
Abstract
Existing research shows that cooperative multi-agent deep reinforcement learning (c-MADRL) is vulnerable to adversarial attacks, and c-MADRL is increasingly being applied to safety-critical domains. However, the robustness of c-MADRL against adversarial attacks has not been fully studied. In the setting of c-MADRL, unlike the single-agent scenario, an adversary can attack multiple agents or all agents at each time step, but the attacker needs more computation to generate adversarial examples and will be more easily detected. Therefore, how the attacker chooses one or several agents instead of all agents to attack is a significant issue in the setting of c-MADRL. Aiming to address this issue, this paper proposes a novel adversarial attack approach, which dynamically groups the agents according to relevant features and selects a group to attack based on the group’s contribution to the overall reward, thus effectively reducing the cost and number of attacks, as well as improving attack efficiency and decreasing the chance of attackers being detected. Moreover, we exploit the transferability of adversarial examples to greatly reduce the computational cost of generating adversarial examples. Our method is tested in multi-agent particle environments (MPE) and in StarCraft II. Experimental results demonstrate that our proposed method can effectively degrade the performance of multi-agent deep reinforcement learning algorithms with fewer attacks and lower computational costs.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
With the rapid development of deep reinforcement learning(DRL) [1] , cooperative multi-agent deep reinforcement learning(c-MADRL) has also been increasingly applied in the real world, such as in the autopilot field [2, 3], robot control [4], and other fields. However, deep learning is vulnerable to adversarial perturbations. Adversarial attacks [5] occur when the adversary injects an imperceptible perturbation into the input of the neural network to mislead the agent to choose the wrong action. Therefore, DRL and c-MADRL are also vulnerable to adversarial attacks, because they both use deep learning technology.
The robustness of single-agent DRL against adversarial attacks has been abundantly explored [6,7,8,9,10,11]. However, there are relatively few studies focusing on the robustness of c-MADRL against adversarial attacks. In c-MADRL, agents need to work together to accomplish common tasks to obtain the maximum cumulative team reward, because they form a team and independently have only partial observation [12]. Therefore, it is complex to attack c-MADRL, because when one agent in the team has been attacked and behaves abnormally, the decisions of other agents will be affected. Moreover, the adversary can also attack inter-agent communication to undermine cooperation to decrease the team reward. Thus, the c-MADRL is more vulnerable to adversarial attacks, and the adversary can attack the multi-agent system by attacking only one or several agents. In recent years, multi-agent systems have been widely used in many safety-critical applications, so it is necessary to study adversarial attacks on c-MADRL, which can help people design c-MADRL with high robustness.
ln the multi-agent environment, due to the mutual influence among agents and the nonstationary environment, the attacker can choose some of the agents to attack, which reduces the expected team reward. This has the advantage of reducing the probability of being detected and the computational cost of generating adversarial examples. For example, in the push-box cooperative task, two agents are required to cooperate to push a box to a specified location [13]. In this situation, we only need to attack one agent to destroy the cooperation. Therefore, how to choose the victim agents is an important problem for adversarial attacks against c-MADRL. Some studies [14, 15] adopt the method of designating an agent as a victim to attack in the setting of c-MADRL. However, due to the complexity of the multi-agent environment and the different contributions of agents to the team reward, the losses caused by attacks against different agents are different. When constantly attacking the same agent, its partner will realize the abnormality of the agent and change its policy to adapt to the change, which will lead to the failure of the attack.
The main goal of the adversary is to achieve the best attack effect with the minimum attack cost. As mentioned above, selecting the best victims is an important method to achieve this goal. Intuitively, the best victims are influenced by a number of factors. For example, in StarCraft II [16], the contribution to team reward, the cooperation of the agents, the relative position, and the health value of the agents are the factors that need to be considered. In this paper, we propose an adversarial attack method based on dynamic group partitioning, which divides agents with similar features into a group according to c-MADRL characteristics, and then selects a group of agents to attack based on each group’s contribution to the overall reward. The grouping algorithm needs to consider multi-agent cooperation; for example, cooperation with multiple agents to achieve a common subobjective may require classification into different groups.
After grouping agents, we choose a group to attack according to their contributions to the team reward. Just as the contributions of agents change dynamically as the environment changes, the groups also need to change dynamically. Furthermore, to further improve the attack efficiency, inspired by the transferability of adversarial examples [17], we only obtain the model parameters of one agent in the same group to generate the adversarial example, because the observation information and attributes of the agents within the same group are similar, and then apply the adversarial example to all the agents in the group.
