
Abstract
Accurate prediction is a fundamental and leading work of the emergency medicine reserve management. Given that the emergency medicine reserve demand is affected by various factors during the public health events and thus the observed data are composed of different but hard-to-distinguish components, the traditional demand forecasting method is not competent for this case. To bridge this gap, this paper proposes the EMD-ELMAN-ARIMA (ELA) model which first utilizes Empirical Mode Decomposition (EMD) to decompose the original series into various components. The Elman neural network and ARIMA models are employed to forecast the identified components and the final forecast values are generated by integrating the individual component predictions. For the purpose of validation, an empirical study is carried out based on the influenza data of Beijing from 2014 to 2018. The results clearly show the superiority of the proposed ELA algorithm over its two rivals including the ARIMA and ELMAN models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Given that the emergency medicine reserve is one of the strategic materials to deal with large-scale public health events, emergency medicine reserve management plays an important roles in building up the emergency response capacity. Intuitively, in case of a public health event, the lack of emergency medicines probably wastes valuable rescue time and results in much more loss. For example, at the end of 2017 when the influenza virus was rapidly spreading in several regions of China, the specific medicine “Duffy” was out of stock due to the unexpected demand surge, e.g., a shortfall of 310,000 boxes of "Duffy" only in Beijing. However, overstocking emergency medicines also leads to some major problems like the great stock cost and huge expiration cost. Only with the medicine reserve decision based on the accurate demand forecast, can the above problems be effectively solved. However, the emergency medicine reserve demand is affected by the mixed effects of very complex factors like seasonality, response speed, virus transmission rate (in case of an epidemic), communication network of the people, among others. Consequently, the observed data are composed of different but hard-to-distinguish components; therefore, the traditional demand forecasting method does not work for this case, which presents China Food and Drugs Administration (CFDA) an urgent challenge to optimize the safety stock of emergency medicine reserve. Motivated by the above theoretical as well as practical concerns, this work aims to propose a new forecast algorithm of more accuracy based on the decomposition-ensemble methodology.
The rest of this paper is organized as follows: “Literature review” reviews the latest studies on the medicine demand forecasting; “Problem description” systematically expounds the problems and corresponding methods; “Model” elaborates the EMD-ELMAN-ARIMA (ELA) model; “Empirical study” concludes this paper and makes a discuss on the future studies.
Literature review
The most widely applied paradigm of forecasting the medicine demand is composed of two phases. The first phase predicts the number of infected cases (persons) while the second generates the forecast of the quantity of medicine demand based on the outcome in the first phase. In terms of forecasting the number of the infected cases, system dynamics models and statistical models are the two mainstream approaches to predict the number of patients in public health events. The most typical system dynamics model is the classic SIR model proposed by Kermack and McKendrick, which lays the foundation of infectious disease dynamics [1]. Since then, infectious disease dynamics models have experienced a rapid development, many variants have emerged, like SEIR model considering epidemic latency [2], SIQR model considering isolation term [3], etc. System dynamics models considered the evolution law and transmission characteristics of public health events, but the prediction accuracy of the models depends on the predefined epidemic transmission mechanism and the parameter settings. Besides, the dynamics of the parameters are expressed by linear models, which cannot capture the non-linear relationship among factors in the epidemic transmission process. Although some studies have tried to simulate the individual behavior and social network in the system with the help of complex network models, such as the random network, small-world network and scale-free network [4,5,6], these models do not apply to the large-scale systems subject to high complexity.
