
Abstract
For continuous growth and sustaining the competitiveness of a company, product developers spend most of their time making crucial decisions to address a great variety of unpredictable and uncontrollable information. Several mathematical approaches have already been adopted to aid the developers in selecting the best product concept for meeting customers’ requirements and exceeding their expectations. However, those methods do not cope with fully revealed developers’ preferences and do not take into account the random distribution of the target values of engineering characteristics (ECs). In this paper, the application of a quality function deployment (QFD)-based model and a stochastic dominance-based method is presented for product concept development. The first phase in the approach is to construct a product planning house of quality (PPHoQ), which is the core and the engine of the entire QFD model. This model depicts the relationship between the customers’ requirements (CRs) and the ECs for a product. The proposed approach addresses both the relationships between CRs and ECs, in addition to the correlations among the ECs. In this study, developers are invited to express their preferences using different types of linguistic terms dependent on their diverse backgrounds and understanding levels of the product. Based on the outcomes of the PPHoQ process, a variety of alternative concepts can be created. The alternatives are then prioritized and ranked in the second phase. The proposed approach facilitates the random distribution with stochastic variables rather than fuzzy methods to obtain more realistic product concept alternatives. Several examples and comparative results further illustrate that unbalanced linguistic terms and stochastic dominance efficiently endow the product concept selection model with uncertain information and the random distribution in a realistic style.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Dynamically changing customer desires and globally dispersed product design activities present tremendous challenges to companies these days as they respond to rapidly evolving international markets. It is imperative that companies must realize the importance of offering new and improved products to compete for survival and continuous success [1,2,3]. Typically, product development processes encompass numerous steps, involving customer requirements (CRs) (identification, prioritization, and translation), product concept design and selection, technical implementation, manufacturing, and commercialization [4]. The two initial steps seek to generate new and valuable innovative products for customers; these steps have a tremendous impact on the organization, as they shape the products that are offered [5]. Given their critical role, these early stages have received considerable attention in the literature [6, 7]. At this time, however, the recent publications are somewhat limited with respect to how to effectively address the vagueness and multi-criteria nature. In addition, various business cases have suggested that the optimal levels of the engineering characteristics and their distributions are of significant importance during these stages [8, 9]. The main problems are uncertainties and information distribution, which are difficult to be effectively dealt with. It is critical for companies to balance their concept selection when faced with the complicated situations and limited resources. Therefore, this research focuses on providing a novel approach to addressing these issues in the CRs identification, prioritization, and translation stages, in addition to the product concept design and selection stages. Besides, the total investment, the varying tendency of the data generated in the product development should also be adequately taken into consideration to determine the most reasonable product concept.
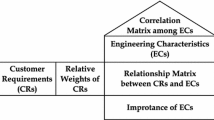
To tackle the aforementioned issues of developing new products, one of the most effective tools is the quality-function-deployment (QFD) approach, which is customer-driven tool to assist developers in determining the important engineering characteristics (ECs) that should realize in the development process [10, 11]. The QFD process consists of four inter-linked planning phases: product, parts, process, and production. Each phase is documented with a matrix [12]. The house of quality (HoQ) is the central concept of the QFD, and demonstrates how the final products satisfy the customer requirements (CRs). The matrix for the product planning phase is also known as the product planning house of quality (PPHoQ). This matrix represents the relationships between the CRs and the ECs. In the PPHoQ construction process, the prioritized CRs can be transformed into ECs, and then, the gap between customers and developers is bridged. The creation of innovative product concept options is derived from the outcomes of PPHoQ using market research, technical data, and systems engineering methods. However, the developers’ assessments and judgments of the PPHoQ process could be subjective and imprecise, which makes the outcomes of the PPHoQ process ambiguous. Moreover, owing to constraints like time pressure, limited resources, etc., the developers have to address the PPHoQ process within uncertain information environments.
Once the product concept alternatives are created, another important consideration in the concept selection process is the target value distribution of each engineering characteristic (EC). Ideally, the supporting documentation for the alternatives represents a strong majority, if not a unanimous group consensus [13]. In practice, developers should select the alternatives by comparing them based on several key attributes and using objective, multi-attribute decision-making methods, and the results are obtained by looking for the best concordance between the comparisons [14, 15]. Moreover, the natural heuristic based on a majority of the opinions when developers perform pairwise comparisons should be preserved [16]. Nevertheless, this comparison is not entirely accurate due to ambiguous and imprecise information available during the development process. Therefore, it is very difficult for developers to numerically express their preferences. As a consequence, the selection of a product concept is a typical decision-making problem with multiple attributes, which takes place in the context of uncertainty.
The inherent uncertainty in constructing the PPHoQ makes it complicated to systematically select the best product concept during the development process. The following problems persist, and they need further investigation:
-
(1) Determining the important ECs within uncertain information environments.
-
(2) Identifying the construction of PPHoQ generating concept alternatives and examining the alternatives in a customer-oriented manner.
-
(3) Eliciting the target value distributions of ECs to form an effective tool for determining the best alternative.
To achieve these purposes, a novel approach for analyzing and satisfying CRs by employing development technology and handling the information distribution is proposed. The remainder of this paper is organized as follows. The related literature is reviewed in “Related work”. In “Proposed approach”, the new approach is presented; it is illustrated in “Case study” using a case study. In addition, a comparison of the new approach with an existing approach is presented in “Discussions and comparisons”. The existing approach is based on an axiomatic design. Finally, in “Conclusion”, the key findings are summarized and conclusions are drawn.
Related work
In a demand-pull era, manufacturers have to conceive what customers want to maintain their competitiveness. Product concept alternatives are attempts to incorporate the voice of the customers into the process of product concept designing and selecting. The alternatives are prioritized using a process that usually consists of a sequence of steps in which companies design and evaluate product alternatives [17]. However, in the process of prioritization, many influencing factors, such as customer demands, objective environments, important ECs, availability of resources, etc. have to be considered. These factors make the process an uncertain and multi-criteria decision-making problem [18]. The capabilities to generate and prioritize concepts have been recognized as key determinants for many companies to compete within an extremely uncertain environment [19]. The approaches in the literature are compared below.
Constructing the PPHoQ in QFD
QFD is a well-known quality management system which produces many benefits, including the promotion of teamwork, lower start-up cost, and shorter design cycle. This important technique is characterized by a matrix called the PPHoQ (refer to Fig. 1) that clearly defines the relationships between CRs and ECs.

