
Abstract
In a streaming environment, the characteristics and labels of instances may change over time, forming concept drifts. Previous studies on data stream learning generally assume that the true label of each instance is available or easily obtained, which is impractical in many real-world applications due to expensive time and labor costs for labeling. To address the issue, an active broad learning based on multi-objective evolutionary optimization is presented to classify non-stationary data stream. The instance newly arrived at each time step is stored to a chunk in turn. Once the chunk is full, its data distribution is compared with previous ones by fast local drift detection to seek potential concept drift. Taking diversity of instances and their relevance to new concept into account, multi-objective evolutionary algorithm is introduced to find the most valuable candidate instances. Among them, representative ones are randomly selected to query their ground-truth labels, and then update broad learning model for drift adaption. More especially, the number of representative is determined by the stability of adjacent historical chunks. Experimental results for 7 synthetic and 5 real-world datasets show that the proposed method outperforms five state-of-the-art ones on classification accuracy and labeling cost due to drift regions accurately identified and the labeling budget adaptively adjusted.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In many practical applications, such as industrial manufacturing, risk prediction, fault and disease diagnosis, instances arrive sequentially in the form of stream, called data stream [1]. Unlike traditional static datasets, their distribution of different classes may vary over time, forming concept drift. Suppose that the distribution of a data stream at time t obeys \(P_{t}\left( X,Y \right) = P_{t}\left( X \right) \times P_{t}\left( Y \right) \). A new concept appears as its distribution changes at time \(t+1\), represented by \(P_{t + 1}\left( X,Y \right) \ne P_{t}\left( X,Y \right) \) [2]. In this case, the classifier at time t may not adapt to the current concept, resulting in poor classification accuracy. For example, traditional diagnostic models based on historical virus information may not accurately diagnose the latest disease when the strain has changed.
To address this issue, scholars have conducted rich researches on the adaptation of new concepts. Without loss of generality, tackling concept drift consists of three steps, including detection, understanding and adaptation of a drift [3]. Once a drift is detected, the adaptation is triggered after its type. In traditional drift adaptations, the labels of data are available, which depends on prior knowledge [4]. However, labeling a data in streaming scenarios shall be completed by human, causing expensive labeling cost [5, 6]. Also, a tired person easily assigns a wrong label to data. For example, judging whether the bearings output on the industrial assembly line are up to standard requires complex inspection steps and high costs. In order to reduce labeling costs, active learning has been introduced to seek the most valuable instances for querying true labels [7]. In general, active learning consists of “selection module” and “learning module”, as shown in Fig. 1. Instances are actively selected from an unlabeled chunk and provided for experts [8]. Following that, ones after being labeled are transmitted to the learning module for updating. Although active learning has achieved good performance on labeling static data, few concerns have been done on data stream with concept drift [9, 10]. In addition, the number of samples in each data chunk for being labeled is set in advance and remains unchanged, leading to a waste of labeling budget.

Active learning framework
Existing deep learning models (DLM) with multilayer network architecture have been proved an effective way to improve the performance of classification tasks [11]. As DLM sacrifices computational efficiency in exchange for higher accuracy, it cannot meet the needs of online classification where the model must be dynamically updated to adapt the latest concept [12]. Therefore, the broad learning system (BLS) proposed by Chen et al. was introduced to achieve fast incremental update without retrain full network [13]. More especially, BLS adds mapping features and augmented nodes through incremental learning, successfully avoiding significant computational costs and adapting to incoming instances. Notably, existing applications of BLS in real-time systems ignore the pre-processing of input instances or use only a single criterion to select instances [14]. However, when the quality of new input instances is extremely poor, i.e., high redundancy, low correlation, etc., are present at the same time, the performance of BLS suffers from a devastating degradation.
To overcome above shortcomings, an active broad learning system based on multi-objective evolution (MOE-ABLS) is proposed for detecting and adapting concept drift. The most valuable instances that may contribute to the accurate classification are first selected for labeling under limited budget. Following that, a fast local drift detection is designed to recognize drifted regions in a chunk-by-chunk manner. Once a drift occurs, the instances lying in drifted regions are chosen for updating the BLS model, with the purpose of guaranteeing high relevance to the new concept and diversity of instances. Considering the particularity of BLS construction, the instances selected for incremental update must be of high relevance and diversity. In a non-stationary stream, high relevance means keeping as many instances as possible that are related to the new concept, while diversity means minimizing the similarity between the selected instances [15]. However, relevance and diversity of instances are two objectives conflict with each other. To solve this multi-objective optimization problem, non-dominated sorting genetic algorithm II (NSGA-II), as a widely used problem-solver, is employed to seek representative candidate set of instances. Moreover, the number of labeled instances depends on whether drift occurs and the stability of the adjacent chunks. The contributions of this paper can be summarized as follows:
-
A specific active broad learning system is designed to improve classification accuracy of non-stationary stream, especially under scarcity of labels.
-
Taking the relevance and diversity of instances into account, a NSGA-II-based candidate selection strategy is constructed.
-
A fast local drift detection is presented, with the purpose of capturing new concepts in the unsupervised manner and identifying drifted regions accurately.
The rest of the paper is organized as follows, some studies related to the proposed algorithm are briefly discussed in “Preliminary”. “Active broad learning with multi-objective evolution” introduces the framework and key issues of MOE-ABLS proposed in the paper. Experimental results and analysis is conducted in “Experimental study”, and the main contributions and future work are summarized in “Conclusion”.
Preliminary
Definition of concept drift detection
In general, the distribution of data streams and their labels may change as a concept drift occurs, leading to the failure of historical models on current chunk [16]. Thus, whether the drift can be accurately detected poses a challenge for data stream classification.