Statistical models generally predict the evolution trend of public health events based on the historical observations. For examples, [7,8,9,10,11,12] used ARIMA model and its variants flexibly to predict the propagation path and the number of COVID-19 cases in various countries in the world, and achieved a satisfactory forecasting accuracy. In the study of influenza incidence prediction, Rao et al. collected the data set of a reported influenza epidemic of hospitalized children in a certain hospital, identified the characteristics of the prevalent influenza virus subtypes in different months, seasons, years, and patients' age, and finally used ARIMA model to make the short-term prediction [13]. Wu et al. constructed a stochastic forest regression model for predicting the weekly incidence of influenza-like illness [14]. Furthermore, Tapak et al. made a comparative evaluation of different models for predicting influenza outbreaks, the result showed that neural network was better in outbreaks detection, and time series models had promising performances [15]. In the study of forecasting the incidence of hepatitis B, Wang et al. found that ARIMA model showed better forecasting performance than GM(1,1) model [16]. Zheng et al. showed that ELMAN model was superior to ARIMA (0,1,1) model in predicting the incidence of hepatitis B in Guangxi through comparative experiments [17]. In addition, Wei et al. announced that the ARIMA-GRNN mixed model performs better than the ARIMA model and the GRNN model in predicting the incidence of hepatitis [18].
The advantage of the statistical models is that the models include fewer predefined parameters compared with the system dynamics models. However, these kinds of models are heavily dependent on the historical data, which explain why a statistical prediction model shows inconsistent performance in different studies. The “data-driven” nature makes the input data dominate the outcome of the statistical models, namely “garbage in garbage out”. To provide the suited input data, it is necessary to decompose the original data into different components and select the statistical model according to the component characteristics. Empirical Mode Decomposition (EMD) provides a way to solve this problem. EMD is an analysis and processing method for non-linear and non-stationary signals [19] and has been successfully applied in a wide range of fields, such as energy, finance, agricultural products, hydrometeorology, mechanical fault diagnosis, and so on [20,21,22,23,24,25,26,27,28]. However, the application of EMD has not been found in predicting the medicine reserve demand in public health events.
There are some studies presenting the whole forecasting process, very few though. These scanty studies include, Guo et al. used the BP neural network method to predict the population of wounded and deaths in the Yushu earthquakes, and then used the safety stock theory to estimate the demand for emergency supplies [29]. Zhang et al. constructed a grey Verhulst prediction model to predict the number of casualties in the earthquakes, and based on average use requirements to determine medical supplies [30]. In addition, Wang further explored a continuous interval gray Verhulst model to work out the demand for emergency medicines in a same mechanism [31]. It can be seen that the existing research only focuses on the immediate demand after the disaster event, and the long-term reserve demand forecast of special emergency medicines for treating public health events has not been found yet.
The current related studies on emergency medicine reserve demand forecasting present 4 characteristics: (1) a majority of studies are focused on forecasting the number of cases, only few studies present a complete solution to forecasting the emergency medicine reserve demand. (2) Compared with the system dynamics model, the statistical model need much less predefined parameters and can capture the development trend in the data-driven way. (3) The statistical models like ARIMA and neural network have been widely used in the research of medicine demand forecasting. However, the performance is sample-sensitive, namely the forecasting accuracy values are different on different samples. (4) Empirical Mode Decomposition has widely been applied to improve the calculation accuracy of the single prediction models in various fields.
Based on the above-mentioned, this paper proposes the EMD-ELMAN-ARIMA (ELA) hybrid forecasting model. ELA uses EMD method to decompose the historical data of the infected cases into different components, then ARIMA and ELMAN neural networks are employed to capture the linear and the non-linear components, respectively. Furthermore, based on the projection from the number of the infected cases to the medicine reserve demand dominated by nature of the public health events (i.e., the average medicine demand per person during the public health event), the emergency medicine reserve demand can be obtained. Finally, to validate the model, an empirical study is carried out based on the actual data of influenza cases during the period from 2014 to 2018 in Beijing. To the best of our knowledge, this paper is the first to apply EMD to the emergency medicine reserve demand forecasting.
Problem description
-
A.
Characteristics of emergency medicine demand
Before forecasting the emergency medicines reserve demand, it is necessary to identify the characteristics of the data so as to select the matching forecasting methods. The demand for emergency medicines is characterized by suddenness, surge, and urgency. First, it is difficult to foresee the outbreaks of public health events, especially to accurately predict its infection scope and population, so the need for emergency medicine that will take on a sudden character. Second, the denser population and complex movement of people within cities accelerate the spread of epidemic, with the spread of online public opinion, the sales of emergency medicines will show a stronger surge character. Finally, the needs of emergency medicines are also extremely urgent, as the availability of emergency medicines cannot be delayed after the disease outbreak, the lack of emergency medicines reserve tends to fuel social panic, which can lead to more serious social problems.
