
Abstract
Object detection in unmanned aerial vehicle (UAV) images has attracted the increasing attention of researchers in recent years. However, it is challenging for small object detection using conventional detection methods because less location and semantic information are extracted from the feature maps of UAV images. To remedy this problem, three new feature extraction modules are proposed in this paper to refine the feature maps for small objects in UAV images. Namely, Small-Kernel-Block (SKBlock), Large-Kernel-Block (LKBlock), and Conv-Trans-Block (CTBlock), respectively. Based on these three modules, a novel backbone called High-Resolution Conv-Trans Network (HRCTNet) is proposed. Additionally, an activation function Acon is deployed in our network to reduce the possibility of dying ReLU and remove redundant features. Based on the characteristics of extreme imbalanced labels in UAV image datasets, a loss function Ployloss is adopted to train HRCTNet. To verify the effectiveness of the proposed HRCTNet, corresponding experiments have been conducted on several datasets. On VisDrone dataset, HRCTNet achieves 49.5% on AP50 and 29.1% on AP, respectively. As on COCO dataset, with limited FLOPs, HRCTNet achieves 37.9% on AP and 24.1% on APS. The experimental results demonstrate that HRCTNet outperforms the existing methods for object detection in UAV images.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
With the development of UAV technology, object detection in UAV images has become a highly competitive field [1,2,3]. UAVs can be employed rapidly in a wide range of new applications at a relatively low cost, such as aerial photography and video surveillance. Owing to the characteristics of small objects in UAV images, object detection in UAV images achieves researchers’ attention. Existing detectors such as the YOLO family [4,5,6,7] and FPN networks [8,9,10] can achieve satisfying performance on natural images. However, since small objects have minimal numbers of pixels and features in UAV images, the color change of the edge is not as obvious as that of the big objects, and small objects are easily misjudged as background pixels [11,12,13,14]. There is a simple and rude way to solve this problem: to increase the size of the input picture and the pixel ratio of each target. However, this will also significantly increase the amount of calculation, and it is not conducive to the scene that needs to process the input picture in real-time. So another idea is to improve the existing object detection algorithms to make them more suitable for the scene of object detection in UAV images.
Such as the Improved YOLOv3 model with feature map cropping for multi-scale road object detection [15]. The network pays more attention to hard-to-classify samples by introducing an extra item in K-means-GIoU, which considers the length–width ratio difference between priory boxes and these samples. At the same time, CBAM attention mechanism and detector are added to pay attention to more information on the scale. The network performance has been improved to some extent through these two improvements while maintaining high-speed inference. Similarly, there is Multi-Scale Detector for Accurate Vehicle Detection in Traffic Surveillance Data [16]. The authors use five detectors to improve the multi-scale information of the network and avoid the false detection of small objects in the feature map. At the same time, using a Spatial Pyramid Pooling Network (SPP-Network) in the Neck structure can improve the feature extraction ability. Finally, the network makes better use of the rich semantic information in the feature map during training.
There are several common directions to improve detectors’ ability for object detection in UAV images, for instance: 1. Improve the ability of feature extraction [17, 18] by redesigning the feature extraction module; 2. Improve the ability of feature fusion [19, 20] by adding feature fusion modules or skip connections, and the networks can better utilize multi-scale information. In addition to these two directions, there are many ways. The following is a summary.
They can be roughly grouped into five major streams, i.e., Super-resolution-based (SR-based) methods, Context-based methods, multi-scale representation-based (MR-based) methods, Anchor-based methods and a relatively new way: Hybrid-model-based methods. But there are still some problems with these methods. SR-based methods are difficult to separate the foreground and background ideally. Context-based methods will significantly increase the computational cost. MR-based methods will increase the probability of misclassifications. Anchor-based methods will increase the cost of network regression. Unreasonable use of Hybrid-model-based methods will lead to problems such as slow network convergence and substandard accuracy.
So after summing up the problems in the previous work, this paper proposes a brand-new network, HRCTNet, to capture the location and semantic information in the feature maps for the accuracy and speed of object detection in UAV images. First, HRCTNet is a parallel five-branch network, through this structure, it can effectively avoid destroying information in feature maps after down-sampling and up-sampling in the traditional pyramid model. Moreover, HRCTNet abandons the traditional design mode of the Backbone + Neck structure and directly integrates the feature enhancement network into the backbone. In this way, HRCTNet efficiently uses high-resolution feature maps and avoids the over-design of the network by the original SR-based and context-based methods.
Second, HRCTNet contains three newly designed feature extraction modules: SKBlock, LKBlock, and CTBlock, to improve the ability of multi-scale feature extraction. Although the traditional object detection algorithms have achieved excellent results using a single feature extraction module, through the ablation experiment in section “Feature extraction module choosing strategy”, we found that the optimal detection performance cannot be obtained using either SKBlock or LKBlock alone. It means that using three different feature extraction modules is not an over-design. On the contrary, it is imperative to improve the performance of HRCTNet. They extract features on feature maps of different sizes to obtain more prosperous location and semantic information. At the same time, learnable parameters are used to determine the contribution ratio of feature maps of different resolutions during feature fusion, thereby enhancing the feature extraction ability of HRCTNet. Combining three different feature extraction modules, compared with the single SKBlock, it has achieved a 1.8% improvement in AP, and compared with the single LKBlock, it has achieved a 6.4% improvement in AP.
In addition to the above two leading solutions aimed at the problems existing in the previous algorithm for object detection in UAV images, there are still some issues in the design process of HRCTNet. So we put forward targeted solutions. HRCTNet contains numerous convolutions, which leads to the problem of redundant features and dying ReLU. Therefore, HRCTNet introduces Activate or not(Acon), which can learn which neurons to activate through training. Lastly, as UAV image datasets contain an uneven data distribution problem, slight tweaks have been made to the Focal Loss in HRCTNet. By adjusting a hyperparameter, HRCTNet can adapt to different UAV image datasets without too much burden.
The main contributions are shown as follows:
-
To extract the location and semantic information of the targets in UAV images to the greatest extent, we propose three new feature extraction modules: SKBlock, LKBlock, and CTBlock.
-
To avoid losing useful location information of the targets in UAV images, we design HRCTNet. It sustains extracting features from high-resolution images to obtain beneficial location information.
-
To improve the performance of the HRCTNet, both an activation function and a loss function are applied. Specifically, to solve the problem of dying ReLU, an activation function is introduced in the HRCTNet. Moreover, to solve the problem of imbalanced samples, a loss function is adopted in this work.
The section of the experiment demonstrated that HRCTNet achieves outstanding detection results on considering datasets. On VisDrone dataset, our accuracy is enhanced by 10.4% and 9.8%, respectively on AP50 and AP compared to YOLOv5; On COCO dataset, HRCTNet obtains 37.9% on AP and 57.6% on AP50, and on DOTA dataset reaches 69.1% on AP50. These results present that our method is superior to the previous methods on multiple UAV image datasets.
The remainder of this paper is organized as follows: The focus of section “Methodology” will be on three extraction modules (SKBlock, LKBlock, and CTBlock), the building of HRCTNet, and other implementations. The ablation studies, experimental findings, and explanations of various datasets are provided in section “Experiment”. Finally, section “Conclusions” concludes the paper with a summary.
Related works
SR-based methods
The SR-based methods attempt to super-resolve the whole image or the Regions of Interest (RoIs) [13, 21, 22], and then they perform object detection with a general-purpose object detector [6, 23]. The newly generated details of RoIs can boost the detector’s performance to a higher degree. Efficiently selecting regions to be reconstructed is critical to the algorithm's efficiency. While foreground reconstruction can effectively improve detection accuracy, background reconstruction just increases the calculation burden of the algorithm [21]. However, locating foreground regions containing objects of interest is challenging while excluding any background.
Context-based methods
Context-based methods leverage the relationship between the object and its surrounding environment to infer the original region of the small object [24,25,26,27]. However, due to the complexity and diversity of UAV background scenes, it is often difficult to build such contextual relationships. By reconstructing the spatial resolution of small feature images, many models can tackle the complex issues in object detection in UAV images. EfficientDet [28] and VSSA-Net [29] built a feature fusion architecture with pyramid feature maps and a jumping connection. These architectures demonstrated notable performance increases. SR-based and context-based methods generally explicitly design a module specifically used for super-resolving RoIs or encoding context information, which can significantly increase the computation cost. Therefore, these algorithms are difficult to be deployed on UAVs.
MR-based methods
The MR-based methods first use different level features to represent objects and then recognize these objects in separate feature levels [30,31,32,33]. Specifically, a high-level feature with a low resolution treats an object as a whole, and a low-level feature with a high-resolution focuses on the object's parts, such as its boundaries. Such as MDSSD [34], DR-CNN [35], and MR-CNN [36]. These methods build the coarse-grained features, which treat each object as a whole region and process them separately. However, this strategy neglects the fine-grained features in an object, which has been demonstrated to improve object detection performance [37, 38]. Furthermore, there is severe background interference in the combination of low-level and high-level features. The background interference, in turn, adversely affects the learning in the subsequent layers, resulting in misclassifications in the final predictions, especially for recognizing small objects.
Anchor-based methods
The Anchor-based methods set multiple discrete-scale base boxes at each pixel point of the image to ensure that the recall closely matches the ground truth. As anchors can only regress the box in a limited range, the object beyond the bound regression is easily ignored by networks [39]. As such, the anchor scale discontinuity problem needs to be addressed. Setting massive anchor boxes on each image pixel point has become a commonly accepted practice. However, this undifferentiated tiling strategy requires significant computing resources and does not achieve suitable results for particular remote sensing objects. For this reason, various adaptive anchor strategies have been proposed [40,41,42]. But a new problem has arisen: hyperparameter settings results in the low generalization of the anchor strategy. To this end, the anchor-free approach was put forward [43,44,45,46,47]. It treats object location as the key point detection mechanism and assigns the problem of setting information, such as the size and direction of the object, to the network, completely avoiding the headache of setting the priority information. But anchor-free approaches will lead to too many bounding boxes, increasing the cost of network regression.
Hybrid-model-based methods
The hybrid-model-based method combines the advantages of CNN and Transformers. Transformers have been widely used in computer vision in recent years, such as ViT [48] and DETR [49]. But as illustrated in How Do Vision Transformers Work? [50], Transformer is a bottom-up modeling method, whereas CNN is a top-down one. Therefore, Transformers typically require a large amount of data for pre-training. Thus lots of hybrid models have been proposed, such as Conformer [51], Mixformer [52], CvT [53], TPH-YOLOv5 [54], and CoAtNet [55]. Most existing hybrid models employ a parallel architecture or incorporate CNN as a minor component into the Transformer backbone. So they still end up applying to extensive datasets. Considering that UAV image datasets do not have many samples, it is evident that such a network design cannot exploit the power of Transformers.
Methodology
Overview
Object detection in UAV images must urgently address the following two issues: first, the network structure design does not emphasize the importance of high-resolution features. Existing networks lacked continuous feature extraction of high-resolution feature maps, which resulted in inadequate location information. Second, the feature extraction module is singular, and there is an absence of targeted extraction module design and insufficient semantic information extraction for feature maps of varying sizes.
These problems [14] have long plagued object detection in UAV images. HRCTNet addresses the issues above mainly through two innovations. On the one hand, it proposes a multi-resolution parallel network structure, and by repeatedly extracting features from high-resolution maps, the network can obtain more location information. On the other hand, HRCTNet adopts three feature extraction modules. Its main idea is to construct the different sizes of receptive fields to gain semantic information of different scales, as shown in Fig. 1.

