
Abstract
Small object tracking in infrared images is widely utilized in various fields, such as video surveillance, infrared guidance, and unmanned aerial vehicle monitoring. The existing small target detection strategies in infrared images suffer from submerging the target in heavy cluttered infrared (IR) maritime images. To overcome this issue, we use the original image and the corresponding encoded image to apply our model. We use the local directional number patterns algorithm to encode the original image to represent more unique details. Our model is able to learn more informative and unique features from the original and encoded image for visual tracking. In this study, we explore the best convolutional filters to obtain the best possible visual tracking results by finding those inactive to the backgrounds while active in the target region. To this end, the attention mechanism for the feature extracting framework is investigated comprising a scale-sensitive feature generation component and a discriminative feature generation module based on the gradients of regression and scoring losses. Comprehensive experiments have demonstrated that our pipeline obtains competitive results compared to recently published papers.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Visual tracking can be considered as the ability to look at something and follow its movement. Visual tracking in videos that learns to estimate the locations of a target object has been broadly employed for several applications, such as infrared search and track (IRST) system (or infra-red sighting and tracking), video surveillance, autonomous driving, and human motion analysis [1, 2]. However, due to the long observation distance in the infrared image, the target has a low signal-to-noise ratio (SNR) and a small size leading to obtain limited information for tracking [3, 4].
Moreover, under a range of environmental conditions make infrared small target tracking even more difficult. It mostly comprises some concrete scenes such as intense noise, low contrast, competing for background clutter, and camera ego-motion, and so on. For instance, the camera ego-motion leads to the happening of an impulsive motion of the target between two sequential frames, which simply causes to miss the target. Also, as small objects in infrared images can be simply submerged in a complex background with a low signal-to-clutter ratio (SCR), it makes the tracker drift to the background. The intense noise and low value of the contrast can lead to a drop in target SNR. Besides, because of the long imaging distance, small targets have no concrete texture and shape. Hence, robust and accurate small object tracking in infrared images remains a challenging task in crowded scenes [5, 6]. Several models that try to track small targets in infrared images efficiently have been implemented in the literature. Although many researches have been conducted using visible cameras, due to their high dependency on the illumination condition, these cameras are not good options for the night-time environment. So, to overcome this issue, we employ an infrared imaging system that is more robust to illumination variations and is able to work well in night-time and day-time [7].
In the last few years, deep learning (DL) pipelines have reached better classification and prediction results compared to the state-of-the-art performance in the different fields of computer vision tasks [8,9,10,11,12,13]. However, there are only some DL strategies to track objects in the infrared images, and their efficiency is not as competitive as the algorithms based on hand-crafted features. Moreover, they are unable to detect and track objects with variation both in size and shape effectively. So, in this paper, we suggest a small object tracking approach using infrared images which uses a deep learning model that is able to track even small objects at the presence of size and shape variations. As each texture includes many textural information that are crucial when dealing with a real scene, we apply a textural descriptor approach to explore key features. The employed textural descriptor is an illumination-invariant technique that is very beneficial for tracking tasks. Moreover, we propose a deep learning model which accept both original image and image obtained by textural descriptor method (encoded image). Our DL model includes target attention mechanism and size attention mechanism. The attention mechanism means one or more features are more important than others and we need to pay more attention on them.
The remaining parts of this paper are organized as follows. Firstly, related works are discussed in “Literature review”. The characteristics and architecture of the suggested model are presented in “Materials and methods”. “Experiments” describes the implementation details of the suggested model. “Conclusions” provides conclusions.
Literature review
A small target tracking technique infrared images based on Kalman filter and multiple cues fusion is proposed to overcome the problem of complex environmental conditions in [1]. In the first step, they employed the Kalman filter to estimate the preliminary target position that is considered as the center of the region of interest (ROI). Next, the motion, contrast, and grey color cues in the ROI are investigated to produce the confidence map to locate the small target. Finally, the target models and the fusion weights are updated, and the predicted target position can be considered as a measurement of the Kalman filter. A robust maritime dim small target detection scheme to overcome the problem of submerging weak targets in heavy cluttered infrared (IR) maritime images introduced in [14]. They enhanced the quality of employing images by the multidirectional improved top-hat filter. Also, they established directional morphological filtering (DMF) by incorporating morphological operations and constructed multidirectional structuring elements (MSEs) to explore the multidirectional differences between target area and local proximate objects.
