
Abstract
Recently, a broad learning system (BLS) has been theoretically and experimentally confirmed to be an efficient incremental learning system. To get rid of deep architecture, BLS shares the same architecture and learning mechanism of the well-known functional link neural networks (FLNN), but works in broad learning way on both the randomly mapped features of original features of data and their randomly generated enhancement nodes. As such, BLS often requires a huge heap of hidden nodes to achieve the prescribed or satisfactory performance, which may inevitably cause both overwhelming storage requirement and overfitting phenomenon. In this study, a stacked architecture of broad learning systems called D&BLS is proposed to achieve enhanced performance and simultaneously downsize the system architecture. By boosting the residuals between previous and current layers and simultaneously augmenting the original input space with the outputs of the previous layer as the inputs of current layer, D&BLS stacks several lightweight BLS sub-systems to guarantee stronger feature representation capability and better classification/regression performance. Three fast incremental learning algorithms of D&BLS are also developed, without the need for the whole re-training. Experimental results on some popular datasets demonstrate the effectiveness of D&BLS in the sense of both enhanced performance and reduced system architecture.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Introduction
As everyone may know well, over the past decade, deep learning systems have earned great success in many application fields [1, 2] and have been drawing more and more attentions in today’s academic and industrial communities. Typical deep learning systems include deep restricted Boltzmann machines (RBM) [3], deep belief networks (DBN) [4, 5] and deep convolutional neural networks (CNN) [6]. Deep learning systems exhibit their overwhelming performance by taking their complicated deep structures and deep learning methods. However, they often suffer from very time-consuming training because a huge number of hyperparameters in the corresponding complicated deep structures are involved. Besides, updating their deep structure becomes an extraordinarily tedious task, due to the need for the whole re-training. To get rid of complicated deep architecture and effectively avoid very time-consuming training (and even re-training), as an alternative to deep learning systems, broad learning system (BLS in brevity) [7] has been recently invented to organize the well-known functional link neural networks (FLNN) [8, 9] in broad learning way. Up to date, several variants of BLS have been developed. A typical example is fuzzy BLS [10] which is based on Takagi–Sugeno–Kang fuzzy systems [11,12,13]. Theoretical and experimental evidences have revealed BLS’s excellent classification/regression performance, with fast wide learning capability.
Since FLNN has both its simple structure of single-layer feedforward neural networks and its fast learning which can be realized quickly using its analytical solution, BLS takes FLNN as its basic structure and then expands it in broad learning way. In contrast to FLNN, BLS has two distinctive discrepancies in the structure sense: (1) BLS transforms the set of the original input features of data into randomly mapped features and then take sparse autoencoders (SAE) to optimize them into sparse mapped features [14] so as to capture the intrinsic correlations of the input features. (2) BLS generates the enhancement nodes using nonlinear activation functions with randomly generated weights on all the sparse mapped features. All the sparse mapped features and the enhancement nodes are linked to the output layer, where the weights between the hidden nodes and the output layer are determined analytically by ridge regression [15], without the need for iterative updates of the weights. More importantly, without the need for re-training the whole network, BLS can train its structure in broad learning way for the incremental increase of randomly mapped features, enhancement nodes and input data, thereby avoiding very time-consuming training especially for big data. BLS has been theoretically proved to be a universal approximator [16]. A large amount of experimental evidences has indicated that BLS indeed has at least comparably and even much more satisfactory classification/regression performance and strong generalization capability, in contrast to the corresponding deep learning system. However, because the mapped features and enhancement nodes are randomly generated, BLS often needs a huge heap of enhancement nodes to achieve the prescribed performance, which may inevitably cause both overwhelming storage requirement and overfitting phenomenon, therefore, how to downsize a BLS system and simultaneously keep the strong capability of the whole system is becoming an urgent demand.
In this study, we attempt to tackle with this issue by stacking several lightweight BLS sub-systems with both feature augmentation and residuals boosting into its stacked structure called D&BLS. The basic idea can be clearly stated as follows.
-
1.
To avoid overfitting phenomenon of the general BLS and simultaneously downsize its structure, D&BLS is proposed to stack several lightweight BLS sub-systems. As a deep classifier, the whole stacked structure and learning of D&BLS has its novelty in the sense of two joint stacking ways: feature augmentation and residuals boosting, which indeed guarantees enhanced performance of D&BLS.
-
2.
Using the bootstrap strategy on feature nodes of each lightweight BLS sub-system, enhancement nodes are generated and hence each lightweight BLS sub-system is built to maintain powerful capability in both fast training and good generalization.
-
3.
When D&BLS has its fixed depth, three incremental learning algorithms are designed for three incremental cases to endow D&BLS with the ability of fast learning in broad expansion of each layer without the whole re-training process.
-
4.
Experimental results on six classification datasets demonstrate that D&BLS can reduce the number of enhancement nodes of BLS to about 76% or less with the same or better performance. On ten regression datasets, D&BLS can achieve smaller error with comparable number of enhancement nodes. On the MNIST dataset, three incremental algorithms of D&BLS can reach the performance comparable to that of D&BLS with one-shot construction and the training time of three incremental algorithms is much less than that of D&BLS with the one-shot construction, In addition, D&BLS only needs much less running time than BLS when they both share the same sizes. In general, D&BLS with some (i.e., from 2 to 4) lightweight sub-systems can obtain promising learning ability.
The rest of this paper is organized as follows. Section “On BLS” reviews BLS in brevity. Section “On D&BLS” proposes the structure of D&BLS, gives the learning algorithm of D&BLS, and discusses its computational complexity. Besides, three incremental algorithms of D&BLS are also designed in this section. Experimental results about image/non-image dataset classification, regression and incremental learning are presented in section “Experimental results”. And the last section concludes this paper.
On BLS
In this section, we give a brief review about BLS’s structure and three incremental learning algorithms.
Framework of BLS
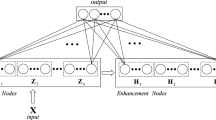
In [7], BLS is conceptually composed of four basic parts: (1) original input; (2) feature nodes; (3) enhancement nodes; and (4) output layer. BLS begins with the original input as the input to certain feature mapping algorithms [7], which then generates the feature nodes by taking the sparse autoencoder to slightly fine-tune the random features. As such, all the mapped feature nodes actually form an efficient representation way of the original data. Accordingly, BLS generates a series of enhancement nodes by consecutively acting certain activation function with random parameters on all the mapped feature nodes, then all mapped features generated an enhancement node. Finally, BLS links both feature nodes and enhancement nodes to the output layer with each output weight. As one of the most famous merits, all the output weights can be trained analytically by the well-known ridge regression method [15].
Figure 1 gives an illustrative structure of BLS. According to Fig. 1, we can concretely state how to construct a BLS as follows.

