
Abstract
Pistachio produce is of great importance in the world and considered as a valuable agricultural produce. This product is important for the economy of the producing countries as well as other importer countries. In this regard, countries which are capable of getting control over this product’s market would obtain considerable benefits; one way to do so is predicting market trend or the price of this product and the affecting factors. In this survey, initially, the affecting parameters on pistachio price are identified. Then, using a novel combined intelligent method, the price of this product is predicted. In addition, using analysis of variance method, the results of the proposed method are compared to other intelligent combined methods, such as Feed Forward-Particle Swarm Optimization, Elman- Imperialist Competitive Algorithm, Feed Forward-Imperialist Competitive Algorithm, Elman-Genetic Algorithm, and Feed Forward-Genetic Algorithm. The results of the mentioned comparison indicate that the proposed method owns an excellent performance.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Nowadays, managers’ success in various decision-making conditions and the identification of the future events for better decision-making requires a methodology to predict these events and obtain a better estimate. The economic decision-making to achieve the maximum benefit is regarded as one of management success determinants. Since prediction is the process to forecast almost near future [1], therefore, using methods which result in less error prediction has a broad application in many fields. In the recent decade, global market of agricultural produce has experienced significant fluctuations; as in some cases, considerable amount instability was observed.
The aforementioned issue may be intensified in some countries due to the currency instability which is dramatic in case of US dollar. These fluctuations can be extremely harmful for the developing countries’ stable benefits—resulted from export, and consequently, may lead to some problems in paying off their debts and growth [2]. Pistachio produce has a great importance and high value in agricultural and economic sectors of the producing countries. In recent years, those countries, capable to dominate the pistachio market, using great mass production, have gained considerable benefit.
There are several methods to model and predict time series; the traditional–statistical methods which introduce linear predictions for future values of the variables, such as: Moving Average, Weighted Average, ARIMA, Regression Method, Markov Chain, Neural Networks, and etc. Despite some advantages, linear methods face some limitations like incapability to work with non-linear relations. To compensate this shortcoming, several non-linear methods have been suggested. In addition, in recent years, artificial neural networks have been employed to predict time series. One of the most important advantages of neural networks is their flexibility in prediction of different types of non-linear models. These networks are inspired by human neural network and brain; therefore, they have better efficiency compared to other mentioned methods in different problems. Some of the studies conducted on economic dimensions of pistachio are: Moshiri and Cemeron reviewed advantages of neural networks over econometric models and compared Back-Propagation Artificial Neural Network (BPN) model with statistic and econometric models [3]. Their results showed that BPN model is capable of excellent prediction. Olson and Mossman compared error back-propagation neural network method with Logit model and Ordinary Least Square methods [4]. The results show that the neural network model is more accurate and possesses lower error. In a study, Chen claimed that currency fluctuations of China’s agricultural export have had a positive effect on Japan [5]. Abolagba et al. evaluated the export of agricultural products [6]. In their study, the effective factors on agricultural produce export with Ordinary Least Square regression method (OLS) was estimated, regarding variables of product amount, export amount, and currency rate, production price, and the amount of domestic and national consumption. In a study, Zheng et al. investigated the role of US in the global production and pistachio business as well as affecting factors on the US’s demand of pistachio export [7]. Results of this study indicated that, using advanced technologies and higher food standards, US pistachio production was able to increase its rank in the global markets. In a case study by Yazdani, risk management tools of pistachio farmers were discussed. Sirjan city is one of the main pistachio producers in Kerman which itself is a very significant pistachio producer province in Iran. The author mentioned and analyzed 144 dangers that farmers face while producing pistachio. The results indicate that: use poisons before damage (3.55), use risk management tools before damage (3.52), do not using new products (3.21), agricultural insurance (2.85) has the highest preference on risk management tools. In addition, stepwise regression results show these three factors: family members, Education, and age of farmers approximately 67% effect on risk management tools [8]. Tohidi et al. represented the hybrid artificial neural network-panel data method to predict the price of pistachio, raisin, and date exports. The results show that the novel artificial hybrid neural network-panel data method has a better performance in the prediction of the price of Iran’s pistachio, raisin, and date exports than that of the regression method. Thus, it is proposed that exporters, policy makers, and researchers use this method to predict economic variables [9].
Based on the previous conducted studies about pistachio, there has been no study on pistachio price prediction. In this study, two methods are used to determine the effective parameters on pistachio price. In addition, a new hybrid method (El-PSO) is used to predict the price of pistachio. The results of the suggested method were compared with other combined methods, such as El-GA, El-ICA, FF-PSO, FF-GA, and FF-ICA. It was pointed out the proposed method has an excellent performance and a relatively negligible error.
This investigation is organized as follows: “Data and methods” explains the methods to determine correlation coefficient. Intelligent methods are illustrated in the next section. The proposed method for prime cost is explained further. “Numerical results” and “Conclusion” present the study’s results of the proposed intelligent combined methods, their comparison, and a general conclusion of this investigation, respectively.
Data and methods
Nowadays, due to economic crisis, fluctuation in currency rate, and inflation rate, it is difficult to predict the produce’s price; in addition, the identification of the influential parameters has its own complexity. The employed parameters in this study are: Domestic Pistachio Market Price (DPMP), Pistachio Global Price (PGP), Iran’s Pistachio Export Quantity (IPEQ), Iran’s Pistachio Production Quantity (IPPQ), Pistachio Global Production Quantity (PGPQ), Domestic Inflation Rate (DIR), Pistachio Production Cost Index (PPCI), and currency rate [US Dollar (UD), Canadian Dollar (CD), England Pound (EP), Emirate Dirham (ED)]. These data were collected in a period of 15 years (1996–2010). Consider Fig. 1.

