
Abstract
Introduction
Ankylosing spondylitis (AS) is a chronic progressive inflammatory disease of the spine and its affiliated tissues. AS mainly affects the axial bone, sacroiliac joint, hip joint, spinal facet, and adjacent ligaments. We used machine learning (ML) methods to construct diagnostic models based on blood routine examination, liver function test, and kidney function test of patients with AS. This method will help clinicians enhance diagnostic efficiency and allow patients to receive systematic treatment as soon as possible.
Methods
We consecutively screened 348 patients with AS through complete blood routine examination, liver function test, and kidney function test at the First Affiliated Hospital of Guangxi Medical University according to the modified New York criteria (diagnostic criteria for AS). By using random sampling, the patients were randomly divided into training and validation cohorts. The training cohort included 258 patients with AS and 247 patients without AS, and the validation cohort included 90 patients with AS and 113 patients without AS. We used three ML methods (LASSO, random forest, and support vector machine recursive feature elimination) to screen feature variables and then took the intersection to obtain the prediction model. In addition, we used the prediction model on the validation cohort.
Results
Seven factors—erythrocyte sedimentation rate (ESR), red blood cell count (RBC), mean platelet volume (MPV), albumin (ALB), aspartate aminotransferase (AST), and creatinine (Cr)—were selected to construct a nomogram diagnostic model through ML. In the training cohort, the C value and area under the curve (AUC) value of this nomogram was 0.878 and 0.8779462, respectively. The C value and AUC value of the nomogram in the validation cohort was 0.823 and 0.8232055, respectively. Calibration curves in the training and validation cohorts showed satisfactory agreement between nomogram predictions and actual probabilities. The decision curve analysis showed that the nonadherence nomogram was clinically useful when intervention was decided at the nonadherence possibility threshold of 1%.
Conclusion
Our ML model can satisfactorily predict patients with AS. This nomogram can help orthopedic surgeons devise more personalized and rational clinical strategies.
Plain Language Summary
AS is a chronic progressive inflammatory disease of the spine and its affiliated tissues. AS starts gradually, and its early symptoms are mild. Some hospitals lack HLA-B27 and related imaging instruments to assist in the diagnosis of AS. There are relatively few studies on liver function and kidney function of patients with AS. We used ML methods to construct diagnostic models. Our model can satisfactorily predict patients with AS. This diagnostic model can help orthopedic surgeons devise more personalized and rational clinical strategies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
We consecutively screened 348 patients with AS through complete blood routine examinations, liver function tests, and kidney function tests. |
We used three ML methods [LASSO, random forest, and support vector machine recursive feature elimination (SVM-RFE)] to screen feature variables and then took the intersection to obtain the prediction model. In addition, we used the prediction model on the validation cohort. |
Our diagnostic models can help orthopedic surgeons devise more personalized and rational clinical strategies. |
Introduction
Ankylosing spondylitis (AS) is a chronic progressive inflammatory disease of the spine and its affiliated tissues [1]. AS mainly affects the axial bone, sacroiliac joint, hip joint, spinal facet, and adjacent ligaments [2]. The main clinical manifestations are pain in the waist, sacroiliac joints, and hip and progressive joint stiffness, resulting in joint mobility limitation and joint deformity [3].
Millions of people are diagnosed with AS each year, but the cause of AS remains unknown. The ratio of male to female patients with AS is approximately 3:1 [4], and the incidence rate among relatives of patients is 20 times higher than that in the general population [5]. However, the genetic heritability of AS is influenced by variations in the MHC region, accounting for 40–50% of the total genetic risk of developing the disease, specifically with positivity for HLA-B27 [3].
Machine learning (ML) is a scientific discipline focusing on how computers learn using data. It is the intersection of statistics, which learns relationships from data, and computer science, which emphasizes efficient computational algorithms. ML is now widely used in the study of clinically relevant data [6, 7]. Liang et al. used LASSO regression to find that the platelet-to-lymphocyte ratio could be an independent factor in diagnosing AS [8]. Zhang et al. used machine learning to predict the volumetric response of patients with acute kidney injury [9].
AS starts gradually, and its early symptoms are mild. Patients with AS often have nephropathy and cardiovascular disease [10, 11]. Some hospitals lack HLA-B27 and related imaging instruments to assist in the diagnosis of AS. There are relatively few studies on liver function and kidney function of patients with AS. We used ML methods to construct diagnostic models based on blood routine examination, liver function test, and kidney function test of patients with AS to help clinicians enhance diagnostic efficiency and allow patients to receive systematic treatment as soon as possible.
Methods
Patients
Subjects volunteering for the study signed informed consent forms. The Ethics Committee of the First Affiliated Hospital of Guangxi Medical University approved this study, which adhered to the tenets of the Helsinki Declaration of 1964.
