
Abstract
Deep learning (DL) models are highly research-oriented field in image compressive sensing in the recent studies. In compressive sensing theory, a signal is efficiently reconstructed from very small and limited number of measurements. Block-based compressive sensing is most promising and lenient compressive sensing (CS) approach mostly used to process large-sized videos and images: exploit low computational complexity and requires less memory. In block-based compressive sensing, a number of deep models are needed to train with each corresponding to different sampling rate. Compressive sensing performance is highly degraded through allocating low sampling rates to various blocks within same image or video frames. In this work, we proposed multi-rate method using deep neural networks for block-based compressive sensing of magnetic resonance images with performance that greatly outperforms existing state-of-the-art methods. The proposed approach is capable in smart allocation of exclusive sampling rate for each block within image, based on the image information and removing blocking artifacts in reconstructed MRI images. Each image block is separately sampled and reconstructed with different sampling rate and reassembled into a single image based on inter-correlation between blocks, to remove blocking artifacts. The proposed method surpasses the current state-of-the-arts in terms of reconstruction speed, reconstruction error, low computational complexity, and certain evaluation metrics such as peak signal-to-noise ratio (PSNR), structural similarity (SSIM), feature similarity (FSIM), and relative l2-norm error (RLNE).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Medical imaging plays a key role in diagnosis process and considered a most research-oriented field in clinical set-up. Medical resonance imaging is an important imaging modality offers better resolution with clear contrast to reveal the inside anatomy. Magnetic resonance imaging has been applied for the diagnosis of many diseases and considered non-invasive, having higher soft-tissue contrast. However, MRI is slow imaging modality and due to other limitations of scanning system and Nyquist sampling formula, MRI scanners take long time in acquiring k-space data and diagnosing diseases [1]. Due to lengthy scanning time, the patient heart beat and respiratory functions can cause streaking artifacts which often leads to degrade the image quality and misdiagnosis. In recent studies, the main aim is to accelerate the sampling speed and eliminating the artifacts. Under sampling data in k-space are a possible way to accelerate the acquisition process; however, under-sampling process in k-space violates the Nyquist–Shannon formula which in result generates aliasing artifacts in the resultant image. The main challenge associated with the above discussed limitation is to find out an appropriate algorithm that is able to reconstruct fully uncorrupted image considering the under-sampling regime and prior information of image.
Compressive sensing (CS) is one of the hottest and emerging areas in medical image processing especially in MRI. Compressive sensing is mathematical tools that focus on the reconstruction of image or signal from very fewer number of data points and able to recover original signal with sampling rate lower than Nyquist rate [2]. Optimization techniques are used to reconstruct signal from its linear domains. Compressive sensing has extensive application in magnetic resonance imaging [3], sensor networks [4], radar imaging system [5], and camera positioning system [6]. Deep learning-based compressive sensing techniques have shown an enhanced performance and reduced computational complexity [7]. Compressive sensing using block-based idea is a lightweight method, efficiently deal with medical images having high resolution and high dimension. In block-based compressive sensing, an image is divided into multiple patches for the efficient processing which minimizes the computational complexity. The reconstruction method uses the prior information to enhance the overall features and streak of recovered image. The improved performance of deep model is based on the allocation of the sampling rate for each block and removing the blocking artifacts [8] from the whole model. Correlation between blocks is used to reconstruct a single model from images blocks with different sampling rate. A block-based CS approach is used to remove the blocking artifact phenomena after reassembling the reconstructed blocks into full image. An image is partitioned into many small patches in block-based compressive sensing; these patches are then sampled and each patch is reconstructed separately. Usually, an image is not fully consisting of meaningful information, so block-based division of the whole image is more beneficial for utilizing the sensing resources. The advantages of the block-based compressive sensing [9] over the existing techniques are:
-
Low cost sampling.
-
Lightweight reconstruction.
-
Ability to assign sensing resources in more adaptive manner.
Deep learning models have been very successful at handling many real-time problems in the recent literature. Convolutional neural network (CNN) efficiently and effectively solves problems and existing limitation in image classification task [10], human detection [11], and image segmentation [12]. Recently, deep learning architectures replace conventional and traditional approaches and capable of extracting many useful features from images and videos to construct abstract demonstration. CNNs have shown an enhanced performance in both reconstruction and computational speed [13] in super-resolution problems than sparsity-based techniques [14].
Several deep learning-based compressive sensing methods [15,16,17,18,19] have been proposed in the literature which has performed significantly faster and more accurate in reconstruction than traditional CS reconstruction algorithm. Fully connected layer in deep neural networks imitates the compressive sensing sampling, and thus, deep models have the ability to mutually reform the sampling matrix and CS process, eventually improve the reconstruction quality of overall recovered image. Machine learning and deep learning-based compressive sensing models are designed in such a way to enhance the learning abilities of the whole system to improve the reconstruction parameters; however, blocking artifacts still exist in several deep neural networks [16, 18, 19], especially when the model is trained with various low sampling rates. Ignoring structural intuition of CS algorithm and training deep neural network as black box often lead to achieve reduce reconstruction accuracy. In the literature, there has been only introductory work done on DL-based compressive sensing, the employment of DL in compressive sensing yet need to fully explore. Our current approach is needed to address the above-mentioned problems of real-time MRI. Furthermore, it takes advantage of deep networks' speed and learning capabilities while maintaining the benefits of previous algorithms, thus accelerating the real-time MRI scanner speed and eliminating the blocking artifacts.
In this work, a multi-rate method using deep neural networks is proposed for block-based compressive sensing of MR images. Proposed algorithm works on the phenomena of famous BCS algorithm while maintaining the computational speed and features learning abilities of deep neural network models. To smooth the progress of proposed depiction and eliminate the existing limitation of storage space, we utilized multi-rate architecture to knob block-based allotment of sensing network. Residual learning is exploited to design a more robust and in-depth deep reconstruction network. Residual learning offers variety of advantage over the previous work in terms of improved image reconstruction and training deep reconstruction model in much faster way. Recovered MR image patches with different sampling rates are given as in input to deep reconstruction network. In addition, we explored the wide application of loss function by adding image prior in the proposed model to further increase the reconstruction quality of recovered MRI images.