Parameters affecting pistachio price
Pearson correlation
Correlation method is employed as a statistic tool to measure the state of the relation between variables. Several correlation methods exist to determine the effects of variables on each other. One of the most common of all is Pearson correlation coefficient, because when there is a linear relation between two variables, Pearson correlation coefficient shows a high sensitivity [10,11,12]. Pearson correlation coefficient measures the relationship between two variables by dividing the covariance of the two variables by their standard deviation [13]. The correlation coefficient \(\rho _{X,Y} \) between two random variables X and Y, with expected value of \(\mu _X ,\mu _Y \), and standard deviation \(\sigma _X \sigma _Y \) is calculated as:
where E is the expected value, Cov is the covariance, \(\sigma \) is the standard deviation, and Corr stands for Pearson correlation coefficient.
Mutual information
Based on the following definitions and equations, the effect of two variables on each other can be specified.
Definition 1
MI between two the discrete random variables of X and Y regarding the distribution of p( x, y ) is simultaneously and collectively obtained as follows [14]:
In addition, it should be considered that an appropriate MI is in arguments as follows [15]:
Definition 2
MI between two continuous random variables of X and Y is obtained by p.d.f, f( x, y ) as follows [15]:
The coefficient of the selected parameters
All parameters, already introduced to predict pistachio price, are evaluated and their effectiveness is studied, using two suggested methods. Table 1 shows the influence of the introduced parameters on pistachio price.
As it can be observed in Table 1, the obtained coefficients are in the interval of [0 1] and these coefficients illustrate that larger coefficients (closer to 1) are more influential. All the parameters, except the quantity of internal production and export quantity, have large coefficients. Figures 2, 3, and 4 illustrate the trend of export quantity, pistachio global price, and pistachio the price in Iran, respectively.