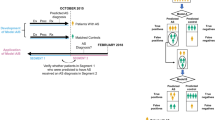
From 2012 to 2021, we consecutively screened 348 patients with AS through complete blood routine examination, liver function test, and kidney function test at the First Affiliated Hospital of Guangxi Medical University according to the modified New York criteria (diagnostic criteria for AS) [12]. Inclusion criteria: (1) patients with AS who met the Modified New York Criteria; (2) patients who had good compliance and no serious cardiovascular and cerebrovascular diseases; (3) patients who voluntarily accepted blood routine examinations, liver function tests, and kidney function tests. Exclusion criteria: (1) patients who cannot tolerate blood drawing or have coagulation dysfunction; (2) patients with a temperature > 37.3 °C at admission; (3) patients with liver and kidney disease .
A total of 360 patients without AS were recruited from among all the inpatients diagnosed with the other disease to complete the blood drawing test. Inclusion criteria: (1) patients clearly diagnosed with non-AS; (2) patients who had good compliance and no serious cardiovascular and cerebrovascular diseases; (3) patients who voluntarily accepted blood routine examinations, liver function tests, and kidney function tests. Exclusion criteria: (1) patients who cannot tolerate blood drawing or have coagulation dysfunction; (2) patients with a temperature > 37.3 °C at admission; (3) patients with liver and kidney disease .
By using random sampling, the patients were randomly divided into training and validation cohorts. The training cohort included 258 patients with AS and 247 patients without AS, whereas the validation cohort included 90 patients with AS and 113 patients without AS (Fig. 1).

Recruitment and screening
All clinical data were obtained from the Information System of the First Affiliated Hospital of Guangxi Medical University. The information of patients was identified by their ID number. Age, diagnosis, erythrocyte sedimentation rate (ESR), high-sensitivity C-reactive protein (hs-CRP), blood routine examination, liver function examination, and kidney function examination of all the patients were collected and statistically analyzed. Blood routine examination included white blood cell (WBC) count, red blood cell count (RBC), hemoglobin (HGB), hematocrit value (HCT), mean corpuscular volume (MCV), mean corpuscular hemoglobin (MCH), mean corpuscular hemoglobin concentration (MCHC), blood platelet count (BPC), mean platelet volume (MPV), platelet distribution width (PDW), absolute value of neutrophil (NEUT#), percentage of neutrophils (NEUT), absolute value of lymphocytes (LYM#), percentage of lymphocytes (LYM), monocyte absolute value (MONO#), percentage of monocytes (MONO), absolute value of eosinophils (ESO#), percentage of eosinophils (ESO), absolute value of basophils (BASO#), percentage of basophils (BASO), red cell distribution width (RDW), and thrombocytocrit (PCT). The liver function examination included total bilirubin (TBil), direct bilirubin (DBil), indirect bilirubin (IBil), DBil/IBil, total protein (TP), albumin (ALB), globulin (GLB), ALB/GLB ratio, gamma-glutamyl transpeptidase (GGT), total bile acid (TBA), aspartate aminotransferase (AST), alanine aminotransferase (ALT), AST/ALT, A-alkaline phosphatase (ALP), prealbumin (PAB), and cholinesterase (ChE). The kidney function examination included blood urea nitrogen (BUN), creatinine (Cr), uric acid (UA), bicarbonate radical (HCO), creatinine clearance rate (Ccr), and cysteine C (Cys-C). We tried to keep the data as complete as possible, and we excluded the very few patients who were missing before we did the statistical analysis.
Statistical Analysis
We used IBM SPSS Statistics 23 and R software (version 4.1.3; https://www.R-project.org) for data analysis. Student t-test was used to compare the mean of continuous variables between the two cohorts (i.e., patients with AS and patients without AS). t-Test data are normally distributed and have homogeneous variances. We verified the data calculation several times. hs-CRP was analyzed using chi-square test. A two-sided probability value of less than 0.05 was considered to be statistically significant for all analyses.
The nomogram survival model was constructed to predict AS by using the “rms” package [13]. The “rms” package was also used to calculate the C value and multifactor logistic regression [14, 15] to verify nomogram prediction ability. The area under the curve (AUC) of the receiver operating characteristic curve (ROC) curve and Harrell’s concordance index were used to evaluate the performance of nomogram predictions. Harrell’s concordance index was calculated to assess nomogram discrimination by using a bootstrap method with 1000 samples [16]. The “corrplot” package was used to analyze the correlation of the independent variables [17]. Decision curve analysis was conducted to determine the clinical usefulness of the nonadherence nomogram by quantifying the net benefits at different threshold probabilities in patients with AS [18]. The net benefit was calculated by subtracting the proportion of all patients who were false-positive cases from the proportion of the patients who were true-positive cases and by weighing the relative harm of forgoing interventions compared with the negative consequences of an unnecessary intervention [19]. In this study, the “rms” and “rmda” packages were used to obtain the thresholds and visualize them.
