
Abstract
The Weighted Influence Nonlinear Measurement System (WINGS) method originates from DEMATEL, which has the advantage of analyzing the interweaved determinants and the causal relationships within them. The innovation is mainly reflected in considering both the strength of the influencing factors themselves and the relationship of their mutual influence. To address the problems of ambiguity in assessing information and uncertainty in the judgment of expert group, this paper proposes fuzzy WINGS improved by D numbers (fuzzy D-WINGS). Combining D numbers with Triangular fuzzy numbers can overcome the limitation of mutually exclusive and collectively extensive set. The WINGS method is used to reveal the interdependent causal relationships by recognizing the orientation and strength of the factors. Utilizing the MICMAC method to draw matrix analysis diagrams can further reveal the relationship among them. Finally, a practical case study is conducted to prove the practicability of this fuzzy D-WINGS–MICMAC method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
With the development of management, social sciences, operations research, medicine, economics, artificial intelligence, and decision problems, the structure methods have been implemented to unravel the limitations and restrictions encountered by managers and researchers under existing conditions, but decision makers frequently supply little information, and their subjective judgments are utilized to create uncertainty [1]. Multi-criteria decision-making (MCDM) is a prominent strategy for managing difficult decision-making issues facing several typically contradicting factors. Under the circumstances, the combination of structured evaluation methods with scientific data in MCDM is one of the key prerequisites for making the right decisions. But meanwhile existing evaluation methods often ignore the correlation between indicators and the ambiguity of the preferences expressed by experts [2].
To handle and manage the influence of ambiguity, the research of fuzzy logic is an excellent tool in MCDM, pioneered by Zadeh in 1965, which is frequently employed and developed nowadays. The fuzzy logic has the ability to deal with the information of partial truth, which is prevalent with ambiguous, inadequate, unclear, and inaccurate data. So it can formalize the human ability to make rational decisions for ambiguity problems without precision or calculations [3]. The issues with interdependent variables in MCDM, fuzzy logic utilizes a linguistic scale to represent the strength of cause-effect interactions. This scale is transformed into numerical values using fuzzy sets [4].
Dempster–Shafer evidence theory (DST) [5, 6] was established as a useful method to analyze the dynamic and unpredictable context as an extension of Bayesian probability theory, which has the advantage of describing the uncertain data by assigning a level of confidence. Consequently, DST is preferred by many researchers than the traditional methodologies as Bayesian probability theory [7]. Aside from the betterment that DST can tackle many issues, such as decision-making problems and risk theory [8, 9], it also has drawbacks as the limitation of mutually exclusive and collectively extensive set, as well as the sum of the values of the basic probability assignment must be one, which is hard to unravel in the real-world applications [10]. Exclusivity is one restriction which limits the wider practical implementation of DST while parsing elements of a subset. To overcome this shortage, Deng created a model to tackle the antagonistic issue as D numbers under uncertainty. D numbers theory appropriately eliminates this significant restriction, which can deal with these sorts of uncertainties by the trustworthy and effective depiction of uncertain information [11]. Therefore, D number theory is a powerful mathematical paradigm for coping with ambiguity and imperfect information [12]. Its border area provides the concept of ambiguity, which can be addressed using upper and lower approximations of the actual set using any equivalence relation [10]. As a result, it has been applied in a variety of application areas, including risk assessment [13], quality assessment [14, 15], supplier selection [16, 17], healthcare assessment [18, 19], and building assessment [20, 21].
A decision support model can be used and the results must be designed and configured in a real-world scenario. It is critical to ensure that the model can be dictated and guided to achieve its goals. In 1980, Saaty popularized the AHP as an MCDM technique [22]. The hierarchical structure in AHP can be shown as a visualization of the effect of criteria on the alternatives. ANP is extension of AHP which considers complicated interaction of selection factors in the hierarchical structure. In various disciplines, the fuzzy AHP and ANP have been utilized to deal with the fuzzy condition, such as Tolga et al. [23] used the fuzzy ANP method in location selection problem. Kumar et al. [24] estimated barriers in the agriculture supply chain by ANP. In addition, many other methods could be combined to solve the real problems. Kashav et al. [25] combined FAHP and TOPSIS, Buyukozkan and Guler [26] coupled AHP and VIKOR method to estimate the supply chain. Kumar and Barman [27] associated fuzzy TOPSIS and VIKOR in selecting green suppliers.
