
Abstract
The ability to capture pixels' long-distance interdependence is beneficial to semantic segmentation. In addition, semantic segmentation requires the effective use of pixel-to-pixel similarity in the channel direction to enhance pixel regions. Asymmetric Non-local Neural Networks (ANNet) combine multi-scale spatial pyramidal pooling modules and Non-local blocks to reduce model parameters without sacrificing performance. However, ANNet does not consider pixel similarity in the channel direction in the feature map, so its segmentation effect is not ideal. This article proposes a Mutually Reinforcing Non-local Neural Networks (MRNNet) to improve ANNet. MRNNet consists specifically of the channel enhancement regions module (CERM), and the position-enhanced pixels module (PEPM). In contrast to Asymmetric Fusion Non-local Block (AFNB) in ANNet, CERM does not combine the feature maps of the high and low stages, but rather utilizes the auxiliary loss function of ANNet. Calculating the similarity between feature maps in channel direction improves the category representation of feature maps in the channel aspect and reduces matrix multiplication computation. PEPM enhances pixels in the spatial direction of the feature map by calculating the similarity between pixels in the spatial direction of the feature map. Experiments reveal that our segmentation accuracy for cityscapes test data reaches 81.9%. Compared to ANNet, the model's parameters are reduced by 11.35 (M). Given ten different pictures with a size of 2048 × 1024, the average reasoning time of MRNNet is 0.103(s) faster than that of the ANNet model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Semantic segmentation aims to label each pixel in an image [1,2,3], a fundamental direction in computer vision tasks. Semantic segmentation is utilized extensively in automatic driving [4, 5], human–computer interaction [6], augmented reality [7] and medical imaging [8]. It is considered an intensive segmentation task, so it will inevitably increase the number of model parameters. Early deep convolution neural network is the main method of character recognition, such as MNIST [9]. In previous years, DCNNs became the mainstream of computer vision, including image classification networks [10, 11], and deep detection networks [12, 13]. Deep convolution neural networks have superior feature extraction capabilities when compared to the conventional machine learning methods. Specifically, Long et al. [14] directly applied the deep neural network to the entire image, and the convolution layer replaced the full connection layer, enabling FCNet to receive end-to-end training and enhancing semantic segmentation efficiency. Recent advancements in neural networks [11, 15] have promoted the emergence of a series of networks [16, 17]. FCN serves as the foundation of these networks. To extract features, their encoder increases the number of feature channels and compresses the spatial dimension, while their decoder uses upsampling to restore the size of the feature map. Based on this method, many researchers later focused on these two issues in an effort to improve the performance of semantic segmentation. The first issue is to enhance the coding structure, so the encoder can extract more robust feature information. Specifically, DeeplabV2 [18] and Chen et al. [19] improved the ASPP module in the encoder, which consists of heterogeneous convolution and BN layers with varying sampling rates, and attempted to arrange the modules serially or in parallel. The second challenge is how to model the multi-scale context and encode context information into the original feature map data to improve the representation of each pixel. For example, Deeplabv3 + [17], SegNet [20], and OCRNet [13]. DeeplabV2 introduces the Spatial Pyramid Pool (ASPP) with atrous for multi-scale context modeling, so it can capture multi-scale context information using various expansion convolutions. Zhao et al. [21] proposed a network algorithm called "PSPNet" that aggregates multi-scale contextual information via spatial pyramid pooling. However, these strategies require a large number of parameters and computational effort, so Wang et al. [22] designed a non-local block to weighted aggregate the contextual information in the whole image, and this approach can capture the long-range interdependencies between pixels by simply designing a self-attention. Since non-local block matrix multiplication is computationally intensive and can impose a video memory burden, Zhu et al. [23] proposed ANNet based on the asymmetric pyramidal non-local block to reduce the standard non-local module's computation and GPU memory consumption. Although ANNet can capture interdependencies at long distances, it only considers the relationship between pixels in the feature map space direction and does not consider the relationship between pixels in the feature map channel direction. As a result, it cannot establish the global relationship between targets or objects, which is essential for semantic segmentation. In addition, ANNet focuses primarily on the relationship between pixels in the spatial direction, but it cannot distinguish between classes with similar appearances that do not share the same label. In this paper, we designed The Channel Enhancement Region Module to accentuate the distinction between categories (CERM). CERM is used to solve the problem of class inconsistency. Semantic segmentation is a classification task at the pixel level that typically requires multi-scale context features to encode both local and global information. Due to a lack of global contextual semantic information, small objects, such as traffic lights, fences, etc., are often incorrectly predicted.
ANNet incorporated multi-scale pyramid pooling modules [21, 24, 25] into APNB and AFNB modules, thereby decreasing the amount of computation. AFNB first calculated the similarity of the fourth- and fifth-stage feature maps of ResNet101 [26], and then weighted the feature map of the V (Value) branch using the similarity matrix, without considering the use of channels at all. Given a feature map of the APNB module with a size of C × H × W, the multiplication computation of two matrices in the AFNB module is \(\mathcal{O}({C}^{*}NS)\), where N = H × W, S represents the pixels in the spatial direction of the feature map. ANNet further aggregates the location context information by calculating \(\mathcal{O}({C}^{*}NS)\). Since ANNet does not consider the use of pixel similarity in the feature map channel direction, we compute the pixel relationships in the feature map channel direction to improve the feature class region representation with reduced computational effort, noting that CERM uses a total of one matrix multiplication with \(\mathcal{O}({C}_{\mathrm{class}}NC)\), where \({C}_{\mathrm{class}}\) represents the number of category channels, N = H × W, and C is the number of feature map channels after convolutional compression.