If all variables are included, machine learning operations become very difficult. So, for the training cohort, we first screened all variables with P < 0.05 using the SPSS software and then continued screening using three ML methods.
Random Forest
The random forest model uses the “randomforest” package in R software to screen out variables and calculate and visualize the relative importance of variables [20]. “%IncMSE” means an increase in the mean squared error. Values are randomly assigned to each prediction variable; if the prediction variable is more important, the model prediction error increases after its value is randomly replaced [21]. Therefore, the greater the value, the greater the importance of the variable. “IncNodePurity” denotes an increase in node purity, which is measured as the sum of the squares of residual errors and represents the impact of each variable on the heterogeneity of observed values at each node of the classification tree. The greater the value, the greater the importance of the variable [22]. Either “%IncMSE” or “IncNodePurity” was chosen as an indicator to judge the importance of the prediction variable. The most important quantity was obtained as the most suitable predictive variable through five iterations of tenfold cross-validation.
Lasso Regression
The LASSO regression model is a contraction method that actively selects from a large, potentially multicollinear set of variables in the regression to screen out risk factors and optimal predictive characteristics from the data of patients with AS. The dependent variables with P < 0.05 after calculation using Student’s t-test were used, and the “glmnet” package in R software was used for LASSO regression analysis and visualization [23, 24].
Support Vector Machine Recursive Feature Elimination
Support vector machine (SVM) recursive feature elimination (SVM-RFE) is a powerful tool, often grouped under ML. The SVM-RFE model was constructed to predict AS by using the “rms” package. In this study, tenfold cross-validation was performed on the data, the output vector characteristic index was obtained, and the variables were sorted from “most useful” to “least useful.” The smaller the AvgRank value, the greater the influence of the dependent variable on the independent variable. After sorting, we generalized error estimation for the entire data and screened the variable with the lowest common diagnosis error rate [25, 26].
Results
Data feature
Tables 1, 2, 3 and 4 show the differences in sex, age, ESR, blood routine examination, liver function and kidney function, and hypersensitive C-reactive protein between patients with AS and patients without AS in the training and validation cohorts. In the training cohort, the majority of patients with AS were male (Tables 1 and 2). The mean age of patients with AS was smaller than that of patients without AS, but the difference was not statistically significant. The proportion of ESR and hs-CRP > 10 in patients with AS was higher than that in patients without AS, and the proportion of hs-CRP < 0.8 was significantly lower than that in patients without AS. WBC, RBC, HGB, HCT, BPC, PDW, NEUT#, NEUT%, and MONO# were higher in patients with AS than in patients without AS, whereas MCHC, MPV, LYM%, and ESO# were lower in patients with AS (Tables 1 and 4). There was no significant difference in MCV, MCH, LYM#, MONO%, ESO%, BASO#, BASO%, RDW, and PCT on blood routine examination. Cr and Ccr of patients with AS were higher than those of patients without AS, whereas BUN and Cys-C were lower than those of patients without AS (Table 3). There was no statistical difference in UA and HCO between patients with AS and those without AS. Furthermore, the liver function test showed no significant differences in IBil, GGT, ALT, or PAB (Table 2). Moreover, DBil/TBil, TP, ALB, GLB, ALB/GLB, and ChE of patients with AS were higher than those of patients without AS, whereas TBil, DBil, TBA, AST, AST/ALT, and ALP were lower.
The correlation heat map (Fig. 2) shows the correlations between all the variables. Positive correlation was noted between HGB and HCT (hematocrit value), TBil and DBil, TBil and IBil, MCV and MCH, WBC and absolute value of neutrophils, BPC and PCT, TP and GLB, EO and absolute value of eosinophils, and BASO and absolute value of basophils. In contrast, a negative correlation was noted between LYM and NEUT and between Ccr and Cys-C (Fig. 3).

Heat map of the correlations between all the variables

LASSO coefficient profiles of the factors, using cross-validation to the optimal penalty parameter lambda. A The results of the LASSO regression analysis of dependent variables. B The 20 factors that exhibited significant differences between the patients with AS and those without AS
Machine Learning
In the training cohort, 30 factors were included in ML with P < 0.05 after t-test screening.
Random Forest
Figure 4A shows the 23 most important factors calculated using the two random forest algorithms “%IncMSE” and “IncNodePurity.” Fig. 4B shows that the ideal regression effect can be obtained by retaining the ten most important factors after tenfold cross-validation. Table 6 lists the ten important factors for the final selection of random forest regression.

