
Abstract
Multi-label feature selection, a crucial preprocessing step for multi-label classification, has been widely applied to data mining, artificial intelligence and other fields. However, most of the existing multi-label feature selection methods for dealing with mixed data have the following problems: (1) These methods rarely consider the importance of features from multiple perspectives, which analyzes features not comprehensive enough. (2) These methods select feature subsets according to the positive region, while ignoring the uncertainty implied by the upper approximation. To address these problems, a multi-label feature selection method based on fuzzy neighborhood rough set is developed in this article. First, the fuzzy neighborhood approximation accuracy and fuzzy decision are defined in the fuzzy neighborhood rough set model, and a new multi-label fuzzy neighborhood conditional entropy is designed. Second, a mixed measure is proposed by combining the fuzzy neighborhood conditional entropy from information view with the approximate accuracy of fuzzy neighborhood from algebra view, to evaluate the importance of features from different views. Finally, a forward multi-label feature selection algorithm is proposed for removing redundant features and decrease the complexity of multi-label classification. The experimental results illustrate the validity and stability of the proposed algorithm in multi-label fuzzy neighborhood decision systems, when compared with related methods on ten multi-label datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In recent years, multi-label classification occupies a very important position in the fields of artificial intelligence and machine learning, which attracts the attention of more and more scholars and a series of multi-label classification methods are proposed [1,2,3,4,5]. In traditional classification learning, each sample has only one category label, namely single-label learning [6, 7]. However, in actual application, most of the samples may belong to multiple category labels at the same time, which named multi-label learning [8,9,10]. There are a large number of features in multi-label data, but some of which may be irrelevant or redundant information, which will lead to such problems such as high computational cost, over-fitting, low classification performance of multi-label learning algorithm and long process of classification learning. Therefore, dimension reduction of multi-label data is the focus of current research. Feature selection is one of the most common dimensionality reduction methods for analyzing high dimensional multi-label data, which aims to eliminate redundant and irrelevant features in classification learning task, and extract useful information [11,12,13].
With the increasing availability of multi-label data related to multiple labels in an instance, a great quantity of feature selection methods for multi-label learning are developed to reduce dimensions and improve learning performance [14,15,16,17]. These methods commonly can be divided into three categories: filter [18,19,20], wrapper [21, 22] and embedded [23] methods, where the filter method is independent of the specific learner, and it has less computation cost and stronger generalization ability. Therefore, our proposed method focuses on the filter strategy. The evaluation criteria commonly based on filter method include information measure [24,25,26,27,28,29,30,31,32], dependency measure [33,34,35,36,37,38], distance measure [39,40,41,42] and consistency measure [43, 44].
Rough set theory is a familiar method to deal with uncertain data, which does not need any prior information except data, so it has been widely used in feature selection of data [45]. However, the traditional rough set theory is based on equivalence relation, which is only suitable for discrete data. To solve this problem, some scholars have extended the rough set model. For example, the neighborhood rough sets model (NRS), which is the most common model to deal with numerical data, and the neighborhood relation is used to replace the equivalence relation. Duan et al. [46] defined the lower approximation and dependency of NRS in multi-label learning, and proposed a multi-label feature selection algorithm based on neighborhood rough sets model (MNRS). Unfortunately, NRS cannot deal with the fuzziness of data effectively. So Lin et al. [47] used different fuzzy relations to construct a multi-label fuzzy rough sets model (MFRS), which estimated the similarity between samples under different labels, and directly evaluated the attributes of multi-label data, solved the problem of low separability about fuzzy similarity and defined the dependency function. But FRS is sensitive to noise, these noisy data will affect the calculation of fuzzy lower approximation and limit their practical application [48]. To solve the above problems, the fuzzy neighborhood rough sets model (FNRS) is designed. Wang et al. [49] combined NRS with FRS, proposed a feature selection algorithm based on FNRS via dependency to select feature subset. Chen et al. [48] designed a multi-label attribute reduction method based on variable precision FNRS, which used parameterized fuzzy neighborhood granule to define the fuzzy decision and decision class, and calculated importance of features using dependency measure, but the reduction based on the positive region does not take into account the influence of the uncertain information in the upper approximation on the importance of the attribute. Inspired by these observations, this paper designs a multi-label feature selection method based on FNRS and the approximation accuracy is introduced into our proposed multi-label feature selection method.
In the latest decades, the multi-label feature selection methods are classified into two kinds of views. The first is the algebra view based on approximate accuracy, which considers the effect of some features on the labels with the change of approximation accuracy, while confirms whether these features can be eliminated. For instance, Liang et al. [17] presented the selection of the optimal number of particles in the multi-grain and multi-label decision table, which makes certain positive region reduction more suitable for multi-label datasets. Li et al. [35] designed a robust MFRS by the kernelized information and obtained a lower approximation. The second is the information view based on information entropy, which considers the influence of some features on the decision subset with the information entropy and decides whether these features can be eliminated. For example, Lin et al. [25] designed a multi-label feature selection based on neighborhood mutual information, extended neighborhood information entropy to adapt to multi-label data, and introduced three new measurement methods. Li et al. [29] developed a multi-label feature selection based on information gain, which measured the correlation between features and labels. Xu et al. [24] proposed a fuzzy neighborhood conditional entropy for feature selection. Inspired by these contributions, we design a novel fuzzy neighborhood conditional entropy to judge whether exclude these features on multi-label data. However, these methods cannot provide a more accurate and comprehensive assessment of the importance of features from different perspectives. Therefore, Sun et al. [39] developed a multi-label feature selection which combined neighborhood mutual information with the approximate accuracy in multi-label neighborhood decision systems, and this method of combining two views obtained great the classification performance. Combine the above contributions, this paper proposes a multi-label feature selection method, which combines the fuzzy neighborhood conditional entropy with the approximate accuracy, to evaluate the importance of features from two views. Thus, the major contributions of this article can be briefly described as follows:
-
Considering that the similarity of samples is also affected by 0-value label, the average value of decision under different labels is calculated as fuzzy decision. The concepts of fuzzy neighborhood upper approximation, lower approximation and fuzzy neighborhood approximation accuracy are proposed, which improves the integrity of multi-label fuzzy neighborhood decision system.
-
This work proposed the definitions of fuzzy neighborhood information entropy, fuzzy neighborhood joint entropy and fuzzy neighborhood conditional entropy for multi-label data, and their related properties and proofs are discussed, by improving the single-label fuzzy neighborhood entropy.
-
Combining the approximate accuracy of fuzzy neighborhood under the view of algebra with the fuzzy neighborhood conditional entropy under the view of information theory, a mixed measure method is proposed to evaluate the correlation between feature subset and label set in the multi-label fuzzy neighborhood decision system. Finally, a forward multi-label feature selection algorithm based on fuzzy neighborhood rough sets is designed for multi-label classification.
The remainder of this paper is structured as follows. The next section briefly introduces the related knowledge of NRS, MNRS and FNRS. In the subsequent section, the fuzzy neighborhood rough set model, fuzzy neighborhood conditional entropy and hybrid measure are introduced. The multi-label feature selection algorithm is designed in the next section. Then the experimental results are provided. Finally, the conclusions of our research are provided in the last section.
Related knowledge
Classical neighborhood rough sets
Suppose there exists a neighborhood decision system which can be simplified as NDS \(=<U,A\bigcup D,V,\varDelta ,\delta>\), where \(U=\{{{x}_{1}},{{x}_{2}},\ldots , {{x}_{n}}\}\) is a nonempty samples set; \(A=\{{{a}_{1}},{{a}_{2}},\ldots , {{a}_{m}}\}\) is a features set; D is decision class of samples; \(V={{\bigcup }}_{a\in A}\,{{V}_{a}}\), where \({{V}_{a}}\) is the value of feature a; \(\varDelta \) indicates distance function; and \(\delta (0\le \delta \le 1)\) is a neighborhood radius. If \(\varDelta \) satisfy the following properties [50] as
-
(1)
\(\forall {{x}_{1}},{{x}_{2}}\in U,\varDelta ({{x}_{1}},{{x}_{2}})\ge 0, \)where \(\varDelta ({{x}_{1}},{{x}_{2}})=0\) if and only if \({{x}_{1}}={{x}_{2}}\);
-
(2)
\(\forall {{x}_{1}},{{x}_{2}}\in U,\varDelta ({{x}_{1}},{{x}_{2}})=\varDelta ({{x}_{2}},{{x}_{1}})\);
-
(3)
\(\forall {{x}_{1}},{{x}_{2}},{{x}_{3}}\in U,\varDelta ({{x}_{1}},{{x}_{3}})\le \varDelta ({{x}_{1}},{{x}_{2}})+\varDelta ({{x}_{2}},{{x}_{3}})\).
Then \(\left\langle U,\varDelta \right\rangle \) is called metric space, in general, the distance in the metric space can be expressed as
when \(p=1\), \(\varDelta \) represents Manhattan distance; when \(p=2\), \(\varDelta \) represents Euclidean distance; when \(p\rightarrow \infty \), \(\varDelta ({{x}_{i}},{{x}_{j}})={\max }_{a}\,\left| {{x}_{ia}},{{x}_{ja}} \right| \).