Following points summarized the contributions of our proposed work:
-
1.
A multi-rate approach using deep neural network architecture for block-based compressive sensing MRI is proposed. Block-based compressive sensing of MRI images with different sampling rates is fully explored in the multi-rate deep architecture.
-
2.
Robust and in-depth deep reconstruction network is designed to learn more multifaceted features to further improve the MRI reconstruction characteristic. Deep blocks and transition layers are two significant and elementary units of deep reconstruction network. Deep block comprise modified GoogleNet architecture which contain convolutional layers and inception modules. Our proposed deep reconstruction model is composed of 3 transition layers and each layer consists of 4 convolutional layers.
-
3.
Extensive experimental work is carried out on publicly available datasets. Experimental results validate that the proposed multi-rate approach based on deep neural network outperforms the state-of-the-arts on several evaluation metrics.
Related work
In this section, general compressive sensing theory, block-based compressive sensing, and deep neural networks in CS-MRI are discussed.
Compressive sensing theory
There are two necessary steps involve in compressive sensing process (a) sampling process (2) reconstruction process. Let \(x\) represent a sparse signal and \(\phi ~\) represent a sensing matrix which have order \(~m \times n\), and then, the sampling process can be represented by a \(y = \phi x\) measurement vector which is the aim of compressive sensing to reconstruct the signal from its sparse measurements. \(R = {\raise0.7ex\hbox{$M$} \!\mathord{\left/ {\vphantom {M N}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{$N$}}\) denotes the sampling rate, and if \(~R~{\text{is~much~less~than}}~1\), then the fully reconstruction of signal \(x\) is not conceivable. Keeping in mind compressive sensing ideas and theory [20], fully reconstruction of a signal is only possible if it is sparse in some linear transform domain. Suppose a signal \(x\) is not fully sparse but compressible, a sampling process is represented by \(y = \phi x = \phi .\psi \alpha\) in which \(~\psi\) represent the sparse transform and \(\alpha\) shows the coefficient vector. The reconstruction procedure of signal \(x\) is more complex compare to sampling process as it involves solving \(l_{1} - norm\) optimization problem which can be given by
Signal \(x\) can be fully recovered by solving the optimization problem in (1). A large number of reconstruction methods have been introduced in the literature; however, these methods have certain limitation as it involves long reconstruction time [21] and higher computational complexity [22, 23].
Block-based compressive sensing
Block-based CS is an effective method for processing MRI images due to the higher resolution of MRI which ultimately requires more scanning time and high storage space [24]. The whole MRI is partitioned into smaller non-intersecting blocks. Each small block is represented by a measurement matrix. Block-by-block approach is used in sampling and reconstruction process [7]. This approach efficiently minimizes the computational complexity in compressive sensing process by employing simplified sampling rates. Figure 1 shows the block-by-block partitioning of MRI images. It can be observed in Fig. 1 that the valuable information is not uniformly distributed in all blocks. Various sampling rates are allocated to each block depending on the degree of information to lessen the overall sampling rate. Lower sampling rate can be assigned to block 7 in Knee MRI in Fig. 1 compared to other blocks.

Partitioning of two MRI images for the allocation of sampling resources
Reasonable sampling rate and sensing resources should be assigned to each block, rather than assigning equally to all blocks. Following block-based partitioning approach comparatively breaks the inter-correlation of whole image, thus full image recovered as a result of block-based compressive sensing is relatively of low quality. The work done in [9] used the BCS iterative approach to remove the blocking artifacts. A development to the BCS approach was presented by [25] using Dual-tree discrete wavelet transform offering better reconstruction performance. In [26], author proposed a multi-scale approach which improves the performance of [25] by applying block-based sensing and reconstruction in multiple stages.
Deep neural networks in compressive sensing-MRI
Machine learning and neural networks ideas and techniques were investigated in the domain of MRI reconstruction from very long ago. Recent improvement and development in the hardware and software have allowed to trained network models including deep neural networks, which laid a foundation for DL-based compressive sensing magnetic resonance imaging. Different DL networks have been investigated for CS-MRI but most of the methods using private available datasets. There are four main categories of deep neural network-based compressive sensing MRI [27]: (a) image domain learning, (b) transform domain learning, (c) k-space learning, and (d) hybrid learning. Jin et al. [28] presented a deep learning network to solve ill-imposed inverse problems. In the proposed approach, filtered back projections reconstruction is used for training and then CNN with residual learning is utilized for effective results. Lee et al. [29] come up with a DL-based model to recover MRI from sparsely sampled k-space data. Proposed deep model is also used to explore the aliasing artifacts in MRI images generated as a result of CS process. Schlemper et al. [30] proposed cascaded deep CNNs for the recovering 2-dimentional cardiac MRI images from under-sampled k-space data. The deep cascaded approach is simply used to accelerate and speed up the data acquisition process and particularly explore the case when data are attained, utilizing aggressive Cartesian under-sampling. Experimental results validate the effectiveness of the proposed approach in terms of reconstruction accuracy and preserving anatomical structure of recovered MRI images. Zeng et al. [31] proposed deep dense connected network for the compressive sensing MRI. Dense connections were used to build relation between the sub-networks of the proposed model so that to fully know the former network prediction, which effectively enhanced the reconstruction performance.
Zhang et al. [32] proposed generative adversarial network (GAN) based on multi-channel deep approach for the reconstruction of MRI images in k-space to remove the aliasing artifacts. The specialty of using multi-channel GAN is it has ability of parallel matching of data acquisition system with MRI scanner. Kim et al. [33] presented an iterative method based on recurrent neural network for the reconstruction of MRI images in k-space. The developed method was validated and tested on under-sampled brain dataset. Zhu et al. [34] developed a unified architecture based on automated transform by manifold approximation for the image reconstruction. The proposed approach considers recovering of images as a supervised learning task which allow mapping between k-space and image domain. Automated transform by manifold approximation along with deep learning model is evaluated on different medical resonance imaging to exhibit its reconstruction flexibility at different time acquisition. However, the proposed model cannot be trained on image dimension greater than 128 \(\times\) 128 due to its hardware limitation.
