
Abstract
This paper addresses a multi-objective energy-efficient scheduling problem of the distributed permutation flowshop with sequence-dependent setup time and no-wait constraints (EEDNWFSP), which have important practical applications. Two objectives minimization of both makespan and total energy consumption (TEC) are considered simultaneously. To address this problem, a new mixed-integer linear programming (MILP) model is formulated. Considering the issues faced in solving large-scale instances, an improved non-dominated sorting genetic algorithm (INSGA-II) is further proposed that uses two variants of the Nawaz-Enscore-Ham heuristic (NEH) to generate high-quality initial population. Moreover, two problem-specific speed adjustment heuristics are presented, which can enhance the qualities of the obtained non-dominated solutions. In addition, four local and two global search operators are designed to improve the exploration and exploitation abilities of the proposed algorithm. The effectiveness of the proposed algorithm was verified using extensive computational tests and comparisons. The experimental results show that the proposed INSGA-II is more effective compared to other efficient multi-objective algorithms.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
With rapid economic globalization, transnational cooperation among enterprises has become common practice. Distributed manufacturing improves product quality, reduces production costs, and minimizes management risk [1]. Incidentally, development of the manufacturing industry causes environmental problems, and green manufacturing has been gaining attention. Production scheduling is vital in realizing intelligent green manufacturing [2]. Therefore, it is important to pay more attention to energy consumption in actual production, especially to combine energy-saving with traditional criterions.
The no-wait flow-shop scheduling problem (NWFSP) is a typical production shop scheduling problem, and is widely used in the plastic, chemical, and pharmaceutical industries [3]. When the number of machines exceeds three, the problem is proved to be NP-hard [4]. Specifically, in a no-wait flow-shop, each job needs to be processed continuously to complete a set of processes without interruption. Consequently, the concept of distributed scheduling is added to make the problem more complex. The distributed permutation flowshop scheduling problem (DPFSP) [5] is decomposed into two sub-problems: assign jobs to factories and get the sequence of each job in each factory. In the actual production process, the machine needs to perform additional operations between the processing of consecutive jobs, such as machine cleaning, tool replacement, and operation transportation [6]. Therefore, a sequence-dependent setup time (SDST) is also considered. A literature review of the above-mentioned problems is provided below.
Recently, the distributed flow shop scheduling problem has interested industry and academia. An increasing number of studies have focused on the distributed scheduling of permutation flow shop [6,7,8,9,10,11], hybrid flow shop [12,13,14,15], assembly flow shop [16,17,18] and so on. Lin et al. [19] developed an iterated cocktail greedy (ICG) algorithm to solve the distributed no-wait flow-shop scheduling problem (DNWFSP). Shao et al. [20] investigated the multiobjective DNWFSP with sequence-dependent setup time and solved it through a Pareto-based estimation of distribution algorithm (PEDA). Komaki and Malakooti [21] addressed the DNWFSP using a General Variable Neighborhood Search (GVNS). Shao et al. [22] proposed iterated greedy (IG) algorithms. Li et al. [23] solved the distributed heterogeneous DNWFSP using a discrete artificial bee colony algorithm (DABC). Other literature considered the sequence-dependent setup time in different actual production system [24,25,26].
To solve the multi-objective optimization problem of green shop scheduling, Wang et al. [7] proposed a knowledge-based cooperative algorithm (KCA) to solve an energy-efficient scheduling of the distributed permutation flow-shop (EEDPFSP). Wang et al. [8] used a multi-objective whale swarm algorithm (MOWSA) to solve EEDPFSP. Wu et al. [27] proposed a green scheduling algorithm NSGA-II that considered the energy consumption of equipment on–off and different rotating speeds to solve the flexible job shop scheduling problem (FJSP). Du et al. [28] investigated an FJSP with the time-of-use electricity price constraint via a hybrid multi-objective optimization algorithm of estimation of distribution algorithm (EDA) and deep Q-network (DQN) to minimize the makespan and total electricity price simultaneously. Li et al. [29] addressed an FJSP with crane transportation processes using a hybrid of the iterated greedy and simulated annealing algorithms to optimize both the makespan and energy consumption during machine processing as well as crane transportation. Qi et al. [30] researched a multi-objective time-dependent green vehicle routing problems and proposed a Q-learning-based multiobjective evolutionary algorithm to solve it. Jiang et al. [31] developed an effective modified multi-objective evolutionary algorithm with decomposition (MMOEA/D) to solve the energy-efficient distributed job shop scheduling problem. Li et al. [32] designed an energy-aware multi-objective optimization algorithm (EA-MOA) to solve the hybrid flow shop (HFS) scheduling problem with setup energy consumptions. Li et al. [33] introduced a distributed HFS with variable speed constraints using a knowledge-based adaptive reference points multi-objective algorithm. A collaborative optimization algorithm (COA) based on specific properties of the problem was proposed by Chen et al. [34] to solve an energy-efficient distributed no-idle permutation flow-shop scheduling problem. In addition, the indicator based multi-objective evolutionary algorithm with reference point adaptation (AR-MOEA) and hyperplane assisted evolutionary algorithm (hpaEA) are the latest algorithms to solve multi-objective problems. AR-MOEA is versatile in solving problems with various types of Pareto fronts, and is superior to several existing evolutionary algorithms for multi-objective optimization [35]. While solving multi-objective optimization problems, the proportion of non-dominated solutions in the population increases sharply with an increase in the number of objectives. It becomes more challenging to strengthen the selection pressure of population toward the Pareto-optimal front. To address these issues, Chen et al. [36] proposed the hpaEA.
In this study, we investigate a distributed no-wait permutation flow shop scheduling problem with sequence-dependent setup time to minimize the total energy consumption and makespan simultaneously. The contributions of this research work can be summarized as follows: (1) The energy-efficient distributed permutation flow shop scheduling problem with no-wait and setup time constraints in the presence of dynamic speed-scaling technique is formulated and solved for the first time. (2) Two problem-specific effective speed adjustment heuristics are proposed, which perform local enhancement together with four mutation operators. (3) Two types of crossover operators are designed to improve the algorithm’s global search abilities.
The remainder of this paper is organized as follows. In “Problem description and formulation”, the problem is formally described and the MILP is established. The subsequent section presents the problem-specific properties. and “Improved NSGA-II algorithm” introduces all the components of INSGA-II. In “Experiments and results”, numerical experiments and comparative analysis are carried out. “Conclusion” concludes this paper, and points out several research directions.
Problem description and formulation
Definition of multi-objective optimization problem
To explain the proposed EEDNWFSP that considers the optimization of two conflicting objectives, the basic concepts of multi-objective optimization problems are briefly introduced here:
where \(f_{1} (x),f_{2} (x),...,f_{m} (x)\) denote m conflicting objective functions, and \(\Omega\) is the search space of a solution \(x\).
-
(1)
Pareto Dominance: For two feasible solutions \(x\) and \(x^{\prime}\), if \(\forall l \in \{ 1,2,...,m\}\), \(f_{l} (x) \le f_{l} (x^{\prime})\) and \(\exists l^{^{\prime}} \in \{ 1,2,...m\}\), \(f_{l^{\prime}} (x) < f_{l^{\prime}} (x^{\prime})\), then \(x\) is said to dominate \(x^{\prime}\) (denoted as \(x \succ x^{\prime}\)). If the solution \(x\) is not dominated by any other feasible solutions, it is called a non-dominated solution.
-
(2)
Pareto front: All the non-dominated solutions constitute the Pareto-optimal set and their projection in objective space forms the optimal Pareto front.
Description of EEDNWFSP
This paper considers an energy-efficient no-wait permutation flow shop scheduling problem to optimize both makespan and total energy consumption in the presence of dynamic speed-scaling technique. Specifically, there are g parallel factories, each one contains m machines. A set of jobs n can be assigned to any factory \(f \in \{ 1,2,...,g\}\) and should be processed according to the same processing order, i.e., from machine j = 1 to j = m in the assigned factory. The job processing sequence is the same for all machines in a factory. Formally, for each factory, it is a regular PFSP [5]. Moreover, each job \(i \in \{ 1,2,...,n\}\) should be processed between consecutive operations without interruptions; that is, as soon as a job finishes its processing on one machine, it must be processed by the next one immediately. Each machine has a set of variable processing speeds s, which can be selected for each operation. After assigning a processing speed \(v \in \{ 1,2,...,s\}\), the operation should be processed at speed v until its completion. Each job needs a basic processing time to be processed at the slowest speed. The basic processing time of jobs is fixed, and the actual processing time is obtained through dividing the basic processing time by the processing speed. Setup time and energy consumption are also considered. As show in Fig. 1, the EEDNWFSP is to assign jobs to factories, determine the job processing sequence of the assigned factory, and select the appropriate processing speed to optimize certain scheduling objectives. In this study, the objective is to minimize the maximum completion time (makespan) and the total energy consumption (TEC) simultaneously.