Suppose the nonempty metric space \(<U,\varDelta>\), for \(\forall B\subseteq A\), \({{\delta }_{B}}(x)=\{y\left| x,y\in U,\varDelta (x,y)\le \delta , \right. \delta \ge 0\}\) [46]. \(\varDelta (x,y)\) is a function to measure the distance between x and y, \({{\delta }_{B}}(x)\) can also be called the neighborhood granularity of x under B.
Multi-label neighborhood rough sets
Suppose there exists a multi-label neighborhood decision system which can be abbreviated to MNDS \(=<U,A\bigcup D,\delta>\), for \(\forall B\subseteq A\), \(D=\{{{d}_{1}},{{d}_{2}},\ldots ,{{d}_{t}}\}\), \({{D}_{i}}=\{{{d}_{j}}|{{d}_{j}}({{x}_{i}})=1,{{d}_{j}}\in D\}\) represents the related label set of \({{x}_{i}}\), and \({{D}^{\text {j}}}=\{{{x}_{i}}|{{d}_{j}}({{x}_{i}})=1,{{x}_{i}}\in U\}\) denotes a set of samples with the label \({{d}_{j}}\). Then the upper approximation and lower approximation of the neighborhood rough sets of D with respect to B are defined [46], respectively, as
Then, for \(\forall B\subseteq A\), the neighborhood entropy of \({{x}_{i}}\in U\) is expressed [25] as
Fuzzy neighborhood rough sets
Suppose there exists a fuzzy neighborhood decision system which can be short for FNDS \(=<U,A\bigcup D,\delta>\), where \(U=\{{{x}_{1}},{{x}_{2}},\ldots ,{{x}_{n}}\}\) is the nonempty set of samples, and A is the set of features for \(\forall B\subseteq A\). The fuzzy binary relation \({{R}_{B}}\) is derived from B [49]. For \(\forall x,y\in U\), \({{R}_{B}}(x,y)\) is called fuzzy similarity relation between samples x and y under features set B when it satisfies the following conditions:
-
(1)
Reflexivity: \({{R}_{B}}(x,x)=1,\forall x\in U\);
-
(2)
Symmetry: \({{R}_{B}}(x,y)={{R}_{B}}(y,x),\forall x,y\in U\).
Then \({{R}_{B}}\) is also known as the fuzzy similarity relation.
Suppose there exists FNDS \( =<U,A\bigcup D,\delta>\) with for \(\forall B\subseteq A\), \(\forall a\in B\), \(\forall x,y\in U\), the fuzzy similarity matrix is \({{\left[ x \right] }_{a}}(y)={{R}_{\text {a}}}(x,y)\), \({{R}_{a}}\) is a fuzzy similarity relation for \(\forall a\in B\), then we can express \({{R}_{B}}=\bigcap \nolimits _{a\in B}{{{R}_{a}}}\). Then the fuzzy similarity matrix of x with respect to B over U is defined [24] as
Given FNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \({U}/{D}=\{{{D}_{1}},{{D}_{2}},\ldots {{D}_{\text {r}}}\}\), for \(\forall x,y\in U\), the parameterized fuzzy neighborhood information granule is constructed as follows:
where \(\delta \) is called the fuzzy neighborhood radius and satisfies \(0\le \delta \le 1\). The fuzzy neighborhood of \(\forall x\in U\) can be determined by fuzzy similarity relation \({{R}_{B}}\) and neighborhood radius \(\delta \).
Let FNDS \(=<U,A\bigcup D,\delta>\) be a fuzzy neighborhood decision system, \({U}/{D}=\{{{D}_{1}},{{D}_{2}},\cdots {{D}_{\text {r}}}\}\), for \(\forall B\subseteq A\), the upper and lower approximations of D with respect to B are expressed, respectively, as
For \(\forall B\subseteq C\), the fuzzy neighborhood approximation accuracy of D with respect to B is described as
Proposed method
In this section, we improve the multi-label fuzzy neighborhood rough set model based on the relevant basic knowledge introduced in the previous section. First, the parameterized fuzzy similarity relation is used to calculate the fuzzy neighborhood granule. Because a sample in multi-label data may belong to multiple labels at the same time, the multi-label fuzzy decision is obtained by averaging values in multiple labels, which is different from the single-label fuzzy decision. Secondly, the fuzzy neighborhood approximation accuracy is introduced to consider the uncertain information of upper approximation. Then the fuzzy neighborhood conditional entropy for multi-label data is proposed. Finally, the fuzzy neighborhood approximation accuracy and fuzzy neighborhood conditional entropy are combined to form a mixed measure, and the relevant proof process is given.
Multi-label fuzzy neighborhood approximation accuracy and fuzzy decision
Definition 1
A multi-label fuzzy neighborhood decision system can be denoted as MFNDS \(=<U,A\bigcup D,T,\delta>\). \(U=\{{{x}_{1}},{{x}_{2}},\ldots ,{{x}_{n}}\}\) is a nonempty finite set of samples; \(A=\{{{a}_{1}},{{a}_{2}},\ldots {{a}_{m}}\}\) indicates a set of features; \(D=\{{{d}_{1}},{{d}_{2}},\ldots ,{{d}_{t}}\}\) represents a set of labels; \(T=\{({{x}_{i}},A({{x}_{i}}),D({{x}_{i}}))|{{x}_{i}}\in U\}\), \(\forall {{x}_{i}}\in U\), it allows \(A({{x}_{i}})=({{a}_{1}}({{x}_{i}}),{{a}_{2}}({{x}_{i}}),\ldots ,{{a}_{m}}({{x}_{i}}))\), where \({{a}_{m}}({{x}_{i}})\) is the value of the sample \({{x}_{i}}\) in the feature \({{a}_{m}}\), \(D({{x}_{i}})=({{d}_{1}}({{x}_{i}}),{{d}_{2}}({{x}_{i}}),\ldots ,{{d}_{t}}({{x}_{i}}))\), where \({{d}_{j}}({{x}_{i}})=\{0,1\}\), \({{d}_{j}}({{x}_{i}})\) indicates whether the sample \({{x}_{i}}\) contains label \({{d}_{j}}\), if \({{x}_{i}}\) contains label \({{d}_{j}}\), then \({{d}_{j}}({{x}_{i}})=1\); otherwise, \({{d}_{j}}({{x}_{i}})=0\).
Definition 2
Given MFNDS \(=<U,A\bigcup D,T,\delta>\), let \(\{D_{0}^{1},D_{1}^{1},D_{0}^{2},D_{1}^{2},\ldots ,D_{1}^{t}\}\) denote a label determined coverage of U, then the parameterized fuzzy decision is constructed as follows:
where \(D_{p}^{j}\) represents a sample set which is p in the column of the label \({{d}_{j}}\), \(j=1,2,\ldots ,t\), \(p=0,1\).
where \({\tilde{D}}_{\text {p}}^{j}({x}_{i})\) is the fuzzy membership degree of \({x}_{i}\) with respect to \({D}_{\text {p}}^{j}\); \({\tilde{D}}_{\text {p}}^{j}\) is the fuzzy set of the equivalence decision class of the samples.
where \({\tilde{D}}_{\text {p}}({{x}_{i}})\) is the fuzzy set of the sample \({x}_{i}\) which belongs label p.
where \(\{{{{\tilde{D}}}_{0}},{{{\tilde{D}}}_{1}}\}\) is the fuzzy decision of the samples induced by D.
Definition 3
[49] Let \({F}'\) and \({R}'\) are the two fuzzy sets, the inclusion degree between \({F}'\) and \({R}'\) can be defined as
where \(P({F}',{R}')\) represents the inclusion degree of fuzzy set \({F}'\) in fuzzy set \({R}'\), \(\left| {F}'\bigcap {R}' \right| \) represents the number of samples whose membership degree of fuzzy set \({F}'\) is not greater than that of fuzzy set \({R}'\).
Example 1
Given a set \(U=\{{{x}_{1}},{{x}_{2}},\ldots ,{{x}_{6}}\}\), \({F}'\) and \({R}'\) are two fuzzy sets defined on U, which represent the membership degree of samples separately, as follows:
So, we can get
Definition 4
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \(D=\{{{d}_{1}},{{d}_{2}},\ldots ,{{d}_{t}}\}\) represents a set of labels; \(\delta \) is called the fuzzy neighborhood radius and satisfies \(0\le \delta \le 1\). For \(\forall x,y\in U\), the parameterized fuzzy neighborhood information granule is constructed as follows:
where \({{R}_{B}}\) is the fuzzy similarity relation induced by B on U, when \({{B}_{1}}\subseteq {{B}_{2}}\), \({{R}_{{{B}_{2}}}}\subseteq {{R}_{{{B}_{1}}}}\); when \({{\delta }_{1}}\le {{\delta }_{2}}\), for \(\forall x\in U\), \({\left[ x \right] _{B}^{{\delta }_{1}}}\subseteq {\left[ x \right] _{B}^{{\delta }_{2}}}\).