Random forest screening variables. A The 23 most important factors calculated using the two random forest algorithms “%IncMSE” and “IncNodePurity.” B The ideal regression effect can be obtained by retaining the ten most important factors after tenfold cross-validation
Lasso Regression
Figure 3A shows the results of the LASSO regression analysis of dependent variables. Figure 3B shows the 20 factors that exhibited significant differences between the patients with AS and those without AS. Table 5 presents the factors screened by LASSO regression (Table 6).
Svm-Rfe
Figure 5 shows that, when 30 factors were selected as diagnostic models after SVM-RFE calculation, the error rate was the lowest, and all the factors included were meaningful for diagnosis. Table 7 shows the order of importance of the 30 factors in SVM-RFE. The smaller the AvgRank value, the greater the influence of the dependent variable on the independent variable.

The 30 factors were selected as diagnostic models after SVM-RFE calculation
Figure 6 shows the intersection of variables screened using LASSO, random forest, and SVM-RFE; nine variables were finally obtained: sex, ESR, RBC, HGB, MPV, TP, ALB, AST, and Cr. The AUC values for the nine variables are shown in Fig. 7.

The intersection of variables screened using LASSO, random forest, and SVM-RFE

AUCs of the intersection of variables screened
Diagnostic Mode
As can be seen in Fig. 8A, nine variables were included in the nomogram model. The optimal cutoff value of this nine-variable nomogram model is 179.459, with a sensitivity of 0.857 (95% CI 0.814–0.899), specificity of 0.806 (95% CI 0.756–0.855), and PPV of 0.822 (95% CI 0.766–0.867). NPV was 0.843 (95% CI 0.797–0.890). The C-index for the prediction nomogram was 0.878. The AUC value of the nomogram curve was 0.8777422 (95% CI 0.847–0.908) (Fig. 8C). In addition, calibration curves exhibited a satisfactory agreement between nomogram predictions and actual probabilities (Fig. 8B). The decision curve (Fig. 8D) showed that if the threshold probability of a patient and a doctor is > 1 and < 92%, respectively, using this nonadherence nomogram to predict AS nonadherence risk is more beneficial than the intervention-in-all-patients scheme or the intervention-in-none scheme[27].

The nine factors establish a nomogram for AS. A Nomogram for predicting AS probability. B Calibration curves for predicting AS probability. C AUC of the nomogram based on the nine characteristics. D Decision curve analysis for the nine-characteristic AS prediction nomogram
Simplified Diagnostic Mode
On the basis of the importance of the variables screened by ML and combined with clinical practicability, we attempted to simplify the diagnostic model to achieve high diagnostic efficiency. RBC, HGB, ALB, and TP are partially repeatable, and deletion of HGB and TP does not seriously impact the final diagnostic model, but also makes the model more concise. Finally, we selected seven variables, namely sex, ESR, RBC, MPV, ALB, AST, and CR, for the simplified diagnostic model. The optimal cutoff value of this nine-variable nomogram model is 173.139, with a sensitivity of 0.860 (95% CI 0.818–0.903), specificity of 0.798 (95% CI 0.747–0.848), and PPV of 0.816 (95% CI 0.770–0.862). NPV was 0.845 (95% CI 0.799–0.892). The C-index for the prediction nomogram was 0.878. The AUC value of the nomogram curve was 0.8779462 (95% CI 0.847–0.909) (Fig. 9C). In addition, calibration curves exhibited a satisfactory agreement between nomogram predictions and actual probabilities (Fig. 9B). The decision curve (Fig. 9D) revealed that when the threshold value of the model was set in the range of 1%–100%, the decision curve was above the NONE line and ALL line, thus indicating that the model has clinical usefulness in this range.

The seven factors establish a nomogram for AS. A Nomogram for predicting AS probability. B Calibration curves for predicting AS probability. C AUC of the nomogram based on the seven characteristics. D Decision curve analysis for the seven-characteristic AS prediction nomogram
Validation Cohort
The two diagnostic models were employed for the validation cohort for verification. The C values of this nomogram were 0.827 (nine-factor diagnostic model) and 0.823 (seven-factor diagnostic model). The calibration curves exhibited a satisfactory agreement between nomogram predictions and actual probabilities (Fig. 10A, B). Figures 10C, D show the AUC values of the two diagnostic models were 0.8267453 (nine-factor diagnostic model) and 0.8232055 (seven-factor diagnostic model). We selected the seven-factor diagnostic model for subsequent analyses.