A learning discriminative prediction model was proposed in [15] which is capable of fully investigating the background and target appearance information. Firstly, a steepest descent-based technique is employed that calculates an optimal step length in each iteration. Then, a module that efficiently initializes the target model is integrated. Zhang et al. [16] suggested an RGB-infrared fusion tracking strategy using visible and infrared images. To this end, a fully convolutional network based on the Siamese Networks (SiamFT) was suggested. In the first step, infrared and visible images are processed by an infrared network and a visible network. Next, to form fused template image, convolutional features of infrared and visible images explored from two Siamese Networks are merged. A modality weight calculation technique using the response value of Siamese network is employed for estimating the reliability of dissimilar images. Finally, a cross-relation approach is used to create the final response map.
An improvement of a fully convolutional neural network (FCNN) to estimate object location was proposed in [17]. Their strategy uses a comprehensive sampling technique as well as better scoring scheme. The possible object positions are computed using a two-stage sampling that combines clustered foreground contour information and stochastically distributed samples. The best sample is chosen based on a combined score of model reliability, predicted location, and appearance similarity. Yang et al. [18] proposed a tracking system using a correlation filter (CF) tracker strategy. Moreover, a Gabor filter (GF) feature extractor is used in the frequency domain (GF-KCF). By constructing a set of frequency-domain GFs, the suggested method tries to suppress background noise effectively and highlight target texture information. Yao et al. [19] suggested a Siamese network for tracking task that using a dilated convolution module for enhancing scales adaptability of network. To diminish the dependence of the model on the initially given exemplar, they used a target template library update technique based on the tracking outcomes of historical frames.
Materials and methods
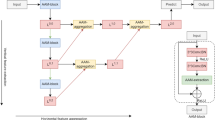
As infrared images take from a long distance, the target signals include insufficient texture information. Besides, the complex background clutters such as sea clutter, sea-sky line, forest, mountains, island, and cloud clutter are usually changeable, which diminishes the efficiency of a tracking model. So, in this section, we describe the importance of the textural features when we are dealing with a complex background while a small object needs to be tracked. Moreover, we propose a new deep learning pipeline that uses two attention mechanisms for a size-invariant and target tracking model. The proposed strategy to detect and estimate an object in infrared images is displayed in Fig. 4.
Texture descriptor
Textural analysis of any kinds of images endeavors to explore some key informative details and characterizations of a surface texture such as entropy, contrast, shapes correlation, smoothness, energy, homogeneity contrast, roughness, and colors [13, 20, 21]. As introduced in many works [22, 23], several kinds of local descriptors are employed to represent an image into an encoded image based on the code-book of visual patterns or some pre-defined coding rules.
These strategies have a wide range of usage in many fields of research like object tracking [24], image segmentation [13, 25,26,27], and aerial image analysis [28, 29]. Generally, in texture segmentation and classification, the main aim is to split the image into a set of homogeneous textured segments [30].
Local binary pattern (LBP), local directional pattern (LDP), and local ternary patterns (LTP) feature descriptors can be easily implemented and are influenced by varying the pixel intensity of nearest-neighbor (rectangular, circular, etc. neighborhood) in clockwise or counter-clockwise to encode (altering) the low-level information of a curve, line, edges, and spot inside an image and generate the result as a binary value [31,32,33].
As in encoding applications, the gradient value shows more robustness compared to a graylevel intensity. Some strategies based on the gradient value such as local directional number patterns (LDN) and local word directional pattern (LWDP) have attained much attention [34]. The LDN is used in the gradient domain for generating an illumination-invariant representation of the image. The LDN utilizes directional information for investigating the location of all edges that their magnitudes are insensitive to lighting variations.
This is implemented by operating the 8 directions Kirsch kernels (filters) that are rotated by 45° in the 8 main compass directions (Fig. 1). Each kernel generates a feature map and only the maximum value in each location is chosen to obtain a final edge map [35, 36]. An example of employing the non-linear kirsch kernel to an infrared image is indicated in Fig. 2.

Non-linear Kirsch kernels in 8 rotations [37]

The result of applying Kirsch kernels to an image
The LDN algorithm is defined by
As Eq. 1 demonstrates, pixel \(\left( {{\text{cpx}},{\text{cpy}}} \right)\) implies the medial pixel of a neighborhood, while \({\text{nr}}\) is defined as the minimum negative replication and \({\text{pr}}\) states the maximum positive response [38]. The result of applying the LDN approach to some images is indicated in Fig. 3.

The result of applying the LDN approach to some images
Our deep learning model
In this part, we explain how our model is able to learn more informative and unique features from the original and encoded image for visual tracking. In the first step, the gap between the obtained features from a pre-trained convolutional neural network (CNN) and efficient representations of best features for visual tracking is introduced. Formerly, the attention mechanism for feature extracting framework is investigated comprising a scale-sensitive feature generation component and a discriminative feature generation module based on the gradients of regression and scoring losses. Our pipeline is displayed in Fig. 4.