As mentioned above, the environment is dynamic, coupled with the impact of attacks, so by always attacking the same group, the attack effect will obviously worsen. By observing the results of grouping experiments, we find that the results of grouping do not change in a few consecutive steps of one episode, so it is not necessary to group every step. Therefore, we define a frequency to achieve grouping every N steps. Our experiments found that the frequency of grouping affects the performance of the attacker; therefore, we consider clustering frequency to achieve a good attack effect while reducing computation cost.
We experiment with the group-based adversarial attack method in multi-agent particle environment (MPE) [18] and StarCraft II [16] environments. Experimental results show that our algorithm can significantly reduce the mean episode reward and lower the win rate with less attack cost, indicating that the algorithm has high attack efficiency. We also conduct experiments on the transferability of adversarial examples, and the experimental results show that the method is effective.
The main contributions of our work are listed as follows:
-
We propose an adversarial attack algorithm (GMA-FGSM) based on dynamic grouping in c-MADRL, which calculates the group contribution by designing a mechanism to calculate the degree of contribution of agents to the overall reward, and merges domain-related features to select a specific group of agents to attack, avoiding indiscriminate attacks on all agents, effectively reducing the attack cost and the number of attacks, and improving the attack efficiency while decreasing the probability of adversaries being detected.
-
For the first time, we use the adversarial sample transferability to reduce the attack cost in the white-box attack of c-MADRL. This method only needs to use an agent model parameter in the attacked group to generate adversarial samples, which will be used for other agents in the attacked group, thus further reducing the attack cost and improving the attack efficiency.
-
We study the impact of the k value of cluster number and grouping frequency on our attack algorithm, and also quantitatively discuss the attack efficiency of our proposed algorithm. We conduct sufficient experiments on MPE and StarCraft II environments. The experimental results demonstrate the effectiveness of our proposed method.
Related work
Adversarial attacks are widely applied in deep learning for image classification, which generates an adversarial example by adding small perturbations to the input image, causing the model to give an error output. With the improvement of the theory, adversarial attack techniques have been extended to the fields of reinforcement learning, computer vision, natural language processing, etc.
Huang [19] first applied the FGSM attack method to reinforcement learning, and achieved great success. Since then, researchers have designed various adversarial attack methods to attack DRL. Lin [20] proposed a strategically timed attack method that attacks the victim only at some time steps to prevent detection by the agent, that is, to reduce the frequency of attacks while increasing the accuracy of successful attacks. Carlini [21] proposed a targeted attack method, where the added perturbation can lure the agent to a specific state or conduct a specific action. Sun [22] proposed a critical point attack based on the strategically timed attack, calculated the moment when the agent’s reward was minimized in advance, and then attacked at this moment. Pattanaik [23] demonstrated a gradient-based adversarial attack using a loss function different from that in the FGSM method and performed a multi-step gradient attack. Zhang [24] introduced two strong adversarial attack methods, the robust sarsa (RS) attack, and the maximal action difference (MAD) attack.
However, the above adversarial attack methods are for single-agent situations. The existing attack methods in the field of c-MADRL have remained largely unexplored. Lin [14] proposed a two-step attack method against c-MADRL, which first trains an adversarial policy network to find the worst action, with the adversary then exploiting the targeted adversarial examples to induce the agent to choose this action. Adam [25] designed adversarial strategies to produce adversarial natural observations, which can mislead victims to choose the wrong actions. Nisioti [26] considered a novel type of attack in which a team of adversaries chooses the worst-performing agents to attack and directly manipulate their actions. Then, they designed a temporal difference learning algorithm to find robust policies. Hu [27] proposed a sparse adversarial attack on c-MADRL systems. They made a stronger assumption: the attacker can directly modify the agent’s action. Li [28] introduced the minimax approach to improve the robustness of learned policies in multi-agent DRL. They update policies considering that other agents are adversaries. Guo [29] proposed adversarial attacks for c-MADRL algorithms from multiple aspects and tested the robustness of c-MADRL algorithms from multiple aspects, including state, action, and reward. Pham [30] increased the total team reward. The added perturbations encourage the victim agents’ state to be close to a desired failure state corresponding to a low reward. Nevertheless, in these papers, they predefined a victim or chose the worst-performing agent as the victim and did not consider the contribution of different agents to team rewards.
In a cooperative multi-agent system environment, information exchange and distributed work enable autonomous agents to perform tasks better and communicate efficiently. However, the exchange relies on a communication channel, and the channel is vulnerable to adversarial attacks. Tu [31] developed an adversarial attack method against multi-agent communication, where a malicious agent injects adversarial messages into the communication channels of a special multi-agent environment, in which agents exchange intermediate representations for communication. Xue [15] studied the robustness of multi-agent communication and first implemented a message attack against multi-agent communication reinforcement learning, where an adversary sends malicious messages to influence the communication.