The product planning house of quality
The detailed steps of the PPHoQ can be shown as follows:
1. Identify the CRs and ECs and prioritize the CRs;
2. Establish the relationships (CRs to ECs, ECs to ECs);
3. Calculate the importance of the ECs;
4. Determine the optimal levels of the ECs.
Many methods and tools have been studied to support the PPHoQ analysis. The earliest methods for determining the importance of ECs use crisp numbers [20]. However, it is difficult for developers to express their preferences exactly. To address this concern, Bhowmik et al. [21] suggested the AHP methodology to calculate the intensity of relative priority for customer requirements with fuzzy pairwise comparisons because of its reliability and consistency in decision-making process. Mistarihi et al. [8] focused on the application of FANP methodology, in which triangular fuzzy numbers were adopted to represent the degree of importance of CRs and ECs, as they bore in mind the fact that human judgments of the intensity of preference for these attributes are subjective, vague, and uncertain. Even though the AHP and ANP have already been widely used in product development, in particular those utilizing the QFD ISO 16355 standard, some theoretical deficiencies remain owing to their hierarchical analyses [22]. In practice, it is difficult for developers to explore the use of these methods, as often limited data are available [23, 24]. In addition, each CR or EC in the process is assumed to be independent; nevertheless, there is a universality of correlation in the PPHoQ analysis [25].
Going beyond the use of crisp numbers, many researchers have sought to analyze the subjective and imprecise nature of CRs and ECs using fuzzy number [26]. Some studies propose hybrid approaches, which combine fuzzy numbers and the above-mentioned method to overcome the difficulties of uncertain environments [27,28,29]. To cope with the ambiguous information in a QFD, Mistarihi et al. [8] proposed an approach that utilizes a fuzzy ANP with an extent analysis. Nevertheless, there are two major issues that can be further investigated. The first issue is that the effectiveness of the model relies heavily on the defuzzification step, which transforms a fuzzy number to a crisp number. This transformation incurs a loss of information [30, 31]. A second issue is the difficulty in defining and subjectively assessing the quality of the appropriate membership functions [32].
To overcome the referred difficulty, a comprehensive linguistic-based foundation has been proven intuitively for constructing the PPHoQ [33,34,35]. Linguistic expressions are considered to be natural representations of unreliable or inexact preferences; these expressions include dissatisfied, fair, and satisfied [36, 37]. Their novel methodology based on linguistic terms can fulfill the construction process using words; this approach can make full use of available information and reduce the probability of information loss. However, the above-mentioned linguistic-based technique does not consider the objective circumstances, as all of the preferences involved in the QFD are expressed using a certain, limited set of linguistic terms. In practice, the assessments can be completed in the presence of uncertainty arising from a lack of contextual knowledge or resource constraints [38]. Moreover, the linguistic terms adopted in most of the previously reported linguistic-based approaches are uniformly distributed and symmetrical [39, 40]. Since developers are averse to introducing undesirable changes in the PPHoQ construction process due to limitations in the linguistic terms available, a broader collection is needed, which includes non-symmetrical and non-uniformly distributed linguistic terms. Therefore, this study includes certain and uncertain linguistic terms to support a comprehensive and reasonable decision-making process in the PPHoQ.
As for the optimal levels of ECs, many rational methods with different considerations to determine the optimal levels of ECs have attracted attention in recent decades. Wasserman [41] pioneered a prescriptive modeling-based approach to deal with the problem of determination. Considering the determination issues typically requires meeting multiple constraints, such as the development cost and time, skill level, customer satisfaction, and so on. The most widely used method to optimize the target values of the ECs is the optimization model based on linear programming [42]. The limited availability and imprecise nature of the data available during product development creates a situation in which it is very difficult to investigate the technique further [43, 44]. Then, the fuzzy optimization model is utilized to compute the optimal EC levels; different types of fuzzy numbers are considered [45]. Luo et al. [46] also proposed a fuzzy mathematical model which derives the optimal EC levels; this fuzzy optimization model is transformed into a linear programming model that can be solved using established techniques. Although powerful, the fuzzy optimization model has practical limitations. In this work, we integrate the uncertain linguistic terms and the linear programming mathematical model to determine the optimal levels of the ECs.
Selecting product concepts
As described above, a collection of product concept alternatives can be generated using the PPHoQ. This has a number of benefits, which include a deeper understanding of the product planning process and a rational deployment of resources by the developers. Selecting the product concept to pursue from among the alternatives is complex. It involves multiple stakeholders with distinct views on multiple criteria. In general, the selection of a product concept embodies critical factors that impact the success of the new product: satisfaction of the customers; experience of the design team; and the importance and the optimal levels of the ECs and their distribution [45, 47].
Previous work has made important contributions on the product concept selection problem. Butler et al. [48] proposed a multiple attribute utility theory-based approach to select the best alternative for meeting the CRs. Lee et al. [49] employed the ANP method under incomplete information circumstances by pairwise comparisons on the alternatives. Kulak and Kahraman [50] proposed a fuzzy multi-attribute model using an axiomatic design, in which AHP is adopted as the decision-making method. However, these methods assume that developers express their preferences with crisp numbers. In practice, there is uncertainty and imprecision concerning the comparison of the actions in relation to the key attributes; developers are unable to express themselves with the degree of precision required by conventional decision-making methods.
In recent years, how to address the uncertain preferences has received significant attention. The literature also indicates that the product concept selection problem involves handling development parameter characteristics (i.e., importance, distribution, and thresholds) of alternatives [51, 52]. Consequently, the selection process is a decision-making problem that involves both uncertainty and multiple attributes. As developers are unwilling or unable to evaluate alternatives precisely, the target EC values of the considered alternatives are often expressed within large bounds of uncertainty. The corresponding multi-attribute decision-making models have been employed to cope with the uncertainty problem, such as stochastic ordinal regression method [53], stochastic dominance [54], multi-attribute decision-making approach based on stochastic dominance [55], and stochastic multi-attribute acceptability analysis [56]. These approaches address the distribution problem of the target EC values. The results obtained from the multi-attribute decision-making approach based on stochastic dominance considering preference and veto thresholds have been validated and found to be consistent with real data [57]. They better reflect the distribution of the target EC values, and adopt simple functions in the computation of the importance and the optimal levels of ECs. Consequently, the adoption of stochastic dominance in the proposed method is investigated to evaluate the alternatives; the new method is an effective and practical tool for selecting a number of concept alternatives through pairwise comparisons.
Given that uncertainty and imprecision exist during the product development process due to various subjective and objective factors, methods are needed to address these issues. The current approaches have significant constraints, imposed by the mathematical foundations used. In this work, a decision analysis model based on non-symmetrical (i.e., unbalanced) linguistic terms in combination with an enhanced stochastic dominance-based method is proposed to identify the best product concept. Since the preferences of the CRs and ECs are too complex to be addressed by current models in the construction of PPHoQ, the developers are invited to express their preferences with linguistic terms. Moreover, the adoption of stochastic dominance in the proposed methods, which is an effective and practical tool for selection of a number of concept alternatives through pairwise comparisons, is investigated to evaluate the alternatives.
