
Abstract
Recently, tensor ring networks (TRNs) have been applied in deep networks, achieving remarkable successes in compression ratio and accuracy. Although highly related to the performance of TRNs, rank selection is seldom studied in previous works and usually set to equal in experiments. Meanwhile, there is not any heuristic method to choose the rank, and an enumerating way to find appropriate rank is extremely time-consuming. Interestingly, we discover that part of the rank elements is sensitive and usually aggregate in a narrow region, namely an interest region. Therefore, based on the above phenomenon, we propose a novel progressive genetic algorithm named progressively searching tensor ring network search (PSTRN), which has the ability to find optimal rank precisely and efficiently. Through the evolutionary phase and progressive phase, PSTRN can converge to the interest region quickly and harvest good performance. Experimental results show that PSTRN can significantly reduce the complexity of seeking rank, compared with the enumerating method. Furthermore, our method is validated on public benchmarks like MNIST, CIFAR10/100, UCF11 and HMDB51, achieving the state-of-the-art performance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Deep neural networks have made great successes in various areas, such as image classification [6, 15, 21], autonomous driving [1, 14, 30], game artificial intelligence [16, 20] and so on [13, 24, 25]. However, parameters redundancy leads to two major drawbacks for deep neural networks: (1) difficult training, and (2) poor ability to run on resource-constrained devices (e.g., mobile phones [7] and internet of things (IoT) devices [11]). To address these problems, Tensor Ring (TR) has been introduced to deep neural networks. With a ring-like structure as shown in Fig. 3, TR can significantly reduce the parameters of convolutional neural network (CNN) [26] and recurrent neural network (RNN) [17], and even can achieve better results than uncompressed models in some tasks. Thus, tensor ring is increasingly being researched.

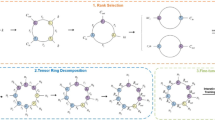
The overview of progressive searching tensor ring network (PSTRN), where different color represents different rank element candidate. PSTRN initializes search space by sampling from state space, then alternately executes evolutionary phase and progressive phase for P times to derive optimal TRN
However, as the crucial component of tensor ring, setting of rank (e.g. \(R_{0} \sim R_{3}\) in Fig. 3) is seldom investigated. In most of the existing works, it merely sets to be equal in whole network [26]. Such an equal setting requires multiple manual attempts for a feasible rank value and often leads to a weak result. Fortunately, as shown in our synthetic experiment, we discover the relationship between the rank distribution and its performance. Experimental results demonstrate the link that part of rank elements with good performance will gather to the interest region. Then we extend this phenomenon to build our Hypothesis 1. Utilizing the hypothesis, we design a heuristic algorithm to explore the potential power of tensor ring.
Specifically, we propose progressive searching tensor ring network (PSTRN) inspired by neural architecture search (NAS) [31]. Similarly, our approach is divided into three parts,
-
search space: combinations of rank element candidates for TRN in evolutionary phase;
-
search strategy: the Non-dominated Sorted Genetic Algorithm-II (NSGA-II) [3] to search rank;
-
performance estimation strategy: stochastic gradient descent to train TRN.
The overall framework of PSTRN is illustrated in Fig. 1. In the searching process, we initialize search space first. Then through evolutionary phase, we derive optimized rank within search space. Next, to draw near interest region, the proposed approach shrinks the bound of search space to the around of optimized rank during progressive phase. By alternately executing evolutionary phase and progressive phase, our algorithm can find rank with high performance. Additionally, on large-scale models (i.e. ResNet20/32 [6] and WideResNet28-10 [29]), the performance estimation is time-consuming, which is harmful to search speed. So we employ a weight inheritance strategy [18] to accelerate the evaluation of rank.
Experimental results prove that PSTRN can obtain optimal rank of TRN according to Hypothesis 1. And our algorithm can compress LeNet5 [12] with compression ratio as 16x and 0.49% error rate in MNIST [4] image classification task. In TR-ResNets, our approach can achieve state-of-the-art performance on CIFAR10 and CIFAR100 [9]. PSTRN also exceeds TR-LSTM models that set rank elements equal on HMDB51 and UCF11. Furthermore, compared with the enumerating method, our work can greatly reduce the complexity of seeking rank. Overall, our contributions can be summarized as follows:
-
1.
PSTRN can search rank automatically instead of manual setting. At the meantime, The time cost is reduced significantly by progressively searching, compared with an enumerating method.
-
2.
To speed up the search on large-scale model, our proposed method adopts weight inheritance into the search process. And the proposed method achieves about \(200 \times \) speed-up ratio on classification tasks of CIFAR10/100 datasets.
-
3.
As a heuristic approach based on Hypothesis 1, our algorithm can achieve better performance with fewer parameters than existing works. All the experimental results demonstrate the rationality of the hypothesis that is first found by us.
Background
In this section, we will introduce the tensor background and some related works that consist of rank fixed method and rank selection method. The rank fixed method is the work that sets rank manually, while rank selection method means the work of learning the rank.
Tensor background
In this part, we would like to introduce the background of tensor.

