
Abstract
For incomplete datasets with mixed numerical and symbolic features, feature selection based on neighborhood multi-granulation rough sets (NMRS) is developing rapidly. However, its evaluation function only considers the information contained in the lower approximation of the neighborhood decision, which easily leads to the loss of some information. To solve this problem, we construct a novel NMRS-based uncertain measure for feature selection, named neighborhood multi-granulation self-information-based pessimistic neighborhood multi-granulation tolerance joint entropy (PTSIJE), which can be used to incomplete neighborhood decision systems. First, from the algebra view, four kinds of neighborhood multi-granulation self-information measures of decision variables are proposed by using the upper and lower approximations of NMRS. We discuss the related properties, and find the fourth measure-lenient neighborhood multi-granulation self-information measure (NMSI) has better classification performance. Then, inspired by the algebra and information views simultaneously, a feature selection method based on PTSIJE is proposed. Finally, the Fisher score method is used to delete uncorrelated features to reduce the computational complexity for high-dimensional gene datasets, and a heuristic feature selection algorithm is raised to improve classification performance for mixed and incomplete datasets. Experimental results on 11 datasets show that our method selects fewer features and has higher classification accuracy than related methods.
Similar content being viewed by others
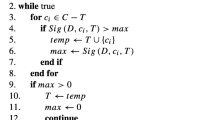

Avoid common mistakes on your manuscript.
Introduction
With the rapid development of information technology, the databases expand rapidly. In daily production and life, more and more information is obtained and stored [1,2,3,4,5]. However, these information may contain a great quantity of redundancy, noise, or even missing feature values [6,7,8]. Nowadays, how to deal with missing values, reduce redundant features, and simplify the complexity of the classification model, so as to improve the generalization ability of model classification is a huge challenge we are facing [9,10,11,12,13,14,15]. As an important step of data preprocessing, feature selection based on granular computing has been widely used in knowledge discovery, data mining, machine learning, and other fields [16,17,18,19,20,21,22,23].
Related work
Neighborhood rough sets [24] and multi-granularity rough sets [25] models, as two commonly used mathematical tools for dealing with uncertainty and incomplete knowledge, are widely employed in feature selection and attribute reduction [26,27,28,29,30,31,32]. Hu et al. [33]introduced the neighborhood relationship into different weights, constructed a weighted rough set model based on the weighted neighborhood relationship, and fully tapped the correlation between attributes and decision. Yang et al. [34] introduced fuzzy preference relations to propose a neighborhood rough set model based on the degree of dominance and applied it to the problem of attribute reduction in large-scale decision problems. Wang et al. [28] presented a neighborhood discriminant index to characterize the discriminative relationship of neighborhood information, which reflects the distinguishing ability of a feature subset. Qian et al. [35] developed a pessimistic multi-granulation rough sets decision model based on attribute reduction. Lin et al. [36] advanced a neighborhood-based coverage reduction multi-granulation rough set model. Sun et al. [37] combined the fuzzy neighborhood rough sets with the multi-granulation rough set model, and proposed a new fuzzy neighborhood multi-granulation rough set model, which expanded the types of rough set models. Meanwhile, the neighborhood multi-granulation rough sets’ (NMRS) model has been widely used. Ma et al. [38] constructed an NMRS model based on the two-particle criterion, which effectively reduced the number of iterations in the attribute reduction calculation. Hu et al. [39] presented a matrix-based incremental method to update the knowledge in NMRS. To obtain more accurate rough approximation and reduce the interference of noise data, Luo et al. [40] developed a neighborhood multi-granular rough set variable precision decision method based on multi-threshold. Although a variety of NMRS-based feature selection methods have been proposed and applied, most of the evaluation functions of them are constructed only based on the lower approximation of decision. This construction method ignores the information contained in the upper approximation, which easily leads to the loss partial information [58].
In various fields datasets, missing values (null or unknown values) often occur [9, 41]. Recently, tolerance relation or tolerance rough sets have emerged in the field of processing incomplete datasets [42]. Qian et al. [43] presented an incomplete rough set model based on multiple tolerance relations from the multi-granulation view. Yang et al. [44] proposed supporting feature functions for processing multi-source datasets through the perspective of multi-granulation. Sun et al. [45] developed neighborhood tolerance-dependent joint entropy for feature selection and revealed better classification performance on incomplete datasets. Zhao et al. [42] constructed an extended rough set model based on neighborhood tolerance relation, which was successfully applied to incomplete datasets with mixed categories and numbers. Inspired by these research achievements, this paper is dedicated to developing a heuristic feature selection method based on neighborhood tolerance relation to solve mixed incomplete datasets.
In recent years, the uncertainty measures had developed rapidly from the algebra view or the information view [46, 47]. Hu et al. [39] constructed a matrix-based feature selection method to realize the uncertainty of the boundary region in the NMRS model. You et al. [48] proposed the relative reduction for covering information system. Zhang et al. [49] employed local pessimistic multi-granulation rough set to deal with larger size datasets. In general, the above studies are only from algebra view. Unfortunately, the attribute importance based on algebra view only describes the influence of the features contained in the subset. In the past decades, information entropy and its variants have been extensively used in feature selection as an important method [50, 51]. Zeng et al. [52] improved multi-granulation entropy by developing multiple binary relations. Feng et al. [53] studied the reduction problem of multi-granulation fuzzy information system according to merging entropy and conditional entropy. In short, these literatures discussed feature selection only from information view. However, feature significance only from the information view barely reflects the significance on features in uncertainty classification [54, 55]. It would be a better topic to integrate the two views to improve the uncertainty measure quality in feature selection for incomplete neighborhood decision systems. Wang et al. [56] studied rough reduction and relative reduction from two views simultaneously. Chen et al. [57] proposed the roughness based on entropy and the approximate roughness measurement of the neighborhood system. Xu et al. [58] presented a feature selection method using fuzzy neighborhood self-information measures and entropy in combination with algebra and information views. Table 1 summarizes and highlights some feature selection methods from the perspective of whether to deal with missing data and uncertainty measure views.
Our work
To solve the problem, some feature evaluation functions only consider the information contained in the lower approximation of the decision, which may lead to loss some information, moreover comprehensively evaluate the uncertainty of the incomplete neighborhood decision systems. This paper will focus on researching a new feature selection method in multi-granulation terms. The main work of this paper is as follows:
-
Based on the related definitions of NMRS, the shortcomings of the related neighborhood functions are analyzed.
-
Three kinds of uncertain indices are proposed, including decision index, sharp decision index, and blunt decision index, using upper and lower approximations of NMRS. Then, we redefine three types of precision and roughness based on three indices. Next, combining with the concept of self-information, four kinds of neighborhood multi-granulation self-information measures are proposed and their related properties are studied. According to theoretical analysis, the fourth measure, named lenient neighborhood multi-granulation self-information (NMSI), is suitable for select the optimal feature subsets.
-
To better study the uncertainty measure for the incomplete neighborhood decision systems from the algebra and information views, the self-information measures and information entropy are combined to propose a neighborhood multi-granulation self-information-based pessimistic neighborhood multi-granulation tolerance joint entropy (PTSIJE). PTSIJE not only considers the upper and lower approximations of the incomplete decision systems at the same time, but also can measure the uncertainty of the incomplete neighborhood decision systems from the algebra and information views simultaneously.