DEMATEL is a popular decision-making tool for dealing with interdependencies in MCDM environments with structure of complex causal relationships [28]. DEMATEL approach has been widely used in many areas, such as Shahidzadeh and Shokouhyar [29] discussed the logistics performance by fuzzy DEMATEL. Rajabpour et al. [30] combined Fuzzy AHP and type-2 fuzzy DEMATEL. Gao et al. [31] and Sun et al. [32] analyzed green supplier evaluation with DEMATEL, respectively. Liu et al. [33] studied Green supply chain management with the Grey-DEMATEL method.
Michnik created Weighted Influence Nonlinear Gauge System method [34]. Compared with DEMATEL method analyzing the direction and power of criteria, WINGS method utilizes the strength of factors, which can provide theoretical support and practical assistance for supply chain management. Reviewing the existing literature, integrated AHP, ANP, TOPSIS, and DEMATEL have been utilized to address hierarchical decision-making issues with interlaced factors, as shown in Table 1. These complicated issues can also be solved using the WINGS approach. The benefit of adopting WINGS over these integrated approaches is that the computational cost does not rise significantly when the number of criteria, sub-criteria, or alternatives grows. So far, it has been used in a few areas, as advanced technology projects [7], a case study in the automotive industry [35], green building development [20].
In this work, one of the main goals is to develop an integrated WINGS method with D number theory and MICMAC. The WINGS approach could be applied to find interrelations between assessment criteria by determining the direction of components, the intensity of the factors, and the strength of assessment criteria. The fuzzy logic can reduce the influence of ambiguous information and present subjective opinions in the form of a linguistic scale. D numbers has absolute advantage in dealing with the uncertain information, which can eliminate the restriction of mutually exclusive and collectively extensive set. Obviously, it is clear that the mutual influence of factors in supply chain management is interacting and ambiguous, which need to apply more objective and accurate evaluation in MCDM. Therefore, fuzzy logic and D number are employed to combine with the WINGS method. In addition, we use the MICMAC method to explain the interrelationships of the components more clearly. Finally, a case in ASCM is presented to illustrate the applicability of the fuzzy D-WINGS–MICMAC approach in this study. And the main contributions of the paper list as:
-
1.
This study contributes to decision theory by presenting a complete fuzzy D-WINGS–MICMAC approach that may be used by researchers to simultaneously modify judgement ambiguity, group choice variety, complicated interrelationships, and excessive computation effort in evaluation problems.
-
2.
The D number is extended to the fuzzy WINGS method. The combination of D number and fuzzy set can provide viable technique to reduce the subjectivity of expert preferences, as the D numbers theory can integrate group information more accurately.
-
3.
The factors affecting agriculture supply chain management are evaluated by previous features to demonstrate preferences of every expert group and aggregated into a complete result. The proposed technique is more objective than fuzzy WINGS since it overcomes the influence limitations of similar group perspectives.
The remainder of this article is shown as below. Section “Preliminaries” focuses on the preliminaries. Section “Methodology” details the fuzzy D-WINGS–MICMAC research methodology. Section “Empirical analysis” shows empirical analysis. Whereas, section “Conclusion” covers conclusion.
Preliminaries
D numbers
D numbers can handle uncertainty in the information being processed more efficiently. D numbers do not require the exclusivity of set components, which considerably broadens the practical application of D numbers [12].
Definition 1
([12]). Let T be a bounded non-empty set, and the mapping is D:T → [0,1],
\(\sum\nolimits_{S \subseteq T} {D(S) \le 1}\) and \(D(\emptyset ) = 0\), where \(S\) is any subset of \(T\) and \(\emptyset\) is an empty set.
The theory of D numbers, as described previously, has the advantage that does not need to be mutually exclusive. So, D numbers can be referred to presenting full information, such as \(\sum\nolimits_{S \subseteq T} {D(S) < 1}\).
If \(G\) is an individual set of ingredients \(G = \left\{ {a_{1,} a_{2} ,...,a_{j,} a_{k} ,...,a_{n} } \right\}\), where \(a_{j} \in R\) and \(a_{j} \ne a_{k}\) (when \(j \ne k\)), then the form of D numbers can be expressed as:
And the simplified description is \(D =[ ( {a_{1} ,u_{1} } ),( {a_{2} ,u_{2} } ),...,( {a_{j} ,u_{j} }),( {a_{k} ,u_{k} } ),...,( {a_{n} ,u_{n} } )]\). This presentation also satisfies the condition as \(u_{j} > 0\) and \(\sum\nolimits_{j = 1}^{n} {u_{j} \le 1}\).
