
Abstract
Neural networks have been very successful in many applications; we often, however, lack a theoretical understanding of what the neural networks are actually learning. This problem emerges when trying to generalise to new data sets. The contribution of this paper is to show that, for the residual neural network model, the deep layer limit coincides with a parameter estimation problem for a nonlinear ordinary differential equation. In particular, whilst it is known that the residual neural network model is a discretisation of an ordinary differential equation, we show convergence in a variational sense. This implies that optimal parameters converge in the deep layer limit. This is a stronger statement than saying for a fixed parameter the residual neural network model converges (the latter does not in general imply the former). Our variational analysis provides a discrete-to-continuum \(\Gamma \)-convergence result for the objective function of the residual neural network training step to a variational problem constrained by a system of ordinary differential equations; this rigorously connects the discrete setting to a continuum problem.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Recent advances in neural networks have proven immensely successful for classification and imaging tasks [81]. These practical successes have inspired many theoretical studies that try to understand why certain network architectures work better than others and what role the various parameters of the networks play. Over the years, these studies have come from such diverse areas as computational science [16, 77, 82], discrete mathematics [2], control theory and dynamical systems [23, 36, 53, 72], approximation theory [15, 50, 51], frame theory [92], and statistical consistency [26]. To the best of our knowledge, this and [26] are the only papers to study variational limits of neural networks.
Stemming from the work of Haber and Ruthotto [36] and E [23], there has been recent interest in interpreting neural networks as dynamical systems. The connection with dynamical systems follows from an idealised infinitely deep interpretation of a neural network where one treats the depth as a time variable. There is a well-developed theory, such as Hamilton–Jacobi–Bellman equations and Pontryagin’s maximum principle, which can be applied to analyse the dynamical system and therefore clarify the behaviour of the discrete neural network [24]. Many more results have recently appeared in the literature, e.g. [4, 11, 33, 66, 67, 80, 87], and we refer to [8] for a more detailed overview. The aim of this paper is to connect discrete neural networks to a dynamical system using (a small modification) of the model presented in [36].
Classification of data is the task of assigning each element of a data set a label which indicates membership of one of several classes. Each of those classes has some a priori data assigned to it. A neural network approaches this task in two steps. First the a priori classified data is used to train the network. Then the trained network is used to classify other data. In this paper we will consider input data \(x\in {\mathbb {R}}^d\) leading to network output \(F(x) \in {\mathbb {R}}^m\) for some function \(F: {\mathbb {R}}^d \rightarrow {\mathbb {R}}^m\). A neural network assigns a classification to some given input datum by performing a series of sequential operations to it, which are known as layers. Each layer is said to consist of neurons, by which it is meant that the output of each of the operations can be represented as a vector in \({\mathbb {R}}^d\) (encoding the state of d neurons). In our paper we assume there are n hidden layersFootnote 1 and each layer has the same number, d, of neurons. (Note that by making this assumption, the networks we consider cannot be used for dimensionality reduction; the network makes the classification decision based on the final layer, which contains a number of neurons equal to the dimension of the input datum.) We also assume that each input datum can be represented by a vector of the same dimension d. Hence, an input datum \(x\in {\mathbb {R}}^d\) leads to a response in the first layer, \(f_0(x)\in {\mathbb {R}}^d\), which in turn leads to a response in the second layer \(f_1(f_0(x))\in {\mathbb {R}}^d\), etc. After the response of the final layer \(f_{n-1}(f_{n-2}(\ldots f_0(x)\ldots ))\in {\mathbb {R}}^d\) is obtained, a final function \({{\hat{f}}}: {\mathbb {R}}^d \rightarrow {\mathbb {R}}^m\) can be applied to map that response to the labels of the various pre-defined classes. The final output of the network then becomes \(F(x):= {{\hat{f}}}(f_{n-1}(f_{n-2}(\ldots f_0(x)\ldots )))\).
In the training step training data \(\{(x_s,y_s)\}_{s=1}^S\) is available, where \(\{x_s\}_{s=1}^S\subset \mathbb {R}^d\) are inputs with class labels \(\{y_s\}_{s=1}^S\subset \mathbb {R}^m\). The goal is to learn the form of the functions \(f_i\) such that the network’s classifications \(F(x_s)\) are close to the corresponding labels \(y_s\). In this paper we restrict ourselves to functions \(f_i\) from a parametrised family of functions, as described in (4) below. The choice of cost function which is used to measure this “closeness” is one of many choices whose consequences are being studied, for example for classification [54] and image restoration tasks [98]. In this paper we consider a cost function with mild conditions, which allow for, for example, a quadratic error term (or loss function) \(\sum _{s=1}^S \Vert F(x_s)-y_s\Vert ^2\), together with regularisation terms which we will discuss later.
Implied in the architecture is the choice of parameterisation for \(f_i\). A typical choice is to let \(f_i\) be of the form
where \(K_i \in {\mathbb {R}}^{d\times d}\) is a matrix which determines the weights with which neurons in layer i activate neurons in layer \(i+1\) and \(b_i\in {\mathbb {R}}^d\) is a bias vector. The functions \(\sigma _i\) are called the activation functions. Many, although not all, activation functions used in practice are continuous approximations of a step function that effectively turn neurons “on” or “off” depending on the value of the input \(K_i x + b_i\). In this paper, we assume every layer uses the same (Lipschitz continuous) activation function, \(\sigma _i=\sigma \). Results from recent years have shown that the rectified linear unit (ReLU) activation function (or “positive part” [55]) performs well in many situations [17, 57, 71]. It is given by
where its action on a vector should be interpreted componentwise (see Subsect. 1.1 for details). This, however, is not the only choice that can be made. The impact of the activation function on the performance of a given network is studied in many papers. For example, if ReLU is used the network trains faster than when some of the classical saturating nonlinear activation functions such as \(x \mapsto \tanh x\) and \(x \mapsto \frac{1}{1+e^{-x}}\) are used instead [57]. Moreover, ReLU has been observed to lead to sparsity in the resulting weights, with many of them being zero. These are sometimes referred to as “dead neurons” [68, 89, 96].
The activation function(s) are oftenFootnote 2 specified beforehand for a given network and are not a part of what should be “learned” by the network. That still leaves, however, a large number of parameters for the learning problem. Each layer contains \(d\times d + d\) parameters in the form of \(K_i\) and \(b_i\). Different types of networks restrict the admissible sets for the \(K_i\) and \(b_i\). For example, some networks impose that the biases \(b_i\) are completely absent, such as the Finite Impulse Response (FIR) networks in [49, 79, 90, 93] or that each layer has the same shared bias [75], while the traditional convolutional neural networks (CNN) restrict the choice of \(K_i\) to convolution matrices, i.e. matrices in which each row is a shifted version of a filter vector \((0, \ldots , 0, v_1, \ldots , v_k, 0, \ldots , 0)\), such that the product \(K_i x\) becomes a discrete convolution of the vector \(v=(v_1, \ldots , v_k)\) with x [47, 59]. In this paper we will not restrict the choice of \(K_i\) and \(b_i\) by such hard constraints. Instead, we include regularisation terms in the cost function, which penalise \(K_i\) and \(b_i\) which vary too much between layers or whose entries in the first layer are too large (see Sect. 1.2 for details).
Finley et al. [26] study, in a variational sense, the data rich limit \(S\rightarrow \infty \). In particular, they consider, a sequence of variational problems of the form
where L is a loss term, \(\mu _S\) is an empirical measure induced by the training data set \(\{x_s,y_s\}_{s=1}^S\), and R a regularisation term; for example,
The set of admissible F is determined by a neural network. The main result of [26] is to show that minimisers \(F_S\) of (3) converge as \(S\rightarrow \infty \) to a solution of the variational problem
for an appropriate measure \(\mu \) obtained as limit of the empirical measures \(\mu _S\).
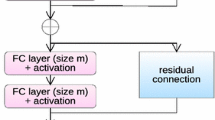
In this paper we study the deep layer limit (i.e. the limit \(n\rightarrow \infty \)) of a residual neural network (ResNet) [45], which are related in spirit to the highway networks of [86]. A crucial way in which ResNet type neural networks differ from other networks such as CNNs, is the form of the functions \(f_i\). Instead of assuming a form as in (1), in ResNet the assumption
is made. This can be interpreted as the network having shortcut connections: The additional term x on the right-hand side represents information from the previous layer “skipping a layer” (or, more accurately, skipping the processing associated with the layer) and being transmitted to the next layer without being transformed. The reason for introducing these shortcut connections is to tackle the degradation problem [43, 45]: It has been observed that increasing the depth of a network (i.e. its number of layers) can lead to an increase in the error term instead of the expected decrease. Crucially, this behaviour appears while training the network, which indicates that it is not due to overfitting (as that would be an error which would be only present during the testing phase of an already trained network). In [45] it is argued that, if \({{\hat{f}}}_i(x)\) is the actual desired output in layer \(i+1\), the residual \({{\hat{f}}}_i(x)-x\) is easier to learn in practice than \({{\hat{f}}}_i(x)\) itself. Deep networks using the architecture (1) can suffer from vanishing or exploding gradients during backpropagation [3, 31, 49, 75], resulting in weights which either do not change much at all during the training phase or which change wildly in each step. In general, learning the residual does not suffer from vanishing/exploding gradients by approximately preserving the norm of the gradient between layers [95]. In [31] it is shown that these problems might be avoided by choosing a careful initialisation; [68] argues that using the ReLU activation function also helps in avoiding vanishing gradients.
Crucially for our purposes, the additional term x in (4) compared to (1) allows us to write
where \(X_{i+1}^{(n)}=f_i(X_i^{(n)}) \in {\mathbb {R}}^d\) is the output in layer \(i+1\) and where we have introduced a factor \(\frac{1}{n}\) with \(\sigma \) for scaling purposes. We have also added superscripts (n) to \(X_i^{(n)}\), \(K^{(n)}_i\) and \(b^{(n)}_i\) to indicate that these weights and biases belong to the network with n layers. Remember that, in this paper, we will use the same activation function in each layer: \(\sigma _i = \sigma \). As observed in [23, 37, 67], this setup describes an explicit Euler characterisation of the ordinary differential equation (ODE)
with time step 1/n. Here X, K, and b denote real-valued functions on [0, 1]. This observation has been used to motivate new neural network architectures based on discretisations of partial/ordinary differential equations, e.g. [11, 33, 36, 67, 80, 87].
Since the forward pass through ResNet is given by a discretised ODE in (5), a natural question is whether the deep limit (\(n\rightarrow \infty )\) of ResNet indeed gives us back the ODE. We need to be a bit more careful, however, when formulating this question, and distinguish between the training step and the use of a trained network. The latter consists of applying (5) through all layers (with known \(K^{(n)}_i\) and \(b^{(n)}_i\) obtained by training the network) with a single given input datum x as initial condition, \(X_0=x\). The deep limit question in this case then becomes whether solutions of this discretised process converge to the solution (Lipschitz continuity of \(x\mapsto \sigma (Kx+b)\) guarantees a unique solution, by standard ODE theory) of the ODE. Our Corollary 2.3 shows that they do, in a pointwise sense. In order to derive this corollary we require the trained weights and biases, \(K^{(n)}_i\) and \(b^{(n)}_i\), to converge (up to a subsequence) to sufficiently regular weights and biases, K and b, which can be used in the ODE. This requires us to carefully analyse the training step. The main result of this paper, Theorem 2.1, does exactly that.
Theorem 2.1 uses techniques from variational methods to show that the trained weights and biases have (up to a subsequence) deep layer limits. In particular, it uses \(\Gamma \)-convergence, which is explained in further detail in Sect. 3.3. Variational calculus deals with problems which can be formulated in terms of minimisation problems. In this paper we formulate the training step (or learning problem) of an n-layer ResNet as a minimisation problem for the function \(\mathcal {E}_n\) in (8), which consists of a quadratic cost function with regularisers for all the coefficients that are to be learned. We then identify the \(\Gamma \)-limit of the sequence \(\{\mathcal {E}_n\}_{n=1}^\infty \), which is given by \(\mathcal {E}_\infty \) in (12). \(\Gamma \)-convergence is a type of convergence which (in combination with a compactness result) guarantees that minimisers of \(\mathcal {E}_n\) converge (up to a subsequence) to a minimiser of the \(\Gamma \)-limit \(\mathcal {E}_\infty \). It has been successfully applied for discrete-to-continuum limits in a machine learning setting, for example in [88] and the references in the following sentence. The specific tools we use in this paper to obtain the discrete-to-continuum \(\Gamma \)-limit were developed in [30] and have been successfully applied in a series of papers since [22, 27,28,29, 83].
The impact of this \(\Gamma \)-convergence result is twofold. On the one hand it is an important ingredient in showing that the output of an already trained network for given input data is, in the sense made precise by Corollary 2.3, approximately the output of a dynamical system which has the input data as initial condition. On the other hand, it shows that the training step itself is a discrete approximation of a continuum variational problem. This opens up the possibility of using techniques from partial differential equations (PDEs) to solve the minimisation problem for \(\mathcal {E}_\infty \) in order to obtain (approximate) solutions to the n-layer training step; such as Pontryagin’s maximum principle [25, 64]. It also opens up the possibility to construct different networks by using different discretisations of the ODE, as in the midpoint network in [9].
We note that connecting discrete difference equations to a continuum differential equation in the setting of recursive algorithms (i.e. \(X_{i+1} = f_i(X_i,\theta )\) where \(\theta \) are given parameters) is well studied, for example [13, 65]. However, these results are in the pointwise convergence setting, i.e. the parameter \(\theta \) is fixed. Pointwise convergence is not strong enough to imply convergence of minimisers, i.e. what we want is that the \(\theta ^*_n\) that minimises a variational problem converges as \(n\rightarrow \infty \) to some \(\theta \) that minimises a variational problem with the constraint \({\dot{X}} = f_\infty (X,\theta )\). This is the novelty of our result.
In the remainder of the introduction we introduce our framework; namely the neural network architecture, the choice and motivation of regularisation of the neural network parameters, and the continuum deep layer limit. In Sect. 2 we state our assumptions and main results connecting the discrete neural network with its continuum limit. In Sect. 3 we give some preliminary material which includes (1) defining the topology we use for convergence of the parameters \(\textbf{K}^{(n)}\), \(\textbf{b}^{(n)}\), i.e. we make precise \(\textbf{K}^{(n)}\rightarrow K\) and \(\textbf{b}^{(n)}\rightarrow b\), and (2) giving a brief background on variational methods and in particular \(\Gamma \)-convergence. Section 4 is devoted to the proofs of the main results. We conclude the paper in Sect. 5 with a brief discussion of open questions.
1.1 The finite layer neural network
We recap a simplified version of ResNet as presented in [36]. In this model there are n layers and the number of neurons in each layer is d. In particular, we let \(X_i^{(n)}\in \mathbb {R}^d\) be the state of each neuron in the ith layer. For clarity we will denote with a superscript the number of layers, this is to avoid confusion when talking about two versions of the neural network with different numbers of layers. The relationship between layers is given by
where \(\textbf{K}^{(n)} = \{K^{(n)}_i\}_{i=0}^{n-1}\subset \mathbb {R}^{d\times d}\), \(\textbf{b}^{(n)} = \{b^{(n)}_i\}_{i=0}^{n-1}\subset \mathbb {R}^d\) determine an affine transformation at each layer and \(\sigma :\mathbb {R}^d\rightarrow \mathbb {R}^d\) is an activation function which characterises the difference between layers. We will assume that \(\sigma \) acts componentwise, i.e. \(\sigma (x) = ({{\tilde{\sigma }}}(x_1), {{\tilde{\sigma }}}(x_2), \dots , {\tilde{\sigma }}(x_d))^T\), for some \({\tilde{\sigma }}: {\mathbb {R}}\rightarrow {\mathbb {R}}\). For example, a valid, but not necessary choice for \({\tilde{\sigma }}\) is the ReLU function from (2). With a slight abuse of notation, \({\tilde{\sigma }}\) is sometimes also denoted by \(\sigma \), as for example in (2). The layers \(\{X_i^{(n)}\}_{i=1}^{n-1}\) are called hidden, \(X_0^{(n)}\) is the input to the network, and \(X_n^{(n)}\) is the output.
In order to apply the neural network (6) to labelling problems an additional, classification, layer is appended to the network. For example, one can add a linear regression model, that is we let \(Y = WX_n^{(n)}+c\) where \(W\in \mathbb {R}^{m\times d}\) and \(c\in \mathbb {R}^m\). More generally, we assume the classification layer takes the form
for a given function \(h:\mathbb {R}^m\rightarrow \mathbb {R}^m\). Given all parameters, the forward model/classifier for input \(X_0^{(n)}=x\) is \(Y=h(WX_n^{(n)}[x;\textbf{K}^{(n)},\textbf{b}^{(n)}]+c)\) where \(X_n^{(n)}[x;\textbf{K}^{(n)},\textbf{b}^{(n)}]\) is given by the recursive formula (6) with input \(X_0^{(n)}=x\).
