
Abstract
Visual tracking is an important field of computer vision research. Although transformer-based trackers have achieved remarkable performance, the transformer structure is globally computationally inefficient, it does not screen important patches, and it cannot focus on key target regions. At the same time, temporal motion features are easily overlooked. To solve these problems, this paper proposes a new method, SKRT, that removes the CNN structure and directly uses a transformer as the backbone network to extract multiframe video features. Then, these feature maps are mixed and superimposed to obtain spatiotemporal information. To focus on important parts efficiently, we use key region extraction to obtain a small set of template and search feature map patches and reinput them into the transformer as a cross-correlation computation. Finally, we predict the position of a tracking object through center-corner prediction. To demonstrate the effectiveness of our method, we conduct experiments on challenging benchmark datasets (GOT-10K, TrackingNet, VOT2018, OTB100, LaSOT), and the results show that SKRT is competitive with other state-of-the-art methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Visual tracking is an important branch in the field of computer vision. Its main research task is to obtain a target in the first frame of a video template and continue to track it in subsequent video frames. At present, various methods of research are mainly applied to the intelligent interaction, autonomous driving, augmented reality, and military fields [1,2,3,4]. Although these methods have made considerable progress, they are still challenged by size changes, rotations, occlusions, fast movements, lighting changes, etc. [5,6,7,8,9,10].
Siamese neural networks, as a general visual tracking structure, are widely used in various tasks. Although they have made a large impact, these frameworks also produce many defects related to convolutional neural networks (CNNs). Currently, many trackers use CNN structures, which are mainly used as backbone networks and for cross-correlation calculations. However, CNNs not only limit the capture of global features and complex nonlinear interactions between features but also result in the loss of semantic information involving template and search features [11, 12]. To improve the shortcomings of CNNs, the proposed method uses a transformer to extract and fuse features to better capture global context information and generate more semantic features [13, 14]. A transformer, as a global attention network, can effectively focus on long-distance feature relationships [15]. However, the simultaneous existence of the target and background also contains many useful and useless features. At present, transformer-based tracking methods often pay too much attention to useless background information. Although the patches obtained by using a transformer structure can establish a certain connection between the target and the background, if the distance between the patches is too far or the degree of correlation response is not high, these connections are often redundant, and it is easy to contaminate the features of the tracking object.
In addition, compared with a transformer, the convolution kernel of a CNN is still local, and the performance of a transformer is better than that of a CNN when training with a large number of datasets, which also provides a prerequisite for us to directly replace the CNN with the transformer [13, 16]. In many trackers, spatial information is more widely used than temporal information, and temporal information is often overlooked [13]. Although some methods also exploit temporal features, they cannot focus on important temporal regions, lack the interconnection of key locations in multiframe videos, and ignore the tendency of object motion. During the generation of the prediction box, the corner prediction is at the edge of the target and is easily affected by interference information. Although the bounding box can be estimated, it is not sufficiently accurate, and the robustness needs to be improved.
In our work, we need to consider some issues. First, how can a transformer be used to extract spatiotemporal information and establish target temporal motion connections? Second, how can we selectively input transformer patches while maintaining efficiency? Third, how can we select the input patches at the attention highlight position? Fourth, how can we make the predicted box closer to the ground truth box to make the prediction more accurate and robust? A new method named SKRT is proposed, and its performance is validated. Our tracker consists of four parts: a transformer, a spatiotemporal overlay structure, key region extraction and center-corner prediction. As an attention mechanism, a transformer can establish a global relationship, through which it can be used as a cross-correlation operation, thus replacing the previous CNN structure. By stacking the feature maps of 3 consecutive frames, we can highlight the motion trajectories of the target and establish temporal connections. Key region extraction can select the features of the target highlight position, form multiple patches in a certain range of pixel blocks, and input them into the transformer, deepening the connection between the template and the search features and improving the efficiency. Finally, the center-corner prediction of the target is directly estimated to locate it.
In summary, compared with those in other papers, four different viewpoints are proposed.
In this paper, we replace the backbone network using a CNN with a transformer and use it as a cross-correlation operation. In this way, more global long-distance nonlinear features can be established, and the algorithm performs better under existing dataset training.
To use the transformer architecture to fuse the spatiotemporal information, we overlay feature maps of three consecutive frames to establish motion relationships based on temporal information, which can focus on the temporal variation of important targets.
Many transformer patches are redundant, and they have the potential to negatively impact tracking. Through key region extraction, we can not only extract the key and effective parts but also ensure efficiency.
For a predicted bounding box based on a corner, a center point is added for the prediction, and when the edge of the tracked object encounters interference information, the predicted box is more robust.
