
Abstract
To ensure no private information is leaked in the aggregation phase in federated learning (FL), many frameworks use homomorphic encryption (HE) to mask local model updates. However, the heavy overheads of these frameworks make them unsuitable for cross-device FL, where the clients are a huge number of mobile and edge devices with limited computing resources. Even worse, some of them also fail to manage the dynamic changes of clients. To overcome these shortcomings, we propose a threshold multi-key HE scheme tMK-CKKS and design an efficient and robust privacy-preserving FL framework. Robustness means that our framework allows clients to join in or drop out during the training process. Besides, because our tMK-CKKS scheme can pack multiple messages in a single ciphertext, our framework significantly reduces the computation and communication overhead. Moreover, the threshold mechanism in tMK-CKKS ensures that our framework can resist collusion attacks between the server and no more than t (threshold value) curious internal clients. Finally, we implement our framework in FedML and conduct extensive experiments to evaluate our framework. Utility evaluations on 6 benchmark datasets show that our framework can protect privacy without sacrificing the model accuracy. Efficiency evaluations on 4 typical deep learning models demonstrate that: our framework can speed up the computation by at least 1.21\(\times \) over xMK-CKKS-based framework, 15.84\(\times \) over Batchcrypt-based framework, and 20.30\(\times \) over CRT-Paillier-based framework. Our framework can reduce the communication burden by at least 8.61 MB over Batchcrypt-based framework, 35.36 MB over xMK-CKKS-based framework and 42.58 MB over CRT-Paillier-based framework. The advantages in both computation and communication expand with the size of deep learning models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Traditional machine learning (ML) builds high-quality model by collecting a massive amount of training data from different clients (e.g., devices or organizations). However, due to industry competition, data security, and user privacy, data sharing between them is difficult, if not impossible. To break the barriers between data sources and protect data privacy, federated learning (FL) [14, 15, 24] is proposed to collaboratively build a global ML model, where clients only need to upload their local updates (e.g., weights or gradients) to a central server for aggregation. Because FL does not require clients to share local data, it mitigates the problem of data privacy leakage and enables ML benefits to cross-device domains, where sufficient training data are unavailable to build a standalone ML model. Notably, it is estimated that the number of mobile and IoT devices worldwide will grow to 75 billion by 2025, which holds enormous potential for cross-device FL.

FL frameworks based on different HE schemes. In a, the same decryption key is shared by all clients. In b, the decryption key can be generated only when all clients collaborate. In c, the decryption key can be generated when any t clients collaborate
However, studies have shown that, by exploiting the shared local updates, adversaries can still infer privacy information of the datasets. To protect the privacy of updates transmitted during the training process, many approaches have been proposed. Because HE directly applies to existing learning systems and requires no modifications other than encrypting/decrypting model parameters, approaches built upon HE have been hot topics in the study of privacy-preserving federated learning (PPFL) [17, 22, 26, 37].
Most HE-based PPFL frameworks adopt additively homomorphic encryption, notably the Paillier scheme, to encrypt model parameters. However, because encryption with the Paillier scheme consists of expensive modular exponentiation with the message as the exponent, their computation and communication overheads are heavy. Even worse, all clients in most of these frameworks use the same key pairs for encryption and decryption (Fig. 1a), they cannot resist attacks from curious internal clients as well as collusion attacks between clients and the server. To resist internal attacks and improve efficiency, Ma et al. [22] proposed a Multi-Key Homomorphic Encryption (MK-HE)-based PPFL framework based on xMK-CKKS. By requiring collaboration between all clients for decryption, their framework can resist attacks from curious internal clients and the collusion attacks between \(K-1\) (K is the total number of clients) clients and the server (Fig. 1b). Nevertheless in this way, the aggregation would fail if some clients drop out from the training process. What is worse, if a new client applies to join in the learning process, the framework should regenerate and rebroadcast new key pairs for all clients.
However, the clients in cross-device FL are a vast number of mobile or IoT devices [13]. They change (e.g., join in or drop out) frequently because of unreliable connections and limited computing resources. Thus, a practical privacy-preserving framework for cross-device FL should strive for solid privacy guarantee, robustness to client changes, and high efficiency. To meet these requirements and address the shortcomings of PPFLs mentioned above, we propose a threshold multi-key homomorphic encryption scheme tMK-CKKS and design a robust and efficient PPFL framework based on it. Specifically, our contributions are as follows:
-
(1)
We propose a threshold MK-HE scheme: tMK-CKKS. In our scheme, the master public key is shared by all clients for encryption. The secret keys for each client are generated based on the linear secret sharing scheme. The decryption of aggregated ciphertexts requires the cooperation of only t (threshold value) clients. Besides, because the security of tMK-CKKS is based on the hardness of ring learning with errors (RLWE) assumption, our scheme is post-quantum secure.
-
(2)
We design a privacy-preserving framework for cross-device FL based on tMK-CKKS. Our framework needs only t clients to decrypt the aggregated ciphertexts (Fig. 1c), so it allows up to \(K-t\) clients to drop out during the training process. In addition, our framework also allows a new client to join in the learning process by only generating a secret key for it and keeping the public key and secret key of other clients unchanged.
-
(3)
We theoretically prove that our framework can provide postquantum security, protect the privacy of the updates from curious internal clients, and also resist collusion attacks between the server and up to \(t-1\) clients. Finally, we analyze and evaluate the performance of our FL framework. Extensive experimental results show that our framework preserves model accuracy while protecting the privacy and is more efficient in computation and communication than existing collusion-attack resistant HE-based PPFLs.
The remainder of this paper is organized as follows. In Sects. 2 and 3, we introduce related works and the preliminaries, respectively. In Sect. 4, we describe the threat model, our tMK-CKKS scheme, and our PPFL framework. Then, we prove the security and privacy of our framework in Sect. 5. Next, we analyze and evaluate our framework on benchmark datasets and models in Sect. 6. Finally, we conclude the paper in Sect. 7.