Preliminary knowledge
Dec-POMDP
A fully cooperative multi-agent task can be described as a decentralized partially observable Markov decision process(Dec-POMDP) [32]. The process can be represented by a tuple \(<S,U,P,r,Z,O,n,\gamma>\). At each time step, the environment is in a certain state s, \(s\in S\), and each agent \(a\in A\equiv \left\{ 1,2,......n\right\} \) selects an action \(u^a\in U\), and then obtains a joint action \({\textbf{u} } \in U^n\). Then, the environment will change, which will cause the environment to shift from s to \(s^{\prime } \), and the transition probability is \(P=(s^{\prime } \mid s,{\textbf{u} } )\): \(S\times U\times S \rightarrow [0,1]\). All agents have the same reward function \(r(s,u):S\times U\rightarrow R\). The goal of agents is to maximize the common reward \(G^t=\sum _{i=0} ^{\propto } \gamma ^ir_{t+i} \). The discount factor \(\gamma \) determines how large the direct reward is compared to more distant rewards. When \(\gamma \)=0, the agent only cares about which action will produce the largest expected immediate reward; when \(\gamma \)=1, the agent cares about maximizing the expected sum of future rewards.

Group-based adversarial attacks in a multi-agent environment
Adversarial perturbation
The fast signed gradient method (FGSM) [5] is a popular adversarial attack method applied in image classification. It uses the gradient of the neural network to generate adversarial examples. Goodfellow [19] applied this method to reinforcement learning for the first time, obtaining the derivative of the model concerning the input to find the specific gradient direction through a sign function and then multiplying it by a step size to obtain a perturbation, which is added to the original input to generate an adversarial example. The formula for generating adversarial examples is
where x is the original example, y is the true label, \(\theta \) is the weight parameter, \(\epsilon \) is the size of the perturbation, and \(adv_x\) is the adversarial example. Then, we obtain the loss value of the neural network through the loss function J.
Group-based adversarial attacks
The attack model
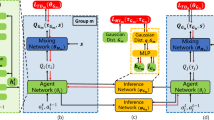
This paper considers white-box adversarial attack algorithms on c-MADRL by attacking the agent’s observations rather than changing the environment. We assume that the adversary knows the network model and parameters of each agent. According to this information, the adversary can divide all agents into groups and obtain the gradient information with respect to observations to generate adversary examples. The attack process is shown in Fig. 1. Suppose there are five agents in the environment; we set the number of clusters to 3. First, we use a clustering method to group the agents and then select one of the groups to be the victims, and the victim agents’ observations will be injected with the perturbations generated by gradient information.
The whole process is shown in Fig. 1. First, we divide agents into different groups using the k-means clustering method. Then, we calculate the average contribution of agents in each group and choose the victim group \(G_v\). After that, we use our attack method to generate adversarial perturbations \(\eta _1\), \(\eta _2\). Finally, we add this perturbation to victim agents’ observations; thus, we obtain the adversarial observation \(o_1+\eta _1\). We use a red line to indicate the process of adding perturbation. The right part is the interaction process between the environment and agent. Agent 1 obtains its observation \(o_1\) from the environment, performs an action \(a_1\), and obtains its reward \(r_1\). O, A, and R are the team’s overall observation value, actions, and rewards.
To facilitate description, we first define the following concepts:
Definition 1
(Agent Group) Let G be a set of agents with similar characteristics.
Select some observation information of the agent for similarity comparison. The agents with high similarity are divided into a group. We use the k-means clustering method to determine the grouping. In Algorithm 1, we use the grouping algorithm to describe the whole process of grouping specifically.
Definition 2
(Group Collection) Let W be the set of all groups in the current system.
Definition 3
(Group Contribution) Let \(C_{G_i} \) be the contribution of all agents in the group \(G_i\) to the team reward.
Definition 4
(Victim Group): Let \(G_v\) be the set of agents that minimize the team reward after being attacked.
In a cooperative environment, the agents share a team reward, but each agent contributes differently. If the victim agent does not contribute to the team reward, the attack is invalid. Therefore, we select the group that makes a greater contribution to the team reward.
Definition 5
(Grouping Frequency) Let \(G_f\) be the number of steps between two cluster groupings in each episode.
Definition 6
(Attack Effect) Let \(A_e\) be the attack effect, which is the difference between the normal mean reward and the mean reward under attack.
Definition 7
(Attack Cost) Let \(A_c\) be the attack cost to generate adversarial examples.