Definition 5
Given \(MFNDS=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \(\delta \) is called the fuzzy neighborhood radius; \(\left\{ {{{{\tilde{D}}}}_{0}},{{{{\tilde{D}}}}_{1}} \right\} \) is the fuzzy decision of samples induced by D. The upper and lower approximations of the fuzzy neighborhood of D is relative to B are defined, separately, as
where
Definition 6
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \(\delta \) is called the fuzzy neighborhood radius; \(\left\{ {{{{\tilde{D}}}}_{0}},{{{{\tilde{D}}}}_{1}} \right\} \) is the fuzzy decision of samples induced by D; \({{R}_{B}}\) is the fuzzy similarity relation induced by B on U. The fuzzy neighborhood approximation accuracy is defined as
where \(\left| \centerdot \right| \) represents the cardinality of the set. \(\left| \underline{R_{B}^{\delta }}({{{{\tilde{D}}}}_{p}}) \right| \le \left| \overline{R_{B}^{\delta }}({{{{\tilde{D}}}}_{p}}) \right| \), so \(0\le \alpha _{B}^{\delta }(D)\le 1\).
Property 1
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \({{\delta }_{1}}\) and \({{\delta }_{2}}\) are two fuzzy neighborhood radii, if \({{\delta }_{1}}\le {{\delta }_{2}}\), then \(\alpha _{B}^{{{\delta }_{2}}}(D)\le \alpha _{B}^{{{\delta }_{1}}}(D)\).
Proof
For \(\forall x\in U\), according to Definition 4, the fuzzy neighborhood information granule satisfies the relation is obtained \({\left[ x \right] _{B}^{{\delta }_{1}}}\subseteq {\left[ x \right] _{B}^{{\delta }_{2}}}\), then \(\underline{R_{B}^{{{\delta }_{2}}}}({{{\tilde{D}}}_{p}})\subseteq \underline{R_{B}^{{{\delta }_{1}}}}({{{\tilde{D}}}_{p}})\), \(\overline{R_{B}^{{{\delta }_{1}}}}({{{\tilde{D}}}_{p}})\subseteq \overline{R_{B}^{{{\delta }_{2}}}}({{{\tilde{D}}}_{p}})\), so there is \(\alpha _{B}^{{{\delta }_{2}}}(D)\le \alpha _{B}^{{{\delta }_{1}}}(D)\). \(\square \)
Property 2
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \(\delta \) is a fuzzy neighborhood radius, if \({{B}_{1}}\subseteq {{B}_{2}}\), we can get the property: \(\alpha _{{{B}_{1}}}^{\delta }(D)\le \alpha _{{{B}_{2}}}^{\delta }(D)\).
Proof
Since \({{B}_{1}}\subseteq {{B}_{2}}\), according to the fuzzy neighborhood granule satisfies the relation is obtained \(\left[ x \right] _{{{B}_{2}}}^{\delta }\subseteq \left[ x \right] _{{{B}_{1}}}^{\delta }\), then according to Definitions 5 and 6, we have \(\underline{R_{{{B}_{1}}}^{\delta }}({{{\tilde{D}}}_{p}})\subseteq \underline{R_{{{B}_{2}}}^{\delta }}({{{\tilde{D}}}_{p}})\), \(\overline{R_{{{B}_{2}}}^{\delta }}({{{\tilde{D}}}_{p}})\subseteq \overline{R_{{{B}_{1}}}^{\delta }}({{{\tilde{D}}}_{p}})\). Then, \(\alpha _{{{B}_{1}}}^{\delta }(D)\le \alpha _{{{B}_{2}}}^{\delta }(D)\) holds. \(\square \)
Example 2
Given a multi-label decision table MDT=\(<U,A\bigcup D>\) to display in Table 1, \(U=\{{{x}_{1}},{{x}_{2}},{{x}_{3}},{{x}_{4}},{{x}_{5}},{{x}_{6}}\}\) represents a sample set, \(A=\{{{a}_{1}},{{a}_{2}},{{a}_{3}}\}\) means a feature set, \(D=\{{{d}_{1}},{{d}_{2}},{{d}_{3}}\}\) indicates a label set, \({{R}_{A}}\) is based on the fuzzy similarity relation induced by A, let the value of fuzzy neighborhood radius be 0.
The data in Table 1 were normalized according to literature [24], so that the numerical value was within the range of [0,1]. The fuzzy similarity relationship \({{R}_{{{a}_{k}}}}\) between the samples \({{x}_{i}}\) and \({{x}_{j}}\) relative to the attribute \({{a}_{k}}\) is calculated by
where \({{a}_{k}}\in A\), \(k=1,2,3\), \({{x}_{i}},{{x}_{j}}\in U\), \(i=1,2,3,4,5,6\), \(j=1,2,3,4,5,6\). So, we can obtain the fuzzy similarity matrix \({{\left[ x \right] }_{{{a}_{k}}}}\left( y \right) \) about the attribute \({{a}_{k}}\), and \({{\left[ x \right] }_{A}}(y)={\min }_{{{a}_{k}}\in A}\,\left( {{\left[ x \right] }_{{{a}_{k}}}}(y) \right) \). Because the fuzzy similarity relation \({{R}_{{{a}_{k}}}}\) satisfies the reflexivity, \({{R}_{{{a}_{k}}}}=1\) when \(i=j\), then we can get
The fuzzy decision under the labels \({{d}_{1}},{{d}_{2}},{{d}_{3}}\) are calculated as follows:
where \(D_{r}^{j}\) represents the sample set of the value is p under the label \({{d}_{j}}\), where \(j=1,2,3\), \(p=0,1\). According to Definition 2, we can obtain
Then we can get
From the above, we can derive that \({{{\tilde{D}}}_{0}}(x)+{{{\tilde{D}}}_{1}}(x)=1\), so the eventual fuzzy decision of entire label space is
Multi-label fuzzy neighborhood conditional entropy
Definition 7
Suppose there exists MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \(\delta \) is the neighborhood radius, then fuzzy neighborhood entropy of B is defined as
where \(\left| {{\delta }_{B}}({{x}_{i}}) \right| \) represents the number of nonzero values in the fuzzy neighborhood particle of an object \({{x}_{i}}\), then \(\frac{\left| {{\delta }_{B}}({{x}_{i}}) \right| }{\left| U \right| }\) represents the probability of the number of nonzero values in fuzzy neighborhood granule \(\left| {{\delta }_{B}}({{x}_{i}}) \right| \) in U.
Definition 8
Suppose there exists MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall {{B}_{1}},{{B}_{2}}\subseteq A\), \({{\delta }_{{{B}_{1}}}}(x)\) and \({{\delta }_{{{B}_{2}}}}(x)\) are fuzzy neighborhood granules, then the fuzzy neighborhood joint entropy of \({{B}_{1}}\) and \({{B}_{2}}\) is defined as
Definition 9
Suppose there exists MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall {{B}_{1}},{{B}_{2}}\subseteq A\), \({{\delta }_{{{B}_{1}}}}(x)\) and \({{\delta }_{{{B}_{2}}}}(x)\) are fuzzy neighborhood granules, then the fuzzy neighborhood conditional entropy of \({{B}_{1}}\) and \({{B}_{2}}\) is defined as
Property 3
Suppose there exists MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall {{B}_{1}},{{B}_{2}}\subseteq A\), \({{\delta }_{{{B}_{1}}}}(x)\) and \({{\delta }_{{{B}_{2}}}}(x)\) are fuzzy neighborhood granules, for \(\forall {{B}_{1}},{{B}_{2}}\subseteq A\). The property is as follows:
Proof
According to Definitions 6 and 7, it can be proved
Then, from Definition 8, it follows that \({{E}_{fn}}({{B}_{1}}\left| {{B}_{2}} \right. )={{E}_{fn}}({{B}_{1}},{{B}_{2}})-{{E}_{fn}}({{B}_{2}})\). \(\square \)
Definition 10
Suppose there exists MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \({{\delta }_{B}}(x)\) is the fuzzy neighborhood granule, \({\tilde{D}}=\{{{{\tilde{D}}}_{0}},{{{\tilde{D}}}_{1}}\}\) is a fuzzy decision, then the conditional entropy of decision attribute set D on feature subset B is defined as
where \(\left| {{\delta }_{B}}({{x}_{i}}) \right| \) represents the number of nonzero values in the fuzzy neighborhood particle of an object \({{x}_{i}}\), then \(\left| {{\delta }_{B}}({{x}_{i}})\bigcap {{{{\tilde{D}}}}_{p}} \right| \) represents the number of nonzero values of samples whose membership degree of \({{\delta }_{B}}({{x}_{i}})\) is not greater than \({{{\tilde{D}}}_{p}}\).