Related work
In this section, we provide a brief overview of PPFLs published in recent years according to their supporting techniques: differential privacy(DP), secure aggregation(SA), and homomorphic encryption(HE). We compare the properties of those PPFLs in Table 1.
Differential privacy-based PPFL
Differential privacy ensures that a learned model does not reveal private information on the data (record-level or client-level) by adding noise to the updating parameters during the training process. Shokri and Shmatikov [29] proposed to employ selective parameter update atop DP to protect record-level privacy. McMahan et al. [25] proposed a client-level privacy-preserving language model. Similarly, Geyer et al. [11] applied the Gaussian mechanism to FL to protect the client’s datasets. Wu et al. [33] utilized local differential privacy in graph neural network for privacy-preserving recommendation to protect user privacy. Asoodeh et al. [5] proposed a new technique for deriving the differential privacy parameters in FL by interpreting each iteration as a Markov kernel. Stevens et al. [31] presented a novel differential private FL protocol based on the techniques from learning with errors (LWE). To improve privacy–utility tradeoff, Cheng et al. [8] studied the cause of model performance degradation and mitigated the issue by bounding and sparsifying the local updates. However, because of adding noise into model updates during aggregation, all these approaches protect privacy at the cost of reduced model performance.
Secure aggregation-based PPFL
Secure aggregation is proposed to ensure that the server learns nothing about individual updates but only the aggregated model parameters. By employing linear secret sharing and authenticated encryption, Bonawitz et al. [7] designed a secure aggregation based on double masking protocol. Similarly, Xu et al. [34] proposed a verifiable FL framework by integrating the homomorphic hash function with the double masking protocol. In the double masking protocol, each client should synchronize its public keys and secret shares with other clients, and the communication expansion factor increases quadratically as the number of clients increases. Focusing on the robustness of secure aggregation, Pillutla et al. [27] made federated learning less susceptible to corrupted updates by replacing the weighted arithmetic mean aggregation with an approximate geometric median. However, their method triples the communication cost. To reduce the overhead of secure aggregation, So et al. [30] proposed Turbo-Aggregate by employing a multi-group circular strategy. Kadhe et al. [12] designed FAST-SECAGG based on Fast Fourier Transform. Unfortunately, all those solutions require 3 communication rounds in each aggregation. Because the clients in cross-device FL have unreliable connections, those solutions are more susceptible to communication instability than DP-based and HE-based PPFLs. In addition, the classical key agreement protocol in these solutions cannot resist quantum attacks.
Homomorphic encryption-based PPFL
Homomorphic encryption allows certain computation to be performed directly on ciphertexts, generating an encrypted result that, when decrypted, matches the result of the operations as if they had been performed on the plaintexts. Many recent HE-based works [9, 17, 19, 26, 34] adopted the Paillier scheme to encrypt model parameters. To reduce the computation costs of encryption, Zhang et al. (referred to as CRT-Paillier) [38] took advantage of the Chinese Remainder Theorem (CRT) and Paillier encryption to protect privacy. However, because encryption with the Paillier scheme consists of modular exponentiation with the message as the exponent, their computation and communication overheads are heavy. What is worse, because all clients in their framework use the same key pairs for encryption and decryption, they cannot resist attacks from curious internal clients and collusion attacks between clients and the server. To improve efficiency further, Batchcrypt [37] combined Paillier encryption with batch encoding and gradient quantization to reduce encryption operations. But their framework does not allow clients to drop out and join in dynamically. To improve robustness, Truex et al. [32] employed the threshold Paillier (tPaillier) scheme to encrypt model updates, but their framework still faces the problem of low efficiency. Recently Ma et al. [22] proposed xMK-CKKS by improving an RLWE-based MK-HE scheme MK-CKKS [10] to resist collusion attacks in cross-device FL. Unfortunately, because their framework requires an aggregated public key for encryption, the scheme should rebroadcast a new aggregated public key for all clients if a new client applies to join the framework, and the aggregation round would fail if some clients drop out from the decryption phase. Since these two situations are not uncommon in cross-device FL, their framework should be improved accordingly.
To summarize, PPFL framework based on HE can protect privacy without accuracy loss or complex synchronization protocols, which gains an advantage over DP-based and SA-based PPFL. However, the high computation and communication overheads and(or) vulnerability to dynamic changes of clients make them unsuitable for cross-device FL. Our work is trying to address these issues by proposing a secure, efficient and robust HE-based PPFL.
Preliminaries
Notations
We denote vectors in bold (e.g., \({\varvec{a}}\)) and use \(\langle \varvec{u,v} \rangle \) to denote the dot product of two vectors \({\varvec{u}}\) and \({\varvec{v}}\). We denote by \(x \leftarrow \Gamma \) the sampling of x according to the distribution \(\Gamma \). We let \(\lambda \) denote the security parameter throughout the paper: all known valid attacks against the cryptographic scheme under scope should take \(\Omega (2^{\lambda })\) operations. We assume that each client has a reference (index) \(i \in \{1,2,\cdots ,K\}\) to its public and secret keys. A multi-key ciphertext implicitly always contains an ordered set \(T \subset \{1,2,\dots ,K\}\) of associated references.
Overview of federated learning
FL is a distributed machine learning setting where many clients collaboratively train a model under the coordination of a central server, while the training data are kept at decentralized clients. Thus, FL can tackle the problem of data island while preserving data privacy [16]. Many scholars have recently published papers to review advances and open challenges in FL. These studies provide multiple further aspects to enhance FL contribution [18, 23, 36].