Definition 8
(Attack Efficiency) Let \(E_A\) be the ratio of attack effect \(A_e\) to the attack cost \(A_c\), which can be defined as
The number of steps we take for clustering is determined by the total number of steps in each episode. We determine different frequencies according to different environments, because the influence of clustering frequency on different environments is different. The goal of the group-based attack against observations can be expressed as Eq. (2)
where \(v(\textrm{obs})\) represents the perturbation of the local observations of the victim, and \(B(\textrm{obs})\) represents the set of desirable states that satisfy certain constraints after the attack.
Grouping methods
In a multi-agent environment, the agents only have local observations, and the agents need to cooperate to achieve a common goal. Therefore, we do not need to attack all agents. The more victims we choose, the more computation is required, which increases the probability of being detected. In this paper, we propose a group-based adversarial attack to reduce the number of attacks and improve the efficiency of attacks.
The agents can obtain much observation information from the environment. We choose important observation information that has a greater impact on the team reward and divide the agents into different groups. For example, in the MPE environment, the agent’s position and the distance from each landmark are important data, so we focus on the two parameters to group the agents. In the StarCraft II environment, there are too many factors to observe, and we choose several of the more influential factors: the location of the agent, the health value, the distance from the enemy, etc. The grouping process is shown in Algorithm 1.

A grouping algorithm based on K-means clustering
Adversarial examples on MADDPG
The multi-agent deep deterministic policy gradient (MADDPG) algorithm [33] originates from the deep deterministic policy gradient (DDPG) [34] algorithm, which is based on the actor-critic network structure. Based on the idea of the FGSM, we use \(Q^{tar} (\textrm{obs}_N,{\textbf{u} } )\) to replace the loss function \(J(\theta ,x,y)\). \(J(\theta ,x,y)\) is the cross-entropy loss between the true image label and predicted distribution over the labels of the image. The goal of the attacker is to minimize \(Q^{tar} (\textrm{obs}_N,{\textbf{u} } )\).
In FGSM, the \(L_\propto \) norm is used to limit the size of the disturbance [19], and the adversarial perturbation is expressed as Eq. (3)
where \(\textrm{obs}_N\) represents the observations of N agents, \({\textbf{u} } \) represents the joint actions of N agents, \(\epsilon \) is the step size, and \(Q^{tar} \) is the action-value function of the target network. Thus, the adversarial example can be expressed as Eq. (4 )
where \(\textrm{obs}_{vic} \) is the observation of victim agents and \(\eta _{vic} \) is the perturbation of victim agents. In the MADDGP algorithm, each agent can obtain its own reward. Therefore, when we use Algorithm 1 to group the agents, the group contribution \(C_G\) of the agent group G can be expressed as
Thus, we propose a group-based multi-agent fast gradient sign method(GMA-FGSM), where, first, the agents are grouped by Algorithm 1 to obtain the group collection W, and then, the group contribution \(C_G\) of all groups in W is calculated by Eq. (5 ). Then, the group with the largest group contribution value is selected as the attacked group \(G_v\). Finally, FGSM is used to attack the agents in the group. The pseudocode of the GMA-FGSM attack based on the MADDPG algorithm is shown in Algorithm 2.

GMA-FGSM Based on MADDPG
In the MPE environment, we use cooperative navigation and predator–prey scenarios. The group contribution is calculated as follows: we mark the agent closest to each landmark, the agent with the largest number of marks contributes more to the team reward, and finally, we calculate the average number of marks within the group after grouping to select the attacked group.
Adversarial examples on QMIX
The QMIX algorithm [35] is essentially a value function approximation algorithm in the framework of centralized training and decentralized execution (CTDE). Each agent has its value function network, and there is a mixed network that gives the centralized action-value function \(Q_\textrm{tot} \). The agent utilizes its own agent network to choose actions. In the QMIX algorithm, we define the loss function Eq. (6) as the cross-entropy loss between the output of the model and the action selected by the agent. It can be defined as
where \(\theta \) is the neural network parameter, \(\textrm{obs}_i\) is the observation of the agent i, \(u^i\) is the action of the agent i, and \(U^i\) is the set of actions of the agent i. Our attack goal is to maximize this loss function.
From “Adversarial perturbation”, the GMA-FGSM attack method is used in the QMIX algorithm to generate adversarial examples such as the following equation [Eq. (7)]
The QMIX algorithm assumes that the environment returns only the team reward. Therefore, we need to design a mechanism to estimate the contribution value of each agent to the team reward. The contribution c of the agent i can be expressed as [36]
where \({\textbf{u} } \) represents the current joint actions, \(u^i\) is the action of the agent i, \({\textbf{u} } ^{-i} \)represents the other agents’ actions, and \(\tau ^i\) is the action-observation history of agent i. The pseudocode of the GMA-FGSM attack algorithm based on QMIX is shown in Algorithm 3.