The structure of the rest of this paper is as follows: some related concepts of self-information and NMRS are reviewed in “Previous knowledge”. “The deficiency of relative function and PTSIJE- based uncertainty measures” illustrates the shortcomings of neighborhood correlation function. Then, to improve the shortcomings, we propose four neighborhood multi-granulation self-information measures and study their related properties. Finally, the fourth measure is combined with neighborhood tolerance joint entropy to construct a feature selection model based on PTSIJE. “PTSIJE-based feature selection method in incomplete neighborhood decision systems” designs a heuristic feature subset selection method. In “Experimental results and analysis” six UCI datasets and five gene expression profile datasets were used to verify the results. “Conclusion” is the conclusion of this paper and our future work.
Previous knowledge
Self-information
Definition 1
[59] Metric I(x) is proposed by Shannon to represent the uncertainty of a signal x, is called the self-information of x if it met the following properties:
-
(1)
Non-negative:\(I(x) \ge 0\).
-
(2)
If \(p(x) \rightarrow 0\) , then \(I(x) \rightarrow \infty \).
-
(3)
If \(p(x)\mathrm{{ = }}0\) , then \(I(x) = 1\).
-
(4)
Monotonic: If \(p(x) < p(y)\) , then \(I(x) < I(y)\).
Here, p(x) is the probability of x.
Neighborhood multi-granulation rough sets
Given a neighborhood decision \(NDS=<U,CA,D,V,f,\) \(\varDelta ,\lambda > \), \(U = \{ {x_1},{x_2},...,{x_m}\} \) is an universe, \(CA\mathrm{{ = }}{B_S} \cup {B_N}\) is a conditional attribute set that depicts the samples with mixed data, here \({B_S}\) is a symbolic attribute set, \({B_N}\) is the a numerical attribute set; D is the decision attribute set; \(V = { \cup _{a \in CA \cup DS}}{V_a}\) which \({V_a}\) is a value of attribute a; f is the map function; \(\varDelta \) is the distance function; \(\lambda \) is the neighborhood radius and \(\lambda \in [0,1]\). Suppose that \(x \in U\) and f(a, x) is equal to a missing value (an unknown value or a null, recorded as “*”), which means that there is at least one attribute \(a \in CA\), \(f(a,x)\mathrm{{ = *}}\), then this decision systems can be called an incomplete neighborhood decision system \(INDS\mathrm{{ = }} < U,CA,D,V,f,\varDelta ,\lambda>\), it can be abbreviated as \(INDS = < U,CA,D,\lambda > \).
Definition 2
Suppose an incomplete neighborhood decision system \(INDS = < U,CA,D,\lambda > \) with any \(B \in CA\) and \(B\mathrm{{ = }}{B_S} \cup {B_N}\), then the neighborhood tolerance relation of B is described as [42]
For any \(x,y \in U\), the neighborhood tolerance class is expressed as [42]
Definition 3
Given \(INDS = < U,CA,D,\lambda > \) with \(X \subseteq U\), \(A = \{ {A_1},{A_2},...,{A_r}\} \) and \(A \subseteq CA\), the optimistic neighborhood multi-granulation lower and upper approximations of X with regard to \({A_1},{A_2},...,{A_r}\) are denoted, respectively, as
here, \(NT_{{A_i}}^\lambda (x)\) represents the neighborhood tolerance class, \({A_i} \subseteq A\) with \(i = 1,2,...,r\) . Then, \(\underline{\Bigg (\sum \nolimits _{i = 1}^r {A_i^{O,\lambda }} } (X),\) \(\overline{\sum \nolimits _{i = 1}^r {A_i^{O,\lambda }} } (X)\Bigg )\) can be called an optimistic NMRS model (ONMRS) in incomplete neighborhood decision systems [60].
Definition 4
Assume that an incomplete neighborhood decision system \(INDS = < U,CA,D,\lambda > \) with \({A_i} \subseteq A\), \(A = \{ {A_1},{A_2},...,{A_r}\} \), and \(U/D = \{ {D_1},{D_2},...,{D_t}\} \), the optimistic positive region and the optimistic dependency degree of D with respect to A based on ONMRS are expressed[60], respectively, as
where \({A_i} \subseteq A\), \(i = 1,2,...,r\), \({D_l} \in U/D\), \(l = 1,2,...,t\).
Definition 5
Let \(INDS = < U,CA,D,\lambda > \) with \(X \subseteq U\), \(A = \{ {A_1},{A_2},...,{A_r}\} \) and \(A \subseteq CA\) , then the pessimistic neighborhood multi-granulation lower and upper approximations of X with respect to \({A_1},{A_2},...,{A_r}\) are denoted [60], respectively, as
here, \(NT_{{A_i}}^\lambda (x)\) represents the neighborhood tolerance class, \({A_i} \subseteq A\) with \(i = 1,2,...,r\) .
Then,\(\underline{\Bigg (\sum \nolimits _{i = 1}^r {A_i^{P,\lambda }} } (X),\overline{\sum \nolimits _{i = 1}^r {A_i^{P,\lambda }} } (X)\Bigg )\) can be called a pessimistic NMRS model (PNMRS) in incomplete neighborhood decision systems [60].
Definition 6
Given \(I\!N\!D\!S = <U,CA,D,\lambda>\) with \({A_i} \subseteq A\), \(A = \{ {A_1},{A_2},...,{A_r}\}\), and \(U/D = \{ {D_1},{D_2},...,{D_t}\}\), the pessimistic positive region and the pessimistic dependency degree of D with respect to A based on PNMRS are expressed [60], respectively, as
where \({A_i} \subseteq A\), \(i = 1,2,...,r\), \({D_l} \in U/D\), \(l = 1,2,...,t\).
The deficiency of relative function and PTSIJE-based uncertainty measures
The deficiency of relative function
The classic NMRS model employs Eq. (10) as the evaluation function for feature selection. However, this construction method only considers the positive region, that is to say, only a part of the decision information is taken into account, and the information contained in the upper approximation of the decision is often not negligible, so this construction method is easy to cause the loss of some information. Thus, an ideal evaluation function should take into account the information whether it is consistent with the decision. For this reason, in the next part, we construct PTSIJE to measure the uncertainty in the mixed incomplete neighborhood decision systems, making the feature selection mechanism more comprehensive and reasonable.
PTSIJE-based uncertainty measures
Definition 7
Let \(INDS = < U,CA,D,\lambda > \), \(U/D = \{ {D_1},{D_2},...,{D_t}\} \), \(A \subseteq CA\), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \({A_i} \subseteq A\), \(NT_A^\lambda \) is a neighborhood tolerance relation induced by A. The decision index \(dec({D_k})\), the sharp decision index \(sha{r_A}({D_k})\), and the blunt decision index \(blu{n_A}({D_k})\) of \({\mathrm{{D}}_k}\) are denoted, respectively, by
where the sharp decision index \(sha{r_A}({D_k})\) of \({D_k}\) is illustrated as the cardinal number of its lower approximation, which is expressing the number of samples with consistent neighborhood decision classification. The blunt decision index \(blu{n_A}({D_k})\) of \({D_k}\) is showed by the cardinal number of its upper approximation, which representing number of samples may belong to \({D_k}\). \(\left| \cdot \right| \) means the cardinality of the set.
Property 1
\(sha{r_A}({D_k}) \le dec({D_k}) \le blu{n_A}({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Property 2
Assume \(A1 \subseteq A2 \subseteq CA\) and \({D_k} \in U/D = \{ {D_1},{D_2},...,{D_t}\} \), then
-
(1)
\(sha{r_{A1}}({D_k}) \le sha{r_{A2}}({D_k})\).
-
(2)
\(blu{n_{A1}}({D_k}) \ge blu{n_{A2}}({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Property 2 reveals that both the sharp decision and the blunt decision indices are monotonic. The sharp decision index \(sha{r_A}({D_k})\) boosts and the consistency of decision is enhanced with the increase of the number of features. A smaller blunt decision index \(blu{n_A}({D_k})\) is generates by decrease of decision uncertainty. In other words, attribute reduction is produced by the uncertainty of decision decreases.
