
Abstract
Blur detection is aimed to recognize the blurry pixels from a given image, which is increasingly valued in vision-centered applications. Albeit great improvement achieved by recent deep learning-based methods, the overweight model and rough boundary still pose challenges to blur detection. In this paper, we propose a Hierarchical Edge-guided Region-complemented Network (HER-Net) to tackle the above issues in quest of a favorable accuracy–complexity trade-off. First, we propose novel olive-shaped and pear-shaped inverted bottleneck structures based on large-kernel depth-wise convolutions to build a very concise architecture. Second, we provoke and exploit region-concerned and edge-concerned morphological priors to refine the boundary. To this end, we propose a reverse-region spatial attention to mine the complementary affinities between blurry and sharp regions so as to enrich the residual details around the boundary. In addition, we propose an edge spatial attention to guide the edge-concerned cues to emphasize the features related to the boundary. Both attentions are embedded into the model with hierarchical manners. Extensive experiments on three benchmark datasets demonstrate that the proposed method can achieve better detection performance using fewer parameters and lower floating-point operations compared to competitive methods. It proves the efficiency and effectiveness of our method in blur detection task.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Motivation
As to image-centered academic and industrial applications, blur is an undesired but ubiquitous phenomenon caused mainly by defocus and motion. Image blur inherently degrades perceptual quality and damages usable information. Due to this fact, detecting the blurry region from a given image, i.e., blur detection, is increasingly valued and studied in many computer vision tasks such as deblurring [1, 2], quality assessment [3, 4], saliency detection [5] and depth estimation [6, 7].
Along with the rapid development of image processing and artificial intelligence techniques through the past decade, many efforts have been devoted to blur detection. Traditionally, a slew of blur detection methods tend to characterize the image blur by handcrafting some specific features in domains such as gradient [8], frequency [9], intensity [10] and sequency [11]. These traditional methods are effective in simple scenes but far less effective in complex scenes, because those handcrafted features based on low-level knowledge are hard to capture high-level semantics or contexts required for understanding complex scenes. Recently, deep learning techniques typified by convolutional neural network (ConvNet) have been one of the most attractive methodologies and achieved remarkable effects in many computer vision fields [12] including blur detection. To date, quite a few ConvNet-based blur detection methods [13,14,15,16,17,18,19,20,21,22,23,24] have been successfully developed. They show generally better performance than traditional methods owing to their prominent capability of capturing high-level semantic features. Albeit great improvement achieved, however, these deep learning-based methods are still challenged by two following problems.
Overweight model
Existing ConvNet-based blur detection methods are concentrated on well-designed and deep-enough architecture, leading to increasingly complicated models. Although complicated ConvNets usually provide higher accuracy than simple ones, the amount of model parameters easily reaches dozens of millions [25] and even hundreds of millions [26]. However, in many real-world applications such as intelligent robot and self-driving vehicle, vision tasks have to be implemented on computation-limited devices [27]. Such an overweight model with lots of parameters and high floating-point operations (FLOPs) requires huge computational resources for training and deploying, which is extremely difficult to be satisfied in embedded, mobile and edge devices. Therefore, in view of the actual requirement, an expense-economical yet high-performance model is just what the real-world blur detection task really concerns.
Rough boundary
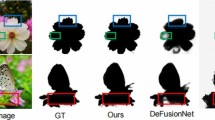
Current state-of-the-art blur detection methods depend on massive convolutional layers to extract high-level semantic features. By such learning, the model would focus more and more on the regions with high response values [28] and thereby fails to capture residual details, especially around the boundary. Consequently, the detection result will suffer from rough and inaccurate boundaries between blurry and sharp regions. This would definitely hurt the performance of blur detection models and damage the success of subsequent image processing tasks like deblurring, especially in complicated scenes. As can be seen in Fig. 1, several recent top-class methods [13, 16,17,18, 21, 29, 30] show unsatisfactory blur detection results with rough boundaries when they face a complex scene containing both low-contrast clear foreground and deceptive background clutters. Therefore, how to guarantee fine boundaries during blurry region segmentation is another central concern of the blur detection model.

A typical challenging case containing low-contrast in-focus foreground (marked by red rectangle) and deceptive background clutters (marked by blue rectangle). In this case, nearly all recent deep learning-based methods such as DHDE [14], BTBFRR [17], DMENet [44], BTBCRL [18], CENet [29], EFENet [19] and DeFusionNet [22] have poor performance
Contribution
In this paper, we seek to tackle the above concerns in quest of a favorable accuracy–complexity trade-off in the blur detection task.
Concise architecture
For purpose of efficiency, we follow an explicit philosophy including three guidelines: (1) applying depth-wise convolutions to lighten the complexity; (2) using large convolutional kernels to enlarge the receptive fields; (3) designing bottleneck-style structures to rebuild the feature representation capability. In view of these, two novel inverted bottleneck blocks based on large depth-wise convolutions are built to serve as the core of the network.
Morphological priors
The key to refine the boundary between blurry and sharp regions, we believe, lies in provoking and fusing more morphological priors during learning. Under this perspective, both a region-concerned prior for complementation and an edge-concerned prior for guidance are embedded into the model in hierarchical and attentional manners.
Our contributions are summarized as follows.
-
We propose a Hierarchical Edge-guided Region-complemented Network (HER-Net) to detect possible blurry regions from images. Particularly, HER-Net has a very concise but effective architecture attributed to its large depth-wise convolutions, novel olive-shaped and pear-shaped inverted bottlenecks, parallel decoders and inbuilt morphological priors.
-
Region-concerned and edge-concerned morphological priors are hierarchically exploited to refine the boundary. Concretely, we propose a reverse-region spatial attention (RrSA) to mine the complementary affinities between blurry and sharp regions so as to enrich the residual details around the boundary. In addition, we design an edge spatial attention (ESA) to guide the edge-concerned cues to reinforce the features related to the boundary.