Without loss of generality, drift detection methods are categorized into active and passive ones in terms of their triggering mechanisms [17]. In active ones, drift detection is performed by monitoring the change of model performance or data distribution. As mainstream algorithms of active approaches, drift detection method (DDM) [18] and exponentially weighted moving average for concept drift detection (ECDD) [19] are conducted by analyzing error rate of data chunks. To measure the change degree of date distribution, “warning” and “drift” are performed as results of drift detection. In order to improve the sensitivity of DDM, average distance between two misclassifications is taken into account in ECDD. Although the abovementioned methods have proven good performance in drift detection, they are not applicable in practical industrial scenarios since they are over-dependent on sample labels. Thus, distribution-based active approaches are developed to quantify the dissimilarity between the distribution of historical and current chunks. Taking ADaptive WINdow drift detection algorithm based on two time window (ADWIN) [20] as an example, newly arrived instances are stored in a window, and the size of window is adaptively adjusted according to the difference of samples between the current and previous windows. More especially, the size of window is adaptively adjusted according to the difference in the average value of the samples between the current and previous window. Based on this, the model can be better adapted to the new concept without ignoring the distribution information. However, abovementioned detectors suspend all historical chunk after a drift, leading to a delay in drift adaptation. Thus, in local drift degree (LDD) [21], current chunk is partitioned into multiple sub-regions, and density synchronization algorithm is employed on distribution of nearest one to recognize drifted regions.
Different from above active approaches, passive ones update the model to adapt new concept based on chunk newly arrived. Thus, the constructed model is able to maintain a good performance whenever drift occurs. Streaming ensemble algorithm (SEA) [22] adaptively assigns weights based on the classification accuracy of the base classifier on the current chunk. The base classifier with the lowest weight is eliminated when the scale of the ensemble classifier exceeds the threshold. Similarly, the combination of time decay factor and classification performance is employed to reduce the weight of historical base classifiers in Learn++NSE [23]. Unlike SEA-type algorithms that directly discard outdated base classifiers, accuracy updated ensemble (AUE) [24] taking validity of historical information into account, and retrains the outdated base classifiers with new data.
To sum up, the passive methods are well adapted to a new concept without explicit drift detection, however, spent more computational cost than the active ones. Moreover, the active and passive methods both depend on the label of the entire data chunk, leading to a delay in drift adaptation. Therefore, designing an effective local drift detection and adaptation method under limited label budget is necessary.
Broad learning system
The data with high-dimensional features are a major challenge for traditional machine learning methods [25]. Especially, in scenarios where just-in-time performance is required, e.g., recommendation systems, real-time fault diagnosis, etc.
To address the above issues, a new framework of broad learning system (BLS) [13] is proposed by Chen et al. Denoted as \(Z = \left[Z_{1},~Z_{2},\ldots ,Z_{n} \right]\) the mapped feature space, and \(H = \left[H_{1},~H_{2},\ldots ,H_{m} \right]\) as corresponding enhancement nodes, the ith feature space and the jth enhancement node is represented as follows
where \(W_{z_{i}}\), \( \beta _{z_{i}}\), \(W_{h_{j}}\) and \(b_{h_{j}}\) are randomly generated weights and bias, respectively. Based on this, the mapping relationship between inputs and outputs Y in BLS is described as \(Y = [Z,H]W\). In order to improve the computational efficiency of the network, the weights between the hidden and output layer is trained by a pseudo-inverse algorithm. As a new concept occurs, the whole network is updated incrementally not retrained according to the newly arrived instances.
In recent studies, rich variants of BLS are developed to improve classification performance. Take regularized robust BLS (RBLS) [26] as an example, regression residual and output weights are employed to decide objective function of BLS, and the output weights can be calculated by maximum a posterior estimation. Based on this, robustness of BLS is enhanced further. In fuzzy broad learning system (FBLS) [27], a pre-processing of the input is performed by fuzzy inference, and then the output of the system is transferred to the enhancement layer to improve the generalization capability of BLS. As a typical incremental learning model, the whole network of BLS is updates incrementally, not retrained as a new instance arrives. To meet various requirement of real-world applications, rich variants of BLS have been developed and shown promising performance in machine vision, industrial fault diagnosis, biomedical field, etc. In the field of machine vision, Zhang et al. [28] performed face recognition by introducing a module with the concept of feature block in BLS, which effectively addresses the influence of external factors on recognition accuracy in face recognition. In addition, Dang et al. [29] performed human behavior recognition based on 3D skeleton with the help of BLS. In the field of fault detection, Zhao et al. [30] proposed a novel fault diagnosis method that integrates BLS and PCA to classify the faults of rotor systems; based on this, Wang et al. [31] proposed an aero-engine wear fault diagnosis method based on BLS and integrated learning, which is of great significance to ensure aircraft safety. In the biomedical field, Wang et al. [32] proposed an important graph convolutional generalized network architecture based on graph CNN and BLS, aiming to explore advanced graph topological information for EEG emotion recognition. Based on this, Yang et al. [33] designed a fatigue driving recognition method, which is based on a novel complex network of BLS, which analyzes the EEG and then detects whether the driver is in the state of fatigue.
Apparently, BLS-based algorithms have high efficiency and accuracy, as well as rapid adaptation to the new data. However, once the new data have low quality and high redundancy, their classification accuracy becomes worse. Thus, choosing the valuable data from a stream has a direct impact on BLS-based model performance.
Multi-objective evolutionary algorithms on instance selection
As an important part of data mining research, instance selection improves the classification performance of model and reduces training costs by preserving valuable instances [34]. Since most of the existing algorithms select instances based on the observation of data distribution, the ones with high uncertainty near the decision boundary is easily treated as noise, and removed [35].
To address this issue, evolutionary algorithm (EA) is employed to produce a better subset of instances by iteratively evolution [36]. As the early application, EA combined with regression tasks is proposed by Tolvi et al. with the aim of selecting high-quality instances to improve the performance of the model [37]. Similarly, García-Pedrajas et al. proposed the coevolutionary instance selection (CCIS) [38] algorithm to obtain better solution by cooperative coevolution. Candidate instances are partitioned into several sub-populations, and each one is evolved by genetic algorithm. However, abovementioned algorithms consider only a single objective as the criterion for instance selection. This may lead to a significant degradation in the performance of model like BLS as the input instances is redundant. Thus, a growing number of scholars are working on the application of multi-objective evolutionary algorithms in instance selection.
In general, the Multi-objective optimization problem (MOP) is formalized as follows [39]:
where x is the d-dimensional feature vector, and X is a set of candidate solutions. Any objective conflicts with the remaining ones which means that there is no single best solution for all objectives [40]. The solution \(x_{a}\) is non-dominate to \(x_{b}\) if it is better than \(x_{b}\), but has at least one objective that is worse than \(x_{b}\).