Example of EEDNWFSP
The assumptions and constraints for this study are as follows:
-
All factories have the same processing capacities, i.e., the number of machines and processing ability are the same.
-
All machines are available at time zero, and all jobs can be scheduled at this time.
-
Each job can be processed on exactly one machine at a time in the same factory.
-
Each machine can process only one job at a time.
-
Preemption is not permitted, that is, one job should be completed on the assigned machine without any interruption.
-
The processing speed of each machine can be adjusted; therefore, the actual processing time and machine energy consumption should be varied with the speed.
-
During the processing of a job, the speed of each machine cannot be changed.
-
For two successive operations on the same machine, the start processing time of the subsequent operation should be greater than or equal to the completion time of the previous one.
-
No-wait constraint should be guaranteed, that is, after completing the previous stage, the job should start its next stage immediately.
-
The sequence dependent setup times cannot be ignored.
Notations and parameters
Indexes
\(i\): | Index for jobs, \(i = 1,2,...,n\) |
\(k\): | Index for job positions in a sequence, \(i = 1,2,...,n\) |
\(j\): | Index for machines, \(j = 1,2,...,m\) |
\(f\): | Index for factories, \(f = 1,2,...,g\) |
\(v\): | Index for speeds, \(v = 1,2,...,s\) |
Parameters
\(n\): | The number of jobs |
\(m\): | The number of machines in each factory |
\(g\): | The number of factories |
\(s\): | The number of processing speeds |
\(p_{i,j}\): | The standard processing time of job i at machine j |
\(V_{v}\): | The processing speed at v th |
\(st_{j,i,i^{\prime}}\): | The setup-time of job i' on machine j if job i is the immediately preceding job |
\(PE_{j,v}\): | The unit time energy consumption of machine j running at v th speed |
\(SPE_{j}\): | The unit time energy consumption of machine j in stand-by state |
\(SE_{j,i,i^{\prime}}\): | The unit setup-time energy consumption of job \(i^{\prime}\) on machine j if job i is the immediately preceding job |
\(M\): | A very large positive value |
Variables
\(x_{i,f,k}\): | Binary variable, if job i occupies position k in factory f, then the value is 1, and 0 otherwise |
\(y_{i,j,v}\): | Binary variable, if job i is processed with speed v on machine j, then the value is 1, and 0 otherwise |
\(t_{i,j}\): | The actual processing time of job i at machine j |
\(pec_{i,j}\): | The processing energy consumption of job i at machine j |
\(S_{i,j,f}\): | The time that job i in factory f starts processing on machine j |
\(C_{i,j,f}\): | The completion time of job i on machine j in factory f |
\(C_{f}\): | The completion time of factory f |
\(C_{\max }\): | The total completion time, that is, the maximum completion time in g factories |
\(PEC\): | The energy consumption of the machine in the processing state |
\(SPEC\): | The energy consumption of the machine in stand-by state |
\(SEC\): | The energy consumption of the machine in the state of setup |
\(TEC\) | The total energy consumption |
Formulation of EEDNWFSP
With the above notations, the following mathematical model of the problem is presented:
Objective functions:
Objective (2) is to minimize the maximum completion time, where \(C_{f}\) represents the completion time of factory f. Objective (3) is to minimize the total energy consumption, where PEC represents the energy consumption when the machines stay at the processing state. SPEC represents the energy consumption when the machines stay at the stand-by state. SEC represents the energy consumption when the machines stay at the setup state.
Constraints:
Constraint (7) ensures that each job is assigned to only one factory and to one position in the assigned factory. Constraint (8) requires that a position in a factory is assigned to at most one job. Constraint (9) ensures that the jobs must be assigned at the preceding positions of a factory. Constraint (10) guarantees that each operation \(Oi,j\) has one and only one speed processing. Equation (11) calculates the actual processing time. Constraint (12) ensures that the first job assigned to a factory can begin only after the setup is finished, while Constraint (13) restricts that a job (except the job in the first position) can only start after the job at the preceding position as well as the setup have been finished. Constraint (14) ensures that the subsequent operation of each job is started immediately after the completion of the precursor. Constraint (15) specifies that the operation cannot be interrupted. Constraints (16) and (17) are defined to calculate the completion time of the factory f. Constraints (18) and (19) define the intermediate variable \(pec_{i,j}\) for calculating the processing energy consumption. All the binary variables are defined in Constraints (20) and (21), where \(x_{i,f,k}\) gives the factory assignment of each job and the processing sequence in the assigned factory and \(y_{i,j,v}\) gives the speed of each operation.
In the problem, different machines can be set to different units of energy consumption at a given speed. Moreover, it is assumed that machines cannot be turned off until all jobs assigned to the factory are completed. It is obvious that the higher the processing speed, the shorter the processing time and the higher the energy consumption of the machine. Thus, the two optimization objectives are conflicting.
Problem-specific properties
In this section, two lemmas are proposed based on the problem-specific properties. Then, according to these properties and lemmas, two efficient heuristics are designed and utilized in the local search discussed in “DST-based speed adjustment heuristics”.
Before the study of problem properties, an assumption is made: when a job \(i \in n\) is processed at a higher speed on a machine \(j \in m\), the processing time decreases, but the processing energy consumption is increased. This implies that
with this assumption, the following property is observed.
Property 1
Consider two solutions \(a = (\Pi ,V)\) and \(b = (\Pi ,V^{\prime})\), that is, the scheduling Π of both are fixed. The solution b is dominated by the solution a if the previous solution has a faster processing speed. Namely, we have \(a \prec b\), if the following conditions are satisfied, then \(TEC(a) < TEC(b)\):
-
(1)
\(C\max (a) \le C\max (b)\);
-
(2)
\(\forall i \in \{ 1,2,...,n\} ,j \in \{ 1,2,...,m\} ,v_{i,j} (a) \le v_{i,j} (b)\);
-
(3)
\(\exists i \in \{ 1,2,...,n\} ,j \in \{ 1,2,...,m\} ,v_{i,j} (a) < v_{i,j} (b)\).
This property can be proved by a method similar to Property 2 of Ding et al. [37]. To describe the lemmas in detail, the following definitions are given. For the sake of simplicity, the following \(S_{i,j,f}\) represents the starting time of job i on machine j in factory f, that is, it is calculated from the time of preparation.
Definition 1
(Right side idle time): right side idle time \(R_{i,j}\) of an operation \(O_{i,j}\) is calculated as follows:
Definition 2
(Left side idle time): left side idle time \(L_{i,j}\) of an operation \(O_{i,j}\) is defined by
Definition 3
(Critical machine): machine \(\underline{j}_{\pi (i)}\) or \(\overline{j}_{\pi (i)}\) is called a critical machine for job i if \(Ci,j,f = Si + 1,j,f\) (for right side idle time) or \(Si,j,f = Ci - 1,j,f\) (for left side idle time). Note that there is only one \(\underline{j}_{\pi (i)}\) and one \(\overline{j}_{\pi (i)}\) for job i, that is, once found, the search will stop.
In particular, for the first processing job in the scheduling, there is only the right idle time. And for the last processing job, there is only the left idle time. A detailed explanation is provided in Fig. 2. It is obvious that \(R_{i,j}\) of job i refers to the same area as \(L_{i,j}\) of job \(i + 1\).