Definition 2
([12]). Two D numbers defined as \(D_{1} = \left[ {\left( {a_{1} ,u_{1}^{1} } \right),...,\left( {a_{j} ,u_{j}^{1} } \right),...,\left( {a_{n} ,u_{n}^{1} } \right)} \right]\) and \(D_{2} = \left[ {\left( {a_{1} ,u_{1}^{2} } \right),...,\left( {a_{j} ,u_{j}^{2} } \right),...,\left( {a_{n} ,u_{n}^{2} } \right)} \right]\), then the combination of D numbers: \(C = D_{1} \odot D_{2}\):
with
Rule (2) generalizes the rule of Dempster [10]. Such as Q1 = Q2 = 1, then Rule (2) converts into Dempster’s rule. Rule (2) shows as a method for combining and fusing ambiguous data. For an individual \(D = \left[ {\left( {a_{1} ,u_{1} } \right),...,\left( {a_{j} ,u_{j} } \right),...,\left( {a_{n} ,u_{n} } \right)} \right]\), the integration operator presents as: \(M(D) = \sum\nolimits_{j = 1}^{n} {a_{j} u_{j} }\),where \(a_{j} \in R^{ + } ,u_{j} > 0,\sum\nolimits_{j = 1}^{n} {u_{j} \le 1}\).
Triangular fuzzy numbers
Zadeh initially introduces fuzzy set theory, which could effectively characterize the limitation of human cognitive processes. Because the advantage of fuzzy set can shift degrees of membership [36]. A Triangular fuzzy number symbolizes as \(\widetilde{\psi } = \left( {w,v,b} \right)\), where \(w \le v \le b\), then the membership function can be described by:
The basic operations can be denoted as:
where \(w_{1} ,w_{2} > 0;v_{1} ,v_{2} > 0;q_{1} ,q_{2} > 0.\)
Methodology
The fuzzy WINGS technique is expanded using D numbers under the vagueness present in group decision-making. The D numbers can be used to demonstrate include: (1) accounting for the ambiguity which processes in the expert comparison process; (2) constructing a range of fuzzy linguistic forms based on the inconsistencies and inaccuracies in expert preferences. Many multi-criteria models use fuzzy numbers to depict the ambiguity. With the advantage of D numbers, it is now feasible to handle the uncertainties in selecting fuzzy linguistic elements. D numbers presents the likelihood degree of each fuzzy linguistic variable. Furthermore, D numbers improve the effectiveness of the data collected by expert group. The next part describes the algorithm, which involves nine steps:
Step 1. Select the fuzzy linguistic scale for evaluation.
The corresponding numbers and scale defined as:
Step 2. Generate fuzzy initial strength-relation matrix of different group.
Factors analyzed by experts: Assuming that m experts are divided into two homogenous groups, GP1 and GP2, with comparing the n criteria, then the comments are transformed into the form of Triangular fuzzy numbers, where \(x = \left[ {x_{a} ,a = 1,2,...,n} \right]\).
The members in expert group should determine the degree of influence of criteria l on criteria m. The D numbers denote each expert group's comparative evaluation of the pair of jth and kth criteria.
\(D_{lm}^{1} = \left[ {\left( {a_{lm(1)}^{1} ,u_{lm(1)}^{1} } \right),...,\left( {a_{lm(j)}^{1} ,u_{lm(j)}^{1} } \right),...,\left( {a_{lm(s)}^{1} ,u_{lm(s)}^{1} } \right)} \right]\) and \(D_{lm}^{2} = \left[ {\left( {a_{lm(1)}^{2} ,u_{lm(1)}^{2} } \right),...,\left( {a_{lm(j)}^{2} ,u_{lm(j)}^{2} } \right),...,\left( {a_{lm(s)}^{2} ,u_{lm(s)}^{2} } \right)} \right],\) where \(D_{jk}^{1}\) and \(D_{jk}^{2}\) explicit the subjective preferences of GP1 and GP2. Then two nonnegative matrices can be gained as \(X_{{}}^{1} = \left[ {D_{lm}^{1} } \right]_{n \times n}\) and \(X_{{}}^{2} = \left[ {D_{lm}^{2} } \right]_{n \times n}\), which represents each expert group by the form of D numbers.
Step 3. Constructing a Triangular fuzzy strength-relation matrix X: Three stages are processed the conversion of D matrices values.
Phase 1: The vagueness indicated by the experts’ choices could be intermingled. As a result, using the property of \(D_{lm} = D_{l} \odot D_{m}\)(Eq. 3) to combine the numbers, the data given by experts as \(X_{{}}^{1} = \left[ {D_{lm}^{1} } \right]_{n \times n}\) and \(X_{{}}^{2} = \left[ {D_{lm}^{2} } \right]_{n \times n}\) could be analyzed and synthesized.