The feature selection only from the algebraic or information viewpoint is limited. For the algebraic viewpoint, feature selection under the definition of information theory may also exist redundancy features, for information theory, feature selection under definitions of algebraic viewpoint, conditional entropy may have changed. So we combine the approximate precision from the algebraic viewpoint with the measurement method of conditional entropy from information theory to calculate the importance degree of candidate features.
Definition 11
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \({{\delta }_{B}}(x)\) is the fuzzy neighborhood granule, \({\tilde{D}}=\{{{{\tilde{D}}}_{0}},{{{\tilde{D}}}_{1}}\}\) is a fuzzy decision, then the mixed measure based on the approximate accuracy of the fuzzy neighborhood and the conditional entropy of the fuzzy neighborhood is defined as
Property 4
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \({{\delta }_{B}}(x)\) is the fuzzy neighborhood granule, \({\tilde{D}}=\{{{{\tilde{D}}}_{0}}, {{{\tilde{D}}}_{1}}\}\) is a fuzzy decision, then \(E{{M}_{fn}}(D\left| B \right. )\ge 0\).
Proof
Assume \(E{{M}_{fn}}(D\left| B \right. )<0\), then \({{\log }_{2}}\frac{\left| {{\delta }_{B}}({{x}_{i}})\bigcap {{{{\tilde{D}}}}_{p}}({{x}_{i}}) \right| }{\left| {{\delta }_{B}}({{x}_{i}}) \right| }>0\), then \(\frac{\left| {{\delta }_{B}}({{x}_{i}})\bigcap {{{{\tilde{D}}}}_{p}}({{x}_{i}}) \right| }{\left| {{\delta }_{B}}({{x}_{i}}) \right| }>1\); therefore, \(\left| {{\delta }_{B}}({{x}_{i}}) \right| <\left| {{\delta }_{B}}({{x}_{i}}) \right. \bigcap \left. {{{{\tilde{D}}}}_{p}}({{x}_{i}}) \right| \), but this is obviously not established. So, \(\frac{\left| {{\delta }_{B}}({{x}_{i}})\bigcap {{{{\tilde{D}}}}_{p}}({{x}_{i}}) \right| }{\left| {{\delta }_{B}}({{x}_{i}}) \right| }\le 1\), that is, \({{\log }_{2}}\frac{\left| {{\delta }_{B}}({{x}_{i}})\bigcap {{{{\tilde{D}}}}_{p}}({{x}_{i}}) \right| }{\left| {{\delta }_{B}}({{x}_{i}}) \right| }\le 0\). Therefore, \(E{{M}_{fn}}(\left. D \right| B)\ge 0\). \(\square \)
Property 5
Let MFNDS \(=<U,A\bigcup D,\delta>\) be a multi-label fuzzy neighborhood decision system, for \(\forall {{B}_{1}},{{B}_{2}}\subseteq A\), if \({{B}_{1}} \subseteq {{B}_{2}}\), according to Property 2, \({{\delta }_{{{B}_{2}}}}(x)\subseteq {{\delta }_{{{B}_{1}}}}(x)\), then \(E{{M}_{fn}}(D\left| {{B}_{1}} \right. )\ge E{{M}_{fn}}(D\left| {{B}_{2}} \right. )\), if and only if \({{\delta }_{{{B}_{1}}}}(x)={{\delta }_{{{B}_{2}}}}(x)\), then the equal sign is true.
Proof
According to Eq. (26), \(E{{M}_{fn}}(D\left| {{B}_{1}} \right. )\ge E{{M}_{fn}}(D\left| {{B}_{2}} \right. )\) holds.
\(\square \)
Property 6
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), \(\forall a\in B\), if \(E{{M}_{fn}}(D\left| B \right. -\{a\})=E{{M}_{fn}}(D\left| B \right. )\), then the feature a is unnecessary.
Proof
Assume there exists \(a\in B\) satisfies \(E{{M}_{fn}}(D\left| B \right. -\{a\})=E{{M}_{fn}}(D\left| B \right. )\) and the feature a is necessary. We can see from previous knowledge that \({{\delta }_{B-\{a\}}}(x)\ne {{\delta }_{B}}(x)\), and \(B-\{a\}\subseteq B\), according to Property 5, we know that \(E{{M}_{fn}}(D\left| B \right. -\{a\})>E{{M}_{fn}}(D\left| B \right. )\), this contradicts the hypothesis. So, for \(\forall a\in B\), if \( E{{M}_{fn}}(D\left| {} \right. B-\{a\})=E{{M}_{fn}}(D\left| B \right. )\), then the feature a is unnecessary. \(\square \)
Definition 12
Given MFNDS \(=<U,A\bigcup D,\delta>\)with \(\forall B\subseteq A\),we call B a reduction of A in the fuzzy neighborhood decision information system, relative to decision class D when it satisfies that
-
(1)
\(E{{M}_{fn}}(D\left| B \right. )=E{{M}_{fn}}(D\left| A \right. )\);
-
(2)
\(\forall a\in B,E{{M}_{fn}}(D\left| B \right. -\{a\})>E{{M}_{fn}}(D\left| B \right. )\).
Definition 13
Given MFNDS \(=<U,A\bigcup D,\delta>\) with \(\forall B\subseteq A\), the importance of feature for \(a\in B\) relative to D is expressed as
To get a reduced subset, two preconditions from the Definition 12 must be met. However, there are many redundant and unrelated features in the multi-label datasets, and searching for the minimum reduced subset is an NP-complete problem. Therefore, we set a threshold value \(\lambda \) to control subset selection before selecting the final feature subset. If the difference of the mixing measure between the current feature subset and the original feature subset is less than \(\lambda \), then a relatively approximate reduced subset Red is selected, which shall meet the following requirements:
Then the importance of feature for \(R\in A-Red\) relative to D is expressed as
Remark 1
Sun et al. [51] considered that the upper and lower approximations of rough set belong to the viewpoint of algebraic theory, and information entropy and its extension belong to the viewpoint of information theory. Then Definition 6 shows the fuzzy neighborhood approximate accuracy \(\alpha _{B}^{\delta }(D)\) from the algebraic point of view, and Definition 10 shows the conditional entropy \({{E}_{fn}}(D\left| B \right. )\) of the feature subset B of the fuzzy information decision set \({\tilde{D}}\) from the information theory. Therefore, Definition 11 measures the uncertainty of the multi-label fuzzy neighborhood decision systems from both the algebraic view and information view.
Multi-label feature selection algorithm based on fuzzy neighborhood rough sets
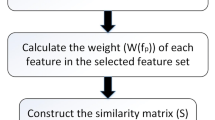
According to the relevant definitions in the third section, this paper constructs a multi-label feature selection algorithm based on fuzzy neighborhood rough sets. To clearly understand our proposed algorithm, the process of feature selection for multi-label classification is described by the framework is shown in Fig. 1.


The framework of proposed multi-label feature selection algorithm
In Algorithm 1, a multi-label feature selection algorithm (MFSFN) is proposed based on fuzzy neighborhood rough sets, assume that the multi-label fuzzy neighborhood decision system contains n is the size of samples, m is the number of features and t is the number of labels which have \(\left| D \right| \) decision classes. The time complexity on the calculation of the fuzzy similarity relation is \({\text {O}}(\frac{1}{2}{{n}^{2}}m)\), which is the basis for the calculation of the fuzzy decision is \(O(tn\left| D \right| )\) in Steps 4–6, the time complexity on calculation of the approximation accuracy is \({\text {O}}(nm\left| D \right| )\) in Step 7 and the time complexity on calculation of the fuzzy neighborhood conditional entropy is \({\text {O}}(nm\left| D \right| )\) in Steps 8–9. In Steps 11–24, assume the size of selected subset is r, its time complexity is \({\text {O}}(mr\left| D \right| )\). Therefore, the worst time complexity of MFSFN is approximately \({\text {O}}(\frac{1}{2}{{n}^{2}}m\text {+}tn\left| D \right| +nm\left| D \right| +mr\left| D \right| )\). Since the decision classes in the proposed algorithm is constant and that is \(\left| D \right| =2\), the total computational time complexity of Algorithm 1 is \({\text {O}}(\frac{1}{2}{{n}^{2}}m)\).