Proposed approach
This section introduces a novel approach for exploring the design and selection of alternative concepts. The approach consists of two main phases: the PPHoQ construction and the alternative selection (refer to Fig. 2). In the first phase, a typical PPHoQ process is applied to identify, prioritize, and translate CRs, this is an effective means to generate alternative design options. In QFD, constructing the PPHoQ is a crucial yet uncertain process under limited resources and information [58]. In this phase, developers prefer to use linguistic terms to express their preferences; an unbalanced linguistic label set is employed to determine the importance and the optimal levels of the ECs. Immediately followed by various product concept alternatives are designed according to the outcomes of the PPHoQ construction. Due to practical constraints (available budget, technology), only the best alternative can be pursued. In the second phase, the concept selection requires an evaluation of the stochastic distribution of the target values of the ECs with consideration of the subjective and objective conditions. To support the evaluation of the stochastic distribution, a decision-making model with a foundation of stochastic dominance is investigated. In practice, a product’s technical architecture, manufacturing processes, and features are often determined in the alternative selection phase. The best alternative can be identified by solving the stochastic dominance model. The two phases are described in detail below on a step-by-step basis.

The procedures of the proposed decision-making approach
The PPHoQ construction phase
Step 1: Acquiring the CRs and ECs. As a systematic method, QFD provides a means of developing, as much as possible, a product that embeds CRs (initial and potential). The CRs can be transformed into the ECs by a stepwise analysis and deployment of the PPHoQ. Various departments are represented by developers who participate in the product development process. An effective tool of setting the weights in a compromise-based delegation process has been proposed in [59], in which each developer designates the weights of the other developers. However, in Bodily’s method, the utility function of the developers is expressed in crisp numbers. In this paper, Bodily’s method is improved to better address uncertainty, and the preferences provided by each developer are represented by linguistic terms rather than digital numbers. Consequently, the weight vector can be calculated, denoted as \(\mathbf{{u}} = \left( {{u_1},{u_2}, \ldots ,{u_\upsilon }} \right) \). Using customer interviews and surveys, m major CRs are identified, denoted as \(\mathrm{{CR = }}\left\{ {\mathrm{{C}}{\mathrm{{R}}_i}\left| {i = 1,2, \ldots ,m} \right. } \right\} \). These CRs and technical data are used to create the related ECs, denoted as \(\mathrm{{EC = }}\left\{ {\mathrm{{E}}{\mathrm{{C}}_j}\left| {j = 1,2, \ldots ,n} \right. } \right\} \).
Step 2: Determining the importance of CRs. As development progresses, the inputs provided by product developers, which may be imprecise or vague, may need to be decoded. Linguistic terms are often preferred by developers to express their preferences, rather than numerical ones. Currently, existing methods for new product development propose the use of symmetrical and uniformly distributed linguistic label sets [36, 39]. Xu [38] demonstrates that the introduction of unbalanced linguistic label sets results in a higher degree of consensus on the outputs in comparison to the use of a balanced set of terms. In this work, an unbalanced linguistic set S is adopted from earlier results [39]; the center of this set is zero
where x is a positive integer, \({s_\alpha }\) denotes a possible value provided by customers, and S is a completely ordered, finite discrete term set. Xu [38] has also proposed the definition of an extended linguistic label set \({{\overline{S}}} \) in addition to a collection of operational laws. When only ambiguous or limited information is available, the interval terms provide a reasonable option for product developers to express their preferences. The group importance vector \(\mathbf{{T}} = \left( {{{{{\tilde{s}}}}_1},{{{{\tilde{s}}}}_2}, \ldots ,{{{{\tilde{s}}}}_m}} \right) \) can be obtained by aggregating the weight vector of product developers and their preferences.
Definition 1
Let \({{\tilde{s}}} = \left[ {{s_\alpha },{s_\beta }} \right] \) and \({s_\alpha },{s_\beta } \in {{\overline{S}}}\), where \({s_\alpha }\) and \({s_\beta }\) represent the limits (lower, upper) of an interval linguistic variable \({{\tilde{s}}}\), respectively.
Definition 2
Let \({{{\tilde{s}}}_1} = \left[ {{s_{{\alpha _1}}},{s_{{\beta _1}}}} \right] \), \({{{\tilde{s}}}_2} = \left[ {{s_{{\alpha _2}}},{s_{{\beta _2}}}} \right] \) be two interval linguistic terms, and \({s_{{\alpha _1}}},{s_{{\beta _1}}},{s_{{\alpha _2}}},{s_{{\beta _2}}} \in S\), the possibility degree of \({{{\tilde{s}}}_1} \ge {{{\tilde{s}}}_2}\) can be defined as
The possibility degree matrix \(\mathbf{{P}} = {\left( {{p_{\left( {{i_1},{i_2}} \right) }}} \right) _{m \times m}}\) can be constructed based on the results of paired comparisons, where \({p_{\left( {{i_1},{i_2}} \right) }} = p\left( {{{{{\tilde{s}}}}_{{i_1}}} \ge {{{{\tilde{s}}}}_{{i_2}}}} \right) \), \({i_1},{i_2} = 1,2, \ldots ,m\). Finally, let \({{\phi }} = \left( {{\phi _1},{\phi _2}, \ldots ,{\phi _m}} \right) \) be the importance vector of CRs, let \({\phi _{{i_1}}}\) be the importance of \(C{R_{{i_1}}}\), which can be computed by Eq. (3)
Step 3: Determining the relation matrix (between CRs and ECs) and the correlation matrix (among ECs). Effectively determining the relation matrix of CRs and ECs and the correlation matrix of ECs are critical tasks. These matrices are at the heart of the activity to create alternative product concepts. Because the developers have a deep understanding of the production process and technical requirements, they can choose certain linguistic terms from the specified unbalanced linguistic label set. The developers provide their individual judgements; these are utilized to create assessment matrices at the group level. The group relation matrices \(\mathbf{{R}} = {\left( {{r_{\left( {i,j} \right) }}} \right) _{m \times n}}\) and \(\mathbf{{B}} = {\left( {{b_{\left( {{j_1},{j_2}} \right) }}} \right) _{n \times n}}\) can be obtained by aggregating the weight vector of developers and their preferences.
Step 4: Determining the importance of ECs. Let \({{\xi }}\) denote the importance vector of ECs, which is expressed as
Let \({\omega _{{j_1}}}\) denote the important coefficient with respect to \(E{C_{{j_1}}}\). This can be calculated using Eq. (5)
Step 5: Determining the optimal EC levels. Luo et al. [46] presented an effective approach to determine the optimal EC level. An optimization model can be established, using the information provided in the PPHoQ, and utilizing fuzzy terms. The objective of the model is to maximize the overall customer satisfaction under multiple constraints, such as limited budget, technological level, and potential risks. In the new approach proposed, the existing method is improved: each developer estimates the coefficients of the market segment and the development cost and captures them with linguistic terms. The optimal level vector of the ECs can be determined, denoted as \(\mathbf{{Z}} = \left( {{z_1},{z_2}, \ldots ,{z_n}} \right) \). The product that can meet the optimal level of each engineering characteristic can be named the “ideal product”.