Schlemper et al. [35] presented a novel decomposed automated transform by manifold approximation approach which reduced the complexity by decomposing two-dimensional transform into two one-dimensional, nearly making the model linear. The proposed d-AUTOMAP outperforms the work done in [34] in terms of reconstruction accuracy and reduced complexity. Souza et al. [36] presented a hybrid framework W-net which efficiently works in both k-space and image domain. The proposed W-net composed mainly of residual U-net in frequency domain, an iFFT operation, and real-valued U-net in image domain. The obtained experimental results validated that the proposed hybrid model potentially enhances the compressive sensing reconstruction compared to other deep learning models working in k-space or image domain. Eo et al. [37] developed KIKI-net based on cross domain CNNs that is used for reconstruction of MRI images. A cascaded CNN approach was used followed by data consistency layer. First deep CNN (K-net) was used to operate on k-space data followed by second deep CNN working on image domain (I-net). Experimental results validate the advantage of K-net and I-net compare to single domain CNN.
Multi-rate deep framework
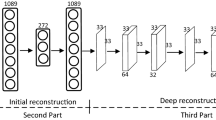
In this work, a multi-rate approach using deep neural network architecture for block-based compressive sensing MRI is proposed. Block-based compressive sensing of MRI images with different sampling rates is fully explored in the multi-rate deep architecture. The proposed architectures composed of three tasks: (a) multi-rate network for sampling process; (b) network for initial reconstruction; (c) a deep reconstruction network. These three sub-networks are integrated end-to-end and jointly optimized in the training process. Figure 2 shows the framework illustration of our developed model.

Framework of the proposed architecture
Multi-rate sampling network
The main focus associated with multi-rate sampling network is the smoothing of MRI images and obtaining under-sampling measurements. Smoothing of MRI images is done through utilizing Gaussian filters and difference of Gaussian between different layers is also calculated. Gaussian filters in multi-rate network are implemented with different convolutional kernels. The highest value of Gaussian difference between two adjacent layers gives better smoothing of MRI images.
A k-channel network is proposed to imitate the sampling process in the block-based compressive sensing MRI. The proposed model has k-channel; each channel corresponds to a unique sampling rate specifically assigned to a particular image block. Higher the value of k, higher the blocks in image and it indicates a more detail partition of image. X is an input image which is divided into K non-overlapping image block each of size B × B × k, and in the next step, each image block is convolved with \({\text{n}}_{f}\) number of filters having size B × B × k. Suppose each block is represented by a vector x having size of \(kB^{2}\) and filtering each single image block with \(\Phi _{f}\) to find compressed vector y having size \(n_{{\text{f}}}\) where \(n_{{\text{f}}} = \frac{M}{N}kB^{2} .\) Taking image X in Fig. 3 is an example, setting the value of K to 9, Using the CS theory, the sampling matrix for image \(x_{i}\) will be equal to \(y_{i} = \Phi _{{B,j}} \cdot x_{i}\) where \(\Phi _{{B,j}}\) represent the measurement matrix of image block \(x_{i}\) and \(y_{i}\) is the corresponding measurement. In this sampling network, every channel has its own unique sampling rate; therefore, there is a combination of k sampling rates. Therefore, the main purpose of sampling network is to attain under-sampled data in compressive sensing and \({\text{n}}_{{\text{f}}}\) filter size can also be explored in the training process of whole network. For jth channel, convolutional layer is used to imitate the sampling process. The size of convolution kernel is based on the sampling rate and the size of total number of image blocks. K-channel corresponds to k sampling rates in the sampling network and it is also possible that k may be less than K which represents the total number of blocks in an image. If the whole image is not fully divided into block, it may need many parameters to store the weights and the network can be easily vulnerable to over-fitting problem, therefore most of the work in the literature, using block-by-block strategy to reconstruct the image. In our experiments, we set \(B\) = 32 as done in many BCS algorithm [38,39,40,41] and k = 5. For sampling rate of 0.5, there will be 512 filters in this layer and the same is calculated for other sampling rates. Figure 3 depicts the proposed framework of the sampling network.

Framework of the proposed k-channel sampling network, the blocks with various sampling rates are fed into the network through their specific channels in a k-channel sampling network
Initial reconstruction network
An initial reconstruction network is designed to attain original magnetic resonance images from compressed measurements. Given we have compressed block y, the original MRI image x can be obtained by taking the inverse transform of \(~y\). The initial stage is divided into k number of inputs, in which each input refers to a channel, where every block is then convolved with a kernel. Initial reconstruction network utilizes one convolutional layer with kernel size of \(~3 \times 3\). Given we have compressed block y, the original MRI image x can be obtained by taking the inverse of transform of \(y = \Phi _{{B,j}} x\) that is \(\hat{x} = \Phi _{{B,j}}^{\iota } y \cdot \hat{x}\) is the initial reconstruction of x. Figure 4 shows the initial reconstruction network.

Initial reconstruction network
Deep reconstruction network
There are two processes in the proposed deep reconstruction network: (a) deep blocks and (b) transition layers which can be seen in Fig. 5. Image reconstruction performance is enhanced through employing GoogleNet [42], first introduced by Szegedy et al. in 2014, in the deep reconstruction network. The GoogleNet architecture incorporates the concept of multiple-size filters that can run on the same tier. The network becomes larger rather than deeper as a result of this concept. GoogleNet architecture which contain two convolutional layers, four max-pooling layer, a fully connect layer, and nine inception modules. We use a GoogLeNet-based technique [43] to eliminate artifacts from sparse MRI reconstructions. GoogleNet is a deep CNN framework that produces state-of-the-art classification and detection results. The inception modules, which include multi-scale convolutional kernels, have a key role in GoogleNet. With various filter sizes, the existing incarnations of the inception architecture are limited. One of the most precise architectures is GoogleNet. Our proposed deep reconstruction model is composed of 3 transition layers and each layer consists of 4 convolutional layers.