Given a set of training data \(\{(x_s,y_s)\}_{s=1}^S\), where \(\{x_s\}_{s=1}^S\subset \mathbb {R}^d\) are inputs with labels \(\{y_s\}_{s=1}^S\subset \mathbb {R}^m\), one wishes to find parameters \(\textbf{K}^{(n)}\), \(\textbf{b}^{(n)}\), W, c that minimise the error of the neural network on the training data. There are clearly multiple ways to measure the error. To maximise generality, we define
where the function \(\mathcal {L}\) is nonnegative and has to satisfy a continuity condition in its first argument, as detailed in Theorem 2.1 and Proposition 2.2. A typical allowed choice is \(\mathcal {L}(z,y) = \Vert z-y\Vert ^2\). The error \(E_n(\textbf{K}^{(n)},\textbf{b}^{(n)},W,c;x,y)\) should be interpreted as the error of the parameters \(\textbf{K}^{(n)}\), \(\textbf{b}^{(n)}\), W, c when predicting x given that the true value is y. Naively, one may wish to minimise the sum of \(E_n(\textbf{K}^{(n)},\textbf{b}^{(n)},W,c;x_s,y_s)\) over \(s\in \{1,\dots , S\}\). However this problem is ill-posed once the number of layers, n, is large. In particular, the number of parameters being greater than the number of training data points leading to overfitting. The solution, as is common in the calculus of variations, is to include regularisation terms, e.g. (applicable to neural networks) [32, 36, 74, 78], on each of \(\textbf{K}^{(n)}\), \(\textbf{b}^{(n)}\), W and c, this is discussed in the next section.
The finite layer objective functional, with regularisation weights \(\alpha _1,\dots ,\alpha _4\), is given by
Here the \(R^{(i)}\) are regularisation terms, which will be introduced in detail in Subsect. 1.2. The learning problem is to find \((\textbf{K}^{(n)},\textbf{b}^{(n)},W^{(n)},c^{(n)})\) which minimises \(\mathcal {E}_n\).
The problem we concern ourselves with is the behaviour in the deep layer limit, i.e. what happens to \(\textbf{K}^{(n)},\textbf{b}^{(n)},W^{(n)},c^{(n)}\) as \(n\rightarrow \infty \). The results of this paper are theoretical and in particular ignore the considerable challenge of finding such minimisers. However, we do hope that a better understanding of the deep layer limit can aid the development of numerical methods by, for example, allowing PDE approaches to the minimisation of \(\mathcal {E}_n\). Indeed, the authors of [56] view neural networks as inverse problems and apply filtering methods such as the ensemble Kalman filter which are gradient free. We note that theory is often developed for continuum models as it reveals what behaviour will be expected for large discrete problems. For example, the authors of [97] analyse stability properties of continuum analogues of neural networks.
In this paper we are not concerned with the actual numerical method used to compute the learning or training step, i.e. the method to compute minimisers of (8). However, for completeness we briefly point to some optimisation methods and potential pitfalls. Currently, a variety of different methods are being used to compute the training step; [89] gives an overview of various methods. One of the most popular ones is backpropagation [41, 42, 46, 58, 99] using stochastic gradient descent [47]. Since the minimisation problem is not convex, any gradient descent method risks running into critical points which are not minima. In [19] it is argued that in certain setups critical points are more likely to be saddle points than local minima and [61] proves that (under some assumptions on the objective function and the step size) gradient descent does not converge to a saddle point for almost all initial conditions. Moreover, [12] empirically verifies that in deep networks most local minima are close in value to the global minimum and the corresponding minimisers give good results. In some cases it can even be proven that all local minima are equal to the global minimum [60]. These results suggest that the critical points of the non-convex optimisation problem are not necessarily a major problem for gradient descent methods.
Variants of gradient descent, such as blended coarse gradient descent, which is not strictly speaking a gradient descent algorithm—rather it chooses an artificial ascent direction—have been explored in [94]. The authors of [10] show that the (local entropy) loss function satisfies a Hamilton-Jacobi equation and use this to analyse and develop stochastic gradient descent methods (in continuous time) which converge to gradient descent in the limit of fast dynamics. Outside of gradient-based methods the authors of [35] apply an Ensemble Kalman Filter method to the training of parameters.
Overfitting is also an issue to take into account during training. Techniques such as max pooling [81] (for a PDE-based interpretation of max pooling and ReLU as morphological convolutions in a CNN, see [84]) or Dropout [48] work well in practice to avoid overfitting. The former consists of downsampling a layer by pooling the neurons into groups and assigning to each group the maximum value of all its neurons. The latter consists of randomly omitting neurons on each presentation of each training case. The ReLU activation function works well with Dropout [17]. Recently [70] made the case that improvements can be obtained by using sparsely connected layers. Adding regularisation terms which encourage some level of smoothness to the cost functional can also help to avoid overfitting [47].
1.2 Regularisation
Explicit regularisation in neural networks dates back to at least [20], where the authors added a penalty on the rate of change of \(E_n\) with respect to the input \(x_s\). Here we approximately follow [36]. We refer to [76] for a more in-depth discussion on regularisation in machine learning.
We define regularisation terms \(R^{(1)}_n(\textbf{K}^{(n)})\), \(R^{(2)}_n(\textbf{b}^{(n)})\), \(R^{(3)}(W)\), \(R^{(4)}(c)\) by
where \(\tau _i>0\). Since all norms on finite-dimensional vector spaces are topologically equivalent, many of the results in this paper do not depend on the specific choices for the norms \(\Vert \cdot \Vert \) that are used in the definitions above. In some places, such as in Sect. 4.4 however, an inner product structure is assumed on certain norms, while in others, such as Lemma 4.16 and the derived Corollary 2.3, the constants in the estimates will depend on the specific choice of norm.
Since we eventually wish to interpret the n layers of the network as a discretisation of (one-dimensional) time with time step \(\frac{1}{n}\), the scaling by n of the difference terms in \(R_n^{(1)}\) and \(R_n^{(2)}\) is the correct one to view these terms as discretised integrals of finite-difference approximations to squared gradients. This will be further clarified in Sect. 1.2.1 and follows as a consequence of the approximation
We emphasise that \(R^{(3)}\) and \(R^{(4)}\) do not depend on n. We refer to \(R^{(1)}_n,R^{(2)}_n\) as the nonparametric regularisers, and \(R^{(3)},R^{(4)}\) as the parametric regularisers (we consider \(\textbf{K}^{(n)}\) and \(\textbf{b}^{(n)}\) to be non-parametric as their complexity grows with the number of layers n, whilst W and c are parametric as their complexity is independent of n). The point of including regularisation is to enforce compactness in the minimisers; without compactness we cannot find converging sequences of minimisers which, in particular, can lead to objective functionals that become ill-posed in the deep layer limit. We justify the regularisation below; however, we note that the regularisation is quite strong. In particular, we are imposing \(H^1\) bounds on \(\textbf{K}^{(n)}\) and \(\textbf{b}^{(n)}\)—which are also suggested in [36]— as well as norm bounds on W and c. The cost of treating a wide range of activation functions \(\sigma \) and classification functions h is to include strong regularisation functions. In specific cases it may be possible to reduce the regularisation, for example by setting \(\tau _i=0\) and/or removing the terms \(R^{(3)},R^{(4)}\). In the next two subsections, we give a discussion on why these terms, in general, are necessary.
It should also be noted that it is sometimes observed that techniques such as stochastic node or layer dropout [52] can act as regularisers, without the need for explicitly added regularisation terms. A good mathematical understanding of this phenomenon is still missing from the literature, to the current knowledge of the authors, and in this paper we have restricted ourselves to adding explicit regularisation terms, as is common in the calculus of variations.
1.2.1 The nonparametric regularisation
By construction the regularisation terms on \(\textbf{K}^{(n)}\) and \(\textbf{b}^{(n)}\) resemble \(H^1\) norms. These terms are used for compactness in order to apply the direct method of the calculus of variations. By standard Sobolev embeddings sequences bounded in \(H^1\) are (pre-)compact in \(L^2\). There is a little work to be done in order to match discrete sequences \(\textbf{K}^{(n)}=\{K^{(n)}_j\}_{j=0}^{n-1}\), \(\textbf{b}^{(n)}=\{b^{(n)}_j\}_{j=0}^{n-1}\) with continuum sequences \(K^{(n)}:[0,1]\rightarrow \mathbb {R}^{d\times d}\), \(b^{(n)}:[0,1]\rightarrow \mathbb {R}^d\), but with an appropriate identification we can show that \(R^{(1)}_n(\textbf{K}^{(n)}) \approx \Vert {\dot{K}}^{(n)}\Vert _{L^2}^2 + \tau _1\Vert K^{(n)}(0) \Vert ^2\) and similarly for \(\textbf{b}^{(n)}\). In that sense they are very natural choices from a calculus of variations point of view as they allow us to conclude strong \(L^2\) convergence of the parameters.
Of course, given \(K:[0,1]\rightarrow \mathbb {R}^{d\times d}\) we can define \({\tilde{K}}^{(n)}_i=K(i/n)\) and then \(R^{(1)}_n(\tilde{\textbf{K}}^{(n)}) \rightarrow \Vert {\dot{K}}\Vert _{L^2}^2 + \Vert K(0)\Vert ^2\). This we would call pointwise convergence. The main result of this paper is stronger, in particular we show variational convergence. Without the \(H^1\) semi-norm part of our regularisation terms (i.e. without the \(L^2\) norm of the gradient) we would a priori only get weak \(L^2\) convergence. The question whether this suffices to still derive our results is a very interesting one, but goes beyond the scope of this paper, as it introduces a lot of extra technical difficulties. We note that \(R^{(i)}_n\), \(i=1,2\), are very similar to the choice of regularisation in [36], but we add the terms \(\Vert K_0^{(n)}\Vert ^2\), \(\Vert b_0^{(n)}\Vert ^2\).
The penalty on finite differences is natural; in order to achieve a limit it is necessary to bound oscillations in the parameters between layers. Physically this relates to imposing the condition that close layers discriminate similar features. For our analysis this is needed to establish compactness. It is interesting to note that one can obtain limits without including explicit regularisation terms. The limiting behaviour of the deep network, however, may no longer be given by a deterministic ODE system of the type we will describe in (10) and, in particular, could be stochastic [14]. The coefficients appearing in the limiting equations described in [14] are obtained through a different limiting procedure than the one we use (and describe in Sect. 3.2).
The additional terms, \(\Vert K_0^{(n)}\Vert ^2\), \(\Vert b_0^{(n)}\Vert ^2\), are perhaps less physically reasonable and introduce a bias into the methodology (meaning that preference is given to smaller values of \(K^{(n)}_0\) and \(b^{(n)}_0\)). As examples of why it is necessary to have these additional terms, i.e. to have \(\tau _1>0\) and \(\tau _2>0\), consider the following. First assume \(\tau _1=0\), let \(d=m=1\), \(h=\textrm{Id}\), \(\sigma = \textrm{Id}\), \(\mathcal {L}(z,y) = |z-y|^2\), and fix \(n\in {\mathbb {N}}\). Consider the set \(\{(x_s,y_s)\}_{s=1}^S\subset \mathbb {R}\times \mathbb {R}\), where \(y_s=x_s\), and the sequence \(\{(\textbf{K}^{(n)}_l, \textbf{b}^{(n)}_l, W_l, c_l)\}_{l\in {\mathbb {N}}}\), with, for all i and l, \((K_i^{(n)})_l = l\), \((b_i^{(n)})_l = 0\), \(W_l = (1+l)^{-n}\), \(c_l = 0\). Then,
Moreover, for all l, \(R_n^{(1)}(\textbf{K}^{(n)}_l) = R_n^{(2)}(\textbf{b}^{(n)}_l) = R^{(4)}(c_l) = 0\) and \(R^{(3)}(W_l) \rightarrow 0\) as \(l\rightarrow \infty \). Therefore, \(\{(\textbf{K}^{(n)}_l, \textbf{b}^{(n)}_l, W_l, c_l)\}_{l\in {\mathbb {N}}}\) is a minimising sequence for \(\mathcal {E}_n\) (as \(l\rightarrow \infty \) with n fixed) with no converging subsequence. As the elementary example shows, if one were to set \(\tau _1=0\) then an additional assumption would be needed to guarantee relative compactness of minimising sequences. A second example showing a similar necessity to have \(\tau _2>0\) is constructed by setting \(\tau _1\ge 0\), \(\tau _2=0\), \((K_i^{(n)})_l = 0\), and \((b_i^{(n)})_l = l\) in the previous example.
1.2.2 The parametric regularisation
An example showing why \(\alpha _3>0\) and \(\alpha _4>0\) are necessary, can be constructed in a similar fashion. Let \(d=m=1\), \(h=\textrm{Id}\), \(\sigma =\textrm{Id}\), \(\mathcal {L}(z,y) = |z-y|^2\), and fix \(n\in {\mathbb {N}}\). Let \(S=1\), so that we have only one training pair \((x_1, y_1) = (x, y)\). Define the sequence \(\{(\textbf{K}^{(n)}_l, \textbf{b}^{(n)}_l, W_l, c_l)\}_{l\in {\mathbb {N}}}\), with, for all i and l, \((K_i^{(n)})_l = 0\), \((b_i^{(n)})_l = 0\), \(W_l = l\), \(c_l = y-lx\). Then,
Also, for all l, \(R_n^{(1)}(\textbf{K}^{(n)}_l) = R_n^{(2)}(\textbf{b}^{(n)}_l) = 0\). We conclude, as before, that \(\{(\textbf{K}^{(n)}_l, \textbf{b}^{(n)}_l, W_l, c_l)\}_{l\in {\mathbb {N}}}\) is a minimising sequence for \(\mathcal {E}_n\) (as \(l\rightarrow \infty \) with n fixed) with no converging subsequence.
1.3 The deep layer differential equation limit
By considering pointwise limits it is not difficult to derive our candidate limiting variational problem. Although pointwise convergence is not enough to imply convergence of minimisers, it is informative. Let \(X:[0,1]\rightarrow \mathbb {R}^d\) solve the differential equation
for some given parameters \(K:[0,1]\rightarrow \mathbb {R}^{d\times d}\) and \(b:[0,1]\rightarrow \mathbb {R}^d\) (as is usual we understand \({\dot{X}}(0)\) to be the right-derivative of X at \(t=0\) and \({\dot{X}}(1)\) to be the left-derivative of X at \(t=1\)). For shorthand we write X(t; x, K, b) for the solutions of (10) with initial condition \(X(0) = x\) and parameters K, b. One can see that (6) is the discrete analogue of (10) with \(K_i^{(n)}=K(i/n)\) and \(b_i^{(n)}=b(i/n)\). In fact one can show (under sufficient conditions) that \(X_{\lfloor nt\rfloor }^{(n)}[x,\textbf{K}^{(n)},\textbf{b}^{(n)}] \rightarrow X(t;x,K,b)\) as \(n\rightarrow \infty \) (see Lemma 4.6).
Similarly, the regularisation terms \(R^{(i)}_n\), \(i=1,2\), are discretisations of the functionals
and \(R^{(3)}\), \(R^{(4)}\) are unchanged. We note that \(R^{(i)}_\infty \), \(i=1,2\) are well defined on \(H^1\), since by regularity properties of Sobolev spaces any \(u\in H^1\) is continuous and therefore pointwise evaluation is well defined; in particular we may define \(\Vert K(0)\Vert \), \(\Vert b(0)\Vert \) for \(H^1\) functions. In fact, see the discussion in Sect. 3.4, \(R_\infty ^{(i)}\), \(i=1,2\), are equivalent to the \(H^1\) norm whenever \(\tau _i>0\).
Once we append the classification layer to the neural network, we arrive at the limiting objective functional
where
The main result of the paper is to show that minimisers of \(\mathcal {E}_n\) converge to minimisers of \(\mathcal {E}_\infty \).
2 Main results
Our main results concern the convergence of the variational problem \(\min \mathcal {E}_n\) to \(\min \mathcal {E}_\infty \). In particular we show
as \(n \rightarrow \infty \). At this point we have not specified the topology on which we define the discrete-to-continuum convergence. For now it is enough to say that the distance is given by a function \(d:\Theta ^{(n)}\times \Theta \rightarrow [0,+\infty )\) where \(\Theta ^{(n)}\) is the parameter space of \(\mathcal {E}_n\) and \(\Theta \) is the parameter space of \(\mathcal {E}_\infty \). The topology is described in detail in Sect. 3.2. We do want to emphasise at this point that although d appears to depend on n —and in fact appears not to be a distance at all, due to a lack of symmetry between its two arguments— it is in fact a restriction of an n-independent metric on a higher-dimensional space to an n-dependent subset.
We will use the following assumptions for our results.
Assumptions 1
The following assumptions will be used in our main convergence result:
-
1.
\(\alpha _i>0\) for \(i=1,2,3,4\) and \(\tau _j>0\) for \(j=1,2\);
-
2.
\(h\in C^0(\mathbb {R}^m;\mathbb {R}^m)\);
-
3.
\(\sigma \) is Lipschitz continuous and acts componentwise;
-
4.
\(\sigma (0) = 0\);
-
5.
\(\mathcal {L}\ge 0\) and is continuous in its first argument;
We note that the condition on \(\mathcal {L}\) does not restrict it to be a typical loss function. There is no requirement for \(\mathcal {L}\) to be a norm on the difference between its two arguments.
Our main result is the convergence of optimal parameters.