FL process flow
Given K clients with datasets \({\mathcal {D}}={\mathcal {D}}^1,{\mathcal {D}}^2,\dots ,{\mathcal {D}}^K\), which locate at K clients, respectively, the problem of FL is to learn a model with parameters \({\hat{\omega }}\) from all possible hypotheses W, while minimizing the expectation of loss over the distribution of all dataset \({\mathcal {D}}\). The first FL algorithm FedAvg was proposed by McMahan et al. [24], which allows each client to train on its local dataset for multiple times before averaging the model parameters. This way, the training process can be expressed as:
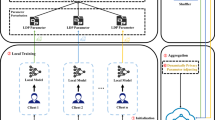
where t is the index of the training round, \(g^k\) is the averaged gradients of the loss function over client k’s local dataset \({\mathcal {D}}^k\). As shown in Fig. 2, the FL implementations can be generalized into to three steps: \(\textcircled {1}\)Model Initialization, \(\textcircled {2}\)Local Model Training and \(\textcircled {3}\)Local Model Aggregation. FL is in a continuous iterative learning process that repeats the training steps of \(\textcircled {2}\) and \(\textcircled {3}\) to keep the global ML model updated across the clients. In this paper, we adapt FedAvg as the training algorithm.
Compared with distributed stochastic gradient descent algorithm, FL requires fewer communication rounds and is robust to unbalanced and non-I.I.D data distributions. Thus, FL is often referred to as a new dawn in AI.
Depending on the application scenarios, FL can be divided into cross-device FL and cross-silo FL. In the cross-silo setting, the clients are a small number of organizations with reliable communications and abundant computing resources. In contrast, the clients in the cross-device setting are a large number of mobile or IoT devices with limited computing power and unreliable connections. We focus on cross-device FL in this paper.
Ring learning with errors
Let \(R={\mathbb {Z}}[X]/(X^n+1)\) be the cyclotomic ring with a power-of-two dimension n and with \({\mathbb {Z}}[X]\) being a polynomial ring with integer coefficients. \(R_{q}={\mathbb {Z}}_{q}[X]/(X^n+1)\) is the residue ring of R with coefficients modulo an integer q. For parameters \((n,q,\chi ,\psi )\), the RLWE assumption [21] is that given polynomials of the from \((a_i,b_i=s\cdot a_i+e_i)\), the term \(b_i\) is computationally indistinguishable from uniformly random elements of \(R_q\), when \(a_i\) is chosen uniformly at random from \(R_q\), s is chosen form the key distribution \(\chi \) over \(R_q\), and \(e_i\) is drawn from the error distribution \(\psi \) over R. According to [20], the RLWE distribution is pseudorandom even under quantum attackers. Thus, the RLWE-based HE schemes have the property of postquantum security.
MK-CKKS
MK-CKKS is a RLWE-based HE scheme. Because homomorphic multiplication is not involved in our framework, we only introduce the homomorphic addition of MK-CKKS. The MK-CKKS consists of following eight algorithms:
Setup(\(1^{\lambda }\)). For a given security parameter \(\lambda \), set the RLWE dimension n, ciphertext modulus q, key distribution \(\chi \) and error distribution \(\psi \) over R. Generate a random vector \({\varvec{a}}\leftarrow {U}(R_{q}^{d})\). Return the public parameter \(pp=(n,q,\chi ,\psi ,{\varvec{a}})\).
KeyGen(pp). Sample the secret key \(s^i\leftarrow \chi \) and an error vector \(\varvec{e^{i}}\leftarrow \psi ^{d}\). Set the public key as \(b^i=-s^i\cdot {{\varvec{a}}}+\varvec{e^i} \in R_{q}^{d}\).
Ecd(\(\varvec{\omega }\)). Take a message vector \(\varvec{\omega }\) as an input and return a plaintext polynomial \(m \in R\).
Enc(\(m,pk^i\)). Encrypt a plaintext \(m \in R\) and output a ciphertext \(\varvec{ct^i}=(c_0^i,c_1^i)\), where \(c_0^i=v^i\cdot {b^i}+m^i+e_0^i(mod\ q)\) and \(c_1^i=v_i\cdot {a}+e_1^i(mod\ q)\). Here, \(a={\varvec{a}}[0]\) and \(b^i=\varvec{b^i}[0]\), \(v_i\leftarrow \chi \) and \(e_0^i,e_1^i \leftarrow \psi \).
Dec(\(\varvec{ct^i},\varvec{sk^i}\)). Decrypt the ciphertext by computing \(\langle \varvec{ct^i},\varvec{sk^i}\rangle (mod\ q)\), where \(\varvec{ct^i}=(ct_0^i,c_1^i)\) and \(\varvec{sk^i}=(1,s^i)\).
Add(\(\varvec{ct^i,ct^j}\)). Given two ciphertexts \(\varvec{ct^i}\) and \(\varvec{ct^j}\), the sum of the ciphertexts is \(\varvec{C_{sum}}\triangleq (c_0^i+c_0^j,c_1^i,c_1^j)\).
Decsum(\(\varvec{C_{sum}}\)). For client i, given a polynomial \(c_1^i\) and a secret \(s^i\), sample an error \(e^i_{*}\leftarrow \phi \), return \(D^i=c_1^i\cdot {s^i}+e^i_{*}(mod\ q)\). Here, \(e^i_{*}\) is generated from error distribution \(\phi \) which has a larger variance than the standard error distribution \(\psi \). For the server, given \(D^{i}\), compute and return \(\mu _{sum}=\sum _{i=1}^{N}{c^{i}_{0}}+\sum _{i=1}^{N}{D^{i}}(mod\ q)\).
Dcd(m). Take a plaintext polynomial m as input and return a message vector \(\varvec{\omega }\).