Based on abovementioned framework, Rosales-Pérez et al. presented an evolutionary multi-objective instance selection method based on support vector machines [41, 42]. In this method, minimize the training set and maximize the classification performance are treated as two optimization objectives. To address the impact of the overfitting problem on model, multi-objective evolutionary algorithm for prototype (MOPG) [43] updates the split ratio between the training and test sets in each iteration of genetic algorithm, and re-evaluates all solutions. Furthermore, multi-objective evolutionary instance selection for regression (MEISR) [44] discusses the effect of different parameters in the iterative process on classification performance while guaranteeing low computational complexity. These algorithms have played an important role on selecting instances and deserved to be followed in the incremental update of BLS. More especially, the instances selected in data stream for incremental update must be of high relevance and diversity. Thus, a multi-objective evolutionary optimization algorithm for finding the trade-off of these two conflicting objectives are considered in this paper.
Active broad learning with multi-objective evolution
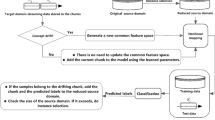
MOE-ABLS proposed in the paper provides a novel framework for adapting new concepts in data stream under scarcity of labels. As shown in Fig. 2, the new coming instances without labels are first stored one by one until the maximum size m of a chunk is reached, forming current chunk, represented by \(W_{c}\) (line 2 to line 4 of Algorithm 1). Following that, drift detection is triggered to compare distribution of \(W_{c}\) with adjacent historical one, called reference chunk \(W_{r}\) (line 5 of Algorithm 1). Once a new concept occurs, the instances from drifted regions with high relevance-diversity constitute a candidate subset. Among them, only a part of instances is selected as representative and labeled by experts. Their amount is dynamically adjusted according to the stability of adjacent chunks. Finally, the incremental update is performed on BLS by the labeled representative so as to adapt new concepts (line 6 to line 10 of Algorithm 1). Obviously, detecting a new concept, selecting the representative instances and adapting drift are their key issues. More details about them are illustrated in the following three subsections. The pseudocodes of MOE-ABLS are listed in Algorithm 1.

Fast local drift detection
Without loss of generality, a data stream consisted of instances arriving in time order is represented by: \(S = \left\{ \left. d_{t} \right| _{t = 0}^{\infty } \right\} \) and \(d_t=\left( x_t, y_t\right) \), where \(x_{t}\) is a n-dimension vector and \(y_{t}\) is its label at time t. Once the distribution of the instance at \(t+1\) is different from that at t, a new concept has occurred. Existing chunk-based detection suspends the drifted and non-drifted regions together after the drift is detected, leading to a decrease in learning efficiency. To better adapt the drift, a fast local drift detection is proposed.

The flowchart of MOE-ABLS

The sort of drifted and non-drifted regions in a chunk
In the initialization stage, the original \(W_{r}\) consisting of m instances with true labels is divided into K clusters by K-means clustering algorithm. The centers of all clusters remain unchanged and are sent to \(W_{c}\). More especially, the parameters of the centers in \(W_{c}\) will be updated by the labeled instances whenever the drift adaptation is completed. According to the distance between instances and the cluster centers, each instance in \(W_{c}\) is categorized into the cluster closest to it. Based on this, Kolmogorov–Smirnov test (KS test) [45] is employed to compare difference in distribution between it and \(W_{r}\) by means of the cumulative distribution functions. Furthermore, a strict confidence level \(\alpha \) is set to reduce false positives caused by repeated detection. Finally, a detection matrix T is constructed to recognize the drifted regions.
where \(W_{ck}\) and \(W_{rk}\) represent the kth cluster in \(W_{c}\) and \(W_{r}\), respectively. The null hypothesis of KS test is that two regions have the same distribution. Thus, when and only when \(W_{ck}\) satisfies Eq. (5), \({T}({k}, {k})=0\), that is, no drift occurs. Otherwise, \({T}({k}, {k})=1\) means that a drift occurs in the kth cluster of \(W_{c}\). Intuitively, the rank of the detection matrix tr\((T) = 1\) means that new concepts appear in \(W_{c}\):
where \(F( \cdot )\) is cumulative frequency function and \(p_\textrm{value}( \cdot )\) refers to []. Assuming that there are N drifted regions in \(W_{c}\), \(\left\{ C_{1},\ldots ,C_{N} \right\} \) and \(\left\{ C_{N + 1},\ldots ,C_{K} \right\} \) represent drifted and non-drifted regions, respectively, as shown in Fig. 3. It is worth noting that each region corresponds to a cluster.
Candidate selection strategy based on multi-objective evolutionary algorithm
In this subsection, the dynamically updated weights are assigned to instance subsets generated by multi-objective evolutionary algorithm. The instances with the highest weights are selected as the candidate for querying the true labels.
Denoted \(x_{t}^{l}\), \(l \le N\) as the ith instance from lth region, two conflicting indicators, i.e., relevance and diversity are defined to evaluate the representativeness of an instance. Based on them, a multi-objective optimization problems for selecting the valuable candidate to be labeled is formalized as follows:
In the above formula, \(f_{1}(x_{t}^{l})\) and \(f_{2}(x_{t}^{l})\) represent diversity and relevance of \(x_{t}^{l}\), respectively. Inspired by Pearson correlation coefficient theory [46], the so-called diversity is defined as the correlation of \(x_{i}^{l}\) with other instances in the same region:
where \(\textrm{Var}\left( \cdot \right) \) and \(\textrm{Cov}\left( \cdot \right) \) are variance and covariance, respectively.
Relevance of \(x_{t}^{l}\) measures the contribution of the instance to the new concept in \(W_{c}\). More especially, instance with highest relevance must have the minimum average distance to other instances in the same region and the maximum distance to other regions:
In the above formula, \(\textrm{DIS}_{w}\left( x_{i}^{l} \right) \) represents intra-distance of \(x_{t}^{l}\) with other instances in lth region. \(\textrm{DIS}_{b}\left( x_{i}^{l} \right) \) calculates inter-distance of \(x_{t}^{l}\) with other regions:
where \(c_{k}\) is center of the kth region.
To solve this problem, non-dominated sorting genetic algorithm II (NSGA-II) is employed to find the Pareto-optimal solution set (PS). Each instance in drifted regions corresponds to a genotype. If the instance is selected as a candidate, corresponding bit is set to 1, vice versa. Based on binary encoding, an individual is randomly generated, and L individuals form an initial population. After crossover and mutation operations, the offsprings are merged with the current population, and non-dominated sorting is performed. Only the solutions with the minimum non-dominated rank and the maximum crowdedness are remained to the next generation. The above evolution process is repeated until the terminal iteration G reaches, and then the final Pareto-optimal solutions is output.