Theorem 2.1
Let \(\Theta ^{(n)}\) and \(\Theta \) be given by (14) and (15) respectively. Define \(\mathcal {E}_n\), \(\mathcal {E}_\infty \), \(E_n\), \(E_\infty \), \(R^{(i)}_n\), \(R^{(i)}_\infty \), \(R^{(j)}\) for \(i=1,2\), \(j=3,4\) as in Sect. 1.1-1.3. Let Assumptions 1 hold. Let \(\{(x_s,y_s)\}_{s=1}^S\) be any given set of training data (\(S\ge 1\)). Then minimisers of \(\mathcal {E}_n\) and \(\mathcal {E}_\infty \) exist in \(\Theta ^{(n)}\) and \(\Theta \) respectively. Furthermore let \(\theta ^{(n)} \subset \Theta ^{(n)}\) be any sequence of minimisers of \(\mathcal {E}_n\), then
\(\{\theta ^{(n)}\}_{n\in \mathbb {N}}\) is relatively compact, and any limit point of \(\{\theta ^{(n)}\}_{n\in \mathbb {N}}\) is a minimiser of \(\mathcal {E}_\infty \).
Through the following proposition, and under the additional and stronger assumptions in Assumptions 2, we remark that one obtains extra regularity on minimisers to the deep limit variational problem (as is to be expected based on elliptic regularity).
Assumptions 2
The following additional assumptions will be used in our regularity result:
-
1.
\(\sigma \in C^2({\mathbb {R}}^d; {\mathbb {R}}^d)\);
-
2.
\(h\in C^2({\mathbb {R}}^m; {\mathbb {R}}^m)\);
-
3.
\(\mathcal {L}(\cdot ,y) \in C^2({\mathbb {R}}^m; {\mathbb {R}})\) for all \(y\in \mathbb {R}^m\);
-
4.
all norms on \(\mathbb {R}^d\) and \(\mathbb {R}^{d\times d}\) are induced by inner products.
Proposition 2.2
Let Assumptions 1 and 2 hold. Then any minimiser \(\theta =(K,b,W,c)\in \Theta \) of \(\mathcal {E}_\infty \) satisfies \(K\in H^2_{\textrm{loc}}([0,1];\mathbb {R}^{d\times d})\) and \(b\in H^2_{\textrm{loc}}([0,1];\mathbb {R}^d)\).
The proof of the proposition is given in Sect. 4.4.
Theorem 2.1 states that, up to subsequences, minimisers of \(\mathcal {E}_n\) converge to minimisers of \(\mathcal {E}_\infty \). If the minimiser of \(\mathcal {E}_\infty \) is unique then we have that the sequence of minimisers converges (without recourse to a subsequence) to the minimiser of \(\mathcal {E}_\infty \). The proof of the theorem relies on variational methods and is given in Sects. 4.1-4.3. We do not prove a convergence rate for the minimisers, but we conjecture a convergence rate of \(\frac{1}{n}\). The conjecture is motivated by considering Taylor expansions for a fixed \(\theta =(K,b,W,c)\in \Theta \); indeed one can show that for \(K,b\in H^2\) the recovery sequence \(\theta ^{(n)}\) given by (26-29) satisfies
where \(C(\theta )\) is a constant that depends on \(\Vert {\ddot{K}}\Vert _{L^2}\) and \(\Vert \ddot{b}\Vert _{L^2}\). Assuming that this can be extended to minimising sequences (i.e. the above holds for any sequence of minimisers \(\theta ^{(n)}\rightarrow \theta \)) one can conclude that the rate of convergence of the minima is \(O(n^{-1})\). Making another conjecture that one can show a local bound of the form \(d(\theta ^{(n)},\theta ) \le C \left| \mathcal {E}_n(\theta ^{(n)}) - \mathcal {E}_\infty (\theta ) \right| \) whenever \(d(\theta ^{(n)},\theta )\) is small implies
We do not prove a rate of convergence for either the minimisers or the minimum here. However, we are able to show a rate of convergence for the forward pass through the Neural Network; more precisely, the output of the ResNet model is converging to the output of a dynamical system with the rate given by the following corollary.
Corollary 2.3
Let Assumptions 1 hold. We use the matrix operator norm on \(\textbf{K}^{(n)}\) in \(R^{(1)}_n\) and \(R^{(1)}_\infty \), and let \(L_\sigma >0\) be a Lipschitz constant for \(\sigma \). Let \(\{(x_s,y_s)\}_{s=1}^S \subset {\mathbb {R}}^d \times {\mathbb {R}}^m\) be a set of training data and, for all \(n\in {\mathbb {N}}\), let \((\textbf{K}^{(n)},\textbf{b}^{(n)},W^{(n)},c^{(n)}) \in \mathop {\mathrm {\textrm{argmin}}}\limits _{(\textbf{K}^{(n)},\textbf{b}^{(n)},W,c)} \mathcal {E}_n(\textbf{K}^{(n)},\textbf{b}^{(n)},W,c)\). Let \(x\in {\mathbb {R}}^d\). Let (K, b, W, c) be the minimiser of \(\mathcal {E}_\infty \) which we assume is unique. For all \(n\in {\mathbb {N}}\) and for all \(i\in \{1, \ldots , n\}\), let \(X_i^{(n)}\) be the solution to (6) with \(X_0^{(n)} = x\), and \(X:[0,1]\rightarrow \mathbb {R}^d\) be the solution to the ODE in (10) (with coefficients K and b) with initial condition \(X(0)=x\). Then, for all \(\delta >0\), there exists an \(N\in {\mathbb {N}}\) such that, for all \(n\ge N\), there exists an \(\varepsilon _n \in {\mathbb {R}}\) such that, for all \(i\in \{0, 1, \dots , n\}\),
where
Moreover, \(\varepsilon _n = o\left( \frac{1}{n}\right) \) as \(n\rightarrow \infty \).
We provide the proof of Corollary 2.3 in Sect. 4.5.
Remark 2.4
In Corollary 2.3 we made the assumption that the minimiser (K, b, W, c) of \(\mathcal {E}_\infty \) is unique, mainly to keep the notation as simple as possible. If minimisers of \(\mathcal {E}_\infty \) are not unique, we need to be more careful in our statement of the corollary. In that case, by Theorem 2.1 there exists a minimiser (K, b, W, c) of \(\mathcal {E}_\infty \) such that, up to subsequences, \(K^{(n)}\rightarrow K\) and \(b^{(n)} \rightarrow b\) as \(n\rightarrow \infty \) in the topology of Sect. 3.2 (where the same indices can be chosen for both subsequences). Taking \({\mathcal {N}}\) to be the (infinite) set containing the (common) indices n of these subsequences, the statement of the corollary still holds if we restrict the indices n to the set \({\mathcal {N}}\) instead of allowing them to vary over all of \({\mathbb {N}}\).
3 Background material
In this section we give background material necessary to present the proofs of the main results. In particular, we start by clarifying our notation. We then give a description on the discrete-to-continuum topology. Finally, for the convenience of the reader, we give a brief overview on \(\Gamma \)-convergence.
3.1 Notation
Let \(\Omega \) be an open subset of a Euclidean space. Given a probability measure \(\mu \in \mathcal {P}(\Omega )\) on \(\Omega \) we write \(L^p(\mu ;\Xi )\) for the set of functions from \(\Omega \) to \(\Xi \) that are \(L^p\) integrable with respect to \(\mu \), when appropriate we will shorten notation to \(L^p(\mu )\). The \(L^p(\mu )\) norm for a function \(f:\Omega \rightarrow \Xi \) is denoted by \(\Vert f\Vert _{L^p(\mu )}\). When \(\mu \) is the Lebesgue measure on \(\Omega \) we will also write \(L^p\) or \(L^p(\Omega )\) for \(L^p(\mu ;\Xi )\), and \(\Vert f\Vert _{L^p}\) or \(\Vert f\Vert _{L^p(\Omega )}\) for \(\Vert f\Vert _{L^p(\mu )}\). The \(L^2\) inner product with respect to the Lebesgue measure is denoted by \(\langle \cdot ,\cdot ,\rangle _{L^2}\). The Sobolev space of functions that are k-times weakly differentiable and with each weak derivative in \(L^2\) is denoted by \(H^k\). In order to make clear the domain \(\Omega \) and range \(\Xi \) of \(H^k\), we will also write \(H^k(\Omega ;\Xi )\) (in order to avoid complications defining derivatives, the underlying measure in Sobolev spaces when \(k>0\) is always the Lebesgue measure). For functions \(f:\Omega \rightarrow \mathbb {R}\) that are k times continuously differentiable, we write \(f\in C^k(\Omega )\), and if all its kth partial derivatives are Hölder continuous with exponent \(\gamma \) —i.e. if \(\max _{\alpha : |\alpha |=k} \sup _{\begin{array}{c} x,y\in \Omega \\ x\ne y \end{array}}\frac{|D^\alpha f(x)-D^\alpha f(y)|}{\Vert x-y\Vert ^\gamma } < \infty \), where the \(\alpha \) are multi-indices with sum \(|\alpha |\) equal to k and \(D^\alpha f\) denotes the corresponding partial derivative of f of order k— we write \(f\in C^{k,\gamma }(\Omega )\).
We often do not specify a matrix or vector norm, clearly these are finite-dimensional spaces and therefore all norms are topologically equivalent. If \(b\in \mathbb {R}^d\) is a vector and \(K\in \mathbb {R}^{d\times d}\) is a matrix then we will write \(\Vert b\Vert \) and \(\Vert K\Vert \) for both the vector norm and the matrix norm. In particular we point out that we only use subscripts for \(L^p\) norms. Sometimes we will need that the norms are induced by inner products, we will write when we need this additional structure.
We use superscripts on the parameters \(\textbf{K}^{(n)}\) and \(\textbf{b}^{(n)}\) (later denoted \(K^{(n)}\) and \(b^{(n)}\)) in order to clearly denote the dependence of the number of layers on the parameters themselves (this is particularly important as we take the limit \(n\rightarrow \infty \)). The parameters W, c are respectively a \(m\times d\) matrix and a m-dimensional vector and therefore we do not include any reference to n unless we are considering sequences.
Vectors are always column vectors. For two vectors \(A,B\in \mathbb {R}^\kappa \) we use \(\odot \) to denote componentwise multiplication, i.e. \(A\odot B = [A_1B_1, A_2B_2,\dots , A_\kappa B_\kappa ]^\top \). When \(A\in \mathbb {R}^\kappa \) and \(C\in \mathbb {R}^{\kappa \times d}\) then \(\odot \) represents row-wise multiplication, i.e.
We can also interpret this product as \(A \odot C = \text {diag}(A) C\), where \(\text {diag}\) is the diagonal \(\kappa \times \kappa \) matrix with the vector A on its diagonal.
We use the convention that \(0\not \in \mathbb {N}\).
3.2 Discrete-to-continuum topology
We introduced the parameters for the ResNet model with n layers \(\textbf{K}^{(n)}\) and \(\textbf{b}^{(n)}\) as sets of matrices/vectors, i.e. \(\textbf{K}^{(n)}=\{K^{(n)}_i\}_{i=0}^{n-1}\subset \mathbb {R}^{d\times d}\) and \(\textbf{b}^{(n)}=\{b_i^{(n)}\}_{i=0}^{n-1}\subset \mathbb {R}^d\). In fact it is more convenient to think of them as functions with respect to the discrete measure \(\mu _n=\frac{1}{n}\sum _{i=0}^{n-1} \delta _{\frac{i}{n}}\) on [0, 1]. More precisely, for \(\textbf{K}^{(n)}\) we make the identification with \(K^{(n)}\in L^0(\mu _n;\mathbb {R}^{d\times d})\) by \(K^{(n)}(i/n) = K^{(n)}_i\). In the sequel we will, with a small abuse of notation, write both \(K^{(n)}\) and \(K_i^{(n)}\), where the former is understood as a function in \(L^0(\mu _n;\mathbb {R}^{d\times d})\) and the latter as the matrix \(K^{(n)}_i = K^{(n)}(i/n)\in \mathbb {R}^{d\times d}\). Similarly for \(b^{(n)}\) and \(b^{(n)}_i\).
With this notation we can define the finite layer parameter space by
For any \(p,q>0\) the discrete spaces \(L^p(\mu _n), L^q(\mu _n)\) are topologically equivalent. Since we apply a discrete analogue of an \(H^1\) regularisation penalty to parameters of the neural network (see also Sect. 3.4), it will transpire that the natural limiting space to work in is given by
Given \(K\in L^2([0,1];\mathbb {R}^{d\times d})\) and \(K^{(n)}\in L^2(\mu _n;\mathbb {R}^{d\times d})\) we define a distance by extending \(K^{(n)}\) to a function on [0, 1] by \({\tilde{K}}^{(n)}(t) = K^{(n)}(t_i)\) (for \(t\in (t_{i-1},t_i)\), \(t_i=i/n\), \(i=1,\dots , n\)) and comparing in \(L^2\); that is
We note the distance \(d_1\) is closely related to the \(TL^2\) distance, see [30], when the discrete measure is of the form \(\mu _n = \frac{1}{n} \sum _{i=1}^n \delta _{t_i}\) and the domain is [0, 1]. The \(TL^2\) distance (see (16) below), or more generally the \(TL^p\) distance, is a topology useful for metrising discrete-to-continuum convergence on a general domain \(\Omega \subseteq \mathbb {R}^d\). The idea is to think of functions on different domains as the coupling of a function with a measure; that is the \(TL^p\) space is the space of pairs \((\mu ,K)\) where \(K\in L^p(\mu )\) and \(\mu \) is a probability measure on \(\Omega \) with finite pth moment. The \(TL^p\) space is metrised by a Wasserstein distance on the graphs of functions. To compare a discrete function \(K^{(n)}:\{x_i\}_{i=1}^n\rightarrow \mathbb {R}\) with associated discrete measure \(\mu _n=\sum _{i=1}^n\delta _{x_i}\) to a continuum function \(K:\Omega \rightarrow \mathbb {R}\) with the continuum measure \(\mu \in \mathcal {P}(\Omega )\) associated with \(\Omega \), we perform the following steps. Firstly, we find an “optimal” partitioning of equal mass of the underlying state space, \(T^{(n)}:\Omega \rightarrow \{x_i\}_{i=1}^n\) (where optimal is in the sense of solving an optimal transport problem between the discrete measure \(\mu _n\) and the continuum measure \(\mu \).). Secondly, we extend \(K^{(n)}\) to \(\Omega \) to be piecewise constant, i.e. \({\tilde{K}}^{(n)} = K^{(n)}\circ T^{(n)}:\Omega \rightarrow \mathbb {R}\). Lastly we compare \({\tilde{K}}^{(n)}\) to K in an \(L^p\) norm. The notation \(TL^p\) stands for “transport” and “\(L^p\)”. We leave further details of the topology that is constructed in this way to [30].
To make the connection between \(d_1\) and \(TL^2\) precise consider the following. For pairs \((\mu ,K),(\nu ,L)\) where \(\mu ,\nu \in \mathcal {P}(\Omega )\) and \(K\in L^2(\mu )\), \(L\in L^2(\nu )\) the \(TL^2\) distance is defined (in the Kantorovich formulation) by
Here \(\Pi (\mu ,\nu )\) denotes the set of all Borel probability measures on \(\Omega \times \Omega \) whose marginals on the first and second variable are \(\mu \) and \(\nu \), respectively (so-called couplings). We say that \((\mu _n,K^{(n)})\rightarrow (\mu ,K)\) in \(TL^2\) if \(d_{TL^2}^2((\mu _n,K^{(n)}),(\mu ,K))\rightarrow 0\). In the Monge formulation we write
We note that the Monge formulation is not always defined as there may not exist transport maps T between \(\mu \) and \(\nu \). Comparing the metric in \(TL^2\) to the Wasserstein distance
we can see that \(d_{TL^2}((\mu ,K),(\nu ,L)) = d_W((\textrm{Id}\times K)_{\#}\mu ,(\textrm{Id}\times L)_{\#}\nu )\).
In our case we choose \(\mu \) to be the Lebesgue measure on [0, 1], \(\nu =\mu _n\) the discrete measure defined above, and \(L=K^{(n)}\). It is a consequence of results in [30] (since \(\mu _n\) converges weakly\(^*\) to \(\mu \)—we say weak\(^*\) to be consistent with notation in functional analysis rather than weak which is often the notation in statistics) that
More precisely, in our setting \(d_{TL^2}((\mu ,K),(\mu _n,K^{(n)})) \rightarrow 0\) is equivalent to \(\mu _n{{\,\mathrm{{\mathop {\rightharpoonup }\limits ^{*}}}\,}}\mu \) and the existence of a sequence of transport maps \(T^{(n)}\) (between \(\mu _n\) and \(\mu \)) such that \(T^{(n)}\rightarrow \textrm{Id}\) in \(L^2\) and \(K^{(n)}\circ T^{(n)}\rightarrow K\) in \(L^2\). The existence of such a sequence \(T^{(n)}\) is guaranteed in our case, since we can choose \(T^{(n)}(t) = {\bar{t}}_i\) for \(t\in ({\bar{t}}_{i-1},{\bar{t}}_i)\) where \({\bar{t}}_i=\frac{i}{n-1}\), which leads to \(K^{(n)} \circ T^{(n)}\) being a piecewise constant interpolation of \(K^{(n)}\). Hence, we can use the simpler function \(d_1\). We note that \(d_1\) is not a metric (for example \(d_1(K,K^{(n)})\) does not make sense; hence, \(d_1\) is not symmetric), however due to the relationship of \(d_1\) with \(d_{TL^2}\) we can still take advantage of metric properties.