Deep reconstruction network
The deep reconstruction network can be expressed by \(\left( {\hat{X}} \right)\), and final result can be shown as
where \(A\left( {\hat{x}} \right)\) represent the operation of deep blocks and transition layer.
Deep block using the idea of GoogleNet that is, the input of each layer is the feature map and the feature maps of each layer is also the input of all subsequent layers. Figure 6 illustrates the modified GoogleNet architecture utilized in this work. Information flow is further improved by the direct connection of all layers of deep blocks. For \(l\)th layer, we can get

Modified GoogleNet architecture
\(x_{l}\) represent the feature map of \(l\)th layer, \(x_{1} ,x_{2} ,x_{3} , \ldots ,x_{{l - 1}}\) represent the concatenation of layer 1, 2, 3…and \(l - 1\) and \(N_{l} \left( . \right)\) is the operator of \(l - th\) which represent batch normalization (BN)-rectified linear unit (ReLU)-convolution. Several convolutional layers are connected together in the transition layer. The main focus of the transition layer is to facilitate the whole reconstruction process by altering the features map of each deep block. Each phase in the transition layer corresponds to iteration process which consists of approximation and denoising operations. Our proposed deep reconstruction model composed of 3 transition layers and each layer consist of 4 convolutional layers which efficiently eliminate the blocking artifact and improve the denoising process. ReLU is selected as activation function for all convolutional layers except the last layer. In our research, we choose ReLU as an activation function, because it is simple to compute, does not saturate, and does not cause the Vanishing Gradient Problem. Overall 12 convolutional layers contribute in the transition block to make possible elimination of blocking artifacts. \(d\) feature maps are generated after the first layer with \(d\) kernels of size \(f \times f \times 1\) and 1 feature map is generated with kernel size \(~f \times f \times d\). The other two layers also use kernel of size \(f \times f \times d\). In our experiments, we set \(d\) and \(f\) as 64 and 3, respectively. Figure 7 shows the detail illustration of the transition layers in the deep reconstruction network. Let \(\hat{X}\) be the output reconstructed image of deep reconstruction network, and \(z_{t}^{{{\text{deep}}}}\) be the parameter of transition layers, then \(\hat{X}\) can be shown by
where \(x_{l}\) represent the approximated image in the first deep block of deep reconstruction layer.

Detail illustration of transition layers
Performance evaluation
Training of the proposed model
We explore two-phase training of the proposed model, in the first phase, the training of sampling matrix \(\Phi _{{B,j}}\) is done, while in the second phase, deep reconstruction network utilized \(\Phi _{{B,j}}^{\iota }\) to smoothly and efficiently improve the reconstruction performance. Convolutional kernels in the sampling network are used to obtain the values of \(\Phi _{{B,j}}\) and \(~\Phi _{{B,j}}^{\iota }\). It can be observed and has been experimentally verified that participation of both \(\Phi _{{B,j}}\) and \(~\Phi _{{B,j}}^{\iota }\) in the training process does not achieve the preferred reconstructed MRI image, because \(\Phi _{{B,j}}\) needs real-time update in each backpropagation of the training process.
In the first phase, we combine sampling network and initial reconstruction network to facilitate the training process of sampling matrix \(\Phi _{{B,j}}\). The loss function can be represented by
\(n\) is the number of training samples, \(x_{i}\) represents the ith training sample, and P represents the filtering for reconstruction process in the initial reconstruction phase.
In the second phase, the initial reconstruction network is combined together with deep reconstruction network to take part in the training process that can be represented by \(z_{t}^{{{\text{deep}}}} \left( {z_{t}^{{{\text{init}}}} \left( . \right).} \right)\). However, the parameters and weights in \(~\Phi _{{B,j}}^{\iota }\) can always be updated which come from \(~\Phi _{{B,j}}\). The loss function in the second phase of training process aims to minimize error between the input and output reconstructed images instead of using individual image blocks
\(n~\) represents the total number of training samples and \(x_{i}\) represents the \(i - th\) training sample. The proposed network is trained more accurately to reconstruct MRI images using the two loss functions.
We aimed to find k optimal sampling matrices \(\{ \Phi _{{B,j}} \} _{{j = 1}}^{k}\) and their pseudo-inverse matrices \(~\{ \Phi _{{B,j}}^{\iota } \} _{{j = 1}}^{k}\) that correspond to them. In the training phase, initial weights for sampling matrices are initialized \(~\{ \Phi _{{B,j}} \} _{{j = 1}}^{k}\), a new weight for sampling matrices are updated after each iteration of training, and the corresponding difference between new and prior weights are calculated in each iteration step and updated for next iteration. The main aim is to achieve minimum error between the reconstructed sample and original sample.

We have adopted the same strategy implemented in [44, 45] for partitioning the training set and testing set. The amount of data are enough for evaluating the reconstruction performance of the proposed approach and have not experienced over-fitting problem. Furthermore, we have also utilized two large-scale MRI dataset MASSIVE [46] and MRNet [47] to evaluate and validate the reconstruction efficiency of the proposed model. If the whole image is not fully divided into block, it may need many parameters to store the weights and the network can be easily vulnerable to over-fitting problem, therefore most of the work in the literature, using block-by-block strategy to reconstruct the image. The training set (300 images) and testing set (300 images) were taken from the fastMRI dataset. 5675 images of fastMRI dataset are arbitrarily cropped to 96 × 96 size, and at the output, we also obtain size of 96 × 96. In the next stage, each of these images is subdivided into nine different blocks having size of 32 × 32 that lead to 51,075 blocks in training dataset.
