
Abstract
We develop a new formulation of deep learning based on the Mori–Zwanzig (MZ) formalism of irreversible statistical mechanics. The new formulation is built upon the well-known duality between deep neural networks and discrete dynamical systems, and it allows us to directly propagate quantities of interest (conditional expectations and probability density functions) forward and backward through the network by means of exact linear operator equations. Such new equations can be used as a starting point to develop new effective parameterizations of deep neural networks and provide a new framework to study deep learning via operator-theoretic methods. The proposed MZ formulation of deep learning naturally introduces a new concept, i.e., the memory of the neural network, which plays a fundamental role in low-dimensional modeling and parameterization. By using the theory of contraction mappings, we develop sufficient conditions for the memory of the neural network to decay with the number of layers. This allows us to rigorously transform deep networks into shallow ones, e.g., by reducing the number of neurons per layer (using projection operators), or by reducing the total number of layers (using the decay property of the memory operator).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
It has been recently shown that new insights into deep learning can be obtained by regarding the process of training a deep neural network as a discretization of an optimal control problem involving nonlinear differential equations [19, 21, 57]. One attractive feature of this formulation is that it allows us to use tools from dynamical system theory such as the Pontryagin maximum principle or the Hamilton–Jacobi–Bellman equation to study deep learning from a rigorous mathematical perspective [22, 35, 37]. For instance, it has been recently shown that by idealizing deep residual networks as continuous-time dynamical systems it is possible to derive sufficient conditions for universal approximation in \(L^p\), which can also be understood as an approximation theory that leverages flow maps generated by dynamical systems [34].
In the spirit of modeling a deep neural network as a flow of a discrete dynamical system, in this paper we develop a new formulation of deep learning based on the Mori–Zwanzig (MZ) formalism. The MZ formalism was originally developed in statistical mechanics [42, 64] to formally integrate under-resolved phase variables in nonlinear dynamical systems by means of a projection operator. One of the main features of such formulation is that it allows us to systematically derive exact evolution equations for quantities of interest, e.g., macroscopic observables, based on microscopic equations of motion [5, 7, 9, 16, 25, 26, 55, 60, 61].
In the context of deep learning, the MZ formalism can be used to reduce the total number of degrees of freedom of the neural network, e.g., by reducing the number of neurons per layer (using projection operators), or by transforming deep networks into shallows networks, e.g., by approximating the MZ memory operator. Computing the solution of the MZ equation for deep learning is not an easy task. One of the main challenges is the approximation of the memory term and the fluctuation (noise) term, which encode the interaction between the so-called orthogonal dynamics and the dynamics of the quantity of interest. In the context of neural networks, the orthogonal dynamics is essentially a discrete high-dimensional flow governed by a difference equation that is hard to solve. Despite these difficulties, the MZ equation of deep learning is formally exact, and can be used as a starting point to build useful approximations and parameterizations that target the output function directly. Moreover, it provides a new framework to study deep learning via operator-theoretic approaches. For example, the analysis of the memory term in the MZ formulation may shed light on the behavior of recent neural network architectures such as the long short-term memory (LSTM) network [20, 51].
This paper is organized as follows. In Sect. 2, we briefly review the formulation of deep learning as a control problem involving a discrete stochastic dynamical system. In Sect. 3, we introduce the composition and transfer operators associated with the neural network. Such operators are the discrete analogs of the stochastic Koopman [10, 62] and Frobenius–Perron operators in classical continuous-time nonlinear dynamics. In the neural network setting, the composition and transfer operators are integral operators with kernel given by the conditional transition density between one layer and the next. In Sect. 4, we discuss different training paradigms for stochastic neural networks, i.e., the classical “training over weights” paradigm, and a novel “training over noise” paradigm. Training over noise can be seen as an instance of transfer learning in which we optimize for the PDF of the noise to repurpose a previously trained neural network to another task, without changing the neural network weights and biases. In Sect. 5, we present the MZ formulation of deep learning and derive the operator equations at the basis of our theory. In Sect. 6, we introduce a particular class of projection operators, i.e., Mori’s projections [61] and study their properties. In Sect. 7, we develop the analysis of the MZ equation, and derive sufficient conditions under which the MZ memory term decays with the number of layers. This allows us to approximate the MZ memory term with just a few terms and re-parameterize the network accordingly. The main findings are summarized in Sect. 8. We also include two appendices in which we establish theoretical results concerning the composition and transfer operators for neural networks with additive random perturbations and prove the Markovian property of neural networks driven by discrete random processes characterized by statistically independent random vectors.
2 Modeling neural networks as discrete stochastic dynamical systems
We model a neural network with L layers as a discrete stochastic dynamical system of the form
Here, the index n labels a specific layer in the network, \(\varvec{H}_n\) is the transition function of the \((n+1)\) layer, \(\varvec{X}_0\in \mathbb {R}^d\) is the network input, \(\varvec{X}_{n}\in \mathbb {R}^{d_{n}}\) is the output of the nth layer,Footnote 1\(\{\varvec{\xi }_0,\ldots ,\varvec{\xi }_{L-1}\}\) are random vectors, and \(\varvec{w}_n\in \mathbb {R}^{q_n}\) are parameters characterizing the \((n+1)\) layer. We allow the input \(\varvec{X}_0\) to be random. Furthermore, we assume that the random vectors \(\{\varvec{\xi }_{0},\ldots ,\varvec{\xi }_{L-1}\}\) are statistically independent, and that \(\varvec{\xi }_n\) is independent of past and current states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\). In this assumption, the neural network model (1) defines a Markov process \(\{\varvec{X}_n\}\) (see “Appendix B”). Further assumptions about the mapping \(\varvec{H}_n\) and its relation to the noise process will be stated in subsequent sections.

Sketch of a stochastic neural network model of the form (2), with L layers and N neurons per layer. We assume that the random vectors \(\{\varvec{\xi }_{0},\ldots ,\varvec{\xi }_{L-1}\}\) are statistically independent, and that \(\varvec{\xi }_n\) is independent of past and current states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\). With these assumptions, \(\{\varvec{X}_0,\ldots ,\varvec{X}_L\}\) is a Markov process (see “Appendix B”)
The general formulation (1) includes the following important classes of neural networks:
-
1.
Neural networks perturbed by additive random noise (Fig. 1). These models are of the form
$$\begin{aligned} \varvec{X}_{n+1} = \varvec{F}_n(\varvec{X}_n,\varvec{w}_n)+\varvec{\xi }_n, \quad n=0,\ldots , L-1. \end{aligned}$$(2)The mapping \(\varvec{F}_n\) is often defined as a composition of a layer-dependent affine transformation with an activation function \(\varphi \), i.e.,
$$\begin{aligned} \varvec{F}_n(\varvec{X}_n,\varvec{w}_n) = \varphi (\varvec{W}_n \varvec{X}_n+\varvec{b}_n) \quad \varvec{w}_n = \{\varvec{W}_n,\varvec{b}_n\}, \end{aligned}$$(3)where \(\varvec{W}_n\) is a \(d_{n+1}\times d_n\) weight matrix, and \(\varvec{b}_n\in \mathbb {R}^{d_{n+1}}\) is a bias vector.
-
2.
Neural networks perturbed by multiplicative random noise (Fig. 2). These models are of the form
$$\begin{aligned} \varvec{X}_{n+1} =\varvec{F}_n(\varvec{X}_n,\varvec{w}_n)+ \varvec{M}_n(\varvec{X}_n)\varvec{\xi }_n, \quad n=0,\ldots , L-1, \end{aligned}$$(4)where \(\varvec{M}_n(\varvec{X}_n)\) is a matrix depending on \(\varvec{X}_n\).
-
3.
Neural networks with random weights and biases [18, 58]. These models are of the form
$$\begin{aligned} \varvec{X}_{n+1}= \varphi \left( {\varvec{Z}}_n \varvec{X}_n+{\varvec{z}}_n\right) , \quad n=0,\ldots , L-1 \end{aligned}$$(5)where \({\varvec{Z}}_n \) are random weight matrices, and \({\varvec{z}}_n\) are random bias vectors. The pairs \(\{{\varvec{Z}}_n, {\varvec{z}}_n\}\) and \(\{{\varvec{Z}}_j, {\varvec{z}}_j\}\) are assumed to be statistically independent for \(n\ne j\). Moreover, \(\{{\varvec{Z}}_j, {\varvec{z}}_j\}\) are independent of the neural network states \(\{\varvec{X}_0,\ldots ,\varvec{X}_{j}\}\) for all \(j=0,\ldots , L-1\).

Sketch of the stochastic neural network model (4). We assume that the random vectors \(\{\varvec{\xi }_{0},\ldots ,\varvec{\xi }_{L-1}\}\) are statistically independent, and that \(\varvec{\xi }_n\) is independent of past and current states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\). In this assumption, the neural network model (4) defines a Markov process \(\{\varvec{X}_n\}\). Note that the dimension of the vectors \(\varvec{X}_n\) can vary from layer to layer, e.g., in encoding or decoding neural networks
In this article, we will focus our attention primarily on neural network models with additive random noise, i.e., models of the form (2). The functional setting for these models is extensively discussed in “Appendix A.” The neural network output is usually written as
where \(\varvec{\alpha }\) is a vector of output weights, and \(\mathbb {E}\left[ \varvec{X}_L|\varvec{X}_0=\varvec{x}\right] \) is the expectation of the random vector \(\varvec{X}_L\) conditional to \(\varvec{X}_0=\varvec{x}\). In the absence of noise, (6) reduces to the well-known function composition rule
The neural network parameters \(\{\varvec{\alpha },\varvec{w}_0,\ldots ,\varvec{w}_{L-1}\}\) appearing in (6) or (7) are usually determined by minimizing a dissimilarity measure between \(q_L(\varvec{x})\) and a given target function \(f(\varvec{x})\) (supervised learning). By adding random noise to the neural network, e.g., in the form of additive noise or by randomizing weights and biases, we are essentially adding an infinite number of degrees of freedom to the system, which can be leveraged for training and transfer learning (see Sect. 4).
3 Composition and transfer operators for neural networks
In this section, we derive the composition and transfer operators associated with the neural network model (1), which map, respectively, the conditional expectation \(\mathbb {E}\left\{ \varvec{u}(\varvec{X}_L)|\varvec{X}_n=\varvec{x}\right\} \) (where \(\varvec{u}(\cdot )\) is a user-defined measurable function) and \(p_n(\varvec{x})\) (the probability density of \(\varvec{X}_n\)) forward and backward across the network. To this end, we assume that the random vectors \(\{\varvec{\xi }_0,\ldots ,\varvec{\xi }_{L-1}\}\) in (1) are statistically independent, and that \(\varvec{\xi }_n\) is independent of past and current states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\), With these assumptions, \(\{\varvec{X}_n\}\) in (1) is a discrete Markov process (see “Appendix B”). Hence, the joint probability density function (PDF) of the random vectors \(\{\varvec{X}_0,\ldots ,\varvec{X}_L\}\), i.e., joint PDF of the state of the entire neural network, can be factoredFootnote 2 as
By using the identity (Bayes’ theorem)
we see that the chain of transition probabilities (8) can be reverted, yielding
From these expressions, it follows that
for all indices n, j and q in \(\{0,\ldots ,L\}\), excluding \(n=j=q\). The transition probability equation (11) is known as discrete Chapman–Kolmogorov equation and it allows us to define the transfer operator mapping the PDF \(p_n(\varvec{x}_n)\) into \(p_{n+1}(\varvec{x}_{n+1})\), together with the composition operator for the conditional expectation \(\mathbb {E}\{\varvec{u}(\varvec{x}_L)|\varvec{X}_n=\varvec{x}_{n}\}\). As we shall see hereafter, the discrete composition and transfer operators are adjoint to one another.
3.1 Transfer operator
Let us denote by \(p_q(\varvec{x})\) the PDF of \(\varvec{X}_q\), i.e., the output of the qth neural network layer. We first define the operator that maps \(p_q(\varvec{x})\) into \(p_n(\varvec{x})\). By integrating the joint probability density of \(\varvec{X}_n\) and \(\varvec{X}_q\), i.e., \(p_{n|q}(\varvec{x}|\varvec{y})p_q(\varvec{y})\) with respect to \(\varvec{y}\) we immediately obtain
At this point, it is convenient to define the linear operator
\(\mathcal {N}(n,q)\) is known as transfer (or Frobenius–Perron) operator [16]. From a mathematical viewpoint, \(\mathcal {N}(n,q)\) is a integral operator with kernel \(p_{n|q}(\varvec{x},\varvec{y})\), i.e., the transition density integrated “from the right.” It follows from the Chapman–Kolmogorov identity (11) that the set of integral operators \(\{\mathcal {N}(n,q)\}\) satisfies
where \(\mathcal {I}\) is the identity operator. The operator \(\mathcal {N}\) allows us to map the one-layer PDF, e.g., the PDF of \(\varvec{X}_q\), either forward or backward across the neural network (see Fig. 3). As an example, consider a network with four layers and states \(\varvec{X}_0\) (input), \(\varvec{X}_1\), \(\varvec{X}_2\), \(\varvec{X}_3\), and \(\varvec{X}_4\) (output). Then, Eq. (13) implies that
In summary, we have
where
We emphasize that modeling the PDF dynamics via neural networks has been studied extensively in machine learning, e.g., in the theory of normalizing flows for density estimation or variational inference [31, 50, 52].
3.2 Composition operator
For any measurable deterministic function \(\varvec{u}(\varvec{x})\), the expectation of \(\varvec{u}(\varvec{X}_j)\) conditional to \(\varvec{X}_n=\varvec{x}\) is defined as
A substitution of (11) into (17) yields
which holds for all \(j,n,q\in \{0,\ldots , L-1\}\). At this point, it is convenient to define the integral operator
which is known as composition [16] or “stochastic Koopman” [10, 62] operator. The operator (19) is also related to the Kolmogorov backward equation [48] . Thanks to the Chapman–Kolmogorov identity (11), the operators \(\mathcal {M}(q,j)\) satisfy
where \(\mathcal {I}\) is the identity operator. Equation (20) allows us to map the conditional expectation (17) of any measurable phase space function \(\varvec{u}(\varvec{X}_j)\) forward or backward through the network. As an example, consider again a neural network with four layers and states \(\{\varvec{X}_0,\dots ,\varvec{X}_4\}\). We have
Equation (21) holds for every \(j\in \{0,\ldots ,4\}\). Of particular interest in the machine learning context is the conditional expectation of \(\varvec{u}(\varvec{X}_L)\) (network output) given \(\varvec{X}_0=\varvec{x}\) (network input), which can be computed as
i.e., by propagating \(\varvec{u}(\varvec{x})=\mathbb {E}\{\varvec{u}(\varvec{X}_L)| \varvec{X}_L=\varvec{x}\}\) backward through the neural network using single layer operators \(\mathcal {M}(i-1,i)\). Similarly, we can compute, e.g., \(\mathbb {E}\{\varvec{u}(\varvec{X}_0)|\varvec{X}_L=\varvec{x}\}\) as
For subsequent analysis, it is convenient to define
In this way, if \(\mathbb {E}\{\varvec{u}(\varvec{X}_L)|\varvec{X}_n=\varvec{x}\}\) is propagated backward through the network by \(\mathcal {M}(n-1,n)\), then \(\varvec{q}_n(x)\) is propagated forward by the operator
In fact, Eqs. (24)–(25) allow us to write (22) in the equivalent form
i.e., as a forward propagation problem (see Fig. 3). Note that we can write (26) (or (22)) explicitly in terms of iterated integrals involving single-layer transition densities as