Illustration of deceleration and left shift
Lemma 1
For each job i, find its \(\underline{j}_{\pi (i)}\) from Mm to M1. If the critical machine is not used for the last operation of the job, there is \(R_{i,j}\) of each subsequent operation. Slowing down the processing speed under the premise that the \(\Delta PT_{i,j}\) will not exceed the minimum \(R_{i,j}\) can reduce both the PEC and SPEC.
Proof
To prove this lemma, we first show that slowing down any operation that satisfies \(\Delta PT_{i,j} \le \min R_{i,j}\) does not worsen the makespan. For each \(O_{i,j}\), this condition guarantees that the starting time of job i + 1 is not be delayed. Both the start and completion times of all operations after the \(O_{i,j}\) for job i are changed, as shown in Eqs. (26) and (27).
In particular, for job i, all operations can be processed in advance if there is no \(S_{i,j,f} = C_{i - 1,j,f}\) due to the start time that is delayed. In this case, the completion time is be reduced, as shown in Fig. 2b and d.
Lemma 2
For each job i, find its critical machine from M 1 to M m . If the \(\overline{j}_{\pi (i)}\) is not M 1 , there is \(L_{i,j}\) of each preceding operation. Slowing down the processing speed under the premise that the \(\Delta PT_{i,j}\) will not exceed the minimum \(L_{i,j}\) can reduce both the PEC and SPEC.
Proof
Similar to the proof of Lemma 1, for each \(O_{i,j}\), condition \(\Delta PT_{i,j} \le \min L_{i,j}\) ensures that the completion time of all jobs will not be delayed. Besides, the time of all operations before the \(O_{i,j}\) for job i are changed, as shown in Eqs. (28) and (29).
Similarly, for job i + 1, all operations can be processed in advance if there is no \(S_{i + 1,j,f} = C_{i,j,f}\). As shown in Fig. 2b and f, the completion time will also reduce.
In sum, by slowing down the operations that satisfy \(\Delta PT_{i,j} \le \min R_{i,j}\) or \(\Delta PT_{i,j} \le \min L_{i,j}\), there is always \(C_{\max } (a) \le C_{\max } (b)\). And combined with \(v_{i,j} (a) < v_{i,j} (b)\), it follows from Property 1 that \(TEC(a) < TEC(b)\).
Improved NSGA-II algorithm
Framework of INSGA-II
The nondominated sorting genetic algorithm II (NSGA-II) presented by Deb et al. [38] is a classical algorithm tailored to solve multi-objective problems. It has three outstanding contributions to address the shortcomings of the NSGA: fast nondominated sorting, crowded-comparison approach, and a novel elite selection strategy. Although the existing NSGA-II has made creative improvements in the above three aspects and showed the superiority to generate good individuals, two classical genetic operators of crossover and mutation have not been further researched. The traditional crossover and mutation operators are random and aimless, which cannot guarantee the generation of high-quality offspring and affects the efficacy of the algorithm. Therefore, an improved non-dominated sorting genetic algorithm (INSGA-II) is proposed here for arriving at the multi-objective solutions of the problem.
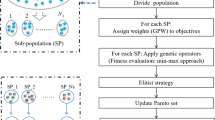
The proposed improved NSGA-II algorithm is presented, which includes the main framework, an encoding and decoding method, two efficient initialization heuristics, two problem-specific speed adjustment heuristics combined with four mutation operators to form a local search strategy, and two crossover operators to conduct global search. The framework of the INSGA-II for solving the EEDNWFSP is described in Fig. 3.