GMA-FGSM Based on QMIX
In the StarCraft environment, the group contribution is calculated as follows. We use the advantage function to calculate the agent’s contribution to the team reward by performing the current action. The greater the advantage of taking action, the higher the contribution to the team reward. We determine the contribution of the actions taken by the current agent to the overall Q value by fixing the actions of other agents and only changing the actions of the current agent. Calculate the contribution of N agents. According to the grouping results, we calculate the average contribution rate of each group and select the group with the largest contribution rate to become the victim group.

The scenarios used in our experiments. From left to right are cooperative navigation, predator–prey, 2s3z, and 5 m_vs_6m
Group-based transfer attack
In practical applications, the attacker rarely knows the model parameters of the victim to obtain the gradient. Therefore, in recent years, many black-box attack methods [17, 37] have been developed in single-agent scenarios, where the adversary usually employs a surrogate model, which is pretrained, to generate adversarial examples. Similar to the black-box attack method, due to the high similarity of the agents in one group, we use the adversarial example generated by one agent in the victim group to attack all agents with the same group, which can greatly reduce the computational workload and improve the attack efficiency.
The pseudocode of the group-based transfer attack algorithm on QMIX is shown in Algorithm 4.

Group-based transfer attack algorithm on QMIX
Experiments
We have fully experimentally validated our algorithms in an MPE [18] environment and the StarCraft II [16] environment. In the MPE environment, we select cooperative navigation and predator–prey tasks for our experiments, using the MADDPG algorithm. For the two tasks, we use a network of two hidden layers, each containing 64 neurons, to parameterize the policy and the Q-function. The total training episodes are set to 60,000 and the maximum number of execution steps per episode is 45. The discount factor \(\gamma \) is set to 0.97. In StarCraft II, we choose the 2s3z and 5 m_vs_6m maps for the experiments. We use the QMIX algorithm for training, with a total of 2,000,000 training steps. The discount factor \(\gamma \) is set to 0.99. In QMIX, each agent has its own value function network, which is presented as DRQN. The network consists of three layers: input layer (MLP), intermediate layer (GRU), and output layer (MLP). The hidden layer includes 64 neurons. The mixing network which be shared by all agents is a feed-forward neural network. It actually consists of two neural networks, one receiving state values and generating weights and bias. Another receives the Q values of all agents and the weights and bias parameters generated by the previous network, thereby inferring the global Q value. Figure 2 shows these scenes in our experiments.
Environments
Cooperative navigation : In this environment, there are \(N=5\) agents and \(L=5\) landmarks. The agent can observe the relative positions of other agents and landmarks, and its goal is to navigate to each landmark. The rewards for agents are the same. The closer to the landmark, the greater the reward, and there will be a penalty for collision between agents. Agents need to learn to cooperate to maximize the reward, so the best situation is that each agent covers a landmark and tries not to collide.

The grouping results of predator–prey and 2s3z

Results of GMA-FGSM attacks in cooperative navigation, predator–prey, 2s3z and 5 m_vs_6m
Predator–prey : In this environment, there are slower but larger predators and faster but smaller prey, and we make \(L=2\) landmarks to limit the activity of the agent. The goal of the \(N=4\) cooperative predators is to collide with the \(M=2\) prey. If a collision occurs, the predator is rewarded, and the prey is punished. The agent can observe the relative positions, velocities, and locations of landmarks and other agents.
2s3z : We choose a simple scene in the StarCraft environment, including two arms, which containing 2 Stalkers and 3 Zealots per team. The training process uses the QMIX algorithm. There are two teams: allies and opponents. The goal of the allies is to beat the opponent.
5 m_vs_6m : The 5 m_vs_6m map present the more difficult scene in the StarCraft environment, which consists of five Marines for the allies and six Marines for the enemy. We also use the QMIX algorithm to train our agents. The Allies’ goal is to defeat their opponents.
Group-based adversarial attacks
In this section, we evaluate the effectiveness of the group-based attack method in the cooperative navigation, predator–prey, 2s3z, and 5 m_vs_6m scenarios. The experiments were conducted for a total of 6000 episodes in the MPE environment and 2000 episodes in the StarCraft II environment.
In the two scenarios, we choose a group of agents to become victims in each episode through Algorithm 1. Figure 3 shows the results of clustering. Circles represent agents, and agents with the same color are a group. The five-pointed star represents the cluster center, and different colors represent different cluster centers. We use the mean episode reward before and after the attacks as the evaluation metric. The results of attacks are shown in Fig. 4, which are repeated ten times to plot the mean episode reward curve with standard deviation.
