
Abstract
We investigate graph-based Laplacian semi-supervised learning at low labeling rates (ratios of labeled to total number of data points) and establish a threshold for the learning to be well posed. Laplacian learning uses harmonic extension on a graph to propagate labels. It is known that when the number of labeled data points is finite while the number of unlabeled data points tends to infinity, the Laplacian learning becomes degenerate and the solutions become roughly constant with a spike at each labeled data point. In this work, we allow the number of labeled data points to grow to infinity as the total number of data points grows. We show that for a random geometric graph with length scale \(\varepsilon >0\), if the labeling rate \(\beta \ll \varepsilon ^2\), then the solution becomes degenerate and spikes form. On the other hand, if \(\beta \gg \varepsilon ^2\), then Laplacian learning is well-posed and consistent with a continuum Laplace equation. Furthermore, in the well-posed setting we prove quantitative error estimates of \(O(\varepsilon \beta ^{-1/2})\) for the difference between the solutions of the discrete problem and continuum PDE, up to logarithmic factors. We also study p-Laplacian regularization and show the same degeneracy result when \(\beta \ll \varepsilon ^p\). The proofs of our well-posedness results use the random walk interpretation of Laplacian learning and PDE arguments, while the proofs of the ill-posedness results use \(\Gamma \)-convergence tools from the calculus of variations. We also present numerical results on synthetic and real data to illustrate our results.





Similar content being viewed by others
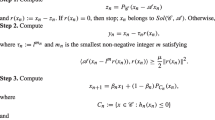

Data Availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Notes
The standard deviation in accuracy over the trials was less than 1 for the trials with at least 160 labels, and between 6 and 10 for the lower label rate trials.
References
Belkin, M., Niyogi, P.: Semi-supervised learning on Riemannian manifolds. Mach. Learn. 56(1–3), 209–239 (2004)
Belkin, M., Niyogi, P., Sindhwani, V.: Manifold regularization: a geometric framework for learning from labeled and unlabeled examples. J. Mach. Learn. Res. 7, 2399–2434 (2006)
Bercu, B., Delyon, B., Rio, E.: Concentration Inequalities for Sums and Martingales. Springer, New York (2015)
Boucheron, S., Lugosi, G., Massart, P.: Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, Oxford (2013)
Calder, J.: The game theoretic \(p\)-Laplacian and semi-supervised learning with few labels. Nonlinearity (2018)
Calder, J.: Consistency of Lipschitz learning with infinite unlabeled data and finite labeled data. SIAM J. Math. Data Sci. 1(4), 780–812 (2019)
Calder, J.: GraphLearning Python Package (2022). https://doi.org/10.5281/zenodo.5850940
Calder, J., GarcíaTrillos, N.: Improved spectral convergence rates for graph Laplacians on \(\varepsilon \)-graphs and k-NN graphs. Appl. Comput. Harmon. Anal. 60, 123–175 (2022)
Calder, J., Slepčev, D.: Properly-weighted graph Laplacian for semi-supervised learning. Appl. Math. Optim.: Spec. Issue Optim. Data Sci. 1–49 (2019)
Caroccia, M., Chambolle, A., Slepčev, D.: Mumford-Shah functionals on graphs and their asymptotics. Nonlinearity 33(8), 3846–3888 (2020)
Chapelle, O., Scholkopf, B., Zien, A.: Semi-Supervised Learning. MIT, London (2006)