An illustrative structure of BLS
Without loss of generality, here we only consider the multi-input and single-output case. Suppose the training dataset X contains the total T original input samples with D dimensions and its output vector Y corresponds the total T target outputs, i.e., \( \varvec{X} \in {\mathbb{R}}^{T \times D} ,\;\varvec{Y} \in {\mathbb{R}}^{T \times 1} \). We assume BLS has the total n groups of feature nodes in which the ith group of feature nodes takes the mapping function \( \phi_{i} ,\;i = 1,2, \ldots ,n \) and contains the total \( d_{i} \) feature nodes and the total m groups of enhancement nodes in which the jth group of enhancement nodes takes the activation function \( \xi_{j} ,\;j = 1,2, \ldots ,m \) and contains the total \( q_{j} \) enhancement nodes. As such, the ith group of feature nodes may be expressed as:
where the weight matrix \( {\mathbf{W}}_{ei} \in {\mathbb{R}}^{{D \times d_{i} }} \) and the bias matrix \( \varvec{\beta}_{ei} \in {\mathbb{R}}^{{T \times d_{i} }} \) are randomly generated according to a certain distribution, such as normal distribution. According to [7], sparse autoencoder is taken to slightly fine-tune the random feature matrix \( \varvec{M}_{i} \) into sparse and compact feature matrix. Using alternating direction method of multiplier (ADMM), the weight matrix tuned by sparse autoencoder can be solved by the following iterative steps:
where \( \hat{\varvec{M}}_{i} \) is the desired sparse feature matrix, \( \hat{\varvec{W}} \) is the sparse autoencoder solution, \( \hat{\varvec{W}}_{0} \), \( \varvec{o}_{0} \) and \( \varvec{u}_{0} \) are zero matrices, \( \lambda \) is the given regularization parameter. In addition, r > 0 and S is the soft thresholding operator which is defined as:
After a certain number of iterations, the sparse feature matrix can be obtained by:
We collect all the groups of feature nodes to form the group \( \varvec{M}^{n} \triangleq \left[ {\varvec{M}_{1} ,\varvec{M}_{2} , \ldots ,\varvec{M}_{n} } \right] \), which will be used to generate the enhancement nodes. Similarly, the jth group of enhancement nodes may be expressed as:
where the weight matrix \( \varvec{W}_{hj} \in {\mathbb{R}}^{{\left( {\sum\nolimits_{i = 1}^{n} {d_{i} } } \right) \times q_{j} }} \) and the bias matrix \( \varvec{\beta}_{hj} \in {\mathbb{R}}^{{T \times q_{j} }} \) are also randomly generated according to a certain distribution. We collect all the groups of enhancement nodes \( \varvec{E}_{j} \) to form the group \( \varvec{E}^{m} \triangleq \left[ {\varvec{E}_{1} ,\varvec{E}_{2} , \ldots ,\varvec{E}_{m} } \right] \). In this way, the output vector of such a BLS becomes:
where \( \varvec{W}_{n}^{m} \in {\mathbb{R}}^{{\left( {\sum\nolimits_{i = 1}^{n} {d_{i} } + \sum\nolimits_{j = 1}^{m} {q_{j} } } \right)\, \times \,1}} \) are the output weight vector that can be solved analytically by ridge regression method. That is to say, after denoting \( \varvec{U}_{n}^{m} = \left[ {\varvec{M}^{n} |\varvec{E}^{m} } \right] \), with the Moore–Penrose inverse of \( \varvec{U}_{n}^{m} \), we have the analytical solution of \( \varvec{W}_{n}^{m} \).
Using ridge regression [15], the pseudoinverse of \( \varvec{U}_{n}^{m} \) can be solved as follows:
where \( \lambda \) is the given regularization parameter, \( h = \sum\nolimits_{i = 1}^{n} {d_{i} } + \sum\nolimits_{j = 1}^{m} {q_{j} } \) is the total number of hidden nodes of BLS.
As a result, such a BLS is built quickly, without the need for iterative updates at a very slow learning speed, likewise in BP neural network learning [18].
Incremental learning of BLS
Except for fast training of BLS, another famous merit exists in its simple yet fast incremental learning methods, which indeed reveals its very applicability in online scenarios and/or practical situations where the more promising performance is expected. According to [7], without re-training the whole network structure, incremental learning of BLS can be realized from three cases.
Increment of enhancement nodes
In this case, BLS is expanded by adding the (m + 1)th group of enhancement nodes. That is to say, we have
After denoting \( \varvec{U}^{ex} = \varvec{E}_{m + 1} \), we can decompose the pseudoinverse of \( \varvec{U}_{n}^{m + 1} \) as,
where
Therefore, the new output weight vector \( \varvec{W}_{n}^{m + 1} \) becomes
Since \( \varvec{W}_{n}^{m} \), \( \varvec{U}_{n}^{m} \) and \( \left[ {\varvec{U}_{n}^{m} } \right]^{\dag } \) have been obtained in advance, \( \varvec{W}_{n}^{m + 1} \) can be quickly obtained according to Eqs. (12) and (13).
Increment of feature nodes
In this case, BLS is expanded by adding the (n + 1)th group of feature nodes. As such, we have,
where \( \varvec{E}_{1}^{ex} |\varvec{E}_{2}^{ex} | \cdots |\varvec{E}_{m}^{ex} \) are the additional outputs of the enhancement nodes corresponding to the (n + 1)th group of feature nodes. After denoting \( \varvec{U}^{ex} = \left[ {\varvec{M}_{n + 1} |\varvec{E}_{1}^{ex} |\varvec{E}_{2}^{ex} | \cdots |\varvec{E}_{m}^{ex} } \right] \), we can decompose the pseudoinverse of \( \left[ {\varvec{U}_{{n{ + }1}}^{m} } \right] \) as,
where A and B can be obtained according to Eq. (12). Therefore, the new output weight vector \( \varvec{W}_{{n{ + }1}}^{m} \) is,
Obviously, since \( \varvec{W}_{n}^{m} \), \( \varvec{U}_{n}^{m} \) and \( \left[ {\varvec{U}_{n}^{m} } \right]^{\dag } \) have been obtained in advance, \( \varvec{W}_{{n{ + }1}}^{m} \) can be quickly obtained according to Eqs. (12) and (17).