Among them, only a part of representative solutions are selected to be labeled by fuzzy decision [47]. For \(f_{i},~i = \left\{ 1,2 \right\} \), a membership function \(\gamma _{i}\) that decreases in a strictly monoatomic way is defined as following:
where \(f_{i}^{\min }\) and \(f_{i}^{\max }\) are the minimum and maximum values of the ith objective on non-dominated solutions, respectively. Assume that there are \(N_{s}\) Pareto-optima. Let \(\gamma _{j}^{1}\) and \(\gamma _{j}^{2}\) be the membership values of two objectives for the jth solution, the candidate is selected from PS in terms of the following probability for each solution. Based on this, the instances with maximum \(\gamma _{j}\) are selected as candidate:
Active broad learning
In the practical production process, inspections are needed to be conducted to prevent products from falling short of standards in the assembly line. As an important part of the inspection, labeling the class of each product by human is an indispensable step. However, the daily workload of each inspector is limited. Considering labor costs and production efficiency, it is difficult to label each product in time. To tackle this issue, an improved active learning is proposed to incrementally update BLS on non-stationary stream.
In the initialization stage of ABLS, a small amount of labeled instances is available for training BLS. Denoted \(W_{e_j}\) and \(\beta _{e_j}\) as randomly generated weights and bias, the jth mapped feature in BLS is calculated as follows [13]:
All mapped features constituent the feature vector: \(Z^h=\left[ Z_1, Z_2, \ldots , Z_h\right] \). Assume that there are M groups of enhancement nodes, represented by
Based on the known labels of instances, the output of BLS is represented by \(Y=\left\{ y_1, y_2, \ldots , y_m\right\} \), and then the following initial broad model is obtained:
Defined \(\left[ Z^h \mid H^M\right] ^{+}\) as the pseudo-inverse, and the connecting weights are achieved:
Different from previous active learning, the number of instances to be labeled is controlled in terms of labeling budget and stability of adjacent chunks. Generally, we believe that a data stream is stable if data distribution of adjacent chunks remains unchanged. In this case, labeling the smaller number of instances saves the cost without lowering algorithm performance. On the contrary, as a new concept occurs, the number of instances to be labeled becomes larger, and labeling budget \(B \in \left[0,1 \right]\) increases synchronously. For example, \(B=0.2\) means that twenty percent of instances in current chunk are relabeled, while the whole chunk is relabeled as \(B=1\). Noteworthy, B is generally determined in advance according to the labeling capability, such as inspectors’ number, experience, etc.
Except for labeling budget, the data distribution of adjacent historical chunks also has a significant impact on the number of candidate instances for being labeled. As the distribution of adjacent chunks remain unchanged, the number of instances for labeled becomes smaller. Assume that \(N_{d}\) is the total number of adjacent historical chunks that have the same concept with \(W_{c}\), the stability of it is evaluated as follows:
where
According to stability of adjacent historical chunks and labeling budget, the number of instances for labeling is \(mB\textrm{St}\left( W_{c} \right) \). The ones randomly selected from the candidate forms a set with true labels, represented by \(X_{c}\). Once a drift occurs, more instances need to be labeled for better adapting a new concept, and the amount of them is \(B_\textrm{cache}=mB[1- \textrm{St}\left( W_{r} \right) ]\). Based on this, the number of representative instances is defined as follows:
Define \(A_{h}^{M}\) as the initial network with h groups of mapping nodes and M groups of enhancement nodes, the mapping matrix is updated as follows [13]:
where
Based on this, its corresponding pseudo-inverse is updated:
where
From the improved active learning, let \(Y_{c}\) be corresponding labels of \(X_{c}\), the weights of BLS are updated as follows:
Under the infinite continuous data stream, the number of mapping and enhancement nodes in a broad learning system may become larger. In order to effectively control the scale of the network structure in MOE-ABLS, low-rank approximation methods presented by Chen et al. is introduced to simplify its structure, avoiding the decrease of computational efficiency caused by increasing mapping and enhancement nodes. For more details about low-rank approximation methods, please refer to the literature [13].
Experimental study
To evaluate the effectiveness of the proposed MOE-ABLS algorithm, we conducted four experiments on public datasets. The first experiment analyzes sensitivity of four parameters in MOE-ABLS on the prediction accuracy. Second, the effectiveness of the fast local drift detection is verified on synthetic datasets. Following that, feasibility and necessity of candidate selection strategy is investigated. Finally, the performance of MOE-ABLS proposed in this paper is compared with five state-of-art algorithms on all datasets. All experiments are realized by Scikit-Multiflow learning library, and done on Windows 11, 64 GB memory, i7-8700 CPU.

The time-varying data distributions of five real-world datasets
Datasets
7 synthetic and 5 real-world datasets are employed in experiments, and their details are shown in Table 1. All synthetic data streams are generated by SEA, WAVEFORM, Random Tree and HYPERPLANE generators in Scikit-Multiflow Library.
-
1.
SEA generator [48]: The data stream generated by the SEA generator consists of three properties, but only two of them are relative to each other. The values of all attributes belong to \(\left[0,10 \right]\). The labels of two classes, represented by \(c_{1}:\beta _{1} + \beta _{2} \le \theta \) and \(c_{2}:\beta _{1} + \beta _{2} > \theta \), where \(\beta _{1}\) and \(\beta _{2}\) are the values of two attributes and \(\theta \) is a threshold. Moreover, an adjustable parameter is employed to generate abrupt and gradual concept drift.
-
2.
WAVEFORM generator [49]: This generator produces the data stream consisting of two or three fundamental waves with two classes. Moreover, 21 numeric attributes and 19 irrelevant attributes are combined in it.
-
3.
RANDOMTREE generator [50]: The data stream is formed by a randomly generated tree that is built based on its description in Domingo and Hulten’s ‘Knowledge Discovery and Data Mining’. Each instance is labeled by randomly segmenting the features and assigning on their leaves. Afterwards, a new instance is generated by assigning a random value to each attribute. Based on the tree structure, the abrupt and gradual drift data streams are constructed.
-
4.