In combination with the above characteristics, it is easy to infer that the data on the number of people affected by public health events are destined to be strongly non-stable, so the traditional time series prediction method, which requires a high requirement for data stationarity, will not be too accurate. At the same time, traditional regression analysis methods are difficult to apply to such issues because of the difficulty of identifying and quantifying the factors that lead to the surge in demand for emergency medicines. In addition, considering the rapid population movements, frequent trade and commerce, and rapid development of the cities, premature demand data do not provide much guidance for the current forecast results. Therefore, models of emergency medicine reserve requirements also require the ability to handle small sample data. To sum up, forecasting the demand for emergency medicines is not only a hot academic issue, but also a very difficult practical issue.
-
B.
Paradigm of emergency medicine reserve demand forecasting
In practice of CFDA, the medicine reserve demand is estimated by multiplying the number of suspected cases by the effective infections coefficient (i.e., the average medicine demand per person). Therefore, this paper proposes a paradigm of emergency medicine reserve demand forecasting (see Fig. 1).

Paradigm of emergency medicine reserve demand forecasting
The proposed paradigm proceeds as follows: First, historical data are collected on the actual number of people suffering from public health events in cities. Second, historical data are used to forecast the specific number of people suffering from diseases and the trend over the coming period. Finally, based on the prediction of the patients, the demand for emergency medicine reserve is estimated according to the medicine production capacity, reserve demand characteristics, as well as the guidance and recommendations of experts, all the mechanisms and relevant factors can be summarized as the demand coefficient of emergency medicine \(\alpha\). Denote \(S\) the reserve demand of emergency medicines and p the predicted value of cases in a public health event, the emergency medicines reserve demand can be expressed as follows:
The demand coefficient \(\alpha\) of treatment medicines is usually equal to 1, that is, one patient corresponds to one person's medicine demand. However, in the real storage situation, the medicine storage units often need to adopt a safer demand coefficient bigger than 1, and their values are not the same according to the operation situation of the medicine storage enterprises, the instructions of the national medicine regulatory authorities, and the medicines production and procurement situation.
Model
Statistical prediction models can classified into three categories including regression models (e.g., Logistic Regression, Multiple Regression, etc.), time series models (e.g., Exponential Smoothing method, ARIMA, Bayesian VAR, etc.), and artificial intelligence models (e.g., Neural Networks, Support Vector Machines, etc.). In previous studies, the reliable performance of ARIMA and neural network models like ELMAN motivates this paper employ them as individual models.
-
A.
Autoregressive integrated moving average model
The Autoregressive Integrated Moving Average Model (ARIMA) is one of the most frequently used models. The ARIMA model is based on the idea of transforming a non-stable time series into a stable time series \(x\left( t \right)\) composed of the auto-regression of \(x\left( t \right)\) and the moving average of the random term. The mathematical expression is as follows:
where \(x\left( t \right)\) is the actual number of the cases caused by public health events, \(c\) is constant, \( \emptyset_{i}\) and \(\theta_{i}\) are the coefficients, \(p\) and \(q\) referred to as autoregressive and moving average, respectively.
-
B.
ELMAN neural network model
Neural network models have been proved to be a kind of effective prediction models in a wide range of fields [32,33,34]. ELMAN neural network is a specific realization of the feedback neural network and shows its power in the prediction of influenza epidemics [15]. The network consists of the input layer, the hidden layer, the context layer, and the output layer. The functions of the input layer, hidden layer and output layer are alike to those of other neuro networks. The context layer acts as a time delay operator in the model, linking the previous output value from the hidden layer to the next input of the hidden layer, forming an internal feedback network. An illustrative structure of ELMAN neural network is shown in Fig. 2.