Figure 4 shows the experimental results of GMA-FGSM attacks in four scenarios, where the horizontal axis is the number of episodes, and the vertical axis is the mean episode reward. The curve labeled Normal represents the average episode reward without attacks. FGSM (attack-one) means that the adversary randomly selects one agent to attack. FGSM (attack-x) represents that the attacker randomly selects x agents to attack, where x is the mean number of victim agents per episode in the GMA-FGSM attack.
It can be seen that in the cooperative navigation and predator–prey scenarios, we randomly select an agent to attack, and the attack effect is poor. This is because adversarial attacks on one agent may have little impact on the whole team when there are many agents. Our GMA-FGSM attack algorithm achieves the best attack effect in three types of attacks. When selecting the same number of victim agents in each episode, GMA-FGSM achieves a better attack effect than FGSM (attack-x). Because each agent contributes to the team reward differently, agents randomly selected by us may not contribute to the rewards. That is, our group can select agents that have a great impact on the team reward. In the 2s3z and 5 m_vs_6m scenarios, all types of attacks have obvious effects, but our method has better performance than the others.

Transfer attacks in cooperative navigation tasks, predator–prey, 2s3z, and 5 m_vs_6m
All mean episode rewards are shown in Tables 1 and 2. The results show that the GMA-FGSM attack can achieve a better attack effect while reducing the attack frequency and the number of victim agents. For example, after some agents die in the StarCraft scenarios, they continue to be attacked, which has little effect on the team reward but increases the cost of attack. After grouping them, the surviving agents and the dead agents are separated. In this situation, only surviving agents need to be attacked. Because the states of the agents change dynamically, our grouping is also dynamic, so our methods can reduce the cost of attacks while preventing adversarial examples from being detected.
Transfer attacks in grouping
We investigate the transferability of adversarial examples in c-MADRL due to the similarity of agents within a group. After completing the grouping, the similarity of the agents in the same group is high. We only exploit the model parameters of one victim agent and generate the adversarial examples according to the model. Due to the similarity of the agents in the same group, we add these adversarial examples to the observations of other agents in this group. We take the GMA-FGSM attack as an example and conduct our experiments in four scenarios to determine the efficacy of the transfer attacks.
From Fig. 5, we can see that the transfer attack method is effective. The efficiency of the transfer attack is close to that of the GMA-FGSM attack.
Grouping frequency
The state of the agent is greatly affected by the initialization of the environment. When we perform clustering, we mainly group the agents according to some state information. However, in the successive steps of an episode, the state changes very little, and the grouping results are mostly the same. Thus, if we perform a grouping at each step, it will greatly increase the amount of computation. Therefore, we consider the effect of clustering frequency to reduce the amount of computation while also achieving good attack performance. Figure 6 illustrates the impact of clustering frequency on the attack effect using the GMA-FGSM attack method in four scenarios. We evaluate the effectiveness of the GMA-FGSM attacks on clustering every 1 step, 10 steps, and 20 steps. Among them, when the frequency \(G_f\) is set to 1, the result of the attack is best. When the \(G_f\) is increased to 10 and 20, the attack effect does not change much. Therefore, we can appropriately reduce the attack frequency to find a balance between the attack effect and clustering frequency.

The effect of grouping frequency on GMA-FGSM attacks
In different environments, the observations of agents are different, and the impact on clustering is also different. In the MPE environment, the scenario is relatively simple, and the group is affected by self-position and distance from landmarks. In the StarCraft environment, the environment is more complex, and the observations of agents are also diversified, such as their health values, distance ratio between agent and enemy, health value ratio between agent and enemy, etc. As the game goes on, the observations change considerably, so the clustering result changes quickly. For scenarios such as this, we need to increase the frequency of clustering. In general, the impact of clustering frequency on adversarial attacks cannot be ignored. The specific clustering frequency should be appropriately determined according to the specific environment.
Attack efficiency of GMA-FGSM
This section mainly studies the attack efficiency required by the attack method proposed in this paper. We assume that the cost of generating adversarial examples for different agents is the same, and then use attack cost to express the calculation amount of our attack method. In addition, we set up a control group which considers the case that attacking the observation of all agents using FGSM attacking methods. We abbreviate this method as FGSM (attack-all). Then, we use these two attack methods to experiment in four scenarios. The results are shown in Fig. 7.

The mean episode rewards of different attacks on four scenes
The legend Normal in Fig. 7 means that we test the model without attack, the legend GMA-FGSM shows the grouping attack method proposed in this paper, and the legend FGSM (attack-all) indicates that the FGSM attack method is used to attack all agents. From Fig. 7, we can see that our attack method GMA-FGSM and FGSM (attack-all) methods both can achieve good attack effects. We use the mean episode reward before and after the attack to express the attack effect.
