
Abstract
Weakly supervised semantic segmentation (WSSS) is a challenging task of computer vision. The state-of-the-art semantic segmentation methods are usually based on the convolutional neural network (CNN), which mainly have the drawbacks of inability to explore the global information correctly and failure to activate potential object regions. To avoid such drawbacks, the transformer approach is explored in the WSSS task, but no effective semantic association between different patch tokens can be determined in the transformer. To address this issue, inspired by the graph convolutional network (GCN), this paper proposes a graph structure to learn the semantic category relationships between different blocks in the vector sequence. To verify the effectiveness of the proposed method in this paper, a large number of experiments were conducted on the publicly available PASCAL VOC2012 dataset. The experimental results show that our proposed method achieves significant performance improvement in the WSSS task and outperforms other state-of-the-art transformer-based methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In recent years, the breakthroughs achieved in the field of computer vision have led to the rapid development of related applications, such as driverless automobile, drones, and virtual reality. Taking driverless automobile[1] for example, the conventional iterative learning control methods[2] can solve some driving control problems, but the neural networks are usually used to solve some nonlinear system events in driving currently[3]. Semantic segmentation is a key technical breakthrough in computer vision, which plays a critical role in the development of computer vision. As the traditional fully supervised semantic segmentation (FSSS) is costly for the pixel-level labeling, many researchers switched to the weakly supervised approaches. The image-level labeling is an inexpensive and low-cost weak labeling method, which is also one of the most popular weakly supervised methods.
Most of the previous WSSS methods rely on the class activation map (CAM) as the initialization seed. Although these methods have made sophisticated extensions to the CAM strategy, the labeling of local objects in CAM cannot demonstrate the completeness of the category. To solve this problem, some studies have tried to find the semantic correlation between images. In [4], they attempted to construct a semantic correlation module between images, and their method cannot only obtain the semantic information of a single image, but also the similarities and differences between different images for complementary supervision. In [5], on the other hand, efforts were made to explore a new approach based on the multi-head attention mechanism, and this approach is called cooperative information, which is used to aggregate the contextual relations within the image. When mining the information, the biggest drawback of these methods is that they are limited to the information of a single image, while ignoring the semantic correlation between different images. To address this problem, in [6], the GCN is introduced to construct the node relationship between different images, and the semantic relationships between different image groups are mined.
Although the above methods can well improve the performances of WSSS, the CNN structure still has certain limitations, because the classification model is often used to classify the loss-activated object regions, which makes it difficult to pinpoint the seed. However, very few researches tried to address this inherent semantic defect between images. Therefore, how to capture the semantic correlation between different spatial location features is crucial for WSSS. To this end, the transformer model designed in the Vision Transformer (ViT) [7] has been recently used in the field of computer vision, and great breakthroughs in performances have been achieved. For example, in the TS-CAM [8] work, the information of image semantic segmentation is explicitly shown in the ViT features, and the self-attention mechanism of transformer can be employed to construct the relationships between global features, so as to overcome the limitations of the CNN structure. However, with the ViT model, the image is split into different blocks, which are then converted into vector sequences. Although many current researches have demonstrated that different vector sequences can focus on the semantic features in different regions of the image, there is still no study investigating the relationships between semantic categories and different blocks.
To address the above problem, in this paper, the graph structure is constructed to learn the semantic category relations between different blocks of the vector sequences, and the CAM initialized seed is generate using the transformer, which can avoid the defects of the CNN structure. To this end, this paper proposes the learning graph structure with transformer for discovering the object of interest via WSSS. Specifically, as shown in Fig. 1, for the input image nodes, a set of semantically related image groups are constructed, and the attention mechanism of transformer is used to establish the feature relationships. Using an iterative training approach, different categories of semantic information can be effectively propagated in the graph structure. With this design, not only the defect of spatial location features in the CNN structure can be solved, but also the relationship between blocks and semantic categories can be further refined.

Semantic category relationship of graph
Our main contributions can be summarized as follows.
-
(1)
We propose the learning graph structure with transformer framework (LGST) for the WSSS with image-level labels. Moreover, to the best of our knowledge, our approach is the first method that combines the graph structure and transformer for the WSSS tasks.