An illustrative Structure of ELMAN Neural Network Model
To describe the non-linear state space of the ELMAN neural network model [35], the definitions can be made as follow: \(w^{1} ,w^{2} ,w^{3}\) are the weights of the three steps of the input layer-hidden layer, hidden layer-context layer, and hidden layer-output layer, respectively; \(x\left( k \right)\) is the output of the hidden layer and \(x_{c} \left( k \right)\) is the output of the context layer; \(f\left( \cdot \right)\) and \(g\left( \cdot \right)\) are the transfer functions of the hidden layer and the output layer, respectively; \(0 < \partial < 1\) indicates the internal feedback gain factor, and the final network output is represented by \(y\left( k \right)\). The derivation of the relationship of the model is as follows:
-
C.
Distinguishing components by EMD
Although the above-mentioned models have seen some successful applications in emergency medicine demand forecasting studies [36,37,38,39], their performances are affected by the noise in original data in the prediction process. There are many factors that affect the number of people affected by a public health event, for example, the number of people infected by a specific influenza outbreak may be influenced by temperature, moderation, population density, mode of transmission, precautions, and other factors. Therefore, the original time series tends to comprise very complex components, which renders a big challenge for the forecasting task. Despite that it is proved that including the key factors into the model can improve the prediction results [40, 41], it is impossible to identify and quantify all the factors, consequently some useful components cannot be captured by the traditional models and are ignored as noise, which lead to unsatisfactory performance of the traditional models.
To overcome the above problem, inspired by the studies [42, 43], this paper uses Empirical Modal Decomposition method (EMD) to decompose the original data. EMD is an adaptive method suitable for processing non-stationary and non-linear series. EMD is totally data-driven and enjoys advantages compared to wavelet decomposition owing to its non-parametric nature. Out of the original data, a set of Intrinsic Mode Functions (IMFs) can be extracted, which provides more insight into the dynamics of the data and facilitates the forecasting work.
-
D.
The EMD-ELMAN-ARIMA (ELA) model
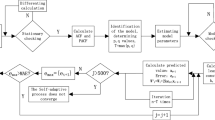
It is a unanimous agreement in the forecasting field that the models, including time series models, econometric models and artificial intelligence methods, should be carefully tailored to fit the data characteristics. Given that the emergency medicine demand against the public healthy events comprise multiple components of different characteristics, a single model is not sufficient. Considering some studies have shown the power of combined forecasting models in this case [44, 45], this paper proposes the combined model, namely ELA, based on the decomposition-ensemble methodology, which proceeds as follows: First, the time series of the cases (patients) is decomposed into different components by EMD. Second, ARIMA and ELMAN neural network are employed to predict the components, based on which the integrated outcome is generated to be the sum of the forecasts of the components; finally, the prediction of emergency medicines reserve demand is obtained by Eq. (1). Figure 3 visually depicts the proposed ELA model.

The model of EMD-ELMAN-ARIMA
Empirical study
-
A.
Data introduction
With the support of CDFA, we obtained the weekly data on historical influenza cases from Beijing Center for Disease Prevention and Control (Beijing CDC) during the period of 01/07/2014 to 25/12/2018. The first 200 observations are used to tune the parameters of the models, and the remainder 21 observations from August to December 2018 are used to validate the model.
Figure 4 visualizes the original data and shows a significant increase of the peak level of the reported cases after 2018. According to the experts from Beijing CDC, the main reasons are as follows: First, at the end of 2017, a new influenza virus subtype appeared in Beijing, and the population did not have immunity to this new virus subtype, resulting in an increase in susceptible populations; Second, due to the previous media propaganda, including the posts of influenza deaths reprinted on the Internet, the public's awareness of the dangers of influenza and the awareness of vigilance have increased significantly, resulting in a significant increase in the rate of medical treatment and the number of reported cases; Third, a new detection technology has been widely used in medical institutions in Beijing since 2017, and the detection rate and detection rate have been improved. The superposition of the three factors led to a significant increase in the number of influenza cases reported, but it still did not reach the outbreak level.
-
B.