Increment of input data
In this case, BLS is fed with the additional training data \( {\text{\{ }}\varvec{X}^{ex} ,\varvec{Y}^{ex} {\text{\} }} \). The additional feature node \( \varvec{M}^{ex} \) generated from \( \varvec{X}^{ex} \) is
The output of enhancement nodes corresponding to \( \varvec{M}^{ex} \) is
Please note, both \( \varvec{W}_{ei} \), \( \varvec{\beta}_{ei} \) (i = 1,…,n) and \( \varvec{W}_{hj} \), \( \varvec{\beta}_{hj} \) (j = 1,…,m) are initialized by taking their corresponding values in Eqs. (1) and (5). Let
and \( \varvec{U}^{ex} = \left[ {\varvec{M}^{ex} |\varvec{E}^{ex} } \right] \), the pseudoinverse of \( \left( {\varvec{U}_{n}^{m} } \right)^{ex} \) can be decomposed as,
where
Therefore, the new output weight vector \( \left( {\varvec{W}_{n}^{m} } \right)^{ex} \) is
Obviously, since \( \varvec{W}_{n}^{m} \), \( \varvec{U}_{n}^{m} \) and \( \left[ {\varvec{U}_{n}^{m} } \right]^{\dag } \) have been obtained in advance, \( \left( {\varvec{W}_{n}^{m} } \right)^{ex} \) can be quickly obtained according to Eqs. (22) and (23).
While BLS shares the fast training originating from the flexible yet random construction of both feature nodes and enhancement nodes, it indeed requires a large amount of feature nodes and especially enhancement nodes to achieve satisfactory performance, which may cause an overwhelming storage requirement and overfitting phenomenon. For example, for MNIST dataset, according to [7], the built BLS needs 11,000 enhancement nodes. Therefore, in the next section, we will deepen BLS by stacking its structures into the proposed classifier so as to downsize the structure of BLS and simultaneously share the promising advantages of BLS.
On D&BLS
In this section, by means of feature augmentation, we first state the deep structure of D&BLS and its learning algorithm and then derive three incremental learning algorithms of D&BLS for three incremental cases. Their computational complexities are also discussed.
Structure and learning of D&BLS
Given D&BLS with L layers, the original training dataset \( \varvec{X} \in {\mathbb{R}}^{T \times D} \) and its target output vector \( \varvec{Y} \in {\mathbb{R}}^{T \times 1} \). The parameters of the ith lightweight sub-system include the total \( n_{i} \) groups of feature nodes in which each group contains the total \( d_{i} \) feature nodes, the number of the selected feature nodes \( p_{i} \) that are chosen to generate enhancement nodes, and the total \( m_{i} \) groups of enhancement nodes in which each group contains the total \( q_{i} \) enhancement nodes. For convenience, we use \( \left( {d_{1} \times n_{{{\kern 1pt} 1}} ,p_{1} ,q_{1} \times m_{1} } \right) - \cdots - \left( {d_{L} \times n_{{{\kern 1pt} L}} ,p_{L} ,q_{L} \times m_{L} } \right) \) to represent the parameters setting of this D&BLS and \( \left( {\sum\nolimits_{i = 1}^{L} {\sum\limits_{{}}^{{}} {d_{i} \times n_{{{\kern 1pt} i}} } ,\;\sum\nolimits_{i = 1}^{L} {q_{i} \times m_{{{\kern 1pt} i}} } } } \right) \) to denote its whole structure.
Figure 2 illustrates its deep structure. According to Fig. 2, D&BLS essentially stacks several lightweight BLS sub-systems into its deep structure simultaneously by two ways: (1) augmenting the original input space with the outputs of previous layer as the inputs of current layer; (2) boosting the residual outputs between the original outputs and the outputs of all the previous layers as the target outputs of current layer. According to stacked generalization principle [17], the use of feature augmentation guarantees enhanced performance of D&BLS, whereas the use of residual outputs maintains good local approximation of current BLS sub-system for subtle output differences remaining in current layer. In general, a lightweight BLS sub-system takes not so many feature nodes and enhancement nodes, in contrast to the BLS system for the same training dataset. To stack lightweight BLS sub-systems well, the deep structure of D&BLS embodies our three reliable considerations as follows.

Structure of D&BLS
(1) According to the adopted feature augmentation, the ith lightweight sub-system has its augmented training dataset \( \varvec{X}_{i} \), i.e.,
where \( \varvec{Y^{\prime}}_{i - 1} \) corresponds to the augmented feature and denotes the output vector of the (i − 1)th sub-system. In other words, the augmented training dataset \( \varvec{X}_{i} \) contains the output information of previous sub-system. Please note, each system always has only one augmented feature whose values are the outputs of previous layer in D&BLS.
(2) Inspired by the idea of residuals boosting [19,20,21], each target output of sub-system in current layer is taken to be the residual value between the corresponding target output and the corresponding outputs of the sub-systems of all the previous layers. As such, the ith sub-system has its target output vector \( \varvec{Y}_{i} \):
Obviously, according to stacked generalization principle, the above stacking way of both feature augmentation and residuals boosting can surely enhance the performance of D&BLS with the increase of the number of sub-systems. In other words, with the prescribed performance, a downsized structure can be expected in the sense of the total number of hidden nodes, in contrast to the general BLS.
(3) When combining all the lightweight sub-systems together, diversity between them should be emphasized to achieve an effective ensemble. To do so, D&BLS only randomly boostraps [22] some feature nodes to generate an enhancement node. Suppose the ith sub-system selects \( p_{i} \) feature nodes to generate an enhancement node. After denoting \( \varvec{M}^{{p_{i} }} \triangleq \left[ {\varvec{M}_{{c_{1} }} ,\varvec{M}_{{c_{2} }} , \ldots ,\varvec{M}_{{c_{{p_{i} }} }} } \right] \) as the random selected feature nodes, where \( c_{1} ,c_{2} , \ldots ,c_{{p_{i} }} \in \left[ {1,n_{i} } \right] \) denote random integers, then an enhancement node \( \varvec{E}_{j} \) can be generated as,
Once feature nodes and enhancement nodes of each lightweight BLS system are fixed according to the above strategy, this sub-system can be quickly constructed by the same learning algorithm of BLS as in the last section.
D&BLS begins with the construction of the first lightweight. BLS sub-system on the original training dataset X and its target output vector Y. And then D&BLS obtains the output vector \( \varvec{Y^{\prime}}_{1} \) of the first lightweight BLS sub-system. After generating \( \varvec{X}_{2} = \left[ {\varvec{X}|\varvec{Y^{\prime}}_{1} } \right] \) and \( \varvec{Y}_{2} = \varvec{Y} - \varvec{Y^{\prime}}_{1} \), respectively, as the inputs and target outputs of the second lightweight BLS sub-system, the second sub-system is built in the same way as in the above. This procedure is repeated until the maximum number of sub-systems (i.e., layers) or the prescribed performance of D&BLS is achieved. As a result, the final output vector of D&BLS on the original training dataset can be expressed as,
In summary, the learning algorithm is given in Algorithm 1. To visualize the effectiveness of Algorithm 1, a simple two-class classification dataset contained 200 training samples (100 positive samples) is taken for didactic experimentation. The dataset is generated from the model make_moons of Scikit-learn [29] package with 0 noise, as shown in Fig. 3a. Four D&BLSs with different number of sub-systems are taken and the deeper one is deepened from the shallower one. The deepest one is a four-layer D&BLS: (6 × 6, 9, 1 × 3)–(5 × 6, 9, 1 × 2)–(5 × 6, 9, 1 × 2)–(5 × 6, 9, 1 × 2), its whole structure becomes (126, 9). Here the average results of the ten runs are reported. Figure 3b–e shows the decision boundary of all D&BLSs.