Sketch of the forward/backward integration process for probability density functions (PDFs) and conditional expectations. The transfer operator \(\mathcal {N}(n+1,n)\) maps the PDF of \(\varvec{X}_n\) into the PDF of \(\varvec{X}_{n+1}\) forward through the neural network. On the other hand, the composition operator \(\mathcal {M}\) maps the conditional expectation \(\mathbb {E}\left[ \varvec{u}(\varvec{X}_L)|\varvec{X}_{n+1}=\varvec{x}\right] \) backwards to \(\mathbb {E}\left[ \varvec{u}(\varvec{X}_L)|\varvec{X}_{n}=\varvec{x}\right] \). By defining the operator \(\mathcal {G}(n,m)=\mathcal {M}(L-n,L-m)\) we can transform the backward propagation problem for \(\mathbb {E}\left[ \varvec{u}(\varvec{X}_L)|\varvec{X}_{n}=\varvec{x}\right] \) into a forward propagation problem for \(\varvec{q}_n(\varvec{x})=\mathbb {E}\left[ \varvec{u}(\varvec{X}_L)|\varvec{X}_{L-n}=\varvec{x}\right] \)
3.3 Relation between composition and transfer operators
The integral operators \(\mathcal {M}\) and \(\mathcal {N}\) defined in (19) and (13) involve the same kernel function, i.e., the multilayer transition density \(p_{q|n}(\varvec{x},\varvec{y})\). In particular, \(\mathcal {M}(n,q)\) integrates \(p_{q|n}\) “from the left,” while \(\mathcal {N}(q,n)\) integrates it “from the right.” It is easy to show that \(\mathcal {M}(n,q)\) and \(\mathcal {N}(q,n)\) are adjoint to each other relative to the standard inner product in \(L^2\) (see [16] for the continuous-time case). In fact,
Therefore,
where \(\mathcal {M}(q,j)^*\) denotes the operator adjoint of \(\mathcal {M}(q,j)\) with respect to the \(L^2\) inner product. By invoking the definition (25), we can also write (29) as
In “Appendix A,” we show that if the cumulative distribution function of each random vector \(\varvec{\xi }_n\) in the noise process has partial derivatives that are Lipschitz continuous in \(\mathscr {R}(\varvec{\xi }_n)\) (range of \(\varvec{\xi }_n\)), then the composition and transfer operators defined in Eqs. (19) and 13 are bounded in \(L^2\) (see Propositions 16 and 17). Moreover, is possible to choose the probability density of \(\varvec{\xi }_n\) such that the single-layer composition and transfer operators become strict contractions. This property will be used in Sect. 7 to prove that the memory of a stochastic neural network driven by particular types of noise decays with the number of layers.
3.4 Multilayer conditional transition density
We have seen that the composition and the transfer operators \(\mathcal {M}\) and \(\mathcal {N}\) defined in Eqs. (19) and (13) allow us to push forward and backward conditional expectations and probability densities across the neural network. Moreover, such operators are adjoint to one another (Sect. 3.3) and also have the same kernel, i.e., the transition density \(p_{n|q}(\varvec{x}_n|\varvec{x}_q)\). In this section, we derive analytical formulas for the one-layer transition density \(p_{n+1|n}(\varvec{x}_{n+1}|\varvec{x}_n)\) corresponding to the neural network models we discussed in section 2. The multilayer transition density \(p_{n|q}(\varvec{x}_n|\varvec{x}_q)\) is then obtained by composing one-layer transition densities as follows:
We first consider the general class of stochastic neural network models defined by Eq. (1). By the definition of conditional probability density, we have
By assumption, \(p_{\varvec{\xi }_n|\varvec{X}_n}(\varvec{\xi }_{n}|\varvec{x}_{n})=\rho _n(\varvec{\xi }_n)\) (the random vector \(\varvec{\xi }_n\) is independent of \(\varvec{X}_n\)) and therefore
where we denoted by \(\delta (\cdot )\) the Dirac delta function, and set \(\rho _n(\varvec{\xi }_{n})=p_{\varvec{\xi }_n}(\varvec{\xi }_n)\). The delta function arises because if \(\varvec{x}_n\) and \(\varvec{\xi }_n\) are known then \(\varvec{x}_{n+1}\) is obtained by a purely deterministic relationship, i.e., Eq. (1).
The general expression (33) can be simplified for particular classes of stochastic neural network models. For example, if the neural network has purely additive noise as in Eq. (2), then by using elementary properties of the delta function we obtain
Note that such transition density depends on the PDF of random vector \(\varvec{\xi }_n\) (i.e., \(\rho _n\)), the one-layer transition function \(\varvec{F}_n\), and the parameters \(\varvec{w}_n\). Similarly, one-layer transition density associated with the stochastic neural network model (4) can be computed by substituting \(\varvec{H}_n(\varvec{x}_n,\varvec{w}_n,\varvec{\xi }_n)= \varvec{F}_n(\varvec{x}_n,\varvec{w}_n) - \varvec{M}_n(\varvec{x}_n)\varvec{\xi }_n\) into (33). This yields
By using well-known properties of the multivariate delta function [29], it is possible to rewrite the integrand in (35) in a more convenient way. For instance, if the matrix \(\varvec{M}_n(\varvec{x}_n)\) has full rank then
which yields
Other cases where \(\varvec{M}_n(\varvec{x}_n)\) is not a square matrix can be handled similarly [29, 46]. Finally, consider the neural network model with random weights and biases (5). The one-layer transition density in this case can be expressed as
where \(p(\varvec{Z}_n,\varvec{z}_n)\) is the joint PDF of the weight matrix and bias vector in the nth layer.
Remark
The transition density (34) associated with the neural network model (2) can be computed explicitly once we choose a probability model for \(\varvec{\xi }_n\in \mathbb {R}^N\). For instance, if we assume that \(\{\varvec{\xi }_0,\varvec{\xi }_1,\ldots ,\varvec{\xi }_{L-1}\}\) are i.i.d. Gaussian random vectors with PDF,
then we can explicitly write the one-layer transition density (34) as
In “Appendix A,” we provide an analytical example of transition density for a neural network with two layers, one neuron per layer, \(\tanh (\cdot )\) activation function, and uniformly distributed random noise.
3.5 The zero noise limit
An important question is what happens to the neural network as we send the amplitude of the noise to zero. To answer this question, consider the neural network model (2) with N neurons per layer and introduce the parameter \(\epsilon \ge 0\), i.e.,
We are interested in studying the orbits of the discrete dynamical system (41) as \(\epsilon \rightarrow 0\). To this end, we assume \(\{\varvec{\xi }_n\}\) independent random vectors with density \(\rho _n(\varvec{x})\). This implies that the PDF of \(\epsilon \varvec{\xi }_n\) is
It is shown in [32, Proposition 10.6.1] that the transfer operator \(\mathcal {N}(n+1,n)\) associated with (41), i.e.,
converges in norm to the Frobenius–Perron operator corresponding to \(\varvec{F}_n(\varvec{X}_n,\varvec{w}_n)\) as \(\epsilon \rightarrow 0\). Indeed, in the limit \(\epsilon \rightarrow 0\) we have, formally
Substituting this expression into (13), one gets
Similarly, a substitution into Eq. (26) yields
Iterating this expression all the way back to \(n=1\) yields the familiar function composition rule for neural networks, i.e.,
Recalling that \(\varvec{q}_0(\varvec{x})=\varvec{u}(\varvec{x})\) and assuming that \(\varvec{u}(\varvec{x})= \varvec{A} \varvec{x}\) (linear output layer), where \(\varvec{A}\) is a matrix of output weights and \(\varvec{x}\) is a column vector, we can write (47) as
If \(\varvec{u}(\varvec{x})\) is a linear scalar function, i.e., \(u(\varvec{x})=\varvec{\alpha }\cdot \varvec{x}\) then (48) coincides with Eq. (7).
4 Training paradigms
By adding random noise to a neural network we are essentially adding an infinite number of degrees of freedom to our system. This allows us to rethink the process of training the neural network from a probabilistic perspective. In particular, instead of optimizing a performance metricFootnote 3 relative to the neural network weights \(\varvec{w}=\{\varvec{w}_0,\varvec{w}_1,\ldots ,\varvec{w}_{L-1}\}\) (classical “training over weights” paradigm), we can now optimize the transition densityFootnote 4\(p_{n+1|n}(\varvec{x}_{n+1}|\varvec{x}_n)\). Clearly, such transition density depends on the neural network weights and on the functional form of the one-layer transition function, e.g., as in Eq. (34). Hence, if we prescribe the PDF of \(\varvec{\xi }_n\) (e.g., \(\rho _n\) in (34)), then the transition density \(p_{n+1|n}\) is uniquely determined by the functional form of function \(\varvec{F}_n\), and by the weights \(\varvec{w}_n\). On the other hand, if we are allowed to choose the PDF of the random vector \(\varvec{\xi }_n\), then we can optimize it during training. This can be done while keeping the neural network weights \(\varvec{w}_n\) fixed, or by including them in the optimization process.
The interaction between random noise and the nonlinear dynamics modeled by the network can yield surprising results. For example, in stochastic resonance [44, 54] it is well known that random noise added to a properly tuned a bi-stable system can induce a peak in the Fourier power spectrum of the output, hence effectively amplifying the signal. Similarly, the random noise added to a neural network can be leveraged to achieve specific goals. For example, noise allows us to repurpose a previously trained network on a different task without changing the weights of network. This can be seen as an instance of stochastic transfer learning. To describe the method, consider the two-layer neural network model
with N neurons per layer, input \(\varvec{X}_0\in \Omega _0\subseteq \mathbb {R}^d\), linear output \(u(\varvec{x}) =\varvec{\alpha }\cdot \varvec{x}\), hyperbolic tangent activation function, and intra-layer random perturbation \(\varvec{\xi }_0\). We are interested in training the input–output map represented by the conditional expectation (see Eq. (6))
Let us first rewrite (52) in a more explicit form. To this end, we recall that
where \(\mathscr {R}(\varvec{X}_2)\) denotes the range of the mapping \(\varvec{X}_2=\varvec{F}_1(\varvec{F}_0(\varvec{X}_0,\varvec{w}_0)+\varvec{\xi }_0,\varvec{w}_1)\) for \(\varvec{X}_0\in \Omega _0\) and arbitrary weights \(\varvec{w}_0\) and \(\varvec{w}_1\). By using the definition of the operator \(\mathcal {G}(i+1,i)\) in (25) and the composition rule \(q_{i+1}=\mathcal {G}(i+1,i)q_i\) (\(i=0,1\)) we easily obtain
and
where \(\mathscr {R}(\varvec{\xi }_0)\) is the range of the random variable \(\varvec{\xi }_0\), i.e., the support of \(\rho _0\). Hence, we can equivalently write input–output map (52) as
4.1 Training over weights
In the absence of noise, the PDF of \(\varvec{\xi }_0\) appearing in (56), i.e, \(\rho _0(\varvec{z})\), reduces to the delta function \(\delta (\varvec{z})\). Hence, the output of the neural network (56) can be written as
This is consistent with the well-known composition rule for deterministic networks. The parameters \(\{\varvec{\alpha }, \varvec{w}_0, \varvec{w}_1\}\) appearing in (57) can be optimized to minimize a dissimilarity measure between \(q_2(\varvec{x})\) and a given target function \(f(\varvec{x})\), e.g., relative to the \(L^2(\Omega _0)\) norm
or a discrete \(L^2(\Omega _0)\) norm computed on point set \(\left\{ \varvec{x}{[1]},\ldots ,\varvec{x}{[S]}\right\} \in \Omega _0\)
The brackets \([\cdot ]\) here are used to label the data points.
4.2 Training over noise
By adding noise \(\varvec{\xi }_0\in \mathbb {R}^N\) to the output of the first layer, we obtain the input–output map (56), hereafter rewritten for convenience
where \(\rho _0\) denotes the PDF of \(\varvec{\xi }_0\). Equation (60) looks like a Fredholm integral equation of the first kind. In fact, it can be written as
where
However, differently from standard Fredholm equations of the first kind, in (61) we have that \(\varvec{x}\in \Omega _0\subseteq \mathbb {R}^d\) while \(\varvec{\xi }\in \mathbb {R}^N\), i.e., the integral operator with kernel \(\kappa _2\) maps functions with N variables into functions with d variables. We are interested in finding a PDF \(\rho _0(\varvec{y})\) that solves (60) for a given function \(h(\varvec{x})\), i.e., find \(\rho _0\) such that
If such PDF \(\rho _0\) exists, then we can repurpose the neural network (57) with output \(q_2(\varvec{x})\simeq f(\varvec{x})\) to approximate a different function \(h(\varvec{x})\), without modifying the weights \(\{\varvec{w}_1,\varvec{w}_0\}\) but rather simply adding noise \(\varvec{\xi }_0\) between the first and the second layer, and then averaging the output over the PDF \(\rho _0\). Equation (63) is unfortunately ill-posed in the space of probability distributions. In other words, for a given kernel \(\kappa _2\), and a given target function \(h(\varvec{x})\), there is (in general) no PDF \(\rho _0\) that satisfies (63) exactly. However, one can proceed by optimization. For instance, \(\rho _0\) can be determined by solving the constrained least squares problemFootnote 5
Note that the training-over-noise paradigm can be seen as an instance of transfer learning [45], in which we turn the knobs on the PDF of the noise \(\rho _0\) (changing it from a Dirac delta function to a proper PDF), and eventually the coefficients \(\varvec{\alpha }\), to approximate a different function while keeping the neural network weights and biases fixed. Training over noise can also be performed in conjunction with training over weights, to improve the overall optimization process of the neural network.
An example: Let us demonstrate the “training over noise” and the “training over weights’ paradigms with a simple numerical example. Consider the following one-dimensional function
We are interested in approximating f(x) with the two-layer neural network depicted in Fig. 4 (\(N=5\) neurons per layer).