Framework of the INSGA-II
Encoding and illustration
For the EEDNWFSP, a solution is represented by two vectors, that is, the scheduling vector, which contains the factory assignment, and the speed vector for each job processed on each machine. The scheduling vector contains \(n + g - 1\) elements [39], i.e., \(\Pi = (\pi_{1} ,\pi_{2} ,...,\pi_{i} ,...,\pi_{n + g - 1} )\), where \(\pi_{i} \in \{ 0,1,2,...,n\}\). There are n indexes of jobs and \(g - 1\) indexes with value ‘0’ as the separators. The separators divide Π into g sections, each of which contains a scheduling sequence of partial jobs. The speed of each operation is listed in \(m * n\) elements. Thus, a solution is encoded as \((\Pi ,V) = (\pi_{1} ,\pi_{2} ,...,\pi_{i} ,...,\pi_{n + g - 1} ;v_{1,1} ,...,v_{1,m} ,...,v_{n,1} ,...v_{n,m} )\). As show in Fig. 4.

Encoding of EEDNWFSP
A simple example is provided to understand the encoding and decoding method. There are two parallel factories, each of which has three machines. Each machine has two different speeds for processing. And there are six jobs to be processed. That is, g = 2, m = 3, and n = 6. The standard processing times, the energy consumption of each machine run at each speed and in stand-by mode are listed in Table 1. The sequence-dependent setup time and the setup energy consumption are given in Table 2.
For ease of presentation, V is presented as the following matrix:
Considering a solution \(\Pi = \{ 2,5,4,0,6,3,1\}\), a detailed description is given as follows: job 2 is processed first, then jobs 5 and 4 are processed in turns in factory 1. The real processing time of job 2 on machine 1 is \(t_{2,1} = p_{2,1} /V_{2,1} = 21 \div 2 = 10.5\). The operation times related to the sequence are \(st_{1,2,2} = 2,st_{2,2,2} = 9,st_{3,2,2} = 10\). Consequently, the completion time of factory 1 is the completion time of job 4 on machine 3, which is \(C(1) = 88.5\) after calculation. Similarly, the completion time of factory 2 can be obtained \(C(2) = 66.5\). Thus, \(C_{\max }\) is 88.5. Next, the calculation of energy consumption is explained. For instance, in factory 1, machine 1–3 run at the speed of 2, 2, and 2 when processing job 2, respectively. Thus, the energy consumption of job 2 in the processing and setup states is calculated as follows:\(PEC_{2} = t_{2,1} \cdot PE_{1,2} + t_{2,2} \cdot PE_{2,2} + t_{2,3} \cdot PE_{3,2} = 10.5 \times 6 + 10 \times 12 + 15.5 \times 6 = 276\);\(SEC_{2} = st_{1,2,2} \cdot SE_{1,2,2} + st_{2,2,2} \cdot SE_{2,2,2} + st_{3,2,2} \cdot SE_{3,2,2} = 2 \times 2 + 9 \times 2 + 10 \times 2 = 42\). Therefore, the TEC can be calculated by accumulating the PEC, SPEC, and SEC of each factory.

Initialization procedure
In multi-objective evolutionary algorithms, the quality of the initial population has an important impact on the algorithm performance. As we know, the two objectives considered in this paper conflict with each other, and finding the extreme value of each objective can effectively guide optimization. The NEH [40] heuristic has been identified as one of the most efficient constructive heuristics for the PFSP with the makespan criterion [41]. Combined with distributed characteristics, Ruiz et al. [5] proposed two factory assigned rules that extended the basic NEH. In addition, Wang et al. [7] proposed the extended NEHFF (NEHFF2) that considers energy efficiency. Inspired by these previous studies and based on the two current objectives, we propose two extended distributed NEH heuristics, named ENEH and ENEH2, respectively. In this paper, random initialization is performed, and then two individuals are replaced by two solutions generated by ENEH and ENEH2. The procedure of ENEH is shown in Algorithm 1. The difference between ENEH2 and ENEH is that the TEC is compared first in Step 14. Then, the makespan is compared so as to construct another solution that is more optimal in terms of energy consumption.
Local search
DST-based speed adjustment heuristics
Based on Lemmas 1 and 2 discussed in “Problem-specific properties”, two effective speed adjustment heuristics are proposed. For either of the two algorithms, a new neighborhood solution is constructed by appropriately slowing down the speed matrix V. Therefore, a better solution is obtained, which can reduce the TEC without increasing the makespan values. The two heuristics, named dynamic speed-scaling technique 1 (DST1) and 2 (DST2), are described in Algorithm 2 and Algorithm 3 respectively.

Mutation operators
For the optimization of completion time, several search operators are designed. Specifically, this section proposes four local search methods to improve the solution using insert and swap operators between or within factories.
Definition 4
(Critical factory): critical factory fc is the one with the maximum completion time.
-
(1)
Operators to adjust factory assignment:
\(FA_{i}\): a job is randomly removed from fc and inserted into a random position in another factory. The factory to be inserted is selected from small to large according to completion times.
\(FA_{s}\): a job i is randomly selected from a factory and job i' from another factory is randomly selected, and then the two jobs are swapped.
First, the factories are arranged in the descending order of completion times. Then while swapping, the first factory swaps with the last factory, the second factory swaps with the penultimate factory, and so on.