Validation cohort. A In validation cohort, calibration curves for nine characteristics predicting AS probability. B In validation cohort, calibration curves for seven characteristics predicting AS probability. C In validation cohort, AUC of the nomogram based on the nine characteristics. D In validation cohort, AUC of the nomogram based on the nine characteristics
Discussion
Using clinically relevant data and ML algorithms, we established a prediction model (Fig. 8A) for AS. The prediction model is based on a series of predictions. In addition, three ML models were used to filter variables and then verified on a validation cohort. This artificial-intelligence-based strategy can be used by clinicians to help them choose easier diagnostic methods [28].
ML has contributed to a paradigm shift in health care wherein computers learn from patient data without employing explicit programming tasks [29]. ML offers the advantages of extensive applicability, objectivity, and repeatability when dealing with large datasets and reliable data [30, 31]. Moreover, it can help improve the quality of early diagnosis, identify disease progression, and increase the likelihood of predicting specific patient outcomes in orthopedic procedures, such as outcome scores, risk of complications, and implant survival [32, 33]. These benefits facilitate decision-making and information sharing between clinicians and patients and facilitate effective planning and rational use of healthcare services [34].
AS is a chronic progressive inflammatory disease of the spine and its affiliated tissues. Through ML screening, we screened a total of nine variables that can be used to predict AS: sex, ESR, RBC, MPV, ALB, AST, and Cr. Most of the patients with AS are male [35], but the prevalence of AS in women is gradually increasing [36]. The proportion of male patients with AS receiving medical treatment is much higher than that of female patients [8]. Male patients with AS are more likely to develop hip and spinal mobility disorders than women [36, 37]. Males score higher in our diagnostic model.
ESR is the distance of the erythrocyte subsidence at the end of the first hour to represent the rate of erythrocyte sedimentation. An increase in ESR is considered an inflammatory reaction or hyperglobulinemia in clinicopathology [38]. AS is a chronic inflammatory disease that can lead to accelerated ESR [39]. Studies have shown that ESR is associated with poor physical activity in patients with AS [40]. In our diagnostic model, ESR is positively correlated with the final score. The higher ESR is, the more likely it is to be diagnosed AS.
The results of the current study revealed that RBC and HGB increased in patients with AS [41]. Ninety percent of RBC is composed of HGB, which is mainly responsible for the transport of oxygen and carbon dioxide in the body. In addition, RBC can clear circulating immune complexes, reduce T-cell proliferation, and promote phagocytosis [42, 43]. The proportion of CD4+ T-cells in patients with AS is reduced, which may be the reason for the increase in RBC and HGB in patients with AS [44]. The higher the RBC, the higher the nomogram score. In clinical practice, MPV is often used to determine the risk of bleeding and changes in bone marrow hematopoietic function. A decrease in the MPV in patients with AS may be caused by bone marrow suppression caused by a chronic inflammatory reaction due to AS [45]. So, the lower the MPV, the higher the score in nomogram. Further research on the mechanism is required.
TP and ALB are often used in the clinical monitoring of a patient’s nutritional status. Our study showed that TP and ALB of patients with AS were higher than those of patients without AS. Elevated AST is often used for the diagnosis of liver diseases, and AST decreases significantly in patients with AS, which has no special clinical significance [46]. Cr is the product of muscle metabolism in the human body, and Cr increases significantly in patients with AS, which may be caused by impaired immune function in patients with AS. The average UA in patients with AS was also higher than that in patients without AS. These studies on AS provide a new direction for further research. In our diagnostic model, ALB and Cr values correlated positively with the final nomogram score, while AST correlated inversely.
The proportion of hs-CRP (Table 4) in patients with AS > 10 was significantly higher than that in patients without AS, and the proportion of hs-CRP < 0.8 was lower than that in patients without AS. In a study by Seulkee et al., CRP was higher in patients with symptoms of AS than in patients without symptoms [6]. WBC and NEUT were elevated in patients with AS, consistent with chronic inflammation. However, ML did not include them in predictive models .
Machine learning is widely used in diagnosing, treating, treating, preventing, and managing AS diseases. Riel et al. used computed tomography (CT) to construct an early diagnosis model using machine learning methods [47]. Samuel et al. used single-cell transcriptome and surface epitope analysis of AS to classify diseases using machine learning methods [48]. Liang et al. used LASSO regression to find that the severity of the platelet-to-lymphocyte ratio was related to the severity of AS, which is helpful for diagnosing and treating physicians [8].
This study aimed to use a dataset of 708 patients to select the best ML model. Our work has several advantages. First, there are few studies on AS using age, ESR, blood routine examination, liver function, and kidney function, and we did not find similar studies. Second, we used three ML methods to filter the data and used the validation cohort for verification. Finally, upon comparison, our model exhibited superior predictive power and ease of usage for clinicians to diagnose AS.