Sketch of the stochastic neural network model used approximate the functions (65) (training-over-weight paradigm) and (70) (training-over-noise paradigm). The five-dimensional random vector \(\varvec{\xi }_0\) is assumed to have statistically independent components. We proceed by first training the neural network with no noise on the target function f(x) defined in (65). Subsequently, we perturb the network with the random vector \(\varvec{\xi }_0\), and optimize the PDF of \(\varvec{\xi }_0\) so that the conditional expectation of the neural network output, i.e., (71), approximates a second target function h(x) for the same weights and biases
In the absence of noise, the output of the network is given by Eq. (57), hereafter rewritten in full form for \(\tanh (\cdot )\) activation functions [12]
Here, \(\varvec{W}_0\), \(\varvec{b}_0\), \(\varvec{b}_1\) and \(\varvec{\alpha }\) are five-dimensional column vectors, while \(\varvec{W}_1\) is a \(5\times 5\) matrix. Hence, the input–output map (66) has 45 free parameters \(\{\varvec{W}_0,\varvec{W}_1,\varvec{b}_0,\varvec{b}_1,\varvec{\alpha }\}\) which are determined by minimizing the discrete 2-norm
where \(\left\{ x{[1]},\ldots ,x{[30]}\right\} \) is an evenly spaced set of points in [0, 1]
In Fig. 5, we show the neural network output (66) we obtained by minimizing the cost (67) relative to the weights \(\{\varvec{W}_0,\varvec{W}_1,\varvec{b}_0,\varvec{b}_1,\varvec{\alpha }\}\) (training over weights paradigm).
Next, we add noise to our fully trained deterministic neural network. Specifically, we perturb the output of the first layer by an additive random vector \(\varvec{\xi }_0\) with independent components supported in \([-0.4,0.4]\). Since the random vector \(\varvec{\xi }_0\) is assumed to have independent components, we can write its PDF \(\rho _0\) as
where \(\{\rho ^1_0,\ldots ,\rho _1^N\}\) are one-dimensional PDFs, each one of which is supported in \([-0.4,0.4]\). In the training-over-noise paradigm, we are interested in finding the PDF of the random vector \(\varvec{\xi }_0\), i.e., the one-dimensional PDFs \(\{\rho ^1_0,\ldots ,\rho _1^N\}\) appearing in (69), and a new vector of coefficients \(\varvec{\alpha }\) such that the output of the neural network (with the same weights and biases) averaged over all realizations of the noise \(\varvec{\xi }_0\), approximates a new one-dimensional map h(x), different from (65). For this example, we choose
In the presence of noise, the neural network output takes the form (see Eq. (61))
where \(\mathscr {R}(\varvec{\xi }_0)=[-0.4,0.4]^5\) is the range of \(\varvec{\xi }_0\), and
We approximate the five-dimensional integral in (71) with a Gauss–Legendre–Lobatto (GLL) quadrature formula [23] on a tensor product grid with 6 quadrature points per dimension. To this end, let \(\{z[1],\ldots , z[6]\}\) be the GLL quadrature points in \([-0.4,0.4]\). The tensor product quadrature approximation of (71) takes the form
where \(H=6^5=7776\) is the total number of quadrature pointsFootnote 6 in the domain \([-0.4,0.4]^5\), \(\theta _k\) are tensor product GLL quadrature weights, and
represents a grid in \([-0.4,0.4]^5\) indexed by \(\{i_1(j),\ldots ,i_5(j)\}\), where \(i_k(j)\in \{1,\ldots ,6\}\) for each j and each k. Such indices are obtained by an appropriate ordering of the nodes in the tensor product grid. We represent each one-dimensional PDF \(\rho _0^k(z)\) using a polynomial interpolant through the GLL points, i.e.,
where \(l_j(z)\) are Lagrange characteristic polynomials associated with the one-dimensional GLL grid. Thus, the degrees of freedom of each PDF are represented by the following vector of PDF values at the GLL nodes
Note that in this setting we are approximating the PDF of \(\varvec{\xi }_0\) using a nonparametric method, i.e., a polynomial interpolant through a tensor product GLL grid. For non-separable PDFs, or for PDFs in higher dimensions, it may be more practical to consider a tensor representation [13, 14], or a parametric inference method, i.e., a method that leverages assumptions on the shape of the probability distribution of \(\varvec{\xi }_0\).
At this point, we have all the elements to solve the minimization problem (64), or an equivalent problem defined by the discrete 2-norm
subject to the linear constraintsFootnote 7

Demonstration of “training over weights” and “training over noise” paradigms. In the training over weights paradigm we minimize the dissimilarity measure (67) between the output (66) of the two-layer neural network depicted in Fig. 4 (with \(\varvec{\xi }_0=\varvec{0}\)) and the target function (65). The training data are shown with red circles. In the training-over-noise paradigm, we add random noise to the output of the first layer and optimize for \(\varvec{\alpha }\) and the PDF of the noise as in (64). This can be seen as an instance of transfer learning, in which we keep the neural network weights and biases fixed but update the output weights \(\varvec{\alpha }\) and the PDF of the random vector \(\varvec{\xi }_0\) to approximate a different function h(x) defined in (70)
In Fig. 5, we demonstrate the training-over-weight and the training-over-noise paradigms for the neural network depicted in Fig. 4. In the classical training over weight paradigm we minimize the error between the neural network output (66) and the function (65) in the discrete 2-norm (67). The training data are shown with red circles. In the training-over-noise paradigm, we add random noise \(\varvec{\xi }_0\) to the output of the first layer. This yields the input–output map (71). By optimizing for the PDF of the noise \(\rho _0\) and the coefficients \(\varvec{\alpha }\) as in (64) we can repurpose the network previously trained on f(x) to approximate a different function h(x) defined in (70), without changing the neural network weights and biases.
In Fig. 6, we plot the one-dimensional PDFs of each component of the random vector \(\varvec{\xi }_0\) we obtained from optimization. Such PDFs depend on the neural network weights and biases, which in this example are kept fixed.

Training-over-noise paradigm. One-dimensional probability density functions of each component of the random vector \(\varvec{\xi }_0\) obtained by solving the optimization problem (64) for the function h(x) defined in Eq. (70) (see Fig. 5). The PDF of \(\varvec{\xi }_0\) is a product of all five PDFs (see Eq. (69)). The degrees of freedom of each PDF, i.e., the vectors defined in Eq. (76), are visualized as red dots (PDF values at GLL points). Each PDF is a polynomial of degree at most 5
The PDF of \(\varvec{\xi }_{0}\) is (by hypothesis) a product of five one-dimensional PDFs. Therefore, it is quite straightforward to sample \(\varvec{\xi }_{0}\) by using, e.g., rejection sampling applied independently to each one-dimensional PDF shown in Fig. 6. With the samples of \(\varvec{\xi }_0\) available, we can easily compute samples of the neural network output as
Clearly, if we compute an ensemble average over a large number of output samples then we obtain an approximation of \(\widehat{q}_2(x)\). This is demonstrated in Fig. 7.