Display of different receptive fields of SKBlock, LKBlock, and CTBlock
In addition to the above two major innovations, HRCTNet also makes some improvements in the implementation stage. As GhostNet [56] stated, excessive convolutions will inevitably result in redundant features. However, unlike GhostNet, HRCTNet introduces Acon into convolution operations. Acon determines which neurons should be activated during training, thereby reducing the redundant features. Furthermore, Acon helps prevent dying ReLU. Lastly, slight tweaks have been made to the Focal Loss in HRCTNet, referred to as Ployloss, making the network more suitable for object detection in UAV images. Experiments demonstrate that the optimal choice of Ployloss hyperparameter can enhance the performance of HRCTNet.
Multi-scale feature extraction modules
SKBlock
We proposed a novel module SKBlock in HRCTNet. Given an input feature map \(\mathbf{X}\in {\mathbb{R}}^{D\times W\times H}\), where \(D\) is the dimension of the input feature, and \(W\) and \(H\) are the height and width of the input data. The main structure of SKBlock can be present in Eq. (1). In SKBlock, \(SKConv\) presented as \(\phi (\cdot )\) is used. Each \(SKConv\) contains three parts: 2D convolution, batch normalization, and Acon activation, which present Conv2d, BN, and Acon in Fig. 2a. An operation \(f\left( \cdot \right)\) is applied between two \(SKConv\) s.
where \(m\) is the number of the uses of \(f(\cdot )\), \(\mathbf{Y}\in {\mathbb{R}}^{{D}^{\mathrm{^{\prime}}}\times {W}^{\mathrm{^{\prime}}}\times {H}^{\mathrm{^{\prime}}}}\) is the output feature maps with new shape. In each \(SKConv\), BN is used to deal with the sample imbalance problem, specifically in UAV image datasets. Figure 2c shows the distribution of four groups of normal distribution data and the distributions after batch normalization. One can see that data from all categories concentrated to 0. Furthermore, through experiments, we found that only adding BN in the convolution part has limited improvement on UAV image datasets, so we innovatively add BN into the residual connection. Details will be discussed in section “LKBlock”. The network can learn the correlation between channels by incorporating a channel attention mechanism. Thus, the channel attention model is used as \(f(\cdot )\). Finally, the formulation of SKBlock is given as Eq. (2).

