
Abstract
Due to the exponential overflow of textual information in various fields of knowledge and on the internet, it is very challenging to extract important information or to generate a summary from some multi-document collection in a specific field. With such a gigantic amount of textual content, human text summarization becomes impractical since it is expensive and consumes a lot of time and effort. So, developing automatic text summarization (ATS) systems is becoming increasingly essential. ATS approaches are either extractive or abstractive. The extractive approach is simpler and faster than the abstractive approach. This work proposes an extractive ATS system that aims to extract a small subset of sentences from a large multi-document text. First, the whole text is preprocessed by applying some natural language processing techniques such as sentences segmentation, words tokenization, removal of stop-words, and stemming to provide a structured representation of the original document collection. Based on this structured representation, the ATS problem is formulated as a multi-objective optimization (MOO) problem that optimizes the extracted summary to maintain the coverage of the main text content while avoiding redundant information. Secondly, an evolutionary sparse multi-objective algorithm is developed to solve the formulated large-scale MOO. The output of this algorithm is a set of non-dominated summaries (Pareto front). A novel criterion is proposed to select the target summary from the Pareto front. The proposed ATS system has been examined using (DUC) datasets, and the output summaries have been evaluated using (ROUGE) metrics and compared with the literature.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Nowadays, there are various huge resources of textual data on the internet in the form of websites, news, social media networks, user reviews. In addition, numerous archives of news articles, books, legal documents, scientific papers, and biomedical documents contain huge textual content. More important, these textual contents grow exponentially every moment. Extracting only relevant information from all these media and archives is a tedious task for a user who has to consume a lot of time and effort to find the information he needs. Practically, it is very difficult for humans to manually summarize this huge amount of textual data [1, 2]. Therefore, automatic summarization of the text resources becomes much more essential. Automatic text summarization (ATS) becomes an important way of finding relevant information precisely in large text in a short time with little effort [3]. The objective of ATS is the reduction of a given text to a smaller number of sentences without leaving out the main ideas of the original text [4]. ATS is a challenging problem since when a human summarizes some text written in a natural language, he usually reads the whole text, understands it, and then he writes a summary to highlight only the important ideas in the text. Since computers lack human capabilities of understanding natural languages, ATS is a very challenging task. Generally, natural languages are informal. In contrast to natural languages, a computer programming language is a formal language that has a proper structure and syntax. Advances in the Natural Language Processing (NLP) techniques help computers to understand a text in a natural language and to generate a text in a natural language. Despite the progress in the NLP area thus far, ATS still has many challenges. The first step in the ATS is to apply some of the NLP techniques to analyze the text. These techniques include parts-of-speech tagging, parsing, and tokenization. ATS approaches can be classified into three categories: extractive, abstractive, and hybrid [1, 3]. An extractive summary is a subset of sentences from the input document. However, an abstractive summary like an abstract of the document is a summary in which some of its material is not present in the input document [5]. The hybrid approach merges the advantages of extractive and abstractive approaches. The extractive approach is fast and simple compared with the abstractive one. Moreover, the extractive summary has sentences and terminologies identical to those that exist in the original text. Therefore, most researches focus on extractive ATS systems. Several extractive methods have been developed for an automatic summary generation that implements: clustering [6], machine learning [7], fuzzy-logic-based methods[8], and optimization techniques[9]. Statistical-based approaches assign a score to each sentence in the document based on analysis of some statistical features. The highest scored sentences form the final summary. The advantages of statistical-based approaches include: (1) less computational recourses (memory and processing) (2) no linguistic preprocessing is requires, and (3) being language independent. However, the quality of statistical-based summaries is poor since some similar sentences may have high scores while other important sentences have less scores. Fuzzy logic based-approaches are compatible with ATS where selection of a sentence is not a two-value (0 and 1) but they handle the uncertainties in the selection as the fuzzy inference systems. However, the obtained summaries based on Fuzzy logic approaches suffer from redundancy and hence a postprocessing redundancy removal algorithm is essential to improve the summary. Machine-learning based-approaches for ATS can produce summaries suitable to human reader's style and can be prepared according to user requirements. However, machine-learning approaches require a huge set of manually generated summaries to improve the sentence selection. Recently, optimization-based approaches have gained much interest due to their ability to solve the ATS problem and to optimize different criteria, specifically, redundancy reduction, and content coverage. In this work, we propose a novel hybrid approach that combines MOO and machine learning to solve the ATS problem.
According to the number of input documents, ATS can be classified into two categories; single- document and multi-document summarizations. The task of summarizing multi-documents is more difficult than the task of summarizing single-documents due to the presence of redundancy in multi-documents [10, 11].
A multi-document extractive text summarization (ETS) approach aims to generate a summary that covers the main content while avoiding redundant information. Such an approach can be addressed through multi-objective optimization techniques. Compared with classical optimization methods such as mathematical programming, meta-heuristic optimization algorithms are becoming popular during the last two decades. The main advantage of meta-heuristics is their ability to provide higher quality solutions for difficult multi-objective optimization tasks in various application fields [12,13,14,15,16,17].
ETS can be formulated as a single- or multi-objective optimization problem. In a single-objective approach, a single function is formulated as a weighted sum of all of the objectives [18]. The weights have to be provided according to a predefined criterion. In a multi-objective approach, every criterion corresponds to a different objective function and all the objective functions are optimized simultaneously. In recent years, multi-objective optimization (MOO) approaches have been applied in the field of extractive text summarization. Many researches formed the MOO as a single objective function [7, 18,19,20,21,22,23], while other researches concerned multi-objective optimization approaches [11, 24,25,26,27,28]. Different MOO algorithms have been implemented to solve the ETS-MOO problem including artificial bee colony algorithm based on decomposition [24], cat swarm algorithm [26], crow search algorithm [27], and a memetic algorithm [28].