4.2.1 Random shifts
A related but simpler setting for repurposing a neural network is to introduce a random shift in the input variable rather than perturbing the network layersFootnote 8. In this setting, the output of the network can be written as
where \(q_2\) is defined in (57), and \(\rho \) is the PDF of vector \(\varvec{\eta }\) defining the random shift \(\varvec{x}\rightarrow \varvec{x} - \varvec{\eta }\). Clearly, Eq. (60) is the expectation of the noiseless neural network output \(q_2(\varvec{x})\) under a random shift with PDF \(\rho (\varvec{y})\). To repurpose a deterministic neural net using random shifts in the input variable, one can proceed by optimization, i.e., solving an optimization problem similar to (64) for a target function \(h(\varvec{x})\).
Remark
Given a target function \(h(\varvec{x})\) we can, in principle, compute the analytical solution of the integral equation
using Fourier transforms. This yieldsFootnote 9
where \(\mathcal {F}[\cdot ]\) denotes the multivariate Fourier transform operator
However, the function \(\rho (\varvec{y})\) defined in (82) is, in general, not a PDF.
5 The Mori–Zwanzig formulation of deep learning
In Sect. 3, we defined two linear operators, i.e., \(\mathcal {N}(n,q)\) and \(\mathcal {M}(n,q)\) in Eqs. (13) and (19), mapping the probability density of the state \(\varvec{X}_n\) and the conditional expectation of a phase space function \(\varvec{u}(\varvec{X}_n)\) forward or backward across different layers of the neural network. In particular, we have shown that
Equation (84) maps the PDF of the state \(\varvec{X}_j\) forward through the neural network, i.e., from the input to the output as n increases, while (85) maps the conditional expectation backward. We have also shown in Sect. 3.2 that upon definition of
we can rewrite (85) as a forward propagation problem, i.e.,
where \(\mathcal {G}(n,q)=\mathcal {M}(L-n,L-q)\) and \(\mathcal {M}\) is defined in (19). The function \(\varvec{q}_n(\varvec{x})\) is defined on the domain
i.e., on the range of the random variable \(\varvec{X}_{L-n}(\omega )\) (see Definition (A.4)). \(\mathscr {R}(\varvec{X}_{L-n})\) is a deterministic subset of \(\mathbb {R}^N\).
Equations (85) constitute the basis for developing the Mori–Zwanzig (MZ) formulation of deep neural networks. The MZ formulation is a technique originally developed in statistical mechanics [42, 64] to formally integrate out phase variables in nonlinear dynamical systems by means of a projection operator. One of the main features of such formulation is that it allows us to systematically derive exact equations for quantities of interest, e.g., low-dimensional observables, based on the equations of motion of the full system. In the context of deep neural networks such equations of motion are Eqs. (84)–(85), and (87).
To develop the Mori–Zwanzig formulation of deep learning, we introduce a layer-dependent orthogonal projection operator \(\mathcal {P}_n\) together with the complementary projection \(\mathcal {Q}_n=\mathcal {I}-\mathcal {P}_n\). The nature and properties of \(\mathcal {P}_n\) will be discussed in detail in Sect. 6. For now, it suffices to assume only that \(\mathcal {P}_n\) is a self-adjoint bounded linear operator, and that \(\mathcal {P}_n^2= \mathcal {P}_n\), i.e., \(\mathcal {P}_n\) is idempotent. To derive the MZ equation for neural networks, let us consider a general recursion,
where \(\{\varvec{g}_{n},\mathcal {R}(n+1,n)\}\) can be either \(\{p_n,\mathcal {N}(n+1,n)\}\) or \(\{\varvec{q}_n,\mathcal {G}(n+1,n)\}\), depending on the context of the application.
5.1 The projection-first and propagation-first approaches
We apply the projection operators \(\mathcal {P}_n\) and \(\mathcal {Q}_n\) to (89) to obtain the following coupled system of equations
By iterating the difference equation (91), we obtain the following formulaFootnote 10 for \(\mathcal {Q}_n \varvec{g}_{n}\)
where \(\Phi _\mathcal {R}(n,m)\) is the (forward) propagator of the orthogonal dynamics, i.e.,
Since \(\varvec{g}_n=\mathcal {R}(n,0)\varvec{g}_0\), and \(\varvec{g}_0\) is arbitrary, we have that (94) implies the operator identity
A substitution of (94) into (90) yields the Mori–Zwanzig equation
We shall call the first term at the right-hand side of (97) streaming (or Markovian) term, in agreement with the classical literature on MZ equations. The streaming term represents the change in \(\mathcal {P}_n\varvec{g}_n\) as we go from one layer to the next. The second term is known as “noise term” in classical statistical mechanics. The reason for this definition is that \(\Phi _\mathcal {R}(n,0)\mathcal {Q}_0 \varvec{g}_0\) represents the effects of the dynamics generated by \(\mathcal {Q}_{m}\mathcal {R}(m,m-1)\), which is usually under-resolved in classical particle systems and therefore modeled as random noise. Such noise, however, is very different from the random noise \(\{\varvec{\xi }_0,\ldots , \varvec{\xi }_{L-1}\}\) we introduced into the neural network model (1). The third term represents the memory of the neural network, and it encodes the interaction between the projected dynamics and its entire history.
Note that if \(\varvec{g}_0\) is in the range of \(\mathcal {P}_0\), i.e., if \(\mathcal {P}_0 \varvec{g}_0=\varvec{g}_0\), then the second term drops out, yielding a simplified MZ equation,
To integrate (98) forward, i.e., from one layer to the next, we first project \(\varvec{g}_m\) using \(\mathcal {P}_m\) (for \(m=0,\ldots ,n\)), then apply the evolution operator \(\mathcal {R}(n+1,n)\) to \(\mathcal {P}_n\varvec{g}_n\), and the memory operator \(\Phi _\mathcal {R}\) to the entire history of \(\varvec{g}_m\) (memory of the network). It is also possible to construct an MZ equation based on the reversed mechanism, i.e., by projecting \(\mathcal {R}(n+1,n)\varvec{g}_n\) rather than \(\varvec{g}_m\). To this end, rewrite (90) as
i.e., the propagation via \(\mathcal {R}(n+1,n)\) precedes projection (propagation-first approach). By applying the variation of constant formula (96) to (99) we arrive at a slightly different (though completely equivalent) form of the MZ equation, namely
5.2 Discrete Dyson’s identity
Another form of the MZ equation (97) can be derived based on a discrete version of the Dyson identityFootnote 11. To derive this identity, consider the sequence
By using the discrete variation of constant formula, we can rewrite (103) as
Similarly, solving (102) yields
where \(\Phi _\mathcal {R}\) is defined in (95). By substituting (105) into (104) for both \(\varvec{y}_n\) and \(\varvec{y}_m\), and observing that \(\varvec{y}_0\) is arbitrary, we obtain
The operator identity (106) is the discrete version of the well-known continuous-time Dyson’s identity. A substitution of (106) into \(\varvec{g}_{n} = \mathcal {R}(n,0)\varvec{g}_{0}\) yields the following form of the MZ equation (97)
Here, we have arranged the terms in the same way as in (97).
5.3 Mori–Zwanzig equations for probability density functions
We have seen that the PDF of the random vector \(\varvec{X}_n\) can be mapped forward and backward through the neural network via the transfer operator \(\mathcal {N}(q,n)\) in (13). Replacing \(\mathcal {R}\) with \(\mathcal {N}\) in (97) yields the following Mori–Zwanzig equation for the PDF of \(\varvec{X}_n\)
Alternatively, by using the MZ equation (107), we can write
where
5.4 Mori–Zwanzig equation for conditional expectations
Next, we discuss MZ equations in neural nets propagating conditional expectations
backward across the network, i.e., from \(\varvec{q}_0(\varvec{x})=\varvec{u}(\varvec{x})\) into \(\varvec{q}_{L}(\varvec{x}) = \mathbb {E}\{\varvec{u}(\varvec{X}_L)| \varvec{X}_{0}=\varvec{x}\}\). To simplify the notation, we denote the projection operators in the space of conditional expectations with the same letters as in the space of PDFs, i.e., \(\mathcal {P}_n\) and \(\mathcal {Q}_n\).Footnote 12 Replacing \(\mathcal {R}\) with \(\mathcal {G}\) in (97) yields the following MZ equation for the conditional expectations
where
Equation (113) can be equivalently written by incorporating the streaming term into the summation of the memory term
Alternatively, by using Eq. (107) we obtain
Remark
The Mori–Zwanzig equations (108)–(109) and (113)–(116) allow us to perform dimensional reduction within each layer of the network (number of neurons per layer, via projection), or across different layers (total number of layers, via memory approximation). The MZ formulation is also useful to perform theoretical analysis of deep learning by using tools from operator theory. As we shall see in Sect. 7, the memory of the neural network can be controlled by controlling the noise process \(\{\varvec{\xi }_0,\varvec{\xi }_1,\ldots ,\varvec{\xi }_{L-1}\}\).
6 Mori–Zwanzig projection operator
Suppose that the neural network model (2) is perturbed by independent random variables \(\{\varvec{\xi }_n\}\) with bounded range \(\mathscr {R}(\varvec{\xi }_n)\). In this hypothesis, the range of each random vector \(\varvec{X}_m\), i.e., \(\mathscr {R}(\varvec{X}_m)\), is bounded. In fact,
and \(\Omega _{m}\) is clearly a bounded set if \(\mathscr {R}(\varvec{\xi }_{m-1})\) is bounded. With specific reference to MZ equations for scalar conditional expectations (i.e., conditional averages of scalar quantities of interest)
and recalling that
we define the following orthogonal projection operatorFootnote 13 on \(L^2(\mathscr {R}(\varvec{X}_{L-m}))\)
Since \(\mathcal {P}_m\) is, by definition, an orthogonal projection we have that \(\mathcal {P}_m\) is idempotent (\(\mathcal {P}_m^2=\mathcal {P}_m\)), bounded, and self-adjoint relative to the inner product in \(L^2\left( \mathscr {R}(\varvec{X}_{L-m})\right) \). These conditions imply that the kernel \(K_{L-m}(\varvec{x},\varvec{y})\) is a symmetric Hilbert–Schmidt kernel that satisfies the reproducing kernel condition
Note that the classical Mori’s projection [60, 63] can be written in the form (120) if we set
where \(\{\eta ^m_0,\ldots ,\eta ^m_M\}\) are orthonormal functions in \(L^2\left( \mathscr {R}(\varvec{X}_{L-m})\right) \). Since the range of \(\varvec{X}_{L-m}\) can vary from layer to layer we have that the set of orthonormal functions \(\{\eta ^m_j(\varvec{x})\}\) also depends on the layer (hence the label “m”). The projection operator \(\mathcal {P}_m\) is said to be nonnegative if for all positive functions \(v(\varvec{x})\in L_{\mu _m}^2(\mathscr {R}(\varvec{X}_{L-m}))\) (\(v>0\)) we have that \(\mathcal {P}_m v\ge 0\) [27]. Clearly, this implies that the kernel \(K_{L-m}(\varvec{x},\varvec{y})\) is nonnegative in \(\mathscr {R}(\varvec{X}_{L-m})\times \mathscr {R}(\varvec{X}_{L-m})\) [17]. An example of a kernel defining a nonnegative orthogonal projection is
More generally, if \(K_{L-m}(\varvec{x},\varvec{y})\) is any square-integrable symmetric conditional probability density function on \(\mathscr {R}(\varvec{X}_{L-m})\times \mathscr {R}(\varvec{X}_{L-m})\), then \(\mathcal {P}_m\) is a nonnegative projection.
7 Analysis of the MZ equation
We now turn to the theoretical analysis of the MZ equation. In particular, we study the MZ equation for conditional expectations discussed in Sect. 5.4, i.e., Eq. (113). Clearly, the operator \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) plays a very important role in such an equation via the memory operator \(\Phi _\mathcal {G}\) defined in (114). Indeed, \(\Phi _\mathcal {G}\) appears in both the memory term and the noise term and is defined by operator products involving \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\).
In this section, we aim at determining conditions on \(Q_{m}\mathcal {G}(m,m-1)=(\mathcal {I}-\mathcal {P}_{m})\mathcal {G}(m,m-1)\), e.g., noise level and distribution, such that
In this way, the operator \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) becomes a contraction, and therefore the MZ memory term in (113) decays with the number of layers, while the noise term decays zero. Indeed, if (124) holds true, then the norm of memory operator \(\Phi _\mathcal {G}(n,m)\) defined in (114) (similar in (115) and (116) ) decays with the number of “\(\mathcal {Q}\mathcal {G}\)” operator products taken, i.e., with the number of layers.
7.1 Deterministic neural networks
Before turning to the theoretical analysis of the operator \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\), it is convenient to dwell on the case where the neural network is deterministic (no random perturbations), and has \(\tanh ()\) activation functions. This case is quite common in practical applications, and also allows for significant simplifications of the MZ framework. First of all, in the absence of noise the output of each neural network layer has the same range, i.e.,
where N is the number of neurons, assumed to be constant for each layer. Hence, we can choose a projection operator (120) that does not depend on the particular layer. For simplicity, we consider
where
Here, \(\{\eta _0,\ldots ,\eta _M\}\) are orthonormal functions in \(L^2\left( [-1,1]^N\right) \), e.g., normalized multivariate Legendre polynomials [56]. We sort \(\{\eta _k\}\) based on degree lexicographic order. In this way, the first \(N+1\) orthonormal functions in (127) are explicitly written as
Moreover, if the neural network has linear output we have \(q_0(\varvec{x})=\varvec{\alpha }\cdot \varvec{x}\) and therefore
This implies that the noise term in the MZ equation (113) is zero for the projection kernel (127)–(128) and networks with linear output.
To study the MZ memory term, we consider a simple example involving a two-layer deterministic neural net with d-dimensional input \(\varvec{x}\in \Omega _0\subseteq \mathbb {R}^d\) and scalar output \(q_2(\varvec{x})\). The MZ equation (113) with projection operator (126)–(128) can be written as
Clearly, if \(q_1\) is approximately in the range of \(\mathcal {P}\) (i.e., if \(q_1\simeq \mathcal {P}q_1\)) then the neural network is essentially memoryless (the memory term in (130) drops out). The next question is whether the nonlinear function \(q_1\) can indeed be approximated accurately by \(\mathcal {P}q_1\). This is a well-established result in multivariate polynomial approximation theory. In particular, it can be shown that \(\mathcal {P}q_1\) converges exponentially fast to \(q_1\)as we increase the polynomial degree in the multivariate Legendre expansion (i.e., as we increase M in (127)Footnote 14). Exponential convergence follows immediately from the fact that the function
admits an analytical extension on a Bernstein poly-ellipse enclosing \([-1,1]^N\) (see [56] for details). The projection of the nonlinear function \(q_1(\varvec{x})\) onto the linear space spanned by the \(N+1\) orthonormal basis functions (128) (i.e., the space of affine functions defined on \([-1,1]^N\)) can be written as
where the coefficients \(\{\beta _0,\ldots ,\beta _N\}\) are given by
Hence, if \(q_1\) is approximately in the range of \(\mathcal {P}\) (i.e., \(\mathcal {P}q_1 \simeq q_1\)), then we can explicitly write the MZ equation (130) as
Note that this reduces the total number of degrees of freedom of the two-layer neural network from \(N(N+d+3)\) to \(N(d+2)+1\), under the condition that \(q_1\) in Eq. (131) can be accurately approximated by the hyperplane \(\mathcal {P}q_1\) in Eq. (132). This depends of course on the weights \(\varvec{W}_{1}\) and biases \(\varvec{b}_{1}\) in (131). In particular, if the entries of the weight matrix \(\varvec{W}_{1}\) are sufficiently small, then by using Taylor series it is immediate to prove that \(\mathcal {P}q_1\simeq q_1\).
An example: In Fig. 8, we compare the MZ streaming and memory terms for the two-layer deterministic neural network we studied in Sect. 4 and the target function (65). Here we consider \(N=20\) neurons, and approximate the integrals in (133) using Monte Carlo quadrature. Clearly, it is possible to constrain the norm of the weight matrix \(\varvec{W}_1\) during training so that the nonlinear function \(q_1\) in (131) is approximated well by the affine function \(\mathcal {P}q_1\) in (132). This essentially allows us to control the approximation error \(\left\| q_1-\mathcal {P}q_1\right\| _{L^2([-1,1]^N)}\) and therefore the the amplitude of the MZ memory term in (130). For this particular example, we set \(\left\| \varvec{W}_1\right\| _{\infty }\le 0.1\), which yields the following contraction factor
Note that (135) is not the operator norm of \(\mathcal {Q}\mathcal {G}(2,1)\) we defined in (124). In fact, the operator norm requires computing the supremum of \(\Vert \mathcal {Q}\mathcal {G}(2,1) v\Vert _{L^2([-1,1])}/\Vert v\Vert _{L^2([-1,1])}\) over all nonzero functions \(v\in L^2([-1,1]^N)\), not just the linear function \(v=q_0\) If training over weights of deterministic nets is done in a fully unconstrained optimization setting then there is no guarantee that the MZ memory term is small.