a Shows the composition of SKBlock. b Shows the composition of LKBlock. c Shows the effect of BN in dealing with sample imbalance
LKBlock
For a long period, large kernel convolutions have been criticized for their abundant computational consumption. Even PyTorch and TensorFlow have unique optimization for small kernel convolutions. But as Park et al. illustrated in HOW DO VISION TRANSFORMERS WORK? [50], the Multi-head self-attention(MHSA) reaches astonishing results by modeling the whole feature map. In other words, MHSA is a special convolution operation with a kernel the same size as the feature map. However, due to the computational complexity of the MHSA module being square with the size of feature maps, MHSA's application on large feature maps(e.g., \(1/16\) and \(1/32\) of the original size, respectively) will bring huge computational consumption, which is unacceptable for a lightweight network. So when we design the middle feature extraction module, we naturally think about enlarging the receptive field by adopting the large convolution kernel.
So to explore the full potential of large kernel convolutions, we propose a large-kernel convolution block, LKBlock for HRCTNet in this paper. When the feature maps are \(1/16\) and \(1/32\) of the original size, due to the choice of Depthwise convolution and the size of kernels in LKBlock, the computational cost of LKBlock is acceptable. Ablation study details about the choice of large-kernel sizes are discussed in Section "Performance variation with different sizes of kernel". The LKBlock can be formulated as Eq. (3).
where \({\mathbf{X}}^{\mathrm{^{\prime}}}\in {\mathbb{R}}^{D\times W\times H}\) denotes feature maps in the third and fourth stages in HRCTNet. \(Conv\) is an ordinary 1 × 1 convolution, and it shrinks channel number to half, as depicted in Fig. 2b. Due to even though Depthwise convolution can significantly reduce the computational cost, without shrinking channels, it still comes with a considerable increase in floating point of operations(FLOPs) and parameters when applying LKBlock. After that, the second \(Conv\) is used to restore the channel for further feature extraction. It is a \(3\times 3\) convolution to extract more information. Like SKBlock, activation is only employed in the second \(Conv\), and batch normalization is also employed in residual connection.
CTBlock
Attention-based models [57,58,59,60] have been introduced to the vision domain for years. Traditionally, scaled dot-product attention in vision Transformers [48, 61] is formulated as Eq. (4).
the input sequence of vectors is formulated by the concatenation of a class token \(CLS\) and the flattened feature vectors \({x}_{1}, \cdots , {x}_{hw}\) as image tokens from the feature maps \(F\in {\mathbb{R}}^{D\times W\times H}\), and a total length of \(N=HW+1\). The softmax logits in Eq. (4) become unaffordable for high-resolution images (i.e., \(N "C\)) due to its \(O({N}^{2})\) space complexity and \(O({N}^{2})\) time complexity.
Inspired by LambdaNet [62], HRCTNet introduced a new conv-attention module called CTBlock, as shown in Fig. 3. HRCTNet proposes a linear self-attention mechanism to lower the computation complexity for high-resolution images. Inspired by recent works on the linearization of self-attention, we approximate the softmax attention map by factorizing it using two functions \(\phi (\cdot )\), \(\psi (\cdot )\): \({\mathbb{R}}^{N\times C}\to {\mathbb{R}}^{{N}^{\mathrm{^{\prime}}}\times {C}^{\mathrm{^{\prime}}}}\) and compute the second matrix multiplication (keys and values) together, as showed in Eq. (5).
where \(\mathrm{FA}\) is the abbreviation of Factorized Attention. Following the instruction of LambdaNet, the projection we used in CTBlock for \(\phi \mathrm{and} \psi\) is identity function and softmax. The entire formulation is given in Eq. (6).
where \(softmax(\cdot )\) is applied across the tokens in the sequence in an element-wise manner and the projected channels. In LambdaNet, the scaling factor \(Q/\sqrt{C}\) is implicitly included in the weight initialization, while our factorized attention applies the scaling factor explicitly. This factorized attention takes \(O(NC+{C}^{2})\) space complexity and \(O(N{C}^{2})\) time complexity, significantly increasing the inference speed and reducing the computational cost.

Overview of CTBlock
High-resolution conv-trans network
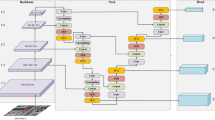
Figure 4 illustrates the overall architecture of HRCTNet. HRCTNet starts from high-resolution, gradually adding high-to-low-resolution streams as new stages. The multi-resolution streams are connected in parallel. The main body consists of a sequence of stages. In each stage, the feature representation of the resolution stream is updated with multiple feature extraction blocks (SKBlock, LKBlock, CTBlock) independently. At the same time, the information across resolutions is exchanged repeatedly with the convolutional multi-scale fusion modules.

Overview of HRCTNet
This structure is inspired by HRNet [63], but there are many significant differences between HRNet and HRCTNet. (I) HRNet only designs a backbone structure, and its internal feature extraction module is single and needs to be combined with neck structures such as FPN and BiFPN. HRCTNet can have excellent performance without an enhanced feature extraction network by introducing three feature extraction modules. In other words, HRCTNet innovatively integrates the backbone and neck structures, which simplifies the network design.
(II) On the basis of HRNet, HRCTNet adds one more branch and introduces the self-attention module: CTBlock to the last branch. It can make use of the powerful global modeling ability of the MHSA. Also, it enhances the generalization and robustness of HRCTNet without introducing too much extra computational cost. Moreover, after the feature extraction, the feature maps of the last branch are not input into the detection head. As mentioned above, the MHSA usually has slow convergence problems and a large amount of data demand. Not using the last branch for regression calculation can ensure the convergence speed of the network.
(III) Because UAV images have objects with different angles, it is difficult to guarantee the robustness of the model to image flipping and rotation only by conventional convolution, and HRCTNet does not use a feature enhancement network. So in addition to designing three feature extraction modules and adding a branch, we also use asymmetric convolution groups to enhance the robustness of the network before regression calculation. Its composition structure is shown in Fig. 5. Mainly through a combination of 1 × 3 and 3 × 1 convolution, and the bottleneck structure to enhance feature extraction, and the rotation invariance of asymmetric convolution is used to improve the network's ability to deal with different angles of detection targets and network's robustness.

Overview of C3x
(IIII) The design of convolutional multi-scale fusion modules is different from the original HRNet. HRCTNet uses a group of learnable parameters to decide the features' importance.
In brief, our network can be logically described as Fig. 6.

Logical description of HRCTNet
\({\mathcal{N}}_{sl}\) in Fig. 6 is a sub-stream in the \(s\) th stage and \(l\) is the layer index. The layer index of the first stream is \(s=1\). The resolution of index \(s\) is \(1/{2}^{s-1}\) of the resolution of the first stream. Detailed information of network layer parameters is illustrated in Table 1. HRCTNet features four blocks stacked in SKBlock and LKBlock to extract features, making the network acquire richer location information and semantic features.
Implementation details
In addition to the above main changes, HRCTNet has some other minor modifications: first, we changed our activation function from ReLU to Acon. As shown in Table 1, to fully exploit the information from feature maps, HRCTNet employed numerous convolutions. Through Han et al.'s analysis in GhostNet: More Features from Cheap Operations [56], numerous convolutions will inevitably bring redundant features, and excessive use of ReLU will increase the probability of dying ReLU.
To this end, HRCTNet adopted Acon. It is an improved version of ReLU. As shown in Fig. 7 (a), ReLU is a simple piecewise function to avoid gradient vanishing. However, it also brings a new problem: dying ReLU. Acon introduces two groups of learnable parameters \({p}_{1}\), \({p}_{2}\) to make the activate function self-adaptively adjust in the training process. Moreover, another parameter \(\beta\) which is calculated channel-wise to control whether neurons should activate or not. As shown in Fig. 7b, the network can choose the most appropriate activation function by learning \({p}_{1}\), \({p}_{2}\) channel-wise. At the same time, Acon can selectively activate neurons by adjusting \(\beta\), thus reducing the amount of computation and effectively improving the network's overall performance. A simple example of changes of a set of values after entering Acon is depicted in Fig. 7c.

Illustration of the functionality of Acon
Another modification is that instead of using common Focal Loss to compute class and object loss, HRCTNet adopted Ployloss. Essentially, HRCTNet is a single-stage object detection structure. In the prediction stage, redundant predicted Bounding Boxes(BBox) would be generated according to the preset anchors. One of the characteristics of UAV images is that there are many targets in a single picture, usually hundreds of them, and they are all close to each other, which will lead to the generation of redundant negative samples. And thus, Focal Loss is needed. Furthermore, object detection in UAV images is different from general object detection, and data distribution is highly uneven. For example, the frequency of the two types of labels, person and car, will be much higher than in other categories, but there will be no such extreme situation in the general object detection datasets. Therefore, it is necessary to adopt a targeted loss function according to the characteristics of this kind of dataset.
That is why HRCTNet adopted Ployloss. It is inspired by the Taylor expansion of Cross-Entropy loss and Focal Loss in the bases of \({\left(1-{P}_{t}\right)}^{j}\) as given in Eqs. (7) and (8), respectively.
according to the definition of Taylor expansion, the effect of changing the first term leads to the most significant gain, so by adding a \(\varepsilon\) to \(\left( {1 - P_{t} } \right)\), we can find the loss function that is most suitable for object detection in UAV image. The formulation of Ployloss is shown in Eq. (9).