Tensor diagrams. a Presents the graphical notation of a tensor \(\varvec{{\mathcal {T}}} \in {\mathbb {R}}^{L_1\times L_2 \times L_3}\). b Demonstrates the contraction between two 4-order tensors, which is the contraction between \(\varvec{{\mathcal {A}}}\) and \(\varvec{{\mathcal {B}}}\)
Notation
A tensor is a high-order array. In this paper, a d-order tensor \(\varvec{{\mathcal {T}}} \in {\mathbb {R}}^{L_1\times L_2 \cdots \times L_d} \) is denoted by a boldface Euler script letter. With all subscripts fixed, each element of a tensor is expressed as: \(\varvec{{\mathcal {T}}}_{l_1,l_2,\ldots l_d}\in {\mathbb {R}}\). Given a subset of subscripts, we can get a sub-tensor. For example, given a subset \(\{L_1=l_1, L_2=l_2\}\), we can obtain a sub-tensor \(\varvec{{\mathcal {T}}}_{l_1, l_2} \in {\mathbb {R}}^{L_3 \cdots \times L_d}\). Figure 2 draws the tensor diagrams that present the graphical notations and the essential operations.
Tensor contraction
Tensor contraction can be performed between two tensors if some of their dimensions are matched. As shown in Fig. 2b, given two 4-order tensors \(\varvec{{\mathcal {A}}}\in {\mathbb {R}}^{I_1\times I_2\times I_3\times I_4}\) and \(\varvec{{\mathcal {B}}} \in {\mathbb {R}}^{J_1\times J_2 \times J_3 \times J_4}\), when \(I_3 = D_1 = J_1\) and \(I_4 = D_2 =J_2\), the contraction between these two tensors results in a tensor with the size of \(I_1\times I_2 \times J_3 \times J_4\), where the matching dimension is reduced, as shown in equation:
Tensorization
Given a matrix \(\mathbf {M} \in {\mathbb {R}}^{ I \times O}\), we transfer it into a new tensor
satisfying the equation:
where M, N are the number of the input nodes and output nodes respectively. Therefore, a corresponding element of \(\mathbf {W}_{i, o}\) is \(\varvec{{\mathcal {C}}}_{i_0, \ldots , i_{m-1}, o_0, \ldots , o_{n-1}}\), where \(i \in \{1, \dots , I\}\), \(o \in \{1, \ldots , O\}\), \(i_*\in \{1, \dots , I_*\}\), \(o_*\in \{1, \ldots , O_*\}\) are indexes, following the ruleFootnote 1

The representations of TRF
Tensor ring format (TRF)
TRF is constructed with a series of 3-order nodes linked one by one, forming a ring-like structure. The TRF of a d-order tensor can be formulated as
where \({\mathbf {R}} = \{R_i | i \in \{0, 1, \dots , d-1\}\}\) denotes the rank of TRF, and the symbol \(\varvec{{\mathcal {Z}}}\) represents the tensor ring node. Figure 3 shows a graph structure of a simple TRF.
Through replacing layers(e.g. convolutional layer, fully-connected layer) of a network with TRF, we can derive a TRN.
Rank fixed
Tensor ring decomposition has been successfully applied to the compression of deep neural networks. Wenqi et al. [26] compress both the fully connected layers and the convolutional layers of CNN with the equal rank elements for whole network. Yu et al. [17] replace the over-parametric input-to-hidden layer of LSTM with TRF, when dealing with high-dimensional input data. Rank of these models are determined via multiple manual attempts by manipulation, which requires much time.

Tensor ring model
Rank selection
In this part, we would like to introduce the works of rank selection. Yerlan et al. [28] formulate the low-rank compression problem as a mixed discrete-continuous optimization jointly over the rank elements and over the matrix elements. Zhiyu et al. [2] propose a novel rank selection scheme for tensor ring, which apply deep deterministic policy gradient to control the selection of rank. Their algorithms calculate the optimal rank directly from the trained weight matrix without the analysis of rank. Different from them, our approach is inspired by the relevance between the rank distribution and performance of Hypothesis 1, towards a better result.
Methodology
To verify the optimization of PSTRN on TRN, we choose two most commonly used deep neural networks for evaluation, i.e. tensor ring CNN (TR-CNN) and tensor ring LSTM (TR-LSTM).
In the section, we first present preliminaries of TR-CNN and TR-LSTM, including graphical illustrations of the two TR-based models. Then we elaborate on evolutionary phase and progressive phase of PSTRN. The implementation of weight inheritance will be given in final.
