
Abstract
How to effectively reflect the randomness and reliability of decision information under uncertain circumstances, and thereby improve the accuracy of decision-making in complex decision scenarios, has become a crucial topic in the field of uncertain decision-making. In this article, the loss –aversion behavior of decision-makers and the non-compensation between attributes are considered. Furthermore, a novel generalized TODIM-ELECTRE II method under the linguistic Z-numbers environment is proposed based on Dempster–Shafer evidence theory for multi-criteria group decision-making problems with unknown weight information. Firstly, the evaluation information and its reliability are provided simultaneously by employing linguistic Z-numbers, which have the ability to capture the arbitrariness and vagueness of natural verbal information. Then, the evaluation information is used to derive basic probability assignments in Dempster–Shafer evidence theory, and with the consideration of both inner and outer reliability, this article employed Dempster’s rule to fuse evaluations. Subsequently, a generalized TODIM-ELECTRE II method is conceived under the linguistic Z-numbers environment, which considers both compensatory effects between attributes and the bounded rationality of decision-makers. In addition, criteria weights are obtained by applying Deng entropy which has the ability to deal with uncertainty. Finally, an example of terminal wastewater solidification technology selection is offered to prove this framework’s availability and robustness. The predominance is also verified by a comparative analysis with several existing methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Multi-criteria group decision-making (MCGDM) has always been a hotspot due to its complexity and universality in daily life and business management, such as supplier selection [1,2,3,4], hospital management [5] and site selection of new energy power station [6]. A MCGDM problem requires multiple decision-makers (DMs) to evaluate a series of alternatives from distinct perspectives and eventually determine the best one. However, classic fuzzy sets are inadequate to describe the dependability of evaluation information. For describing uncertain, imprecise and incomplete information more accurately, the notion of Z-number is introduced [7]. A Z-number is an ordered pair of fuzzy numbers configured as Z = (A, B). The constraint part A and the reliability measure B endow Z-numbers the capacity to reflect the constraint and reliability of information synchronously, making it superior to traditional fuzzy sets and widely applicable to natural human expression. For example, the sentence “The salt content of seawater reverse osmosis influent is usually 8 g/L ~ 50 g/L.” can be represented by a Z-number as X is Z = (8 g/L ~ 50 g/L, usually), where X indicates the water salinity of seawater reverse osmosis. The existing literature mainly studies Z-numbers in two categories. The first category can be classified as fundamental research, including arithmetic operations over Z-numbers [8,9,10], comparison and measurement methods [11,12,13,14], converting methods [15] and so on. The second is the employment of Z-number in the decision-making process, such as medical diagnosis [16] and failure mode identification and sequencing [17]. Also, the two elements of a Z-number are most expressed as the trapezoidal or triangular fuzzy number [16, 18], or a mix of both [17].
Linguistic Z-numbers (LZNs) is a subclass of Z-numbers, whose two components merge in the form of linguistic terms. The fuzziness and randomness of LZNs precisely accord to the restraint and reliability of Z-numbers, respectively [19]. This extension caters more to human habits and makes qualitative information to be described more accurately, thus can help reduce the information distortion, increase the flexibility and credibility of decision-making. The fuzzy restriction of a LZN may be represented by linguistic terms like “a little bad”, “good”, “very good”, the reliability can be measured by linguistic terms like “uncertain”, “relatively certain”, “very certain” or “seldom”, “often” and “usual”. LZNs are practical tools for expressing most decision-making information. For example, an expert can use a LZN (very good, certain) to evaluate the effect of evaporative crystallization technology on the solidification of terminal wastewater. Due to the universality and applicability, LZN shave a wide range of application. For example, Song et al. [20] designed a novel quality function deployment framework employing LZNs. Jiang et al. [5] developed an extended evaluation laboratory method under The LZNs environment as a large group evaluation approach.
However, the determination of membership functions linked with linguistic terms is not a simple matter; aggregating linguistic terms is also a complex undertaking. Since constraint and reliability fall into distinct categories, the direct conversion of LZNs to classical fuzzy numbers will cause distortion and loss of initial information, which is nevertheless a common approach for the aggregation of evaluations in Z-numbers form [17, 21,22,23]. As a generalization of probability theory and promotion of traditional Bayes reasoning approach, Dempster–Shafer evidence theory (DEST) has been found great effectiveness in processing uncertainty resulting from the unknown or incomplete information [24, 25]. Its core, Dempster’s combination rule, can effectively fuse the evaluation information from multiple individuals. Li and Chen (2018) provided an approach to transfer fuzzy information into BPAs and adopted DEST to integrate evaluation opinions of multiple experts [26]. Liu and Zhang (2019) developed a hesitant fuzzy linguistic fusion arithmetic based on DEST and suggested a novel multiple attribute decision making (MADM) method [4]. Ren et al. (2020) built a bridge between Z-numbers and the DEST, which formed the foundation to aggregate Z-evaluations [21]. Nevertheless, there has been no research on how to apply DEST to the effective integration of LZNs. Thus, this paper employs LZNs to express the initial evaluation information. Then the evaluations in the form of LZNs are converted into BPAs by extending the method in [27] to the LZNs environment. To be more specific, the membership function is substituted with the utility function, and the reliability is measured using linguistic scale function.
There are many traditional multicriteria decision making (MCDM) methods, such as VIKOR, grey relational analysis, etc. On the basis of these methods, many scholars have improved these methods or developed new methods to better solve the MCDM problem. For example, Gou et al. (2020) corrected the neglect of the traditional VIKOR method on the relationship between the alternatives and the negative ideal solution, and used the improved VIKOR method in probabilistic double hierarchy linguistic context [28]. Jiang et al. (2020) extended the decision-making trial and evaluation laboratory (DEMATEL) method by incorporating LZNs, to make up for the shortcomings of existing DEMATEL methods in expressing reliability of DMs’ cognition [5]. Geetha et al. (2021) provided a hesitant Pythagorean fuzzy (HPF) ELECTRE III method which extended the ELECTRE III method to HPF environment [29]. Lin et al. (2021) proposed two methods based on a new score function of probabilistic linguistic term sets (PLTSs), which named TOPSIS-ScoreC-PLTS and VIKOR-ScoreC-PLTS, respectively [30]. As a classification of multitudinous multicriteria decision making (MCDM) methods, the outranking methods perform best in decision support at the strategic level. The outranking methods have the indisputable advantage in leveraging incomplete information and coping with uncertain or fuzzy information. Among them, the ELECTRE method is the most extensively used owing to its prominent ability to effectively avoid the compensation effect between attributes while fully considering incomparability and indifference. In other words, an alternative with a significantly weaker performance value cannot be directly compensated by other good attribute values. The ELECTRE method has so far developed multiple versions suitable for different types of problems. Among them, ELECTRE II concerned more about the degree to which one alternative outranks another, which serve the purpose of settling sorting problems [31]. ELECTRE II method can be applied in copious fuzzy circumstances. Wan et al. (2016) suggested a MCDM method combining AHP and ELECTRE II for supplier selection problems with interval 2-tuple linguistic information [32]. Liao et al. (2017) proposed two ELECTRE-based MCDM approaches under hesitant fuzzy linguistic environment [33]. Tian et al. (2020) put forward a novel MCGDM method suitable to the single-valued neutrosophic environment and weight unknown circumstances [34]. However, no scholars have applied the ELECRE II method to the LZNs context currently. Consequently, this article chooses ELECTRE II as the ranking method of alternatives.