Shamir’s secret sharing scheme
We rely on Shamir’s t-out-of-n linear secret sharing scheme (LSSS) [28] in our tMK-CKKS scheme, which allows the public key generator (PKG) to split a master secret y into n shares, such that any t shares can be used to reconstruct y, but any set of less than t shares give no information about y. The scheme is parameterized over a finite field \({\mathbb {F}}\) of size at least \(l>2^{\lambda }\) (where \(\lambda \) is the security parameter of the scheme), e.g., \({\mathbb {F}}={\mathbb {Z}}_p\) for some large public prime p. We also assume that integers \(1,2,\dots ,K\) can be identified with distinct field elements in \({\mathbb {F}}\). Given these parameters, the scheme consists of two algorithms: SS.share and SS.recon:
SS.share(y, t, K). PKG randomly selects \(a_1,a_2,\dots ,a_{t-1}\in {\mathbb {Z}}_p\), and sets \(a_0=y\). With \(a_i\) as coefficients, the PKG constructs a polynomial of degree \(t-1\) as \(f(x)=\sum _{j=0}^{t-1}{a_ix^j}(mod\ p)\). For client i, the PKG computes \(y_i=f(i)\) as its secret share.
SS.recon(\(\{i,y_i\}_{i\in T},t\)). For any set of clients T with \(\left|T \right|=t\), after collecting their shares \((i,y_i)_{i\in T}\), one can reconstruct the secret as \(y=f(0)=\sum _{i\in T}(\lambda _i\cdot y_i)(mod\ p)\) where \(\lambda _i=\prod _{\forall j \in T, j\ne i}(\frac{-j}{i-j})\).
Our proposed PPFL
Threat model
We consider the following threat model:
Honest but curious server: We assume that the server correctly follows the algorithm and protocols, but may try to learn private information by inspecting the updates sent by the clients in the training process. This is a common assumption in [7, 22, 26, 37].
Curious and colluding clients: Just as in [7, 22, 32, 37], we assume that clients may collude to infer private information about other clients by inspecting the messages exchanged with the server.
Public key generator: This agency is an independent agency widely trusted by the clients and the server. The PKG is in charge of holding the master secret key, generating and distributing public/private key pairs. We also note that assuming such a trusted and independent agency is a common assumption in existing PPFLs [7, 32, 34].
Our proposed tMK-CKKS scheme
To prevent attacks from curious internal clients and collusion attacks between clients and(or) the server, we propose tMK-CKKS. In tMK-CKKS, all clients use the same public key \({\varvec{b}}\) for encryption which are generated according to the master secret key S, the secret key of the clients are generated based on the LSSS in 3.5. For decryption, the server requires a decryption share \(D_i\) from client i. \(D_i\) combines the sum over all ciphertexts as well as the secret key \(s^i\) of the master secret key S and error term \(e^i_{*}\) (see Eq. 5). Thus, the server can use these t decryption shares to decrypt the aggregated ciphertexts according to LSSS, but can not infer any information about the secret keys. The following describes the details of the scheme.
Setup(\(1^\lambda \)). Given a given security parameter \(\lambda \), set the RLWE dimension to be n, ciphertext modulus q, key distribution \(\gamma \) and error distribution \(\psi \) over R. Generate a random vector \({\varvec{a}}\leftarrow U(R_q^d)\). Return the public parameters \((n,q,\gamma ,\psi ,{\varvec{a}})\).
KeyGen(\(n,q,\gamma ,\psi ,{\varvec{a}}\)). The scheme randomly selects the master secret \(y\in {\mathbb {Z}}_q\) and splits it into n shares \((i,y^i)_{i\in \{1,2,\dots ,K\}}\). Let \(s\leftarrow \gamma \), then the master secret key of the scheme is \(S=y\cdot s(mod\ q)\), the master public key is \({\varvec{b}}= -S\cdot {\varvec{a}}+\varvec{e^p}(mod\ q)\), and the secret key for client i is \(s^i=y^i\cdot s(mod\ q)\).
Ecd(\(\varvec{\omega _i}\)). Take a message vector \(\varvec{\omega ^i}\) as an input and return a plaintext polynomial \(m^i\).
Enc(\(m^i,{\varvec{b}},{\varvec{a}}\)). The plaintext of client i is encrypted as follows:
Here, \(a=\varvec{a[0]}, b=\varvec{b[0]}, v^i\leftarrow \gamma , e_0^i,e_1^i\leftarrow \psi \).
Aggregation(\(\varvec{ct^{1},ct^2,\cdots ,ct^K}\)). The ciphertexts is aggregated as follows:
Dec(\(C_{sum},s^{j}(j\in T),T\)). For any set of clients T with \(|T|=t\), they can jointly decrypt the aggregated ciphertext \(C_{sum}\). The decryption consists of two algorithms:
-
PartDec(\(c_{sum_{0}},s^j\)). For every client \(j \in T\), it computes \(s^{'j}=s^j\prod _{l \in T {\backslash }\{j\}}{(\frac{j}{j-l}) }\), then returns its decryption share:
$$\begin{aligned} D^j&=s^{'j}\cdot C_{sum^1}+e^j_* \nonumber \\ {}&=s^{'j}\cdot \sum _{j=1}^K(v^i\cdot a+e_1^i)+e^j_*(mod\ q). \end{aligned}$$(5) -
Merge(\(c_{sum_0},\{D^j\}_{j \in T}\)). Compute and return \(\mu =c_{sum_0}+\sum _{j=1}^{t}{D^j}(mod\ q)\).
Dcd(\(m^i\)). Take a plaintext polynomial \(m^i\) as an input and return a message \(\varvec{\omega ^i}\).
Correctness: The correctness of the decryption can be checked as follows:

Our FL framework based on tMK-CKKS
Our PPFL based on tMK-CKKS
We propose an efficient privacy-preserving cross-device FL framework based on tMK-CKKS that is robust to dynamic changes of clients. We apply the FedAvg algorithm during the training process. Figure 3 sketches the main steps the framework. It mainly consists of 6 steps: \(\textcircled {1}\)Setup, \(\textcircled {2}\)Local training, \(\textcircled {3}\)Model parameters encryption, \(\textcircled {4}\)Homomorphic aggregation, \(\textcircled {5}\)Decryption share computation, and \(\textcircled {6}\)New global model computation. The details of our framework are as follows:
Step\(\textcircled {1}\): Given the security parameter \(\lambda \), the PKG firstly setups the public parameters by calling Setup(\(1^{\lambda }\)) and generate keys for the clients (Step \(\textcircled {1}\)a). The server selects the model to be trained. All clients upload the size of their local training dataset \(d^{i}=\left|{\mathcal {D}}^{i}\right|\) to the server, which will be used to normalize the aggregation result (Step \(\textcircled {1}\)b).