As illustrated in Algorithm 1, by adjusting the hyperparameter \(\varepsilon\), we can get different forms of Focal Loss. Moreover, Ployloss can still handle the imbalance of positive and negative samples well because it is only a minor change. Empirical studies found that this simple modification leads to a significant gain in performance. As is evident from Algorithm 1, it only modifies the original Focal Loss by a single line of code. So all the training hyperparameters optimized for Focal Loss can be applied without any change. That means there is no need for grid search to find suitable hyperparameters, which saves much computational cost. The ablation experiments are shown in section “Effect of ployloss parameter”.
Experiment
Experimental settings
Datasets
MS COCO [64] dataset contains lots of small targets, and it is a standard dataset in object detection. It contains over 200,000 images and 250,000 person instances. HRCTNet was trained on COCO train2017 and evaluated on COCO val2017, including 117,266 and 4952 images.
VisDrone2019 [11] provides a dataset of 10,209 images, and 6471 images are exploited to train HRCTNet in this paper. The object categories mainly comprise people and vehicles in daily life. The ten categories provided by the dataset include pedestrian, person, bicycle, car, van, truck, tricycle, awning tricycle, bus, and motor. As it contains a larger number of smaller targets and is more difficult to detect than other existing datasets, its excellent performance can represent the good performance of HRCTNet in the object detection task in UAV images to a certain extent.
DOTA[65] is another common dataset for object detection in UAV images. There are 15 categories in this dataset. Due to there being enough small targets, all of which are UAV images, the DOTA dataset is suitable as a measurement index. We used 10,276 pictures to train and 3278 for validation.
In addition, we use the VOC dataset to analyze some experimental results and do some ablation studies due to our limited GPU resources. We used 16,551 images in the VOC dataset (including VOC-2007 and VOC-2012) to train and 4952 images to evaluate. And we conducted three ablation experiments (effectiveness of BN, large kernel size and Ployloss parameter) on VOC.
Evaluation metrics
In the Ablation Study Section, we use two evaluation metrics, FLOPs and Parameters for the comparison of model size, and average precision(AP) for comparing performance. Finally, we use frames per second(FPS) to measure the inference speed of the model.
AP refers to the area under the PR curve composed of precision rate and recall rate and is expressed as: \({\int }_{0}^{1}P(r)dr\), where \(P(r)\) is the PR curve drawn using the points on the vertical axis of precision and the point of recall rate on the horizontal axis. The calculation formulas of precision rate and recall rate are shown in Eqs. 10 and 11:
where \({P}_{\mathrm{r}}\) represents the ratio of the number of bounding boxes of correctly identified object categories to the total number of bounding boxes of the identified object category. \({R}_{\mathrm{e}}\) is the ratio of the number of bounding boxes of correctly identified object categories to the total number of bounding boxes in the ground truth. \({P}_{\mathrm{TP}}\) represents the number of bounding boxes whose IoU values (normally set to 0.5) of the actual and predicted boxes are greater than the set threshold. \({P}_{\mathrm{FP}}\) represents the number of bounding boxes whose IoU value of the real and predicted boxes is less than the set threshold. \({P}_{\mathrm{FN}}\) represents the number of ground truths that have not been detected. AP is a useful metric because it takes into account both precision and recall, and it provides a single number that summarizes the algorithm's performance across all IoU thresholds. For VisDrone and MS COCO datasets, we mainly use AP to evaluate the model's performance, In detail, AP is \({\mathrm{AP}}_{0.5:0.05:0.95}\), it refers to the computation on the average value over all ten IoU thresholds from 0.5 to 0.95 with the step size 0.05. In addition, we also have some other evaluation indicators, mAP50 is mean average precision when IoU threshold is 0.5. APS is also a critical measure on MS COCO dataset, it refers to AP for small objects: area < 322, this is vital to measure the detection ability of small objects.
FPS is the evaluation index of detection speed. FPS represents how many pictures the network model can process per second. For example, the average time required for a small object detection algorithm to process a picture is 0.02 s, then FPS = 1/0.02 = 50.
Implementation details
Our experiment was trained and tested on the device equipped with NVIDIA GeForce RTX 3080 and Intel Xeon w-2295 3.00 GHz. All codes are based on PyTorch 1.11.0 and python 3.8.
In the process of determining the parameters, because of the large number of comparative experiments and high consumption, we chose the VisDrone and VOC datasets to verify the correctness of model parameters. Specifically, we used the VisDrone dataset to verify the rationality of branch selection, the grouping of large, small, and medium-sized feature maps, and the application of modules. To verify the effectiveness of BN, select the appropriate convolution kernel size in LKBlock, and select the reasonable parameters of Ployloss, we used the VOC dataset.
The specific ablation experiments' parameters are as follows: First, on VisDrone, we loaded the pre-trained model obtained by training 300 epochs on the COCO dataset, and the input picture size was 640 × 640. Second, we use 640 × 640 to fine-tune on the VisDrone, and the number of training epochs is 150. The epoch numbers for warmup are all three. On VOC, since the sample distribution of VOC is suitable for model training, we trained from scratch, and the training epochs is 300. All parameters and GFLOPs are obtained with the input picture size of 640 × 640.
Later, when comparing with SOTA models, the pictures' resolution for VOC and COCO datasets in the training process are 640 × 640 and 1024 × 1024 for VisDrone and DOTA datasets. SGD optimizer is adopted to update parameters for 300 epochs. The learning rate is initialized to 1e–2, the momentum and the weight decay are 0.937 and 5e–4, respectively. For VOC and COCO, we trained from scratch. For VisDrone and DOTA, we fine-tuned the pre-trained model, which is trained on COCO. Finally, we use the NMS with 0.55 IoU threshold to remove redundant predictions.
Finally, in the subsequent comparison with SOTA models, the data of HRNet and YOLOv5 models are reproduced through the local environment, and the training parameters are consistent with HRCTNet on each dataset. The results of other models are quoted: COCO [63, 66], VisDrone [67], DOTA [65].
Ablation Study
Necessity of 5-branch structure
In Sect. 1, we mentioned that the pyramid network does not consider the retention of high-resolution features. In the process of down-sampling and up-sampling, the location information is destroyed, which is not conducive to object detection in UAV images. So we decided to use a multi-branch parallel network structure for feature extraction to ensure that high-resolution features remain intact, which brings another question: what value should be selected for the number of branches?
To this end, first, to ensure the ability of small target detection, we select four detection heads for the final regression calculation, the number of branches should be close to 4, so we initially designed a four-branch network for training, and its results are not close to the existing SOTA models. Then we consider that our model needs to adapt to the low computing power of edge devices, so we try to reduce one branch, but the results are even worse. And because only one branch with LKBlock is reduced, the amount of computation and the number of parameters is not significantly reduced. So naturally, we are considering continuing to add branches to the four-branch network.
There are three parameters \(b, g, m\) that mainly affect the model's performance. They represent the number of branches, grouping selection, and module selection. Due to section “CTBlock” mentioned that one of the prerequisites for applying CTBlock is that the feature map is small enough that the cost of introducing CTBlock will not be a burden. So applying CTBlock to the large feature maps is unacceptable. When the network is expanded to 6 branches and grouped feature maps according to 2:2:2, the number of parameters is nearly four times higher than that of the 5-branch network (4.48B FLOPs → 16.06B FLOPS). So when adding branches, we uniformly introduce LKBlock to measure performance.
Second, our ablation experiment for branches consists of four sets of data: three branches, four branches, five branches, and six branches. we fixed the groups, and they are 2:1, 2:2, 2:2:1, 2:2:2 to avoid the problems caused by different grouping. This can ensure that the main structure of the network remains unchanged and more clearly reflect the impact of branch selection on the performance of the network model.
Finally, the experimental ablation results are shown in Fig. 8a. As shown in the figure, when the branch is 5, the model's performance is optimal. At the same time, FLOPs do not increase significantly compared to the model with fewer branches, and the inference speed remains fast (31 FPS), which has an advantage compared to other models, so HRCTNet finally adopts five branches.