Similarly, we define \(d_2(b^{(n)},b) = \Vert {\tilde{b}}^{(n)}-b\Vert _{L^2}\) and the distance between \(\theta = (K,b,W,c)\) and \(\theta ^{(n)} = (K^{(n)},b^{(n)},W^{(n)},c^{(n)})\) is given by
We could also have used a piecewise linear interpolation rather than the piecewise constant interpolation we use, i.e. we could have defined
and compared \({\bar{d}}_1(K^{(n)},K):=\Vert {\bar{K}}^{(n)} - K\Vert _{L^2}\). However, under appropriate conditions (which are satisfied in this paper)
Since the piecewise constant and piecewise linear constructions both generate the \(TL^2\) topology, we choose the simpler former one. This also gives us a metric space structure that we can use to establish \(\Gamma \)-limits.
3.3 \(\Gamma \)-Convergence
Recall that we wish to show minimisers of \(\mathcal {E}_n\) converge to minimisers of \(\mathcal {E}_\infty \). In particular, we want to show that \(\mathcal {E}_\infty \) is the variational limit of \(\mathcal {E}_n\). To characterise variational convergence we first define the \(\Gamma \)-limit in a general metric space setting.
Definition 3.1
Let \(\mathcal {E}_n:\Omega \rightarrow \mathbb {R}\cup \{\pm \infty \}\), \(\mathcal {E}_\infty :\Omega \rightarrow \mathbb {R}\cup \{+\infty \}\) where \((\Omega ,d)\) is a metric space. Then \(\mathcal {E}_n\) \(\Gamma \)-converges to \(\mathcal {E}_\infty \), and we write \(\mathcal {E}_\infty =\mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{n\rightarrow \infty } \mathcal {E}_n\), if for all \(u\in \Omega \) the following holds:
-
1.
(the liminf inequality) for any \(u_n\rightarrow u\)
$$\begin{aligned} \liminf _{n\rightarrow \infty } \mathcal {E}_n(u_n) \ge \mathcal {E}_\infty (u); \end{aligned}$$ -
2.
(the recovery sequence) there exists \(u_n\rightarrow u\) such that
$$\begin{aligned} \limsup _{n\rightarrow \infty } \mathcal {E}_n(u_n) \le \mathcal {E}_\infty (u). \end{aligned}$$
For brevity we focus only on the key property of \(\Gamma \)-convergence, and the property that justifies the term variational convergence. For a more substantial introduction to \(\Gamma \)-convergence, we refer to [5, 18].
Theorem 3.2
Let \((\Omega ,d)\) be a metric space and \(\mathcal {E}_n\) a proper sequence of functionals on \(\Omega \). Let \(u_n\) be a sequence of almost minimisers for \(\mathcal {E}_n\), i.e. \(\mathcal {E}_n(u_n)\le \max \{\inf _{u\in \Omega } \mathcal {E}_n(u_n) + \varepsilon _n,-\frac{1}{\varepsilon _n}\}\) for some \(\varepsilon _n\rightarrow 0^+\). Assume that \(\mathcal {E}_\infty = \mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{n\rightarrow \infty } \mathcal {E}_n\) and \(\{u_n\}_{n=1}^\infty \) are relatively compact. Then,
where the minimum of \(\mathcal {E}_\infty \) exists. Moreover if \(u_{n_m}\rightarrow u_\infty \) is a convergent subsequence then \(u_\infty \) minimises \(\mathcal {E}_\infty \).
Clearly if one assumes that the minimum of \(\mathcal {E}_\infty \) is unique then, by the above theorem, \(u_n\rightarrow u_\infty \) (without recourse to subsequences) where \(u_\infty \) is the unique minimiser of \(\mathcal {E}_\infty \).
Theorem 3.2 forms the basis for our proof of Theorem 2.1. In order to apply Theorem 3.2, we must show that minimisers are relatively compact and \(\mathcal {E}_\infty =\mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{n\rightarrow \infty } \mathcal {E}_n\).
We note that Definition 3.1 and Theorem 3.2 are in the context of metric spaces. As we described in Sect. 3.2 we can describe the convergence of \(K^{(n)}\) in terms of the \(TL^2\) distance \(d_{TL^2}\) which is a metric on the space \(\Omega =\{(\mu ,f) \, : \, f\in L^2(\mu ;\mathbb {R}^{d\times d}), \mu \in \mathcal {P}([0,1])\}\) (and similarly for \(b^{(n)}\)). Hence, we can use the distance
which is a metric on the space
Since convergence in \({\tilde{d}}\) is equivalent to convergence in d, we can simplify our notation by considering sequences that converge in d whilst still being able to apply Theorem 3.2.
3.4 Sobolev spaces
For readers unfamiliar with Sobolev spaces, in this section we provide some definitions and results that are needed to read the remainder of the current paper. For a more detailed introduction and further in-depth study of these concepts we refer the reader to [1, 62].
We define the Sobolev space \(H^k([0,1])\) recursively: for \(k\ge 2\), \(f\in H^k([0,1])\) if \({\dot{f}}\in H^{k-1}([0,1])\) where \({\dot{f}}\) is the weak derivative of f, and for \(k=1\), \(f\in H^1([0,1])\) if \(f\in L^2([0,1])\) and \({\dot{f}}\in L^2([0,1])\). We can replace \(H^k\) with \(H^k_{\textrm{loc}}\) by replacing \(L^2\) with \(L^2_{\textrm{loc}}\) in the previous definition (where \(L^2_{\textrm{loc}}([0,1])\) is the set of functions that are in \(L^2([a,b])\) for every \(0<a<b<1\)). The Sobolev norm in \(H^1([0,1])\) is defined by
Of course these definitions extend to p-norms and functions of several variables [62].
Morrey’s inequality in one dimension [62, Theorem 11.34] implies that there exists a constant C such that \(\Vert f\Vert _{C^{0,\scriptscriptstyle \frac{1}{2}}} \le C\Vert f\Vert _{H^1}\) for all \(f\in H^1\). We note in particular that such an f has a continuous representative, so that the pointwise evaluation f(0) is well-defined. Therefore,
Moreover, for any \(f\in H^1\) we have \(|f(x)-f(y)|\le C\sqrt{|x-y|}\Vert {\dot{f}}\Vert _{L^2}\) [62, Remark 11.35] so that \(|f(x)| \le |f(0)| + C\sqrt{|x|}\Vert {\dot{f}}\Vert _{L^2} \le |f(0)| + C\Vert {\dot{f}}\Vert _{L^2}\) implying
It follows that \(|f(0)| + \Vert {\dot{f}}\Vert _{L^2}\) and \(\Vert f\Vert _{H^1}\) are equivalent norms. In particular, our regularisation terms \(R_\infty ^{(1)}\) and \(R_\infty ^{(2)}\) in the deep layer limit (see (11)) are equivalent to \(H^1\) norms. We furthermore have the Rellich–Kondrachov type embedding result that \(H^1([0,1])\) is compactly embedded in both \(C^{0,\scriptscriptstyle \frac{1}{2}}([0,1])\) and \(L^2([0,1])\) [62, Section 11.3].
Although the finite layer regularisation uses a finite difference approximation of the derivative (as one cannot use usual derivatives in discrete spaces), one can expect minimisers of \({\mathcal {E}}_n\) to enjoy similar regularity properties in the deep layer limit when the scale in the discretisation goes to zero, as minimisers of \({\mathcal {E}}_\infty \) have.
Non-local characterisations of Sobolev spaces are possible, see for example [62, Theorem 10.55], and we utilise such ideas to prove \(\Gamma \)-convergence.
4 Proofs
The proof of Theorem 2.1 is a straightforward application of the following theorem, Theorem 4.1, with Theorem 3.2. This section is devoted to the proofs of Theorem 4.1, Proposition 2.2 and Corollary 2.3.
Theorem 4.1
Under the assumptions of Theorem 2.1, the following holds:
-
1.
for every \(n\in \mathbb {N}\) there exists a minimiser of \(\mathcal {E}_n\) in \(\Theta ^{(n)}\),
-
2.
any sequence \(\{(K^{(n)},b^{(n)},W^{(n)},c^{(n)})\}_{n\in \mathbb {N}}\) which is bounded in \(\mathcal {E}_n\), i.e.
$$\begin{aligned} \sup _{n\in \mathbb {N}} \mathcal {E}_n(K^{(n)},b^{(n)},W^{(n)},c^{(n)})<\infty , \end{aligned}$$is relatively compact, and
-
3.
\(\mathop {\mathrm {\Gamma \text {-}\lim }}\limits _{n\rightarrow \infty } \mathcal {E}_n = \mathcal {E}_\infty \).
The first three subsections are each dedicated to the proof of one part of the above theorem. In Sect. 4.1 we show that sequences bounded in \(\mathcal {E}_n\) are relatively compact. The argument relies on approximating discrete sequences \(\theta ^{(n)} = (K^{(n)},b^{(n)},W^{(n)},c^{(n)})\in \Theta ^{(n)}\) with a continuum sequence \(\tilde{\theta }^{(n)} = ({\tilde{K}}^{(n)},{\tilde{b}}^{(n)},W^{(n)},c^{(n)})\in \Theta \) and using standard Sobolev embedding arguments to deduce the compactness of \(\tilde{\theta }^{(n)}\), and therefore, \(\theta ^{(n)}\).
In Sect. 4.2 we prove the existence of minimisers. The strategy is to apply the direct method from the calculus of variations. That is, we show that \(\mathcal {E}_n\) is lower semi-continuous (in fact continuous). For compactness of minimising sequences it is enough to show bounded in norm (since for finite n parameters are finite-dimensional). Compactness plus lower semi-continuity is enough to imply the existence of minimisers.
In the third subsection we prove the \(\Gamma \)-convergence of \(\mathcal {E}_n\) to \(\mathcal {E}_\infty \). This relies on a variational convergence of finite differences.
In Sect. 4.4 we analyse the regularity of minimisers of \(\mathcal {E}_\infty \) and prove Proposition 2.2. To show this we compute the Gâteaux derivative then apply methods from elliptic regularity theory to infer additional smoothness. In this section we assume that the norms \(\Vert \cdot \Vert \) on \(\mathbb {R}^d\) and \(\mathbb {R}^{d\times d}\) are induced by an inner product \(\langle \cdot ,\cdot \rangle \).
Finally, in Sect. 4.5 we prove the uniform convergence of the parameters of the neural network to parameters of the continuum model (Corollary 2.3).
4.1 Proof of compactness
We start with a preliminary result which implies that \(\Vert K^{(n)}\Vert _{L^\infty (\mu _n)} \le C R^{(1)}_n(K^{(n)})\), this is a discrete analogue of the well-known Morrey’s inequality. We include the proof as it is important that the constant C can be chosen independently of \(\mu _n\).
In the following, where we write \({\mathbb {R}}^\kappa \), \(\kappa \) can be any integer. Specific choices for \(\kappa \) will be made when the result is applied.
Proposition 4.2
Fix \(n\in \mathbb {N}\) and let \(t_i=\frac{i}{n}\), \(\mu _n=\frac{1}{n} \sum _{i=0}^{n-1} \delta _{t_i}\), and \(f_n:\{t_i\}_{i=0}^{n-1}\rightarrow \mathbb {R}^\kappa \). Then
Proof
We note that
by Jensen’s inequality. Hence,
Taking the supremum over \(i\in \{0,1,\dots ,n-1\}\) proves the proposition. \(\square \)
Let \((K^{(n)},b^{(n)},W^{(n)},c^{(n)})\in \Theta ^{(n)}\) be a sequence such that \(\sup _{n\in \mathbb {N}}\mathcal {E}_n(K^{(n)},b^{(n)},W^{(n)},c^{(n)})<+\infty \). Then compactness of \(\{W^{(n)}\}_{n\in \mathbb {N}}\) and \(\{c^{(n)}\}_{n\in \mathbb {N}}\) is immediate from the regularisation functionals \(R^{(3)}\) and \(R^{(4)}\). For \(K^{(n)}\) and \(b^{(n)}\) we deduce compactness by using a smooth continuum approximation. In particular, let \(f_n:\{t_i\}_{i=0}^{n-1}\rightarrow \mathbb {R}^\kappa \), where \(t_i=\frac{i}{n}\), be a sequence of discrete functions that are bounded in the discrete \(H^1\) norm \(\mathcal {R}_n\) given by
We compare \(f_n\) to a smooth continuum function \(g_n:[0,1]\rightarrow \mathbb {R}^\kappa \) with the property \(\Vert g_n\Vert _{H^1} \lesssim \mathcal {R}_n(f_n)\). By Sobolev embedding arguments we have that \(\{g_n\}_{n\in \mathbb {N}}\) is relatively compact in \(L^2([0.1];{\mathbb {R}}^\kappa )\). Compactness of \(\{f_n\}_{n\in \mathbb {N}}\) follows from \(\Vert f_n\circ T_n - g_n\Vert _{L^2}\rightarrow 0\) where \(T_n\) is the map \(T_n(t) = t_i\) if \(t\in [t_i,t_{i+1})\).
In the following proposition \(\textrm{Leb}\lfloor _{[0,1]}\) is the Lebesgue measure on \(\mathbb {R}\) restricted to the interval [0, 1].
Proposition 4.3
For each \(n\in \mathbb {N}\) let \(t_i^{(n)}=\frac{i}{n}\), \(\mu _n=\frac{1}{n} \sum _{i=0}^{n-1} \delta _{t_i^{(n)}}\), and \(f_n:\{t_i^{(n)}\}_{i=0}^{n-1}\rightarrow \mathbb {R}^\kappa \). If
then \(\{(\mu _n,f_n)\}_{n\in \mathbb {N}}\) is relatively compact in \(TL^2\) and any cluster point \((\mu ,f)\) satisfies \(\mu =\textrm{Leb}\lfloor _{[0,1]}\) and \(f\in C^{0,\gamma }\left( [0,1]; \mathbb {R}^\kappa \right) \) for any \(\gamma <\frac{1}{2}\). Furthermore, for any converging subsequence there exists a further subsequence (which we relabel), and a \(f\in C^{0,\gamma }\left( [0,1]; \mathbb {R}^\kappa \right) \), such that
Proof
First note that
with the last line following from Young’s inequality, so by (18) \(\Vert f_n\Vert _{L^\infty (\mu _n)}\) is bounded. In particular, there exists \(M<+\infty \) such that
Let \({\tilde{f}}_n\) be the continuum extension of \(f_n\) defined by
Define \(g_n=J_{\varepsilon _n}*{\tilde{f}}_n\) where \(J\in C^\infty (\mathbb {R})\) is a standard mollifier [62, Remark C.18(ii)] with \(\Vert J\Vert _{L^1} = 1\), \(\Vert J\Vert _{L^\infty }\le \beta \), for some \(\beta >0\), \(J_\varepsilon =\frac{1}{\varepsilon } J(t/\varepsilon )\), for all \(\varepsilon >0\), and \(\varepsilon _n=\frac{1}{2n}\). We recall the following facts about mollifiers (which are stated in the domain \(\mathbb {R}\), but hold for higher-dimensional Euclidean spaces as well):
-
(M1)
\(\Vert J_\varepsilon *f\Vert _{L^\infty }\le \Vert f\Vert _{L^\infty }\), for any \(f\in L^\infty \) and any \(\varepsilon >0\) (by Young’s inequality [62, Theorem C.15]);
-
(M2)
\(\frac{\textrm{d}}{\textrm{d}t} (J_\varepsilon *f) = \frac{1}{\varepsilon } ({\dot{J}})_\varepsilon *f\), for any \(f\in L^1\) and any \(\varepsilon >0\), where \(({\dot{J}})_\varepsilon (t) = \frac{1}{\varepsilon } {\dot{J}}(t/\varepsilon )\) [62, Theorem C.20];
-
(M3)
\(\int _\mathbb {R}({\dot{J}})_\varepsilon (s)\, \textrm{d}s = 0\) (since the order of integration and differentiation can be reversed, as \((\dot{J})_\varepsilon \) is continuous and supported on a compact subset of \({\mathbb {R}}\));
-
(M4)
\(\Vert ({\dot{J}})_\varepsilon \Vert _{L^\infty } \le \frac{\Vert J\Vert _{L^\infty }}{\varepsilon }\), for any \(\varepsilon >0\).
We first show that \(g_n\) is bounded in \(H^1([0,1]; {\mathbb {R}}^\kappa )\). As \(\Vert f_n\Vert _{L^\infty (\mu _n)}\) is bounded then \(\Vert {\tilde{f}}_n\Vert _{L^\infty ([0,1])}\) is bounded, so by (M1) \(g_n\) is bounded in \(L^\infty ([0,1]; {\mathbb {R}}^\kappa )\). It is therefore sufficient to show that \(\sup _{n\in \mathbb {N}} \Vert {\dot{g}}_n\Vert _{L^2}<+\infty \). For \(t\in [t_i^{(n)},t_i^{(n)}+\varepsilon _n]\) and \(i\ge 1\) we have,
Similarly, for \(t\in [t_i^{(n)}+\varepsilon _n,t_{i+1}^{(n)}]\) and \(i\le n-2\) we have,
From the definition of \({\tilde{f}}_n\) we have that \({\dot{g}}_n(t)=0\) for all \(t\le \varepsilon _n\) or \(t\ge 1-\varepsilon _n\). Squaring and integrating the above inequality over \(t\in [0,1]\) implies
Hence, \(g_n\) is bounded in \(H^1([0,1]; {\mathbb {R}}^\kappa )\).
