
Abstract
In complex traffic scenes, accurate identification of pedestrian orientations can help drivers determine pedestrian trajectories and help reduce traffic accidents. However, there are still many challenges in pedestrian orientation recognition. First, due to the irregular appearance of pedestrians, it is difficult for general Convolutional Neural Networks (CNNs) to extract discriminative features. In addition, more features of body parts help to judge the orientation of pedestrians. For example, head, arms and legs. However, they are usually small and not conducive to feature extraction. Therefore, in this work, we use several discrete values to define the orientation of pedestrians, and propose a Gated Graph Neural Network (GGNN)-based Graph Recurrent Attention Network (GRAN) to classify the orientation of pedestrians. The contributions are as follows: (1) We construct a body parts graph consisting of head, arms and legs on the feature maps output by the CNN backbone. (2) Mining the dependencies between body parts on the graph via the proposed GRAN, and utilizing the encoder–decoder to propagate features among graph nodes. (3) In this process, we propose an adjacency matrix with attention edge weights to dynamically represent graph node relationships, and the edge weights are learned during network training. To evaluate the proposed method, we conduct experiments on three different benchmarks (PDC, PDRD, and Cityscapes) with 8, 3, and 4 orientations, respectively. Note that the orientation labels for PDRD and Cityscapes are annotated by our hand. The proposed method achieves 97%, 91% and 90% classification accuracy on the three data sets, respectively. The results are all higher than current state-of-the-art methods, which demonstrate the effectiveness of the proposed method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Recognizing the orientation of pedestrians can provide an important basis for the automatic driving system to judge their future trajectories. For example, a pedestrian standing on the side of the road and facing a zebra crossing indicates that he may want to cross the road, or a pedestrian standing on the sidewalk and facing forward indicates that he is just walking, Fig. 1 examples of several pedestrian orientations. Therefore, recognizing the orientation of pedestrians can plan a safe driving route for vehicles and avoid collisions with pedestrians. This is a problem worth investigating. The current pedestrian orientation recognition is divided into two categories, one is the classification of discrete orientations, and the other is the regression of continuous orientations. In this manuscript we propose a solution for the classification of discrete orientations.