-
(2)
To address the disadvantage of transformer in learning of the local fine-level features, a graph structure is constructed, and the relationship between the semantic categories and different blocks of Transformer is redefined, which further enhances the local semantic feature information of the network.
-
(3)
Experiment was carried out to evaluate the performance of LGST on the PASCAL VOC 2012 dataset with image-level annotations, and the results show that our method can offer substantial improvement over the existing transformer methods. For example, compared with the state-of-the-art method TransCAM [9], the performance of our method is improved by 1.6% on the validation set and 1.5% on the test set.
Related work
CAM-based learning method
CAM is a method used in CNN to identify different classes of image regions for segmentation, and with this method, the feature map of the last convolutional layer is multiplied with the object-specific weights of the classification layer. In the WSSS approach, the classification network is trained for feature extraction, and the global average pooling (GAP) layer and linear classification layer are available to generate the pseudo labels. The mainstream approaches use CAM for heuristic-driven exploration of objects, such as SEAM [10]. However, this localization approach has a main drawback that the semantic information is sparse, which cannot provide enough supervised information for the segmentation networks.
Recently, some researchers have used subcategories and cross-image semantics to locate more precise object regions, such as EDAM [5], but this process is quite complicated. Besides, the dilation convolution has been introduced to address the limited perceptual field of view of CNN, and this approach encourages CAM to propagate around and expand the area of CAM. For example, the AffinityNet [11] learns the correlation between the neighboring pixels according to the reliable seed generated by the original CAM. The learned affinity can be used to predict a correlation matrix that propagates the CAM mapping by random traversal. Similarly, SEC [12] also uses the confidence pixels in the segmentation results to learn the near-neighbor affinity relationships. In IRNet [13], affinity is learned directly from the feature maps of the classification network to refine the CAMs. In addition, AuxSegNet [14] proposes a cross-task affinity that is learned from the saliency and segmentation representations in a weakly supervised multi-task framework.
Graph convolutional networks for WSSS
Graph convolution is a relatively special neural network structure with translation invariance and parameter sharing, which is particularly effective in feature extraction of image sequences based on the Euclidean space. The graph structure can be employed to perform convolutional operations on irregular information of numerous semantic nodes and perform feature propagation, which is an advantage that the CNN structure does not have. In a study published in 2017 [15], the proposed graph structure can provide better performance, which is also robust to different label perturbations. In [16], it is shown that GCN provides an effective solution for solving the semantic segmentation problem of weakly supervised images. Some recent works [6, 17] address the under-labeling problem in WSSS by mining the comprehensive semantic information from graphs through structured modeling and iterative inference. Besides, [18] uses imprecise annotation markers to convert weakly supervised learning to semi-supervised learning, so as to improve the segmentation performance of model, which is also an effective method. Meanwhile, by improving the attention mechanism, the affinity attention [19] based on GCN also proves that the graph structure has important research significance.
Vision transformer attention map generation
The application of transformer can be traced back to the researches on natural language processing, and the most central part of its structure is the multi-head self-attention module. The transformer relies on this module for global modeling, so as to improve the perceptual field of view and enhance performances. The applications of the ViT model in computer vision demonstrate that the transformer could improve the model performances in the vision tasks. For this reason, some researches tried to improve the performances of their methods in the vision tasks using the transformer. Among them, the TransUnet [20] and SETR [21] make the most audacious attempts to perform the segmentation tasks using the transformer, but these approaches still essentially combine CNN with the traditional underlying framework of the transformer. The Swin transformer [22], on the other hand, truly uses the transformer as the encoder of the backbone structure. Recently, some new transformer-based methods have been proposed for segmentation, such as Segmenter [23], and these researches took the first step to understand the image from a global perspective in the coding stage. However, it is worth considering the high performance requirements for hardware in order to obtain the complete global information and whether too many global semantic features are required for segmentation.