Experimental results and analysis
Experimental preparation
The main goal of feature selection is to select fewer feature subsets and achieve higher classification performance. To prove the validity and classification performance of our method, we select ten multi-label datasets of four different fields from http://mulan.sourceforge.net/datasets.html and http://www.uco.es/kdis/mllresources/. The Flags dataset contains details of some countries and their flags; Cal500 is a music dataset, composed of 502 songs; Emotions is about the music fragments that can cause emotions; Scene stores pattern information for a series of scenes; Yeast contains the biological information about gene microarray data and phylogenetic spectrum; the BBC and Guardian datasets include 654 news articles covering 416 distinct news stories; the Gnegative, Plant and Virus datasets are used to predict the subcellular locations of proteins according to their sequences, where Gnegative stores 1392 sequences for Gram-negative bacterial species, Plant contains 978 sequences for plant species, Virus contains 207 sequences for virus species. The basic information description of these datasets, including the size of samples set, the dimensionality of attributes set, the cardinality of the labels set, the domains of ten multi-label datasets, which are demonstrated in Table 2, where LC \((D)=\frac{1}{n}\sum \nolimits _{i=1}^{n}{\sum \nolimits _{j=1}^{t}{\left[ {{d}_{j}}({{x}_{i}})= \right. }}+1]\) is cardinality of the labels; LD\((D)=\frac{1}{nt}\sum \nolimits _{i=1}^{n}{\sum \nolimits _{j=1}^{t}{[{{d}_{i}}({{x}_{i}})=+1]}}\) is density of the labels; \([{{d}_{j}}({{x}_{i}})=+1]\) denotes that the sample \({{x}_{i}}\) is associated with the label \({{d}_{j}}\). When \(\left[ {{d}_{j}}({{x}_{i}})=+1 \right] \) holds, \(\left[ \cdot \right] \) equal to 1, otherwise it is 0 [52].
The following all experiments were performed using MATLAB R2016b on Windows10 with the experimental platform of Inter(R) Core(TM) i5-8500 CPU at 3.00 GHz, memory 16.00 GB. Two classifiers MLKNN [52] and MLFE [53], which are used to prove the classification performance of MFSFN. The smoothing factor is equal to 1, and the size of nearest neighbor K is equal to 10 in MLKNN and MLFE [54]. We select several the common evaluation indexes of multi-label classification to evaluate the classification performance based on our proposed method in multi-label learning, including the number of selected features (N), average precision (AP), coverage (CV), Hamming loss (HL), one error (OE), ranking loss (RL), macro-averaging F1 (MacF1) and micro-averaging F1 (MicF1) [25, 36, 40, 54], each of these indexes measures different aspects of the classification performance. The higher the value of AP, CV, MacF1 and MicF1 are, the better the classification performance is, and the lower the CV, OE, RL and HL are, the better the classification performance is. In the following experimental results, “\(\uparrow \)” represents “the larger the better”, and “\(\downarrow \)” represents “the smaller the better”. The number in bold indicates that this algorithm is better than other algorithms in the corresponding index.
Parameter discussion
Since parameters \(\delta \) and \(\lambda \) will impact the classification performance of the MFSFN, to obtain the best classification results, in this subsection we will demonstrate the influence of parameters on the feature selection results. The parameter \(\delta \) represents the fuzzy neighborhood radius, and the parameter \(\lambda \) is threshold to control the selection of feature subset. In this paper, we set the variation range of \(\delta \) be [0,0.5] with step size of 0.05, and the variation range of \(\lambda \) is [0,1] with the step size of 0.05. As shown in Figs. 2 and 3, where the X-axis refers to the neighborhood radius \(\delta \), the Y-axis refers to \(\lambda \) that controls the selection of feature subset. We select the Scene dataset by our proposed algorithm MFSFN to demonstrate the training process that is the selection of parameters \(\delta \) and \(\lambda \) under two classifiers MLKNN and MLFE. Finally, we select the most appropriate parameters for each multi-label dataset are shown in Tables 3 and 4.
The purpose of first portion is to analysis the change of evaluation indexes with parameters under classifier MLKNN. Figure 2 illustrates the change of each evaluation index with the parameters on the Scene dataset. For the Scene dataset, when \(\delta =0.15\), \(\lambda =0.65\), the five evaluation indexes AP, CV, RL, OE and N are the most appropriate. Therefore, the following will take \(\delta =0.15\), \(\lambda =0.65\) as the best parameter on the Scene dataset. Using the same process to obtain the best parameters of the other nine datasets from Table 2. The parameter values and evaluation index values are displayed in Table 3.

Variation of each evaluation index with parameters \(\delta \) and \(\lambda \) on Scene dataset
The second portion of this subsection is to analysis change of evaluation indexes with parameters under classifier MLFE. Figure 3 demonstrates the change of each evaluation index with parameters on the Scene dataset. For the Scene dataset, when \(\delta =0.05\), \(\lambda =1\), the eight evaluation indexes N, AP, HL, CV, OE, RL, MacF1 and MicF1 are the optimal value. Therefore, the following will take \(\delta =0.05\), \(\lambda =1\) as the best parameters on the Scene dataset, use the same procedure to get the best parameters of the other nine datasets from Table 2. The parameter values and each evaluation index value are shown in Table 4.

Variation of each evaluation index with parameters \(\delta \) and \(\lambda \) on Scene dataset
Comparison results of methods under MLKNN
This subsection exhibitions the comparison results of our proposed method with other related algorithms under MLKNN. First, our improved algorithm is compared with eight most advanced multi-label feature selection algorithms on the Scene dataset, including MLNB [55], MDDMspc [56], MDDMproj [56], PMU [57], RF-ML [58], MFNMIopt [25], MFNMIneu [25], MFNMIpes [25] were tested in aspects of AP, CV, HL and RL. Using the experimental techniques and results provided in [25], where \(\mu \) is set as 0.5 in MDDMspc. The parameters \(\delta \) and \(\lambda \) of MFSFN in the experiment select the optimal parameter values in Table 3. As shown in Table 5, it is the experimental result of comparing MFSFN on the Scene dataset with the other eight algorithms. The AP value of MFSFN is optimal, which is 0.0117 higher than MFNMIopt. On the CV index, MFSFN achieves lowest on the eight algorithms, which is 0.0292 lower than MDDMspc. The RL value of MFSFN is lower than other seven algorithms, where MFSFN is 0.0043 lower than MLNB. In terms of HL, MFSFN is compared with the other eight algorithms on the Scene dataset is ranked 2nd, and MFSFN is only 0.0002 higher than MFNMIopt, but MFSFN has obvious advantages over MFNMIopt for indexes AP, CV and RL. Obviously, for the Scene dataset, MFSFN achieves better results in each evaluation indications compared with other eight algorithms, and the validity of the selected parameters \(\delta \) and \(\lambda \) is proved.
This part of the subsection adopts the classifier MLKNN and proves the validity of MFSFN in the aspects of N, AP,OE, CV and HL. Our method is compared with ParetoFS [59], ELA-CHI [60], PPT-CHI [61], and MUCO [62] on the Scene and Yeast datasets, the experimental techniques and results in reference [59] are used, as shown in Tables 6 and 7.
According to the experimental results in Table 6, the AP index of the proposed algorithm yields the most competitive performance on five algorithms. On the CV index, MFSFN has obvious advantages over other algorithms, MFSFN is 0.6526 lower than ELA-CHI. On the OE index, the proposed method achieves higher performance than other algorithms, which is 0.2649 lower than the algorithm ELA-CHI. On the HL index, the proposed algorithm obtains better results than other algorithms, and MFSFN is 0.0934 lower than MUCO. The number of selected features obtains fewest by algorithm ParetoFS, but our proposed method performs fairly better than ParetoFS in the aspects of AP, CV, HL and OE. In Table 7, we can observe that AP of the proposed algorithm has obvious advantages over other algorithms on the Yeast dataset, MFSFN is at least 0.0023 and at most 0.0248 larger than other algorithms. For CV, MFSFN achieves superior performance than other algorithms except for algorithm ParetoFS, and ranks 2nd, but MFSFN performs better than ParetoFS in aspects of AP, OE and HL. As a whole, our proposed algorithm MFSFN has better classification performance than other algorithms on the Scene and Yeast datasets, the validity of the selected parameters \(\delta \) and \(\lambda \) is proved.
Then seven multi-label datasets: Flags, Yeast, Plant, Gnegative, Virus, BBC and Guardian are selected from Table 2, carry out a series of experiments which compare the proposed algorithm MFSFN with the six advanced related algorithms, including RF-ML, PMU, MDDMproj, MDDMspc, FSRD [63] and MFSMR [20], the experimental techniques and results in reference [63] are used, and in reference [20], the number of missing labels is set up to 0. In the aspects of AP, CV, OE and RL, the results of this classification are demonstrated in Tables 8, 9, 10 and 11.
In Table 8, the OE index of MFSFN performs obvious advantages compared with other algorithms on most of the datasets, which exhibits superior performance against other algorithms on four datasets: Flags, Yeast, Plant and Virus, the highest value on Guardian dataset is achieved by FSRD and the highest value on Gnegative and BBC is achieved by MFSMR, the other four algorithms do not achieve optimal performance on all datasets. As an example, with the respect to the Flags dataset, the AP value of MFSFN is 0.8357, which compares better than other five algorithms with 0.8093 for MDDMproj, 0.8226 for MDDMspc, 0.7970 for PUM, 0.8148 for RF-ML,0.8288 for FSRD and 0.8182 for MFSMR. It is evident that the proposed method has the advantage over other methods.
