our model is higher by 3.71% and 4% in mAP@0.5 and mAP@0.5:0.95 than the ScaledYOLOv4-csp model, while the number of parameters in our method is only 0.18 times the number of parameters in ScaledYOLOv4-csp. The number of parameters in the YOLOv5s model, the YOLOv5m model, and the YOLOv5l model increases sequentially. The mAP@0.5 and mAP@0.5:0.95 of the three YOLOv5 models also increase sequentially. Our method outperforms the YOLOv5l model (0.85% and 0.83% in mAP@0.5 and mAP@0.5:0.95, respectively) and has a lower number of parameters. Compared with the SOTA object detection model, YOLOv7, the designed model still obtains higher mAP@0.5 and mAP@0.5:0.95. Therefore, the proposed method achieves the best results while keeping a small number of parameters.

Comparison of the proposed method and the baseline YOLOv5s. a mAP curve. b Loss curve
Ablation studies
In this section, several ablation studies on the NEU-DET dataset are conducted to verify the effectiveness of the modules proposed in this work. Table 3 displays the experimental results, which show the changes of the number of parameters, mAP@0.5 and mAP@0.5:0.95 during the ablation studies. The YOLOv5s model is called Model A, which is the baseline model. First, to verify the validity of the MSFE module, the C3 module is replaced by the MSFE module. This model is called Model B. Second, the EFF module is integrated into Model B to prove the efficiency of the EFF module, and the resulting model is called Model C. Third, the new Bottleneck is introduced into Model C to validate its effect. The obtained model is named Model D. Finally, the backbone network of Model D is deepened to verify the effectiveness of a deeper backbone network, and the obtained model is called Model E.
Performance of the MSFE module
It can be found from Table 3 that after Model A uses the MSFE module, mAP@0.5 increases by 0.81%, and mAP@0.5:0.95 increases by 1%. At the same time, the number of parameters of the model reduces about 1 M. Therefore, the MSFE module proposed in this paper is an efficient feature extraction module that can improve the detection accuracy of the model while reducing the number of parameters. The use of the MSFE module is worthwhile. The reason is that the designed MSFE module uses three branches with convolutional kernels of different sizes for multiscale feature extraction, which effectively enhances the model’s ability to extract features.
Performance of the EFF module
From Table 3, it can be found that after the introduction of the EFF module into model B, mAP@0.5 increases by 0.61%, and mAP@0.5:0.95 increases by 1.12%. The improvement brought by the EFF module is considerable, so the EFF module is effective. The reason is that the EFF module efficiently fuses the generated features in the backbone network with the features in the neck network.
Impact of the new bottleneck
Looking closely, it can be noted from Table 3 that the model C has almost no change in parameters after using the bottleneck module with reduced normalization layer and activation function. The mAP@0.5 of model C increases by 0.23% and the mAP@0.5:0.95 increases by 0.05%. The lift is small, but it is worth adding the new bottleneck to the model. The new Bottleneck is effective, and the reason is that the new Bottleneck reduces the negative impact of having too many normalization layers and activation functions in the model.
Impact of deepening the backbone network
It can be seen from Table 3 that after deepening the backbone network of model D, the mAP@0.5 increases by 0.56%, mAP@0.5:0.95 increases by 0.38%, and the number of parameters increases by 0.18 M. Deepening the backbone network can further improve the feature extraction ability of the model, and it is effective.
Comprehensive performance of the proposed model
Figure 9a shows the comparison of the mAP curve for the proposed method and the YOLOv5s model, and the comparison of the Loss curve during training is shown in Fig. 9b. It is clear that the proposed method is higher than the YOLOv5s model from the mAP curve and lower than the YOLOv5s method from the Loss curve. Compared with the YOLOv5s model, our final model increases by 2.21% and 2.55% in mAP@0.5 and mAP@0.5:0.95, respectively.