HYPERPLANE generator [51]: This generator is used to construct the classification problems of a rotation hyperplane, named as CVFDT and VFDT. In hyperplane, a d-dimensional sample x satisfying \(x{\sum _{i = 1}^{d}{\omega _{i}x_{i}}} = \omega _{0} = {\sum _{i = 1}^{d}{\omega _{i}x_{i}}}\) is labeled to positive, but the label of the one satisfying \(x{\sum _{i = 1}^{d}{\omega _{i}x_{i}}} > \omega _{0}{\sum _{i = 1}^{d}{\omega _{i}x_{i}}} \le \omega _{0}\) is negative. Based on this, the direction and position of the hyperplane transform smoothly by changing the weights, forming the concept varying over time.
-
5.
Electricity [52]: The electricity data stream is collected from Australian New South Wales Electricity Market. It contains 45,312 samples with two classes, and each sample has six features. Considering the instability of the market, the main goal of this data stream is to predict whether electricity prices will increase or decrease.
-
6.
Covtype [53]: This dataset was collected by the U.S. Forest Service (USFS) and recorded the percent cover of forest vegetation at a given location. Two data streams consisting of 45,247 instances and 53,121 instances, respectively, with 7 classes is employed in experiments. Each instance has 53 attributes.
-
7.
Weather [54]: Weather data stream provided by U.S. National Oceanic and Atmospheric Administration (NOAA) covers a large-scale weather trends collected from over 9000 weather stations worldwide. It contains 18,159 samples and each sample has 8 features. 31% instances belong to positive class (rain). This data stream not only memories short-term seasonal changes, but also long-term climate trend.
-
8.
Steel plates: All data are collected by Research Center of Sciences of Communication in Rome and employed to detect the changes of each parameter during the steel production process. There are 1941 samples, and each instance describes the working conditions by 27 attributes. The dataset contains 7 fault states, forming the concept drifts.
Figure 4 depicts the time-varying distribution of the real-world data streams. In electricity, the distribution of data chunk at time t is different from that at \(t+1\), but same at \(t+2\), forming reoccurring concepts. The similar case occurs for Steel Plates, as shown in Fig. 4d. Figure 4c, e are interpreted as gradual drift and sudden drift appearing in Fig. 4b. Apparently, all above real-world datasets contain drifted concepts.
Analyzing the sensitivity of parameters on algorithm performance
In this subsection, we further discuss the effect of four main parameters in MOE-ABLS on algorithm performance, including the number of instances in a chunk m, labeling budget B, the terminated iterations G and population size Pop. To avoid the larger computation cost, G and Pop, as the key parameters in NSGA-II, are set to \(\{\)40, 50, 80, 100\(\}\) and \(\{\)20, 40, 60, 80\(\}\), respectively. Too large chunk size may cause the drift adaption untimely, thus m is set to \(\{\)50, 100, 150, 200\(\}\) in experiment. The considerable labeling budget is \(\{\)0.1, 0.2, 0.3, 0.4, 0.5\(\}\). Except for them, the activation functions for different datasets are selected from \(\{\)relu, tanh, sigmoid, linear\(\}\). The crossover and mutation probabilities are set to 1.0 and 0.1, respectively. Here, accuracy (Acc) of the classifier is employed as a metric to evaluate the classification performance.

Accuracy of MOE-ABLS under different activation function
In order to select the most suitable activation functions for all dataset, an experiment was performed under default values of \(m=100\), \(B=0.4\), \(G=100\) and Pop = 40. Moreover, crossover and mutation probabilities are set to 1.0 and 0.1, respectively. The empiric values of these main parameters refer to [15, 43, 44]. Four activation functions, including Relu, Tanh, Sigmoid and Linear, are, respectively, imported in MOE-ABLS to classify 7 synthetic datasets and 5 real-world datasets. Figure 5 depicts the classification accuracy of MOE-ABLS with various activation functions. Intuitively, Relu shows good classification performance on SEA (1) and SEA (2) due to its property of linear separability. However, it becomes inactive for all inputs with negative values, leading to poor performance on other datasets. As classical activation functions, Sigmoid is found to be the best one for RTREE (1) and has a similar classification performance with Tanh on RTREE (2) and electrical. Although Sigmoid and Tanh are suitable for solving the above binary classification problems, they suffer from vanishing gradients, causing slow convergence on complex datasets. To the best of our knowledge, Linear can handle datasets with complex and non-linear decision boundaries well, thus shows a better classification performance on multiclassification and high-dimensional datasets. The most suitable activation functions for all datasets are shown in Table 2.
Figures 6, 7, 8 and 9 depict the performance of MOE-ABLS with different m, B, Pop and G, respectively. We observe from Fig. 6 that the accuracy first become better and then worser with the increase of m. Too large m hides the drift information especially when the drift occurs in local regions. In Fig. 7, the classification accuracy of most datasets is positively correlated with B, except for RTREE, HYP and Electrical. RTREE and HYP as synthetic datasets with higher dimensionality form delay of drift adaptation when label too many instance. For Electrical, the classification accuracy does not improve significantly with the increase of B since the electricity consumption habits of customers are relatively stable. To keep the trade-off between labeling cost and classification performance, a smaller B is preferable. Figures 8 and 9 illustrate that the classification performance become better with the increase of G and Pop, and tends to be stable when \(G=80\), \(Pop=60\).
Comprehensively considering the classification accuracy, computational efficiency and cost, the sensitive parameters and activation function for 12 datasets are shown in Table 2.

Accuracy of MOE-ABLS under different m

Accuracy of MOE-ABLS under different B

Accuracy of MOE-ABLS under different G

Accuracy of MOE-ABLS under different Pop
Component contribution analysis
In subsection, the effectiveness of the fast local drift detection and MOE-based candidate selection strategy in MOE-ABLS is discussed. Two additional evaluation metrics, i.e., recall rate (Rec) and false alarm rate (FPR) are employed to demonstrate the sensitivity and anti-disturbance performance of the proposed drift detection, respectively.
-
1.
Rec: The proportion of detected drift chunks out of all drifted ones.
-
2.
FPR: The proportion of non-drift chunks present in the chunks with drift alarm.
Figure 10 only shows the effectiveness of drift detection on synthetic datasets, since the drift information of the real-world ones is unknown. It can be clearly seen that the detection exhibits outstanding performance with high Acc, Rec and low FPR.
Following that, the feasibility and necessity of candidate selection strategy based on multi-objective evolutionary algorithm is investigated. The algorithm without candidate selection strategy (ABLS) is employed for comparisons.