In the proposed work, k has been set to 5 in the k-channel sampling network with sampling rates of {0.02, 0.06, 0.1, 0.3, and 0.5}. Then, there are \(n_{{\text{f}}} = \frac{M}{N}kB^{2}\) filters with \(\frac{M}{N}\) = {0.02, 0.06, 0.1, 0.3, and 0.5},\(~k\) = 5 and \(B =\) 32. Most apposite channel in the network is found out through processing of each image pair. Sub-rate of each block is approximated using the following equation for any given sampling rate
where \({\text{sr}}_{i}\) represents the sampling rate of each individual block, \(v_{i}\) is the proportion of saliency information of each MRI image, and \(p\) and \(p_{{\text{b}}}\) symbolize the size of an image and its block, respectively. The sampling rates are divided into five different intervals and each sampling rate corresponds to a specific channel. Training of the model is carried out in 70 epochs. Since each image must be partitioned into 9 blocks, which are then reassembled in initial reconstruction network, the batch size is set to 1. The error for back-gradient propagation is measured as the mean square error between the original image and the network output. We fully explored the Adam optimizer [48] with a learning rate of \(10^{{ - 3}}\) and \(10^{{ - 5}}\) as decay value. We train the proposed network with TensorFlow 1.4 on a desktop platform with one NVIDIA 1080Ti GPUs, one Intel(R) Core (TM) i7-4790 K CPU running at 4.00 GHz, and 16 GB of RAM. For one period, the training phase takes approximately 3 h.
Quantitative evaluation criteria
The performance of the proposed CS-MRI model is evaluated based on PSNR, SSIM, FSIM, and RLNE.
-
1.
Peak signal-to-noise ratio (PSNR): The ratio of signal maximal power to the maximum noise power of that specific signal is known as PSNR. PSNR is determined as a function of peak signal power. Decibel is the unit of PSNR. Let the original image can be represented by f and g represent the distorted image then
$$ {\text{PSNR}} = 20\log _{{10}} \frac{{P^{2} }}{{\sqrt {\frac{1}{{XY}}\mathop \sum \nolimits_{{i = 0}}^{X} \mathop \sum \nolimits_{{i = 0}}^{Y} \left[ {f\left( {i,j} \right) - g\left( {i,j} \right)} \right]^{2} } }}, $$
where image's dimensions are denoted by M and N. P represents the pixels of image. A greater PSNR value indicates a good value. For white noise interference, PSNR is an outstanding quality indicator.
-
2.
Structural similarity (SSIM):
SSIM compares two images to see how close they are. The visual disparity between two identical images is measured by SSIM. It cannot determine which of the two images is superior. Structural similarity can be calculated by
\(k_{1}\) and \(k_{2}\) denote constants, \(\mu\) represents the average value, \(\sigma _{{ij}}\) shows covariance, and \(\sigma _{i} ~\) and \(\sigma _{j}\) denotes the variance of \(i\) and \(j\), respectively.
-
3.
Feature similarity (FSIM)
The FSIM indicator embeds an image using low-level characteristics such as phase congruency (PC) and gradient magnitude (GM). PC is a fundamental feature in FSIM, since it provides a lot of detail. Contrast data are encoded using GM. The gradient magnitude is calculated using the Sobel, Prewitt, or Scharr operators. Grayscale images or the luminance elements of colored images are suitable to be measured based on FSIM.
-
4.
Relative l2-norm error (RLNE)
The difference between the reconstructed image and the ground truth is measured by the relative l2-norm error (RLNE), which is a typical image quality parameter. RLNE can be calculated using below expression
where \(x^{\prime}\) denotes the reconstructed image and x represents the ground truth image. Lower the value of RLNE, the lower the reconstructed error.
Results and experiments
In the following section, extensive experimental analysis is done to evaluate the performance of the proposed block-based compressive sensing model on the fastMRI dataset. Furthermore, we also compare our proposed method with several state-of-the-arts methods used in the area of MRI image reconstruction.
We used MATLAB 2015a simulation platform with 3.10 GHz Intel core i5 2400 CPU and 8 GB RAM to perform multiple experiments utilizing the proposed trained model for the reconstruction of MRI images and also a brief comparison is made with the state-of-the-arts.
Two real-valued images, i.e., head MRI and knee MRI, were chosen to perform experiments using the proposed model. It can be observed that one image is rich in texture, while the other image is smooth. Several radial sampling schemes have been implemented in the experimental phase which proven more feasible and have better performance than Cartesian sampling [49]. To evaluate and validate the effectiveness of the multi-rate deep learning approach, a comparison is made with SparseMRI [50], ISTA-Net [19], FCSA [51], FISTA [52], DR2-Net [53], and BM3D-MRI [54] in terms of PSNR, SSIM, FSIM, and RLNE evaluation metrics.
Quantitative comparison
To provide more quantitative evaluation, the proposed model is compared with existing reconstruction methods based on PSNR, SSIM, FSIM, and RLNE for the two head and knee MRI images under different sampling rates, as given in Tables 1, 2 respectively. It can be clearly observed from the achieved results in Tables 1, 2 that the proposed model attains best reconstruction performance under different sampling rates (SR) for both head and knee MRI image.
Effect of sampling rate
The effect of different sampling rate on the reconstruction performance in terms of PSNR, SSIM, FSIM, and RLNE has also been explored for various compressive sensing methods. It can be observed from Tables 1, 2 that for both head and knee MRI images, the PSNR, SSIM, and FSIM obtained by our proposed method are higher compared to other reconstruction methods, while the results obtained by our method for RLNE are lower than the other methods. Thus, it can be concluded that our method performs far better than the existing reconstruction methods.