The moon dataset and corresponding decision boundary of four D&BLSs with different number of sub-systems
From Fig. 3, the decision boundary of D&BLS becomes more complex to match the distribution of training samples as D&BLS becomes deeper. It indicates that Algorithm 1 is effective and the learning ability of D&BLS can be enhanced by adding more sub-systems with appropriate parameters.
The computational complexity of Algorithm 1 can be analyzed in terms of D&BLS with L sub-systems. Without loss of generality, according to the same strategy of BLS in [7], here we suppose \( \xi \) in step 12 is a sigmoid activation function [23] and the number of iterations of sparse autoencoder taken in step 6 is K.
Thus the computational complexity of step 2 and 3 can be calculated to be \( O\left( {2T} \right) \approx O\left( T \right) \). The computational burden from step 4 to step 7 about the generation of feature nodes takes,
In general, \( d_{i} < T \), \( d_{i} < D \) and \( 2 < K \) can be assured, so the computational complexity mentioned above will be reduced to \( O\left( {KTDn_{i} d_{i} } \right) \). Then step 8 requires \( O\left( {Tn_{i} d_{i} } \right) \). The computational burden of the generation of enhancement nodes from step 9 to step 13 takes
Then steps 14 and 15 require \( O\left( {2Tm_{i} q_{i} } \right) \approx O\left( {Tm_{i} q_{i} } \right) \). The calculation of the pseudoinverse of \( \left( {U_{{n_{i} }}^{{m_{i} }} } \right)_{i} \) in step 16 requires
while step 17 and step 18 require
Hence, with the total L sub-systems, the computational complexity of Algorithm 1 becomes
As we can see, the most time-consuming parts for each sub-system in D&BLS are the generation of feature nodes, the generation of enhancement nodes and the calculation of pseudoinverse. Similarly, we can calculate the computational complexity of BLS for comparison. Suppose BLS contains d × n feature nodes and q × m enhancement nodes, its computational complexity is
For easy comparison, here we suppose each sub-system of D&BLS has the total \( \left\lceil {n/L} \right\rceil \times d \) feature nodes and \( \left\lceil {m/L} \right\rceil \times q \) enhancement nodes. As such, the computational complexity of Algorithm 1 becomes
In general, \( \frac{1}{L}\sum\nolimits_{i = 1}^{L} {p_{i} } < nd \) and \( \left( {nd + mq} \right) \le T \) can be assured. Thus the computational complexity is obviously less than that of BLS.

Incremental learning for D&BLS
To achieve enhanced performance, it seems that we may expand D&BLS by increasing a lightweight BLS sub-system successively. However, too many lightweight BLS sub-systems often cause overfitting phenomenon. Our experimental evidences demonstrate that the total number of layers (i.e., sub-systems) should generally take a small integer (i.e., from 2 to 4). Therefore, a feasible strategy is to develop its incremental algorithms with the fixed number of layers. What is more, we should still consider how to expand D&BLS for the case of incremental input data. Here we develop three incremental algorithms of D&BLS for three incremental cases, without the need of re-training the whole classifier.
Increment of enhancement nodes
In this case, each sub-system in D&BLS is expanded by adding \( \bar{m} \) (i.e., a small integer) groups of enhancement nodes in which each group contains \( \bar{q} \) enhancement nodes.
The additional enhancement nodes \( \varvec{E}_{1}^{ex} ,\varvec{E}_{2}^{ex} , \cdots ,\varvec{E}_{{\bar{m}}}^{ex} \) are generated from a portion of the original feature nodes. After denoting \( \varvec{U}^{ex} = \left[ {\varvec{E}_{1}^{ex} ,\varvec{E}_{2}^{ex} , \cdots ,\varvec{E}_{{\bar{m}}}^{ex} } \right] \), the pseudoinverse of \( \varvec{U}_{{n_{i} }}^{{m_{i} + \bar{m}}} = \left[ {\varvec{U}_{{n_{i} }}^{{m_{i} }} |\varvec{U}^{ex} } \right] \) can be calculated by Eqs. (11) and (12). Then the output weight vector can be determined by \( \left( {\varvec{W}_{{n_{i} }}^{{m_{i} + \bar{m}}} } \right)_{i} = \left( {\varvec{U}_{{n_{i} }}^{{m_{i} + \bar{m}}} } \right)^{\dag } \varvec{Y}_{i} \), and hence the output of this sub-system after expansion becomes \( \varvec{Y}_{i}^{\prime } { = }\varvec{U}_{{n_{i} }}^{{m_{i} + \bar{m}}} \left( {\varvec{W}_{{n_{i} }}^{{m_{i} + \bar{m}}} } \right)_{i} \). The incremental algorithm for this case is summarized in Algorithm 2.

Below let us analyze the computational complexity of Algorithm 2 in terms of L sub-systems. Because the training of each sub-system in this incremental case only deals with both the generation of the incremental enhancement nodes and the calculation of the corresponding pseudoinverse, we mainly observe the corresponding steps in Algorithm 2.
That is to say, the computational complexity from step 3 to step 7 takes \( O\left( {T\bar{m}\bar{q}p_{i} } \right) \), while steps 8 and 9 require \( O\left( {2T\bar{m}\bar{q}} \right) \approx O\left( {T\bar{m}\bar{q}} \right) \). What is more, because the number of the additional enhancement nodes is generally a small integer, i.e., \( \bar{m}\bar{q} < \left( {n_{i} d_{i} + m_{i} q_{i} } \right) \) and \( \bar{m}\bar{q} < T \), the calculation of the pseudoinverse \( \left( {U_{{n_{i} }}^{{m_{i} + \bar{m}}} } \right)^{\dag } \) in step 10 requires
Obviously, step 11 and step 12 require \( O\left( {2T\left( {n_{i} d_{i} + m_{i} q_{i} + \bar{m}\bar{q}} \right)} \right) \approx O\left( {T\left( {n_{i} d_{i} + m_{i} q_{i} } \right)} \right) \). Hence, with the total L iterations, the computational complexity of Algorithm 2 becomes
If we re-train the whole model based on Algorithm 1 and assume \( \left( {n_{i} d_{i} + m_{i} q_{i} } \right) < T \) is assured, its computation complexity will become
Obviously, increment of enhancement nodes can save much training time.
Increment of feature nodes
In this case, after \( \bar{n} \) (i.e., a small integer) groups of feature nodes with \( \bar{d} \) feature nodes are added, each sub-system in D&BLS is further expanded by the corresponding additional \( \bar{m} \) (i.e., a small integer) groups of enhancement nodes with \( \bar{q} \) enhancement nodes.
