
Abstract
In group decision making with social network analysis (SNA), determining the weights of experts and constructing the consensus-reaching process (CRP) are hot topics. With respect to the generation of weights of experts, this paper firstly develops a distributed linguistic trust propagation operator and a path order weighted averaging (POWA) operator to explore the trust propagation and aggregation between indirectly connected experts, and the weights of experts can be derived by using relative node in-degree centrality in a complete distributed linguistic trust relationship matrix. Then, three levels of consensus are proposed, in which the most inconsistent evaluation information in distributed linguistic trust decision-making matrices can be pinpointed. Subsequently, the distance between experts’ evaluation information and collective evaluation information is designed to be applied as the adjustment cost in CRP. Finally, a novel feedback mechanism supported by the minimum adjustment cost is activated until the group consensus degree reaches the predefined threshold. The novelties of this paper are as follows: (1) the proposed POWA considers the trust value as well as the propagation efficiency of trust path when aggregating the trust relationship in SNA; (2) the consensus reaching mechanism can gradually improve the value of group consensus degree by continuously adjusting the most inconsistent evaluation information.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Group decision-making (GDM) process is a decision circumstance where some individuals make great efforts to come to an agreement based on their views, attitudes, intentions and individualities on an identical issue [1]. In actual GDM activities, people’s evaluations are always vague and uncertain. To describe the ambiguous evaluation information, starting with the pioneering work of Zadeh, interval-valued fuzzy sets, intuitionistic fuzzy sets, Pythagorean fuzzy sets, hesitant fuzzy sets and other extension and integration languages were proposed successively to describe the vague information [2,3,4,5,6]. It can be concluded that the fuzzy sets mentioned above represent vague information from the perspective of a single term. In practical applications, the decision makers (DMs) may be hesitant between several possible linguistic terms rather than being limited to using a single term. To lift this restriction, Rodriguez et al. [7] defined hesitant fuzzy linguistic term set (HFLTS), allowing DMs to use several consecutive terms for a linguistic variable. Considering that linguistic variables may be discontinuous, Zhang and Wu [8] proposed extended hesitant fuzzy linguistic term sets (EHFLTSs). However, when describing the evaluation information, most existing languages are inclined to use partial linguistic variables to express but lack of considering the importance of linguistic variables [9]. By integrating proportional information into linguistic terms, Zhang et al. [10] proposed the linguistic distribution assessment model, where the proportion represents DM’s personal preference. Chen et al. [11] defined proportional hesitant fuzzy linguistic fuzzy term sets (PHFLTSs), where the proportion represents DMs’ team preference. In this paper, the concept of distributed linguistic information in which the linguistic variables are assigned a corresponding non-negative trust weight is introduced, making DMs’ evaluation information more comprehensive and accurate [10]. Then we propose the distributed linguistic trust function to facilitate the calculation of trust information [12].
When coming to solving the GDM problems, introducing social network analysis (SNA) which studies the relationships among individuals, teams, corporations and regions to it becomes a trend today [13, 14]. In the real social network, decision makers may not be familiar with each other, so they cannot express a complete trust relationship. Based on the transitivity of trust relationship, some scholars built trust paths through trusted third-partners (TTPs) to connect DMs without direct trust relationship. Victor et al. [15] proposed several trust propagation operators for trust/distrust values and developed aggregation operators subsequently [16]. Wu et al. [17] presented a more rational dual trust propagation operator on the basis of t-norms and t-conorms to solve the problem of severe information attenuation. Risk attitude was integrated into trust score induced order weighted averaging operator to improve the flexibility of the operator in Ref. [18]. Lu et al. [19] introduced a social network clustering method based on grey clustering algorithm. However, these methods mentioned above are not suitable for distributed language variables. So based on Einstein product operator, Wu et al. [14] developed a novel trust propagation operator to fill this research gap. In addition, in the process of trust propagation, the trust relationship attenuates with the increase in trust path length [20, 21]. Nasir et al. [22] estimated the final trust by aggregating information from the most reliable in-neighbors of the target person. Some papers adopted the trust relationship carried by the shortest indirect path to avoid the influence of propagation path length on the final trust value [14, 17]. In this case, the original information conveyed by distributed linguistic trust relationship matrix (DLTRM) is not fully utilized. Considering the existence of information attenuation, this article performs as follows to fully use the trust relationship of each indirect path. Firstly, based on the distributed linguistic trust propagation operator, the trust relationship of each path between indirectly connected experts can be obtained. Then, calculate the propagation efficiency of each path, which decreases with the increase of the number of TTPs. Finally, we introduce the path order weighted averaging (POWA) operator to aggregate the trust value and propagation efficiency to get the final trust value between indirectly connected experts.
Reaching an appropriate group consensus degree (GCD) by adjusting evaluation information is the other critical issue in SN-GDM problems. High GCD means a high degree of recognition and less disagreement of the final decision among DMs [23]. When the GCD is lower than the predefined threshold, we need to set a mechanism to adjust the evaluation information of inconsistent experts to improve group consensus. Some consensus-reaching process (CRP) models used static feedback parameters to adjust the inconsistent evaluation information [24,25,26]. However, these feedback mechanisms are compulsive and do not consider DMs' attitudes towards changing their evaluation information. To solve this problem, Ben-Arieh and Easton [27] used a linear cost function to define the concept of minimum-cost consensus (MCC). Wu et al. [12] proposed a feedback mechanism that can produce the boundary feedback parameter based on minimum adjustment cost. Liu et al. [28] presented a novel trust induced recommendation mechanism which used the recommendations of certain experts trusted by the inconsistent experts to adjust the inconsistent evaluation information. Wu et al. [14] designed an optimization model with the maximum retention of self-esteem degree to obtain optimal feedback parameters in the process of reaching the GCD. Li et al. [29] set the assumption that experts accept the opinions of trusted experts, and then introduced the opinion dynamics model to adjust the opinions of experts. Yu et al. [30] set up a punishment-driven consensus reaching process and take different adjustment measures based on four different levels of consensus. As for the unacceptable consistent probabilistic linguistic preference relation, Zhang et al. [31] introduced an automatic optimization method to improve GCD. However, in the process of using feedback parameters to reach a high consensus, all the evaluation information whose consensus degree is lower than the threshold is modified at one time. As a result, the adjustment width is large, damaging the integrity of the original information. Therefore, the research on how to achieve the consensus threshold with the minimum adjustment cost while maintaining the maximum integrity of the original information is of great significance. In this paper, to maximize the preservation of the original information, three levels of consensus are put forward to pick up the most inconsistent evaluation information in each circulation. Then, we introduce adjustment cost as the basis for selecting the evaluation information that needs to be adjusted until the value of GCD reaches the predefined threshold.
The remainder of this article contains six sections. In the following section, some preliminaries about linguistic term sets (LTSs) and distributed linguistic trust functions (DLTFs) are introduced. The subsequent section proposes the concept of propagation efficiency and developed the POWA operator to aggregate the trust value of each trust chain. In “CRP for distributed linguistic trust decision-making information”, three different levels of consensus are put forward to pick up the most inconsistent evaluation information and a novel feedback mechanism based on minimum adjustment cost is presented to improve the value of GCD. In the subsequent section, a case study is provided to prove the validity of our model. The next section remarks on the conclusions of this paper.