By Morrey’s inequality [62, Theorem 11.34], \(g_n\) is relatively compact in \(C^{0,\gamma }([0,1]; {\mathbb {R}}^\kappa )\) for any \(\gamma \in (0,\frac{1}{2})\). In particular \(g_n\) is relatively compact in \(L^\infty ([0,1]; {\mathbb {R}}^\kappa )\). Hence, we may assume that there exists a subsequence (which we relabel) and \(g\in C^{0,\gamma }\) such that \(g_n\rightarrow g\) in \(L^\infty ([0,1]; {\mathbb {R}}^\kappa )\). The proposition is proved once we show \(\Vert {\tilde{f}}_n-g_n\Vert _{L^\infty }\rightarrow 0\). For \(t\in [t_i^{(n)},t_i^{(n)}+\varepsilon _n]\) we have
Similarly, for \(t\in [t_i^{(n)}+\varepsilon _n,t_{i+1}^{(n)}]\) we have
Hence
It follows that \({\tilde{f}}_n\rightarrow g\) in \(L^\infty ([0,1]; {\mathbb {R}}^\kappa )\) (and therefore in \(L^2([0,1]; {\mathbb {R}}^\kappa )\)) which proves (19). Clearly \(\mu _n{{\,\mathrm{{\mathop {\rightharpoonup }\limits ^{*}}}\,}}\textrm{Leb}\lfloor _{[0,1]}\); hence, \((\mu _n,f_n)\rightarrow (\textrm{Leb}\lfloor _{[0,1]},g)\) in the \(TL^2\) topology, from which it follows that \(\{(\mu _n,f_n)\}_{n\in \mathbb {N}}\) is relatively compact in \(TL^2\). \(\square \)
Compactness of sequences bounded in \(\mathcal {E}_n\) is now a simple corollary of the above proposition.
Corollary 4.4
Let \(\Theta ^{(n)}\) and \(\Theta \) be given by (14) and (15) respectively. Define \(\mathcal {E}_n\), \(\mathcal {E}_\infty \), \(E_n\), \(E_\infty \), \(R^{(i)}_n\), \(R^{(i)}_\infty \), \(R^{(j)}\) for \(i=1,2\), \(j=3,4\) as in Sects. 1.1-1.3. Assume that \(\alpha _i>0\) for \(i=1,2,3,4\), \(\tau _j>0\) for \(j=1,2\), \(h(x)\in (-\infty ,+\infty )\) for all \(x\in \mathbb {R}^d\), \(\mathcal {L}(z,y)\in [0,+\infty )\) for all \(x,z\in \mathbb {R}^d\), and \(\sigma \) is Lipschitz continuous with \(\sigma (0)=0\). If
then there exists a subsequence \(n_m\) and \((K,b,W,c)\in \Theta \) such that
Furthermore, \(\mathcal {E}_\infty (K,b,W,c)<+\infty \).
Proof
Relative compactness in \(TL^2\) of \(\{(K^{(n)}\}_{n=1}^\infty \) and \(\{b^{(n)}\}_{n=1}^\infty \) follows from Proposition 4.3 and compactness of \(\{W^{(n)}\}_{n=1}^\infty \) and \(\{c^{(n)}\}_{n=1}^\infty \) is immediate from the bounds on \(R^{(3)}(W^{(n)})\) and \(R^{(4)}(c^{(n)})\). To see that \(\mathcal {E}_\infty (K,b,W,c)<+\infty \), we note that, by the bound on \(\sigma \) we must have that X(1; x, K, b) is finite for any x; hence, \(E_\infty (K,b,W,c;x,y)<+\infty \) for any (x, y). \(\square \)
In fact one can obtain compactness in a stronger sense; in particular one can show that, if
then there exists a subsequence such that
See Lemma 4.17.
4.2 Proof of existence of minimisers
The existence of minimisers is a straightforward application of the direct method from the calculus of variations. In particular, for \(n\in \mathbb {N}\) all parameters are finite-dimensional; hence, it is enough to show that minimising sequences are bounded. For W, c this is clear from the regularisation, for \(K^{(n)},b^{(n)}\) this follows from Proposition 4.2. Lower semi-continuity then implies that converging minimising sequences converges to minimisers.
Proposition 4.5
Let \(n\in \mathbb {N}\) and \(\Theta ^{(n)}\) be given by (14). Define \(\mathcal {E}_n\), \(E_n\), \(R^{(i)}_n\), \(R^{(j)}\) for \(i=1,2\), \(j=3,4\) as in Sect. 1.1 and 1.2. Assume that \(\alpha _i>0\) for \(i=1,2,3,4\) and \(\tau _j>0\) for \(j=1,2\). Further assume that \(\sigma \) and h are continuous, that \(\sigma (0)=0\), and that \(\mathcal {L}\) is non-negative and continuous in its first argument. Then, there exists a minimiser of \(\mathcal {E}_n\) in \(\Theta ^{(n)}\).
Proof
Let \(\theta ^{(n)}_m=(K^{(n)}_m,b^{(n)}_m,W_m,c_m)\in \Theta ^{(n)}\) be a minimising sequence, i.e.
Since \(\mathcal {E}_n(\underline{0}) = \sum _{s=1}^S \mathcal {L}\left( h(\underline{0}), y_i\right) =: C<\infty \), we can assume that \(\mathcal {E}_n(\theta _m^{(n)}) \le C\) for all m. Hence, \(\sup _{m\in \mathbb {N}}\max \{R_n^{(1)}(K_m^{(n)}),R_n^{(2)}(b_m^{(n)}),R^{(3)}(W_m),R^{(4)}(c_m)\} \le C\). We emphasise that all the parameters are finite-dimensional. Since \(\Vert W_m\Vert \le \sqrt{C}\) and \(\Vert c_m\Vert \le \sqrt{C}\), we immediately have that \(\{W_m\}_{m\in \mathbb {N}}\) and \(\{c_m\}_{m\in \mathbb {N}}\) are bounded, hence relatively compact. By Proposition 4.2\(\{K_m^{(n)}\}_{m\in \mathbb {N}}\) and \(\{b_m^{(n)}\}_{m\in \mathbb {N}}\) are also bounded in the supremum norm, hence relatively compact.
With recourse to a subsequence, we assume that \((K^{(n)}_m,b^{(n)}_m,W_m,c_m)\rightarrow (K^{(n)},b^{(n)},W,c)=\theta ^{(n)}\in \Theta ^{(n)}\). By induction on i it is easy to see that \(X_i[x,K_m^{(n)},b_m^{(n)}]\rightarrow X_i[x,K^{(n)},b^{(n)}]\) as \(m\rightarrow \infty \) (by continuity of \(\sigma \)). Hence, by continuity of h and \(\mathcal {L}(\cdot ,y_i)\), it follows that \(\mathcal {E}_n(\theta ^{(n)}_m)\rightarrow \mathcal {E}_n(\theta ^{(n)})\). Now since,
it follows that \(\mathcal {E}_n(\theta ^{(n)}) = \inf _{\Theta ^{(n)}} \mathcal {E}_n\). \(\square \)
4.3 \(\Gamma \)-Convergence of \(\mathcal {E}_n\)
In this section we prove the \(\Gamma \)-convergence of \(\mathcal {E}_n\) to \(\mathcal {E}_\infty \). We divide the result into two parts: the liminf inequality is in Lemma 4.9, and the existence of a recovery sequence is given in Lemma 4.11. Before getting to these results we start with some preliminary results, the first is that, for any \(K^{(n)}\rightarrow K\) and \(b^{(n)}\rightarrow b\), the discrete model (6) converges uniformly to the continuum model (10). The next preliminary result uses this to infer the convergence of \(E_n(\theta ^{(n)};x,y)\rightarrow E(\theta ;x,y)\).
Lemma 4.6
Consider sequences \(K^{(n)}\in L^2(\mu _n;\mathbb {R}^{d\times d})\), \(b^{(n)}\in L^2(\mu _n;\mathbb {R}^d)\) where \(\mu _n=\frac{1}{n}\sum _{i=0}^{n-1} \delta _{t_i}\) and \(t_i=\frac{i}{n}\). Let \(d_1(K^{(n)}, K)\rightarrow 0\) and \(d_1(b^{(n)}, b)\rightarrow 0\) where \(K\in H^1([0,1];\mathbb {R}^{d\times d})\) and \(b\in H^1([0,1];\mathbb {R}^d)\). Define \(R_n^{(i)}\), \(i=1,2\), as in Sect. 1.2 with \(\tau _i>0\). Assume that \(\sigma \) is Lipschitz continuous with constant \(L_\sigma \), \(\sigma (0)=0\), \(\max \{\sup _{n\in \mathbb {N}} R_n^{(1)}(K^{(n)}),\sup _{n\in \mathbb {N}} R_n^{(2)}(b^{(n)})\}<+\infty \) and \(x\in \mathbb {R}^d\). Then \(\Vert X(\cdot ;x,K,b)\Vert _{L^\infty } \le C\) where C depends only on \(L_\sigma \), \(\Vert x\Vert \), \(\Vert K\Vert _{L^\infty }\), and \(\Vert b\Vert _{L^\infty }\) and furthermore
where X(t; x, K, b) and \(X^{(n)}_i[x,K^{(n)},b^{(n)}]\) are determined by (10) and (6) respectively.
Proof
Let \(X_i^{(n)} = X_i^{(n)}[x;K^{(n)},b^{(n)}]\) and \(X(t) = X(t;x,K,b)\). We have
Using the iterative update for \(X_{i}^{(n)}\), i.e. (6), the continuum differential equation governing the dynamics of X(t), i.e. (10), and the Lipschitz bound on \(\sigma \), we may bound the second term above by the following:
By Proposition 4.2 we can show that \(\Vert K\Vert _{L^\infty },\Vert b\Vert _{L^\infty }\) is finite (since \(K^{(n)}\rightarrow K\) and \(K^{(n)}\) is uniformly bounded in \(L^\infty (\mu _n; {\mathbb {R}}^{d\times d})\), analogously for b). Now we show that \(\sup _{n\in \mathbb {N}} \Vert X^{(n)}\Vert _{L^\infty (\mu _n)}<+\infty \). We have, by (6) and the Lipschitz assumption on \(\sigma \),
where \(M_1=\sup _{n\in \mathbb {N}} \max \{\Vert K^{(n)}\Vert _{L^\infty (\mu _n)},\Vert b^{(n)}\Vert _{L^\infty (\mu _n)}\} < + \infty \) by Proposition 4.2. Hence,
Since \(X_j^{(n)}=x\), by induction it follows that, for \(j\in \{1,\dots ,n\}\),
Hence, \(\sup _{n\in \mathbb {N}} \Vert X^{(n)}\Vert _{L^\infty (\mu _n)}<+\infty \).
Now consider, for \(0\le s_1<s_2\le 1\),
Therefore, if we choose \(s_2 = \min \{1,s_1+\frac{1}{2L_\sigma \Vert K\Vert _{L^\infty }}\}\) we have \(\Vert X\Vert _{L^\infty ([s_1,s_2])} \le 2L_\sigma \Vert b\Vert _{L^\infty } + 2\Vert X(s_1)\Vert \). Let \(s_i = \min \{1,\frac{i}{2L_\sigma \Vert K\Vert _{L^\infty }}\}\) and \(N = \lceil 2L_\sigma \Vert K\Vert _{L^\infty }\rceil \) (we note that \(s_{N-1}<1 = s_N\)). For \(i\in \{2,\dots ,N\}\) we have
For \(i=1\) we have \(\Vert X\Vert _{L^\infty ([0,s_1])} \le 2L_\sigma \Vert b\Vert _{L^\infty } +\Vert x\Vert \), and by induction for \(i\in \{2,\dots , N\}\) we have
In particular, for \(i=N\) we have
Now, using \(\sigma (0) = 0\) and the Lipschitz assumption on \(\sigma \), we have
hence, X is Lipschitz. Let \(L_X\) be the Lipschitz constant for X.
Returning to (20) we concentrate on the second term, we bound
where \(M_2=\max \{M_1,\Vert X^{(n)}\Vert _{L^\infty (\mu _n)}\}\). Continuing to manipulate the first term on the right-hand side of the above expression, we have,
Combining the bounds (20), (21) and (22), we have
By induction, for any \(k\in \{0,1,\dots , n\}\), we have
for any \(\varepsilon >0\) by employing Young’s inequality, \(\alpha \beta \le \frac{\varepsilon \alpha ^2}{2}+\frac{\beta ^2}{2\varepsilon }\), for appropriately chosen \(\alpha \) and \(\beta \), on the first two terms for the final inequality (notice that the right hand side is independent of k). By Hölder’s inequality and the assumption that \(d_1(K^{(n)}, K) \rightarrow 0\) we have
(and similarly for the sequence \(b^{(n)}\)). Hence, to show
it is enough to show (i) \(\frac{1}{n^2} \sum _{i=0}^{n-1} \left( 1+\frac{L_\sigma M_2}{n}\right) ^i \rightarrow 0\) and (ii) \(\sup _n \frac{1}{n} \sum _{i=1}^n \left( 1+\frac{L_\sigma M_2}{n}\right) ^{2(n-i)} < \infty \).
For (i) we have that
And for (ii) we have
Hence, if we replace \(\varepsilon \) by a sequence \(\varepsilon _n\) that converges to zero sufficiently slowly and that satisfies
then we have that (23) holds.
Finally,
where the convergence is uniform over \(k\in \{0,1,\dots ,n\}\) as required. \(\square \)
We say that \(\Theta \ni \theta _n = (K^{(n)},b^{(n)},W^{(n)},c^{(n)})\rightarrow \theta = (K,b,W,c)\in \Theta \) if \(d_1(K^{(n)},K)\rightarrow 0\), \(d_2(b^{(n)},b)\rightarrow 0\) and \(W^{(n)}\rightarrow W\), \(c^{(n)}\rightarrow c\) (where, since \(W^{(n)}\) and \(c^{(n)}\) are sequences in \(\mathbb {R}^{d\times d}\) and \(\mathbb {R}^d\), we choose any norm induced-topology for the latter). The above result implies the following lemma.
Lemma 4.7
In addition to the assumptions of Theorem 2.1 let \(\Theta ^{(n)}\ni \theta ^{(n)}\rightarrow \theta \in \Theta \), with \(\max \{\sup _{n\in \mathbb {N}} R_n^{(1)}(K^{(n)}),\sup _{n\in \mathbb {N}} R_n^{(2)}(b^{(n)})\}<+\infty \) and \(x\in \mathbb {R}^d\), \(y\in \mathbb {R}^m\), then
Proof
By continuity of h and \(\mathcal {L}\) (in its first argument), convergence of \(W^{(n)}\rightarrow W\), \(c^{(n)}\rightarrow c\) and \(X^{(n)}_n[x,K^{(n)},b^{(n)}]\rightarrow X(1;x,K,b)\) (with the latter following from Lemma 4.6) we can easily conclude the result. \(\square \)
The following is a small generalisation of Theorem 10.55 in [62]. The difference between the results stated here and the result in [62] is that here we treat sequences of functions \(f_n\), whilst in [62] \(f_n=f\). We also only state the result on the domain [0, 1] and for \(L^2\) convergence (the result generalises to bounded sets in higher dimensions and \(L^p\) convergence where \(p>1\)).
Proposition 4.8
Let \(f_n\in L^2([0,1]; {\mathbb {R}}^\kappa )\), \(f\in L^2([0,1]; {\mathbb {R}}^\kappa )\) and \(\varepsilon _n \rightarrow 0^+\). Assume that \(f_n\rightarrow f\) in \(L^2([0,1]; {\mathbb {R}}^\kappa )\). If
then \(f\in H^1([0,1]; {\mathbb {R}}^\kappa )\) and
Proof
The strategy is to show the following two inequalities:
for any \({{\tilde{g}}}\in L^2([0,1]; {\mathbb {R}}^\kappa )\) and any \(\delta ,\delta ^\prime >0\) that satisfy \(\varepsilon _n+\delta <\delta ^\prime \), and where \(J_\delta \) is a standard mollifier; and
for any \(g,g_n \in C^\infty ([\delta ^\prime ,1-\delta ^\prime ]; {\mathbb {R}}^\kappa )\) with \({\dot{g}}_n \rightarrow {\dot{g}}\) in \(L^\infty ([\delta ^\prime ,1-\delta ^\prime ]; {\mathbb {R}}^\kappa )\) and \(\sup _n \Vert \ddot{g}_n \Vert _{L^\infty ([\delta ^\prime ,1-\delta ^\prime ])}<\infty \).