Methodology
Preliminaries
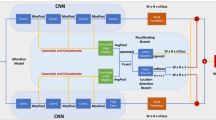
The LGST framework encoder is designed for progressive fusion of local feature learning of the global semantic features of the transformer based on the graph structure, as shown on the bottom right of Fig. 2. Specifically, LGST contains a transformer backbone network, followed by a structural graph layer of the CNN of graph structure. Note that the structure learning of the graph structure only provides the effective features, and the CNN does not have any other effect on the transformer.

The framework of the proposed LGST for WSSS
System architecture
As shown in Fig. 2, our semantic encoder mainly uses the transformer as the backbone. For the input image, a variant of transformer's self-attention module—the data-efficient image transformer (DeiT) [24] is utilized for telematics preservation. For the input image \(I = \left\{ {\left( {I_{i} ,c} \right),I_{i} \in {\mathbb{R}}^{D \times W \times H} } \right\}\), where \(D\) represents the transformer embedding dimensions, the picture resolution \(W \times H\) is divide into \(N^{2}\) patches, and \(c\) is the label class token category for classification, \(c \in \left\{ {0,1, \ldots ,K - 1} \right\}\). Then, each token path is flattened and linearized. These token patches are fed into the transformer encoder blocks \(T_{{{\text{att}}}}\), and the encoder includes a graph multi-head self-attention layer to produce the feature attention maps \(G_{{{\text{cam}}}}\). At last, a multilayer perceptron (MLP) block \(mlp\left( \cdot \right)\) is used to obtain the classification probability, which can be defined as follows:
Graph structure attention learning design
The proposed graph structure attention learning module can effectively address the loss of local feature details in the transformer network. In the construction process, to fully utilize the structural feature dependency of class tokens in the transformer blocks, the graph structure is employed to focus on the local class relevance, as described in Fig. 3.

Graph structure method
In the above inference scheme, the graph structure attention can be used to better discover the common semantic information present in different images. For the semantic image nodes, the semantic nodes that contain correlation δ can be constructed:
In Eq. (2), \({\text{ran}}_{idx} \left( \cdot \right)\) constructs the semantic nodes, which is a construction method that randomly retrieves the category information of different nodes. At this point, the graph node features satisfy the following conditions:
The main purpose of the convolution operation on node features is to expand the field of view and enhance the representation of semantic information. After the node information is flattened, \(f_{n}^{\prime }\) is the node that is centered, and the transpose operation is performed on the semantic related nodes \(f^{\prime}_{k}\) as follows:
In Eq. (4), the \({\text{gan}}( \cdot )\) function aims to enhance the class semantic information, but in order to compensate for the diluted feature information of \(f_{n}\), as shown in Eq. (5), more information should be added.
The process of enhancing the feature information is more likely to result in the fusion of non-critical categories of information, and in order to filter out the non-essential information, a special convolution function \({\text{Conv}}\left( \cdot \right)\) is performed here:
In this way, according to the above equation, the feature cross-fertilization can be performed in the same information enhanced \(f^{\prime\prime}_{n}\), thus obtaining a richer semantic:
Here, \({\text{Global}}(f_{n} )\) undergoes different semantic associations at different training stages of feature changes due to the randomness of \({\text{ran}}_{idx} \left( \cdot \right)\), as shown in Eq. (2), and the dominant factor is δ.
Complementarity to refine CAM
The attention weights change continuously with the training iterations of \({\text{Global}}(f_{n} )\), which indirectly reflects the semantic information. CAM can be further refined based on the fusion of weight information collected in different iterations.
\(\Gamma\) is the weight at different epoch iterations, and \(W^{ * }\) contains all the weight information.
\(f_{{{\text{cam}}\_{\text{refine}}}}\) is the refined CAM; \({\text{Mean}}(W^{ * } ;H \times W)\) is the balance scale of semantic weights that can reshape \(f_{n}\) and further expand the semantic information generation region.
Training to generate the pseudo labels
A more complete object region is obtained for the activation maps generated by the transformer network. The GAP layer is added at the end of the transformer to predict the class. During the design of the loss function, the multi-label soft margin loss is used for calculation in the training phase. The probability of an arbitrary location for a class can be expressed as:
\(\iota \left( \cdot \right)\) is a sigmoid function, so the semantic segmentation class loss function is calculated as follows:
It should be noted that during the experiments, the final loss function is found to be best achieved by \({\mathcal{L}}_{g}\) and \({\mathcal{L}}_{t}\), where \({\mathcal{L}}_{g}\) is based on the graph structure attention learning module, and \({\mathcal{L}}_{t}\) is the loss calculated using the transformer network.