The alternative selection phase
Step 6: Determining the probability density functions of each alternative. The outcomes of the PPHoQ, denoted as \(\mathrm{{Y = }}\left( {{y_1},{y_2}, \ldots ,{y_k}} \right) \), are used to formulate product concept alternatives. Considering the influence of the follow-up development process and imprecise information, it is impossible to compare the degree of compliance between the alternatives and the ideal product. Generally, the target values of alternatives usually follow a random distribution. For the sake of convenience, it is assumed that they are normally distributed stochastic variables. The probability density functions of target values of each alternative are determined by developers, denoted as \({f_{\left( {h,j} \right) }}\left( x \right) = \frac{1}{{\sqrt{2\pi } {\sigma _{\left( {h,j} \right) }}}}{e^{\frac{{ - {{\left( {x - {\mu _{\left( {h,j} \right) }}} \right) }^2}}}{{2\sigma _{\left( {h,j} \right) }^2}}}}\), where \(h = 1,2, \ldots ,k\), \(j = 1,2, \ldots ,n\).
Step 7: Calculating the expected value of the overall distribution with respect to each alternative. The gap between the target values and the optimal ones of the ECs can be partitioned into several intervals, denoted as \(\left\{ {\left( {\lambda _{\left( {1,j} \right) }^\phi ,\lambda _{\left( {1,j} \right) }^\varphi } \right) ,\left( {\lambda _{\left( {2,j} \right) }^\phi ,\lambda _{\left( {2,j} \right) }^\varphi } \right) , \ldots ,\left( {\lambda _{\left( {\zeta ,j} \right) }^\phi ,\lambda _{\left( {\zeta ,j} \right) }^\varphi } \right) } \right\} \). Product developers expect the gap to be minimal. In particular, the smaller the gap between the interval and the optimal levels, the more important the interval is in the development process. Similarly, the larger the gap between the interval and the optimal levels, the less important the interval is in the development process. Using pairwise comparisons, the proportionment vector of the indifference interval can be determined, and it is denoted by \({{\theta }} = \left( {{\theta _1},{\theta _2}, \cdots ,{\theta _\zeta }} \right) \), where \({\theta _l} \ge 0\), \(\sum \limits _{l = 1}^\zeta {{\theta _l}} = 1\). Let \({F_{\left\{ {l,h\left( j \right) } \right\} }}\) be the probability of the indifference is in the interval \(\left( {\lambda _{\left( {l,j} \right) }^\phi ,\lambda _{\left( {l,j} \right) }^\varphi } \right) \), which can be calculated by Eq. (6)
Finally, let \({E_{\left( {h,j} \right) }}\) be the expected value of the overall distribution, which can be defined by Eq. (7)
Step 8: Calculating the concordance index and the discordance index. Let \(\mathbf{{D}} = {\left( {d_{\left( {{h_1},{h_2}} \right) }^j} \right) _{k \times k}}\) be the stochastic dominance matrix of two alternatives \({y_{{h_1}}}\) and \({y_{{h_2}}}\). With respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\), \(d_{\left( {{h_1},{h_2}} \right) }^j\) can be defined by Theorem 1 [60].
Theorem 1
Let \({f_1}\left( x \right) = \frac{1}{{\sqrt{2\pi } {\sigma _1}}}{e^{\frac{{ - {{\left( {x - {\mu _1}} \right) }^2}}}{{2\sigma _1^2}}}}\) and \({f_2}\left( x \right) = \frac{1}{{\sqrt{2\pi } {\sigma _2}}}{e^{\frac{{ - {{\left( {x - {\mu _2}} \right) }^2}}}{{2\sigma _2^2}}}}\) be the probability density functions of two alternatives with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\), respectively. If \({\mu _1} > {\mu _2}\) and \({\sigma _1} = {\sigma _2}\), then \({f_1}\left( x \right) \mathrm{{FSD}}{f_2}\left( x \right) \).
Let \({\chi _j}\) and \({\gamma _j}\) be the preference threshold and veto threshold with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\), respectively, which can be determined by the product developers according to their knowledge and experience.
The concordance index \(a_{\left( {{h_1},{h_2}} \right) }^j\) for each pair of alternatives with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\) can be expressed by Eq. (8). Then, the concordance matrix \(\mathbf{{A}} = {\left( {a_{{h_1}{h_2}}^j} \right) _{k \times k}}\) can be constructed
The discordance index \(c_{\left( {{h_1},{h_2}} \right) }^j\) for each pair of alternatives with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\) can be expressed by Eq. (9). Then, the discordance matrix \(\mathbf{{C}} = {\left( {c_{{h_1}{h_2}}^j} \right) _{k \times k}}\) can be constructed
Step 9: Determining the overall concordance matrix. The overall concordance index \({g_{\left( {{h_1},{h_2}} \right) }}\) for each pair of alternatives with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\) can be expressed by Eq. (10). Then, the overall concordance matrix \(\mathbf{{G}} = {\left( {{g_{\left( {{h_1},{h_2}} \right) }}} \right) _{k \times k}}\) can be constructed
Step 10: Determining the overall evaluation values. Let \({q_{\left( {{h_1},{h_2}} \right) }}\) be the superior index of alternative \({y_{{h_1}}}\), which precedes alternative \({y_{{h_2}}}\). This can be expressed by Eq. (11). Then, the superior matrix \(\mathbf{{Q}} = {\left( {{q_{\left( {{h_1},{h_2}} \right) }}} \right) _{k \times k}}\) can be constructed
Let \(\mathrm{{V}}{\mathrm{{I}}_{{h_1}}}\) be the overall evaluation value of each alternative, and Eq. (12) is used to calculate this value
The proposed approach is based on the identification and translation of the CRs, the optimization of ECs target levels, the concept alternative designing, and finally the evaluation of the performance respect to each alternative. In comparison to existing methods, the proposed approach uniquely integrates non-symmetrical and non-uniformly distributed linguistic terms; it also adopts the stochastic dominance method. The new approach strictly focuses on the representation of human actions and objective environments in the first phase. The construction of PPHoQ-based unbalanced linguistic terms involves CRs identification, prioritization, and translation. The adoption of human homogeneous and evaluation methodologies in the process for different purposes assures that the outcomes of the model are more realistic. The stochastic dominance through pair-comparison approach, initially developed to evaluate the performance of alternatives, is based on how well they meet the optimal levels of ECs. Compared to the traditional method, the proposed stochastic dominance-based approach allows the developers to express their preferences in a more flexible and verifiable manner.
Case study
In this section, an example is presented for selecting a concept alternative for a new product widely used in mining, metallurgy, and building sites: a new jaw crusher. A new product development team was set up in the company to improve its product offering. The company occupies a favorable position in the market; however, they recognize that the business environment is changing and they need to innovate to retain their standing.