Performance of fast local drift detection

Comparison of the classification accuracy between MOE-ABLS and ABLS
As shown in Fig. 11, it can be seen that MOE-ABLS outperforms ABLS on both synthetic and real-world datasets. This is because the instance selected by ABLS will inevitably contain redundancy and low-value.
Comparison of performance among MOE-ABLS and other methods
To analyze the effectiveness and efficiency of MOE-ABLS, five state-of-the-art algorithms are employed for comparison, and details of them are introduced as following:
-
1.
Accuracy updated ensemble (AUE) [24]: This method updates the ensemble classifier in an incremental manner, in which a new base classifier is built for a chunk newly arrived. To be more specific, accuracy-based weighting mechanism and Hoeffding trees are integrated in AUE. In this way, the response of the ensemble classifier to different types of concept drift is improved and the effect in size of data chunks is reduced.
-
2.
Online AUE (OnlineAUE) [55]: As an online version of AUE, Online AUE replaces the batch component classifier in AUE with an incremental classifier to improve the performance of drift adaptation.
-
3.
Adaptive random forest (ARF) [56]: This method is constructed on the basis of random forests, replacing historical trees with new ones to adapt new concept.
-
4.
Adaptable diversity-based online boosting (ADOB) [57]: ADOB adjusts diversity dynamically based on the accuracy of the underlying classifier to improve the generalization of the model on data stream.
-
5.
Density synchronized drift adaptation (LDD-DSDA) [21]: A density synchronization algorithm is employed over the drift regions to fit the density differences.
Since the above AUE, OnlineAUE, ARF and ADOB do not have a drift detection component, drift detector ADWIN is equipped on them for fair comparison. Moreover, key parameters of all comparison algorithms are provided by the papers they come from.
Two groups of experiments have been performed to compare the performance of all comparative algorithms under \(B=0.4\) and \(B=0.8\), respectively. Each algorithm is repeatedly executed ten times. The average accuracy and G-mean of all comparative algorithm under different B are listed in Tables 3 and 4, as well as Tables 5 and 6. Inspired by statistical analysis methods in [58], Friedman test and Nemenyi test are employed to statistically analyze the obtained results. If P value of Friedman test is less than the null hypothesis, there exists the significant difference among the performance of comparative algorithms.

The critical difference between MOE-ABLS and other comparative algorithms
We observe from average accuracy that MOE-ABLS proposed in the paper significantly outperforms the others on all datasets as \(B=0.4\), except for ARF on CovType(1). By analysis, ARF updates nodes of its tree for each newly arrived chunk, thus obtains a better performance. However, its high computational cost makes it limited in practical engineering applications. As the labeling budgets of the other comparative algorithms is two or three times of MOE-ABLS, the proposed algorithm achieves the superior performance on SEA(2), RTREE(1), WAVE(1), HYP. Its average ranking of 2.75 also proves the effectiveness of MOE-ABLS. Experimental results of G-mean illustrated in Table 5 show that MOE-ABLS obtains the best classification performance, except for Covtype(1). The reason for this phenomenon is that the number of classes in Covtype changes over time. BLS trained on historical data affects the classification effect on other classes when facing the disappearance and emergence of classes, leading to the degradation in the efficiency and classification accuracy of the proposed algorithm. Under smaller labeling budget, MOE-ABLS still has relatively good classification performance as shown in Table 6. In addition, p values of Friedman test on both accuracy and G-mean are small, which means that there is a significant difference in classification performances among comparative methods.
For further analyzing the significant differences in classification performance among all algorithms, Nemenyi test is employed and the corresponding critical difference are depicted in Fig. 12. Intuitively, there is a significant difference between MOE-ABLS and the others. To sum up, MOE-ABLS provides better classification performance under smaller labeling budget.
Conclusion
In non-stationary data stream classification, scarcity of labels poses an extra challenge for traditional drift detection. To address the issue, an active broad learning with multi-objective evolutionary optimization is presented in this paper. First, fast local drift detection is proposed to recognize the drifted regions in current chunk. Following that, a candidate selection strategy based on multi-objective evolutionary algorithm is designed to seek candidate instances with high relevance and diversity. More especially, the number of representative ones is determined by the stability of adjacent historical chunks. Based on this, broad learning model is incrementally updated to adapt new concept. Experimental results on 7 synthetic and 5 real-world datasets show that MOE-ABLS proposed in the paper has higher classification accuracy and less labeling budget than the other state-of-the-art classification algorithms. Moreover, the feasibility and necessity of candidate selection strategy have been proven in ablation studies.
In industrial application, an equipment or component may be failed with the increase of operation time, forming a sudden drift in its monitoring stream. However, only part of faults have been labeled in advance, causing scarcity of labeled samples. Due to the promising performance of MOE-ABLS on detecting and adapting a new concept in a data stream, it provides a feasible problem-solver for fault diagnosis.
In the future, we focus on the high-efficient detection and adaptation for virtual drift, as well as its real-world application, such as outlier detection in wireless network transmission [59].