-
(2)
Operators to adjust the scheduling of jobs in the same factory:
\(J_{i}\): randomly select two jobs from the same factory and then insert the successor into the position before the previous one.
\(J_{s}\): randomly select two jobs from the same factory and then swap them.
In order to find a better solution, based on the above four search operators and the two speed adjustment heuristics in “DST-based speed adjustment heuristics”, a novel local search strategy is proposed which is described in Algorithm 4. To be specific, it combines four mutation operators and two speed adjustment heuristics and implements them according to probability. First, the completion time of each factory is normalized by Formula (28), where the \(F_{\min }\) is 0. Then, find the factory (\(C_{\min }\)) with the smallest completion time, and select the corresponding mutation operator according to the completion time. For factories with \(C_{\min } < 0.8\), \(FA_{i}\) is executed because it means that the completion times of this factory and critical factory \(fc\) are quite different. The insertion operator between the factories is used to balance the completion time. The remaining three mutation operators are executed with almost an equal probability. Finally, one of DST1 and DST2 is arbitrarily selected in accordance with the equal probability to adjust the speed.

Global search
Considerable research on intelligent scheduling exists, which focus on designing crossover operators for specific problems to improve the performance of evolutionary algorithms. Specially, Han et al. [42] proposed two enhanced crossover operators based on similar block order crossover (SBOX) [43] and artificial chromosome (ACJOX) [44], which are named improved SBOX (ISBOX) and improved SJOX (ISJOX), respectively. Inspired by the idea of using the information of non-dominated solutions to preserve good gene blocks, the corresponding ISBOXII and ISJOXII are conceived according to the specific encoding.
The steps of ISBOXII are presented as follows:
-
Step 1: for each job, count the number of subsequent jobs in the current non-dominated solution set to find the one with the most occurrences. A temporary set is consisted of these gene pairs.
-
Step 2: two individuals were randomly selected as parents from the parent population.
-
Step 3: in a parent, for a job in each position, a gene pair is formed with its subsequent job, and the gene pair is searched in the temporary set.
-
Step 4: if the parent and the temporary set have the common gene pairs, the identical gene pairs are put into offspring at the same position.
-
Step 5: otherwise, compare two parent genes in the same position, and put the common gene into the same position of the corresponding offspring respectively.
-
Step 6: the genes of the offspring in the rest positions are filled using the one-point order crossover (OP) [45] based on the two parents.
An example is provided below to illustrate how ISBOXII works. Suppose that there are five non-dominated solutions in the current set, expressed as Πi, i = 1,2,3,4,5, each containing seven jobs and two factories. The crossover operator only considers the operation of the scheduling part and ignores the speed part temporarily. That is, the speed part uses random crossover. Their expressions are given in Fig. 5. For all the non-dominated solutions, count the times job j (j = 1,2,…,7) appears immediately after job i (i = 1,2,…,7). Moreover, according to the occurrence of the highest number of gene pairs, a temporary set {(1, 4), (2, 1), (3, 5), (4, 5), (5, 2), (6, 3), (7,6)} I s obtained, as shown in Fig. 6.

Non-dominated solution set

Temporary set
Then, two parents from the population are randomly selected, e.g., parent1 = (1, 6, 7, 4, 0, 3, 5, 2) and parent2 = (5, 2, 7, 0, 1, 4, 3, 6), the common gene pairs between parent 1 and the temporary set, i.e., (3, 5) and (5, 2), are sought and put into offspring 1 at positions 6–8. The same gene 7 was also located in the same position in two parents, which was put into position 3 of offspring 1 and 2, respectively.
To obtain the genes for the unfilled position of offspring 1, a crossover point is randomly generated between positions 1 and 2, and the OP operator is performed on parents 1 and 2, leading offspring1 to (1, 0, 7, 4, 6, 3, 5, 2). Similarly, offspring2 = (5, 2, 7, 6, 1, 4, 0, 3) is generated. The whole process of generating offspring 1 and 2 is illustrated in Fig. 7.

Process of ISBOXII
The second new crossover operator, ISOJXII, can be described as follows. First, a temporary individual is generated based on the current non-dominated solution set. Then, two parents are randomly selected from the population, and the genes of each parent are compared with those of the temporary individual at the same position. Similarly, genes at the same position are compared between the two parents. If they are the same, the gene is put in the same position of its offspring. Furthermore, similar to ISBOXII, the genes in the rest positions of the offspring are generated by performing the OP operator between the two parents.
In the following, the same example as above is used to illustrate the main work of ISOJXII. Count the number of times job i appears in all the non-dominated solutions at position k (k = 1,2,…,8). Then place the jobs with the most occurrences at each location, and obtain the temporary individual (2, 6, 2, 4, 1, 3, 5, 1). The generation process is shown in Fig. 8.

Process of generating a temporary individual

Then, randomly select two parents using the above-mentioned same example. To obtain the genes for the unfilled position of offspring 1, a crossover point is randomly generated between positions 2 and 3. Then the OP operator is performed on parents 1 and 2, leading offspring1 to (1, 6, 7, 4, 2, 3, 5, 0). Similarly, offspring2 = (5, 2, 7, 6, 1, 4, 0, 3) is generated. The whole process of generating offspring 1 and offspring 2 is illustrated in Fig. 9.