In this paper, a simple and effective Mutually Reinforcing Non-local Neural Network for Semantic Segmentation (MRNNet) network is proposed to enhance the ANNet semantic segmentation network. There are two improvements: the first improvement is a reduction in the number of ANNet parameters, and the second is an enhancement of the AFNB module in ANNet to improve the feature map channel category region representation by utilizing the similarity of feature map channel directions. Inspired by the methods of DANet [27] and DFNet [28], we can effectively distinguish inconsistent problems within the classification by weighting and summing the characteristic maps of the channel directions, such as the spine of cattle and the network divides left and right sides of cattle into distinct categories. Therefore, we need to make the network better distinguish each category. We observed that the auxiliary loss function of ANNet was added to the fourth stage of ResNet101 to aid in network training, and that the number of characteristic graph channels of the input loss function was equal to the number of categories. Inspired by the auxiliary loss function of ANNet, we supervised the formation of the category region of the feature map using the auxiliary loss function of ANNet. In the fifth stage of ResNet101, we normalized the feature map input of ANNet and weighted the feature map summation. Through this operation, the feature maps of the auxiliary loss function can be distinguished in the direction of the channel, with each feature map representing a category.
In addition, we discovered that ANNet utilized multi-scale spatial pyramid pooling to reduce the computation of matrix multiplication, whereas AFNB did not account for the channel direction similarity of the characteristic graph. Moreover, the computation of two matrix multiplications was considerably greater than that of single matrix multiplication, and the use of multi-scale spatial pyramid pooling would inevitably result in the loss of detailed information. Thus, we reduce two matrix multiplications to single matrix multiplication and use this matrix multiplication to perform a weighted summation of the feature maps along the channel direction. On the other hand, we do not utilize multi-scale spatial pyramid pooling as ANNet does, but by reducing one matrix multiplication, we can reduce the matrix multiplications generated by the computational effort. To better demonstrate the efficiency of our model, we compare it to ANNet in terms of model parameters, reasoning time, and segmentation accuracy. Our model parameter is 51.82(MB), 11.35(MB) less than ANNet's parameter, which is 63.17(MB) (MB). Our reasoning time is 0.508(s), which is 0.103(s) faster than ANNet's s reasoning time of 0.611(s). Our model's segmentation accuracy is 81.9%, 0.6% higher than that of ANNet [23], which is 81.3%.
The pixel information in the feature space direction and the pixel information in the channel direction are equally important DANet [27], DFNet [28], CBAM [29], and CoordAttention [30]. The channel attention module of DANet is utilized to determine the channel dependency between any two-channel mappings, while the weighted sum of all channel mappings is used to update each channel mapping. However, too many channels will cause some feature maps to contain less context information than others, which is not conducive to the segmentation of small target objects and edge objects. To include as much context information as possible in the channel. We use cross-entropy loss to supervise the formation of feature map channel categories, and we reduce the number of feature map channels using compression, so that the number of feature map channels equals the number of categories. This ensures that each channel in the feature map represents a category and contains rich context information. Through this operation, we achieve equal treatment of multi-scale objects and improve segmentation accuracy by assigning greater weight to the feature map representing the objects that are difficult to segment and less weight to the feature map representing the objects that are easy to segment.
In summary, our main contributions are as follows:
-
1.
We propose a simple and effective Mutually Reinforcing Non-local Neural Networks for Semantic Segmentation (MRNNet) to reduce the number of parameters and the mean inference time of ANNet [23].
-
2.
Motivated by DANet and CBAM, we improved the AFNB module in ANNet to become the channel enhancement regions module (CERM). Specific implementation entails reducing AFNB's two matrix multiplications to single matrix multiplication. AFNB focuses on capturing the spatial dependence between any two feature map locations. PEPM identifies channel dependencies between any two-channel mappings and updates each channel mapping with the weighted sum of all channel mappings. Compared with the AFNB model, CERM has fewer parameters and computation.
-
3.
We designed the position-enhanced pixels module (PEPM) to further improve segmentation accuracy. PEPM can not only establish the long-distance interdependence between pixels, but also create a spatial attention matrix and improve the spatial feature dependence. By establishing rich context dependence for pixels in the spatial direction of the feature graph, PEPM greatly improves the performance of semantic segmentation.
Related work
In the following section, we briefly review the development of semantic segmentation. FCN performed exceptionally well in semantic segmentation tasks [31, 32]. After that, FCN promoted a number of additional works, including SegNet, UNet [33], Deeplabv3 + , and DeconvNet [34].