Data processing

Original data of influenza cases
Due to the complexity of influenza in megacities, the cases of influenza patients tend to be highly volatile and unstable. Using the Augmented Dickey–Fuller test, the stationarity of the data can be tested. Table 1 lists the test results showing that the original series is not stationary, which implies that the models for stationary series cannot be applied in this case.
This section uses the proposed ELA model to predict the influenza cases. First, the data were decomposed by EMD using the MATLAB software package. As shown in Figs. 5, 6, 7, IMFs and one residual mode were obtained after EMD decomposition. The IMF1 has the highest frequency and fluctuating most strongly at random. The frequency decreases when we check the modes from IMF2 to the residual series. As shown by [40, 41], data preprocessing plays a very important role in forecasting. For higher forecasting accuracy, it is necessary to appropriately preprocess the data before run the forecasting models, among which, matching the IMFs, individually or in combinations, with the suited models is a key task.

IMFs generated by EMD

Original time series V.S. modes of IMF1-3

Original time series V.S. modes of IMF4-Res
We tested various combinations of 8 modes by “trial and error”. According to the results, the sum of IMF1 to IMF3, denoted by \(x_{1}\), fits best the influenza cases data. While the sum of IMF4 to the residual series, denoted by \(x_{2}\), simulates well the seasonality. Thus, the series of influenza cases is decomposed into two subseries \(x_{1}\) and \(x_{2}\), and the original series \(x\) of influenza cases in Beijing can be expressed as Eq. (6).
The ELMAN neural network and ARIMA models are used to capture the nonlinearity in × 1 and seasonality in × 2, respectively (Figs. 8, 9, 10, 11).
-
C.
Forecasting process

Decomposition of original time series by hodrick-prescott filter

ADF test results of first-order difference in the original time series

ADF test results of second-order difference in the original time series

Fitting results of ARIMA(0,2,4) model
The whole forecasting process is composed of 4 steps. First, ARIMA model is used to predict the original time series. Because the data fluctuate excessively and include the growth trend brought by the progress of influenza virus detection technology, it is necessary to strip the trend items brought by the progress of detection technology from the original data before using ARIMA model. With the help of Hodrick–Prescott filtering method, the original time series is divided into the period term and trend term, and the trend term is added to ARIMA model as an explanatory variable for model fitting [46].
Because the original data fluctuate violently, the original time series is processed by difference, and the first-order and second-order difference series are tested by the ADF test.
As shown in the above test results, at the significance level of 0.05, the null hypothesis is rejected, indicating that the second-order difference series of the original influenza cases data is stationary. The Box–Jenkins method is used to determine the order of the model, and the ARIMA (0,2,4) model is obtained on the premise that the residual error sequence is a white noise sequence.
Second, in the ELMAN neural network, we used the training data set (the blue points in Fig. 12) to estimate the network parameters, based on which we obtained the forecasts (the red points in Fig. 12).

The ELMAN model predicts results
Third, the ELA model was used to predict the number of cases given the two combinations of IMFs, i.e.,\({ }x_{1}\) and \(x_{2}\). The ELMAN neuro network was used to get the forecasted value of \({ }x_{1}\). Using the AIC rule, ARIMA (4,1,1) was identified to be the best fit for \(x_{2}\). The final predicted values were obtained by summing up 21 predicted values of the \(x_{1}\) and \(x_{2}\) in the forecasting horizon from 07/08/2018 to 25/12/2018.
Fourth, after obtaining the prediction results of the number of influenza patients, it is necessary to estimate the projection coefficient \(\alpha\) from the number of cases to the emergency medicine reserve demand. According to the experts from CDFA and Beijing CDC, \(\alpha\) is dependent on the treatment course and dosage, and \(\alpha = 1\) would be acceptable by rule of thumb in case of the influenza (Fig. 13).
-
D.
Prediction results and analysis

The comparison of three prediction methods
In this paper, Mean Absolute Percentage Error (MAPE) is used to evaluate the prediction error. Denote \(\widehat{{x_{t} }}\) the predicted value and \(x_{t}\) the data of the original time series, then MAPE is mathematically expressed as follows:
On the one hand, for the prediction results of the number of influenza patients, the combined prediction model constructed in this paper is superior to the traditional time series model and machine learning model alone.