-
Our method shows a superior accuracy–complexity trade-off in blur detection task. Experimental results on benchmark datasets demonstrate that HER-Net can achieve better detection accuracy with finer boundaries as well as more than 72% reduction in parameters compared to competitive methods. Such performance superiority on accuracy, efficiency and lightweight can inspire further studies for real-world blur detection applications.
Related works
Handcrafted feature-based methods
Blur detection methods using traditional techniques have been well studied. Basically, traditional methods prefer to handcraft specific features under explicit principles.
The most popular features used in blur detection are handcrafted from the perspective of gradient and frequency, following the principle that the sharp region has stronger gradients or frequencies than the blurry one in an image. Along this direction, researchers have proposed many handcrafted feature-based methods. Su et al. [31] developed a technique to detect the blurry region by examining pixel-wise singular values and gradient distribution of alpha channel. Shi et al. [32] engineered a set of blur features including image gradient, Fourier transformation and data-driven local filters to discriminate in-focus and out-of-focus regions. Tang et al. [33] mined the log-averaged spectrum residual to measure the image blur, which was refined based on gradient and color similarities between neighbor pixels. Xu et al. [34] estimated the spatially varying defocus blur by exploiting patch-level maximum ranks in gradient domain. Golestaneh et al. [35] utilized high-frequency DCT coefficients of gradient magnitudes at multiple scales to compute the blur map. Liu et al. [9] proposed to combine region-based frequency information and edge-based linear information by regression tree fields to estimate the defocus blur.
Besides the widely used gradient-based and frequency-based features, some other principles are also effective. For instance, Yi et al. [10] designed a blur detection framework based on local binary patterns. Wang et al. [36] utilized Walsh–Hadamard coefficients in sequency domain to detect the image blur and segment the blurry region; on this basis, Liang et al. [11] further introduced a noise-robust blur detection framework via sequency spectrum truncation.
For traditional blur detection approaches, handcrafting a number of features in empirical and manual manners is a very common practice. However, these handcrafted features can hardly capture high-level semantics and contextual information. Therefore, traditional methods could work well in simple cases but often underperform when dealing with complex scenes.
Deep learning-based methods
The past decade has witnessed the rapid growth of deep learning in the realm of computer vision. Motivated by such success, researchers begin to apply deep learning techniques like ConvNet in blur detection.
Initially, ConvNet was simply used as the feature extractor or patch-level classifier to coordinate with traditional techniques. For example, Park et al. [13] made the first attempt at unifying handcrafted features and deep features to estimate the defocus blur via a series of elaborate filters. Huang et al. [14] predicted the patch-level blur likelihoods map through a six-layer ConvNet and fused multi-scale results into a refined one. Zeng et al. [15] built a local blur metric based on deep features assisted by their principal components.
Recently, researchers have developed more in deep feature exploitation and fusion, which continuously improves the performance of blur detection. Zhao et al. [16, 17] constructed a bottom–top–bottom fully convolutional network to integrate multi-scale features and further optimize the architecture via multi-stream mode and cascaded residual learning. In their follow-up studies, two diversity-boosting deep ensemble networks [18] and an image-scale-symmetric cooperative network [19] were successively proposed for defocus blur detection and achieved state-of-the-art performance. Tang et al. [20, 21] built and updated a defocus blur detection framework, which recurrently fused and refined multi-scale features in a cross-layer manner. Zhai et al. [26] boosted the performance for blur detection by aggregating low-level detail features, high-level semantic and global context information in a hierarchical manner. Karaali et al. [23] estimated defocus blur by weight-sharing ConvNets to distinguish depth edges from pattern edges.
Attention mechanism as an effective tool for reweighting features is also utilized by recent methods to facilitate the learning. Tang et al. [22] implanted the channel attention into a bi-directional residual refining network to select more discriminative features for defocus blur. Inspired by the nested network, Guo et al. [25] embedded small U-shaped networks and the channel attention into an end-to-end ConvNet to detect the blurry region. Jiang et al. [24] introduced channel-wise and spatial-wise attentions to obtain more discriminative features and suppressed unreliable predictions by a generative adversarial training strategy.
Therefore, it can be seen that deep learning-based blur detection methods do outperform traditional methods by a large margin. The superiority is attributed to the exploitation of different-level information, such as the bottom–top–bottom manner [17] and alternate cross-layer manner [21]. Nonetheless, two major problems, i.e., overweight model (even up to hundreds of megabytes) and rough boundary (especially in complicated scenes), still challenge recent deep learning-based approaches.
As to the former problem, since an overweight model is quite not appropriate in many real-world applications, a concise yet effective model is required. In this paper, we decide to follow a philosophy of designing the bottleneck-style structures around depth-wise convolutions and large kernels in order to achieve lightweight but expressive feature representation. As to the latter problem, since the rough boundary of the detected blurry region could severely impede the success of subsequent tasks like deblurring, morphological priors are taken into account to refine the boundary. Li et al. [37] designed two symmetric branches to jointly estimate the blur probabilities of both in-focus and out-of-focus pixels. Lin et al. [38] introduced the reverse attention [28] to capture in-focus and out-of-focus features. Inspired by them, we propose the RrSA mechanism to take in complementary morphological affinities between blurry and sharp regions and hope to pay coequal attention on blurry and sharp pixels around the boundary. Besides, we also propose the ESA mechanism to further emphasize the edge information for finer boundary.
Proposed algorithm
Pipeline
The overview architecture of our HER-Net is illustrated in Fig. 2, consisting of a backbone encoder, two parallel decoders (i.e., region-aware decoder and edge-aware decoder), the reverse-region complementation connection and the edge guidance connection. Each above part can be divided into four stages from low level (large scale, small channel dimension) to high level (small scale, large channel dimension). The resolution of feature maps keeps the same inside one stage. Detailed configurations are shown in Table 1.