Enhance contextual aggregation
Semantic segmentation has made significant progress with the FCN-based method. Deeplabv2 makes full use of atrous convolution, which can effectively expand the receptive field and merge more context information without increasing the parameters; DeepLabv3 enhances the use of atrous convolution, expands the ASPP module, and can obtain a larger receptive field to obtain multi-scale information. PSPNet proposes to use spatial pyramid pooling to aggregate multi-scale context information. Pyramid spatial pooling can collect data at different scales. Moreover, models comprised of encoding and decoding structures [35, 36] can improve context aggregation.
Semantic segmentation
FCN first applied the full convolution network to the entire image, while semantic segmentation is a classification task at the pixel level. Usually, there are two kinds of semantic prediction tasks at the pixel level. The first one is to design a new backbone network [37,38,39,40] to extract more robust feature graphs for pixels. Because it is crucial to maintain the backbone network's high resolution to extract spatial location information, Zhang et al. [41] applied channel attention to different network branches to leverage their methods for capturing cross-feature interactions and learning different representations. The other task is to design different decoders, which typically work in tandem with encoders to achieve optimal results. There are different types for different working decoders. For example, obtaining different receptive fields [18, 19, 21], enhancing edge features [42,43,44], and obtaining global context information [27, 45].
Attention mechanisms
The attention mechanism is an automatic selection process that allows the model to concentrate on the essential components. Usually, attention mechanisms are divided into channel attention and spatial attention. Different attention plays different roles. The primary focus of spatial attention is on spatial regions [27, 46,47,48]. However, channel attention primarily enables the model to select essential categories. Channel attention is equally important than spatial attention [27, 49, 50]. However, some recent works [23, 51] ignore the application of channel attention in feature map channel direction to enhance semantic segmentation networks. Therefore, DANet uses the spatial attention module and the channel attention module in parallel to improve the semantic segmentation network. Unlike DANet, our MRNNet model uses the channel attention module and the spatial attention module in series to enhance the semantic segmentation network.
Methods
In this section, we will first introduce the overall framework of our network, followed by an explanation of how the CERM and PEPM modules enhance the performance of semantic segmentation in the channel dimension and spatial dimension.
Network architecture
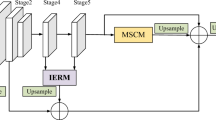
As shown in Fig. 1, with the introduction of CERM and PEPM, we propose MRNNet. We followed ANNet in selecting ResNet101 as the network's backbone. Similarly, we eliminated the last two downsampling operations and used atrous convolution to maintain the feature map size of ResNet101 stages 4 and 5 at \(\frac{1}{8}\) of the input image. In other words, the fourth and fifth stages of ResNet101 output feature maps of the same size.

Overview of the proposed MRNNet for semantic segmentation
In the fourth and fifth stages, CERM is used to capture the long-distance pixel relationship in the feature map's channel direction. In particular, the fourth-stage generated channel attention matrix is multiplied by the fifth-stage generated feature map. The output of the fourth stage is supplemented with a cross-entropy loss function, which is used to supervise and learn the category area of the output characteristic map of the fourth stage. In the fourth stage, the number of channels of the output feature map is equal to the number of categories to be segmented. By performing such an operation, the output feature map in the fourth stage can be enhanced, so that it contains more context information. To make full use of the feature map output by CERM, we input this feature map and the feature map output by the fifth stage into PEPM. On the V (Value) branch, PEPM can generate a spatial attention matrix and weighted sum with a feature map. This allows for the capture of the long-distance interdependence between pixels in the spatial direction of the feature map. To enhance the contextual information of the PEPM output feature maps, we parallelized the feature maps on the \(Q_{2}\) branch. For the PEPM module, we follow the design approach of OCNet [52] \(. T_{\theta }\), \(T_{\gamma }\) sharing parameters can reduce the model parameters and computational effort. Our model, unlike ANNet, does not use multi-scale pyramid pooling [21,22,23]. Furthermore, our model can reduce model parameters and improve reasoning speed and accuracy. Notably, ANNet did not use the loss function to monitor the learned feature map, whereas we added the loss function to CERM and obtained outstanding results.