Preliminaries
TR-CNN
For a convolutional core \(\varvec{{\mathcal {C}}} \in {\mathbb {R}}^{K \times K \times C_\mathrm{in} \times C_\mathrm{out}}\) where K denotes the kernel size, \(C_{in}\) means the input channel and \(C_{out}\) represents the output channel. We first reshape it as \(\hat{\varvec{{\mathcal {C}}}} \in {\mathbb {R}}^{K \times K \times I_1 \times \cdots \times I_{\alpha } \times O_1 \times \cdots \times O_{\beta }}\), satisfying the rule
Then we decompose it into input nodes \(\varvec{{\mathcal {U}}}^{(i)} \in {\mathbb {R}}^{{R_{i-1}}\times {I_{i}}\times {R_{i}}}, i \in \{1, 2, \ldots , {\alpha }\}\), output nodes \(\varvec{{\mathcal {V}}}^{(j)} \in {\mathbb {R}}^{{R_{{\alpha }+j}}\times {O_{i}}\times {R_{{\alpha }+j+1}}}, j \in \{1, 2, \ldots , {\beta }\}\) and one convolutional node \(\varvec{{\mathcal {G}}} \in {\mathbb {R}}^{K\times K\times {R_{\alpha }}\times {R_{{\alpha }+1}}}\), where \(R_{{\alpha }+{\beta }+1} = R_0\). An instance (\({\alpha }=2\), \({\beta }=2\)) is illustrated in Fig. 4a. And the compression ratio of TR-CNN is calculated as
where R is a simplification of rank element. The TR-CNN is proposed by Wenqi et al. [26].
TR-LSTM
By replacing each matrix of the affine matrices \(\mathbf {W}_{*} \in {\mathbb {R}}^{I \times O}\) of input vector \(x \in {\mathbb {R}}^I\) with TRF in LSTM, we implement the TR-LSTM model as introduced by Yu et al. [17]. Similar to TR-CNN, the nodes are combined by input nodes \(\varvec{{\mathcal {U}}}^{(i)}\) and output nodes \(\varvec{{\mathcal {V}}}^{(j)}\), and the decomposition needs to follow
A 6-node example is shown in Fig. 4b. Compression ratio of TR-LSTM can be computed as
Progressive searching tensor ring network
In our search process, the rank \({\mathbf {R}}\) of a TRN is formulated as
where d is the number of rank elements, \(r_{*}\) is a rank element candidate, and m is the quantity of rank element candidates. Full combinations of the rank elements (i.e. state space) can be calculated as
Next, we would like to introduce Hypothesis 1, the extension of the aforementioned gathering phenomenon.
Hypothesis 1
When a shape-fixed TRN performs well, part or all of its rank elements are sensitive and each of them will tend to aggregate in a narrow region, which is called interest region.
According to Hypothesis 1, the optimal rank can be found in the interest region. It is a more efficient and accurate way to find a optimal rank in interest region rather than a much wider range of the whole rank element candidates. Thus, we build an pipeline of PSTRN to achieve the purpose by two alternative procedures:
-
Evolutionary phase: finding good models in the search space and locating the interest region through well-performed models.
-
Progressive phase: calculating the width of a rough approximation of interest region and defining search space within this region.

The overall pipeline of progressive phase, where different color represents different rank. The search space is sampled at interval b within given range first. Then we gradually reduce the interval b. Obviously, progressive phase narrows search space close to interest region progressively
Through these two procedures, the rank of a TRN will approach the interest region and be optimized. Additionally, we apply weight inheritance to accelerate the training process. The pseudocode of the algorithm is shown as below, where P is the number of progressive phase, and G is the generations of each evolutionary phase.

Evolutionary phase
As described in Hypothesis 1 that well-performed models aggregate in interest region, good models keep a high probability of appearing in interest region. Therefore, we determine interest region around the models with high performance.
In PSTRN, we adopt multi-objectives genetic algorithm NSGA-II [3] to search for TR-based models with high performance and few parameters.
A typical genetic algorithm requires two prerequisites, the genetic representation of solution domain (i.e. search space), and the fitness functions (i.e. classification accuracy and compression ratio) that is used to evaluate each individual. In the process, an individual means the rank \({\mathbf {R}}\) and each rank element \(R_{*}\) is in \(\{\hat{r}_1, \hat{r}_2, \ldots , \hat{r}_n\}\) that is sampled from the whole rank element candidates. The search space is a sub-space of the state space and can be calculated as
The method of choosing the search space will be introduced in the progressive phase. Classification accuracy is obtained by testing the model on the test dataset. And compression ratio of TR-CNN and TR-LSTM are calculated by Eqs. (5) and (7), respectively.
The key idea of the genetic algorithm is to evolve individuals via some genetic operations. At each evolutionary generation, the selection process preserves strong individuals as a population and then sorts them according to their fitness function, while eliminating weak ones. The retained strong individuals reproduce new children through mutation and crossover with a certain probability. After this, we obtain the new population consists of the new children and the retained strong individuals. The new population executes the evolution to derive next generation. When the termination condition is met, evolutionary phase stops and optimization of the rank will be completed. Eventually, taking the top-k individuals into consider, we derive the most promising rank element \(\hat{R}_{*}\) by
where \(R_{*, i}\) is a rank element of the i-th individual and floor denotes the rounding down operation. The interest region is around the \(\hat{R}_{*}\).