Related work
Siamese network tracker
In recent years, the visual tracking method based on the Siamese network has been widely used. The method of extracting the template features and search branches and then calculating the similarity has become the current mainstream method. SiamFC [11], which is a method proposed in 2016, has attracted great attention in the field of visual tracking. This two-branch cross-correlation method had a large impact on subsequent research. Since the SiamFC bounding box is fixed at multiple scales, the tracking accuracy will be affected. Thus, an RPN [17] was added, and a new method named SiamRPN [12] was developed. In SiamRPN++ [17], the AlexNet [18] backbone network is replaced with the deeper ResNet [19] backbone network, which can extract and fuse deeper features, improving the accuracy and reducing the number of parameters. SiamDW [20] also focuses on backbone networks. Based on ResNet [19], the outermost pixels of each module feature map are removed to eliminate the padding effect. Gao et al. investigated the impacts of three main aspects of visual tracking, i.e., the backbone network, the attention mechanism, and the detection component, and proposed a Siamese attention keypoint network named SATIN for efficient tracking and accurate localization [21]. PrDiMP [22] incorporates a model predictor in the Siamese network, and it can predict the conditional probability density of the target state and train the regression network with a minimum KL dispersion to improve the performance of the algorithm. Although the anchor base-based approach yields good results, the anchor-free-based approach performs better. Siam R-CNN [23] uses the idea of redetection for tracking, and a novel hard example mining method, which is specifically trained for difficult distractors, is proposed. The tracklet dynamic programming algorithm (TDPA) can simultaneously track all potential targets, including interferers. In SiamFC++ [24], a classification branch and target motion estimation branch with an unambiguous classification score and a no prior knowledge branch with an estimated quality score were designed, and extensive analysis and extensive research confirmed its effectiveness. SiamCAR [25] adds a discussion of the size of the tracking box, removes the influence of the anchor parameter, and makes the network faster. The anchor-based Siamese tracker has achieved significant progress in terms of accuracy, but further improvements are limited by the robustness of lag tracking. In Ocean [26], a novel object-aware anchor-free network is proposed to solve this problem. It directly predicts the location and scale of target objects in an anchor-free manner and introduces a feature alignment module to learn object-aware features from the predicted bounding boxes. CGACD [27] learns about correlation-guided attention in a two-stage corner detection network, which includes correlation-guided spatial attention in the pixel direction and correlation-guided channel attention in the channel direction, enabling accurate visual tracking. CSART [28] proposes a novel channel and spatial attention-guided residual learning framework for tracking, which can improve the feature representation of Siamese networks by exploiting a self-attention mechanism to capture powerful contextual information.
Vision transformer
The use of a transformer as an attention mechanism first occurred in natural language processing. At present, transformers have also attracted great attention in the field of computer vision. DETR [29] uses a CNN and a transformer to perform end-to-end detection. It obtains the relationship between the target object and the global image context and directly outputs the final prediction result. As a visual classification task, ViT [30] only uses a transformer. It slices the image and builds a sequence as input. When the training dataset is sufficiently large, the accuracy is better than that of a CNN. In the Swin transformer [31], a hierarchical transformer, whose representation is computed by shifting windows, is proposed. The window-shifting scheme improves the efficiency by confining the self-attention computation to nonoverlapping local windows while allowing cross-window connections. On the basis of a vision transformer, Bertasius et al. focused on the time dimension and extended image classification to video classification. This was also the first video classification model that completely abandoned CNNs and only used transformers to build the entire network [32]. Wang et al. [33] proposed a concise and novel transformer-assisted tracking framework. They modified the classic transformer to better explore the transformer’s potential and make it more suitable for tracking tasks. TrTr [34] introduces a transformer encoder-decoder architecture, where the explicit cross-correlation between feature maps extracted from templates and search images is replaced by self and cross-attention operations to obtain global and rich contextual correlations. A confidence-based object classification head and a shape-agnostic anchor-based object regression head were developed. At the same time, a plug-in online update module for classification is designed to further enhance the tracking performance. TransT [13] uses a transformer to combine template and search area features and designs a feature fusion network based on a self-attention-based self-context augmentation module and a cross-attention cross-feature augmentation module. It adaptively focuses on useful information such as edges and similar objects and establishes associations between distance features, enabling the tracker to obtain better classification and regression results.