Definition 8
For an incomplete neighborhood decision system \(INDS = < U,CA,D,\lambda > \) with \(A \subseteq CA\), \({D_k} \in U/D\), the precision and roughness of the sharp decision index are defined, respectively, as
Evidently, \(0 \le \theta _A^{(1)}({D_k}),\sigma _A^{(1)}({D_k}) \le 1\), \(\theta _A^{(1)}({D_k})\) shows the degree to which the sample is completely grouped into \(D_k\). \(\sigma _A^{(1)}({D_k})\) indicates that the sample is not classified to the degree of correct decision \(D_k\). Both \(\theta _A^{(1)}({D_k})\) and \(\sigma _A^{(1)}({D_k})\) mean the classification ability of feature subset in different ways.
If \(\theta _A^{(1)}({D_k}) = 1\), \(\sigma _A^{(1)}({D_k}) = 0\), then \(dec({D_k}) = sha{r_A}({D_k})\); it describes that all samples can be correctly divided into corresponding decision by feature subset A; at this time, feature subset reaches the optimal classification ability. If \(\theta _A^{(1)}({D_k}) = 0\), \(\sigma _A^{(1)}({D_k}) = 1\), then \(sha{r_A}({D_k}) = 0\); it indicates that all samples cannot be classified into correct decision \(D_k\) through A; in this case, feature subset A has the weakest classification ability.
Property 3
Assume that \(A1 \subseteq A2 \subseteq CA\) with \({D_k} \in U/D\), then
-
(1)
\(\theta _{A1}^{(1)}({D_k}) \le \theta _{A2}^{(1)}({D_k})\).
-
(2)
\(\sigma _{A1}^{(1)}({D_k}) \ge \sigma _{A2}^{(1)}({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Property 3
explains that the precision and roughness of the sharp decision index are monotonic. As the number of new features increases, higher precision and lower roughness of the sharp decision index will be generated.
Definition 9
Let \(A \subseteq CA\), \({D_k} \in U/D\), the sharp decision self-information of \(D_k\) is defined as
It is obvious to testify that \(I_A^1({D_k})\) meets properties (1), (2), and (3) of the definition of self-information. Then, (4) can be confirmed according to Property 4.
Property 4
Let \(A1 \subseteq A2 \subseteq CA\) and \({D_k} \in U/D\), then \(I_{A1}^1({D_k}) \ge I_{A2}^1({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Definition 10
Given \(INDS = < U,CA,D,\lambda > \), \(U/D = \{ {D_1},{D_2},...,{D_t}\} \), \(A \subseteq CA\), then the sharp decision self-information of INDS can be defined as
As we know, self-information was originally used to characterize the instability of signal output. Here, the application of self-information in the incomplete neighborhood decision systems can be used to picture the uncertainty of decision, which it is an effective medium to evaluating decision ability.
\(I_A^1(D)\) delivers the classification information of the feature subset about the sharp decision. The smaller \(I_A^1(D)\) is, the stronger classification ability of feature subset A is. When \(I_A^1(D) = 0\), illustrates that all samples in U can be completely classified into the correct categories according to feature subset A.
However, the feature subset selected by sharp decision only focuses on the information contained in the consistent decision, while ignoring the information contained in the uncertain classification object. In addition, these uncertain informations are essential to decision classification, which cannot be ignored. Therefore, it is vital to analyze the information which contained in the uncertain classification objects. Next, we will define the precision and roughness of blunt decision to discuss the classification ability of feature subset.
Definition 11
Letting \(INDS = < U,CA,D,\lambda > \), \(U/D = \left\{ {{D_1},{D_2}, \cdots ,{D_t}} \right\} \), then precision and roughness of the blunt decision index are denoted, respectively, as
Clearly, \(0 \le \theta _A^{(2)}({D_k}),\sigma _A^{(2)}({D_k}) \le 1\). \(\theta _A^{(2)}({D_k})\) shows the uncertain information contained in \(D_k\). \(\sigma _A^{(2)}({D_k})\) expresses the degree that the samples cannot be completely classified into the corresponding decision class. When \(\theta _A^{(2)}({D_k}) = 1\), \(\sigma _A^{(2)}({D_k}) = 0\), then \(dec({D_k}) = blu{n_A}({D_k})\). It explains that all possible decisions are correctly divided into the decision \(D_k\), and the feature subset has the strongest classification ability. On the contrary, feature subset A has no classification ability.
Property 5 Suppose that \(A1 \subseteq A2 \subseteq CA\) and \({D_k} \in U/D\), then
-
(1)
\(\theta _{A1}^{(2)}({D_k}) \le \theta _{A2}^{(2)}({D_k})\).
-
(2)
\(\sigma _{A1}^{(2)}({D_k}) \ge \sigma _{A2}^{(2)}({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
According to Property 5, it explicitly illustrates that the precision and roughness of the blunt decision index are monotonic. When new features are added, the precision of the blunt decision increases with the roughness falls.
Definition 12
Suppose that \({A} \subseteq {CA}\) with \(D_k \in U/D\), then blunt decision self-information of \(D_k\) can be defined as
It is obvious to testify that \(I_A^2({D_k})\) meets properties (1), (2), and (3) of the definition of self-information, (4) can be confirmed according to Property 6.
Property 6
Letting \(A1 \subseteq A2 \subseteq CA\) and \({D_k} \in U/D\), then \(I_{A1}^2({D_k}) \ge I_{A2}^2({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Definition 13
Assume an incomplete decision system \(INDS = < U,CA,D,\lambda > \) with \(U/D = \left\{ {{D_1},{D_2}, \cdots , {D_t}} \right\} \), and \(A \subseteq CA\), then the blunt decision self-information of INDS is defined as
Through the above analysis, we can obtain that sharp decision self-information \(I_A^1(D)\) relies on samples with consistent decision classification, while blunt decision self-information \(I_A^2(D)\) considers samples with inconsistent classification information, but it cannot ensure that all classification information is definitive. Therefore, both \(I_A^1(D)\) and \(I_A^2(D)\) have insufficient classification capabilities in describing feature subsets, and they are rather one-sided. For this reason, we will propose two other kinds of self-information about classification decision to measure the uncertainty of incomplete neighborhood systems.
Definition 14
Let \(A \subseteq CA\) and \({D_k} \in U/D\), the sharp-blunt decision self-information of \(D_k\) can be denoted as
It is obvious to testify that \(I_A^3({D_k})\) meets properties (1), (2), and (3) of the definition of self-information, (4) can be proofed by Property 7.
Property 7
Assume \(A1 \subseteq A2 \subseteq CA\) and \({D_k} \in U/D\), then \(I_{A1}^3({D_k}) \ge I_{A2}^3({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Definition 15
Suppose that \(INDS = < U,CA,D,\lambda > \), \(U/D = \left\{ {{D_1},{D_2}, \cdots ,{D_t}} \right\} \) and , then the sharp-blunt decision self-information of INDS is defined as
Definition 16
Let \(A \subseteq CA\) and \({D_k} \in U/D\), the precision and roughness of the lenient decision index are defined as
Apparently, \(0 \le \theta _A^{(3)}({D_k}),\sigma _A^{(3)}({D_k}) \le 1\). \(\theta _A^{(3)}({D_k})\) portrays the proportion of the cardinal number of sharp and blunt decision-making samples. In other words, \(\theta _A^{(3)}({D_k})\) characterizes the classification ability of feature subset A according to compare sharp decision index with blunt decision index.