Progressive phase
Progressive phase is used to determine the next search space as shown in Fig. 5. At the begining of the PSTRN, we first obtain initial search space via sampling from the state space at equal intervals as below:
where \(R_\mathrm{min}\) is the minimum of rank element candidates, and \(b_{1}\) is the initial sampling interval. Then through carrying out evolutionary phase within initial search space, we derive the promising rank
where \(\hat{R}_{i,j}, i \in \{0, 1, 2, \ldots , d-1\}, j \in \{2, 3, \dots , P\}\) denotes the ith promising rank element in jth evolutionary phase. Based on the optimized rank, our PSTRN shrinks bound of search space to
-
Low bound: \(\min (\hat{R}_{i,j-1}-s_{j}, R_{min})\),
-
High bound: \(\max (\hat{R}_{i,j-1}+s_{j}, R_{max})\),
where \(R_\mathrm{max}\) is the maximum of rank element candidates, and \(\{s_j | j\in \{2, 3, \ldots , P\}\}\) is the offset coefficient and usually sets to \(b_{j-1}\). Thus, the rank element candidates of the next search space can be expressed as
where \(b_{j}\) is the sampling interval of the jth progressive phase, satisfying
The interval \(b_{j}\) is gradually reduced, and when \(b_{j}\) decreases to 1, the progressive phase will stop.
In addition, considering the above Hypothesis 1 cannot be proved by theory, the progressive genetic algorithm may fall into local optima. Therefore, we adds an exploration mechanism to the algorithm. Concretely speaking, except for the initial phase, the algorithm has a \(10\%\) probability to choose rank within the search space in the previous evolutionary phase.
In the above evolutionary phase, the solution domain is one of the key components. Generally speaking, it will try to cover all possible states. Such an excessive solution domain may lead to the divergence of search algorithm. Compared with full state space, our algorithm can improve the search process in computational complexity significantly.

Rank distribution between \(R_1\) and other rank elements \(R_0\), \(R_2\), \(R_3\) of top-100 models. The size of the circle denotes the number of models that has the same two rank elements, and the circle color represents ranking. The blue line is the border of the interest region
Weight inheritance
During evolutionary phase, to validate the performance, the searched TRN needs to be fully trained, which is the most time-consuming part of the search process. On MNIST, we can train searched TR-LeNet5 from scratch because of its fast convergence. But the training speed is slow on ResNets. Thus, we employ weight inheritance as a performance estimation acceleration strategy, which is inspired by the architecture evolution [18].
In our algorithm, to inherit trained weight directly, the rank \(R=\{R^k_i | i \in [0, 1, \ldots , d-1]\}\) of kth layer needs to follow
Obviously, the number of rank elements to be searched is reduced to k from d. For the kth layer, we will load the checkpoint whenever possible. Namely, if the kth layer matches \(V_k\), the weights are preserved. Such a method is called warm-up.
During search process, we directly inherit the weights trained in warm-up stage and fine-tune the weights for each searched TRN. Instead of training from scratch, fine-tuning the trained weights can greatly resolve the time-consuming problem. For example, training ResNet20 on CIFAR10 from scratch requires about 200 epochs. On the contrary, our training with fine-tuning only needs 1 epoch, which brings the acceleration of 200\(\times \).
Experiments
In this section, we conduct experiments to verify the effectiveness of PSTRN. First, to display the relation between the rank elements and performance of TR-based models, we design the synthetic experiment. Then we estimate the effect of the searched TR-based models on prevalent benchmarks. The optimization objectives of NSGA-II [3] are classification performance and compression ratio, namely PSTRN-M. In addition, to gain the TR-based model with high performance, we also conduct optimization algorithm PSTRN-S that only consider classification accuracy. In the tables of all experiments, the best results of the compressing models in the same magnitude are denoted in bold. All the experiments are implemented on Nvidia Tesla V100 GPUs.Footnote 2
Synthetic experiment
Previous works of rank search lack of heuristic method, so they derive rank elements depending on decomposition, which limits the exploration of searching rank. Hypothesis 1 would bring a promising way to solve this problem, and we would like show the phenomenon of interest region in a synthetic experiment.
Experimental setting Given a low-rank weight matrix \(\mathbf{W} \in {\mathbb {R}}^{144\times 144}\). We generate 5000 samples, and each dimension follows the normal distribution, i.e. \(x \sim {\mathcal {N}}(0, 0.05\mathbf{I} )\), where \(\mathbf{I} \in {\mathbb {R}}^{144}\) is the identity matrix. Then we generate the label y according to \(y = \mathbf{W} (x+\epsilon )\) for each x, where \(\epsilon \sim {\mathcal {N}}(0, 0.05\mathbf{I} )\) is a random Gaussian noise. Data pairs of \(\{x, y\}\) constitute the dataset. We divide it into 4000 samples as the training set and 1000 samples as the testing set. For the model, we constructed the TR-linear model by replacing the \(\mathbf{W} \in {\mathbb {R}}^{144 \times 144}\) with a TRF \(\in {\mathbb {R}}^{12 \times 12 \times 12 \times 12}\). Then we train the TR-linear model with different ranks to completion, and validate the performance on the testing set with mean-square error (MSE) between the prediction \(\hat{y}\) and label y. The rank is denoted as \({\mathbf {R}} = \{R_0, R_1, R_2, R_3 | R_{*} \in \{3, 4, \dots , 15\}\}\).
In the experiment, optimizer sets to Adam with a learning rate \(1e-2\), MSE is adopted as loss function and batch size is 128. The total epoch is 100, and the learning rate decreases 90% every 30 epoch. For a comparison, we run the enumerating results as the baseline, which needs \(13^4=28561\) times training.