Another point worth noting is that the existing MCDM or MCGDM methods, including the ELECTRE II method, typically take DMs as risk-neutral, even though the fact is often not the case. DMs usually have reference dependence and loss-aversion psychology during the decision-making process, which means DMs are more sensitive to losses than to profits. Inspired by prospect theory, the TODIM method is introduced with the strength of considering the psychological characteristics of the DMs [35] and extended to various information contexts. For instance, Krohling and de Souza (2012) proposed the fuzzy TODIM [36], which is then generalized to uncertain and random environment successively [37, 38]. In addition, how to reasonably combine the TODIM method with other methods to impart decision-making higher reliability and validity is also a problem deserves research. Passos et al. (2014) proposed the TODIM-FSE method by adopting some stages of Fuzzy Synthetic Evaluation (FSE) and the TODIM respectively, which provided the possibility to consider the prevalent inaccuracies in human judgment when constructing the contribution function [39]. Zhang et al. (2017) developed the SMAA-TODIM method to process the intrinsic indeterminacy of the TODIM or TODIM-based models [40]. Wu et al. (2018) extended TODIM to fuzzy context and combined it with PROMETHEE-II method to settle the compensation problem during the ranking process [41]. Llamazares (2018) pointed out two types of paradoxes in the traditional TODIM method, thus the generalized TODIM method is introduced [42]. This generalized version can effectively avoid these two paradoxes and has been gradually expanded [43]. Therefore, generalized TODIM is managed to integrate into ELECTRE II so that the influence of DM’s bounded rationality on the ranking results can be subtly considered in this article.
After the foregoing analysis, a decision-making framework is constructed for the ranking and selection problem. The main work of this article can be outlined as follows:
-
1.
A LZN is an appropriate and remarkable tool to express assessments. On the one hand, it embraces both fuzzy evaluation and reliability information. On the other hand, the introduction of linguistic term sets makes it retain more original evaluation information and reduce the information distortion compared to a Z-number. Therefore, LZNs are employed in this article to describe original evaluation values.
-
2.
DEST is extended to the LZNs context, which not only reduces the distortion of evaluation information but also better handles the fusion of multi-source information under uncertain conditions. Moreover, a novel discounting coefficients determination method is established to modify BPAs, which considers both the inner and outer credibility of the evidence.
-
3.
A novel decision framework for MCGDM problems with LZNs and unknown weight information is established based on DEST and Deng entropy. Within this framework, the alternatives are ranked according to the calculation results of the generalized TODIM-ELECTRE II method under the LZNs environment. The novel method can deal with non-compensatory issues of criteria while reflecting the loss-avoidance psychology of DMs, hence further enhances the persuasiveness and reliability of the results.
The remainder of this paper is fabricated as follows: Section “Preliminaries” reviews the relevant knowledge concerning LZNs, DEST and Deng entropy. In Section “An integrated decision-making framework based on the generalized TODIM-ELECTER II method and DEST”, the decision framework developed in this paper is introduced. A case of terminal wastewater solidification technology selection is devised in Section “An illustrative example of terminal wastewater solidification technology selection” to verify the feasibility of the above method. Section “Analysis and discussion” carries out a series of analysis, including sensitivity and comparative analyses, the robustness and superiority of the proposed method are manifested in this section. Finally, the conclusion comes in section “Conclusion”.
Preliminaries
Z-number
The notion of Z-numbers is proposed by Zadeh (2011) as an implementation to depict the reliability or the confidence in the information released by natural language statement, which appears as a 2-tuple: Z = (A, B).
Typically, A and B occur in the form of words or clauses, and both are fuzzy numbers. Component A plays the role of a fuzzy restriction, R(X), on the values taken by a real-valued uncertain variable X. More specifically, R(X): X is A → Poss (X = u) = μA (u), where μA (u) is the membership function of A and u represents a general value of X, μA (u) can be constructed as the degree to which u belongs to the constraint.
In light of the relation between Z-numbers and Z+-numbers, the meaning of a Z-number can be explained by \(Z = (A,\;B) = Z^{ + } (A,\;\mu_{A} \cdot p_{{X_{A} }} \;is\;B)\), where XA is a random variable and \(p_{{X_{A} }}\) is the probability of XA for fuzzy set A. In addition, \(\mu_{A} \cdot p_{{X_{A} }} \;is\;B\) indicates \(\mu_{B} \left( {\int {\mu_{A} \left( X \right) \cdot p_{{X_{A} }} } \left( X \right)dx} \right)\) [7]. The diagram of a Z-number is shown in Fig. 1 [27], where b represents an element in fuzzy set B.

The diagram of a simple Z-number [27]
Linguistic Z-numbers
The linguistic Z-numbers can effectively avoid information loss and distortion while considering uncertainty in the decision-making process.
Definition 2.1
Let X be the discourse domain, \(S_{1} = \left\{ {s_{0} ,s_{1} , \cdots ,s_{2t} } \right\}\) and \(S_{2} = \left\{ {s^{\prime}_{0} ,s^{\prime}_{1} , \cdots ,s^{\prime}_{2t} } \right\}\) are two linguistic term sets containing a finite number of elements, the terms is ordered and discrete, t is a non-negative integer. Suppose Aϕ(x) ∈ S1 and Bφ(x) ∈ S2. Then the form of a linguistic Z-number set in X is as follows: Z = {(x, Aϕ(x), Bφ(x))| x ∈ X}, where Aϕ(x) is the limit on the possible value of the uncertain variable x, and Bφ(x) is +the measure of the reliability of the first component. These two components usually contain different linguistic terms, representing different preference information.
When X contains only a single element, the linguistic Z-number set degenerates into a linguistic Z-number Zα = (x, Aϕ(α), Bφ(α)), where Aϕ(α) ∈ S1 and Bφ(α) ∈ S2 are two linguistic terms.
Dempster–Shafer evidence theory
As an extension of probability theory, Dempster–Shafer evidence theory (DEST) has outstanding performance in the fusion of multi-source uncertain information. The following is a brief review of DEST.
Definition 2.2
Let \(\Theta = \left\{ {H_{1} ,H_{2} , \cdots ,H_{N} } \right\}\), the elements in the collection are exhaustive and mutually exclusive, we define the set Θ as a frame of discernment (FOD). The power set of Θ is denoted as \(P\left( \Theta \right) = \left\{ {\emptyset ,\left\{ {H_{1} } \right\},\left\{ {H_{2} } \right\}, \cdots ,\left\{ {H_{N} } \right\}, \cdots ,\left\{ {H_{1} \cup H_{2} } \right\}, \cdots ,\Theta } \right\}\).
Every element in P(Θ) can be called a proposition, which represents the possible values of the evaluated object.
The mass function is also called basic probability assignment, or BPA, which is defined as m: P(Θ) → [0,1]. It satisfies the conditions: \(\left( i \right)m\left( \emptyset \right) = 0;\;\left( {ii} \right)\sum\nolimits_{A \in P\left( \Theta \right)} {m\left( A \right)} = 1\), m(A) reflects the extent to which the evidence supports A. If m(A) > 0, A is called a focal element. Any belief that is not assigned to a specific subset is considered “unexpressed” and assigned to the environment Θ, denote by m(Θ).
To show the reliability of evidence, we introduce the concept of discounting coefficient. A discounting coefficient \(\alpha \in \left[ {0,1} \right]\) can be seen as the weight of a piece of evidence. By updating the BPA with a discounting coefficient, we can get the discounted BPA:
The core of DEST is its rules of combination, which is commonly used to integrate multi-source information.
Definition 2.3
For two bodies of evidence m1 and m2, the combination indicated by m = m1 ⊕ m2 is defined by Dempster’s rule as follows:
where B and C are both focal elements. In the formula, K is called the conflict coefficient and \(K = \sum\nolimits_{B \cap C = \emptyset } {m_{1} \left( B \right)m_{2} \left( C \right)}\).