Based on Fig. 7, we calculate the attack efficiency of two attacks, and the results are shown in Fig. 8. Attack efficiency is the ratio of attack effect to attack cost. The attack cost is the amount of computation required to generate the adversarial example. We assume that the attack cost of generating adversarial examples is the same for different agents, so the attack efficiency can be discussed by taking the attack cost against one agent as a unit attack cost. Therefore, the attack efficiency is the degree of damage to the overall reward per unit attack cost, that is, the average reward reduction value of the system by attacking an agent. The attack efficiency of the two attack methods is shown in Fig. 8 .

Attack efficiency of two attack methods
In Fig. 8, we show the attack efficiency of two attack methods in four experimental scenarios, and we can know that our method has high attack efficiency. Thus, GMA-FGSM can reach the same attack effect with a lower attack cost. This is because the contribution of agents to the overall reward is different. In some scenarios, the contribution of some agents is even 0. If these agents are attacked, the help to attack effect is limited. After grouping with the clustering algorithm, we select a group of agents with high group contribution to the attack, so the attack efficiency is improved
The effect of cluster number k
The selection of the k value affects the clustering result, so it may have a certain impact on the attack effect. If the value of k is too small, the loss will increase. If the value of k is too large, some clusters will be redundant and can be merged. Therefore, we observe the effect of different k values on our attack algorithm through experiments. We increase the number of agents in the environment to 10 and 15, and then test the effect of our attack method under different k values. We use the mean episode reward as the evaluation indicator. The result is shown in Table 3 .
In the predator–prey environment, it will get the best attack effect when \(k=2\) where there are ten agents in the environment. However, if the number of agents is set to 15, the GMA-FGSM method will achieve the best performance when \(k=3\). While in the cooperative navigation environment, when \(k=4\), the attack effect is the best in both \(N=10\) and \(N=15\) environments. The attack effect under different k values is not very different, and the impact of the k value on the GMA-FGSM attack algorithm is small, so the selection of the k value should be based on the specific environment and the number of agents.
Conclusions and discussion
In this paper, a group-based adversarial attack algorithm is proposed in c-MADRL, which uses the clustering algorithm to group the agents. We use the group contribution to select a group of agents to attack. Experiments show that the algorithm we proposed can effectively reduce the number of attacks and improve attack efficiency. In each episode, we choose victim agents dynamically. This can not only prevent malicious agents from being detected but also improve attack efficiency and reduce attack costs. Using the transferability of adversarial examples, we only need to know one agent’s parameters to generate the adversarial sample, which will be used to attack all agents in the same group. This method can effectively reduce the amount of computation required for attacks while decreasing the likelihood of attackers being detected. Experiments in an MPE environment and StarCraft environment also prove that our method is effective. This paper only considers multi-agent deep reinforcement learning in a cooperative environment. To learn better, agents also communicate with each other to achieve better learning results. In future research work, we will consider the robustness of multi-agent communication mechanisms. Compared with single-agent DRL, multi-agent deep reinforcement learning has an unstable environment, large action space, and more practical applications, so it is very necessary to improve the robustness of c-MADRL.
Data availability
Not applicable.
Code Availability
Not applicable.
References
Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, et al. (2015) Human-level control through deep reinforcement learning 518(7540):529–533
Sharif A, Marijan D (2021) Evaluating the robustness of deep reinforcement learning for autonomous and adversarial policies in a multi-agent urban driving environment
Shalev-Shwartz S, Shammah S, Shashua A (2016) Safe, multi-agent, reinforcement learning for autonomous driving
Gu S, Holly E, Lillicrap T, Levine S (2017) Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In: 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 3389–3396
Goodfellow IJ, Shlens J, Szegedy C (2014) Explaining and harnessing adversarial examples
Carlini N, Wagner D (2016) Defensive distillation is not robust to adversarial examples
Kos J, Song D (2017) Delving into adversarial attacks on deep policies
Lin Y-C, Liu M-Y, Sun M, Huang J-B (2017) Detecting adversarial attacks on neural network policies with visual foresight