Comparison between the MZ streaming and memory terms for the two-layer deterministic neural network we studied in Sect. 4 and the target function (65). Here we consider \(N=20\) neurons, and approximate the high-dimensional integrals in (133) by using Monte Carlo quadrature. The neural network is trained by constraining the entries of the weight matrix \(\varvec{W}_1\) as \(\left\| \varvec{W}_1\right\| _{\infty }\le 0.1\). This allows us to control the approximation error \(\left\| q_1-\mathcal {P}q_1\right\| _{L^2([-1,1]^N)}\) when projecting the nonlinear function (131) onto the space of affine functions (132) which, in turn, controls the magnitude of the MZ memory term
The discussion about the approximation of the MZ memory term can be extended to deterministic neural networks with an increasing number of layers. For example, the output of a three-layer deterministic neural network can be written as
Note that if \(\mathcal {P}q_1\) is a linear function of the form (132), then the term \(\mathcal {G}(3,2)\left[ \mathcal {I}- \mathcal {P}\right] \mathcal {G}(2,1)\mathcal {P}q_1\) has exactly the same functional form as the MZ memory term \(\mathcal {G}(2,1)\left[ \mathcal {I}- \mathcal {P}\right] \mathcal {G}(1,0)\mathcal {P}q_0 = \mathcal {G}(2,1)[q_1-\mathcal {P}q_1]\). Hence, everything we said about the accuracy of a linear approximation of \(\varvec{\alpha }\cdot \tanh (\varvec{W}_{1}\varvec{x} +\varvec{b}_{1})\) can be directly applied now to \(\mathcal {G}(2,1)\mathcal {P}q_1=\varvec{\beta }\cdot \tanh (\varvec{W}_{2}\varvec{x}+\varvec{b}_{2})\).
On the other hand, if \(q_1\) can be approximated with accuracy by the linear function \(\mathcal {P}q_1\), then the term \(\mathcal {G}(2,1)[q_1-\mathcal {P}q_1]\) is likely to be small. This implies that the last term in (136) is likely to be small as well (bounded operator \(\mathcal {G}(3,2)\) applied to the difference between two small functions). In other words, if the weights and biases of the network are such that \(q_1(\varvec{x})=\varvec{\alpha }\cdot \tanh (\varvec{W}_n\varvec{x}+ b_n)\) can be approximated with accuracy by the linear function (132) then the MZ memory term of the three-layer network is small.
More generally, by using error estimates for multivariate polynomial approximation of analytic functions [56], it is possible to derive an upper bound for the operator norm of \(\mathcal {Q}\mathcal {G}(m,m-1)\) in (124). Such a bound is rather involved, but in principle it allows us to determine conditions on the weights and biases of the neural network such that \(\left\| \mathcal {Q}\mathcal {G}(m,m-1)\right\| \le \kappa \), where \(\kappa \) is a given constant smaller than one. This allows us to simplify the memory term in (113) by neglecting terms involving a large number of “\(\mathcal {Q}_m \mathcal {G}(m,m-1)\)” operator products in (114). Hereafter, we determine general conditions for the operator \(\mathcal {Q}_m \mathcal {G}(m,m-1)\) to be a contraction in the presence of random perturbations.
7.2 Stochastic neural networks
Consider the stochastic neural network model (2) with L layers, N neurons per layer, and transfer functions \(\varvec{F}_n\) with range in \([-1,1]^{N}\) for all n. In this section, we determine general conditions for the operator \(\mathcal {Q}_m \mathcal {G}(m,m-1)\) to be a contraction (i.e., to satisfy the inequality (124)) independently of the neural network weights. To this end, we first write the operator \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) as
where
The conditional density \(p_{L-m+1|L-m}(\varvec{y}|\varvec{x})=\rho _{L-m} (\varvec{y}-\varvec{F}_{L-m}(\varvec{x}, \varvec{w}_{L-m}))\) is defined on the set
As before, we assume that \(K_{L-m}\) is an element of \(L^2(\mathscr {R}(\varvec{X}_{L-m})\times \mathscr {R}(\varvec{X}_{L-m}))\) and expand it asFootnote 15
where \(c_m\) is a real number and \(\eta ^m_i\) are zero-mean orthonormal basis functions in \(L^2(\mathscr {R}(\varvec{X}_{L-m})\), i.e.,
Lemma 1
The kernel (140) satisfies the idempotency requirement (121) if and only if
where \(\lambda (\mathscr {R}(\varvec{X}_{L-m}))\) is the Lebesgue measure of the set \(\mathscr {R}(\varvec{X}_{L-m})\).
Proof
By substituting (140) into (121) and taking into account (141), we obtain
from which we obtain \(c_m=0\) or \(c_m=1/\lambda (\mathscr {R}(\varvec{X}_{L-m}))\). \(\square \)
Clearly, if \(\mathcal {G}(m,m-1)\) is itself a contraction and \(\mathcal {Q}_{m}\) is an orthogonal projection, then the operator product \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) is a contraction. In the following Proposition, we compute a simple bound for the operator norm of \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\).
Proposition 2
Let \(\mathcal {Q}_{m}\) be an orthogonal projection in \(L^2(\varvec{X}_{L-m})\). Suppose that the PDF of \(\varvec{\xi }_{L-m}\), i.e., \(\rho _{L-m}\), is in \(L^2(\mathscr {R}(\varvec{\xi }_{L-m}))\). Then,
where \(\lambda (\Omega _{L-m})\) is the Lebesgue measure of the set \(\Omega _{L-m}\) defined in (117) and
In particular, if \(\mathcal {G}(m,m-1)\) is a contraction then \(\mathcal {Q}_{m} \mathcal {G}(m,m-1)\) is a contraction.
Proof
The last statement in the Proposition is trivial. In fact, if \(\mathcal {Q}_{m}\) is an orthogonal projection then its operator norm is less or equal to one. Hence,
Therefore, if \(\mathcal {G}(m,m-1)\) is a contraction and \(\mathcal {Q}_{m}\) is an orthogonal projection then \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) is a contraction. We have shown in “Appendix A” that if \(\rho _{L-m}\in L^2(\mathscr {R}(\varvec{\xi }_{L-m}))\) then \(\mathcal {G}(m,m-1)\) is a bounded linear operator from \(L^2(\mathscr {R}(\varvec{X}_{L-m+1})\) to \(L^2(\mathscr {R}(\varvec{X}_{L-m})\). Moreover, the operator norm of \(\mathcal {G}(m,m-1)\) can be bounded as (see Eq. (A.28))
Hence,
which completes the proof of (144). \(\square \)
The upper bound in (144) can be slightly improved using the definition of the projection kernel \(K_{L-m}\). This is stated in the following theorem.
Theorem 3
Let \(K_{L-m}\) be the projection kernel (140) with \(c_m=1/\lambda (\mathscr {R}(\varvec{X}_{L-m}))\). Then the operator norm of \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) can be bounded as
The upper bound in (149) is independent of the neural network weights.
Proof
The function \(\gamma _{L-m}(\varvec{y},\varvec{x})\) defined in (138) is a Hilbert–Schmidt kernel. Therefore,
The \(L^2\) norm of \(\gamma _{L-m}\) can be written as (see (138))
By using (147), we can write the first term at the right-hand side of (151) as
A substitution of the series expansion (140) into the second term at the right-hand side of (151) yields
Here, we used the fact that the basis functions \(\eta ^m_k(\varvec{x})\) are zero-mean and orthonormal in \(\mathscr {R}(\varvec{X}_{L-m})\) (see Eq. (141)). Similarly, by substituting the expansion (140) in the third term at the right-hand side of (151) we obtain
At this point, we use the Cauchy–Schwarz inequalityFootnote 16
and well-known properties of conditional PDFs to bound the integral in the second term and the integrals in the last summation, respectively, as
and
By combining (155)–(159), we finally obtain
which proves the Theorem. \(\square \)
Remark
The last two terms in (155) represent the \(L^2\) norm of the projection of \(\rho _{L-m}\) onto the orthonormal basis \(\{\lambda (\mathscr {R}(\varvec{X}_{L-m}))^{-1/2}, \eta ^m_1,\ldots ,\eta ^m_M\}\). If we assume that \(\rho _{L-m}(\varvec{y}-\varvec{F}_{L-m}(\varvec{x},\varvec{w}_{L-m})\) is in \(L^2(\mathscr {R}(\varvec{X}_{L-m+1})\times \mathscr {R}(\varvec{X}_{L-m}))\), then by using Parseval’s identity we can write (151) as
where \(\{\eta _{M+1},\eta _{M+2}\ldots \}\) is an orthonormal basis for the orthogonal complement (in \(L^2(\mathscr {R}(\varvec{X}_{L-m}))\)) of the space spanned by the basis \(\{\lambda (\mathscr {R}(\varvec{X}_{L-m}))^{-1/2}, \eta ^m_1,\ldots ,\eta ^m_M\}\). This allows us to bound (159) from below (with a nonzero bound). Such lower bound depends on the basis functions \(\eta ^m_k\), on the weights \(\varvec{w}_{L-m}\) as well as on the choice of the transfer function \(\varvec{F}_{L-m}\). This implies that the bound (149) can be improved, if we provide information on \(\eta ^m_k\) and the activation function \(\varvec{F}\). Note also that the bound (149) is formulated in terms of the Lebesgue measure of \(\Omega _{L-m}\), i.e., \(\lambda (\Omega _{L-m})\). The reason is that \(\lambda (\Omega _{L-m})\) depends only on the range of the noise (see definition (117)), while \(\lambda \left( \mathscr {R}(\varvec{X}_{L-m})\right) \) depends on the range of the noise, on the weights of the layer \(L-m\), and on the range of \(\varvec{X}_{L-m+1}\).
Lemma 4
Consider the projection kernel (140) with \(c_m=1/\lambda (\mathscr {R}(\varvec{X}_{L-m}))\) and let \(\kappa \ge 0\). If
then
In particular, if \(0\le \kappa <1\) then \(\mathcal {Q}_{m}\mathcal {G}(m,m-1)\) is a contraction.
Proof
The proof follows immediately from Eq. (149). \(\square \)
The upper bound in (162) is a slight improvement in the bound we obtained in “Appendix A,” Lemma 19.
7.3 Contractions induced by uniform random noise
Consider the neural network model (2) and suppose that each \(\varvec{\xi }_n\) is a random vector with i.i.d. uniform components supported in \([-b_{n},b_{n}]\) (\(b_n>0\)). In this assumption, the \(L^2(\mathscr {R}(\varvec{\xi }_{L-m}))\) norm of \(\rho _{L-m}\) appearing in Theorem 3 and Lemma 4 can be computed analytically as
where N is the number of neurons in each layer. For uniform random variables with independent components it straightforward to show that the Lebesgue measure of the set \(\Omega _{L-m}\) defined in (117) and appearing in Lemma 4 is
i.e.,
A substitution of (164) and (165) into the inequality (162) yields
Upon definition of \(n=L-m\) this can be written as
A lower bound for the coefficient \(b_0\) can be set using Proposition 20 in 8, i.e.,
With a lower bound for \(b_0\) available, we can compute a lower bound for each \(b_n\) (\(n=1,2,\ldots \)) by solving the recursion (168) with an equality sign.

Lower bound on the noise amplitude (168) versus the number of neurons (N) for \(\lambda (\Omega _0)=1\) (Lebesgue measure of domain \(\Omega _0\) defining the neural network input), and different user-defined contraction factors \(\kappa \). With these values of \(b_n\) the operator \(\mathcal {Q}_{L-n}\mathcal {G}(L-n,L-n-1)\) is a contraction satisfying \(\left\| \mathcal {Q}_{L-n}\mathcal {G}(L-n,L-n-1)\right\| ^2\le \kappa \) regardless of the neural network weights and biases
This is done in Fig. 9 for different user-defined contraction factors \(\kappa \).Footnote 17 It is seen that for a fixed number of neurons N, the noise level (i.e., a lower bound for \(b_n\)) that yields operator contractions in the sense of
increases as we move from the input to the output, i.e.,
For instance, for a neural network with layers and \(N=100\) neurons per layer the noise amplitude that induces a contraction factor \(\kappa = 10^{-4}\) independently of the neural network weights is \(b_0\simeq 0.55\). This means that if each component of the random vector \(\varvec{\xi }_0\) is a uniform random variable with range \([-0.55,0.55]\) then the operator norm of \(\mathcal {Q}_2\mathcal {G}(2,1)\) is bounded by \(10^{-4}\). Moreover, we notice that as we increase the number of neurons N, the smallest noise amplitude that satisfies the operator contraction condition
converges to a constant value that depends on the layer n but not on the contraction factor \(\kappa \). Such asymptotic value can be computed analytically.
Lemma 5
Consider the neural network model (2) and suppose that each perturbation vector \(\varvec{\xi }_n\) has i.i.d. components distributed uniformly in \([-b_n,b_n]\). The smallest noise amplitude \(b_n\) that satisfies the operator contraction condition (173) satisfies the asymptotic result
independently of the contraction factor \(\kappa \) and \(\Omega _0\) (domain of the neural network input).
Proof
The proof follows immediately by substituting the identity
into (168). \(\square \)
7.4 Fading property of the neural network memory operator
We now discuss the implications of the contraction property of \(\mathcal {Q}_m\mathcal {G}(m,m-1)\) on the MZ equation. It is straightforward to show that if Proposition 2 or Lemma 4 holds true then the MZ memory and noise terms in (113) decay with the number of layers. This property is summarized in the following theorem.
Theorem 6
If the conditions of Lemma 4 are satisfied, then the MZ memory operator in Eq. (114) decays with the number of layers in the neural network, i.e.,
Moreover,
i.e., the memory operator \(\Phi _\mathcal {G}(n,0)\) decays exponentially fast with the number of layers.
Proof
The proof follows from \(\left\| Q_{m+1}\mathcal {G}(m+1,m)\right\| ^2\le \kappa \) and Eq. (114). In fact, for all \(n\ge m+1\)
\(\square \)
This result can be used to approximate the MZ equation of a neural network with a large number of layers to an equivalent one involving only a few layers. A simple numerical demonstration of the fading memory property (177) is provided in Fig. 8 for a two-layer neural deterministic network.
The fading memory property allows us to simplify terms in the MZ equation that are smaller than others. The most extreme case would be a memoryless neural network, i.e., a neural network in which the MZ memory term is zero. Such network is essentially equivalent to a one-layer network. To show this, consider the MZ equation (115) in the case where the neural network is deterministic. Suppose that the \(L^2\) projection operator \(\mathcal {P}\) is the same for each layer and it satisfies \((\mathcal {I}-\mathcal {P})q_0=0\), i.e., \(q_0\) is in the range of \(\mathcal {P}\). Then the output of the memoryless network, with input \(\varvec{x}\in \Omega _0\subseteq \mathbb {R}^d\), \(\tanh ()\) activation function, L layers, N neurons per layer, can be written as
where \(\mathcal {P} q_{L-1}= \varvec{\beta }\cdot \varvec{\eta }(\varvec{x})\) and \(\varvec{\eta }=[\eta _0(\varvec{x}),\ldots ,\eta _M(\varvec{x})]^T\) is a vector of orthonormal basis functions on \([-1,1]^N\). Regarding what types of input–output maps can be represented by memoryless neural networks, the answer is provided by the universal approximation theorem for non-affine activation functions of the form (179). We emphasize that there is no information loss associated with the fading MZ memory property as the MZ equation is formally exact. However, if we approximate the MZ equation by neglecting small terms then we may lose some information.
7.5 Reducing deep neural networks to shallow neural networks
Consider the MZ equation (116), hereafter rewritten for convenience
We have seen that the memory operator \(\Phi _\mathcal {G}(m,0)\) decays exponentially fast with the number of layers if the operator \(\mathcal {Q}_m\mathcal {G}(m,m-1)\) is a contraction (see Lemma 4). Specifically, we proved in Theorem 6 that
where \(\kappa \) is a contraction factor our choice.Footnote 18 Hereafter, we show that the magnitude of each term at the right-hand side of (180) can be controlled by \(\kappa \) independently of the neural network weights. In principle, this allows us to approximate a deep stochastic neural network using only a subset of terms in (180).
Proposition 7
Consider the stochastic neural network model (2) and assume that each random vector \(\varvec{\xi }_{m}\) has bounded range \(\mathscr {R}(\varvec{\xi }_{m})\) and PDF \(\rho _{m}\in L^2(\mathscr {R}(\varvec{\xi }_{m}))\). Then
where \(\kappa \) is defined in Lemma 3 and
The upper bound in (182) is independent of the neural network weights.
Proof
We have shown in 8 (Proposition 17) that if \(\varvec{\xi }_{m}\) has bounded range \(\mathscr {R}(\varvec{\xi }_{m})\) the PDF \(\rho _{m}\in L^2(\mathscr {R}(\varvec{\xi }_{m}))\) then it is possible to find an upper bound for \(\mathcal {G}(m+1,m)\) that is independent of the neural network weights and \(\rho _m\). By using standard operator norm inequalities and recalling Theorem 6, we immediately obtain
where B is defined in (183). \(\square \)
8 Summary
We developed a new formulation of deep learning based on the Mori–Zwanzig (MZ) projection operator formalism of irreversible statistical mechanics. The new formulation provides new insights into how information propagates through neural networks in terms of formally exact linear operator equations, and it introduces a new important concept, i.e., the memory of the neural network, which plays a fundamental role in low-dimensional modeling and parameterization of the network (see, e.g., [33]). By using the theory of contraction mappings, we developed sufficient conditions for the memory of the neural network to decay with the number of layers. This allowed us to rigorously transform deep networks into shallow ones, e.g., by reducing the number of neurons per layer (using projections), or by reducing the total number of layers (using the decay property of the memory operator). We developed most of the analysis for MZ equations involving conditional expectations, i.e., Eqs. (113)–(116). However, by using the well-known duality between PDF dynamics and conditional expectation dynamics [16], it is straightforward to derive similar analytic results for MZ equations involving PDFs, i.e., Eqs. (108)–(109). Also, the mathematical techniques we developed in this paper can be generalized to other types of stochastic neural network models, e.g., neural networks with random weights and biases.
An important open question is the development of effective approximation methods for the MZ memory operator and the noise term. Such approximations can be built upon continuous-time approximation methods, e.g., based on functional analysis [36, 60, 63], combinatorics [61], data-driven methods [3, 38, 40, 49], Markovian embedding techniques [8, 24, 28, 33, 39], or projections based on reproducing kernel Hilbert or Banach spaces [1, 47, 59].
Data availability
The data that support the findings of this study are available from the corresponding author upon request.
Notes
The dimension of the vectors \(\varvec{X}_n\) and \(\varvec{X}_{n+1}\) can vary from layer to layer, e.g., in encoding or decoding neural networks [30].
In Eq. (8) we used the shorthand notation \(p_{i|j}(\varvec{x}_i|\varvec{x}_j)\) to denote the conditional probability density function of the random vector \(\varvec{X}_i\) given \(\varvec{X}_j=\varvec{x}_j\). With this notation we have that the conditional probability density of \(\varvec{X}_i\) given \(\varvec{X}_i=\varvec{y}\) is \(p_{i|i}(\varvec{x}|\varvec{y})=\delta (\varvec{x}_i-\varvec{x}_j)\), where \(\delta (\cdot )\) is the Dirac delta function.
In a supervised learning setting the neural network weights are usually determined by minimizing a dissimilarity measure between the output of the network and a target function. Such measure may be an entropy measure, the Wasserstein distance, the Kullback–Leibler divergence, or other measures defined by classical \(L^p\) norms.
The transition density for a deterministic neural network model of the form \(\varvec{X}_{n+1}=\varvec{F}_n(\varvec{X}_n,\varvec{w}_n)\) is
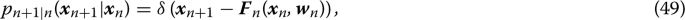
where \(\delta (\cdot )\) is the Dirac delta function. Such density does not have any degree of freedom other than \(\varvec{w}_n\). On the other hand, in a stochastic setting we may be allowed to choose the PDF of \(\varvec{\xi }_n\). For a neural network model of the form \(\varvec{X}_{n+1}=\varvec{F}_n(\varvec{X}_n,\varvec{w}_n)+\varvec{\xi }_n\) the transition density has the form
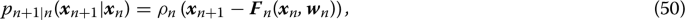
where \(\rho _n(\varvec{\xi })\) is the PDF of \(\varvec{\xi }_n\). This allows us to rethink the process of training the neural network from a probabilistic perspective, e.g., by optimizing over \(\rho _n\).
In a discrete setting, the nonnegativity constraints on the PDFs in (78) are enforced using a finite set of linear inequality constraints. In practice we evaluate the Lagrange interpolation formula (75) on a grid of 200 points in \([-0.4,0.4]\) and enforce that the polynomial interpolant of each PDF is nonnegative at each point in the grid. Similarly, the \(L^1\) normalization condition of each PDF is enforced using one-dimensional GLL quadrature.
Note that if we do not have access to the layers of the neural network, then we can introduce random perturbations in the input in the form of random shifts or other types of perturbations. In this setting one can repurpose a pre-trained neural network in which the user is allowed only to modify the input and observe the output.
In Eq. (82) we assumed that \(\mathcal {F}[q_2(\varvec{x})] (\varvec{\zeta })\ne 0\) for all \(\zeta \in \mathbb {R}^d\).
Note that the difference equation (91) can be written as