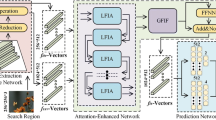
Illustration of SKRT: The 3-frame template and search video are input into the transformer to extract attention features, and then the respective feature maps are superimposed to obtain the important spatiotemporal information. Key region patches are extracted and input into the transformer for similarity calculation. Finally, the bounding box is predicted by the center-corner
Spatiotemporal tracking method
Visual tracking video is composed of multiple frames of images, which increase the temporal dimension and include motion features. Zhang et al. [35] proposed a tracking method that incorporates the spatiotemporal environment, which can enhance the different features of the target and make online adjustments to the target localization based on the background information. Teng et al. [36] proposed a deep temporal and spatial network that can solve sparse optimization problems and collect key historical temporal samples. The temporal network can feed the spatial network back to refine the location of the tracked target. Liu et al. [37] designed a spatiotemporal future prediction method that addresses the occlusion problem by exploiting the current and future possible locations of the target object from its past trajectory. GCT [38] utilizes the appearance model of the spatiotemporal structure to extract the contextual information of historical tracking objects. STGL [39] presents a novel spatiotemporal graph representation and learning model to generate a robust target representation for visual tracking problems. TRAT [40] designs a two-stream network, including a 2D and 3D CNN, and achieves excellent results based on ATOM [41]. In SiamSTM [42], a spatiotemporal matching procedure is proposed to deeply explore the capabilities of four-dimensional matching in space (height, width, and channels) and time. STARK [14] can capture the global features of spatiotemporal information in video sequences. The entire method is an end-to-end method, and it does not require any postprocessing steps, greatly simplifying existing tracking pipelines.
According to previous research, we have learned that visual tracking is a similarity calculation that requires the use of a Siamese network to establish the relationship between a target and background; at the same time, the joint spatiotemporal algorithm helps to predict the motion pose. In addition, the transformer has gradually replaced the CNN as a research hotspot in vision algorithms. To make our related research more suitable for visual tracking, we focus on the following aspects: how to reasonably use a transformer to make it more suitable for visual tracking and how to efficiently select transformer patches and highlight important spatiotemporal information under the premise of ensuring accuracy. To solve these problems, we conduct in-depth research and design a new tracker combined with a transformer.
Methods
We propose a new visual tracker named SKRT, as shown in Fig. 1. It contains 3 important components: a transformer mechanism, key region extraction with spatiotemporal fusion and center-corner prediction. We introduce it below and specifically show the composition of each part.
Transformer
Transformers, as attention mechanisms, can replace CNNs to extract important features [15]. We slice the feature map into multiple patch sequences. We output the matrices from the same sequence as query (Q), key (K), and value (V). By comparing Q and K and multiplying by V, we obtain the final result, as defined in Eq. 1.
where Q, \(K\in {\mathbb {R}}^{n\times d_{k}}\), \(V\in {\mathbb {R}}^{n\times d_{v}}\), Q and K are multiplied to obtain the similarity between each pair of patches and divided by \(\sqrt{d_{k}}\) to obtain the attention score. The scaled attention score is obtained and multiplied by V to obtain the weighted sum and the final output.
Equation 1 is altered by different linear changes, such as mapping the input to different subspaces, so that the model can understand the input sequence from different perspectives, as shown in Eqs. 2 and 3.
where \(W_{i}^{Q}\in {\mathbb {R}}^{d_{m}\times d_{k}}\), \(W_{i}^{K}\in {\mathbb {R}}^{d_{m}\times d_{k}}\), \(W_{i}^{V}\in {\mathbb {R}}^{d_{m}\times d_{v}}\) and \(W^{o}\in {\mathbb {R}}^{hd_{v}\times d_{m}}\) are parameter matrices.
In Fig. 2, we show the structure of the transformer. It contains alternating layers of multihead self-attention and MLP. LayerNorm (LN) is applied before each block, and residual connections are applied after each block. The MLP contains two layers with GELU nonlinearity. To distinguish the position information of the transformer sequence, which is affected by the DETR [29], we use the sine function to generate the positional encodings. It can be described by Eqs. 4 and 5.
\(X\in {\mathbb {R}}^{d\times m}\) represents the transformer input sequence, \(X_{T}\in {\mathbb {R}}^{d\times m}\) represents the transformer output, and \(P_{x}\in {\mathbb {R}}^{d\times m}\) is the positional encoding. d and m are the number of channels and sequences, respectively.

Structure of transformer

Key regions extraction method
Key regions extraction
To focus on important spatiotemporal regions, we superimpose the feature maps of 3 frames. As shown in Eqs. 6 and 7, after stacking, TF represents the template feature maps, SF represents the search feature maps, and t–1, t–2, and t–3 represent 3-frame feature maps. During the historical temporal period, objects will move at any time, forming different focuses. We superimpose the historical features and increase the weight of the motion relationship.
As shown in Fig. 3, we obtain M patches, which contain the highest weight pixel in TF, and based on them, we select a matrix whose length and width are \(S_{hw}\) regions. Similar to TF, we obtain N patches, which contain the highest weight pixel in SF, and based on them, we also select a matrix whose length and width are \(S_{hw}\) regions. To minimize overlap, we do not choose center points within the extracted regions. Finally, we concatenate the selected region matrices and use them as the input into the transformer. As described in Eq. 8, \(TF_{S_{hw}\times {S_{hw}}}\) and \(SF_{S_{hw}\times {S_{hw}}}\) represent the key regions for template and search feature extraction, respectively. in this paper, we set \(S_{hw}\) = 5, M = 6, N=12.