Channel enhancement regions module
Effectively distinguishing the channel number of a feature graph can improve class consistency, which is crucial for semantic segmentation. However, ANNet did not consider differentiating the channel categories of the feature map, instead relying on the attention of pixels in the spatial direction of the feature map to capture the long-distance dependency between pixels. Additionally, ANNet employed multi-scale pyramid pooling to reduce model parameters and computational overhead. However, the segmentation effect of ANNet is not ideal. As shown in Fig. 2, one of the matrix multiplication calculations in ANNet is \({\mathcal{O}}\left( {C^{*} NS} \right)\), while the matrix multiplication calculation of CERM is \({\mathcal{O}}\left( {C^{*} NC_{{{\text{class}}}} } \right)\).Where \(C_{class}\) represents the number of characteristic map channels, that is, the number of categories to be divided. It is ideal that \(C_{{{\text{class}}}}\) should be much smaller than \(S\). In semantic segmentation, it is crucial to maintain a high resolution for the feature map. However, ANNet uses multi-scale pyramid improving semantic segmentation performance. However, CERM does not use multi-scale pyramid pooling to reduce model parameters, resulting in a loss of feature map resolution that is not conducive to pooling but rather a loss function to supervise the formation of a category area channel feature map. The channel attention generated by the channel feature map of the category area attempts to weight the feature map of the fifth stage to improve the category channel's representation in the feature map. The detailed structure diagram of CERM and AFNB is shown in Fig. 2, and a more intuitive operation flow of CERM and AFNB is given in Eq. 1

From left to right are the frames of the CERM and AFNB
We reduce two matrix multiplications of AFNB to single matrix multiplication, thereby drastically reducing the amount of calculation required. The feature map of \({\text{Stage}}_{4}\) is supervised by the loss function. The size is \(C_{{{\text{class}}}} \times H \times W\). Here, \(C_{{{\text{class}}}}\), \(H\), and \(W\) represent the channel number, height, and width of the feature map, respectively. \(C_{{{\text{class}}}}\) represents the number of categories to be split. Consider the channel attention matrix generated by the feature map of Stage4 to weigh the feature map of \({\text{Stage}}_{5}\). According to Figs. 2 and 3, the CERM operation flow is shown as follows:

The details of the CERM
ANNet embeds the pyramid pool module to select the pixel representative point set S, but it does not use all of the pixel points, so resolution is inevitably lost. In light of this issue, we eliminate pyramid pooling and switch from analyzing the relationship between spatial pixels to analyzing the relationship between pixels along the channel direction of the feature map. As depicted in Fig. 3, we propose CERM based on this concept, and the calculation flow of CERM's feature map is shown as follows:
Here, \({\mathcal{F}}_{l} \, and\, {\mathcal{F}}_{h}\) denote the feature maps output at the low − level stage and the high − level stage with dimensions \(C_{l} \times H \times W\), \(C_{h} \times H \times W\), respectively. \(T_{1}^{l}\) and \(T_{3}^{h}\) denote \(1 \times 1Conv\) at the low-level stage and \(3 \times 3 \, Conv\) at the high-level stage. \(\ell_{l}\) and \(\hbar_{h}\) denote the feature maps with dimensions \(C_{{{\text{class}}}} \times H \times W{\text{ and}} \, C^{*} \times H \times W\). We normalize \(\ell_{l}\) to the attention matrix \(\widetilde{{\ell_{l} }} \in {\mathcal{R}}^{{C_{class} \times N}}\), and then the matrix multiply \(\widetilde{{\ell_{l} }}\) with \(\hbar_{h}\), as shown in Eq. 4
where \(O\) stands for the feature map of CERM output with dimensions \(C_{{{\text{class}}}} \times C^{*}\).
The computation of ANNet matrix multiplication, \({\mathcal{O}}\left( {C^{*} NS} \right)\), is much larger than that of CERM matrix multiplication, \({\mathcal{O}}\left( {C^{*} NC_{{{\text{class}}}} } \right)\), because \(S\) > > \(C_{{{\text{class}}}}\). In addition, the multi-scale pyramid pooling embedded in ANNet inevitably causes a loss of feature map resolution. Thus, our CERM does not use multi-scale pyramid pooling. To improve the performance of semantic segmentation DANet, and DFNet, we also try to reduce the matrix multiplication computation using matrix multiplication and converting the pixel relationship in the spatial direction to the relationship between pixels in the feature map channel direction. In addition, ANNet makes the necessary adjustments to the sampling points S to compensate for the resolution loss brought on by multi-scale pyramid pooling. ANNet ablation experiments show that the more sampling points segmented, the higher the accuracy, which corresponds to a reduction in the efficiency of the model. ANNet experiments show that S is usually taken to be 110, which is much larger compared to \(C_{{{\text{class}}}}\). Thus, the corresponding matrix multiplication computation will also be much larger than that of CERM.
Position-enhanced pixels module
Position-enhanced pixels module (PEPM) model structure is identical to that of APNB in the ANNet. The only difference is that the input feature map of APNB is the output feature map of AFNB, whereas our PEPM makes full use of the output feature maps of CERM and \(S_{5}\). In other words, APNB has one input, while PEPM has two. PEPM is capable of capturing the context information of an entire image from a global perspective. The function of PEPM is similar to that of DANet's position attention module, which can obtain distinguishing features, which is very important for PEPM to capture long-distance interdependent context information. As shown in Fig. 4, we stack the feature map output by PEPM with the feature map \(C_{6}\) of the fifth stage to improve the ability to represent features. Fu et al. [25] proposed that the features generated by the conventional FCNs are prone to incorrect object classification. To generate rich context information for local features, we developed PEPM, which in the fifth stage integrated the rich context information into the six feature maps to generate a more robust feature map and enhance the feature representation capability. Finally, the feature map is input to the classifier. Next, we describe the detailed structure diagram of PEPM in detail. As shown in Fig. 4, we provide two input feature maps \(\alpha \in {\mathbb{R}}^{{C_{6} \times H \times W}} {\text{ and }}\beta \in {\mathbb{R}}^{{C_{6} \times C_{class} \times 1}}\). Then, we reshape \(\alpha\) and \(\beta \) into \(\alpha \in {\mathbb{R}}^{{C_{6} \times N_{K} }} ,\beta \in {\mathbb{R}}^{{C_{6} \times N_{Q} }}\), where \(N_{K}\) = \(H \times W\) and \(N_{Q} = 1 \times C_{class} { }\). Finally, we perform a matrix multiplication operation between the transpose of \(\alpha\) and \(\beta\), and apply a softmax layer to compute the spatial attention map \(S \in {\mathbb{R}}^{{N_{K} \times N_{Q} }}\)
where \(s_{ji}\) represents the impact of the \(i\)th position of the space pixel on the \(j\)th position of space pixel. The more similar the feature representations of two locations are, the greater the correlation between them. We reshape the feature map \(\beta \in {\mathbb{R}}^{{C_{6} \times C_{{{\text{class}}}} \times 1}}\) of the CERM output into \(\beta \in {\mathbb{R}}^{{C_{6} \times C_{{{\text{class}}}} }}\), while we perform a matrix multiplication between the transpose of \(\beta\) and S, and reshape the result into \(\gamma \in {\mathbb{R}}^{{C^{*} \times H \times W}}\). Finally, we multiply it by a scaling parameter \(\rho\) and concatenate with the characteristic \(\alpha\) to obtain the final output \(\delta \in {\mathbb{R}}^{{C_{{Stage_{4} }} \times H \times W}}\) as follows:
where \(\rho\) is initialized to 0, which gradually learns to assign more weights [53]. It can be deduced from Eq. 6 that the resulting feature \(\delta\) for each location is a weighted sum of the features of all locations and the original features. Therefore, features in the spatial direction of the feature map have a global contextual view and aggregate contexts selectively based on spatial attention maps. Similar semantic features achieve reciprocity, thereby enhancing intra-class compactness and semantic consistency.

