
Abstract
Using differential privacy to provide privacy protection for classification algorithms has become a research hotspot in data mining. In this paper, we analyze the defects in the differentially private decision tree named Maxtree, and propose an improved model DPtree. DPtree can use the Fayyad theorem to process continuous features quickly, and can adjust privacy budget adaptively according to sample category distributions in leaf nodes. Moreover, to overcome the inevitable decline of classification ability of differentially private decision trees, we propose an ensemble learning model for DPtree, namely En-DPtree. In the voting process of En-DPtree, we propose a multi-population quantum genetic algorithm, and introduce immigration operators and elite groups to search the optimal weights for base classifiers. Experiments show that the performance of DPtree is better than Maxtree, and En-DPtree is always superior to other competitive algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
With the rapid development of information technology, in addition to the government, many companies now have a large amount of data about citizens’ personal information. As a powerful data analysis tool, data mining can identify and extract implicit, unknown, novel and potentially useful knowledge and rules from a large number of incomplete and noisy data. Data mining makes great contributions in scientific research, business decision-making, medical research, and other fields [1,2,3]. At the same time, it also produces the inevitable problem of privacy disclosure, which has attracted more and more attention from the industry and society. For example, using data mining and machine learning to mine medical case records can obtain sensitive information, such as patients’ diseases. Privacy protection technology can solve the privacy threat caused by data analysis. How to analyze and not disclose private information is the main purpose of privacy protection technology. In recent years, many privacy protection technologies have emerged, such as k-anonymity, l-diversity, and t-proximity. K-anonymity [4] can make every individual information contained in anonymous datasets indistinguishable from other \(k-1\) individual information. However, k-anonymity cannot prevent the attributes disclosure, so attackers can obtain sensitive information through the background knowledge attack and consistency attack [5, 6]. The idea of l-diversity [7] is that the values of sensitive attributes should be diverse, so as to ensure that the user’s sensitive information cannot be inferred from the background knowledge. In a real dataset, the attribute values are likely to be skewed or semantically similar, while l-diversity only guarantees diversity, and it is not recognized that the attribute values are semantically similar. Therefore, l-diversity will be attacked by similarity attack [6]. T-proximity [8] means that the distribution of sensitive attributes in a category is close to the distribution of the attribute in the whole data, and does not exceed the threshold value t. Because t-proximity can prevent attribute disclosure but not identity disclosure, k-anonymity and l-diversity may be required when dealing with problems. And t-proximity has a large amount of information loss and is more difficult to generalize. In addition, there are some new attack models, such as combined attack [9] and foreground knowledge attack [10]. These new attack models pose a severe challenge to the effectiveness of the above methods.
Differential privacy (DP) is a widely recognized strict privacy protection technology, which was first proposed by Dwork [11]. It makes malicious adversaries unable to infer the user’s sensitive information even if they know the results published by the user. DP has become the de-facto privacy standard around the world in recent years, with the U.S. Census Bureau using it in their Longitudinal Employer-Household Dynamics Program in 2008 [12], and the technology company Apple implementing DP in their latest operating systems and applications [13]. Applying DP to machine learning model can protect training data from model reverse attack when model parameters are released.
Classification technology plays a key role in data prediction and analysis, and decision tree (DT) is a typical representative of classification models. DT is a non-parametric supervised learning method, and it makes no assumptions about the distribution of the underlying data [14]. However, the transparency property of DT can be used by attackers to steal personal information. Suppose there are two adjacent datasets used to train two trees, which are different in one record at most. Opponents can obtain sensitive personal information from the database by comparing the counting results. To solve the problem of privacy disclosure of DT, scholars apply DP to the construction of DT to realize privacy protection.
Although scholars have put forward many DPDT models, there are still some problems need to be overcome:
-
When inner nodes use the Laplace mechanism to realize privacy protection, no matter what split criterion is adopted, there must be a lot of fine-grained counting queries, which will inevitably lead to the accumulation of noise.
-
In the process of privacy budget allocation, none of the DPDT models takes into account the importance of leaf nodes in the final classification prediction. When the difference in the number of samples between the category with the most samples and the category with the second most samples in leaf nodes is small, adding more noise will directly lead to error classification results. On the contrary, when the difference between them is large, leaf nodes can bear more noise, so as to improve privacy protection ability of DPDT. Obviously, we should formulate a unique privacy budget allocation strategy for each leaf node.
-
Many DPDT models can only deal with discrete attributes, and the other part directly uses the exponential mechanism to select partition points in discretization of continuous attributes. The exponential mechanism needs to traverse all potential partition points of each continuous attribute, which will lead to low efficiency and need to consume privacy budget.
-
The bootstrap sampling makes each training set intersect, so the total privacy budget needs to be evenly allocated to each base classifier. The smaller the privacy budget, the greater the noise, and the worse the classification performance of base classifiers.
-
In the ensemble learning models based on DPDT, the voting strategy always use the majority voting or assign weights by the accuracy of base classifiers. To improve the privacy protection ability, DPDT has to introduce noise in the process of constructing nodes, which will lead to the weak classification ability of some base learners. Therefore, it is necessary to set an appropriate weight for each basic classifier to obtain an ensemble model with strong classification ability.
To overcome the above issues, we propose a DPDT model, called DPtree. In addition, to improve the classification ability of DPtree, we propose an ensemble learning model based on DPtree, called En-DPtree. And the main contributions in this article are as follows:
-
The exponential mechanism is utilized in inner nodes, which can obtain the split attribute only by one calculation without multiple counting queries, so as to avoid noise accumulation.