Overview architecture of HER-Net (best viewed in color). The stage from 1 to 4 denotes the level from low (large scale, small channel dimension) to high (small scale, large channel dimension). Detailed structures about OLIVE, PEAR, RrSA, ESA, Stem, Head, and Dense Transition will be illustrated in Figs. 3, 4, and 5
First, the backbone encoder extracts multi-level features progressively from the original image and its input pyramid. Next, these encoded feature maps are passed through a dense transition block and then fed into two parallel decoders. Thereinto, the region-aware decoder is the main decoder designed for blurry region segmentation, which is the major task of this paper. The edge-aware decoder is the auxiliary decoder used to emphasize the boundary. The reverse-region complementation connection inlaid with a reverse-region spatial attention (RrSA) mechanism is analogous to a skip connection between the encoder and main decoder. In addition, between the auxiliary encoder and main decoder, we build another skip connection inlaid with an edge spatial attention (ESA) mechanism. Lastly, the main loss \(\mathcal{L}^{r}\) (between the output of main decoder and the ground truth) and the auxiliary loss \(\mathcal{L}^{e}\) (between the output of auxiliary decoder and the edge of ground truth) are hierarchically computed to supervise the entire network across all levels.
Backbone encoder
The backbone encoder, constructed as a lightweight but effective feature extractor, contains three designs: multi-input pyramid, OLIVE block, and dense transition block.
-
(1)
Multi-input pyramid It has been known that low-level spatial information is very helpful for searching and locating a region in an image. To preserve sufficient low-level information when the encoder extracts deeper and deeper semantic cues, we design a multi-input pyramid structure herein. First, three consecutive max-pooling operations are applied on the original image with a resolution of I to generate an input pyramid with decreasing scales {I, 1/2I, 1/4I, 1/8I}. Second, each input is passed through the stem cell and then hierarchically concatenated into corresponding encoder stage in channel dimension. The stem cell can be formulated as
$$ {\varvec{S}} = {\text{Conv}}^{1 \times 1} \left( {{\text{Conv}}^{d9 \times 9} \left( {\text{input}} \right)} \right), $$(1)where d9 × 9 denotes a depth-wise convolution with the kernel size of 9 × 9 and 1 × 1 denotes a point-wise convolution. Specially, the d9 × 9 kernel in the stem cell has a stride of 2, while other kernels in HER-Net default to a stride of 1. The stem cell is intended to not only down-sample the input image for reducing its inherent redundancy [39], but also expand the channels from 3 (RGB) to an appropriate dimension. It should be also noted that each convolutional layer is sequentially followed by batch normalization (BN) and rectified linear unit (ReLU) unless otherwise indicated. The proposed multi-input pyramid enables the encoder to keep enough low-level information taken directly from the original image.
-
(2)
OLIVE block To achieve more expressive feature extraction while keeping low complexity, we propose a novel olive-shaped inverted bottleneck structure (named OLIVE) based on the classic inverted bottleneck from MobileNetV2 [40] by employing larger convolutional kernels and transferring large kernels to low-dimension space. As shown in Fig. 3a, the OLIVE block includes two d9 × 9, two 1 × 1 and one identity shortcut, which can be formulated as
$$ {\varvec{O}} = {\text{Conv}}^{d9 \times 9} \left( {{\text{Conv}}^{1 \times 1} \left( {{\text{Conv}}^{1 \times 1} \left( {{\text{Conv}}^{d9 \times 9} \left( {\varvec{F}} \right)} \right)} \right)} \right) \oplus {\varvec{F}}, $$(2)where denotes the addition operation, F is the input feature map from the previous layer, and O is the output feature map of the OLIVE block.
The design motivation of OLIVE is depicted in Fig. 4, which can be detailed as follows: (a) we base the OLIVE block on the classic inverted bottleneck centered on depth-wise convolutions for the purpose of efficiency; (b) considering the fact that depth-wise convolution can reduce the complexity and yet also weaken the accuracy, we replace original d3 × 3 kernel with d9 × 9 kernel for larger receptive field so as to lift the accuracy; (c) in order to save parameters, we transfer the d9 × 9 kernel from the high-dimension space to the low-dimension side; (d) we add one more d9 × 9 kernel at the other low-dimension side to boost the representation capability. Meanwhile, most of ReLUs are deleted and only one ReLU located in high-dimensional space between two 1 × 1 kernels is retained to reduce information loss, since that using nonlinear activation in low-dimensional space easily leads the feature values to zero and hence lose much helpful information [40]. From the perspective of the parameters, replacing d3 × 3 with d9 × 9 (Fig. 4a → 4b) will lead to a large increase by 13.8% in parameters of the OLIVE block. Subsequently, moving d9 × 9 to the low-dimension side (Fig. 4b → 4c) will significantly decrease the parameters by 10.4%, and then adding one more d9 × 9 (Fig. 4c → 4d) will induce a small rise of 5.2% in parameters.
-
(3)
Dense transition block. To further improve the feature reuse for multi-level information fusion but not increase the model parameters, inspired by [41], we design a densely connected context fusion structure as a transition block between the encoder and parallel decoders, named dense transition block. As illustrated in Fig. 3b, multi-level features can be aggregated by concatenating all its previous feature maps as the input of the present layer. In this block, the kernel sizes of depth-wise convolutions are 3, 5, 7, and 9 followed by 1 × 1 convolutions with reduction factors of 1/2, 1/3, 1/4, and 1/5, respectively, to control the channel dimension. Therefore, the dense transition block can be defined as
$$ {\varvec{D}}_{1} = {\text{Conv}}^{1 \times 1} \left( {\left[ {{\varvec{F}};\text{Conv}^{d3 \times 3} \left( {\varvec{F}} \right)} \right]} \right), $$(3)$$ \varvec{D}_{i} = \text{Conv}^{1 \times 1} \left( {\left[ {\varvec{F}; \varvec{D}_{1} ; \ldots ;\text{Conv}^{d(2i + 1) \times (2i + 1)} \left( {\varvec{D}_{i - 1} } \right)} \right]} \right), $$(4)where [;] denotes the concatenation operation and Di is the feature map of the ith layer in the dense transition block (i = 1, 2, 3, 4).