Ablation studies on branch and group
Rationality of grouping feature maps
After determining the branches, we will next decide on another crucial parameter \(g\). This represents how HRCTNet groups five different sizes of feature maps. At the beginning of designing HRCTNet, we abandoned the neck structure, thus simplifying the network. So, we first directly applied the method of extracting network features in HRNet to HRCTNet. However, HRNet performs uniform feature extraction operations on feature maps of all sizes, as shown in Eq. (12).
where \({F}_{\mathrm{in}}\) and \({F}_{\mathrm{out}}\) represent the input and output feature maps, respectively. \(HRConv\) is the combination of ordinary 3 × 3 convolution, ReLU activation function, and BN. In experiments, we found that although this design is simple and straightforward, the performance is not as good as expected. It also shows that this simple backbone design must be used in conjunction with neck structure, that is, feature enhancement network.
So, in HRCTNet, we decided to group feature images of different sizes and apply different modules to improve the ability of feature extraction. As for how to group, we first have a precondition, as mentioned in the previous section, CTBlock can only be applied to the small feature maps to avoid excessive computation when MHSA is introduced. Therefore, the remaining four branches are divided into four groups: 4:0, 3:1, 2:2, 1:3, and 0:4. On the large feature map, we use SKBlock for feature extraction. On the medium feature map, we use LKBlock, and on the small feature map, we use CTBlock.
The final experimental results are shown in Fig. 8b. As we can see from the figure, as more and more branches are classified into medium sizes, the FLOPs of the network are also increased. Before the grouping reaches 2:2:1, the network performance is improved with the increasing introduction of LKBlock, but after that, the network performance starts to decrease to a certain extent. At the same time, due to the introduction of large convolution kernels in large feature maps, the amount of computation is also huge. So after weighing the performance and computation, we finally chose the 2:2:1 grouping method.
Feature extraction module choosing strategy
Finally, there is the last parameter \(m\) remains undetermined. First, we know that introducing CTBlock on large feature maps comes with an increase in the amount of computation, which is unacceptable. So in this part of the ablation experiment, we fixed the CTBlock on the small and medium-sized feature maps. Due to the computation cost of SKBlock and LKBlock is not huge compared with CTBlock, applying them on smaller feature maps will not bring a noticeable performance impact.
So, we tested eight different combinations, as shown in Table 2. First, we can see that the design of a single feature extraction module cannot achieve the optimal result. Similarly, if only two feature extraction modules are used, the performance cannot be optimal, which shows that the combination of SKBlock, LKBlock and CTBlock is reasonable. We speculate that when the feature maps are large, using small convolutions for feature extraction helps the model learn adequate location information. Using large convolution in the middle stages and keeping the kernel size smaller than the feature map area helps the network obtain more semantic information. In the last stage, using conv-attention modules, the whole feature maps are extracted globally, and the learning ability of the Transformer helps HRCTNet to utilize global features fully. Therefore, we think using SK-LK-CT to run through the model is the optimal solution.
The Effectiveness of batch normalization
At the initial stage of building our model, the performance on the VisDrone dataset was not as expected. The label distributions are uneven in VisDrone and DOTA, as shown in Fig. 10. Also, the positive and negative samples are uneven due to HRCTNet being a single-stage algorithm. To this end, we think adding a certain amount of batch normalizations will help enhance the learning ability of the model. Furthermore, where to add batch normalization is also a question. Improper use of batch normalization will reduce the sample difference and artificially increase the difficulty of training and destroy the feature space, making the result unsatisfactory. Inspired by EfficientNetV2 [68], we tried to add batch normalization at residual connections. The experimental results showed that adding batch normalizations can significantly improve the network performance, which is our adopted method.
Performance variation with different sizes of kernel
As mentioned above, we speculated that in the middle stages, the convolution kernel size must be close to the size of the feature maps, neither too big nor small. The results shown in Table 3 proved this conjecture to be correct. First, we started with 11 × 11, a relatively large size, and then we gradually increased the size. When the convolution kernel reached 13 × 13, the model achieved the best results; then as the convolution kernel size continued to increase to 21 × 21, the performance decreased to a certain extent. At this time, both parameters and the calculation amount will be exponential. The parameters can be easily calculated by Eq. (13).
as \({k}_{w}, {k}_{h}\) are the height and width of convolution kernel, \({C}_{\mathrm{in}}, {C}_{\mathrm{out}}\) are the in-channel and out-channel of a convolution layer. We can know by simple calculation this is too much for a lightweight network to burden.
So finally, we chose 13 × 13 as the final convolution kernel size for the middle stages. We assume that in the third and fourth stages, while the convolution kernel is too small, the network tends to extract obvious location information. However, there is little location information left in the feature maps, and it is useless to extract again. LKBlock is like a simple identity function with lots of unnecessary computation when the convolution kernels are too large. Therefore, the size of 13 × 13 convolution kernel is reasonable.
Effect of ployloss parameter
Hyperparameter \(\varepsilon\) is introduced into Ployloss to help loss function better adapt to different data distributions in different datasets, especially in aerial image datasets. There may be much data concentrated in one or two categories. For example, cars are too many in the VisDrone dataset. And there is a similar situation in the DOTA dataset. Therefore, applying Ployloss in HRCTNet is necessary. Additionally, fine-tuning Ployloss by \(\varepsilon\) will not affect the characteristics of Focal Loss, in contrast, it will give full play to its advantages. And the comparative experimental results in Table 4 also confirmed this point. Its value is finally determined to be 2.0 after our detailed ablation study. Too high or too low a parameter value will bring problems such as slow convergence and decreased accuracy as we observed.
Comparison to SOTA detectors
Performance on mainstream datasets
In this Section, we will prove the effectiveness and feasibility of HRCTNet from multiple dimensions through visualization of test results, tables, graphs, and text description. First, from Fig. 9, we can see that compared with HRNet and YOLOv5, HRCTNet has improved the detection density and accuracy where the density of objects is higher, and the pixels per inch of a single target is more petite. Compared with the other two networks, HRCTNet is more sensitive to the information on the critical location of the target, and the focused area is more accurate. Owing to the brand-new structure and extraction modules, HRCTNet reached comparative results in serval datasets. Figure 10 depicts the label distribution of the VisDrone dataset and DOTA dataset. From the figure, we can see that their sample distribution is highly unbalanced. This kind of imbalance will make the model biased toward the category with more samples during training and reduce the detection ability of labels with fewer samples. That is why HRCTNet introduced Ployloss. With this Focal-Loss-like loss function, HRCTNet can adapt to this dataset without much modification. Although HRCTNet has achieved good results on many datasets, it is undeniable that there are still some problems in our network. As mentioned in this paper, it can be seen from Fig. 12a that due to the implementation of CTBlock, the peak arrival time of network performance is delayed, that is to say, when computing resources are extremely limited, the network may not achieve competitive performance. And in some categories, HRCTNet cannot achieve the best results, we also analyze the reasons in detail in the following comparison. Next, we will analyze the specific results on each dataset.