-
We formulate an adaptive privacy budget allocation strategy for each leaf node according to its sample category distribution, which can not only ensure that the classification result of each leaf node is not distorted, but also improve the privacy protection ability of DPtree.
-
The Fayyad theorem is applied to quickly locate the best partition points of continuous attributes by comparing the adjacent boundary points of different categories, which can greatly improve the computational efficiency and does not occupy privacy budget.
-
To economize on privacy budget, we use the sampling without replacement method to obtain training sets. Therefore, the privacy budget of each DPtree is equal to the total privacy budget.
-
We design multi-population quantum genetic algorithm (MPQGA) to search the appropriate weight for each base classifier, so as to improve the classification ability of En-DPtree. In MPQGA, the individuals of each population evolve to the optimal solution of their own population, which will reduce the possibility of the algorithm finally falling into the local optimal solution. In addition, we also design immigration operators and elite groups to avoid premature convergence of each population.
The rest of this paper is organized as follows. The section “Related work” presents previous works related to DPDT. The section “Differential privacy” introduces the contents of DP. The section “Analysis on MaxTree algorithm” shows the analysis on MaxTree. The section “Differentially private decision tree” describes the specific implementation steps of DPtree and En-DPtree. The section “The ensemble learning based on DPtree” shows the experimental process and results. The section “Time complexity analysis” shows the time complexity analysis of DPtree and En-DPtree. The section “Conclusion” presents the conclusion.
Related work
The representative schemes in the DPDT models are SuLQ-based ID3, DiffP-C4.5, and DiffGen. In 2005, Blum et al. first introduced DP into DT based on the SuLQ framework and proposed SuLQ-based ID3 [15]. This algorithm achieves the ability of privacy protection by adding Laplace noise to the query results in ID3. However, adding Laplace noise to each count of information gain will lead to a large amount of accumulated noise and waste of privacy budget. To solve the problems, Friedman and Schuster proposed PINQ-based ID3 [16]. This algorithm implements ID3 on multiple mutually exclusive data subsets, so it can effectively use privacy budget. However, PINQ-based ID3 also needs to add Laplace noise in the calculation of information gain, which still cannot significantly reduce the noise. Besides, Friedman and Schuster proposed DiffP-ID3 by the exponential mechanism [17]. Since the exponential mechanism can evaluate attributes only through one query, DiffP-ID3 can reduce the introduction of noise. Because ID3 can only deal with discrete data, Friedman and Schuster proposed DiffP-C4.5 [17] which can deal with continuous data based on the exponential mechanism. Different from the above methods, DiffGen [18] uses the classification tree to divide all records in the dataset into leaf nodes from top to bottom, and then adds Laplace noise to the count value in leaf nodes. The classification accuracy of DiffGen is improved and each classification attribute corresponds to a classification tree. When the dimensions of sample attributes are very large, this will lead to inefficient selection based on the exponential mechanism, and may exhaust privacy budget. In addition, there are many other DPDT models. During the construction of DT, the number of instances in each layer is usually decreasing. If each layer is given the same privacy budget, it will inevitably lead to imbalance of signal-to-noise ratio of DT. Therefore, Liu et al. [19] designed a budget allocation strategy, so that less noise would be added in larger depth to balance between true counts and noise. To reduce influence of noisy by the Laplace mechanism, Wu et al. [20] designed the up–down and bottom–up approaches to reduce the number of nodes in a random DT. However, no matter which strategy is used to build DPDT, it cannot avoid introducing noise in the process of node generation, resulting in weak and unstable classification ability. How to not only protect privacy but also improve classification ability of DT is a difficult problem.
Luckily, ensemble learning can always significantly improve the generalization ability of base learners in most cases by training multiple learners and combining their results. Therefore, scholars use ensemble learning to improve the classification performance of DPDT. Random forest under DP was first proposed by Jagannathan et al. [21]. In this model, the base classifier is ID3 DPDT. However, they found that to obtain reasonable privacy protection, it needed to pay a great loss of prediction accuracy. Therefore, they proposed an improved ensemble learning based on random DT, which we call it as En-RDT. Fletcher and Islam [22] proposed a DP decision forest that took advantage of a theorem for the local sensitivity of the Gini Index. In addition, they used the theory of Signal-to-Noise Ratios to automatically tune the model parameters [23]. However, the split features are randomly selected which might make the tree worse. Patil and Singh [24] designed a random forest algorithm satisfying DP, which is called DiffPRF. DiffPRF first uses entropy to discrete continuous attributes, and then uses DiffP-ID3 as the base learner to generate random forest. Subsequently, Yin et al. [25] further proposed DiffP-RFs based on DiffPRF. DiffP-RFs does not need to preprocess dataset, and it extends the monotonic privacy budget allocation strategy that DiffPRF can only deal with discrete attributes. Compared with random forests, boosting with DP has rarely been researched. Privacy-preserving boosting usually uses distributed training. Each party uses their own data to train a DP boosting classifier, and finally aggregates classifiers through a trusted third party without sharing their own datasets [26,27,28]. This method allows users to define privacy levels according to their own needs, but training data are often limited. Li et al. [29] proposed a gradient boosting based on DP. They filter the data based on gradient and use geometric leaf cutting to ensure a smaller sensitivity boundary. Shen [30] proposed DP-AdaBoost using single-layer ID3. The algorithm does not use counting function directly when adding noise, but considers the weights of each record at the same time. However, the algorithm ignores the influence of tree depth on classification ability. Jia and Qiu [31] proposed DP-AdaBoost based on CART and this model can handle continuous features.