Totally, a concise yet effective backbone encoder is built by stacking four OLIVE blocks corresponding to four stages, inserting the separate down-sampling layer (d9 × 9 with stride 2) between stages, and being equipped with the multi-input pyramid and dense transition block.

Basic blocks of the backbone encoder. a The OLIVE block. b The dense transition block where the inset number denotes the reduction factor of channels for each convolutional layer

Design motivation of the OLIVE block. a The original inverted bottleneck [40]. In (b), d3 × 3 is replaced with d9 × 9 for larger receptive field. In (c), d9 × 9 is moved to the low-dimension side for saving parameters. In (d), we add one more d9 × 9 to boost the feature representation capability and retain only one ReLU located in high-dimension space between two 1 × 1 to reduce information loss
Parallel decoders (region-aware and edge-aware)
In HER-Net, feature maps from the encoder will be fed into two parallel but interconnected decoders, i.e., the region-aware decoder (main) and the edge-aware decoder (auxiliary). The former is designed to decode the feature map level by level to segment the blurry region, and the latter is to detect the boundary information so as to provide guidance on region segmentation. As the core unit of parallel decoders, the PEAR block named after its pear-like shape includes d9 × 9, 1 × 1 with a expansion factor of 2, 1 × 1 with a reduction factor of 1/4 and identity shortcut, as shown in Fig. 5a. The PEAR block can be formulated as
where P denotes the output feature map of the PEAR block. The design motivation of PEAR is similar to that of OLIVE, as depicted in Fig. 6. First, we modify the classic inverted bottleneck [42] by replacing original d3 × 3 kernel with d9 × 9 kernel for larger receptive field and higher accuracy. Then, we move the d9 × 9 kernel to the low-dimension side for saving parameters. Finally, we retain only one ReLU located in high-dimension space between two 1 × 1 kernels to reduce information loss. Specifically in terms of parameters, using larger d9 × 9 (Fig. 6a → 6b) will cause a 18.3% rise in parameters of the PEAR block, and then moving d9 × 9 to the low-dimension side (Fig. 6b → 6c) will generate a 10.3% drop in parameters. In short, the PEAR block has larger kernel size, leaner parameters and fewer nonlinear activation. It is worth mentioning that our modification results in two back-to-back 1 × 1 kernels naturally, which is a Transformer-style structure [43] and also used in ConvNeXt [39]. Such back-to-back 1 × 1 kernels whose channels expand first and then reduce can boost cross-channel information interaction and help to learn complex representation via full connection and nonlinear activation.

Basic blocks of parallel encoders. a The PEAR block of parallel decoders. b The detection head for yielding the final or intermediate prediction result. c The RrSA block exploiting reverse-region complementation priors to enrich the residual details around the boundary. e The ESA block exploiting edge guidance priors to emphasize boundary features

Design idea of the PEAR block. a The original inverted bottleneck [40]. In (b), d3 × 3 is replaced with d9 × 9 for larger receptive field. In (c), d9 × 9 is moved to the low-dimension side for saving parameters and only one ReLU located in high-dimension space between two 1 × 1 kernels is retained to reduce information loss
Between PEAR blocks in the main decoder, a simple fusion module (seen in Fig. 2) containing concatenation and 1 × 1 with a reduction factor of 1/4 is used to fuse and adjust the channels. There is also a 2 × 2 nearest neighbor interpolation for up-sampling between stages. As parallel decoders go from deep back to shallow, the resolution will be stage-wise restored from I/16 to I and the channel dimension will be stage-wise reduced from high to 1. As shown in Fig. 5b, we use a detection head at the output end of each decoder to produce the final prediction result (region-oriented or edge-oriented) with the same resolution as the original image. The detection head is formed by two d9 × 9, two 1 × 1 with the reduction factor of 1/2 and 1/N, respectively (N is the number of input channels), and one Sigmoid activation. It can be formulated as
where σ denotes the Sigmoid function and H is the output of the detection head. It should be noted that each convolution herein is followed by BN and ReLU unless otherwise indicated.
Reverse-region complementation via RrSA
An encoder stacked by a lot of convolutions is prone to cause the network to focus on the regions with high response values and thereby miss out on residual details, especially around the boundary [28]. The consequent rough boundary could undermine the effectiveness of blur detection model in complex scenes. Evidently, how to sufficiently keep and exploit residual information around the boundary is the key to solve this problem. Blurry region and sharp region have a mutually disjoint but closely complementary relationship due to the fact that they two can be grouped into a complete image without any intersection. In view of this, we hope residual details ignored by one region can be learned by the other via the latent complementary relationship. Therefore, we reify a reverse-region spatial attention mechanism and propose the RrSA block to hierarchically mine the complementary affinities between blurry and sharp regions in a spatially attentional manner. Thus, the network can enrich residual information to refine the boundary.
As depicted in Fig. 5c, the feature map PM ∈ ℝw×h× 0.5c from a PEAR block of the main decoder is first squeezed into two single channel by global average pooling (GAP) and global maximum pooling (GMP), respectively, where w × h is the size of feature map and c is the number of channel. Then, the two aggregated feature maps are concatenated and passed through the sequential d9 × 9, 1 × 1 and Sigmoid activation to yield a spatial attention map ΩM ∈ ℝw×h×1. According to the complementary relationship between blurry and sharp regions, we can also obtain its reverse attention map 1 − ΩM ∈ ℝw×h×1. Finally, the encoder-feature map O ∈ ℝw×h×c produced by the OLIVE block will be re-weighted simultaneously by ΩM and 1 − ΩM to generate the output feature map FM ∈ ℝw×h×c, which is defined as follows:
where denotes dot product. By erasing the current spatial attention ΩM, the reverse attention 1 − ΩM can enable the network to pay new attention to those ignored parts, which leads to rediscover the missing residual details quickly and effectively. The simultaneous work of spatial attention and its reverse attention can make full use of complementary priors between blurry and sharp regions so that the network can keep ample attention on both blur-concentrated parts and residual parts around the boundary. This helps to refine the blurry-sharp boundary and further improve the segmentation accuracy.