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Lu J, Liu A, Dong F, Gu F, Gama J, Zhang G (2018) Learning under concept drift: a review. IEEE Trans Knowl Data Eng 31(12):2346–2363. https://doi.org/10.1109/TKDE.2018.2876857
Jiao B, Guo Y, Gong D, Chen Q (2022) Dynamic ensemble selection for imbalanced data streams with concept drift. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2022.3183120
Lu J, Liu A, Song Y, Zhang G (2020) Data-driven decision support under concept drift in streamed big data. Complex Intell Syst 6(1):157–163. https://doi.org/10.1007/s40747-019-00124-4
Fahy C, Yang S, Gongora M (2021) Classification in dynamic data streams with a scarcity of labels. IEEE Trans Knowl Data Eng. https://doi.org/10.1109/TKDE.2021.3135755
Lu Y, Cheung YM, Tang YY (2017) Dynamic weighted majority for incremental learning of imbalanced data streams with concept drift. In: IJCAI, pp 2393–2399
Liao G, Zhang P, Yin H, Deng X, Li Y, Zhou H, Zhao D (2023) A novel semi-supervised classification approach for evolving data streams. Expert Syst Appl 215:119273. https://doi.org/10.1109/TFUZZ.2021.3128210
Settles B (2012) Active learning. Synthesis lectures on artificial intelligence and machine learning, vol 6, no 1, pp 1–114. https://doi.org/10.2200/S00429ED1V01Y201207AIM018
Carr R, Palmer S, Hagel P (2015) Active learning: the importance of developing a comprehensive measure. Act Learn High Educ 16(3):173–186. https://doi.org/10.1177/1469787415589529
Zhu X, Zhang P, Lin X, Shi Y (2010) Active learning from stream data using optimal weight classifier ensemble. IEEE Trans Syst Man Cybern Part B (Cybernetics) 40(6):1607–1621. https://doi.org/10.1109/TSMCB.2010.2042445
Shan J, Zhang H, Liu W, Liu Q (2018) Online active learning ensemble framework for drifted data streams. IEEE Trans Neural Netw Learn Syst 30(2):486–498. https://doi.org/10.1109/TNNLS.2018.2844332
Kamilaris A, Prenafeta-Boldú FX (2018) Deep learning in agriculture: a survey. Comput Electron Agric 147:70–90. https://doi.org/10.1016/j.compag.2018.02.016
Priya S, Uthra RA (2021) Deep learning framework for handling concept drift and class imbalanced complex decision-making on streaming data. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00456-0
Chen CP, Liu Z (2017) Broad learning system: an effective and efficient incremental learning system without the need for deep architecture. IEEE Trans Neural Netw Learn Syst 29(1):10–24. https://doi.org/10.1109/TNNLS.2017.2716952
Gong X, Zhang T, Chen CP, Liu Z (2021) Research review for broad learning system: algorithms, theory, and applications. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2021.3061094
Jiao B, Guo Y, Yang S, Pu J, Gong D (2022) Reduced-space multistream classification based on multi-objective evolutionary optimization. IEEE Trans Evol Comput. https://doi.org/10.1109/TEVC.2022.3232466
Brzezinski D, Stefanowski J (2013) Reacting to different types of concept drift: the accuracy updated ensemble algorithm. IEEE Trans Neural Netw Learn Syst 25(1):81–94. https://doi.org/10.1109/TNNLS.2013.2251352
Jiao B, Guo Y, Yang C, Pu J, Zheng Z, Gong D (2022) Incremental weighted ensemble for data streams with concept drift. IEEE Trans Artif Intell. https://doi.org/10.1109/TAI.2022.3224416
Baena-Garcıa M, del Campo-Ávila J, Fidalgo R, Bifet A, Gavalda R, Morales-Bueno R (2006) Early drift detection method. In: 4th international workshop on knowledge discovery from data streams, vol 6, pp 77–86
Ross GJ, Adams NM, Tasoulis DK, Hand DJ (2012) Exponentially weighted moving average charts for detecting concept drift. Pattern Recognit Lett 33(2):191–198. https://doi.org/10.1016/j.patrec.2011.08.019
Bifet A, Gavalda R (2007) Learning from time-changing data with adaptive windowing. In: Proceedings of the 2007 SIAM international conference on data mining. Society for Industrial and Applied Mathematics, pp 443–448. https://doi.org/10.1137/1.9781611972771.42
Liu A, Song Y, Zhang G, Lu J (2017) Regional concept drift detection and density synchronized drift adaptation. In: IJCAI international joint conference on artificial intelligence. http://hdl.handle.net/10453/126374
Street WN, Kim Y (2001) A streaming ensemble algorithm (SEA) for large-scale classification. In: Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, pp 377–382. https://doi.org/10.1145/502512.502568
Elwell R, Polikar R (2011) Incremental learning of concept drift in nonstationary environments. IEEE Trans Neural Netw 22(10):1517–1531. https://doi.org/10.1109/TNN.2011.2160459
Brzezinski D, Stefanowski J (2013) Reacting to different types of concept drift: the accuracy updated ensemble algorithm. IEEE Trans Neural Netw Learn Syst 25(1):81–94. https://doi.org/10.1109/TNNLS.2013.2251352
Huang H, Zhang T, Yang C, Chen CP (2019) Motor learning and generalization using broad learning adaptive neural control. IEEE Trans Ind Electron 67(10):8608–8617. https://doi.org/10.1109/TIE.2019.2950853
Jin JW, Chen CP (2018) Regularized robust broad learning system for uncertain data modeling. Neurocomputing 322:58–69. https://doi.org/10.1016/j.neucom.2018.09.028
Feng S, Chen CP (2018) Fuzzy broad learning system: a novel neuro-fuzzy model for regression and classification. IEEE Trans Cybern 50(2):414–424. https://doi.org/10.1109/TCYB.2018.2857815
Zhang D, Yang H, Chen P, Li T (2019) A face recognition method based on broad learning of feature block. In: 2019 IEEE 9th annual international conference on cyber technology in automation, control, and intelligent systems (CYBER). IEEE, pp 307–310
Dang Y, Yang F, Yin J (2020) DWnet: deep-wide network for 3D action recognition. Robot Auton Syst 126:103441
Zhao H, Zheng J, Xu J, Deng W (2019) Fault diagnosis method based on principal component analysis and broad learning system. IEEE Access 7:99263–99272
Wang M, Ge Q, Jiang H, Yao G (2019) Wear fault diagnosis of aeroengines based on broad learning system and ensemble learning. Energies 12(24):4750
Wang XH, Zhang T, Xu XM, Chen L, Xing XF, Chen CP (2018) EEG emotion recognition using dynamical graph convolutional neural networks and broad learning system. In: 2018 IEEE international conference on bioinformatics and biomedicine (BIBM). IEEE, pp 1240–1244
Yang Y, Gao Z, Li Y, Cai Q, Marwan N, Kurths J (2019) A complex network-based broad learning system for detecting driver fatigue from EEG signals. IEEE Trans Syst Man Cybern Syst 51(9):5800–5808
Kordos M, Blachnik M (2012) Instance selection with neural networks for regression problems. In: International conference on artificial neural networks, pp 263–270. https://doi.org/10.1007/978-3-642-33266-1_33