Illustration of pedestrian orientation classification in traffic scenes
Pedestrian orientation classification is essentially image classification. In the early days, due to insufficient data, some methods used hand-crafted features to solve the problem. In recent years, with the increase of data, traditional methods have limitations. Convolutional Neural Networks (CNNs) exhibit stronger performance when dealing with problems with more data, such as image classification [1], object detection [2], image segmentation [3] and speech recognition [4]. Furthermore, some advanced network models are well reviewed in [5]. In the field of pedestrian orientation classification, researchers have also proposed some methods based on CNN. For example, Raza et al. [6] designed a 14-layer CNN to extract pedestrian head and body orientations, respectively. Lee et al. [7] designed a convolutional random projection forests (CRPforest) to randomly extract local pedestrian features on images for orientation classification.
Most of the above works deal with fully visible pedestrians; however, in reality, the traffic scenes, where pedestrians are located are more complex, and pedestrians are easily occluded by cars, large intermediate areas, complex roadblocks and various traffic signs [8]. Therefore, the results are not ideal when encountering actual occlusion problems. Although Gaussian noise is used to add occlusion to the image in [7], this is different from the actual occlusion. Therefore, general convolution kernels cannot extract the occluded appearance information. In addition, the appearance of pedestrians in different orientations is similar, especially the difference in the appearance of pedestrians in adjacent orientations is smaller, which makes the classification task more challenging.
In this work, we create a pedestrian orientation data set by extracting pedestrians from Ctiyscapes and manually annotating orientations. This data set can provide more pedestrian occlusion samples in real traffic scenes to solve the problem of insufficient occlusion samples. Furthermore, for the challenges of occlusion and small appearance differences between adjacent orientations, previous CNN-based works identify orientations by extracting features of heads and bodies or randomly extracting pedestrian parts, but the randomness leads to very unstable final recognition results. Since the head, arms and legs are crucial for judging the orientation of pedestrians, we propose to focus on the features of these body parts to optimize this problem.
Traditional CNN is used to extract Euclidean data. If the body parts are still modeled under the Euclidean structure, the intrinsic correlation between them will be ignored, so we propose to model them in a body parts graph. Graph networks are widely used due to their advanced performance in processing graph-structured data. Gated Graph Neural Network (GGNN) [9] is a novel graph network combined with Recurrent Neural Networks (RNNs). It introduces a gated recurrent unit (GRU) to complete the learning on the graph, and the amount of parameters that can be learned is independent of time, because the number of nodes input at each moment is the same. However, the fixed adjacency matrix in GGNN is not enough to express the relationship between body parts. Therefore, we propose to use an adjacency matrix with attention edge weights, which represent the contribution of neighbor nodes to the current node, and the attention edge weights can be automatically learned from the training data. To this end, we propose Graph Recurrent Attention Network (GRAN) based on GGNN.
Specifically, we first input pedestrian images into a CNN for pixel-level feature extraction, which can reduce the interference of irrelevant information and enhance the feature expression ability. Next, we construct a body parts graph on superpixel-level feature maps, and exploit the proposed GRAN to mine the dependencies between body parts on the graph. In GRAN, the graph recurrent encoder uses a fixed adjacency matrix to learn graph node features and generate contextual information, and the graph recurrent attention decoder uses an adjacency matrix with attention for automatic learning to extract features from the most relevant neighbor nodes. Finally, the orientation classification of pedestrians is implemented on feature maps with graph features.
Our proposed method has the following contributions:
-
i.
We propose to construct a body parts graph on superpixel-level feature maps to represent the relationships between body parts, and propose a graph recurrent encoder and a graph recurrent attention decoder to propagate node features on the body parts graph. Through the learning on the graph, the relationship expression between nodes is increased to solve the lack of appearance information caused by occlusion, so that the orientation classification is more accurate.
-
ii.
We first use traditional CNN to extract pixel-level features instead of building body parts graph directly on pixel-level feature maps, as this reduces the complexity of the graph structure and facilitates graph learning. Furthermore, our scheme integrates traditional CNN and GRAN, enabling end-to-end learning.
-
iii.
An adjacency matrix with attention is proposed in the graph recurrent attention decoder, which can learn attention weights during training, instead of adopting an artificially designed fixed adjacency matrix, which can improve the graph network’s ability to understand different body parts feature learning ability.
-
iv.
Finally, we construct a new pedestrian orientation data set for experiments by extracting more complex pedestrian samples from Cityscapes and manually annotating pedestrian orientations. Compared with other methods, our scheme achieves the best classification results on this data set.
The remaining chapters of this article are organized as follows. The second section is related work. The third section will introduce our proposed method in detail. The fourth section will show our experimental results and an introduction to the data set. The fifth section discusses the advantages of the proposed scheme and proposes how to address the shortcomings of this work in the future. The sixth section concludes this manuscript.
Related work
By consulting the available literature, pedestrian orientation recognition is divided into discrete and continuous. Among them, it is treated as a classification problem for the discrete situation, hereinafter referred to as pedestrian orientation classification; it is treated as a regression problem for the continuous situation, hereinafter referred to as pedestrian orientation regression. This article will focus on the classification of pedestrian orientations, and only briefly introduce pedestrian orientation regression.
Pedestrian orientation classification is usually divided into 4 classes (front, back, left, right) or 8 classes (front, back, left, right, rear right, front right, front left, rear left). Pedestrian orientation regression is different. Most methods define orientation as any angle from 0° to 360° [10,11,12,13], which is a continuous value. In real-world applications, choose according to the needs of the application scenario. The former has a rough orientation estimation and is mainly used in areas, such as autonomous driving, while the latter has a more precise orientation for human–computer interaction and robot vision.
For pedestrian orientation classification, conventional methods use a combination of hand-craft features and classifiers to estimate pedestrian orientation. Gandhi et al. [14] divided pedestrian orientations into 8 classes, and used HOG to extract features and SVM classifiers for orientation estimation. In [15], a weight generating function was proposed to fuse visible and thermal feature vectors to classify pedestrian head orientations at night. Tosato et al. [16] divided orientations into five classes: front, back, left, right and background. By extending the binary classification problem to multiple classifications, an expressive descriptor was used. When illuminations and viewpoints change, appearance information and motion information will be affected. To this end, Liu et al. [17] proposed an appearance-based classifier that uses motion information to update. In addition, there are many other methods, such as the use of body skeleton features for orientation recognition [18]. Schulz et al. [19] used particle filters to predict head poses that change over time. Raman et al. [20] propose a joint video-based and frame-based estimation method to classify walking orientations using a rule-based look-up table to perform fractional fusion of the two results. Liu et al. [21] proposed a superpixel view feature histogram (SVFH) method based on the view feature histogram (VFH) for feature extraction and used a multi-class support vector machine to build the final classifier. However, these traditional methods based on hand-crafted features show limitations when dealing with more data.
With the increase of data, CNN has outstanding performance in the field of image recognition. Some researchers have also proposed CNN-based methods for pedestrian direction recognition. Raza et al. [6] used CNN to classify pedestrian orientations but only considered pedestrian head and body orientations to predict the final pedestrian orientation. Lee et al. [7] proposed the random projection forest method to classify the head and body orientation of pedestrians, while the author only regressed the head orientation of pedestrians. Hara et al. [22] designed a Deep Convolutional Neural Network (DCNN) for object orientation estimation, but their method is aimed at multiple objects, including not only pedestrians but also cars. Beyer et al. [23] proposed a method based on CNN, which learns on simple labels, but only regresses the orientation of the head. Kumamoto et al. [40] use a simple VGG network to classify pedestrian orientations. This method feeds the pedestrian's head and body into two VGG networks and outputs two feature maps. The two feature maps are concatenated to obtain a joint feature map of the head and the body. Use softmax to output the classification results. Similar to the method in [24], Raza et al. By feeding the head and body of the pedestrian into the CNN designed by themselves, the classification of the pedestrian orientation is completed. To improve the performance of pedestrian orientation classification algorithms, researchers have proposed a variety of methods. Among them, it is an effective method to estimate the orientation of the head and body separately. Chen et al. [25] treated pedestrian orientation as a joint model adaptation problem in semi-supervised learning to solve. First, the head and body are detected using a support vector machine based on the histogram of gradient, and then the detection results are sent to the coupled adaptive classifier for classification learning, and the classification results of the head and body orientations are obtained. Flohr et al. [26] designed a joint probability estimation method that estimates the head and body orientations of pedestrians in autonomous driving scenes, and experiment on disparity and gray images. However, as the CNN gets deeper and deeper, not only does the recognition accuracy reach a bottleneck, but it also leads to higher computational complexity.
We note that extracting dependencies between body parts makes it easier to distinguish different orientations; however, CNN cannot accurately express this relationship. In recent years, graph neural network (GNN) shows excellent performance in processing graph structure data [27,28,29]. In addition, there are variants of GNN, such as Graph Convolutional Networks (GCN) [30] and Graph Attention Aetworks (GAT) [31]. Recently, these graph-based neural networks have also been applied to image processing, such as pedestrian detection [32], pedestrian trajectory prediction [33, 34], image classification [35,36,37]. The performance is equally powerful. However, through literature search, no graph-based methods were found for pedestrian orientation recognition, but some graph-based pedestrian pose estimation methods caught our attention. For instance, Han [38] proposed to regard human joints as nodes, and the spatial context relationship between joints as edges, so as to construct a human pose graph. Using GCN to learn the relationship between nodes to estimate human pose. Schirmer et al. [39] considered building a global model for different joints of the body, which they mentioned would have some improvement in solving the occlusion problem. They utilize global relation reasoning–graph convolutional networks (GRR–GCN) to capture the global relations between different body joints. Wu et al. [40] pointed out that changes in a part of the human body (known as the poselet) will cause changes in posture. Therefore, consider dividing the body into 5 primitives as poselets, and use the proposed hierarchical poselet-guided graph convolutional network (HPGCN) to estimate the 3D human pose. Since pedestrian face in different orientations, their bodies will also show different poses, so the above graph-based human pose estimation method also inspires us.
Inspired by previous research methods, we believe that considering more body parts features is effective for orientation classification. Therefore, we build a graph on the backbone feature map with high-level semantics, treat the head, arms and legs as graph nodes, respectively, and use GRAN to propagate features between the nodes. We use the encoder–decoder structure for feature propagation between backbone and GRAN, and the entire network can achieve end-to-end learning.
Proposed methodology
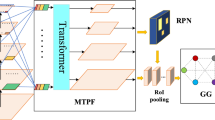
The whole framework of our proposed method is shown in Fig. 2. It consists of four parts. One is the backbone network based on CNN. The second is the graph structure module. The third is the graph recurrent encoder module. The fourth is the graph recurrent attention decoder module. The process of the system is as follows: First, the image is input to the VGG11 backbone network for extracting global features, and the output of the network is the learned feature map. Next, a body parts graph is constructed on the feature map, and the relationship between body parts is represented in the form of a graph structure. After that, the graph structure is sent to the encoder module, and the GRAN is used in the encoder module to transfer node information to generate context information. Finally, the context information is sent to the decoder module. In the decoder module, attention is used to screen neighbor nodes. Each decoder still uses GRAN for node information transfer, and the image output by the decoder is passed to the classifier for final classification. Modeling the relationship between body parts through GRAN improves the effectiveness of feature extraction and enables end-to-end learning. In the following sections, these four modules will be introduced, respectively.