Process of ISJOXII
The framework of the proposed INSGAII is shown in Algorithm 5.
Experiments and results
Experimental setup
This section discusses computational experiments used to evaluate the performance of the proposed algorithm. All the algorithms are implemented in the PlatEMO v3.0 on a DELL with Intel Core i7-10,700 CPU operating at 2.90 GHz and 8 GB RAM, and the same library functions are employed to make peer comparisons. Furthermore, all the compared algorithms are recoded to adapt them to solve the considered problem, including the encoding and decoding method. The parameters are set in accordance with the literature. In this paper, the population size is 100. For each instance, the stopping criterion is set to 200 iterations. To verify the effectiveness and efficiency of the proposed algorithm, after 30 independent runs, the resulted non-dominated solutions found by all the compared algorithms were collected for performance comparisons. The relative percentage increase (RPI) is used for the ANOVA comparison, which is calculated as follows:
The relative percentage increase (RPI) is used as a performance measure and is calculated as follows:
where Cb is the best fitness value of all the compared algorithms, and Cc denotes the fitness value of the current algorithm. The fitness values used in this paper are the performance indicators HV and IGD mentioned in “Performance indicators”.
In order to test the performance of INSGA-II, we generate test instances based on the literature [46, 47]. To be specific, a set of instances includes several combinations of the number of jobs, machines, and factories, i.e., the combinations of n = {20, 40, 60, 80, 100}, m = {4, 8, 16}, g = {2, 3, 4, 5}. The processing time Pi,j is uniformly distributed within the range of [5 h, 50 h] and the processing speed v is set as {1, 2, 3}. The EC is set as \(PE_{j,v} = 4 \times vkW\), \(SPE_{j} = 1kW\) and the \(SE_{j,i,i^{\prime}}\) is generated uniformly within the range [1 kW, 2 kW]. The setup times are 50% of the processing times, that is, the setup times are generated by a uniform [2 h, 25 h] distribution. The instances and experimental results can be obtained from the website: http://ischedulings.com/data/CAIS_EEDNWFSP.rar.
Performance indicators
Since the exact Pareto front of the investigated problem is unknown, we use a so-called reference set to approximate it. The reference set is generated using a method similar to that of Wu et al. [3]. Specifically, all the non-dominated solutions obtained by the comparison algorithms are combined into a set, from which the dominated solutions are removed to obtain the reference set. In this study, each instance is solved by all the comparison algorithms iterating 30,000 times independently, and the non-dominated solutions obtained are considered the final reference set.
To assess the quality of the obtained solutions, the following two representative indicators are used in terms of convergence and diversity: the hypervolume (HV) [48] and the inverted generational distance (IGD) [49]. The detailed calculation process of the two indicators is as follows.
-
(1)
hypervolume HV
The Lebesgue measure is a metric used to measure the volume, denoted by \(\delta\). Where \(|S|\) is the number of non-dominated solutions and vi is the hypervolume of the ith solution in the reference solution set. The larger the volume of the region in the target space surrounded by the non-dominated solution set and reference points, the better the comprehensive performance of the algorithm. In this work, we select (1, 1) as the reference point.
-
(2)
inverted generational distance IGD
IGD is used to compute the average distance from each reference solution to the nearest solution. Here P is the solution set obtained by the algorithm, and P* represents a group of uniformly distributed reference solutions sampled from the reference solution set. The \({\text{dis}}(x,y)\) represents the Euclidian distance between the solution x in the reference solution set P* and the solution y in the solution set P.
Parameter setting
In the proposed algorithm, two parameters crossover probability (pc), and mutation probability (pm) have the main effects for the performance. In this section, we conduct a design of experiments (DOE) test for selecting the levels of the two parameters. More precisely, we apply a full factorial design using the two parameters as factors. Five levels are considered for each parameter, as listed in Table 3. Based on the results of detailed experiments, parameters of pc and pm are set to 0.8 and 0.4, respectively.
Efficiency of the proposed components
Effect of initialization
To investigate the effectiveness of the ENEH heuristics discussed in “Initialization procedure”, we compare the INSGAII to the INSGAII with random initialization (denoted as G1). A multi-factor analysis of variance (ANOVA) is performed to test whether the performance differences between the algorithms are significant, and the two compared algorithms are considered as factors. Tables 4 and 5 report the comparison results of HV and IGD values for the given 60 different scale instances (each instance runs 10 times independently). Moreover, the 60 instances are further classified according to the number of factories. In the tables, the first column gives the instance number. Then, the results collected by INSGAII and G1 are shown in the following eight columns.
From the comparison results, the following can be observed: (1) considering the HV values, compared with G1, INSGAII obtains 59 better results, and the slightly worse results for only one instance; (2) for the IGD values, INSGAII obtains 56 better results, the rest one is slightly inferior in small-scale cases; and (3) from the average performance in HV and IGD given in the last line and the ANOVA results from Fig. 10a, it can be seen that INSGAII is significantly better than G1, which verify the efficiency of the proposed ENEH heuristics.

ANOVA comparison results
Effect of search strategies
To show the effectiveness of the local search strategy and crossover operators discussed in “Local Search” and “Global search”, we conduct detailed comparisons of the algorithms with and without the proposed strategies. The algorithm without the local search strategy is represented by G2, the algorithm without the crossover operators is denoted as G3, and the INSGAII with all the components.
As illustrated by Tables 6 and 7, (1) IGD and HV values of INSGAII are significantly better than G2 in all instances; (2) the ANOVA results from Fig. 10b shows that the local search strategy is very effective in solving the EEDNWFSP; and (3) the results indicate that the proposed local search contributes to improve the diversity and convergence of solutions. This proves the effectiveness of the proposed local search, which helps in improving the performance of the algorithm. In the INSGAII, we take advantage of the knowledge specific to the problem, and then combine this knowledge with classical mutation operators to form a local search strategy. This local search based on knowledge can effectively guide the solution to Pareto optimal solution.
Tables 8 and 9 separately list the comparison results with G3 as follows: (1) considering the HV and IGD values, G3 also achieved several superior values, but the overall effect of INSGAII performs better; and (2) the ANOVA results from Fig. 10c shows that INSGAII obtained significantly better results, where p values of HV and IGD are both less than 0.05. This shows that the two crossover operators designed based on the knowledge of Pareto set are effective.
Comparisons of the efficient algorithms
To further verify the performance of the proposed algorithm compared with other efficient algorithms, the following three algorithms are selected, namely, NSGAII [31], ARMOEA [32], and hpaEA [33]. Each algorithm run 30 times independently on the same computer, and 15 × 4 instances are tested. According to the number of factories, the detailed results of the experimental comparison are shown in Tables 10, 11, 12 and 13.
Specifics of the table are as follows: the scales of the examples are presented in the first column, the second column presents the information of HV for all algorithms, and the last column is IGD value. It can be observed that: (1) for the given 60 instances, the proposed INSGAII algorithm obtains all the better indicators, which is significantly better than the other compared algorithms; and (2) the average values of the last line further verify the efficiency of the INSGAII, which prove that the solutions obtained by INSGAII have good convergence and distribution.
Figure 11 reports the Pareto results for a given scale instance (i.e., M = 8, J = 20) belonging to four factories. PF in the figure represents the near Pareto front obtained as described in “Performance indicators”. Moreover, all the four compared algorithms are drawn with different marks. From the four sub-figures, the following can be concluded: (1) the results obtained by the proposed INSGAII algorithm have better dominance performance compared with other compared algorithms; (2) the population diversity of INSGAII is significantly better than the three compared algorithms; and (3) considering different scale instances, the proposed INSGAII is the best one to balance the abilities of diversity and convergence.