However, there are some limitations to this study. First, the retrospective nature of this study may have led to subjective bias and selection bias. Second, the ML algorithm model we developed is limited to one hospital, which may limit its use in other areas and requires further validation. Third, our study lacks imaging data, which may improve our diagnostic efficacy. Fourth, the predictive performance is average and can be improved further.
Conclusion
We established two prediction models that offer the advantages of good performance, high accuracy, and simplicity of use. We can effectively serve patients with AS and help doctors make a diagnosis by using predictive models. Of course, clinicians always have the final word for interpretation based on their domain expertise. In future studies, we will attempt to cover a wide range of clinical variables so that our diagnostic model can be used more accurately in a wider population.
References
Ranganathan V, Gracey E, Brown MA, Inman RD, Haroon N. Pathogenesis of ankylosing spondylitis—recent advances and future directions. Nat Rev Rheumatol. 2017;13(6):359–67.
Fiorillo MT, Haroon N, Ciccia F, Breban M. Editorial: ankylosing spondylitis and related immune-mediated disorders. Front Immunol. 2019;10:1232.
Mauro D, Thomas R, Guggino G, Lories R, Brown MA, Ciccia F. Ankylosing spondylitis: an autoimmune or autoinflammatory disease? Nat Rev Rheumatol. 2021;17(7):387–404.
Wright GC, Kaine J, Deodhar A. Understanding differences between men and women with axial spondyloarthritis. Semin Arthritis Rheum. 2020;50(4):687–94.
Morin M, Hellgren K, Frisell T. Familial aggregation and heritability of ankylosing spondylitis—a Swedish nested case–control study. Rheumatology (Oxford). 2020;59(7):1695–702.
Lee S, Kang S, Eun Y, Won HH, Kim H, Lee J, et al. Machine learning-based prediction model for responses of bDMARDs in patients with rheumatoid arthritis and ankylosing spondylitis. Arthritis Res Ther. 2021;23(1):254.
Van Calster B, Wynants L. Machine learning in medicine. N Engl J Med. 2019;380(26):2588.
Liang T, Chen J, Xu G, Zhang Z, Xue J, Zeng H, et al. Platelet-to-lymphocyte ratio as an independent factor was associated with the severity of ankylosing spondylitis. Front Immunol. 2021;12: 760214.
Zhang Z, Ho KM, Hong Y. Machine learning for the prediction of volume responsiveness in patients with oliguric acute kidney injury in critical care. Crit Care (London, England). 2019;23(1):112.
He D, Wang R, Liang S, Liang D, Xu F, Zeng C, et al. Comparison of secondary IgA nephropathy in patients with ankylosing spondylitis and rheumatoid arthritis. Mod Rheumatol. 2020;30(4):648–56.
Ding T, Li B, Su R, Su R, Wang Y, Gao C, et al. Elevated Th17 cells are associated with cardiovascular complications in ankylosing spondylitis. Rheumatology (Oxford). 2021 Keab888.
van der Linden S, Valkenburg HA, Cats A. Evaluation of diagnostic criteria for ankylosing spondylitis. A proposal for modification of the New York criteria. Arthritis Rheum. 1984;27(4):361–8.
Pan X, Jin X, Wang J, Hu Q, Dai B. Placenta inflammation is closely associated with gestational diabetes mellitus. Am J Transl Res. 2021;13(5):4068–79.
Zhang S, Tong YX, Zhang XH, Zhang YJ, Xu XS, Xiao AT, et al. A novel and validated nomogram to predict overall survival for gastric neuroendocrine neoplasms. J Cancer. 2019;10(24):5944–54.
Jiang R, He S, Sun H, Gong H, Yang X, Cai X, et al. Identifying the risk factors and estimating the prognosis in patients with pelvis and spine ewing sarcoma: a population-based study. Spine. 2021;46(19):1315–25.
Wu M, Li X, Zhang T, Liu Z, Zhao Y. Identification of a nine-gene signature and establishment of a prognostic nomogram predicting overall survival of pancreatic cancer. Front Oncol. 2019;9:996.
Zhang H, Liu R, Sun L, Guo W, Ji X, Hu X. Comprehensive analysis of gene expression changes and validation in hepatocellular carcinoma. Onco Targets Ther. 2021;14:1021–31.
Vickers AJ, Holland F. Decision curve analysis to evaluate the clinical benefit of prediction models. Spine J. 2021;21(10):1643–8.
Wang H, Zhang L, Liu Z, Wang X, Geng S, Li J, et al. Predicting medication nonadherence risk in a Chinese inflammatory rheumatic disease population: development and assessment of a new predictive nomogram. Patient Prefer Adherence. 2018;12:1757–65.