Center-corner prediction
The FCN consists of Conv-BN-ReLU layers, and it outputs three probability maps, the top-left corner, the center, and the bottom-right corner of the prediction box. We denote them as \(P_{t}(x,y)\), \(P_{c}(x,y)\) and \(P_{r}(x,y)\),respectively, as shown in Eqs. 9, 10 and 11, respectively.
\((\widehat{x}_{t},\widehat{y}_{t})\),\((\widehat{x}_{r},\widehat{y}_{r})\) and \((\widehat{x}_{c},\widehat{y}_{c})\) represent the corner and center coordinates of the prediction box. However, the target box can be predicted using only the corner points. Thus, to increase the influence of the center point and improve the accuracy of tracking, in Fig. 4 and Eq. 12, we calculate the center coordinate of the corner point and average it with the center point, \((\widehat{x}_{pc},\widehat{y}_{pc})\) is the center point of the prediction box, \(n = 0.5.\) Under the condition of keeping the length and width unchanged, the bounding box is finally predicted by calculating the offset.

All the red points are predicted corner points, and the green point \((\widehat{x}_{trc},\widehat{y}_{trc})\) is the center of the top-left and bottom-right corner points. We calculate the midpoint between it and the center point as the center blue point of the prediction box, and the length and width remain unchanged
As shown in Eq. 13, we use GIoU loss [43] and \(L_1\) loss [44]. \(b_i\) is the ground truth, \(\widehat{b}_{i}\) is the predicted box, and \(\gamma _{GIoU}\) and \(\gamma _{L_1}\) are hyperparameters.
Experiments
Implementation details
Our trackers are implemented using Python and PyTorch. SKRT training is conducted on 4 11 GB GeForce RTX 2080Ti GPUs. We calculate the params and FLOPs of the network architecture, which are 30.9 M and 19.57 G, respectively. We pretrain the network with ImageNet-22k [45]. The training datasets include LaSOT [46], GOT-10k [47], TrackingNet [48], COCO [49] and ImageNet VID [45]. We resize the template and search images to 128\(\times \)128 and 320\(\times \)320, respectively. AdamW [50] is used as our optimization method. During training, the learning rate is set to 1e–5, and the weight decay is set to 0.0005. We set a total of 500 training epochs. The learning rate decreases by a factor of 10 after 400 epochs.
In the online tracking stage, we use the last new frame t as the tracking frame. We create a 3-frame video sequence, and if the number of sequences is less than 3, then we duplicate the initial frames to complement the sequence. The template frame directly affects the tracking accuracy, and the shape appearance of the template target will change over time, which requires us to set a robust template.
Tracking template update According to STARK [14], we design an online template update mechanism. As shown in Fig. 5, transformer cross-correlation operations are performed on the initial frame, the new frame, and the template frame to generate a confidence score. When the score is higher than the threshold and the update interval is reached, the template is dynamically updated. We use cross-entropy as the loss function to optimize the similarity, as shown in Eq. 14.

Tracking template update
where \(y_{i}\) is the ground truth label and \(p_{i}\) is the predicted confidence.
Comparison to state-of-the-art trackers
Experiments on the GOT-10K dataset GOT-10K [47] is a large object tracking dataset that contains 9335 training videos and 180 testing videos in total. To make the trained model have stronger generalization ability, there is no overlap between the training set and the test set. As shown in Fig. 6 and Table 1, our method compares with other state-of-the-art methods, including TransT [13], STARK [14], TrDiMP [33], SiamRCNN [23], FCOT [51], Ocean [26], SiamFC++ [24], ATOM [41], SiamRPN++ [17], DaSiamRPN [52], SiamFC [11], MDNet [53]. AO, \(SR_{0.5}\) and \(SR_{0.75}\) of SKRT reach 0.728, 0.837 and 0.688, respectively, ranking first among all methods. The FPS in Table 1 is assessed by the hardware level of the methods listed.

SKRT is compared with other trackers in the GOT-10K dataset

Our method is visually compared with STARK and TransT. In the presence of occlusion, deformation, scale change and motion change, the bounding boxes of SKRT and the ground truth are similar, and the effect is more robust
Compared to other trackers using the transformer structure (TransT [13], STARK [14], TrDiMP [33]), our method achieves the best results. This is because we process spatiotemporal information in a fused manner, and at the same time, we extract the patches of key parts, making the training more focused on the highlighted locations, more efficient and refined. Figure 7 shows a visual comparison of SKRT with STARK [14] and TransT [13]. Our method can pay attention to the feature information of boundary locations, while the motion weights improve the ability of the temporal prediction of objects. Center-corner prediction is more robust, so the predicted bounding box of our tracker is closer to the ground truth bounding box. In addition, Table 2 shows that the efficiency and performance of SKRT are more balanced than those of STARK [14] and TransT [13]. This is because we remove the CNN backbone with multiple residuals and add the key regions extraction component, which requires much less algorithm complexity, resulting in a significant reduction in params. Key region extraction focuses on the local features of the tracking object, similar to the local advantages of CNN structures, and the tracking is best when combined with transformer structures.