a Interest region approximation of three phases, and groundtruth is the interest region. b Rank performance of models. There are lowest losses of first phase, second phase, third phase and groundtruth from left to right sequentially
Experimental results Figure 6 shows the distribution of top-100 rank elements sorted by the value of loss. The size of the circle denotes the number of models who has the same two rank elements. And the circle color represents ranking. It shows that it is not ideal to set each rank element the same arbitrarily. We calculate the mean \(\mu \)(3.6) and standard variance \(\delta \)(0.96) of top-100 models, and derive the interest region \([\mu - \delta , \mu + \delta ]\)([2.64, 4.56]). Obviously, \(R_1\) mostly distributes in the interest region. Should be noted that other rank elements do not show an apparent phenomenon, for the reason that they do not play a critical role in the performance. Our model can find the interest region that is important to the ability of models and achieve good results.
As shown in Fig. 7a, the approximation of interest region gradually approaches groundtruth, which demonstrates that PSTRN can locate interest region precisely. As illustrated in Fig. 7b, our model can find the best rank in the second phase, which proves the powerful capacity of PSTRN algorithm. Compared with 28561 enumerating results, we only need \(n\_gen \times pop\_size \times P=10 \times 20 \times 3=600\) times training, which is much smaller. \(pop\_size\) and \(n\_gen\) are the population size and the number of generations, respectively. Undoubtedly, our PSTRN can find the optimal rank efficiently and precisely.
To prove the performance of the progressive search, we also conduct an ablation experiment to compare PSTRN and NSGA-II. \(pop\_size\) of NSGA-II is set to 20, which is the same as PSTRN. And \(n\_gen\) is set to 30. The experimental results are shown in Table 1. The ranking of the searched model among all 28561 possible models is shown in the last column. It can be seen that our proposed progressive evolutionary algorithm can converge faster.
Experiments on MNIST and Fashion MNIST
MNIST dataset has 60k grayscale images with 10 object classes, and the resolution of each data is \(28\times 28\). Fashion MNIST is more complicated and easy to replace MNIST in experiments.
Experimental setting We evaluate our PSTRN on MNIST and Fashion MNIST by searching TR-LeNet5 that is proposed by Wenqi et al. [26]. As shown in Table 2, TR-LeNet5 is constructed with two tensor ring convolutional layers and two tensor ring fully-connected layers. Thus, the total rank is \(R = \{R_0, R_1, \ldots , R_{19} | R_{*} \in \{2, 3, \ldots , 30\}\}\). Accordingly, the computational complexity size is \(29^{20}\approx 1.77\times 10^{29}\) for enumeration.
TR-LeNet5 is trained by Adam [8] on mini-batches of size 128. The random seed is set to 233. The loss function is cross entropy. Models are trained for 20 epochs with an initial learning rate as 0.002 that is decreased by 0.9 every 5 epochs. PSTRN runs 40 generations at each evolutionary phase with population size 30. The number of rank elements searched is 20. The number of progressive phase is 3. The interval \(b_{*}\) of each phase is 5, 2 and 1, respectively. Thus, complexity of our PSTRN is \(n\_gen\times pop\_size \times P=30 \times 40 \times 3=3600\).
Experimental results Experimental results are summarized in Tables 3 and 4, where original LeNet5 is proposed by LeCun et al. [12], Bayesian automatic model compression (BAMC) [23] leverages Dirichlet process mixture models to explore the layer-wise quantization policy, LR-L [28] learn the rank of each layer for SVD, and TR-Nets [26] compresses deep neural network via tensor ring decomposition with equal rank elements. The superscript ri represents there are results of re-implement, and r is the rank of works that set rank elements to equal. These settings would be retained in subsequent experiments. Both of the search processes for MNIST and Fashion MNIST cost about 5 GPU days. In Table 3, the first block shows the results of rank-fixed methods, which manually set rank elements to equal. The second block is the work that automatically compresses the model. As expected, both PSTRN-M and PSTRN-S achieve best performance on MNIST. Our algorithm compress LeNet5 with compression ratio as 6.5x and 0.49% error rate. And our PSTRN can also exceed models that set rank manually on Fashion MNIST as shown in Table 4. Further, Fig. 8 demonstrates that our proposed approach outperforms rank-fixed works on MNIST. Obviously, when fixed rank r is bigger than 20, the TR-Nets will be over-fitting. And our proposed work can find the suitable rank with best performance.
The ranks of searched TR-LeNet5 are shown in Table 5. The symbol // indicates the different layers.

Training process on MNIST. TRN-10/20/30 are TR-Nets that set rank to 10, 20 and 30, respectively. TRN-20 and TRN-30 are over-fitting
Experiments on CIFAR10 and CIFAR100
Both CIFAR10 and CIFAR100 datasets consist of 50,000 train images and 10,000 test images with size as \(32 \times 32 \times 3\). CIFAR10 has 10 object classes and CIFAR100 has 100 categories.