Schematic of our framework for target detection and tracking in infrared images
Target attention mechanism
There are many differences between the extracted features’ aims to track a predefined object tracking and the visual recognition of a general target. Firstly, most of the features extracted by a pre-trained CNN are uninformative and do not cover all key details about general objects. This means for a predefined object tracking task, the class labels for testing and training samples are consistent and pre-defined, whereas in an online object tracking system (general purposes) there are countless number of classes. Secondly, all trained weights and biases in a pre-trained CNN model aim to increase difference between inter classes and cannot able to deal with the variation in intra-classes properly. This is due to encountering of some insignificant features among all features to predict the happening of scale variations and distinguishing the aimed objects among some much similar objects. Lastly, as differences among inter-classes are principally related to some feature maps, all extracted features using a trained deep learning model are sparsely activated using each class annotation. Moreover, some significant parts of applying convolution kernels (filters) results in detecting uninformative details and redundancy leading to overfitting and a high computational load. Accordingly, only some convolutional kernels are able to detect some patterns related to the target object.
Many strategies in the field of image processing that use convolution kernels imply the significant role of convolutional kernels to recognize hidden patterns inside the image. This group-level object information is calculated through the corresponding gradients [2, 39,40,41,42,43,44].
Recently, a gradient-weighted class activation mapping (Grad-CAM) model was proposed by [2] to produce a highlighted feature map by calculating a sum of weighted neurons along the feature channels. This strategy acts by calculating the gradient at each input pixel which demonstrates the corresponding importance belonging to given class annotation. In other words, by computing the mean pooling of all the gradients in entire the channel, the weight of a feature channel is produced. Different from the gradient-based models employing classification losses, a ranking loss and a regression loss has been used in our study. Our strategy is specifically designed for the tracking task to recognize the best convolutional kernels contributing to detecting the pattern of targets and is sensitive to scale variations.
Using the gradient-based strategy, in this study a target attention mechanism with losses has been implemented designed for visual tracking. Given a CNN employing for extracting features has the output feature map \(\Gamma \), a subspace \(\zeta \) is computed using the channel importance \(\varpi \) as
where \({\psi }_{1}\) and \({\psi }_{2}\) are selecting function to choose the key channels for image1 and image2, respectively. The score of the i-th channel \({\varpi }_{{1}_{i}}\) and \({\varpi }_{{2}_{i}}\) can be calculated by
where \({\text{Filter}}_{i}\) demonstrates the output of ith filter and Loss indicates the loss function.
In this study, we explore the best convolutional filters to obtain best possible visual tracking results by finding those inactive to the backgrounds while active to the target region. This means, in the training process using a loss function, the best possible values for weights and biases are found. These weights and biases learned how to respond to the backgrounds and target region. So, a regression approach is employed to explore all the \({\mathrm{pixels}}_{i,j}\) inside the image patch aligned with the center of the target center for obtaining a Gaussian label map by
where \(\left(i,j\right)\) demonstrates the difference in distance with the target and \(\sigma \) stands for the dimension of filter (width). Moreover, to overcome the problem of computing time a ridge regression loss is employed to formulate the issue by
where W indicates the weight of regressor and ∗ implies the convolution operation. The importance of each kernel is calculated based on the derivation of \({\mathrm{Loss}}_{\mathrm{regression}}\) with respect to the input feature \({\mathrm{pixels}}_{\mathrm{input}}\) \(\mathrm{and}\) its contribution to fitting the label map. By considering Eq. 4 and the chain rule, the gradient of the \({\mathrm{Loss}}_{\mathrm{regression}}\) can be calculated by
According to Eq. 3 and the gradient of the regression loss, the target-active kernels can be defined which are able to distinguish between the background and the target. These produced features by employing the gradient strategy are able to select only some kernels to produce more discriminative deep features to focus on the specified target. This strategy leads to eliminating many uninformative parts of the image and overcoming the problem of over-fitting. In other words, when we remove much informative parts of the image, we eliminate many uninformative features from the training feature vectors. So, the rate of unbalancing data will dramatically be decreased and lead to overcoming the problem of over-fitting.
Size attention mechanism
To increase the target detection robustness against strong occlusion and noises, it is essential to find some robust kernels that are able to detect the variation size of the target. As due to non-continuous change rate of the target’s size, it is not an easy task to find the size of the object in each frame precisely. But by using the proposed network to find a paired sample we can estimate the closest size variation. So, by formulating the issue as a scoring model and finding and scoring the size of all possible target size, we are able to select the higher score as the target size. The obtained gradients from the score loss demonstrate which kernels are more sensitive to size variations.