Differential privacy
DP is a strict privacy definition against the individual privacy leakage that guarantees the outcome of a calculation to be insensitive to any particular record in the dataset. In the following, we introduce the definition of DP and two important theorems.
Definition 1
(Differential privacy [11]) We say a randomized computation F provides \(\epsilon \)-DP if for any adjacent datasets \(D_{1}\) and \(D_{2}\) with symmetric difference \(D_{1}\mathrm{\Delta } D_{2}=1\), and any set of possible outcomes \(S\in Range(F)\)
The parameter \(\epsilon \) is called the privacy budget and is inversely proportional to the strength of privacy protection.
Definition 2
(Sensitivity [32]) Given an arbitrary function \(f:D\rightarrow R^{d}\), the sensitivity of f is defined as
where \(D_{1}\) and \(D_{2}\) differ in one record and d is the dimension of the function f.
Theorem 1
(Laplace mechanism [32]) Given an arbitrary function \(f:D\rightarrow R^{d}\), for an arbitrary domain D, the function F provides \(\epsilon \)-DP, if F satisfy
where the noise \(Lap\left( \frac{\Delta f}{\epsilon }\right) \) is drawn from a Laplace distribution, and d is the dimension of the function f.
Theorem 2
(Exponential mechanism [33]) Given a random mechanism F, its input is dataset D, and the output is an entity object \(r\in Range\). Let q(D, r) be a score function to assign each output r a score, and \(\Delta q\) be the sensitivity of the score function. Then, the mechanism F maintains \(\epsilon \)-DP, if F satisfies
Analysis on MaxTree algorithm
Maxtree algorithm [19] proposed by Liu et al. is shown in Algorithm 1. When constructing DT, it introduces noise to relevant counting results by the Laplace mechanism to realize privacy protection. Generally, as tree depth increases, the node counting results decrease accordingly. If all nodes are allocated the same privacy budget, signal-to-noise ratio of nodes at different depths must be unbalanced. To overcome this defect, Maxtree allocates more privacy budget for deeper nodes.
Specifically, assuming that only k attributes are used to build branch nodes, \(\frac{1}{k-i}\) shares of privacy budget are allocated to each inner node of the ith layer and 1 share to each leaf node. Then, the total privacy budget shares of DT are
Suppose \(\epsilon \) denotes total privacy budget of DT, then Maxtree allocates \(\frac{\epsilon }{s_{t}}*\frac{1}{k-i}\) privacy budget to each inner node in the ith layer. At this point, there are \(k-i\) attributes need to be evaluated through related attribute evaluation function. Therefore, the privacy budget required to evaluate each attribute is \(\epsilon _{i}=\frac{\epsilon }{s_{t}}*\frac{1}{(k-i)^2}\).
In internal nodes, the use of the Laplace mechanism must involve counting queries. The more counting queries, the more shares of the privacy budget are divided, which will lead to the greater noise disturbance for each query. Maxtree selects the maximum label vote rather than information gain in attribute evaluation process, which can relatively reduce the number of queries. However, after allocating privacy budget for each layer, Maxtree still needs to divide the budget again to each feature for evaluation. Obviously, the use of the Laplace mechanism in internal nodes cannot fundamentally avoid quadratic partition of privacy budget.
In leaf nodes, the query datasets do not intersect, so the privacy budget allocated to leaf nodes does not need to be divided again. Because leaf nodes are the key to classification, Maxtree allocates the most privacy budget for each leaf node, that is, 1 share. The larger the privacy budget, the less noise generated, and the weaker the privacy protection capability. Therefore, the privacy budget strategy in leaf nodes of Maxtree leads to weak privacy protection ability.

On the whole, there are several difficulties in constructing DPDT. First, the counting queries of attributes in internal nodes need to subdivide privacy budget, resulting in high noise and low accuracy of DT. Second, assigning the same share of privacy budget to all leaf nodes only takes into account the reduction of noise, but leads to weak privacy protection ability.
Differentially private decision tree
In this section, we design an improved DPDT algorithm called DPtree. DPtree uses the Fayyad theorem to quickly discretize continuous attributes. Besides, DPtree uses the exponential mechanism and Laplace mechanism to construct inner nodes and leaf nodes, respectively. Each inner node has the same privacy budget, and each leaf node can adaptively adjust privacy budget according to the sample category distribution. The generation process of DPtree can not only ensure that the classification results are not distorted, but also improve the privacy protection ability. The key of constructing DPDT lies in the generation of tree structure and the allocation of privacy budget. In the section “Generation of tree structure”, we introduce some important problems involved in the generation of tree structure. In the section “Privacy budget allocation strategy”, we introduce a practical privacy budget allocation strategy. The privacy analyze is shown in the section “Privacy analyze”.
Generation of tree structure
In the process of growing DT, two kinds of nodes are involved, namely inner nodes and leaf nodes. According to the analysis of Maxtree, if inner nodes use the Laplace mechanism, no matter which rule is used to evaluate attributes, it inevitably needs some low granularity queries. Fine-grained queries lead to accumulation of noise and ultimately affect classification accuracy. Therefore, we choose the exponential mechanism in inner nodes, and quality function is the information gain rate. The exponential mechanism does not need to multiple counting queries, it only needs one time calculation to acquire split attributes. Obviously, the exponential mechanism can economize on privacy budget and overcome the inherent defects of the Laplace mechanism in inner nodes. In leaf nodes, we still use the Laplace mechanism to compare the number of samples in each category.