Before we prove these two inequalities, we use them to prove the result of the lemma. We note that \(\Vert \frac{\textrm{d}}{\textrm{d}t} J_\delta *f - \frac{\textrm{d}}{\textrm{d}t} J_\delta *f_n\Vert _{L^\infty ([\delta ^\prime ,1-\delta ^\prime ])}\le \Vert \frac{\textrm{d}}{\textrm{d}t} J_\delta \Vert _{L^2(\mathbb {R})}\Vert f_n-f\Vert _{L^2([0,1])}\) and \(\Vert \frac{\textrm{d}^2}{\textrm{d}t^2} J_\delta *f_n\Vert _{L^\infty ([\delta ^\prime ,1-\delta ^\prime ])}\le \Vert \frac{\textrm{d}^2}{\textrm{d}t^2} J_\delta \Vert _{L^2(\mathbb {R})} \Vert f_n\Vert _{L^2([0,1])}\). Therefore, we may apply (25) to \(g=J_\delta *f\) and \(g_n=J_\delta *f_n\).
To show existence of \({\dot{f}}\in L^2([2\delta ^\prime ,1-2\delta ^\prime ]; {\mathbb {R}}^\kappa )\) we assume the above inequalities hold, then by (24) and the assumptions on \(f_n\) there exists M such that
Furthermore, by (25) \(\int _{2\delta ^\prime }^{1-2\delta ^\prime } \Vert \frac{\textrm{d}}{\textrm{d}t} J_\delta *f (t) \Vert ^2 \textrm{d}t \le M\). In addition to the four standard properties of mollifiers which we recalled in the proof of Proposition 4.3, we list a fifth one here:
-
(M5)
\(J_\delta *{{\tilde{g}}} \rightarrow {{\tilde{g}}}\) in \(L^2([0,1]; {\mathbb {R}}^\kappa )\), as \(\delta \rightarrow 0^+\), for any \({{\tilde{g}}} \in L^2([0,1]; {\mathbb {R}}^\kappa )\) [62, Theorem C.19].
By (M5) and since \(\frac{\textrm{d}}{\textrm{d}t} J_\delta *f\) is bounded in \(L^2([2\delta ^\prime ,1-2\delta ^\prime ]; {\mathbb {R}}^\kappa )\), uniformly in \(\delta \), there exists an \(h\in L^2([2\delta ^\prime ,1-2\delta ^\prime ]; {\mathbb {R}}^\kappa )\) such that, after potentially passing to a subsequence, \(J_\delta *f \rightarrow f\) and \(\frac{\textrm{d}}{\textrm{d}t} (J_\delta *f) {{\,\mathrm{\rightharpoonup }\,}}h\) in \(L^2([0,1]; {\mathbb {R}}^\kappa )\), as \(\delta \rightarrow 0^+\). Therefore, for any differentiable \(\varphi \) with compact support in \([2\delta ^\prime ,1-2\delta ^\prime ]\),
Hence, \(h = {\dot{f}}\) and in particular \({\dot{f}}\in L^2([2\delta ^\prime ,1-2\delta ^\prime ]; {\mathbb {R}}^\kappa )\). Since \(\frac{\textrm{d}}{\textrm{d}t} (J_\delta *f) = J_{\delta }*{\dot{f}}\), we can use again the convergence of mollifiers to infer \(\frac{\textrm{d}}{\textrm{d}t} (J_\delta *f)\rightarrow {\dot{f}}\) (strongly) in \(L^2([2\delta ^\prime ,1-2\delta ^\prime ]; {\mathbb {R}}^\kappa )\).
Applying (25) followed by (24) we have
By \(L^2([2\delta ^\prime ,1-2\delta ^\prime ]; {\mathbb {R}}^\kappa )\) convergence of \(\frac{\textrm{d}}{\textrm{d}t} J_\delta *f\) as \(\delta \rightarrow 0\) we have
with the inequality above valid for any \(\delta ^\prime >0\) (since the additional constraint imposed by \(\delta ^\prime >\delta +\varepsilon _n\) vanishes when taking \(\delta \rightarrow 0\) and \(\varepsilon _n\rightarrow 0\)). Taking \(\delta ^\prime \rightarrow 0\) proves the lemma under the assumption of (24) and (25).
To show (24) we have, assuming \(\delta +\varepsilon _n< \delta ^\prime \),
where the antepenultimate line follows from Minkowski’s inequality for integrals.
For inequality (25), by Taylor’s theorem we have
Therefore, for \(t\in [2\delta ^\prime ,1-2\delta ^\prime ]\), when \(\varepsilon _n<\delta ^\prime \),
For any \(\eta >0\) there exists \(C_\eta >0\) such that \(|a+b|^2\le (1+\eta )|a|^2 + C_\eta |b|^2\) for any \(a,b\in \mathbb {R}\) (a consequence of Young’s inequality, and one can show that \(C_\eta = 1+\frac{1}{\eta }\)), hence
In particular, by Lebesgue’s dominated convergence theorem and \(\sup _{n\in \mathbb {N}} \Vert \ddot{g}_n\Vert _{L^\infty ([\delta ^\prime ,1-\delta ^\prime ])}<\infty \),
Taking \(\eta \rightarrow 0\) proves (25). \(\square \)
By application of the preceeding lemma we can now prove the liminf inequality for the \(\Gamma \)-convergence of \(\mathcal {E}_n\).
Lemma 4.9
Under the assumptions of Theorem 2.1 let \(\Theta ^{(n)}\ni \theta ^{(n)}\rightarrow \theta \in \Theta \), then,
Proof
Let \(\theta ^{(n)}=(K^{(n)},b^{(n)},W^{(n)},c^{(n)})\) and \(\theta =(K,b,W,c)\). We only need to consider the case when \(\liminf _{n\rightarrow \infty } \mathcal {E}_n(\theta ^{(n)})<+\infty \). Hence, we assume that \(\mathcal {E}_n(\theta ^{(n)})\) is bounded and therefore by the compactness property (Corollary 4.4) \(\mathcal {E}_\infty (\theta )<+\infty \). We will show the following
Indeed (A) holds by Lemma 4.7 and since \(R^{(1)}_n(K^{(n)})\), \(R^{(2)}_n(b^{(n)})\) are uniformly (in n) bounded.
Parts (B) and (C) are analogous, so we only show (B). Let \({\tilde{K}}^{(n)}(t) = K_i^{(n)}\) for \(t\in \left( \frac{i}{n},\frac{i+1}{n}\right] \), for \(i=0,\dots , n-1\), then
with the last inequality holding as, by Proposition 4.3, \({\tilde{K}}_n\rightarrow K\) in \(L^2([0,1])\). Hence, we may apply Proposition 4.8. \(\square \)
We now turn our attention to the recovery sequence. For any \(\theta \in \Theta \) we define a sequence \(\theta ^{(n)}\in \Theta ^{(n)}\) by
The above sequence is our candidate recovery sequence. We first show that \(\theta ^{(n)}\rightarrow \theta \) in the \(TL^2\) topology.
Lemma 4.10
Under the assumptions of Theorem 2.1 let \(\theta =(K,b,W,c)\in \Theta \) and define \(\theta ^{(n)}=(K^{(n)},b^{(n)},W^{(n)},c^{(n)})\in \Theta ^{(n)}\) by (26-29). Then \(\theta ^{(n)}\rightarrow \theta \) in the \(TL^2\) topology.
Proof
We show that \(K^{(n)}\rightarrow K\); the argument for \(b^{(n)}\rightarrow b\) is analogous and \(W^{(n)}=W\), \(c^{(n)}=c\) so there is nothing to show for these parts. Let \({\tilde{K}}^{(n)}(t) = K_i^{(n)}\) for \(t\in \left[ \frac{i}{n},\frac{i+1}{n}\right) \) for \(i=0,\dots ,n-1\) and \({\tilde{K}}^{(n)}(1) = K_{n-1}^{(n)}\). Since \(K\in H^1([0,1]; {\mathbb {R}}^{d\times d})\), by Morrey’s inequality we have that \(K\in C^{0,\frac{1}{2}}([0,1]; {\mathbb {R}}^{d\times d})\). In particular, \(\Vert K(s)-K(t)\Vert \le L_K \sqrt{|t-s|}\) for some \(L_K\). So,
Therefore, \(K^{(n)}\rightarrow K\). \(\square \)
We now prove that the sequence from Lemma 4.10 is a recovery sequence.
Lemma 4.11
Under the assumptions of Theorem 2.1 for any \(\theta \in \Theta \) we define \(\theta ^{(n)}\in \Theta ^{(n)}\) as in Lemma 4.10. Then \(\theta ^{(n)}\rightarrow \theta \) and
Proof
Let \(\theta =(K,b,W,c)\in \Theta \) and assume \(\mathcal {E}_\infty (\theta )<\infty \) (else the result is trivial). By Lemma 4.10 we already have that \(\theta ^{(n)}\rightarrow \theta \).
We show that \(\theta ^{(n)}\) is a recovery sequence. It is enough to show the following.
Part (A) follows from Lemma 4.7 once we show parts (B) and (C). Since (B) and (C) are analogous, we only show (B).
Let \(\varepsilon >0\) and \(C_\varepsilon =1+\frac{1}{\varepsilon }\), then \(\Vert a+b\Vert ^2\le (1+\varepsilon )\Vert a\Vert ^2 + C_\varepsilon \Vert b\Vert ^2\) (as a consequence of Young’s inequality). So,
where the last line follows from [62, Theorem 10.55] (we note that we cannot use Proposition 4.8 here, since it gives the lower bound \(\liminf _{n\rightarrow \infty } n^2 \int _{\frac{1}{n}}^1 \left\| K(t) - K\left( t-\frac{1}{n}\right) \right\| ^2 \, \textrm{d}t\ge \int _0^1 \left\| {\dot{K}}(t) \right\| ^2 \, \textrm{d}t\), rather than an upper bound). Taking \(n\rightarrow \infty \) we have
Taking \(\varepsilon \rightarrow 0^+\) proves (B). \(\square \)
4.4 Regularity of minimisers
The aim of this section is to show the higher regularity (i.e. \(H^2_{\textrm{loc}}\) rather than \(H^1\)) of minimisers. The strategy is to apply elliptic regularity techniques. For this we need to compute the Euler–Lagrange equation for \(\mathcal {E}_\infty \). We start by showing how the finite layer model (6) behaves when the parameters \(K^{(n)}\) and \(b^{(n)}\) are perturbed. By taking the limit \(n\rightarrow \infty \) we can then infer the corresponding result for the ODE limit (10).
Lemma 4.12
Let \(n\in \mathbb {N}\), \(t_i=\frac{i}{n}\), \(\mu _n=\frac{1}{n} \sum _{i=1}^n \delta _{t_i}\) and \(K^{(n)},L^{(n)}\in L^2(\mu _n;\mathbb {R}^{d\times d})\) and \(b^{(n)},\beta ^{(n)}\in L^2(\mu _n;\mathbb {R}^{d})\). Assume
where \(R^{(j)}_n\), \(j=1,2\) are defined in Sect. 1.2 with \(\tau _i>0\). Furthermore, we assume that \(\sigma \in C^2\), \(\sigma (0)=0\), and \(\sigma \) acts componentwise. Let \(\theta ^{(n)} = (K^{(n)},b^{(n)})\) and \(\xi ^{(n)} = (L^{(n)},\beta ^{(n)})\) and define \(X_i^{(n)}[x;\theta ^{(n)}]\), \(i\in \{0,\dots ,n-1\}\), as a solution to (6) with initial condition \(X_0^{(n)}=x\). We define, for \(r>0\) and \(i\in \{0,\dots ,n-1\}\),
Then,
where the O(r) term depends on \(K^{(n)},L^{(n)},b^{(n)},\beta ^{(n)}\) only through the parameter C and does not depend on n in any other way.
Remark 4.13
Not that for vectors \(A,C\in \mathbb {R}^d\) and a matrix \(B\in \mathbb {R}^{d\times d}\) we have \([BC]\odot A = A\odot [BC] = [A\odot B] C = [B\odot A] C\) where \(A\odot B\) is understood to be taken componentwise in each row, i.e. \((A\odot B)_{ij} = A_i B_{ij}\). Hence, the usual matrix multiplication \(\times \) and componentwise multiplication \(\odot \) commute.
Proof of Lemma 4.12
Since \(\theta ^{(n)}\), \(\xi ^{(n)}\) and x are fixed, we may shorten our notation by writing
throughout the proof.
Fix \(i\in \{0,1,\dots ,n\}\). Then, where we understand the square of the brackets below to be taken componentwise,
where the first equality follows from the definitions of \(D_{r,i}^{(n)}\), \(X_{i-1}^{(n)}(r)\) and \(X_{i-1}^{(n)}\), the second equality follows from Taylor’s theorem for some \(\xi _i\in \mathbb {R}^d\), and the third equality follows from the definition of \(D_{r,i-1}^{(n)}\). We can bound \(\xi _i\) by
where we understand the inequalities, minimum and maximum to hold componentwise.
By Lemma 4.6\(X^{(n)}\), \(X^{(n)}(r)\) are uniformly bounded by a constant depending only on C (for \(r\le 1\) say), and so we can assume \(\xi _i\) is uniformly bounded independent of i and n. Hence, if we can show that \(\sup _{r\in (0,1]} \sup _{i\in \{0,1,\dots , n\}} \Vert D_{r,i}^{(n)}\Vert \le C^\prime \) where \(C^\prime \) depends only on C, in particular is independent of n, then
By induction the above implies (31).
We are left to show that \(D^{(n)}_{r,i}\) is uniformly bounded in i and r. From (35) we may infer the existence of constants \(c_1\) and \(c_2\), that are independent of r and n and, given C can also be made independent of \(K^{(n)},L^{(n)},b^{(n)},\beta ^{(n)}\), such that
Hence, by induction,
It follows that \(\sup _{r\in (0,1]} \sup _{i\in \{0,1,\dots , n\}} \Vert D_{r,i}^{(n)}\Vert \) can be bounded as claimed. \(\square \)
We now use the above result to deduce the behaviour of the output of the ODE model (10) when the parameters K and b are perturbed.
Lemma 4.14
Assume \(\sigma \in C^2\), \(\sigma (0)=0\) and \(\sigma \) acts componentwise. Let \(\theta =(K,b)\) and \(\xi =(L,\beta )\) where \(K,L\in H^1([0,1];\mathbb {R}^{d\times d})\) and \(b,\beta \in H^1([0,1];\mathbb {R}^d)\). Furthermore, let \(X(t;x,\theta )\) be defined as a solution to (10) for the input \(\theta \) and initial condition \(X(0)=x\). Define, for \(r>0\),
Then,
Proof
Let \(K^{(n)},L^{(n)},b^{(n)},\beta ^{(n)}\) be any discrete sequences converging to \(K,L,b,\beta \) respectively with
and where the convergence is uniform:
For example, the recovery sequences, as defined by (26) and (27), are sufficient. To shorten notation we write
and again use the abbreviations in (32)-(34) where \(D_{r,i}^{(n)}(x,\theta ,\xi )\) is defined by (30).
By Lemma 4.6 we have \(X_n^{(n)}(r) \rightarrow X_r(1)\) as \(n\rightarrow \infty \) for all \(r\ge 0\). Hence, \(\lim _{n\rightarrow \infty } D^{(n)}_{r,n} = D_r\). By Lemma 4.12 (and in particular using that the O(r) term in (31) is independent of n given the bound (37) on \(K^{(n)},L^{(n)},b^{(n)},\beta ^{(n)}\)) we have that
where
Convergence in \(TL^\infty \) implies convergence of the empirical integral, i.e. a relatively standard argument implies that, if \(\max _{i\in \{0,1,\dots ,n-1\}} \sup _{t\in [t_i,t_{i+1}]} \Vert F(t)-F_n(t_i)\Vert \rightarrow 0\), then \(\frac{1}{n} \sum _{i=0}^{n-1} F_n(t_i) \rightarrow \int _0^1 F(t) \, \textrm{d}t\) (with the result also being true for weaker assumptions, e.g. convergence in \(TL^1\)). By assumptions on the sequences \(K^{(n)},L^{(n)},b^{(n)},\beta ^{(n)}\) we easily have that
We are left to find the uniform limit of \(A^{(n)}_i\).
If \(\max _{i\in \{0,1,\dots ,n-1\}} \sup _{t\in [t_i,t_{i+1}]} \Vert F(t)-F_n(t_i)\Vert \le \varepsilon \) and \(\Vert F\Vert _{L^\infty }\le M\), then
for any \(t\in [0,1]\). Hence,
using the inequality \(\Vert e^{X+Y}-e^X\Vert \le \Vert Y\Vert e^{\Vert X\Vert } e^{\Vert Y\Vert }\) (for any square matrices X, Y; see Appendix A) applied to \(X=\int _t^1 F(s) \, \textrm{d}s\) and \(Y=\frac{1}{n}\sum _{i=\lfloor tn\rfloor +1}^{n-1} F_n(t_i)-\int _t^1 F(s) \, \textrm{d}s\). We define \(F_n:\{t_j\}_{j=0}^{n-1}\rightarrow \mathbb {R}^{d\times d}\) and \(F:[0, 1]\rightarrow \mathbb {R}^{d\times d}\) by
By construction \(\prod _{j=i+1}^{n-1} \exp \left( \frac{1}{n}F_n(t_j)\right) = A_i^{(n)}\). The \(L^\infty \) bound, M, on F is readily verified from the \(L^\infty \) bounds on each of K, X and b. We show the uniform convergence of \(F_n\) to F shortly. For now we assume this is true, so we can fix an arbitrary \(\varepsilon >0\) and have an N such that
for all \(n\ge N\). For \(t\in [t_i,t_{i+1}]\) we have \(\lfloor tn\rfloor = i\), and so
Hence, \(A_i^{(n)}\) converges uniformly to \(\exp \left( \int _t^1 F(s) \, \textrm{d}s \right) \).