Experimental setting The dimension of TR-RseNet is shown in Table 6, \(\varPsi \) is the number of ResBlock. TR-ResNet32 is built as introduced by Wenqi et al. [26] with \(\varPsi \) as 5, and TR-ResNet20 is constructed as proposed by Zhiyu et al. [2] with \(\varPsi \) as 3. First, we apply the PSTRN-M/S to search TR-ResNet20/32 on CIFAR10. Further, we transfer TR-ResNet20/32 searched by PSTRN-M/S on CIFAR10 into CIFAR100 to evaluate the transferability of PSTRN. Considering that training TR-ResNet20/32 on CIFAR10 is time-consuming, we apply the weight inheritance to accelerate the process. Specifically, we pre-train weight of the model in warm-up stage. Then we load pre-trained weights directly. The training epoch of warm-up is set to 30. The rank \(R = \{R_0, R_1, \ldots , R_{6} | R_{*} \in \{2, 3, \dots , 20\}\}\).
TR-ResNets are trained via SGD [19] with momentum 0.9 and a weight decay of \(5\times 10^{-4}\) on mini-batches of size 128. The random seed is set to 233. The loss function is cross entropy. TR-ResNets are trained for 200 epochs with an initial learning rate as 0.02 that is decreased by 0.8 after every 60 epochs. Our approach runs 20 generations at each evolutionary phase with population size 30. The number of rank elements searched is 7. The number of progressive phase is 3. The interval \(b_{*}\) of each phase is 3, 2 and 1, respectively. The complexity of our approach is \(n\_gen \times pop\_size \times P=30 \times 40 \times 3=3600\), which is much smaller than computational complexity \(19^{7}\approx 8.9 \times 10^{8}\) of enumeration method.
To better validate our algorithm, we also apply the proposed algorithm to TR-WideResNet28-10 on CIFAR10. The experimental setting is exactly same as TR-ResNet. The dimension of TR-WideResNet28-10 is shown as Table 7. The rank \(R = \{R_0, R_1, \ldots , R_{7} | R_{*} \in \{2, 3, \ldots , 20\}\}\).
Experimental results The results for ResNet20 and ResNet32 are given in Tables 8 and 9. The search process for ResNet20/32 and WideResNet28-10 cost about 2.5/3.2 GPU days and 3.8 GPU days, respectively. In Tables 8 and 9, original ResNet20/32 are the model proposed by Kaiming et al. [6]. Tucker [7] and TT [5] are works that compress neural networks by other tensor decomposition methods. TR-RL [2] search the rank of TR-based model based on reinforcement learning. The first block compares PSTRN-M with the results of low rank decomposition works that have fewer parameters. Obviously, PSTRN-M surpasses other methods in both classification accuracy and compression ratio. The second block reports the performance of PSTRN-S and models that are poor on compression. Results tell that our algorithm achieves high performance and beyond works with 0.10+M parameters.
The results for TR-WideResNet28-10 are given in Table 10. Apparently, PSTRN-M exceeds other methods in both classification accuracy and compression ratio. The experimental results show that PSTRN-M can exceed the manually designed models in terms of classification accuracy and compression ratio. In the case that the number of parameters is smaller than the manually designed model with r as 15, the accuracy of PSTRN-M is higher.
In addition, through transferring the searched PSTRN-M/S on CIFAR10 into CIFAR100, PSTRN obtain excellent results as well. This proves that our proposed PSTRN can not only find well-performed models, but also possesses transferability.
The ranks of searched TR-ResNet20 and TR-ResNet32 are shown in Tables 11, 12, and 13.
Experiments on HMDB51 and UCF11
HMDB51 dataset is a large collection of realistic videos from various sources, such as movies and web videos. The dataset is composed of 6766 video clips from 51 action categories. UCF11 dataset contains 1600 video clips of a resolution \(320 \times 240\) and is divided into 11 action categories. Each category consists of 25 groups of videos, within more than 4 clips in one group.
Experimental setting In this experiment, we sample 12 frames from each video clip randomly. And then we extract features from the frames via Inception-V3 [22] input vectors and reshape it into \(64 \times 32\). The shape of hidden layer tensor is set as \(32 \times 64 = 2048\). For TR-LSTM, as shown in Table 14, the rank is denoted as \({\mathbf {R}} =\{R_0, R_1, R_2, R_3 | R_{*} \in \{15, 16, \ldots , 60\}\}\). The complexity of enumerating approach is \(46^{4}\approx 4.5\times 10^{6}\).
TR-LSTM is trained via Adam with a weight decay of \(1.7\times 10^{-4}\) on mini-batches of size 32. The random seed is set to 233. The loss function is the cross-entropy. In the search phase, searched models are trained for 100 epochs with an initial learning rate of 1e−5. Our approach runs 20 generations at each evolutionary phase with a population size of 20. The number of rank elements searched is 4. The number of progressive phases is 3. The interval \(b_{*}\) of each phase is 8, 3 and 1, respectively. The computational complexity of our PSTRN is \(n\_gen \times pop\_size \times P=20 \times 20 \times 3=1200\) that is much smaller.