Cristoferi, R., Thorpe, M.: Large data limit for a phase transition model with the \(p\)-Laplacian on point clouds. To appear in the European Journal of Applied Mathematics (2018). arXiv preprint arXiv:1802.08703v2
Davis, E., Sethuraman, S.: Consistency of modularity clustering on random geometric graphs. Ann. Appl. Probab. 28(4), 2003–2062 (2018)
Dunlop, M.M., Slepčev, D., Stuart, A.M., Thorpe, M.: Large data and zero noise limits of graph-based semi-supervised learning algorithms. Appl. Comput. Harmon. Anal. 49(2), 655–697 (2020)
El Alaoui, A., Cheng, X., Ramdas, A., Wainwright, M.J., Jordan, M.I.: Asymptotic behavior of \(\ell _p\)-based Laplacian regularization in semi-supervised learning. In: Conference on Learning Theory, pp. 879–906 (2016)
Evans, L.C.: Partial differential equations, volume 19. American Mathematical Soc. (2010)
Fitschen, J.H., Laus, F., Schmitzer, B.: Optimal transport for manifold-valued images. In: Scale Space and Variational Methods in Computer Vision, pp. 460–472 (2017)
Flores, M., Calder, J., Lerman, G.: Analysis and algorithms for Lp-based semi-supervised learning on graphs. Appl. Comput. Harmon. Anal. 60, 77–122 (2022)
GarcíaTrillos, N., Gerlach, M., Hein, M., Slepčev, D.: Error estimates for spectral convergence of the graph Laplacian on random geometric graphs toward the Laplace-Beltrami operator. Found. Comput. Math. 20(4), 827–887 (2020)
García Trillos, N., Kaplan, Z., Samakhoana, T., Sanz-Alonso, D.: On the consistency of graph-based Bayesian learning and the scalability of sampling algorithms (2017). arXiv:1710.07702
GarciaTrillos, N., Murray, R.W.: A maximum principle argument for the uniform convergence of graph Laplacian regressors. SIAM J. Math. Data Sci. 2(3), 705–739 (2020)
García Trillos, N., Sanz-Alonso, D.: Continuum limit of posteriors in graph Bayesian inverse problems. SIAM J. Math. Anal. (2018)
GarcíaTrillos, N., Slepčev, D.: Continuum limit of Total Variation on point clouds. Arch. Ration. Mech. Anal. 220(1), 193–241 (2016)
GarcíaTrillos, N., Slepčev, D.: A variational approach to the consistency of spectral clustering. Appl. Comput. Harmon. Anal. 45(2), 239–381 (2018)
GarcíaTrillos, N., Slepčev, D., von Brecht, J.: Estimating perimeter using graph cuts. Adv. Appl. Probab. 49(4), 1067–1090 (2017)
GarcíaTrillos, N., Slepčev, D., von Brecht, J., Laurent, T., Bresson, X.: Consistency of Cheeger and ratio graph cuts. J. Mach. Learn. Res. 17(1), 6268–6313 (2016)
Gilbarg, D., Trudinger, N.S.: Elliptic partial differential equations of second order. Classics in Mathematics. Springer-Verlag, Berlin (2001). Reprint of the 1998 edition
Green, A., Balakrishnan, S., Tibshirani, R.: Minimax optimal regression over sobolev spaces via laplacian regularization on neighborhood graphs. In: Banerjee, A., Fukumizu, K. (eds.) Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pp. 2602–2610. PMLR (2021)
Hein, M., Audibert, J.-Y., von Luxburg, U.: From graphs to manifolds—weak and strong pointwise consistency of graph Laplacians. In: Conference on Learning Theory, pp. 470–485 (2005)
Lawler, G.F., Limic, V.: Random Walk: A Modern Introduction, vol. 123. Cambridge University Press, Cambridge (2010)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Leoni, G.: A First Course in Sobolev Spaces, volume 105. American Mathematical Society (2009)
Müller, T., Penrose, M.D.: Optimal Cheeger cuts and bisections of random geometric graphs. Ann. Appl. Probab. 30(3), 1458–1483 (2020)
Nadler, B., Srebro, N., Zhou, X.: Statistical analysis of semi-supervised learning: the limit of infinite unlabelled data. In: Advances in Neural Information Processing Systems, pp. 1330–1338 (2009)