Preliminaries
This section briefly presents some basic concepts and definitions about LTSs, distributed linguistic term sets (DLTSs) and DLTF), which are conducive to understanding this article.
LTSs and DLTSs
Let \(S = \{ s_{0} ,s_{1} , \ldots ,s_{2r} \}\) be an ordered and definite LTS, where \(s_{i}\) is the linguistic variable and r is a non-negative and finite integer [32]. There are two characteristics of \(S\): (a) If \(\alpha \ge \beta\), then \(s_{\alpha } \ge s_{\beta }\); (b) \({\text{neg}}(s_{\alpha } ) = s_{2\tau - \alpha }\), especially \({\text{neg}}(s_{\tau } ) = s_{\tau }\).
Example 1
\(S = \{ s_{0} ,s_{1} , \ldots ,s_{8} \}\) with nine terms can be expressed as follows:
To reduce the attenuation of information, Xu [33] expanded the dispersed LTS into a continuous one \(\overline{S} = \{ s_{\alpha } |s_{0} \le s_{\alpha } \le s_{2r} \alpha \in [0,2r]\}[0,2r]\), where \(2r\) represents a sufficiently large integer. The operational laws between any two linguistic terms \(s_{\alpha }\), \(s_{\beta }\)\(\in S\) are as follows:
-
(1)
\(s_{\alpha } \oplus s_{\beta } = s_{\alpha + \beta }\);
-
(2)
\(s_{\alpha } \oplus s_{\beta } = s_{\beta } \oplus s_{\alpha }\);
-
(3)
\(\mu s_{\alpha } = s_{\mu \alpha } ,\mu > 0\);
-
(4)
\((\mu_{1} + \mu_{2} )s_{\alpha } = \mu_{1} s_{\alpha } + \mu_{2} s_{\alpha } ,\mu_{1} > 0,\mu_{2} > 0\);
-
(5)
\(\mu (s_{\alpha } \oplus s_{\beta } ) = \mu s_{\alpha } \oplus \mu s_{\beta } ,\mu > 0\).
Considering experts' different preference for linguistic terms, Zhang et al. [10] have generalized the LTSs to the DLTSs by assigning symbolic proportions to each linguistic term.
Definition 1
[10] Assuming that \(S = \{ s_{0} ,s_{1} , \ldots ,s_{2r} \}\) is an ordered and definite LTS, then a DLTS can be defined as \(m = \left\{ {(s_{i} ,\lambda^{i} )|i = 0,1,2 \ldots ,2r} \right\}\), where \(s_{i} \in S\),\(\lambda^{i} \ge 0\), \(\sum\nolimits_{i = 0}^{2r} {\lambda^{i} = 1}\) and \(\lambda^{i}\) is the corresponding symbolic proportion of \(s_{i}\).
Definition 2
[10] Let \(S = \{ s_{0} ,s_{1} , \ldots ,s_{2r} \}\) be an LTS, \(P = \left\{ {(s_{i} ,\lambda^{i} )|i = 0,1,2 \ldots ,2r} \right\}\) be a DLTS, where \(s_{i} \in S\),\(\lambda^{i} \ge 0\), \(\sum\nolimits_{k = 0}^{2r} {\lambda^{i} = 1}\) and \(\lambda^{i}\) is the symbolic proportion of \(s_{i}\). The expectation degree of \(P\) can be defined as follows:
DLTFs
SNA is concerned with relational data, which allows us to learn the structural and locational properties, including centrality, prestige and trust relationships [34]. The set of actors, their relationships, and the actor attributes are the three main elements in SNA. The following three representation schemes are introduced to explain the important network concepts (see Table 1).
However, the trust relationship conveyed by the social network matrix is merely the terms of ‘trusting’ and ‘not trusting’, which are binary and direct. In daily life, people cling to define trust as a gradual concept, thus, they tend to use trust with varying degrees, such as ‘extremely trust’ or ‘very trust’ or ‘slight trust’ [35]. To definitely present the extent of trust, the concept of DLTF based on DLTSs is introduced below [12].
Definition 3
[10] Assuming that \(S = \{ s_{0} ,s_{1} , \ldots ,s_{2r} \}\) is an ordered and definite LTS, then a DLTF can be defined as follows:
where \(s_{i} \in S\),\(T^{(i)} \ge 0\), \(\sum\nolimits_{i = 0}^{2r} {T^{(i)} = 1}\) and \(T^{{^{(i)} }}\) is the corresponding trust weight of \(s_{i}\).
Definition 4
Let \(P_{j} = \big\{ (s_{i} ,T_{j}^{(i)} )|i = 0,1, \ldots 2r,T^{(i)} \ge 0, \sum\nolimits_{i = 0}^{2r} {T_{j}^{(i)} } = 1 \big\}(j = 1,2)\) be two DLTFs, the operational laws among them are as follows:
-
(1)
\(P_{1} \oplus P_{2} = \left\{ {(s_{i} ,T_{1}^{(i)} + T_{2}^{(i)} )|i = 0,1, \ldots 2r} \right\}\);
-
(2)
\(P_{1} \otimes P_{2} = \left\{ {(s_{i} ,T_{1}^{(i)} \times T_{2}^{(i)} )|i = 0,1, \ldots 2r} \right\}\);
-
(3)
\(\lambda P_{1} = \left\{ {(s_{i} ,\lambda T_{1}^{(i)} )|i = 0,1, \ldots 2r} \right\},\lambda > 0\);
-
(4)
\(P_{1}^{\lambda } = \left\{ {\left( {s_{i} ,\left( {T_{1}^{(i)} } \right)^{\lambda } } \right)|i = 0,1, \ldots 2r} \right\},\lambda > 0\).
Theorem 1
Let \(P_{j} = \big\{ (s_{i} ,T_{j}^{(i)} )|i = 0,1, \ldots 2r,T^{(i)} \ge 0,\sum\nolimits_{i = 0}^{2r} {T_{j}^{(i)} } = 1 \big\}(j = 1,2)\) be two DLTFs, then we have
(i) \(P_{1} \oplus P_{2} = P_{2} \oplus P_{1}\);
(ii) \(P_{1} \otimes P_{2} = P_{2} \otimes P_{1}\);
(iii) \(\lambda (P_{1} \oplus P_{2} ) = \lambda P_{1} \oplus \lambda P_{2}\),\(\lambda > 0\);
(iv) \((P_{1} \otimes P_{2} )^{\lambda } = P_{1}^{\lambda } \otimes P_{2}^{\lambda }\),\(\lambda > 0\);
(v) \(\lambda_{1} P_{1} \oplus \lambda_{2} P_{1} = (\lambda_{1} + \lambda_{2} )P_{1}\),\(\lambda_{1} ,\lambda_{2} > 0\);
(vi) \(P_{1}^{{\lambda_{1} }} \otimes P_{1}^{{\lambda_{2} }} = P_{1}^{{\lambda_{1} + \lambda_{2} }} ,\lambda_{1} ,\lambda_{2} > 0\).
Then, the distributed linguistic trust weighted average (DLTWA) operator based on the basic operation laws of DLTFs is proposed to aggregate a list of DLTFs.