In addition, continuous attributes are usually involved in the construction of DT. C4.5 algorithm [34] has a great advantage over ID3 algorithm, that is, it can deal with both discrete attributes and continuous attributes. C4.5 algorithm utilizes dichotomy to discretize continuous attributes. The specific process is as follows: assume that there are m different values of continuous attribute A in dataset D, and sort them in ascending order to get \(\{a_{1}, a_{2},\ldots , a_{m}\}\). Calculate the middle points \(t=(a_{i}+a_{i+1})/2\) of every two adjacent elements, and t denotes a potential partition point (there are \(m-1\) potential partition points in total). Among the \(m-1\) potential partition points, the point with the largest information gain rate is the optimal partition point of attribute A. Obviously, C4.5 algorithm needs to traverse all potential partition points of each continuous attribute, which will lead to low efficiency. How to quickly locate the best partition point of continuous attributes has become an urgent problem to be solved.
We use the Fayyad theorem [35] to quickly locate the best partition point of each continuous attributes. According to the Fayyad theorem, the best partition point always appears on the boundary points of two adjacent heterogeneous instances. Therefore, there is no need to compare each threshold point, just compare the adjacent boundary points of different categories to discretize continuous attributes. Suppose the instance attribute values after ascending sorting are \(\{a_{1}, a_{2},\ldots , a_{9}\}\), in which the first three samples belong to category \(c_{1}\), the middle three belong to category \(c_{2}\), and the last three belong to category \(c_{3}\). According to the Fayyad theorem, only boundary points \(a_{3}\) and \(a_{6}\) are the potential partition points, and the potential partition point with the largest information gain rate is the best partition point of attribute A. If we use the dichotomy, there are eight potential partition points. Obviously, the continuous attribute discretization method based on the Fayyad theorem can greatly improve the efficiency.
During the construction of DPtree, it is necessary to determine whether the current node is a leaf node or an inner node. If all the samples of the current node belong to the same category, or the attribute set to be selected is empty, or the current node reaches the maximum depth, the current node is a leaf node. In addition, the Laplace noise is added to the number of samples contained in the current node, that is, \(N_{node}=NoisyCount_{\epsilon _{0}}(node)\). If \(N_{node}\) is smaller than the threshold \(\tau \), the current node is a leaf node. Otherwise, the current node is an inner node. When it is a leaf node, use the Laplace mechanism to add noise to the number of all categories of the node, and classify the node according to \(argmax_{c}(n_{c}+Lap(1/\epsilon _{l}))\). When it is an inner node, the exponential mechanism is used to select split attributes, that is, \(\overline{A}=ExpMech_{\epsilon _{0}}(\mathcal {A},q)\). The score function q of the exponential mechanism is the information gain rate. On the whole, we grow a DPtree model, as shown in Algorithm 2. And an overview of DPtree is shown in Fig. 1. DPtree discretizes continuous attributes based on the Fayyad idea, and adopts the exponential mechanism and the Laplace mechanism in internal nodes and leaf nodes, respectively.

An overview of DPtree

Privacy budget allocation strategy
For inner nodes, when we use the exponential mechanism to select split attributes, it has little correlation with the number of instances, so each inner node is allocated an equal privacy budget \(\epsilon _{0}\). In addition, since the classification of leaf nodes directly affects the final classification results, enough privacy budget is allocated to leaf nodes, that is, \(2\epsilon _{0}\), so less noise is introduced to ensure that the classification results are not distorted. From the above analysis of Maxtree, it can be seen that allocating the same and enough privacy budget to each leaf node only considers noise reduction, but it will lead to weak privacy protection ability. Therefore, we should formulate an unique privacy allocation strategy for each leaf node.
When there is a large difference between the number of samples contained in the maximum category and the submaximum category in a leaf node, even if large noise is added, the classification result will not be distorted. At this time, less privacy budget can be allocated to it, so as to improve the privacy protection ability. Suppose there are two types of data in the leaf nodes \(n_{a}\) and \(n_{b}\). In the leaf node \(n_{a}\), there are ten samples which belong to the category \(c_{1}\) and two samples belong to the category \(c_{2}\). In the leaf nodes \(n_{b}\), there are seven samples belong to the category \(c_{1}\) and five samples belong to the category \(c_{2}\). Suppose that the Laplace noise of the category \(c_{1}\) and the category \(c_{2}\) in leaf nodes are \(L_{1}\) and \(L_{2}\). When \(L_{2}<8+L_{1}\), the classification result of the leaf node \(n_{a}\) will not be distorted. When \(L_{2}<2+L_{1}\), the classification result of the leaf node \(n_{b}\) will not be distorted. It is obvious that the leaf node \(n_{a}\) can tolerate more noise than the leaf node \(n_{b}\). Therefore, we can formulate an adaptive privacy budget allocation strategy for each leaf node according to its sample category distribution. Let \(\alpha \) be the ratio of the submaximum category to the maximum category, then the privacy budget of this leaf node is \(\epsilon _{l}=\alpha *2\epsilon _{0}\). On the one hand, when the difference between the submaximum and the maximum is very small, the privacy budget is almost equal to \(2\epsilon _{0}\), which can ensure that the classification result is not distorted. On the other hand, the greater the difference between the submaximum and the maximum, the lower the privacy budget and the stronger the privacy protection ability. Therefore, this adaptive privacy allocation scheme can not only ensure that the classification result of each leaf node is not distorted, but also improve the privacy protection ability.