Experiments on the trackingnet dataset TrackingNet [48] is a large-scale tracking dataset, whose videos are sampled from YouTube, providing more than 30K video labels with more than 14 million dense bounding boxes, including various object classes and scenes. From Table 3, we find that SKRT achieves the best performance with the large dataset benchmark.

precision and success plots on OTB100

precision and success plots on LaSOT
Experiments on the VOT2018 dataset The VOT2018 [56] benchmark contains 60 challenging videos, including videos with fast motion, deformation, occlusion, etc. The dataset contains three metrics. The expectation average overlap (EAO) is the nonreset overlap expected value for each tracker on a short image sequence. The accuracy (A\(\uparrow \)) is the average overlap rate of the tracker under a single test sequence. The robustness (R\(\downarrow \)) is the number of tracker failures under a single test sequence that can be determined as failures when the overlap rate is 0. As shown in Table 4, SKRT achieves competitive results. Under the precondition of using an attention mechanism, SKRT has better results than other trackers (CGACD [27], etc.), which reflects the superiority of our method. First, a transformer is a multihead attention patch structure that captures richer feature information, expands the viewing field of the image and extracts more context information than traditional spatial and channel CNN attention methods. Second, the key regions extraction component obtains patches with high response values, which optimizes the patches input into the transformer, making them more refined and efficient.

Tracking results based on precision plots for 14 different attributes

Tracking results based on success plots for 14 different attributes
Experiments on the OTB100 dataset OTB100 [57] s a commonly used challenging benchmark that contains 100 challenging video sequences, and the performance is evaluated in terms of precision and AUC. As shown in Fig. 8, we compared our method with other, including TransT [13], Ocean [26], SiamRPN++ [17], MDNet [53], SiamCAR [25], PrDiMP [22], ATOM [41], SiamRPN [12], SiamFC [11], and find that SKRT performs best.
Experiments on the LaSOT dataset LaSOT [46] is a large-scale dataset for long-term tracking, and its test set has 280 videos, with an average of 2512 frames per video. Compared to other datasets, it focuses on long-term tracking, so it is more difficult. In the LaSOT [46] dataset experiment, SKRT is compared with STARK [14], TransT [13], TrDiMP [33], Ocean [26], GlobalTrack [58], DiMP [59], SiamCAR [25], DaSiamRPN [52], ATOM [41], SiamRPN++ [17], C-RPN [60], SiamDW [20]. As shown in Fig. 9, our method achieves the best results, ranking first for both precision and success plots, which are 0.678 and 0.681, respectively. This is because the transformer performs better than the CNN in the current training dataset, and the novel structure in our proposed method is more suitable for test object tracking experiments than that of other trackers.
As shown in Figs. 10 and 11, we compare all methods based on 14 attributes of the dataset, including the aspect ratio change, background clutter, camera motion, deformation, fast motion, full occlusion, illumination variation, low resolution, motion blur, out-of-view, partial occlusion, rotation, scale variation, and viewpoint change. Although SKRT achieves excellent performance in most attribute experiments, there are also some shortcomings. In terms of deformation, rotation and out-of-view, the results of SKRT are not as good as those of STARK [14], and in terms of illumination variation, the success plot using SKRT is not as good as that of TrDiMP [33]. To determine the reasons for these results, we analyze them from several aspects. First, the temporal method of continuous frame extraction will generate a certain inertia for predicting the target position. If the tracked object undergoes irregular changes, such as disordered deformation and rotation, the temporal method cannot predict such abrupt changes, which will eventually adversely affect the prediction. In addition, illumination changes cause the target color feature to change rapidly. The fusion of multiple frames makes this feature less similar to the template, and the superimposed highlights will cause more interference. The online template update cannot adapt to this change, resulting in inaccurate tracking. Second, since the transformer sequence selected by our method is at a position with a high response value of the feature map, this sequence of selected sequences ignores nonfocus regions. When the tracked object disappears from view, the influence of the nonfocus region increases, which helps to establish a relationship with the target. These relationships are useful for locating tracked objects when the target reappears. To improve efficiency, these nonfocus factors are removed, which is not conducive to the experiment of out-of-view attributes.
Ablation studies
To verify the effects of various parts of SKRT, we perform ablation experiments with the LaSOT [46] and GOT-10K [47] datasets.
Component parameter setting experiment Key region extraction is an important module in SKRT, and the number of key patches will also affect the final result. To verify the appropriate number, as shown in Table 5, when \(M = 6\) and \(N = 12,\) the results are the best. This is because when the number is insufficient and there are few features, it is difficult to extract effective information, and when the number is too large and the features are redundant, interference information will be extracted.