Step\(\textcircled {2}\): During each aggregation round r, client i first downloads the current global model parameters \(\varvec{\omega _{r}}\) from the server, then trains the model for multiple epochs on its local data and derives a local model with parameters \(\varvec{\omega ^{i}_{r}}\). After multiplying the size of its local dataset, the weighted model parameters are \(\varvec{w_{i}^{r}}=d_{i}\cdot \varvec{\omega _{i}^{r}}\).
Step\(\textcircled {3}\): Client i encodes the model updates with \(m^{i}_{r}={} {\textbf {Ecd}}(\varvec{w^{i}_{r}}{} {\textbf {)}}\) and computes the ciphertext \(\varvec{ct^{i}_{r}}=\)Enc(\(m^{i}_{r},b,a\)), then uploads \(\varvec{ct^{i}_{r}}\) to the server.
Step\(\textcircled {4}\): After receiving encrypted parameters from a set of clients \(U(2\leqslant \left|U\right|\leqslant K)\), the server aggregates the ciphertexts to get \(\varvec{C_{sum}}=(C_{sum_0},C_{sum_1})=\) Aggregation(\(\varvec{ct^{1}_{r},ct^{2}_{r},\dots ,ct^{K}_{r}}\)), which is the weighted aggregation of model parameters from all clients.
Step\(\textcircled {5}\): The server selects any set of clients T with \(\left|T\right|=t\), and sends \(C_{sum_1}\) to them. For each client \(j\in T\), it computes its decryption share \(D^{j}=\)
ParDec(\(C_{sum_1},s^{j}\)) and uploads it to the server.
Step\(\textcircled {6}\): After receiving all the decryption shares from clients in T, the server decrypts the aggregated ciphertext by \(\mu _{sum}= \,\,\)Dec(\(C_{sum},s_{j\in T},\left|T\right|\,\,=t\))\(\thickapprox \sum _{\forall i\in U}{m^i}\). Then, the server decodes the plaintext polynomials to get the weighted parameters Dec(\(\mu _{sum}\))\(\,\,\thickapprox \sum _{\forall i\in U}(d^{i}\cdot \varvec{\omega _{r}^{i}})\). According to the total dataset size of this aggregation round \(d=\sum _{\forall j\in U}{d^{j}}\), the server normalizes the weighted parameters to get the new global parameters \(\varvec{\omega _{r+1}}=\,\)Dcd(\(\mu _{sum}\))/\(d\thickapprox \sum _{\forall i\in U}(d^\cdot \varvec{\omega ^{i}_{r}})/d\).
Security analysis
We discuss how our cross-device FL framework protects the privacy of the data hosted at distributed clients by ensuring the confidentiality of the model parameters. In particular, the following theorems describe the security of the framework concerning various potential adversaries.
Theorem 5.1
An honest but curious server cannot infer any private information about the clients.
Proof
In our tMK-CKKS-based FL framework, clients i sends two types of information to the server, the ciphertext of its model parameters:
and its decryption share:
The server can compute:
and
All messages contain an added error. According to the RLWE assumption in [20], \(c_{0}^{j},C_{sum_{0}},D^{j}\) and \(\sum _{\forall j \in T}{D_{j}}\) are computationally indistinguishable from uniformly random elements of \(R_{q}\), even under quantum attacks, so they do not leak any information of \(m^{j},s^{j}\) and S. After collaborative decryption, the server can only get a weighted sum of all parameters \(\varvec{\omega _{r+1}}\thickapprox \sum _{\forall i \in U}({d_{i}\cdot \varvec{\omega _{r}^{i}}})\), which also does not leak information of the individual model parameters. Therefore, our framework can protect the security and privacy of individual model parameters, even under quantum attacks. The server cannot infer any private information about the clients from the intermediate data it receives. \(\square \)
Theorem 5.2
An honest but curious client cannot infer any private information about other clients by stealing their shared intermediate messages.
Proof
In our framework, the model parameters of each client are encrypted under the master public key, and their decryption shares have been added errors to protect their secret keys (see Eq. 5). According to the RLWE assumption in [20], they are secure even under quantum attacks. Therefore, an honest but curious client cannot infer any private information by inspecting the intermediate data uploaded by other clients. \(\square \)
Theorem 5.3
Collusion between \(t-1\) clients and the server does not leak information about model parameters from other clients, where t is the threshold value of the tMK-CKKS.
Proof
In our framework, the Shamir secret sharing is information-theoretically secure, therefore, even \(t-1\) clients collude with the server, they cannot infer any information about the master secret S. Assume the set of collusion clients is A with \(\left|A\right|=t-1\). For any client \(i\notin A\), its ciphertext \(c_{0}^{i}=-v^{i}\cdot a\cdot S+v^{i}\cdot \varvec{e^{p}}[0]+m_{i}+e_{0}^{i}(mod\ q)\). According to the RLWE assumption in [20], \(c_{0}^{i}\) is computationally indistinguishable from a uniform random sample from \(R_{q}\) to any client in A and the server. Therefore, our framework is post-quantum secure under the collusion attack between \(t-1\) clients and the server. \(\square \)
Evaluation
This section evaluates the utility and efficiency of our tMK-CKKS based PPFL framework. In machine learning tasks, the utility is measured by comparing the evaluation accuracy of the task using the protected data and the original data [35]. Thus, we evaluate the utility of our PPFL framework by comparing its accuracy against the original FL framework on the benchmark datasets: Federated MNIST, Federated Shakespeare, Federated CIFAR-100, CINIC10 and CIFAR100. For efficiency, we evaluate its computation and communication cost against other recent state-of-the-art HE-based PPFLs: CRT-Paillier-based PPFL, Batchcrypt-based PPFL and xMK-CKKS-based PPFL.