Privacy analyze
DP has two important properties, namely the sequential combination and the parallel combination, which play an important role in privacy budget allocation. Suppose a randomization mechanism \(F_{i}\) is applied to subsets of database D providing \(\epsilon _{i}\)-DP. When the subsets are joint, the sequential combination makes the whole mechanism provides \(\sum _{i}\epsilon _{i}\)-DP [36]. When the subsets are disjoint, the parallel combination indicates the whole mechanism provides \(max\ \epsilon _{i}\)-DP [36].
Theorem 3
DPtree satisfies \(\epsilon \)-DP.
Proof
Assume adjacent datasets D and \(D^{'}\) with symmetric difference \(D\mathrm{\Delta } D^{'}=1\), F(D) and \(F(D^{'})\), respectively, represent the output of the random algorithm; each attribute \(A_{x}\) has \(|r_{x}|\) division methods, and we can get
The degree of differential privacy protection for inner nodes is
Therefore, the total privacy budget of inner nodes is \(d\epsilon _{0}\).
Add the Laplace noise to class counting function \(Count(D)\), and the output after disturbance is denoted as \(NoisyCount(D)=Count(D)+Lap(1/\epsilon _{l})\). We can get
Therefore, the total privacy budget of leaf nodes is \(2\epsilon _{0}\).
Besides, each node of DPtree needs to be judged as an inner node or a leaf node, and the privacy budget of the process is \(\epsilon _{0}\). We can get the total privacy budget of DPtree is \(d\epsilon _{0}+2\epsilon _{0}+(d+1)\epsilon _{0}\). Therefore, DPtree satisfies \(\epsilon \)-DP. \(\square \)
The ensemble learning based on DPtree
DP improves the security of DT, but the accuracy decreases. By constructing multiple DT models into an integration, decision forest reduces the impact of large variance of DT models on generalization performance to a certain extent. On the other hand, the greedy strategy is used in the construction of DT, and the decision forest can get better performance through integration. Therefore, we use the bagging technology to build the ensemble model based on DPtree.
Generally, the bagging technology [37] uses bootstrap sampling to obtain a set of training sets \(\{D_{1}, D_{2},\ldots , D_{M}\}\), each DT is trained based on these training sets, and then, test samples are predicted by voting method. Assume the total privacy budget is \(\epsilon \), due to the intersection between each training set, the privacy budget allocated to each DT is only \(\epsilon /M\). To economize on privacy budget, we use the sampling without replacement method to obtain training sets \(\{D_{1}, D_{2},\ldots , D_{M}\}\). Therefore, the privacy budget of each DT is \(\epsilon \). Furthermore, the weighted voting scheme usually sets the weights manually or sets the confidence of base learners as the weights, which are usually not optimal. The weights of base classifiers play a great role in the final classification results. It is necessary to get a set of better weights by searching weight space. Therefore, we need to design an intelligent optimization algorithm to generate a set of better weights for ensemble model.
Genetic algorithm (GA) [38] is good at solving global optimization problem, and it can efficiently jump out of local optimal points to find the global optimal point. However, when the selection, crossover, and mutation operators are not appropriate, GA will cost many iterations, and have slow convergence, premature convergence, and many other defects. In recent years, using quantum theory to further improve intelligent optimization algorithm has become a very popular research direction [39, 40]. Quantum genetic algorithm (QGA) [41] is a kind of fusion algorithm that introduces efficient quantum computing into GA, uses the quantum state to encode, and selects the quantum rotating gate to perform genetic operation. Compared with ordinary GA, QGA can keep the population diversity because of the quantum superposition state, and it simplifies the calculation and reduces the operation steps through using the quantum rotating gate. With the help of QGA, we can generate appropriate weights for each DT, so as to further improve the performance of ensemble model.
In the evolution process of QGA, the individuals of each iteration are updated in the direction of the current optimal solution. If the current optimal solution is a local solution, the algorithm may eventually fall into a local optimal solution. Therefore, we design a multi-population strategy. The individuals of each population evolve to the optimal solution of their own population, which will reduce the possibility of the algorithm finally falling into the local solutions. In addition, an immigration operation is designed to exchange the individuals with the largest fitness and the smallest fitness between populations, which can avoid premature convergence of each population.

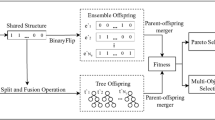
An overview of En-DPtree
When we use MPQGA to optimize the M weights of base classifiers, each chromosome is coded by qubits as follows:
where \( q_{j}^{t}\) is the jth chromosome in the population of the tth generation, k represents the number of qubits coding each gene, and M is the number of genes on the chromosome which is equal to the number of weights to be optimized. The qubit code of each individual in the population is initialized to
which means that all possible states expressed by each chromosome are equal. Besides, the prediction output of each DPtree \(T_{i}(i=1,2,\ldots ,M)\) on sample x is expressed as a C-dimensional vector \((T_{i}^{1}(x), T_{i}^{2}(x),\ldots , T_{i}^{C}(x),)\), where \(T_{i}^{c}(x)\) represents the output of \(T_{i}\) on category c. Then, the fitness function in the MPQGA is as follows:
where
E and T(x) is the error and the prediction label of the ensemble model individually. The ensemble model based on MPQGA is shown in Algorithm 3 and the overview of it is shown in Fig. 2.
Theorem 4
En-DPtree satisfies \(\epsilon \)-DP.