When \(\theta _A^{(3)}({D_k}) = 1\), \(\sigma _A^{(3)}({D_r}) = 0\). It is the ideal state of the feature subset. At this time, the feature subset A has the strongest classification ability. On the contrary, when \(\theta _A^{(3)}({D_r}) = 0\), the feature subset A has no effect on classification and has the weakest classification ability.
Property 8
Let \(A1 \subseteq A2 \subseteq CA\) and \({D_k} \in U/D\), then
-
(1)
\(\theta _{A1}^{(3)}({D_k}) \le \theta _{A2}^{(3)}({D_k})\), \(\sigma _{A1}^{(3)}({D_k}) \ge \sigma _{A2}^{(3)}({D_k})\).
-
(2)
\(\theta _A^{(3)}({D_k}) = \theta _A^{(1)}({D_k}) \cdot \theta _A^{(2)}({D_k})\).
-
(3)
\(\sigma _A^{(3)}({D_k}) = \sigma _A^{(1)}({D_k}) + \sigma _A^{(2)}({D_k}) - \sigma _A^{(1)}({D_k}) \cdot \sigma _A^{(2)}({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Definition 17
Assume \(A \subseteq CA\) and \({D_k} \in U/D\), the lenient self-information of \({D_k}\) can be defined as
It is obvious to testify that \(I_A^4({D_k})\) meets properties (1), (2), and (3) of the definition of self-information, and (4) can be confirmed according to Property 9.
Property 9 Letting \(A1 \subseteq A2 \subseteq CA\) with \({D_k} \in U/D\), then \(I_{A1}^4({D_k}) \ge I_{A2}^4({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Property 10
\(I_A^4({D_k}) \ge I_A^3({D_k})\).
Proof
The detailed proof can be found in the supplementary file.
Definition 18
Suppose an incomplete neighborhood decision system \(INDS = < U,CA,D,\lambda > \) with \(U/D = \left\{ {{D_1},{D_2}, \cdots ,{D_t}} \right\} \), and \(A \subseteq CA\), the lenient self-information of INDS is defined as
Property 11
Let \(A1 \subseteq A2 \subseteq CA\), then \(I_{A1}^4(D) \ge I_{A2}^4(D)\).
Proof
The detailed proof can be found in the supplementary file.
Remark 1
Through the above theoretical analysis, we receive that the lenient neighborhood multi-granulation self-information (NMSI) not only considers the upper and lower approximations of decision-making, but also can measure the uncertainty of the incomplete neighborhood decision-making system from a more comprehensive perspective. In addition, NMSI is more sensitive for the change of feature subset, and hence, it is more suitable for feature selection.
Definition 19
[45] Assume an incomplete neighborhood decision system \(INDS = < U,CA,D,\lambda > \), \(A \subseteq CA\), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \({A_i} \subseteq A\), \(NT_{{A_i}}^\lambda (x)\) is a neighborhood tolerance class for \(x \in U\), the neighborhood tolerance entropy of A is defined as
Definition 20
Letting \(INDS = < U,CA,D,\lambda > \), \(U/D = \left\{ {{D_1},{D_2}, \cdots ,{D_t}} \right\} \), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \(A \subseteq CA\), \(NT_{{A_i}}^\lambda (x)\) is a neighborhood tolerance class. Then, the neighborhood tolerance joint entropy of A and D is defined as
Definition 21
Assume an incomplete neighborhood decision system \(I\!N\!D\!S\! = < U,CA,D,\lambda > \), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \(U/D = \left\{ {{D_1},{D_2}, \cdots ,{D_t}} \right\} \), \(NT_{{A_i}}^\lambda (x)\) is a neighborhood tolerance class for \(x \in U\), the neighborhood multi-granulation self-information-based pessimistic neighborhood multi-granulation tolerance joint entropy (PTSIJE) of A and D is defined as
Here, \(I_B^4(D)\) is the lenient NMSI measure of INDS.
Property 12
Letting \(INDS = < U,CA,D,\lambda > \), \(U/D = \left\{ {{D_1},{D_2}, \cdots ,{D_t}} \right\} \), \(A \subseteq CA\), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \(NT_{{A_i}}^\lambda (x)\) is a neighborhood tolerance class for \(x \in U\), then
Remark 2
From Definition 20 and Property 12, we can vividly realize that \(I_A^4(D)\) represents the lenient NMSI measure in algebraic view, and \(NT{E_\lambda }(A\cup D)\) is the neighborhood tolerance joint entropy of A and D in information view. Therefore, PTSIJE can measure the uncertainty of incomplete neighborhood decision systems from both algebraic and information views based on self-information measures and entropy.


Process flow of the feature selection method for data classification
PTSIJE-based feature selection method in incomplete neighborhood decision systems
Feature selection based on PTSIJE
Definition 22
Letting \(INDS = < U,CA,D,\lambda > \), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \(A' \subseteq A \subseteq CA\), then \(A'\) is the reduction of A and D if:
-
(1)
\(PTSIJE_\lambda ^p(A',D) = PTSIJE_\lambda ^p(CA,D)\).
-
(2)
For any \({A_i}\! \subseteq \!A'\), \(PTSIJE_\lambda ^p(A',D)\!<PTSIJE_{_\lambda }\!^p(A' - \!{A_i},\!D)\).
Here, the formula (1) illustrates that the reduced subset and the entire dataset have the same classification ability, and the formula (2) guarantees that the reduced subset has no redundant attributes.
Definition 23
Let \(INDS = < U,CA,D,\lambda > \), \(A = \{ {A_1},{A_2},...,{A_r}\} \), \(A' \subseteq A \subseteq CA\), for any \({A_i} \subseteq A'\), \(i = 1,2,...,r\), the attribute significance of attribute subset \(A'\) with respect to D in granularity set \({A_i}\) is defined as
Feature selection algorithm
To show the feature selection method more clearly, the process of data classification for feature selection is expressed in Fig. 1, and the algorithm description is shown in Algorithm 1.
For the PTSIJE-FS algorithm, it mainly involves two aspects: getting neighborhood tolerance classes and counting PTSIJE. The calculation of neighborhood tolerance class has a great impact on the time complexity. To reduce the computational complexity of the neighborhood tolerance classes, the bucket sorting algorithm [37] is used here, and the time of complexity of neighborhood tolerance classes is cut back to O(mn). Here, m is the number of samples and n is the number of features. Meanwhile, the computational time complexity of the PTSIJE is O(n) . The PTSIJE-FS algorithm is a loop in steps 8-14. In the worst case, its time complexity is \(O({n^3}m)\). Assuming that the number of selected granularities is \({n_R}\), since only candidate granularities need to be considered but not all granularities, the time complexity of calculating the neighborhood tolerance classes is \(O({n_R}m)\). In most cases \({n_R} \ll n\), so the time complexity of PTSIJE-FS is about O(mn).
Experimental results and analysis
Experiment preparation
To demonstrate the effectiveness and robustness of our proposed feature selection method, we conducted experiments on 11 public datasets, including 6 UCI datasets and 5 high-dimensional microarray gene expression data- sets. The datasets used are listed in Table 1. Among them, six UCI datasets can be downloaded from http://archive.ics.uci.edu/ml/datasets.php, and five gene expression datasets can be downloaded from http://portals.broadinstitute.org/cgi-bin/cancer/datasets.cgi. It should be noted here that the Wine, Wdbc, Sonar, Heart datasets and five gene expression datasets are usually complete. Therefore, to convenience, we randomly modify some known feature values to missing values to achieve incomplete neighborhood decision systems.
Table 2 lists all datasets.
All simulation experiments are running on MATLAB 2016a, under Window10 operating system with an Intel(R) i5 CPU at 3.20 GH and 4.0 GB RAM. The classification accuracy is verified by three classifiers KNN, CART, and C4.5 whose default values of all parameters are selected under Weka 3.8 software. To ensure the consistency of experiments, we use the tenfold cross-validation method in all our experiments.