To complete the proof, we show that (38) holds. Analogously to when we considered the sequence \(B_n\), we can infer the existence of N such that, if \(n\ge N\), then
By [40, Proposition 2.9], there exists a constant c (independent of all parameters) such that (assuming \(\Vert C_j^{(n)}\Vert \le \frac{n}{2}\))
Since \(\Vert C_j^{(n)}\Vert \) is uniformly bounded in j and n, (39) and (40) imply (38). \(\square \)
The previous result shows the limit \(\lim _{r\rightarrow 0^+} D_r(t;x,\theta ,\xi )\) exists for \(t=1\). Whilst this is all we require in the sequel, we note that a rescaling argument implies that the limit exists for all \(t>0\). In particular, if we fix \(t>0\) and let \({\hat{X}}(\cdot ;x,{\hat{\theta }})\) satisfy \(\frac{\textrm{d}}{\textrm{d}s}{\hat{X}}(s) = {\hat{\sigma }}({\hat{K}}(s){\hat{X}}(s)+{\hat{b}}(s))\) where \({\hat{\sigma }}(\cdot )=t\sigma (\cdot )\) and \({\hat{\theta }} = ({\hat{K}}(\cdot ),{\hat{b}}(\cdot )) = (K(\cdot t),b(\cdot t))\), then we can apply the above lemma directly to \({\hat{X}}\) to deduce the existence of \(\lim _{r\rightarrow 0^+} {\hat{D}}_r(1;x,{\hat{\theta }},{\hat{\xi }})\), where \({\hat{D}}_r(s;x,{\hat{\theta }},{\hat{\xi }}) = \frac{1}{r} ({\hat{X}}(s;x,{\hat{\theta }}+r\xi ) - {\hat{X}}(s;x,{\hat{\theta }}))\). Because \({\hat{X}}(s;x,{\hat{\theta }}) = X(st;x,\theta )\), we have \({\hat{D}}_r(1;x,{\hat{\theta }},{\hat{\xi }}) = D_r(t;x,\theta ,\xi )\).
Using the above result we can compute the Gâteaux derivative of \(\mathcal {E}_\infty \), defined as
Lemma 4.15
Define \(\mathcal {E}_\infty \), \(E_\infty \), \(R_\infty ^{(i)}\), for \(i=1,2\), and \(R^{(j)}\), for \(j=3,4\), as in Sects. 1.2-1.3. In addition to the assumptions in Lemma 4.14 we assume that \(h\in C^2({\mathbb {R}}^m; {\mathbb {R}}^m)\), \(\mathcal {L}(\cdot ,y) \in C^2({\mathbb {R}}^m; {\mathbb {R}})\) for all \(y\in {\mathbb {R}}^m\), and all norms \(\Vert \cdot \Vert \) on \(\mathbb {R}^d\) and \(\mathbb {R}^{d\times d}\) are induced by inner products. Let \(\{(x_s,y_s)\}_{s=1}^S\subset \mathbb {R}^d\times \mathbb {R}^m\), \(\theta =(K,b,W,c)\in \Theta \) and \(\xi =(L,\beta ,V,\gamma )\in \Theta \) where \(\Theta \) is given by (15). We define \(D_r(t;x,\theta ,\xi )\) by (36) for \(r>0\) and
Then,
where with a small abuse of notation we wrote \(X(t;x,\theta ) = X(t;x,K,b)\), \(\nabla _z\) is the derivative with respect to the first argument, and
Proof
We consider the derivative of each term in \(\mathcal {E}_\infty \) separately. For ease of notation let
Applying this new notation to (36), we get \(D_r(t) = \frac{1}{r} (X_r(t)-X(t))\).
By Taylor’s theorem, for each r there exists \(z_r\in \mathbb {R}^m\) such that
Similarly, by another application of Taylor’s theorem, for each r there exists \(t_r\in \mathbb {R}^m\) such that
where the square is to be evaluated componentwise and we use that \(h\in C^2\) and \(t_r\) is bounded as function of r. Hence,
Taking \(r\rightarrow 0\) and applying Lemma 4.14 gives
It is straightforward to show that the Gâteaux derivatives of the regularisation functionals \(R^{(1)}_\infty \), \(R^{(2)}_\infty \), \(R^{(3)}\), and \(R^{(4)}\) are as claimed. Summing the individual terms completes the proof. \(\square \)
Finally we can deduce the regularity of minimisers of \(\mathcal {E}_\infty \) by applying techniques from the study of elliptic differential equations (see for example [34, Section 2.2.2] for the same techniques).
Proof of Proposition 2.2
Assume that \(\theta =(K,b,W,c)\in \Theta \) be a minimiser of \(\mathcal {E}_\infty \). We will show that \(K\in H^2_{\textrm{loc}}([0,1];\mathbb {R}^{d\times d})\) (the argument for \(b\in H^2_{\textrm{loc}}([0,1];\mathbb {R}^d)\) is analogous).
Since \(\theta \) is a minimiser of \(\mathcal {E}_\infty \), \(\textrm{d}\mathcal {E}_\infty (\theta ;\xi ) = 0\) for all \(\xi \in \Theta \). Let \(\Omega _N = [1/N,1-1/N]\) and \(\gamma _N\in C^\infty \) be a cut-off function that has support in \(\Omega _{2N}\) and is identically one on \(\Omega _N\). Let \(K_N = \gamma _N\odot K\). We extend \(K_N\) to the whole of \(\mathbb {R}\) by setting \(K_N(t) = 0\) for all \(t\in \mathbb {R}\setminus [0,1]\). Clearly \(K_N\in H^1(\mathbb {R};\mathbb {R}^{d\times d})\), \(K_N=K\) on \(\Omega _N\) and \(K_N\) has support in \(\Omega _{2N}\). Let \(\xi = (L,0,0,0)\) where \(L\in H^1([0,1];\mathbb {R}^{d\times d})\) satisfies \(L(0) = 0\), then \(\textrm{d}\mathcal {E}_\infty (\theta ;\xi ) = 0\) implies
Using the equality above with \(\gamma _N\odot L\) in place of L implies,
We choose \(L = L_{N,r}\) where
Clearly \(L_{N,r}\in H^1(\mathbb {R};\mathbb {R}^{d\times d})\) for every \(r>0\) and all \(N>2\). Furthermore, \(L_{N,r}\) has support in \([\frac{1}{2N}-r,1-\frac{1}{2N}+r]\). Since the support of \({\dot{K}}_N(\cdot -r)\) and \({\dot{K}}_N\) is contained in [r, 1] for \(r\le \frac{1}{N}\),
where \({\hat{\xi }}_{N,r} = (\gamma _N\odot L_{N,r},0,0,0)\). From (41), it follows that
where
(we note that the constants \(C_1, C_2\) may depend on N, but do not depend on r).
We note that we can rewrite \(L_{N,r} = \frac{2-\tau _r-\tau _{-r}}{r^2} K_N = \frac{(1-\tau _r)(1-\tau _{-r})}{r^2} K_N\), where \(\tau _r\) is the shift operator defined by \(\tau _r\varphi (x) = \varphi (x+r)\). By [62, Theorem 10.55] for any \(\psi \in H^1([0,1]; {\mathbb {R}}^{d\times d})\) we have \(\left\| \frac{\tau _r-1}{r}\psi (t+r)\right\| _{L^2([r,1-r])} \le \Vert {\dot{\psi }}\Vert _{L^2([r,1])}\). Applying this to \(\psi = \frac{(1-\tau _{-r})K_N}{r}\) we have, for r sufficiently small,
We can write \(D_0(1;x_s,\theta ,{\hat{\xi }}_{N,r}) = \int _0^1 A_{N,s}(t) \odot L_{N,r}(t) \, \textrm{d}t\) where
Hence,
Combining (44) with (42) and (43) and Young’s inequality we obtain
Hence, by [62, Theorem 10.55] \({\dot{K}}_N\in H^1([0,1];\mathbb {R}^{d\times d})\). Since this is true for all N, we have that \({\dot{K}}\in H^1_{\textrm{loc}}([0,1];\mathbb {R}^{d\times d})\). Hence, \(K\in H^2_{\textrm{loc}}([0,1];\mathbb {R}^{d\times d})\).
The argument for \(b\in H^2_{\textrm{loc}}([0,1];\mathbb {R}^d)\) is analogous. \(\square \)
4.5 The forward pass as a discretised ODE
In this section we prove Corollary 2.3.
Lemma 4.16
Let \(K \in H^1([0,1];\mathbb {R}^{d\times d})\), \(b\in H^1([0,1];\mathbb {R}^d)\), and let \(\sigma : {\mathbb {R}}^d \rightarrow {\mathbb {R}}^d\) be Lipschitz continuous with Lipschitz constant \(L_\sigma >0\). Let \(x\in {\mathbb {R}}^d\) and suppose that \(X:[0,1]\rightarrow \mathbb {R}^d\) is the solution to the ODE in (10) with initial condition \(X(0)=x\). Let \(n\in {\mathbb {N}}\) and let \(K^{(n)} \in L^0(\mu _n; \mathbb {R}^{d\times d})\), \(b^{(n)} \in L^0(\mu _n; \mathbb {R}^d)\) be such that there exists a \(\delta _n>0\) such that, for all \(i\in \{0, 1, \dots , n-1\}\), \(\Vert K_i^{(n)} - K(i/n)\Vert < \delta _n\) in matrix operator norm and \(\Vert b_i^{(n)}-b(i/n)\Vert < \delta _n\). Moreover, let \(X_i^{(n)}\) (\(i=0, 1, \ldots , n\)) be the solutions to (6) with \(X_0^{(n)} = x\). Then there exists an \(\varepsilon _n \in {\mathbb {R}}\) such that, for all \(i \in \{0, 1, \ldots , n\}\), (13) is satisfied with \(\delta =\delta _n\) and \(A_n = \frac{1}{n} \left( 1+ \Vert X\Vert _{L^\infty }\right) L_\sigma \delta _n + \varepsilon _n\). Moreover, \(\varepsilon _n = o\left( \frac{1}{n}\right) \) as \(n\rightarrow \infty \).
Proof
We follow closely standard proofs of the convergence of the explicit Euler scheme for well-posed ODEs, [7, Theorem 5.9], [63, Section 6.3.3].
First we note that the case \(i=0\) is trivial, so we will consider \(i\ge 1\) from here on.
By the Sobolev embedding theorem [1] K and b are continuous. Since \(y \mapsto \sigma (K(t)y+b(t))\) is Lipschitz continuous, by standard ODE theory [39] there is a unique solution X to (10) and this X is continuous. Moreover, \(t\mapsto \sigma \big (K(t) X(t) + b(t)\big )\) is continuous and thus \(\dot{X}\) is continuous. In particular, \(\dot{X}\) is bounded on [0, 1]. Let \(n, k\in {\mathbb {N}}\) with \(k\le n\). We compute, using Taylor’s theorem, for \(C^1\) functions [21, (2.22)],
where \(r_{k,n}\in {\mathbb {R}}^d\) is such that \(\Vert r_{k,n}\Vert = o\left( \frac{1}{n}\right) \) as \(n\rightarrow \infty \). Moreover
and thus
Using \(\Vert K_i^{(n)} - K(i/n)\Vert < \delta _n\) and \(\Vert b_i^{(n)}-b(i/n)\Vert < \delta _n\) and the fact that \(L_\sigma >0\) is a Lipschitz constant for \(\sigma \), we find
For the final inequality, we used
Since K is continuous on [0, 1], we have \(\Vert K\Vert _{L^\infty } <\infty \). Similarly, since X is continuous, we have \(\Vert X\Vert _{L^\infty } < \infty \). Combining the above we get
where we have defined \(\varepsilon _n = \max _{1\le k\le n} \Vert r_{k,n}\Vert \). We note that \(\varepsilon _n=o\left( \frac{1}{n}\right) \) as \(n\rightarrow \infty \) and recall that \(A_n=\frac{1}{n} \left( 1+\Vert X\Vert _{L^\infty }\right) L_\sigma \delta _n + \varepsilon _n\). Write \(a_k = \left\| X(k/n) - X_k^{(n)}\right\| \) and \(C=1+\frac{1}{n} L_\sigma (\Vert K\Vert _{L^\infty }+\delta _n)\), where we have repressed the dependency on n for notational simplicity. Let \(i \in {\mathbb {N}}\) with \(i\le n\). We claim that
We prove this claim by induction. Since (45) holds for arbitrary k, we have \(a_1 \le C a_0 + A_n\) directly from (45). Since \(a_0 = \Vert x-x\Vert =0\), (46) holds for \(i=1\). Now let \(k\in {\mathbb {N}}\) with \(k\le n\) and assume that (46) holds for \(i=k-1\). Then, combining (46) with (45) we deduce that
Thus claim (46) is proven. Since \(C>1\), we compute
Using that \(\left( 1+\frac{1}{n} L_\sigma (\Vert K\Vert _{L^\infty }+\delta _n)\right) ^i \le \exp \left( \frac{i}{n} L_\sigma (\Vert K\Vert _{L^\infty }+\delta _n)\right) \), we find that
as required. \(\square \)
We now check that the conditions of Lemma 4.16 hold.
Lemma 4.17
Let \(\Theta ^{(n)}\) and \(\Theta \) be given by (14) and (15) respectively. Define \(\mathcal {E}_n\), \(\mathcal {E}_\infty \), \(E_n\), \(E_\infty \), \(R^{(i)}_n\), \(R^{(i)}_\infty \), \(R^{(j)}\) for \(i=1,2\), \(j=3,4\) as in Sects. 1.1-1.3. Assume that the assumptions of Theorem 2.1 hold. If \(\{(K^{(n)},b^{(n)},W^{(n)},c^{(n)})\} \subset \Theta ^{(n)}\) is a sequence of minimisers of \(\mathcal {E}_n\) and \((K,b,W,c)\in \Theta \) is the minimiser of \(\mathcal {E}_\infty \) which we assume to be unique then we have
as \(n\rightarrow \infty \).
Proof
Let \((K^{(n)},b^{(n)},W^{(n)},c^{(n)})\) minimise \(\mathcal {E}_n\). Choose any subsequence \(\{n_m\}_{m\in \mathbb {N}}\) of \(\mathbb {N}\). By Theorem 2.1 there exists a further subsequence that converges to a minimiser (K, b, W, c) of \(\mathcal {E}_\infty \). Since the minimiser is unique, we have \((K^{(n_m)},b^{(n_m)},W^{(n_m)},c^{(n_m)})\rightarrow (K,b,W,c)\). Furthermore, since \(\mathcal {E}_{n_m}(K^{(n_m)},b^{(n_m)},W^{(n_m)},c^{(n_m)})<+\infty \), we have, by Proposition 4.3, that there exists a further subsequence \(\{n_{m_k}\}_{k\in \mathbb {N}}\) such that
as \(k\rightarrow \infty \). We have that any subsequence of \((K^{(n)},b^{(n)},W^{(n)},c^{(n)})\) contains a further subsequence that converges uniformly. Now if we suppose that \((K^{(n)},b^{(n)},W^{(n)},c^{(n)})\) does not converge uniformly to (K, b, W, c), then there exists an \(\varepsilon >0\) and a subsequence (which we index by \(n_m\)) such that the \(L^\infty \) norm of \((K^{(n_m)}-K,b^{(n_m)}-b,W^{(n_m)}-W,c^{(n_m)}-c)\) is bounded from below by \(\varepsilon \). But this subsequence cannot now contain a further subsequence that converges uniformly; a contradiction. It follows that uniform convergence holds across the whole sequence as required. \(\square \)
The proof of Corollary 2.3 follows directly from Lemmas 4.16 and 4.17.
5 Discussion and conclusions
In this paper we proved that the variational limit of the residual neural network is an ODE system, thereby rigorously justifying the observations in [23, 37]. These and similar observations have already inspired new architectures for neural networks, e.g. [36, 67, 80, 87] and the hope is that this work can help in the justification and analysis of these new architectures. In addition, we proved a regularity result for the coefficients obtained by ResNet training.
We left the question of rates of convergence for the minimisers open (see after Proposition 2.2). We believe this can be approached through a higher order \(\Gamma \)-convergence argument, for example see [6, Theorem 1.5.1], and a coercivity argument, but it falls outside the scope of this current paper.
An interesting open question which the authors intend to field in future work is to recover partial differential equations by simultaneously taking \(d\rightarrow \infty \) (where d is the number of neurons per layer) and \(n\rightarrow \infty \). This will mean imposing certain restrictions on the inter-layer connections; in particular, the choice of inter-layer connections is expected to alter the continuum partial differential equation limit.
Another open question concerns our use of explicit regularisation terms in the cost function. In practice often implicit regularisation techniques are used, such as dropout or stochastic gradient descent [38, 69, 73, 85, 91]. Incorporating these methods into our setting requires the rigorous mathematical establishment of their regularising effects, which to the best of our knowledge, has not been accomplished as of yet. However, recent work [14] shows that, at least in certain circumstances, the deep layer limit in the absence of explicit regularisation results in a stochastic limit.