Since the target summary is a small subset of large number of sentences in the multi-document collection, ETS is formulated as a large-scale sparse MOP (see section “Formulation of ETS as a multi-objective optimization problem”). In the field of MOO, evolutionary algorithms have been successfully applied in various fields of science and engineering. However, most existing evolutionary algorithms encounter difficulties in dealing with a MOP problem that has a large number of decision variables while its optimal solution is associated with spares decision variables. Another example of such large-scale sparse MOPs is feature selection where a small subset of features has to be selected from a large number of candidate features. More than one kind of encoding methods can be found in the literature [27, 28] that represent the sparse individuals in sparse MOPs. Considering the sparse nature of the Pareto optimal solutions, Tian et al. [31] proposed a new population initialization strategy and two genetic operators for a large-scale MOO algorithm.
In this paper, we propose an automatic ETS system that optimally extracts a small subset of sentences from an input multi-document text using an evolutionary sparse multi-objective algorithm. The extracted definite length summary is optimized to (1) maintain the coverage of the main content while (2) avoid redundant information. For this purpose, a hybrid approach that combines MOO and machine learning is proposed. Application of the MOO algorithm results in a set of non-dominated (optimal) summaries lying on the Pareto front. Of course, other linguistic objectives in human text summarization are not included in the formulated ATS MOO problem. To account for human preferences, a simple automatic method is employed to select a single solution from the Pareto front. In this work, a weighted sum of the normalized objectives for each non-dominated solution is calculated and the solution with minimum weighted sum is selected as the best summary. The weights are determined through training of a sample of topics with given human summaries (see section “The proposed criterion to select an optimal summary from the Pareto front”). In fact, this approach is a posterior method that exploit human experience to select the optimal summary from the Pareto-optimal solutions. Other than this a posterior technique, there exist interactive preference-based multiobjective evolutionary algorithms that guide the evolution process to obtain the optimal solution. More details can be found in [32, 33].
The proposed ETS system is examined using Document Understanding Conferences (DUC) datasets (http://duc.nist.gov, Last accessed: 13-February-2019), and the generated summaries have been evaluated with Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics [34].
Problem statement and its mathematical formulation
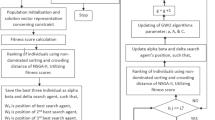
In general, an automatic ETS system consists of three main steps: preprocessing, processing, and post-processing. These whole ETS systems with the three processing steps are presented schematically in Fig. 1.

Proposed multi-document automatic text summarizer (ATS)
In the preprocessing step, different NLP techniques are applied to provide a structured representation of the original document collection [35]. Details of the tasks in the preprocessing step are:
-
Sentence segmentation. By identifying the start and end of each sentence, the document collection is separated into a set of sentences.
-
Word tokenization. After removing exclamation, interrogation, punctuation, and other marks, all of the sentences are broken into a continuous stream of tokens.
-
Stop-word removal. Words that have no relevant meaning such as prepositions, conjunctions, articles, possessives, pronouns, and others are called stop words. These words have to be deleted from the sentences since they have no effect in extracting the significant tokens. In this work, we used the list of 598 English stop words provided in the ROUGE package (ROUGE [32]).
-
Word stemming. It is a process in which a token that originates from the same root or stem word is replaced by that word. Accordingly, the words with the same lexical root will be processed as the same term. In this work, the Porter stemming algorithm (The porter stemming algorithm, 2019, http://www.tartarus.org/ martin/PorterStemmer/, Last accessed: 13-February-2021) is used to extract the roots of the remaining words. Porter stemming algorithm is one of the most adopted and extended algorithms in a wide range of languages [34].
By the end of the pre-processing task, the document collection is transformed into a set \(\mathcal{D}\) of \(n\) sentences consisting of a set of stems (terms) \(T=\{{t}_{1}, {t}_{2}, . . . , {t}_{m}\}\) of m terms. In addition, the similarity matrix SIM and the similarity-to-center SO vector are calculated as they are repeatedly needed for the calculations of the objective function. More details are presented in the next subsections.
In the processing task, as the ATS problem is formed as a MOO problem, the set of optimal summaries (Pareto front) are determined through the solution of the MOO. In this work, a Large-Scale Sparse (LSS) Evolutionary Algorithm (EA) is applied, for the first time, for the ATS problem. In the post-processing task, a post-Pareto analysis has to be performed to pick one summary from the Pareto front. A new criterion is presented and employed to extract the target summary. Before describing details of these two processing tasks, some definitions, notations, special mathematical representations have to be clarified.
Mathematical formulation
Let \(D\) be a text composed from N documents. If the documents collection \(D\) contains \(n\) sentences, then \(D\) is represented by \(\mathcal{D}=\{{s}_{1}, {s}_{2}, . . . , {s}_{n}\}\) where \({s}_{i}\) refers to the \({i}^{\mathrm{th}}\) sentence in \(\mathcal{D}\). The goal is to extract an optimal summary \(\widehat{\mathcal{S}}\subset \mathcal{D}\). The main objective of an Extractive Text Summarization (ETS) system is to produce a summary that includes the important information in the input document using fewer words and to keep repetition to a minimum. In other words, the summary length (number of words) should not exceed a specified limit while maintaining the following two objectives:
-
Content coverage: the summary \(\widehat{\mathcal{S}}\) must include the appropriate sentences from \(D\) to cover the main ideas that exist in the document collection.
-
Redundancy reduction: redundant sentences which have a high degree of similarity with other sentences must be avoided in the generated summary but instead, other valuable sentences must be kept in the summary.
Thus, the main processing task in the proposed ETS system involves the simultaneous optimization of the content coverage and redundancy reduction. However, these two objectives are conflicting. To construct the target summary, the content coverage criterion aims to include the main ideas in the document, whereas the redundancy reduction criterion tries to avoid similar sentences even they may contain new ideas. Accordingly, a MOO approach is required to address this optimization problem.