Visual analysis
Figures 8, 9 show the visual comparisons of head and knee MRI images reconstructed using different methods. These results obtained at the sampling rate of 0.3. It can be observed that head MR image contains rich texture, for which the results obtained through SparseMRI, ISTA-Net, FCSA, FISTA, DR2-Net, BM3D-MRI contain streaking artifacts, while the reconstruction performance of our proposed method is much improved and shows less artifacts with clear and sharp edges. Observing the knee MRI which has less texture and edges, all methods gives better reconstruction performance than that of head MRI. However, it is verified from the results in both cases of head and knee MRI that our proposed method gives more satisfying and enhanced performance with apparent contours, sharp edges, and fewer artifacts. It can be clearly visualized that error occurs mainly in the edges regions.

Reconstruction results of different methods for head MRI: a SparseMRI; b ISTA-Net; c FCSA; d FISTA; e DR2-Net; f BM3D-MRI g our proposed

Reconstruction results of different methods for knee MRI: a SparseMRI; b ISTA-Net; c FCSA; d FISTA; e DR2-Net; f BM3D-MRI g our proposed
Computation time
Table 3 shows the average computational time for various reconstruction methods concerning different sampling rates for head and knee MR images. It can be observed that proposed method takes a long time compared to other methods. However, for different methods, a very slight and minor change in computational time can be observed. The computational time is directly proportional to the size of image, and increasing the size of MR images will lead to increase in the computational time.
Impact of noise
The reconstruction accuracy and performance of our developed model depend on the variation of ISNR (Improvement in Signal-to-Noise ratio) and sampling rates. Experimental and graphical results in Figs. 10 and 11 show that reconstruction errors can be reduced by increasing sampling ratio, while on the other hand, reconstruction errors increase with reducing ISNR. Figures 10 and 11 show the detailed illustration of the reconstruction performance of the developed approach with different sampling rates and ISNRs.

Reconstruction performance of the proposed method for head MRI with different ISNR and sampling rates: a PSNR vs SNR; b SSIM vs SNR; c FSIM vs SNR; d RLNE vs SNR

Reconstruction performance of the proposed method for knee MRI with different ISNR and sampling rates: a PSNR vs SNR; b SSIM vs SNR; c FSIM vs SNR; d RLNE vs SNR
Optimization on large-scale dataset
We perform experiments to compare the developed method with reconstruction algorithms on large-scale MRI datasets, such as MASSIVE [46] containing 8000 images and MRNet [47] containing 1370 images, to validate the robustness of the proposed multi-rate approach. These datasets are used to train our proposed model and other reconstruction algorithms. At sampling rates of 0.1, 0.3, and 0.5, our proposed methodology outperforms ReconNet [55] and ISTA-Net [19] as seen in Fig. 12. Our proposed multi-rate approach significantly outperforms ReconNet and IST-Net, specifically for cases with higher sampling rates. Figure 13 depicts multiple test images and the performance of the reconstruction by our suggested multi-rate method, ReconNet, and ISTA-Net at sampling rate of 0.5. Our multi-rate method simply outperforms ReconNet and ISTA-Net on a consistent basis. Images with higher reconstruction quality are usually smoother, while images with poorer reconstruction quality have richer textures. As a result, texture specificity has an effect on the construction performance of all these three methods.

Reconstruction performance of ReconNet, ISTA-Net, and our proposed approach at sampling rate of 0.1, 0.3, and 0.5

a, b reconstruction results of ISTA-Net, ReconNet and our proposed approach on MASSIVE and MRNet dataset at sampling rate of 0.5
Discussion
We examined a multi-rate method for block-based compressive sensing MRI using deep neural network architecture. The multi-rate deep architecture thoroughly investigates block-based compressive sensing of MRI images with various sampling rates. Three functions are included in the planned architectures: (a) a multi-rate network for sampling; (b) a network for initial reconstruction; and (c) a network for deep reconstruction. Smoothing MRI images and collecting under-sampling measurements are the two key goals of a multi-rate sampling network. Gaussian filters are used to smooth MRI images, and the difference in Gaussian between different layers is measured. Different convolutional kernels are used to enforce Gaussian filters in multi-rate networks. Smoothing of MRI images is improved using the maximum value of Gaussian difference between two adjacent layers. An initial reconstruction network is used to create original magnetic resonance images from compressed measurements. The first stage is divided into k inputs, each of which corresponds to a channel, and each block is then convolved with a kernel. The proposed deep reconstruction network has two processes: deep blocks and transition layers. Deep blocks work on GoogleNet architecture. We use a GoogLeNet-based technique to eliminate artifacts from sparse MRI reconstructions. GoogleNet is a deep CNN framework that produces state-of-the-art classification and detection results. The inception modules, which include multi-scale convolutional kernels, have a key role in GoogleNet. With various filter sizes, the existing incarnations of the inception architecture are limited. Our deep reconstruction model consists of three transition layers, each of which contains four convolutional layers. Deep block is based on the GoogleNet concept, in which each layer's input is the feature map, and each layer's feature maps are also the input for all subsequent layers. Our experimental results show that the multi-rate approach improves CS-MRI reconstruction. In contrast to the state-of-the-art system, which consists of SparseMRI [50], ISTA-Net [19], FCSA [51], FISTA [52], DR2-Net [53], and BM3D-MRI [54], our proposed approach produced statistically better results in experiments conducted at sampling rates of 0.02, 0.06, 0.1, 0.3, and 0.5. In terms of PSNR, SSIM, FSIM, and RLNE, our proposed model outperformed the current state-of-the-art for compressive sensing MRI. Reconstruction performance of our proposed approach is also compared with ReconNet and ISTA-Net on MASSIVE and MRNet dataset. Our multi-rate solution is a more flexible model that works over various scales, so these observations are not surprising. The output reconstructed images are visually consistent with the quantitative findings. At low sample rates, the visual variations between the developed scheme and other reconstruction approaches are more noticeable. Multiple channel methods are best suited for the reconstruction of these types of data, followed by hybrid learning approaches, and finally k-space learning models, according to the reconstruction findings.