Defect improvement experiment As shown in Table 6, to test the influence of the number of input frames on the experimental results, we run experiments with 1–5 frames. We can see that the experiment works best when 3 frames are used. When the number of frames is less than 3, due to the limited motion information extracted, the temporal prediction features are lacking, which will cause the experimental results to drop. When the number of frames is greater than 3, since much motion information is redundant, it will affect the prediction of unnecessary noise features, so the experimental results will also decrease.

Visualization of KRE and the transformer
To verify the effect of center-corner and corner prediction, we perform ablation experiments. As shown in Table 7, the center-corner is used for the best performance. This is because the center position retains most of the important features of the tracking object, and adding center corners can enhance the feature influence of the object center position. The information collected in the top-left and bottom-right corners can provide more identifiable information for the central region. If only the corners are used, the central information may be ignored. To fuse the influences of these positions and increase the prediction accuracy, we take the median value so that the experimental effect is the best.
As shown in Table 8, to verify the impacts of the CNN, transformer and key regions extraction (KRE), we also conduct ablation experiments. In the case of a large number of training datasets, we replace the transformer structure with a CNN, and the success plot is 0.568, which shows that the transformer can establish a global long-distance relationship and is better than that of the CNN. When we only use the transformer and do not select key regions, the attention can easily focus on the meaningless features of the background, causing the weight of key regions to drop and the tracking results to drop. When we use the CNN (ResNet-101) as the backbone network and combine it with the transformer, although the CNN helps to increase local attention, the experimental improvement is not significant. To improve the defects based on the transformer input, we design the KRE component. KRE can reduce the redundancy of the sequence input transformer, focus more on the parts related to the tracking target, improve efficiency and achieve the best tracking results.
To verify the efficiency of SKRT when combining different components, we calculate the params and FLOPs and test the speed (FPS) with the GOT-10K dataset. As shown in Table 9, we only use the transformer, which has the least complexity, the lowest computation cost and the fastest tracking speed. When we add a CNN (ResNet-101) and combine it with the transformer as the backbone network, because of the multilayer residual structure of the CNN, the algorithm complexity is greatly increased, and the tracking speed is the lowest. Because the model complexity and calculation cost of key region extraction (KRE) are much lower than those of the CNN and the efficiency of inputting patches is improved, our method can run in real time at a tracking speed of more than 50 FPS.
Visualization
Fig. 12 shows the attention weights after input to the transformer using key region extraction. We can see that the attention regions are mainly focused on the target, and the interference of the surrounding background information is relatively small. At the same time, the motion features of the tracked objects are obvious, and the target is highlighted to make the tracking more accurate.
To demonstrate that KRE improves defects based on the transformer model, we visualize the feature maps. As shown in Fig. 13, we remove the KRE component and use only the transformer structure. Because it is global, the target region of interest is too large, and many locations with less relevance to the target receive more response values, resulting in redundancy. In addition, the transformer will focus on interfering objects that are similar to the target, which will increase some irrelevant response values. When we add the KRE component, we can see that the focus is on the most significant regions of the target, and the related response is partially efficient, eliminating the impact of similar backgrounds.

Visualization after using the KRE components
Conclusions
This paper proposes a new tracker named SKRT, which is a Siamese network structure. It uses a transformer instead of a CNN as the backbone network, which can extract global context information more efficiently. At the same time, three frames of feature maps are superimposed, and the spatiotemporal information of the tracking target can be obtained. Before the transformer similarity calculation is performed on the template and the search feature map, the key regions of interest are concentrated through key region extraction, and the background interference information is ignored, making the method more efficient. Finally, the bounding box is predicted by the center-corner, which ensures more robustness. Our method is tested with the GOT-10K, TrackingNet, VOT2020, OTB100 and LaSOT datasets, and the results show that SKRT achieves competitive results. We hope to conduct more in-depth research on the transformer in the future to increase the important weights of relevant features in the extraction of patch sequences, ignore the parts with low response values, improve the network efficiency, and make its structure more suitable for visual tracking.