Notations and symbols
Most notations and symbols used in this work are summarized in Table 1.
Sentence representation and similarity measure
In this subsection, text summarization is formulated as an optimization problem. Vector Space Model (VSM) is commonly used in most text organizing approaches. As mentioned in the preceding section, the main task in the preprocessing step is to transform the document collection into a structured numerical form. Let the document collection be segmented into a set \(\mathcal{D}\) of \(n\) sentences consisting of distinct set of stems (terms) \(T=\{{t}_{1}, {t}_{2}, . . . , {t}_{m}\}\) of m terms. Each sentence consists of a subset of these terms which may be repeated. The structured numerical representation of the document collection can be put in the following term-frequency matrix\(TF\).
where \(t{f}_{ik}\) counts the number of occurrences of the term \({t}_{k}\) in the sentence \({s}_{i}\).
In the present model, each sentence is represented as a row in a \(n\times m\) matrix and the similarity between two sentences is computed using some criterion. Each sentence \({s}_{i}\in \mathcal{D}\) is represented as a row in the \(n\times m\)-matrix,
where each element \({w}_{ik}\) is the weight of the \({k}^{th}\) term in sentence\({s}_{i}\). The weight \({w}_{ik}\) can be calculated using \(term frequency\_inverse sentence frequency\) scheme \((tf\_isf )\) where \(tf\) measures how many times a term appears in a sentence, and \(isf\) measures how many sentences of the document collection contain the term (the definition and some properties are detailed in [35]. Therefore, the weights are calculated as:
where \(log(n/{n}_{k})\) is the \(isf\) factor with \({n}_{k}\) denoting the number of sentences containing the term \({t}_{k}\).
The main content of a document collection D can be expressed as a mean vector \(O = ({o}_{1}, {o}_{2}, . . . , {o}_{m})\) representing the average weights of the \(m\) terms in \(T\) such that the \({k}^{th}\) component is defined as
Different similarity measures have been adopted in text-related applications such as text summarization, text clustering, text mining, and information retrieving. These applications show that the computation of sentence similarity has become a generic component for the research community involved in knowledge representation and discovery. In this work, similarity between two sentences is measured as the cosine of the angle between their representative vectors. When the two vectors are identical (the two sentences are very similar), the angle is zero and its cosine (similarity between the two sentences) equals 1. On the other side, if the two vectors are perpendicular (the terms in the two sentences are completely different), the cosine of the angle and hence the similarity between the two sentences is zero. Cosine similarity is one of the most used criteria [9, 18, 36].
Cosine similarity relies on the previously defined weights in Eqs. (2, 3). The cosine similarity measure between two sentences \({s}_{i}=\left({w}_{i1}, {w}_{i2}, \cdots ,{w}_{im}\right)\) and \({s}_{j}=\left({w}_{j1}, {w}_{j2}, \cdots ,{w}_{jm}\right)\) is defined as:
Formulation of ETS as a multi-objective optimization problem
Unlike single objective function problems, multi-objective optimization problems do not have an optimal solution that minimizes all objective functions at the same time. Rather, there are a set of dominated solutions. Generally, a multi-objective optimization problem can be defined as a minimization problem
where \(X=({x}_{1}, \cdot \cdot \cdot , {x}_{n}) \in \Omega \) is a solution consisting of \(n\) decision variables, \(\Omega \subseteq {\mathcal{R}}^{\mathrm{n}}\) is the decision space, \(F: \Omega \to \Lambda \subseteq {\mathcal{R}}^{p}\) consists of \(p\) objectives, and Λ is the objective space. A solution \({{Y}}^{*}\) is said to dominate another solution \(Y\) if and only if \({f}_{i}({Y}^{*}) \le {f}_{i}(Y)\) for every \(i\in \{1, \cdot \cdot \cdot , p\}\) and \({f}_{j} ({Y}^{*})<{f}_{j} (Y)\) for at least one\(\mathrm{j}\in \{1, \cdot \cdot \cdot ,\mathrm{ p}\}\). A solution is called a Pareto optimal solution if it is not dominated by any solution in Ω. In other words, \({{Y}}^{*}\) is Pareto optimal if there is no other feasible vector \(Y\) that can reduce some objective without causing an increase in at least another objective. Usually, MOO leads to a set of optimal solutions, called the Pareto Optimum Set.
The goal of extractive text summarization is to cover as many conceptual sentences as possible using only a limited number of sentences. In this study, we attempt to find a subset \(\mathcal{S}\) from the sentences collection \(\mathcal{D}=\{{s}_{1}, {s}_{2}, . . . , {s}_{n}\}\) that (1) covers the main content of the document collection and (2) reduces the redundancy in the summary while satisfying the constraint that the summary length must be less than a specified number of words \(L\). Note that \(\mathcal{S}\) can be represented as a binary vector of length \(n\) \(\mathcal{S}=\left[{\mathcalligra{s}}_{1},{\mathcalligra{s}}_{2}, \cdots {\mathcalligra{s}}_{n}\right]\) such that its \({i}^{\mathrm{th}}\) entry \({\mathcalligra{s}}_{i}\) is defined as
That is, each individual (candidate summary) consists of \(n\) binary decision variables. The \({i}^{th}\) decision variable indicates whether the \({i}^{\mathrm{th}}\) sentence (in the document) is selected in the summary or not. For example, if a document contains ten sentences, \(n=10\), a summary \(\mathcal{S}\) that contains three sentences {the first, fifth and ninth} form the document is represented by \(\mathcal{S}= [\mathrm{1,0},\mathrm{0,0},\mathrm{1,0},\mathrm{0,0},\mathrm{1,0}]\).