Whole proposed framework
Graph structure
Pedestrian orientation classification is a very challenging problem. Although many methods have been proposed for this problem, these methods are inefficient and the model complexity is high. Therefore, it cannot be applied to real-world scenes. In recent years, the proposed graph-based neural network has shown good performance when processing non-European structure data and can be used for feature extraction of graph structure data. What is exciting is that the application of graph methods in the field of image classification or object detection has significant effects. Therefore, in this work, we propose an adjacency matrix with attentive edge weights, utilizing the proposed GRAN for efficient learning on body parts graph to improve the accuracy of pedestrian orientation classification.
When extracting features, CNNs usually work on pixel-based nodes. However, the GRAN works on superpixel-based nodes, which can avoid a lot of calculations. In our work, the points on the output feature map of the backbone network are called superpixel nodes.
The backbone network outputs the learned feature map. Next, we number the superpixels in the feature map, and each superpixel represents a body part. As shown by the Graph node numbers in Fig. 3, The superpixels 1 and 2 represent the left and right parts of the head, respectively; Superpixels 3 and 4 represent left arm and right arm (left upper limb and right lower limb), respectively; Superpixels 5 and 6 represent the left leg and the leg (left lower limb or right lower limb), respectively. Here, we refer to these numbered superpixels as nodes. Then it is sent to the graph structure module, as shown in Graph structure in Fig. 3.

Illustration of the graph node number and graph structure
We define the graph \(G=(V,E)\) on the numbered feature graph. Where \(V=\left\{{v}_{i}|i\in \left(\mathrm{1,2},\mathrm{3,4},\mathrm{5,6}\right)\right\}\) is used to represent the 6 superpixels in the feature map, which are called nodes in the graph structure; \(E=\left\{{e}_{i,j}|{\forall }_{i,j}\in \left(\mathrm{1,2},\mathrm{3,4},\mathrm{5,6}\right)\right\}\) is used to represent the relationship between nodes i and j, that is, the relationship between head, arms and legs, which are called edges in the graph structure. Considering that the relationship between body parts is mutual, the undirected edge representation is used. In addition, to reduce manual intervention, we propose an adjacency matrix with attention in the decoder, and the model can automatically select the most suitable neighbor node. In the encoder we still use the standard adjacency matrix \(A\in {R}^{6\times 6}\), the graph structure is shown in Fig. 4, that is.

Graph structure with standard adjacency matrix
The attention mechanism can make the adjacency matrix trainable, because the attention weights can be learned. In this way, it can be judged which neighbor nodes are more important to the current node, so that when assigning weights, the nodes with large contributions are given higher, and the nodes with small contributions are given lower weights. Figure 5 shows the graph structure of an adjacency matrix with attention, where the color of the edges in the graph from dark to light indicates that the contribution decreases gradually.

Graph structure of an adjacency matrix with attention
Graph recurrent encoder module
In the graph recurrent encoder module (Fig. 6), the standard adjacency matrix is used to aggregate the neighbor node information of each node \(v(v=\mathrm{1,2},\mathrm{3,4},\mathrm{5,6})\), and the aggregation can be formulated as follows:
where \({A}_{v}^{t}\) is a sub-matrix of the adjacency matrix \({A}^{t}\), which denotes the dependency between the current node and its neighbors. \({h}_{1}^{t-1}\dots {h}_{N}^{t-1}\) denotes the hidden state of a neighbor node at the previous time step. \({x}_{v}^{t}\) is obtained by aggregating the neighbor nodes of node \(v\).

Graph recurrent encoder module
After the aggregation of neighbor node information, different methods are used to update the node information (or hidden state) according to the various models. For example, GCN use convolution operations, and GNN use matrix multiplication. In our work, we update the node information in the encoder–decoder structure based on GRU. The first is the coding stage. We set a time step \(t\), which denotes the number of times each node needs to be encoded. The time step is set as a hyperparameter in the model, each node generates an encoding sequence. In the encoder, GRU is used to update node information, and update the hidden state \({h}_{v}^{t}\) of each node by aggregating neighbor node information \({x}_{v}^{t}\) and information from the previous time step. The specific calculation method is given by the following formulas:
where \({h}_{v}^{t-1}\) denotes the hidden state of node \(v\) at the previous time step, and ⊗ denotes the Hadamard product. The encoder will output context information for each sequence, denoted by \({C}_{v}\). There are six sequences in this work, which are denoted by \({C}_{1}\), \({C}_{2}\), \({C}_{3}\), \({C}_{4}\), \({C}_{5}\) and \({C}_{6}\).
Graph recurrent attention decoder module
Attention mechanism has achieved satisfactory results in machine translation and object tracking. Inspired by the attention of previous machine translation. In our work, we will use the attention mechanism in the decoding stage to aggregate the neighbor node information. The context information output by the encoder is used as the initial input of the decoder. As shown in Fig. 7, a recurrent attention decoder module framework is shown.