Effect of different neighborhood parameters
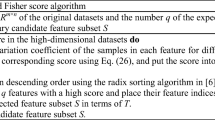
This subsection will focus on the analysis of the impact of different neighborhood parameters \(\lambda \) on the classification performance of our method, and find the best parameters for each dataset. For five high-dimensional gene expression datasets (hereinafter referred to as gene datasets), to effectively reduce the time cost, we use Fisher score (FS) [45] for preliminary dimensionality reduction. There are some advances of FS: less calculation, strong operability, and can effectively reduce the computational complexity. Figure 2 illustrates the variation trend of the accuracy of the number of selected genes under the classifier KNN in different dimensions (10, 50, 100, 200, 300, 400, 500) on the five gene datasets.

Classification accuracy via the size of gene subsets on five gene datasets
As shown in Fig. 2, the accuracy in most cases changes with the size of the gene subset. The optimal balance between the size and accuracy of the selected feature gene subset is found to obtain the appropriate dimension of each gene subset for the next feature selection. Therefore, the values of two datasets DLBCL and Lung are set as 100 dimensions, the 200 dimensions are favorable for datasets Leukemia and MLL, and the 400 dimensions are appropriate for dataset Prostate.
The classification accuracy of selected feature subsets using PTSIJE-FS on 11 datasets is obtained with different neighborhood parameters. For six UCI datasets, the classification performance is evaluated under two classifiers KNN (k=10) and CART, which is displayed in Fig. 3a–f, and the classification performance for five gene datasets under three classifiers KNN (k=10), CART, and C4.5 is illustrated in Fig. 3g–k. The classification accuracy under different parameters \(\lambda \) is shown in Fig. 3, where the abscissa represents different neighborhood parameters \(\lambda \in [0.05,1]\), and the ordinate is the classification accuracy.

Classification accuracy for 11 datasets with different neighborhood parameter values
Figure 3 reveals that the neighborhood parameters increase from 0.05 to 1, and the classification accuracy of features selected by PTSIJE-FS is changing. Different parameters have a certain impact on the classification performance of PTSIJE-FS. Fortunately, every dataset can reach the high result in the wider range of \(\lambda \). Figure 3a displays that for Credit dataset, the neighborhood parameter will be 0.4 under KNN and 0.1 under CART. From Fig. 3b, for Heart dataset, the neighborhood parameter set 1.0 under classifier KNN and 0.75 under classifier CART, the classification accuracy achieves maximum. In Fig. 3c, for Sonar dataset, the classification performance is at best level when neighborhood parameters are 0.5 and 0.6 under classifiers KNN and CART, respectively. As shown in Fig. 3d, when the neighborhood parameter is set to 0.15 under classifiers KNN and CART, the classification performance is optimal. It can be seen from Fig. 3e that for the Wine dataset, the classification performance is best when the neighborhood parameter is set to 0.8 under the classifier KNN, and the neighborhood parameter is set to 0.2 under the classifier CART. From Fig. 3f that on the Wpbc dataset, when the neighborhood parameters are set to 0.15 and 0.3, the classification performance of the selected feature subset under the classifiers KNN and CART reaches the high level at the same time. Figure 3g shows the accuracy of DLBCL dataset and the neighborhood parameters will be set 0.45, 1.0, and 0.4 under three classifiers KNN, CART, and C4.5, respectively. In Fig. 3h, for the gene dataset Leukemia, when the neighborhood parameter is set to 0.35 under KNN, 0.05 under CART, and 0.45 under C4.5, the gene subset with the best classification performance can be obtained. As shown in Fig. 3i, when the neighborhood parameter under KNN is set to 0.8, CART is set to 0.05, and C4.5 is set to 0.7, the classification performance of the gene subset selected from Lung dataset achieves the best level. Figure 3j demonstrates that the optimal neighborhood parameter values should be set to 0.4 under KNN, and set to 0.65 under classifiers CART and C4.5 for MLL. Similarly, for the Prostate dataset, the parameter values are 0.75, 0.8, and 0.3 under classifiers KNN, CART, and C4.5, respectively.
Classification results of the UCI datasets
In this subsection, to illustrate the classification performance of the method PTSIJE-FS on the low-dimensional UCI datasets, the PTSIJE-FS is compared with six existing feature selection methods: (1) the neighborhood tolerance dependency joint entropy-based feature selection method (FSNTDJE) [45], (2) the discernibility matrix-based reduction algorithm (DMRA) [27], (3) the fuzzy positive region-based accelerator algorithm (FPRA) [61], (4) the fuzzy boundary region-based feature selection algorithm (FRFS) [62], (5) the intuitionistic fuzzy granule-based attribute selection algorithm (IFGAS) [63], and (6) the pessimistic neighborhood multi-granulation dependency joint entropy (PDJE-AR) [60].
The first part of this subsection focuses on the size of feature subsets selected by all comparative feature selection methods. Using neighborhood parameters \(\lambda \), the tenfold cross-validation method is used on six UCI datasets. The original data and average size of the selected feature subset by the above seven feature selection methods are shown in Table 3. Under two classifiers KNN and CART, PTSIJE-FS selects the optimal feature subset for six UCI datasets as displayed in Table 4 where “original” represents the original dataset.
Table 3 shows the average number of the selected feature subset by seven feature selection methods. Compared with method IFGAS, PTSIJE-FS selects more features for datasets Heart and Sonar. The average size of the selected feature subsets by PTSIJE-FS is 7.2, 5.5, and 5.0, respectively, and reaches the minimum on datasets Credit, Wine, and Wpbc. In a word, the mean number of the selected feature subset by PTSIJE-FS is the minimum compare with six related methods for six UCI datasets.
The second part in this subsection is to exhibit the classification effectiveness for PTSIJE-FS. There are six feature selection methods, including FSNTDJE, DMRA, FPRA, FRFS, IFGAS, and PDJE-AR, are used to prove the accuracy on the selected feature subsets under two classifiers KNN and CART for six UCI datasets. Tables 5 and 6, respectively, list the average classification accuracy using the seven methods of selected feature subsets under two classifiers KNN and CART. In Tables 3, 7, the bold font shows that the size of the reduced datasets is least with respect to other methods. In Tables 5, 6, 9, 10, the bold numbers indicate that the classification accuracy of the selected feature subsets is the highest with respect to other methods.
Combined with Tables 3 and 5, we can clearly see the differences between the seven methods. For almost all UCI datasets, the classification accuracy of the selected feature subsets by PTSIJE-FS apparently outperforms the other six methods under the KNN classifier. In addition, PTSIJE-FS not only selects the fewer features, but also has the highest classification accuracy on datasets Credit, Wine, and Wpbc. In brief, the PTSIJE-FS method deletes redundant features to the greatest extent and still shows better classification performance than six compared methods on UCI datasets.
Similarly, from Tables 3 and 6, the differences among seven feature selection methods are illustrated under the classifier CART. The average accuracy of PTSIJE-FS is larger than other six comparison methods on the datasets Heart, Sonar, Wine, and Wpbc, which are 82.22%, 75.96%, 91.57%, and 76.26%, respectively. Although the average accuracy of the feature subset selected by PTSIJE-FS on the dataset Credit is 0.95% lower than that of the feature subset selected by DMRA, PTSIJE-FS selects the fewer features for the dataset Credit.