The PPHoQ construction phase
Step 1: Acquiring the CRs and ECs. Five product developers from the research and development center, the production center, and the marketing center are chosen to participate in the development process. The weight vector \(\mathbf{{d}} = \left( {0.213,0.225,0.207,0.192,0.163} \right) \) is computed using the improved Bodily method. In-depth interviews with customers and comprehensive surveys implemented by the selected developers are used to identify five major CRs: “larger crush output” (CR1); “greater flexibility” (CR2); “smaller product granularity” (CR3); “lower power consumption” (CR4); and “greater stability” (CR5), respectively. Based on the CRs and the technical data available, five related ECs are generated. They are “max feeding grain size” (EC1), “discharge range opening” (EC2), “production capacity” (EC3), “motor power” (EC4), and “total weight” (EC5), respectively.
Step 2: Determining the importance of the CRs. The product developers use the unbalanced linguistic terms to express their preferences. They choose the appropriate linguistic terms based on their understanding of what the customer’s need in the new product. In this paper, the variable x in the set can be chosen as follows, e.g., \(x = 4\).
The group importance vector can be obtained by aggregating the weight vector of the product developers and their individual preferences, which can be shown as
According to Eq. (2), the possibility degree matrix can be constructed, which can be shown as
The importance of each customer requirement can be computed by Eq. (3), which can be shown as \({{\phi }} = \left( {0.306,0.178,0.129,0.099,0.288} \right) \).
Step 3: Determining the relation matrix (between CRs and ECs) and the correlation matrix (among ECs). The group relation matrix and group correlation matrix can be obtained by aggregating the weight vector of the developers and their preferences, as shown in Tables 1 and 2.
Step 4: Determining the importance of ECs. The importance vector of ECs can be expressed by Eq. (4), which can be shown as \({{\xi }} = \left( {0.288,0.455,0.645,0.443,0.424} \right) \).
The important coefficients of ECs can be calculated by Eq. (5), which can be shown as \({{\omega }} = ( 0.128,0.202,0.286,0.196,0.188)\).
Step 5: Determining the optimal EC levels. Based on the improved Luo’s method [46], the optimal level vector of ECs can be determined; these results are presented in Table 3.
Step 6: Determining the probability density functions for each alternative. After the PPHoQ of the jaw crusher is constructed, the product concept alternatives can be produced by applying the developers’ skills and experience. Five alternatives and their probability density functions of target values are generated in this study through the comprehensive analysis of available information; these results are presented in Table 4.
The alternative selection phase
Step 7: Calculating the expected value of the overall distribution with respect to each alternative. The gap can be partitioned into five intervals; these results are presented in Table 5.
The probability of the gap occurring within an interval can be calculated by Eq. (6), and the expected value of the overall distribution can be defined by Eq. (7), as shown in Tables 6 and 7, respectively.
Step 8: Calculating the concordance index and the discordance index. The stochastic dominance index with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\) can be defined by Theorem 1, as shown in Table 8.
Table 9 demonstrates the preference threshold and veto threshold with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\) .
The concordance index and the discordance index can be calculated by Eqs. (8) and (9), as shown in Tables 10 and 11, respectively.
Step 9: Determining the overall concordance matrix. The overall concordance index for each pair of alternatives can be expressed by Eq. (10), as shown in Table 12.
The superior index of alternative \({y_{{h_1}}}\) precedes alternative \({y_{{h_2}}}\) can be calculated by Eq. (11); these results are presented in Table 13.
Step 10: Determining the overall evaluation values. After employing Eq. (12), the overall evaluation index of each alternative is: \(\mathrm{{V}}{\mathrm{{I}}_1} = 1.180\), \(\mathrm{{V}}{\mathrm{{I}}_2} = 1.080\), \(\mathrm{{V}}{\mathrm{{I}}_3} = 0.000\), \(\mathrm{{V}}{\mathrm{{I}}_4} = 1.739\), and \(\mathrm{{V}}{\mathrm{{I}}_5} = 0.083\), respectively. Based on the overall evaluation index, the priority of the alternatives is determined to be:\({y_4} \succ {y_1} \succ {y_2} \succ {y_5} \succ {y_3}\).
Discussions and comparisons
An illustrative example based on previous literature
The proposed approach incorporates the unbalanced linguistic variables and enhanced stochastic dominance method. This section employs an illustrative example adopted by [61] to show the strengths of our product concept selection model.
Let us recall the illustrative example applied by [61], in which the author has investigated the designing process of an aluminum window. The five important CRs and the corresponding ECs are listed as follows:
\(\mathrm{{C}}{\mathrm{{R}}_1}\) : reducing the noise of the car; \(\mathrm{{C}}{\mathrm{{R}}_2}\): enhancing the acceleration; \(\mathrm{{C}}{\mathrm{{R}}_3}\): saving fuel; \(\mathrm{{C}}{\mathrm{{R}}_4}\): improving security; \(\mathrm{{C}}{\mathrm{{R}}_5}\): seat comfort;\(\mathrm{{E}}{\mathrm{{C}}_1}\) : reducing the noise of the exhaust system; \(\mathrm{{E}}{\mathrm{{C}}_2}\) : increasing the horsepower of the engine; \(\mathrm{{E}}{\mathrm{{C}}_3}\): reducing the amount of fuel per mile; \(\mathrm{{E}}{\mathrm{{C}}_4}\): increasing the controlling force of the braking system; \(\mathrm{{E}}{\mathrm{{C}}_5}\) : enlarging the space of the seat.
The ranking results of CRs and ECs are \(\mathrm{{C}}{\mathrm{{R}}_2} \succ \mathrm{{C}}{\mathrm{{R}}_3} \succ \mathrm{{C}}{\mathrm{{R}}_1} \succ \mathrm{{C}}{\mathrm{{R}}_4} \succ \mathrm{{C}}{\mathrm{{R}}_5}\) and \(\mathrm{{E}}{\mathrm{{C}}_2} \succ \mathrm{{E}}{\mathrm{{C}}_1} \succ \mathrm{{E}}{\mathrm{{C}}_5} \succ \mathrm{{E}}{\mathrm{{C}}_3} \succ \mathrm{{E}}{\mathrm{{C}}_4}\), respectively. Finally, the priority result of the prototype aluminum windows is \({y_4} \succ {y_3} \succ {y_2} \succ {y_1}\).
We employ the proposed model to solve the illustrative example; the applied steps are described below:
Step 1: Determining the importance of the CRs. The product developers use the predetermined linguistic terms to express their preferences. The group importance vector can be obtained as
. According to Eqs. (2) and (3), the importance of each CR can be shown as \({{\phi }} = \left( {0.208,0.289,0.257,0.130,0.116} \right) \).
Step 2: Determining the importance of the ECs. According to Eqs. (4) and (5), the importance coefficients of ECs can be shown as \({{\omega }} = \left( {0.292,0.233,0.178,0.107,0.190} \right) \).
Step 3: Determining the optimal levels of the ECs. The optimal levels of the ECs can be shown in Table 14.
Step 4: Determining the probability density functions for each prototype alternative. The probability density functions of the four prototype alternatives are presented in Table 15.