Graph recurrent attention decoder module
We use an adjacency matrix with attention in the decoder. The attention weights are represented by computing the correlations of all neighbor nodes with the current node and performing a softmax. Attention is performed once at each time step \({t}^{^{\prime}}\). The node correlation at time step \({t}^{^{\prime}}\) can be expressed as
where \({\widetilde{h}}_{{v}^{\mathrm{^{\prime}}}}^{{t}^{\mathrm{^{\prime}}}-1}\) denotes the hidden state of the neighbor node of the decoded node, and \({\widetilde{h}}_{v}^{{t}^{\mathrm{^{\prime}}}-1}\) denotes the hidden state of the decoded node. In each time step \({t}^{^{\prime}}\) of the decoder, the correlation degree \({p}_{{t}^{\mathrm{^{\prime}}}}^{{v}^{\mathrm{^{\prime}}}\to v}\) between the decoded node \(v\) and each neighbor node \({v}^{^{\prime}}\) is generated. \(w\), \({W}_{{v}^{^{\prime}}}\) and \({W}_{v}\) are model parameters that can be learned. Then, perform softmax on the correlation \({p}_{{t}^{^{\prime}}}^{{v}^{^{\prime}}\to v}\) between each decoding node and its neighboring nodes, and get the attention weight \({a}_{{t}^{\mathrm{^{\prime}}}}^{v}\):
When the decoder aggregates neighbor node information, each neighbor node information will have an attention weight a, and the neighbor node aggregation formula is
Graph classification
After the feature map is processed by the above encoder (graph recurrent encoder)–decoder (graph recurrent attention decoder) module, the backbone network output feature map is converted into a graph with six nodes, thus turning the problem into a graph classification problem. To obtain the classification probability of the graph, we connect a fully connected layer after the encoder–decoder to output the probability distribution of the graph in n (8, 3 and 4) classes. Finally, when training the network, we use the two indicators of cross-entropy loss and accuracy (acc) to measure the performance of the model. The calculation formula is as follows:
where \({y}^{(i)}\) and \({\widehat{y}}^{(i)}\) denote the ground truth label and predicted label of sample \(i\), respectively. \(m\) denotes the number of classes (pedestrian orientation), and \({TP}_{c}\) denotes the number of correctly classified classes of \(c\), \(n\) denotes the total number of samples.
In addition, we use a confusion matrix to denote the model classification results, where the columns denote the predicted labels of the samples, and the rows denote the ground truth labels of the samples. Therefore, the precision (pre) and the true positive rate (TPR) (also known as the recall rate) can be calculated through the confusion matrix, which are represented as follows:
where \({\mathrm{TP}}_{c}\) denotes the number of correctly predicted class \(c\), \({\mathrm{FN}}_{c}\) denotes the number of incorrectly predicted class \(c\), and \({FP}_{c}\) denotes the number of other classes predicted to be class \(c\). For all classes pre and TPR can be expressed as follows:
Experiments
To be able to accurately evaluate the proposed method, we conducted experiments on three public data sets. The experiment was divided into two parts: training and testing. Since few data sets can be directly used in this experiment, we will preprocess them to meet the requirements of this experiment. The Pedestrian Direction Classification (PDC) [41] is based on the Daimler Mono Pedestrian Classification Benchmark [42, 43]. It is a data set for pedestrian orientation recognition, covering pedestrian images in 8 orientations, a total of 11562 images. The pedestrian movement direction recognition data set (PDRD) [44] is a data set with three pedestrian orientations. Images are collected from a fixed camera and obtained through consecutive frames. To obtain more pedestrian images in traffic scenes, we filter and crop out pedestrian images from Cityscapes [45,46,47], which is a very large data set system, so there are more types of pedestrians. Our experiment will be conducted on these data sets and compared with the current state-of-the-art methods. In this part, we will first describe the experimental parameters setup, then give a detailed introduction to the three data sets, and describe the training process of the model in detail. Finally, a detailed analysis of the experimental results will be made.
Our experiment is done on the current mainstream PyTorch framework. Experiment on a computer equipped with Core i7-7800X CPU and dual NVIDIA TITAN Xp GPUs, with a video memory capacity of 12 GB for a single graphics card. Since the graph structure module needs to use 3 × 2 fixed-size feature maps, the input image size of the feature backbone network is unified to 96 × 48. The original PDC data set meets this size requirement and can be directly input into the network. Therefore, the other two data sets (PDRD and Cityscapes) need to be cropped and resized.
Network training
Since there is no VGG11 model pre-trained on the pedestrian orientation data set available, we do not use the pre-training mode for learning. For the different classes of pedestrian directions in the three data sets, we will learn the models separately for the three data sets. First, the model is fully trained on PDC. Then the final model of PDC will be adopted as pre-training when learning on PDRD and Cityscapes. Note that the final fully connected layer cannot be shared due to the different final orientation classifications of the three data sets. Therefore, only the pretrained weights of the backbone and GRAN layers are used and fine-tuned. Furthermore, in this work we also determine the final model by experimenting with setting different hyperparameters, GRAN with different number of layers and data augmentation. The parameter settings provided during training on the three data sets are shown in Table 1. Figure 8a–c shows the variation of validation accuracy (VA) in the learning phase of GRAN with different number of layers on three data sets. Figure 8d–e shows the training error (TE), validation error (VE) and test accuracy (TA) before and after applying data augmentation on PDC (described in the next section).