Osting, B., Reeb, T.: Consistency of Dirichlet partitions. SIAM J. Math. Anal. 49(5), 4251–4274 (2017)
Penrose, M.: Random Geometric Graphs. Oxford University Press, Oxford (2003)
Shi, Z., Osher, S., Zhu, W.: Weighted nonlocal Laplacian on interpolation from sparse data. J. Sci. Comput. 73(2–3), 1164–1177 (2017)
Shi, Z., Wang, B., Osher, S.J.: Error estimation of weighted nonlocal Laplacian on random point cloud (2018). arXiv:1809.08622
Singer, A.: From graph to manifold Laplacian: the convergence rate. Appl. Comput. Harmon. Anal. 21(1), 128–134 (2006)
Slepčev, D., Thorpe, M.: Analysis of \(p\)-Laplacian regularization in semi-supervised learning. SIAM J. Math. Anal. 51(3), 2085–2120 (2019)
Thorpe, M., Park, S., Kolouri, S., Rohde, G.K., Slepčev, D.: A transportation \(L^p\) distance for signal analysis. J. Math. Imaging Vis. 59(2), 187–210 (2017)
Thorpe, M., Theil, F.: Asymptotic analysis of the Ginzburg–Landau functional on point clouds. Proc. R. Soc. Edinb. Sect. A: Math. 149(2), 387–427 (2019)
Thorpe, M., van Gennip, Y.: Deep limits of residual neural networks (2018). arXiv:1810.11741
Yuan, A., Calder, J., Osting, B.: A continuum limit for the PageRank algorithm. Eur. J. Appl. Math. (2021)
Zhou, D., Bousquet, O., Lal, T., Weston, J., Schölkopf, B.: Semi-supervised learning by maximizing smoothness. J. Mach. Learn. Res. (2004)
Zhou, D., Bousquet, O., Lal, T.N., Weston, J., Schölkopf, B.: Learning with local and global consistency. In: Advances in Neural Information Processing Systems, pp. 321–328 (2004)
Zhou, D., Huang, J., Schölkopf, B.: Learning from labeled and unlabeled data on a directed graph. In: Proceedings of the 22nd International Conference on Machine Learning, pp. 1036–1043. ACM (2005)
Zhou, D., Schölkopf, B.: Regularization on discrete spaces. In: 27th DAGM Conference on Pattern Recognition, pp. 361–368 (2005)
Zhu, X., Ghahramani, Z., Lafferty, J.D.: Semi-supervised learning using Gaussian fields and harmonic functions. In Proceedings of the 20th International Conference on Machine Learning, pp. 912–919 (2003)
Acknowledgements
JC was supported by NSF DMS Grant 1713691 and is grateful for the hospitality of the Center for Nonlinear Analysis at Carnegie Mellon University, and to Marta Lewicka for helpful discussions. DS is grateful to NSF for support via grant DMS-1814991. MT is grateful for the hospitality of the Center for Nonlinear Analysis at Carnegie Mellon University and the School of Mathematics at the University of Minnesota, for the support of the Cantab Capital Institute for the Mathematics of Information and Cambridge Image Analysis at the University of Cambridge and has received funding from the European Research Council under the European Union’s Horizon 2020 research and innovation programme grant agreement No 777826 (NoMADS) and grant agreement No 647812.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
1.1 Appendix A: Concentration inequalities
For completeness, we include some inequalities from probability theory. We start with Azuma’s inequality, which is a standard concentration inequality for martingales in probability theory (see, e.g., [3, 4]). The textbook proof is usually given for martingales, and our application requires the version for super (or sub) martingales. For the reader’s convenience, we give the proof of Azuma’s inequality for supermartingales below.