Step 5: Calculating the expected value of the overall distribution with respect to each prototype alternative. According to Eqs. (6) and (7), the expected value of the overall distribution with respect to each prototype alternative is shown in Table 16.
Step 6: Determining the preference threshold and the veto threshold with respect to \(\mathrm{{E}}{\mathrm{{C}}_j}\). The preference threshold and the veto threshold of the ECs are shown in Table 17.
Step 7: Determining the superior index of each pair of prototype alternatives. According to Eqs. (8), (9), (10) and (11), the superior index of alternative \({y_{{h_1}}}\)precedes alternative \({y_{{h_2}}}\) is presented in Table 18.
Step 8: Determining the overall evaluation values. After employing Eq. (12), the overall evaluation index of each alternative is: \(\mathrm{{V}}{\mathrm{{I}}_1} = 0.116\), \(\mathrm{{V}}{\mathrm{{I}}_2} = 0.267\), \(\mathrm{{V}}{\mathrm{{I}}_3} = 1.453\), and\(\mathrm{{V}}{\mathrm{{I}}_4} = 0.996\), respectively. Based on the overall evaluation index, the priority of the alternatives is determined to be: \({y_3} \succ {y_4} \succ {y_2} \succ {y_1}\).
After employing the proposed method, the outcomes are compared to those of the model proposed by [62]. The results are shown in Table 19.methods. However, the two approaches differ in the ranking order of the ECs and the priority of prototype alternatives. The two most important ECs obtained by the proposed method are \(\mathrm{{E}}{\mathrm{{C}}_1}\) and \(\mathrm{{E}}{\mathrm{{C}}_2}\), respectively, whereas the two most important ECs obtained by Liu’s method are\(\mathrm{{E}}{\mathrm{{C}}_1}\) and \(\mathrm{{E}}{\mathrm{{C}}_2}\), respectively. The ranking orders of prototype alternatives differ only between \({y_3}\) and \({y_4}\) , that is, \({y_3} \succ {y_4}\) for the proposed method, whereas \({y_4} \succ {y_3}\) for Liu’s method.
The measurement of robustness was introduced to compare further the results of the two methods. As Wu et al. [63] indicated that the robustness on the priority of alternatives can be measured as the degree to which the relative priority relationship among different alternatives is kept despite uncertainty. Consequently, the robustness index of alternatives is expressed as the likelihood that a priority relationship in V is kept. The robustness index on the priority relationship between \({y_{{h_1}}}\) and \({y_{{h_2}}}\), denoted as \(RI\left( V \right) _{{h_2}}^{{h_1}}\), can be obtained by using Eq. (13)
where
In particular, \(f\left( {{E_h}} \right) \) is an indicator variable, \({y_{{V_{{h_1}}}}}\) denotes the \(h_1\)th alternative in V, and h(V) denotes the array size of V. \(RI\left( V \right) _{{h_2}}^{{h_1}}\) is expressed as a type of likelihood measured through comparative investigation, so its value is \(0 \le RI\left( V \right) _{{h_2}}^{{h_1}} \le 1\). The larger value of RI(V) implies that the robustness on the priority relationship in V is higher.
The priority of alternatives with respect to the normalization of the ECs is shown in Table 20. And the comparison of the expected values with respect to each alternative can be depicted in Fig. 3.
Using Eq. 13, the robustness index of \(y_3\) and \(y_4\) is shown in Table 21.
Then, the \(RI\left( V \right) _3^4\) value based on Liu’s method can be calculated as follows:
Then, the \(RI\left( V \right) _4^3\) value based on the proposed method can be calculated as follows:
The robustness index values for the prioritization based on Liu’s method and the proposed method are computed above. It is obvious that the proposed method outperforms the Liu’s method.

The comparison of the expected values with respect to each alternative of the two methods
The different results between the two methods are mainly due to incorporating linguistic variables and stochastic dominance, which leads to a completely different concept selection process, and these differences significantly affect the final selection outcomes. On one hand, our approach indicates that obtaining evaluation information does not need to be transformed into other forms. The fuzzy numbers should be transformed into crisp values in Liu’s method, which is more likely to distort the final outcomes due to loss of information. On the other hand, we are able to identify the superior index which can show if one prototype alternative is better than another. using our approach, the enhanced stochastic dominance method considering the random distributions has more dependable outcomes in comparison with Liu’s method.
The case example applied in a previous method
Our case example is used again in this section to illustrate the applicability of the proposed approach. Here, another approach proposed in the literature is applied to determine the sorted results for comparison purposes. [50] investigate an approach based on axiomatic design and AHP for addressing the alternatives selection problem. The steps of selecting alternatives based on the method proposed by [50] are defined as follows:
-
Step 1. Constructing the PPHoQ in QFD, determine the importance and the optimal levels of the ECs.
-
Step 2. Identify the design range for a certain engineering characteristic in all the alternatives.
-
Step 3. Acquire the common area between the design range and the optimal levels.
-
Step 4. Obtain the information content of the alternatives.
-
Step 5. Calculate the overall information content and determine the priority of the alternatives.
The information content for each alternative with respect to ECs is listed in Table 22. Based on the axiomatic design, the alternatives \({y_3}\) and \({y_5}\) should be eliminated. At this point, the overall information contents of the other alternatives are determined to be \(\mathrm{{V}}{\mathrm{{I}}_1} = 0.058\) , \(\mathrm{{V}}{\mathrm{{I}}_2} = 0.048\) ,\(\mathrm{{V}}{\mathrm{{I}}_4} = 0.063\). In the end, the priority order of the alternatives can be determined as \({y_4} \succ {y_1} \succ {y_2}\).
It can be concluded by the results obtained from the axiomatic design and AHP that the ranking of the alternatives is\({y_4} \succ {y_1} \succ {y_2}\). When comparing the results, both the newly proposed method and the one proposed by Kulak and Kahraman [50] indicate \({y_4}\) is the best alternative, while \({y_1}\) and \({y_2}\) are the next two best alternatives. However, the two approaches differ in the ranking order of \({y_3}\) and\({y_5}\). The method proposed by Kulak and Kahraman [50] eliminates the alternatives \({y_3}\) and\({y_5}\), whereas the newly proposed method produces a ranking result for them. The different results between the two methods are mainly due to the uncertain information being treated in different manners. In the method proposed by Kulak and Kahraman [50], linguistic terms are systematically converted to their corresponding fuzzy numbers, and all the fuzzy numbers are assigned crisp scores. This results in information loss during the transformation processes. Moreover, the approach does not provide an adequate description of the target value distribution of alternatives. Therefore, the outcomes of the proposed method tend to be more realistic.
Nevertheless, the proposed product concept development model should be employed by a manufacturer after setting up a development team organized by various departments to assure the availability of the approach. Another crucial limitation is related to the testing and verification, as the outcomes of the PPHoQ and the selection model have been explored in the context of a pilot study, and they have not continued in subsequent product development processes. The selected product concept is a reference that should be reviewed when real-life applications are conducted.