Definition 5
(DLTWA) Let \(P_{j} = \Bigl\{ (s_{i} ,T_{j}^{(i)} )|i = 0,1, \ldots 2r,T^{(i)} \ge 0,\sum\nolimits_{i = 0}^{2r} {T_{j}^{(i)} } = 1 \Bigr\}(j = 1,2, \ldots ,n)\) be a series of DLTFs and \(w = (w_{1} ,w_{2} , \ldots w_{n} )\) be the corresponding weight vector, where \(w_{j} > 0\) and \(\sum\nolimits_{j = 1}^{n} {w_{j} } = 1\). Then, the \({\text{DLTWA}}\) is defined as follows:
Then, the expectation degree and uncertainty degree are introduced to present the ranking among a series of DLTFs.
Definition 6
Let \(P = \big\{ (s_{i} ,T^{(i)} )|i = 0,1, \ldots 2r,T^{(i)} \ge 0,\sum\nolimits_{t = 0}^{2r} {T^{(i)} } = 1 \big\}\) be a DLTF, the expectation and uncertainty degree of \(E(P) = \sum\nolimits_{i = 0}^{2r} {T^{(i)} I(s_{i} )}\) can be defined as follows:
where \(I( \cdot ):\tilde{S} \to [0,1]\) is a subscript function, and \(I(s_{i} ) = i/2r\). In addition, there must be an inverse function \(I^{ - 1} ( \cdot ):[0,1] \to \tilde{S}\), such as \(I^{( - 1)} (\alpha ) = s_{2r\alpha }\).
Based on the expectation and uncertainty degree of trust functions, a distributed linguistic trust decision space (DLTDS) is constructed to make an order of a series of trust functions.
Definition 7
Assume that \(P_{j} = \left\{ {(s_{i} ,T_{j}^{(i)} )|i = 0,1, \ldots 2r,T^{(i)} \ge 0,\sum\nolimits_{i = 0}^{2r} {T_{j}^{(i)} } = 1} \right\} \, (j = 1,2, \ldots ,n)\) is a set of DLTFs. The DLTDS on \(DLTDS\mathop = \limits^{\Delta } ({\rm M}, \le_{E(P)} , \le_{U(P)} )\) can be defined as follows:
where \(E(P)\) and \(E(P)\) are the order of expectation degree and uncertainty degree. \(E(P)\) reflects the trust degree of DLTF, which means that the trust degree of DLTF changes in the same direction as the value of \(E(P)\). Specifically, the greater the expectation, the higher the trust degree of DLTF. \(U(P)\) reflects the deviation between linguistic term variables and trust expectation of DLTFs, which means that the trust degree of DLTF changes in the opposite direction as the value of \(U(P)\). Specifically, the bigger the deviation is, the lower the trust degree of DLTF is. Then we are able to conclude the following properties:
Definition 8
(Order regulations) Let \(P_{j} = \left\{ {(s_{i} ,T_{j}^{(i)} )|i = 0,1, \ldots 2r,T^{(i)} \ge 0,\sum\nolimits_{i = 0}^{2r} {T_{j}^{(i)} } = 1} \right\} \, (j = 1,2)\) be two DLTFs; the ranking methods among two DLTFs are defined as follows:
-
(1)
If \(E(P_{1} ) > E(P_{1} )\), then \(P_{1} > P_{2}\);
-
(2)
If \(E(P_{1} ) < E(P_{1} )\), then \(P_{1} < P_{2}\);
-
(3)
If \(E(P_{1} ) = E(P_{2} )\), then
when \(U(P_{1} ) < U(P_{2} )\), \(P_{1} > P_{2}\);
when \(U(P_{1} ) = U(P_{2} )\), \(P_{1} = P_{2}\);
when \(U(P_{1} ) > U(P_{2} )\), \(P_{1} < P_{2}\).
Trust propagation and aggregation in social network
This section focuses on the trust relationship between experts who are indirectly connected in social network. First, the distributed trust propagation operator based on Einstein product operator is introduced to calculate the trust value of each path [17]. Then, the POWA operator in which we set the propagation efficiency as the path weight can be used to aggregate the trust value of each path. Finally, in a complete DLTRM, we can calculate the weights of experts through relative node in-degree centrality.
DLTRM
Trust network reflects the trust relationship among experts. However, experts usually cannot determine the trust relationship towards unfamiliar experts [36], which accounts for an incomplete trust network, as shown in Fig. 1. In order to facilitate the calculation of the propagation and aggregation, we construct a DLTRM to represent the trust relationships among experts.

The two types of the social network
Definition 9
Let \(e = \left\{ {e_{1} ,e_{2} , \ldots e_{l} } \right\}\) be an expert term set. The trust degree from expert \(e_{p}\) to expert \(e_{q}\) can be expressed as follows:
Definition 10
A DLTRM \(TD\) on \(e\) in \(e \times e\) can be defined as follows:
In \(TD\), the distributed linguistic trust relationship from \(e_{p}\) to \(e_{q}\) is always not the same as the distributed linguistic trust relationship from \(e_{q}\) to \(e_{p}\). Simultaneously, unfamiliarity between experts can lead to a lack of direct trust relationships in trust networks. Then, the characteristics of \(TD\) can be concluded as follows:
-
(1)
Directional: \(TD\) can be regarded as a directed relation matrix;
-
(2)
Incomplete: Unfamiliarity can lead to a lack of direct trust relationships in social trust network;
-
(3)
Asymmetric: The expression \(TD_{pq} = TD_{qp}\) is usually not valid;
-
(4)
Transitive: Trust relationship in social network can be transferred through TTPs.
Trust propagation
Given that the Einstein product operator has been proved suitable in the process of propagation [17], we select the distributed trust propagation operator to propagate the trust value for completing the indirect relationship.
Definition 11
Triangular norm (briefly t-norm) is a binary operation T on the unit interval \([0,1]\). Its function \(T:[0,1]^{2} \to [0,1]\) satisfies the four conditions as follows for \(\forall m,n,l \in [0,1]\):
-
(1)
\(\forall m,n \in [0,1]\), \(T(m,n) = T(n,m)\);
-
(2)
\(\forall m,n,l \in [0,1]\), \(T(m,T(n,l)) = T(T(m,n),l)\);
-
(3)
\(\forall m,n,l \in [0,1]\) \(T(m,n) \le T(m,l)\) whenever \(n \le l\);
-
(4)
\(\forall m \in [0,1]\) \(T(m,1) = m\).