Algorithm 1 describes the core pseudo code for all the above ideas. For a demonstration of the pseudo mask performance, see Sect. "Comparison with the state-of-the-art approaches".

Experiment
Experimental dataset and metrics
The experiment was carried out on dataset PASCAL VOC 2012, which contains 20 object classes and 1 background class. The images in PASCAL VOC 2012 were divided into three subsets: the training set, the validation set and the test set, which contain 1464, 1449 and 1456 images, respectively. Evaluation was conducted on these subsets using our WSSS method. In addition, a semantic boundaries dataset (SBD) with 10,582 images was used for augmentation training, with the special note that only the image-level annotations were used for these images, and the SBD was used to augment the Pascal VOC 2012 dataset.
Implementation details
In the LGST framework structure, the transformer is used as the backbone, while the residual learning [25] pre-trained model is utilized to obtain the convolutional map feature information. To enhance the generalization capability of the model, the initialized size of the training images was randomly cropped and set to the specified size of 336 × 336. The SGD optimizer was used for iterative updating of the model parameters during the model training phase. Other specific classification parameters include: the initial learning rate was set to 1 × 10–3, and the weight decay was 2 × 10. Finally, for the generated pseudo labels, the DeepLab-ASPP-S [26] model was used as the semantic segmentation model. In the segmentation model, all hyper parameters remained unchanged, except the batch size was adjusted to 32, and the output stride was set to 16; the learning rate was 0.06.
For the deployment of the hardware and software platform, LGST was implemented using the Pytorch 1.17 framework and built on the Ubuntu 20.04 operating system. All experimental procedures were set up on the hardware with the following configuration for model training: Intel Core (TM) i9-12900KF, RAM 64 GB, and single NVIDIA GPU RTX 3090 graphics card.
Metrics of performance evaluation
One of the most critical semantic segmentation evaluation metrics is the Intersection over Union (IoU), which is the intersection region between the segmentation results of a particular class and the ground truth. When there are multiple semantic segmentation results of different classes, it is necessary to perform summation averaging operation on the results of different classes, such as the VOC2012 dataset in this paper, and the mean Intersection over Union (mIoU) is often used to evaluate the segmentation performance. It is defined as follows:
In the above equation, for the VOC 2012 dataset, the relationship between the classes is \(c \in \left[ {0 \sim 20} \right]\), and \(P\) represents the probabilities of true and false positives of the pixel points.
Comparison with the state-of-the-art approaches
Previous research [27] demonstrated that the CAM is the most effective means to address weakly supervised image-level labeling, as shown in Table 1. In our experiment, we further verified the performance of our method in generating the initialized CAM regions for pseudo label training. According to the results in Table 1, although our method does not show the optimal performance in the process of generating initialized CAM, for example, there is still a difference of 0.5% compared with the SEAM method, but the graph structure shows certain advantages in the training phase, and the final pseudo mask generated shows an improvement of by 7.4% compared with that generated by the SEAM method.
Figure 4 shows the pseudo mask generation results of our method and other GCN methods (DGCN [18], A2GNN [19], and WSGCN [16]). According to these results, we can see that our method has been a 2.8% performance improvement over the current optimal GCN-based method WSGCN in generating pseudo masks.

Comparison between Ours and others GCN (DGCN, A2GNN, WSGCN) on Pascal VOC 2012 training set
Moreover, to compare the segmentation performances of different classes, our method is compared with other state-of-the-art methods for WSSS developed in the past five years with more detailed data, which may benefit further study on the applications of the transformer model. The final results of the experiment are shown in Table 2.
In addition, the segmentation performances of the traditional CNN, GCN and Transformer methods developed in recent years are also compared in Table 3, so as to demonstrate the research significance of our method.