Experimental results The comparisons between our approach and manually-designed method are shown in Tables 15 and 16. The search process for HMDB51 and UCF11 cost about 1.4 GPU days and 0.5 GPU days, respectively. Experimental results on Table 15 show that our searched rank exceed in others with equal rank elements on HMDB51. The results for UCF11 are given in Table 16. As can be seen, with the compression ratio greater than twice that of the manually designed model with r as 40, the classification accuracy of PSTRN-S is 1.26% higher. PSTRN-M also achieves higher accuracy with fewer parameters. Table 17 demonstrates the ranks for TR-LSTM that searched via PSTRN.
Remark
Unlike the Pytorch, Keras is a high level package with many tricks under the table, e.g. hard sigmoid in RNNs. Thus, for fairer comparison and validation of search results, we implement this experiment in Pytorch and remove the tricks in the Keras package. Additionally, through Keras implement, our searched TR-LSTM achieve 64.5% accuracy with a compression ratio 48, which is better than 63.8% with a compression ratio 25 [17].
Another important component is the shape of a tensor ring decomposition. The method of choosing the shape is notorious. And actually there are almost not any way to select the shape efficiently. Therefore, our PSTRN simply chooses a shape with a similar size by manipulation. The effect of shape on TR-based model is unknown and waits to be solved in the future.
Generally, the rank has similar attribution in different kinds of tensor decomposition like Tucker, Tensor Train and so on. It is reasonable to assume that Hypothesis 1 is suitable for them. Therefore, it is promising to employ PSTRN on them to explore their potential power.
Conclusion
In this paper, we propose a novel algorithm PSTRN based on Hypothesis 1 to search optimal rank. As a result, our algorithm compresses LeNet5 with \(16\times \) compression ratio and 0.22% accuracy improvement on MNIST. And on CIFAR10 and CIFAR100, our work achieves state-of-the-art performance with a high compression ratio for ResNet20, ResNet32 and WideResNet28-10. Not only the CNN, we also show excellent performance of LSTM on HMDB51 and UCF11. Further, for large-scale datasets, we will explore more performance evaluation acceleration strategies to optimize rank elements more efficiently.
Notes
Here, define \(\prod ^{0}_{v}{(\bullet )} = 1, v > 0\).
TR-based Models can be found at https://github.com/tnbar/tednet. In the initial experiments (TR-LeNet5 on MNIST/Fashion MNIST, TR-ResNets on CIFAR10/100 and TR-LSTM on HMDB51), the accuracy in search process was obtained on the test dataset instead of the validation dataset which is widely used in works of NAS [31]. Thus, we supplemented the relevant experiments and shown them in the Appendix.
References
Chen Y, Zhao D, Lv L, Zhang Q (2018) Multi-task learning for dangerous object detection in autonomous driving. Inf Sci 432:559–571
Cheng Z, Li B, Fan Y, Bao Y (2020) A novel rank selection scheme in tensor ring decomposition based on reinforcement learning for deep neural networks. In: 2020 IEEE international conference on acoustics, speech and signal processing, ICASSP 2020, Barcelona, Spain, May 4–8, 2020. IEEE, pp 3292–3296
Deb K, Agrawal S, Pratap A, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
Deng L (2012) The MNIST database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process Mag 29(6):141–142
Garipov T, Podoprikhin D, Novikov A, Vetrov D (2016) Ultimate tensorization: compressing convolutional and fc layers alike. arXiv:1611.03214
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016. IEEE Computer Society, pp 770–778
Kim Y, Park E, Yoo S, Choi T, Yang L, Shin D (2016) Compression of deep convolutional neural networks for fast and low power mobile applications. In: 4th international conference on learning representations, ICLR 2016
Kingma DP, Ba J (2015) Adam: a method for stochastic optimization. In: 3rd international conference on learning representations, ICLR 2015, San Diego, May 7–9, 2015, conference track proceedings
Krizhevsky A, Hinton G et al (2009) Learning multiple layers of features from tiny images
Kuehne H, Jhuang H, Garrote E, Poggio TA, Serre T (2011) HMDB: a large video database for human motion recognition. In: IEEE international conference on computer vision, ICCV 2011, Barcelona, November 6–13, 2011. IEEE Computer Society, pp 2556–2563
Lane ND., Bhattacharya S, Georgiev P, Forlivesi C, Kawsar F (2015) An early resource characterization of deep learning on wearables, smartphones and internet-of-things devices. In: Proceedings of the 2015 international workshop on internet of things towards applications, IoT-App 2015. ACM, pp 7–12
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Li C, Sun Z (2020) Evolutionary topology search for tensor network decomposition. In: Proceedings of the 37th international conference on machine learning, ICML 2020, 13–18 July 2020, virtual event, proceedings of machine learning research, vol 119. PMLR, pp 5947–5957. http://proceedings.mlr.press/v119/li20l.html
Li D, Zhao D, Chen Y, Zhang Q (2018) Deepsign: deep learning based traffic sign recognition. In: 2018 international joint conference on neural networks, IJCNN 2018. IEEE, pp 1–6