From Table 9, in the CV index, MFSFN has obvious advantages compared with other five algorithms on the Yeast and Plant datasets. On the Gnegative dataset, MFSFN is inferior to MFSMR and MDDMproj, but it has obvious advantages over the other four algorithms. On the Virus dataset, the CV of MFSFN is 1.2530, is in close proximity to the lowest CV value of FSRD, 1.2417, which represents that our method has certain competitiveness with other methods. Additionally, MDDMproj, PMU and RF-ML do not outperform the other algorithms on any dataset. The CV value of MFSFN on the Guardian dataset is slightly lower than the algorithm FSRD, and ranks 2nd. In short, our proposed method is superior to other algorithms in most cases.
As seen from Table 10, on the datasets Yeast and Plant, the RL of the proposed method is obviously better than other algorithms. On the Virus dataset, MFSFN was 0.0186 lower than MDDMSPC and 0.0031 lower than the algorithm RF-ML. On the datasets Gnegative and Guardian, the RL value of MFSFN ranks 2nd. It is clear that the 2nd best performance for MFSFN is slightly inferior to FSRD or MFSMR, but better than other five algorithms.
As shown in Table 11, the OE index of MFSFN performs exhibits superior performance against other algorithms on three datasets Flags, Plant,and Virus. On the Yeast dataset, the best performance of OE is FSRD, our method is only 0.0072 larger than FSRD. On the dataset BBC, MFSFN is larger 0.268 of the lowest value which is achieved by the algorithm MFSMR and ranks 2nd. On the dataset Guardian, the proposed algorithm is slightly inferior to MDDMspc and RF-ML, but MFSFN is about 0.037 lower than PMU. On the whole, our proposed method is fairly well to other algorithms. From Tables 8, 9, 10 and 11, comprehensive analysis shows that our algorithm has higher classification performance than other algorithms in AP, CV, RL and OE.
To verify the validity and stability of proposed algorithm MFSFN, the experimental comparisons for multi-label classification on the selected features are carried out by fivefold cross-validation. We select four multi-label datasets of different fields from Table 2, including Yeast, Emotions, Scene and Cal500 datasets. Combine the proposed algorithm MFSFN with MUCO, MDDMproj, MDDMspc, PMU, MFS-KA [64] and RFNMIFS [39] in four multi-label datasets. The six comparison algorithms verify the validity of our proposed algorithm using the classification in AP, CV, OE, RL and HL measures, and using the experimental techniques and results in the literature [39], The results of classification are demonstrated in Tables 12, 13, 14, 15 and 16. From Table 12, the index AP of MFSFN apparently outperforms other algorithms on the four datasets Yeast, Emotions, Cal500 and Scene; as an example, with respect to the Scene dataset, the maximum value of MFSFN is 0.0099 lower than MDDMspc, and the minimum value of MFSFN is 0.0941 higher than MDDMspc. Thus, MFSFN obtained better classification performance than other algorithms on AP. As can be seen from Table 13 that the CV value of MFSFN has a significant advantage over other algorithms on the three datasets: Yeast, Emotions and Scene. On the Cal500 dataset, the proposed algorithm MFSFN is 0.0917 higher than the minimum value of RFNMIFS, but the maximum value of MFSFN is 0.6717 lower than RFNMIFS, so MFSFN is more stable than RFNMIFS. As shown in Table 14, for the Yeast, Emotions and Scene datasets in metrics of OE, MFSFN achieves the lowest mean values. On the Cal500 dataset, the lowest value of RFNMIFS is 0.0143 lower than that of the MFSFN algorithm, but the highest value of RFNMIFS is 0.0047 higher than that of MFSFN, which proves that the stability of MFSFN is stronger than other algorithms. It can be seen from Table 15 that the RL of MFSFN is significantly better than other the six algorithms and obtains satisfactory results on the four datasets. From Table 16, the HL of MFSFN is better than other algorithms on the Yeast, Scene, Emotions and Cal500 four datasets. The results show that our algorithm can not only eliminate the redundant features on the four datasets, but also achieve better performance than other six algorithms in terms of AP, CV, OE, RL and HL.
Comparison results of methods under MLFE
This subsection illustrates the performance of the proposed method by comparing with other methods under classifier MLFE. We select three datasets from Table 2, including Flags, Yeast and Scene. MFSFN is compared with six most advanced multi-label feature selection methods, including PCT-CHI2 [19], CSFS [65], SFUS [66], Avg.CHI [67], MCLS [54], and RFNMIFS, on three multi-label datasets. The algorithm MFSFN is tested on the aspects of AP, CV, OE, RL, MacF1, and MicF1, the experimental techniques and results in reference [39] are used, as shown in Tables 17, 18 and 19. MFSFN prevails over other algorithms for the optimal mean values in the each evaluation index. It can be seen from Table 17 that the six metrics of MFSFN are better than other algorithms in the Flags dataset. The CV, MacF1 and MicF1 value of MFSFN have obvious advantages against the other six algorithms. On the RL index, MFSFN is 0.0172 higher than the lowest value of RFNMIFS and 0.0112 lower than its highest value. On the whole, MFSFN has better classification performance on the Flags dataset. From Table 18, the AP, MacF1 and MicF1 indexes of MFSFN are better than other algorithms on the Yeast dataset; on the CV, MFSFN is 0.0176 larger than the lowest value of RFNMIFS and 0.2832 lower than the highest value of RFNMIFS, so MFSFN has better performance for CV. For the OE index, MFSFN is 0.0056 higher than the lowest value of RFNMIFS, but 0.0164 lower than the highest value, in short, MFSFN still has advantages in OE measurement. In the terms of RL, MFSFN is 0.0010 higher than the lowest value of RFNMIFS, but 0.0216 lower than its highest value. MFSFN is more stable than other algorithms. It can be seen from Table 19 that the six indicators of MFSFN are significantly better than other algorithms on the Scene dataset. Based on the above analysis of the classification results of the three datasets on MLFE classifier, MFSFN algorithm can not only effectively eliminate the redundant features of the three datasets, but also has higher classification performance than other algorithms.

Comparison of the seven methods with Bonferroni–Dunn test under MLKNN
Statistical analysis
To systematically analyze the classification performance of MFSFN and intuitively display the statistical performance of each evaluation index under various comparison algorithms, Friedman statistical test [68] and Bonferroni–Dunn test [69] are used in this section. Friedman test is demonstrated as follows
where M and T are the numbers of methods and datasets, respectively, and \({{R}_{i}}\) is the average order value of the \(i-th\) method in all datasets. In the Bonferroni–Dunn test, the average rank difference between methods is calculated to evaluate whether there are significant differences between methods. The critical difference is expressed as follows
where \({{q}_{\alpha }}\) indicates the critical tabulated value of the test, and \(\alpha \) represents the significance level. According to the statistical tests in references [36, 70], the mean order of all datasets is obtained by averaging all levels on each metric. The optimal value under each index is set to the rank of 1, the second is set to the rank of 2, and so on. With CD value chart is used to visually display MFSFN correlations with other algorithms, each of these algorithms, the average ranking of each method is drew along the axis, in which the rank value on the axis increases from left to right. The MFSFN and compared algorithms are linked together with a thick line if the mean rank difference between these algorithms is within a criticality difference, indicating there is no significant difference between algorithms; otherwise, any algorithm that is not connected together will be considered markedly different from the other algorithms.
From the classification results in Tables 8, 9, 10 and 11, we can get the average ranking of MFSFN and six comparison algorithms on the four aspects of AP, CV, RL and OE under the MLKNN classifier, and the corresponding \({{F}_{F}}\) values are demonstrated in Table 20. When the significance level \(\alpha =0.1\), each indicator rejects the zero hypotheses that seven algorithms have the same performance under the Friedman test. At that time, \({{q}_{\alpha }}= 2.394\), then CD = 2.7644 (\(M=7,T=7\)). The accuracy comparison of seven algorithms by Bonferroni–Dunn test is demonstrated in Fig. 4. It can be obtained from Fig. 4 that MFSFN is significantly better than other algorithms in AP and OE evaluation indicators. From Fig. 4a, for the metric AP, the proposed algorithm has obvious advantages compared with PMU, MDDMspc, MDDMproj, RF-ML, and MFSFN is no significant difference with algorithms FSRD and MFSMR. It can be seen from Fig. 4b, in the aspect of CV index, there is no significant difference with algorithm MFSMR, and it has obvious advantages over algorithms MDDMproj, PMU, RF-ML and MDDMspc, and there is no definite evidence to prove that MDDMproj, RF-ML, MDDMspc and PMU have prominent differences. As shown in Fig. 4c, in metric of RL index, the algorithms MFSFN, FSRD and MFSMR is significantly better than MDDMproj, RF-ML, MDDMspc and PMU, and there is no consistent evidence to prove a statistical equivalence between MDDMproj, PMU, RF-ML and MDDMspc. From Fig. 4d, the OE index of the algorithm MFSFN is distinctly better than other algorithms, and and the distinction among the performance of FSRD, MFSMR, RF-ML, PMU and MDDMspc is insignificant. To sum up, the proposed algorithm has more excellent classification performance than other algorithms.