In this paper we have established convergence at a variational level. A third open question of interest relates to the convergence of the corresponding gradient flow for the parameters. Except in certain special circumstances, gradient flow convergence does not follow directly from \(\Gamma \)-convergence; in this case an additional difficulty that needs to be taken into account is the ODE constraint. The authors are planning to address this question in future work.
Data Availability
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
Change history
31 May 2024
A Correction to this paper has been published: https://doi.org/10.1007/s40687-024-00454-x
Notes
For simplicity we usually speak of n layers, even though it can be argued there are \(n+2\) layers if one includes the \(0^{\text {th}}\) input layer and the final classification layer from (7) in the count.
But not always; see for example [44] for parametric ReLU, which contains a learnable parameter.
References
Adams, R. A., Fournier, J. J. F.: Sobolev spaces, volume 140. Elsevier, (2003)
Anthony, M.: Discrete mathematics of neural networks: selected topics, volume 8. SIAM, (2001)
Bengio, Y., Simard, P., Frasconi, P.: Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5(2), 157–166 (1994)
Bo, L., Capponi, A., Liao, H.: Deep residual learning via large sample mean-field optimization. preprint arXiv:1906.08894v3, (2020)
Braides, A.: \(\Gamma \)-Convergence for Beginners. Oxford University Press, (2002)
Braides, A.: Local minimization, variational evolution and \(\Gamma \)-convergence. Springer, (2014)
Burden, R. L., Faires, J. D.: Numerical analysis. Cengage Learning, 10th edition, (2010)
Celledoni, E., Ehrhardt, M.J., Etmann, C., McLachlan, R.I., Owren, B., Schönlieb, C.-B., Sherry, F.: Structure-preserving deep learning. Eur. J. Appl. Math. 32(5), 888–936 (2021)
Chang, B., Meng, L., Haber, E., Ruthotto, L., Begert, D., Holtham, E.: Reversible architectures for arbitrarily deep residual neural networks. In; Thirty-Second AAAI Conference on Artificial Intelligence, (2018)
Chaudhari, P., Oberman, A., Osher, S., Soatto, S., Carlier, G.: Deep relaxation: partial differential equations for optimizing deep neural networks. Res. Math. Sci. 5(3), 30 (2018)
Chen, T. Q., Rubanova, Y., Bettencourt, J., Duvenaud, D. K.: Neural ordinary differential equations. In: Advances in Neural Information Processing Systems, pages 6571–6583, (2018)
Choromanska, A., Henaff, M., Mathieu, M., Arous, G. B., LeCun, Y.: The loss surfaces of multilayer networks. In: Artificial Intelligence and Statistics, pages 192–204, (2015)
Chung, K.L.: On a stochastic approximation method. Ann. Math. Stat. 25(3), 463–483 (1954)
Cohen, A.-S., Cont, R., Rossier, A., Xu, R.: Scaling properties of deep residual networks. In International Conference on Machine Learning, pages 2039–2048, (2021)
Cybenko, G.: Approximation by superpositions of a sigmoidal function. Math. Control Sig. Syst. 2(4), 303–314 (1989)
Cybenko, G.: Neural networks in computational science and engineering. IEEE Comput. Sci. Eng. 3(1), 36–42 (1996)
Dahl, G. E., Sainath, T. N., Hinton, G. E.: Improving deep neural networks for LVCSR using rectified linear units and dropout. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, pages 8609–8613. IEEE, (2013)
Dal Maso, G.: An Introduction to \(\Gamma \)-Convergence. Springer, (1993)
Dauphin, Y. N., Pascanu, R., Gulcehre, C., Cho, K., Ganguli, S., Bengio, Y.: Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, Advances in neural information processing systems, pages 2933–2941. Curran Associates, Inc., (2014)
Drucker, H., Le Cun, Y.: Improving generalization performance using double backpropagation. IEEE Trans. Neural Netw. 3(6), 991–997 (1992)
Duistermaat, J. J., Kolk, J. A. C.: Multidimensional real analysis I: differentiation, volume 86. Cambridge University Press, (2004)
Dunlop, M. M., Slepčev, D., Stuart, A. M., Thorpe, M.: Large data and zero noise limits of graph-based semi-supervised learning algorithms. Appl. Comput. Harmonic Anal., (2019)
E, W.: A proposal on machine learning via dynamical systems. Commun. Math. Statistics 5(1), 1–11 (2017)
E, W., Han, J., Li, Q.: A mean-field optimal control formulation of deep learning. Res. Math. Sci. 6(1), 10 (2019)
E, W., Han, J., Li, Q.: A mean-field optimal control formulation of deep learning. Res. Math. Sci. 6(1), 10 (2019)
Finlay, C., Calder, J., Abbasi, B., Oberman, A.L: Lipschitz regularized deep neural networks generalize and are adversarially robust. preprint arXiv:1808.09540v4 (2019)
García Trillos, N., Kaplan, Z., Samakhoana, T., Sanz-Alonso, D.: On the consistency of graph-based Bayesian semi-supervised learning of the scalability of sampling algorithms. J. Mach. Learn. Res. 21(28), 1–47 (2020)
García Trillos, N., Slepčev, D.: A variational approach to the consistency of spectral clustering. Appl. Comput. Harmon. Anal. 45, 239–281 (2018)
García Trillos, N., Slepčev, D.,J. Von Brecht, Laurent, T., Bresson, X.: Consistency of cheeger and ratio graph cuts. J. Mach. Learn. Res., 17(1):6268–6313, (2016)
García Trillos, N., Slepčev, D.: Continuum limit of total variation on point clouds. Arch. Ration. Mech. Anal. 220(1), 193–241 (2016)
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256, (2010)
Goodfellow, I., Lee, H., Le, Q. V., Saxe, A., Ng, A. Y.: Measuring invariances in deep networks. In: Advances in neural information processing systems, pages 646–654, (2009)
Grathwohl, W., Chen, R. T. Q., Bettencourt, J., Sutskever, I., Duvenaud, D.: Ffjord: Free-form continuous dynamics for scalable reversible generative models. preprint arXiv:1810.01367, (2018)
Grisvard, P.: Elliptic problems in nonsmooth domains. Pitman Publishing Inc., (1985)
Haber, E., Lucka, F., Ruthotto, L.: Never look back - a modified EnKF method and its application to the training of neural networks without back propagation. preprint arXiv:1805.08034, (2018)
Haber, E., Ruthotto, L.: Stable architectures for deep neural networks. Inverse Prob. 34(1), 014004 (2017)
Haber, E., Ruthotto, L., Holtham, E., Jun, S.-H.: Learning across scales—multiscale methods for convolution neural networks. In: Thirty-Second AAAI Conference on Artificial Intelligence, (2018)
Haeffele, B. D., Vidal, R.: Global optimality in neural network training. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7331–7339, (2017)
Hale, J.K.: Ordinary Differential Equations. Dover Publications Inc, Mineola, New York, second edition (2009)
Hall, B.C.: Lie Groups, Lie Algebras, and Representations: An Elementary Introduction. Springer, New Delhi (2003)
Hassoun, M. H.: Fundamentals of artificial neural networks. MIT press, (1995)
Haykin, S.: Neural networks: a comprehensive foundation. Prentice Hall PTR, second edition, (1999)
He, K., Sun, J.: Convolutional neural networks at constrained time cost. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5353–5360, (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: 2015 IEEE International Conference on Computer Vision (ICCV), pages 1026–1034, (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, (2016)
Hertz, J., Krogh, A., Palmer, R. G.: Introduction to the theory of neural computation. Westview Press, (1991)
Higham, C.F., Higham, D.J.: Deep learning: an introduction for applied mathematicians. SIAM Rev. 61(4), 860–891 (2019)
Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R. R.: Improving neural networks by preventing co-adaptation of feature detectors. preprint arXiv:1207.0580, (2012)
Hochreiter, S.: Untersuchungen zu dynamischen neuronalen netzen. Diploma, Technische Universität München, 91(1), (1991)
Hornik, K.: Approximation capabilities of multilayer feedforward networks. Neural Netw. 4(2), 251–257 (1991)
Hornik, K., Stinchcombe, M., White, H.: Multilayer feedforward networks are universal approximators. Neural Netw. 2(5), 359–366 (1989)
Huang, G., Sun, Y., Liu, Z., Sedra, D., Weinberger, K.Q.: Deep networks with stochastic depth. In Comput. Vis.- ECCV 2016, 646–661 (2016)
Hunt, K. J., Irwin, G. R., Warwick, K.: Neural network engineering in dynamic control systems. Springer Science & Business Media, (2012)
Janocha, K., Czarnecki, W.M.: On loss functions for deep neural networks in classification. Schedae Informaticae 25, 49–59 (2016)
Jarrett, K., Kavukcuoglu, K., Ranzato, M., LeCun, Y.: What is the best multi-stage architecture for object recognition? In: Computer Vision, 2009 IEEE 12th International Conference on, pages 2146–2153. IEEE, (2009)
Kovachki, N.B., Stuart, A.M.: Ensemble Kalman inversion: a derivative-free technique for machine learning tasks. Inverse Prob. 35(9), 095005 (2019)
Krizhevsky, A., Sutskever, I., Hinton, G. E.: Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pages 1097–1105, (2012)
Kung, S. Y.: Digital Neural Networks. Prentice-Hall, Inc., (1993)
Kuo, C., Jay C.: Understanding convolutional neural networks with a mathematical model. J Vis Commun Image Represent 41, 406–413 (2016)
Laurent, T., Brecht, J.: Deep linear networks with arbitrary loss: All local minima are global. In: International Conference on Machine Learning, pages 2908–2913, (2018)
Lee, J. D., Simchowitz, M., Jordan, M. I., Recht, B.: Gradient descent only converges to minimizers. In: Conference on Learning Theory, pages 1246–1257, (2016)
Leoni, G.: A First Course in Sobolev Spaces, volume 105. American Mathematical Society, (2009)
LeVeque, R. J.: Finite difference methods for ordinary and partial differential equations: steady-state and time-dependent problems, vol. 98. Soc. Ind. Appl. Math, (2007)
Li, Q., Chen, L., Tai, C., E, W.: Maximum principle based algorithms for deep learning. J. Mach. Learn. Res. 18(165), 1–29 (2018)
Ljung, L.: Analysis of recursive stochastic algorithms. IEEE Trans. Autom. Control 22(4), 551–575 (1977)
Lu, Y., Ma, C., Lu, Y., Lu, J., Ying, L.: A mean field analysis of deep ResNet and beyond: Towards provably optimization via overparameterization from depth. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 6426–6436. PMLR, 13–18 Jul (2020)
Lu, Y., Zhong, A., Li, Q., Dong, B.: Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In: International Conference on Machine Learning, pages 5181–5190, (2018)
Maas, A. L., Hannun, A. Y., Ng, A. Y.: Rectifier nonlinearities improve neural network acoustic models. In: International Conference on Machine Learning, vol.30, p. 3, (2013)
Mianjy, P., Arora, R., Vidal, R.: On the implicit bias of dropout. In: International Conference on Machine Learning, pages 3540–3548, (2018)
Mocanu, D.C., Mocanu, E., Stone, P., Nguyen, P.H., Gibescu, M., Liotta, A.: Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nat. Commun. 9(1), 2383 (2018)
Nair, V., Hinton, G. E.: Rectified linear units improve restricted boltzmann machines. In: International Conference on Machine Learning, pages 807–814, (2010)
Narendra, K.S., Parthasarathy, K.: Identification and control of dynamical systems using neural networks. IEEE Trans. Neural Netw. 1(1), 4–27 (1990)
Neyshabur, B., Tomioka, R., Srebro, N.: In search of the real inductive bias: On the role of implicit regularization in deep learning. preprint arXiv:1412.6614, (2014)
Ng, A. Y.: Feature selection, L1 vs. L2 regularization, and rotational invariance. In: International Conference on Machine Learning, (2004)
Nielsen, M. A.: Neural Networks and Deep Learning. Determination Press, (2015)
Oberman, A.M.: Partial differential equation regularization for supervised machine learning. In: Brenner, S.C., Shparlinski, I., Shu, C.-W., Szyld, D.B. (eds.) 75 Years of Mathematics of Computation. American Mathematical Society (2020)
Orponen, P.: Neural networks and complexity theory. In International Symposium on Mathematical Foundations of Computer Science, pages 50–61. Springer, (1992)
Ranzato, M. A., Boureau, Y.-L., LeCunn, Y.: Sparse feature learning for deep belief networks. In: Advances in neural information processing systems, (2008)
Robinson, A. J., Fallside, F.: The utility driven dynamic error propagation network. Technical Report CUED/F-INFENG/TR.1, University of Cambridge Department of Engineering, (1987)
Ruthotto, L., Haber, E.: Deep neural networks motivated by partial differential equations. J. Math. Imag. Vis., pages 1–13, (2018)
Schmidhuber, J.: Deep learning in neural networks: an overview. Neural Netw. 61, 85–117 (2015)
Siegelmann, H. T.: Neural networks and analog computation: beyond the Turing limit. Springer Science & Business Media, (2012)
Slepčev, D., Thorpe, M.: Analysis of \(p\)-Laplacian regularization in semi-supervised learning. SIAM J. Math. Anal. 51(3), 2085–2120 (2019)
Smets, B. M. N., Portegies, J., Bekkers, E. J., Duits, R.: PDE-based group equivariant convolutional neural networks. J. Math. Imaging Vis. (2022). https://doi.org/10.1007/s10851-022-01114-x
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(1), 1929–2958 (2014)
Srivastava, R. K., Greff, K., Schmidhuber, J.: Highway networks. preprint arXiv:1505.00387, (2015)
Treister, E., Ruthotto, L., Sharoni, M., Zafrani, S., Haber, E.: Low-cost parameterizations of deep convolution neural networks. preprint arXiv:1805.07821, (2018)
van Gennip, Y., Bertozzi, A.L.: \(\Gamma \)-convergence of graph Ginzburg-Landau functionals. Adv. Differ. Equs. 17(11–12), 1115–1180 (2012)
Vidal, R., Bruna, J., Giryes, R., Soatto, S.: Mathematics of deep learning. preprint arXiv:1712.04741, (2017)
Wan, E. A.: Finite impulse response neural networks for autoregressive time series prediction. Time Series Prediction: Forecast. Future and Understanding the Past, 2, (1993)
Wan, L., Zeiler, M., Zhang, S., Le Cun, Y., Fergus, R.: Regularization of neural networks using dropconnect. In: International Conference on Machine Learning, pages 1058–1066, (2013)
Wiatowski, T., Bölcskei, H.: A mathematical theory of deep convolutional neural networks for feature extraction. IEEE Trans. Inf. Theory 64(3), 1845–1866 (2018)
Williams, R.J., Zipser, D.: A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1(2), 270–280 (1989)
Yin, P., Zhang, S., Lyu, J., Osher, S., Qi, Y., Xin, J.: Blended coarse gradient descent for full quantization of deep neural networks. Res. Math. Sci. 6(1), 14 (2019)
Zaeemzadeh, A., Rahnavard, N., Shah, M.: Norm-preservation: why residual networks can become extremely deep? IEEE Trans. Pattern Anal. Mach. Intell. 43(11), 3980–3990 (2020)
Zeiler, M. D., Ranzato, M., Monga, R., Mao, M., Yang, K., Le, Q. V., Nguyen, P., Senior, A., Vanhoucke, V., Dean, J., Hinton, G. E.: On rectified linear units for speech processing. In: Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, pages 3517–3521. IEEE, (2013)
Zhang, L., Schaeffer, H.: Forward stability of ResNet and its variants. J. Math. Imag. Vis., pages 1–24, (2019)
Zhao, H., Gallo, O., Frosio, I., Kautz, J.: Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imag. 3(1), 47–57 (2017)
Zurada, J.M.: Introduction to Artificial Neural Systems, vol. 8. West publishing company St, Paul (1992)
Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreements 777826 (NoMADS) and 647812). The authors would like to thank Martin Benning, Jeff Calder, Matthias J. Ehrhardt, Nicolás García Trillos and Lukas Lang for enlightening exchanges regarding the work in this paper. We also thank the anonymous referees for their very insightful comments on an earlier version of the manuscript, which have led to improvements in the final paper. MT is grateful for the support of the Cantab Capital Institute for the Mathematics of Information (CCIMI) and the Cambridge Image Analysis group at the University of Cambridge. YvG did a significant part of the work which has contributed to this paper at the University of Nottingham. The authors state that there are no conflicts of interest.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: The matrix exponential
Appendix A: The matrix exponential
For completeness we include a short proof of the inequality
for any square matrices X, Y, which is used in the proof of Lemma 4.14. Let \(k\in \mathbb {N}\setminus \{0\}\). Then, CA
where we obtained the inequality by expanding \((X+Y)^k\), applying the triangle inequality and using that \(\Vert XY\Vert \le \Vert X\Vert \Vert Y\Vert \). Then the equality follows from the binomial theorem. Hence,
Since \(e^c-1\le ce^c\) for all \(c\ge 0\), we conclude that the inequality holds.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Thorpe, M., van Gennip, Y. Deep limits of residual neural networks. Res Math Sci 10, 6 (2023). https://doi.org/10.1007/s40687-022-00370-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40687-022-00370-y
Keywords
- Deep neural networks
- Ordinary differential equations
- Deep layer limits
- Variational convergence
- Gamma-convergence
- Regularity