Conclusion
To guarantee that CRs can be accurately answered, companies are urged to take into account incomplete information and their distribution characteristics in the product concept development process. However, doing so requires extraordinary efforts and attention from the product developers. Consequently, we proposed an integrated approach based on the PPHoQ analysis and a stochastic dominance-based method to develop the product concept. In the PPHoQ construction phase, the unbalanced linguistic variables have been adopted to determine the importance and the optimal levels of the ECs. The proposed integrated method allows the prioritization of CRs to be translated and product concept alternatives to be designed in accordance with the information asymmetry. In the concept selection phase, the enhanced stochastic dominance method based on normal distribution has been used to address the difficult product development problems.
The proposed approach offers the following benefits, which can be summarized as below.
-
The unbalanced linguistic variables were introduced in the proposed approach to address the uncertain information which is produced in the PPHoQ construction, such as the relationships between CRs and ECs, the correlation among ECs, the importance of CRs and ECs, the optimal levels of ECs, etc.
-
The proposed approach yields stochastic variables rather than fuzzy methods, by means of which, it addresses uncertainties in the input data and develops stochastic strategies that are efficient and resilient.
-
The proposed model provides a better generic methodology that can help developers make a better and more comprehensive response to the product development problems they encounter. This is certified by the case study and comparisons that the proposed method tends to be more realistic than the existing approaches.
-
The proposed approach is not limited to prioritize product concepts. As a matter of fact, the proposed method can be slightly modified and applied to subsequent product development processes.
Several future research directions are introduced herein. First, the present study focuses only on static information; however, other data mining techniques can be adopted to explore the rapidly changing business environment to propose a dynamic portfolio of resilient strategies. Second, other distribution characteristics were not considered in this study as the most frequent normal distribution has been taken into consideration. Last but not the least, the proposed stochastic dominance-based approach is worthy of additional study to investigate the sensitivity in the product concept selection problem. Future studies may also evaluate the impact of a variety of random distributions on the product concept selection outcomes.
References
Lam P-K, Chin K-S (2005) Identifying and prioritizing critical success factors for conflict management in collaborative new product development. Ind Mark Manage 34(8):761–772
Felekoglu B, Moultrie J (2014) Top management involvement in new product development: a review and synthesis. J Prod Innov Manag 31(1):159–175
Yu Y, Li C (2021) Evaluate the priority of product design factors in the process of complex product innovation. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00298-w
Wang Y, Lin Y, Zhong RY, Xu X (2019) IoT-enabled cloud-based additive manufacturing platform to support rapid product development. Int J Prod Res 57(12):3975–3991
Wang L, Jin JL, Zhou KZ, Li CB, Yin E (2020) Does customer participation hurt new product development performance? Customer role, product newness, and conflict. J Bus Res 109:246–259
Shi YL, Peng QJ (2020) A spectral clustering method to improve importance rating accuracy of customer requirements in QFD. Int J Adv Manuf Technol 107(5):2579–2596
Chen Z-S, Martínez L, Chang J-P, Wang X-J, Xionge S-H, Chin K-S (2019) Sustainable building material selection: a QFD-and ELECTRE III-embedded hybrid MCGDM approach with consensus building. Eng Appl Artif Intell 85:783–807
Mistarihi MZ, Okour RA, Mumani AA (2020) An integration of a QFD model with Fuzzy-ANP approach for determining the importance weights for engineering characteristics of the proposed wheelchair design. Appl Soft Comput 90:106136
Chen Z-S, Liu X-L, Chin K-S, Pedrycz W, Tsui K-L, Skibniewski MJ (2021) Online-review analysis based large-scale group decision-making for determining passenger demands and evaluating passenger satisfaction: Case study of high-speed rail system in China. Inf Fusion 69:22–39
Akao Y, Mazur GH, The leading edge in QFD: past, present and future. Int J Qual Reliab Manag
Chan L-K, Wu M-L (2002) Quality function deployment: a literature review. Eur J Oper Res 143(3):463–497
Roy J, Adhikary K (2019) A weighted interval rough number based method to determine relative importance ratings of customer requirements in QFD product planning. J Intell Manuf 30(1):3–16
Certa A, Enea M, Lupo T (2013) ELECTRE III to dynamically support the decision maker about the periodic replacements configurations for a multi-component system. Decis Support Syst 55(1):126–134
Leyva-López JC, Fernández-González E (2003) A new method for group decision support based on ELECTRE III methodology. Eur J Oper Res 148(1):14–27
Chen Z-S, Zhang X, Rodríguez RM, Pedrycz W, Martínez L (2021) Expertise-based bid evaluation for construction-contractor selection with generalized comparative linguistic ELECTRE III. Autom Constr 125:103578
Hashemi SS, Hajiagha SHR, Zavadskas EK, Mahdiraji HA (2016) Multicriteria group decision making with ELECTRE III method based on interval-valued intuitionistic fuzzy information. Appl Math Model 40(2):1554–1564
Rezaei E, Paydar MM, Safaei AS (2020) Customer relationship management and new product development in designing a robust supply chain. RAIRO-Oper Res 54(2):369–391
García-Lapresta JL, Moreno-Albadalejo P, Pérez-Román D, Temprano-García V (2021) A multi-criteria procedure in new product development using different qualitative scales. Appl Soft Comput 106:107279
Li F, Chen C-H, Lee C-H, Khoo L-P (2020) A user requirement-driven approach incorporating TRIZ and QFD for designing a smart vessel alarm system to reduce alarm fatigue. J Navig 73(1):212–232
Chan L-K, Wu M-L (2005) A systematic approach to quality function deployment with a full illustrative example. Omega 33(2):119–139
Bhowmik C, Bhowmik S, Ray A (2021) Selection of optimum green energy sources by considering environmental constructs and their technical criteria: a case study. Environ Dev Sustain:1–29
Zaim S, Sevkli M, Camgöz-Akdağ H, Demirel OF, Yayla AY, Delen D (2014) Use of ANP weighted crisp and fuzzy QFD for product development. Expert Syst Appl 41(9):4464–4474
Wang ZQ, Fung RYK, Li YL, Pu Y (2016) A group multi-granularity linguistic-based methodology for prioritizing engineering characteristics under uncertainties. Comput Ind Eng 91:178–187
Dania W, Sitepu I, Rucitra A (2021) Collaboration quality assessment in the sustainable rice supply chain by using an integrated model of QFD-FANP-DEA: a case study of the rice industry in Malang. In: IOP conference series: earth and environmental science, vol 733. IOP Publishing, p 012041