The details of the PEPM
Experiments
Datasets
Our method is evaluated using three main data sets, PASCALVOC2012 [54], Cityscapes [55], and ADE20k [56]. PASCALVOC2012 is a comprehensive scene dataset with 2,913 images and 20 categories. From the 2913 images, 1464 are used for training, 1449 for verification, and 1456 for testing. Cityscenes dataset contains 5000 high-quality pixel-level annotated images of urban driving scenes, which are divided into 30 categories. From the 5,000 pictures, 2,975 are used for training, 500 for evaluation, and 1525 for testing. These photos were taken in 50 different cities. The data set also contains 19,998 roughly annotated pictures; here, we only use finely marked images for 19 categories. ADE20k has more than 25,000 images (20 k-train, 2 k-val, and 3 k-test), which are intensively annotated with an open dictionary tag set. For 2017 Places Challenge 2, 100 thing and 50 stuff categories covering 89% of all pixels were selected.
Implementation details
To train the model on these three data sets, we use the stochastic gradient descent (SGD) [57] using the multi-learning rate decay strategy, where the initial learning rate is multiplied by.\(\left( {1 - \frac{{\text{ iter }}}{{{\text{ max\_iter }}}}} \right)^{{\text{power }}}\). For training and verification on the Cityscape dataset, we use a 0.0025 learning rate, 0.9 weight attenuation, and 0.0005 momentum. In the training and verification stage, we cut the original image to 1024 × 512 (cityscape), 512 × 512 (PASCAL VOC 2012), and 520 × 520 (ADE20k). During training, the input image is randomly scaled from 0.5 to 2 and flipped horizontally for data enhancement. Our backbone network is ResNet101, which has been pre-trained on the ImageNet data set [58]. For the Cityscape dataset, the batch size is 4, and the training period is 160 K iterations. For PASCAL VOC 2012 dataset, the batch size is 8, and the training period is 100 k iterations. The batch size of ADE20k is 8, and the training period is 200 K iterations. All experiments were performed using 1 × V100 GPU. According to ANNet, our model is optimized using two cross-entropy losses. The first loss function is applied to the output of ResNet101's fourth stage, and the second loss function is applied to the model's output. Thus, the total loss function is
where \(l_{{{\text{backbone}}_{{{\text{stage4}}}} }}\) denotes the loss function at the output of backbone \({\text{Stage}}_{4}\), \(l_{{{\text{model}}}}\) denotes the loss function at the output of the model, and \(\lambda\) is set to 0.4.
Evaluation metrics In this paper, we use pixel accuracy (PA), intersection/merge (IoU), and the mean value of IoU (mIoU) as our evaluation metrics. Their calculation results are as follows:
PA PA indicates the ratio of correctly identified pixels to the total number of pixels. IoU For each category, the IoU is calculated as the intersection ratio of the true and predicted values. MIoU To calculate this metric, the arrears are first calculated for each category, and then the average is calculated.
Ablation study
In this section, we present an ablation test to validate our method. We select various CERM and PEPM components and demonstrate their effect on the model. All subsequent experiments use ResNet101 as the network's backbone and train 160 K iterations on the refined Cityscapes data set. In addition, we train 200 K iterations on the ADE20K dataset and 100 K iterations on the PASCAL VOC 2012 dataset, respectively.