Proof
We have proven that DPtree satisfies \(\epsilon \)-DP. Besides, each private tree only depends on the corresponding training subsets; different trees are built on disjoint data subsets. According to the parallel composition of DP, the privacy budget consumed by all the base learners is still \(\epsilon \). Besides, because DP is immune to post-processing, the voting step of the ensemble model will not damage the degree of privacy protection. Obviously, En-DPtree satisfies \(\epsilon \)-DP. \(\square \)

Time complexity analysis
Suppose the maximal depth of DPtree is d, the number of attributes is \(|\mathcal {A}|\), and the number of data is |D|. When the optimal splitting attribute is selected on the branch node, the time complexity is \(O(|\mathcal {A}|\cdot |D|)\). Besides, the time complexity of privacy budget allocation is O(1). Therefore, the time complexity of DPtree is \(O(d\cdot |\mathcal {A}|\cdot |D|)\). In En-DPtree, M DPtree models need to be constructed, so the time complexity of En-DPtree is \(O(M\cdot d\cdot |\mathcal {A}|\cdot |D|)\).
Performance evaluation
To test the property of the proposed En-DPtree, we select four datasets from the UCI Machine Learning Repository [42], as shown in Table 1. In this section, we select accuracy, F1, and micro-F1 to evaluate the classification ability of the classifiers. In the following, we first analyze the impact of privacy budget allocation strategy on classification performance through comparing our proposed DPtree and En-DPtree with Maxtree [19], Maxforest [19], En-RDT [21], DiffP-RFs [25], DP-AdaBoost, and AdaBoost. Second, we test the effects of the ensemble learning method based on MPQGA. Ultimately, we examine how the classification accuracy of En-DPtree changes with the number of iterations of MPQGA.
Comparison with other competitive classifiers
Privacy budget is a measure of the privacy protection capability. The smaller the privacy budget, the stronger the privacy protection capability of the algorithm, but the classification ability is usually reduced due to the introduction of a large number of noise. Figures 3 and 4 show the experimental results of algorithms DPtree, En-DPtree, Maxtree, Maxforest, En-RDT, DiffP-RFs, DP-AdaBoost, and AdaBoost on datasets in Table 1 under privacy budget from 0.1 to 1.

Impact of privacy budget \(\epsilon \) on classification accuracy on datasets

Impact of privacy budget \(\epsilon \) on F1 or micro-F1 on datasets
Obviously, in the binary classification tasks, the performances of classification algorithms on Mushroom are better than that on Adult. The possible reason is that all attributes of Mushroom are discrete, while Adult has both discrete and continuous attributes. Each algorithm needs to discretize the continuous attributes of Adult to classify. The discretization process may lead to the loss of underlying information or insufficient extraction of features, resulting in the reduction of classification ability. In addition, if the algorithm consumes the privacy budget in the process of discretizing continuous attributes, it will reduce the privacy budget in the process of selecting split attributes, which will affect the classification accuracy of the algorithm.
There is no differential privacy involved in the Adaboost algorithm, so its classification capability remains unchanged. It can be seen from Figs. 3 and 4 that with the increase of privacy budget, the classification ability of each classifier based on differential privacy is increasing as a whole. This is because when the privacy budget increases, the noise in each classifier decreases. However, it leads to decline of the classifier’s privacy protection ability. Therefore, in practical application, we usually need to abandon a certain classification accuracy to ensure the security of the classification model. With the increase of privacy budget, the classification ability of En-RDT becomes stronger rapidly. Compared with other algorithms, the classification ability of En-RDT on Mushroom and Nursery is relatively high, while the classification ability on Adult and Car is relatively lower as a whole. The reason for the instability of classification may be that every DT of En-RDT is constructed by randomly selecting split attributes. Besides, Maxtree and DPtree have relatively poor classification ability. The main reason is that they are two single classifiers, and the introduction of DP adds a lot of noise to the node generation process of trees, which interferes with the experimental results. The classification ability of Maxforest and En-DPtree is greatly improved on the basis of Maxtree and DPtree. Ensemble learning comprehensively considers the learning results of multiple base learners in an appropriate voting way, so that it can usually improve the classification ability of base learners in most cases by training multiple learners. The larger the privacy budget \(\epsilon \), the closer En-DPtree’s classification capability is to AdaBoost. On the whole, En-DPtree have the strongest classification ability compared with other famous models based on differential privacy and it shows that our improvement measures for Maxtree are effective.
Effect of the weighted voting scheme based on MPQGA
To examine the necessity of the weighted voting scheme based on MPQGA, we perform experiments by DPtree, DPtree-1, DPtree-2, and En-DPtree based on the above datasets. DPtree-1 and DPtree-2, respectively, mean that the voting scheme of ensemble learning is based on the majority voting and original QGA.
The classification results are shown in Figs. 5 and 6. The classification ability of DPtree-1, DPtree-2, and En-DPtree is always better than that of DPtree. Therefore, it is necessary to design an ensemble learning process for DPtree. Moreover, En-DPtree has the strongest classification ability, and the performance of DPtree-2 is better than DPtree-1 in these datasets. QGA can search appropriate weights for base classifiers through evolution process, so that DPtree-2 can obtain better classification ability than DPtree-1. Besides, compared with QGA which has only one population in evolutionary process, MPQGA evolves based on multiple populations. Therefore, MPQGA has stronger global search capability and can assist En-DPtree to obtain the strongest classification capability. Therefore, the improvement measures we designed in En-DPtree are effective.