After the total \( \bar{n} \) groups of the additional feature nodes \( \varvec{M}^{ex} \) are generated from \( \varvec{X}_{i} \), the total \( \bar{m} \) groups of the additional enhancement nodes \( \varvec{E}^{ex} \) are accordingly generated from a portion of the additional feature nodes \( \varvec{M}^{ex} \). After denoting \( \varvec{U}^{ex} = \left[ {\varvec{M}^{ex} |\varvec{E}^{ex} } \right] \), the pseudoinverse of \( \varvec{U}_{{n_{i} { + }\bar{n}}}^{{m_{i} }} = \left[ {\varvec{U}_{{n_{i} }}^{{m_{i} }} |\varvec{U}^{ex} } \right] \) can be calculated by Eqs. (12) and (16). As such, the output weight vector can be obtained by \( \left( {\varvec{W}_{{n_{i} + \bar{n}}}^{{m_{i} }} } \right)_{i} = \left( {\varvec{U}_{{n_{i} { + }\bar{n}}}^{{m_{i} }} } \right)^{\dag } \varvec{Y}_{i} \) and the output of this sub-system accordingly becomes \( \varvec{Y}_{i}^{\prime } { = }\varvec{U}_{{n_{i} + \bar{n}}}^{{m_{i} }} \left( {\varvec{W}_{{n_{i} + \bar{n}}}^{{m_{i} }} } \right)_{i} \). The incremental algorithm for this case is summarized in following Algorithm 3.
The computational complexity of Algorithm 3 can be analyzed in terms of L sub-systems. Obviously, the training of each sub-system in this incremental case mainly has three stages, namely, the generation of the additional feature nodes and the corresponding additional enhancement nodes and the calculation of the pseudoinverse. According to Algorithm 3, the computational burden from step 4 to step 7 about the generation of feature nodes takes \( O\left( {KTD\bar{n}\bar{d}} \right) \). Step 8 requires \( O\left( {T\bar{n}\bar{d}} \right) \). The computational complexity from step 9 to step 13 about the generation of enhancement nodes is \( O\left( {T\bar{m}\bar{q}p_{i} } \right) \). Then steps 14 and 15 require \( O\left( {2T\bar{m}\bar{q}} \right) \approx O\left( {T\bar{m}\bar{q}} \right) \), step 16 requires \( O\left( {T\left( {\bar{n}\bar{d} + \bar{m}\bar{q}} \right)} \right) \). Because the number of both the additional feature nodes and the additional enhancement nodes is generally a small integer, i.e., \( \left( {\bar{n}\bar{d} + \bar{m}\bar{q}} \right) < \left( {n_{i} d_{i} + m_{i} q_{i} } \right) \) and \( \left( {n_{i} d_{i} + m_{i} q_{i} } \right) < T \), and the calculation of the pseudoinverse \( \left( {U_{{n_{i} { + }\bar{n}}}^{{m_{i} }} } \right)^{ + } \) in step 17 requires
What is more, step 18 and step 19 require \( O\left( {2T\left( {n_{i} d_{i} + m_{i} q_{i} + \bar{n}\bar{d} + \bar{m}\bar{q}} \right)} \right) \approx O\left( {T\left( {n_{i} d_{i} + m_{i} q_{i} } \right)} \right) \). In summary, with the totalL iterations, the computational complexity of Algorithm 3 becomes
If we re-train the whole structure based on Algorithm 1 and suppose \( \left( {n_{i} d_{i} + m_{i} q_{i} } \right) < T \) is assured, its computation complexity will become
Obviously, increment of feature nodes can save much training time.

Increment of input data
In this case, D&BLS is expanded by adding \( \bar{T} \) input data \( \{ \varvec{X}_{{\bar{T}}} ,\varvec{Y}_{{\bar{T}}} \} ,\varvec{X}_{{\bar{T}}} \in {\mathbb{R}}^{{\bar{T} \times D}} ,\varvec{Y}_{{\bar{T}}} \in {\mathbb{R}}^{{\bar{T} \times 1}} \). Suppose that \( \{ \varvec{X}_{{T + \bar{T}}} ,\varvec{Y}_{{T + \bar{T}}} \} \) denotes the all input data after incremental operation. After the total \( n_{i} \) groups of the additional feature nodes \( \varvec{M}^{ex} \) with \( d_{i} \) feature nodes are generated from \( \varvec{X}_{{\bar{T}}} \), the total \( m_{i} \) groups of the additional enhancement nodes \( \varvec{E}^{ex} \) with \( q_{i} \) enhancement nodes are generated from a portion of the additional feature nodes \( \varvec{M}^{ex} \). After denoting \( \varvec{U}^{ex} = \left[ {\varvec{M}^{ex} |\varvec{E}^{ex} } \right] \), the pseudoinverse of \( \left( {\varvec{U}_{{n\,_{i} }}^{{m_{i} }} } \right)^{ex} = \left[ {\begin{array}{*{20}c} {\varvec{U}_{{n_{\,i} }}^{{m_{i} }} } \\ {\varvec{U}^{ex} } \\ \end{array} } \right] \) can be calculated by Eqs. (21) and (22). As a result, the output weight vector can be obtained by \( \left( {\varvec{W}_{{n_{i} }}^{{m_{i} }} } \right)_{i}^{ez} { = }\left( {\left( {\varvec{U}_{{n\,_{i} }}^{{m_{i} }} } \right)^{ex} } \right)^{\dag } \varvec{Y}_{i} \) and the output of this sub-system becomes \( \varvec{Y}_{\varvec{i}}^{\prime } { = }\left( {\varvec{U}_{{n\,_{i} }}^{{m_{i} }} } \right)^{ex} \left( {\varvec{W}_{{n_{i} }}^{{m_{i} }} } \right)_{i}^{ex} \). The incremental algorithm for this case is summarized in Algorithm 4.

The computational complexity of Algorithm 4 can also be analyzed in terms of L sub-systems. The computational complexity of each sub-system in this incremental case mainly contains three stages: the generation of the additional feature nodes and the additional enhancement nodes and the calculation of pseudoinverse. According to Algorithm 4, the computational complexity from step 4 to step 7 about the generation of feature nodes takes \( O\left( {K\bar{T}Dn_{i} d_{i} } \right) \). Step 8 requires \( O\left( {\bar{T}n_{i} d_{i} } \right) \). Then the computational burden from step 9 to step 13 about the generation of enhancement nodes is \( O\left( {\bar{T}m_{i} q_{i} p_{i} } \right) \). Step 14 and 15 require \( O\left( {2\bar{T}m_{i} q_{i} } \right) \approx O\left( {\bar{T}m_{i} q_{i} } \right) \), then step 16 requires \( O\left( {\bar{T}\left( {n_{i} d_{i} + m_{i} q_{i} } \right)} \right) \). Suppose \( \left( {n_{i} d_{i} + m_{i} q_{i} } \right) < \bar{T} \) and \( \left( {n_{i} d_{i} + m_{i} q_{i} } \right) < T \) are assured, the calculation of \( \left( {\left( {U_{{n\,_{i} }}^{{m_{i} }} } \right)^{ex} } \right)^{ + } \) in step 17 requires
What is more, steps 18 and 19 require \( O\left( {2\left( {T + \bar{T}} \right)\left( {n_{i} d_{i} + m_{i} q_{i} } \right)} \right) \approx O\left( {\left( {T + \bar{T}} \right)\left( {n_{i} d_{i} + m_{i} q_{i} } \right)} \right) \). Suppose \( \bar{T} < T \) and \( KD < T \) are assure, with the total L iterations, the total computational complexity of Algorithm 4 can be described as
If we re-train the whole structure based on Algorithm 1 and suppose \( \left( {n_{i} d_{i} + m_{i} q_{i} } \right) < T + \bar{T} \) is assured, its computation complexity will become
Obviously, increment of input data can save training time.