The Einstein product operator is a t-norm, which can be expressed as follows:
It is necessary to mention that the minimum operator is the greatest of all t-norms. Consequently, we have:
These two expressions can only be applied to the situation of two parameters. To expand the scope of its application, the Eqs. (9) and (10) can be extended to Eqs. (11) and (12), respectively:
Definition 12
Let \(TD_{pq} = T(e_{p} ,e_{q} ) = \left\{ {(s_{i} ,T_{pq}^{(i)} )|i = 0,1, \ldots 2r,T_{pq}^{(i)} \ge 0,\sum\nolimits_{i = 0}^{2r} {T_{pq}^{(i)} } = 1} \right\}\) and \(TD_{qk} = T(e_{q} ,e_{k} ) = \left\{ {(s_{i} ,T_{qk}^{(i)} )|i = 0,1, \ldots 2r,T_{qk}^{(i)} \ge 0,\sum\nolimits_{i = 0}^{2r} {T_{qk}^{(i)} } = 1} \right\}\) be two known distributed trust relationships from expert \(e_{p}\) to expert \(e_{q}\) and from expert \(e_{q}\) to expert \(e_{k}\), respectively. Supposing there is no direct connection between \(e_{p}\) and \(e_{k}\). Consequently, expert \(e_{q}\) acts as an intermediary to transfer the trust relationship. Then, the distributed linguistic trust propagation operator \(P_{DL} :\Lambda \times \Lambda \to \Lambda\), where \(\Lambda\) be the set of \({\text{DLTFs}}\), is introduced to propagate the trust relationship from expert \(e_{p}\) to expert \(e_{k}\):
Equation (13) is applied to the situation where there is only one TTP. If there are two TTPs, we speculate the distributed linguistic trust propagation which has been verified in [14]:
Trust aggregation
There may be several trust paths among indirectly connected experts [37]. In the process of trust propagation, the trust relationship attenuates with the increase of trust path [20, 21]. Specifically, information attenuation intensity increases as the number of intermediaries in the trust path increases. In order to reduce the influence of information attenuation on the final trust value, there should be a decreasing function between the weight of each path and the number of intermediaries [37]. Therefore, this paper proposes the concept of trust propagation efficiency based on the number of intermediaries. Then through the proposed POWA operator, the propagation efficiency and trust values of each path are combined to obtain the total trust relationship between indirect-connected experts.
Definition 13
Given that there is no direct trust relationship from \(e_{p}\) to \(e_{q}\) in the social network and there are \(h\) paths \(\{ C_{1} ,C_{2} , \ldots ,C_{h} \}\) building bridges from expert \(e_{q}\) to \(e_{p}\).The propagation efficiency of trust path \(C_{i}\) is defined as follows:
where \(b_{i}^{\prime } = 1/b_{i}\), \(b_{i}\) is the number of intermediaries of the path \(C_{i}\). From Eq. (15), we can find that with the unchanged total intermediaries, the larger the \(b_{i}\) is, the smaller the path’s weight is.
Definition 14
(POWA) Let \(\left\{ {TD_{pq}^{1} ,TD_{pq}^{2} , \ldots ,TD_{pq}^{h} } \right\}\) be the trust relationship of path \(\{ C_{1} ,C_{2} , \ldots ,C_{h} \}\) between indirect-connected experts \(e_{p}\) and \(e_{q}\), \(PE = \left\{ {pe_{1} ,pe_{2} , \ldots ,pe_{h} } \right\}\) be associated path weighting, where \(\sum\nolimits_{i = 1}^{h} {pe}_{i} = 1\) and \(pw_{i} \ge 0\). Then trust degree between \(e_{p}\) and \(e_{q}\) can be defined as follows:
Important degrees of experts
Definition 15
Let \(\overline{TD} = (\overline{TD}_{pq} )_{l \times l}\) be a complete DLTRM, then the relative node in-degree centrality index can be calculated as follows:
The higher the value of relative centrality index, the high importance of experts. Then the weight of an expert \(e = \left\{ {e_{1} ,e_{2} , \ldots ,e_{l} } \right\}\) can be defined as follows:
Definition 16
Let \(e = \left\{ {e_{1} ,e_{2} , \ldots ,e_{l} } \right\}\) be an expert term set and its corresponding complete DLTRM is \(\overline{TD} = (\overline{TD}_{pq} )_{l \times l}\). We can define the weights of experts as follows:
where \(TP_{q}\) refers to the relative node in-degree centrality index of experts in social network.
CRP for distributed linguistic trust decision-making information
In the process of GDM problems, experts perhaps make different decisions influenced by educational background, personality and risk attitude. Therefore, in order to obtain a common opinion, we need to adjust the evaluation information of some inconsistent experts. The solution in the existing literature is to find experts whose consensus degree is below the threshold value and then start the recommendation mechanism to reach the threshold value. However, the behavior of adjusting multiple experts or multiple decisions of one expert at one time resulting in an excessively wide adjustment width, which affects the integrity of the original information.
To maximize the integrity of the original information while improving the consensus of the group. This part defines three levels of trust consensus in distributed linguistic trust decision-making matrices (DLTDMMs) to pick up the most inconsistent evaluation information. Then a novel feedback mechanism supported by the minimum adjustment cost is introduced to improve GCD until it reaches the predefined threshold.
Consensus measures for distributed linguistic trust decision-making information
Definition 17
Suppose that there are \(m\) alternatives \(\left\{ {a_{1} ,a_{2} , \ldots ,a_{m} } \right\}\), \(n\) attributes \(C = {\text{\{ }}c_{1} ,c_{2} , \ldots ,c_{n} {\text{\} }}\), \(l\) experts \(e = \left\{ {e_{1} ,e_{2} , \ldots ,e_{l} } \right\}\), expert \(e_{p}\) expresses his/her distributed linguistic evaluation information of alternative \(a_{k}\) over attribute \(c_{j}\) as follow:
Definition 18
Let \(D^{p} = (d_{kj}^{p} )_{m \times n} (p = 1,2, \ldots ,l)\) be a set of DLTDMMs, where \(d_{kj}^{p}\) is the evaluation information of alternative \(a_{k}\) over attribute \(c_{j}\) expressed by experts \(e_{p}\), \(W = \left( {w_{1} ,w_{2} , \ldots ,w_{l} } \right)^{T}\) be the corresponding weight vector of expert derived from Eq. (18). The collective DLTDMM \(\overline{D} = (\overline{{d_{kj} }} )_{m \times n}\) can be obtained by the DLTWA operator defined in Eq. (20):
Then, three levels of consensus degree of an expert with the group can be calculated:
(1) Calculate the FV information levels. As \(d_{kj}^{p}\) and \(d_{kj}^{q}\) are the evaluation information from \(D^{p}\) and \(D^{q}\), respectively, then, the consensus degree \(ds_{kj}^{pq}\) between them is:
(2) Calculate consensus degree at expert level. Suppose that \(DS^{pq} = (ds_{kj}^{pq} )_{n \times m}\) is the similarity matrix between expert \(e^{p}\) and expert \(e^{q}\), then the consensus index between expert \(e^{p}\) and expert \(e^{q}\) can be defined as follow:
(3) Calculate consensus degree at trust group level. Suppose that \(DB^{pq} = (db_{{}}^{pq} )_{l \times l}\) is defined as a group consensus matrix. Therefore, the consensus index at group level is:
Example 2
Suppose that three experts \(e_{1}\), \(e_{2}\) and \(e_{3}\) give the following DLTDMMs:
The consensus degree at evaluation information levels can be calculated:
\(DS^{12} = \left( {\begin{array}{lll} {0.85} & {0.86} & {0.76} \\ {0.95} & {0.78} & {0.81} \\ {0.78} & {0.89} & {0.80} \\ \end{array} } \right); DS^{23} = \left( {\begin{array}{lll} {0.79} & {0.75} & {0.81} \\ {0.81} & {0.78} & {0.77} \\ {0.93} & {0.73} & {0.86} \\ \end{array} } \right); DS^{13} = \left( {\begin{array}{lll} {0.80} & {0.61} & {0.95} \\ {0.87} & {0.84} & {0.93} \\ {0.80} & {0.73} & {0.94} \\ \end{array} } \right).\).