Pareto front of the compared algorithms
Comparative analysis
Through experimental comparison and analysis of the results, the following conclusions about the proposed algorithm are obtained:
-
(1)
The use of ENEH heuristics in the initialization phase can produce high-quality individuals, thus effectively guiding the population to approach the optimal solutions.
-
(2)
According to the distributed nature of the problem, the corresponding mutation operators are designed. Combined with the analysis of the characteristics of EEDNWFSP, the DST1 and DST2 heuristics are designed to greatly improve the local search ability of the algorithm.
-
(3)
The Pareto-based crossover operators enhance the population diversity as well as quality.
-
(4)
As the number of factories increases, the superiority of the INSGA-II becomes more prominent. Therefore, the proposed algorithm is efficient for solving EEDNWFSP.
Conclusion
This study is the first one to consider the multi-objective energy-efficient scheduling of the distributed permutation flow-shop with sequence-dependent setup time and no-wait constraints. Two objectives, including minimizing of both makespan and the TEC, are adopted simultaneously. In order to solve the problem, based on the canonical multi-objective algorithm NSGA-II, some effective search strategies are designed according to the characteristics of the problem. First, the initial population is generated randomly, and then two individuals are replaced with the solutions generated by ENEH and ENEH2. Then, the characteristics of the problem are analyzed, two lemmas are proposed, and two speed adjustment heuristics are further developed. Combined with four mutation operators, a local enhancement process is designed, which effectively enhances the convergence of the algorithm and improves the quality of solutions. Finally, using the knowledge of non-dominated solution set, two effective crossover operators are designed to improve the diversity of solutions.
INSGA-II is tested with multiple scale instances and compared with two state-of-the-art multi-objective evolutionary algorithms. The experimental results demonstrate the superiority of the proposed algorithm.
As future work, it is worth investigating other types of distributed scheduling problems, such as resource constraints, heterogeneous factories, and high dimensional multi-objective. We will focus on the extraction and utilization of problem-specific knowledge as well as the design of effective search operators. More and more realistic constraints will be considered, such as fuzzy processing times [50]. In addition, it is extremely important to apply these algorithms to real industrial problems.
References
Wang B, Han K, Spoerre J et al (1997) Integrated product, process and enterprise design: why, what and how? Springer
Wang G, Li X, Gao L et al (2021) Energy-efficient distributed heterogeneous welding flow shop scheduling problem using a modified MOEA/D. Swarm Evol Comput 62(3):100858
Wu X, Che A, Lev B (2020) Energy-efficient no-wait permutation flow shop scheduling by adaptive multi-objective variable neighborhood search. Omega 94:102117
Grabowski J, Pempera J (2005) Some local search algorithms for no-wait flow-shop problem with makespan criterion. Comput Oper Res 32:2197–2212
Ruiz R, Naderi B (2010) The distributed permutation flowshop scheduling problem. Comput Oper Res 37:754–768
Huang JP, Pan QK, Gao L (2020) An effective iterated greedy method for the distributed permutation flowshop scheduling problem with sequence-dependent setup times. Swarm Evol Comput 59:100742
Wang JJ, Wang L (2018) A knowledge-based cooperative algorithm for energy-efficient scheduling of distributed flow-shop. IEEE Trans Syst Man Cybern Syst 50(5):1805–1819
Wang GC, Gao L, Li XY et al (2020) Energy-efficient distributed permutation flow shop scheduling problem using a multi-objective whale swarm algorithm. Swarm Evol Comput 57:100716
Fernandez-Viagas V, Perez-Gonzalez P, Framinan JM (2018) The distributed permutation flow shop to minimise the total flowtime. Comput Ind Eng 118:464–477
Lu C, Gao L, Gong W et al (2021) Sustainable scheduling of distributed permutation flow-shop with non-identical factory using a knowledge-based multi-objective memetic optimization algorithm. Swarm Evol Comput 60:100803
Wang G, Li X, Gao L et al (2019) A multi-objective whale swarm algorithm for energy-efficient distributed permutation flow shop scheduling problem with sequence dependent setup times. IFAC-PapersOnLine 52(13):235–240
Li Y, Li X, Gao L et al (2020) An improved artificial bee colony algorithm for distributed heterogeneous hybrid flowshop scheduling problem with sequence-dependent setup times. Comput Ind Eng 2020:106638
Li JQ, Song MX, Wang L et al (2020) Hybrid artificial bee colony algorithm for a parallel batching distributed flow-shop problem with deteriorating jobs. IEEE Trans Cybern 50(6):2425–2439
Shao W, Shao Z, Pi D (2020) Modeling and multi-neighborhood iterated greedy algorithm for distributed hybrid flow shop scheduling problem. Knowl-Based Syst 194:105527
Cai J, Zhou R, Lei D (2020) Dynamic shuffled frog-leaping algorithm for distributed hybrid flow shop scheduling with multiprocessor tasks. Eng Appl Artif Intell 90:103540
Zhang ZQ, Qian B, Hu R et al (2021) A matrix-cube-based estimation of distribution algorithm for the distributed assembly permutation flow-shop scheduling problem. Swarm Evol Comput 60:100785
Huang YY, Pan QK, Huang JP et al (2020) An improved iterated greedy algorithm for the distributed assembly permutation flowshop scheduling problem. Comput Ind Eng 152(3):107021
Shao Z, Shao W, Pi D (2020) Effective constructive heuristic and metaheuristic for the distributed assembly blocking flow-shop scheduling problem. Appl Intell 50(1):4647–4669