Phase 2: The ambiguities presented at the intersection of FLVs are converted into distinctive FLVs after performing the criterion for the combination of D numbers. FLVs may be defined as the term-set \(X = \left[ {x_{a} ,a = 1,2,...,n} \right]\), where \(x_{a}\) is a FLV seen in \(D_{lm}^{1}\) and \(D_{lm}^{2}\). Each term \(x_{a}\) is represented as a triangle fuzzy number as \(\widetilde{x} = \left( {x^{w} ,x^{v} ,x^{q} } \right)\), where \(x^{v}\) is the Triangular fuzzy number's (TriFN) center point, and \(x^{w}\) and \(x^{q}\) are the lower and higher boundaries.
The ratio between element \(e_{l,l + 1}\) of the FLVs can be used to process as follows:
where \(e_{l,l + 1}\) symbolizes the ratio of intersection between the linguistic values \(Q_{l}\) and \(Q_{l + 1}\), \(e_{l}\) and \(e_{l + 1}\) represent the linguistic value \(L_{l}\) and \(L_{l + 1}\). Then, a D matrix \(M = \left[ {D_{lm}^{{}} } \right]_{n \times n}\) can be obtained.
Phase 3: We translate the matrix \(M = \left[ {D_{lm}^{{}} } \right]_{n \times n}\) into the Triangular fuzzy strength-relation matrix \(\tilde{X} = \left[ {\tilde{x}_{lm}^{{}} } \right]_{n \times n}\), and the elements in \(\tilde{X}\) expressed by \(\widetilde{x}_{lm} = \left( {x_{lm}^{w} ,x_{lm}^{v} ,x_{lm}^{q} } \right)\), where n represents the number of FLVs.
Step 4. Generate the normalized fuzzy direct strength-influence matrix.
After forming the single fuzzy direct strength-influence matrix \(\tilde{X} = \left[ {\tilde{x}_{jk}^{{}} } \right]_{n \times n}\), the normalized fuzzy direct strength-influence matrix shows as \(\tilde{Z} = \left\{ {Z^{w} ,Z^{v} ,Z^{q} } \right\}\).
where \(\tilde{z}_{lm} = \left\{ {z_{lm}^{w} ,z_{lm}^{v} ,z_{lm}^{q} } \right\}\) indicates the values after normalized the matrix \(\tilde{X}\) by utilizing the following equations:
Step 5. The fuzzy total direction matrix \(H\left( {\tilde{Q}} \right)\) is obtained by the following equation:
Let \(H\left( {\tilde{Q}} \right) = \left[ {H\left( {\tilde{q}} \right)} \right]_{n \times n}\), where \(H\left( {\tilde{q}} \right) = \left[ {\left( {q_{lm}^{w} ,q_{lm}^{v} ,q_{lm}^{q} } \right)} \right]\), then:
Step 6. Obtain dependence matrix.
Let \(H\left( Q \right) = \left[ {H\left( {q_{lm} } \right)} \right]_{n \times n}\), then \(q_{jk}^{{}}\) can be calculated as follows:
Step 7. Achieve the sums of row and column in matrix Q.
We can sum the values in the directions of rows (R) and columns (L) in the dependence matrix Q as:
R depicts overall effect of element j as a cause on other elements, while L depicts the complete effect of other elements on element k as an effect.
Step 8. Delineate the cause-effect relationship chart.
In cause-effect chart, the value of (R + L) represents total degree of influence on the elements, which can be used to calculate the prominence of this element. A positive value evinces that the element is dominant, while the negative value expresses that the element is influenced. (R + L) and (R − L) are the symptoms of the horizontal and vertical axes of the cause-effect diagram. Furthermore, the WINGS methodology is more suited for studying real-world scenarios than DEMATEL, since it takes strength of elements into account. Using WINGS technique, it is possible to estimate and exploit the degree of correlation between the elements, as well as the dependencies and feedbacks of the elements in the network structure [20].
Step 9. Reachability matrix and MICMAC analysis.
The development of reachability matrix is remarkable for its ability to analyze the degree of impact. If the influence of a criterion on other criteria exceeds a threshold, the stimulus receives a response, indicating that the factor can directly influence other criteria; if the criterion's influence on other criteria is less than a threshold, the stimulus does not receive a response, indicating that the criteria have no effect on other. After that, the reachability matrix was separated into levels. MICMAC was developed by taking into consideration the interrelationships in the reachability matrix, which was developed to analyze the interrelationships and interactions between elements in a system [37]. The influence (driving) power of an element is calculated by adding all the "1" in the rows, while the dependency is calculated by adding all the "1" in the columns. This leads to an analytical representation of the correlation matrix, which consists of four components: autonomous, dependence, driving, and linkage factors. The autonomous part is composed of stimulus factors with low impact and low dependence. The driving part consists of factors with strong drive and low dependence. Influential factors with weak drive and high dependence make up the dependence part. The linkage part is composed of influences with strong drivers and dependencies.