Iran’s pistachio export quantity data, in a time period of 2006–2010

Pistachio global price data, in a time period of 2006–2010

Domestic pistachio market price data, in a time period of 2006–2010

General schematic of Elman Neural network, along with specific inputs and outputs
Intelligent methods
Elman neural network
In general, Artificial Neural Networks (ANNs) are briefly mathematical techniques planned and designed to accomplish different types of tasks. Nowadays, neural networks can be configured in a variety of arrangements to perform a range of tasks including pattern recognition, data mining, classification, forecasting, and process modeling. ANNs are made up of attributes which lead to perfect solutions in applications where learning a linear or non-linear mapping is needed [16]. Elman network is considered as one of the most common and efficient recurrent neural networks. This network is normally a two-layer network, in which the first layer is the hidden layer or input layer and the second layer is the output layer. This network performs like a perceptron network; however, in the Elman network, the output of the hidden layer is applied to the input of the hidden layer, via feedback loops. Hence, the output value in each moment will depend on the previous efficient values. Figure 5 depicts a schematic of Elman neural network, along with its inputs and outputs of the problem.
Feed-forward neural network
Feed-forward neural network, inspired by biologic classification algorithm, consists of different neurons and layers to process and organize data. The existence of several layers of neurons with a non-linear transfer function makes the network capable to learn linear and non-linear relation between inputs and outputs. Neurons, which are the elements of the signal processing, are connected to each other by synaptic feed-forward cross layer joints. The input–output connection may be performed by non-linear mapping functions [17]. Appropriate determination and selection of weights and biases is very important in network performance. Weight coefficient expresses the level of the given importance to the parameter. In multi-layer neural networks, the output of a layer is the input of the succeeding one. The equation is as follows [18]. Figure 6 shows the feed-forward neural network, along with inputs and outputs of the problem.

Feed-forward neural networks, with specific inputs and outputs
Genetic algorithm
Genetic algorithm is an optimization method, inspired by living nature, which can be introduced as a numerical, direct, and random search method. This algorithm is based on population and repetition. Its principle concepts are derived from genetic science [19]. In addition, to apply the concept of genetic evolution to an optimization problem, in the real world; two points should be considered: (1) encoding the potential solutions; (2) defining the fitness function (cost function) [20]. The general structure of genetic algorithm employed in this study is defined in a step-by-step process [21].
Step 1: Defining the practical solution of the problem as a genetic problem
Step 2: Generating an initial population \(P( 0 )=x_1^0 ,\ldots , x_N^0.~{\text {Set}}~ t=0.\)
Step 3: the calculation of the mean of fitness \(\bar{{f}}( t )=\sum _i^N {{f( {x_i } )}/N} \). Allocating fitness value to each person \({f( {x_i })}/{\bar{{f}}( t )}\).
Step 4: selection operator; in this study, tournament selection operator is employed for selection of parents for crossover.
Step 5: running the crossover operator with a defined probability for each pair.
Step 6: applying mutation operator with a defined probability for each child.
Step 7: forming a new population \(p ( {t+1} )\) using surviving mechanism.
Step 8: setting \(t=t+1\) and returning to the third step.
Imperialist competitive algorithm
Imperialist Competitive Algorithm (ICA) is a novel political–social strategy for optimize different problems [22]. This algorithm, as an evolutionary optimization strategy, possesses an excellent performance in convergence speed and absolute optimum point [22,23,24,25,26,27]. ICA algorithm is simulated based on political-social imperialism process and imperialist competition [28]. In different optimization methods, different arrays have been used to name problem solutions. For example, in PSO, GA, and ICA algorithms, this array is named as particle, chromosome, and country, respectively. Different optimization problems consist of different dimensions. For an \(N_{\text {var}} \) dimension optimization problem, a country has \(1\times N_{\text {var}} \) arrays; the array is defined as below:
where P shows the dimensions of the problem and each dimension of the problem represents a specific characteristic of the country. Figure 7 depicts some of these characteristics [26].