In this work, the multi-objective problem is formulated as a minimization problem. It must be mentioned that maximization of some function \(f(\mathcal{S})\) is equivalent to minimization of \(-f(\mathcal{S})\). From all possible combinations of the \(n\)-binary vectors that represent different summaries, the ETS optimization problem seeks the optimal summary \(\widehat{\mathcal{S}}\) that minimizes the two objective functions.
-
\({f}_{1}\left(\mathcal{S}\right)=-{f}_{\mathrm{cov}}\left(\mathcal{S}\right)\) where \({f}_{\mathrm{cov}}(\mathcal{S})\) provides a measure for the covering of the main content of the document collection, that has to be maximized and is defined as:
$${f}_{\mathrm{cov}}\left(\mathcal{S}\right)=\sum_{i=1}^{n}\mathrm{sim}(O,{s}_{i}) {\mathcalligra{s}}_{i}$$(8) -
where the center \(O\) of document collection D reflects its main content. The \({k}^{\mathrm{th}}\) coordinate \({o}_{k}\) of the mean vector \(O\) is calculated according to Eq. Tot, to avoid unneeded work, the vector \(\mathrm{SO}=\left\{\mathrm{sim}(O,{s}_{i})\right\},i=\mathrm{1,2},\cdots n\) can be computed once in the pre-processing task and stored for repeated computations of the coverage objective function.
\({f}_{2}(\mathcal{S})={f}_{\mathrm{sim}}(\mathcal{S})\), where the similarity function \({f}_{\mathrm{sim}}(\mathcal{S})\) measures the similarity between the sentences included in \(\mathcal{S}\). Of course, \({f}_{\mathrm{sim}}(\mathcal{S})\) has to be minimized to reduce the summary redundant. So, \({f}_{\mathrm{sim}}(\mathcal{S})\) can be defined as:
Note that, Based on Eq. (5), the similarity matrix \(\mathrm{SIM}=\left\{\mathrm{sim}\left({s}_{i},{s}_{j}\right), i,j=\mathrm{1,2}, \cdots n\right\}\) can be formed and stored in the pre-processing stage for later computations of the similarity objective function. Of course, SIM is the n-symmetrically matrix whose diagonal entries are all zeros.
The bi-objective optimization problem is constrained such that
where L is the upper bound for the number of words of the summary and \({l}_{i}\) is the number of words in sentence \({s}_{i}\).
Large-scale sparse (LSS) algorithm for ATS
According to the present formulation of the extractive text summarization problem as a multi-objective problem, one can note the following characteristics of the resulting MOP:
-
Large dimensionality of the search space: \(n\) decision variables (total number of sentences in the documents collection),
-
Sparse Pareto solutions. Since the summary length is limited, it consists of a small number of sentences and hence a small number of nonzero elements in its vector representation.
Most existing evolutionary algorithms encounter difficulties in dealing with such a large number of variables. There exist many real-world optimization problems containing a large number of decision variables. Some new techniques can be found in literature to solve such large-scale problems including: variable interaction analysis [37,38,39], linkage learning [40], and random embedding based Bayesian optimization [34, 35]. However, these techniques did not account for sparse problems. Tian et al. [29] proposed an evolutionary algorithm for solving large-scale sparse MOPs and introduced a new population initialization strategy and a binary crossover operator and a binary mutation operator taking the sparse nature of the Pareto optimal solutions into consideration.
Large-scale sparse (LSS) multi-objective optimization algorithm
The framework of the proposed evolutionary algorithm LSS for ETS-MOP is similar to the nondominated sorting genetic algorithm II (NSGA-II) [41] and Ref. [29]. In the main algorithm, Algorithm 1, a population \(P\) with size N is initialized (see Algorithm 2) and the non-dominated front number [42] and crowding distance (CD) [41] of each solution in \(P\) are calculated. In each of the next generations, 2 N parents are selected from \(P\) by binary tournament selection according to the non-dominated front number and crowding distance of each solution in \(P\). Afterward, N offspring are generated and combined with P. Then, the duplicated solutions in the combined population are deleted and N solutions with the better non-dominated front number and crowding distance in the combined population survive to the next generation.
Similar to the existing genetic operators, the proposed LSS algorithm adopts specific operators designed for binary variables. Moreover, the genetic operators in LSS are tailored for sparse multi-objective problems. Specifically, the proposed genetic operators flip one element in the zero elements or the nonzero elements in the binary vector with the same probability, where the element to be flipped is selected based on the scores of decision variables. Therefore, the off-springs generated by the proposed LSS algorithm are not expected to have the same number of 0 and 1, and the sparsity of the offsprings can be ensured. The constraint handling strategy adopted in this work applies the constraint dominance principles [32].


In Algorithm 2, rand \((n)\) stands for a range between two random integers \({n}_{1}, {n}_{2}, 1\le {n}_{1}<{n}_{2}\le n.\)
Proposed LSS algorithm for text summarization
A general population P consists of \(N\) summaries. A summary \(\mathcal{S}=\left[{\mathcalligra{s}}_{1},{\mathcalligra{s}}_{2}, \cdots {\mathcalligra{s}}_{n}\right]\) is represented by a vector of size \(n\), where \(n\) is the total number of sentences present in all the combined documents. If the \({i}^{\mathrm{th}}\) sentence is to be included in the summary,\({\mathcalligra{s}}_{i}=1\), otherwise \({\mathcalligra{s}}_{i}=0\). By making use of the stored similarity matrix \(\mathrm{SIM}\) and the central vector \(SO\), the fitness \({\varvec{f}}=\left[{f}_{\mathrm{cov}},{f}_{\mathrm{sim}}\right]\) of a summary \(\mathcal{S}\) can be computed using Eqs. (8, 9). The population is initialized using Algorithm 2 then it is optimally updated using the LSS algorithm (Algorithm 1) until a specific number of objective function evaluations (e.g., 10,000) are performed. The final population represents a set of \(N\) Pareto-optimal solutions (i.e., non-dominated summaries) in the sense that one of these Pareto-optimal solutions cannot be said to be better than the other. So, a post-Pareto analysis has to be performed to select a single solution from this set. Based on user preferences, there are several techniques to reduce the Pareto set to a single solution. However, in this work, we are interested in automatic methods that reduce the Pareto front to a single solution without the need for any given priorities or any additional information. Sanchez-Gomez et al. [43] have implemented some approaches to address this task, including those related to the largest hyper-volume, the consensus solution, and the shortest distance techniques.