Edge guidance via ESA
To further emphasize the boundary features, we design the ESA block for exploiting edge-concerned information from the auxiliary decoder to guide the blurry region segmentation in the main decoder. As delineated in Fig. 5d, the ESA block is also based on a spatial attention mechanism. First, GAP and GMP are applied to squeeze the feature map PA ∈ ℝw×h×0.5c derived from a PEAR block of the auxiliary decoder into two individual channels, respectively. Then, two squeezed feature maps will be sequentially fed into the concatenation, d9 × 9, 1 × 1, and sigmoid activation to yield a spatial attention map ΩA ∈ ℝw×h×1. Subsequently, ΩA is used to spatially re-weight the feature map derived from a PEAR block of the main decoder and allocates higher weights to the features related to the boundary. In short, the ESA block is computed as
Overall, these ESA blocks across main and auxiliary decoders can exploit edge-concerned cues to highlight the boundary features of region-aware feature maps in attentional and hierarchical manners. Therefore, the design of ESA is beneficial to the boundary refinement, resulting in a more accurate region segmentation result.
Hierarchical joint loss
Aiming to supervise the HER-Net as well as mitigate the scale ambiguity, we design a hierarchical joint loss \(\mathcal{L},\) as visualized in Fig. 2. Unlike most encoder-decoder networks which only compute the loss at the final output end, we jointly consider losses at all stages of dual decoders to balance the prediction biases between different scales and decoders. The \(\mathcal{L}\) consists of both the main loss \(\mathcal{L}_{\text{main}}\) derived from the region-aware decoder and the auxiliary loss \(\mathcal{L}_{\text{aux}}\) derived from the edge-aware decoder.
Concretely, the \(\mathcal{L}_{\text{main}}\) uses the binary cross entropy function defined as follows:
where \(\mathcal{L}_{k}^{m}\) is the side-out loss of the stage k in the main decoder, and k = 0, 1, 2, 3, 4 denote the final output end and four intermediate output heads, respectively. \(\mathcal{L}_{k}^{m}\) is expressed as
where Rk and Gmk are the prediction result in the main decoder and its ground truth at stage k, respectively; ψ denotes the model parameters; Y+ and Y− are the sets of pixels marked positive (1, blurry) and negative (0, sharp) in the ground truth, respectively; and xi is the predicted value (1 or 0) of pixel i.
Considering the little proportion of boundary pixels in an image, we combine the focal loss and dice loss in the auxiliary decoder to construct an auxiliary loss \(\mathcal{L}_{\text{aux}}\) defined as follows:
where \(\mathcal{L}_{k}^{a}\) is the side-out loss of the stage k. The \(\mathcal{L}_{k}^{a}\) is expressed as
where Ek and Gak are the prediction result in the auxiliary decoder and its ground truth (derived by a canny operator from the ground truth of the main decoder) at stage k, respectively; β is set to 1e − 3 to balance the magnitude between focal loss and dice loss; ε is an infinitesimal value to avoid the numerical issue of dividing by zero.
Finally, the total hierarchical joint loss \(\mathcal{L}\) of HER-Net can be summarized as follows:
where λ is a weighting factor to balance between \(\mathcal{L}_{\text{main}}\) and \(\mathcal{L}_{\text{aux}}\), which is set to 0.1 by experiments.
Experiments
Datasets
We evaluate the proposed approach on three publicly available and well-annotated datasets: CUHK [32], DUT [16] and CTCUG [21]. All three datasets are oriented to partial image blur. More specifically, the CUHK dataset consists of 296 motion-blurred images and 704 defocused images. The motion-blurred part is termed CUHKM, where 250 samples are for training and the rest is for testing. The defocused part is termed CUHKD, where 604 samples are for training and the rest is for testing. The DUT dataset includes 1100 challenging defocused images, where 600 samples are used for training and the rest is used for testing. The CTCUG dataset contains 150 images with different defocus distribution, where all images are only used for testing. CUHK and DUT datasets have similar blur distribution that the foreground is usually sharp while the background is usually blurry. By contrast, the CTCUG dataset has an inverse blur distribution that mostly the foreground is blurry while the background is sharp. Besides, DUT and CTCUG datasets contain many challenging cases such as in-focus but low-contrast areas and half-blurry half-sharp objects. In this paper, in order to train the HER-Net, a Canny operator is used to obtain the edge-oriented ground truth from the region-oriented ground truth, as shown in Fig. 7.

Two ground truths used in this paper, where (c) is obtained by a Canny operator from (b)
Evaluation criteria
Precision (P), recall (R), F-measure (Fβ) and mean absolute error (MAE) are used here to evaluate the segmentation accuracy of the model. Their mathematical definitions are listed in Table 2. P measures the ability to recognize only blurry pixels and R measures the ability to identify all blurry pixels. Fβ is a comprehensive weighted indicator considering both P and R. Here, we use β2 = 0.3 that agrees with the setup in [16,17,18,19,20,21,22]. MAE evaluates the difference between the binarized prediction result B and the ground truth G.
Implementation details
HER-Net is implemented under Pytorch framework and the training is accelerated on Nvidia GeForce RTX 3090 GPU. Stochastic gradient descent (SGD) with the momentum of 0.9 and weight decay of 0.0005 is used for further optimization. Learning rate is initialized to 1e − 4 and decreased by 1e − 6 every iteration. Batchsize is set to 16. We resize images from three datasets to 320 × 320 pixels by bicubic interpolation. Moreover, we augment existing samples by flipping, rotating and noising. An early stop strategy is adopted to end the training in advance when the error of the validation set stops falling within 20 iterations. The training process needs approximately 300 epochs.