Theorem A.1
(Azuma’s inequality) Let \(X_0,X_1,X_2,X_3,\dots \) be a supermartingale with respect to a filtration \(\mathcal {F}_1,\mathcal {F}_2,\mathcal {F}_3,\dots \) (i.e., \(\mathbb {E}[X_{k}-X_{k-1}\left| \mathcal {F}_{k-1}\right. ] \le 0\)). Assume that conditioned on \(\mathcal {F}_{k-1}\) we have \(|X_{k}-X_{k-1}|\le r\) almost surely for all k. Then, for any \(\vartheta >0\)
Proof
We use the usual Chernoff bounding method to obtain
for \(s>0\) to be determined. Since \(|X_k-X_{k-1}|\le r\) conditioned on \(\mathcal {F}_{k-1}\), we use convexity of \(x\mapsto e^{sx}\) to obtain
Therefore,
Continuing by induction, we find that
Choosing \(s=\vartheta /kr^2\) completes the proof. \(\square \)
We also recall Bernstein’s inequality [4]. For \(Y_1,\dots ,Y_n\) i.i.d. with variance \(\sigma ^2 = \mathbb {E}((Y_i-\mathbb {E}[Y_i])^2)\), if \(|Y_i|\le M\) almost surely for all i then Bernstein’s inequality states that for any \(\vartheta >0\)
We often make use of Bernstein’s inequality in the form given by the following lemma.
Lemma A.2
([6, Remark 7]) Let \(Y_1,Y_2,Y_3,\dots ,Y_n\) be a sequence of i.i.d random variables on \(\mathbb {R}^d\) with Lebesgue density \(\rho :\mathbb {R}^d\rightarrow \mathbb {R}\), let \(\psi :\mathbb {R}^d \rightarrow \mathbb {R}\) be bounded and Borel measurable with compact support in a ball B(x, r) for some \(r>0\), and define
Then, for any \(0 \le \vartheta \le 1\),
where \(c>0\), \(C>0\) are constants depending only on \(\Vert \rho \Vert _{\textrm{L}^\infty }\) and d.
Appendix B: \(\textrm{TL}^p\) Convergence of minimizers
The \(\textrm{TL}^p\) topology was introduced in [23] to define a discrete-to-continuum convergence for variational problems on graphs (as is the setting in this paper). The idea is to consider discrete, and continuum, functions as pairs: \((\mu ,u)\) where \(\mu \in \mathcal {P}(\Omega )\) and \(u\in \textrm{L}^p(\mu )\) (and we recall that \(\Omega \) is assumed to be bounded so that \(\mu \) automatically has finite \(p^{\text {th}}\) moment). For example, in the discrete setting we choose \(\mu _n = \frac{1}{n} \sum _{i=1}^n \delta _{x_i}\), where \(x_i{\mathop {\sim }\limits ^{\textrm{iid}}}\mu \in \mathcal {P}(\Omega )\), to be the empirical measure then \(u_n\in \textrm{L}^p(\mu _n)\) implies that \(u_n:\Omega _n\rightarrow \mathbb {R}\). To define a metric, we work on the space:
This space is a metric with
where \(\Pi (\mu ,\nu )\) is the subset of probability measures on \(\Omega \times \Omega \) such that the first marginal is \(\mu \) and the second marginal is \(\nu \). We call any \(\pi \in \Pi (\mu ,\nu )\) a transport plan. The proof that \((\textrm{TL}^p,d_{\textrm{TL}^p})\) is a metric space follows from its connection to optimal transport, we refer to [23, Remark 3.4] for more details.
In the setting of this paper we can characterize \(\textrm{TL}^p\) convergence as follows (the following holds due to existence of a density \(\rho \) of \(\mu \)). A function \(T:\Omega \rightarrow \Omega \) is a transport map between \(\mu \) and \(\nu \) if \(T_{\#}\mu =\nu \), where the pushforward of a measure is defined by
In the notation of transport maps the \(\textrm{TL}^p\) distance can be written
(In general (B.1) and (B.2) are not equivalent but in special cases—such as in the setting of this paper—the two formulations coincide, in optimal transport (B.1) would be called the Kantorovich formulation and (B.2) the Monge formulation.) The following result can be found in [23, Proposition 3.12].