Ablation study
Graph node effect
For the patch tokens, we try to analyze the impact of different number of graph nodes on the semantic segmentation performance. Table 4 shows the segmentation performance of our method under different number of graph nodes. Different nodes are associated with different semantic information, the performances of our method were evaluated when the graph node number δ = 2, 3 or 4, and the segmentation performance was the most optimal when δ = 3.
Model complexity
In general, the model overhead of transformer is much higher than that of traditional CNN, and we use Deit-S to solve such problem in our study. As shown in Table 5, our model is compared with the three most popular semantic segmentation models—EDAM, TS-CAM and TransCam. From the perspective of model overhead, our method achieves good results.
Qualitative results
Table 6 shows the performance changes of the transformer model with the graph structure. In addition, the loss function can further improve the performance of the model. Finally, these measures can improve the performance of the proposed method.
Figure 5 shows the performance of our model under different conditions of multi-label and single-label classification and segmentation. It can be seen that the performance of our method in single-label classification and segmentation can generally meet the application requirements, but its performance in the multi-label classification is less satisfactory, which is where the present method needs to be improved.

Presentation of the qualitative change of the images obtained with our method, and visualization of the generated pseudo masks
Conclusions
This paper proposes a graph-structured LGST for WSSS, which is based on the transformer learning framework. Unlike any other previous transformer-based structures, our framework is able to capture more relevant semantic information and generate more accurate pseudo labels. In particular, the impressive performance achieved by LGST on the PASCAL VOC 2012 dataset further demonstrates the effectiveness of the graph structure in improving the performance of the transformer network. In the future work, we will solve the problem of image instance segmentation based on weakly supervised learning on the basis of this research.
Data availability
All data included in this study are available upon request by contact with the corresponding author.
References
Shen L, Tao H, Ni Y, Wang Y, Vladimir S (2023) Improved YOLOv3 model with feature map cropping for multi-scale road object detection. Measur Sci Technol. https://doi.org/10.1088/1361-6501/acb075
Zhuang Z, Tao H, Chen Y, Stojanovic V, Paszke W (2022) Iterative learning control for repetitive tasks with randomly varying trial lengths using successive projection. Int J Adapt Control Signal Process 36:1196–1215
Song X, Sun P, Song S, Stojanovic V (2022) Event-driven NN adaptive fixed-time control for nonlinear systems with guaranteed performance. J Franklin Inst 359:4138–4159
Sun G, Wang W, Dai J, Van Gool L (2020) Mining cross-image semantics for weakly supervised semantic segmentation. In: European conference on computer vision. Springer, p. 347–65
Wu T, Huang J, Gao G, Wei X, Wei X, Luo X, et al (2021) Embedded discriminative attention mechanism for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p. 16765–74
Zhou T, Li L, Li X, Feng C-M, Li J, Shao L (2021) Group-wise learning for weakly supervised semantic segmentation. IEEE Trans Image Process 31:799–811
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al (2020) An image is worth 16 ×16 words: transformers for image recognition at scale. arXiv preprint arXiv:201011929
Gao W, Wan F, Pan X, Peng Z, Tian Q, Han Z, et al (2021) Ts-cam: Token semantic coupled attention map for weakly supervised object localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, p. 2886–95
Li R, Mai Z, Trabelsi C, Zhang Z, Jang J, Sanner S (2022) TransCAM: transformer Attention-based CAM refinement for weakly supervised semantic segmentation. arXiv preprint arXiv:220307239
Wang Y, Zhang J, Kan M, Shan S, Chen X (2020) Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p. 12275–84.
Ahn J, Kwak S (2018) Ieee. Learning pixel-level semantic affinity with image-level supervision forweakly supervised semantic segmentation. In: 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR): Salt Lake City, UT, p. 4981–90
Kolesnikov A, Lampert CH (2016) Seed, expand and constrain: three principles for weakly-supervised image segmentation. In: European conference on computer vision. Springer, p. 695–711
Ahn J, Cho S, Kwak S (2019) Weakly supervised learning of instance segmentation with inter-pixel relations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, p. 2209–18
Xu L, Ouyang W, Bennamoun M, Boussaid F, Sohel F, Xu D (2021) Leveraging auxiliary tasks with affinity learning for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, p. 6984–93.