The consensus degree at experts’ level is:
\(DB = \left\{ {\begin{array}{*{20}c} - & {0.83} & {0.83} \\ {0.83} & - & {0.81} \\ {0.83} & {0.81} & - \\ \end{array} } \right\}.\).
Therefore, the group consensus degree is \({\text{GCD}} = 0.823\).
From Eq. (23), it is observed that the larger the value of GCD, the larger consensus degree. Specifically, when GCD = 0, it means no consensus among experts. When GCD = 1, It means complete and unanimous consensus among experts. In order to make sure of the rational consensus, we set a threshold value of GCD = 0.8. If the value of GCD is lower than the threshold, the following feedback mechanism is activated to adjust the lowest consensus evaluation information until it reaches the predefined threshold.
Feedback mechanism supported by the minimum adjustment cost
Three parts make up the feedback mechanism supported by minimum adjustment cost. They respectively are (1) recognition of the most inconsistent evaluation information (2) calculate the adjustment cost to determine recommended advice (3) renew the value of GCD.
(1) Recognition of the most inconsistent evaluation information
Step 1: distinguish GCD. If the GCD is lower than the predefined threshold \(\overline{{{\text{GCD}}}}\), it is necessary to adjust evaluation information to improve the consensus level.
Step 2: find \(\min (db_{kj}^{pq} )\) in \(DB^{pq}\). The smaller \(b_{kj}^{pq}\) is, the lower consensus between \(e_{p}\) and \(e_{q}\) is. Then a pair of experts with the lowest consensus level can be pinpointed.
Step 3: find \(\min (ds_{kj}^{pq} )\) in \(DS^{pq}\). The smaller \(ds_{kj}^{pq}\) is, the lower consensus between evaluation information \(d_{kj}^{p}\) and \(d_{kj}^{q}\) is. Then the most inconsistent evaluation information \(\overline{d}_{kj}\) that needs to be adjusted can be pinpointed.
(2) Calculate the adjustment cost to determine recommended advice
Step 1: calculate the distance from \(d_{kj}^{p}\) and \(d_{kj}^{q}\) to \(\overline{d}_{kj}\) respectively.
Step 2: determine the recommended advice.
(3) Renewed the value of GCD
After the adjustment of the most inconsistent evaluation information, calculate the renewed \({\text{GCD}}^{*}\). Repeat the feedback mechanism if the renewed \({\text{GCD}}^{*}\) is still lower than the predefined threshold.
Distributed linguistic GDM model and its application
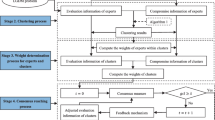
This section first summarizes the overall model framework. Then, a case of evaluating the strength of the company is put forward to show the model’s validity and applicability. Finally, the discussion about the results of this example is presented. The flow chart of the proposed distributed linguistic GDM method is shown in Fig. 2.

Distributed linguistic GDM method
Distributed linguistic GDM model in social network
Stage 1 Calculate the weight of each expert under SNA
Step 1: collect the trust relationship among experts to construct DLTRM \(TD{ = (}TD_{pq} )_{l \times l}\). Simultaneously, every expert expresses their evaluation information with decision matrices \(D^{p} = (d_{kj}^{p} )_{m \times n} (p = 1,2, \ldots ,l)\).
Step 2: construct the complete trust networks matrix \(\overline{TD} { = (}\overline{TD}_{pq} )_{l \times l}\) by propagating and aggregating trust relationships in Eqs. (13) and (16).
Step 3: based on the complete trust networks matrix \(\overline{TD} { = (}\overline{TD}_{pq} )_{l \times l}\), we determine the weights \(w_{q} (q = 1,2, \ldots ,l)\) of experts \(\left\{ {e_{1} ,e_{2} , \ldots ,e_{l} } \right\}\) by utilizing Eq. (18).
Stage 2 Aggregation of DLTDMMs.
Step 4: based on the weights of experts \(w_{q} (q = 1,2, \ldots ,l)\), the DLTDMMs \(D^{p} = (d_{kj}^{p} )_{m \times n} (p = 1,2, \ldots ,l)\) is aggregated into a collective DLTDMM \(\overline{D} { = (}\overline{D}_{kj} )_{m \times n}\) with DLTWA operator.
Stage 3 Consensus test and adjustment
Step 5: calculate three-level consensus index at evaluation information levels, expert level and group level by using Eqs. (21)–(23). Then, if the value of \({\text{GCD}}\) reaches the predefined threshold \(\lambda\), turn to Step 7. Otherwise, turn to step 6.
Step 6: checking the most inconsistent evaluation information and applying the feedback mechanism to adjust the evaluation information with Eqs. (24)–(26), then we obtain the adjusted individual DLTDMM \(D^{\prime {p}} = (d^{\prime {p}}_{kj})_{m \times n} (p = 1,2, \ldots ,l)\).
Stage 4 Determination of the ranking among \(m\) alternatives.
Step 7: Renew the collective DLTDMM. Based on the weight vector of experts \(W = \left( {w_{1} ,w_{2} , \ldots ,w_{l} } \right)^{T}\) and the adjusted individual DLTDMM \(D^{\prime {p}} = (d^{\prime {p}}_{kj} )_{m \times n} (p = 1,2, \ldots ,l)\), the collective adjusted DLTDMM \(D^{\prime} = \left( {d^{\prime}_{kj} } \right)_{m \times n}\) is derived, where
Step 8: Calculate the expectation \(E(a_{k} )\) of each alternative \(\left\{ {a_{1} ,a_{2} , \ldots ,a_{m} } \right\}\) as follows:
and the complete ranking of the alternatives is determined in accordance with the decreasing \(E(a_{k} )(k = 1,2, \ldots ,m)\).
Numerical experiment
In 2019, the Chinese government issued the “Outline of the Yangtze River Delta Regional Integration Development Plan” which clearly pointed out that the Jiangsu, Zhejiang and Anhui provinces should promote their respective strengths and strengthen cross-regional coordination and interaction. The construction of inter-provincial cooperative industrial parks is not only an important way to achieve regional integration, but also is of great significance to improve the market operation level of Anhui's economy.