Alderden J, Pepper GA, Wilson A, Whitney JD, Richardson S, Butcher R, et al. Predicting pressure injury in critical care patients: a machine-learning model. Am J Crit Care. 2018;27(6):461–8.
Zhang H, Wang W, Haggerty J, Schuster T. Predictors of patient satisfaction and outpatient health services in China: evidence from the WHO SAGE survey. Fam Pract. 2020;37(4):465–72.
Pfau M, von der Emde L, Dysli C, Möller PT, Thiele S, Lindner M, et al. Determinants of cone and rod functions in geographic atrophy: AI-based structure–function correlation. Am J Ophthalmol. 2020;217:162–73.
Zhang M, Zhu K, Pu H, Wang Z, Zhao H, Zhang J, et al. An immune-related signature predicts survival in patients with lung adenocarcinoma. Front Oncol. 2019;9:1314.
Wang S, Su W, Zhong C, Yang T, Chen W, Chen G, et al. An Eight-CircRNA assessment model for predicting biochemical recurrence in prostate cancer. Front Cell Dev Biol. 2020;8: 599494.
Duan KB, Rajapakse JC, Wang H, Azuaje F. Multiple SVM-RFE for gene selection in cancer classification with expression data. IEEE Trans Nanobiosci. 2005;4(3):228–34.
Zhao E, Xie H, Zhang Y. Predicting diagnostic gene biomarkers associated with immune infiltration in patients with acute myocardial infarction. Front Cardiovasc Med. 2020;7: 586871.
Huang YQ, Liang CH, He L, Tian J, Liang CS, Chen X, et al. Development and validation of a radiomics nomogram for preoperative prediction of lymph node metastasis in colorectal cancer. J Clin Oncol. 2016;34(18):2157–64.
Sorrentino FS, Jurman G, De Nadai K, Campa C, Furlanello C, Parmeggiani F. Application of artificial intelligence in targeting retinal diseases. Curr Drug Targets. 2020;21(12):1208–15.
Ngiam KY, Khor IW. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019;20(5):e262–73.
Handelman GS, Kok HK, Chandra RV, Razavi AH, Lee MJ, Asadi H. eDoctor: machine learning and the future of medicine. J Intern Med. 2018;284(6):603–19.
Thrall JH, Li X, Li Q, Cruz C, Do S, Dreyer K, et al. Artificial intelligence and machine learning in radiology: opportunities, challenges, pitfalls, and criteria for success. J Am Coll Radiol JACR. 2018;15(3 Pt B):504–8.
Herzog NJ, Magoulas GD. Brain asymmetry detection and machine learning classification for diagnosis of early dementia. Sensors (Basel, Switzerland). 2021;21(3):778.
Lynch CM, Abdollahi B, Fuqua JD, de Carlo AR, Bartholomai JA, Balgemann RN, et al. Prediction of lung cancer patient survival via supervised machine learning classification techniques. Int J Med Inf. 2017;108:1–8.
Doupe P, Faghmous J, Basu S. Machine learning for health services researchers. Value Health. 2019;22(7):808–15.
Nygaard A, Ljungdalh PS, Iachina M, Nikolov TN, Schiottz-Christensen B. Incidence of ankylosing spondylitis and spondyloarthritis in 2000–2013: a nationwide Danish cohort study. Scand J Rheumatol. 2020;49(1):21–7.
Crossfield SSR, Marzo-Ortega H, Kingsbury SR, Pujades-Rodriguez M, Conaghan PG. Changes in ankylosing spondylitis incidence, prevalence and time to diagnosis over two decades. RMD Open. 2021;7(3):e001888.
Ibn Yacoub Y, Amine B, Laatiris A, Hajjaj-Hassouni N. Gender and disease features in Moroccan patients with ankylosing spondylitis. Clin Rheumatol. 2012;31(2):293–7.
Jiao JB, Huang JC, Chen X, Jin Y. Albumin to globulin ratio, neutrophil to lymphocyte ratio, and globulin levels do not outperform ESR or CRP when diagnosing periprosthetic joint infection. BMC Musculoskelet Disord. 2022;23(1):404.
Kang KY, Chung MK, Kim HN, Hong YS, Ju JH, Park SH. Severity of sacroiliitis and erythrocyte sedimentation rate are associated with a low trabecular bone score in young male patients with ankylosing spondylitis. J Rheumatol. 2018;45(3):349–56.
Chen CH, Chen HA, Liao HT, Liu CH, Tsai CY, Chou CT. The clinical usefulness of ESR, CRP, and disease duration in ankylosing spondylitis: the product of these acute-phase reactants and disease duration is associated with patient’s poor physical mobility. Rheumatol Int. 2015;35(7):1263–7.