The proposed criterion to select an optimal summary from the Pareto front
From the N non-dominated solutions on the Pareto front, one has to decide which solution (summary) will be chosen as the best summary \(\widehat{\mathcal{S}}\) and hence estimate its quality. Let the values of the objective functions of the \({i}^{\mathrm{th}}\) summary \({\mathcal{S}}^{i}\), \((i=1, 2. \cdots N)\) be \({f}_{1}^{i}=-{f}_{\mathrm{cov}}^{i}\) and \({f}_{2}^{i}={f}_{Sim}^{i},\) the normalized values of \({f}_{1}^{i}\) and \({f}_{2}^{i}\) can be defined as follows.
where \({f}_{j}^{\mathrm{min}}\) and \({f}_{j}^{\mathrm{max}}, j=\mathrm{1,2}\) are the minimum and maximum values of the \({j}^{th}\) objective function. Several criteria can be adopted to choose \(\widehat{\mathcal{S}}\).
In this work, a weighted sum of the normalized objectives is calculated for all non-dominated solutions and is defined for a summary \({\mathcal{S}}^{i} as\)
where \({w}_{\mathrm{cov}},{w}_{\mathrm{sim}}\) are weights for the coverage and similarity objectives, respectively. The key idea for this automatic criterion is to make use of human linguistic experience in text summarization. The weights \({w}_{\mathrm{cov}},{w}_{\mathrm{sim}}\) are predetermined through training of a sample of textual topics with known human summaries. In this training, after obtaining the Pareto front of the trained document, apply the criterion with different values of parameter \(\mu ={w}_{\mathrm{cov}}/{w}_{\mathrm{sim}}\) to select \({\widehat{\mathcal{S}}}_{\mu }\). Based on the human summary, compute the Rouge scores for \({\widehat{\mathcal{S}}}_{\mu }\). Then the weights \({w}_{\mathrm{cov}},{w}_{\mathrm{sim}}\) are determined as those result in \({\widehat{\mathcal{S}}}_{\mu }\) with maximum Rouge scores.
The best summary \(\widehat{\mathcal{S}}\) is the summary with the minimum weighted sum, i.e.
The locations of nonzero elements \(({1}^{s})\) in \(\widehat{\mathcal{S}}\) refer to the numbers of the document sentences that is contained in the extracted optimum summary.
Experiment and evaluation
In this section, the datasets used for the experiments, the evaluation metrics, and the results of the proposed summarization system are detailed.
Data sets
The performance of the proposed ETS system has been examined using the multi-document summarization datasets provided by Document Understanding Conferences (DUC). DUC is an open benchmark from the National Institute of Standards and Technology (NIST) for the evaluation of generic automatic summarization. The used datasets have been obtained from DUC2002 (NIST). They consist of a set of topics, and each topic is a multi-document collection that contains several newspaper articles about a specific subject. Table 2 shows some information about the used topics. The documents contained in DUC2002 have been pre-processed according to the steps explained in section “Mathematical formulation” and Fig. 1. Table 3 presents the number \(n\) of sentences in each topic and the number of words in this topic before and after pre-processing.
Evaluation metrics
The approach performance has been evaluated by using Recall Oriented Understudy for Gisting Evaluation (denoted by ROUGE evaluation metric) [32]). ROUGE is considered as the official evaluation metric for text summarization by DUC. This metric measures the similarity between an automatic-generated summary and a human-generated one by counting the number of overlapping units. Two variants of ROUGE scores have been used in this work: ROUGE-N and ROUGE-L. ROUGE-N compares the N-gram recall of the system-generated summary and a set of human-generated summaries. ROUGE-L measures the ratio between the length of the summaries’ longest common subsequence and the length of the reference summary. In this work, ROUGE-1, ROUGE-2, and ROUGE-L have been used to provide fair comparisons with other approaches in the literature.
Numerical results
The proposed summarization system has been run on some topics from DUC2002 dataset, namely [d-061j, d-062j, d-063j, d-064j, d-065j, d-066j, d-067f, d-068f, d-069f, d-070f]. Table 3 presents some statistics of these topics to identify the search space size for these ATS problems.
Performance of the proposed large-scale sparse multi-objective algorithm LSSA
This subsection analyzes the outputs of the processing and pos-processing tasks to examine the performance of the proposed LSSA. Firstly, to investigate the convergence of LSSA, the algorithm is applied on topic d-061j from DUC2002 dataset using different stopping criteria (\(ev=10{,}000, 15{,}000, 20{,}000\)) where \(ev\) stands for the maximum permissible number of function evaluations. Topic d-061j consists of 184 sentences and hence has \(n=184\) decision variables while the population size was set to 100. The resulting Pareto fronts are presented in Fig. 2 showing accepted convergence of the algorithm. As expected, and as can be seen from the figure, increasing \(ev\) results in better Pareto front that dominates those produced by less values of \(ev\). In all following experiments, unless otherwise stated, the algorithm is applied with \(ev=20{,}000.\)

Convergence of the proposed large-scale sparse multi-objective algorithm LSS on dataset d-061j
Secondly, a comparison of LSSA with other MOO algorithms is carried out and the resulting Pareto fronts are presented in Fig. 3. Again, Topic d-061j is considered and optimal solution sets obtained using the proposed LSSA, NSGA-II [41], SPEA-2 [44], and SparseEA [29] are compared. This topic contains 184 sentences, so the number of decision variables for the current experiment is \(n=184\). For the sake of fair experiments, each of these algorithms is executed for 25,000 function evaluations and the population size is set to 50. Although there is no obvious difference for the Pareto-optimal solutions obtained from these algorithms, the Pareto front of the proposed LSSA is better with respect to spread and diversity.