Figure 10 shows some samples of the detection results obtained using the proposed method and the YOLOv5s method. From Fig. 10a, it can be found that the YOLOv5s model detects only three labels and misses the top right label. The proposed method detects the four labels correctly. From Fig. 10b, we can see that there are three labels. The YOLOv5s method detects only two targets, while the proposed method finds three precise targets. Thus, the proposed method has an improvement in missed identification compared to the YOLOv5s model. As shown in Fig. 10c, we can find that the YOLOv5s model detects the background as ’patches’ category, and our method has the right detection result. Therefore, our method has a lower misunderstanding rate than the YOLOv5s model. From Fig. 10d, it can be found that the YOLOv5s model can’t precisely detect the right label, while our model detects it correctly. Thus, the proposed method has a forecast improvement over the YOLOv5s model.

Comparison of detection results for our method and YOLOv5s. The left are labels, the middle are the detection results of the YOLOv5s model, and the right are the detection results of our method
Conclusion
In this paper, a steel surface defect detection method based on deep learning is proposed. The steel surface defect is complex and multiscale. It is difficult for the model to extract features. To solve this problem, a multiscale feature extraction (MSFE) module is designed. The MSFE module uses three branches with convolutional kernels of different sizes for multiscale feature extraction. Also, an efficient feature fusion (EFF) module is proposed to overcome the problem of disappearing shallow features. The EFF module adds the feature maps of the backbone network to the neck network to improve the feature fusion ability of the model. Furthermore, a new bottleneck with a single normalization layer and a single activation function is introduced. Besides, the backbone network is deepened to further enhance the feature extraction ability of the model. Extensive ablation experiments on the public NEU-DET dataset are conducted, and the effectiveness of the modules proposed in this work is verified. And several comparison experiments with many SOTA object detection models are carried out to prove the effectiveness of the proposed model. The experimental results demonstrate that the proposed method obtains optimal scores in mAP@0.5 and mAP@0.5:0.95. In the future, we will continue to optimize the model structure and improve the detection performance of the model for steel surface defect detection.
Data Availability
The datasets used in this paper are available from the corresponding author.
References
Luo Q, Fang X, Liu L, Yang C, Sun Y (2020) Automated visual defect detection for flat steel surface: a survey. IEEE Trans Instrum Meas 69(3):626–644
He Y, Song K, Meng Q, Yan Y (2019) An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans Instrum Meas 69(4):1493–1504
Nturambirwe JFI, Opara UL (2020) Machine learning applications to non-destructive defect detection in horticultural products. Biosyst Eng 189:60–83
Krummenacher G, Ong CS, Koller S, Kobayashi S, Buhmann JM (2017) Wheel defect detection with machine learning. IEEE Trans Intell Transp Syst 19(4):1176–1187
Chan Ch, Pang GK (2000) Fabric defect detection by Fourier analysis. IEEE Trans Ind Appl 36(5):1267–1276
Droubi MG, Faisal NH, Orr F, Steel JA, El-Shaib M (2017) Acoustic emission method for defect detection and identification in carbon steel welded joints. J Constr Steel Res 134:28–37
Tulbure AA, Tulbure AA, Dulf EH (2022) A review on modern defect detection models using DCNNs-deep convolutional neural networks. J Adv Res 35:33–48
Hassaballah M, Awad AI (2020) Deep learning in computer vision: principles and applications. CRC Press, Boca Raton
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: IEEE conference on computer vision and pattern recognition. pp 580–587
Girshick R (2015) Fast R-CNN. In: IEEE international conference on computer vision. pp 1440–1448
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY et al (2016) SSD: Single shot multibox detector. In: European conference on computer vision. Springer. pp 21–37