In terms of time complexity, the time complexity of DMRA and IFGAS is \(O(m^{2}n)\) [27, 63], the time complexity of FPRA is O(mlogn) [61], the time complexity of FRFS is \(O(n^{2})\) [62], and the time complexity of PDJE-AR and FSNTDJE is O(mn) [45, 60]. Therefore, the rough ranking of the seven methods on times complexity is as follows: \(O(FRFS)<O(FPRA)<O(PDJE-AR)=O(FSNTDJE)=O(PTSIJE-FS)<O(DMRA)=O(IFGAS)\).
Under different classifiers and learning tasks, no one method always performs better than other methods. PTSIJE-FS shows superior classification performance and stability under the classifiers KNN and CART.
In summary, PTSIJE-FS can eliminate redundant features as a whole, and shows outstanding classification performance on UCI datasets.
Classification results of the gene expression datasets
This subsection illustrates the classification performance of the method PTSIJE-FS on high-dimensional gene expression datasets. PTSIJE-FS is compared with six existing feature selection methods: (1) the neighborhood tolerance dependency joint entropy-based feature selection method (FSNTDJE) [45], (2) the mutual information-based attribute reduction algorithm for knowledge reduction (MIBARK) [64], (3) the decision neighborhood entropy-based heuristic attribute reduction algorithm (DNEAR) [21], (4) the entropy gain-based gene selection algorithm (EGGS) [65], (5) EGGS [65] algorithm combined with Fisher Score (EGGS-FS) [66], and (6) the pessimistic neighborhood multi-granulation dependency joint entropy (PDJE-AR) [60].
The performance of seven feature selection methods is verified on the gene datasets DLBCL, Leukemia, Lung, MLL, and Prostate under tenfold cross-validation. Table 7 lists the average size of gene subsets selected by each feature selection method, where “Original” represents the original dataset and “-” denotes that we have not obtained the result of this method. Under the three classifiers KNN, CART, and C4.5, The optimal gene subsets selected by PTSIJE-FS method for five gene datasets under three classifiers KNN, CART, and C4.5 are demonstrated in Table 8 .
Table 7 reveals the average size of gene subsets selected by seven feature selection methods. PTSIJE-FS do select more genes for five gene datasets, and the average size of the gene subset selected by PTSIJE-FS is smaller than EGGS.
In the next part, according to the results of Tables 7 and 8 , PTSIJE-FS and related six feature selection methods are used to verify the average classification accuracy of gene subsets under the two classifiers KNN and C4.5, and the results are exhibited in Tables 9 and 10 .
From Tables 9 and 10, PTSIJE-FS displays the highest classification accuracy, expect for dataset Prostate under the C4.5 classifier. Especially on the datasets leukemia and MLL, the average classification accuracy of the gene subset selected by PTSIJE-FS is significantly higher than the other six feature selection methods under classifier KNN, and the average accuracy is increased by about 8%-42% and 10%-32%, respectively. As we have seen, the gene subsets selected by PTSIJE-FS show better classification performance on the gene datasets DLBCL, Leukemia, Lung, and MLL under classifier C4.5. There are 4%-39% gaps which obviously exist between PTSIJE-FS and FSNTDJE, MIKARK, DNEAR, EGGS, and EGGS-FS, only lower 0.76% than PDJE-AR. In general, under the classifiers KNN and C4.5, the mean classification accuracy of PTSIJE-FS is higher than the other six feature selection methods, and reach the highest level for five gene datasets.
In terms of time complexity, the time complexity of FSNTDJE, DNEAR, and PDJE-AR is O(mn) [21, 45, 60], the time complexity of MIBARK is \(O(m^{2})\) [64], and the time complexity of EGG and EGG-FS is \(O(m^{3}n)\) [65]. Therefore, the rough ranking of the seven methods on times complexity is as follows: \(O(MIBARK)<O(PDJE-AR)=O(DENAR)=O(FSNTDJE)=O(PTSIJE-FS)<O(EGG)=O(EGG-FS)\).
In summary, PTSIJE-FS can eliminate redundant features as a whole on five gene datasets, and shows better classification performance against the six related methods.
Statistical analysis
To systematically compare the statistical performance of classification accuracy of all methods, Friedman test and corresponding post-test will be employed in this subsection. The Friedman statistic [67] is expressed as
Here, \(r_i\) is the mean rank, and n and k represent the number of datasets and methods, respectively. F obeys the distribution with \(\left( {k - 1} \right) \) and \(\left( {k - 1} \right) \left( {n - 1} \right) \) degrees of freedom. For the six low-dimensional UCI datasets in Tables 5 and 6, PTSIJE-FS, FSNTDJE, DMRA, FPRA, FRFS, IFGAS, and PDJE-AR are employed to conduct the Friedman statistic. According to the classification accuracy obtained in Tables 5 and 6, the rankings of the seven feature selection methods under the classifiers KNN and CART are shown in Tables 11 and 12.
Calling icdf calculation in MATLAB 2016a, when \(\alpha \mathrm{{ = }}0.1\), F(6,30)=1.9803. Assuming that these seven methods are equivalent in classification performance, then the value of Friedman statistics will not exceed the critical value F(6,30). Otherwise, it is said that these seven methods have significant differences in feature selection performance. According to Friedman statistics, F=7.4605 for the classifier KNN and F=5.3738 for the classifier CART. Obviously, the F values under the classifiers KNN and CART are far greater than the critical value F(6,30), indicating that these seven methods are significantly different under the classifiers KNN and CART on six UCI datasets.
Subsequently, we need to perform post-testing on the differences between the seven methods. The post-hoc test used here is the Nemenyi test [68]. The statistics needs to determine the critical value of the mean distance between rankings, which is defined as
where \(q_a\) means a critical value. It is can be obtained that \(q_0.1\) =2.693 when the methods number is 7 and \(\alpha = 0.1\). Then, from formula (33), we can know that \({CD_{0.1}}\)=3.3588(k=7, n=6). According to Table 10, the distance between mean rankings of PTSIJE-FS to FSNTDJE, DMRA, FRFS, and IGFAS are 4.25, 4.25, 3.75, and 3.92, respectively, which are greater than 3.3588 for classifier KNN. In this case, Nemenyi test reveals that PSITE-FS is far superior to FSNTDJE, DMRA, FRFS, and IGFAS under the classifier KNN at \(\alpha = 0.1\). In the same way, from Table 11, the distances between mean rankings of PTSIJE-FS to FSNTDJE, FPRA, FRFS, and FSNTDJE are 4.17, 3.84, and 3.84, respectively, indicating that PSINTE-FS is significantly better than FSNTDJE, FPRA, and FRFS.
In the second part of this subsection, Friedman test is performed on the classification accuracy of the seven feature selection methods in Tables 9 and 10 under the classifiers KNN and C4.5. Tables 13 and 14, respectively, list the mean rankings of the seven methods under the classifiers KNN and C4.5.
After calculation, when \(\alpha = 0.1\), the critical value F(6, 24)=2.0351, F=8.2908 for the classifier KNN and F=3.4692 for the classifier C4.5. It is clear that above two values are both greater than the critical value F(6,24). It explains that these seven methods have significant differences on the classifiers KNN and C4.5 on the five gene datasets.
Next, Nemenyi test is performed on the classification accuracy of the seven feature selection methods in Tables 9 and 10 under the classifiers KNN and C4.5. It can be computed that \(C{D_{0.1}}\)=3.6793(k=7, n=5) when the number of methods is 7, and \(q_{0.1}\)=2.693. The distances between mean rankings of PTSIJE-FS to IBARK, DNEAR, EGGS under the classifier KNN are 4, 5.75, 4.25. This result demonstrates PTSIJE-FS is apparently better than IBARK, DNEAR, EGGS. The distance between mean rankings of PTSIJE-FS to DNEAR is 5.55 greater than the critical value, showing that PTSIJE-FS is far better than DNEAR under the classifier C4.5.