Comparison between Pareto fronts of SPEA-2, NSGA-II, SparseEA and proposed LSSA
Finally, the performance of LSSA is considered in the processing and post-processing stages of the proposed text summarization system. The experiment is applied to study the performance for two multi-document topics from the DUC2002 dataset, namely, \(\mathrm{d}-061\mathrm{j}\) and \(\mathrm{d}-068\mathrm{f}\) which have \(n=184\) and \(n=127\) decision variables, respectively. For these two topics, Fig. 4 visualizes the optimal set of summaries (Pareto front) and three candidate summaries selected according to different criterion parameters \(\mu ={w}_{\mathrm{cov}}/{w}_{\mathrm{sim}} =\{1, 5, 7\}\) (Eqs. 11, 12). Moreover, the positions of the two reference human summaries provided by DUC2002 for each of these topics are located on the associated objective space. Evaluation of each of these summaries using some ROUGE metric depends on the summary location in the search space (n-dimensional large space) where it stores the sentences belonging to each summary. On the other side, the location of a summary in the objective space indicates the values of its objective functions. For each summary, the objective functions in this work are computed based on Eqs. (8, 9). It is noticed from Fig. 4 that using a specific value of \(\mu \), a single summary is chosen from the Pareto front as the candidate summary. For example, \(\mu =1\) chooses the best summary according to the equal importance of the coverage and similarity reduction normalized objectives. As \(\mu \) increases, the coverage objective function becomes more important than the redundant reduction one and hence the chosen summary location moves to the right on the Pareto front. It is worth noting that the locations of the human reference summaries in the objective space are apart from each other and neither of them is optimal with respect the two considered objectives. In general, many points on the Pareto front outperform these references concerning coverage and/or redundant reduction objectives.

Pareto front, two human references and selected candidate summaries based on different criterion parameters \(\mu =\{1, 5, 7\}\) for topics d-061j and d-068f in the objective space. (Population size = 100, \(ev=20{,}000)\)
Evaluation of the proposed LSSA–ATS system
The proposed multi-document automatic text summarization system presented in this work consists mainly of the multi-objective large-scale sparse algorithm LSSA and the proposed weighted normalized criterion that picks the system-generated summary from the Pareto front. In this subsection, the system performance is evaluated by using the ROUGE metric which has been considered as the official evaluation metric for text summarization. This metric computes the similarity between an automatic-generated summary and a human-generated one by counting the number of overlapping units. The used parameter setting for LSSA to compute the results in Table 4 through Table 13 are as follows. The population \(size=100\) and a maximum number of function evaluations \(ev=10,000\). Different numbers of decision variables are used depending on number of sentences in each topic (see Table 3). Concerning the proposed normalized criterion that reduces the Pareto front to a single point (Eqs. (11, 12)), three different values of the criterion parameter \({\varvec{\mu}}={w}_{cov} /{w}_{sim}\) are examined. The reported ROUGE scores are the average of these scores for 20 independent runs. In the case of comparisons, the best values are shown in italic.
Firstly, Tables 4, 5 and 6 presents the average of 20 independent runs of the proposed ATS-system for ROUGE-1, ROUGE-2, and ROUGE-L scores, respectively for each one of the used topics. In addition, for each topic, the last column reports the maximum value of the ROUGE metric of all summaries on the Pareto fronts of the 20 runs. The results in these tables show that the value of the criterion parameter has a significant influence on the summary quality. It is observed also that imposing equal weights for the two normalized objective functions \(({\varvec{\mu}}=1)\) is not the best choice. It is better to increase the weight of the coverage objective concerning the similarity-reduction one in Eqs. (11, 12). For example, using \(({\varvec{\mu}}=5)\) results in best ROUGE-1 scores in 6 out of 10 topics while \(({\varvec{\mu}}=7)\) provides best scores in 3 out of 10 topics. One can conclude that the quality of the system-generated summaries can be improved by introducing \({\varvec{\mu}}={w}_{\mathrm{cov}} /{w}_{\mathrm{sim}}=5\) in Eqs. (11, 12).
Comparing the proposed LSSA with NSGA-II and SparseEA
Next, the efficiency of the proposed multi-objective LSSA is investigated. In the proposed ATS system, we replaced LSSA by NSGA-II [41] and SparseEA [29] which are of the best known evolutional multi-objective algorithms. Considering different values of criterion parameters \(\left(\mu =\mathrm{1,5}, 7\right)\), the ROUGE scores: ROUGE-1, ROUGE-2, and ROUGE-L are presented in Tables 7, 8, and 9, respectively. The reported results in Tables 7 and 8 for ROUGE-1 and ROUGE-2 show clearly that the proposed algorithm LSSA outperforms NSGA-II and SpaseEA for most topics and all values of \(\mu \). Concerning ROUGE-L, Table 9 shows relatively near scores for the two algorithms. However, considering the average of all topics, still LSSA outperforms NSGA-II and SpaseEA.
Comparing different criteria for reducing the Pareto front to a single solution
When a multi-objective optimization approach is applied to automatically generate a summary of the multi-document text, it provides a Pareto front representing a set of many non-dominated summaries. But since only one relevant summary is required, some criterion is essential to reduce this set to a single solution. Several criteria have been considered to address this task [43, 45,46,47,48]. Although Sanchez-Gomez et al. [43] considered the ATS problem with the same objective functions used in the current research; they formulated the automatic text summarization problem as a maximization problem. Accordingly, to reduce the obtained Pareto set to a single solution, they have implemented and compared 11 criteria including the largest hyper-volume method \((LH)\), the consensus method \((C)\), and the shortest distance to the ideal point \(\left({\varvec{S}}{{\varvec{I}}}_{{\varvec{E}}}\right)\) based on Euclidean distance. They concluded that, from the 11 tested criteria, the consensus method \((C)\) achieved the best average values in all ROUGE scores.