Proposition B.1
Let \(\Omega \subset \mathbb {R}^d\) be open, \((\mu ,u),(\mu _n,u_n)\in \textrm{TL}^p(\Omega )\) for all \(n\in \mathbb {N}\) and assume \(\mu \) is absolutely continuous with respect to the Lebesgue measure. Then, \((\mu _n,u_n){\mathop {\rightarrow }\limits ^{\textrm{TL}^p}}(\mu ,u)\) if and only if \(\mu _n\mathop {\mathrm {{\mathop {\rightharpoonup }\limits ^{*}}}}\limits \mu \) and there exists a sequence of transportation maps \(T_n\) satisfying \((T_n)_{\#}\mu = \mu _n\) and \(\Vert \textrm{Id}- T_n\Vert _{\textrm{L}^1(\mu )}\rightarrow 0\) such that
In our context, the sequence of measures \(\mu _n\) are the empirical measure which, with probability one, converge weak\(^*\) to the true data generating measure \(\mu \) when data points are iid. Hence, it is enough to find a transportation map converging to the identity. With an abuse of the definition we will often say \(u_n\) converges to u in \(\textrm{TL}^p\) when we mean \((\mu _n,u_n)\) converges to \((\mu ,u)\) in \(\textrm{TL}^p\).
With the above notion of convergence, we can define a topology in which to study variational limits. In particular, the \(\textrm{TL}^p\) space gives us a way to define \(\Gamma \)-convergence of discrete-to-continuum functionals. We recall the definition of almost sure \(\Gamma \)-convergence.
Definition B.2
(\(\Gamma \)-convergence) Let (Z, d) be a metric space, \(\textrm{L}^0(Z;\mathbb {R}\cup \{\pm \infty \})\) be the set of measurable functions from Z to \(\mathbb {R}\cup \{\pm \infty \}\), and \((\mathcal {X},\mathbb {P})\) be a probability space. The function \(\mathcal {X}\ni \omega \mapsto E_n^{(\omega )} \in \textrm{L}^0(Z;\mathbb {R}\cup \{\pm \infty \})\) is a random variable. We say \(E_n^{(\omega )}\) \(\Gamma \)-converges almost surely on the domain Z to \(E_\infty :Z\rightarrow \mathbb {R}\cup \{\pm \infty \}\) with respect to d, and write \(E_\infty = \mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{n \rightarrow \infty } E_n^{(\omega )}\), if there exists a set \(\mathcal {X}^\prime \subset \mathcal {X}\) with \(\mathbb {P}(\mathcal {X}^\prime ) = 1\), such that for all \(\omega \in \mathcal {X}^\prime \) and all \(f\in Z\):
-
(i)
(liminf inequality) for every sequence \(\{f_n\}_{n=1}^\infty \) converging to f
$$\begin{aligned} E_\infty (f) \le \liminf _{n\rightarrow \infty } E_n^{(\omega )}(f_n), \text { and } \end{aligned}$$ -
(ii)
(recovery sequence) there exists a sequence \(\{f_n\}_{n=1}^\infty \) converging to f such that
$$\begin{aligned} E_\infty (f) \ge \limsup _{n\rightarrow \infty } E_n^{(\omega )}(f_n). \end{aligned}$$
The key property of \(\Gamma \)-convergence is that, when combined with a compactness result, it implies the convergence of minimizers. In particular, the following theorem is fundamental in the theory of \(\Gamma \)-convergence.
Theorem B.3
(Convergence of minimizers) Let (Z, d) be a metric space and \((\mathcal {X},\mathbb {P})\) be a probability space. The function \(\mathcal {X}\ni \omega \mapsto E_n^{(\omega )} \in \textrm{L}^0(Z;\mathbb {R}\cup \{\pm \infty \})\) is a random variable. Let \(f_n^{(\omega )}\) be a minimizing sequence for \(E_n^{(\omega )}\). If, with probability one, the set \(\{f_n^{(\omega )}\}_{n=1}^\infty \) is pre-compact and \(E_\infty = \mathop {\mathrm {\Gamma \text {-}\lim }}\limits _n E_n^{(\omega )}\) where \(E_\infty :Z\rightarrow [0,\infty ]\) is not identically \(+\infty \) then, with probability one,
Furthermore any cluster point of \(\{f_n^{(\omega )}\}_{n=1}^\infty \) is almost surely a minimizer of \(E_\infty \).