Conclusion
In this work, we extensively explored the problems of block-based compressive sensing MRI and presented a multi-rate approach based on deep neural network architecture for the effective reconstruction of MRI images. The proposed model works on the base of popular block-based compressive sensing technique, where block-based approximation along with deep reconstruction network is used for enhancing the reconstruction accuracy. Experimental results validate the effectiveness of our proposed model with the allocation of sensing resources which attained better reconstruction result compared to state-of-the-art methods. The proposed approach is able to accelerate the MRI scanner speed with reduced blocking artifacts and fine reconstruction performance. The experimental results validate the need of the proposed approach for MRI in terms of visual effects, reconstruction performance, and low PSNR, SSIM, FSIM. The proposed model can be further improved through using SSIM as loss function in the training process of deep neural network which in turn will explicitly improving the visual quality of reconstructed image blocks. The proposed model cannot be specifically extended to a large-sized image, because the measurement matrix will be large in turns, requiring a large volume of memory and increasing computing complexity.
References
Lustig M, Donoho D (2008) Compressed sensing MRI. IEEE Signal Process Mag 25(2):72–82
Donoho D (2006) Compressed sensing. IEEE Trans Inf Theory 52(4):1289–1306
Gao X, Zhang J, Che W, Fan X, Zhao D (2015) Block-based compressive sensing coding of natural images by local structural measurement matrix. In: 2015 Data Compression Conference. IEEE, 2015, pp 133–142
Hitomi Y, Gu J, Gupta M, Mitsunaga T, Nayar SK (2011) Video from a single coded exposure photograph using a learned over-complete dictionary. In: IEEE International Conference on computer vision (ICCV), 2011, pp 287–294
Li C, Zhang Y, Xie EY (2019) When an attacker meets a cipher-image in 2018: a year in review. J Inf Secur Appl 48:102361
Duarte MF, Davenport MA, Takhar D, Laska JN, Sun T, Kelly KF, Baraniuk RG (2008) Single-pixel imaging via compressive sampling. IEEE Signal Process Mag 25(2):83–91
Fowler J, Mun S, Tramel E (2010) Block-based compressed sensing of images and video. Found Trends Signal Process 4(4):297–416
Dinh KQ, Shim HJ, Jeon B (2013) Measurement coding for compressive imaging using a structural measurement matrix In: IEEE International Conference on Image Processing (ICIP). IEEE, 2013, pp 10–13
Gan L (2007) Block compressed sensing of natural images In: Proceedings of the International Conference on digital signal processing, 2007, pp.403–406
He K, Zhang X, Ren S, Sun J (2015) Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
Ren S, He K, Girshick R, Sun J (2015) FasterR-CNN: towards real-time object detection with region proposal networks. In: NIPS Montreal, 2015, pp. 91–99.
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. In: Proc. 18th Int. Conf. MICCAI, Munich, 2015, pp. 234–241
Shi W, Caballero J, Huszar F, Totz J, Aitken AP, Bishop R, Rueckert D, Wang Z (2016) Real-time single smage and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proc. IEEE Conf. CVPR, Las Vegas, NV, 2016, pp 1874–1883
Dong C, Loy CC, He K, Tang X (2016) Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell 38(2):295–307
Mousavi A, Baraniuk RG (2017) Learning to invert: Signal recovery via deep convolutional networks. In: IEEE International Conference on acoustics, speech and signal processing (ICASSP), 2017, pp 2272–2276
Kulkarni K, Lohit S, Turaga P, Kerviche R, Ashok A (2016) Recon-net: Non-iterative reconstruction of images from compressively sensed measurements. In: IEEE Conference on computer vision and pattern recognition (CVPR), 2016, pp 449–458
Metzler C, Mousavi A, Baraniuk R (2017) Learned D-AMP: Principled neural network based compressive image recovery. In: Proceedings of the 31st International Conference on neural information processing systems (NIPS’17), 2017, pp 1770–1781
Lohit S, Kulkarni K, Kerviche R, Turaga P, Ashok A (2018) Convolutional neural networks for non-iterative reconstruction of compressively sensed images. IEEE Trans Comput Imaging 4(3):326–340
Zhang J, Ghanem B (2018) Ista-net: Interpretable optimization-inspired deep network for image compressive sensing. In: in IEEE Conference on computer vision and pattern Recognition (CVPR), 2018, pp 1828–1837
Candes EJ, Wakin MB (2008) An introduction to compressive sampling. IEEE Signal Process Mag 25(2):2130
Chen SS, Donoho DL, Saunders MA (2001) Atomic decomposition by basis pursuit. SIAM Rev 43(1):129–159
Yang M, de Hoog F (2015) Orthogonal matching pursuit with thresholding and its application in compressive sensing. IEEE Trans Signal Process 63(20):5479–5486
Metzler CA, Maleki A, Baraniuk RG (2016) From denoising to compressed sensing. IEEE Trans Inf Theory 62(9):5117–5144
Dinh KQ, Shim HJ, Jeon B (2017) Small-block sensing and larger-block recovery in block-based compressive sensing of images. Signal Process-Image Commun 55:10–22
Mun S, Fowler JE (2009) Block compressed sensing of images using directional transforms. In: 16th IEEE International Conference on Image Processing (ICIP), Nov 2009, pp 3021–3024
Fowler JE, Mun S, Tramel EW (2011) Multiscale block compressed sensing with smoothed projected landweber reconstruction. In: 19th European Signal Processing Conference, Aug 2011, pp 564–568
Souza R, Bento M, Nogovitsyn N et al (2019) Dual-domain cascade of U-nets for multi-channel magnetic resonance image reconstruction. Magn Reson Imaging. https://doi.org/10.1016/j.mri.2020.06.002