Pignistic probability represents a point estimate in a belief interval. A BPA can be transformed into a probability distribution by Pignistic probability function defined below:
where A is a focal element and \( \left| \cdot \right|\) represent the cardinality of corresponding sets. Resent the cardinality of corresponding sets.
Definition 2.4
Let m1 and m2 be two BPAs on the same frame of discernment Θ, which contains N mutually exclusive and exhaustive hypotheses. The distance between m1 and m2 can be calculated by Eq. (5)
where \(\overrightarrow {{m_{1} }}\) and \(\overrightarrow {{m_{2} }}\) are the vector representations of the corresponding BPA m1 and m2 respectively and \(\underline{\underline{D}}\) is a \(2^{N} \times 2^{N}\) matrix with elements are evaluated as Eq. (6).
Note that the element 1/2 in Eq. (5) is required for normalizing \(d_{BPA}\) and guaranteeing \(0 \le d_{BPA} \le 1\).
Deng entropy and the maximum Deng entropy
Deng entropy was first proposed by Deng, it can measure the uncertainty of basic probability assignments (BPAs). Deng entropy is the generalization of Shannon entropy and expands the boundary of the latter. The basic form is as follows:
m is the mass function defined in the framework of discriminate. A is the focus element, and |A| is the cardinality of A. This formula shows that a belief is assigned to 2|A|-1 possible states contained in A (except for the empty set). Shannon entropy can be regarded as a special case of Deng entropy where belief is only assigned to a single element and |A| = 1.
which can be interpreted as the measure of discord of the BPA among diverse focal elements.
The classical maximum entropy is calculated by log|N|. However, Kang and Deng (2019) pointed out that if the state of the system was uncertain, ambiguous, the actual maximum entropy might be greater than the traditional maximum entropy [44]. Then the maximum Deng entropy condition was given and the analytical solution of the maximum Deng entropy was obtained.
Theorem 1
The maximum Deng entropy:
where Fi is a focal element and m(Fi) is the mass function of Fi. It is not difficult to infer that the analytical solution of the maximum Deng entropy is \(D_{\max } = \log_{2} \sum\nolimits_{i} {\left( {2^{{\left| {F_{i} } \right|}} - 1} \right)}\).
An integrated decision-making framework based on the generalized TODIM-ELECTER II method and DEST
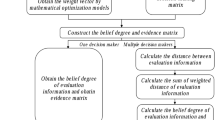
This section introduced the novel decision-making frame constructed to solve problems of ranking and selecting. Figure 2 is the flowchart of the proposed method, which displays the procedure of the decision with evaluation information in the form of LZNs. First, we convert the LZNs into BPAs. Then the discounted BPAs are determined by identifying the credibility of evidence, and the decision matrix is acquired by fusing evaluations from all experts. Further, Deng entropy is employed to obtain criteria weights. Finally, the generalized TODIM-ELECTRE II method is presented by combining the generalized TODIM method and ELECTRE II, the newly proposed method inherits the advantages of both methods and thus can provide a more credible ranking result. The flow of the decision framework will be visualized in the diagram illustrated in Fig. 2.

The flow chart of the proposed MCGDM decision framework
Statement of a MCGDM problem in LZNs environment
Suppose there is a problem for prioritization purpose, which contains m alternatives \(\left\{ {Aa_{1} ,Aa_{2} , \cdots ,Aa_{m} } \right\}\) and n evaluation criteria \(\left\{ {C_{1} ,C_{2} , \cdots ,C_{n} } \right\},\) k experts \(\left\{ {E_{1} ,E_{2} , \cdots ,E_{k} } \right\}\) independently assess the performance of each alternative under each criterion. The criteria weights and expert weights are completely unknown. The evaluation information is given by experts in the form of LZNs. Let \(h_{uv}^{t}\) represents the evaluation for alternative Aau under the attribute Cv provided by expert Et, where \(h_{uv}^{t} = \left( {A_{{\phi_{uv}^{t} }} ,B_{{\varphi_{uv}^{t} }} } \right)\) is a LZN. The original evaluation matrix Ht of Et is shown below:
Generate the basic probability assignment based on linguistic Z-numbers
LZNs are more conform to human expression habits and have a strong ability to retain the original information. For dealing with the uncertainty in the assessment and facilitating subsequent information integration, the recognition framework in DEST is used to represent fuzzy restriction of the variable value and reliability measure in LZNs.
Let \(S = \left\{ {s_{{{ - }l}} , \cdots ,s_{ - 1} ,s_{0} ,s_{1} , \cdots ,s_{l} } \right\}\) be a linguistic term set, \(B_{{\varphi_{uv}^{t} }} =\left\{ {S_{\alpha } |S_{\alpha } \in S;\;\alpha \in \left\{ {{ - }l, \cdots , - 1,0,1, \cdots ,l} \right\}} \right\}\) is the reliability component of a LZN \(h_{uv}^{t} = \left( {A_{{\phi_{uv}^{t} }} ,B_{{\varphi_{uv}^{t} }} } \right)\). Then \(B_{{\varphi_{uv}^{t} }}\) can be quantified by the linguistic scale function L, which is manifested in Eq. (10). Since the conversation result increases with the confidential level, it can be regarded as a score function of the reliability part embedded in the evaluation.
In a recent study, Ren et al. (2020) substitute the membership function μ(x) for the utility function u(ϕj) and used Shapley value method to revise the utility values of non-independent evaluation grades [27].
Definition 3.1
[26]. A fuzzy measure u is a set function on the set of \(\phi =\;\left\{ {\phi_{ - g} ,\; \cdots ,\;\phi_{ - 1} ,\;\phi_{0} ,\;\phi_{1} ,\; \cdots ,\;\phi_{g} } \right\} :\) \(2^{N} \to \left[ {0,1} \right]\) sufficing the following condition: \(\left( 1 \right)\;u\left( \emptyset \right) = 0,\;u\left( \phi \right) = 0\); \(\;\left( 2 \right)\;u\left( P \right) \le \;u\left( Q \right),\;if\;P \subseteq \;Q\;for\;all\) \(P,\;Q \subseteq \phi\). u({ϕj}) indicates the utility or the weight of element ϕj. The Shapley index for each j ∈ ϕ is defined as:
Shapley value is the average value of the marginal contribution, which represents a particular constituent’s share of in the value of all possible unions and can be maneuvered as a contrivance to determine a reasonable marginal contribution of every distinct element \(\phi_{j} \left( {j = \left\{ { - g, \cdots , - 1,0,1, \cdots ,g} \right\}} \right)\) to the set ϕ. Through this operation, we have \(\rho \left( \Delta \right) = \sum\nolimits_{{\phi_{j} \in \Delta }} {\rho \left( {\left\{ {\phi_{j} } \right\}} \right)} ,\;for\;all\;\Delta \subseteq \phi\).
Combining the related concepts of Z-numbers, the probability distribution can be extended to BPAs, so that we can derive the evidence \(m\left( {h_{{_{uv} }}^{t} \left( {\phi_{j} } \right)} \right)\), which refers to the evaluation \(h_{{_{uv} }}^{t} \left( {\phi_{j} } \right)=\left( {A_{{\phi_{uv}^{t} }} \left( j \right),B_{{\varphi_{uv}^{t} }} \left( \alpha \right)} \right)\), that is:
where \(A_{{\phi_{uv}^{t} }}\) indicates the evaluation grade of Aau under Cv provided by Et, \(L\left( {B_{{\varphi_{uv}^{t} }} \left( \alpha \right)} \right)\) represents the score of corresponding reliability part, and ρ(ϕj) is the revised utility value of the evaluation grade.
The remaining beliefs are assigned to the FOD Θ:
Since there are multiple evaluations for each alternative under the same criterion, the BPA is indispensable to be normalized according to Eq. (14).