The theorem is also true if we replace minimizers with almost minimizers.
We recall the definition of our discrete unconstrained functional \(\mathcal {E}_{n,\varepsilon }^{(p)}\), defined by (2.21), and our continuum unconstrained functional \(\mathcal {E}^{(p)}_\infty \), defined by (2.23). When \(p=1\) it was shown in [23] that, with probability one, \(\mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{n\rightarrow \infty } \mathcal {E}^{(1)}_{n,\varepsilon _n} = \mathcal {E}^{(1)}_\infty \) and \(\mathcal {E}^{(1)}_{n,\varepsilon _n}\) satisfies a compactness property where \(\mathcal {E}^{(1)}_\infty \) is a weighted total variation norm. The proof generalizes almost verbatim for \(p>1\) with the additional condition that, if \(d=2\), \(\varepsilon _n\gg \frac{(\log n)^{\frac{3}{4}}}{\sqrt{n}}\). The additional assumption when \(d=2\) has already been shown to be unnecessary. For example, in [26] the authors use the \(\Gamma \)-convergence result (with the more restrictive lower bound for \(d=2\)) to prove convergence of Cheeger and Ratio cuts, this lower bound was removed in [33] using a refined grid matching technique within the \(\Gamma \)-convergence argument. Later results, i.e., [8, 10], avoid the additional assumption via comparing the empirical measure to an intermediary measure; we follow this argument below. For the following result we do not need the compact support assumption in (A3) and so we restate the third assumption.
- (A3’):
-
The interaction potential \(\eta :[0,\infty )\rightarrow [0,\infty )\) is non-increasing, positive and continuous at \(t=0\). We define \(\eta _\varepsilon = \frac{1}{\varepsilon ^d} \eta (\cdot /\varepsilon )\) and assume \(\sigma _\eta := \int _{\mathbb {R}^d} \eta (|x|) |x_1|^2 \, \textrm{d}x<\infty \).
Proposition B.4
Assume (A1,A2,A3’), \(\varepsilon _n\gg \root d \of {\frac{\log n}{n}}\) and \(p> 1\) we define \(\mathcal {E}_{n,\varepsilon }^{(p)}\) by (2.21) and \(\mathcal {E}^{(p)}_\infty \) by (2.23). Then, with probability one,
Furthermore, if \(\{u_n\}_{n=1}^\infty \) is a sequence satisfying \(\sup _{n\in \mathbb {N}} \Vert u_n\Vert _{\textrm{L}^p(\mu _n)}<\infty \) and \(\sup _{n\in \mathbb {N}}\mathcal {E}_{n,\varepsilon _n}^{(p)}(u_n)<\infty \) then \(\{u_n\}_{n=1}^\infty \) is pre-compact in \(\textrm{TL}^p\) and any limit point is in \(\textrm{W}^{1,p}(\Omega )\).
Proof
The proof for \(d\ge 3\), or \(d=2\) with the additional constraint that \(\varepsilon _n\gg \frac{(\log n)^{\frac{3}{4}}}{\sqrt{n}}\), was stated in [40, Theorem 4.7] for \(p>1\) and the proof is a simple adaptation of the \(p=1\) case which was given in [23]. Hence, we only prove the case for \(d=2\) here.
By either [10, Lemma 3.1] or [8, Proposition 2.10] there exists a probability measure \(\widetilde{\mu }_n\) with density \(\widetilde{\rho }_n\) such that, with probability one, there exists \(\widetilde{T}_n:\Omega \rightarrow \Omega _n\) and \(\theta _n\rightarrow 0\) with the property that \(\widetilde{T}_{n\#}\widetilde{\mu }_n = \mu _n\), \(\Vert \widetilde{T}_n-\textrm{Id}\Vert _{\textrm{L}^\infty (\Omega )}\ll \left( \frac{\log n}{n}\right) ^{\frac{1}{d}}\) and \(\Vert \rho - \widetilde{\rho }_n\Vert _{\textrm{L}^\infty (\Omega )}\le \theta _n\). The proof is divided into three parts corresponding to the compactness property, the liminf inequality and the recovery sequence.