Impact of the voting scheme on classification accuracy on datasets

Impact of the voting scheme on F1 or micro-F1 on datasets
Effect of the number of iterations in MPQGA
To illustrate the effect of the number of iterations of MPQGA on finding better weights, we apply En-DPtree based on the above datasets, as shown in Figs. 7 and 8. The horizontal axis is the number of iterations of MPQGA, and the vertical axis is the classification accuracy, F1 or micro-F1 of En-DPtree. It can be seen that when the number of iterations increases, the classification ability of En-DPtree shows an overall upward trend. In addition, the classification ability of En-DPtree changes greatly when the number of iterations is low. The possible reason is that MPQGA cannot find a stable evolution point in the early stage of iteration, and it still needs a series of gene changes to achieve a stable state. In general, MPQGA can obtain the optimal weights through a certain number of iterations. Therefore, using MPQGA in En-DPtree can search appropriate weights for base classifiers, so as to improve the classification ability of En-DPtree.

Impact of MPQGA iterations on classification accuracy on datasets

Impact of MPQGA iterations on F1 or micro-F1 on datasets
Conclusion
By analyzing the problems existing in Maxtree, we propose a new privacy budget allocation strategy and introduce quantum ensemble learning to form En-DPtree scheme. Compared with the existing works, we introduce the Fayyad theorem to quickly locate the best partition points of continuous attributes. In addition, we design an adaptive privacy budget allocation strategy for each leaf node according to its sample category distribution which can not only ensure that the classification result of each leaf node is not distorted, but also improve the privacy protection ability. Moreover, we design MPQGA to generate a set of better weights for ensemble model, so as to improve the classification performance of En-DPtree. Finally, we carry out several experiments on datasets. The experimental results show that the classification ability of En-DPtree is usually superior to other state-of-the-art classifiers. Besides, En-DPtree can obtain the optimal weights through a certain number of genetic iterations.
Data availability statement
The data that support the findings of this study are openly available in [UCI machine learning repository] at http://archive.ics.uci.edu/ml, reference number [42].
References
Li YY, He HY, Wang Y, Xu X, Jiao LC (2015) An improved multiobjective estimation of distribution algorithm for environmental economic dispatch of hydrothermal power systems. Appl Soft Comput 28:559–568. https://doi.org/10.1016/j.asoc.2014.11.039
Xie C, Hua Q, Zhao J, Guo R, Yao H, Guo L (2022) Research on energy saving technology at mobile edge networks of IoTs based on big data analysis. Complex Intell Syst. https://doi.org/10.1007/s40747-022-00735-4
Hu J, Ou X, Liang P, Li B (2022) Applying particle swarm optimization-based decision tree classifier for wart treatment selection. Complex Intell Syst 8:163–177. https://doi.org/10.1007/s40747-021-00348-3
Tsai YC, Wang SL, Kao HY, Hong TP (2015) Edge types vs privacy in K-anonymization of shortest paths. Appl Soft Comput 31:348–359. https://doi.org/10.1016/j.asoc.2015.03.005
Kumar P, Karthikeyan M (2012) \(L\) Diversity on \(K\)-anonymity with external database for improving privacy preserving data publishing. Int J Comput Appl 54:7–13. https://doi.org/10.5120/8632-2341
Li N, Li T, Venkatasubramanian S (2007) \(t\)-closeness: privacy beyond \(k\)-anonymity and \(l\)-diversity. In: Proceedings of the 23rd international conference on data engineering, pp 106–115. https://doi.org/10.1109/ICDE.2007.367856
Machanavajjhala A, Kifer D, Gehrke J, Venkitasubramaniam M (2007) \(l\)-diversity: privacy beyond \(k\)-anonymity. ACM Trans Knowl Discovery Data 1:3. https://doi.org/10.1145/1217299.1217302
Hashem KA (2012) \(T\)-proximity compatible with \(T\)-neighbourhood structure. J Egypt Math Soc 20:108–115. https://doi.org/10.1016/j.joems.2012.08.004
Ganta SR, Kasiviswanathan SP, Smith A (2008) Composition attacks and auxiliary information in data privacy. In: Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining, pp 265–273. https://doi.org/10.1145/1401890.1401926
Wong RCW, Fu AWC, Wang K, Yu PS, Pei J (2011) Can the utility of anonymized data be used for privacy breaches. ACM Trans Knowl Discovery Data 5:16. https://doi.org/10.1145/1993077.1993080
Dwork C (2006) Differential privacy. In: Proceedings of the 33th international colloquim on automata, languages and programming, pp 1-12. https://doi.org/10.1007/11787006_1
Machanavajjhala A, Kifer D, Abowd J, Gehrke J, Vilhuber L (2008) Privacy: theory meets practice on the map. In: Proceedings of the 24th international conference on data engineering, pp 277–286. https://doi.org/10.1109/ICDE.2008.4497436
Greenberg A (2016) Apple’s “Differential Privacy” is about collecting your data-but not your data. https://www.wired.com/2016/06/apples-differential-privacy-collecting-data/. Accessed 13 June 2016
Fletcher S, Islam MZ (2020) Decision tree classification with differential privacy: a survey. ACM Comput Surv 52:83. https://doi.org/10.1145/3337064
Blum A, Dwork C, McSherry F, Nissim K (2005) Practical privacy: the sulq framework. In: Proceedings of the ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems, pp 128–138. https://doi.org/10.1145/1065167.1065184
McSherry FD (2009) Privacy integrated queries: an extensible platform for privacy-preserving data analysis. In: Proceedings of the ACM SIGMOD international conference on management of data, pp 19-30. https://doi.org/10.1145/1559845.1559850