Experimental setup
We evaluate our FL framework in a Dell T7920 workstation with 2 Intel Xeon Silver 4210R CPUs, 1 NVIDIA TITAN RTX GPU and 32 GB RAM. The OS is Ubuntu 18.04. We use the HEAAN library [2] to implement both tMK-CKKS and xMK-CKKS schemes, and wrap the C++ interfaces for Python by employing the Boost library [4]. We use Python-Paillier [1] in to implement the CRT-Paillier-based and Batchcrypt-based PPFLs. We employ the FedML [3] in its standalone simulation computing paradigms to build the baseline framework because FedML is an open research library and provides curated and comprehensive benchmark datasets for a fair comparison.
Model and homomorphic encryption scheme parameters
According to the practice in machine learning, each model parameter is represented by a 32-bit floating point in our experiments. In HE schemes, there is a tradeoff between the security level and the efficiency. We list the parameters with corresponding security level according to NIST [6] in Table 2.
According to the recommendation in the NIST [6] and to balance between security and efficiency, we set the security level to be 128 bits. Thus, the key size of Paillier-based schemes (e.g., CRT-Paillier and Batchcrypt) should be 3072 bits, For CKKS-based schemes (e.g., xMK-CKKS and tMK-CKKS), we have 3 different choices, namely polynomial dimension 1024 with ciphertext modulus size \(logq \le 29\) bits, 2048 with \(logq \le 56\) bits and 4096 with \(logq \le 111\) bits. Because larger ciphertext modulus size will bring heavier computation and communication burden and too small ciphertext modulus may result in overflow of aggregated updates, we choose the polynomial dimension as 2048 with \(logq=32\) bits in our experiments.

Accuracy comparison between our PPFL framework and the original FL framework with different datasets and models
Datasets and models
FedML provides curated and comprehensive benchmark datasets for fair comparison. This paper adopts the datasets and models from FedML for accuracy comparison. Specifically, we evaluate the utility of our PPFL framework based on the benchmark datasets provided in FedML: MNIST, Federated Shakespeare, Federated EMNIST, Federated CIFAR-100, CINIC-10, and CIFAR-100. The related information about the datasets and corresponding training model is listed in Table 3.
Utility evaluation
We compared the accuracy of our PPFL framework with that of the original FL framework (Fig. 4) on the benchmark datasets and models introduced in Efficiency evaluation. For MNIST, Federated Shakespeare, Federated EMNIST, Federated CIFAR-100, CINIC-10, and CIFAR-100, our tMK-CKKS-based PPFL framework provides an accuracy of 81.87%, 50.80%, 81.01%, 33.81%, 70.59%, and 65.23%, respectively, which is almost the same as the original FL framework, which has an accuracy of 81.91%, 50.91%, 80.99%, 34.27%, 70.49%, and 65.60%. From Fig. 4, we can also observe that the training curve of our xMK-CKKS-based framework is pretty close to that of the original framework. All these results on the benchmark datasets demonstrate that our tMK-CKKS-based PPFL framework can guarantee the privacy of the learned model without compromising its accuracy.

Computation cost comparison between CRT-Paillier, Batchcrypt, xMK-CKKS, and tMK-CKKS-based PPFL
Efficiency evaluation
Efficiency analysis. Just as introduced in Utility evaluation, we use Paillier with key size 3072 bits (ciphertext size 6144 bits) and tMK-CKKS (and xMK-CKKS) with dimension 2048 as our HE schemes. We compare the amortized computation cost and total communication cost between CRT-Paillier, Batchcrypt, xMK-CKKS and tMK-CKKS with K clients in Tables 4 and 5, respectively. The threshold value in tMK-CKKS is set to be t, namely tMK-CKKS only needs t clients in decryption. For CRT-Paillier, there is a tradeoff between the packing size and packing process. Thus, we pack 60 parameters in each ciphertext. In Batchcrypt, each parameter is encoded with 2 sign bits and 2 padding bits, so we set the packing size to be \(\frac{3072}{36}\approx 85\). For both xMK-CKKS and tMK-CKKS, a plaintext polynomial can pack at most 1024 parameters.

Comparison of communication cost for tPaillier, xMK-CKKS and tMK-CKKS
Table 4 shows that though xMK-CKSS and tMK-CKKS take more time than CRT-Paillier and Batchcrypt in each encryption/decryption/addition operation, their amortized cost is less because of large packing size. Compared with xMK-CKKS, tMK-CKKS needs less decryption time if \(t<K\), so tMK-CKKS is more efficient than xMK-CKKS, even if they share the same amortized cost.
Table 5 shows the total communication cost in each aggregation round and the corresponding expansion factor. In CRT-Paillier-based and Batchcrypt-based PPFL, the ciphertexts of aggregated parameters are sent to the clients for decryption. Thus, the communication cost is doubled in each aggregation round. Because the ciphertext size is 6144 bits, the total communication costs of both CRT-Paillier-based PPFL and Batchcrypt-based PPFL are \(6144*2*K\) bits. However, due to different packing sizes, the expansion factor of CRT-Paillier-based PPFL and Batchcrypt-based PPFL are \(\frac{6144*2*K}{60*32}=6.4*K\) and \(\frac{6144*2*K}{85*32}=4.5*K\), respectively. In xMK-CKKS and tMK-CKKS, because the ciphertext consists of 2 polynomials of dimension 2048, the decryption share consists of 1 polynomial of dimension 2048, and the ciphertext modulus is 32 bits, the per round communication costs of xMK-CKKS-based PPFL \(4096*32*K+2048*32*K\) bits, while that of tMK-CKKS are 4096*32*K+2048*32*K bits. Similarly, the expansion factor of xMK-CKKS-based PPFL and tMK-CKKS-based PPFL are \(6*K\) and \(4*K+2*t\). Thus, tMK-CKKS-based PPFL is always more efficient than xMK-CKKS and CRT-Paillier-based PPFL in communication. Compared with Batchcrypt-based PPFL, tMK-CKKS-based PPFL is more efficient when \(\frac{t}{K}\le 0.25\).