Comparison with state-of-the-art methods
In this section, we evaluate the proposed method (HER-Net) by intensive comparisons with 11 state-of-the-art methods including eight deep learning-based approaches and three traditional methods. The eight deep learning-based methods include recurrent Deep feature Fusion and refinement Network (DeFusionNet) [21], Bi-directional Residual Refining Network (BR2Net) [22], Encoder-Feature Ensemble Network EFENet [18], Cross-Ensemble Network (CENet) [44], multi-stream Bottom–Top–Bottom network with Cascaded Residual Learning (BTBCRL) [17], multi-stream Bottom–Top–Bottom network with Fusion and Recurrent Reconstruction (BTBFRR) [16], Defocus Map Estimation Network using domain adaptation (DMENet) [41], and multi-scale Deep and Handcrafted features for Defocus Estimation (DHDE) [13]. The three traditional methods are Spectral and Spatial approach (SS) [33], Local Binary Patterns (LBP) [10], and High-frequency multi-scale Fusion and Sort Transform (HiFST) [35].
First, the accuracy (in terms of P, R, Fβ and MAE) and efficiency (in terms of parameters and FLOPs) of HER-Net are reported in Table 3. It shows that our HER-Net achieves an average Fβ of 0.929 and an average MAE of 0.052 over CUHK, DUT and CTCUG datasets by merely 8.34M parameters and 8.55G FLOPs. Several cases are shown in Fig. 8. Although HER-Net is capable of handling both defocused and motion-blurred scenes, the comparisons herein will be limited within the scope of defocus blur considering that most aforementioned methods are designed only for defocus blur. For the sake of fair comparison, we use the results reported in literatures [17, 18, 21, 22, 44] or the codes released by the authors [10, 13, 33, 35, 41] on the same workstation with same testing samples, without any modification.

Some cases including defocused scenes from CUHKD and motion-blurred scenes from CUHKM
Qualitatively comparisons are shown in Figs. 9, 10 and 11 for CUHKD, DUT and CTCUG datasets, respectively. Obviously, recent deep learning-based methods perform generally better than traditional handcrafted feature-based methods. Figure 9 shows some common cases from the CUHKD dataset. It can be observed that our HER-Net has the superiority to other methods and can provide more accurate segmentation results with finer regional boundaries. Figure 10 shows some cases containing low-contrast in-focus objects or deceptive background clutters, which are considered two intractable problems in blur detection tasks. Low-contrast in-focus objects, such as the V, VII rows of Fig. 9 and the I, II, III, IV rows of Fig. 10, are prone to be misjudged as out-of-focus parts due to their smooth and texture-less characteristics. Background clutters, such as the V, VI, VII rows of Fig. 10, are easily mistaken for in-focus foregrounds due to their deceptive pseudo-edges. Even so, our HER-Net gives the most accurate predictions with finest details among all competitive methods. Figure 11 shows some very challenging cases from the CTCUG dataset. Besides low-contrast sharp objects (the I, II, III rows of Fig. 11) and deceptive background clutters (the IV, V rows of Fig. 11), there are also some inversely-distributed blurs (the VI, VII, VIII rows of Fig. 11) that means the foreground is blurry while the background is sharp. Evidently, the proposed HER-Net still outperforms other competitive methods. Especially on inversely distributed blurs, we can see that most methods are trapped in misjudgement while our method is still able to accurately detect. This superiority in dealing with inversely-distributed blurs should be largely attributed to the exploitation of complementary affinities between blurry and sharp regions, which leads to the model paying coequal attention to both in-focus and out-of-focus pixels around the boundary.



Quantitatively comparisons are reported in Table 4. It is obvious that our HER-Net achieves better performance in terms of Fβ and MAE on all three datasets compared to other state-of-the-art methods, which indicates the superiority of our method. Compared to the second-best methods, our method improves the Fβ by 2.63%, 0.32%, and 4.74% and reduces the MAE by 23.73%, 9.26%, and 27.96% on CUHKD, DUT and CTCUG datasets, respectively. It is worth mentioning that such significant improvement is achieved with only 8.34M parameters and 8.55G FLOPs. Since the coding languages and running environments are widely various among different methods, the direct runtime comparison (ours is 38.6 ms per image) makes no sense. Thus, we compare the model complexity in terms of the number of parameters between different deep learning-based methods and ours, as reported in Table 5. Obviously, our method has the most lightweight architecture among competitive methods. Compared to the second-place, HER-Net achieves a 72% reduction in parameters.
Ablation studies
In this section, we ablate the modular HER-Net to prove the effectiveness of several proposed blocks by experiments. Results of ablation studies are summarized in Table 6.
Effectiveness of OLIVE
As depicted in Figs. 3 a and 4, the OLIVE block is modified from the classic inverted bottleneck [42]. Therefore, to explore the role of the OLIVE block, the model with OLIVE (i.e., HER-Net) and the model without OLIVE (using classic inverted bottlenecks instead, denoted by w/o OLIVE) are separately tested. Table 6 (rows 2, 7, 12) shows that the absence of OLIVE blocks leads to 1.62%, 1.96%, 1.55% decrease of Fβ and 14.77%, 12.12%, 10.62% increase of MAE in CUHK, DUT and CTCUG datasets, respectively, which definitely proves the effectiveness of OLIVE blocks.
Effectiveness of PEAR
Similarly, the PEAR block is also modified from the classic inverted bottleneck. We compare two models: one using PEAR blocks (i.e., HER-Net) and the other using classic inverted bottlenecks (named w/o PEAR). Table 6 (rows 3, 8, 13) shows that the Fβ will be decreased by 0.43%, 0.97%, 0.55% and the MAE will be increased by 7.41%, 8.42%, 6.48% in CUHK, DUT and CTCUG datasets, respectively, if discarding all PEAR blocks. It demonstrates the effectiveness of PEAR blocks.