Empirical analysis
This chapter demonstrates the implementation of the TriFN D-WINGS approach for measuring supply chain quality to gain an appropriate understanding the aspects affecting agriculture supply chain management (ASCM), which were precisely extracted and assessed using the TriFN D-WINGS–MICMAC methodology.
Evaluation system with D number and Triangular fuzzy number
Step 1: Construction of the influencing factors of ASCM.
An evaluation technique of the influencing aspects of ASCM has been established based on the state of ASCM and structural analysis methodologies used in supply chain management. We selected ten criteria as monitoring and licensing (P1), Government subsidies (P2), technical level (P3), customer demand/requirement (P4), environmental consciousness (P5), green design (P6), quality of produce (P7), cost and benefits (P8), infrastructure (P9), market channels (P10). To ensure the availability, we got the help from experts in economics, management, and agriculture.
Step 2: Experts’ analysis of factors.
The study included eight experts who were separated into two expert groups: GP1 and GP2, and propose their idea using fuzzy linguistic scale as Table 2. The evaluation values can be seen in Table 3.
Step 3: Obtain aggregated experts’ preferences.
The values of expert preferences should be aggregated into appropriate fuzzy values using Eqs. (3–5). Table 4 shows the use of the combination criterion within the expert dimensional analysis.
Step 4: Calculate the components of the normalized total fuzzy strength-influence matrix.
The components can be esteemed in Table 5 by Eqs. (6) and (7), which provides uncertainty by turning D numbers into Triangular fuzzy numbers. And the matrix is gained with the Eqs. (8) and (9) as shown in Table 6.
Step 5: Achieve the sums of row and column in the fuzzy total strength-influence matrix.
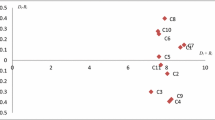
The optimal weight coefficients are determined by the total direct/indirect effects, while Eqs. (10) and (11) are used to enumerate the sums of R and L, which can be shown in Table 7 and Fig. 1.

The chart of interactive influence degree
Analysis of prominence
As indicated in Fig. 1 and Table 7, the terminal level of influencing components is P1 > P2 > P4 > P7 > P10 > P3 > P8 > P9 > P6 > P5. The findings show that monitoring and licensing (P1) is the most important component, meaning that P1 has the most direct and significant effect on ASCM. Government subsidies (P2), customer demand (P4), and quality of produce (P7) all have a significant influence. Environmental consciousness (P5), green design (P6), cost and benefits (P8), and infrastructure (P9) have the low level, meaning that these factors get low direct effect on ASCM. These data indicate that the ASCM is primarily impacted by the government, which provides monitoring, licensing and subsidies, as well as technology, which improves efficiency and quality.
Analysis of relation
Based on the R–L values, the fourteen contributing factors may be divided into two groups. As shown in Table 7 and Fig. 1, the cause group with high R–L values includes P4, P5, P6, P9, and P10, with the order P10 > P4 > P9 > P6 > P5. Market channels (P10) has the highest R–L value of these components, suggesting that market channels have the biggest influence on the ASCM and has a higher impact on other variables than other factors. The customer demand (P4) variable has the second highest R–L value, suggesting that it has a considerable impact on ASCM. Infrastructure (P9) has the third highest R–L score. The environmental factors are conventional roles for ASCM, include environmental consciousness (P5) and green design (P6). Through economic and social factors, they will impact the other aspects and the effect of ASCM.
Members of the effect group with negative R–L values are P1, P2, P3, P7, and P8, and their sequence is P8 > P3 > P7 > P2 > P1. Variables have more influence on other than receive influence by other variables, which is the effect group. The greater the variable influences on other variables, the lower R–L value is. Monitoring and licensing (P1) has the lowest R–L score, suggesting that other variables have the greatest impact on the market channel. Furthermore, cost and benefits (P8) have a high R–L value, indicating that it is a significant variable impacting ASCM. Government subsidies (P2) had the second lowest R–L value, showing that other variables have a significant effect on government subsidies. Technical level (P3) and quality of produce (P7) are the technical factors that are highly impacted by external variables.