Inspired by [45] we investigate a smooth approximation of the scoring loss function by
where \(\left( {{\text{sample}}_{i} ,{\text{sample}}_{j} } \right)\) are pair-wise samples for the training phase and \(\phi\) demonstrates the set of training pairs. As suggested in [45], we compute the derivation of \({\text{Loss}}_{{\text{size score}}}\) with respect to \(f\left( {{\text{sample}}} \right)\) by
where \(\Delta h_{i,j} = h_{i} - h_{j}\) and \(h_{i}\) demonstrates a one-hot vector with zero values while the ith position indicates 1 value. By employing the backpropagation strategy, the gradients scoring loss can be calculated as
where \({\text{sample}}_{{{\text{predicted}}}}\) indicates the output estimation, W implies the filter weights of a Conv layer. According to Eq. 3 and the gradient of the scoring loss, the size-sensitive kernels can be defined. By combining the scoring losses and regression, we are able to detect the kernels that are both sensitive to size variation and active to the target.
Tracking process
The overall pipeline our suggested tracker is demonstrated in Fig. 4. There are two main reasons for integrating the target attention mechanism and feature extraction routes. Firstly, feature extraction routes consider both significant features extracted from original and encoded image which significantly highlight the key details of the target. Secondly, by decreasing the searching area inside the image, the proposed model is able to perform the tracking task efficiently.
Our tracking pipeline includes a target attention mechanism, a pre-trained feature extractor, and a matching block. We only use a pre-trained feature extractor for training the network on the classification task with offline training strategy. Moreover, the target attention mechanism can be employed in the training process in the first frame.
In initial training (offline step), the scoring and regression loss functions are trained independently. Next, once the models are converged, gradients from each loss are computed. By computing these gradients from the pre-trained networks, only those kernels with highest importance scores are chosen to obtain the best possible outcomes.
When we are dealing with an input video (sequential frames) in online finding target, the likelihood scores between the search area inside the image and the initial target in the current frame is directly computed employing the target attention mechanism. This step can be conducted by applying a convolution layer to the extracted output for obtaining a response map. All values in the response map implies the rate of correctness of the real target. Given the exploration area in the existing frame \({h}_{t}\) and the initial target \({\mathrm{sample}}_{1}\), we can predict the position of the target in frame t as
where * implies the convolution operation.
Experiments
Dataset and implementation details
In this study, training, validation, and testing of the suggested strategy have been accomplished on the Dim-small target detection and tracking dataset [46]. This dataset, made by the ATR laboratory of National University of Defense Technology, comprises 22 image sequences, 30 trajectories, 16,944 targets and 16,177 frames. The aim of this dataset is to detect and track of low altitude flying target and the data acquisition scenario covers complex field background and sky background. Figure 5 demonstrates some sample from the dataset. Our pipeline is implemented in Matlab with the MatConvNet toolbox [47] on a PC with a GTX-1080 GPU, core i7 3.6 GHz CPU, over CUDA 9.0, CuDNN 5.1, and 16G memory.

Some examples from the employing dataset
Assessment metrics
The effectiveness of the suggested pipeline is evaluated using the three criteria, namely Sensitivity, Accuracy, and Specificity. Specificity is the measure of non-target that has been estimated appropriately (actual negative rate). Sensitivity is the measure of targets that have been appropriately recognized (True positive rate or Recall). Accuracy is employed as the assessment metric for computing the overlap between the ground truths and the estimated targets [9, 13, 48]. These three criteria are computed by:
where False Negative (FN) implies those objects, which do not cover the target and are classified as the target. While False Positive (FP) states those targets incorrectly predicted by our suggested tracking pipeline. Lastly, True Positive (TP) represents the number of targets over the entire frames that are correctly classified as the targets by the proposes technique. In many cases, higher values of the sensitivity can show lower specificity values. The higher the values for specificity and sensitivity, the better the performance of the pipeline [12, 49, 50].
Experimental results and discussions
We use the VGG-16 model [51] as the base network for increasing in the number of layers with smaller kernels that leads to increasing in non-linearity (a positive in deep learning). The Adaptive Moment Estimation (Adam) is utilized to the train the model, with an initial learning rate 10–4, a batch size 70, the maximum iteration 70, and weight decay 10–5. To obtain more robust and accurate spatial information, the outputs of the Conv4-1 and Conv4-3 layers are employed as the base deep features. Also, the top 80 significant kernels from the Conv4-1 layers to learn the score-sensitive features and the top 250 significant kernels from the Conv4-3 layers to learn the target-active features are selected.