For simplicity, we still use m instead of \(\widetilde{m}\) to represent the normalized BPAs hereunder.
The rationality of this step is that the performance of each alternative in the same dimension is objective, while the evaluation is relatively subjective. When a decision maker is proficient in a certain aspect of knowledge, he will give a higher confidence level to his own evaluation, and the corresponding evaluation is more reliable. Conversely, the lower the decision maker’s confidence in the evaluation is and the lower the credibility of the opinion. An extreme example is that a decision maker on their own evaluation of no confidence thoroughly, then we may not put the comments into account.
Determine the decision matrix and weights of criteria
The entropy weight method takes the degree of dispersion of the index as the basis for determining the weight. As an objective weighting method, it has high credibility and accuracy. Moreover, it has the capacity to reflect the distinguishing ability of indicators and simple algorithm.
Deng entropy is an effective way to measure the uncertainty degree of BPAs [45]. Therefore, this article calculates evidence’s inner reliability and criteria weights based on Deng entropy for avoiding the intervention arisen from subjective factors. The determination of BPAs’ outer reliability is based on the conflict relationship. The following are the specific steps to obtain the final decision matrix and weights of criteria.
Step 1: for every piece of evidence provided by each expert, calculate the Deng entropy of BPA according to Eqs. (7)–(9). Then the inner reliability is determined by Eq. (15)
Step 2: measuring the outer reliability of evidence. As proposed in the previous study [3], the outer reliability of a mass function depends mainly upon the conflict relationship between the polymerized BPAs. Referring to the multi-source data integration framework [46], we know that the outer reliability of a BPA is related to three metrics, that is, the weight or strength of credibility source S, the support for the proposed solution A from the data derived from S and the compatibility of A with As, As means the value proposed by the source S. So below we will introduce the concepts of support degree and the credibility degree for mass functions.
Definition 3.2
Let \(Q = \left\{ {m_{1} ,m_{2} , \cdots ,m_{q} } \right\}\) be q independent sources of evidence, the similarity degree of mρ and mε is defined as.
where d (mρ, mε) is the distance measure between mρ and mε.
Since the distance measure can evaluate the difference between BPAs, a greater distance between \(m_{\rho }\) and evidence from other sources means a lower compatibility between them, thus the support of this piece of evidence for mρ will be lower. The support degree of a BPA is defined as follows:
Definition 3.3
Let \(Q = \left\{ {m_{1} ,m_{2} , \cdots ,m_{q} } \right\}\) be q independent sources of evidence, the support degree of mρ is defined as
The support degree of other evidence for mρ can just indicate its credibility. So, we can define the credibility degree of a mass function as follows.
Definition 3.4
Let \(Q = \left\{ {m_{1} ,m_{2} , \cdots ,m_{q} } \right\}\) be q independent sources of evidence, the credibility degree of mρ is defined as
The definitions of support degree and credibility degree meet the properties in [36], and the outer reliability of a BPA is denoted as \( O\left( \right)\), thus we have:
Step 3: combine the outer reliability with the inner reliability, and the reliability of each piece of evidence can be obtained, which can be regarded as the discounting coefficient of a BPA.
Definition 3.5
Let \(Q = \left\{ {m_{1} ,m_{2} , \cdots ,m_{q} } \right\}\) be q independent sources of evidence, the reliability of mρ is defined as.
where \(\eta \in \left[ {0,1} \right]\) is a parameter used to adjust the influence of inner and outer reliability on the overall reliability.
Step 4: calculate the discounted BPAs using discounting coefficients. Take \(m\left( {h_{uv}^{t} } \right)\) as an example. For the beliefs assigned to the evaluation level ϕj, the discounted BPA can be calculate as
Step 5: aggregate the discounted evidence from all experts using the combination rule introduced in section “Preliminaries”. All evaluation information of the same alternative under the same attribute \(\overline{m} \left( {h_{uv}^{t} } \right)\;\left( {u = 1,2 \cdots ,m;\;\,v = 1,2, \cdots ,n;\,\;t = 1,2, \cdots ,k} \right)\) is aggregated into the synthesized evaluation value \(m\left( {\overline{h}_{uv} } \right)\;\left( {u = 1,\;2, \cdots ,m;\,\;v = 1,\;2, \cdots ,n} \right)\). Let \(\overline{H} = \left( {m\left( {\overline{h}_{uv} } \right)} \right)_{m \times n} .\)
Step 6: determine the criteria weights. For an actual decision-making problem, different criteria usually have different importance. In this paper, Deng entropy is used for the determination of each criterion’s weight.
Fuse different BPAs that correspond to the alternatives under the same criterion converted in last step using the Dempster’s combination algorithm, and the contribution of all alternatives for Cv is obtained according to the following definition.
Definition 3.6
[2]. The degree of contribution of all the alternatives for criterion Cv is defined as BPAv:
Further, the indetermination of Cv is estimated by Deng entropy and recorded as UCv. The calculation steps are shown in Eq. (8). Define the value of UCv between 0 and 1 through standardized operations, then the consistency of criterion Cv can be defined as.
Based on the idea that an index with a lower value of Deng entropy has a greater impact on the comprehensive evaluation (i.e. weight), the criterion weight can be calculated as
Finally, the weights of criteria are obtained through the normalization operation.
Step 7: convert BPAs into probability distributions BetPm according to Eq. (4) using the Pignistic probability function. With an aggregate function, the probability distributions can be integrated into a numerical value as follows.
Definition 3.7
Assume the importance of linguistic terms is \( I = \left\{ {I_{1} ,I_{2} , \cdots I_{L} } \right\}\), and their responding values are \( V = \left\{ {v_{1} ,v_{2} , \cdots v_{L} } \right\}\), the probability distributions \( P = \left\{ {p_{1} ,p_{2} , \cdots p_{L} } \right\}\) can be aggregated as
Through the above operation, the decision matrix can be obtained as \(F_{M} = \left( {f_{{M_{uv} }} } \right)_{m \times n} = \left( {\begin{array}{*{20}c} {f_{{M_{11} }} } & \ldots & {f_{{M_{1n} }} } \\ \vdots & \ddots & \vdots \\ {f_{{M_{m1} }} } & \cdots & {f_{{M_{mn} }} } \\ \end{array} } \right).\)
Obtain the ranking results using the generalized TODIM-ELECTRE II method
For ranking all alternatives in the decision matrix obtained above, a novel method named the generalized TODIM-ELECTRE II method is presented in this subsection. This newly raised method is a hybrid of the generalized TODIM method and the ELECTRE II method, it can not only reflect the outranking relationship between the alternatives, but also reflect the degree of transcendence. Thus, it can handle the compensatory problem between criteria while consider the psychological characteristics of DMs.
Step 1: for the criterion Cv, its positive ideal value and negative ideal value can be determined according to the decision matrix FM:
What’s more, the distance measure between decision values can be calculated as
the absolute value means the size of the gap between the two decision values, rather than comparing the numerical size of their own.
Next, borrow the concept of relative distance function from the TOPSIS method, the relative distance for decision values \(f_{{M_{uv} }}\) is computed by Eq. (29) and used for the subsequent research.