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: unified, real-time object detection. In: IEEE conference on computer vision and pattern recognition. pp 779–788
Redmon J, Farhadi A (2017) YOLO9000: better, faster, stronger. In: IEEE conference on computer vision and pattern recognition. pp 7263–7271
Redmon J, Farhadi A (2018) Yolov3: An incremental improvement. arXiv:1804.02767
Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: Optimal speed and accuracy of object detection. arXiv:2004.10934
Lin TY, Goyal P, Girshick R, He K, Dollár P (2017) Focal loss for dense object detection. In: IEEE international conference on computer vision. pp 2980–2988
Lin H, Li B, Wang X, Shu Y, Niu S (2019) Automated defect inspection of LED chip using deep convolutional neural network. J Intell Manuf 30(6):2525–2534
Wei X, Yang Z, Liu Y, Wei D, Jia L, Li Y (2019) Railway track fastener defect detection based on image processing and deep learning techniques: a comparative study. Eng Appl Artif Intell 80:66–81
Li F, Xi Q (2021) DefectNet: Toward fast and effective defect detection. IEEE Trans Instrum Meas 70:1–9
Ultralytics.: YOLOv5 v6.1. https://github.com/ultralytics/yolov5. Accessed: 22 Feb 2022
Liu S, Qi L, Qin H, Shi J, Jia J (2018) Path aggregation network for instance segmentation. In: IEEE Conference on computer vision and pattern recognition. pp 8759–8768
Ren Z, Fang F, Yan N, Wu Y (2022) State of the art in defect detection based on machine vision. Int J Precis Eng Manuf Green Technol 9:661–691
Yu Z, Wu Y, Wei B, Ding Z, Luo F (2023) A lightweight and efficient model for surface tiny defect detection. Appl Intell 53:6344–6353
Cheng X, Yu J (2020) RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. IEEE Trans Instrum Meas 70:1–11
Liu S, Huang D, Wang Y (2019) Learning spatial fusion for single-shot object detection. arXiv:1911.09516
Su B, Chen H, Zhou Z (2021) BAF-detector: An efficient CNN-based detector for photovoltaic cell defect detection. IEEE Trans Industr Electron 69(3):3161–3171
Ying Z, Lin Z, Wu Z, Liang K, Hu X (2022) A modified-YOLOv5s model for detection of wire braided hose defects. Measurement 190:110683
Chen J, Liu Z, Wang H, Núñez A, Han Z (2017) Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network. IEEE Trans Instrum Meas 67(2):257–269
Zeng N, Wu P, Wang Z, Li H, Liu W, Liu X (2022) A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. IEEE Trans Instrum Meas 71:1–14
Li D, Xie Q, Gong X, Yu Z, Xu J, Sun Y et al (2021) Automatic defect detection of metro tunnel surfaces using a vision-based inspection system. Adv Eng Inform 47:101206
Cui L, Jiang X, Xu M, Li W, Lv P, Zhou B (2021) SDDNet: a fast and accurate network for surface defect detection. IEEE Trans Instrum Meas 70:1–13
Chen H, Pang Y, Hu Q, Liu K (2020) Solar cell surface defect inspection based on multispectral convolutional neural network. J Intell Manuf 31(2):453–468
He Y, Song K, Meng Q, Yan Y (2019) An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans Instrum Meas 69(4):1493–1504
Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T et al (2017) Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861
Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: IEEE conference on computer vision and pattern recognition. pp 2117–2125
Liu Z, Mao H, Wu CY, Feichtenhofer C, Darrell T, Xie S (2022) A convnet for the 2020s. In: IEEE Conference on computer vision and pattern recognition. pp 11976–11986
Wang CY, Bochkovskiy A, Liao HYM (2021) Scaled-Yolov4: Scaling cross stage partial network. In: IEEE conference on computer vision and pattern recognition. pp 13029–13038
Wang CY, Bochkovskiy A, Liao HYM (2022) YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv:2207.02696
Acknowledgements
This work was supported in part by National Key R &D Program of China (No. 2019YFB1707000).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, Z., Wei, X., Hassaballah, M. et al. A deep learning model for steel surface defect detection. Complex Intell. Syst. 10, 885–897 (2024). https://doi.org/10.1007/s40747-023-01180-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01180-7