To demonstrate the effect of the strength of the criteria, we use DEMATEL to compare with the results, for the reason that WINGS and DEMATEL have the similar type of date and simpler operation process than other methods. Through Table 7, we can find that the cause-effect type of the factors is same between two results, but the rank of the prominence is divergent. Obviously, the order of DEMATEL is P1 > P2 > P4 > P10 > P8 > P3 > P7 > P9 > P6 > P5, and the discordant components include P3, P7, P8, and P10. We think the main reason for the difference is the effect of the strength from these factors themselves, which plays an important role in the dimension of prominence.
Strategy analysis
We further separated criteria into four zones at the dimensions of prominence and relation depicted in Fig. 1 using Pan and Chen's [38] notion.
-
1.
Priority zone (high prominence and relationship): customer demand (P4) and market channels (P10) are all primarily from the economic dimension. These are the cause criteria and the basic components that influence the other criteria.
-
2.
Long-term zone (high prominence and low relation): monitoring and licensing (P1), government subsidies (P2), technical level (P3), quality of produce (P7), and cost and benefits (P8) perspectives can be enhanced when other indicators improve.
-
3.
Contingency zone (low prominence and high relationship): environmental consciousness (P5), green design (P6), and infrastructure (P9) are in economic dimension, which have a moderate influence on other components but are less influenced by other elements.
-
4.
No-priority zone (low prominence and relationship): there are no items in this category, which suggests that it’s difficult to have a direct improvement of the indicators in the short term.
Reachability matrix and structural model
We can utilize the threshold equal (1.118), which is determined by average value of all the elements in the total strength-relation matrix, to form the matrix of influence among criteria in Table 8, which is formed by deleting entries with values smaller than those in the total strength–relation matrix.
The data are summed by rows and columns separately to obtain the driving and dependence forces for each factor. Figure 2 shows a graph of driving and dependence power of criteria. The first autonomous component is infrastructure (P9) with a driving force of 4 and no dependencies, indicating that infrastructure is relatively independent in the AGSC. Environmental consciousness (P5) and green design (P6) are the drivers with high drivers and low dependencies, and can be the core factors driving the development of AGSC. In the dependence section, technical level (P3) and quality of produce (P7) have driving force less than 4 and dependency greater than 7, indicating that they receive more influence from other factors and cannot develop these factors independently, but must be developed in combination with other driving forces. The group of linkage factors are the most important factors that policy makers must prioritize for improving the effectiveness of agricultural supply chain management, and these factors include monitoring and licensing (P1), government subsidies (P2), and cost and benefits (P8), where P2 has driving force of 5 and dependency of 9; P1 has driving force and dependency of 5 and 10, respectively; P3 has driving force of 4 and dependency of 7. In the driving section, customer demand (P4) and market channels (P10) have driving force 7 and dependency 2, indicating that they have a high influence on other factors and can develop them independently.

The driving and dependence power diagram
Conclusion
The fuzzy WINGS approach is extended by D numbers in this study to resolve uncertainty which is unavoidable in the traditional decision-making procedures, particularly when there are many decision makers. With the combination of D numbers, it is feasible to consider additional uncertainty in the selection of fuzzy linguistic variables. As a complement to the fuzzy set, D numbers have the advantage of catching the likelihood of picking the fuzzy linguistic variable and improving the validity of current estimation within MCDM. WINGS technique can count both the strength and influence of interdependence, which cannot be captured in other similar approaches as DEMATEL. In addition, this integrated framework also has the capacity to efficiently capture and graphically represent intricate interwind interactions in situations with hierarchical structures, as well as user-friendliness and minimal computational complexity. Furthermore, with the information to capture uncertainties in the experts’ comparisons, the initial strength–influence matrix is then converted into a total strength–influence matrix, and causality is generated through the interaction, centrality, and causality of each component. Finally, the reachability matrix is created by setting a threshold to show the results of MICMAC. Through the ASCM example, this novel integrated fuzzy D-WINGS–MICMAC technique is obviously effective and adaptable, because it does not obey the restriction of mutually exclusive and collectively extensive set, as well as can analyze both the strength and the influence of dependence among the criteria or levels in decision issues.
For future study, other types of fuzzy numbers, such as type-2 fuzzy numbers or Gaussian fuzzy numbers, might be extended in this framework according to their applicability and related membership functions. We also recommend greater study into the MCDM models with evaluation of the degree and intensity of interdependence under the limits of subjective assessments. For this purpose, any other MCDM method (ANP, VIKOR, or DEMATEL, etc.) could be compared to test the suitability and validity of the introduced method. Finally, this method of our paper may be used in various situations such as the healthcare, transportation, risk management, and so on.