Efficacy of the CERM and PEPM
Our model has two main components: CERM and PEPM. Next, let us evaluate the role of each component. As shown in Table 1, we add cross-entropy loss after \(1 \times 1Conv\) of the fourth stage of ResNet101. Compared with no cross-entropy loss function, the performance mIoU increases from 80.64 to 82.67%. Experiments demonstrate that maximizing the use of the features learned by loss function supervision improves semantic segmentation performance. As shown in Table 2, when the fifth stage of ResNet101's feature map is merged with the feature map output by PEPM, the performance is improved by 0.33% compared to when the maps were not merged. This phenomenon demonstrates that combining high-stage and low-stage feature graphs improves the performance of semantic segmentation. To investigate the impact of multi-scale pyramid pooling in ANNet on MRNNet, we incorporate multi-scale pyramid pooling at two CERM inputs. The respective pool sizes are (1, 2, 3, 6), (1, 3, 6, 8), and (1, 4, 8, 12). Similar to Table 3, as the number of pool sampling points increases, the segmentation effect improves. As shown in Table 4, we remove the multi-scale pyramid pooling module from CERM and add it to PEPM to examine the network's response to the addition of different pool sizes. The experiment demonstrates that the mIoU value increases with pool size, with the highest mIoU value occurring when the pool size is (1, 4, 8, 12).
Efficiency comparison with asymmetric non-local neural networks for semantic segmentation
This section compares MRNNet and ANNet in terms of reasoning time, model parameters, and memory consumption. As demonstrated in Table 5, the reasoning time and model parameters of our model are lower than those of ANNet. However, our model's memory is larger than that of ANNet, and our model has more advantages overall than ANNet. For a more intuitive comparison, we visualize the split network of ANNet and MRNNet. As shown in Fig. 5, the first, second, third, and fourth columns represent the evident that our model has a superior effect on segmentation.

Visual comparison on PASCAL VOC 2012 Dataset. a Image, b Ground Truth, c ANNet, and d Ours
Comparisons with other methods on Cityscapes and ADE20K datasets
Cityscapes To demonstrate the superiority of our method, we compare it to other techniques using a test dataset. It is important to note that we do not include the validation set when training the model with 160 K iterations performed directly on the refined images. As shown in Table 6, our method outperforms the above methods, obtaining 81.9%.
In addition, we provide a qualitative comparison with other methods on the Cityscapes dataset, and as depicted in Fig. 6, CERM is able to obtain rich information about class regions and produce consistent segmentation results within classes. In other words, CERM can group categories with the same label into the same class. For example, in Fig. 6, other methods segment the motorcycles in the third column of the first row of images, which are segmented into different classes. The truck's rear end and the car's front end in the fourth row are not segmented effectively, whereas our model does not have this issue. In addition our model is capable of segmenting long-shaped objects, such as the sidewalk in the second row of Fig. 6, whereas the other models are unable to do so. As shown in Table 7, although ADE20K has different image sizes, the training and validation sets have many semantic category gaps, and PSPNet uses the deepest backbone network. Our model segmentation yields a performance of 45.26%, which is superior to other methods.

Visual comparison on the Cityscapes Dataset: a Image, b Ground Truth, c ANNet, d DANet, and e Ours
Conclusion
This paper proposes Mutually Reinforcing Non-local Neural Networks for Semantic Segmentation. The core contribution of Mutually Reinforcing Non-local Neural Networks for Semantic Segmentation is to propose the channel enhancement regions module (CERM), and the position-enhanced pixels module (PEPM). CERM employs the loss function in the fourth stage of ResNet101 to accurately classify each channel in the fourth-stage feature map into one of several categories. PEPM makes effective use of the feature map generated by CERM, calculates the relationship between pixels and the fifth-stage characteristic map, and establishes the long-distance interdependence of pixels. Moreover, under the interaction of CERM and PEPM, our model is able to effectively capture long-distance context information to improve category representation and achieve more accurate segmentation. Experiments demonstrate that our model achieves remarkable performance on three scene segmentation datasets, including Cityscapes, Pascal VOC 2012, and Ade20k.
Data availability
Data related to the current study are available from the corresponding author on reasonable request.