Finally, let us state how to set appropriate parameters in the above algorithms. As pointed out in the above, the total number of layers generally take a small integer (i.e., from 2 to 4). Besides, according to our extensive experiments, the weight matrix \( \varvec{W} \) and the bias matrix \( \varvec{\beta} \) involved in hidden nodes generally are drawn from standard normal distributions, respectively. Since the number \( p_{i} \) of selected feature nodes should generally be much less than the total of feature nodes, it is set to be at most 75% of the total number of feature nodes. As for the regularization parameters \( \lambda \) and \( r \) involved in sparse autoencoder, they are simply set to be 0.001 and 1, respectively. The regularization parameter \( \lambda \) involved in ridge regression is simply set to be 2−30. In our experiments, the number of additional hidden nodes for each sub-system is simply taken to be 10 and the number of additional input data is simply set to be 3000.
Experimental results
In this section, to evaluate the performance of D&BLS, we organize four groups of experiments. The first group about classification is carried out on both five image datasets and 1 UCI [24] classification datasets, the second about regression on ten UCI regression datasets, the third about incremental learning on popular datasets MNIST [25], and the last about running time is compared between BLS and D&BLS. All the experiments are carried out under a computer that equips Intel-i3 3.40 GHz CPU, 4 GB memory. The experiments of LSSVM are carried out in MATLAB environment and the other experiments are carried out in Python environment. Before the experiments, all the datasets are divided into training and testing set.
The comparative methods include BLS [7], support vector machine (SVM) [26], least squared SVM (LSSVM) [27]. Because the regularization parameter \( C \) and the kernel parameter \( \gamma \) of SVM play an essential role in performance, they need to be chosen appropriately for a fair comparison. In our experiments, we determine them by taking a grid search from \( \{ 2^{ - 24} ,2^{ - 23} , \ldots ,2^{24} ,2^{25} \} \) for the parameters \( \left( {C,\gamma } \right) \) in SVM, while the parameters \( \left( {C,\gamma } \right) \) of LSSVM are decided using LS-SVMlab Toolbox.
In our experiments, the original codes of BLS in [7] (classification version) and in [16] (regression version) are taken. As for SVM, its classification version SVC and its regression version SVR are taken from Scikit-learn [29] package.
As for BLS and D&BLS, to make a fair comparison between them, the weight matrix \( \varvec{W} \) and the bias matrix \( \varvec{\beta} \) are drawn from standard normal distributions and the tansig functions are taken as the activation functions of enhancement nodes. All other parameters involved in BLS and D&BLS keep the same and their settings have been stated in the last section.
Classification
This group of experiments consists of two parts. The first part is to observe the performance of D&BLS and the comparative methods on image data, while the second part deals with the 1 UCI non-image classification datasets. Five popular image datasets are MNIST [25] and USPS [29] about handwritten digits, COIL20 [30] and COIL100 [31] about 3-D objects, and extended YaleB [32] about human faces. A UCI classification dataset is isolet [33] about spoken letter recognition. To obtain good performance, we use “one vs. one” strategy for LSSVM when faced with multi-class problems and thus omit its parameters setting here.
According to the accuracies obtained by BLS on the adopted datasets, we determine D&BLS by the trial and error strategy. This involves the number of lightweight BLS sub-systems in D&BLS. To make our comparison fair, here we report average results (i.e., mean and standard deviations) for ten trials on each dataset.
MNIST
MNIST contains 70,000 handwritten digits of ten classes. Every digit is represented by an image with the size of 28 × 28 gray-scaled pixels. 60,000 out of all the handwritten digits are partitioned into the training dataset and the remaining 10,000 handwritten digits into the testing dataset. Here a subset of MNIST is chosen for our experiment with the first 10,000 training images and all the 10,000 testing images. In our experiments, we perform a grid search for the optimal parameters of BLS, including the size of feature node groups, the number of feature node groups and the number of enhancement nodes from [10, 30] × [10, 20] × [100, 5000] with the steps being 1, 1 and 100 due to the large searching range of enhancement nodes. The parameters setting can be checked in Table 1 and the classification accuracies of all the adopted methods are given in Table 2.
Obviously, D&BLS reaches better accuracy (97.37%) than that (97.19%) of BLS, while D&BLS only needs 3490 enhancement nodes, which is about 72.71% number of enhancement nodes (i.e., 4800 nodes) in BLS. In addition, D&BLS exhibits its superiority of classification performance over other comparative methods: SVM (94.32%) and LSSVM (91.40%).
USPS
US Postal Service (USPS) handwritten digits recognition corpus is another well know dataset, which contains 9298 gray images of size 16 × 16 pixels, with ten class digit 0–9. We randomly select 7500 images for training and the rest 1798 images for testing. In our experiment, the search range for BLS is [10, 30] × [10, 20] × [100, 5000] with the steps being 1, 1 and 100. The parameters setting is shown in Table 1 and the classification accuracies are listed in Table 2.
We can see that D&BLS exceeds the accuracy of BLS (i.e. 95.90% vs. 95.77%) with much less enhancement nodes (i.e., only 1877 nodes), which is about half the number of enhancement nodes (i.e., 3700 nodes) in BLS. Compared to SVM (93.44%) and LSSVM (95.27%), D&BLS also achieves the best performance.
COIL20
COIL20 contains 1440 gray images of 20 different 3-D objects with 128 × 128 pixels. The images of each object were taken 5 degrees apart as the object is rotated on a turntable and each object has 72 images. There are 36 images of each object for training and the remaining 720 images for testing. In our experiment, the search range for BLS is [10, 30] × [10, 20] × [100, 3000] with the steps being 1, 1 and 100. The parameters setting are given in Table 1 and the classification accuracies can be checked in Table 2.