To have a clear understanding and for qualitative and quantitative comparison purposes, we also implemented eight other pipelines (Single Shot MultiBox Detector (SSD) [52], Target-aware [3], Discriminative Model [15], Directional morphological filtering (DMF) [14], Kalman filter [1], GF-KCF [18], Siamese network [19] and Grad-CAM [2]) for evaluating the suggested infrared searching and tracking target performance. The SSD [52] strategy uses an Adaptive Pipeline Filter (APF) using the motion information and temporal correlation. The DMF [14] algorithm is based on multidirectional morphological filtering and spatiotemporal cues. The Kalman filter [1] strategy is employed to estimate the preliminary target position that is considered as the center of the region of interest (ROI). The discriminative Model [15] is capable of fully investigating the background and target appearance information. So, this model employs the steepest descent-based technique that calculates an optimal step length in each iteration. Then, a module that efficiently initializes the target model is integrated.
The Accuracy, Specificity, and Sensitivity values of all frames employing all mentioned frameworks are described in Table 1. For each index in Table 1, the highest Accuracy, Specificity, and Sensitivity values are highlighted in bold. Notice that when employing the DMF [14] and Target-aware [3], accuracy values were enhanced in comparison to other mentioned networks, but the values of sensitivity using Siamese network [19] and SSD [52] is still higher. Moreover, there is a minimum difference between the values of Specificity employing DMF [14] and Kalman filter [1] and the values of Sensitivity using DMF [14] and Target-aware [3]. The Grad-CAM [2] gains the worst outcomes for all three measures.
Moreover, it is clear that DMF [14], SSD [52], GF-KCF [18], Siamese network [19] and Target-aware [3] models are more stable than the Grad-CAM [2], Discriminative Model [15], and Kalman filter [1]. For Grad-CAM [2], all metrics are less than the other models and it suffer from overfitting. The gap between the value of accuracies by utilizing DMF [14], SSD [52], and Target-aware [3] models for tracking tasks equals zero which is relatively smaller than this gap when employing Grad-CAM [2] and Discriminative Model [15]. The specificity value of the SSD [52] is better than all other techniques with 0.89. Also, using only the original image by our model obtains an unacceptable result, but its performance is still higher than Discriminative Model [15]. Moreover, using only an encoded image as the input image to feed the network obtains the worst results among all compared methods.
From Table 1, it is recognizable that the suggested pipeline obtained the highest criterion values for recognizing and tracking targets than those obtained by all eight other models. This enhancement is because of: firstly, the suggested pipeline pays special attention to finding important parts of image rather than investigate all areas inside the image. Secondly, our framework explores the changing size of the target before it happens in the next frame. Lastly, by encoding the original image into a new image, we can find more informative details. Moreover, our strategy can analyze all frames more rapidly than other approaches. Also, there is a minimum difference between the evaluating time of some videos employing Grad-CAM [2], SSD [52], and Discriminative Model [15].
Figure 6 indicates a visual demonstration of the good outcomes attained by the proposed framework on the Dim-small target detection and tracking dataset. As indicated, due to employing the target attention mechanism, the difference between the value of target and background inside the images is increased and the border between them is recognized with a high rate of accuracy. Also, using the size attention mechanism make our pipeline more robust to track the target when varying size occurs. But it is not true when we are dealing some targets with varying size at the same time. Moreover, owing to the use of the LDN encoding approach, the suggested tracking framework can explore more unique contextual information from the target and background which leads to better tracking outcomes. The analysis of our attention-based mechanism CNN model is indicated employing epoch versus loss in Fig. 7. Although our technique provides outstanding outcomes compared to the other recently published frameworks, the suggested strategy still has limitations when encountering changing size of multi-targets at the same time. This is due to an increase in the size of the target’s expected region which leads to decreasing performance in the feature exploration.

The results of target tracking in infrared images using our framework in different frames in two streams

The analysis of the suggested network using epoch versus loss
Conclusions
In this paper, a novel target detection and tracking in infrared images has been developed that benefits from the characterization of an original image and an encoded image. It means that each image has unique and informative characteristics to aid the framework efficiently even if varying size effects are present. We introduced a target attention mechanism which is able to highlight only significant part of the image to work on it. Moreover, we have described that working only on a part of the image including potential target area allows our network to reach performance close to human observers. This leads to decreasing computational burden of the model and capability to make estimations faster as it eliminates some uninformative parts of the image. Comprehensive experiments have been conducted, which indicate the effectiveness of the suggested framework by the comparison with the state-of-the-art models.
Availability of data and materials
The dataset used in this study can be obtained from the corresponding author on reasonable request.