Step 2: determine three types of linguistic Z-number concordance sets (LZCSs) for fχv and fγv, which represent the decision values corresponding to any two alternatives’ performance ratings on criterion Cv by the following classification standards:
(1) the strong concordance set
(2) the medium concordance set
(3) the weak concordance set
Since \(d_{lz} \left( {f_{{M_{\chi v} }} ,f_{M}^{v + } } \right)\) is the distance between \(f_{{M_{\chi v} }}\) and \(f_{M}^{v + }\), it can identify the gap between the performance rating \(f_{{M_{\chi v} }}\) and the positive ideal values, for \(d_{lz} \left( {f_{{M_{\chi v} }} ,f_{M}^{{v{ - }}} } \right)\) is the same principle. Therefore the determination of \(CC_{\chi \gamma }^{s}\) and \(CC_{\chi \gamma }^{s}\) is unambiguous to explain. However, for the determination of the weak concordance set, this paper considers two peculiar conditions in which \(f_{{M_{\chi v} }}\) may transcend \(f_{{M_{\gamma v} }}\):
If \(\overline{{d_{lz} }} \left( {f_{{M_{\chi v} }} } \right) > \overline{{d_{lz} }} \left( {f_{{M_{\gamma v} }} } \right)\), it can be considered Aaχ behaves better than Aaγ in adjusting its relationship with the positive and negative benchmarks.
Step 3: determine the linguistic Z-number strong, medium, weak discordance sets (Collectively called LZDSs) for \(f_{{M_{\chi v} }}\) and \(f_{{M_{\gamma v} }}\).
(1) the strong discordance set
(2) the medium discordance set
(3) the weak discordance set
Step 4: in addition to the above classification, there is another situation when \(d_{lz} \left( {f_{{M_{\chi v} }} ,f_{M}^{v + } } \right)=d_{lz} \left( {f_{{M_{\gamma v} }} ,f_{M}^{v + } } \right)\) and \(d_{lz} \left( {f_{{M_{\chi v} }} ,f_{M}^{{v{ - }}} } \right)=d_{lz} \left( {f_{{M_{\gamma v} }} ,f_{M}^{{v + { - }}} } \right)\), then we regard these two alternatives as nondiscriminatory concerning the criterion Cv. The linguistic Z-numbers indifference set LZIS is defined as
Step 5: compute the dominance degree between alternative Aaχ and Aaγ concerning the criterion Cv and denote as ϖv (Aaχ, Aaγ). Draw from [42], let f1(x) in the generalized TODIM method be xα, and f2(x) be λxβ, and the weight vector w will not be modified. Therefore the expression for calculating dominance degree can be denoted as:
Step 6: calculate the linguistic Z-number concordance index LZCI on any pair of alternatives Aaχ and Aaγ of LZCSs by
where wv is the weight of Cv, \(\omega^{s}\), \(\omega^{m}\), \(\omega^{w}\),and \(\omega^=\) are attitude weights. CIχγ mirrors the relative importance of Aaχ over Aaγ, and CIχγ ∈ [0,1]. Then all LZCIs of pairs of alternatives comprise the linguistic Z-number concordance matrix CLZ = [ CIχγ]m×m (χ, γ = 1, 2, …, m):
Step 7: calculate the linguistic Z-number discordance index LZDI on any pair of alternatives Aaχ and Aaγ of LZCSs by
DIχγ can mirror the relative inferior of alternative Aaχ over alternative Aaγ, and DIχγ ∈ [0,1]. Then all LZDIs of pairs of alternatives constitute the linguistic Z-number concordance matrix DLZ = [ DIχγ]m×m (χ, γ = 1, 2, …, m):
Step 8: calculate the concordance threshold by \(\overline{C}_{lz} = \frac{{\sum\nolimits_{\chi = 1}^{m} {\sum\nolimits_{\gamma = 1}^{m} {CI_{\chi \gamma } } } }}{{m\left( {m - 1} \right)}}\) and construct the linguistic Z-number concordance Boolean matrix \(B_{LZ}^{C} =\left( {e_{\chi \gamma } } \right)_{m \times m}\), where eχγ is a Boolean variable. Specifically, \(e_{\chi \gamma } =1 \Leftrightarrow e_{\chi \gamma } \ge \overline{C}_{lz}\) and \(e_{\chi \gamma } { = 0} \Leftrightarrow e_{\chi \gamma } < \overline{C}_{lz}\). Furthermore, eχγ = 1 denotes that Aaχ dominants Aaγ in the perspective of concordance.
Compute the discordance threshold as \(\overline{D}_{lz} = \frac{{\sum\nolimits_{\chi = 1}^{m} {\sum\nolimits_{\gamma = 1}^{m} {DI_{\chi \gamma } } } }}{{m\left( {m - 1} \right)}}\) and establish the linguistic Z-number discordance matrix \(B_{LZ}^{D} =\left( {q_{ij} } \right)_{m \times m}\), where qχγ is also a Boolean variable. When (1) \(q_{\chi \gamma } < \overline{D}_{lz} ,\;q_{\chi \gamma } =1\) and (2) \(q_{\chi \gamma } \ge \overline{D}_{lz} ,\;q_{\chi \gamma } { = 0}\), where \(q_{\chi \gamma } =1\) denotes that Aaχ is inferior to Aaγ.
Step 9: multiply \(B_{LZ}^{C}\) and \(B_{LZ}^{D}\) component-wise and obtain the synthetic Boolean matrix BLZ with element bχγ = eχγ × qχγ (χ, γ = 1, 2, …, m).
Step 10: depict the outranking graph according to the preference relationships embodied in BLZ, which can be displayed by a digraph G = (V, A). A digraph is composed of a vector set V and a set of arcs linked with vertices, i.e., A. The vertices represent the alternatives involved in the MCGDM, and a directed arc represents an outranking relation. For example, an arc pointing from vχ to vγ signifies Aaχ precedes Aaγ. A two-way arrow appears between these two alternatives when Aaχ and Aaγ is indifferent. In addition, the absence of arrows between two vertices occurs when these two alternatives are incomparable.
An illustrative example of terminal wastewater solidification technology selection
Case description
Although the total amount of freshwater resources in our country is not small, the per capita amount of freshwater is only about one-fourth of the world average, in general, a serious shortage. Since entering the twenty-first century, the contradiction between the supply and demand of water resources in my country has further intensified. Resource-based and water-quality-based water shortage has become one of the primary bottlenecks limiting our country’s sustainable economic and social development. Water is a high degree of unity of quantity and quality. Pollution reduces the quality of water resources. Due to the increase in sewage discharge and toxicity, not all sewage can be properly treated before it is discharged, which exacerbates the shortage of water resources. The state has successively promulgated relevant laws and regulations. For instance, the “Action Plan for Water Pollution Prevention and Control” issued in 2015 has put forward higher requirements for water resources utilization, water pollution prevention and control, and pollution discharge.
Actively responding to the national call and meeting the requirements of relevant water-saving and environmental protection laws and regulations, a seawater DC power plant intends to treat the power plant’s high-salt wastewater (mainly including desulfurization wastewater and boiler make-up water treatment system high-salt wastewater) through terminal wastewater solidification technology so as to realize zero discharge of wastewater from the whole plant. Figure 3 shows the factors affecting the water quality and quantity of desulfurization wastewater and the sources of pollutants.

Influencing factors of water quality and quantity and pollutant tracer
Now it is necessary to compare a variety of terminal wastewater treatment technical routes by synthesis and select the most appropriate terminal wastewater treatment scheme. Terminal wastewater treatment generally includes two stages: wastewater concentration reduction and terminal wastewater solidification. At present, there are several technical routes for zero discharge of desulfurization wastewater as shown in Fig. 4.