In a word, the PTSIJE-FS method is superior than the other corresponding methods through the Friedman statistic test.
Conclusion
NMRS model is an effectively tool to improve the classification performance in incomplete neighborhood decision systems. However, most feature evaluation functions based on NMRS only consider the information contained in the lower approximation. Such a construction method is likely to lead to the loss of some information. In fact, the upper approximation also contains some classification information that cannot be ignored. To solve this problem, we propose a feature selection model based on PTSIJE. First, from the algebra view, using the upper and lower approximations in NMRS and combining the concept of self-information, four types of neighborhood multi-granulation self-information measures are defined, and related properties are discussed in detail. The proof proves that the fourth neighborhood multi-granulation self-information measure is more sensitive and helps to select the optimal feature subset. Second, from the information views, the neighborhood tolerance joint entropy is given to analyze the redundancy and noise in the incomplete decision systems. Then, inspiring by both algebra and information view, combined with self-information measure and information entropy, a PTSIJE model is proposed to analyze the uncertainty of incomplete neighborhood decision systems. Finally, a heuristic forward feature selection method is designed and compared with other relevant methods. The experimental results show that our proposed method can select fewer features and have higher classification accuracy than related methods. In the future, we will not only focus on more efficient search strategies based on NMRS and self-information measures to achieve the best balance between classification accuracy and feature subset size, but also on constructing more general feature selection methods.
References
Asunción J, Juan MM, Salvador P (2021) A novel embedded min-max approach for feature selection in nonlinear Support Vector Machine classification. Eur J Oper Res 293(1):24–35
Miao JY, Ping Y, Chen ZS, Jin XB, Li PJ, Niu LF (2021) Unsupervised feature selection by non-convex regularized self-representation. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2021.114643
Lang GM, Li QG, Cai MJ, Yang T, Xiao QM (2017) Incremental approaches to knowledge reduction based on characteristic matrices. Int J Mach Learn Cybern 8:203–222
Zhang XH, Bo CX, Smarandache F, Dai J (2018) New inclusion relation of neutrosophic sets with application and related lattice structure. Int J Mach Learn Cybern 9:1783–1763
Xu JC, Shen KL, Sun L (2022) Multi-Label feature selection based on fuzzy neighborhood rough sets. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00636-y
Gao C, Lai ZH, Zhou J, Zhao CR, Miao DQ (2018) Maximum decision entropy-based attribute reduction in decision-theoretic rough set model. Knowl-Based Syst 143:179–191
Huang QQ, Li T, Huang YY, Yang X (2020) Incremental three-way neighborhood approach for dynamic incomplete hybrid data. Inf Sci 541:98–122
Shen HT, Zhu Y, Zheng W, Zhu X (2020) Half-Quadratic minimization for unsupervised feature selection on incomplete data. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2020.3009632
Xie XJ, Qin XL (2017) A novel incremental attribute reduction approach for dynamic incomplete decision systems. Int J Approx Reason 93:443–462
Dong HB, Li T, Ding R, Sun J (2018) A novel hybrid genetic algorithm with granular information for feature selection and optimization. Appl Soft Comput 65:33–46
Thabtah F, Kamalov F, Hammoud S, Shahamiri SR (2020) Least Loss: A simplified filter method for feature selection. Inf Sci 534:1–15
Zhang CC, Dai JH, Chen JL (2020) Knowledge granularity based incremental attribute reduction for incomplete decision systems. Int J Mach Learn Cybern 11:1141–1157
Fu J, Dong J, Zhao F (2020) A deep learning reconstruction framework for differential phase-contrast computed tomography with incomplete data. IEEE Trans Image Process 29:2190–2202
Tran CT, Zhang MJ, Andreae P, Xue B, Bui LT (2018) Improving performance of classification on incomplete data using feature selection and clustering. Appl Soft Comput 73:848–861
Yang W, Shi Y, Gao Y, Wang L, Yang M (2018) Incomplete-data oriented multiview dimension reduction via sparse low-rank representation. IEEE Transactions on Neural Networks and Learning Systems 29(12):6276–6291
Ding WP, Lin CT, Cao ZH (2019) Deep neuro-cognitive co-evolution for fuzzy attribute reduction by quantum leaping PSO with nearest-neighbor memeplexes. IEEE Trans Cybern 49(7):2744–2757
Wu CH, Li WJ (2021) Enhancing intrusion detection with feature selection and neural network. Int J Intell Syst. https://doi.org/10.1002/int.22397
Ding WP, Lin CT, Cao ZH (2019) Shared nearest neighbor quantum game-based attribute reduction with hierarchical co-evolutionary spark and its consistent segmentation application in neonatal cerebral cortical surfaces. IEEE Trans Neural Netw Learn Syst 30(7):2013–2027
Wang CZ, Huang Y, Shao MW, Fan XD (2019) Fuzzy rough set-based attribute reduction using distance measures. Knowl-Based Syst 164:205–212
Chen HM, Li TR, Fan X, Luo C (2019) Feature selection for imbalanced data based on neighborhood rough sets. Inf Sci 483:1–20
Sun L, Zhang XY, Qian YH, Xu JC, Zhang SG (2019) Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Inf Sci 502:18–41
Wang CZ, Huang Y, Ding WP, Cao ZH (2021) Attribute reduction with fuzzy rough self-information measures. Inf Sci 549:68–86
Hudec M, Mináriková E, Mesiar R, Saranti A, Holzinger A (2022) Classification by ordinal sums of conjunctive and disjunctive functions for explainable AI and interpretable machine learning solutions. Knowl-Based Syst 2:106916
Zhang J, Lu G, Li JQ, Li CW (2021) An ensemble classification method for high-dimensional data using neighborhood rough set. Complexity. https://doi.org/10.1155/2021/8358921
Chu XL, Sun BZ, Chu XD, Wu JQ, Han KY, Zhang Y, Huang QC (2022) Multi-granularity dominance rough concept attribute reduction over hybrid information systems and its application in clinical decision-making. Inf Sci 597:274–299
Hu QH, Zhao H, Yu DR (2008) Efficient symbolic and numerical attribute reduction with neighborhood rough sets. Moshi Shibie Yu Rengong Zhineng/pattern Recogn Artif Intell 21(6):732–738
Huang YY, Guo KJ, Yi XW, Li Z, Li TR (2022) Matrix representation of the conditional entropy for incremental feature selection on multi-source data. Inf Sci 591:263–286
Wang CZ, Hu QH, Wang XZ, Chen DG, Qian YH, Dong Z (2018) Feature selection based on neighborhood discrimination index. IEEE Trans Neural Netw Learn Syst 29(7):2986–2999
Mohamed AE, Abu-Donia Hassan M, Rodyna AH, Saeed LH, Rehab AL (2022) Improved evolutionary-based feature selection technique using extension of knowledge based on the rough approximations. Inf Sci 594:76–94
Yang J, Wang GY, Zhang QH, Wang HM (2020) Knowledge distance measure for the multigranularity rough approximations of a fuzzy concept. IEEE Trans Fuzzy Syst 28(4):706–717