Comparison of the seven methods with Bonferroni–Dunn test under MLKNN
From the classification results which are illustrated in Tables 12, 13, 14, 15 and 16, we can get the average ranking of the proposed method and six comparison algorithms on the five aspects of AP, CV, HL, OE and RL under the MLKNN classifier, and the corresponding \({{F}_{F}}\) values are displayed in Table 21. When the significance level \(\alpha =0.1\), each indicator rejects the zero hypotheses that seven algorithms have the same performance under the Friedman test. At that time, \({{q}_{\alpha }}\)= 2.394, then CD = 3.6569 (\(M=7,T=4\)). The accuracy comparison of seven algorithms by the Bonferroni–Dunn test is demonstrated in Fig. 5. It can be seen from Fig. 5 that MFSFN is significantly better than other algorithms in each index. Fig. 5a illustrates that in terms of AP, MFSFN achieves significantly better than four algorithms PMU, MDDMspc, MDDMproj and MUCO and obtains comparable results against MFS-KA and RFNMIFS. As can be seen from Fig. 5b, d, the CV and RL of algorithm MFSFN outperforms PMU, MUCO and MDDMproj and comparable to MDDMspc, MFS-KA and RFNMIFS, and there is no full evidence to demonstrate a statistical equivalence with RFNMIFS, MFS-KA, MDDMspc, MDDMproj, MUCO and PMU. As can be obtained from Fig. 5c, for the index OE, MFSFN is significantly better than other algorithms and comparable to RFNMIFS, MFS-KA and MDDMspc, and there is no consistent evidence to indicate a statistical equivalence with RFNMIFS, MFS-KA, MDDMspc, PMU and MDDMproj, and there is no concrete evidence to determine the significant difference among MFS-KA, MDDMspc, PMU, MDDMproj and MUCO. It can be obtained from Fig. 5e that HL index of MFSFN is more excellent than MDDMspc, MDDMproj, MUCO and PMU. In general, MFSFN has strong classification performance compared with other algorithms under classifier MLKNN.
The classification results in Tables 17, 18 and 19 were statistically tested under the classifier MLFE. The \({{F}_{F}}\) values of the six metrics are listed in Table 22. When \(\alpha =0.1\), \({{q}_{\alpha }}=2.394\), then CD = 4.2226 (\(M=7,T=3\)). The test results are demonstrated in Fig. 6. As can be obtained from Fig. 6a, for the AP index, MFSFN performs better than PCT-CHI2 and CSFS and is comparable to RFNMIFS, MCLS, SFUS and Avg.CHI. As can be seen from Fig. 6b, e, there is not enough evidence to suggest a statistical equivalence among MFSFN and RFNMIFS, MCLS, SFUS, CSFS and Avg.CHI in the aspects of CV and MacF1, and it is significantly superior to PCT-CHI2. As can be seen from Fig. 6c, there is no obvious difference between algorithm MFSFN and RFNMIFS, MCLS, SFUS and CSFS in the OE index, and it is superior to algorithms Avg.CHI and PCT-CHI2. As can be seen from Fig. 6d, for RL index, MFSFN is comparable to RFNMIFS, MCLS, SFUS and PCT-CHI2, and performs better than Avg.CHI and CSFS. As can be seen from Fig. 6f, in metric of MicF1, algorithm MFSFN is comparable to RFNMIFS, MCLS, SFUS, PCT-CHI2 and Avg.CHI, and is significantly superior to CSFS. Therefore, under the classifier MLFE, the algorithm MFSFN has more excellent performance compared with the other algorithms in general.

Comparison of the seven methods with Bonferroni–Dunn test under MLFE
Conclusion
In this article, a multi-label feature selection method based on fuzzy neighborhood rough sets was improved by combining information view with the algebraic view, which achieved highly classification performance in the multi-label fuzzy neighborhood decision system. First, a new multi-label fuzzy neighborhood rough set model was proposed by combining NRS with FRS. Second, the fuzzy similarity matrix was obtained by computing the similarity between samples under different condition attributes, and a new multi-label fuzzy decision was proposed and the fuzzy neighborhood approximation accuracy was defined. Then, the fuzzy neighborhood conditional entropy was introduced, according to the concept of information entropy in information theory, and a hybrid metric was designed by combining the fuzzy neighborhood approximate accuracy with the fuzzy neighborhood conditional entropy, to measure the importance of each attribute. Finally, a multi-label feature selection method based on fuzzy neighborhood rough sets was developed, a novel forward search algorithm for multi-label feature selection is provided. A series of experiments on ten multi-label datasets verify the effectiveness of the proposed algorithm in multi-label classification. In our future work, we will seek multi-label feature selection method of higher classification performance, and more efficient search strategies.
References
Che X-Y, Chen D-G, Mi J-S (2019) A novel approach for learning label correlation with application to feature selection of multi-label data. Inf Sci 512:795–812
Huang M-M, Sun L, Xu J-C, Zhang S-G (2020) Multilabel feature selection using Relief and minimum redundancy maximum relevance based on neighborhood rough sets. IEEE Access 8(99):62011–62031
Che X-Y, Chen D-G, Mi J-S (2021) Feature distribution-based label correlation in multi-label classification. Int J Mach Learn Cybern 12(6):1705–1719
Qian W-B, Huang J-T, Wang Y-L, Xie Y-H (2021) Label distribution feature selection for multi-label classification with rough set. Int J Approx Reason 128:32–55
Zhang P, Gao W-F (2021) Feature relevance term variation for multi-label feature selection. Appl Intell. https://doi.org/10.1007/s10489-020-02129-w
Fujita H, Gaeta A, Loia V, Orciuoli F (2019) Hypotheses analysis and assessment in counterterrorism activities: A method based on OWA and fuzzy probabilistic rough sets. IEEE Trans Fuzzy Syst 28(5):831–845
Yue X-D, Chen Y-F, Miao D-Q, Fujita H (2020) Fuzzy neighborhood covering for three-way classification. Inf Sci 507:795–808
Zhang M-L, Zhou Z-H (2007) ML-KNN: a lazy learning approach to multi-label learning. Pattern Recogn 40(7):2038–2048
Zhang M-L, Zhou Z-H (2014) A review on multi-label learning algorithms. IEEE Trans Knowl Data Eng 26(8):1819–1837
Boutell M-R, Luo J, Shen X, Brown C-M (2004) Learning multi-label scene classification. Pattern Recogn 37(9):1757–1771
Arslan S, Ozturk C (2019) Multi hive artificial bee colony programming for high dimensional symbolic regression with feature selection. Appl Soft Comput 78:515–527
Chen S-B, Zhang Y-M, Ding H-Q, Zhang J, Luo B (2019) Extended adaptive Lasso for multi-class and multi-label feature selection. Knowl Based Syst 173:28–36
Jiang Z-H, Liu K-Y, Yang X-B, Yu H-L, Fujita H, Qian Y-H (2020) Accelerator for supervised neighborhood based attribute reduction. Int J Approx Reason 119:122–150
Xu T-T, Zhao L (2020) A structure-induced framework for multi-label feature selection with highly incomplete labels. IEEE Access 8:71229–71230
Zhang P, Gao W-F, Hu J-C, Li Y-H (2021) Multi-label feature selection based on the division of label topics. Inf Sci 553:129–153
Fan Y-L, Liu J-H, Weng W, Chen B-H, Chen Y-N, Wu S-X (2021) Multi-label feature selection with local discriminant model and label correlations. Neurocomputing 442:98–115
Liang M-S, Mi J-S, Feng T (2019) Optimal granulation selection for multi-label data based on multi-granulation rough sets. Granul Comput 4(3):323–335
Dong H-B, Sun J, Li T, Ding R, Sun X-H (2020) A multi-objective algorithm for multi-label filter feature selection problem. Appl Intell. https://doi.org/10.1007/s10489-020-01785-2
Sun L, Wang L-Y, Ding W-P, Qian Y-H, Xu J-C (2020) Feature selection using fuzzy neighborhood entropy-based uncertainty measures for fuzzy neighborhood multigranulation rough sets. IEEE Trans Fuzzy Syst 29(1):19–33
Sun L, Yin T-Y, Ding W-P, Qian Y-H, Xu J-C (2021) Feature selection with missing labels using multilabel fuzzy neighborhood rough sets and maximum relevance minimum redundancy. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2021.3053844
Ding W-P, Lin C-T, Cao Z-H (2018) Deep neuro-cognitive co-evolution for fuzzy attribute reduction by quantum leaping PSO with nearest-neighbor memeplexes. IEEE Trans Cybern 49(7):2744–2757
Li A-D, Xue B, Zhang M-G (2021) Improved binary particle swarm optimization for feature selection with new initialization and search space reduction strategies. Appl Soft Comput. https://doi.org/10.1016/j.asoc.2021.107302