References
Galoogahi HK, Fagg A, Lucey S (2017) Learning background-aware correlation filters for visual tracking. In International Conference on Computer Vision (ICCV)
Smeulders AW, Chu MD, Cucchiara R, Calderara S, Dehghan A (2013) Visual tracking: an experimental survey. IEEE Trans Pattern Anal Mach Intell 36(7):1442–1468
Zuo W, Wu X, Lin L, Zhang L, Yang MH (2018) Learning support correlation filters for visual tracking. IEEE Trans Pattern Anal Mach Intell 41(5):1158–1172
Alismail H, Browning B, Lucey S (2016) Robust tracking in low light and sudden illumination changes. In Fourth International Conference on 3d Vision(3DV), pages 389–398
Bolme DS, Beveridge JR, Draper BA, Lui YM (2010) Visual object tracking using adaptive correlation filters. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Bouchrika I, Carter JN, Nixon MS (2016) Towards automated visual surveillance using gait for identity recognition and tracking across multiple non-intersecting cameras. Multimed Tools Appl 75(2):1201–1221
Du X, Clancy N, Arya S, Hanna GB, Kelly J, Elson DS, Stoyanov D (2015) Robust surface tracking combining features, intensity and illumination compensation. Int J Comput Assist Radiol Surg (IJCARS) 10(12):1915–1926
Henriques JF, Caseiro R, Martins P, Batista J (2015) High-speed tracking with kernelized correlation filters. IEEE Trans Pattern Anal Mach Intell 37(3):583–596
Li K, He FZ, Yu HP (2018) Robust visual tracking based on convolutional features with illumination and occlusion handing. J Comput Sci Technol 33(1):223–236
Tokekar P, Isler V, Franchi A (2014) Multi-target visual tracking with aerial robots. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Bertinetto L, Valmadre J, Henriques Joo F, Vedaldi A, Torr Phs (2016) Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision (ECCV)
Bo L, Yan J, Wei W, Zheng Z, Hu X (2018) High performance visual tracking with siamese region proposal network. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Xin C, Bin Y, Jiawen Z, Dong W, Xiaoyun Y, Huchuan L (2021) Transformer tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 8126–8135
Bin Yan, Houwen Peng, Jianlong Fu, Dong Wang, and Huchuan Lu (2021) Learning spatio-temporal transformer for visual tracking. In International Conference on Computer Vision (ICCV), pages 10448–10457,
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin (2017). Attention is all you need. In Advances in neural information processing systems, pages 5998–6008,
Salman K, Muzammal N, Munawar H, Syed Waqas Z, Fahad Shahbaz K, Mubarak S (2021) Transformers in vision: a survey. ACM Computing Surveys (CSUR)
Li B, Wu W, Wang Q, Zhang F, Xing J, Yan J (2020) Siamrpn++: evolution of siamese visual tracking with very deep networks. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Krizhevsky A, Sutskever I, Hinton GE (2017) Imagenet classification with deep convolutional neural networks. Commun ACM 60(6):84–90
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Zhang Z, Peng H (2020) Deeper and wider Siamese networks for real-time visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Gao Peng, Yuan Ruyue, Wang Fei, Xiao Liyi, Fujita Hamido, Zhang Yan (2020) Siamese attentional keypoint network for high performance visual tracking. Knowl Based Syst 193:105448
Martin D, Luc Van G, Radu T (2020) Probabilistic regression for visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 7183–7192
Paul V, Jonathon L, Philip HS T, Bastian L (2020) Siam r-cnn: visual tracking by re-detection. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 6578–6588
Yinda X, Zeyu W, Zuoxin L, Ye Y, Gang Yu (2020) Siamfc++: towards robust and accurate visual tracking with target estimation guidelines. In AAAI Conference on Artificial Intelligence (AAAI), pages 12549–12556
Dongyan G, Jun W, Ying C, Zhenhua W, Shengyong C (2020) Siamcar: Siamese fully convolutional classification and regression for visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 6269–6277
Zhipeng Z, Houwen P, Jianlong F, Bing L, Weiming H (2020) Ocean: object-aware anchor-free tracking. In European Conference on Computer Vision (ECCV), pages 771–787. Springer
Fei D, Peng L, Wei Z, Xianglong T (2020) Correlation-guided attention for corner detection based visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 6836–6845
Zhang Dawei, Zheng Zhonglong, Li Minglu, Liu Rixian (2021) Csart: channel and spatial attention-guided residual learning for real-time object tracking. Neurocomputing 436:260–272
Nicolas C, Francisco M, Gabriel S, Nicolas U, Alexander K, Sergey Z (2020) End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), pages 213–229. Springer
Alexey D, Lucas B, Alexander K, Dirk W, Xiaohua Z, Thomas U, Mostafa D, Matthias M, Georg H, Sylvain G, et al (2020) An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Ze L, Yutong L, Yue C, Han H, Yixuan W, Zheng Z, Stephen L, Baining G (2021) Swin transformer: Hierarchical vision transformer using shifted windows. In International Conference on Computer Vision (ICCV), pages 10012–10022