Effectiveness of RrSA
The RrSA block is designed to exploit complementary affinities between blurry and sharp regions. To investigate its contribution, we compare the model with RrSA (i.e., HER-Net) and the model with conventional skip connection (named w/o RrSA). Table 6 (rows 4, 9, 14) shows that, when RrSA blocks are ablated, the Fβ will drop by 2.06%, 2.62%, and 2.01% and the MAE will rise by 22.68%, 23.08%, and 18.67% in CUHK, DUT and CTCUG datasets, respectively. These results demonstrate the effectiveness of RrSA blocks and confirm the vital role of region complementation in blur detection.
Effectiveness of ESA
The ESA block is designed to capture edge-concerned cues from the auxiliary decoder to guide the region segmentation in the main decoder. Comparison between the model with ESA (i.e., HER-Net) and the model with conventional skip connection (named w/o ESA) is conducted. Table 6 (rows 5, 10, 15) shows that the absence of ESA blocks will cause the Fβ being to reduce by 1.73%, 1.52%, and 1.67% and the MAE to enlarge by 16.67%, 9.38%, and 13.68% in CUHK, DUT and CTCUG datasets, respectively. It proves the importance of ESA blocks.
Effectiveness of large kernel
To explore the effect of kernel size, we conduct experiments on six HER-Net variants with different kernel sizes from 3 × 3 to 13 × 13. Results are shown in Fig. 12. Clearly, a larger kernel size quite increases the model size with more parameters and FLOPs. It can be also observed that the accuracy rises with the increasing kernel size from 3 × 3 to 9 × 9, because the larger receptive field produced by larger kernel size is believed to facilitate capturing contextual information. However, the accuracy begins to fall when the kernel size is beyond 9 × 9. For 320 × 320 input images, the resolution of feature maps in four stages of HER-Net is 160 × 160, 80 × 80, 40 × 40, and 20 × 20. In this circumstance, an overlarge kernel size like 11 × 11 or even bigger will lead convolutional filters to ignore lots of local details, which would undermine the accuracy. In this paper, the HER-Net with the kernel of d9 × 9 achieves the best performance of Fβ = 0.929 and MAE = 0.052 over three datasets using 8.34M parameters and 8.55G FLOPs.

Fβ and MAE of the HER-Net variants with different kernel sizes. Each filled circle represents a HER-Net variant. In (a), the circle size represents the model parameters; in (b), the circle size represents the model FLOPs
About the optimizer
Besides the SGD with Momentum (SGDM), we also test two other optimizers including ADAM [29] and DiffGrad [30]. By experiments over three datasets, the SGDM optimizer achieves the highest Fβ measure of 0.929 using the convergence time of 300 epochs. The DiffGrad optimizer gains a good accuracy (Fβ = 0.923) on par with SGDM but a slightly slower convergence speed (370 epochs). In contrast, the ADAM optimizer achieves the Fβ measure of 0.879 and convergence time of 410 epochs, which are obviously inferior to SGDM and DiffGrad. Therefore, we finally select the SGDM optimizer for the investigated blur detection task. Considering the fact that various optimizers perform very differently depending on specific task scenarios [12, 18, 45], we will pay more attention on the adaptability of optimizer to task scenarios in future research.
Conclusion
In this paper, we build a deep learning-based blur detection model named Hierarchical Edge-guided Region-complemented Network (HER-Net). To solve the overweight model problem, two novel inverted bottleneck blocks (olive-shaped and pear-shaped) based on large-kernel size (9 × 9) and depth-wise convolution are designed to serve as the core unit of HER-Net. To solve the rough boundary problem, two morphological priors (region-concerned and edge-concerned) are absorbed into the HER-Net in hierarchical and attentional manners. Concretely, a reverse-region spatial attention is engineered to exploit the regional complementation information and an edge spatial attention is engineered to utilize the edge-concerned cues for guidance. By these designs, we construct a concise yet effective one-encoder-parallel-decoders model. Experimental results on benchmarks demonstrate the effectiveness of our method with an average Fβ of 0.929 and an average MAE of 0.052 on three datasets. Note that such a state-of-the-art performance is achieved with only 8.34M parameters and 8.55G FLOPs, which is far fewer than competitive methods. The superior accuracy–complexity trade-off of the HER-Net could inspire further studies for real-world blur detection applications.
Data availability
Datasets employed in this paper is publicly available.
Code availability
The code is available from the corresponding author upon reasonable request.