where \(\varvec{h}_{n}= \mathcal {Q}_{n}\varvec{g}_n\), \(\varvec{c}_n=\mathcal {Q}_{n+1}\mathcal {R}(n+1,n)\mathcal {P}_n\varvec{g}_n\), and \(\mathcal {A}_n= \mathcal {Q}_{n+1}\mathcal {R}(n+1,n)\). As is well known, the solution to (92) is

A substitution of \(\mathcal {A}_n\), \(\varvec{h}_n\) and \(\varvec{c}_j\) into (93) yields (94).
For continuous-time autonomous dynamical systems the Dyson’s identity can be written as [6, 55, 60, 62, 63]

where \(\mathcal {L}\) is the (time-independent) Liouvillian of the system. The discrete Dyson identity and the corresponding discrete MZ formulation was first derived by Dave et al. [11], and later revisited by Lin and Lu [36]. Both these derivations are for autonomous (time-invariant) discrete dynamical systems, while our derivations also apply to non-autonomous systems, such as those generated by neural networks.
The orthogonal projection for conditional expectations is the operator adjoint of the projection \(\mathcal {P}_m\) that operates on probability densities, i.e.,
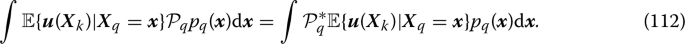
Such adjoint relation is the same that connects the composition and transfer operators (\(\mathcal {M}(q,n)\) and \(\mathcal {N}(n,q)\) in Eq. (29)). The connection between projections for probability densities and conditional expectations was extensively discussed in [16] in the setting of operator algebras.
The projection operator (120) can be extended to vector-valued functions and conditional expectations by defining an appropriate matrix-valued kernel \(\varvec{K}(\varvec{x},\varvec{y})\).
Recall for any choice of contraction factor \(\kappa \) there always exists a sequence of uniformly distributed independent random vectors \(\varvec{\xi }_n\) with increasing amplitude such that \(\left\| \mathcal {Q}_m\mathcal {G}(m+1,m)\right\| \le \kappa \) for all m, independently of the neural network weights (see Lemma 4 and the discussion in Sect. 7.3).
The notation \([-1,1]^N\) denotes a Cartesian product of N one-dimensional domains \([-1,1]\), i.e.,
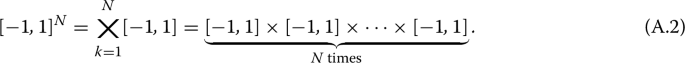
We emphasize that if we are given more information on the activation functions \(\varvec{F}_n\) together with suitable bounds on the neural network parameters \(\varvec{w}_n\), then we can identify a domain that is smaller than \(\Omega _{n+1}\) which still contains \(\mathscr {R}(\varvec{X}_{n+1})\). This allows us to construct a tighter bound for \(\lambda (\mathscr {R}(\varvec{X}_{n+1})\) in Lemma 8, which depends on the activation function and on the parameters of the neural network.
For uniformly distributed random variables we have that

Therefore, Eq. (A.27) yields

Depending on the ratio between the Lebesgue measure of \(\mathscr {R}(\varvec{X}_n)\) and \(\mathscr {R}(\varvec{\xi }_n)\), one can have \(K_n\) smaller or larger than 1.
An linear operator is called a contraction if its operator norm is smaller than one.
In Eq. (A.51), we used the Cauchy–Schwarz inequality

Note that \(\varvec{X}_n\) depends on \(\varvec{\xi }_{n-1}\) via the recursion (B.1).
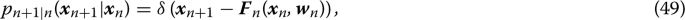
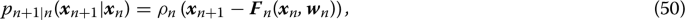