Li N, Chen Y, Ding Z, Zhao D (2020) Shift-invariant convolutional network search. In: 2020 International joint conference on neural networks, IJCNN 2020, Glasgow, July 19–24, 2020. IEEE, pp 1–7
Li W, Zhu Y, Zhao D, et al (2019) Multi-agent reinforcement learning based on clustering in two-player games. In: IEEE symposium series on computational intelligence, SSCI 2019, Xiamen, December 6–9, 2019. IEEE, pp 57–63
Pan Y, Xu J, Wang M, Ye J, Wang F, Bai K, Xu Z (2019) Compressing recurrent neural networks with tensor ring for action recognition. In: The thirty-third AAAI conference on artificial intelligence, AAAI 2019, Honolulu, January 27–February 1, 2019. AAAI Press, pp 4683–4690
Real E, Moore S, Selle A, Saxena S, Suematsu YL, Tan J, Le QV, Kurakin A (2017) Large-scale evolution of image classifiers. In: Proceedings of the 34th international conference on machine learning, ICML 2017, Sydney, 6–11 August 2017, proceedings of machine learning research, vol 70. PMLR, pp 2902–2911
Ruder S (2016) An overview of gradient descent optimization algorithms. arXiv:1609.04747
Shao K, Zhao D, Li N, Zhu Y (2018) Learning battles in vizdoom via deep reinforcement learning. In: 2018 IEEE conference on computational intelligence and games, CIG 2018. IEEE, pp 1–4
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: 3rd international conference on learning representations, ICLR 2015
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016, Las Vegas, June 27–30, 2016. IEEE Computer Society, pp 2818–2826
Wang J, Bai H, Wu J, Cheng J (2020) Bayesian automatic model compression. IEEE J Sel Top Signal Process
Wang M, Su Z, Luo X, Pan Y, Zheng S, Xu Z (2020) Concatenated tensor networks for deep multi-task learning. In: Yang H, Pasupa K, Leung AC, Kwok JT, Chan JH, King I (eds) Neural information processing—27th international conference, ICONIP 2020, Bangkok, November 18–22, 2020, proceedings, part v, communications in computer and information science, vol 1333. Springer, pp 517–525. https://doi.org/10.1007/978-3-030-63823-8_59
Wang M, Zhang C, Pan Y, Xu J, Xu Z (2019) Tensor ring restricted Boltzmann machines. In: International joint conference on neural networks, IJCNN 2019 Budapest, July 14–19, 2019. IEEE, pp 1–8. https://doi.org/10.1109/IJCNN.2019.8852432
Wang W, Sun Y, Eriksson B, Wang W, Aggarwal V (2018) Wide compression: tensor ring nets. In: 2018 IEEE conference on computer vision and pattern recognition, CVPR 2018. IEEE Computer Society, pp 9329–9338
Xiao H, Rasul K, Vollgraf R (2017) Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. CoRR arXiv:1708.07747
Yerlan I, Miguel ÁC (2020) Low-rank compression of neural nets: Learning the rank of each layer. In: 2020 IEEE/CVF conference on computer vision and pattern recognition, CVPR 2020, Seattle, June 13–19, 2020. IEEE, pp 8046–8056
Zagoruyko S, Komodakis N (2016) Wide residual networks. In: Wilson RC, Hancock ER, Smith WAP (eds) Proceedings of the British machine vision conference 2016, BMVC 2016, York, September 19–22, 2016. BMVA Press
Zhao D, Chen Y, Lv L et al (2017) Deep reinforcement learning with visual attention for vehicle classification. IEEE Trans Cogn Dev Syst 9(4):356–367
Zoph B, Le QV (2017) Neural architecture search with reinforcement learning. In: 5th international conference on learning representations, ICLR 2017, Toulon, April 24–26, 2017, conference track proceedings. OpenReview.net
Acknowledgements
This work is supported partly by the National Natural Science Foundation of China (NSFC) under Grant No. 62006226 and the National Key Research and Development Program of China No. 2018AAA0100204.
Funding
This work is supported partly by the National Natural Science Foundation of China (NSFC) under Grant No. 62006226.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Availability of data and material
Yes. https://github.com/koala719/PSTRNdata.
Code availability
The code is not public currently.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
For the following experiments, we randomly split 90% from the original training dataset for training and 10% for validation in the search process. And remaining experimental settings are consistent with the text. The experimental results demonstrate that PSTRN can still achieve better performance in terms of accuracy and compression ratio.
A.1: TR-LeNet5 on MNIST and Fashion MNIST
We search for TR-LeNet5 on MNIST [4] and Fashion MNIST [27] (10 classes, 60k grayscale images of \(28 \times 28\)). The experimental results are shown in Tables 18 and 19.
A.2: TR-ResNets on CIFAR10 and CIFAR100
We search TR-ResNets on CIFAR10 (10 classes, 60k RGB images of \(32 \times 32\)) and transfer the searched model to CIFAR100 [9] (100 classes, 60k RGB images of \(32 \times 32\)). The experimental results are shown in Tables 20 and 21.
A.3: TR-LSTM on HMDB51
We search TR-LSTM on HMDB51 [10] (51 classes, 6766 video clips). Experimental results are shown in Table 22.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, N., Pan, Y., Chen, Y. et al. Heuristic rank selection with progressively searching tensor ring network. Complex Intell. Syst. 8, 771–785 (2022). https://doi.org/10.1007/s40747-021-00308-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00308-x