Abbreviations
- UAV:
-
Unmanned aerial vehicle
- IR:
-
Infrared
- IRST:
-
Infrared search and track
- SNR:
-
Signal-to-noise ratio
- SCR:
-
Signal-to-clutter ratio
- DL:
-
Deep learning
- ROI:
-
Region of interest
- DMF:
-
Directional morphological filtering
- MSEs:
-
Multidirectional structuring elements
- LBP:
-
Local binary pattern
- LDP:
-
Local directional pattern
- LTP:
-
Local ternary pattern
- LDN:
-
Local directional number
- LWDP:
-
Local word directional pattern
- CNN:
-
Convolutional neural network
- Grad-CAM:
-
Gradient-weighted class activation mapping
- FN:
-
False negative
- FP:
-
False positive
- TP:
-
True positive
- FN:
-
False negative
- SSD:
-
Single shot detector
References
Xiao S, Ma Y, Fan F, Huang J, Wu M (2020) Tracking small targets in infrared image sequences under complex environmental conditions. Infrared Phys Technol 104:103102. https://doi.org/10.1016/J.INFRARED.2019.103102
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2017) Grad-CAM: visual explanations from deep networks via gradient-based localization, pp 618–626 [Online]. http://gradcam.cloudcv.org. Accessed 22 Oct 2021
Li X, Ma C, Wu B, He Z, Yang M-H (2019) Target-aware deep tracking. Proc IEEE/CVF Conf, Computer vision and pattern recognition (CVPR), pp 1369–1378. https://doi.org/10.48550/arXiv.1904.01772, arXiv:1904.01772
Sun Y, Yang J, An W (2021) Infrared dim and small target detection via multiple subspace learning and spatial-temporal patch-tensor model. IEEE Trans Geosci Remote Sens 59(5):3737–3752. https://doi.org/10.1109/TGRS.2020.3022069
Zhao J, Zhang X, Zhang P (2021) A unified approach for tracking UAVs in infrared, pp 1213–1222. [Online]. https://anti-uav.github.io/. Accessed 05 Nov 2021
Zhang X, Ye P, Leung H, Gong K, Xiao G (2020) Object fusion tracking based on visible and infrared images: a comprehensive review. Inf Fusion 63:166–187. https://doi.org/10.1016/J.INFFUS.2020.05.002
Wan M et al (2018) Total variation regularization term-based low-rank and sparse matrix representation model for infrared moving target tracking. Remote Sens 10(4):510. https://doi.org/10.3390/RS10040510
Saadi SB et al (2021) Osteolysis: a literature review of basic science and potential computer-based image processing detection methods. Comput Intell Neurosci. https://doi.org/10.1155/2021/4196241
Xu Z, Sheykhahmad FR, Ghadimi N, Razmjooy N (2020) Computer-aided diagnosis of skin cancer based on soft computing techniques. Open Med 15(1):860–871. https://doi.org/10.1515/med-2020-0131
Yao H, Zhang X, Zhou X, Liu S (2019) Parallel structure deep neural network using CNN and RNN with an attention mechanism for breast cancer histology image classification. Cancers (Basel) 11(12):1901. https://doi.org/10.3390/cancers11121901
Aleem S, Kumar T, Little S, Bendechache M, Brennan R, McGuinness K (2021) Random data augmentation based enhancement: a generalized enhancement approach for medical datasets. In: 24th Irish machine vision and image processing conference (IMVIP), pp 153–160. https://doi.org/10.56541/FUMF3414
Valizadeh A, Jafarzadeh Ghoushchi S, Ranjbarzadeh R, Pourasad Y (2021) Presentation of a segmentation method for a diabetic retinopathy patient’s fundus region detection using a convolutional neural network. Comput Intell Neurosci 2021:1–14. https://doi.org/10.1155/2021/7714351
Mousavi SM, Asgharzadeh-Bonab A, Ranjbarzadeh R (2021) Time-frequency analysis of EEG signals and GLCM features for depth of anesthesia monitoring. Comput Intell Neurosci 2021:1–14. https://doi.org/10.1155/2021/8430565
Li Y et al (2021) Infrared maritime dim small target detection based on spatiotemporal cues and directional morphological filtering. Infrared Phys Technol 115:103657. https://doi.org/10.1016/J.INFRARED.2021.103657
Bhat G, Danelljan M, Van Gool L, Timofte R (2019) Learning discriminative model prediction for tracking, pp 6182–6191 [Online]. https://github.com/visionml/pytracking. Accessed 28 Oct 2021
Zhang X, Ye P, Peng S, Liu J, Gong K, Xiao G (2019) SiamFT: an RGB-infrared fusion tracking method via fully convolutional Siamese networks. IEEE Access 7:122122–122133. https://doi.org/10.1109/ACCESS.2019.2936914
Zulkifley MA, Trigoni N (2018) Multiple-model fully convolutional neural networks for single object tracking on thermal infrared video. IEEE Access 6:42790–42799. https://doi.org/10.1109/ACCESS.2018.2859595