References
Tolga A, Basar M (2022) The assessment of a smart system in hydroponic vertical farming via fuzzy MCDM methods. J Intell Fuzzy Syst 42:1–12. https://doi.org/10.3233/JIFS-219170
Asan U, Kadaifci C, Bozdag E, Soyer A, Serdarasan S (2018) A new approach to DEMATEL based on interval-valued hesitant fuzzy sets. Appl Soft Comput 66:34–49. https://doi.org/10.1016/j.asoc.2018.01.018
Chen S-M, Chang C-H (2016) Fuzzy multiattribute decision making based on transformation techniques of intuitionistic fuzzy values and intuitionistic fuzzy geometric averaging operators. Inf Sci 352–353:133–149
Bakioglu G, Atahan A (2021) AHP integrated TOPSIS and VIKOR methods with Pythagorean fuzzy sets to prioritize risks in self-driving vehicles. Appl Soft Comput 2021:99. https://doi.org/10.1016/j.asoc.2020.106948
Seiti H, Hafezalkotob A, Najafi SE, Khalaj M (2019) Developing a Novel risk-based MCDM approach based on D numbers and fuzzy information axiom and its applications in preventive maintenance planning. Appl Soft Comput 82:105559
Zhang H, Peng H, Wang J, Wang J (2017) An extended outranking approach for multi-criteria decision-making problems with linguistic intuitionistic fuzzy numbers. Appl Soft Comput 59:462–474. https://doi.org/10.1016/j.asoc.2017.06.013
Hadi Mousavi-Nasab S, Sotoudeh-Anvari A (2020) An Extension of best-worst method with D numbers: application in evaluation of renewable energy resources. Sustain Energy Technol Assess 40:100771
Borah G, Dutta P (2021) Multi-attribute cognitive decision making via convex combination of weighted vector similarity measures for single-valued neutrosophic sets. Cogn Comput 13:1019–1033. https://doi.org/10.1007/s12559-021-09883-0
Karunathilake H, Bakhtavar E, Chhipi-Shrestha G, Mian HR, Hewage K, Sadiq R (2020) Decision making for risk management: a multi-criteria perspective. Methods Chem Process Saf 4:239–287
Liu P, Zhang X (2019) A multicriteria decision-making approach with linguistic D numbers based on the Choquet integral. Cogn Comput 11:560–575. https://doi.org/10.1007/s12559-019-09641-3
Deng X, Deng Y (2019) D-AHP method with different credibility of information. Soft Comput 23:683–691. https://doi.org/10.1007/s00500-017-2993-9
Mo H, Deng Y (2016) A new aggregating operator for linguistic information based on D numbers. Int J Unc Fuzz Knowl Based Syst 24:831–846
Pourmehdi M, Paydar M, Asadi-Gangraj E (2021) Reaching sustainability through collection center selection considering risk: using the integration of fuzzy ANP-TOPSIS and FMEA. Soft Comput 25:10885–10899. https://doi.org/10.1007/s00500-021-05786-2
Afrasiabi A, Tavana M, Di-Caprio D (2021) An extended hybrid fuzzy multi-criteria decision model for sustainable and resilient supplier selection. Env Sci Pollut Res. https://doi.org/10.1007/s11356-021-17851-2
Chen Y, Ran Y, Huang G, Xiao L, Zhang G (2021) A new integrated MCDM approach for improving QFD based on DEMATEL and extended MULTIMOORA under uncertainty environment. Appl Soft Comput 105:107222
Yildizbasi A, Arioz Y (2022) Green supplier selection in new era for sustainability: a novel method for integrating big data analytics and a hybrid fuzzy multi-criteria decision making. Soft Comput 26:253–270. https://doi.org/10.1007/s00500-021-06477-8
Yu Y, He Y, Zhao X, Zhou L (2019) Certify or not? An analysis of organic food supply chain with competing suppliers. Ann Oper Res 2019:4
Tolga A, Parlak I, Castillo O (2020) Finite-Interval-Valued Type-2 Gaussian fuzzy numbers applied to fuzzy TODIM in a Healthcare problem. Eng Appl Artif Intell 2020:87. https://doi.org/10.1016/j.engappai.2019.103352
Tolga A (2020) Real options valuation of an IoT based healthcare device with interval Type-2 fuzzy numbers. Socio-Econ Plan Sci 2020:69. https://doi.org/10.1016/j.seps.2019.02.008
Wang W, Tian Z, Xi W, Tan YR, Deng Y (2021) The influencing factors of china’s green building development: an analysis using RBF-WINGS method. Build Environ 188:107425
Akhanova G, Nadeem A, Kim JR, Azhar S (2020) A multi-criteria decision-making framework for building sustainability assessment in Kazakhstan. Sustain Cities Soc 52:101842