The feature extraction capabilities of YOLOv5, HRNet, and HRCTNet

Examples of sample unevenness in UAV image datasets
First, the comparison results of different methods on the MS COCO dataset are shown in Table 5. The detection accuracy has reached 37.9% in AP. As we can see from the table, HRCTNet with limited computational cost, has outperformed many standard models. Specifically, on the strict metric AP50, HRCTNet has achieved 57.6%. On the strict metric AP75, HRCTNet has reached 40.9%. In APS, an indicator that pays more attention to the ability of small object detection, HRCTNet reached the best. Meanwhile, the parameter quantity is reduced by 82% compared to FCOS which is the second best in the table.
Meanwhile, we also observed that the result of AP50 is not optimal, which is 0.9% lower than that of LRF512. HRCTNet abandoned the classic design structure of Backbone + Neck, but integrated them. Without using the popular backbone and neck structures, we can only train from scratch on COCO. Whereas most of the networks we compare adopt the design of Backbone + Neck structure, so they can use the pre-trained backbone on ImageNet. As For APL, HRCTNet is aimed at object detection in UAV images, it pays more attention to the small and medium-sized targets in the images, so it sometimes causes HRCTNet mistakenly identify the large targets as the background.
Overall, even though we cannot beat SOTA models in some ways so far, we have much less computational cost and fewer parameters in exchange for a fair result, which we can dig deeper to explore its true potential.
Second, as on the VisDrone dataset, Table 6 displays the experimental results compared with the existing methods. It shows that HRCTNet can improve the accuracy of many kinds of small targets. The precision improvement is different with distinct types of targets. Person, car, and motor's accuracy are improved the most, with an average increase of 10.7% compared to HRNet. Besides, in pedestrian, bicycle, and van classes, HRCTNet still has some advantages. Straightly compared to HRNet and YOLOv5, our mechanism increases the detection accuracy AP by 11.6% and 9.3%, respectively. On other single-stage detectors, HRCTNet still has some advantages to them.
In addition, we can see that in the four categories of Truck, Tricycle, Awning Tricycle, and Bus, HRCTNet has not achieved the best results. We concluded the possible reasons. HRCTNet uses the model pre-trained on the COCO dataset. By observing the data distribution characteristics of COCO, we find that COCO has no category related to Tricycle. So we have no prior knowledge of Tricycle and Awning Tricycle. As for Truck and Bus, we think the sample gap between these two categories is extremely small. HRCTNet has reached or surpassed the SOTA model in most categories, which means that HRCTNet has powerful performance under the premise of small computation.
Also, as shown in Fig. 11, the confusion matrix visualizes the classification of each category on VisDrone. Each row represents the predicted categories, each column represents the actual categories, and the data on the diagonal line represents the proportion of categories that were correctly classified. The experimental data show that HRCTNet is sufficient to avoid the situation of low target confidence and undetected. Moreover, this mechanism has robustness and generalization ability.

The confusion matrix from the HRCTNet results on the VisDrone dataset
Third, the experimental data in Table 7 shows that HRCTNet has superior accuracy in many categories compared to other target detection algorithms on the DOTA dataset. Most of the images in the DOTA dataset have identical characteristics, such as small pixel area of objects to be detected, close arrangement or even coincidence of objects, and little color difference between background and objects, which are not conducive to efficient and accurate detection. While the parallel network structure adopted by HRCTNet and the redesigned SKBlock have very efficient detection abilities for small targets in the pictures. In ships, storage tanks, basketball courts, bridges, small vehicles, helicopters, and other categories, HRCTNet has an advantage of more than 5%.
It is worth noting that the performance of HRCTNet on Plane, Tennis court, and Basketball court is not ideal. This is because the planes in COCO dataset are generally in a horizontal position, while in DOTA, they are all aerial images, the planes are captured at the overlooking angle, and HRCTNet did not learn such objects well. As for Tennis court and Basketball court, we found that the two categories of objects have similar colors and areas, which is difficult to distinguish. Except for this little flaw, HRCTNet is a suitable algorithm for object detection in UAV images that is easier to deploy to edge devices.
Lastly, we showed some curves in the training process. Through Fig. 12a, we can see that with the Transformer module, the initial convergence speed of HRCTNet is not as fast as YOLOv5. However, since the 175 epoch, Transformer's stronger semantic information extraction ability has begun to show, and the result has surpassed YOLOv5. And from Fig. 12b, the P-R curve shows HRCTNet has better precision and recall throughout the training process. Therefore, the performance of this algorithm to detect small objects outperformed the YOLOv5 algorithm and the HRNet algorithm.

AP curve and P-R curve of four different models
In Fig. 13, we presented three different models' box loss curves and class loss curves. As depicted in the figures, HRCTNet has better convergence performance. At the same time, as we can see from Fig. 13, the convergence speed of HRCTNet is not much different from that of YOLOv5, by carefully implementing the self-attention module, as a hybrid network, the convergence speed of HRCTNet is almost the same as that of the pure CNN network. Also, compared with HRNet, due to the addition of a variety of corresponding feature extraction modules and the optimization in many aspects, the convergence of loss during training is more stable without abnormal fluctuations.

Box loss curve and Class loss curve of three different models
Computation cost comparison
We insist on removing the neck structure and using a unified feature extraction network. The main reason is to design a lightweight network to adapt to the low computing power of edge devices. Therefore, it can be imagined that our network has the characteristics of small computation cost and fast inference speed.
From Table 8, we can see that compared with other mainstream object detection models, the parameters and computational cost of HRCTNet are relatively small, which means that HRCTNet can save computing resources and time and run on low-end hardware, which has good portability and compatibility. Moreover, as a backbone structure, it can be applied to many downstream tasks, play a role in many fields, and has a broad application prospect. At the same time, since the small parameters of the model, it can be deployed on the device side and ported to edge computing devices such as mobile devices or IoT devices, which provides the possibility for more intelligent edge computing. Compared with other large-scale models, HRCTNet has shorter training and prediction time, which can improve computational efficiency when processing large amounts of data. To sum up, from the perspective of implementation and computational point of view, HRCTNet has good feasibility. This small-scale and high-efficiency model is expected to play a more significant role in computing, embedded and device-side applications.
In Fig. 14, we visualized the performance of HRCTNet with some classical small object detection algorithms in many dimensions. The horizontal axis represents the inference speed, the vertical axis represents the AP results of different models on the MS COCO dataset, and the circle area represents the values of FLOPs and parameters calculated by \(30\times (FLOPs+Params)\) in the reasoning stage. The experimental platform uses a single RTX 3080. As we can see from the figure, compared with many models, the calculation amount of HRCTNet is significantly reduced, and from the point of algorithm performance, it is second only to R-FCN in the result and second only to YOLOv5 in inference speed. Therefore, HRCTNet balances speed and accuracy and reaches excellent results at a small computational cost. So in the case of real-time detection, our method is improved compared with the baseline.