Carson JL, Stanworth SJ, Dennis JA, Trivella M, Roubinian N, Fergusson DA, et al. Transfusion thresholds for guiding red blood cell transfusion. Cochrane Database Syst Rev. 2021;12(12):Cd002042.
Sherwood TA, Virella G. The binding of immune complexes to human red cells: complement requirements and fate of the RBC-bound IC after interaction with human phagocytic cells. Clin Exp Immunol. 1986;64(1):195–204.
Long K, Meier C, Bernard A, Williams D, Davenport D, Woodward J. T-cell suppression by red blood cells is dependent on intact cells and is a consequence of blood bank processing. Transfusion. 2014;54(5):1340–7.
Li M, Zhou X, Zhou L, Yu Z, Fu L, Yang P. Meta-analysis of changes in the number and proportion of regulatory T cells in patients with ankylosing spondylitis. BioMed Res Int. 2020;2020:8709804. https://doi.org/10.1155/2020/8709804.
Kisacik B, Tufan A, Kalyoncu U, Karadag O, Akdogan A, Ozturk MA, et al. Mean platelet volume (MPV) as an inflammatory marker in ankylosing spondylitis and rheumatoid arthritis. Jt Bone Spine. 2008;75(3):291–4.
Lozano-Paniagua D, Parrón T, Alarcón R, Requena M, López-Guarnido O, Lacasaña M, et al. Evaluation of conventional and non-conventional biomarkers of liver toxicity in greenhouse workers occupationally exposed to pesticides. Food Chem Toxicol. 2021;151: 112127.
Castro-Zunti R, Park EH, Choi Y, Jin GY, Ko SB. Early detection of ankylosing spondylitis using texture features and statistical machine learning, and deep learning, with some patient age analysis. Comput Med Imaging Graph. 2020;82: 101718.
Alber S, Kumar S, Liu J, Huang ZM, Paez D, Hong J, et al. Single cell transcriptome and surface epitope analysis of ankylosing spondylitis facilitates disease classification by machine learning. Front Immunol. 2022;13: 838636.
Acknowledgements
We are grateful to Dr. Xinli Zhan and Dr. Chong Liu (Spine and Osteopathy Ward, The First Affiliated Hospital of Guangxi Medical University) for their kind assistance in all stages of the present study.
Funding
This work was sponsored by the National Natural Science Foundation of China (81560359); National Natural Science Foundation of China (81860393). Funding bodies had no role in the study design, collection, analysis, and interpretation of the data or in writing the manuscript. The authors funded the journal’s Rapid Service Fee.
Author Contributions
All authors contributed to the study conception and design. Jichong Zhu, Chong Liu and Xinli Zhan designed the study. Qing Lu, Tuo Liang, Jie Jiang, Liyi Chen, Shengsheng Huang, Guobing Deng and Xuhua Sun analyze the data. Wenyong Jiang, Jiarui Chen, Tianyou Chen, Hao Li, Xiang Tao, Binguang Fan and Yuanlin Yao digital visualization. Shaofeng Wu, Shian Liao, Chaojie Yu, Zhen Ye, Hao Guo, Wuhua Chen, Wenkang Chen and Chenxin Zhou collected data on routine blood data. Jichong Zhu wrote and revised the manuscript. Chong Liu and Xinli Zhan revised the manuscript. All authors read and approved the final manuscript.
Disclosures
Jichong Zhu, Qing Lu, Tuo Liang, JieJiang, Hao Li, Chenxin Zhou, Shaofeng Wu, Tianyou Chen, Jiarui Chen, Guobing Deng, Yuanlin Yao, Shian Liao, Chaojie Yu, Shengsheng Huang, Xuhua Sun, Liyi Chen, Wenkang Chen, Zhen Ye, Hao Guo, Wuhua Chen, Wenyong Jiang, Binguang Fan, Xiang Tao, Xinli Zhan and Chong Liu declare that they have no competing interests.
Compliance with Ethics Guidelines
All subjects volunteered for the study and signed informed consent forms. To ensure confidentiality, the names of study participants were not included in the data. Information obtained from the data of the study participants is kept confidential. This study was performed in accordance with the Helsinki Declaration of 1964 and its later amendments. In addition, the Ethics Committee of the First Affiliated Hospital of Guangxi Medical University approved the study (2021-(KY-E-136)).
Data Availability
The original contributions presented in the study are included in the article or the supplementary material files. Further inquiries can be directed to the corresponding authors.
Author information
Authors and Affiliations
Corresponding authors
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Zhu, J., Lu, Q., Liang, T. et al. Development and Validation of a Machine Learning-Based Nomogram for Prediction of Ankylosing Spondylitis. Rheumatol Ther 9, 1377–1397 (2022). https://doi.org/10.1007/s40744-022-00481-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40744-022-00481-6