Recently, Anhui Province and Jiangsu Province have cooperated to build an industrial park. In order to enhance the pertinence of investment, these two local governments need to strictly control the conditions of the companies that want to settle. The three criteria are the company’s development prospects (\(x_{1}\)), pollution control capabilities (\(x_{2}\)), and the company’s profitability (\(x_{3}\)). Now Anhui Provincial Government invites four experts \({\text{\{ }}e_{1} ,e_{2} ,e_{3} ,e_{4} {\text{\} }}\) to evaluate the three alternative companies \({\text{\{ }}a_{1} ,a_{2} ,a_{3} {\text{\} }}\) to select the most appropriate one from the three aspects. The above three alternative companies compete with each other. Let \(S = \left\{ {s_{0} :{\text{poor}},s_{1} :{\text{medium}},s_{2} :{\text{good}}} \right\}\) be a LST. In order to make the four experts express their evaluation information reasonably, we explain the related concepts of distributed linguistic in detail. Then, they are required to provide their preference using distributed linguistic. For example, after expert \(e_{1}\) compares the alternative company \(x_{1}\) and alternative company \(x_{3}\), he/she think that the linguistic preference degree of alternative company \(x_{1}\) over alternative company \(x_{3}\) may be \(``poor^{\prime\prime},``medium^{\prime\prime}\) or \(``good^{\prime\prime}\), and the their corresponding probabilities are 20%, 10% and 70%, respectively. Thus, the evaluation information of alternative company \(x_{1}\) over alternative company \(x_{3}\) from expert \(e_{1}\) can be depicted by DLTS \(d_{13}^{1} {\text{ = \{ }}(s_{0} ,0.2),(s_{1} ,0.1),(s_{2} ,0.7)\}\). Therefore, after interviewing 4 experts and selecting the evaluation information in a similar way, four DLTDMMs \(D^{p} = (d_{kj}^{p} )_{3 \times 3} (p = 1,2,3,4)\). In the meanwhile, they are required to give the DLTRM \(D^{p} = (d_{kj}^{p} )_{3 \times 3} (p = 1,2,3,4)\) and a DLTRM \(TD{ = (}TD_{pq} )_{4 \times 4}\) are obtained.
Stage 1 Calculate the weight of each expert under SNA
Step 1: Collect expert’s individual DLTDMMs \(D^{p} = (d_{kj}^{p} )_{3 \times 3} (p = 1,2,3,4)\) and the DLTRM \(TD{ = (}TD_{pq} )_{4 \times 4}\) under social network:
Step 2: complement the uncomplete social networks matrix \(TD{ = (}TD_{pq} )_{4 \times 4}\) by propagating and aggregating trust relationship.
According to \(TD{ = (}TD_{pq} )_{4 \times 4}\), the expert \(e_{1}\) does not directly express his trust relationship towards expert \(e_{2}\), so taking the process of the trust relationship’s propagation and aggregation between expert \(e_{1}\) and expert \(e_{2}\) as an example. There are two indirect paths connecting \(e_{1}\) and \(e_{2}\). Path 1: \(e_{1} \to e_{3} \to e_{4} \to e_{2}\) and Path 2: \(e_{1} \to e_{3} \to e_{2}\). The weights of each path are as follows:
Then calculate the trust relationship conveyed by each path:
The trust relationship between expert \(e_{1}\) and expert \(e_{2}\) can be calculated by Eq. (16):
The complete DLTRM is shown as follows:
Step 3: compute the weight \(w_{q} (q = 1,2,3,4)\) of each expert \(e = \left\{ {e_{1} ,e_{2} ,e_{3} ,e_{4} } \right\}\) by Eqs. (17) and (18):
Stage 2 Aggregation of DLTDM.
Step 4: connecting the weight of each expert and the individual distributed linguistic trust decision matrices \(D^{p} = (d_{kj}^{p} )_{3 \times 3} (p = 1,2,3,4)\), a collective DLTDMM \(\overline{D} { = (}\overline{D}_{kj} )_{3 \times 3}\) can be obtained:
Stage 3 Consensus test and adjustment
Step 5: by using Eqs. (21)–(23), calculate the three-level consensus degree at the evaluation information level, expert level and group level:
(1) The consensus degree at evaluation information levels can be calculated via Eq. (21):
(2) The consensus degree at experts’ level is:
\(db^{12} = 0.7622\);\(db^{13} = 0.7644\);\(db^{14} = 0.8944\);\(db^{23} = 0.7477\);\(db^{24} = 0.8011\);\(db^{34} = 0.7800\).
(3) The value of GCD is:
\({\text{GCD}} = 0.7916 < 0.8000\).
The GCD is lower than the threshold value \(\lambda = 0.8000\), the feedback mechanism is activated to adjust the most inconsistent evaluation information.
Step 6: checking the most inconsistent distribute information with the lowest adjustment cost through Eqs. (24) and (25).
The order of the consensus index at experts’ level:
0.7477 < 0.7622 < 0.7644 < 0.7800 < 0.8011 < 0.8944.
The 0.7477 is derived from \(DS^{23}\), then the smallest number 0.4 in \(DS^{23}\) can be pinpointed. The 0.4 is the consensus degree at evaluation information levels between \(d_{11}^{2}\) and \(d_{11}^{3}\):
Then, calculate the distance between \(d_{11}^{2}\), \(d_{11}^{3}\) and \(\overline{{d_{11} }}\) separately to decide which evaluation information needs to be adjusted:
Owing to 0.2112 < 0.3888, replace the evaluation information \(d_{11}^{3}\) with \(d_{11}^{2}\).Then recalculate the value of \({\text{GCD}}^{*}\):
The value of \({\text{GCD}}^{*}\) is higher than the threshold value \(\lambda = 0.800\), so end the feedback mechanism and turn to step 7.
Stage 4 Determining the order relationship among \(m\) alternatives.
Step 7: renew the collective distributed linguistic trust decision matrices. Combining the weight of each expert \(\left( {w_{1} ,w_{2} ,w_{3} ,w_{4} } \right)^{T}\) and the adjusted individual distributed linguistic trust decision matrices \(D^{\prime {p}} = (d^{\prime {p}}_{kj} )_{3 \times 3} (p = 1,2,3,4)\), the new collective DLTDMM can be obtained:
Step 8: calculate the expectation of each alternative \(\left\{ {a_{1} ,a_{2} ,a_{3} } \right\}\) as follows:
As \(E(a_{2} ) < E(a_{1} ) < E(a_{3} )\), thus the company \(a_{3}\) performs best in the three aspects of the company’s development prospects \((x_{1} )\), pollution control capabilities \((x_{2} )\) and the company’s profitability \((x_{3} )\). The government can choose \(a_{3}\) as a resident enterprise in the industrial park.
Comparative analysis
To prove our model’s validity and applicability, this subsection applies three models proposed in [12, 14, 31] to solve the problem mentioned in Sect. "Numerical experiment".
To solve the unreasonable assumption that the decision maker knows the weight in advance, Wu et al. [12] developed the DLTDMS composed of related properties of DLTFs. Then the weight of expert can be obtained by calculating in-degree of centrality. Finally, a novel feedback mechanism based on the minimum adjustment cost which can produce the boundary feedback parameter was constructed to recommend personalized advice for inconsistent experts.
Step 1: calculate the trust in-degree centrality by Eq. (6) and weight of each expert by Eq. (7) in [12]:
Step 2: get a collective DLTDMM \(\overline{D} { = (}\overline{D}_{pq} )_{3 \times 3}\) by Eq. (8) in [12]:
Step 3: calculate the consensus levels with the group by Eqs. (9)–(11) in [12]:
(1) Consensus degree at the level of evaluation information:
(2) Consensus degree at the level of alternatives:
(3) Consensus degree at the level of group decision matrix level:
Under the condition of \(\lambda { = 0}{\text{.87}}\),then the \({\text{CI}}^{2} < \lambda\) and \({\text{CI}}^{{3}} < \lambda\).