Yang X, Li S, Yu J, Zhang K, Yang J, Yan J (2021) GF-KCF: aerial infrared target tracking algorithm based on kernel correlation filters under complex interference environment. Infrared Phys Technol 119:103958. https://doi.org/10.1016/J.INFRARED.2021.103958
Yao T, Hu J, Zhang B, Gao Y, Li P, Hu Q (2021) Scale and appearance variation enhanced Siamese network for thermal infrared target tracking. Infrared Phys Technol 117:103825. https://doi.org/10.1016/J.INFRARED.2021.103825
Parhizkar M, Amirfakhrian M (2022) Car detection and damage segmentation in the real scene using a deep learning approach. Int J Intell Robot Appl 2022:1–15. https://doi.org/10.1007/S41315-022-00231-5
Karimi N, Ranjbarzadeh Kondrood R, Alizadeh T (2017) An intelligent system for quality measurement of Golden Bleached raisins using two comparative machine learning algorithms. Meas J Int Meas Confed 107:68–76. https://doi.org/10.1016/j.measurement.2017.05.009
Ranjbarzadeh R, Bagherian Kasgari A, Jafarzadeh Ghoushchi S, Anari S, Naseri M, Bendechache M (2021) Brain tumor segmentation based on deep learning and an attention mechanism using MRI multi-modalities brain images. Sci Rep 11(1):10930. https://doi.org/10.1038/s41598-021-90428-8
Aghamohammadi A, Ranjbarzadeh R, Naiemi F, Mogharrebi M, Dorosti S, Bendechache M (2021) TPCNN: two-path convolutional neural network for tumor and liver segmentation in CT images using a novel encoding approach. Expert Syst Appl 183:115406. https://doi.org/10.1016/J.ESWA.2021.115406
Abbasi S, Rezaeian M (2021) Visual object tracking using similarity transformation and adaptive optical flow. Multimed Tools Appl 80(24):33455–33473. https://doi.org/10.1007/S11042-021-11344-7
Mamli S, Kalbkhani H (2019) Gray-level co-occurrence matrix of Fourier synchro-squeezed transform for epileptic seizure detection. Biocybern Biomed Eng 39(1):87–99. https://doi.org/10.1016/j.bbe.2018.10.006
Tuncer T, Dogan S, Ozyurt F (2020) An automated residual exemplar local binary pattern and iterative ReliefF based corona detection method using lung X-ray image. Chemom Intell Lab Syst 203:104054. https://doi.org/10.1016/j.chemolab.2020.104054
Amirfakhrian M, Parhizkar M (2021) Integration of image segmentation and fuzzy theory to improve the accuracy of damage detection areas in traffic accidents. J Big Data. https://doi.org/10.1186/s40537-021-00539-2
Hojatimalekshah A, Uhlmann Z, Glenn NF, Hiemstra CA, Tennant CJ, Graham JD, Spaete L, Gelvin A, Marshall HP, McNamara JP, Enterkine J (2021) Tree canopy and snow depth relationships at fine scales with terrestrial laser scanning. Cryosphere 15(5):2187–2209. https://doi.org/10.5194/TC-15-2187-2021
Ranjbarzadeh R, Saadi SB, Amirabadi A (2020) LNPSS: SAR image despeckling based on local and non-local features using patch shape selection and edges linking. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2020.107989
El Khadiri I et al (2021) Petersen graph multi-orientation based multi-scale ternary pattern (PGMO-MSTP): an efficient descriptor for texture and material recognition. IEEE Trans Image Process 30:4571–4586. https://doi.org/10.1109/TIP.2021.3070188
Liu L, Lao S, Fieguth PW, Guo Y, Wang X, Pietikäinen M (2016) Median robust extended local binary pattern for texture classification. IEEE Trans Image Process 25(3):1368–1381. https://doi.org/10.1109/TIP.2016.2522378
Ali H, Sharif M, Yasmin M, Rehmani MH (2017) Computer-based classification of chromoendoscopy images using homogeneous texture descriptors. Comput Biol Med 88:84–92. https://doi.org/10.1016/J.COMPBIOMED.2017.07.002
Ilie M (2015) A content-based image retrieval approach based on document queries. Emerg Trends Image Process Comput Vis Pattern Recognit. https://doi.org/10.1016/B978-0-12-802045-6.00020-X
Naiemi F, Ghods V, Khalesi H (2021) A novel pipeline framework for multi oriented scene text image detection and recognition. Expert Syst Appl 170:114549. https://doi.org/10.1016/j.eswa.2020.114549
Uddin MZ, Hassan MM, Almogren A, Zuair M, Fortino G, Torresen J (2017) A facial expression recognition system using robust face features from depth videos and deep learning. Comput Electr Eng 63:114–125. https://doi.org/10.1016/j.compeleceng.2017.04.019
Luo YT et al (2016) Local line directional pattern for palmprint recognition. Pattern Recognit 50:26–44. https://doi.org/10.1016/j.patcog.2015.08.025