Arnaiz-González Á, Díez-Pastor JF, Rodríguez JJ, García-Osorio C (2016) Instance selection for regression: adapting DROP. Neurocomputing 201:66–81. https://doi.org/10.1016/j.neucom.2016.04.003
Yinan G, Chen G, Jiang M, Gong D, Liang J (2022) A knowledge guided transfer strategy for evolutionary dynamic multiobjective optimization. IEEE Trans Evolut Comput. https://doi.org/10.1109/TEVC.2022.3222844
Tolvi J (2004) Genetic algorithms for outlier detection and variable selection in linear regression models. Soft Comput 8(8):527–533. https://doi.org/10.1007/s00500-003-0310-2
García-Pedrajas N, Romero del Castillo JA, Ortiz-Boyer D (2010) A cooperative coevolutionary algorithm for instance selection for instance-based learning. Mach Learn 78(3):381–420. https://doi.org/10.1007/s10994-009-5161-3
Guo YN, Zhang X, Gong DW, Zhang Z, Yang JJ (2019) Novel interactive preference-based multiobjective evolutionary optimization for bolt supporting networks. IEEE Trans Evolut Comput 24(4):750–764
Chen G, Guo Y, Huang M, Gong D, Yu Z (2022) A domain adaptation learning strategy for dynamic multiobjective optimization. Inf Sci. https://doi.org/10.1016/j.ins.2022.05.050
Rosales-Pérez A, García S, Gonzalez JA, Coello CAC, Herrera F (2017) An evolutionary multiobjective model and instance selection for support vector machines with pareto-based ensembles. IEEE Trans Evolut Comput 21(6):863–877. https://doi.org/10.1109/TEVC.2017.2688863
Guo Y, Zhang Z, Tang F (2021) Feature selection with kernelized multi-class support vector machine. Pattern Recognit 117:107988. https://doi.org/10.1016/j.patcog.2021.107988
Escalante HJ, Marin-Castro M, Morales-Reyes A, Graff M, Rosales-Pérez A, Montes-y-Gómez M, Gonzalez JA et al (2017) MOPG: a multi-objective evolutionary algorithm for prototype generation. Pattern Anal Appl 20(1):33–47. https://doi.org/10.1007/s10044-015-0454-6
Kordos M, Łapa K (2018) Multi-objective evolutionary instance selection for regression tasks. Entropy 20(10):746. https://doi.org/10.3390/e20100746
Korycki L, Krawczyk B (2019) Unsupervised drift detector ensembles for data stream mining. In: 2019 IEEE international conference on data science and advanced analytics (DSAA), pp 317–325. https://doi.org/10.1109/DSAA.2019.00047
Xu H, Deng Y (2017) Dependent evidence combination based on Shearman coefficient and Pearson coefficient. IEEE Access 6:11634–11640. https://doi.org/10.1109/ACCESS.2017.2783320
Zhou X, Liu Y, Li B, Sun G (2015) Multiobjective biogeography based optimization algorithm with decomposition for community detection in dynamic networks. Phys A 436:430–442. https://doi.org/10.1016/j.physa.2015.05.069
Ren S, Liao B, Zhu W, Li Z, Liu W, Li K (2018) The gradual resampling ensemble for mining imbalanced data streams with concept drift. Neurocomputing 286:150–166. https://doi.org/10.1016/j.neucom.2018.01.063
Lu Y, Cheung YM, Tang YY (2017) Dynamic weighted majority for incremental learning of imbalanced data streams with concept drift. In: IJCAI, pp 2393–2399
Liu A, Lu J, Zhang G (2020) Diverse instance-weighting ensemble based on region drift disagreement for concept drift adaptation. IEEE Trans Neural Netw Learn Syst 32(1):293–307
Bifet A, Holmes G, Kirkby R, Pfahringer B (2010) Moa: massive online analysis. J Mach Learn Res 11:1601–1604
Kolter JZ, Maloof MA (2007) Dynamic weighted majority: an ensemble method for drifting concepts. J Mach Learn Res 8:2755–2790
Liu A, Lu J, Zhang G (2020) Diverse instance-weighting ensemble based on region drift disagreement for concept drift adaptation. IEEE Trans Neural Netw Learn Syst 32(1):293–307
Gama J, Žliobaitė I, Bifet A, Pechenizkiy M, Bouchachia A (2014) A survey on concept drift adaptation. ACM Comput Surv (CSUR) 46(4):1–37. https://doi.org/10.1145/2523813
Brzezinski D, Stefanowski J (2014) Combining block-based and online methods in learning ensembles from concept drifting data streams. Inf Sci 265:50–67. https://doi.org/10.1016/j.ins.2013.12.011
Gomes HM, Bifet A, Read J, Barddal JP, Enembreck F, Pfharinger B, Abdessalem T (2017) Adaptive random forests for evolving data stream classification. Mach Learn 106(9):1469–1495. https://doi.org/10.1007/s10994-017-5642-8
Santos SGTDC, Gonçalves Júnior PM, Silva GDDS, Barros RSMD (2014) Speeding up recovery from concept drifts. In: Joint European conference on machine learning and knowledge discovery in databases, pp 179–194. https://doi.org/10.1007/978-3-662-44845-8_12
Kayvanfar V, Zandieh M, Arashpour M (2022) Hybrid bi-objective economic lot scheduling problem with feasible production plan equipped with an efficient adjunct search technique. Int J Syst Sci Oper Logist 1–24
Wheeb AH (2017) Performance analysis of VoIP in wireless networks. Int J Comput Netw Wirel Commun (IJCNWC) 7(4):1–5
Acknowledgements
This work was supported by National Natural Science Foundation of China under Grant 61973305, the Key Science and Technology Innovation Project of CCTEG under Grant No. 2021-TD-ZD002, National Key R &D Program of China under Grant SQ2022YFB4700381, the Foundation of Key Laboratory of System Control and Information Processing, Ministry of Education, P.R. China under Grant Scip202203.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No conflict of interest exits in the submission of this manuscript, and manuscript is approved by all the authors for publication. I would like to declare on behalf of my co-authors that the work described was original research that has not been published previously, and not under consideration for publication elsewhere, in whole or in part. All the authors listed have approved the manuscript that is enclosed. In this work, with the purpose of classifying data stream under scarcity of labels, an active broad learning with multi-objective evolution is proposed. The context of the paper is organized as follows, the main research contents and contributions of this paper are briefly described in “Introduction”. Some studies related to the proposed algorithm are briefly discussed in “Preliminaries. “Proposed active broad learning with multi-objective evolution algorithm” introduces the framework and key issues of MOE-ABLS.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cheng, J., Zheng, Z., Guo, Y. et al. Active broad learning with multi-objective evolution for data stream classification. Complex Intell. Syst. 10, 899–916 (2024). https://doi.org/10.1007/s40747-023-01154-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01154-9