Step 4: identification of the inconsistent evaluation elements:
Step 5: calculate the boundary feedback parameter by solving the optimization model to obtain the recommendation advice:
The recommendations advice for expert \(e_{2}\) and \(e_{3}\) are:
Step 6: after modifying the inconsistent evaluation information, the new collective DLTDMM would be:
Step 7: their corresponding expected trust scores are by Eq. (3):
Therefore, the alternative \(a_{3}\) is the best choose.
Wu et al. [14] first developed a propagation operator on the basis of t-norms to get a complete DLTRM. Then to complement the incomplete individual DLTDMM, a trust estimation mechanism in which the evaluation information of unknown experts was estimated from other experts’ evaluation information was set up. Finally, an optimization model with the maximum retention of self-esteem degree was designed to obtain optimal feedback parameters in the process of reaching the GCD.
Step 1: complete the DLTRM with the support of the trust propagation operator \(P_{LD}\) in [14]:
Step 2: calculate the relative node in-degree centrality index by Eq. (10) and the weight of each expert by Eq. (11) in [14]:
Step 3: get a collective DLTDMM \(\overline{D} { = (}\overline{D}_{kj} )_{3 \times 3}\) by Eq. (18) in [14]:
Step 4: consensus test.
(1) Deviation indexes at the level of evaluation information:
(2) Deviation indexes at the level of alternatives:
(3) Deviation indexes at the level of group decision matrix:
The evaluation information that does not meet the threshold \(\lambda = 0.04\) are classified into the set APS by Eqs. (23)–(25):
Step 5: determine the optimal boundary feedback parameter:
The value of \(\delta_{2} { = 0}{\text{.1271 }}\delta_{3} { = 0}{\text{.2352}}\) can be obtained by solving the nonlinear model. The recommendation advice for \(e_{2}\) are:
The recommendation advice for \(e_{3}\) are:
After modifying the inconsistent evaluation information, the new collective DLTDMM will be:
The new deviation indexes at the level of decision matrix are as follows:
Step 6: calculate the expectation degree of each alternative and make a rank of them:
Therefore, the best alternative is the company \(a_{3}\).
In Ref. [31], Zhang et al. defined the consistency of PLPR based on graph theory's preference graph. As for the unacceptable consistent probabilistic linguistic preference relation, an automatic optimization method was designed to improve GCD. Finally, Zhang et al. used the aggregation operator to calculate the collective preference value of all the alternatives and make an order of them.
Step 1: see Step 1 in the above method.
Step 2: calculate the consistency indices (CI) by Eq. (13) in [31]:
Step 3: let \(\theta = 0.1\). The modified NPLPR is obtained by Eq. (10) in [31]:
Then we can get \({\text{CI}}^{\prime{1}} = 0.0818 < \overline{{{\text{CI}}}}\).
Step 4: get a collective DLTDMM by applying the model in Stages II and III:
Step 5: calculate the comprehensive preference values (PVs):
Step 6: calculate the expectation of PV by definition 4 in [31]:
Then the order of \({\text{PV}}_{i}\) is as follows:\({\text{PV}}_{3} > {\text{PV}}_{1} > {\text{PV}}_{2}\), and the best option is the company \(a_{3}\).
The GDM results with different methods are displayed in Table 2.
Compared with the models in Refs. [12, 14, 31], the advantages of our model are summarized as follows:
-
1.
Using the distributed linguistic group decision making model with SNA, we can find that the final selection of the settled company is entirely consistent with the result in [12, 14, 31], which verifies the effectiveness of our model.
-
2.
SNA is an important method to determine the weight of DMs, which requires that the designed models are supposed to have the ability to dig deeply into the available information in the DLTRM. The methods proposed in Wu et al. [12] and Zhang et al. [31] did not research the trust’s propagation and aggregation operators in social networks but directly calculated the weight of each expert based on the incomplete DLTRM. In Ref. [14], Wu investigated the propagation operator for experts who are not directly connected and used the shortest indirect path (use the average value of them on the assumption that there is more than one shortest path) as the path of trust transfer. However, it is more common that a series of trust paths of different lengths that transfer trust relationships between indirectly connected experts. This method does not consider the influence of trust paths of different length on the final result. To solve this problem, the model in this article designs a POWA operator, which not only considers the trust relationship from all trust paths between experts, but also takes the weights of each path into consideration. In general, compared with [12, 14, 31], the trust model based on SNA in this paper more comprehensively mines trust relationships in social networks to obtain more accurate weights.
-
3.
Owing to DMs’ different background and knowledge, they may be inconsistent with each other when making decisions. Therefore, CRP is important for selecting a reliable decision. In Ref. [14], Wu designed an optimization model with the maximum retention of self-esteem degree to get optimal feedback parameters in CRP. However, the proposed objective function and solution process are complicated. At the same time, we can find \(\delta_{2} { = 0}{\text{.127}}\), \(\delta_{3} { = 0}{\text{.235}}\), which means that 12.7% and 23.5% of the initial inconsistent information of \(e_{2}\) and \(e_{3}\) need to be adjusted which greatly damages the integrity of the original data. In Ref. [12], an optimization model based on the minimum adjustment cost was established to maintain individual independence while ensuring that the group consensus reaches the threshold. However, it only takes the model to minimize the adjustment cost into account, ignoring the deviation degree between experts and the group. In view of the advantages and disadvantages of the above two models in [12, 14], our model finds the most inconsistent evaluation information in each cycle of CRP, which greatly maintains the integrity of the original information. At the same time, to simplify the complexity of the model, we choose the evaluation information that needs to be adjusted based on the principle of minimum adjustment costs.
Conclusion
This paper presents a SNA and consensus reaching process-driven group decision making method with distributed linguistic information. It mainly consists of two processes: (1) develop a distributed linguistic trust propagation operator and a path order weighted averaging (POWA) operator to explore the trust propagation and aggregation between indirectly connected experts; (2) set up a novel feedback mechanism based on the minimum adjustment cost to gradually improve the group consensus degree. Compared with other literature related with group decision making problems, this model has the following contributions.
-
1.
It proposes a new POWA operator under multi-path scenarios between indirectly connected experts. There are two characteristics of it: (i) considering the influence of trust chain length on trust attenuation, it constructs a decreasing function between trust propagation efficiency (dependent variable) and the number of intermediaries (independent variable). (ii) The trust propagation efficiency is used as the path weight variable in POWA operator. Then, we can then get the final trust value by aggregating the trust value and the corresponding propagation efficiency. Consequently, it can be concluded that the aggregation operator not only utilizes the information transmitted by each path, but also reduces the influence of information decay on the final trust value.
-
2.
It develops a new feedback mechanism based on the minimum adjustment cost to improve the value of GCD. By setting three progressive levels of consensus, we can pinpoint the most inconsistent evaluation information between two experts. Then, the distance between two experts’ evaluation information and collective evaluation information is defined as the adjustment cost. Based on the principle of minimum adjustment cost, the feedback mechanism adjusts the most inconsistent evaluation information in each circulation until the value of group consensus degree reaches the predefined threshold. The feedback mechanism we proposed makes it possible to retain the original information to the greatest extent and continuously improve the value of the group consensus until it reaches the threshold.