Jin K, McCann M, Froustey E, Unser M (2017) Deep convolutional neural network for inverse problems in imaging. IEEE Trans Image Process 26(9):4509–4522
Lee D, Yoo J, Ye JC (2017) Deep residual learning for compressed sensing MRI. In: 2017 IEEE 14th International Symposium on biomedical imaging (ISBI 2017), Melbourne, VIC, 2017, pp 15–18, https://doi.org/10.1109/ISBI.2017.7950457
Schlemper J, Caballero J, Hajnal J, Price A, Rueckert D (2018) A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Trans Med Imaging 37(2):491–503
Zeng K, Yang Y, Xiao G, Chen Z (2019) A very deep densely connected network for compressed sensing Mri. IEEE Access 7:85430–85439
Zhang P, Wang F, Xu W, Li Y (2018) Multi-channel generative ad-versarial network for parallel magnetic resonance image reconstruction in k-space. In: International Conference on medical image computing and computer-assisted intervention (MICCAI). Springer, 2018, pp 180–188
Kim TH, Garg P, Haldar JP (2019) Loraki: Autocalibrated recurrent neural networks for autoregressive MRI reconstruction in k-space. arXiv preprint arXiv:1904.09390, 2019
Zhu B, Liu JZ, Cauley SF, Rosen BR, Rosen MS (2018) Image reconstruction by domain-transform manifold learning. Nature 555(7697):487
Schlemper J, Oksuz I, Clough J, Duan J, King A, Schanbel J, Hajnal J, Rueckert D (2019) dAUTOMAP: Decomposing AUTOMAP to achieve scalability and enhance performance. In: International Society for Magnetic Resonance in Medicine (ISMRM), 2019
Souza R, Frayne R (2019) A hybrid frequency-domain/image-domain deep network for magnetic resonance image reconstruction. In: 2019 32nd SIBGRAPI Conference on graphics, patterns and images (SIBGRAPI), Rio de Janeiro, Brazil, 2019, pp 257–264, https://doi.org/10.1109/SIBGRAPI.2019.00042
Eo T, Jun Y, Kim T, Jang J, Lee H-J, Hwang D (2018) Kiki-net: cross-domain convolutional neural networks for reconstructing under sampled magnetic resonance images. Magn Reson Med 80(5):2188–2201
Gan L (2007) Block compressed sensing of natural images. In: 2007 15th International Conference on digital signal processing. IEEE, 2007, pp 403–406
Haupt J, Nowak R (2006) Signal reconstruction from noisy random projections. IEEE Trans Inf Theory 52(9):4036–4048
Mun S, Fowler JE (2011) Residual reconstruction for block-based compressed sensing of video. In: 2011 Data Compression Conference. IEEE, 2011, pp 183–192
Fowler JE, Mun S, Tramel EW (2011) Multiscale block compressed sensing with smoothed projected landweber reconstruction. In: Signal Processing Conference, 2011 19th European. IEEE, 2011, pp 564–568
Szegedy C et al (2015) Going deeper with convolutions. In: 2015 IEEE Conference on computer vision and pattern recognition (CVPR), 2015, pp 1–9, https://doi.org/10.1109/CVPR.2015.7298594
Xie S, Zheng X, Chen Y et al (2018) Artifact Removal using Improved GoogLeNet for Sparse-view CT Reconstruction. Sci Rep 8:6700. https://doi.org/10.1038/s41598-018-25153-w
Zhou S, He Y, Liu Y, Li C, Zhang J (2020) Multi-channel deep networks for block-based image compressive sensing. IEEE Trans Multimed. https://doi.org/10.1109/TMM.2020.3014561
Shi W, Jiang F, Liu S, Zhao D (2020) Image compressed sensing using convolutional neural network. IEEE Trans Image Process 29:375–388. https://doi.org/10.1109/TIP.2019.2928136
Froeling M, Tax CM, Vos SB, Luijten PR, Leemans A (2017) “MASSIVE” brain dataset: multiple acquisitions for standardization of structural imaging validation and evaluation. Magn Reson Med 77:1797–1809. https://doi.org/10.1002/mrm.26259
Bien N, Rajpurkar P, Ball RL, Irvin J, Park A, Jones E, Bereket M, Patel BN, Yeom KW, Shpanskaya K et al (2018) Deep-learning-assisted diagnosis for knee magnetic resonance imaging: development and retrospective validation of MRNet. PLoS Med 15(11):e1002699
Kingma D, Ba J (2014) Adam: a method for stochastic optimization. In: Proc. of ICLR, 2014
Chan RW, Ramsay EA, Cheung EY, Plewes DB (2012) Teinfuence of radial undersampling schemes on compressed sensing reconstruction in breast MRI. Magn Reson Med 67(2):363–377
Lustig M, Donoho D, Pauly JM (2007) Sparse MRI: the application of compressed sensing for rapid MR imaging. Magn Reson Med 58(6):1182–1195
Huang J, Zhang S, Metaxas D (2011) Efcient MR image reconstruction for compressed MR imaging. Med Image Anal 15(5):670–679
Zibetti M-V-W, Helou E-S, Regatte R-R, Herman G-T (2019) Monotone FISTA with variable acceleration for compressed sensing magnetic resonance imaging. Comput Imaging IEEE Trans 5(1):109–119
Yao H, Dai F, Zhang S, Zhang Y, Tian Q, Xu C (2019) DR2-Net: deep residual reconstruction network for image compressive sensing. Neurocomputing 359:483–493
Eksioglu EM (2016) Decoupled algorithm for MRI reconstruction using nonlocal block matching model: BM3D-MRI. J Math Imag Vis 56(3):430–440
Kulkarni K, Lohit S, Turaga P, Kerviche R, Ashok A (2016) ReconNet: Non-iterative reconstruction of images from compressively sensed measurements. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, 2016, pp 449–458
Acknowledgements
This work is supported by the National Natural Science Foundation of China (No. 61772444, No. U1805264) and Fujian Science and Technology Plan Project (No. 201810026, No. 201910036).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Haq, E.U., Jianjun, H., Huarong, X. et al. Block-based compressed sensing of MR images using multi-rate deep learning approach. Complex Intell. Syst. 7, 2437–2451 (2021). https://doi.org/10.1007/s40747-021-00426-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00426-6