Gao Y, Chen XJ, Yang XB, Mi JS (2019) Ensemble-based neighborhood attribute reduction: a multigranularity view. Complexity 2019:1–17
Li JH, Huang CC, Qi JJ, Qian YH, Liu WQ (2017) Three-way cognitive concept learning via multi-granularity. Inf Sci 378:244–263
Hu M, Tsang ECC, Guo YT, Chen DG, Xu WH (2021) A novel approach to attribute reduction based on weighted neighborhood rough sets. Knowl-Based Syst. https://doi.org/10.1016/j.knosys.2021.106908
Yang S, Zhang H, Baets BD, Jah M, Shi G (2021) Quantitative dominance-based neighborhood rough sets via fuzzy preference relations. IEEE Trans Fuzzy Syst 29(3):515–529
Qian YH, Li SY, Liang JY, Shi ZZ, Wang F (2014) Pessimistic rough set-based decisions: a multi-granulation fusion strategy. Inf Sci 264(20):196–210
Lin GP, Qian YH, Li JJ (2012) NMGRS: neighborhood-based multi-granulation rough sets. Int J Approx Reason 53(7):1080–1093
Sun L, Wang LY, Ding WP, Qian YH, Xu JC (2021) Feature selection using fuzzy neighborhood entropy-based uncertainty measures for fuzzy neighborhood multigranulation rough sets. IEEE Trans Fuzzy Syst 29(1):19–33
Ma FM, Chen JW, Zhang TF (2017) Quick attribute reduction algorithm for neighborhood multi-granulation rough set based on double granulate criterion. Kongzhi yu Juece/Control Decis 32(6):1121–1127
Hu CX, Zhang L, Wang BJ, Zhang Z, Li FZ (2018) Incremental updating knowledge in neighborhood multigranulation rough sets under dynamic granular structures. Knowl-Based Syst 163:811–829
Luo GZ, Qian JL (2019) Neighborhood multi-granulation rough set based on multi-threshold for variable precision decisions. Appl Res Comput 2:2
Lang GM, Cai MJ, Fujita H, Xiao QM (2018) Related families-based attribute reduction of dynamic covering decision information systems. Knowl-Based Syst 163:161–173
Zhao H, Qin KY (2014) Mixed feature selection in incomplete decision table. Knowl-Based Syst 57:181–190
Qian YH, Liang JY, Dang CY (2010) Incomplete multigranulation rough set. IEEE Trans Syst Man Cybern Part A Syst Hum 40(2):420–431
Yang L, Zhang XY, Xu WH, Sang BB (2019) Multi-granulation rough sets and uncertainty measurement for multi-source fuzzy information system. Int J Fuzzy Syst 21:1919–1937
Sun L, Wang LY, Qian YH, Xu JC, Zhang SG (2019) Feature selection using Lebesgue and entropy measures for incomplete neighborhood decision systems. Knowl Based Syst 2:104942
Zhang XY, Yang JL, Tang LY (2020) Three-way class-specific attribute reducts from the information viewpoint. Inf Sci 507:840–872
Wang CZ, Wang Y, Shao MW, Qian YH, Chen DG (2020) Fuzzy rough attribute reduction for categorical data. IEEE Trans Fuzzy Syst 28(5):818–830
You XY, Li JJ, Wang HK (2019) Relative reduction of neighborhood-covering pessimistic multigranulation rough set based on evidence theory. Information (Switzerland). https://doi.org/10.3390/info10110334
Zhang J, Zhang XY, Xu WH, Wu YX (2019) Local multi-granulation decision-theoretic rough set in ordered information systems. Soft Comput 23:13247–13291
Fan XD, Zhao WD, Wang CZ, Huang Y (2018) Attribute reduction based on max-decision neighborhood rough set model. Knowl-Based Syst 151:16–23
Xu JC, Wang Y, Xu KQ, Zhang TL (2019) Feature genes selection using fuzzy rough uncertainty metric for tumor diagnosis. Comput Math Methods Med. https://doi.org/10.1155/2019/6705648
Zeng K, She K, Xiu XZ (2013) Multi-granulation entropy and its applications. Entropy 15(6):2288–2302
Feng T, Fan HT, Mi JS (2017) Uncertainty and reduction of variable precision multi-granulation fuzzy rough sets based on three-way decisions. Int J Approx Reason 85:36–58
Wang GY (2003) Rough reduction in algebra view and information view. Int J Intell Syst 18(6):679–688
Xu JC, Wang Y, Mu HY, Huang FZ (2019) Feature genes selection based on fuzzy neighborhood conditional entropy. J Intell Fuzzy Syst 36(1):117–126
Zhang X, Mei CL, Chen DG, Yang YY, Li JH (2020) Active incremental feature selection using a fuzzy-rough-set-based information entropy. IEEE Trans Fuzzy Syst 28(5):901–915
Chen YM, Wu KS, Chen XH, Tang CH, Zhu QX (2014) An entropy-based uncertainty measurement approach in neighborhood systems. Inf Sci 279:239–250
Xu JC, Yuan M, Ma YY (2022) Feature selection using self-information and entropy-based uncertainty measure for fuzzy neighborhood rough set. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00356-3
Shannon CE (2001) A mathematical theory of communication. Bell Syst Tech J 5(3):3–55
Sun L, Wang LY, Ding WP, Qian YH, Xu JC (2020) Neighborhood multi-granulation rough sets-based attribute reduction using Lebesgue and entropy measures in incomplete neighborhood decision systems. Knowl-Based Syst 2:105373
Qian YH, Wang Q, Cheng HH, Liang JY, Dang CY (2015) Fuzzy-rough feature selection accelerator. Fuzzy Sets Syst 258:61–78
Jensen R, Shen Q (2009) New approaches to fuzzy-rough feature selection. IEEE Trans Fuzzy Syst 17(4):824–838
Tan AH, Wu WZ, Qian YH, Liang JY, Chen JK, Li JJ (2019) Intuitionistic fuzzy rough set-based granular structures and attribute subset selection. IEEE Trans Fuzzy Syst 27(3):527–539
Xu FF, Miao DQ, Wei L (2009) Fuzzy-rough attribute reduction via mutual information with an application to cancer classification. Comput Math Appl 57(6):1010–1017
Chen YM, Zhang ZJ, Zheng JZ, Ma Y, Xue Y (2017) Gene selection for tumor classification using neighborhood rough sets and entropy measures. J Biomed Inform 67:59–68
Saqlain SM, Sher M, Shah FA, Khan I, Ashraf MU, Awais M, Ghani A (2019) Fisher score and Matthews correlation coefficient-based feature subset selection for heart disease diagnosis using support vector machines. Knowl Inf Syst 58:139–167
Friedman M (1940) A comparison of alternative tests of significance for the problem of rankings. Ann Math Stat 11:86–92
Demsar J, Schuurmans D (2006) Statistical comparison of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Wang TH (2018) Kernel learning and optimization with Hilbert-Schmidt independence criterion. Int J Mach Learn Cybern 9:1707–1717
Li WW, Huang ZQ, Jia XY, Cai XY (2016) Neighborhood based decision-theoretic rough set models. Int J Approx Reason 69:1–17
Faris H, Mafarja MM, Heidari AA, Alijarah I, Zoubi AMA, Mirjalili S, Fujita H (2018) An efficient binary Salp Swarm Algorithm with crossover scheme for feature selection problems. Knowl-Based Syst 154:43–67
Chen YM, Zeng ZQ, Lu JW (2017) Neighborhood rough set reduction with fish swarm algorithm. Soft Comput 21:6907–6918
Mu HY, Xu JC, Wang Y, Sun L (2018) Feature genes selection using Fisher transformation method. J Intell Fuzzy Syst 34(6):4291–4300
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant 61976082, 62076089, 62002103, and in part by the Key Scientific Research Project of Henan Provincial Higher Education under Grant 22B520013, and in part by the Key Scientific and Technological Project of Henan Province under Grant 222102210169.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, M., Xu, J., Li, T. et al. Feature selection based on self-information and entropy measures for incomplete neighborhood decision systems. Complex Intell. Syst. 9, 1773–1790 (2023). https://doi.org/10.1007/s40747-022-00882-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00882-8