Zhang J, Luo Z-M, Li C-D, Zhou C-G, Li S-Z (2019) Manifold regularized discriminative feature selection for multi-label learning. Pattern Recogn 95:136–150
Xu J-C, Wang Y, Mu H-Y, Huang F-Z (2018) Feature genes selection based on fuzzy neighborhood conditional entropy. J Intell Fuzzy Syst 36(1):117–126
Lin Y-J, Hu Q-H, Liu J-H, Chen J-K, Duan J (2016) Multi-label feature selection based on neighborhood mutual information. Appl Soft Comput 38:244–256
Wang C-Z, Huang Y, Shao M-W, Hu Q-H, Chen D-G (2019) Feature selection based on neighborhood self-information. IEEE Trans Cybern 50(9):4031–4042
Sha Z-C, Liu Z-M, Ma C, Chen J (2021) Feature selection for multi-label classification by maximizing full-dimensional conditional mutual information. Appl Intell 51(1):326–340
Qian W-B, Huang J-T, Wang Y-L, Shu W-H (2020) Mutual information-based label distribution feature selection for multi-label learning. Knowl Based Syst. https://doi.org/10.1016/j.knosys.2020.105684
Li L, Liu H-W, Ma Z-J, Mo Y-C, Duan Z-J, Zhou J-Q, Zhao J-M (2014) Multi-label feature selection via information gain, vol 8933. Springer International Publishing, pp 345–355
Gao W-F, Hu J-C, Li Y-H, Zhang P (2020) Feature redundancy based on interaction information for multi-label feature selection. IEEE Access 8:146050–146064
Xu J-C, Yuan M, Ma Y-Y (2021) Feature selection using self-information and entropy-based uncertainty measure for fuzzy neighborhood rough set. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00356-3
Qian W-B, Yu S-D, Yang J, Wang Y-L, Zhang J-H (2020) Multi-label feature selection based on information entropy fusion in multi-source decision system. Evol Intell 13(2):255–268
Chen H-M, Li T-R, Cai Y, Luo C, Fujita H (2016) Parallel attribute reduction in dominance-based neighborhood rough set. Inf Sci 373:351–368
Lin Y-J, Li Y-W, Wang C-X, Chen J-K (2018) Attribute reduction for multi-label learning with fuzzy rough set. Knowl Based Syst 152:51–61
Li Y-W, Lin Y-J, Liu J-H, Weng W, Shi Z-K, Wu S-X (2018) Feature selection for multi-label learning based on kernelized fuzzy rough sets. Neurocomputing 318:271–286
Sun L, Yin T-Y, Ding W-P, Xu J-C (2019) Hybrid multilabel feature selection using BPSO and neighborhood rough sets for multilabel neighborhood decision systems. IEEE Access 7:175793–175815
Wang C-Z, Qi Y-L, Shao M-W, Hu Q-H, Chen D-G, Qian Y-H, Lin Y-J (2017) A fitting model for feature selection with fuzzy rough sets. IEEE Trans Fuzzy Syst 25(4):741–753
Che X-Y, Chen D-G, Mi J-S (2021) Label correlation in multi-label classification using local attribute reductions with fuzzy rough sets. Fuzzy Sets Syst. https://doi.org/10.1016/j.fss.2021.03.016
Sun L, Yin T-Y, Ding W-P, Qian Y-H, Xu J-C (2020) Multilabel feature selection using ML-ReliefF and neighborhood mutual information for multilabel neighborhood decision systems. Inf Sci 537:401–424
Huang M-M, Sun L, Xu J-C, Zhang S-G (2020) Multilabel feature selection using Relief and minimum redundancy maximum relevance based on neighborhood rough sets. IEEE Access 8(99):62011–62031
Xie Y-H, Li D-L, Zhang D-Z, Shuang H (2018) An improved multi-label relief feature selection algorithm for unbalanced datasets. Adv Intell Syst Comput 686:141–151
Cai Y-P, Yang M, Gao Y, Yin H-J (2015) ReliefF-based multi-label feature selection. Int J Database Theory Appl 8(4):307–318
Gao W, Zhou Z-H (2013) On the consistency of multi-label learning. Artif Intell 199:22–44
Zhao D-W, Gao Q-W, Lu Y-X, Sun D, Cheng Y-S (2021) Consistency and diversity neural network multi-view multi-label learning. Knowl Based Syst. https://doi.org/10.1016/j.knosys.2021.106841
Pawlak Z (1982) Rough sets. Int J Comput Inf Sci 11(5):341–356
Duan J, Hu Q-H, Zhang L-J, Qian Y-H, Li D-Y (2015) Feature selection for multi-label classification based on neighborhood rough sets. Comput Res Dev 52(1):56–65
Lin Y-J, Li Y-W, Wang C-X, Chen J-K (2018) Attribute reduction for multi-label learning with fuzzy rough set. Knowl Based Syst 152:51–61
Chen P-P, Lin M-L, Liu J-H (2020) Multi-label attribute reduction based on variable precision fuzzy neighborhood rough set. IEEE Access 8:133565–133576
Wang C-Z, Shao M-W, He Q, Qian Y-H, Qi Y-L (2016) Feature subset selection based on fuzzy neighborhood rough sets. Knowl Based Syst 111:173–179
Shannon C-E (2001) A mathematical theory of communication. ACM Sigmobile Mob Comput Commun Rev 5(1):3–55
Sun L, Zhang X-Y, Qian Y-H, Xu J-C, Zhang S-G (2019) Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Inf Sci 502:18–41
He Z-F, Yang M, Liu H-D (2014) Joint learning of multi-label classification and label correlations. J Soft 25(9):1967–1981
Zhang Q-W, Zhang Y, Zhang M-L (2018) Feature-induced labeling information enrichment for multi-label learning. In: Thirty-second AAAI conference on artificial intelligence, Hilton. AAAI 2018, February 2-7, pp 4446–4453 (2018)
Huang R, Jiang W-D, Sun G-L (2018) Manifold-based constraint Laplacian Score for multi-label feature selection. Pattern Recogn Lett 112:346–352
Zhang M-L, Pena J-M, Robles V (2009) Feature selection for multi-label naive Bayes classification. Inf Sci 179(19):3218–3229
Zhang Y, Zhou Z-H (2008) Multi-Label dimensionality reduction via dependence maximization. In: Proceedings of the twenty-third AAAI conference on artificial intelligence, July 13–17, 2008. Chicago, vol 3, pp 1503–1505
Lee J, Kim D-W (2013) Feature selection for multi-label classification using multivariate mutual information. Pattern Recogn Lett 34(3):349–357
Doquire G, Verleysen M (2011) Feature selection for multi-label classification problems. In: Eleventh international work-conference on artificial neural networks, June 8–10, vol 6691, no 1, pp 9–16
Shima K, Hossein N-P (2019) A label-specific multi-label feature selection algorithm based on Pareto dominance concept. Pattern Recogn 88:654–667
Chen W-Z, Yan J, Zhang B-Y, Chen Z (2007) Yang Q (2007) Document transformation for multi-label feature selection in text categorization. In: 7th IEEE international conference on data mining, October 28–31, pp 451–456
Read J (2008) A pruned problem transformation method for multi-label classification. In: 6th New Zealand computer science research student conference, April 14–18, 2008, pp 143–150
Lin Y-J, Hu Q-H, Liu J-H, Li J-J, Wu X-D (2017) Streaming feature selection for multi-label learning based on fuzzy mutual information. IEEE Trans Fuzzy Syst 25(6):1491–1507
Reyes O, Morell C, Ventura S (2015) Scalable extensions of the ReliefF algorithm for weighting and selecting features on the multi-label learning context. Neurocomputing 161:168–182
Chen L-L, Chen D-G (2019) Alignment based feature selection for multi-label learning. Neural Process Lett 50(3):2323–2344
Chang X-J, Nie F-P, Yang Y, Huang H (2014) A convex formation for semi-supervised multi-label feature selection. In: Twenty-eight AAAI conference on artifical intelligence, July 27–31, 2014, Québec City
Ma Z-G, Nie F-P, Yang Y, Uijlings J, Sebe N (2012) Web image annotation via subspace-sparsity collaborated feature selection. IEEE Trans Multimed 14(4):1021–1030
Lim H, Lee J, Kim D-W (2017) Optimization approach for feature selection in multi-label classification. Pattern Recogn Lett 89:25–30
Friedman M (1940) A comparison of alternative tests of significance for the problem of m rankings. Ann Math Stat 11(1):86–92
Dunn O-J (1961) Multiple comparisons among means. Publ Am Stat Assoc 56(293):52–64
Sun L, Wang L-Y, Qian Y-H, Xu J-C, Zhang S-G (2019) Feature selection using Lebesgue and entropy measures for incomplete neighborhood decision systems. Knowl Based Syst. https://doi.org/10.1016/j.knosys.2019.104942
Acknowledgements
This research was funded by the National Natural Science Foundation of China under Grants 61976082, 62076089 and 62002103; and the Key Scientific and Technological Project of Henan Province under Grant 212102210136.
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, J., Shen, K. & Sun, L. Multi-label feature selection based on fuzzy neighborhood rough sets. Complex Intell. Syst. 8, 2105–2129 (2022). https://doi.org/10.1007/s40747-021-00636-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00636-y