According to Table 2, the forecasting error of the ARIMA models reaches 15.31% and 10.62%, the ELMAN neuro network suffers a forecasting error of 7.29%, while the proposed ELA model sees a significantly smaller error of 3.87%, which implies that the ELA model outperforms the individual ARIMA and ELMAN models. With \(\alpha = 1\), we obtained the predicted value of the emergency treatment medicines for influenza in 2018 as shown in Table 3:
Table 3 shows that the forecast by ELA fits best the actual medicine reserve demand, compared with its 3 rivals. It is worth noting that the actual medicine reserve for influenza in 2018 is less than the forecast, which is consistent with the reality according to the administrative of CDFA, saying there was a shortage of the medicine reserve for influenza and China started the emergency production at a higher cost than in usual. The relief action would have been more effective if the demand was estimated accurately, which highlights the practical value of the ELA model.
Conclusion
Based on the decomposition-ensemble methodology, this paper constructs a new combined prediction model based on EMD, ARIMA, and ELMAN, namely the ELA model, to forecast the emergency medicine reserve demand in response to a public health events. This model employs EMD decompose the original series of cases (patients) into different components, then reconstructs all the components into several combinations to avoid the curse of dimensionality. Subsequently ELMAN neuro network and ARIMA are applied to the suited combinations by “trial and error” according to the characteristics, like linearity and nonlinearity in this study. Finally, the forecast of the emergency medicine reserve demand is generated with a projection coefficient \(\alpha\) by the rule of thumb. To validate the model, with the support of CFDA and Beijing CDC, an empirical study was carried out based on the weekly data of influenza cases in Beijing from 07/08/2018 to 25/12/2018. The results clearly show the superiority of the proposed ELA model over its rivals, which indicates the potential of the ELA model to be a more powerful tool for emergency medicine reserve management.
It is notable that although this work promotes better understanding of applying the decomposition-ensemble paradigm to the emergency medicine reserve forecast work, some important issues are left to the future studies. For examples, when EMD generates a large scale of components, it is infeasible to identify the best combinations by “trial and error”. Moreover, there are some optimization problems to be solved in the future, like the optimal length of forecasting horizon, the optimal number of individual models to be integrated, the optimal size of training set, and so forth.
References
Kermack WO, Mckendrick AG (1927) Contribution to the mathematical theory of epidemics. Proc R SocLondSer A 115(772):700–721
Hethcote HW (2000) The mathematics of infectious diseases. SIAM Rev 42(4):599–653
Lih-Ing Wu, Feng Z (2000) Homoclinic bifurcation in an SIQR. Mod Child Dis 168(1):150–167
Ten GV (1999) years of individual-based modelling in ecology: what have we learned and what could we learn in the future? Ecol Model 115(2–3):129–148
Kleczkowski A, Grenfell BT (1999) Mean-field-type equations for spread of epidemics: the “small world” model. Phys A 274(1–2):355–360