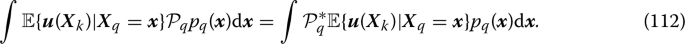



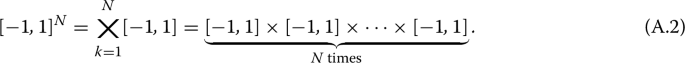



References
Bartolucci, F., De Vito, E., Rosasco, L., Vigogna, S.: Understanding neural networks with reproducing kernel Banach spaces, pp. 1–42 (2021). arXiv:2109.09710
Botev, Z.I., Grotowski, J.F., Kroese, D.P.: Kernel density estimation via diffusion. Ann. Stat. 38(5), 2916–2957 (2010)
Brennan, C., Venturi, D.: Data-driven closures for stochastic dynamical systems. J. Comput. Phys. 372, 281–298 (2018)
Bungartz, H.J., Griebel, M.: Sparse grids. Acta Numer. 13, 147–269 (2004)
Chen, M., Li, X., Liu, C.: Computation of the memory functions in the generalized Langevin models for collective dynamics of macromolecules. J. Chem. Phys 141(6), 064112 (2014)
Cho, H., Venturi, D., Karniadakis, G.E.: Statistical analysis and simulation of random shocks in Burgers equation. Proc. R. Soc. A 2171(470), 1–21 (2014)
Chorin, A.J., Hald, O.H., Kupferman, R.: Optimal prediction and the Mori–Zwanzig representation of irreversible processes. Proc. Natl. Acad. Sci. 97(7), 2968–2973 (2000)
Chu, W., Li, X.: The Mori–Zwanzig formalism for the derivation of a fluctuating heat conduction model from molecular dynamics. Commun. Math. Sci. 17(2), 539–563 (2019)
Ciccotti, G., Ryckaert, J.-P.: On the derivation of the generalized Langevin equation for interacting Brownian particles. J. Stat. Phys. 26(1), 73–82 (1981)
Črnjarić-Žic, N., Maćešić, S., Mezić, I.: Koopman operator spectrum for random dynamical systems. J. Nonlinear Sci. 30, 2007–2056 (2020)
Darve, E., Solomon, J., Kia, A.: Computing generalized Langevin equations and generalized Fokker–Planck equations. Proc. Natl. Acad. Sci. 106(27), 10884–10889 (2009)
De Rick, T., Lanthaler, S., Mishra, S.: On the approximation of functions by tanh neural networks. Acta Numer. 143, 732–750 (2021)
Dektor, A., Venturi, D.: Dynamic tensor approximation of high-dimensional nonlinear PDEs. J. Comput. Phys. 437, 110295 (2021)
Dektor, A., Rodgers, A., Venturi, D.: Rank-adaptive tensor methods for high-dimensional nonlinear PDES. J. Sci. Comput. 88(36), 1–27 (2021)
Dick, J., Kuo, F.Y., Sloan, I.H.: High-dimensional integration: the quasi-Monte Carlo way. Acta Numer. 22, 133–288 (2013)
Dominy, J.M., Venturi, D.: Duality and conditional expectations in the Nakajima–Mori–Zwanzig formulation. J. Math. Phys. 58(8), 082701 (2017)
Gibert, S., Mukherjea, A.: Nonnegative idempotent kernels. J. Math. Anal. Appl. 135(1), 326–341 (1988)
Gonon, L., Grigoryeva, L., Ortega, J.-P.: Risk bounds for reservoir computing. JMLR 21(240), 1–61 (2020)
Han, J., Li, Q.: A mean-field optimal control formulation of deep learning. Res. Math. Sci. 6, 1–41 (2019)
Harlim, J., Jiang, S.W., Liang, S., Yang, H.: Machine learning for prediction with missing dynamics. J. Comput. Phys. 428, 109922 (2021)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: ECCV, pp. 630–645. Springer (2016)
Hesthaven, J.S., Gottlieb, S., Gottlieb, D.: Spectral Methods for Time-Dependent Problems, Volume 21 of Cambridge Monographs on Applied and Computational Mathematics. Cambridge University Press, Cambridge (2007)
Hijón, C., Serrano, M., Español, P.: Markovian approximation in a coarse-grained description of atomic systems. J. Chem. Phys. 125, 204101 (2006)
Hijón, C., Español, P., Vanden-Eijnden, E., Delgado-Buscalioni, R.: Mori–Zwanzig formalism as a practical computational tool. Faraday Discussions 144, 301–322 (2010)
Izvekov, S., Voth, G.A.: Modeling real dynamics in the coarse-grained representation of condensed phase systems. J. Chem. Phys. 125, 151101–151104 (2006)
Jameson, G.J.O., Pinkus, A.: Positive and minimal projections in function spaces. J. Approx. Theory 37, 182–195 (1983)
Kauzlarić, D., Meier, J.T., Español, P., Greiner, A., Succi, S.: Markovian equations of motion for non-Markovian coarse-graining and properties for graphene blobs. New J. Phys. 15(12), 125015 (2013)
Khuri, A.I.: Applications of Dirac’s delta function in statistics. Int. J. Math. Educ. Sci. Technol. 35(2), 185–195 (2004)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
Kobyzev, I., Prince, S.J.D., Brubaker, M.A.: Normalizing flows: an introduction and review of current methods. IEEE Trans. Pattern Anal. Mach. Intell. 43(11), 3964–3979 (2020)
Lasota, A., Mackey, M.C.: Chaos, Fractals and Noise: Stochastic Aspects of Dynamics, 2nd edn. Springer, New York (1994)
Lei, H., Baker, N.A., Li, X.: Data-driven parameterization of the generalized Langevin equation. Proc. Natl. Acad. Sci. 113(50), 14183–14188 (2016)
Li, Q., Lin, T., Shen, Z.: Deep learning via dynamical systems: an approximation perspective. J. Eur. Math. Soc. (2022)
Li, Q., Chen, L., Tai, C.: Maximum principle based algorithms for deep learning. JMLR 18, 1–29 (2018)
Lin, K.K., Lu, F.: Data-driven model reduction, Wiener projections, and the Koopman–Mori–Zwanzig formalism. J. Comput. Phys. 424, 109864 (2021)
Lu, Y., Zhong, A., Li, Q., Dong, B.: Beyond finite layer neural networks: bridging deep architectures and numerical differential equations. arXiv:1710.10121 (2017)
Lu, F., Lin, K., Chorin, A.: Comparison of continuous and discrete-time data-based modeling for hypoelliptic systems. Commun. Appl. Math. Comput. Sci. 11(2), 187–216 (2016)
Ma, L., Li, X., Liu, C.: The derivation and approximation of coarse-grained dynamics from Langevin dynamics. J. Chem. Phys. 145(20), 204117 (2016)
Ma, L., Li, X., Liu, C.: Coarse-graining Langevin dynamics using reduced-order techniques. J. Comput. Phys. 380, 170–190 (2019)
Minguzzi, E.: The equality of mixed partial derivatives under weak differentiability conditions. Real Anal. Exch. 40(1), 81–98 (2014/2015)
Mori, H.: Transport, collective motion, and Brownian motion. Prog. Theor. Phys. 33(3), 423–455 (1965)
Novak, E., Ritter, K.: Simple cubature formulas with high polynomial exactness. Constr. Approx. 15, 499–522 (1999)
Nozaki, D., Mar, D.J., Grigg, P., Collins, J.J.: Effects of colored noise on stochastic resonance in sensory neurons. Phys. Rev. Lett. 82(11), 2402–2405 (1999)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2010)
Papoulis, A.: Probability, Random Variables and Stochastic Processes, 3rd edn. McGraw-Hill, New York (1991)
Parhi, R., Nowak, R.D.: Banach space representer theorems for neural networks and ridge splines. JMLR 22, 1–40 (2021)
Pavliotis, G.A.: Stochastic Processes and Applications: Diffusion Processes, the Fokker–Planck and Langevin Equations, vol. 60. Springer, New York (2014)
Price, J., Stinis, P.: Renormalized reduced order models with memory for long time prediction. Multiscale Model. Simul. 17(1), 68–91 (2019)
Rezende, D., Mohamed, S.: Variational inference with normalizing flows. In: International Conference on Machine Learning, pp. 1530–1538. PMLR (2015)
Sherstinsky, A.: Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 404, 132306 (2020)
Tabak, E.G., Vanden-Eijnden, E.: Density estimation by dual ascent of the log-likelihood. Commun. Math. Sci. 8(1), 217–233 (2010)
Trefethen, L.N.: Multivariate polynomial approximation in the hypercube. Proc. Am. Math. Soc. 145(11), 4837–4844 (2017)
Venturi, D., Karniadakis, G.E.: Convolutionless Nakajima–Zwanzig equations for stochastic analysis in nonlinear dynamical systems. Proc. R. Soc. A 470(2166), 1–20 (2014)
Venturi, D., Cho, H., Karniadakis, G.E.: The Mori–Zwanzig approach to uncertainty quantification. In: Ghanem, R., Higdon, D., Owhadi, H. (eds.) Handbook of Uncertainty Quantification. Springer, New York (2016)
Wang, H., Zhang, L.: Analysis of multivariate Gegenbauer approximation in the hypercube. Adv. Comp. Math. 46(53), 1–29 (2020)
Weinan, E.: A proposal on machine learning via dynamical systems. Commun. Math. Stat. 5, 1–10 (2017)
Yu, T., Yang, Y., Li, D., Hospedales, T., Xiang, T.: Simple and effective stochastic neural networks. In: Proceedings of the Innovative Applications of Artificial Intelligence Conference, vol. 35, pp. 3252–3260 (2021)
Zhang, H., Xu, Y.: Reproducing kernel Banach spaces for machine learning. JMLR 10, 2741–2775 (2009)
Zhu, Y., Venturi, D.: Faber approximation of the Mori–Zwanzig equation. J. Comput. Phys. 372, 694–718 (2018)
Zhu, Y., Venturi, D.: Generalized Langevin equations for systems with local interactions. J. Stat. Phys. 178(5), 1217–1247 (2020)
Zhu, Y., Venturi, D.: Hypoellipticity and the Mori–Zwanzig formulation of stochastic differential equations. J. Math. Phys. 62, 1035051 (2021)
Zhu, Y., Dominy, J.M., Venturi, D.: On the estimation of the Mori–Zwanzig memory integral. J. Math. Phys 59(10), 103501 (2018)
Zwanzig, R.: Memory effects in irreversible thermodynamics. Phys. Rev. 124(4), 983 (1961)
Acknowledgements
Dr. Venturi was partially supported by the U.S. Air Force Office of Scientific Research Grant FA9550-20-1-0174 and by the U.S. Army Research Office Grant W911NF1810309. Dr. Li was supported by the NSF Grant DMS-1953120.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Functional setting
Let \((\mathcal {S},\mathcal {F},\mathscr {P})\) be a probability space. Consider the neural network model (2), hereafter rewritten for convenience as
We assume that the following conditions are satisfied
-
1.
\(\varvec{X}_0\in \Omega _0\subseteq \mathbb {R}^d\) (\(\Omega _0\) compact), \(\varvec{X}_n\in \mathbb {R}^N\) for all \(n=1,\ldots ,L\);
-
2.
The range of \(\varvec{F}_n\) (\(n=0,\ldots ,L-1\)) is the hypercube \([-1,1]^N\).
We also assume that the random vectors \(\{\varvec{\xi }_0,\ldots ,\varvec{\xi }_{L-1}\}\) in (A.1) are statistically independent, and that \(\varvec{\xi }_n\) is independent of past and current neural network states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\). In these hypotheses, we have that \(\{\varvec{X}_0,\ldots , \varvec{X}_L\}\) is a Markov process (see “Appendix B” for details). The range of \(\varvec{X}_{n+1}\) depends on the range of \(\varvec{\xi }_n\), as the image of each \(\varvec{F}_n\) is the hypercube \([-1,1]^N\) (condition 2. above). Let us defineFootnote 19
where
is the range of the random vector \(\varvec{\xi }_n\). Clearly, the range of the random vector \(\varvec{X}_{n+1}\) is a subsetFootnote 20 of \(\Omega _{n+1}\), i.e., \(\mathscr {R}(\varvec{X}_{n+1}) \subseteq \Omega _{n+1}\). This implies the following lemma.
Lemma 8
Let \(\lambda (\Omega _{n+1})\) be the Lebesgue measure of the set (A.3). Then, the Lebesgue measure of the range of \(\varvec{X}_{n+1}\) satisfies
Proof
The proof follows immediately from the inclusion \(\mathscr {R}(\varvec{X}_{n+1}) \subseteq \Omega _{n+1}\). \(\square \)
The \(L^{\infty }\) norm of a random vector \(\varvec{\xi }\) is defined as the largest value of \(r\ge 0\) that yields a nonzero probability on the event \(\{\omega \in \mathcal {S}:\, \left\| \varvec{\xi }(\omega )\right\| _{\infty }>r \}\in \mathcal {F}\), i.e.,
This definition allows us to bound the Lebesgue measure of \(\Omega _{n+1}\) as follows.
Proposition 9
The Lebesgue measure of the set \(\Omega _{n+1}\) defined in (A.3) can be bounded as
where N is the number of neurons and \(\Gamma (\cdot )\) is the Gamma function.
Proof
As is well known, the length of the diagonal of the hypercube \([-1,1]^N\) is \(\sqrt{N}\). Hence, \(\sqrt{N}+\left\| \varvec{\xi }_{n}\right\| _{\infty }\) is the radius of a ball that encloses all elements of \(\Omega _{n+1}\). The Lebesgue measure of such a ball is obtained by multiplying the Lebesgue measure of the unit ball in \(\mathbb {R}^N\), i.e., \(\pi ^{N/2}/\Gamma (1+N/2)\) by the scaling factor \( \left( \sqrt{N}+\left\| \varvec{\xi }_{n} \right\| _{\infty }\right) ^N\). \(\square \)
Lemma 10
If \(\mathscr {R}(\varvec{\xi }_{n})\) is bounded, then \(\mathscr {R}(\varvec{X}_{n+1})\) is bounded.
Proof
The image of the activation function \(\varvec{F}_n\) is a bounded set. If \(\mathscr {R}(\varvec{\xi }_{n})\) is bounded, then \(\Omega _{n+1}\) in (A.3) is bounded. Since \(\mathscr {R}(\varvec{X}_{n+1})\subseteq \Omega _{n+1}\) we have that \(\mathscr {R}(\varvec{X}_{n+1})\) is bounded. \(\square \)
Clearly, if \(\{\varvec{\xi }_{0},\ldots , \varvec{\xi }_{L-1}\}\) are i.i.d. random variables, then there exists a domain \(V=\Omega _1=\cdots =\Omega _{L}\) such that
In fact, if \(\{\varvec{\xi }_{0},\ldots , \varvec{\xi }_{L-1}\}\) are i.i.d. random variables, then we have
which implies that all \(\Omega _i\) defined in (A.3) are the same. If the range of each random vector \(\varvec{\xi }_n\) is a tensor product of one-dimensional domain, e.g., if the components of \(\varvec{\xi }_n\) are statistically independent, then \(V=\Omega _1=\cdots =\Omega _{L}\) becomes particularly simple, i.e., a hypercube.
Lemma 11
Let \(\{\varvec{\xi }_0,\ldots ,\varvec{\xi }_{L-1}\}\) be i.i.d. random variables with bounded range and suppose that each \(\varvec{\xi }_k\) has statistically independent components with range [a, b]. Then, all domains \(\{\Omega _{1},\ldots ,\Omega _L\}\) defined in Eq. (A.3) are the same, and they are equivalent to