The efficiency of the proposed normalized criterion is defined in Eqs. (11, 12) with different values of parameter \(\mu ={w}_{\mathrm{cov}}/{w}_{\mathrm{sim}}\) is investigated in this subsection. The ROUGE scores for the summaries generated using our summarization system for the topics DUC 2002 (d-061j–d-070f) are compared with those in [43] based on different criteria \((LH, C, S{I}_{E})\). Tables 10, 11, and 12 present these comparisons for ROUGE-1, ROUGE-2, and ROUGE-L scores, respectively where the best results are shown in italic. From these Tables, one can conclude that especially for ROUGE-1 and ROUGE-2, the proposed normalized criterion outperforms those in [43] in almost all topics.
Cross-validation between the two reference summaries
In general, evaluation of an automatically generated summary from a multi-document collection by comparing it with a human-generated one is a very challenging task. Humans may extract entirely different sentences from the document collection for their extractive summaries. To demonstrate this fact, we examined the two human-generated summaries provided by the DUC2002 data set for each of the topics d-061j–d-070f. Table 13 presents the results of ROUGE-1, ROUGE-2, and ROUGE-L scores of the cross-validation between the provided two human summary references for each of the topics. As can be seen from Table 13 and most of the previous tables the ROUGE scores of the human-generated summaries are not better than the automatically generated ones. Based on the results in Table 13 and Fig. 4, the proposed ATS system may generate as good summaries as those of the human- generated ones and may outperform them.
Conclusions
The proposed multi-document extractive ATS system is formulated as a constrained bi-objective optimization problem. The two objectives are content coverage that has to be maximized and the redundancy (similarity between the sentences) that must be minimized. A target summary can contain any subset of sentences from the original text such that its length is less than a specific number of words. A large-scale spares multi-objective algorithm (LSSA) is developed to solve the optimization problem. In addition, a new criterion is proposed to pick the target summary from the non-dominated solution set. Using the DUC2002 data set and ROUGE metric, the proposed ATS system is evaluated and compared with related works in the scientific literature. The proposed algorithm LSSA outperforms NSGA-II for all topics and all values of criterion parameter \(\upmu \). It is observed also that imposing equal weights for the two normalized objective functions is not the best choice. It is better to increase the weight of the coverage objective concerning the similarity-reduction one. Based on the current formulation of the ATS as a bi-objective minimization problem, the proposed ATS system generates good summaries that are different from the human-generated summaries and may outperform them.
As future work, there is a need to propose new approaches to improve extractive ATS systems. Some NLP techniques are essential to improve the generated extractive summaries to avoid a lack of cohesion and semantics. In addition, the application of NLP can solve some problems in the generated extracted summary sentences such as anaphora resolution and reordering the selected sentences.
References
El-Kassas WS et al (2021) Automatic text summarization: a comprehensive survey. Expert Syst Appl 165:113679
Vilca, G.C.V. and M.A.S. Cabezudo. A study of abstractive summarization using semantic representations and discourse level information. in International Conference on Text, Speech, and Dialogue. 2017. Springer.
Andhale, N. and L. Bewoor. An overview of text summarization techniques. in 2016 International Conference on Computing Communication Control and automation (ICCUBEA). 2016. IEEE.
Hingu, D., D. Shah, and S.S. Udmale. Automatic text summarization of Wikipedia articles. in 2015 international conference on communication, information & computing technology (ICCICT). 2015. IEEE.
Sanchez-Gomez JM, Vega-Rodriguez MA, Perez CJ (2020) Experimental analysis of multiple criteria for extractive multi-document text summarization. Expert Syst Appl 140:112904
Radev DR et al (2004) Centroid-based summarization of multiple documents. Inf Process Manage 40(6):919–938
Alguliyev RM et al (2019) COSUM: text summarization based on clustering and optimization. Expert Syst 36(1):e12340
Patel D, Shah S, Chhinkaniwala H (2019) Fuzzy logic based multi document summarization with improved sentence scoring and redundancy removal technique. Expert Syst Appl 134:167–177
Saleh HH, Kadhim NJ, Attea B (2015) A genetic based optimization model for extractive multi-document text summarization. Iraqi Journal of Science 56(2):1489–1498
Fattah MA, Ren F (2009) GA, MR, FFNN, PNN and GMM based models for automatic text summarization. Comput Speech Lang 23(1):126–144
Zajic DM, Dorr BJ, Lin J (2008) Single-document and multi-document summarization techniques for email threads using sentence compression. Inf Process Manage 44(4):1600–1610
Abo-Bakr H et al (2020) Weight optimization of axially functionally graded microbeams under buckling and vibration behaviors. Mechanics based design of structures and machines, p 1–22
Abo-bakr H (2021) Multi-objective shape optimization for axially functionally graded microbeams. Compos Struct 258:113370
Abo-Bakr R (2021) Optimal weight for buckling of FG beam under variable axial load using Pareto optimality. Compos Struct 258:113193
Tzanetos A, Dounias G (2021) Nature inspired optimization algorithms or simply variations of metaheuristics? Artif Intell Rev 54(3):1841–1862
Li J-Y et al (2022) A multipopulation multiobjective ant colony system considering travel and prevention costs for vehicle routing in COVID-19-like epidemics. IEEE Transactions on Intelligent Transportation Systems
Li J-Y et al (2021) Surrogate-assisted hybrid-model estimation of distribution algorithm for mixed-variable hyperparameters optimization in convolutional neural networks. IEEE Transactions on Neural Networks and Learning Systems
Alguliev RM, Aliguliyev RM, Mehdiyev CA (2011) Sentence selection for generic document summarization using an adaptive differential evolution algorithm. Swarm Evol Comput 1(4):213–222
Alguliyev RM, Aliguliyev RM, Isazade NR (2015) An unsupervised approach to generating generic summaries of documents. Appl Soft Comput 34:236–250
Benjumea SS, León E (2015) Genetic clustering algorithm for extractive text summarization. In: 2015 IEEE symposium series on computational intelligence. IEEE
Mendoza M et al (2014) A new memetic algorithm for multi-document summarization based on CHC algorithm and greedy search. In: Mexican international conference on artificial intelligence. Springer
Qiang J-P et al (2016) Multi-document summarization using closed patterns. Knowl-Based Syst 99:28–38
Verma P, Om H (2019) MCRMR: Maximum coverage and relevancy with minimal redundancy based multi-document summarization. Expert Syst Appl 120:43–56
Sanchez-Gomez JM, Vega-Rodríguez MA, Perez CJ (2020) A decomposition-based multi-objective optimization approach for extractive multi-document text summarization. Appl Soft Comput 91:106231
Kadhim NJ, Saleh HH (2018) Improving extractive multi-document text summarization through multi-objective optimization. Iraqi J Sci 2135–2149
Debnath, D., R. Das, and P. Pakray, Extractive single document summarization using multi-objective modified cat swarm optimization approach: ESDS-MCSO. Neural Computing and Applications, 2021: p. 1–16.