Nepomuceno EG, Resende D, Lacerda MJ (2019) A survey of the individual-based model applied in biomedical and epidemiology. J Biomed Res Rev 1(1):11–24
Singh RK, Rani M, Bhagavathula AS et al (2020) Prediction of the COVID-19 pandemic for the top 15 affected countries: advanced autoregressive integrated moving average (ARIMA) Model. JMIR Public Health Surveill 6(2):e19115. https://doi.org/10.2196/19115
Singh S, Parmar KS, Kumar J, Makkhan SJS (2020) Development of new hybrid model of discrete wavelet decomposition and autoregressive integrated moving average (ARIMA) models in application to one month forecast the casualties cases of COVID-19. Chaos Solitons Fract 135:109866. https://doi.org/10.1016/j.chaos.2020.109866
Duan X, Zhang X (2020) ARIMA modelling and forecasting of irregularly patterned COVID-19 outbreaks using Japanese and South Korean data. Data Brief 31:105779. https://doi.org/10.1016/j.dib.2020.105779
Ilie OD, Cojocariu RO, Ciobica A, Timofte SI, Mavroudis I, Doroftei B (2020) Forecasting the Spreading of COVID-19 across Nine Countries from Europe, Asia, and the American Continents Using the ARIMA Models. Microorganisms 8(8):E1158. https://doi.org/10.3390/microorganisms8081158
Ceylan Z (2020) Estimation of COVID-19 prevalence in Italy, Spain, and France. Sci Total Environ 729:138817. https://doi.org/10.1016/j.scitotenv.2020.138817
Chakraborty T, Ghosh I (2020) Real-time forecasts and risk assessment of novel coronavirus (COVID-19) cases: a data-driven analysis. Chaos Solitons Fractals 135:109850. https://doi.org/10.1016/j.chaos.2020.109850
Rao X, Chen Z, Dong H et al (2020) Epidemiology of Inluenza in hospitalized children with respiratory tract infection in Suzhou area from 2016 to 2019. J Med Virol 92:3038–3046
Wu H, Cai Y, Wu Y et al (2017) Time series analysis of weekly influenza-like illness rate using a one-year period of factors in random forest regression. Biosci Trends 11(3):292–296
Tapak L, Hamidi O, Fathian M, Karami M (2019) Comparative evaluation of time series models for predicting influenza outbreaks: application of influenza-like illness data from sentinel sites of healthcare centers in Iran. BMC Res Notes. https://doi.org/10.1186/s13104-019-4393-y
Wang YW, Shen ZZ, Jiang Y (2018) Comparison of ARIMA and GM(1,1) models for prediction of hepatitis B in China. PLoS ONE 13(9):e0201987. https://doi.org/10.1371/journal.pone.0201987
Yanling Z, Liping Z, Xun Z et al (2020) A comparative study of two methods to predict the incidence of hepatitis B in Guangxi. China. PLoS One 15:e0234660
Wei W, Jiang J, Liang H et al (2016) Application of a Combined Model with Autoregressive Integrated Moving Average (ARIMA) and Generalized Regression Neural Network (GRNN) in Forecasting Hepatitis Incidence in Heng County, China. PLoS ONE 11(6):e0156768. https://doi.org/10.1371/journal.pone.0156768
Huang NE, Shen Z, Long SR et al (1971) The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc Math Phys Eng 1998(454):903–995
Xun Z, Lean Y, Shouyang W, Kin KL (2009) Estimating the impact of extreme events on crude oil price: an EMD-based event analysis method. Energy Econ 31(5):768–778. https://doi.org/10.1016/j.eneco.2009.04.003
Hu L, Wang J, Qi C (2016) BEMD-based event analysis for crude oil market: evidence using google search data. In: IEEE International Conference on Smart City/socialcom/sustaincom. IEEE.