Metric (VA, TE, VE and TA) changes when training the proposed GRAN model: a training of models with different layers on data-augmented PDC, b training of models with different layers on PDRD, c training of models with different layers on Cityscapes, d TE, VE and TA when training on original PDC, (e) TE, VE and TA when training on data augmented PDC
In Fig. 8a–c, G represents the GGNN layer without attention, and GA represents the GRAN layer with the adjacency matrix with attention. For example, 2G + 2GA means that 2 layers of GGNN and 2 layers of GRAN are stacked after the backbone, and both backbones adopt VGG11 for fair comparison. In the learning phase, the learning rate is set to 1/10 of the original when the VA does not improve for 3 consecutive times. Overall, with the increase of the number of layers, the VA on the three data sets shows an upward trend. However, it is worth noting that when a layer of GA is added after reaching the highest level at 2G + 2GA, the VA on the three data sets has declined to varying degrees. This does not mean that the more layers, the higher the accuracy. Therefore, we determined 2G + 2GA as the final model architecture.
Experimental results and analysis
1) Experiment on PDC: PDC is a data set specially used for pedestrian orientation recognition, which contains more pedestrian orientations, a total of eight orientations, as shown in Fig. 9. The number of images of each class in the original PDC is unbalanced, as shown in Table 2. To balance the classes, data augmentation applied. For fewer classes, use flipping and Gaussian Blur to process these images. For example, an image of the rear right class is flipped 180° along the y-axis, get an image of the left rear class. The comparison of the images before and after the flip is shown in Fig. 10. However, since there are fewer images in the front right and front left classes, it is still not possible to balance the classes by flipping. Therefore, use Gaussian Blur to process images, and the image processed in this way can be used as a new image to supplement the corresponding class. The image after Gaussian Blur is shown in Fig. 11. For classes with too many images, the extra images are deleted. Table 3 shows the number of images in each orientation in the PDC with data augmentation.

PDC data set includes eight different pedestrian orientations

PDC data set image flipping, in which the first line is the original image, and the second line is the new image after the flip processing

PDC data set image Gaussian blur processing, the first line is the original image, and the second line is the image after Gaussian blurring
It is well known that data augmentation often has an impact on the performance of neural networks. Therefore, we train the model on the original PDC and the augmented PDC separately. The impact of data augmentation on the model is illustrated by TE, VE and TA. Figure 8 shows the effect of applying data augmentation during the training stage on TE, VE and TA, (d) shows the training of the proposed scheme on the original PDC, and (e) shows the results of data augmentation. We focus on VE and TA, where TA is the result of testing every 10 epochs. When GRAN is trained on the original PDC, VE decreases to 0.18 and TA reaches 90.5%. After data augmentation, VE is further reduced to 0.05 and TA is increased to 97%. This shows that our data augmentation method is effective for the performance improvement of the proposed model.
We evaluated the proposed algorithm on the PDC data set and compare with some of the current state-of-the-art methods. The experimental results are represented by the confusion matrices, as shown in Fig. 12. To conduct a comprehensive comparison, the comparison methods we selected include traditional, machine learning, and deep learning methods. These methods include the joint Support Vector Machine–Hidden Markov Model (SVM + HMM) proposed by Gandhi et al. [14] to predict the future orientation of pedestrians, the Misclassification Tolerable Learning (MTL) proposed by Kawanishi et al. [48] and the CNN model designed by Raza et al. [6].

Confusion matrices of various pedestrian orientation classification algorithms on the PDC data set (with augmented data set)
To compare performance, we select acc, pre and TPR to perform performance evaluation. As shown in Table 4, our algorithm is higher than other algorithms in terms of acc, showing excellent performance. In addition, the TPR represents the correct rate of classification among all positive samples and is an important performance indicator to measure the sensitivity of the algorithm. As shown in the TPR column in Table 4, compared with other methods, our method has the highest TPR in all categories. Which shows that our model has excellent sensitivity control.
Overall, the proposed method outperforms other methods comprehensively in acc, pre and TPR. We analyze that [14] and [48] adopted traditional machine learning methods based on hand-craft features. Such methods can achieve good results when dealing with small amounts of data, but tend to perform poorly as the amount of data increases. The deep learning method based on neural network is better for the larger the amount of data. Therefore, for PDC with more than 10,000 images, both [6] and our scheme have far more high acc than [14] and [48] (as shown in Table 4). The CNN in [6] distinguishes the orientation of pedestrians only by extracting head and body features, while our scheme extracts 6 body parts. Therefore, more part features provide more difference for different orientations, so our scheme is more acc on PDC.
Because the graph attention mechanism is designed, the relationship between non-adjacent features can be established and can automatically select neighbor nodes. This can make up for the shortcomings of conventional algorithms that require hand-craft features. We show the attention mechanism on the attention map, attention visualization is shown in Fig. 13. The brighter the color in the image, the higher the attention paid to the node.

Attention map
2) Experiment on PDRD: PDRD was filmed on the campus of the University of Alicante, Spain. It is a collection of videos shot with a fixed camera. The camera only captures the three orientations of pedestrians, namely, left, right and front. Because the original image resolution of this data set is 432 × 320, and the background in the image is relatively high. However, such images do not meet the experimental requirements. Therefore, pedestrians are cropped from images and resized to 96 × 48 resolution. Figure 14 shows some image examples, the first row is cropped, the second row is resized. After processing, a total of 10800 pedestrian images are generated, of which the left class is 4035, the right class is 4227, and the front class is 2538. We randomly select 90% from each class for training and 10% for validation.

PDRD preprocessing. 1st row: original image. 2nd row: resized image
Our method is compared with the method in [44] on PDRD. Dominguez-Sanchez et al. [44] used the optical flow method to preprocess the self-built PDRD data set, a black background frame image is generated for every 6 original images, as shown in Fig. 15. After that, the black background frame images are used as input for various CNN variant models (such as AlexNet, GoogLeNet and ResNet-50). Compared with our algorithm, this method requires data preprocessing and cannot achieve end-to-end learning, which increases the processing time of the model and greatly reduces the efficiency. Table 5 shows the acc, pre and TPR of all methods. Our method achieves an acc of 91%, the highest among all methods. The recognition results of all algorithms are shown in the confusion matrices in Fig. 16.