Sarkis J, Talluri S (2002) Efficiency measurement of hospitals: issues and extensions. Int J Oper Prod Manag 11(3):306–313
Zhang W, Zhang G, Li Y, Shao Y, Ran Y (2019) Key engineering characteristics extraction technology based on QFD. IEEE Access 7:75105–75112
Lima-Junior FR, Carpinetti LCR (2016) A multicriteria approach based on fuzzy QFD for choosing criteria for supplier selection. Comput Ind Eng 101:269–285
Liu H-T, Cheng H-S (2016) An improved grey quality function deployment approach using the grey TRIZ technique. Comput Ind Eng 92:57–71
Akkawuttiwanich P, Yenradee P (2018) Fuzzy QFD approach for managing SCOR performance indicators. Comput Ind Eng 122:189–201
Sivasamy K, Arumugam C, Devadasan SR, Murugesh R, Thilak VMM (2016) Advanced models of quality function deployment: a literature review. Qual Quant 50(3):1399–1414
Chen Y, Ran Y, Huang G, Xiao L, Zhang G (2021) A new integrated MCDM approach for improving QFD based on DEMATEL and extended MULTIMOORA under uncertainty environment. Appl Soft Comput 105:107222
Yazdani M, Chatterjee P, Zavadskas EK, Zolfani SH (2017) Integrated QFD-MCDM framework for green supplier selection. J Clean Prod 142:3728–3740
Lin YH, Cheng H-P, Tseng M-L, Tsai JC (2010) Using QFD and ANP to analyze the environmental production requirements in linguistic preferences. Expert Syst Appl 37(3):2186–2196
Li S, Tang D, Wang Q (2019) Rating engineering characteristics in open design using a probabilistic language method based on fuzzy QFD. Comput Ind Eng 135:348–358
Wang SY (2010) Constructing the complete linguistic-based and gap-oriented quality function deployment. Expert Syst Appl 37(2):908–912
Herrera F, Herrera-Viedma E, Martínez L (2008) A fuzzy linguistic methodology to deal with unbalanced linguistic term sets. IEEE Trans Fuzzy Syst 16(2):354–370
Chen Z-S, Zhang X, Pedrycz W, Wang X-J, Chin K-S, Martínez L (2021) K-means clustering for the aggregation of HFLTS possibility distributions: N-two-stage algorithmic paradigm. Knowl-Based Syst 227:107230
Xu ZS (2009) An interactive approach to multiple attribute group decision making with multigranular uncertain linguistic information. Group Decis Negot 18(2):119–145
Xu ZS (2005) On method for uncertain multiple attribute decision making problems with uncertain multiplicative preference information on alternatives. Fuzzy Optim Decis Making 4(2):131–139
Liu P, Liu W (2020) Multiple-criteria decision making method based on the scaled prioritized operators with unbalanced linguistic information. Artif Intell Rev:1–25
Wasserman GS (1993) On how to prioritize design requirements during the QFD planning process. IIE Trans 25(3):59–65
Liu YY, Chen YZ, Zhou J, Zhong SY (2015) Fuzzy linear regression models for QFD using optimized h values. Eng Appl Artif Intell 39:45–54
Liu AJ, Hu HS, Zhang X, Lei DM (2017) Novel two-phase approach for process optimization of customer collaborative design based on fuzzy-QFD and DSM. IEEE Trans Eng Manage 64(2):193–207
Zheng P, Xu X, Xie SQ (2019) A weighted interval rough number based method to determine relative importance ratings of customer requirements in QFD product planning. J Intell Manuf 30(1):3–16
Miao YW, Liu YY, Chen YZ (2015) Determination of target values of engineering characteristics in QFD using uncertain programming. J Uncertain Anal Appl 3(1):16
Luo XG, Kwong CK, Tang JF (2010) Determining optimal levels of engineering characteristics in quality function deployment under multi-segment market. Comput Ind Eng 59(1):126–135
Maddulapalli AK, Azarm S, Boyars A (2007) Sensitivity analysis for product design selection with an implicit value function. Eur J Oper Res 180(3):1245–1259
Butler J, Morrice DJ, Mullarkey PW (2001) A multiple attribute utility theory approach to ranking and selection. Manage Sci 47(6):800–816
Lee AH, Kang H-Y, Yang C-Y, Lin C-Y (2010) An evaluation framework for product planning using FANP, QFD and multi-choice goal programming. Int J Prod Res 48(13):3977–3997
Kulak O, Kahraman C (2005) Fuzzy multi-attribute selection among transportation companies using axiomatic design and analytic hierarchy process. Inf Sci 170(2–4):191–210
Durbach IN, Calder JM (2016) Modelling uncertainty in stochastic multicriteria acceptability analysis. Omega 64:13–23
Riedel R, Jacobs G, Konrad C, Singh R, Sprehe J (2020) Managing knowledge and parameter dependencies with MBSE in textile product development processes. Procedia CIRP 91:170–175
Tomczyk MK, Kadziński M (2019) EMOSOR: evolutionary multiple objective optimization guided by interactive stochastic ordinal regression. Comput Oper Res 108:134–154
Kouaissah N (2021) Using multivariate stochastic dominance to enhance portfolio selection and warn of financial crises. Q Rev Econ Finance 80:480–493
Xiao L, Chen Z-S, Zhang X, Chang J-P, Pedrycz W, Chin K-S (2020) Bid evaluation for major construction projects under large-scale group decision-making environment and characterized expertise levels. Int J Comput Intell Syst 13(1):1227–1242
Song S, Yang F, Yu P, Xie J (2021) Stochastic multi-attribute acceptability analysis with numerous alternatives. Eur J Oper Res 295(2):621–633
Dinçer H, Yüksel S (2019) An integrated stochastic fuzzy MCDM approach to the balanced scorecard-based service evaluation. Math Comput Simul 166:93–112
Yazdani M, Wang Z, Chan FT (2020) A decision support model based on the combined structure of DEMATEL, QFD and fuzzy values. Soft Comput 24(16):12449–12468
Bodily SE (1979) A delegation process for combining individual utility functions. Manage Sci 25(10):1035–1041
Nowak M (2007) Aspiration level approach in stochastic MCDM problems. Eur J Oper Res 177(3):1626–1640
Liu YY, Zhou J, Chen YZ (2014) Using fuzzy non-linear regression to identify the degree of compensation among customer requirements in QFD. Neurocomputing 142:115–124
Liu H-T (2013) An integrated fuzzy decision approach for product design and evaluation. J Intell Fuzzy Syst 25(3):709–721
Wu X, Nie L, Xu M (2017) Robust fuzzy quality function deployment based on the mean-end-chain concept: service station evaluation problem for rail catering services. Eur J Oper Res 263(3):974–995
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant nos. 72171182, 71801175, 71871171, 71971182, and 72031009), the Theme-based Research Projects of the Research Grants Council (Grant no. T32-101/15-R), the Ger/HKJRS project (Grant no. G-CityU103/17), and the City University of Hong Kong SRG (Grant no. 7004969).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Research involving human and animal participants
This paper does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Wang, ZQ., Chen, ZS., Garg, H. et al. An integrated quality-function-deployment and stochastic-dominance-based decision-making approach for prioritizing product concept alternatives. Complex Intell. Syst. 8, 2541–2556 (2022). https://doi.org/10.1007/s40747-022-00681-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00681-1