Veličković P, Cucurull G, Casanova A, Romero A, Lio P, Bengio Y (2017) Graph attention networks. arXiv preprint arXiv:171010903
Pan S-Y, Lu C-Y, Lee S-P, Peng W-H (2021) Weakly-supervised image semantic segmentation using graph convolutional networks. In: 2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, p. 1–6
Li X, Zhou T, Li J, Zhou Y, Zhang Z (2021) Group-wise semantic mining for weakly supervised semantic segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence, p. 1984–92
Feng J, Wang X, Liu W (2021) Deep graph cut network for weakly-supervised semantic segmentation. Sci China Inf Sci 64:1–12
Zhang B, Xiao J, Jiao J, Wei Y, Zhao Y (2021) Affinity attention graph neural network for weakly supervised semantic segmentation. IEEE Trans Pattern Anal Mach Intell 44:8082–8096
Chen J, Lu Y, Yu Q, Luo X, Adeli E, Wang Y, et al (2021) Transunet: transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:210204306
Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, et al (2021) Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, p. 6881–90
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, p. 10012–22
Strudel R, Garcia R, Laptev I, Schmid C (2021) Segmenter: transformer for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, p. 7262–72
Touvron H, Cord M, Douze M, Massa F, Sablayrolles A, Jégou H (2021) Training data-efficient image transformers and distillation through attention. In: International Conference on Machine Learning. PMLR, p. 10347–57
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, p. 770–8
Chen L-C, Zhu Y, Papandreou G, Schroff F, Adam H (2018) Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European conference on computer vision (ECCV), p. 801–18
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2016) Learning deep features for discriminative localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, p. 2921–9
Zhang D, Zhang H, Tang J, Hua X-S, Sun QJAiNIPS (2020) Causal intervention for weakly-supervised semantic segmentation 33:655–66.
Chang Y-T, Wang Q, Hung W-C, Piramuthu R, Tsai Y-H, Yang M-H (2020) Weakly-supervised semantic segmentation via sub-category exploration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p. 8991–9000
Qin J, Wu J, Xiao X, Li L, Wang XJAPA (2021) Activation modulation and recalibration scheme for weakly supervised semantic segmentation
Wei Y, Liang X, Chen Y, Shen X, Cheng M-M, Feng J et al (2016) Stc: a simple to complex framework for weakly-supervised semantic segmentation. IEEE Trans Pattern Anal Mach Intell 39:2314–2320
Zeng Y, Zhuge Y, Lu H, Zhang L (2019) Joint learning of saliency detection and weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, p. 7223–33
Lee J, Kim E, Lee S, Lee J, Yoon S (2019) Ficklenet: weakly and semi-supervised semantic image segmentation using stochastic inference. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p. 5267–76
Zhou L, Gong C, Liu Z, Fu K (2020) SAL: selection and attention losses for weakly supervised semantic segmentation. IEEE Trans Multimed 23:1035–1048
Wan W, Chen J, Yang M-H, Ma H (2022) Co-attention dictionary network for weakly-supervised semantic segmentation. Neurocomputing 486:272–285
Zhang B, Xiao J, Wei Y, Huang K, Luo S, Zhao Y (2022) End-to-end weakly supervised semantic segmentation with reliable region mining. Pattern Recogn 128:108663
Yi S, Ma H, Wang X, Hu T, Li X, Wang Y (2022) Weakly-supervised semantic segmentation with superpixel guided local and global consistency. Pattern Recogn 124:108504
Araslanov N, Roth S (2020) Single-stage semantic segmentation from image labels. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p. 4253–62
Ru L, Du B, Zhan Y, Wu C (2022) Weakly-supervised semantic segmentation with visual words learning and hybrid pooling. Int J Comput Vis 130:1127–1144
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, W., Feng, X., Ma, H. et al. Learning graph structures with transformer for weakly supervised semantic segmentation. Complex Intell. Syst. 9, 7511–7521 (2023). https://doi.org/10.1007/s40747-023-01152-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01152-x