Black background frame

Confusion matrices of various pedestrian orientation classification algorithms on PDRD data set
In [44], RGB images are converted into black background frames by computing the optical flow of the image sequence, providing a new method for data preprocessing. This black background frame can show the contour of the pedestrian and show slight movement in the pedestrian's moving orientation, so it provides important information for pedestrian orientation recognition. However, since it is a multi-frame composite and displayed in grayscale, a lot of pedestrian appearance information is lost. In addition, pedestrians do not occupy a high proportion of black background frames, and a high proportion of the background can interfere with feature extraction. In our data preprocessing, pedestrians are cropped from the original image. The proportion of pedestrians is very high and only one frame is needed for a pedestrian, so the appearance information is fully preserved. From the method point of view, AlexNet, GoogLeNet and ResNet-50 are general image classification models, they mainly classify different objects. The pedestrian orientation classification pays more attention to the subtle movement differences of pedestrians' limbs when facing different orientations, so they perform poorly. We abstract each part into graph nodes through the body parts graph, and rich action information can be mined through GRAN. Therefore, our scheme exhibits high accuracy in experiments.
3) Experiment on Cityscapes: Cityscapes is a large urban landscape data set. The images are collected on the roads of various cities in Germany, and the camera is fixed on the front of the Mercedes–Benz car. Therefore, each image comes from a real road scene, which is very suitable for pedestrian orientation recognition in a traffic scene. Suitable for autonomous driving. Experiment on Cityscapes to further evaluate our model to prove its effectiveness. We extract pedestrian images in four orientations (front, back, left and right) from various road scenes. The resolution of the original image is 3432 × 3432, pedestrians are cropped from images and resized to 96 × 48 resolution, and finally, about 4000 pedestrian images are generated. As shown in Fig. 17, the left column is the original image, the middle column is the cropped image, and the right column is the resized image. Each of the four classes uses 900 images for training and 100 images for validation.

Cityscapes preprocessing
Compared with the first two data sets for pedestrian orientation recognition, this data set has more complex scenes, changeable pedestrian postures, and even occlusions and blurs, which increased the difficulty of recognition. Figure 18 shows some examples of the above complex cases. However, experiments on this data set are more realistic. By adding more complex images to the training, the robustness of the model can be tested.

Examples of images of complex situations in the Cityscapes data set
On the Cityscapes data set, we will compare with the current state-of-the-art methods, including the convolutional random projection network (CRPnet), convolutional random projection forest (CRPforest) [7] and the Capsule Network (CapsNet) proposed by Dafrallah et al. [49]. The confusion matrices for these algorithms are shown in Fig. 19.