Computation cost evaluation. We compared the computation cost of our tMK-CKKS-based PPFL framework with other 3 PPFL frameworks in Fig. 5, which shows the computation cost of these three PPFLs in client encryption, client decryption, ciphertexts aggregation and server decryption. In accordance with the computation analysis above, because xMK-CKKS and tMK-CKKS scheme can pack \(2^{10}\) model parameters per plaintext, they are more efficient than CRT-Paillier and Batchcrypt-based PPFL in client encryption, client decryption, and ciphertexts aggregation, and the advantages grow linearly with the increasing of model parameters (Fig. 5a–c). In server decryption, because our tMK-CKKS scheme need only \(t (t\le K)\) clients to decrypt the aggregated ciphertexts, it takes less computation time than xMK-CKKS which requires K clients for decryption. Obviously, a smaller threshold value will reduce more computation cost (Fig. 5d). We can observe a similar improvement in the total decryption cost of the clients in our PPFL (Fig. 5e Because CRT-Paillier and Batchcrypt take much more time than tMK-CKKS, we set \(K=100\) on purpose in those two PPFLs, while setting \(K=1000\) in xMK-CKKS and tMK-CKKS-based PPFL.) Finally, Fig. 5f shows the total computation cost of a client on different deep learning models with \(t=100\) and \(K=5000\). We can see that our tMK-CKKS-based PPFL is more computationally efficient than the other 3 PPFLs, the speedups are listed in Table 6.
Communication cost evaluation. We compared the communication cost of our tMK-CKKS-based PPFL with other 3 PPFLs in Fig. 6. Since we evaluate different FL frameworks in the standalone computing paradigms of FedML, we use the ciphertext size exchanged in the learning process as the metric for communication cost. Consistent with the communication efficiency analysis, our tMK-CKKS-based PPFL is always more efficient in communication than CRT-based PPFL and more efficient than Batchcrypt-based PPFL when \(\frac{t}{K}\le 0.25\), regardless of the number of parameters and clients (Fig. 6a, b with \(t=100\), \(K=5000\)). When increasing the threshold value, communication cost of our tMK-CKKS than xMK-CKKS grows accordingly, and reaches its maximum when \(t=K\) (Fig. 6c, \(K=5000\)) In Fig. 6d, we show the average total communication per client of all 4 PPFLs on 4 real deep learning models with \(t=100\) and \(K=5000\). We can see that our tMK-CKKS-based PPFL is more efficient in communication than the other 3 PPFLs, the communication reductions are listed in Table 7
Conclusion
In this paper, we have proposed a privacy-preserving framework for cross-device FL based on tMK-CKKS. The privacy of clients is protected by ensuring that no client reveals its model parameters during aggregation. Our framework is robust to clients’ joining in and dropping out. Security analysis proves that it is secure in the honest-but-curious setting, even under collusion attacks between up to \(t-1\) clients and the server. In addition, experiments on image classification and text prediction conducted on realistically partitioned datasets demonstrate the scheme preserves model accuracy against traditional federated learning, and is more efficient in computation and communication compared with existing HE-based PPFL. However, our framework cannot protect the privacy of the model after training, which is the central theme of differential privacy. In our future work, we will try to address this problem.
References
Data61 (2013) Python-Paillier. https://github.com/data61/python-paillier
HEAAN (2018). https://github.com/snucrypto/HEAAN
FedML (2020) A Research Library and Benchmark for Federated Machine Learning. https://fedml.ai/
Boost C++ Libraries (2021). https://www.boost.org/
Asoodeh S, Chen WN, Calmon FP, Ozgur A (2021) Differentially Private Federated Learning: An Information-Theoretic Perspective. In: 2021 IEEE International Symposium on Information Theory (ISIT). IEEE, Melbourne, Australia, pp 344–349. https://doi.org/10.1109/ISIT45174.2021.9518124
Barker E, Chen L, Roginsky A, Vassilev A, Davis R, Simon S (2019) Recommendation for pair-wise key establishment using integer factorization cryptography. Tech. Rep. NIST SP 800-56Br2, National Institute of Standards and Technology, Gaithersburg, MD. https://doi.org/10.6028/NIST.SP.800-56Br2
Bonawitz K, Ivanov V, Kreuter B, Marcedone A, McMahan HB, Patel S, Ramage D, Segal A, Seth K (2017) Practical Secure Aggregation for Privacy-Preserving Machine Learning. In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, Dallas Texas USA, pp 1175–1191. https://doi.org/10.1145/3133956.3133982
Cheng A, Wang P, Zhang XS, Cheng J (2022) Differentially Private Federated Learning With Local Regularization and Sparsification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 10122–10131
Cheng K, Fan T, Jin Y, Liu Y, Chen T, Papadopoulos D, Yang Q (2021) SecureBoost: A Lossless Federated Learning Framework. IEEE Intell Syst 36(6):87–98. https://doi.org/10.1109/MIS.2021.3082561
Cheon JH, Kim A, Kim M, Song Y (2016) Homomorphic Encryption for Arithmetic of Approximate Numbers. Tech. Rep. 421
Geyer RC, Klein T, Nabi M (2018) Differentially Private Federated Learning: A Client Level Perspective. arXiv:1712.07557 [cs, stat]