Plakandaras V, Papadimitriou T, Gogas P (2015) Forecasting daily and monthly exchange rates with machine learning techniques. Duth Res Pap Econ 34(7):560–573
Zhang X, Yu L, Wang S (2009) The impact of financial crisis of 2007–2008 on crude oil price. International conference on computational science. Springer, Berlin
Fang Y, Guan Bo, Shangjuan Wu et al (2020) Optimal forecast combination based on ensemble empirical mode decomposition for agricultural commodity futures prices. J Forecast 39(6):877–886
Xu X, Qi Y, Hua Z (2010) Forecasting demand of commodities after natural disasters[J]. Expert Syst Appl 37(6):4313–4317
Li FF, Wang ZY, Qiu J (2019) Long-term streamflow forecasting using artificial neural network based on preprocessing technique. J Forecast. https://doi.org/10.1016/j.eswa.2009.11.069
Pannakkong W, Sriboonchitta S, Huynh VN (2018) An ensemble model of arima and ann with restricted boltzmann machine based on decomposition of discrete wavelet transform for time series forecasting. J SystSciSystEng. https://doi.org/10.1002/for.2564
Yaguo LJ et al (2013) A review on empirical mode decomposition in fault diagnosis of rotating machinery. MechSyst Signal Process. https://doi.org/10.1016/j.ymssp.2012.09.015
Jinfen GUO (2012) Research on emergency material demand forecast method under large-scale earthquakes. College of management and economics. Tianjin University, Tianjin
Zhang J, Li Z (2013) Forecast of medicine demand for emergency rescue in large-scale earthquake disaster. Stat Decis 13:90–93
Wang T (2016) Medicine demand prediction research in a massive earchquake disaster based on verhulst model of continuous interval grey number. Chongqing Technology and Business University, Chongqing
Saric T, Simunovic G, Vukelic D, Simunovic K, Lujic R (2018) Estimation of CNC grinding process parameters using different neural networks. Tech Gaz 25(6):1770–1775. https://doi.org/10.17559/TV-20180419095119
Afify HM, Mohammed KK, Hassanien AE (2020) Multi-images recognition of breast cancer histopathological via probabilistic neural network approach. J SystManagSci 1(2):53–68
Simeunovic N, Kamenko I, Bugarski V, Jovanovic M, Lalic B (2017) Improving workforce scheduling using artificial neural networks model. Adv Prod EngManag 12(4):337–352. https://doi.org/10.14743/apem2017.4.262
Azim H, Farshid K, Nasser S-P et al (2017) An evolutionary hybrid method to predict pistachio price. Complex IntellSyst 3:121–132
Cheng Y, Yuan J, Chen Q et al (2020) Prediction of nosocomial infection incidence in the department of critical care medicine of Guizhou province with a time series model. Ann Transl Med 8:758
Xie J, Kanghuai Z, Cai Y et al (2020) Application of ARIMA model in monitoring the use rate of antibiotics in outpatients in 2010–2018. Int J ClinPharmacolTher 58:282–288
Wu W, An S-Y, Guan P et al (2019) Time series analysis of human brucellosis in mainland China by using ELMAN and Jordan recurrent neural networks. BMC Infect Dis 19:414
Fanoodi B, Malmir B, Jahantigh FF (2019) Reducing demand uncertainty in the platelet supply chain through artificial neural networks and ARIMA models. ComputBiol Med 113:103415
Rehar T, Ogrizek B, Leber M, Pisnik A, Buchmeister B (2017) Product lifecycle forecasting using system’s indicators. Int J Simul Model 16(1):45–57
Qiu Y, Zhao XN, Zhang XH (2019) Optimal routing for safe construction and demolition waste transportation: a cVaR criterion and big data analytics approach. TechnGaz 26(4):1128–1135
Wang F, Yu L, Wu A (2021) Forecasting the electronic waste quantity with a decomposition-ensemble approach. Waste Manag 120:828–838
Xie G, Zhang N, Wang S (2017) Data characteristic analysis and model selection for container throughput forecasting within a decomposition-ensemble methodology. Transp Res Part E 108:160–178
Verma L, Srivastava S, Negi PC (2018) An intelligent noninvasive model for coronary artery disease detection. Complex IntellSyst 4(1):11–18
Hong WH, Yap JH, Selvachandran G et al (2020) Forecasting mortality rates using hybrid Lee-Carter model, artificial neural network and random forest. Complex IntellSyst. https://doi.org/10.1007/s40747-020-00185-w
Fabio C (2007) Methods for applied macroeconomic research. Princeton University Press, Princeton
Acknowledgement
This work is financially supported by the Fundamental Research Funds for the Central Universities (Project No. 2020YJS053, No. 2019JBZ111), Beijing Intelligent Logistics System Collaborative Innovation Center (Project No. BILSCIC-2019KF-24), and Beijing Logistics Informatics Research Base.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang-ning, L., Xian-liang, S., An-qiang, H. et al. Forecasting emergency medicine reserve demand with a novel decomposition-ensemble methodology. Complex Intell. Syst. 9, 2285–2295 (2023). https://doi.org/10.1007/s40747-021-00289-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00289-x