Confusion matrices of various pedestrian orientation classification algorithms on the Cityscapes data set
The classification performance of the selected methods for comparison on Cityscapes are shown in Table 6. Our method shows higher performance than other methods in terms of acc, pre and TPR. We note that [7] has low TPR on both left and right, 71% and 73% for CRPnet, 76% and 79% for CRPforest. Table 7 shows some left and right examples of errors. Our analysis suggests that [7] extracts pedestrian features using convolutional kernels at random locations. However, it does not completely cover the image, such as normal convolution, which leads to missing features of some body parts. Therefore, left and right can be mistaken for other orientations. Our body parts graph is fully covered, which facilitates the distinction between left and right, so our method has higher TPR on left and right than other algorithms. Furthermore, CapsNet in [49] cannot learn by backpropagation when computing coupling coefficients, so the model generalizes poorly when the number of images is small. Therefore, the acc is not high during verification, only 83%, which is lower than our method.
Model complexity analysis
By observing the experimental results of the three CNN models in Table 5. We note that with the increase of CNN layers, the accuracy also increases, but the increase of CNN depth will bring higher time cost. We show the time cost of the above methods by comparing the number of parameters of the model and floating point operations (FLOPs). As shown in Table 8. It can be seen that our model has a moderate amount of parameters, but the FLOPs will be higher than other methods. This is due to the need to learn a dense adjacency matrix on the graph. Although some models (CNN, Alex, GoogLeNet, and ResNet-50) have low FLOPs, they also have low accuracy. However, CapsNet has 3 times as many FLOPs as ours but does not show higher accuracy. Although, our model increases the computational complexity, the accuracy improvement is obvious. In addition, this computational complexity is acceptable for current hardware capabilities.
Discussion
For a single-frame image containing only one pedestrian, whether it is a dedicated pedestrian orientation data set (PDC, PDRD) or pedestrian images collected from vehicle-mounted cameras (Cityscapes), our proposed scheme achieves higher classification accuracy than other state-of-the-art methods (cf., Tables 4, 5, 6). We note that the results on PDC far outperform the other two data sets compared to their own. We analyze that: first, since PDC provides standard pedestrian orientations without preprocessing, the other two data sets require preprocessing before they can be used for experiments. However, during preprocessing, errors in manual labeling can lead to image distortion, deletion, and offset. Therefore, the accuracy on PDRD and Cityscapes is lower than PDC. Nevertheless, the accuracy of the proposed scheme is still higher than other methods. This shows that our scheme is more robust when dealing with imperfect data. Furthermore, the proposed method achieves only 90% accuracy on Cityscapes (cf., Table 6), which is the lowest among the three data sets (97% for PDC and 91% for PDRD). We believe this is mainly due to the fact that the images in Cityscapes come from complex traffic scenes, where pedestrians have variable shapes, and there are also a large number of occluded and blurred samples. Therefore, it leads to the lack of node information when constructing the body parts graph, so the proposed GRAN is limited in capturing the dependencies between nodes. However, we can still capture useful information from other visible nodes, so we can still achieve higher classification accuracy than other state-of-the-art methods when the data is imperfect.
In summary, we believe that the proposed scheme still has a gap with high-quality data when dealing with low-quality data, so we will further optimize the scheme in the future. Specifically, we consider capturing more dependencies between visible body parts, thereby improving the learning ability of the model to achieve higher classification accuracy. In addition, we also note that the insufficiency of existing data is also the cause of low-quality data classification accuracy. Therefore, we will add reasonable data in the future to break through the limitation that the performance of the algorithm cannot be fully exerted due to insufficient data.
Conclusions
In the proposed method, we treat pedestrian orientation recognition as a graph classification task, and the designed model is an end-to-end structure. The entire model framework contains two modules. One is the graph recurrent encoder module, and the other is the graph recurrent attention decoder module. The graph relationships of body parts are established by converting the CNN feature map into a graph structure, and then GRAN is used in the encoder–decoder to propagate features among graph nodes. Context information can be obtained through the encoder. The decoder uses the neighbor node attention mechanism to assign an attention weight to each neighbor node, which can automatically select features when aggregating neighbor nodes. Extract valid features and suppress invalid features. Finally, we conduct experiments on three public data sets and compare our method with the current state-of-the-art methods. The results show that our method has good performance and is superior to other algorithms.
Experiments on challenging Cityscapes show that although these pictures suffer from occlusion, blur and offset, our scheme is still optimal compared to other state-of-the-art methods. However, there is still a gap compared to the performance of our scheme on other perfect data sets. Therefore, according to the discussion, we will further improve the performance of the algorithm by increasing the amount of data and optimizing the model in the future.
References
Abdollahi A, Pradhan B (2021) Urban vegetation mapping from aerial imagery using explainable AI (XAI). Sensors 21(14):4738. https://doi.org/10.3390/s21144738
Zhao ZQ, Zheng P, Xu ST, Wu XD (2019) object detection with deep learning: a review. IEEE Trans Neural Netw Learn Syst 30(11):3212–3232. https://doi.org/10.1109/TNNLS.2018.2876865
Abdollahi A, Pradhan B (2021) Integrating semantic edges and segmentation information for building extraction from aerial images using UNet image segmentation. Mach Learn Appl 6:100194. https://doi.org/10.1016/j.mlwa.2021.100194
Nassif AB, Shahin I, Attili I, Azzeh M, Shaalan K (2019) Speech recognition using deep neural networks: a systematic review. IEEE Access 7:19143–19165. https://doi.org/10.1109/ACCESS.2019.2896880
Pak M, Kim S (2017) A review of deep learning in image recognition. In: 2017 4th International conference on computer applications and information processing technology (CAIPT), p 1–3. https://doi.org/10.1109/CAIPT.2017.8320684
Raza M, Chen Z, Rehman SU, Wang P, Bao P (2018) Appearance based pedestrians’ head pose and body orientation estimation using deep learning. Neurocomputing 272:647–659. https://doi.org/10.1016/j.neucom.2017.07.029
Lee DH, Yang MH, Oh S (2019) Head and body orientation estimation using convolutional random projection forests. IEEE Trans Pattern Anal Mach Intell 41(1):107–120. https://doi.org/10.1109/TPAMI.2017.2784424
Chen N, Li ML, Hao Y, Su XP, Li YH (2021) Survey of pedestrian detection with occlusion. Complex Intell Syst 7:577–587. https://doi.org/10.1007/s40747-020-00206-8
Li YJ, Zemel R, Brockschmidt M, Tarlow D (2016) Gated graph sequence neural network. In: 2016 International conference on learning representations (ICLR). https://doi.org/10.48550/arXiv.1511.05493
Kim SS, Gwak IY, Lee SW (2020) Coarse-to-fine deep learning of continuous pedestrian orientation based on spatial co-occurrence feature. IEEE Trans Intell Transp Syst 21(6):2522–2533. https://doi.org/10.1109/TITS.2019.2919920
Tepencelik ON, Wei WC, Chukoskie L, Cosman PC, Dey S (2021) Body and head orientation estimation with privacy preserving LiDAR sensors. In: 2021 29th European signal processing conference (EUSIPCO), p 766–770. https://doi.org/10.23919/EUSIPCO54536.2021.9616111
Zhao CC, Qian YQ, Yang M (2019) Monocular pedestrian orientation estimation based on deep 2D–3D feedforward. Pattern Recogn 100:107182. https://doi.org/10.1016/j.patcog.2019.107182