Depiction of computation cost and performance
Conclusions
First of all, this paper analyzed the current situation in the field of object detection in UAV images and the existing problems of related methods, mainly in two aspects: (I) Lack of continuous extraction of high-resolution features, resulting in a serious lack of location information; (II) The design of the feature extraction module is single, which leads to the imperfect extraction of semantic information in the feature Maps. In response to these two problems, this paper presents a high-resolution hybrid network for object detection in UAV images. There are three fundamental differences between existing networks and HRCTNet: (I) Five parallel branches jointly operating feature extraction so the network can continuously obtain location and semantic information; (II) HRCTNet adopted three new feature extraction modules, different feature extraction modules for different feature maps effectively combine location information and semantic information; and (III) By adopting Acon and Ployloss, HRCTNet is more suitable for object detection in UAV images. Then, through detailed comparative experiments, the rationality of each parameter is demonstrated, and compared with the mainstream algorithms for object detection in UAV images on several datasets, the results show that our proposed HRCTNet is a strong backbone for object detection in UAV images.
Data availability
Data available on request from the authors.
References
Avola D, Cinque L, Diko A, Fagioli A, Foresti GL, Mecca A, Pannone D, Piciarelli C (2021) MS-faster R-CNN: multi-stream backbone for improved faster R-CNN object detection and aerial tracking from UAV images. Remote Sens 13:1670
Stojnić V, Risojevic V, Mustra M, Jovanovic V, Filipi J, Kezic N, Babic Z (2021) A method for detection of small moving objects in UAV videos. Remote Sens 13:653
Ma Y, Li Q, Chu L, Zhou Y, Xu C (2021) Real-time detection and spatial localization of insulators for UAV inspection based on binocular stereo vision. Remote Sens 13:230
Redmon J, Farhadi A (2018) YOLOv3: an incremental improvement. arXiv: arXiv:1804.02767abs/1804.02767
Bochkovskiy A, Wang C-Y, Liao H-YM (2020) YOLOv4: optimal speed and accuracy of object detection. arXiv: arXiv:2004.10934
Redmon J, Farhadi A (2017) YOLO9000: better, faster, stronger. In: 2017 IEEE Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Honolulu, USA, 2017), pp 6517–6525
Redmon J, Divvala SK, Girshick RB, Farhadi A (2016) You only look once: unified, real-time object detection. In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Las Vegas, USA, 2016), pp 779–788
Lin T-Y, Dollár P, Girshick RB, He K, Hariharan B, Belongie SJ (2017) Feature pyramid networks for object detection. In: 2017 IEEE Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Honolulu, USA, 2017), pp 936–944
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, Berg AC (2016) Ssd: single shot multibox detector. In: 14th European Conference on computer vision (ECCV), (Cham: Springer International Publishing, Amsterdam, The Netherlands, 2016), pp 21–37
Tao H, Cheng L, Qiu J, Stojanovic V (2022) Few shot cross equipment fault diagnosis method based on parameter optimization and feature mertic. Meas Sci Technol 33:115005
Zhu P, Wen L, Du D, Bian X, Fan H, Hu Q, Ling H (2021), Detection and tracking meet drones challenge. IEEE Trans Pattern Anal Mach Intell 44:7380–7399
Wen L, Du D, Zhu P, Hu Q, Wang Q, Bo L, Lyu S (2021) Detection, tracking, and counting meets drones in crowds: a benchmark. In: 2021 IEEE/CVF Conference on computer vision and pattern Recognition (CVPR), (Piscataway: IEEE Press, Electr Network, 2021), pp 7808–7817
Deng S, Li S, Xie K, Song W, Liao X, Hao A, Qin H (2021) A global-local self-adaptive network for drone-view object detection. IEEE Trans Image Process 30:1556–1569
Chen G, Wang HT, Chen K, Li ZJ, Song ZD, Liu YL, Chen WK, Knoll A (2022) a survey of the four pillars for small object detection: multiscale representation, contextual information, super-resolution, and region proposal. IEEE Trans Syst Man Cybern-Syst 52:936–953
Shen L, Tao H, Ni Y, Wang Y, Vladimir S (2023) Improved YOLOv3 model with feature map cropping for multi-scale road object detection. Meas Sci Technol 34:045406
Kim K-J, Kim P-K, Chung Y-S, Choi D-H (2019) Multi-scale detector for accurate vehicle detection in traffic surveillance data. IEEE Access 7:78311–78319
Stojanovic V, Filipovic V (2014) Adaptive input design for identification of output error model with constrained output. Circ Syst Signal Process 33:97–113
Min K, Lee G-H, Lee S-W (2022) Attentional feature pyramid network for small object detection. Neural Netw 155:439–450
Huang L, Chen C, Yun J, Sun Y, Tian J, Hao Z, Yu H, Ma H (2022) Multi-scale feature fusion convolutional neural network for indoor small target detection. Front Neurorobot 16:881021
Peng B, Ren D, Zheng C, Lu A (2022) TRDet: two-stage rotated detection of rural buildings in remote sensing images. Remote Sensing 14:522
Noh J, Bae W, Lee W, Seo J, Kim G (2019) Better to follow, follow to be better: towards precise supervision of feature super-resolution for small object detection. In: 2019 IEEE/CVF International Conference on computer vision (ICCV), (Piscataway: IEEE Press, Seoul, Korea (South), 2019), pp 9724–9733
Bashir SMA, Wang Y (2021) Small object detection in remote sensing images with residual feature aggregation-based super-resolution and object detector network. Remote Sens 13:1854
Ren S, He K, Girshick RB, Sun J (2015) Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39:1137–1149
Peng J, Wang H, Yue S, Zhang Z (2022) Context-aware co-supervision for accurate object detection. Pattern Recognit 121:108199
Zhang YH, Xu TB, Wei ZZ (2022) Pre-locate net for object detection in high-resolution images. Chin J Aeronaut 35:313–325
Tang X, Du SK, He Z, Liu J (2018), Pyramidbox: a context-assisted single shot face detector. In: Proceedings of the European Conference on computer vision (ECCV), (Cham: Springer International Publishing, 2018), pp 797–813
Kong Y, Feng M, Li X, Lu H, Liu X, Yin B (2021) Spatial context-aware network for salient object detection. Pattern Recognit 114:107867
Tan M, Pang R, Le QV (2020) EfficientDet: scalable and efficient object detection. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Electr Network, 2020), pp 10778–10787
Yuan Y, Xiong Z, Wang Q (2019) VSSA-NET: vertical spatial sequence attention network for traffic sign detection. IEEE Trans Image Process 28:3423–3434
Qiao S, Chen L-C, Yuille AL (2021) DetectoRS: detecting objects with recursive feature pyramid and switchable Atrous convolution. In: 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Electr Network, 2021), pp 10208–10219
Dai X, Chen Y, Xiao B, Chen D, Liu M, Yuan L, Zhang L (2021) Dynamic head: unifying object detection heads with attentions. In: 2021 IEEE/CVF Conference on Computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Electr Network, 2021), pp 7369–7378
Li YD, Dong H, Li HG, Zhang XY, Zhang BC, Xiao ZF (2020) Multi-block SSD based on small object detection for UAV railway scene surveillance. Chin J Aeronaut 33:1747–1755
Jiao J, Gao J, Liu X, Liu F, Yang S, Hou B (2021) Multi-scale representation learning for image classification: a survey. IEEE Trans Artif Intell 4:23–43