Sanchez-Gomez JM, Vega-Rodríguez MA, Pérez CJ (2021) Sentiment-oriented query-focused text summarization addressed with a multi-objective optimization approach. Appl Soft Comput 113:107915
Sanchez-Gomez JM, Vega-Rodríguez MA, Pérez CJ (2022) A multi-objective memetic algorithm for query-oriented text summarization: Medicine texts as a case study. Expert Syst Appl 198:116769
Ji J et al (2021) Evolutionary multi-task allocation for mobile crowdsensing with limited resource. Swarm Evol Comput 63:100872
Ji J-J et al (2021) Q-learning-based hyperheuristic evolutionary algorithm for dynamic task allocation of crowdsensing. IEEE Trans Cybern
Tian Y et al (2019) An evolutionary algorithm for large-scale sparse multiobjective optimization problems. IEEE Trans Evol Comput 24(2):380–393
Chen G et al (2022) A domain adaptation learning strategy for dynamic multiobjective optimization. Inf Sci
Guo Y-N et al (2019) Novel interactive preference-based multiobjective evolutionary optimization for bolt supporting networks. IEEE Trans Evol Comput 24(4):750–764
Lin C-Y (2004) Rouge: aA package for automatic evaluation of summaries. In: Text summarization branches out
Gupta V, Lehal GS (2010) A survey of text summarization extractive techniques. Journal of emerging technologies in web intelligence 2(3):258–268
Willett P (2006) The Porter stemming algorithm: then and now. Program
Salton G, Buckley C (1988) Term-weighting approaches in automatic text retrieval. Inf Process Manage 24(5):513–523
Sanchez-Gomez JM, Vega-Rodríguez MA, Pérez CJ (2018) Extractive multi-document text summarization using a multi-objective artificial bee colony optimization approach. Knowl-Based Syst 159:1–8
Mei Y et al (2016) A competitive divide-and-conquer algorithm for unconstrained large-scale black-box optimization. ACM Transactions on Mathematical Software (TOMS) 42(2):1–24
Omidvar MN et al (2017) DG2: A faster and more accurate differential grouping for large-scale black-box optimization. IEEE Trans Evol Comput 21(6):929–942
Sun Y, Kirley M, Halgamuge SK (2017) A recursive decomposition method for large scale continuous optimization. IEEE Trans Evol Comput 22(5):647–661
Pelikan M, Goldberg DE, Cantu-Paz E (2000) Linkage problem, distribution estimation, and Bayesian networks. Evol Comput 8(3):311–340
Deb K et al (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
Tian Y et al (2017) Effectiveness and efficiency of non-dominated sorting for evolutionary multi-and many-objective optimization. Complex & Intelligent Systems 3(4):247–263
Sanchez-Gomez JM, Vega-Rodríguez MA, Perez CJ (2019) Comparison of automatic methods for reducing the Pareto front to a single solution applied to multi-document text summarization. Knowl-Based Syst 174:123–136
Zitzler E, Laumanns M, Thiele L (2001) SPEA2: Improving the strength Pareto evolutionary algorithm. TIK-report 103
Sudeng S, Wattanapongsakorn N (2015) Post Pareto-optimal pruning algorithm for multiple objective optimization using specific extended angle dominance. Eng Appl Artif Intell 38:221–236
Antipova E et al (2015) On the use of filters to facilitate the post-optimal analysis of the Pareto solutions in multi-objective optimization. Comput Chem Eng 74:48–58
Al Malki A et al (2016) Identifying the most significant solutions from Pareto front using hybrid genetic k-means approach. Int J Appl Eng Res 11(14):8298–8311
Aguirre O, Taboada H (2011) A clustering method based on dynamic self-organizing trees for post-pareto optimality analysis. Procedia Computer Science 6:195–200
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
HA-B: Conception and design of the study. Revising the manuscript critically for important intellectual content. Drafting the manuscript. SAM: Analysis and interpretation of data. Acquisition of data.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
The paper does not deal with any ethical problems.
Informed consent
We declare that all authors have informed consent.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abo-Bakr, H., Mohamed, S.A. Automatic multi-documents text summarization by a large-scale sparse multi-objective optimization algorithm. Complex Intell. Syst. 9, 4629–4644 (2023). https://doi.org/10.1007/s40747-023-00967-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-00967-y