Usual technical routes for zero discharge of desulfurization wastewater
According to the actual situation, there are five technologies for the power plant to choose from: Pretreatment + Multi-effect evaporation (Tc1), Pretreatment + double alkali method + double membrane method + main flue evaporation (Tc2), Triple tank (pH adjustment tank, a reaction tank, flocculation tank) pretreatment + High-temperature flue bypass evaporation (Tc3), Flue gas concentration + End pressure filtration (Tc4) and Flue gas concentration + Fluidization evaporation of end secondary air (Tc5). Four experts {Ex1, Ex2, Ex3, Ex4} were asked to make evaluation independently on the performance of every technology under four criteria, including Operating cost (Cr1), Technology maturity (Cr2), Post-processing effect (Cr3) and Environmental impact (Cr4). Given the complexity of human cognition and the asymmetry of information, neither weights of experts nor weights of criteria are unknown. With the aim of improving the accuracy of the information, experts are required to offer evaluation information in LZNs form. The first linguistic term set S = {δ-3, δ-2, δ-1, δ0, δ1, δ2, δ3} = {very poor (VP), poor (P), slightly poor (SP), medium (M), slightly good (SG), good (G), very good (VG)} was adopted by the experts to judge the performance grade of every alternative concerning each criterion, and the confidence in an evaluation was expressed employing the other linguistic term set S’ = {ξ-3, ξ-2, ξ-1, ξ0, ξ1, ξ2, ξ3} = {very uncertain (VU), uncertain (U), a little uncertain (LU), normal (N), a little certain (LC), certain (C), very certain (VC)}.For better performance, the evaluation level is higher.
Case processing
Step 1: obtain the evaluation results of experts in the form of LZNs. Every expert provides his own judgments and corresponding confidence levels concerning each technology’s performance under each criterion, which are displayed in Tables 1, 2, 3, 4.
Step 2: update evaluation grades’ utility values using Shapley value method in Section “An integrated decision-making framework based on the generalized TODIM-ELECTER II method and DEST”. Firstly, assuming the utility values of performance grades δj ( j = − 3, − 2, − 1, 0, 1, 2, 3) and all possible coalitions, part of which are shown as follows:
Then, the utility of each evaluation grade can be determined through being modified by the Shapley value method according to Eq. (11) and shown as follows:
\(\rho \left( {\delta_{ - 3} } \right) = 0.025,\;\rho \left( {\delta_{ - 2} } \right) = 0.059,\;\rho \left( {\delta_{ - 1} } \right) = 0.098,\;\rho \left( {\delta_{0} } \right) = 0.144,\;\rho \left( {\delta_{1} } \right) = 0.194,\;\rho \left( {\delta_{2} } \right) = 0.229,\;\rho \left( {\delta_{3} } \right) = 0.251\) .
Step 3: calculate the scores of reliability grades according to Eq. (10) and obtain the BPAs by Eqs. (12)–(14). The conversion results obtained are shown in Tables 5, 6, 7, 8.
Step 4: determine the inner reliability of BPA. First, compute the Deng entropy of BPAs by Eq. (8), and next calculate the maximum Deng entropy. In the present example, the scale of the FOD is 7. Hence, its corresponding power set involves 27 elements, and the distribution of propositions (empty set is omitted) should satisfy Eq. (9). The maximum Deng entropy is calculated as 11.0077. The inner reliability can thus be determined (Table 9).
Step 5: determine the outer reliability of BPAs and calculate the discounted BPAs.
First, determine the distance between BPAs according to Eqs. (5) and (6), then the value of support degree of BPAs can be calculated by Eqs. (16) and (17) such as:
Eventually, the credibility degree can be calculated by Eq. (18), and the outer reliability can be determined. Take the value of η in Eq. (20) as 0.5, the overall reliability and discounting coefficients of BPAs can be determined. Table 10 shows the discounted BPA calculated by Eqs. (1) and (2).
Step 6: aggregate the evaluation results of the same alternative under the same criterion from multiple experts using Dempster’s rule. The results obtained by Eq. (3) are shown as follows.
Step 7: determine the weights of criteria. Aggregate all BPAs concerning different alternatives under the same criterion using combination algorithm and obtain the combined BPAs. The weights of criteria can be obtained on the basis of Deng entropy.
Step 8: obtain the final decision matrix. First, convert BPAs in Table 11 into probability distributions by the Pignistic probability distribution (Table 12), the results can be seen in Table 13. Then, the probability distributions are integrated into numerical values according to Eq. (26). Table 14 is the final decision matrix (Table 15).
Step 9: identify the positive ideal value \(f_{M}^{v + }\) and negative ideal value \(f_{M}^{v - }\) of every criterion, and the relative distance for decision values \(f_{{M_{uv} }} \left( {u = 1,2,3,4,5;v = 1,2,3,4} \right)\) calculated by Eq. (29) are displayed in Table 16.
Step 10: classify three types of concordance/discordance sets and the indifference set.
Step 11: calculate the dominance degree between any two technologies. With α = β = 0.88 and λ = 1 in Eq. (37), the dominance degree between Tcρ and Tcε can be determined.
Step 12: set the position weights of the strong, medium, weak concordance/discordance sets and the indifference set as \( =\left( {\omega_{c}^{s} ,\omega_{c}^{m} ,\omega_{c}^{w} ,\omega^= ,\omega_{d}^{s} ,\omega_{d}^{m} ,\omega_{d}^{w} } \right)=\left( {1,0.9,0.8,1,0.9,0.8,0.7} \right)\). Then calculate the linguistic Z-number concordance index LZCI by Eq. (38) and build the concordance matrix CLZ = [CIχγ]5×5. Correspondingly, set up the discordance matrix DLZ = [DIχγ]5×5.
Step 13: compute the concordance threshold \(\overline{C}_{lz} = 0.0738\), construct the concordant Boolean matrix:
Similarly, compute the discordance threshold \(\overline{D}_{lz} = 0.2799\) and construct the discordant Boolean matrix:
Step 14: obtain the synthesized matrix by multiplying the corresponding elements of \(B_{LZ}^{C}\) and \(B_{LZ}^{D}\) in pairs.
Step 15: depict the strong outranking graph as Fig. 5.

The strong outranking graph
It can be noticed from the synthesized matrix BLZ that the elements at symmetrical positions are not complementary completely. It is therefore essential to mark the asymmetric elements and make amendments.
Then \(B_{LZ}^{C}\) and \(B_{LZ}^{D}\) can be revised as follows:
Reconstruct the synthesized matrix based on the revised \(B_{LZ}^{C}\) and \(B_{LZ}^{D}\) as:
The outranking graph is redrawn in Fig. 6, where the colors of the arrows are used to distinguish the intensity of the outranking relationships. The added arrows represent weak preference relationships between alternatives.

The ultimate outranking graph
Step 16: rank the five technologies based on the revised outranking graph and the result is:
Thus the third technology (Triple tank pretreatment + High temperature flue bypass evaporation) is the most desirable option.
Analysis and discussion
Sensitivity analysis and discussion
As mentioned in section “Obtain the ranking results using the generalized TODIM-ELECTRE II method”, the parameter λ in Eq. (37) measures the attitude of DMs in the face of loss, which may vary as the decision-making body changes. When λ > 1, the DM’s perception of damage and defect is intensified, this may suggest the DM is a loss-sensitive individual and more reluctant to take a chance. Conversely, the DM is not susceptible to losses, which may mean that he concerns more about other attributes such as quality and cost. Consequently, for two alternatives with different performance under the same criterion, different types of DMs with different λ values have different judgments on the dominance degree between the two compared, and the discordance index is affected accordingly. Take different values for λ, that is, λ = 0.8, λ = 2.25, λ = 3 and λ = 3.75, then the changes in the discordance index between the five technologies can be observed.
In Fig. 7, the x-axis denotes all five alternatives under different values of λ, the y-axis indicates the sum of discordance indices. Rectangles of different colors indicate the discordance indices between the fixed alternative and other alternatives. It can be seen that when the value of λ increases, the rectangles’ areas of different colors increase with it, which means that the value of the discordance index increases. It is easier to understand the reasons for this trend in combination with the actual situation: a greater λ indicates the loss has a deeper impact on the decision body, that is, for the established two alternatives, although the gap between them is objective, the “inferior” one gives the DM a worse feeling when he is loss-sensitive. In this case, the dominance degree will have a greater absolute value and the discordance index will be higher.