However, the complexity of research questions may prevent experts from expressing their evaluation information, which will lead to incomplete evaluation information. This paper only considers the possibility of an incomplete trust relationship but ignores incomplete evaluation information. Besides, this paper sets the group consensus threshold based on related papers, making it kind of subjective. Therefore, in further research work, we will study how to complete the evaluation information and set the reasonable group consensus threshold by designing a reasonable model, and the proposed methods can also be employed in other fields, such as passenger demands determination, passenger satisfaction evaluation, online product recommendation and social risk evaluation.
References
Karczmarek P, Pedrycz W, Kiersztyn A (2021) Fuzzy analytic hierarchy process in a graphical approach. Group Decis Negot 30(2):463–481
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353
Turksen IB (1986) Interval-valued fuzzy sets based on normal forms. Fuzzy Sets Syst 20(2):191–210
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96
Yager RR, Abbasov AM (2013) Pythagorean membership grades, complex numbers, and decision making. Int J Intell Syst 28(5):436–452
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25(6):529–539
Rodriguez RM, Martinez L, Herrera F (2012) Hesitant fuzzy linguistic term sets for decision making. IEEE Trans Fuzzy Syst 20(1):109–119
Zhang ZM, Wu C (2014) Hesitant fuzzy linguistic aggregation operators and their applications to multiple attribute group decision making. J Intell Fuzzy Syst 26(5):2185–2202
Wang JH, Hao J (2006) A new version of 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans Fuzzy Syst 14(3):435–445
Zhang GQ, Dong YC, Xu YF (2014) Consistency and consensus measures for linguistic preference relations based on distribution assessments. Inf Fusion 17:46–55
Chen ZS, Chin KS, Li YL et al (2016) Proportional hesitant fuzzy linguistic term set for multiple criteria group decision making. Inf Sci 357:61–87
Wu J, Dai L, Chiclana F, Fujita H, Herrera-Viedma E (2017) A minimum adjustment cost feedback mechanism based on consensus model for group decision making under social network with distributed linguistic trust. Inf Fusion 14:232–242
Jin FF, Ni ZW, Langari R, Chen HY (2020) Consistency improvement-driven decision-making methods with probabilistic multiplicative preference relations. Group Decis Negot 29:371–397
Wu J, Zhao ZW, Sun Q, Fujita H (2020) A maximum self-esteem degree based feedback mechanism for group consensus reaching with the distributed linguistic trust propagation in social network. Inf Fusion 67:80–93
Victor P, Cornelis C, Cock MD, Silva PPD (2009) Gradual trust and distrust in recommender systems. Fuzzy Sets Syst 160(10):1367–1382
Victor P, Cornelis C, Cock MD, Herrera-Viedma E (2011) Practical aggregation operators for gradual trust and distrust. Fuzzy Sets Syst 184(1):126–147
Wu J, Chiclana F, Fujita H, Herrera-Viedma E (2017) A visual interaction consensus model for social network group decision making with trust propagation. Knowl Based Syst 122(15):39–50
Wu J, Chiclana F, Herrera-Viedma E (2015) Trust based consensus model for social network in an incomplete linguistic information context. Appl Soft Comput 35:827–839
Liu Y, Liang C, Chiclana F, Wu J (2010) A knowledge coverage-based trust propagation for recommendation mechanism in social network group decision making. Appl Soft Comput 101:107005
Wu T, Zhang K, Liu X, Cao C (2018) A two-stage social trust network partition model for large-scale group decision-making problems. Knowl Based Syst 163(1):632–643
Tan X, Zhu JJ, Palomares I, Liu X (2021) On consensus reaching process based on social network analysis in uncertain linguistic group decision making: exploring limited trust propagation and preference modification attitudes. Inf Fusion 78(08):180–198
Nasir SU, Kim TH (2013) Fast trust computation in online social networks. IEICE Trans Commun 96(11):2774–2783
Xie W, Ren Z, Xu ZS, Wang H (2018) The consensus of probabilistic uncertain linguistic preference relations and the application on the virtual reality industry. Knowl Based Syst 162(15):14–28
Chen ZS, Liu XL, Chin KS, Pedrycz W, Tsui KL, Skibniewski MJ (2021) Online-review analysis based large-scale group decision-making for determining passenger demands and evaluating passenger satisfaction: case study of high-speed rail system in China. Inf Fusion 69:22–39
Wu WY, Ni ZW, Jin FF, Song J (2022) Decision support model with Pythagorean fuzzy preference relations and its application in financial early warnings. Complex Intell Syst 8:443–466
Chen ZS, Zhang X, Rodríguez RM, Pedrycz W, Martinez L (2021) Expertise-based bid evaluation for construction-contractor selection with generalized comparative linguistic ELECTRE III. Autom Constr 125:103578
Ben-Arieh D, Easton T (2007) Multi-criteria group consensus under linear cost opinion elasticity. Decis Support Syst 43(3):713–721
Liu Y, Liang C, Chiclana F, Wu J (2017) A trust induced recommendation mechanism for reaching consensus in group decision making. Knowl Based Syst 119:221–231
Li Y, Liu M, Cao J, Wang X, Zhang N (2021) Multi-attribute group decision-making considering opinion dynamics. Expert Syst Appl 5:115479
Yu SM, Du ZJ, Zhang XY, Luo HY, Lin XD (2021) Punishment-driven consensus reaching model in social network large-scale decision-making with application to social capital selection. Appl Soft Comput 113(12):107912
Zhang YX, Xu ZS, Wang H, Liao HC (2016) Consistency-based risk assessment with probabilistic linguistic preference relation. Appl Soft Comput 49:817–833
Zadeh LA (1975) The concept of a linguistic variable and its application to approximate reasoning. Inf Sci 8(3):199–249
Xu Z (2005) Deviation measures of linguistic preference relations in group decision making. Omega 33(3):249–254
Palomares I, Martinez L, Herrera F (2014) A consensus model to detect and manage noncooperative behaviors in large-scale group decision making. IEEE Trans Fuzzy Syst 22(3):516–530
Li CC, Dong YC, Herrera F, Herrera-Viedma E, Martínez L (2017) Personalized individual semantics in computing with words for supporting linguistic group decision making. An application on consensus reaching. Inf Fusion 33:29–40
Gong ZW, Wang H, Guo WW, Gong ZJ, Wei G (2020) Measuring trust in social networks based on linear uncertainty theory. Inf Sci 508:154–172
Liu B, Zhou Q, Ding RX, Palomares I, Herrera F (2018) Large-scale group decision making model based on social network analysis: trust relationship-based conflict detection and elimination. Eur J Oper Res 275(2):737–754
Acknowledgements
The work was supported by National Natural Science Foundation of China (nos. 71901001, 72071001, 72001001, 72171002), Humanities and Social Sciences Planning Project of the Ministry of Education (no. 20YJAZH066), Natural Science Foundation of Anhui Province (nos. 2008085QG333, 2008085MG226, 2008085QG334, 2108085QG288, 1908085J03), Key Research Project of Humanities and Social Sciences in Colleges and Universities of Anhui Province (nos. SK2020A0038, SK2020A0054), General Project of Soft Science Research in Anhui Province (202106f01050052).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jin, F., Yang, Y., Liu, J. et al. Social network analysis and consensus reaching process-driven group decision making method with distributed linguistic information. Complex Intell. Syst. 9, 733–751 (2023). https://doi.org/10.1007/s40747-022-00817-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00817-3