Friedman A, Schuster A (2010) Data mining with differential privacy. In: Proceedings of the ACM SIGKDD international conference on knowledge discovery data mining, pp 493–502. https://doi.org/10.1145/1835804.1835868
Mohammed N, Chen R, Fung BCM, Yu PS (2011) Differentially private data release for data mining. In: Proceedings of the ACM SIGKDD international conference on knowledge discovery and data mining, pp 493–501. https://doi.org/10.1145/2020408.2020487
Liu XQ, Li QM, Li T, Chen D (2018) Differentially private classification with decision tree ensemble. Appl Soft Comput 62:807–816. https://doi.org/10.1016/j.asoc.2017.09.010
Wu D, Wu T, Wu X (2020) A differentially private random decision tree classifier with high utility. In: Proceedings of the international conference on machine learning for cyber security, pp 378-385. https://doi.org/10.1007/978-3-030-62223-7_32
Jagannathan G, Pillaipakkamnatt K, Wright RN (2009) A practical differentially private random decision tree classifier. In: Proceedings of the IEEE international conference on data mining workshops, pp 114–121. https://doi.org/10.1109/ICDMW.2009.93
Fletcher S, Islam MZ (2015) A differentially private decision forest. In: Proceedings of the 13th Australasian data mining conference, pp 99–108. https://doi.org/10.1007/978-3-319-26350-2_17
Fletcher S, Islam MZ (2015) A differentially private random decision forest using reliable signal-to-noise ratios. In: Proceeding of the 28th Australasian joint conference on artificial intelligence, pp 192–203. https://doi.org/10.1007/978-3-319-26350-2_17
Patil A, Singh S (2014) Differential private random forest. In: Proceeding of the international conference on advances in computing, pp 2623–2630. https://doi.org/10.1109/ICACCI.2014.6968348
Yin Y, Chen L, Wan J, Xu Y (2018) Location-aware service recommendation with enhanced probabilistic matrix factorization. IEEE Access 6:62815–62825. https://doi.org/10.1109/ACCESS.2018.2877137
Gambs S, Kegl B, Aimeur E (2007) Privacy-preserving boosting. Data Min Knowl Discov 14:131–170. https://doi.org/10.1007/s10618-006-0051-9
Yan L, Bai C, Reddy CK (2016) A distributed ensemble approach for mining healthcare data under privacy constraints. Inf Sci 330:245–259. https://doi.org/10.1016/j.ins.2015.10.011
Xiang T, Li Y, Li X, Zhong S, Yu S (2018) Collaborative ensemble learning under differential privacy. Web Intell 16:73–87. https://doi.org/10.3233/WEB-180374
Li Q, Wu Z, Wen Z, He B (2020) Privacy-preserving gradient boosting decision trees. In: Proceeding of the thirty-fourth AAAI conference on artificial intelligence, pp 784–791. https://doi.org/10.48550/arXiv.1911.04209
Shen S (2017) Research on classification algorithm of differential privacy protection. M.S. thesis, Nanjing Aerosp. Univ., Nanjing, China
Jia J, Qiu W (2020) Research on an ensemble classification algorithm based on differential privacy. IEEE Access 8:93499–93513. https://doi.org/10.1109/ACCESS.2020.2995058
Dwork C, McSherry F, Nissim K, Smith AD (2006) Calibrating noise to sensitivity in private data analysis. In: Proceeding of the 3rd theory of cryptography conference on theory of cryptography, pp 265–284. https://doi.org/10.1007/11681878_14
McSherry F, Talwar K (2007) Mechanism design via differential privacy. In: Proceeding of the 48th annual IEEE symposium on foundations of computer science, pp 94–103. https://doi.org/10.1109/FOCS.2007.66
Sundaramurthy S, Jayavel P (2020) A hybrid grey wolf optimization and particle swarm optimization with C4.5 approach for prediction of rheumatoid arthritis. Appl Soft Comput 94:1065. https://doi.org/10.1016/j.asoc.2020.106500
Feyyad UM (1996) Data mining and knowledge discovery: making sense out of data. IEEE Expert 11:20–25. https://doi.org/10.1109/64.539013
McSherry FD (2009) Privacy integrated queries: an extensible platform for privacy-preserving data analysis. In: Proceeding of the ACM SIGMOD international conference on management of data, pp 19–30. https://doi.org/10.1145/1559845.1559850
Shafieian S, Zulkernine M (2022) Multi-layer stacking ensemble learners for low footprint network intrusion detection. Complex Intell Syst. https://doi.org/10.1007/s40747-022-00809-3
Lin L, Wu C, Ma L (2021) A genetic algorithm for the fuzzy shortest path problem in a fuzzy network. Complex Intell Syst 7:225–234. https://doi.org/10.1007/s40747-020-00195-8
Li YY, Bai XY, Jiao LC, Xue Y (2017) Partitioned-cooperative quantum-behaved particle swarm optimization based on multilevel thresholding applied to medical image segmentation. Appl Soft Comput 56:345–356. https://doi.org/10.1016/j.asoc.2017.03.018
Li YY, Xiao JJ, Chen YQ, Jiao LC (2019) Evolving deep convolutional neural networks by quantum behaved particle swarm optimization with binary encoding for image classification. Neurocomputing 362:156–165. https://doi.org/10.1016/j.neucom.2019.07.026
SinghKirar J, Agrawal RK (2020) A combination of spectral graph theory and quantum genetic algorithm to find relevant set of electrodes for motor imagery classification. Appl Soft Comput 97:105519. https://doi.org/10.1016/j.asoc.2019.105519
Lichman M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
Funding
Key Industry Innovation Chain Project of Shaanxi Provincial Science and the Technology Department, Grant no. 2022ZDLGY03-08.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Niu, X., Ma, W. An ensemble learning model based on differentially private decision tree. Complex Intell. Syst. 9, 5267–5280 (2023). https://doi.org/10.1007/s40747-023-01017-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01017-3