Compactness property. Assume \(\sup _{n\in \mathbb {N}} \Vert u_n\Vert _{\textrm{L}^p(\mu _n)}<\infty \) and \(\sup _{n\in \mathbb {N}}\mathcal {E}_{n,\varepsilon _n}^{(p)}(u_n)<\infty \). Find \(a>0\) and \(b>0\) such that \(\eta \ge \widetilde{\eta }\) where \(\widetilde{\eta }(t) = a\) for all \(|t|\le b\) and \(\widetilde{\eta }(t)=0\) for all \(|t|>b\). Let \(\widetilde{u}_n = u_n\circ \widetilde{T}_n\). Then,
since \(\widetilde{\eta }\left( \frac{|x-y|}{\widetilde{\varepsilon }_n}\right) \le \widetilde{\eta }\left( \frac{|\widetilde{T}_n(x)-\widetilde{T}_n(y)|}{\varepsilon _n}\right) \) where \(\widetilde{\varepsilon }_n = \varepsilon _n - \frac{2}{b} \Vert \widetilde{T}_n - \textrm{Id}\Vert _{\textrm{L}^\infty (\Omega )}\). Hence,
where \(\alpha _n = \frac{\widetilde{\varepsilon }_n^{d+p}}{\varepsilon _n^{d+p}} \left( 1 - \frac{\theta _n}{\rho _{\min }}\right) ^2 \rightarrow 1\) and \(\mathcal {E}^{(p,\textrm{NL})}_{\varepsilon }\) is defined in (B.3) with \(\eta = \widetilde{\eta }\). We also have
By Theorem B.5 below \(\{\widetilde{u}_n\}_{n\in \mathbb {N}}\) is precompact in \(\textrm{L}^p(\mu )\), and hence there exists a subsequence (relabeled) such that \(\widetilde{u}_n = u_n\circ \widetilde{T}_n\rightarrow u\) in \(\textrm{L}^p(\mu )\). Now as \(\widetilde{\mu }_n\mathop {\mathrm {{\mathop {\rightharpoonup }\limits ^{*}}}}\limits \mu \) there exists an invertible transport map \(S_n\) such that \(\widetilde{\mu }_n = S_{n\#}\mu \) and \(S_n\rightarrow \textrm{Id}\) in \(\textrm{L}^p(\mu )\). Now choose \(T_n = \widetilde{T}_n\circ S_n\) (note that \(T_{n\#}\mu = \mu _n\)) so, assuming n is sufficiently large such that \(\min _{x\in \Omega } \widetilde{\rho }_n(x) \ge \frac{\rho _{\min }}{2}\), then
The first term above goes to zero since we already established convergence of \(\widetilde{u}_n\) to u in \(\textrm{L}^p(\mu )\) (which bounds the \(\textrm{L}^p(\widetilde{\mu }_n)\) norm), and the second term goes to zero by [23, Lemma 3.10] since \(S_n\rightarrow \textrm{Id}\) in \(\textrm{L}^p(\mu )\) (see also \(\textrm{L}^p\) convergence of translations). By Proposition B.1\(u_n\rightarrow u\) in \(\textrm{TL}^p\).
Liminf inequality. Let \(u_n\rightarrow u\) in \(TL^p\). We start by assuming \(\eta =\widetilde{\eta }\) where \(\widetilde{\eta }\) is given in the compactness proof. Following the argument in the compactness proof we have
with the last inequality following from the \(\Gamma \)-convergence of \(\mathcal {E}^{(p,\textrm{NL})}_{\widetilde{\varepsilon }_n}\) (Theorem B.5). The proof continues as in the proof of [23, Theorem 1.1] by generalizing to piecewise constant \(\eta \) with compact support, then to compactly supported \(\eta \), and finally to non-compactly supported \(\eta \).