In contrast to BLS, D&BLS has higher accuracy (99.78%) with much less enhancement nodes (i.e., only 1357 nodes), which is about 61.68% of the number of enhancement nodes (i.e., 2200 nodes) in BLS. D&BLS also achieves best performance compared to SVM (83.19%) and LSSVM (89.86%).
COIL100
COIL100 contains 7200 color images of 100 different 3-D objects with 128 × 128 pixels. The images of each object were taken 5 degrees apart as the object is rotated on a turntable and each object has 72 images. In this experiment, each image was resized into 32 × 32 and converted into gray image. We randomly select 5000 images for training and the rest 2200 images for testing.
In our experiment, the search range for BLS is [10, 30] × [10, 20] × [100, 5000] with the steps being 1, 1 and 100. The parameters setting are listed in Table 1 and the classification accuracies are shown in Table 2.
As we can see, D&BLS exceeds the accuracies of all the adopted methods with much less enhancement nodes (i.e., only 2710 nodes), which is about 61.59% of the number of enhancement nodes in BLS.
Extended YaleB
Extended YaleB face consists of 2414 cropped images of 38 objects with the size of 32 × 32 pixels. The images contain large variations in terms of illumination conditions and expressions for each subject. There are 30 images of each person for training and the remaining 1274 images for testing. Following [16], BLS contains 60 × 30 feature nodes and 1 × 6000 enhancement nodes. The parameters setting of other models are shown in Table 1 and the classification accuracies of all the adopted methods are listed in Table 2.
From Tables 1 and 2, D&BLS matches the accuracy (97.92%) of BLS with only 232 enhancement nodes, which is about 3.87% of the number of enhancement nodes in BLS. D&BLS also exceeds the accuracy of SVM (89.32%) and LSSVM (89.95%).
UCI
To verify the effectiveness of D&BLS for non-image data, we choose the isolet dataset here, which contains 1560 spoken letter recognition samples of 26 classes with 617 features in each sample. We randomly choose 1092 samples for training and the rest 468 samples for testing. In our experiment, the search range for BLS is [10, 30] × [10, 20] × [100, 3000] with the steps being 1, 1 and 100. The parameter details are shown in Table 1 and the classification performance are given in Table 2.
D&BLS indeed gets the best result (95.49%) among all the adopted methods and only needs about 76% of the number of enhancement nodes in BLS, which actually demonstrates the effectiveness of D&BLS for non-image samples.
Regression
In this subsection, we attempt to verify that D&BLS can achieve smaller regression errors than BLS when they both have comparable number of enhancement nodes. We take ten UCI regression datasets, whose details are listed in Table 3
Following [16], the same parameters setting of BLS are taken by a grid search from [1, 10] × [1, 30] × [1, 200] with step being 1 and the best experimental results about the root-mean-square errors (RMSE) from ten trials are taken to make a fair comparison. The detailed parameter settings and the experimental results by SVM, LSSVM, BLS and D&BLS on these datasets are given in Tables 4 and 5, respectively.
Clearly, D&BLS performs comparably to BLS on the datasets Bodyfat and Weather Izmir and better than BLS with comparable number of enhancement nodes in the remaining eight datasets. It can be concluded that with almost the same sizes of the architectures, D&BLS attractively outperforms BLS in the sense of testing accuracy on these datasets, which actually hints that D&BLS may take smaller sizes of the architectures to achieve comparable regression performance to BLS. Compared to SVM and LSSVM, the D&BLS also achieves the best performance.
Incremental algorithms
In this section, we divide it into three cases to observe the average performances (with their standard deviations) of incremental learning algorithms of D&BLS for ten runs on the dataset MNIST: (1) increment of enhancement nodes (corresponding to Algorithm 2); (2) feature nodes (corresponding to Algorithm 3); and (3) input data (corresponding to Algorithm 4).
Our experiments begin with a three-layer D&BLS, whose whole structure is (696,275) consisting of (30 × 8, 10, 1 × 100)–(29 × 8, 10, 1 × 95)–(28 × 8, 10, 1 × 80) on the MNIST dataset where the first 10,000 samples from the total 60,000 training samples are taken as the initial training samples, and the same 10,000 testing samples are still kept. The parameter \( p_{i} \) of the additional enhancement nodes is also set to be 10. Besides, the testing accuracy, training time and testing time of D&BLS with one-shot construction are also provided to highlight the advantage of the proposed three incremental algorithms.
Increment of enhancement nodes
Two groups of experiments are arranged to observe Algorithm 2 for this case. The first group considers the total 4 times of incremental operations. That is, it takes the addition of ten enhancement nodes in an incremental way. The second group keeps the same except 12 rather 10 enhancement nodes. Thus, the whole network with three sub-systems has 30 or 36 more enhancement nodes after enhancement nodes are increased in a step-by-step way. The results are given in Table 6.
As we can see, the testing accuracy continues to be improved as the additional enhancement nodes are inserted into D&BLS in an incremental way and finally reaches the performance comparable to that of D&BLS with the one-shot construction (see the last row in Table 6). Obviously, the training time of Algorithm 2 is much less than that of D&BLS with the one-shot construction, e.g., 1.8399 s vs. 5.5217 s.
Increment of feature nodes
Two groups of experiments are arranged to observe Algorithm 3 for this case. The first group considers the total 4 times of incremental operations. That is, it takes the addition of ten feature nodes and ten corresponding enhancement nodes in an incremental way. The second group keeps the same except 12 rather 10 feature nodes and enhancement nodes. All the results can be checked in Table 7.
It can be seen that the testing accuracy continues to go up as the additional feature nodes are inserted into D&BLS in an incremental way and finally reaches the performance comparable to that of D&BLS with the one-shot construction (see the last row in Table 7). Obviously, the training time of Algorithm 3 is much less than that of D&BLS with the one-shot construction, e.g., 3.3657 s vs. 6.4858 s.
Increment of input data
Two groups of experiments are arranged to observe Algorithm 4 for this case. The first group considers the total 4 times of incremental operations. That is, it takes the addition of 3000 training samples each time in an incremental way from all the remaining training samples. The second group keeps the same except 8000 rather than 3000 training samples. The incremental results are shown in Table 8.
It can be observed that the testing accuracy has a slight decline (e.g., from 94.18 to 93.54%) when the additional input data are fed in the first time into D&BLS, while the testing accuracy begins to go steadily up as more input data are fed in an incremental way and finally reaches the performance comparable to that of D&BLS with the one-shot construction (see the last row in Table 8). Obviously, the training time of Algorithm 4 is much less than that of D&BLS with the one-shot construction, e.g., 3.6203 s vs. 10.4513 s.
Running time comparison
In this subsection, we will show D&BLS’s another attractive property—it only needs much less running time (i.e., training time and testing time) than BLS when they both share the same sizes (i.e., feature nodes and enhancement nodes). The COIL-100 and the USPS datasets are taken for experiments. For a fair comparison, here we report average results and standard deviations for ten trials on each dataset.