Ma X, Liang Z, Xia L, Zhang J, Blanchet J, Liu M, Zhao Q, Zhou Z (2022) Distributionally robust offline reinforcement learning with linear function approximation
Bravo M, Mertikopoulos P (2017) On the robustness of learning in games with stochastically perturbed payoff observations 103:41–66
Ilahi I, Usama M, Qadir J, Janjua MU, Al-Fuqaha A, Hoang DT, Niyato D (2021) Challenges and countermeasures for adversarial attacks on deep reinforcement learning 3(2):90–109
Hernandez-Leal P, Kartal B, Taylor ME (2019) A survey and critique of multiagent deep reinforcement learning 33(6): 750–797
Christianos F, Papoudakis G, Rahman MA, Albrecht SV (2021) Scaling multi-agent reinforcement learning with selective parameter sharing. In: International Conference on Machine Learning, pp. 1989–1998
Lin J, Dzeparoska K, Zhang SQ, Leon-Garcia A, Papernot N (2020) On the robustness of cooperative multi-agent reinforcement learning. In: 2020 IEEE Security and Privacy Workshops (SPW), pp. 62–68
Xue W, Qiu W, An B, Rabinovich Z, Obraztsova S, Yeo CK (2021) Mis-spoke or mis-lead: achieving robustness in multi-agent communicative reinforcement learning
Vinyals O Ewalds T, Bartunov S, Georgiev P, Vezhnevets AS, Yeo M, Makhzani A, Küttler H, Agapiou J, Schrittwieser J, et al. (2017) Starcraft ii: a new challenge for reinforcement learning
Papernot N, McDaniel P, Goodfellow I (2016) Transferability in machine learning: from phenomena to black-box attacks using adversarial samples
Mordatch I, Abbeel P (2018) Emergence of grounded compositional language in multi-agent populations. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32
Huang S, Papernot N, Goodfellow I, Duan Y, Abbeel P (2017) Adversarial attacks on neural network policies
Lin Y-C, Hong Z-W, Liao Y-H, Shih M-L, Liu M-Y, Sun M (2017) Tactics of adversarial attack on deep reinforcement learning agents
Carlini N, Wagner D (2017) Towards evaluating the robustness of neural networks. In: 2017 Ieee Symposium on Security and Privacy (sp), pp. 39–57
Sun J, Zhang T, Xie X, Ma L, Zheng Y, Chen K, Liu Y (2020) Stealthy and efficient adversarial attacks against deep reinforcement learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 5883–5891
Pattanaik A, Tang Z, Liu S, Bommannan G, Chowdhary G (2017) Robust deep reinforcement learning with adversarial attacks
Zhang H, Chen H, Xiao C, Li B, Liu M, Boning D, Hsieh C-J (2020) Robust deep reinforcement learning against adversarial perturbations on state observations 33:21024–21037
Gleave A, Dennis M, Wild C, Kant N, Levine S, Russell S (2019) Adversarial policies: attacking deep reinforcement learning
Nisioti E, Bloembergen D, Kaisers M (2021) Robust multi-agent q-learning in cooperative games with adversaries
Hu Y, Zhang Z (2022) Sparse adversarial attack in multi-agent reinforcement learning
Li S, Wu Y, Cui X, Dong H, Fang F, Russell S (2019) Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 4213–4220
Guo J, Chen Y, Hao Y, Yin Z, Yu Y, Li S (2022) Towards comprehensive testing on the robustness of cooperative multi-agent reinforcement learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 115–122
Pham NH, Nguyen LM, Chen J, Lam HT, Das S, Weng T-W (2022) Evaluating robustness of cooperative MARL: a model-based approach
Tu J, Wang T, Wang J, Manivasagam S, Ren M, Urtasun R (2021) Adversarial attacks on multi-agent communication. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7768–7777
Oliehoek FA, Amato C (2016) A Concise Introduction to Decentralized POMDPs. Springer
Lowe R, Wu YI, Tamar A, Harb J, Pieter Abbeel O, Mordatch I (2017) Multi-agent actor-critic for mixed cooperative-competitive environments 30
Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, Silver D, Wierstra D (2015) Continuous control with deep reinforcement learning
Rashid T, Samvelyan M, Schroeder C, Farquhar G, Foerster J, Whiteson S (2018) Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning. In: International Conference on Machine Learning, pp. 4295–4304
Foerster J, Farquhar G, Afouras T, Nardelli N, Whiteson S (2018) Counterfactual multi-agent policy gradients. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32
Yang C-HH, Qi J, Chen P-Y, Ouyang Y, Hung I-TD, Lee C-H, Ma X (2020) Enhanced adversarial strategically-timed attacks against deep reinforcement learning. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3407–3411
Funding
This work was supported in part by the National Natural Science Foundation of China (Grant No. 62103375) and the Key project of Philosophy and Social Science of Zhejiang Province (Grant No. 22NDJC009Z).
Author information
Authors and Affiliations
Contributions
LZ: methodology, software, data curation, and writing—original draft. XZ: conceptualization, methodology, and writing—original draft, writing—review and editing, and supervision. Z-LH: project administration and funding acquisition.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zan, L., Zhu, X. & Hu, ZL. Adversarial attacks on cooperative multi-agent deep reinforcement learning: a dynamic group-based adversarial example transferability method. Complex Intell. Syst. 9, 7439–7450 (2023). https://doi.org/10.1007/s40747-023-01145-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01145-w