Cui L (2020) MDSSD: multi-scale deconvolutional single shot detector for small objects, Science China. Inf Sci 63:1–3
Liu Z, Li D, Ge SS, Tian F (2019) Small traffic sign detection from large image. Appl Intell 50:1–13
Liu Z, Du J, Tian F, Wen J (2019) MR-CNN: a multi-scale region-based convolutional neural network for small traffic sign recognition. IEEE Access 7:57120–57128
Song L, Li Y, Jiang Z, Li Z, Sun H, Sun J, Zheng N (2020) Fine-grained dynamic head for object detection. In: 2020 The Thirty-fourth Conference on neural information processing systems (NeurIPS), (New York: Curran Associates Press, Electr Network, 2020), pp 11131–11141
Han J, Yao X, Cheng G, Feng X, Xu D (2022) P-CNN: part-based convolutional neural networks for fine-grained visual categorization. IEEE Trans Pattern Anal Mach Intell 44:579–590
Wang GQ, Zhuang Y, Chen H, Liu X, Zhang T, Li LL, Dong S, Sang QB (2022) FSoD-Net: full-scale object detection from optical remote sensing imagery. IEEE Trans Geosci Remote Sens 60:5602918
Tian ZZ, Zhan RH, Hu JM, Wang W, He ZQ, Zhuang ZW (2020) Generating anchor boxes based on attention mechanism for object detection in remote sensing images. Remote Sens 12:2416
Yu YT, Guan HY, Li DL, Gu TN, Tang E, Li AX (2020) Orientation guided anchoring for geospatial object detection from remote sensing imagery. ISPRS-J Photogramm Remote Sens 160:67–82
Hou JB, Zhu XB, Yin XC (2021) Self-adaptive aspect ratio anchor for oriented object detection in remote sensing images. Remote Sens 13:1318
Shen JQ, Zhou WC, Liu NZ, Sun H, Li DG, Zhang YX An anchor-free lightweight deep convolutional network for vehicle detection in aerial images. IEEE Trans Intell Transp Syst 23:24330–24342
Shi LK, Kuang LY, Xu X, Pan B, Shi ZW (2022) CANet: centerness-aware network for object detection in remote sensing images. IEEE Trans Geosci Remote Sens 60:5603613
Wang P, Niu YX, Xiong R, Ma F, Zhang CX (2021), DGANet: dynamic gradient adjustment anchor-free object detection in optical remote sensing images. Remote Sens 13:1642
Ni L, Huo CL, Zhang X, Wang P, Zhou ZX (2022) GroupNet: learning to group corner for object detection in remote sensing imagery. Chin J Aeronaut 35:273–284
Cui ZY, Leng JX, Liu Y, Zhang TL, Quan P, Zhao W (2021) SKNet: detecting rotated ships as keypoints in optical remote sensing images. IEEE Trans Geosci Remote Sens 59:8826–8840
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N (2021) An image is worth 16x16 words: transformers for image recognition at scale. arXiv: arXiv:2010.11929
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: 16th European Conference on computer vision (ECCV), (Cham: Springer International Publishing, Electr Network, 2020), pp 213–229
Park N, Kim S (2022) How do vision transformers work? arXiv: arXiv:2202.06709
Gulati A, Qin J, Chiu C-C, Parmar N, Zhang Y, Yu J, Han Q, Wang S, Zhang X, Wu Y (2020) Conformer: convolution-augmented transformer for speech recognition. arXiv:2005.08100
Chen Q, Wu Q, Wang J, Hu Q, Hu T, Ding E, Cheng J, Wang J (2022) MixFormer: mixing features across windows and dimensions. In: 2022 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, New Orleans, USA, 2022), pp 5239–5249
Wu H, Xiao B, Codella NCF, Liu M, Dai X, Yuan L, Zhang l (2021) CvT: introducing convolutions to vision transformers. In: 2021 IEEE/CVF International Conference on computer vision (ICCV), (Piscataway: IEEE Press, Montreal, BC, Canada, 2021), pp 22–31
Zhu XK, Lyu SC, Wang X, Zhao Q, Soc IC (2021) TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In: 2021 IEEE/CVF International Conference on computer vision (ICCV), (Piscataway: IEEE Press, Montreal, BC, Canada, 2021), pp 2778–2788
Dai Z, Liu H, Le QV, Tan M (2021) CoAtNet: marrying convolution and attention for all data sizes. In: 2021 The Thirty-fifth Conference on neural information processing systems (NeurIPS), (New York: Curran Associates Press, Electr Network, 2021), pp 3965–3977
Han K, Wang Y, Tian Q, Guo J, Xu C, Xu C (2020) GhostNet: more features from cheap operations. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Electr Network, 2020), pp 1577–1586
Tay Y, Dehghani M, Bahri D, Metzler D (2022) Efficient transformers: a survey. ACM Comput Surv 55:1–28
Qin Z, Sun W, Deng H, Li D, Wei Y, Lv B, Yan J, Kong L, Zhong Y (2022) cosFormer: rethinking softmax in attention. arXiv: arXiv:2202.08791
Ma X, Kong X, Wang S, Zhou C, May J, Ma H, Zettlemoyer L (2021) Luna: Linear unified nested attention. In: 2021 The Thirty-fifth Conference on neural information processing systems (NeurIPS), (New York: Curran Associates Press, Electr Network, 2021), pp 2441–2453.
Lu J, Yao J, Zhang J, Zhu X, Xu H, Gao W, Xu C, Xiang T, Zhang L (2021) SOFT: softmax-free transformer with linear complexity. In: 2021 The Thirty-fifth Conference on neural information processing systems (NeurIPS), (New York: Curran Associates Press, Electr Network, 2021), pp 21297–21309
Touvron H, Cord M, Douze M, Massa F, Sablayrolles A, Jégou H (2021) Training data-efficient image transformers & distillation through attention. In: 2021 International Conference on machine learning (ICML), (PMLR, Electr Network, 2021), pp 10347–10357
Bello I (2021) LambdaNetworks: modeling long-range interactions without attention. arXiv: arXiv:2102.08602
Wang J, Sun K, Cheng T, Jiang B, Deng C, Zhao Y, Liu D, Mu Y, Tan M, Wang X, Liu W, Xiao B (2021) Deep high-resolution representation learning for visual recognition. IEEE Trans Pattern Anal Mach Intell 43:3349–3364
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: common objects in context. In: 13th European Conference on Computer Vision (ECCV), (Cham: Springer International Publishing, Zurich, Switzerland, 2014), pp 740–755
Xia G-S, Bai X, Ding J, Zhu Z, Belongie SJ, Luo J, Datcu M, Pelillo M, Zhang L-p (2018) DOTA: a large-scale dataset for object detection in aerial images. In: 2018 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), (Piscataway: IEEE Press, Salt Lake, USA, 2018), pp 3974–3983
Tian G, Liu J, Zhao H, Yang W (2022) Small object detection via dual inspection mechanism for UAV visual images. Appl Intell 52:4244–4257
Du D, Zhu P, Wen L, Bian X, Lin H, Hu Q, Peng T, Zheng J, Wang X, Zhang Y (2019) VisDrone-DET2019: The vision meets drone object detection in image challenge results. In: Proceedings of the IEEE/CVF international conference on computer vision workshops (CVPR), (Piscataway: IEEE Press, Long Beach, USA, 2019)
Tan M, Le Q (2021) Efficientnetv2: Smaller models and faster training. In: 2021 International Conference on Machine Learning (ICML), (PMLR, Electr Network, 2021), pp 10096–10106
Acknowledgements
The authors thank the editors and reviewers for their work on this manuscript. This work is supported by Important Research Project of Hebei Province (Grant No. 22370301D), Scientific Research Foundation of Hebei University for Distinguished Young Scholars (Grant No. 521100221081), Scientific Research Foundation of Colleges and Universities in Hebei Province (Grant No. QN2022107). This work is supported by the High-Performance Computing Center of Hebei University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xing, W., Cui, Z. & Qi, J. HRCTNet: a hybrid network with high-resolution representation for object detection in UAV image. Complex Intell. Syst. 9, 6437–6457 (2023). https://doi.org/10.1007/s40747-023-01076-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01076-6