Ranjbarzadeh R, Saadi SB (2020) Automated liver and tumor segmentation based on concave and convex points using fuzzy c-means and mean shift clustering. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2019.107086
Michael Revina I, Sam Emmanuel WR (2018) Face expression recognition using LDN and dominant gradient local ternary pattern descriptors. J King Saud Univ Comput Inf Sci. https://doi.org/10.1016/j.jksuci.2018.03.015
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2015) Learning deep features for discriminative localization. Proc IEEE Comput Soc Conf Comput Vis Pattern Recognit 2016-December:2921–2929. https://arxiv.org/abs/1512.04150v1. Accessed 22 Oct 2021 [Online]
Goyal B, Dawa, Lepcha C, Dogra A, Wang S-H, Lepcha DC (2021) A weighted least squares optimisation strategy for medical image super resolution via multiscale convolutional neural networks for healthcare applications. Complex Intell Syst 1:1–16. https://doi.org/10.1007/S40747-021-00465-Z
Ilesanmi AE, Ilesanmi TO (2021) Methods for image denoising using convolutional neural network: a review. Complex Intell Syst 7(5):2179–2198. https://doi.org/10.1007/S40747-021-00428-4
Haq EU, Jianjun H, Huarong X, Li K (2021) Block-based compressed sensing of MR images using multi-rate deep learning approach. Complex Intell Syst 7(5):2437–2451. https://doi.org/10.1007/S40747-021-00426-6
진 배박, Kumar T, 성 호배, Park J, Bae S-H, 약요 (2020) Search for optimal data augmentation policy for environmental sound classification with deep neural networks. J Broadcast Eng 25(6):854–860. https://doi.org/10.5909/JBE.2020.25.6.854
Baseri Saadi S, Tataei Sarshar N, Sadeghi S, Ranjbarzadeh R, Kooshki Forooshani M, Bendechache M (2022) Investigation of effectiveness of shuffled frog-leaping optimizer in training a convolution neural network. J Healthc Eng 2022:1–11. https://doi.org/10.1155/2022/4703682
Li Y, Song Y, Luo J (2017) Improving pairwise ranking for multi-label image classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3617–3625. https://doi.org/10.48550/arXiv.1704.03135
Hui B et al (2019) A dataset for infrared image dim-small aircraft target detection and tracking under ground/air background. https://www.scidb.cn/en/detail?dataSetId=720626420933459968. Accessed 27 Oct 2021
Vedaldi A, Lenc K (2015) MatConvNet: convolutional neural networks for MATLAB. In: MM '15: Proceedings of the 23rd ACM international conference on multimedia, pp 689–692. https://doi.org/10.1145/2733373.2807412
Liu Q, Liu Z, Yong S, Jia K, Razmjooy N (2020) Computer-aided breast cancer diagnosis based on image segmentation and interval analysis. Automatika 61(3):496–506. https://doi.org/10.1080/00051144.2020.1785784
Ghoushchi SJ, Ranjbarzadeh R, Najafabadi SA, Osgooei E, Tirkolaee EB (2021) An extended approach to the diagnosis of tumour location in breast cancer using deep learning. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/S12652-021-03613-Y
Ranjbarzadeh R et al (2021) Lung infection segmentation for COVID-19 pneumonia based on a cascade convolutional network from CT images. Biomed Res Int 2021:1–16. https://doi.org/10.1155/2021/5544742
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. http://www.robots.ox.ac.uk/. Accessed 11 Jun 2021 [Online]
Ding L, Xu X, Cao Y, Zhai G, Yang F, Qian L (2021) Detection and tracking of infrared small target by jointly using SSD and pipeline filter. Digit Signal Process 110:102949. https://doi.org/10.1016/J.DSP.2020.102949
Funding
None.
Author information
Authors and Affiliations
Contributions
The specific contributions made by each author is as follows: MP: conceptualization, methodology, implementation, writing-original draft, writing—review and editing. GK: conceptualization, methodology, implementation, writing-original draft, writing—review and editing. BAR: conceptualization, methodology, implementation, writing-original draft, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Financial interests
The authors declare they have no financial interests.
Non-financial interests
The authors declare they have no non-financial interests.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Parhizkar, M., Karamali, G. & Abedi Ravan, B. Object tracking in infrared images using a deep learning model and a target-attention mechanism. Complex Intell. Syst. 9, 1495–1506 (2023). https://doi.org/10.1007/s40747-022-00872-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00872-w