References
Zhang X, Wang R, Jiang X et al (2016) Spatially variant defocus blur map estimation and deblurring from a single image. J Vis Commun Image Represent 35:257–264
Abuolaim A, Brown MS (2020) Defocus deblurring using dual-pixel data. In: European conference on computer vision. Springer, Cham, pp 111–126
Hosseini MS, Zhang Y, Plataniotis KN (2019) Encoding visual sensitivity by maxpol convolution filters for image sharpness assessment. IEEE Trans Image Process 28(9):4510–4525
Li D, Jiang T, Jiang M (2017) Exploiting high-level semantics for no-reference image quality assessment of realistic blur images. In: Proceedings of the 25th ACM international conference on multimedia, pp 378–386
Cong R, Lei J, Fu H et al (2018) Review of visual saliency detection with comprehensive information. IEEE Trans Circuits Syst Video Technol 29(10):2941–2959
Lin J, Ji X, Xu W et al (2013) Absolute depth estimation from a single defocused image. IEEE Trans Image Process 22(11):4545–4550
Gur S, Wolf L (2019) Single image depth estimation trained via depth from defocus cues. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 7683–7692
Lee H, Kim C (2014) Blurred image region detection and segmentation. In: 2014 IEEE international conference on image processing (ICIP). IEEE, pp 4427–4431
Liu S, Liao Q, Xue JH et al (2020) Defocus map estimation from a single image using improved likelihood feature and edge-based basis. Pattern Recogn 107:107485
Yi X, Eramian M (2016) LBP-based segmentation of defocus blur. IEEE Trans Image Process 25(4):1626–1638
Liang X, Wang X, Lyu L et al (2022) Noise-immune image blur detection via sequency spectrum truncation. Complex Intell Syst 8(2):1323–1337
Chai J, Zeng H, Li A et al (2021) Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach Learn Applications 6:100134
Park J, Tai YW, Cho D et al (2017) A unified approach of multi-scale deep and hand-crafted features for defocus estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1736–1745
Huang R, Feng W, Fan M et al (2018) Multiscale blur detection by learning discriminative deep features. Neurocomputing 285:154–166
Zeng K, Wang Y, Mao J et al (2018) A local metric for defocus blur detection based on CNN feature learning. IEEE Trans Image Process 28(5):2107–2115
Zhao W, Zhao F, Wang D et al (2018) Defocus blur detection via multi-stream bottom-top-bottom fully convolutional network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3080–3088
Zhao W, Zhao F, Wang D et al (2020) Defocus blur detection via multi-stream bottom-top-bottom network. IEEE Trans Pattern Anal Mach Intell 42(8):1884–1897
Zhao W, Hou X, He Y et al (2021) Defocus blur detection via boosting diversity of deep ensemble networks. IEEE Trans Image Process 30:5426–5438
Zhao F, Lu H, Zhao W et al (2022) Image-scale-symmetric cooperative network for defocus blur detection. IEEE Trans Circuits Syst Video Technol 32(5):2719–2731
Tang C, Zhu X, Liu X et al (2019) DefusionNET: defocus blur detection via recurrently fusing and refining multi-scale deep features. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2700–2709
Tang C, Xinwang LIU, Zheng X et al (2022) DeFusionNET: Defocus blur detection via recurrently fusing and refining discriminative multi-scale deep features. IEEE Trans Pattern Anal Mach Intell 44(2):955–968
Tang C, Liu X, An S et al (2021) BR2Net: Defocus blur detection via a bidirectional channel attention residual refining network. IEEE Trans Multimedia 23:624–635
Karaali A, Harte N, Jung CR (2022) Deep multi-scale feature learning for defocus blur estimation. IEEE Trans Image Process 31:1097–1106
Jiang Z, Xu X, Zhang L et al (2022) MA-GANet: A Multi-attention generative adversarial network for defocus blur detection. IEEE Trans Image Process 31:3494–3508
Guo W, Xiao X, Hui Y et al (2021) Heterogeneous attention nested U-shaped network for blur detection. IEEE Signal Process Lett 29:140–144
Zhai Y, Wang J, Deng J et al (2021) Global context guided hierarchically residual feature refinement network for defocus blur detection. Signal Process 183:107996
Howard AG, Zhu M, Chen B et al (2017) Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861
Chen S, Tan X, Wang B et al (2018) Reverse attention for salient object detection. In: Proceedings of the European conference on computer vision (ECCV), pp 234–250
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980
Dubey SR, Chakraborty S, Roy SK et al (2019) DiffGrad: An optimization method for convolutional neural networks. IEEE Trans Neur Netw Learn Syst 31(11):4500–4511
Su B, Lu S, Tan CL (2011) Blurred image region detection and classification. In: Proceedings of the 19th ACM international conference on multimedia, pp 1397–1400
Shi J, Xu L, Jia J (2014) Discriminative blur detection features. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2965–2972
Tang C, Wu J, Hou Y et al (2016) A spectral and spatial approach of coarse-to-fine blurred image region detection. IEEE Signal Process Lett 23(11):1652–1656
Xu G, Quan Y, Ji H (2017) Estimating defocus blur via rank of local patches. In: Proceedings of the IEEE international conference on computer vision, pp 5371–5379
Alireza Golestaneh S, Karam LJ (2017) Spatially-varying blur detection based on multiscale fused and sorted transform coefficients of gradient magnitudes. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5800–5809
Wang X, Liang X, Zheng J et al (2019) Fast detection and segmentation of partial image blur based on discrete Walsh-Hadamard transform. Signal Proc Image Commun 70:47–56
Li J, Fan D, Yang L et al (2021) Layer-output guided complementary attention learning for image defocus blur detection. IEEE Trans Image Process 30:3748–3763
Lin X, Li H, Cai Q (2022) Hierarchical complementary residual attention learning for defocus blur detection. Neurocomputing 501:88–101
Liu Z, Mao H, Wu CY et al (2022) A convnet for the 2020s. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11976–11986
Tan M, Le QV (2019) Mixconv: mixed depth wise convolutional kernels. arXiv preprint arXiv:1907.09595
Lee J, Lee S, Cho S et al (2019) Deep defocus map estimation using domain adaptation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12222–12230
Sandler M, Howard A, Zhu M et al (2018) Mobilenetv2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4510–4520
Liu Z, Lin Y, Cao Y, et al (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 10012–10022
Zhao W, Zheng B, Lin Q et al (2019) Enhancing diversity of defocus blur detectors via cross-ensemble network. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 8905–8913
Mukherjee S, Ahmed SA, Dogra DP et al (2019) Fingertip detection and tracking for recognition of air-writing in videos. Expert Syst Appl 136:217–229
Funding
This research was funded by the National Natural Science Foundation of China (52102467, 62003227), the Natural Science Foundation of Hebei Province (F2021210016, F2022210024), and the Science Research Project of the Education Department of Hebei Province (QN2021135). We also thank the valuable comments and suggestions from the anonymous reviewers for improving the manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, X., Liang, X., Li, S. et al. Efficient image blur detection via hierarchical edge guidance and region complementation. Complex Intell. Syst. 9, 6523–6540 (2023). https://doi.org/10.1007/s40747-023-01093-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01093-5