Gedas B, Heng W, Lorenzo T (2021) Is space-time attention all you need for video understanding? arXiv preprint arXiv:2102.05095
Ning Wang, Wengang Zhou, Jie Wang, and Houqiang Li (2021) Transformer meets tracker: Exploiting temporal context for robust visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 1571–1580,
Moju Z, Kei O, Masayuki I (2021) Trtr: visual tracking with transformer. arXiv preprint arXiv:2105.03817
Kaihua Z, Lei Z, Qingshan L, David Z, Ming-Hsuan Y (2014) Fast visual tracking via dense spatio-temporal context learning. In European Conference on Computer Vision (ECCV), pages 127–141. Springer
Zhu T, Xing J, Qiang W, Lang C, Yi J (2017) Robust object tracking based on temporal and spatial deep networks. In International Conference on Computer Vision (ICCV)
Yuan Liu, Ruoteng L, Robby TT, Yu C, Xiubao S (2020) Object tracking using spatio-temporal future prediction. arXiv preprint arXiv:2010.07605
Gao J, Zhang T, Xu C (2019) Graph convolutional tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Jiang Bo, Zhang Yuan, Luo Bin, Cao Xiaochun, Tang Jin (2020) Stgl: spatial-temporal graph representation and learning for visual tracking. IEEE Trans Multimed 23:2162–2171
Hasan S, Hakan C, Okan K, Bedirhan U (2020) Trat: tracking by attention using spatio-temporal features. arXiv preprint arXiv:2011.09524
Martin D, Goutam B, Fahad Shahbaz K, Michael F (2019) Atom: accurate tracking by overlap maximization. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 4660–4669
Jinpu Z, Yuehuan W (2021) Spatio-temporal matching for Siamese visual tracking. arXiv preprint arXiv:2105.02408
Hamid R, Nathan T, JunYoung G, Amir S, Ian R, Silvio S (2019) Generalized intersection over union: a metric and a loss for bounding box regression. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 658–666
Ren S, He K, Girshick R, Sun J (2017) Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39(6):1137–1149
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M (2014) Imagenet large scale visual recognition challenge. International Journal of Computer Vision(IJCV), pages 1–42
Heng F, Liting L, Fan Y, Peng C, Ge D, Sijia Y, Hexin B, Yong X, Chunyuan L, Haibin L (2019) Lasot: a high-quality benchmark for large-scale single object tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 5374–5383
Huang L, Zhao X, Huang K (2019) Got-10k: a large high-diversity benchmark for generic object tracking in the wild. IEEE Trans Pattern Anal Mach Intell 43(5):1562–77
Matthias M, Adel B, Silvio G, Salman A, Bernard G (2018) Trackingnet: a large-scale dataset and benchmark for object tracking in the wild. In European Conference on Computer Vision (ECCV), pages 300–317
Tsung-Yi L, Michael M, Serge B, James H, Pietro P, Deva R, Piotr D, Lawrence Zitnick C (2014) Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), pages 740–755. Springer
Ilya L, Frank H (2018) Fixing weight decay regularization in adam. arXiv preprint arXiv:1711.05101
Yutao C, Cheng J, Limin W, Gangshan W (2020) Fully convolutional online tracking. arXiv preprint arXiv:2004.07109
Zhu Z, Wang Q, Li B, Wu W, Yan J, Hu W (2018) Distractor-aware Siamese networks for visual object tracking. In European Conference on Computer Vision (ECCV)
Hyeonseob N, Bohyung H (2016) Learning multi-domain convolutional neural networks for visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR)
Yuechen Y, Yilei X, Weilin H, Matthew RS (2020) Deformable siamese attention networks for visual object tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 6728–6737
Alan L, Jiri M, Matej K (2020) D3s-a discriminative single shot segmentation tracker. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 7133–7142
Matej K, Ales L, Jiri M, Michael F, Roman P, LukaCehovin Z, Tomas V, Goutam B, Alan L, Abdelrahman E, et al (2018) The sixth visual object tracking vot2018 challenge results. In European Conference on Computer Vision (ECCV)
Wu Y, Lim J, Yang Ming Hsuan (2015) Object tracking benchmark. IEEE Trans Pattern Anal Mach Intell 37(9):1834–1848
Lianghua H, Xin Z, Kaiqi H (2020) Globaltrack: a simple and strong baseline for long-term tracking. In AAAI Conference on Artificial Intelligence (AAAI), pages 11037–11044
Goutam B, Martin D, Luc Van G, Radu T (2019) Learning discriminative model prediction for tracking. In International Conference on Computer Vision (ICCV), pages 6182–6191
Heng F ,Haibin L (2019) Siamese cascaded region proposal networks for real-time visual tracking. In International Conference on Computer Vision and Pattern Recogintion (CVPR), pages 7952–7961
Acknowledgements
This work was supported by the new-generation AI major scientific and technological special project of Tianjin (18ZXZNGX00150) and the Special Foundation for Technology Innovation of Tianjin (21YDTPJC00250).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, R., Wen, X., Yuan, L. et al. Spatiotemporal key region transformer for visual tracking. Complex Intell. Syst. 9, 5865–5879 (2023). https://doi.org/10.1007/s40747-023-01040-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01040-4