Saaty T (2013) The modern science of multicriteria decision making and its practical applications: the AHP/ANP approach. Oper Res 61:1101–1118. https://doi.org/10.1287/opre.2013.1197
Tolga A, Tuysuz F, Kahraman C (2013) A fuzzy multi-criteria decision analysis approach for retail location selection. Int J Inf Technol Decis Mak 12:729–755. https://doi.org/10.1142/S0219622013500272
Kumar S, Raut R, Nayal K, Kraus S, Yadav V, Narkhede B (2021) To identify industry 4.0 and circular economy adoption barriers in the agriculture supply chain by using ISM-ANP. J Clean Prod 2021:293. https://doi.org/10.1016/j.jclepro.2021.126023
Kashav V, Garg C, Kumar R (2021) Ranking the strategies to overcome the barriers of the maritime supply chain (MSC) of containerized freight under fuzzy environment. Ann Oper Res. https://doi.org/10.1007/s10479-021-04371-y
Buyukozkan G, Guler M (2021) A combined hesitant fuzzy MCDM approach for supply chain analytics tool evaluation. Appl Soft Comput 2021:112. https://doi.org/10.1016/j.asoc.2021.107812
Kumar S, Barman A (2021) Fuzzy TOPSIS and Fuzzy VIKOR in selecting green suppliers for sponge iron and steel manufacturing. Soft Comput 25:6505–6525. https://doi.org/10.1007/s00500-021-05644-1
Uygun Ö, Kaçamak H, Kahraman ÜA (2015) An integrated DEMATEL and Fuzzy ANP techniques for evaluation and selection of outsourcing provider for a telecommunication company. Comput Ind Eng 86:137–146. https://doi.org/10.1016/j.cie.2014.09.014
Shahidzadeh M, Shokouhyar S (2022) Toward the closed-loop sustainability development model: a reverse logistics multi-criteria decision-making analysis. Env Dev Sustain. https://doi.org/10.1007/s10668-022-02216-7
Rajabpour E, Fathi M, Torabi M (2022) Analysis of factors affecting the implementation of green human resource management using a hybrid fuzzy AHP and Type-2 Fuzzy DEMATEL approach. Env Sci Pollut Res. https://doi.org/10.1007/s11356-022-19137-7
Gao H, Ju Y, Gonzalez E, Zeng X, Dong P, Wang A (2021) Identifying critical causal criteria of green supplier evaluation using heterogeneous judgements: an integrated approach based on cloud model and DEMATEL. Appl Soft Comput 2021:113. https://doi.org/10.1016/j.asoc.2021.107882
Sun H, Mao W, Dang Y, Xu Y (2022) Optimum path for overcoming barriers of green construction supply chain management: a Grey possibility DEMATEL-NK approach. Comput Ind Eng 2022:164. https://doi.org/10.1016/j.cie.2021.107833
Liu J, Feng Y, Zhu Q (2021) Involving second-tier suppliers in green supply chain management: drivers and heterogenous understandings by firms along supply chains. Int J Prod Res. https://doi.org/10.1080/00207543.2021.2002966
Michnik J (2013) Weighted influence non-linear gauge system (WINGS)—an analysis method for the systems of interrelated components. Eur J Oper Res 228:536–544. https://doi.org/10.1016/j.ejor.2013.02.007
Kaviani MA, Tavana M, Kumar A, Michnik J, Niknam R, de Campos EAR (2020) An integrated framework for evaluating the barriers to successful implementation of reverse logistics in the automotive industry. J Clean Prod 272:122714
Chen Z, Ming X, Zhang X, Yin D, Sun Z (2019) A Rough-Fuzzy DEMATEL-ANP method for evaluating sustainable value requirement of product service system. J Clean Prod 228:485–508. https://doi.org/10.1016/j.jclepro.2019.04.145
Usmani M, Wang J, Ahmad N, Ullah Z, Iqbal M, Ismail M (2022) Establishing a corporate social responsibility implementation model for promoting sustainability in the food sector: a hybrid approach of expert mining and ISM-MICMAC. Env Sci Pollut Res 29:8851–8872. https://doi.org/10.1007/s11356-021-16111-7
Pan J, Chen S (2012) A new approach for assessing the correlated risk. Ind Manag Data Syst 112:1348–1365. https://doi.org/10.1108/02635571211278965
Acknowledgements
This work was supported by the National Social Science Foundation of China (No. 21BJY027)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, M., Tian, Y. & Zhang, K. The fuzzy Weighted Influence Nonlinear Gauge System method extended with D numbers and MICMAC. Complex Intell. Syst. 9, 719–731 (2023). https://doi.org/10.1007/s40747-022-00832-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00832-4