Country including a combination of some socio-political features

Imperialistic competition
Each country’s value is evaluated by a cost function. This function, based on the type of the problem, is different and its general form is as:
This algorithm starts its work by generating an initial population from countries with \(N_{\text {POP}} \) size. The countries are divided to two categories: imperialist and colony. A number equal to \(N_{\text {imp}} \) and \(N_{\text {col}} \) is selected from the powerful countries and countries as the empire and colony, respectively. Each colony belongs to an empire. To form the initial empires, colonies are attracted to the empire, based on empire’s power. In other words, the initial number of colonies is directly proportional to the power of the empire. The normalized cost of an imperialist to divide the colonies among the appropriate imperialists is as follows [26]:
where \(c_n \) is the cost of nth imperialist and \(C_n \) is the normalized cost. Regarding the normalized cost of all imperialists, the normal power of each imperialist is defined as follows:
First, the initial colonies are divided based on the power of the empire. Afterward, the initial number of colonies of the nth empire is calculated as follows:
where \(NC_n \) is the initial number of colonies of the nth imperialist and \(N_{\text {col}} \) is the number of all colonies. To divide the colonies between imperialists, a quantity equal to \(NC_n \) from the colonies was randomly selected and allocated to imperialists. The power of an empire equals to the power of the colonial country plus a percentage of total power of its colonies. In this way, the total cost of an empire is as:
where \(T.C._n \) is the total cost of the nth empire and \(\xi \) is a positive number, normally considered between 0 and 1 and close to 0. A smaller value of \(\xi \) leads to an approximate balance between the total cost of an empire and the cost of its central government, while, if \(\xi \) increases, it will increase the influence of the quantity of the colonies’ cost of an empire on the determination of its total cost. Typically, \(\xi =0.05\) leads to desirable responses in most of the applications [26].
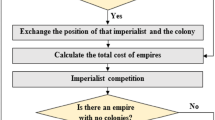
Each empire which is unable to improve its power and loses its competition power will be eliminated through imperialist completions; this elimination is performed gradually. In other words, as time goes on, weak empires lose their colonies and more powerful empires occupy these colonies and enhance their power. In order to model this, it is assumed that the eliminating empire is the weakest existing one. Hence, in the algorithm’s repetition process, one or several weakest colonies are selected, and then—to seize these colonies—a competition is generated within all empires. The mentioned colonies are not necessarily seized by most powerful empire; although the more powerful empires are a higher chance to seize. Figure 8 illustrates the schematic of this section of the algorithm [26].
In this figure, empire 1 is considered as the weakest empire and one of its colonies is exposed to imperialistic competition, and empires 2 to N compete to seize it. To model the competition among empires to seize the colony, primarily, the probability of each empire to seize—which is proportional to the power of that empire—is calculated, regarding the total cost of the empire. First, through the total cost of the empire, its total normalized cost is determined:
In this equation, \(T.C._n \) is the total cost of the nth empire and \(N.T.C._n \) is the total normalized cost of the empire. Each empire which has less \(T.C._n \), the higher its \(N.T.C._n \) will be. As a matter of fact, \(T.C._n \) is equal to the total cost of an empire, while NTCn is its total power. The empire with the least cost is the one with the highest power. Having the total normalized cost, the probability of the ownership, by each empire, of the colony—exposed to the competition—is calculated as:
Regarding the probability of each empire to seize, it is required to have a mechanism like roulette wheel in genetic algorithm to assign the colony—exposed to the competition—to one empires, based on their appropriate probability. Having probability of each empire to seize, to divide the colony to empires randomly, but with the dependent probability to the seizing probability of each empire, P vector is formed based on the above probability values as follows [26]:
where P vector is of \(1\times N_{\text {imp}} \) size and consists of probability values of empires’ seizing. Consequently, random vector R is generated with the same size of P vector. Elements of this vector are random numbers with uniform distribution in [0, 1] interval:
Therefore, D vector is generated as:
Possessing vector D, the colonies are given to an empire that its index is greater in D vector, as compared to other empires; the empire which has the highest probability to seize, whose index—with higher probability—in vector D, will have the greatest quantity [26].
Particle swarm optimization
Particle swarm optimization algorithm is a social search algorithm which is modeled based on social behavior of bird species. First, this algorithm was employed to identify patterns of simultaneous flight of birds and rapid path change and optimum re-formation of the group. In this algorithm, each solution of the problem is modeled as a particle that has a value and fitness value. In this algorithm, vector method is used to search for the optimum solution. This algorithm has been used in many study fields, such as problem optimization, economic problems, neural network training, and optimization of production systems [29]. PSO is designed to search for the best global solution, using a swarm of particles, and is updated through each stage [30]. Each particle represents a potential solution in search space, which sets its location and velocity regarding the its own best experience or local best and the so-far-obtained best experience or local best of all particles (global best) [31]. Consider an N dimensional problem with i particles and t generations. \(X_{i,N} (t)\) and \(V_{i,N} ( t )\) are location and velocity of the ith particle, respectively. The velocity of the ith particle for the \(( {t+1} )\) generation is calculated through the following equation [32, 33]:
where \(1\le i\le m\), \(1\le t\le k\); and \(c_1 \) and \(c_2 \) have the values \(c_1 =c_2 =2\). \(r_1 \) and \(r_2 \) are the two independent random numbers that follow the uniform functions in [\(-1,\) 1] interval. \(\omega \) is the inertia coefficient that controls the effect of the previous speed on the current speed:
where \(\omega ( 1 )\) is the initial inertia weight and \(\omega ( k )\) is equal to the inertia weight which evolved swarm in the last generation of k and t is equal to maximum repetition and initial repetition of the maximum generation, respectively. PSO, as a type of simple and effective random searching algorithm, may lead to better results than the gradient descent method, penalty function method, and genetic algorithm, when solving some non-linear optimization problems [34, 35].
Proposed method
Within the last two decades, optimization has spread its application in different fields, such as industrial engineering, electrical engineering, computer engineering, telecommunication, and transportation. Nowadays, the application of intelligent methods such as artificial neural networks and meta-heuristic algorithms has an important position in different study fields. In this survey, Genetic, Imperialist Competitive, and Particle Swarm (GA, ICA, and PSO) algorithms have been used as optimizers of the neural network parameters. Since the performance of these algorithms is based on population, the combination of each algorithm with the Elman neural network and feed-forward network is almost similar. However, based on their nature, they show different performance. The purpose of combining these algorithms with the neural network is to optimize weights and biases of the neural network. As stated in the previous sections, these algorithms are of a population based nature, and the problem has to be defined, so that the algorithms can optimize it as a swarm of the population. In problem-defining stage, chromosome (GA), particle (PSO), or country (ICA) should be in a way to optimize the weights and biases, which mean the number of each chromosome’s gens, and should be equal to the number of weights and biases. Training the neural network, the number of weights and biases depends on the number of layers and neurons. To make a particle, the following procedure is performed:

where N is the number of neural network parameters or in other words, the dimension of the optimization problem. \(n_{l_i } \) and I are the number of neurons in the ith layer and input of the network, respectively. When the solution chromosome is specified, a cost function should be defined for the optimization problem to calculate the optimal value of parameters (W, b). The employed cost function is represented in the following section.
Cost function
MMSE cost function is used in this section to optimize parameters of the neural network. Here, each solution of the problem (chromosome, particle, or country) has a cost; the cost function calculates these costs for solutions. Furthermore, based on the nature of the cost function, it should be minimized using optimization algorithms: to find a solution with the least possible cost. In this investigation, three optimization algorithms of PSO, ICA, and GA methods are used to minimize the cost function. MMSE is the Minimum Mean Squares Error of (MSE). MSE and MMSE are:
where, \(X_{\text {FOR}} \) is the predicted value, \(X_{\text {ACT}} \) is the actual value, and n is the number of data.
Training and testing of the neural network
After defining the neural network parameters as a problem and optimizing the problem with aforementioned algorithms, the neural network should be trained and tested. In this stage, the optimal value of the parameters should be provided to the neural network and the network employs a part of input data (75% in this study) for training. Optimized parameters by the optimization algorithms such as PSO, ICA, and GA as well as transfer functions (here, tangent sigmoid transfer function is used), relation, and behavior of the data are obtained, and then, the trained network is evaluated by different criteria. In the current study, to evaluate the performance of the neural network training, two criteria of Mean Squared Errors (MSE) and Root Mean Square of Errors (RMSE) are used.
If the training is performed well, the neural network testing phase would be initiated. The network is tested by data which had been preserved for this phase. Afterwards, the network is evaluated by different error criteria. To evaluate testing phase, two error criteria of Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) are used:
where \(X_{\text {ACT}} \) and \(X_{\text {FOR}} \) are actual value and predicted value, respectively. Figure 9 illustrates flowchart of combination of the proposed method.

Flowchart of the proposed method (El-PSO)
Input data
In the current investigation, monthly data in a period of 15 years (1996–2010) were used as inputs of the neural network. These data are for Islamic Republic of Iran collected from different organizations, such as Iran’s Pistachio Research Institute (IPRI), customhouse, and the Central Bank of I.R.I. After the determination of input and output variables of the network, the data should be normalized prior to each procedure of neural network training in the bracket of [−1 1]. The purpose of normalizing the data is that all the training data should have a uniform statistic distribution. In this study, linear normalization is used to convert data.
where \(X_{\text {norm}} \) is the normalized value, X is the non-normal value, and \(\text {Min}( X )\) and \(\text {Max}( X )\) is minimum and maximum of the non-normal, respectively.
Numerical results
Case study
Pistachio product is of great importance in either producing countries or other countries and is considered as the green gold. Two major pistachio producing countries are Iran and the US. In this study, the price in Iran of pistachio data is used to predict the price of this produce. In addition to Iran’s domestic market prices data, the data of inflation rate, export value, and production amount, and etc.—which have been mentioned in previous sections—were used as well.
Results of the proposed method and other combined methods
As stated in the previous sections, combined method of El-PSO was used to predict Iran’s domestic market pistachio prices. Table 2 illustrates the best results of this method and other combined methods. Figure 10 shows the actual and the predicted data by the El-PSO method.