Recovery sequence. It is enough to prove the recovery sequence for \(u\in \textrm{W}^{1,p,(}\Omega )\cap \textrm{Lip}\). In which case we can define \(u_n=u\lfloor _{\Omega _n}\) and it is straightforward to show that \(u_n\rightarrow u\) in \(\textrm{TL}^p\). Assume that \(\eta =\widetilde{\eta }\) is again as defined in the compactness proof. One has \(\widetilde{\eta }\left( \frac{|x-y|}{\widetilde{\varepsilon }_n}\right) \ge \widetilde{\eta }\left( \frac{|\widetilde{T}_n(x)-\widetilde{T}_n(y)|}{\varepsilon _n}\right) \) where now we define \(\widetilde{\varepsilon }_n = \varepsilon _n+\frac{2}{b}\Vert \widetilde{T}_n-\textrm{Id}\Vert _{\textrm{L}^\infty (\Omega )}\). A very similar calculation as in the compactness property implies \(\mathcal {E}_{n}^{(p)}(u_n) \le \beta _n \mathcal {E}^{(p,\textrm{NL})}_{\widetilde{\varepsilon }_n}(\widetilde{u}_n)\) where \(\beta _n = \frac{\widetilde{\varepsilon }_n^{d+p}}{\varepsilon _n^{d+p}}\left( 1 + \frac{\theta _n}{\rho _{\min }}\right) ^2 \rightarrow 1\). Hence, by Theorem B.5(2) we have \(\limsup _{n\rightarrow \infty } \mathcal {E}_{n}^{(p)}(u_n) \le \mathcal {E}^{(p)}_\infty (u)\). The proof generalizes to any \(\eta \) satisfying Assumption (A3’) as in the liminf inequality. \(\square \)
The following theorem was stated in [23, Theorem 4.1] for \(p=1\) and generalizes easily to \(p>1\). Part (1) was also stated in [40, Lemma 4.6], and (2) is either contained within the proof of [23, Theorem 4.1] or can be arrived at easily from the characterization of \(\textrm{W}^{1,p}\) found, for example, in [32, Theorem 10.55]. We include the result here for convenience.
Theorem B.5
Let \(\Omega \subset \mathbb {R}^d\) be open, bounded and with Lipschitz boundary, let \(\rho :\Omega \rightarrow \mathbb {R}\) be continuous and bounded from above and below by positive constants, let \(\eta \) satisfy (A3), and let \(\mu \) be the measure with density \(\rho \). Define \(\mathcal {E}^{(p,\textrm{NL})}_{\varepsilon }\) by
and \(\mathcal {E}^{(p)}_\infty \) by (2.23). Then,
-
(1)
\(\mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{\varepsilon \rightarrow 0} \mathcal {E}^{(p,\textrm{NL})}_{\varepsilon } = \mathcal {E}^{(p)}_\infty \),
-
(2)
if \(u\in \textrm{W}^{1,p,(}\Omega )\) then \(u_n = u\) is a recovery sequence, and
-
(3)
if \(\varepsilon _n\rightarrow 0\) and \(\{u_n\}_{n\in \mathbb {N}}\) satisfies \(\sup _{n\in \mathbb {N}} \Vert u_n\Vert _{\textrm{L}^p(\mu )}<+\infty \) and \(\sup _{n\in \mathbb {N}} \mathcal {E}^{(p,\textrm{NL})}_{\varepsilon _n}(u_n)<+\infty \) then \(\{u_n\}_{n\in \mathbb {N}}\) is precompact in \(\textrm{L}^p(\mu )\).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Calder, J., Slepčev, D. & Thorpe, M. Rates of convergence for Laplacian semi-supervised learning with low labeling rates. Res Math Sci 10, 10 (2023). https://doi.org/10.1007/s40687-022-00371-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40687-022-00371-x
Keywords
- Semi-supervised learning
- Regression
- Asymptotic consistency
- Gamma-convergence
- PDEs on graphs
- Non-local variational problems
- Random walks on graphs