Zhao CC, Li H (2020) Amplifying the anterior-posterior difference via data enhancement—a more robust deep monocular orientation estimation solution. https://doi.org/10.48550/arXiv.2012.11431
Gandhi T, Trivedi MM (2008) Image based estimation of pedestrian orientation for improving path prediction. In: 2008 Proceedings of the intelligent vehicles symposium, IEEE, p 506–511. https://doi.org/10.1109/IVS.2008.4621257
Shojaiee F, Baleghi Y (2022) Pedestrian head direction estimation using weight generation function for fusion of visible and thermal feature vectors. Optik 254:168688. https://doi.org/10.1016/j.ijleo.2022.168688
Tosato D, Spera M, Cristani M, Murino V (2013) Characterizing humans on Riemannian manifolds. IEEE Trans Pattern Anal Mach Intell 35(8):1972–1984. https://doi.org/10.1109/TPAMI.2012.263
Liu H, Ma L (2015) Online person orientation estimation based on classifier update. In: 2015 IEEE international conference on image processing (ICIP), IEEE, p 1568–1572. https://doi.org/10.1109/ICIP.2015.7351064
Paiva de PVV, Batista MR, Ramos GJJ (2020) Estimating human body orientation using skeletons and extreme gradient boosting. In: 2020 Latin American robotics symposium (LARS), 2020 Brazilian symposium on robotics (SBR) and 2020 workshop on robotics in education (WRE), p 1–6. https://doi.org/10.1109/LARS/SBR/WRE51543.2020.9307079
Schulz A, Stiefelhagen R (2012) Video-based pedestrian head pose estimation for risk assessment. In: 2012 Proceedings of the 15th International IEEE conference on intelligent transportation systems, IEEE, p 1771–1776. https://doi.org/10.1109/ITSC.2012.6338829
Raman R, Sa PK, Bakshi S, Majhi B (2020) Kinesiology-inspired estimation of pedestrian walk direction for smart surveillance. Futur Gener Comput Syst 108:1008–1026. https://doi.org/10.1016/j.future.2017.10.033
Liu W, Zhang YD, Tang S, Tang JH, Hong RC, Li JT (2013) Accurate estimation of human body orientation from RGB-D sensors. IEEE Trans Cybern 43(5):1442–1452. https://doi.org/10.1109/TCYB.2013.2272636
Hara K, Vemulapalli R, Chellappa R (2017) Designing deep convolutional neural networks for continuous object orientation estimation. https://doi.org/10.48550/arXiv.1702.01499
Beyer L, Hermans A, Leibe B (2015) Biternion Nets: continuous head pose regression from discrete training labels. In: Gall J, Gehler P, Leibe B (eds) Pattern recognition. DAGM 2015. Lecture notes in computer science, p 157–168. https://doi.org/10.1007/978-3-319-24947-6_13
Kumamoto K, Yamada K (2017) CNN-based pedestrian orientation estimation from a single image. In: 2017 4th IAPR Asian conference on pattern recognition (ACPR), p 13–18. https://doi.org/10.1109/ACPR.2017.10
Chen C, Odobez JM (2012) We are not contortionists: coupled adaptive learning for head and body orientation estimation in surveillance video. In: 2012 IEEE conference on computer vision and pattern recognition, p 1544–1551. https://doi.org/10.1109/CVPR.2012.6247845
Flohr F, Dumitru-Guzu M, Kooij JFP, Gavrila DM (2015) A probabilistic framework for joint pedestrian head and body orientation estimation. IEEE Trans Intell Transp Syst 16(4):1872–1882. https://doi.org/10.1109/TITS.2014.2379441
Bacciu D, Micheli A (2020) Deep learning for graphs. Recent Trends Learn Data 896:99–127. https://doi.org/10.1007/978-3-030-43883-8_5
Mohan A, Pramod KV (2022) Temporal network embedding using graph attention network. Complex Intell Syst 8:13–27. https://doi.org/10.1007/s40747-021-00332-x
Zhu HL, Lin N, Leung H, Leung R, Theodoidis S (2020) Target classification from SAR imagery based on the pixel grayscale target classification from SAR imagery based on the pixel grayscale decline by graph convolutional neural network. IEEE Sens Lett 4(6):1–4. https://doi.org/10.1109/LSENS.2020.2995060
Kipf TN, Welling M (2017) Semi-supervised classification with graph convolutional networks. In: 2017 5th International conference on learning representations (ICLR), p 24–26. https://doi.org/10.48550/arXiv.1609.02907
Velikovi P, Cucurull G, Casanova A, Romero A, Liò P, Bengio Y (2017) Graph attention networks. https://doi.org/10.48550/arXiv.1710.10903
Shen C, Zhao XM, Fan X, Lian XY, Zhang F, Kreidieh AR, Liu ZW (2019) Multi-receptive field graph convolutional neural networks for pedestrian detection. IET Intel Transport Syst 13(9):1319–1328. https://doi.org/10.1049/iet-its.2018.5618
Tang HW, Wei P, Li JP, Zheng NN (2022) EvoSTGAT: Evolving spatiotemporal graph attention networks for pedestrian trajectory prediction. Neurocomputing 491:333–342. https://doi.org/10.1016/j.neucom.2022.03.051
Yang J, Sun X, Wang RG, Li XX (2022) PTPGC: Pedestrian trajectory prediction by graph attention network with ConvLSTM. Robot Auton Syst 148:103931. https://doi.org/10.1016/j.robot.2021.103931
Liu QC, Xiao L, Yang JX, Wei ZH (2021) CNN-enhanced graph convolutional network with pixel- and superpixel-level feature fusion for hyperspectral image classification. IEEE Trans Geosci Remote Sens 59(10):8657–8671. https://doi.org/10.1109/TGRS.2020.3037361
Zhu HL, Lin N, Leung H, Leung R, Theodoidis S (2020) Target classification from SAR imagery based on the pixel grayscale decline by graph convolutional neural network. IEEE Sens Lett 4(6):1–4. https://doi.org/10.1109/LSENS.2020.2995060
Liang JL, Deng YF, Zeng D (2020) A deep neural network combined CNN and GCN for remote sensing scene classification. IEEE J Select Top Appl Earth Observ Remote Sens 13:4325–4338. https://doi.org/10.1109/JSTARS.2020.3011333
Han N (2020) Human pose estimation with spatial context relationships based on graph convolutional network. In: 2020 IEEE 5th Information technology and mechatronics engineering conference (ITOEC), p 1566–1570. https://doi.org/10.1109/ITOEC49072.2020.9141561
Wang R, Huang CY, Wang XY (2020) Global relation reasoning graph convolutional networks for human pose estimation. IEEE Access 8:38472–38480. https://doi.org/10.1109/ACCESS.2020.2973039
Wu YP, Kong DH, Wang SF, Li JH, Yin BC (2022) HPGCN: Hierarchical poselet-guided graph convolutional network for 3D pose estimation. Neurocomputing 487:243–256. https://doi.org/10.1016/j.neucom.2021.11.007
Tao J, Klette R (2014) Part-based RDF for direction classification of pedestrians, and a benchmark. In: 2014 Proceedings of the computer vision-ACCV 2014 workshops, Springer, p 418–432. https://doi.org/10.1007/978-3-319-16631-5_31
Munder S, Gavrila DM (2006) An experimental study on pedestrian classification. IEEE Trans Pattern Anal Mach Intell 28(11):1863–1868. https://doi.org/10.1109/TPAMI.2006.217
Jung HG, Kim J (2010) Constructing a pedestrian recognition system with a public open database, without the necessity of re-training: an experimental study. Pattern Anal Appl 13:223–233. https://doi.org/10.1007/s10044-009-0153-2
Dominguez-Sanchez A, Orts-Escolano S, Cazorla M (2017) Pedestrian movement direction recognition using convolutional neural networks. IEEE Trans Intell Transp Syst 18(12):3540–3548. https://doi.org/10.1109/TITS.2017.2726140
Gählert N, Jourdan N, Cordts M, Franke U, Denzler J (2020) Cityscapes 3D: dataset and benchmark for 9 DoF vehicle detection. https://doi.org/10.48550/arXiv.2006.07864
Zhang S, Benenson R, Schiele B (2017) CityPersons: a diverse dataset for pedestrian detection. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), p 4457–4465. https://doi.org/10.1109/CVPR.2017.474
Meletis P, Wen X, Lu C, Geus DD, Dubbelman G (2020) Cityscapes-panoptic-parts and PASCAL-panoptic-parts datasets for scene understanding. https://doi.org/10.48550/arXiv.2004.07944
Kawanishi Y, Deguchi D, Ide I, Murase H, Fujiyoshi H (2016) Misclassification tolerable learning for robust pedestrian orientation classification. In: 2016 23rd international conference on pattern recognition (ICPR), pp 486–491. https://doi.org/10.1109/ICPR.2016.7899681
Dafrallah S, Amine A, Mousset S, Bensrhair A (2021) Monocular pedestrian orientation recognition based on capsule network for a novel collision warning system. IEEE Access 9:141635–141650. https://doi.org/10.1109/ACCESS.2021.3119629
Acknowledgements
This work was supported by the National Natural Science Foundation of China (no. 61371108).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, X., Ma, S., Shan, L. et al. GRAN: graph recurrent attention network for pedestrian orientation classification. Complex Intell. Syst. 9, 891–908 (2023). https://doi.org/10.1007/s40747-022-00836-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00836-0