The comparison of actual data and predicted data of the El-PSO method
Moreover, 60 data were selected (for 5 years) and the performance was once again evaluated. Table 3 depicts the performance result of this part of data, which was obtained by El-PSO and other methods.
According to the results of the table, El-PSO method has an excellent performance as compared to other methods, which proves that the efficiency of this method to predict pistachio price is, indeed, a complicated task.
Results analysis, using analysis of variance method
Since several novel combined methods are used to predict pistachio price in this study, one of the best techniques to evaluate these methods’ performance is analysis of variance method (ANOVA). Using this technique, more than a society (method) can be evaluated. In this section, the results of MAE error criterion, which are obtained by all the methods, are compared by ANOVA. Figures 11 and 12 are the output of this method, which show mean and distribution, respectively.

Mean of the proposed method and other methods, using MAE criterion

Distribution of the proposed method and other methods, using MAE criterion
Table 4 represents statistical characteristics obtained by ANOVA method. Using these results, it can be concluded that the suggested method of El-PSO has an excellent performance and limited distribution. It should be mentioned that Minitab 16 software is employed to implement ANOVA.
Conclusion
According to complexity of pistachio price in Iran and the world, it is very difficult to propose a model capable to predict pistachio price, based on relevant factors and results with a lower error. Suggesting an efficient method can be helpful to the economy of producing countries, as well. In the current survey, El-PSO method is proposed to predict pistachio price. This method owns an excellent performance and so efficient that can be used in other problems, also.
References
Makridakis S, Wheelwright SC (1989) Forecasting methods for management, 5th edn. Wiley, Chichester
Hazell PB, Jaramillo M, Williamson A (1990) The relationship between world price instability and the prices farmers receive in developing countries. J Agric Econ 41(2):227–41
Moshiri S, Cameron NE (2000) Neural network versus econometric models in forecasting inflation. J Forecast 19(3):201–217
Olson D, Mossman C (2003) Neural network forecasts of Canadian stock returns using accounting ratios. Int J Forecast 19(3):453–465
Chen L (2011) The effect of China’s RMB exchange rate movement on its agricultural export: a case study of export to Japan. China Agric Econ Rev 3(1):26–41
Abolagba EO, Onyekwere NC, Agbonkpolor BN, Umar HY (2010) Determinants of agricultural exports. J Hum Ecol 29(3):181
Zheng Z, Saghaian S, Reed M (2012) Factors affecting the export demand for US pistachios. Int Food Agribus Manag Rev 15(3):139–54
Yazdani F, Tash MN (2014) Identifying and analysis of risk management tools of pistachio farmers (a case study of Sirjan region). Int J Agric Crop Sci 7(9):555–559
Tohidi A, Zare MM, Mehrabi BH, Nezamabadi PH (2015) Evaluation of Artificial Neural Network-Panel Data Hybrid Model in Predicting Iran’s Dried Fruits Export Prices. 12(3):95–116
Croxton FE, Klein S, Cowden DJ (1968) Applied general statistics, vol 9, 10, 3rd edn. Sir Isaac Pitman and Sons, London
Dietrich CF (1991) Uncertainty, calibration and probability: the statistics of scientific and industrial measurement (2nd ed.). Higler series on science and technology. CRC Press, Boca Raton, p 331. ISBN 9780750300605
Aitken AC (1939) Statistical mathematics. Oliver and Boyd, Edinburgh
Lee Rodgers J, Nicewander WA (1988) Thirteen ways to look at the correlation coefficient. Am Stat 42(1):59–66
Mai V (2013) Lecture 2: entropy and mutual information. McGill University Electrical and Computer Engineering. ECSE 612— Multiuser Communications