Lin SW, Ying KC (2016) Minimizing makespan for solving the distributed no-wait flowshop scheduling problem. Comput Ind Eng 99:202–209
Shao W, Pi D, Shao Z (2019) A pareto-based estimation of distribution algorithm for solving multiobjective distributed no-wait flow-shop scheduling problem with sequence-dependent setup time. IEEE Trans Autom Sci Eng 2019:1–17
Komaki M, Malakooti B (2017) General variable neighborhood search algorithm to minimize makespan of the distributed no-wait flow shop scheduling problem. Prod Eng 11(3):315–329
Shao W, Pi D, Shao Z (2017) Optimization of makespan for the distributed no-wait flow shop scheduling problem with iterated greedy algorithms. Knowl-Based Syst 137:163–181
Li H, Li X, Gao L (2021) A discrete artificial bee colony algorithm for the distributed heterogeneous no-wait flowshop scheduling problem. Appl Soft Comput 100:106946
Behjat S, Salmasi N (2017) Total completion time minimisation of no-wait flowshop group scheduling problem with sequence dependent setup times. Eur J Indust Eng 11(1):22
Ruiz R, Stützle T (2008) An iterated greedy heuristic for the sequence dependent setup times flowshop problem with makespan and weighted tardiness objectives. Eur J Oper Res 187(3):1143–1159
Ciavotta M, Minella G, Ruiz R (2013) Multi-objective sequence dependent setup times permutation flowshop: a new algorithm and a comprehensive study. Eur J Oper Res 227(2):301–313
Wu X, Sun Y (2018) A green scheduling algorithm for flexible job shop with energy-saving measures. J Clean Prod 172:3249–3264
Du Y, Li JQ, Chen XL, Duan PY, Pan QK (2022) A knowledge-based reinforcement learning and estimation of distribution algorithm for flexible job shop scheduling problem. IEEE Trans Emerg Topics Comput Intell. https://doi.org/10.1109/TETCI.2022.3145706
Li JQ, Du Y, Gao KZ, Duan PY et al (2022) A hybrid iterated greedy algorithm for a crane transportation flexible job shop problem. IEEE Trans Autom Sci Eng 19(3):2153–2170
Qi R, Li JQ, Wang J, Jin H, Han YYQMOEA (2022) A Q-learning-based multiobjective evolutionary algorithm for solving time-dependent green vehicle routing problems with time windows. Inf Sci 608:178–201
Jiang ED, Wang L, Peng ZP (2020) Solving energy-efficient distributed job shop scheduling via multi-objective evolutionary algorithm with decomposition. Swarm Evol Comput 2020:100745
Li JQ, Sang HY, Han YY et al (2018) Efficient multi-objective optimization algorithm for hybrid flow shop scheduling problems with setup energy consumptions. J Clean Prod 181:584–598
Li JQ, Chen XL, Duan PY, Mou JH (2021) KMOEA: a knowledge-based multi-objective algorithm for distributed hybrid flow shop in a prefabricated system. IEEE Trans Industr Inf. https://doi.org/10.1109/TII.2021.3128405
Chen JF, Wang L, Peng ZP (2019) A collaborative optimization algorithm for energy-efficient multi-objective distributed no-idle flow-shop scheduling. Swarm Evol Comput 50:100557
Tian Y, Cheng R, Zhang XY et al (2018) An indicator-based multiobjective evolutionary algorithm with reference point adaptation for better versatility. IEEE Trans Evol Comput 22(4):609–622
Chen H, Tian Y, Pedrycz W et al (2019) Hyperplane assisted evolutionary algorithm for many-objective optimization problems. IEEE Trans Cybern 2019:1–14
Ding JY, Song S, Wu C (2015) Carbon-efficient scheduling of flow shops by multi-objective optimization. Eur J Oper Res 000:1–14
Deb K, Pratap A, Agarwal S et al (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
Xiong F, Chu M, Li Z et al (2021) Just-in-time scheduling for a distributed concrete precast flow shop system. Comput Oper Res 129:105204
Muhammad N, Emory E, Enscore et al (1983) A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 11(1):91–95
Fernandez-Viagas V, Ruiz R, Framinan JM (2017) A new vision of approximate methods for the permutation flowshop to minimise makespan: state-of-the-art and computational evaluation. Eur J Oper Res 257(3):707–721
Han Y, Gong D, Jin Y et al (2019) Evolutionary multiobjective blocking lot-streaming flow shop scheduling with machine breakdowns. IEEE Trans Cybern 49(1):184–197
Ruiz R, Maroto C, Alcaraz J (2006) Two new robust genetic algorithms for the flowshop scheduling problem. Omega 34(5):461–476
Yi Z, Li X, Qian W (2009) Hybrid genetic algorithm for permutation flowshop scheduling problems with total flowtime minimization. Eur J Oper Res 196(3):869–876
Michalewic Z (1996) Genetic algorithms + data structures = evolution programs. Springer, Berlin. https://doi.org/10.1007/978-3-662-03315-9
Deng J, Wang L, Wu C et al (2016) A competitive memetic algorithm for carbon-efficient scheduling of distributed flow-shop. Int Conf Intell Comput 9771:476–488 (Springer International Publishing)
Ruiz R, Maroto C, Alcaraz J (2005) Solving the flowshop scheduling problem with sequence dependent setup times using advanced metaheuristics. Eur J Oper Res 165(1):34–54
Zitzler E, Thiele L (1999) Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach. IEEE Trans Evol Comput 3(4):257–271
Coello CAC, Cortes NC (2005) Solving multiobjective optimization problems using an artificial immune system. Genet Program Evolvable Mach 6(2):163–190
Li JQ, Liu ZM, Li CD, Zheng ZX (2021) Improved artificial immune system algorithm for Type-2 fuzzy flexible job shop scheduling problem. IEEE Trans Fuzzy Syst 29(11):3234–3248
Funding
This work was supported in part by the National Science Foundation of China under Grant 62173216.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zeng, Qq., Li, Jq., Li, Rh. et al. Improved NSGA-II for energy-efficient distributed no-wait flow-shop with sequence-dependent setup time. Complex Intell. Syst. 9, 825–849 (2023). https://doi.org/10.1007/s40747-022-00830-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00830-6