Kadhe S, Rajaraman N, Koyluoglu OO, Ramchandran K (2020) FastSecAgg: Scalable Secure Aggregation for Privacy-Preserving Federated Learning
Kairouz P (2019) McMahan: Advances and Open Problems in Federated Learning. arXiv:1912.04977 [cs, stat]
Konečný J, McMahan HB, Ramage D, Richtárik P (2016) Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv:1610.02527 [cs]
Konečný J, McMahan HB, Yu FX, Richtárik P, Suresh AT, Bacon D (2017) Federated Learning: Strategies for Improving Communication Efficiency. arXiv:1610.05492 [cs]
Li L, Fan Y, Tse M, Lin KY (2020) A review of applications in federated learning. Computers & Industrial Engineering 149:106854. https://doi.org/10.1016/j.cie.2020.106854
Liu C, Chakraborty S, Verma D (2019) Secure Model Fusion for Distributed Learning Using Partial Homomorphic Encryption. In: Calo S, Bertino E, Verma D (eds) Policy-Based Autonomic Data Governance, vol 11550. Springer International Publishing, Cham, pp 154–179. https://doi.org/10.1007/978-3-030-17277-0_9
Liu J, Huang J, Zhou Y, Li X, Ji S, Xiong H, Dou D (2022) From Distributed Machine Learning to Federated Learning: A Survey. Knowl Inf Syst 64(4):885–917. https://doi.org/10.1007/s10115-022-01664-x
Liu Y, Kang Y, Xing C, Chen T, Yang Q (2020) A Secure Federated Transfer Learning Framework. IEEE Intell Syst 35(4):70–82. https://doi.org/10.1109/MIS.2020.2988525
Lyubashevsky V, Peikert C, Regev O (2010) On ideal lattices and learning with errors over rings. In: Gilbert H (ed) Advances in Cryptology - EUROCRYPT 2010. Springer, Berlin Heidelberg, Berlin, Heidelberg, pp 1–23
Lyubashevsky V, Peikert C, Regev O (2012) On Ideal Lattices and Learning with Errors Over Rings. Tech. Rep. 230
Ma J, Naas SA, Sigg S, Lyu X (2021) Privacy-preserving Federated Learning based on Multi-key Homomorphic Encryption. arXiv:2104.06824 [cs]
Mathews SM, Assefa SA (2022) Federated Learning: Balancing the Thin Line Between Data Intelligence and Privacy. Tech. Rep. arXiv:2204.13697
McMahan HB, Moore E, Ramage D, Hampson S, y Arcas BA (2016) Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv:1602.05629 [cs]
McMahan HB, Ramage D, Talwar K, Zhang L (2018) Learning Differentially Private Recurrent Language Models. In: arXiv:1710.06963 [Cs]
Phong LT, Aono Y, Hayashi T, Wang L, Moriai S (2017) Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. Tech. Rep. 715
Pillutla K, Kakade SM, Harchaoui Z (2022) Robust Aggregation for Federated Learning. IEEE Trans Signal Process 70:1142–1154. https://doi.org/10.1109/TSP.2022.3153135
Shamir A (1979) How to Share a Secret. Commun ACM 22:612–613. https://doi.org/10.1145/359168.359176
Shokri R, Shmatikov V (2015) Privacy-Preserving Deep Learning. In: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, pp. 1310–1321. ACM, Denver Colorado USA. https://doi.org/10.1145/2810103.2813687
So J, Guler B, Avestimehr AS (2020) Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. https://doi.org/10.48550/arXiv.2002.04156
Stevnes T, Skalka C, Vincent C (2022) Efficient Differentially Private Secure Aggregation for Federated Learning via Hardness of Learning with Errors. In: 31st USENIX Security Symposium (USENIX Security 22)
Truex S, Baracaldo N, Anwar A, Steinke T, Ludwig H, Zhang R, Zhou Y (2019) A Hybrid Approach to Privacy-Preserving Federated Learning. arXiv:1812.03224 [cs, stat]
Wu C, Wu F, Cao Y, Huang Y, Xie X (2021) FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation
Xu G, Li H, Liu S, Yang K, Lin X (2019) VerifyNet: Secure and Verifiable Federated Learning. IEEE Trans Inf Forensics Secur PP:1–1. https://doi.org/10.1109/TIFS.2019.2929409
Yin X, Zhu Y, Hu J (2021) A Comprehensive Survey of Privacy-preserving Federated Learning: A Taxonomy, Review, and Future Directions. ACM Comput Surv 54(6):1–36. https://doi.org/10.1145/3460427
Yu B, Mao W, Lv Y, Zhang C, Xie Y (2022) A survey on federated learning in data mining. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 12. https://doi.org/10.1002/widm.1443
Zhang C, Li S, Xia J, Wang W, Yan F, Liu Y (2020) BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning. In: 2020 USENIX Annual Technical Conference. USENIX Association, pp 493–506
Zhang J, Chen B, Yu S, Deng H (2019) PEFL: A Privacy-Enhanced Federated Learning Scheme for Big Data Analytics. In: 2019 IEEE Global Communications Conference (GLOBECOM), pp 1–6. https://doi.org/10.1109/GLOBECOM38437.2019.9014272
Zhang X, Fu A, Wang H, Zhou C, Chen Z (2020) A Privacy-Preserving and Verifiable Federated Learning Scheme. In: ICC 2020 - 2020 IEEE International Conference on Communications (ICC), pp 1–6. IEEE, Dublin, Ireland. https://doi.org/10.1109/ICC40277.2020.9148628
Acknowledgements
This work was supported by National Natural Science Foundation of China (Grant No. 62172436), Natural Science Basic Research Plan in Shaanxi Province of China (2020JQ-492).
Funding
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Du, W., Li, M., Wu, L. et al. A efficient and robust privacy-preserving framework for cross-device federated learning. Complex Intell. Syst. 9, 4923–4937 (2023). https://doi.org/10.1007/s40747-023-00978-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-00978-9