The discordance index under different λ
It should also be noted that when the value of λ varies from 0.8 to 3, the discordance relationship between the alternatives will not change with the increment of the discordance indices and will constantly be \(dTc_{3} \prec dTc_{1} \prec dTc_{5} \prec dTc_{2} \prec dTc_{4}\), where \(dTc_{i}\) denotes the discordance index of \(Tc_{i}\). This verifies to a certain extent the robustness of the decision-making framework established in this paper. In addition, when the value of λ increases to 3.75, there is a subtle alteration in this relationship, that is, the order of Tc1 and Tc5 is swapped. It can be seen that the decision subject will exert influence on the priority relationship of the alternatives, and the DM’s attitude towards losses may change the final ranking result. However, regardless of the tweak of the parameter’s value, in the present embodiment, the best choice is still Tc3, which further verifies the robustness of the method.
Feasibility analysis and discussion
Considering the the LZNs environment and the reference to the TOPSIS method [47], two existing method are used to recalculate this example. One is a MCGDM method proposed by Peng and Wang [48], the other is the traditional TOPSIS method.
As can be seen from Table 17, the order acquired by the above two approaches is roughly the same as that of the method proposed in this article. In particular, for the method of Peng and Wang, the ranking results by Q and U value are consistent with that of our method. The above results verify that our method is effective and feasible.
It is worth mentioning that TOPSIS’s ignorance of the relative importance of distance to the ideal solution can frequently lead to inaccurate results. Moreover, the method in [45] is an incorporation of the power aggregation (PA) operators and VIKOR. Compared to the PA operator, DEST is more effective in processing uncertainty originating from the unknown or incomplete information. In addition, the method in [48] is essentially the traditional VIKOR method, which overlooks the relationship between every alternative and the negative ideal solution [28]. The last one is that the method framework in [48] only suitable for the case where the expert weights and attribute weights are partially known, while the decision framework developed in this article is available for MCGDM problems with completely unknown weight information.
Superiority recognition and discussion
In this part, five other comparable methods are employed for the selection problem of terminal wastewater solidification technology. They are the traditional ELECTRE II method, the generalized method, the DS-VIKOR method proposed in [2], the ELECTRE-Based method in [3] and the PDHL-VIKOR method developed by Gou et al. [28], respectively. Among them, due to the difference in language environment, we only use the part of the improved VIKOR in method proposed in [28] for comparison, thence we don’t obtain the probabilistic double hierarchy linguistic compromise (PDHLCi) but the linguistic Z-number compromise (LZCi) measure. The superiority of the newly proposed method is further demonstrated in this subsection.
The ranking results calculated by the four methods in Table 18 are at variance with that of the introduced framework. However, the best solution is always Tc3, and except for the ELETRE II method and the improved method in [28], the worst option points to Tc4. The above results further prove the effectiveness of the method in this article.
The reason why the ranking result obtained by the ELETRE II method is different from that of the method proposed in this article is that, the concordance index and the discordance index obtained by the two methods have different values. This leads to the concordance matrix and the discordance matrix obtained accordingly are different, so the comprehensive performance of Tc2 and Tc4 are distinct in their respective synthesized matrix. As can be seen in concordance set and discordance set in Step 10 of section “Case description”, Tc2 outperforms Tc4 under Cr3 and Cr4, however, Tc4 outperforms Tc2 under Cr1 and Cr2. The calculation of concordance and discordance indices of ELECTRE II method only considers the criteria weights, under the circumstances, since the weights of Cr1 and Cr2 are greater than the weights of Cr3 and Cr4, it seems reasonable to think Tc4 precedes Tc2. But is this really the case? It can be found when employing the generalized TODIM method, the performance of Cr2 is significantly better than that of Cr4. Obviously, the bounded rationality of the DM is an important reason that affects the result of the MCDM problems. This is the reason for the different results between method in 28[] and the method in this article, and is also one of the reasons why the ELECTRE-Based method proposed by Fei et al. [3] cannot distinguish the priority relationship between Tc2 and Tc4. In the process of determining the linguistic Z-number concordance and discordance matrices, the method proposed in this article not only covers the criteria weight information, but also takes into account the impact of the gap between the alternatives on the decision-making of loss-averse DMs. Compared with the improved VIKOR in [28], the newly proposed method concerns the relationship between alternatives and negative ideal solution, too. Therefore, it can overcome the flaw of traditional VIKOR and achieve the goal of [28] to improve the VIKOR method. In addition, the construction of the concordance and discordance indices effectively avoids the compensation effect between the criteria, the consideration of the DMs’ psychology make the results more convincing.
Furthermore, the ELECTRE-Based method in [3] can merely infers that Tc3 is preferred Tc2 and Tc4, and Tc5 is preferred Tc4. However, the relationship between Tc1, Tc2 and Tc4 cannot be determined, which reveals the method in [3] only has the ability to prioritize, but cannot get the priority relationship of all the alternatives. In contrast, the total order can be obtained using our method, which can visibly identify the gaps between all solutions.
Compared with the results of newly proposed framework, the preference relation between Tc1 and Tc5 obtained by ELECTRE II, DS-VIKOR and ELECTRE-Based methods is different. In section “Sensitivity analysis and discussion”, it has already been shown that when λ increases to a certain value, the positions of Tc1 and Tc5 will be exchanged. Therefore, this sequence can be regarded as a special case where the DM is more sensitive to losses. One of the advantages of the generalized TODIM-ELECTRE II method has thus emerged, that is, fully consider the loss-aversion behavior of the DMs, the degree or the extent to which one alternative is dominated by the other is also reflected. Furthermore, the incorporation of ELECTRE II method allows the compensatory effects among criteria to be solved with precision. Obviously the generalized TODIM method neglects this point, which will inevitably lead to the unreliable results and may explain why the positions of Tc2 and Tc5 are swapped.
Conclusion
In the paper, a new integrated framework suitable for MCGDM problems with unknown weight information in LZNs environment is established. In this framework, the original information in the form of LZNs is first transformed into the basic probability distributions in DEST, which not only fully considers the inner and outer reliability of the evidence through discount procedure, but can also cope with uncertain information during the process of fusing multi-source information. Next, for eliminating uncertainty arising from the subjective judgment, Deng entropy is employed to acquire criteria weights. Afterwards, the generalized TODIM-ELECTRE II method is put forward to obtain the full priority order of the alternatives, which is competent to handle the compensation problems between criteria while taking the loss-aversion behavior of DMs into account. The feasibility of this method is demonstrated by the solution to a terminal wastewater solidification technology selection problem. Finally, the sensitivity analysis is conducted to further verify the effectiveness and robustness of the method, the superiority is also illustrated by a series of comparative analysis.