References
Zhou B, Zhao H, Puig X, et al (2017) Scene parsing through ADE20K dataset. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR). IEEE, Honolulu, HI, pp 5122–5130.https://doi.org/10.1109/CVPR.2017.544
Li Y, Guo Y, Kao Y, He R (2016) Image piece learning for weakly supervised semantic segmentation. IEEE Trans Systems Man Cybern Syst 47(4):648–659. https://doi.org/10.1109/TSMC.2016.2623683
Gao G, Xu G, Yu Y et al (2021) MSCFNet: a lightweight network with multi-scale context fusion for real-time semantic segmentation. IEEE Trans Intell Transp Syst 23(12):25489–25499. https://doi.org/10.1109/TITS.2021.3098355
Teichmann M, Weber M, Zollner M, et al (2018) MultiNet: real-time joint semantic reasoning for autonomous driving. In: 2018 IEEE intelligent vehicles symposium (IV). IEEE, Changshu, June 2018, pp 1013–1020. https://doi.org/10.1109/IVS.2018.8500504
Siam M, Elkerdawy S, Jagersand M, Yogamani S (2017) Deep semantic segmentation for automated driving: taxonomy, roadmap and challenges. In: 2017 IEEE 20th international conference on intelligent transportation systems (ITSC). IEEE, Yokohama, pp 1–8. https://doi.org/10.1109/ITSC.2017.8317714
Hardens M, Szekely G (2003) Enhancing human-computer interaction in medical segmentation. Proc IEEE 91:1430–1442. https://doi.org/10.1109/JPROC.2003.817125
Alhaija H A, Mustikovela S K, Mescheder L, et al (2017) Augmented reality meets deep learning for car instance segmentation in urban scenes. In: British Machine Vision Conference, vol 1, p 2
Zhou Z, Rahman Siddiquee MM, Tajbakhsh N, Liang J (2018) UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In: Stoyanov D, Taylor Z, Carneiro G et al (eds) Deep learning in medical image analysis and multimodal learning for clinical decision support. Springer International Publishing, Cham, pp 3–11
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86:2278–2324. https://doi.org/10.1109/5.726791
Szegedy C, Liu W, Jia Y, et al (2015) Going deeper with convolutions. In: Proceedings of the IEEE Conference on computer vision and pattern recognition (CVPR), pp 1–9
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. In: arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/ARXIV.1409.1556
Li Y, Chen W, Zhang Y et al (2020) Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens Environ 250:112045. https://doi.org/10.1016/j.rse.2020.112045
Tao C, Qi J, Li Y et al (2019) Spatial information inference net: Road extraction using road-specific contextual information. ISPRS J Photogramm Remote Sens 158:155–166. https://doi.org/10.1016/j.isprsjprs.2019.10.001
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. IEEE Trans Pattern Anal Mach Intell 39(4):640–651. https://doi.org/10.1109/TPAMI.2016.2572683
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Yuan Y, Chen X, Wang J (2020) Object-contextual representations for semantic segmentation. In: Vedaldi A, Bischof H, Brox T, Frahm J-M (eds) Computer Vision—ECCV 2020. Springer International Publishing, Cham, pp 173–190
Chen L-C, Zhu Y, Papandreou G, et al (2018) Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on computer vision (ECCV), pp 801–818. https://doi.org/10.48550/ARXIV.1802.02611
Chen L-C, Papandreou G, Kokkinos I et al (2018) DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell 40:834–848. https://doi.org/10.1109/TPAMI.2017.2699184
Chen L-C, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. In: arXiv preprint arXiv:1706.05587
Badrinarayanan V, Handa A, Cipolla R (2015) SegNet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. In: arXiv preprint arXiv:1505.07293
Zhao H, Shi J, Qi X, et al (2017) Pyramid scene parsing network. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, pp 6230–6239. https://doi.org/10.1109/CVPR.2017.660
Wang X, Girshick R, Gupta A, He K (2018) Non-local neural networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp 7794–7803. https://doi.org/10.1109/CVPR.2018.00813
Zhu Z, Xu M, Bai S et al (2019) Asymmetric non-local neural networks for semantic segmentation. In: 2019 IEEE/CVF international conference on computer vision (ICCV), Seoul, Korea (South), pp 593–602. https://doi.org/10.1109/ICCV.2019.00068
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37:1904–1916. https://doi.org/10.1109/TPAMI.2015.2389824
Lazebnik S, Schmid C, Ponce J (2006) Beyond Bags of features: spatial pyramid matching for recognizing natural scene categories. In: 2006 IEEE Computer Society Conference on computer vision and pattern recognition (CVPR’06), IEEE, New York, NY, USA, pp 2169–2178. https://doi.org/10.1109/CVPR.2006.68
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Fu J, Liu J, Tian H et al (2019) Dual attention network for scene segmentation. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), Long Beach, CA, USA, pp 3146–3154. https://doi.org/10.1109/CVPR.2019.00326
Yu C, Wang J, Peng C et al (2018) Learning a discriminative feature network for semantic segmentation. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, Salt Lake City, UT, USA, pp 1857–1866. https://doi.org/10.1109/CVPR.2018.00199
Woo S, Park J, Lee J-Y, Kweon IS (2018) CBAM: convolutional block attention module. In: Proceedings of the European Conference on computer vision (ECCV), pp 3–19. https://doi.org/10.48550/arXiv.1807.06521
Hou Q, Zhou D, Feng J (2021) Coordinate attention for efficient mobile network design. In: 2021 IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, pp 13713–13722. https://doi.org/10.1109/CVPR46437.2021.01350
Mottaghi R, Chen X, Liu X et al (2014) The role of context for object detection and semantic segmentation in the wild. In: 2014 IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, pp 891–898. https://doi.org/10.1109/CVPR.2014.119
Zhao B, Zhang X, Li Z, Hu X (2019) A multi-scale strategy for deep semantic segmentation with convolutional neural networks. Neurocomputing 365:273–284. https://doi.org/10.1016/j.neucom.2019.07.078