V includes the range of all random vectors \(\varvec{X}_{n}\) (\(n=1,\ldots ,L\)) and has Lebesgue measure
Proof
The proof is trivial and therefore omitted. \(\square \)
Remark
It is worth noticing that if each \(\varvec{\xi }_k\) is a uniformly distributed random vector with statistically independent components in \([-1,1]\), then for \(N=10\) neurons the upper bound in (A.7) is \(3.98\times 10^6\) while the exact result (A.11) gives \(1.05\times 10^6\). Hence the estimate (A.7) is sharp in the case of uniform random vectors.
1.1 Boundedness of composition and transfer operators
Lemma 10 states that if we perturb the output of the nth layer of a neural network by a random vector \(\varvec{\xi }_n\) with finite range, then we obtain a random vector \(\varvec{X}_{n+1}\) with finite range. In this hypothesis, it is straightforward to show that the composition and transfer operators defined in (19) and (13) are bounded. We have seen in Sect. 3 that these operators can be written as
where \(p_{n+1|n}(\varvec{y}|\varvec{x})=\rho _n(\varvec{y}-\varvec{F}_n(\varvec{x},\varvec{w}_n))\) is the conditional transition density of \(\varvec{X}_{n+1}\) given \(\varvec{X}_n\), and \(\rho _n\) is the joint PDF of the random vector \(\varvec{\xi }_n\). The conditional transition density \(p_{n+1|n}(\varvec{y}|\varvec{x})\) is always nonnegative, i.e.,
Moreover, the conditional density \(p_{n+1|n}\) is defined on the set
Both \(\mathscr {R}(\varvec{X}_{n+1})\) and \(\mathscr {R}(\varvec{X}_{n})\) depend on \(\Omega _0\) (domain of the neural network input), the neural network weights, and the noise amplitude. Thanks to Lemma 8, we have that
The Lebesgue measure of \(\mathscr {B}_{n}\) can be calculated as follows.
Lemma 12
The Lebesgue measure of the set \(\mathscr {B}_{n}\) defined in (A.14) is equal to the product of the measure of \(\lambda (\mathscr {R}(\varvec{X}_{n}))\) and the measure of \(\mathscr {R}(\varvec{\xi }_{n})\), i.e.,
Moreover, \(\lambda (\mathscr {B}_{n})\) is bounded by \(\lambda (\mathscr {R}(\Omega _{n})) \lambda (\mathscr {R}(\varvec{\xi }_{n}))\), which is independent of the neural network weights.
Proof
Let \(\chi _{n}\) be the indicator function of the set \(\mathscr {R}(\varvec{\xi }_{n})\), \(\varvec{y}\in \mathscr {R}(\varvec{X}_{n+1})\) and \(\varvec{x} \in \mathscr {R}(\varvec{X}_{n})\). Then,
By using Lemma 8 we conclude that \(\lambda (\mathscr {B}_{n})\) is bounded from the above by \(\lambda (\mathscr {R} (\Omega _{n})) \lambda (\mathscr {R}(\varvec{\xi }_{n}))\), which is independent of the neural network weights. \(\square \)
Remark
The equality (A.16) has a nice geometrical interpretation in two dimensions. Consider a ruler of length \(r=\lambda (\mathscr {R}(\xi _{n}))\) with endpoints that can leave markings if we slide the ruler on a rectangular table with side lengths \(s_b=\lambda (\mathscr {R}( X_{n+1}))\) (horizontal sides) \(s_h=\lambda (\mathscr {R}(X_{n}))\) (vertical sides). If we slide the ruler from the top to the bottom of the table, while keeping it parallel to the horizontal side of the table (see Fig. 10), then the area of the domain within the markings left by the endpoints of the ruler is always \(r\times s_h\) independently of the way we slide the ruler—provided the ruler never gets out of the table and never inverts its vertical motion.
Lemma 13
If the range of \(\varvec{\xi }_{n-1}\) is a bounded subset of \(\mathbb {R}^N\), then the transition density \(p_{n+1|n}(\varvec{y}|\varvec{x})\) is an element of \(L^1\left( \mathscr {R}(\varvec{X}_{n+1})\times \mathscr {R}(\varvec{X}_{n})\right) \).
Proof
Note that
The Lebesgue measure \(\lambda (\Omega _n)\) can be bounded as (see Proposition 9)
Since the range of \(\varvec{\xi }_{n-1}\) is bounded by hypothesis we have that there exists a finite real number \(M>0\) such that \(\left\| \varvec{\xi }_{n-1} \right\| _{\infty }\le M\). This implies that the integral in (A.18) is finite, i.e., that the transition kernel \(p_{n+1|n}(\varvec{y}|\varvec{x})\) is in \(L^1\left( \mathscr {R}(\varvec{X}_{n+1})\times \mathscr {R}(\varvec{X}_{n})\right) \).
\(\square \)
Theorem 14
Let \(C_{\varvec{\xi }_n}(\varvec{x})\) be the cumulative distribution function \(\varvec{\xi }_{n}\). If \(C_{\varvec{\xi }_n}(\varvec{x})\) is Lipschitz continuous on \(\mathscr {R}(\varvec{\xi }_n)\) and the partial derivatives \(\partial C_{\varvec{\xi }_n}/\partial x_k\) (\(k=1,\ldots , N\)) are Lipschitz continuous in \(x_1\), \(x_2\),..., \(x_N\), respectively, then the joint probability density function of \(\varvec{\xi }_{n}\) is bounded on \(\mathscr {R}(\varvec{\xi }_n)\).
Proof
By using Rademacher’s theorem, we have that if \(C_{\varvec{\xi }_n}(\varvec{x})\) is Lipschitz on \(\mathscr {R}(\varvec{\xi }_n)\), then it is differentiable almost everywhere on \(\mathscr {R}(\varvec{\xi }_n)\) (except on a set with zero Lebesgue measure). Therefore, the partial derivatives \(\partial C_{\varvec{\xi }_n}/\partial x_k\) exist almost everywhere on \(\mathscr {R}(\varvec{\xi }_n)\). If, in addition, we assume that \(\partial C_{\varvec{\xi }_n}/\partial x_k\) are Lipschitz continuous with respect to \(x_k\) (for all \(k=1,\ldots ,N\)), then by applying [41, Theorem 9] recursively we conclude that the joint probability density function of \(\varvec{\xi }_n\) is bounded. \(\square \)
Lemma 15
If \(\rho _n\) is bounded on \(\mathscr {R}(\varvec{\xi }_n)\), then the conditional PDF \(p_{n+1|n}(\varvec{y}|\varvec{x})=\rho _n(\varvec{y}-\varvec{F}_n(\varvec{x}, \varvec{w}_n))\) is bounded on \(\mathscr {R}(\varvec{X}_{n+1})\times \mathscr {R}(\varvec{X}_{n})\).
Proof
Theorem 14 states that \(\rho _n\) is a bounded function. This implies that the conditional density \(p_{n+1|n}(\varvec{y}|\varvec{x})= \rho _n(\varvec{y}-\varvec{F}_n(\varvec{x}, \varvec{w}_n))\) is bounded on \(\mathscr {R}(\varvec{X}_{n+1})\times \mathscr {R}(\varvec{X}_{n})\). \(\square \)
Proposition 16
Let \(\mathscr {R}(\varvec{\xi }_n)\) and \(\mathscr {R}(\varvec{\xi }_{n-1})\) be bounded subsets of \(\mathbb {R}^N\). If \(\rho _n \in L^2(\mathscr {R}(\varvec{\xi }_n))\), then the composition and the transfer operators defined in (A.12) are bounded in \(L^2\).
Proof
Let us first prove that \(\mathcal {M}(n,n+1)\) is a bounded linear operator from \(L^{2}(\mathscr {R}(\varvec{X}_{n+1}))\) into \(L^{2}(\mathscr {R}(\varvec{X}_{n}))\). To this end, note that
Clearly, \(K_n<\infty \) since \(\rho _n\in L^2(\mathscr {R}(\varvec{\xi }_n))\). By following the same steps, it is straightforward to show that the transfer operator \(\mathcal {N}\) is a bounded linear operator, i.e.,
Alternatively, simply recall that \(\mathcal {N}\) is the adjoint of \(\mathcal {M}\) (see Sect. 3.3), and the fact that the adjoint of a bounded linear operator is bounded. \(\square \)
Remark
The integrals
can be computed by noting that
is essentially a shift of the PDF \(\rho _n\) by a quantity \(\varvec{F}_n(\varvec{x},\varvec{w}_n)\) that depends on \(\varvec{x}\) and \(\varvec{w}_n\) (see, e.g., Fig. 10). Such a shift does not influence the integral with respect to \(\varvec{y}\), meaning that the integral of \(p_{n+1|n}(\varvec{y}|\varvec{x})\) or \(p_{n+1|n}(\varvec{y}|\varvec{x})^2\) with respect to \(\varvec{y}\) is the same for all \(\varvec{x}\). Hence, by changing variables we have that the integral (A.22) is equivalent to
where \(\lambda (\mathscr {R}(\varvec{X}_n))\) is the Lebesgue measure of \(\mathscr {R}(\varvec{X}_n)\), and \(\mathscr {R}(\varvec{\xi }_n)\) is the range of \(\varvec{\xi }_n\). Note that \(K_n\) depends on the neural net weights only through the Lebesgue measure of \(\mathscr {R}(\varvec{X}_n)\). Clearly, since the set \(\Omega _{n}\) includes \(\mathscr {R}(\varvec{X}_n)\) we have by Lemma 8 that \(\lambda (\mathscr {R}(\varvec{X}_n)) \le \lambda (\Omega _n)\). This implies that
The upper bound here does not depend on the neural network weights. The following lemma summarizes all these remarks.
Proposition 17
Consider the neural network model (A.1) and let \(\mathscr {R}(\varvec{\xi }_n)\) and \(\mathscr {R}(\varvec{\xi }_{n-1})\) be bounded subsets of \(\mathbb {R}^N\). If \(\rho _n \in L^2(\mathscr {R}(\varvec{\xi }_n))\), then the composition and the transfer operators defined in (A.12) can be bounded as
where
Moreover, \(K_n\) can be bounded as
where \(\Omega _{n}\) is defined in (A.3) and \(\rho _n\) is the PDF of \(\varvec{\xi }_n\). The upper bound in (A.28) does not depend on the neural network weights and biases.
Under additional assumptions on the PDF \(\rho _n(\varvec{x})\) it is also possible to bound the integrals on the right-hand side of (A.27) and (A.28). Specifically, we have the following sharp bound.
Lemma 18
Let \(\mathscr {R}(\varvec{\xi }_n)\) be a compact subset of \(\mathbb {R}^N\), \(\rho _n\) continuous on \(\mathscr {R}(\varvec{\xi }_n)\). Denote by
If \(s_n>0\), then
Proof
Let us first notice that if \(\rho _n\) is continuous on the compact set \(\mathscr {R}(\varvec{\xi }_n)\), then it is necessarily bounded, i.e., \(S_n\) is finite. By using the definition (A.29), we have
This implies
where we used the fact that the PDF \(\rho _n\) integrates to one over \(\mathscr {R}(\varvec{\xi }_n)\). Next, define
Clearly,
which implies that
A substitution of (A.35) into (A.32) yields (A.30). \(\square \)
An example: Let us demonstrate the definitions and theorems above with a simple example. To this end, let \(X_0 \in \Omega _0=[-1,1]\) and consider
where \(\xi _0\) and \(\xi _1\) are uniform random variables with range \(\mathscr {R}(\xi _0)=\mathscr {R}(\xi _1)=[-2,2]\). In this setting,
The conditional density of \(X_1\) given \(X_0\) is given by
This function is plotted in Fig. 10 together with the domain \(\mathscr {R}(X_1)\times \mathscr {R}(X_0)\) (interior of the rectangle delimited by dashed red lines).

Conditional probability density function \(p_{1|0}(x_1|x_0)\) defined in Eq. (A.37). The domain \(\mathscr {R}(X_1)\times \mathscr {R}(X_0)\) is the interior of the rectangle delimited by dashed red lines
Clearly, the integral of the conditional PDF (A.37) is
where \(\lambda (\mathscr {R}(X_0))\) is the Lebesgue measure of \(\mathscr {R}(X_0)=[-1,1]\). The \(L^2\) norm of the operators \(\mathcal {N}\) and \(\mathcal {M}\) is bounded byFootnote 21
Hence, both operators \(\mathcal {N}(1,0)\) and \(\mathcal {M}(0,1)\) are contractions (Proposition 17). On the other hand,
Next, define V as in Lemma 11, i.e., \(V=[-3,3]\). Clearly, both \(\mathscr {R}(X_0)\) and \(\mathscr {R}(X_1)\) are subsets of V. If we integrate the conditional PDF shown in Fig. 10 in \(V\times V\), we obtain
1.2 Operator contractions induced by random noise
In this section, we prove a result on neural networks models (A.1) which states that it is possible to make both operators \(\mathcal {N}\) and \(\mathcal {M}\) in (A.12) contractionsFootnote 22 if the noise is properly chosen. To this end, we begin with the following lemma.
Lemma 19
Let \(\mathscr {R}(\varvec{\xi }_n)\) and \(\mathscr {R}(\varvec{\xi }_{n-1})\) be bounded subsets of \(\mathbb {R}^N\), \(\rho _n \in L^2(\mathscr {R}(\varvec{\xi }_n))\). If
then \(\mathcal {M}(n,n+1)\) and \(\mathcal {N}(n+1,n)\) are operator contractions. The upper bound in (A.44) is independent of the neural network weights and biases.
Proof
The proof follows immediately from Eq. (A.28). \(\square \)
Hereafter, we specialize Lemma 19 to neural network perturbed by uniformly distributed random noise.
Proposition 20
Let \(\{\varvec{\xi }_0,\ldots ,\varvec{\xi }_{L-1}\}\) be independent random vectors. Suppose that the components of each \(\varvec{\xi }_n\) are zero-mean i.i.d. uniform random variables with range \([-b_n,b_n]\) (\(b_n> 0\)). If
where \(\Omega _0\) is the domain of the neural network input, \(0\le \kappa <1\), and N is the number of neurons in each layer, then both operators \(\mathcal {M}(n,n+1)\) and \(\mathcal {N}(n+1,n)\) defined in (A.12) are contractions for all \(n=0,\ldots , L-1\), i.e., their norm can be bounded by a constant \(K_n \le \kappa \), independently of the weights and biases of the neural network.
Proof
If \(\varvec{\xi }_n\) is uniformly distributed, then from (A.27) it follows that
By using Lemma 11, we can bound \(K_n\) as
where N is the number of neurons in each layer of the neural network. Therefore, if \(b_n \ge (b_{n-1}+1)/\kappa ^{1/N}\) (\(n=1,\ldots ,L-1\)) we have that \(K_n\) is bounded by a quantity \(\kappa \) smaller than one. Regarding \(b_0\), we notice that
where \(\Omega _0\) is the domain of the neural network input. Hence, if \(b_0\) satisfies (A.45), then \(K_0\le \kappa \). \(\square \)
One consequence of Proposition 20 is that the \(L^2\) norm of the neural network output decays with both the number of layers and the number of neurons if the noise amplitude from one layer to the next increases as in (A.45). For example, if we represent the input–output map as a sequence of conditional expectations (see (22)), and set \(u(\varvec{x})=\varvec{\alpha }\cdot \varvec{x}\) (linear output), then we have
By iterating the inequalities (A.45) in Proposition 20, we find that
In Fig. 11, we plot the lower bound at the right-hand side of (A.50) for \(\kappa =0.2\) and \(\kappa =10^{-4}\) as a function of the number of neurons (N).

Lower bound on the coefficients \(b_n\) defined in (A.50) for \(\lambda (\Omega _0)=1\) as a function of the number of neurons N and the number of layers of the neural network. With such values of \(b_n\) the operator \(\mathcal {M}(n,n+1)\) is a contraction satisfying \(\left\| \mathcal {M}(n,n+1)\right\| ^2\le \kappa \). Shown are results for \(\kappa =0.2\) and \(\kappa =10^{-4}\) (contraction index)
With \(b_n\) given in (A.50) we have that the operator norms of \(\mathcal {M}(n,n+1)\) and \(\mathcal {N}(n+1,n)\) (\(n=0,\ldots ,L-1\)) are bounded exactly by \(\kappa \) (see Lemma 19). Hence, by taking the \(L^2\) norm of (A.49), and recalling that \(\left\| \mathcal {M}(n,n+1)\right\| ^2\le \kappa \) we obtain
whereFootnote 23
The inequality (A.51) shows that the 2-norm of the vector of weights \(\varvec{\alpha }\) must increase exponentially fast with the number of layers L if we chose the noise amplitude as in (A.50). As shown in the following lemma, the growth rate of \(b_n\) that guarantees that both \(\mathcal {M}\) and \(\mathcal {N}\) are contractions is linear (asymptotically with the number of neurons).
Lemma 21
Under the same assumptions in Proposition 20, in the limit of an infinite number of neurons (\(N\rightarrow \infty \)), the noise amplitude (A.50) satisfies
independently of the contraction factor \(\kappa \) and the domain \(\Omega _0\). This means that for a finite number of neurons the noise amplitude \(b_n\) that guarantees that \(\Vert \mathcal {M}(n,n+1)\Vert \le \kappa \) is bounded from below (\(\kappa <1\)) or from above (\(\kappa >1\)) by a function that increases linearly with the number of layers.
Proof
The proof follows by taking the limit of (A.50) for \(N\rightarrow \infty \). \(\square \)
Appendix B: Markovian neural networks
Consider the neural network model (1), hereafter rewritten for convenience
In this appendix, we show that if the random vectors \(\{\varvec{\xi }_0,\ldots ,\varvec{\xi }_{L-1}\}\) are statistically independent, and if \(\varvec{\xi }_n\) is independent of past and current states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\), then (B.1) defines a Markov process.Footnote 24 To this end, we first notice that the full statistical information of the neural network is represented by the joint probability density function of \(\{\varvec{X}_L,\ldots , \varvec{X}_0,\varvec{\xi }_{L-1}, \ldots , \varvec{\xi }_0\}\). Let us denote by \(p\left( \varvec{x}_L,\ldots , \varvec{x}_0, \varvec{\xi }_{L-1},\ldots ,\varvec{\xi }_0\right) \) such joint density function. By using well-known identities for conditional PDFs we can write
Clearly, from Eq. (B.1) it follows that
This allows us to rewrite (B.2) as
If \(\{\varvec{\xi }_{L_1},\ldots ,\varvec{\xi }_0\}\) are statistically independent, and if \(\varvec{\xi }_k\) is independent of \(\{\varvec{X}_0,\ldots , \varvec{X}_k\}\), then
Substituting (B.5) into (B.4) and integrating over \(\{\varvec{\xi }_{L-1},\ldots ,\varvec{\xi }_0\}\) yields
which clearly represents the joint PDF of a Markov process. Note that the Markovian property of the process \(\{\varvec{X}_n\}\) representing the neural network states relies heavily on the fact that the joint PDF of the random vectors \(\{\varvec{\xi }_{L-1},\ldots ,\varvec{\xi }_0\}\) can be factorized as a product of conditional densities as in (B.5), i.e., that the random vectors are statistically independent, and also that \(\varvec{\xi }_n\) is independent of past and current states, i.e., \(\{\varvec{X}_0,\ldots ,\varvec{X}_{n}\}\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Venturi, D., Li, X. The Mori–Zwanzig formulation of deep learning. Res Math Sci 10, 23 (2023). https://doi.org/10.1007/s40687-023-00390-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40687-023-00390-2