References
Duan CY, Liu HC, Zhang LJ, Shi H (2019) An extended alternative queuing method with linguistic Z-numbers and its application for green supplier selection and order allocation. Int J Fuzzy Syst 21(8):2510–2523
Fei L, Deng Y, Hu Y (2019) DS-VIKOR: A new multi-criteria decision-making method for supplier selection. Int J Fuzzy Syst 21(1):157–175
Fei L, Xia J, Feng Y, Liu L (2019) An ELECTRE-based multiple criteria decision making method for supplier selection using Dempster-Shafer theory. IEEE Access 7:84701–84716
Liu P, Zhang X (2020) A new hesitant fuzzy linguistic approach for multiple attribute decision making based on Dempster-Shafer evidence theory. Appl Soft Comput 86:105897
Jiang S, Shi H, Lin W, Liu HC (2020) A large group linguistic Z-DEMATEL approach for identifying key performance indicators in hospital performance management. Appl Soft Comput 86:105900
Chen ZY, Peng JJ, Wang XK, Zhang HY, Wang JQ (2020) Solar power station site selection: A model based on data analysis and MCGDM considering expert consensus. J Intell Fuzzy Syst, https://doi.org/10.3233/JIFS-191739
Zadeh LA (2011) A note on Z-numbers. Inf Sci 181(14):2923–2932
Aliev RA, Alizadeh A, Huseynov OH (2015) The arithmetic of discrete Z-numbers. Inf Sci 290:134–155
Aliev RA, Huseynov OH, Zeinalova LM (2016) The arithmetic of continuous Z-numbers. Inf Sci 373:441–460
Massanet S, Riera JV, Torrens J (2020) A new approach to Zadeh’s Z-numbers: mixed-discrete Z-numbers. Inf Sci 53:35–42
Qiao D, Wang XK, Wang JQ, Chen K (2019) Cross entropy for discrete Z-numbers and its application in multi-criteria decision-making. Int J Fuzzy Syst 21(6):1786–1800
Das S, Garg A, Pal SK, Maiti J (2019) A weighted similarity measure between Z-numbers and bow-tie quantification. IEEE Trans Fuzzy Syst 28(9):2131–2142
Kang B, Deng Y, Hewage K, Sadiq R (2018) A method of measuring uncertainty for Z-number. IEEE Trans Fuzzy Syst 27(4):731–738
Kang B, Deng Y, Sadiq R (2018) Total utility of Z-number. Appl Intell 48(3):703–729
Kang B, Wei D, Li Y, Deng Y (2012) A method of converting Z-number to classical fuzzy number. J Inf Comput Sci 9(3):703–709
Wu D, Liu X, Xue F, Zheng H, Shou Y, Jiang W (2018) A new medical diagnosis method based on Z-numbers. Appl Intell 48(4):854–867
Mohsen O, Fereshteh N (2017) An extended VIKOR method based on entropy measure for the failure modes risk assessment–A case study of the geothermal power plant (GPP). Safety Sci 92:160–172
Shen KW, Wang JQ (2018) Z-VIKOR method based on a new comprehensive weighted distance measure of Z-number and its application. IEEE Trans Fuzzy Syst 26(6):3232–3245
Wang JQ, Cao YX, Zhang HY (2017) Multi-criteria decision-making method based on distance measure and Choquet integral for linguistic Z-numbers. Cogn Comput 9(6):827–842
Song C, Wang JQ, Li JB (2020) New framework for quality function deployment using linguistic Z-numbers. Mathematics 8(2):224
Kang B, Wei D, Li Y, Deng Y (2012) Decision making using Z-numbers under uncertain environment. J Comput Inf Syst 8(7):2807–2814
Salari M, Bagherpour M, Wang J (2014) A novel earned value management model using Z-number. Int J Appl Decis Sci 7(1):97–119
Bakar ASA, Gegov A (2015) Multi-layer decision methodology for ranking Z-numbers. Int J Comput Int Syst 8(2):395–406
Dempster AP (1967) Upper and lower probabilities induced by a multivalued mapping. Ann Math Stat 38(2):325–339
Shafer G (1976) A mathematical theory of evidence. Princeton University Press, Princeton
Li Z, Chen L (2019) A novel evidential FMEA method by integrating fuzzy belief structure and grey relational projection method. Eng Appl Artif Intel 77:136–147
Ren Z, Liao H, Liu Y (2020) Generalized Z-numbers with hesitant fuzzy linguistic information and its application to medicine selection for the patients with mild symptoms of the COVID-19. Comput Ind Eng 145:106517
Gou X, Xu Z, Liao H, Herrera F (2020) Probabilistic double hierarchy linguistic term set and its use in designing an improved VIKOR method: The application in smart healthcare. J Oper Res Soc. https://doi.org/10.1080/01605682.2020.1806741
Geetha S, Narayanamoorthy S, Kureethara JV, Baleanu D, Kang D (2021) The hesitant Pythagorean fuzzy ELECTRE III: an adaptable recycling method for plastic materials. J Clean Prod 291:125281
Lin M, Chen Z, Xu Z, Gou X, Herrera F (2021) Score function based on concentration degree for probabilistic linguistic term sets: an application to TOPSIS and VIKOR. Inform Sciences 551:270–290
He SS, Wang T, Wang Q, Cheng PF, Li L (2020) A novel risk assessment model based on failure mode and effect analysis and probabilistic linguistic ELECTRE II method. J Intell Fuzzy Syst 551:270–290
Wan S, Xu G, Dong J (2017) Supplier selection using ANP and ELECTRE II in interval 2-tuple linguistic environment. Inf Sci 385:19–38
Liao H, Yang L, Xu Z (2018) Two new approaches based on ELECTRE II to solve the multiple criteria decision making problems with hesitant fuzzy linguistic term sets. Appl Soft Comput 63:223–234
Tian ZP, Nie RX, Wang XK, Wang JQ (2020) Single-valued neutrosophic ELECTRE II for multi-criteria group decision-making with unknown weight information. Comput Appl Math 39(3):1–32
Gomes LFAM, Lima MMPP (1992) TODIM: basics and application to multicriteria ranking of projects with environmental impacts. Found Comput Decis Sci 16(4):113–127
Krohling RA, de Souza TT (2012) Combining prospect theory and fuzzy numbers to multi-criteria decision making. Expert Syst Appl 39(13):11487–11493
Krohling RA, Pacheco AG, Siviero AL (2013) IF-TODIM: An intuitionistic fuzzy TODIM to multi-criteria decision making. Knowl-Based Syst 53:142–146
Lourenzutti R, Krohling RA (2013) A study of TODIM in a intuitionistic fuzzy and random environment. Expert Syst Appl 40(16):6459–6468
Passos AC, Teixeira MG, Garcia KC, Cardoso AM, Gomes LFAM (2014) Using the TODIM-FSE method as a decision-making support methodology for oil spill response. Comput Oper Res 42:40–48
Zhang W, Ju Y, Gomes LFAM (2017) The SMAA-TODIM approach: Modeling of preferences and a robustness analysis framework. Comput Ind Eng 114:130–141
Wu Y, Wang J, Hu Y, Ke Y, Li L (2018) An extended TODIM-PROMETHEE method for waste-to-energy plant site selection based on sustainability perspective. Energy 156:1–16
Llamazares B (2018) An analysis of the generalized TODIM method. Eur J Oper Res 269(3):1041–1049
Wang W, Liu X, Qin J, Liu S (2019) An extended generalized TODIM for risk evaluation and prioritization of failure modes considering risk indicators interaction. IISE Trans 51(11):1236–1250
Kang B, Deng Y (2019) The maximum Deng entropy. IEEE Access 7:120758–120765
Deng Y (2016) Deng entropy. Chaos Solitons Fract 91:549–553
Yager RR (2004) A framework for multi-source data fusion. Inf Sci 163(1–3):175–200
Opricovic S, Tzeng GH (2004) Compromise solution by MCDM methods: a comparative analysis of VIKOR and TOPSIS. Eur J Oper Res 156(2):445–455
Peng HG, Wang JQ (2017) Hesitant uncertain linguistic Z-numbers and their application in multi-criteria group decision-making problems. Int J Fuzzy Syst 19(5):1300–1316
Acknowledgements
This study was funded by the Special Funds of Taishan Scholars Project of Shandong Province (No. Ts201511045), the National Natural Science Foundation of China (Nos. 71771140, 71801142).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest statement
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, Z., Bi, Y., Wang, X. et al. A generalized TODIM-ELECTRE II method based on linguistic Z-numbers and Dempster–Shafer evidence theory with unknown weight information. Complex Intell. Syst. 8, 949–971 (2022). https://doi.org/10.1007/s40747-021-00523-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00523-6