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. In: Navab N, Hornegger J, Wells WM, Frangi AF (eds) Medical image computing and computer-assisted intervention—MICCAI 2015. Springer International Publishing, Cham, pp 234–241
Noh H, Hong S, Han B (2015) Learning deconvolution network for semantic segmentation. In: 2015 IEEE International Conference on computer vision (ICCV), Santiago, Chile, pp 1520–1528. https://doi.org/10.1109/ICCV.2015.178
Juraska J, Walker M (2021) Attention is indeed all you need: semantically attention-guided decoding for data-to-text NLG. In: arXiv preprint arXiv:2109.07043
Chaurasia A, Culurciello E (2017) LinkNet: exploiting encoder representations for efficient semantic segmentation. In: 2017 IEEE visual communications and image processing (VCIP), St. Petersburg, FL, USA, pp 1–4. https://doi.org/10.1109/VCIP.2017.8305148
Wang J, Sun K, Cheng T et al (2021) Deep high-resolution representation learning for visual recognition. IEEE Trans Pattern Anal Mach Intell 43:3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686
Zheng S, Lu J, Zhao H et al (2021) Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: 2021 IEEE/CVF conference on computer vision and pattern recognition (CVPR), Nashville, TN, USA, pp 6881–6890. https://doi.org/10.1109/CVPR46437.2021.00681
Xie E, Wang W, Yu Z et al (2021) SegFormer: simple and efficient design for semantic segmentation with transformers. Adv Neural Inf Process Syst 34:12077–12090. https://doi.org/10.48550/arXiv.2105.15203
YUAN Y, Fu R, Huang L et al (2021) HRFormer: high-resolution vision transformer for dense predict. Adv Neural Inf Process Syst 34:7281–7293. https://doi.org/10.48550/arXiv.2110.09408
Zhang H, Wu C, Zhang Z et al (2022) ResNeSt: split-attention networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2736–2746. https://doi.org/10.48550/arXiv.2004.08955
Zhen M, Wang J, Zhou L et al (2020) Joint semantic segmentation and boundary detection using iterative pyramid contexts. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 13666–13675. https://doi.org/10.48550/arXiv.2004.07684
Li X, Li X, Zhang L, et al (2020) Improving semantic segmentation via decoupled body and edge supervision. In: Vedaldi A, Bischof H, Brox T, Frahm J-M (eds) Computer Vision—ECCV 2020. Springer International Publishing, Cham, pp 435–452
Yuan Y, Xie J, Chen X, Wang J (2020) SegFix: model-agnostic boundary refinement for segmentation. In: Vedaldi A, Bischof H, Brox T, Frahm J-M (eds) Computer Vision—ECCV 2020. Springer International Publishing, Cham, pp 489–506
Guo M-H, Liu Z-N, Mu T-J, Hu S-M (2022) Beyond self-attention: external attention using two linear layers for visual tasks. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2022.3211006
Chen C-F (Richard), Fan Q, Panda R (2021) CrossViT: cross-attention multi-scale vision transformer for image classification. In: Proceedings of the IEEE/CVF International conference on computer vision, pp 357–366. https://doi.org/10.48550/arXiv.2103.14899
Liu Z, Lin Y, Cao Y, et al (2021) Swin Transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 10012–10022. https://doi.org/10.48550/arXiv.2103.14030
Guo M-H, Cai J-X, Liu Z-N et al (2021) PCT: Point cloud transformer. Comp Vis Media 7:187–199. https://doi.org/10.1007/s41095-021-0229-5
Chen L, Zhang H, Xiao J et al (2017) SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, pp 6298–6306. https://doi.org/10.1109/CVPR.2017.667
Wang Q, Wu B, Zhu P, et al (2020) Supplementary Material for “ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks”. In: 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR), Seattle, WA, USA, pp 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155
Huang Z, Shi X, Zhang C, et al (2022) FlowFormer: a transformer architecture for optical flow. In: arXiv preprint arXiv:2203.16194
Yuan Y, Huang L, Guo J, et al (2018) OCNet: object context network for scene parsing. In: arXiv preprint arXiv:1809.00916.
Zhang H, Goodfellow I, Metaxas D, Odena A (2019) Self-attention generative adversarial networks. In: International conference on machine learning, PMLR, pp 7354–7363. https://doi.org/10.48550/arXiv.1805.08318
Everingham M, Van Gool L, Williams C et al (2010) The PASCAL visual object classes challenge 2012 (VOC2012) development kit. Int J Comput Vision 88(2):303–338
Cordts M, Omran M, Ramos S et al (2016) The cityscapes dataset for semantic urban scene understanding. In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, pp 3213–3223. https://doi.org/10.1109/CVPR.2016.350
Zhou B, Zhao H, Puig X et al (2019) Semantic understanding of scenes through the ADE20K dataset. Int J Comput Vision 127(3):302–321. https://doi.org/10.1007/s11263-018-1140-0
Krizhevsky A, Sutskever I, Hinton GE (2017) ImageNet classification with deep convolutional neural networks. Commun ACM 60(6):84–90. https://doi.org/10.1145/3065386
Deng J, Dong W, Socher R et al (2009) ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on computer vision and pattern recognition, Miami, FL, USA, pp 248–255. https://doi.org/10.1109/CVPR.2009.5206848
Acknowledgements
The authors gratefully acknowledge the financial support from the National Natural Science Foundation of China (Grant Nos. 61472220, 61572286).
Author information
Authors and Affiliations
Contributions
Formal analysis, YW and TL; methodology, YW and TL; supervision, HZ; writing—original draft, TL.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest in the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, T., Wei, Y., Cui, Z. et al. Mutually reinforcing non-local neural networks for semantic segmentation. Complex Intell. Syst. 9, 6037–6049 (2023). https://doi.org/10.1007/s40747-023-01056-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01056-w