D&BLS takes a three-layer structure and each sub-system keeps the same parameters setting, especially the number of selected feature nodes is 1. In other words, if a BLS has 30 × 10 feature nodes and 1 × 2100 enhancement nodes, each sub-system in the corresponding D&BLS will contain 10 × 10 feature nodes, 1 selected feature node, and 1 × 700 enhancement nodes. The obtained experimental results are given in Table 9.
According to Table 9, D&BLS indeed needs much less running time than BLS. What is more, D&BLS runs much more quickly than BLS with the increasing number of enhancement nodes. This tendency becomes considerably surprising in the case of 3600 enhancement nodes for the USPS dataset. That is, BLS occupies 27.2773 s while D&BLS occupies only 9.8075 s for the USPS dataset.
Conclusion
While the recently developed broad learning system BLS has been exhibiting its promising performance without the need of deep structure, it often requires a huge heap of hidden nodes, which may perhaps inevitably cause both overwhelming storage requirement and overfitting phenomenon. In this paper, D&BLS is proposed to synthesize both deep and broad learning so as to guarantee enhance performance, downsize the structure and reduce the running time of the general BLS. D&BLS consists of several lightweight BLS sub-systems. D&BLS has its structure novelty in its joint stacking way of feature augmentation and residuals boosting. The whole learning algorithm and three incremental algorithms of D&BLS are proposed and then verified by our experiments about image datasets and UCI datasets.
Since the parameter settings of each sub-system in D&BLS are given only by the trial and error strategy, a deeper D&BLS sometimes cannot assure better performance than a shallower D&BLS. As a result, how to determine the structure of D&BLS in a moderate time and how to design a deeper D&BLS with desirable ability for practical application scenarios are our research works in near future.
References
Gong M, Zhao J, Liu J, Miao Q, Jiao L (2016) Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans Neural Netw Learn Syst 27(1):125–138
Shao F, Lin W, Wang S, Jiang G, Yu M (2015) Blind image quality assessment for stereoscopic images using binocular guided quality lookup and visual codebook. IEEE Trans Broadcast 61(2):154–165
Salakhutdinov R, Hinton GE (2009) Deep boltzmann machine. In: Proceedings of AISTATS, vol 1, p 3
Hinton GE, Osindero S, The Y-W (2006) A fast learning algorithm for deep belief nets. Neural Comput 18:0899–7667
Hinton GE, Salakhutdinov RR (2006) Reducing the dimensionality of data with neural networks. Science 313(5786):504–507
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition (online). https://arxiv.org/abs/1409.1556
Chen CLP, Liu ZL (2018) Broad learning system: an effective and efficient increment learning system without the need for deep architecture. IEEE Trans Neural Netw Learn Syst 29(1):10–24
Pao Y-H, Takefuji Y (1992) functional-link net computing: theory, system architecture and functionalities. Computer 25(5):76–79
Pao Y-H, Park G-H, Sobajic DJ (1994) Learning and generalization characteristics of the random vector functional-link net. Neurocomputing 6(2):163–180
Feng S, Chen CLP (2018) Fuzzy broad learning system: a novel neuro-fuzzy model for regression and classification. In: IEEE transactions on cybernetics
Jiang Y, Chung F, Ishibuchi H, Deng Z, Wang S (2015) Multitask TSK fuzzy system modeling by mining intertask common hidden structure. IEEE Trans Cybern 45(3):534–547
Gu X, Chung F, Wang S (2017) Bayesian Takagi–Sugeno–Kang fuzzy classifier. IEEE Trans Fuzzy Syst 25(6):1655–1671
Deng Z, Cao L, Jiang Y, Wang S (2015) Minimax probability TSK fuzzy system classifier: a more transparent and highly interpretable classification model. IEEE Trans Fuzzy Syst 23(4):813–826
Gong M, Liu J, Li H, Cai Q, Su L (2015) A multiobjective sparse feature learning model for deep neural networks. IEEE Trans Neural Netw Learn Syst 26(12):263–327
Hoerl ZAE, Kennard RW (2000) Ridge regression: biased estimation for nonorthogonal problems. Technometrics 42(1):80–86
Chen CLP, Liu ZL, Shuang F (2019) Universal approximation capability of broad learning system and its structural variations. IEEE Trans Neural Netw Learn Syst 30(4):1191–1204
Ting KM, Witten IH (1997) Stacked generalization: when does it work? In: Fifteenth international joint conference on artificial intelligence. Morgan Kaufmann
Rumelhart DE, Mcclelland JL (1986) Parallel distributed processing: explorations in the microstructure of cognition, vol 1. Foundations of Research. MIT Press, Cambridge
Freund Y, Schapire R, Abe N (1999) A short introduction to boosting. Jpn Soc Artif Intell 14(771–780):1612
Bühlmann P, Hothorn T (2007) Boosting algorithms: regularization, prediction and model fitting. Statistical Science, pp 477–505
Friedman J, Hastie T, Tibshirani R (2000) Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). Ann Stat 28(2):337–407
Notley SV, Bell SL, Simpson D, Smith DC (2008) Applying boostrap techniques to detect differences in auditory evoked potentials: possible use in anaesthesia monitoring. In: 4th IET international conference on advances in medical, signal and information processing—MEDSIP 2008, Santa Margherita Ligure, pp 1–4
Gulcehre C, Moczulski M, Denil M et al (2016) Noisy activation functions. In: International conference on machine learning, pp 3059–3068
Blake CL, Merz CJ (1988) UCI repository of machine learning databases, vol. 55. Dept. Inf. Comput. Sci., Univ. California, Irvine (online). http://archive.ics.uci.edu/ml/dataset.html
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Cortes C, Vapnik VN (1995) Support vector networks. Mach Learn 20(3):273–297
Suykens JAK, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9(3):293–300
Pedregosa et al (2011) Scikit-learn: machine Learning in Python. JMLR 12:2825–2830
Hull JJ (1994) A database for handwritten text recognition research. IEEE Trans Syst Man Cybern B Cybern 16(5):550–554
S. A. Nene, S. K. Nayar and H. Murase, “Columbia Object Image Library (COIL-20),” Technical Report CUCS-005-96, February 1996
Nene SA, Nayar SK, Murase H (1969) Columbia Object Image Library (COIL-100), Technical Report CUCS-006-96
Lee K-C, Ho J, Kriegman D (2005) Acquiring linear subspaces for face recognition under variable lighting. IEEE Trans Pattern Anal Mach Intell 27(5):138–142
Isolet Dataset (1994) (online). http://featureselection.asu.edu/datasets.php
Funding
This work was supported in part by the National Natural Science Foundation of China under Grants 61572236, 6197071117.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xie, R., Wang, S. Downsizing and enhancing broad learning systems by feature augmentation and residuals boosting. Complex Intell. Syst. 6, 411–429 (2020). https://doi.org/10.1007/s40747-020-00139-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-020-00139-2