Chen CP (2009) Entropy and mutual information notes on information theory. Department of Computer Science and Engineering, National Sun Yat-Sen University, Kaohsiung
Azadeh A, Asadzadeh SM, Jafari-Marandi R, Nazari-Shirkouhi S, Khoshkhou GB, Talebi S, Naghavi A (2013) Optimum estimation of missing values in randomized complete block design by genetic algorithm. Knowle Based Syst 37:37–47
Heydari A, Keynia F, Shahsavari Pour N (2013) Machinery cost prediction based on a new neural network method. J Basic Appl Sci Res 3(7):484–491
Hagan MT, Demuth HB, Beale MH (2002) Neural network design: Campus Pub. Service. University of Colorado Bookstore, Boulder 1284
Qasem SN, Shamsuddin SM, Zain AM (2012) Multi-objective hybrid evolutionary algorithms for radial basis function neural network design. Knowl Based Syst 27:475–97
Hsu CM, Chen KY, Chen MC (2005) Batching orders in warehouses by minimizing travel distance with genetic algorithms. Comput Ind 56(2):169–78
Mühlenbein H (1997) Genetic algorithms. In: Aarts E, Lenstra JK (eds) Local search in combinatorial optimization. Wiley, New York, pp 137–171
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In 2007 IEEE congress on evolutionary computation 2007 Sep 25 (pp 4661–4667). IEEE
Rajabioun R, Atashpaz-Gargari E, Lucas C (2008a) Colonial competitive algorithm as a tool for Nash equilibrium point achievement. International conference on computational science and its applications. Jun 30, pp 680–695. Springer, Berlin
Biabangard-Oskouyi A, Atashpaz-Gargari E, Soltani N, Lucas C (2009) Application of imperialist competitive algorithm for materials property characterization from sharp indentation test. Int J Eng Simul 10(1):11–12
Sepehri Rad H, Lucas C (2008) Application of imperialistic competition algorithm in recommender systems. In13th Int’l CSI Computer Conference (CSICC’08), Kish Island, Iran
Atashpaz Gargari E, Hashemzadeh F, Rajabioun R, Lucas C (2008) Colonial competitive algorithm: a novel approach for PID controller design in MIMO distillation column process. Int J Intell Comput Cybern 1(3):337–55
Rajabioun R, Hashemzadeh F, Atashpaz-Gargari E, Mesgari B, Salmasi FR (2008b) Decentralized PID controller design for a MIMO evaporator based on colonial competitive algorithm. IFAC Proc 41(2):9952–7
Mousavi SM, Tavakkoli-Moghaddam R, Vahdani B, Hashemi H, Sanjari MJ (2013) A new support vector model-based imperialist competitive algorithm for time estimation in new product development projects. Robot Comput Integr Manuf 29(1):157–68
Onwunalu JE, Durlofsky LJ (2010) Application of a particle swarm optimization algorithm for determining optimum well location and type. Comput Geosci 14(1):183–98
Zhou C, Ding LY, He R (2013) PSO-based Elman neural network model for predictive control of air chamber pressure in slurry shield tunneling under Yangtze River. Autom Constr 36:208–217
Zhang H, Li X, Li H, Huang F (2005) Particle swarm optimization-based schemes for resource-constrained project scheduling. Autom Constr 14(3):393–404
Lu M, Lam HC, Dai F (2008) Resource-constrained critical path analysis based on discrete event simulation and particle swarm optimization. Autom Constr 17(6):670–81
Chen JH, Yang LR, Su MC (2009) Comparison of SOM-based optimization and particle swarm optimization for minimizing the construction time of a secant pile wall. Autom Constr 18(6):844–8
Yaghini M, Khoshraftar MM, Fallahi M (2013) A hybrid algorithm for artificial neural network training. Eng Appl Artif Intell 26(1):293–301
Yu C, Teo KL, Zhang L, Bai Y (2010) A new exact penalty function method for continuous inequality constrained optimization problems. J Ind Manag Optim 6(4):895
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Heydari, A., Keynia, F., Shahsavari-Pour, N. et al. An evolutionary hybrid method to predict pistachio price. Complex Intell. Syst. 3, 121–132 (2017). https://doi.org/10.1007/s40747-017-0038-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-017-0038-8